You are viewing a plain text version of this content. The canonical link for it is here.
Posted to dev@tvm.apache.org by Andrew Tulloch <no...@github.com> on 2019/08/28 08:26:54 UTC
[dmlc/tvm] [RFC] [Vulkan] [WIP] Alternative Vulkan runtime
implementation (stream approach) (#3849)
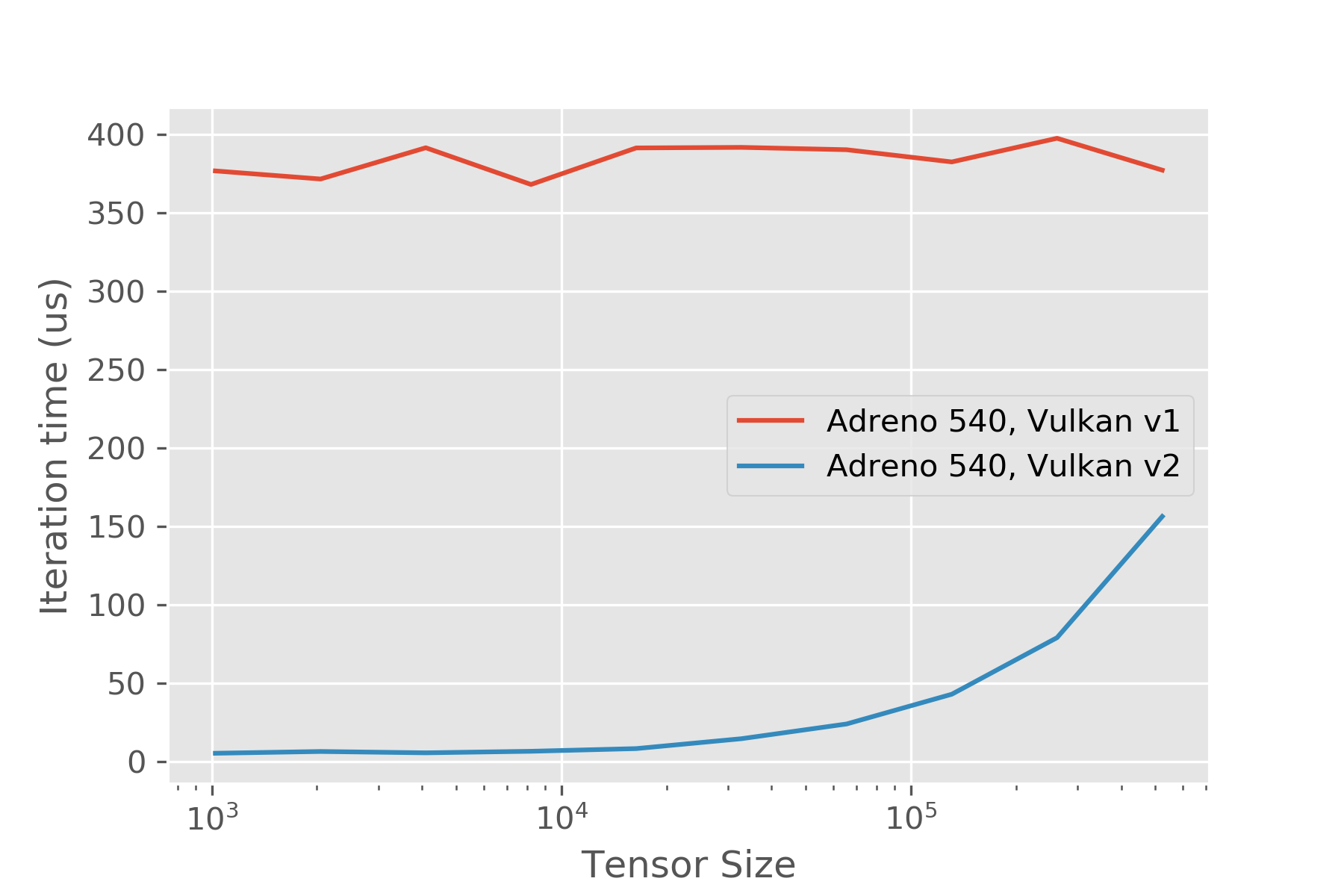
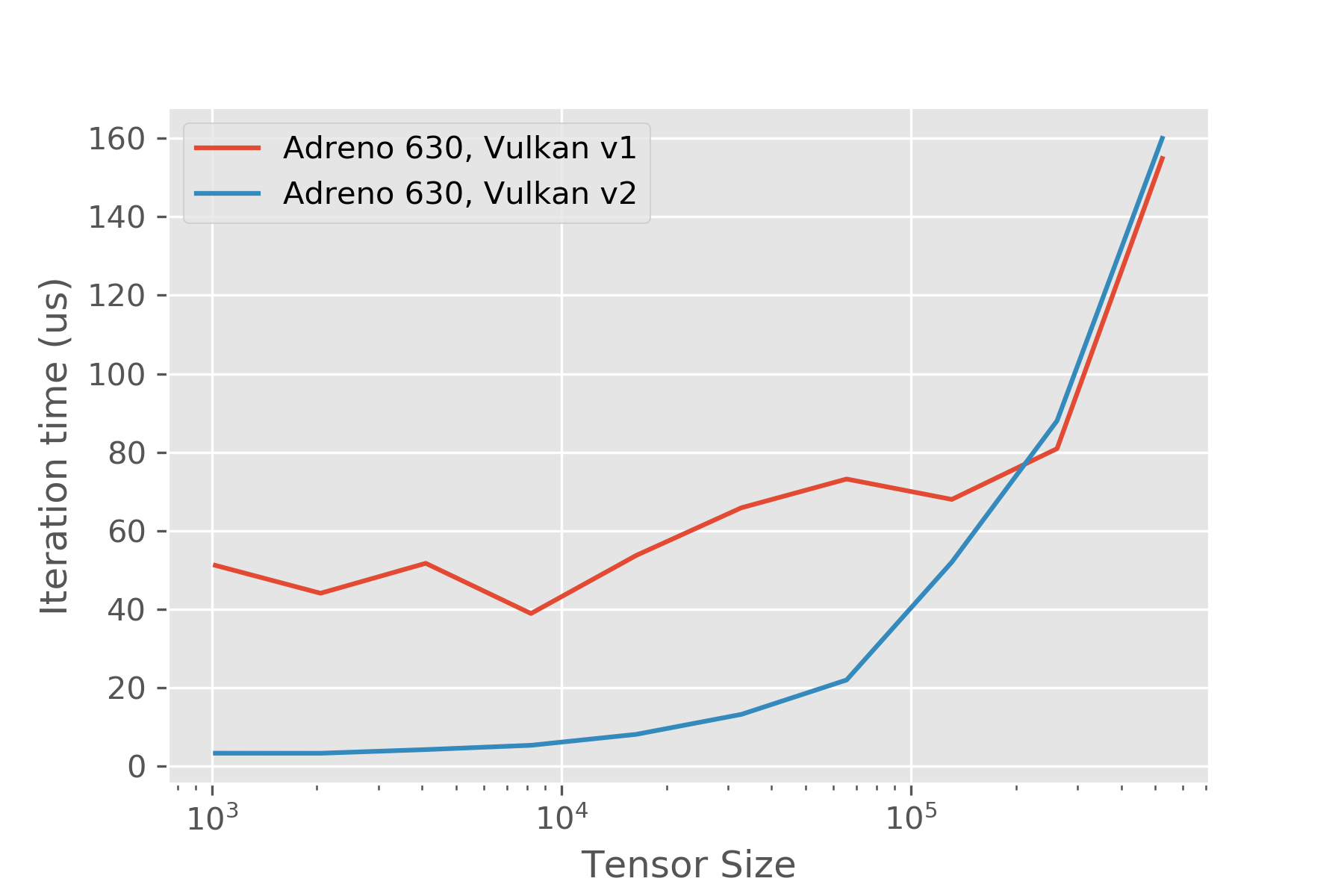
In the Vulkan API, it is recommended to launch multiple command buffers per kernel. See http://on-demand.gputechconf.com/gtc/2016/events/vulkanday/High_Performance_Vulkan.pdf, https://devblogs.nvidia.com/vulkan-dos-donts/, etc. The extant TVM Vulkan runtime uses one command buffer per kernel, which can lead to significant overheads for smaller-kernels (on the order of half a millisecond on some of the devices I looked at).
An alternative approach leverages an approach similar to a CUDA stream abstraction, where we record commands onto the command buffer, and at synchronization points, submit the command buffer to the queue and wait on the fence. This is non-trivially more efficient - similar to the approach taken by [`ncnn`](https://github.com/Tencent/ncnn/tree/master/src/layer/vulkan/) - there are some useful ideas in there that applied here. In particular it's quite convenient to depend on the KHR push descriptors extension, but that could be removed without too much pain similar to how ncnn does it.
This code isn't production ready, and it's not super clear how much interest there is in the Vulkan side of things. I think it's quite promising and was planning on spending some time looking at codegen stuff, but the difficulty in getting reasonable numbers for small B/W bound kernels was the motivator in working on this to begin with.
If there's interest we could probably figure out a way to merge this into the existing Vulkan runtime, perhaps gated by a feature flag?
Performance improves for simple pointwise kernels as expected, using a script like:
```.py
import tvm
import numpy as np
tx = tvm.thread_axis("threadIdx.x")
bx = tvm.thread_axis("blockIdx.x")
num_thread = 256
from tvm import rpc
tracker = rpc.connect_tracker('localhost', 9090)
remote = tracker.request("android", priority=1,
session_timeout=6000)
ctx = remote.vulkan(0)
def check_vulkan(dtype, n):
A = tvm.placeholder((n,), name='A', dtype=dtype)
B = tvm.compute((n,), lambda i: A[i]+tvm.const(1, A.dtype), name='B')
s = tvm.create_schedule(B.op)
xo, xi = s[B].split(B.op.axis[0], factor=num_thread * 4)
s[B].bind(xo, bx)
xi, vx = s[B].split(xi, factor=4)
s[B].bind(xi, tx)
s[B].vectorize(vx)
f = tvm.build(
s, [A, B],
target="vulkan",
target_host="llvm -target=arm64-linux-android")
import os
os.environ['TVM_NDK_CC'] = os.path.expanduser("~/opt/android-toolchain-arm64/bin/aarch64-linux-android-g++")
fname = f"dev_lib_vulkan_{np.random.random()}.so"
path_dso_vulkan = fname
from tvm.contrib import ndk
f.export_library(path_dso_vulkan, ndk.create_shared)
ctx = remote.vulkan(0)
remote.upload(path_dso_vulkan)
f1 = remote.load_module(fname)
a_np = np.random.uniform(size=(n,)).astype(dtype)
a = tvm.nd.array(a_np, ctx)
c = tvm.nd.empty((n,), B.dtype, ctx)
f1(a, c)
tvm.testing.assert_allclose(c.asnumpy(), a.asnumpy() + 1)
te = f1.time_evaluator(f.entry_name, ctx=ctx, min_repeat_ms=500, number=5)
for _ in range(3):
perf = te(a, c).mean
print(f"N: {n}, t: {perf * 1.0e6:.2f}us, GFLOP/s: {n / perf / 1.0e9}")
for log_n in range(10, 20):
check_vulkan("float32", 2 ** log_n)
```
You can view, comment on, or merge this pull request online at:
https://github.com/dmlc/tvm/pull/3849
-- Commit Summary --
* Vulkan2 Runtime API
-- File Changes --
M CMakeLists.txt (1)
M cmake/modules/Vulkan.cmake (9)
M src/codegen/spirv/build_vulkan.cc (7)
A src/runtime/vulkan/README.md (36)
A src/runtime/vulkan/vulkan2.cc (965)
A src/runtime/vulkan/vulkan2_common.h (144)
A src/runtime/vulkan/vulkan2_module.h (16)
A src/runtime/vulkan/vulkan2_stream.h (101)
A src/runtime/vulkan/vulkan_shader.h (37)
A tests/python/test_codegen_vulkan.py (84)
-- Patch Links --
https://github.com/dmlc/tvm/pull/3849.patch
https://github.com/dmlc/tvm/pull/3849.diff
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/pull/3849
Re: [dmlc/tvm] [RFC] [Vulkan] [WIP] Alternative Vulkan runtime
implementation (stream approach) (#3849)
Posted by Andrew Tulloch <no...@github.com>.
Thanks @nihui, @tqchen, @jwfromm.
I generalized this approach to handle devices that don't support the push descriptor (see the Stream::LaunchDeferred APIs), and devices that don't support dedicated allocation APIs, and removed the previous runtime implementation as @tqchen suggested. I also added some more tests which (under Vulkan API validation) revealed some thread safety bugs.
I think this should be closer to something that is acceptable, so I'll remove the RFC and WIP tags, this should be ready for review.
File/class structure is certainly up for debate. I'm fine with whatever folks propose.
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/pull/3849#issuecomment-528190493
Re: [dmlc/tvm] [RFC] [Vulkan] [WIP] Alternative Vulkan runtime
implementation (stream approach) (#3849)
Posted by nihui <no...@github.com>.
I also found that it took a lot of time to wait for each operator results, so I put multiple operators in a single command buffer and apply the lazy execution.
But I'm not familiar with TVM, and the code in the PR seems to be very different from ncnn, so I cannot judge if this PR is the best, but it must be much better than the current TVM approach I think.
If you have any questions about the ncnn vulkan backend, feel free to post an issue to https://github.com/Tencent/ncnn/issues
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/pull/3849#issuecomment-527072640
Re: [dmlc/tvm] [RFC] [Vulkan] [WIP] Alternative Vulkan runtime
implementation (stream approach) (#3849)
Posted by Andrew Tulloch <no...@github.com>.
@nihui would you be interested in taking a look at this PR and this approach? Are there more useful things in NCNN’s Vulkan backend that TVM should learn from?
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/pull/3849#issuecomment-526176917
Re: [dmlc/tvm] [RFC] [Vulkan] [WIP] Alternative Vulkan runtime
implementation (stream approach) (#3849)
Posted by Andrew Tulloch <no...@github.com>.
cc @jwfromm, @tqchen
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/pull/3849#issuecomment-525639619
Re: [dmlc/tvm] [RFC] [Vulkan] [WIP] Alternative Vulkan runtime
implementation (stream approach) (#3849)
Posted by Tianqi Chen <no...@github.com>.
Awesome, this is something that i overlooked and definitely should be the way to go.
The main reason that I took the current approach was because there is no clear way to do synchronization other than the fence. Your proposed approach is definitely better and we should just move toward this new runtime IMO
--
You are receiving this because you are subscribed to this thread.
Reply to this email directly or view it on GitHub:
https://github.com/dmlc/tvm/pull/3849#issuecomment-525994251