You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@iotdb.apache.org by su...@apache.org on 2020/03/10 09:29:21 UTC
[incubator-iotdb-website] branch asf-site updated: Add local files
This is an automated email from the ASF dual-hosted git repository.
sunzesong pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/incubator-iotdb-website.git
The following commit(s) were added to refs/heads/asf-site by this push:
new e3a02a5 Add local files
e3a02a5 is described below
commit e3a02a58cd42106a7426ee09971f0f5d906cb411
Author: samperson1997 <sz...@mails.tsinghua.edu.cn>
AuthorDate: Tue Mar 10 17:28:04 2020 +0800
Add local files
---
.../docs/Community/Community-History&Vision.md | 24 +
.../master/docs/Community/Community-Powered By.md | 44 +
.../docs/Community/Community-Project Committers.md | 49 +
.../master/docs/Development/Development-Chinese.md | 99 +
.../docs/Development/Development-Contributing.md | 214 +
.../docs/Development/Development-Document.md | 51 +
.../master/docs/Development/Development-IDE.md | 65 +
.../docs/Development/Development-VoteRelease.md | 198 +
.../SystemDesign/0-Architecture/1-Architecture.md | 55 +
.../SystemDesign/1-TsFile/1-TsFile.md | 31 +
.../SystemDesign/1-TsFile/2-Format.md | 470 +
.../SystemDesign/1-TsFile/3-Write.md | 65 +
.../SystemDesign/1-TsFile/4-Read.md | 566 +
.../SystemDesign/2-QueryEngine/1-QueryEngine.md | 64 +
.../SystemDesign/2-QueryEngine/2-Planner.md | 63 +
.../SystemDesign/2-QueryEngine/3-PlanExecutor.md | 26 +
.../3-SchemaManager/1-SchemaManager.md | 26 +
.../4-StorageEngine/1-StorageEngine.md | 68 +
.../SystemDesign/4-StorageEngine/2-WAL.md | 26 +
.../SystemDesign/4-StorageEngine/3-FlushManager.md | 84 +
.../SystemDesign/4-StorageEngine/4-MergeManager.md | 26 +
.../4-StorageEngine/5-DataPartition.md | 86 +
.../4-StorageEngine/6-DataManipulation.md | 96 +
.../SystemDesign/5-DataQuery/1-DataQuery.md | 40 +
.../SystemDesign/5-DataQuery/2-SeriesReader.md | 384 +
.../SystemDesign/5-DataQuery/3-RawDataQuery.md | 301 +
.../SystemDesign/5-DataQuery/4-AggregationQuery.md | 114 +
.../SystemDesign/5-DataQuery/5-GroupByQuery.md | 260 +
.../SystemDesign/5-DataQuery/6-LastQuery.md | 119 +
.../5-DataQuery/7-AlignByDeviceQuery.md | 203 +
.../SystemDesign/6-Tools/1-Sync.md | 299 +
.../SystemDesign/7-Connector/2-Hive-TsFile.md | 114 +
.../SystemDesign/7-Connector/3-Spark-TsFile.md | 101 +
.../SystemDesign/7-Connector/4-Spark-IOTDB.md | 89 +
.../UserGuide/0-Get Started/1-QuickStart.md | 293 +
.../0-Get Started/2-Frequently asked questions.md | 166 +
.../UserGuide/0-Get Started/3-Publication.md | 37 +
.../UserGuide/1-Overview/1-What is IoTDB.md | 26 +
.../UserGuide/1-Overview/2-Architecture.md | 36 +
.../UserGuide/1-Overview/3-Scenario.md | 78 +
.../UserGuide/1-Overview/4-Features.md | 51 +
.../2-Concept/1-Data Model and Terminology.md | 220 +
.../UserGuide/2-Concept/2-Data Type.md | 42 +
.../UserGuide/2-Concept/3-Encoding.md | 67 +
.../UserGuide/2-Concept/4-Compression.md | 33 +
.../UserGuide/3-Server/1-Download.md | 122 +
.../UserGuide/3-Server/2-Single Node Setup.md | 32 +
.../UserGuide/3-Server/3-Cluster Setup.md | 25 +
.../UserGuide/3-Server/4-Config Manual.md | 442 +
.../UserGuide/3-Server/5-Docker Image.md | 89 +
.../4-Client/1-Command Line Interface (CLI).md | 148 +
.../4-Client/2-Programming - Native API.md | 103 +
.../UserGuide/4-Client/3-Programming - JDBC.md | 278 +
.../4-Client/4-Programming - Other Languages.md | 66 +
.../4-Client/5-Programming - TsFile API.md | 701 +
.../UserGuide/4-Client/6-Status Codes.md | 65 +
.../1-DDL (Data Definition Language).md | 181 +
.../2-DML (Data Manipulation Language).md | 726 +
.../3-Account Management Statements.md | 134 +
.../5-Operation Manual/4-SQL Reference.md | 885 +
.../UserGuide/6-System Tools/1-Sync Tool.md | 276 +
.../6-System Tools/2-Memory Estimation Tool.md | 90 +
.../UserGuide/6-System Tools/3-JMX Tool.md | 34 +
.../UserGuide/6-System Tools/4-Watermark Tool.md | 209 +
.../UserGuide/6-System Tools/5-Log Visualizer.md | 147 +
.../6-Query History Visualization Tool.md | 32 +
.../6-System Tools/7-Monitor and Log Tools.md | 449 +
.../6-System Tools/8-Load External Tsfile.md | 78 +
.../UserGuide/7-Ecosystem Integration/1-Grafana.md | 136 +
.../7-Ecosystem Integration/2-MapReduce TsFile.md | 217 +
.../7-Ecosystem Integration/3-Spark TsFile.md | 345 +
.../7-Ecosystem Integration/4-Spark IoTDB.md | 176 +
.../7-Ecosystem Integration/5-Hive TsFile.md | 192 +
.../UserGuide/8-Architecture/1-Files.md | 63 +
.../8-Architecture/2-Writing Data on HDFS.md | 171 +
.../8-Architecture/3-Shared Nothing Cluster.md | 26 +
.../Documentation/OtherMaterial-Sample Data.txt | 60509 +++++++++++++++++++
.../docs/Documentation/SystemDesign/0-Content.md | 54 +
.../SystemDesign/1-TsFile/1-TsFile.md | 30 +
.../SystemDesign/1-TsFile/2-Format.md | 470 +
.../Documentation/SystemDesign/1-TsFile/3-Write.md | 22 +
.../Documentation/SystemDesign/1-TsFile/4-Read.md | 559 +
.../docs/Documentation/SystemDesign/release.adoc | 519 +
.../docs/Documentation/UserGuide/0-Content.md | 72 +
.../UserGuide/0-Get Started/1-QuickStart.md | 258 +
.../0-Get Started/2-Frequently asked questions.md | 167 +
.../UserGuide/0-Get Started/3-Publication.md | 36 +
.../UserGuide/1-Overview/1-What is IoTDB.md | 26 +
.../UserGuide/1-Overview/2-Architecture.md | 36 +
.../UserGuide/1-Overview/3-Scenario.md | 78 +
.../UserGuide/1-Overview/4-Features.md | 52 +
.../2-Concept/1-Data Model and Terminology.md | 221 +
.../UserGuide/2-Concept/2-Data Type.md | 44 +
.../UserGuide/2-Concept/3-Encoding.md | 66 +
.../UserGuide/2-Concept/4-Compression.md | 34 +
.../Documentation/UserGuide/3-Server/1-Download.md | 75 +
.../UserGuide/3-Server/2-Single Node Setup.md | 32 +
.../UserGuide/3-Server/3-Cluster Setup.md | 24 +
.../UserGuide/3-Server/4-Config Manual.md | 482 +
.../UserGuide/3-Server/5-Docker Image.md | 90 +
.../4-Client/1-Command Line Interface (CLI).md | 144 +
.../4-Client/2-Programming - Native API.md | 127 +
.../UserGuide/4-Client/3-Programming - JDBC.md | 275 +
.../4-Client/4-Programming - Other Languages.md | 74 +
.../4-Client/5-Programming - TsFile API.md | 709 +
.../UserGuide/4-Client/6-Status Codes.md | 66 +
.../1-DDL (Data Definition Language).md | 180 +
.../2-DML (Data Manipulation Language).md | 660 +
.../3-Account Management Statements.md | 124 +
.../5-Operation Manual/4-SQL Reference.md | 922 +
.../UserGuide/6-System Tools/1-Sync Tool.md | 295 +
.../6-System Tools/2-Memory Estimation Tool.md | 84 +
.../UserGuide/6-System Tools/3-JMX Tool.md | 34 +
.../UserGuide/6-System Tools/4-Watermark Tool.md | 201 +
.../UserGuide/6-System Tools/5-Log Visualizer.md | 162 +
.../6-Query History Visualization Tool.md | 32 +
.../6-System Tools/7-Monitor and Log Tools.md | 471 +
.../6-System Tools/8-Load External Tsfile.md | 72 +
.../UserGuide/7-Ecosystem Integration/1-Grafana.md | 140 +
.../7-Ecosystem Integration/2-MapReduce TsFile.md | 213 +
.../7-Ecosystem Integration/3-Spark TsFile.md | 343 +
.../7-Ecosystem Integration/4-Spark IoTDB.md | 173 +
.../7-Ecosystem Integration/5-Hive TsFile.md | 190 +
.../UserGuide/8-Architecture/1-Files.md | 62 +
.../8-Architecture/2-Writing Data on HDFS.md | 171 +
.../8-Architecture/3-Shared Nothing Cluster.md | 26 +
.../0.8/docs/Community/Community-History&Vision.md | 24 +
.../rel/0.8/docs/Community/Community-Powered By.md | 44 +
.../docs/Community/Community-Project Committers.md | 49 +
.../0.8/docs/Development/Development-Chinese.md | 99 +
.../docs/Development/Development-Contributing.md | 214 +
.../0.8/docs/Development/Development-Document.md | 51 +
.../rel/0.8/docs/Development/Development-IDE.md | 65 +
.../docs/Development/Development-VoteRelease.md | 198 +
.../SystemDesign/0-Architecture/1-Architecture.md | 55 +
.../SystemDesign/1-TsFile/1-TsFile.md | 31 +
.../SystemDesign/1-TsFile/2-Format.md | 470 +
.../SystemDesign/1-TsFile/3-Write.md | 65 +
.../SystemDesign/1-TsFile/4-Read.md | 27 +
.../SystemDesign/2-QueryEngine/1-QueryEngine.md | 64 +
.../SystemDesign/2-QueryEngine/2-Planner.md | 63 +
.../SystemDesign/2-QueryEngine/3-PlanExecutor.md | 26 +
.../3-SchemaManager/1-SchemaManager.md | 26 +
.../4-StorageEngine/1-StorageEngine.md | 92 +
.../SystemDesign/4-StorageEngine/2-WAL.md | 26 +
.../SystemDesign/4-StorageEngine/3-FlushManager.md | 84 +
.../SystemDesign/4-StorageEngine/4-MergeManager.md | 26 +
.../SystemDesign/5-DataQuery/1-DataQuery.md | 67 +
.../SystemDesign/6-Tools/1-Sync.md | 24 +
.../SystemDesign/7-Connector/2-Hive-TsFile.md | 114 +
.../docs/Documentation-CHN/UserGuide/0-Content.md | 26 +
.../UserGuide/1-Overview/1-What is IoTDB.html | 306 +
.../UserGuide/1-Overview/1-What is IoTDB.md | 26 +
.../UserGuide/1-Overview/2-Architecture.html | 306 +
.../UserGuide/1-Overview/2-Architecture.md | 36 +
.../UserGuide/1-Overview/3-Scenario.md | 78 +
.../UserGuide/1-Overview/4-Features.html | 306 +
.../UserGuide/1-Overview/4-Features.md | 51 +
.../1-Key Concepts and Terminology.html | 307 +
.../1-Key Concepts and Terminology.md | 179 +
.../2-Data Type.html | 306 +
.../2-Data Type.md | 42 +
.../3-Encoding.html | 306 +
.../3-Encoding.md | 69 +
.../4-Compression.html | 306 +
.../4-Compression.md | 28 +
.../3-Operation Manual/1-Sample Data.html | 306 +
.../UserGuide/3-Operation Manual/1-Sample Data.md | 28 +
.../3-Operation Manual/2-Data Model Selection.html | 307 +
.../3-Operation Manual/2-Data Model Selection.md | 114 +
.../3-Operation Manual/3-Data Import.html | 306 +
.../UserGuide/3-Operation Manual/3-Data Import.md | 85 +
.../UserGuide/3-Operation Manual/4-Data Query.html | 306 +
.../UserGuide/3-Operation Manual/4-Data Query.md | 503 +
.../3-Operation Manual/5-Data Maintenance.html | 306 +
.../3-Operation Manual/5-Data Maintenance.md | 88 +
.../6-Priviledge Management.html | 306 +
.../3-Operation Manual/6-Priviledge Management.md | 134 +
.../4-Deployment and Management/1-Deployment.html | 306 +
.../4-Deployment and Management/1-Deployment.md | 121 +
.../2-Configuration.html | 306 +
.../4-Deployment and Management/2-Configuration.md | 294 +
.../3-System Monitor.html | 306 +
.../3-System Monitor.md | 152 +
.../4-Performance Monitor.html | 306 +
.../4-Performance Monitor.md | 78 +
.../4-Deployment and Management/5-System log.html | 306 +
.../4-Deployment and Management/5-System log.md | 64 +
.../6-Data Management.html | 307 +
.../6-Data Management.md | 74 +
.../7-Build and use IoTDB by Dockerfile.html | 306 +
.../7-Build and use IoTDB by Dockerfile.md | 24 +
.../1-IoTDB Query Statement.html | 343 +
.../1-IoTDB Query Statement.md | 477 +
.../5-IoTDB SQL Documentation/2-Reference.html | 306 +
.../5-IoTDB SQL Documentation/2-Reference.md | 137 +
.../UserGuide/6-JDBC API/1-JDBC API.html | 306 +
.../UserGuide/6-JDBC API/1-JDBC API.md | 24 +
.../UserGuide/7-TsFile/1-Installation.html | 306 +
.../UserGuide/7-TsFile/1-Installation.md | 24 +
.../UserGuide/7-TsFile/2-Usage.html | 306 +
.../UserGuide/7-TsFile/2-Usage.md | 24 +
.../UserGuide/7-TsFile/3-Hierarchy.html | 306 +
.../UserGuide/7-TsFile/3-Hierarchy.md | 24 +
.../UserGuide/8-System Tools/1-Sync.html | 484 +
.../UserGuide/8-System Tools/1-Sync.md | 281 +
.../8-System Tools/2-Memory Estimation Tool.html | 331 +
.../8-System Tools/2-Memory Estimation Tool.md | 90 +
.../Documentation/OtherMaterial-Sample Data.txt | 60509 +++++++++++++++++++
.../docs/Documentation/SystemDesign/0-Content.md | 46 +
.../SystemDesign/1-TsFile/1-TsFile.md | 30 +
.../SystemDesign/1-TsFile/2-Format.md | 470 +
.../Documentation/SystemDesign/1-TsFile/3-Write.md | 22 +
.../Documentation/SystemDesign/1-TsFile/4-Read.md | 22 +
.../docs/Documentation/SystemDesign/release.adoc | 519 +
.../0.8/docs/Documentation/UserGuide/0-Content.md | 58 +
.../UserGuide/0-Get Started/1-QuickStart.html | 308 +
.../UserGuide/0-Get Started/1-QuickStart.md | 251 +
.../2-Frequently asked questions.html | 306 +
.../0-Get Started/2-Frequently asked questions.md | 167 +
.../UserGuide/0-Get Started/3-Publication.html | 306 +
.../UserGuide/0-Get Started/3-Publication.md | 30 +
.../UserGuide/1-Overview/1-What is IoTDB.html | 306 +
.../UserGuide/1-Overview/1-What is IoTDB.md | 26 +
.../UserGuide/1-Overview/2-Architecture.html | 306 +
.../UserGuide/1-Overview/2-Architecture.md | 36 +
.../UserGuide/1-Overview/3-Scenario.html | 306 +
.../UserGuide/1-Overview/3-Scenario.md | 78 +
.../UserGuide/1-Overview/4-Features.html | 306 +
.../UserGuide/1-Overview/4-Features.md | 33 +
.../1-Key Concepts and Terminology.html | 306 +
.../1-Key Concepts and Terminology.md | 180 +
.../2-Data Type.html | 306 +
.../2-Data Type.md | 44 +
.../3-Encoding.html | 306 +
.../3-Encoding.md | 68 +
.../4-Compression.html | 306 +
.../4-Compression.md | 28 +
.../3-Operation Manual/1-Sample Data.html | 306 +
.../UserGuide/3-Operation Manual/1-Sample Data.md | 28 +
.../3-Operation Manual/2-Data Model Selection.html | 307 +
.../3-Operation Manual/2-Data Model Selection.md | 110 +
.../3-Operation Manual/3-Data Import.html | 306 +
.../UserGuide/3-Operation Manual/3-Data Import.md | 87 +
.../UserGuide/3-Operation Manual/4-Data Query.html | 306 +
.../UserGuide/3-Operation Manual/4-Data Query.md | 485 +
.../3-Operation Manual/5-Data Maintenance.html | 306 +
.../3-Operation Manual/5-Data Maintenance.md | 86 +
.../6-Priviledge Management.html | 306 +
.../3-Operation Manual/6-Priviledge Management.md | 124 +
.../4-Deployment and Management/1-Deployment.html | 310 +
.../4-Deployment and Management/1-Deployment.md | 164 +
.../2-Configuration.html | 306 +
.../4-Deployment and Management/2-Configuration.md | 329 +
.../3-System Monitor.html | 307 +
.../3-System Monitor.md | 359 +
.../4-Performance Monitor.html | 306 +
.../4-Performance Monitor.md | 79 +
.../4-Deployment and Management/5-System log.html | 308 +
.../4-Deployment and Management/5-System log.md | 66 +
.../6-Data Management.html | 306 +
.../6-Data Management.md | 77 +
.../7-Build and use IoTDB by Dockerfile.html | 306 +
.../7-Build and use IoTDB by Dockerfile.md | 91 +
.../1-IoTDB Query Statement.html | 343 +
.../1-IoTDB Query Statement.md | 503 +
.../5-IoTDB SQL Documentation/2-Reference.html | 306 +
.../5-IoTDB SQL Documentation/2-Reference.md | 137 +
.../UserGuide/6-JDBC API/1-JDBC API.html | 306 +
.../UserGuide/6-JDBC API/1-JDBC API.md | 188 +
.../UserGuide/7-TsFile/1-Installation.html | 307 +
.../UserGuide/7-TsFile/1-Installation.md | 96 +
.../Documentation/UserGuide/7-TsFile/2-Usage.html | 358 +
.../Documentation/UserGuide/7-TsFile/2-Usage.md | 532 +
.../UserGuide/7-TsFile/3-Hierarchy.html | 400 +
.../UserGuide/7-TsFile/3-Hierarchy.md | 241 +
.../UserGuide/8-System Tools/1-Sync.html | 487 +
.../UserGuide/8-System Tools/1-Sync.md | 285 +
.../8-System Tools/2-Memory Estimation Tool.html | 331 +
.../8-System Tools/2-Memory Estimation Tool.md | 83 +
.../rel/0.9/docs/Community-History&Vision.md | 24 +
.../rel/0.9/docs/Community-Powered By.md | 44 +
.../rel/0.9/docs/Community-Project Committers.md | 44 +
.../0.9/docs/Community/Community-History&Vision.md | 24 +
.../rel/0.9/docs/Community/Community-Powered By.md | 44 +
.../docs/Community/Community-Project Committers.md | 49 +
.../rel/0.9/docs/Development-Contributing.md | 207 +
.../rel/0.9/docs/Development-Document.md | 48 +
incubator-iotdb/rel/0.9/docs/Development-IDE.md | 65 +
.../0.9/docs/Development/Development-Chinese.md | 99 +
.../docs/Development/Development-Contributing.md | 214 +
.../0.9/docs/Development/Development-Document.md | 51 +
.../rel/0.9/docs/Development/Development-IDE.md | 65 +
.../docs/Development/Development-VoteRelease.md | 198 +
.../SystemDesign/0-Architecture/1-Architecture.md | 55 +
.../SystemDesign/1-TsFile/1-TsFile.md | 31 +
.../SystemDesign/1-TsFile/2-Format.md | 470 +
.../SystemDesign/1-TsFile/3-Write.md | 65 +
.../SystemDesign/1-TsFile/4-Read.md | 27 +
.../SystemDesign/2-QueryEngine/1-QueryEngine.md | 64 +
.../SystemDesign/2-QueryEngine/2-Planner.md | 63 +
.../SystemDesign/2-QueryEngine/3-PlanExecutor.md | 26 +
.../3-SchemaManager/1-SchemaManager.md | 26 +
.../4-StorageEngine/1-StorageEngine.md | 92 +
.../SystemDesign/4-StorageEngine/2-WAL.md | 26 +
.../SystemDesign/4-StorageEngine/3-FlushManager.md | 84 +
.../SystemDesign/4-StorageEngine/4-MergeManager.md | 26 +
.../SystemDesign/5-DataQuery/1-DataQuery.md | 67 +
.../SystemDesign/6-Tools/1-Sync.md | 24 +
.../SystemDesign/7-Connector/2-Hive-TsFile.md | 114 +
.../UserGuide/0-Get Started/1-QuickStart.html | 307 +
.../UserGuide/0-Get Started/1-QuickStart.md | 283 +
.../2-Frequently asked questions.html | 306 +
.../0-Get Started/2-Frequently asked questions.md | 24 +
.../UserGuide/0-Get Started/3-Publication.html | 306 +
.../UserGuide/0-Get Started/3-Publication.md | 31 +
.../UserGuide/1-Overview/1-What is IoTDB.html | 306 +
.../UserGuide/1-Overview/1-What is IoTDB.md | 26 +
.../UserGuide/1-Overview/2-Architecture.html | 306 +
.../UserGuide/1-Overview/2-Architecture.md | 36 +
.../UserGuide/1-Overview/3-Scenario.html | 306 +
.../UserGuide/1-Overview/3-Scenario.md | 78 +
.../UserGuide/1-Overview/4-Features.html | 306 +
.../UserGuide/1-Overview/4-Features.md | 51 +
.../2-Concept/1-Data Model and Terminology.html | 308 +
.../2-Concept/1-Data Model and Terminology.md | 220 +
.../UserGuide/2-Concept/2-Data Type.html | 306 +
.../UserGuide/2-Concept/2-Data Type.md | 42 +
.../UserGuide/2-Concept/3-Encoding.html | 306 +
.../UserGuide/2-Concept/3-Encoding.md | 69 +
.../UserGuide/2-Concept/4-Compression.html | 306 +
.../UserGuide/2-Concept/4-Compression.md | 33 +
.../UserGuide/3-Server/1-Download.html | 306 +
.../UserGuide/3-Server/1-Download.md | 122 +
.../UserGuide/3-Server/2-Single Node Setup.html | 306 +
.../UserGuide/3-Server/2-Single Node Setup.md | 23 +
.../UserGuide/3-Server/3-Cluster Setup.html | 306 +
.../UserGuide/3-Server/3-Cluster Setup.md | 23 +
.../UserGuide/3-Server/4-Config Manual.html | 308 +
.../UserGuide/3-Server/4-Config Manual.md | 402 +
.../UserGuide/3-Server/5-Docker Image.html | 306 +
.../UserGuide/3-Server/5-Docker Image.md | 24 +
.../4-Client/1-Command Line Interface (CLI).html | 307 +
.../4-Client/1-Command Line Interface (CLI).md | 148 +
.../UserGuide/4-Client/2-Programming - JDBC.md | 276 +
.../4-Client/2-Programming - Native API.html | 314 +
.../4-Client/2-Programming - Native API.md | 101 +
.../UserGuide/4-Client/3-Programming - JDBC.html | 307 +
.../UserGuide/4-Client/3-Programming - JDBC.md | 278 +
.../UserGuide/4-Client/3-Programming - Session.md | 106 +
.../4-Client/4-Programming - Other Languages.html | 306 +
.../4-Client/4-Programming - Other Languages.md | 24 +
.../4-Client/5-Programming - TsFile API.html | 384 +
.../4-Client/5-Programming - TsFile API.md | 24 +
.../1-DDL (Data Definition Language).html | 309 +
.../1-DDL (Data Definition Language).md | 178 +
.../2-DML (Data Manipulation Language).html | 314 +
.../2-DML (Data Manipulation Language).md | 193 +
.../3-Account Management Statements.html | 306 +
.../3-Account Management Statements.md | 134 +
.../5-Operation Manual/4-SQL Reference.html | 492 +
.../5-Operation Manual/4-SQL Reference.md | 727 +
.../UserGuide/6-System Tools/1-Sync Tool.html | 472 +
.../UserGuide/6-System Tools/1-Sync Tool.md | 276 +
.../6-System Tools/2-Memory Estimation Tool.html | 331 +
.../6-System Tools/2-Memory Estimation Tool.md | 90 +
.../UserGuide/6-System Tools/3-JMX Tool.html | 306 +
.../UserGuide/6-System Tools/3-JMX Tool.md | 34 +
.../UserGuide/6-System Tools/4-Watermark Tool.html | 306 +
.../UserGuide/6-System Tools/4-Watermark Tool.md | 213 +
.../UserGuide/6-System Tools/5-Log Visualizer.html | 343 +
.../UserGuide/6-System Tools/5-Log Visualizer.md | 147 +
.../6-Query History Visualization Tool.html | 306 +
.../6-Query History Visualization Tool.md | 32 +
.../6-System Tools/7-Monitor and Log Tools.html | 306 +
.../6-System Tools/7-Monitor and Log Tools.md | 257 +
.../6-System Tools/8-Load External Tsfile.html | 310 +
.../6-System Tools/8-Load External Tsfile.md | 78 +
.../7-Ecosystem Integration/1-Grafana.html | 308 +
.../UserGuide/7-Ecosystem Integration/1-Grafana.md | 136 +
.../2-MapReduce TsFile.html | 306 +
.../7-Ecosystem Integration/2-MapReduce TsFile.md | 217 +
.../7-Ecosystem Integration/3-Spark TsFile.html | 306 +
.../7-Ecosystem Integration/3-Spark TsFile.md | 24 +
.../7-Ecosystem Integration/4-Spark IoTDB.html | 306 +
.../7-Ecosystem Integration/4-Spark IoTDB.md | 23 +
.../7-Ecosystem Integration/5-Hive TsFile.html | 314 +
.../7-Ecosystem Integration/5-Hive TsFile.md | 192 +
.../8-System Design (Developer)/1-Hierarchy.html | 233 +
.../8-System Design (Developer)/1-Hierarchy.md | 3 +
.../8-System Design (Developer)/2-Files.html | 306 +
.../8-System Design (Developer)/2-Files.md | 42 +
.../3-Writing Data on HDFS.html | 306 +
.../3-Writing Data on HDFS.md | 150 +
.../4-Shared Nothing Cluster.html | 233 +
.../4-Shared Nothing Cluster.md | 5 +
.../0.9/docs/Documentation/Developers/release.adoc | 519 +
.../Documentation/OtherMaterial-Sample Data.txt | 60509 +++++++++++++++++++
.../docs/Documentation/SystemDesign/0-Content.md | 46 +
.../SystemDesign/1-TsFile/1-TsFile.md | 30 +
.../SystemDesign/1-TsFile/2-Format.md | 470 +
.../Documentation/SystemDesign/1-TsFile/3-Write.md | 22 +
.../Documentation/SystemDesign/1-TsFile/4-Read.md | 22 +
.../docs/Documentation/SystemDesign/release.adoc | 519 +
.../0.9/docs/Documentation/UserGuide/0-Content.md | 72 +
.../UserGuide/0-Get Started/1-QuickStart.html | 308 +
.../UserGuide/0-Get Started/1-QuickStart.md | 228 +
.../2-Frequently asked questions.html | 306 +
.../0-Get Started/2-Frequently asked questions.md | 124 +
.../UserGuide/0-Get Started/3-Publication.html | 233 +
.../UserGuide/0-Get Started/3-Publication.md | 9 +
.../UserGuide/1-Overview/1-What is IoTDB.html | 306 +
.../UserGuide/1-Overview/1-What is IoTDB.md | 26 +
.../UserGuide/1-Overview/2-Architecture.html | 306 +
.../UserGuide/1-Overview/2-Architecture.md | 36 +
.../UserGuide/1-Overview/3-Scenario.html | 306 +
.../UserGuide/1-Overview/3-Scenario.md | 78 +
.../UserGuide/1-Overview/4-Features.html | 306 +
.../UserGuide/1-Overview/4-Features.md | 52 +
.../2-Concept/1-Data Model and Terminology.html | 306 +
.../2-Concept/1-Data Model and Terminology.md | 221 +
.../UserGuide/2-Concept/2-Data Type.html | 306 +
.../UserGuide/2-Concept/2-Data Type.md | 44 +
.../UserGuide/2-Concept/3-Encoding.html | 306 +
.../UserGuide/2-Concept/3-Encoding.md | 68 +
.../UserGuide/2-Concept/4-Compression.html | 306 +
.../UserGuide/2-Concept/4-Compression.md | 34 +
.../UserGuide/3-Server/1-Download.html | 308 +
.../Documentation/UserGuide/3-Server/1-Download.md | 75 +
.../UserGuide/3-Server/2-Single Node Setup.html | 306 +
.../UserGuide/3-Server/2-Single Node Setup.md | 32 +
.../UserGuide/3-Server/3-Cluster Setup.html | 306 +
.../UserGuide/3-Server/3-Cluster Setup.md | 24 +
.../UserGuide/3-Server/4-Config Manual.html | 309 +
.../UserGuide/3-Server/4-Config Manual.md | 438 +
.../UserGuide/3-Server/5-Docker Image.html | 306 +
.../UserGuide/3-Server/5-Docker Image.md | 90 +
.../4-Client/1-Command Line Interface (CLI).html | 312 +
.../4-Client/1-Command Line Interface (CLI).md | 144 +
.../UserGuide/4-Client/2-Programming - JDBC.md | 275 +
.../4-Client/2-Programming - Native API.html | 306 +
.../4-Client/2-Programming - Native API.md | 127 +
.../UserGuide/4-Client/3-Programming - JDBC.html | 307 +
.../UserGuide/4-Client/3-Programming - JDBC.md | 267 +
.../UserGuide/4-Client/3-Programming - Session.md | 116 +
.../4-Client/4-Programming - Other Languages.html | 316 +
.../4-Client/4-Programming - Other Languages.md | 74 +
.../4-Client/5-Programming - TsFile API.html | 388 +
.../4-Client/5-Programming - TsFile API.md | 710 +
.../1-DDL (Data Definition Language).html | 308 +
.../1-DDL (Data Definition Language).md | 177 +
.../2-DML (Data Manipulation Language).html | 324 +
.../2-DML (Data Manipulation Language).md | 581 +
.../3-Account Management Statements.html | 306 +
.../3-Account Management Statements.md | 124 +
.../5-Operation Manual/4-SQL Reference.html | 491 +
.../5-Operation Manual/4-SQL Reference.md | 835 +
.../UserGuide/6-System Tools/1-Sync Tool.html | 490 +
.../UserGuide/6-System Tools/1-Sync Tool.md | 295 +
.../6-System Tools/2-Memory Estimation Tool.html | 331 +
.../6-System Tools/2-Memory Estimation Tool.md | 84 +
.../UserGuide/6-System Tools/3-JMX Tool.html | 306 +
.../UserGuide/6-System Tools/3-JMX Tool.md | 34 +
.../UserGuide/6-System Tools/4-Watermark Tool.html | 306 +
.../UserGuide/6-System Tools/4-Watermark Tool.md | 201 +
.../UserGuide/6-System Tools/5-Log Visualizer.html | 357 +
.../UserGuide/6-System Tools/5-Log Visualizer.md | 162 +
.../6-Query History Visualization Tool.html | 306 +
.../6-Query History Visualization Tool.md | 32 +
.../6-System Tools/7-Monitor and Log Tools.html | 309 +
.../6-System Tools/7-Monitor and Log Tools.md | 471 +
.../6-System Tools/8-Load External Tsfile.html | 312 +
.../6-System Tools/8-Load External Tsfile.md | 72 +
.../7-Ecosystem Integration/1-Grafana.html | 309 +
.../UserGuide/7-Ecosystem Integration/1-Grafana.md | 140 +
.../2-MapReduce TsFile.html | 306 +
.../7-Ecosystem Integration/2-MapReduce TsFile.md | 213 +
.../7-Ecosystem Integration/3-Spark TsFile.html | 386 +
.../7-Ecosystem Integration/3-Spark TsFile.md | 343 +
.../7-Ecosystem Integration/4-Spark IoTDB.html | 322 +
.../7-Ecosystem Integration/4-Spark IoTDB.md | 173 +
.../7-Ecosystem Integration/5-Hive TsFile.html | 315 +
.../7-Ecosystem Integration/5-Hive TsFile.md | 190 +
.../8-System Design (Developer)/1-Hierarchy.html | 309 +
.../8-System Design (Developer)/1-Hierarchy.md | 397 +
.../8-System Design (Developer)/2-Files.html | 306 +
.../8-System Design (Developer)/2-Files.md | 41 +
.../3-Writing Data on HDFS.html | 306 +
.../3-Writing Data on HDFS.md | 150 +
.../4-Shared Nothing Cluster.html | 233 +
.../4-Shared Nothing Cluster.md | 5 +
491 files changed, 278149 insertions(+)
diff --git a/incubator-iotdb/master/docs/Community/Community-History&Vision.md b/incubator-iotdb/master/docs/Community/Community-History&Vision.md
new file mode 100644
index 0000000..64fcf07
--- /dev/null
+++ b/incubator-iotdb/master/docs/Community/Community-History&Vision.md
@@ -0,0 +1,24 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# History&Vision
+
+Comming Soon.
diff --git a/incubator-iotdb/master/docs/Community/Community-Powered By.md b/incubator-iotdb/master/docs/Community/Community-Powered By.md
new file mode 100644
index 0000000..e826a95
--- /dev/null
+++ b/incubator-iotdb/master/docs/Community/Community-Powered By.md
@@ -0,0 +1,44 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+<!-- TOC -->
+
+## Outline
+
+- Powered By
+ - Project and Product names using "IoTDB"
+ - Companies and Organizations
+
+<!-- /TOC -->
+## Powered By
+
+### Project and Product names using "IoTDB"
+
+Organizations creating products and projects using Apache IoTDB, along with associated marketing materials, should take care to respect the trademark in “Apache IoTDB” and its logo. Please refer to [ASF Trademarks Guidance](https://www.apache.org/foundation/marks/) and associated [FAQ](https://www.apache.org/foundation/marks/faq/) for comprehensive and authoritative guidance on proper usage of ASF trademarks.
+It is recommended to not include “IoTDB” in any names to prevent potential trademark issue with the IoTDB project.
+As an example, names like “IoTDB BigDataProduct” should not be used, as the name include “IoTDB” in general. The above links, however, describe some exceptions, like for names such as “BigDataProduct, powered by Apache IoTDB” or “BigDataProduct for Apache IoTDB”. In summary, any names contain "Apache IoTDB" as a whole are acceptable.
+A common practice you can take is to create software identifiers (Maven coordinates, module names, etc.) like “iotdb-tool”. These are permitted. Nominative use of trademarks in descriptions is also allowed, as in “BigDataProduct is a subproduct for Apache IoTDB”.
+
+### Companies and Organizations
+To add yourself to the list, please email dev@iotdb.apache.org with your organization name, URL, a list of IoTDB components you are using, and a short description of your use case.
+
+- School of Software (Tsinghua University), and National Engineering Laboratery for Big Data Software that initially launched IoTDB
+ - We have both graduate students and a team of professional software engineers working on the stack
diff --git a/incubator-iotdb/master/docs/Community/Community-Project Committers.md b/incubator-iotdb/master/docs/Community/Community-Project Committers.md
new file mode 100644
index 0000000..518c33c
--- /dev/null
+++ b/incubator-iotdb/master/docs/Community/Community-Project Committers.md
@@ -0,0 +1,49 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# Project Committers
+
+| Name | Organization |
+| :----------- | -------------: |
+| Jianmin Wang | Tsinghua University |
+|Xiangdong Huang | Tsinghua University |
+| Jun Yuan | Tsinghua University |
+| Chen Wang | Tsinghua University |
+| Jialin Qiao | Tsinghua University |
+| Jinrui Zhang | Tsinghua University |
+| Rong Kang | Tsinghua University |
+| Tian Jiang | Tsinghua University |
+| Shuo Zhang | K2Data Company |
+| Lei Rui | Tsinghua University |
+| Rui Liu | Tsinghua University |
+| Gaofei Cao | Tsinghua University |
+| Kun Liu | Tsinghua University |
+| Xinyi Zhao | Tsinghua University |
+| Yi Xu | Tsinghua University |
+| Dongfang Mao | Tsinghua University |
+| Tianan li | Tsinghua University |
+| Yue Su | Tsinghua University |
+| Hui Da | Lenovo |
+| Yuan Tian | Tsinghua University |
+| Zesong Sun | Tsinghua University |
+| Kaifeng Xue | Tsinghua University |
+| Tianci Zhu | |
+| Jack Tsai | |
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Development/Development-Chinese.md b/incubator-iotdb/master/docs/Development/Development-Chinese.md
new file mode 100644
index 0000000..acf70de
--- /dev/null
+++ b/incubator-iotdb/master/docs/Development/Development-Chinese.md
@@ -0,0 +1,99 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 一、工作流程
+
+## 主要链接
+
+IoTDB 官网:https://iotdb.apache.org/
+
+代码库:https://github.com/apache/incubator-iotdb/tree/master
+
+快速上手:https://iotdb.apache.org/#/Documents/Quick%20Start
+
+## 订阅邮件列表
+
+邮件列表是 Apache 项目进行技术讨论和用户沟通的地方,关注邮件列表就可以收到邮件了。
+
+邮件列表地址:dev@iotdb.apache.org
+
+关注方法:用想接收邮件的邮箱向 dev-subscribe@iotdb.apache.org 发一封邮件,主题内容不限,收到回复后,再次向确认地址发一封确认邮件(确认地址比较长,推荐qq邮箱)。
+
+## 新功能、Bug 反馈、改进等
+
+所有希望 IoTDB 做的功能或修的 bug,都可以在 Jira 上提 issue:https://issues.apache.org/jira/projects/IOTDB/issues/IOTDB-9?filter=allopenissues
+
+可以选择 issue 类型:bug、improvement、new feature等。新建的 issue 会自动向邮件列表中同步邮件,之后的讨论可在 jira 上留言,也可以在邮件列表进行。当问题解决后请关闭 issue。
+
+## 邮件讨论内容(英文)
+
+* 第一次参与邮件列表可以简单介绍一下自己。(Hi, I'm xxx ...)
+
+* 开发功能前可以发邮件声明一下自己想做的任务。(Hi,I'm working on issue IOTDB-XXX,My plan is ...)
+
+## 贡献文档
+
+IoTDB 所有官网上的内容都在项目根目录的 docs 中:
+
+* docs/Documentation/SystemDesign: 系统设计文档-英文版
+* docs/Documentation-CHN/SystemDesign: 系统设计文档-中文版
+* docs/Documentation/UserGuide: 用户手册-英文版
+* docs/Documentation-CHN/UserGuide: 用户手册-中文版
+* docs/Community: 社区
+* docs/Development: 开发指南
+
+官网上的版本和分支的对应关系:
+
+* In progress -> master
+* major_version.x -> rel/major_version (如 0.9.x -> rel/0.9)
+
+注意事项:
+
+* Markdown 中的图片可上传至 https://github.com/thulab/iotdb/issues/543 获得 url
+* 新增加的系统设计文档和用户手册的 md 文件,需要在英文版对应的根目录下的 0-Content.md 中增加索引
+
+## 贡献代码
+
+可以到 jira 上领取现有 issue 或者自己创建 issue 再领取,评论说我要做这个 issue 就可以。
+
+* 克隆仓库到自己的本地的仓库,clone到本地,关联apache仓库为上游 upstream 仓库。
+* 从 master 切出新的分支,分支名根据这个分支的功能决定,一般叫 f_new_feature(如f_storage_engine) 或者 fix_bug(如fix_query_cache_bug)
+* 在 idea 中添加code style为 根目录的 java-google-style.xml
+* 修改代码,增加测试用例(单元测试、集成测试)
+ * 集成测试参考: server/src/test/java/org/apache/iotdb/db/integration/IoTDBTimeZoneIT
+* 提交 PR, 以 [IOTDB-jira号] 开头
+* 发邮件到 dev 邮件列表:(I've submitted a PR for issue IOTDB-xxx [link])
+* 根据其他人的审阅意见进行修改,继续更新,直到合并
+* 关闭 jira issue
+
+## 二、IoTDB 调试方式
+
+推荐使用 Intellij idea。```mvn clean package -DskipTests``` 之后把 ```server/target/generated-sources/antlr4``` 和 ```service-rpc/target/generated-sources/thrift``` 标记为 ```Source Root```。
+
+* 服务器主函数:```server/src/main/java/org/apache/iotdb/db/service/IoTDB```,可以debug模式启动
+* 客户端:```client/src/main/java/org/apache/iotdb/client/```,linux 用 Clinet,windows 用 WinClint,可以直接启动,需要参数"-h 127.0.0.1 -p 6667 -u root -pw root"
+* 服务器的 rpc 实现(主要用来客户端和服务器通信,一般在这里开始打断点):```server/src/main/java/org/apache/iotdb/db/service/TSServiceImpl```
+ * jdbc所有语句:executeStatement(TSExecuteStatementReq req)
+ * jdbc查询语句:executeQueryStatement(TSExecuteStatementReq req) * native写入接口:insert(TSInsertReq req)
+
+* 存储引擎 org.apache.iotdb.db.engine.StorageEngine
+* 查询引擎 org.apache.iotdb.db.qp.QueryProcessor
+
diff --git a/incubator-iotdb/master/docs/Development/Development-Contributing.md b/incubator-iotdb/master/docs/Development/Development-Contributing.md
new file mode 100644
index 0000000..247a2e2
--- /dev/null
+++ b/incubator-iotdb/master/docs/Development/Development-Contributing.md
@@ -0,0 +1,214 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+<!-- TOC -->
+
+## Outline
+- Have Questions
+ - Mailing Lists
+ - JIRA issues
+- How to contribute
+ - Becoming a committer
+ - Contributing by Helping Other Users
+ - Contributing by Testing Releases
+ - Contributing by Reviewing Changes
+ - Contributing by Documentation Changes
+ - Contributing Bug Reports
+ - Contributing Code Changes
+ - Cloning source code
+ - JIRA
+ - Pull Request
+ - The Review Process
+ - Closing Your Pull Request / JIRA
+ - Code Style
+
+<!-- /TOC -->
+
+# Have Questions
+
+## Mailing Lists
+
+It is recommended to use our mailing lists to ask for help, report issues or contribute to the project.
+dev@iotdb.apache.org is for anyone who wants to contribute codes to IoTDB or have usage questions for IoTDB.
+
+Some quick tips when using email:
+* For error logs or long code examples, please use GitHub gist and include only a few lines of the pertinent code/log within the email.
+* No jobs, sales, or solicitation is permitted on the Apache IoTDB mailing lists.
+
+PS. To subscribe our mail list, you can send an email to dev-subscribe@iotdb.incubator.apache.org and you will receive a "confirm subscribe to dev@iotdb.apache.org" email, following the steps to confirm your subscription.
+
+## JIRA issues
+
+The project tracks issues and new features on [JIRA issues](https://issues.apache.org/jira/projects/IOTDB/issues). You can create a new issue to report a bug, request a new feature or provide your custom issue.
+
+# How to contribute
+
+## Becoming a committer
+
+To become a committer, you should first be active in our community so that most of our existing committers recognize you. Pushing codes and creating pull requests is just one of the committer's rights. Moreover, it is committer's duty to help new users on the mail list, test new releases and improve documentation.
+
+### Contributing by Helping Other Users
+
+Since Apache IoTDB always attracts new users, it would be great if you can help them by answering questions on the dev@iotdb.apache.org mail list. We regard it as a valuable contribution. Also, the more questions you answer, the more people know you. Popularity is one of the necessary conditions to be a committer.
+
+Contributors should subscribe to our mailing list to catch up the latest progress.
+
+### Contributing by Testing Releases
+
+IoTDB's new release is visible to everyone, members of the community can vote to accept these releases on the dev@iotdb.apache.org mailing list. Users of IoTDB will be invited to try out on their workloads and provide feedback on any performance or correctness issues found in the newer release.
+
+### Contributing by Reviewing Changes
+
+Changes to IoTDB source codes are made through Github pull request. Anyone can review and comment on these changes. Reviewing others' pull requests can help you comprehend how a bug is fixed or a new feature is added. Besides, Learning directly from the source code will give you a deeper understanding of how IoTDB system works and where its bottlenecks lie. You can help by reviewing the changes, asking questions and pointing out issues.
+
+### Contributing by Documentation Changes
+
+To propose a change to release documentation (that is, docs that appear under <https://iotdb.apache.org/#/Documents/progress/chap1/sec1>), edit the Markdown source files in IoTDB’s docs/ directory(`documentation-EN` branch). The process to propose a doc change is otherwise the same as the process for proposing code changes below.
+
+Whenever updating **User Guide** documents, remember to update `0-Content.md` at the same time. Here are two brief examples to show how to add new documents or how to modify existing documents:
+
+1. Suppose we have "chapter 1:Overview" already, and want to add a new document `A.md` in chapter 1.
+Then,
+ * Step 1: add document named `5-A.md` in folder "1-Overview", since it is the fifth section in this chapter;
+ * Step 2: modify `0-Content.md` file by adding `* 5-A.md` in the list of "# Chapter 1: Overview".
+
+2. Suppose we want to create a new chapter "chapter7: RoadMap", and want to add a new document `B.md` in chapter 7.
+Then,
+ * Step 1: create a new folder named "7-RoadMap", and add document named `1-B.md` in folder "7-RoadMap";
+ * Step 2: modify `0-Content.md` file by adding "# Chapter 7: RoadMap" in the end, and adding `* 1-B.md` in the list of this new chapter.
+
+If you need to insert **figures** into documents, you can firstly update the figures in [this issue](https://github.com/thulab/iotdb/issues/543) for storing pictures in IoTDB website or other MD files.
+Drag a picture and then quote the figure's URL link.
+
+### Contributing Bug Reports
+
+If you encounter a problem, try to search the mailing list and JIRA to check whether other people have faced the same situation. If it is not reported before, please report an issue.
+
+Once you are sure it is a bug, it may be reported by creating a JIRA without creating a pull request. In the bug report, you should provide enough information to understand, isolate and ideally reproduce the bug. Unreproducible bugs, or simple error reports, may be closed.
+
+It’s very helpful if the bug report has a description about how the bug was introduced, by which commit, so that reviewers can easily understand the bug. It also helps committers to decide how far the bug fix should be backported, when the pull request is merged. The pull request to fix the bug should narrow down the problem to the root cause.
+
+Performance regression is also one kind of bug. The pull request to fix a performance regression must provide a benchmark to prove the problem is indeed fixed.
+
+Note that, data correctness/loss bugs are our first priority to solve. Please make sure the corresponding bug-reporting JIRA ticket is labeled as correctness or data-loss. If the bug report doesn’t gain enough attention, please include it and send an email to dev@iotdb.apache.org.
+
+### Contributing Code Changes
+
+> When you contribute code, you affirm that the contribution is your original work and that you license the work to the project under the project’s open-source license. Whether or not you state this explicitly, by submitting any copyrighted material via pull request, email, or other means you agree to license the material under the project’s open-source license and warrant that you have the legal authority to do so. Any new files contributed should be under Apache 2.0 License with a hea [...]
+
+#### Cloning source code
+
+```
+$ git clone git@github.com:apache/incubator-iotdb.git
+```
+Following `README.md` to test, run or build IoTDB.
+
+#### JIRA
+
+Generally, IoTDB uses JIRA to track logical issues, including bugs and improvements and uses Github pull requests to manage the review and merge specific code changes. That is, JIRAs are used to describe what should be fixed or changed, proposing high-level approaches. Pull requests describe how to implement that change in the project’s source code. For example, major design decisions discussed in JIRA.
+
+1. Find the existing IoTDB JIRA that the change pertains to.
+ 1. Do not create a new JIRA if you send a PR to address an existing issue labeled in JIRA; add it to the existing discussion.
+ 2. Look for existing pull requests that are linked from the JIRA, to understand if someone is already working on the JIRA
+2. If the change is new, then it usually needs a new JIRA. However, trivial changes, such as changes are self-explained, do not require a JIRA. Example: Fix spelling error in JavaDoc
+3. If required, create a new JIRA:
+ 1. Provide a descriptive Title. “Problem in XXXManager” is not sufficient. “IoTDB failed to start on jdk11 because jdk11 does not support -XX:+PrintGCDetail” is good.
+ 2. Write a detailed description. For bug reports, this should ideally include a short reproduction of the problem. For new features, it may include a design document.
+ 3. Set the required fields:
+ 1. Issue Type. Generally, Bug, Improvement and New Feature are the only types used in IoTDB.
+ 2. Priority. Set to Major or below; higher priorities are generally reserved for committers to set. The main exception is correctness or data-loss issues, which can be flagged as Blockers. JIRA tends to unfortunately conflate “size” and “importance” in its Priority field values. Their meaning is rough:
+ 1. Blocker: pointless to release without this change as the release would be unusable to a large minority of users. Correctness and data loss issues should be considered Blockers.
+ 2. Critical: a large minority of users are missing important functionality without this, and/or a workaround is difficult
+ 3. Major: a small minority of users are missing important functionality without this, and there is a workaround
+ 4. Minor: a niche use case is missing some support, but it does not affect usage or is easily worked around
+ 5. Trivial: a nice-to-have change but unlikely to be any problem in practice otherwise
+ 3. Affected Version. For Bugs, assign at least one version that is known to reproduce the issue or need to be changed
+ 4. Label. Not widely used, except for the following:
+ * correctness: a correctness issue
+ * data-loss: a data loss issue
+ * release-notes: the change’s effects need mention in release notes. The JIRA or pull request should include detail suitable for inclusion in release notes – see “Docs Text” below.
+ * starter: small, simple change suitable for new contributors
+ 5. Docs Text: For issues that require an entry in the release notes, this should contain the information that the release manager should include. Issues should include a short summary of what behavior is impacted, and detail on what behavior changed. It can be provisionally filled out when the JIRA is opened, but will likely need to be updated with final details when the issue is resolved.
+ 4. Do not set the following fields:
+ 1. Fix Version. This is assigned by committers only when resolved.
+ 2. Target Version. This is assigned by committers to indicate a PR has been accepted for possible fix by the target version.
+ 5. Do not include a patch file; pull requests are used to propose the actual change.
+4. If the change is a large change, consider raising a discussion on it at dev@iotdb.apache.org first before proceeding to implement the change. Currently, we use https://cwiki.apache.org/confluence/display/IOTDB to store design proposals and release process. Users can also send them there.
+
+
+#### Pull Request
+
+1. Fork the Github repository at https://github.com/apache/incubator-iotdb if you haven’t done already.
+2. Clone your fork, create a new branch, push commits to the branch.
+3. Please add documentation and tests to explain/cover your changes.
+Run all tests with [How to test](https://github.com/thulab/iotdb/wiki/How-to-test-IoTDB) to verify your change.
+4. Open a pull request against the master branch of IoTDB. (Only in special cases would the PR be opened against other branches.)
+ 1. The PR title should be in the form of "IoTDB-xxxx", where xxxx is the relevant JIRA number.
+ 2. If the pull request is still under work in progress stage but needs to be pushed to Github to request for review, please add "WIP" after the PR title.
+ 3. Consider identifying committers or other contributors who have worked on the code being changed. Find the file(s) in Github and click “Blame” to see a line-by-line annotation of who changed the code last. You can add @username in the PR description to ping them immediately.
+ 4. Please state that the contribution is your original work and that you license the work to the project under the project’s open source license.
+5. The related JIRA, if any, will be marked as “In Progress” and your pull request will automatically be linked to it. There is no need to be the Assignee of the JIRA to work on it, though you are welcome to comment that you have begun work.
+6. The Jenkins automatic pull request builder will test your changes
+ 1. If it is your first contribution, Jenkins will wait for confirmation before building your code and post “Can one of the admins verify this patch?”
+ 2. A committer can authorize testing with a comment like “ok to test”
+ 3. A committer can automatically allow future pull requests from a contributor to be tested with a comment like “Jenkins, add to whitelist”
+7. Watch for the results, and investigate and fix failures promptly
+ 1. Fixes can simply be pushed to the same branch from which you opened your pull request
+ 2. Jenkins will automatically re-test when new commits are pushed
+ 3. If the tests failed for reasons unrelated to the change (e.g. Jenkins outage), then a committer can request a re-test with “Jenkins, retest this please”. Ask if you need a test restarted. If you were added by “Jenkins, add to whitelist” from a committer before, you can also request the re-test.
+
+#### The Review Process
+
+* Other reviewers, including committers, may comment on the changes and suggest modifications. Changes can be added by simply pushing more commits to the same branch.
+* Lively, polite, rapid technical debate is encouraged by everyone in the community. The outcome may be a rejection of the entire change.
+* Keep in mind that changes to more critical parts of IoTDB, like its read/write data from/to disk, will be subjected to more review, and may require more testing and proof of its correctness than other changes.
+* Reviewers can indicate that a change looks suitable for merging with a comment such as: “I think this patch looks good” or "LGTM". If you comment LGTM, you will be expected to help with bugs or follow-up issues on the patch. Consistent, judicious use of LGTMs is a great way to gain credibility as a reviewer with the broader community.
+* Sometimes, other changes will be merged which conflict with your pull request’s changes. The PR can’t be merged until the conflict is resolved. This can be resolved by, for example, adding a remote to keep up with upstream changes by
+
+```shell
+git remote add upstream git@github.com:apache/incubator-iotdb.git
+git fetch upstream
+git rebase upstream/master
+# or you can use `git pull --rebase upstream master` to replace the above two commands
+# resolve your conflicts
+# push codes to your branch
+```
+
+* Try to be responsive to the discussion rather than let days pass between replies
+
+#### Closing Your Pull Request / JIRA
+* If a change is accepted, it will be merged, and the pull request will automatically be closed, along with the associated JIRA if any
+ * Note that in the rare case you are asked to open a pull request against a branch beside the master, you actually have to close the pull request manually
+ * The JIRA will be Assigned to the primary contributor to the change as a way of giving credit. If the JIRA isn’t closed and/or Assigned promptly, comment on the JIRA.
+* If your pull request is ultimately rejected, please close it promptly
+ * … because committers can’t close PRs directly
+ * Pull requests will be automatically closed by an automated process at Apache after about a week if a committer has made a comment like “mind closing this PR?” This means that the committer is specifically requesting that it be closed.
+* If a pull request has gotten little or no attention, consider improving the description or the change itself and ping likely reviewers again after a few days. Consider proposing a change that’s easier to include, like a smaller and/or less invasive change.
+* If it has been reviewed but not taken up after weeks, after soliciting review from the most relevant reviewers, or, has met with neutral reactions, the outcome may be considered a “soft no”. It is helpful to withdraw and close the PR in this case.
+* If a pull request is closed because it is deemed not the right approach to resolve a JIRA, then leave the JIRA open. However, if the review makes it clear that the issue identified in the JIRA is not going to be resolved by any pull request (not a problem, won’t fix) then also resolve the JIRA
+
+#### Code Style
+
+For Java code, Apache IoTDB follows Google’s Java Style Guide.
+
+#### Unit Test
+
+When writing unit tests, note the path to generate the test file at test time, which we require to be generated in the `target` directory and placed under the `constant` package for each test project
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Development/Development-Document.md b/incubator-iotdb/master/docs/Development/Development-Document.md
new file mode 100644
index 0000000..56677a0
--- /dev/null
+++ b/incubator-iotdb/master/docs/Development/Development-Document.md
@@ -0,0 +1,51 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+Documents of Apache IoTDB (incubating) are open source. If you have found any mistakes and would like to contribute, here is a brief step:
+
+## Contributing by Documentation Changes
+
+### Fork and open pull Request
+
+1. Fork the Github repository at https://github.com/apache/incubator-iotdb if you haven’t done already.
+2. Clone your fork, create a new branch, push commits to the branch.
+3. Open a pull request against the master branch of IoTDB. (Only in special cases would the PR be opened against other branches.) Please state that the contribution is your original work and that you license the work to the project under the project’s open source license.
+
+### Documentation Changes
+
+To propose a change to release documentation (that is, docs that appear under <https://iotdb.apache.org/#/Documents/progress/chap1/sec1>), edit the Markdown source files in IoTDB’s docs/ directory(`documentation-EN` branch). The process to propose a doc change is otherwise the same as the process for proposing code changes below.
+
+Whenever updating **User Guide** documents, remember to update `0-Content.md` at the same time. Here are two brief examples to show how to add new documents or how to modify existing documents:
+
+1. Suppose we have "chapter 1:Overview" already, and want to add a new document `A.md` in chapter 1.
+Then,
+ * Step 1: add document named `5-A.md` in folder "1-Overview", since it is the fifth section in this chapter;
+ * Step 2: modify `0-Content.md` file by adding `* 5-A.md` in the list of "# Chapter 1: Overview".
+
+2. Suppose we want to create a new chapter "chapter7: RoadMap", and want to add a new document `B.md` in chapter 7.
+Then,
+ * Step 1: create a new folder named "7-RoadMap", and add document named `1-B.md` in folder "7-RoadMap";
+ * Step 2: modify `0-Content.md` file by adding "# Chapter 7: RoadMap" in the end, and adding `* 1-B.md` in the list of this new chapter.
+
+If you need to insert **figures** into documents, you can firstly update the figures in [this issue](https://github.com/thulab/iotdb/issues/543) for storing pictures in IoTDB website or other MD files.
+Drag a picture and then quote the figure's URL link.
+
+> If you want to contribute more (for example, reviewing Changes, reporting bugs, or even being commiters), please refer to [this page](/#/Development/Contributing).
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Development/Development-IDE.md b/incubator-iotdb/master/docs/Development/Development-IDE.md
new file mode 100644
index 0000000..45e93e2
--- /dev/null
+++ b/incubator-iotdb/master/docs/Development/Development-IDE.md
@@ -0,0 +1,65 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+<!-- TOC -->
+
+## Outline
+- How to develop IoTDB in IDE
+ - IDEA
+ - Eclipse
+ - Debugging IoTDB
+
+<!-- /TOC -->
+# How to develop IoTDB in IDE
+
+There are many ways to compile the source code of IoTDB,
+e.g., modify and compile with IDEA or Eclipse.
+
+Once all UTs are passed after you modify codes, your modification basically works!
+
+## IDEA
+
+* "File" -> "Open" -> choose the root path of IoTDB source code.
+* use `mvn clean compile -Dmaven.test.skip=true`to get target.
+* mark directory ***server/target/generated-sources/antlr4*** as source code
+* mark directory ***service-rpc/target/generated-sources/thrift*** as source code
+
+## Eclipse
+
+Using Eclipse to develop IoTDB is also simple but requires some plugins of Eclipse.
+
+- If your Eclipse version is released before 2019, Antlr plugin maybe not work in Eclipse. In this way, you have to run the command in your console first: `mvn eclipse:eclipse -DskipTests`.
+After the command is done, you can import IoTDB as an existing project:
+ - Choose menu "import" -> "General" -> "Existing Projects into Workspace" -> Choose IoTDB
+ root path;
+ - Done.
+
+- If your Eclipse version is fashion enough (e.g., you are using the latest version of Eclipse),
+you can just choose menu "import" -> "Maven" -> "Existing Maven Projects".
+
+## Debugging IoTDB
+The main class of IoTDB server is `org.apache.iotdb.db.service.IoTDB`.
+The main class of IoTDB cli is `org.apache.iotdb.client.Client`
+(or `org.apache.iotdb.client.WinClient` on Win OS).
+
+You can run/debug IoTDB by using the two classes as the entrance.
+
+Another way to understand IoTDB is to read and try Unit Tests.
diff --git a/incubator-iotdb/master/docs/Development/Development-VoteRelease.md b/incubator-iotdb/master/docs/Development/Development-VoteRelease.md
new file mode 100644
index 0000000..db95aab
--- /dev/null
+++ b/incubator-iotdb/master/docs/Development/Development-VoteRelease.md
@@ -0,0 +1,198 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# How to vote for a release (如何给发布版本投票)
+
+For non-Chinese users, please read https://cwiki.apache.org/confluence/display/IOTDB/Validating+a+staged+Release
+
+## 下载投票的 版本/rc 下的所有内容
+
+https://dist.apache.org/repos/dist/dev/incubator/iotdb/
+
+## 导入发布经理的公钥
+
+https://dist.apache.org/repos/dist/dev/incubator/iotdb/KEYS
+
+最下边有 Release Manager (RM) 的公钥
+
+安装 gpg2
+
+### 第一种方法
+
+```
+公钥的开头是这种
+pub rsa4096 2019-10-15 [SC]
+ 10F3B3F8A1201B79AA43F2E00FC7F131CAA00430
+
+或这种
+
+pub rsa4096/28662AC6 2019-12-23 [SC]
+```
+
+下载公钥
+
+```
+gpg2 --receive-keys 10F3B3F8A1201B79AA43F2E00FC7F131CAA00430 (或 28662AC6)
+
+或 (指定 keyserver)
+gpg2 --keyserver p80.pool.sks-keyservers.net --recv-keys 10F3B3F8A1201B79AA43F2E00FC7F131CAA00430 (或 28662AC6)
+```
+
+### 第二种方法
+
+把下边这段复制到一个文本文件中,起个名叫 ```key.asc```
+
+```
+-----BEGIN PGP PUBLIC KEY BLOCK-----
+Version: GnuPG v2
+...
+-----END PGP PUBLIC KEY BLOCK-----
+```
+
+导入 RM 的公钥到自己电脑
+
+```
+gpg2 --import key.asc
+```
+
+## 验证源码发布版
+
+* (孵化阶段)验证是否名字中有 ```incubating```
+
+* 验证是否有 DISCLAIMER、NOTICE、LICENSE,以及内容是否正确。
+
+* 验证 README、RELEASE_NOTES
+
+* 验证 header
+
+```
+mvn -B apache-rat:check
+```
+
+* 验证签名和哈希值
+
+```
+gpg2 --verify apache-iotdb-0.9.0-incubating-source-release.zip.asc apache-iotdb-0.9.0-incubating-source-release.zip
+
+出现 Good Singnature
+
+shasum -a512 apache-iotdb-0.9.0-incubating-source-release.zip
+
+和对应的 .sha512 对比,一样就可以。
+```
+
+* 验证编译
+
+```
+mvnw.sh install
+
+应该最后全 SUCCESS
+```
+
+## 验证二进制发布版
+
+* (孵化阶段)验证是否名字中有 ```incubating```
+
+* 验证是否有 DISCLAIMER、NOTICE、LICENSE,以及内容是否正确。
+
+* 验证 README、RELEASE_NOTES
+
+* 验证签名和哈希值
+
+```
+gpg2 --verify apache-iotdb-0.9.0-incubating-bin.zip.asc apache-iotdb-0.9.0-incubating-bin.zip
+
+出现 Good Singnature
+
+shasum -a512 apache-iotdb-0.9.0-incubating-bin.zip
+
+和对应的 .sha512 对比,一样就可以。
+```
+
+* 验证是否能启动以及示例语句是否正确执行
+
+```
+./sbin/start-server.sh
+
+./sbin/start-client.sh
+
+SET STORAGE GROUP TO root.turbine;
+CREATE TIMESERIES root.turbine.d1.s0 WITH DATATYPE=DOUBLE, ENCODING=GORILLA;
+insert into root.turbine.d1(timestamp,s0) values(1,1);
+insert into root.turbine.d1(timestamp,s0) values(2,2);
+insert into root.turbine.d1(timestamp,s0) values(3,3);
+select * from root;
+
+打印如下内容:
++-----------------------------------+------------------+
+| Time|root.turbine.d1.s0|
++-----------------------------------+------------------+
+| 1970-01-01T08:00:00.001+08:00| 1.0|
+| 1970-01-01T08:00:00.002+08:00| 2.0|
+| 1970-01-01T08:00:00.003+08:00| 3.0|
++-----------------------------------+------------------+
+
+```
+
+## 示例邮件
+
+验证通过之后可以发邮件了
+
+```
+Hi,
+
++1 (PMC could binding)
+
+The source release:
+Incubating in name [ok]
+Has DISCLAIMER [ok]
+LICENSE and NOTICE [ok]
+signatures and hashes [ok]
+All files have ASF header [ok]
+could compile from source: ./mvnw.sh clean install [ok]
+
+The binary distribution:
+Incubating in name [ok]
+Has DISCLAIMER [ok]
+LICENSE and NOTICE [ok]
+signatures and hashes [ok]
+Could run with the following statements [ok]
+
+SET STORAGE GROUP TO root.turbine;
+CREATE TIMESERIES root.turbine.d1.s0 WITH DATATYPE=DOUBLE, ENCODING=GORILLA;
+insert into root.turbine.d1(timestamp,s0) values(1,1);
+insert into root.turbine.d1(timestamp,s0) values(2,2);
+insert into root.turbine.d1(timestamp,s0) values(3,3);
+select * from root;
+
+Thanks,
+xxx
+```
+
+
+## 小工具
+
+* 打印出包含某些字符的行(只看最上边的输出就可以,下边的文件不需要看)
+
+```
+find . -type f -exec grep -i "copyright" {} \; -print | sort -u
+find **/src -type f -exec grep -i "copyright" {} \; -print | sort -u
+```
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/0-Architecture/1-Architecture.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/0-Architecture/1-Architecture.md
new file mode 100644
index 0000000..676b4e8
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/0-Architecture/1-Architecture.md
@@ -0,0 +1,55 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 应用概览
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/73625222-ddd88680-467e-11ea-9098-e808ed4979c5.png">
+
+物联网时序数据库 Apache IoTDB 的架构图如上所示,覆盖了对时序数据的采集、存储、查询、分析以及可视化等全生命周期的数据管理功能,其中灰色部分为 IoTDB 组件。
+
+## IoTDB 架构介绍
+
+IoTDB 采用客户端-服务器架构,如下图所示。
+
+<img style="width:100%; max-width:400px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/73625221-ddd88680-467e-11ea-9cf3-70367e5886f4.png">
+
+其中服务器端主要包括查询引擎,用来处理用户的所有请求,并分发到对应的管理组件,包括数据写入层、数据查询、元数据管理、权限管理等模块。
+
+* [数据文件](/#/SystemDesign/progress/chap1/sec1)
+* [查询引擎](/#/SystemDesign/progress/chap2/sec1)
+* [元数据管理](/#/SystemDesign/progress/chap3/sec1)
+* [存储引擎](/#/SystemDesign/progress/chap4/sec1)
+* [数据查询](/#/SystemDesign/progress/chap5/sec1)
+
+## 系统工具
+
+* [数据同步工具](/#/SystemDesign/progress/chap6/sec1)
+
+## 连接器
+
+IoTDB 与大数据系统进行了对接。
+
+* [Hadoop-TsFile](/#/SystemDesign/progress/chap7/sec1)
+* [Hive-TsFile](/#/SystemDesign/progress/chap7/sec2)
+* [Spark-TsFile](/#/SystemDesign/progress/chap7/sec3)
+* [Spark-IoTDB](/#/SystemDesign/progress/chap7/sec4)
+* [Grafana](/#/SystemDesign/progress/chap7/sec5)
+
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/1-TsFile.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/1-TsFile.md
new file mode 100644
index 0000000..4cf33ae
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/1-TsFile.md
@@ -0,0 +1,31 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 数据文件
+
+TsFile 是 IoTDB 的底层数据文件,专门为时间序列数据设计的列式文件格式。
+
+
+## 相关文档
+
+* [文件格式](/#/SystemDesign/progress/chap1/sec2)
+* [写流程](/#/SystemDesign/progress/chap1/sec3)
+* [读流程](/#/SystemDesign/progress/chap1/sec4)
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/2-Format.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/2-Format.md
new file mode 100644
index 0000000..3db4efb
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/2-Format.md
@@ -0,0 +1,470 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# TsFile 文件格式
+
+
+## 1. TsFile 设计
+
+ 本章是关于 TsFile 的设计细节。
+
+### 1.1 变量的存储
+
+- **大端存储**
+ - 比如: `int` `0x8` 将会被存储为 `00 00 00 08`, 而不是 `08 00 00 00`
+- **可变长的字符串类型**
+ - 存储的方式是以一个 `int` 类型的 `Size` + 字符串组成。`Size` 的值可以为 0。
+ - `Size` 指的是字符串所占的字节数,它并不一定等于字符串的长度。
+ - 举例来说,"sensor_1" 这个字符串将被存储为 `00 00 00 08` + "sensor_1" (ASCII编码)。
+ - 另外需要注意的一点是文件签名 "TsFile000001" (`Magic String` + `Version`), 因为他的 `Size(12)` 和 ASCII 编码值是固定的,所以没有必要在这个字符串前的写入 `Size` 值。
+- **数据类型**
+ - 0: BOOLEAN
+ - 1: INT32 (`int`)
+ - 2: INT64 (`long`)
+ - 3: FLOAT
+ - 4: DOUBLE
+ - 5: TEXT (`String`)
+- **编码类型**
+ - 0: PLAIN
+ - 1: PLAIN_DICTIONARY
+ - 2: RLE
+ - 3: DIFF
+ - 4: TS_2DIFF
+ - 5: BITMAP
+ - 6: GORILLA
+ - 7: REGULAR
+- **压缩类型**
+ - 0: UNCOMPRESSED
+ - 1: SNAPPY
+- **预聚合信息**
+ - 0: min_value
+ - 1: max_value
+ - 2: first_value
+ - 3: last_value
+ - 4: sum_value
+
+### 1.2 TsFile 概述
+
+下图是关于TsFile的结构图。
+
+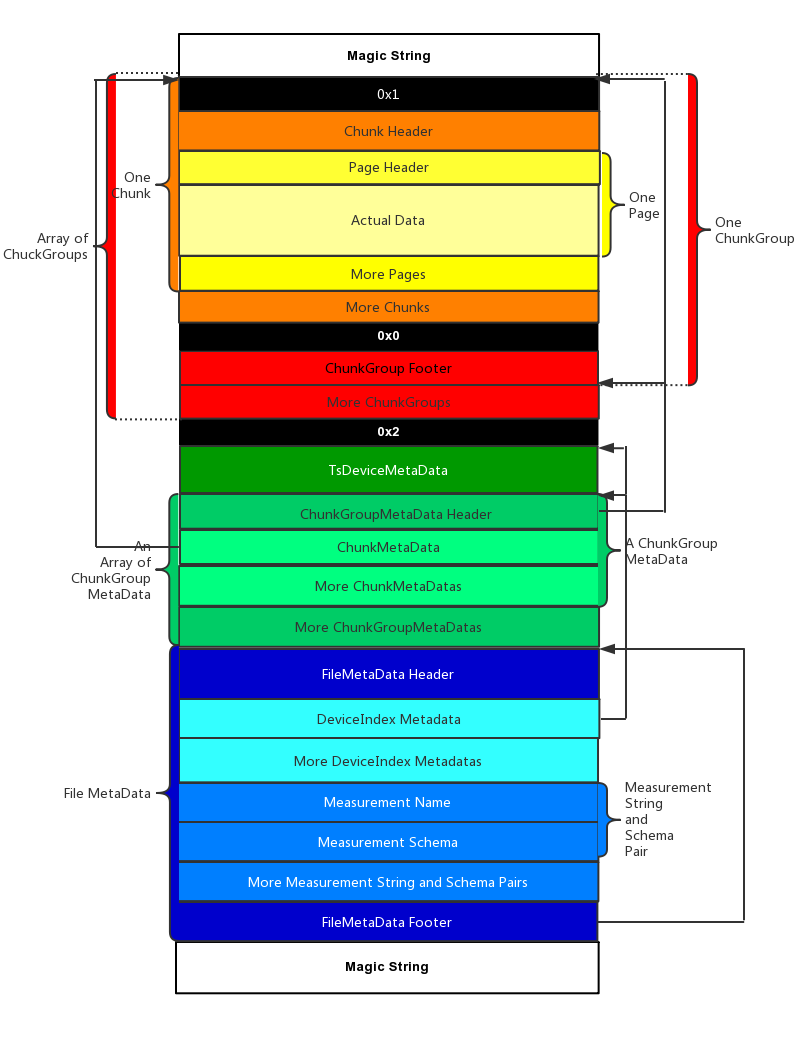
+
+#### 1.2.1 文件签名和版本号
+
+TsFile 是由 6 个字节的 "Magic String" (`TsFile`) 和 6 个字节的版本号 (`000001`)组成。
+
+
+#### 1.2.2 数据文件
+
+TsFile文件的内容可以划分为两个部分: 数据和元数据。数据和元数据之间是由一个字节的 `0x02` 做为分隔符。
+
+`ChunkGroup` 存储了一个 *设备(device)* 一段时间的数据。
+
+##### ChunkGroup
+
+`ChunkGroup` 由若干个 `Chunk`, 一个字节的分隔符 `0x00` 和 一个`ChunkFooter`组成。
+
+##### Chunk
+
+一个 `Chunk` 存储了一个 *传感器(sensor)* 的数据。`Chunk` 是由一个字节的分隔符 `0x01`, 一个 `ChunkHeader` 和若干个 `Page` 构成。
+
+##### ChunkHeader
+
+| 成员 | 类型 |
+| :--------------------------: | :----: |
+| 传感器名称(measurementID) | String |
+| chunk大小(dataSize) | int |
+| chunk的数据类型(dataType) | short |
+| 包含的page数量(numOfPages) | int |
+| 压缩类型(compressionType) | short |
+| 编码类型(encodingType) | short |
+| Max Tombstone Time(暂时没用) | long |
+
+##### Page
+
+一个 `Page` 页存储了 `Chunk` 的一些数据。 它包含一个 `PageHeader` 和实际的数据(time-value 编码的键值对)。
+
+PageHeader 结构
+
+| 成员 | 类型 |
+| :----------------------------------: | :--------------: |
+| 压缩前数据大小(uncompressedSize) | int |
+| SNAPPY压缩后数据大小(compressedSize) | int |
+| 包含的values的数量(numOfValues) | int |
+| 最大时间戳(maxTimestamp) | long |
+| 最小时间戳(minTimestamp) | long |
+| 该页最大值(max) | Type of the page |
+| 该页最小值(min) | Type of the page |
+| 该页第一个值(first) | Type of the page |
+| 该页值的和(sum) | double |
+| 该页最后一个值(last) | Type of the page |
+
+##### ChunkGroupFooter
+
+| 成员 | 类型 |
+| :--------------------------------: | :----: |
+| 设备Id(deviceID) | String |
+| ChunkGroup大小(dataSize) | long |
+| 包含的chunks的数量(numberOfChunks) | int |
+
+#### 1.2.3 元数据
+
+##### 1.2.3.1 TsDeviceMetaData
+
+第一部分的元数据是 `TsDeviceMetaData`
+
+| 成员 | 类型 |
+| :----------------------------------------------: | :--: |
+| 开始时间(startTime) | long |
+| 结束时间(endTime) | long |
+| 包含的ChunkGroup的数量 | int |
+| 所有的ChunkGroupMetaData(chunkGroupMetadataList) | list |
+
+###### ChunkGroupMetaData
+
+| 成员 | 类型 |
+| :-----------------------------------------------------: | :----: |
+| 设备Id(deviceID) | String |
+| 在文件中ChunkGroup开始的偏移量(startOffsetOfChunkGroup) | long |
+| 在文件中ChunkGroup结束的偏移量(endOffsetOfChunkGroup) | long |
+| 版本(version) | long |
+| 包含的ChunkMetaData的数量 | int |
+| 所有的ChunkMetaData(chunkMetaDataList) | list |
+
+###### ChunkMetaData
+
+| 成员 | 类型 |
+| :------------------------------------------------: | :------: |
+| 传感器名称(measurementUid) | String |
+| 文件中ChunkHeader开始的偏移量(offsetOfChunkHeader) | long |
+| 数据的总数(numOfPoints) | long |
+| 开始时间(startTime) | long |
+| 结束时间(endTime) | long |
+| 数据类型(tsDataType) | short |
+| chunk的统计信息 | TsDigest |
+
+###### TsDigest
+
+目前有五项统计数据: `min_value, max_value, first_value, last_value, sum_value`。
+
+在 v0.8.0 版本中, 统计数据使用 name-value 编码的键值对。 也就是 `Map<String, ByteBuffer> statistics`。 name使用的一个字符串类型(需要注意的是字符串前有个长度标识)。 对于值来讲,它有可能是很多种类型,所以需要用 integer 类型用来描述值的长度。 比如, 如果 `min_value` 是一个 integer 类型的 0, 那么在 TsFile 中将被存储为 [9 "min_value" 4 0]。
+
+下面是一个调用 `TsDigest.deserializeFrom(buffer)` 方法后的数据示例。在 v0.8.0 版本中, 我们会得到
+
+```
+Map<String, ByteBuffer> statistics = {
+ "min_value" -> ByteBuffer of int value 0,
+ "last" -> ByteBuffer of int value 19,
+ "sum" -> ByteBuffer of double value 1093347116,
+ "first" -> ByteBuffer of int value 0,
+ "max_value" -> ByteBuffer of int value 99
+}
+```
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/33376433/63765352-664a4280-c8fb-11e9-869e-859edf6d00bb.png">
+
+在 v0.9.0 版本中, 为了提高空间和时间的效率,存储的结构被修改为数组的形式。也就是 `ByteBuffer[] statistics`。用固定的位置代表某一个具体的统计信息, 在 StatisticType 中定义的顺序如下:
+
+```
+enum StatisticType {
+ min_value, max_value, first_value, last_value, sum_value
+}
+```
+
+修改存储形式后,在上面的示例中,我们将得到
+
+```
+ByteBuffer[] statistics = [
+ ByteBuffer of int value 0, // associated with "min_value"
+ ByteBuffer of int value 99, // associated with "max_value"
+ ByteBuffer of int value 0, // associated with "first_value"
+ ByteBuffer of int value 19, // associated with "last_value"
+ ByteBuffer of double value 1093347116 // associated with "sum_value"
+]
+```
+
+另一个关于 v0.9.0 的示例数据, 当我们从 buffer [3, 0,4,0, 1,4,99, 3,4,19] 反序列化为 TsDigest 结构时, 我们将得到
+
+```
+//这里可能会有些难理解,读取顺序为:1.读取一个int类型的数据总数(3) 2.读取short类型的位于数组中的位置(0) 3.读取int类型的数据长度(4) 4.根据第3步的长度读取数据(0)
+//因为示例数据中,索引值只出现了(0,1,3),所以 first_value sum_value 的值为null
+
+ByteBuffer[] statistics = [
+ ByteBuffer of int value 0, // associated with "min_value"
+ ByteBuffer of int value 99, // associated with "max_value"
+ null, // associated with "first_value"
+ ByteBuffer of int value 19, // associated with "last_value"
+ null // associated with "sum_value"
+]
+```
+
+##### 1.2.3.2 TsFileMetaData
+
+上节讲到的是 `TsDeviceMetadatas` 紧跟其后的数据是 `TsFileMetaData`。
+
+| 成员 | 类型 |
+| :-------------------------------------------------: | :--------------------------------: |
+| 包含的设备个数 | int |
+| 设备名称和设备元数据索引的键值对(deviceIndexMap) | String, TsDeviceMetadataIndex pair |
+| 包含的传感器个数 | int |
+| 传感器名称和传感器元数据的键值对(measurementSchema) | String, MeasurementSchema pair |
+| 水印标识 | byte |
+| 当标识为0x01时的水印信息(createdBy) | String |
+| 包含的Chunk总数(totalChunkNum) | int |
+| 失效的Chunk总数(invalidChunkNum) | int |
+| 布隆过滤器序列化大小 | int |
+| 布隆过滤器所有数据 | byte[Bloom filter size] |
+| 布隆过滤器容量 | int |
+| 布隆过滤器容量包含的HashFunction数量 | int |
+
+###### TsDeviceMetadataIndex
+
+| 成员 | 类型 |
+| :------------------------------------: | :----: |
+| 设备名 | String |
+| 文件中TsDeviceMetaData的偏移量(offset) | long |
+| 序列化后数据大小(len) | int |
+| 存储的设备最小时间(startTime) | long |
+| 存储的设备最大时间(endTime) | long |
+
+###### MeasurementSchema
+
+| 成员 | 类型 |
+| :-----------------------: | :-----------------: |
+| 传感器名称(measurementId) | String |
+| 数据类型(type) | short |
+| 编码方式(encoding) | short |
+| 压缩方式(compressor) | short |
+| 附带参数的数量 | int |
+| 所有附带的参数(props) | String, String pair |
+
+如果附带的参数数量大于 0, 传感器的附带参数会以一个数组形式的 <String, String> 键值对存储。
+
+比如说: "max_point_number""2".
+
+##### 1.2.3.3 TsFileMetadataSize
+
+在TsFileMetaData之后,有一个int值用来表示TsFileMetaData的大小。
+
+
+#### 1.2.4 Magic String
+
+TsFile 是以6个字节的magic string (`TsFile`) 作为结束.
+
+
+恭喜您, 至此您已经完成了 TsFile 的探秘之旅,祝您玩儿的开心!
+
+### 1.3 TsFile工具集
+
+#### 1.3.1 IoTDB Data Directory 快速概览工具
+
+该工具的启动脚本会在编译 server 之后生成至 `server\target\iotdb-server-0.10.0\tools\tsfileToolSet` 目录中。
+
+使用方式:
+
+For Windows:
+
+```
+.\print-iotdb-data-dir.bat <IoTDB数据文件夹路径,如果是多个文件夹用逗号分隔> (<输出结果的存储路径>)
+```
+
+For Linux or MacOs:
+
+```
+./print-iotdb-data-dir.sh <IoTDB数据文件夹路径,如果是多个文件夹用逗号分隔> (<输出结果的存储路径>)
+```
+
+在Windows系统中的示例:
+
+```
+D:\incubator-iotdb\server\target\iotdb-server-0.10.0-SNAPSHOT\tools\tsfileToolSet>.\print-iotdb-data-dir.bat D:\\data\data
+````````````````````````
+Starting Printing the IoTDB Data Directory Overview
+````````````````````````
+output save path:IoTDB_data_dir_overview.txt
+TsFile data dir num:1
+21:17:38.841 [main] WARN org.apache.iotdb.tsfile.common.conf.TSFileDescriptor - Failed to find config file iotdb-engine.properties at classpath, use default configuration
+|==============================================================
+|D:\\data\data
+|--sequence
+| |--root.ln.wf01.wt01
+| | |--1575813520203-101-0.tsfile
+| | |--1575813520203-101-0.tsfile.resource
+| | | |--device root.ln.wf01.wt01, start time 1 (1970-01-01T08:00:00.001+08:00[GMT+08:00]), end time 5 (1970-01-01T08:00:00.005+08:00[GMT+08:00])
+| | |--1575813520669-103-0.tsfile
+| | |--1575813520669-103-0.tsfile.resource
+| | | |--device root.ln.wf01.wt01, start time 100 (1970-01-01T08:00:00.100+08:00[GMT+08:00]), end time 300 (1970-01-01T08:00:00.300+08:00[GMT+08:00])
+| | |--1575813521372-107-0.tsfile
+| | |--1575813521372-107-0.tsfile.resource
+| | | |--device root.ln.wf01.wt01, start time 500 (1970-01-01T08:00:00.500+08:00[GMT+08:00]), end time 540 (1970-01-01T08:00:00.540+08:00[GMT+08:00])
+|--unsequence
+| |--root.ln.wf01.wt01
+| | |--1575813521063-105-0.tsfile
+| | |--1575813521063-105-0.tsfile.resource
+| | | |--device root.ln.wf01.wt01, start time 10 (1970-01-01T08:00:00.010+08:00[GMT+08:00]), end time 50 (1970-01-01T08:00:00.050+08:00[GMT+08:00])
+|==============================================================
+````````````````````````
+
+#### 1.3.2 TsFileResource 打印工具
+
+该工具的启动脚本会在编译 server 之后生成至 `server\target\iotdb-server-0.10.0\tools\tsfileToolSet` 目录中。
+
+使用方式:
+
+Windows:
+
+```
+.\print-tsfile-sketch.bat <TsFileResource文件夹路径>
+```
+
+Linux or MacOs:
+
+```
+./print-tsfile-sketch.sh <TsFileResource文件夹路径>
+```
+
+在Windows系统中的示例:
+
+```
+D:\incubator-iotdb\server\target\iotdb-server-0.10.0\tools\tsfileToolSet>.\print-tsfile-resource-files.bat D:\data\data\sequence\root.vehicle
+````````````````````````
+Starting Printing the TsFileResources
+````````````````````````
+12:31:59.861 [main] WARN org.apache.iotdb.db.conf.IoTDBDescriptor - Cannot find IOTDB_HOME or IOTDB_CONF environment variable when loading config file iotdb-engine.properties, use default configuration
+analyzing D:\data\data\sequence\root.vehicle\1572496142067-101-0.tsfile ...
+device root.vehicle.d0, start time 3000 (1970-01-01T08:00:03+08:00[GMT+08:00]), end time 100999 (1970-01-01T08:01:40.999+08:00[GMT+08:00])
+analyzing the resource file finished.
+````````````````````````
+
+#### 1.3.3 TsFile 描述工具
+
+该工具的启动脚本会在编译 server 之后生成至 `server\target\iotdb-server-0.10.0\tools\tsfileToolSet` 目录中。
+
+使用方式:
+
+Windows:
+
+```
+.\print-tsfile-sketch.bat <TsFile文件路径> (<输出结果的存储路径>)
+```
+
+- 注意: 如果没有设置输出文件的存储路径, 将使用 "TsFile_sketch_view.txt" 做为默认值。
+
+Linux or MacOs:
+
+```
+./print-tsfile-sketch.sh <TsFile文件路径> (<输出结果的存储路径>)
+```
+
+- 注意: 如果没有设置输出文件的存储路径, 将使用 "TsFile_sketch_view.txt" 做为默认值。
+
+在Windows系统中的示例:
+
+```$xslt
+D:\incubator-iotdb\server\target\iotdb-server-0.10.0\tools\tsfileToolSet>.\print-tsfile-sketch.bat D:\data\data\sequence\root.vehicle\1572496142067-101-0.tsfile
+````````````````````````
+Starting Printing the TsFile Sketch
+````````````````````````
+TsFile path:D:\data\data\sequence\root.vehicle\1572496142067-101-0.tsfile
+Sketch save path:TsFile_sketch_view.txt
+-------------------------------- TsFile Sketch --------------------------------
+file path: D:\data\data\sequence\root.vehicle\1572496142067-101-0.tsfile
+file length: 187382
+
+ POSITION| CONTENT
+ -------- -------
+ 0| [magic head] TsFile
+ 6| [version number] 000001
+||||||||||||||||||||| [Chunk Group] of root.vehicle.d0 begins at pos 12, ends at pos 186469, version:102, num of Chunks:6
+ 12| [Chunk] of s3, numOfPoints:10600, time range:[3000,13599], tsDataType:TEXT,
+ TsDigest:[min_value:A,max_value:E,first_value:A,last_value:E,sum_value:0.0]
+ | [marker] 1
+ | [ChunkHeader]
+ | 11 pages
+ 55718| [Chunk] of s4, numOfPoints:10600, time range:[3000,13599], tsDataType:BOOLEAN,
+ TsDigest:[min_value:false,max_value:true,first_value:true,last_value:false,sum_value:0.0]
+ | [marker] 1
+ | [ChunkHeader]
+ | 11 pages
+ 68848| [Chunk] of s5, numOfPoints:10600, time range:[3000,13599], tsDataType:DOUBLE,
+ TsDigest:[min_value:3000.0,max_value:13599.0,first_value:3000.0,last_value:13599.0,sum_value:8.79747E7]
+ | [marker] 1
+ | [ChunkHeader]
+ | 11 pages
+ 98474| [Chunk] of s0, numOfPoints:21900, time range:[3000,100999], tsDataType:INT32,
+ TsDigest:[min_value:0,max_value:99,first_value:0,last_value:19,sum_value:889750.0]
+ | [marker] 1
+ | [ChunkHeader]
+ | 22 pages
+ 123369| [Chunk] of s1, numOfPoints:21900, time range:[3000,100999], tsDataType:INT64,
+ TsDigest:[min_value:0,max_value:39,first_value:8,last_value:19,sum_value:300386.0]
+ | [marker] 1
+ | [ChunkHeader]
+ | 22 pages
+ 144741| [Chunk] of s2, numOfPoints:21900, time range:[3000,100999], tsDataType:FLOAT,
+ TsDigest:[min_value:0.0,max_value:122.0,first_value:8.0,last_value:52.0,sum_value:778581.0]
+ | [marker] 1
+ | [ChunkHeader]
+ | 22 pages
+ 186437| [Chunk Group Footer]
+ | [marker] 0
+ | [deviceID] root.vehicle.d0
+ | [dataSize] 186425
+ | [num of chunks] 6
+||||||||||||||||||||| [Chunk Group] of root.vehicle.d0 ends
+ 186469| [marker] 2
+ 186470| [TsDeviceMetadata] of root.vehicle.d0, startTime:3000, endTime:100999
+ | [startTime] 3000tfi
+ | [endTime] 100999
+ | [num of ChunkGroupMetaData] 1
+ | 1 ChunkGroupMetaData
+ 187133| [TsFileMetaData]
+ | [num of devices] 1
+ | 1 key&TsDeviceMetadataIndex
+ | [num of measurements] 6
+ | 6 key&measurementSchema
+ | [createBy isNotNull] false
+ | [totalChunkNum] 6
+ | [invalidChunkNum] 0
+ | [bloom filter bit vector byte array length] 31
+ | [bloom filter bit vector byte array]
+ | [bloom filter number of bits] 256
+ | [bloom filter number of hash functions] 5
+ 187372| [TsFileMetaDataSize] 239
+ 187376| [magic tail] TsFile
+ 187382| END of TsFile
+
+---------------------------------- TsFile Sketch End ----------------------------------
+````````````````````````
+
+#### 1.3.4 TsFileSequenceRead
+
+您可以使用示例中的类 `example/tsfile/org/apache/iotdb/tsfile/TsFileSequenceRead` 顺序打印 TsFile 中的内容.
+
+### 1.4 TsFile 的总览图
+
+#### v0.8.0
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/33376433/65209576-2bd36000-dacb-11e9-9e43-49e0dd01274e.png">
+
+#### v0.9.0
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/33376433/69341240-26012300-0ca4-11ea-91a1-d516810cad44.png">
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/3-Write.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/3-Write.md
new file mode 100644
index 0000000..7a27f66
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/3-Write.md
@@ -0,0 +1,65 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# TsFile 写流程
+
+* org.apache.iotdb.tsfile.write.*
+
+TsFile 的写入流程如下图所示:
+
+< img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/73625238-efba2980-467e-11ea-927e-a7021f8153af.png">
+
+其中,每个设备对应一个 ChunkGroupWriter,每个传感器对应一个 ChunkWriter。
+
+文件的写入主要分为三种操作,在图上用 1、2、3 标注
+
+* 1、写内存换冲区
+* 2、持久化 ChunkGroup
+* 3、关闭文件
+
+## 1、写内存缓冲区
+
+TsFile 文件层的写入接口有两种
+
+* TsFileWriter.write(TSRecord record)
+
+ 写入一个设备一个时间戳多个测点。
+
+* TsFileWriter.write(RowBatch rowBatch)
+
+ 写入一个设备多个时间戳多个测点。
+
+当调用 write 接口时,这个设备的数据会交给对应的 ChunkGroupWriter,其中的每个测点会交给对应的 ChunkWriter 进行写入。ChunkWriter 完成编码和打包(生成 Page)。
+
+
+## 2、持久化 ChunkGroup
+
+* TsFileWriter.flushAllChunkGroups()
+
+当内存中的数据达到一定阈值,会触发持久化操作。每次持久化会把当前内存中所有设备的数据全部持久化到磁盘的 TsFile 文件中。每个设备对应一个 ChunkGroup,每个测点对应一个 Chunk。
+
+持久化完成后会在内存中缓存对应的元数据信息,以供查询和生成文件尾部 metadata。
+
+## 3、关闭文件
+
+* TsFileWriter.close()
+
+根据内存中缓存的元数据,生成 TsFileMetadata 追加到文件尾部,最后关闭文件。
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/4-Read.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/4-Read.md
new file mode 100644
index 0000000..55450ab
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/1-TsFile/4-Read.md
@@ -0,0 +1,566 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# TsFile 读流程
+
+本章节介绍 TsFile 的读取流程,内容总体上分为两部分,对过滤条件和时间表达式的介绍,以及对查询流程的详细介绍。
+
+* 1 过滤条件和查询表达式
+ * 1.1 Filter
+ * 1.2 Expression表达式
+ * 1.2.1 SingleSeriesExpression 表达式
+ * 1.2.2 GlobalTimeExpression 表达式
+ * 1.2.3 IExpression 表达式
+ * 1.2.4 可执行表达式
+ * 1.2.5 IExpression 转化为可执行表达式的优化算法
+* 2 TsFile 查询执行过程
+ * 2.1 设计原理
+ * 2.2 三大查询组件
+ * 2.2.1 FileSeriesReader 组件
+ * 2.2.2 FileSeriesReaderByTimestamp 组件
+ * 2.2.3 TimeGeneratorImpl 组件
+ * 2.3 归并查询
+ * 2.4 连接查询
+ * 2.5 查询入口
+ * 2.6 相关代码介绍
+
+## 1 过滤条件和查询表达式
+
+本章节首先介绍 Tsfile 文件读取时需要用到的过滤条件和查询表达式的相关定义;其次介绍如何将用户输入的过滤条件转化为系统可以执行的查询条件。
+
+### 1.1 Filter
+
+Filter 表示基本的过滤条件。用户可以在时间戳上、或某一列的值上给出具体的过滤条件。将时间戳和列值的过滤条件加以区分后,设 t 表示某一时间戳常量,Filter 有以下12种基本类型,在实现上是继承关系。
+
+Filter|类型|含义|示例
+----|----|---|------
+TimeEq|时间过滤条件|时间戳等于某个值|TimeEq(t),表示时间戳等于 t
+TimeGt|时间过滤条件|时间戳大于某个值|TimeGt(t),表示时间戳大 t
+TimeGtEq|时间过滤条件|时间戳大于等于某个值|TimeGtEq(t),表示时间戳大于等 t
+TimeLt|时间过滤条件|时间戳小于某个值|TimeLt(t),表示时间戳小 t
+TimeLtEq|时间过滤条件|时间戳小于等于某个值|TimeLtEq(t),表示时间戳小于等 t
+TimeNotEq|时间过滤条件|时间戳不等于某个值|TimeNotEq(t),表示时间戳不等 t
+ValueEq|值过滤条件|该列数值等于某个值|ValueEq(2147483649),表示该列数值等于2147483649
+ValueGt|值过滤条件|该列数值大于某个值|ValueGt(100.5),表示该列数值大于100.5
+ValueGtEq|值过滤条件|该列数值大于等于某个值|ValueGtEq(2),表示该列数值大于等于2
+ValueLt|值过滤条件|该列数值小于某个值|ValueLt("string"),表示该列数值字典序小于"string"
+ValueLtEq|值过滤条件|该列数值小于等于某个值|ValueLtEq(-100),表示该列数值小于等于-100
+ValueNotEq|值过滤条件|该列数值不等于某个值|ValueNotEq(true),表示该列数值的值不能为true
+
+Filter 可以由一个或两个子 Filter 组成。如果 Filter 由单一 Filter 构成,则称之为一元过滤条件,及 UnaryFilter 。若包含两个子 Filter,则称之为二元过滤条件,及 BinaryFilter。在二元过滤条件中,两个子 Filter 之间通过逻辑关系“与”、“或”进行连接,前者称为 AndFilter,后者称为 OrFilter。AndFilter 和 OrFilter 都是二元过滤条件。UnaryFilter 和 BinaryFilter 都是 Filter。
+
+下面给出一些 AndFilter 和 OrFilter 的示例,其中“&&”表示关系“与”,“||”表示关系“或”。
+
+1. AndFilter(TimeGt(100), TimeLt(200)) 表示“timestamp > 100 && timestamp < 200”
+2. AndFilter (TimeGt(100), ValueGt(0.5)) 表示“timestamp > 100 && value > 0.5”
+3. AndFilter (AndFilter (TimeGt(100), TimeLt(200)), ValueGt(0.5)) 表示“(timestamp > 100 && timestamp < 200) && value > 0.5”
+4. OrFilter(TimeGt(100), ValueGt(0.5)) 表示“timestamp > 100 || value > 0.5”
+5. OrFilter (AndFilter(TimeGt(100), TimeLt(200)), ValueGt(0.5)) 表示“(timestamp > 100 && timestamp < 200) || value > 0.5”
+
+下面,给出“Filter”、“AndFilter”和“OrFilter”的形式化定义:
+
+ Filter := Basic Filter | AndFilter | OrFilter
+ AndFilter := Filter && Filter
+ OrFilter := Filter || Filter
+
+为了便于表示,下面给出 Basic Filter、AndFilter 和 OrFilter 的符号化表示方法,其中 t 表示数据类型为 INT64 的变量;v表示数据类型为 BOOLEAN、INT32、INT64、FLOAT、DOUBLE 或 BINARY 的变量。
+
+<style> table th:nth-of-type(2) { width: 150px; } </style>
+名称|符号化表示方法|示例
+----|------------|------
+TimeEq| time == t| time == 14152176545,表示 timestamp 等于 14152176545
+TimeGt| time > t| time > 14152176545,表示 timestamp 大于 14152176545
+TimeGtEq| time >= t| time >= 14152176545,表示 timestamp 大于等于 14152176545
+TimeLt| time < t| time < 14152176545,表示 timestamp 小于 14152176545
+TimeLtEq| time <= t| time <= 14152176545,表示 timestamp 小于等于 14152176545
+TimeNotEq| time != t| time != 14152176545,表示 timestamp �等于 14152176545
+ValueEq| value == v| value == 10,表示 value 等于 10
+ValueGt| value > v| value > 100.5,表示 value 大于 100.5
+ValueGtEq| value >= v| value >= 2,表示 value 大于等于 2
+ValueLt| value < v| value < “string”,表示 value [1e小于“string”
+ValueLtEq| value <= v| value <= -100,表示 value 小于等于-100
+ValueNotEq| value != v| value != true,表示 value 的值不能为true
+AndFilter| \<Filter> && \<Filter>| 1. value > 100 && value < 200,表示 value大于100且小于200; <br>2. (value >= 100 && value <= 200) && time > 14152176545,表示“value 大于等于100 且 value 小于等于200” 且 “时间戳大于 14152176545”
+OrFilter| \<Filter> || \<Filter>| 1. value > 100 || time > 14152176545,表示value大于100或时间戳大于14152176545;<br>2. (value > 100 && value < 200)|| time > 14152176545,表示“value大于100且value小于200”或“时间戳大于14152176545”
+
+### 1.2 Expression表达式
+
+当一个过滤条件作用到一个时间序列上,就成为一个表达式。例如,“数值大于10” 是一个过滤条件;而 “序列 d1.s1 的数值大于10” 就是一条表达式。特殊地,对时间的过滤条件也是一个表达式,称为 GlobalTimeExpression。以下章节将对表达式进行展开介绍。
+
+#### 1.2.1 SingleSeriesExpression表达式
+
+SingleSeriesExpression 表示针对某一指定时间序列的过滤条件,一个 SingleSeriesExpression 包含一个 Path 和一个 Filter。Path 表示该时间序列的路径;Filter 即为2.1章节中介绍的 Filter,表示相应的过滤条件。
+
+SingleSeriesExpression 的结构如下:
+
+ SingleSeriesExpression
+ Path: 该 SingleSeriesExpression 指定的时间序列的路径
+ Filter:过滤条件
+
+在一次查询中,一个 SingleSeriesExpression 表示该时间序列的数据点必须满足 Filter所表示的过滤条件。下面给出 SingleSeriesExpression 的示例及对应的表示方法。
+
+例1.
+
+ SingleSeriesExpression
+ Path: "d1.s1"
+ Filter: AndFilter(ValueGt(100), ValueLt(200))
+
+该 SingleSeriesExpression 表示"d1.s1"这一时间序列必须满足条件“值大于100且值小于200”。
+
+其符号化的表达方式为:SingleSeriesExpression(“d1.s1”, value > 100 && value < 200)
+
+---------------------------
+例2.
+
+ SingleSeriesExpression
+ Path:“d1.s1”
+ Filter:AndFilter(AndFilter(ValueGt(100), ValueLt(200)), TimeGt(14152176545))
+
+该 SingleSeriesExpression 表示"d1.s1"这一时间序列必须满足条件“值大于100且小于200且时间戳大于14152176545”。
+
+其符号化表达方式为:SingleSeriesExpression(“d1.s1”, (value > 100 && value < 200) && time > 14152176545)
+
+#### 1.2.2 GlobalTimeExpression 表达式
+GlobalTimeExpression 表示全局的时间过滤条件,一个 GlobalTimeExpression 包含一个 Filter,且该 Filter 中包含的子 Filter 必须全为时间过滤条件。在一次查询中,一个 GlobalTimeExpression 表示查询返回数据点必须满足该表达式中 Filter 所表示的过滤条件。GlobalTimeExpression 的结构如下:
+
+
+ GlobalTimeExpression
+ Filter: 由一个或多个时间过滤条件组成的 Filter。
+ 此处的Filter形式化定义如下:
+ Filter := TimeFilter | AndExpression | OrExpression
+ AndExpression := Filter && Filter
+ OrExpression := Filter || Filter
+
+下面给出 GlobalTimeExpression 的一些例子,均采用符号化表示方法。
+1. GlobalTimeExpression(time > 14152176545 && time < 14152176645)表示所有被选择的列的时间戳必须满足“大于14152176545且小于14152176645”
+2. GlobalTimeExpression((time > 100 && time < 200) || (time > 400 && time < 500))表示所有被选择列的时间戳必须满足“大于100且小于200”或“大于400且小于500”
+
+#### 1.2.3 IExpression 表达式
+IExpression 为查询过滤条件。一个 IExpression 可以是一个 SingleSeriesExpression 或者一个 GlobalTimeExpression,这种情况下,IExpression 也称为一元表达式,即 UnaryExpression。一个 IExpression 也可以由两个 IExpression 通过逻辑关系“与”、“或”进行连接得到 “AndExpression” 或 “OrExpression” 二元表达式,即 BinaryExpression。
+
+下面给出 IExpression 的形式化定义。
+
+ IExpression := SingleSeriesExpression | GlobalTimeExpression | AndExpression | OrExpression
+ AndExpression := IExpression && IExpression
+ OrExpression := IExpression || IExpression
+
+我们采用一种类似于树形结构的表示方法来表示 IExpression,其中 SingleSeriesExpression 和 GlobalTimeExpression 均采用上文中介绍的符号化表示方法。下面给出示例。
+
+1. 只包含一个 SingleSeriesExpression 的 IExpression:
+
+ IExpression(SingleSeriesExpression(“d1.s1”, value > 100 && value < 200))
+
+2. 只包含一个 GlobalTimeExpression 的 IExpression:
+
+ IExpression(GlobalTimeExpression (time > 14152176545 && time < 14152176645))
+3. 包含多个 SingleSeriesExpression 的 IExpression:
+
+ IExpression(
+ AndExpression
+ SingleSeriesExpression(“d1.s1”, (value > 100 && value < 200) || time > 14152176645)
+ SingleSeriesExpression(“d1.s2”, value > 0.5 && value < 1.5)
+ )
+
+ **解释**:该 IExpression 为一个 AndExpression,其中要求"d1.s1"和"d1.s2"必须同时满足其对应的 Filter。
+
+4. 同时包含 SingleSeriesExpression 和 GlobalTimeExpression 的 IExpression
+
+ IExpression(
+ AndExpression
+ AndExpression
+ SingleSeriesExpression(“d1.s1”, (value > 100 && value < 200) || time > 14152176645)
+ SingleSeriesExpression(“d1.s2”, value > 0.5 && value < 1.5)
+ GlobalTimeExpression(time > 14152176545 && time < 14152176645)
+ )
+
+ **解释**:该 IExpression 为一个 AndExpression,其要求"d1.s1"和"d1.s2"必须同时满足其对应的 Filter,且时间列必须满足 GlobalTimeExpression 定义的 Filter 条件。
+
+
+#### 1.2.4 可执行表达式
+
+便于理解执行过程,定义可执行表达式的概念。可执行表达式是带有一定限制条件的 IExpression。用户输入的查询条件或构造的 IExpression 将经过特定的优化算法(该算法将在后面章节中介绍)转化为可执行表达式。满足下面任意条件的 IExpression 即为可执行表达式。
+
+* 1. IExpression 为单一的 GlobalTimeExpression
+* 2. IExpression 为单一的 SingleSeriesExpression
+* 3. IExpression 为 AndExpression,且叶子节点均为 SingleSeriesExpression
+* 4. IExpression 为 OrExpression,且叶子节点均为 SingleSeriesExpression
+
+可执行表达式的形式化定义为:
+
+ executable expression := SingleSeriesExpression| GlobalTimeExpression | AndExpression | OrExpression
+ AndExpression := < ExpressionUNIT > && < ExpressionUNIT >
+ OrExpression := < ExpressionUNIT > || < ExpressionUNIT >
+ ExpressionUNIT := SingleSeriesExpression | AndExpression | OrExpression
+
+下面给出 一些可执行表达式和非可执行表达式的示例:
+
+例1:
+
+ IExpression(SingleSeriesExpression(“d1.s1”, value > 100 && value < 200))
+
+是否为可执行表达式:是
+
+**解释**:该 IExpression 为一个 SingleSeriesExpression,满足条件2
+
+----------------------------------
+例2:
+
+ IExpression(GlobalTimeExpression (time > 14152176545 && time < 14152176645))
+
+是否为可执行表达式:是
+
+**解释**:该 IExpression 为一个 GlobalTimeExpression,满足条件1
+
+-----------------------
+例3:
+
+ IExpression(
+ AndExpression
+ GlobalTimeExpression (time > 14152176545)
+ GlobalTimeExpression (time < 14152176645)
+ )
+
+是否为可执行表达式:否
+
+**解释**:该 IExpression 为一个 AndExpression,但其中包含了 GlobalTimeExpression,不满足条件3
+
+--------------------------
+
+例4:
+
+ IExpression(
+ OrExpression
+ AndExpression
+ SingleSeriesExpression(“d1.s1”, (value > 100 && value < 200) || time > 14152176645)
+ SingleSeriesExpression(“d1.s2”, value > 0.5 && value < 1.5)
+ SingleSeriesExpression(“d1.s3”, value > “test” && value < “test100”)
+ )
+
+是否为可执行表达式:是
+
+**解释**:该 IExpression 作为一个 OrExpression,其中叶子结点都是 SingleSeriesExpression,满足条件4.
+
+----------------------------
+
+例5:
+
+ IExpression(
+ AndExpression
+ AndExpression
+ SingleSeriesExpression(“d1.s1”, (value > 100 && value < 200) || time > 14152176645)
+ SingleSeriesExpression(“d1.s2”, value > 0.5 && value < 1.5)
+ GlobalTimeExpression(time > 14152176545 && time < 14152176645)
+ )
+
+是否为可执行表达式:否
+
+**解释**:该 IExpression 为一个 AndExpression,但其叶子结点中包含了 GlobalTimeExpression,不满足条件3
+
+#### 1.2.5 IExpression转化为可执行表达式的优化算法
+
+本章节介绍将 IExpression 转化为一个可执行表达式的算法。
+
+如果一个 IExpression 不是一个可执行表达式,那么它一定是一个 AndExpression 或者 OrExpression,且该 IExpression 既包含了 GlobalTimeExpression 又包含了 SingleSeriesExpression。根据前面章节的定义,我们知道 AndExpression 和 OrExpression 均由两个 IExpression 构成,即
+
+ AndExpression := <IExpression> AND <IExpression>
+ OrExpression := <IExpression> OR <IExpression>
+
+令左右两侧的表达式分别为 LeftIExpression 和 RightIExpression,即
+
+ AndExpression := <LeftIExpression> AND <RightIExpression>
+ OrExpression := <LeftIExpression> OR <RightIExpression>
+
+下面给出算法定义:
+
+ IExpression optimize(IExpression expression, List<Path> selectedSeries)
+
+ 输入:待转换的 IExpression 表达式,需要投影的时间序列
+ 输出:转换后的 IExpression,即可执行表达式
+
+在介绍优化算法的具体步骤之前,我们首先介绍表达式、过滤条件合并基本的方法。这些方法将在 optimize() 方法中使用。
+
+* MergeFilter: 合并两个 Filter。该方法接受三个参数,分别为:
+
+ Filter1:第一个待合并的 Filter
+ Filter2:第二个待合并的 Filter
+ Relation:两个待合并 Filter 之间的关系( relation 的取值为 AND 或 OR)
+
+ 则,该方法执行的策略为
+
+ if relation == AND:
+ return AndFilter(Filter1, Filter2)
+ else if relation == OR:
+ return OrFilter(Filter1, Filter2)
+
+ 算法实现是,使用 FilterFactory 类中的 AndFilter and(Filter left, Filter right) 和 OrFilter or(Filter left, Filter right)方法进行实现。
+
+* combineTwoGlobalTimeExpression: 将两个 GlobalTimeExpression 合并为一个 GlobalTimeExpression。
+
+ 该方法接受三个输入参数,方法的定义为:
+
+ GlobalTimeExpression combineTwoGlobalTimeExpression(
+ GlobalTimeExpression leftGlobalTimeExpression,
+ GlobalTimeExpression rightGlobalTimeExpression,
+ ExpressionType type)
+
+ 输入参数1:leftGlobalTimeExpression,左侧表达式
+ 输入参数2:rightGlobalTimeExpression,右侧表达式
+ 输入参数3:type,表达式二元运算类型,为“AND”或“OR”
+
+ 输出:GlobalTimeExpression,最终合并后的表达式
+
+ 该方法分为两个步骤:
+ 1. 设 leftGlobalTimeExpression 的 Filter 为 filter1;rightGlobalTimeExpression 的 Filter 为 filter2,通过 MergeFilter 方法将其合并为一个新的Filter,设为 filter3。
+ 2. 创建一个新的 GlobalTimeExpression,并将 filter3 作为其 Filter,返回该 GlobalTimeExpression。
+
+ 下面给出一个合并两个 GlobalTimeExpression 的例子。
+
+
+ 三个参数分别为:
+
+ leftGlobalTimeExpression:GlobalTimeExpression(Filter: time > 100 && time < 200)
+ rightGlobalTimeExpression: GlobalTimeExpression(Filter: time > 300 && time < 400)
+ type: OR
+
+ 则,合并后的结果为
+
+ GlobalTimeExpression(Filter: (time > 100 && time < 200) || (time > 300 && time < 400))
+
+* handleOneGlobalExpression: 将 GlobalTimeExpression 和 IExpression 合并为一个可执行表达式。该方法返回的可执行表达式仅由 SingleSeriesExpression 组成。方法的定义如下:
+
+ IExpression handleOneGlobalTimeExpression(
+ GlobalTimeExpression globalTimeExpression,
+ IExpression expression,
+ List<Path> selectedSeries,
+ ExpressionType relation)
+
+ 输入参数1:GlobalTimeExpression
+ 输入参数2:IExpression
+ 输入参数3:被投影的时间序列
+ 输入参数4:两个待合并的表达式之间的关系,relation 的取值为 AND 或 OR
+
+ 输出:合并后的 IExpression,即为可执行表达式。
+
+ 该方法首先调用 optimize() 方法,将输入的第二个参数 IExpression 转化为可执行表达式(从 optimize() 方法上看为递归调用),然后再分为两种情况进行合并。
+
+ *情况一*:GlobalTimeExpression 和优化后的 IExpression 的关系为 AND。这种情况下,记 GlobalTimeExpression 的 Filter 为 tFilter,则只需要 tFilter 合并到 IExpression 的每个 SingleSeriesExpression 的 Filter 中即可。void addTimeFilterToQueryFilter(Filter timeFilter, IExpression expression)为具体实现方法。例如:
+
+ 设要将如下 GlobaLTimeFilter 和 IExpression 合并,
+
+ 1. GlobaLTimeFilter(tFilter)
+ 2. IExpression
+ AndExpression
+ OrExpression
+ SingleSeriesExpression(“path1”, filter1)
+ SingleSeriesExpression(“path2”, filter2)
+ SingleSeriesExpression(“path3”, filter3)
+
+ 则合并后的结果为
+
+ IExpression
+ AndExpression
+ OrExpression
+ SingleSeriesExpression(“path1”, AndFilter(filter1, tFilter))
+ SingleSeriesExpression(“path2”, AndFilter(filter2, tFilter))
+ SingleSeriesExpression(“path3”, AndFilter(filter3, tFilter))
+
+ *情况二*:GlobalTimeExpression 和 IExpression 的关系为 OR。该情况下的合并步骤如下:
+ 1. 得到该查询所要投影的所有时间序列,其为一个 Path 的集合,以一个包含三个投影时间序列的查询为例,记所有要投影的列为 PathList{path1, path2, path3}。
+ 2. 记 GlobalTimeExpression 的 Filter 为 tFilter,调用 pushGlobalTimeFilterToAllSeries() 方法为每个 Path 创建一个对应的 SingleSeriesExpression,且每个 SingleSeriesExpression 的 Filter 值均为 tFilter;将所有新创建的 SingleSeriesExpression 用 OR 运算符进行连接,得到一个 OrExpression,记其为 orExpression。
+ 3. 调用 mergeSecondTreeToFirstTree 方法将 IExpression 中的节点与步骤二得到的 orExpression 中的节点进行合并,返回合并后的表达式。
+
+
+ 例如,将如下 GlobaLTimeFilter 和 IExpression 按照关系 OR 进行合并,设该查询的被投影列为 PathList{path1, path2, path3}
+
+ 1. GlobaLTimeFilter(tFilter)
+ 2. IExpression
+ AndExpression
+ SingleSeriesExpression(“path1”, filter1)
+ SingleSeriesExpression(“path2”, filter2)
+
+ 则合并后的结果为
+
+ IExpression
+ OrExpression
+ AndExpression
+ SingleSeriesExpression(“path1”, filter1)
+ SingleSeriesExpression(“path2”, filter2)
+ OrExpression
+ OrExpression
+ SingleSeriesExpression(“path1”, tFilter)
+ SingleSeriesExpression(“path2”, tFilter)
+ SingleSeriesExpression(“path3”, tFilter)
+
+* MergeIExpression: 将两个 IExpression 合并为一个可执行表达式。该方法接受三个参数,分别为
+
+ IExpression1:待合并的第一个 IExpression
+ IExpression2:待合并的第二个 IExpression
+ relation:两个待合并的 IExpression 的关系(Relation 的取值为 AND 或 OR)
+
+ 该方法的执行策略为:
+
+ if relation == AND:
+ return AndExpression(IExpression1, IExpression2)
+ else if relation == OR:
+ return OrExpression(IExpression1, IExpression2)
+
+使用以上四种基本的过滤条件、表达式合并方法,optimize() 算法的执行步骤如下:
+1. 如果 IExpression 为一元表达式,即单一的 SingleSeriesExpression 或单一的 GlobalTimeExpression,则直接将其返回;否则,执行步骤二
+2. 算法达到该步骤,说明 IExpression 为 AndExpression 或 OrExpression。
+
+ a. 如果LeftIExpression和RightIExpression均为GlobalTimeExpression,则执行combineTwoGlobalTimeExpression方法,并返回对应的结果。
+
+ b. 如果 LeftIExpression 为 GlobalTimeExpression,而 RightIExpression 不是GlobalTimeExpression,则调用 handleOneGlobalTimeExpressionr() 方法进行合并。
+
+ c. 如果 LeftIExpression 不是 GlobalTimeExpression,而 RightIExpression 是 GlobalTimeExpression,则调用 handleOneGlobalTimeExpressionr()方法进行合并。
+
+ d. 如果 LeftIExpression 和 RightIExpression 均不是 GlobalTimeExpression,则对 LeftIExpression 递归调用 optimize() 方法得到左可执行表达式;对 RightIExpression 递归调用 optimize() 方法得到右可执行表达式。使用 MergeIExpression 方法,根据 type 的值将左可执行表达式和右可执行表达式合并为一个 IExpression。
+
+## 2 TsFile 查询执行过程
+
+### 2.1 设计原理
+
+TsFile 文件层查询接口只包含原始数据查询,根据是否包含值过滤条件,可以将查询分为两类“无过滤条件或仅包含时间过滤条件查询”和“包含值过滤条件的查询”
+
+为了执行以上两类查询,有两套查询流程
+
+* 归并查询
+
+ 生成多个 reader,按照 time 对齐,返回结果集。
+
+* 连接查询
+
+ 根据查询条件生成满足过滤条件的时间戳,通过满足条件的时间戳查询投影列的值,返回结果集。
+
+### 2.2 三大查询组件
+
+#### 2.2.1 FileSeriesReader 组件
+org.apache.iotdb.tsfile.read.reader.series.FileSeriesReader
+
+**功能**:该组件用于查询一个文件中单个时间序列满足过滤条件的数据点。根据给定的查询路径和被查询的文件,按照时间戳递增的顺序查询出该时间序列在文件中的所有数据点。其中过滤条件可为空。
+
+**实现**:该组件首先获取给定的路径查询出所有 Chunk 的信息,然后按照起始时间戳从小到大的顺序遍历每个 Chunk,并从中读取出满足条件的数据点。
+
+#### 2.2.2 FileSeriesReaderByTimestamp 组件
+
+org.apache.iotdb.tsfile.read.reader.series.FileSeriesReaderByTimestamp
+
+**功能**:该组件主要用于查询一个文件中单个时间序列在指定时间戳上的数据点。
+
+**实现**:该组件提供一个接口,getValueInTimestamp(long timestamp),通过接口依次传入递增的时间戳,返回时间序列上与该时间戳相对应的数据点。如果满足该时间戳的数据点不存在,则返回 null。
+
+#### 2.2.3 TsFileTimeGenerator 组件
+org.apache.iotdb.tsfile.read.query.timegenerator.TsFileTimeGenerator
+
+**功能**:根据“选择条件”,计算出满足该“选择条件”的时间戳,先将“选择条件”转化为一棵二叉树,然后递归地计算满足“选择条件”的时间戳。主要用于连接查询。
+
+一个可执行的过滤条件由一个或多个 SingleSeriesExpression 构成,且 SingleSeriesExpression 之间具有相应的与或关系。所以,一个可执行的过滤条件可以转为一棵表示“查询条件”的二叉树,二叉树的叶子节点( LeafNode )为 FileSeriesReader,中间节点为 AndNode 或 OrNode。特殊地,当可执行的过滤条件仅由一个 SingleSeriesExpression 构成时,该二叉树仅包含一个节点。得到由“选择条件”转化后的二叉树后,便可以计算“满足该选择条件”的时间戳。
+该组件提供两个基本的功能:
+
+1. 判断是否还有下一个满足“选择条件”的时间戳
+
+2. 返回下一个满足“选择条件”的时间戳
+
+
+### 2.3 归并查询
+org.apache.iotdb.tsfile.read.query.dataset.DataSetWithoutTimeGenerator
+
+设当查询 n 个时间序列,为每个时间序列构建一个 FileSeriesReader,如果有 GlobalTimeExpression,则将其中的 Filter 传入 FileSeriesReader。
+
+根据所有的 FileSeriesReader 生成一个 DataSetWithoutTimeGenerator,由于每个 FileSeriesReader 会按照时间戳从小到大的顺序迭代地返回数据点,所以可以采用“多路归并”对所有 FileSeriesReader 的结果进行按时间戳对齐。
+
+数据合并的步骤为:
+
+(1) 创建一个最小堆,堆里面存储“时间戳”,该堆将按照每个时间戳的大小进行组织。
+
+(2) 初始化堆,依次访问每一个 FileSeriesReader,如果该 FileSeriesReader 中还有数据点,则获取数据点的时间戳并放入堆中。此时每个时间序列最多有1个时间戳被放入到堆中,即该序列最小的时间戳。
+
+(3) 如果堆的 size > 0,获取堆顶的时间戳,记为t,并将其在堆中删除,进入步骤(4);如果堆的 size 等于0,则跳到步骤(5),结束数据合并过程。
+
+(4) 创建新的 RowRecord。依次遍历每一条时间序列。在处理其中一条时间序列时,如果该序列没有更多的数据点,则将该列标记为 null 并添加在 RowRecord 中;否则,判断最小的时间戳是否与 t 相同,若不相同,则将该列标记为 null 并添加在 RowRecord 中。若相同,将该数据点添加在 RowRecord 中,同时判断该时间序列是否有新的数据点,若存在,则将下一个时间戳 t' 添加在堆中,并将 t' 设为当前时间序列的最小时间戳。最后,返回步骤(3)。
+
+(5) 结束数据合并过程。
+
+### 2.4 连接查询
+
+org.apache.iotdb.tsfile.read.query.executor.ExecutorWithTimeGenerator
+
+连接查询生成满足“选择条件”的时间戳、查询被投影列在对应时间戳下的数据点、合成 RowRecord。主要流程如下:
+
+(1) 根据 QueryExpression,初始化时间戳计算模块 TimeGeneratorImpl
+
+(2) 为每个被投影的时间序列创建 FileSeriesReaderByTimestamp
+
+(3) 如果“时间戳计算模块”中还有下一个时间戳,则计算出下一个时间戳 t ,进入步骤(4);否则,结束查询。
+
+(4) 根据 t,在每个时间序列上使用 FileSeriesReaderByTimestamp 组件获取在时间戳 t 下的数据点;如果在该时间戳下没有对应的数据点,则用 null 表示。
+
+(5) 将步骤(4)中得到的所有数据点合并成一个 RowRecord,此时得到一条查询结果,返回步骤(3)计算下一个查询结果。
+
+
+### 2.5 查询入口
+
+ org.apache.iotdb.tsfile.read.query.executor.TsFileExecutor
+
+TsFileExecutor 接收一个 QueryExpression ,执行该查询并返回相应的 QueryDataSet。基本工作流程如下:
+
+(1)接收一个 QueryExpression
+
+(2)如果无过滤条件,执行归并查询。如果该 QueryExpression 包含 Filter(过滤条件),则通过 ExpressionOptimizer 对该 QueryExpression 的 Filter 进行优化。如果是 GlobalTimeExpression,执行归并查询。如果包含值过滤,交给 ExecutorWithTimeGenerator 执行连接查询。
+
+(3) 生成对应的 QueryDataSet,迭代地生成 RowRecord,将查询结果返回。
+
+
+
+### 2.6 相关代码介绍
+
+* Chunk:一段时间序列的内存结构,可供 IChunkReader 进行读取。
+
+* ChunkMetaData:记录对应 Chunk 在文件中的偏移量及数据类型和编码方式,便于对 Chunk 进行读取。
+
+* IMetadataQuerier:一个 TsFile 的元数据加载器。可以加载整个文件的元数据和一个序列的所有 ChunkMetaData。
+
+* IChunkLoader: IChunkLoader 为 Chunk 的加载器,主要功能为,给定一个 ChunkMetaData,返回对应的 Chunk。
+
+* IChunkReader:对一个 Chunk 中的数据进行读取,其接收一个 Chunk,根据其中 ChunkHeader 中的相关信息,对该 Chunk 进行解析。其提供两套接口:
+
+ * hasNextSatisfiedPage & nextPageData:迭代式的返回一个一个的 Page
+ * getPageReaderList:一次返回所有 PageReader
+
+* IPageReader:对一个 Page 中的数据进行读取,提供两个基本的接口:
+
+ * getAllSatisfiedPageData():一次返回所有满足条件的值
+ * getStatistics():返回 Page 的统计信息
+
+* QueryExpression
+
+ QueryExpression 为查询表达式,包含投影的时间序列和过滤条件。
+
+* QueryDataSet
+
+ 一次查询所返回的结果,具有相同时间戳的数据点合并为一个 RowRecord。 QueryDataSet 提供两个基本的功能:
+
+ * 判断是否还有下一个 RowRecord
+ * 返回下一个 RowRecord
+
+
+
+
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/2-QueryEngine/1-QueryEngine.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/2-QueryEngine/1-QueryEngine.md
new file mode 100644
index 0000000..ce9943e
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/2-QueryEngine/1-QueryEngine.md
@@ -0,0 +1,64 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 查询引擎
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/73625242-f648a100-467e-11ea-921c-b954a3ecae7a.png">
+
+## 设计思想
+
+查询引擎负责所有用户命令的解析、生成计划、交给对应的执行器、返回结果集。
+
+## 相关类
+
+* org.apache.iotdb.db.service.TSServiceImpl
+
+ IoTDB 服务器端 RPC 实现,与客户端进行直接交互。
+
+* org.apache.iotdb.db.qp.Planner
+
+ 解析 SQL,生成逻辑计划,逻辑优化,生成物理计划。
+
+* org.apache.iotdb.db.qp.executor.PlanExecutor
+
+ 分发物理计划给对应的执行器,主要包括以下四个具体的执行器。
+
+ * MManager: 元数据操作
+ * StorageEngine: 数据写入
+ * QueryRouter: 数据查询
+ * LocalFileAuthorizer: 权限操作
+
+* org.apache.iotdb.db.query.dataset.*
+
+ 分批构造结果集返回给客户端,包含部分查询逻辑。
+
+## 查询流程
+
+* SQL 解析
+* 生成逻辑计划
+* 生成物理计划
+* 构造结果集生成器
+* 分批返回结果集
+
+## 相关文档
+
+* [查询计划生成器](/#/SystemDesign/progress/chap2/sec2)
+* [计划执行器](/#/SystemDesign/progress/chap2/sec3)
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/2-QueryEngine/2-Planner.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/2-QueryEngine/2-Planner.md
new file mode 100644
index 0000000..82640d0
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/2-QueryEngine/2-Planner.md
@@ -0,0 +1,63 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 执行计划生成器 Planner
+
+* org.apache.iotdb.db.qp.Planner
+
+将 SQL 解析出的语法树转化成逻辑计划,逻辑优化,物理计划。
+
+## SQL 解析
+
+SQL 解析采用 Antlr4
+
+* server/src/main/antlr4/org/apache/iotdb/db/qp/strategy/SqlBase.g4
+
+mvn clean compile 之后生成代码位置:server/target/generated-sources/antlr4
+
+## 逻辑计划生成器
+
+* org.apache.iotdb.db.qp.strategy.LogicalGenerator
+
+## 逻辑计划优化器
+
+目前有三种逻辑计划优化器
+
+* org.apache.iotdb.db.qp.strategy.optimizer.ConcatPathOptimizer
+
+ 路径优化器,将 SQL 中的查询路径进行拼接,与 MManager 进行交互去掉通配符,进行路径检查。
+
+* org.apache.iotdb.db.qp.strategy.optimizer.RemoveNotOptimizer
+
+ 谓词去非优化器,将谓词逻辑中的非操作符去掉。
+
+* org.apache.iotdb.db.qp.strategy.optimizer.DnfFilterOptimizer
+
+ 将谓词转化为析取范式。
+
+* org.apache.iotdb.db.qp.strategy.optimizer.MergeSingleFilterOptimizer
+
+ 将相同路径的谓词逻辑合并。
+
+## 物理计划生成器
+
+* org.apache.iotdb.db.qp.strategy.PhysicalGenerator
+
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/2-QueryEngine/3-PlanExecutor.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/2-QueryEngine/3-PlanExecutor.md
new file mode 100644
index 0000000..529ef45
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/2-QueryEngine/3-PlanExecutor.md
@@ -0,0 +1,26 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 计划执行器
+
+* org.apache.iotdb.db.qp.executor.PlanExecutor
+
+执行物理计划。
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/3-SchemaManager/1-SchemaManager.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/3-SchemaManager/1-SchemaManager.md
new file mode 100644
index 0000000..08e9971
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/3-SchemaManager/1-SchemaManager.md
@@ -0,0 +1,26 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 元数据管理
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/73625246-fc3e8200-467e-11ea-8815-67b9c4ab716e.png">
+
+IoTDB 的元数据管理采用目录树的形式,倒数第二层为设备层,最后一层为传感器层。
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/1-StorageEngine.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/1-StorageEngine.md
new file mode 100644
index 0000000..94a5e72
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/1-StorageEngine.md
@@ -0,0 +1,68 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 存储引擎
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/73625255-03fe2680-467f-11ea-91ae-64407ef1125c.png">
+
+## 设计思想
+
+存储引擎基于 LSM 设计。数据首先写入内存缓冲区 memtable 中,再刷到磁盘。内存中为每个设备维护当前持久化的(包括已经落盘的和正在持久化的)最大时间戳,根据这个时间戳将数据区分为顺序数据和乱序数据,不同种类的数据通过不同的 memtable 和 TsFile 管理。
+
+每个数据文件 TsFile 在内存中对应一个文件索引信息 TsFileResource,供查询使用。
+
+此外,存储引擎还包括异步持久化和文件合并机制。
+
+## 写入流程
+
+### 相关代码
+
+* org.apache.iotdb.db.engine.StorageEngine
+
+ 负责一个 IoTDB 实例的写入和访问,管理所有的 StorageGroupProsessor。
+
+* org.apache.iotdb.db.engine.storagegroup.StorageGroupProcessor
+
+ 负责一个存储组一个时间分区内的数据写入和访问。管理所有分区的TsFileProcessor。
+
+* org.apache.iotdb.db.engine.storagegroup.TsFileProcessor
+
+ 负责一个 TsFile 文件的数据写入和访问。
+
+
+## 数据写入
+详见:
+* [数据写入](/#/SystemDesign/progress/chap4/sec6)
+
+## 数据访问
+
+* 总入口(StorageEngine): public QueryDataSource query(SingleSeriesExpression seriesExpression, QueryContext context,
+ QueryFileManager filePathsManager)
+
+ * 找到所有包含这个时间序列的顺序和乱序的 TsFileResource 进行返回,供查询引擎使用。
+
+## 相关文档
+
+* [写前日志 (WAL)](/#/SystemDesign/progress/chap4/sec2)
+
+* [memtable 持久化](/#/SystemDesign/progress/chap4/sec3)
+
+* [文件合并机制](/#/SystemDesign/progress/chap4/sec4)
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/2-WAL.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/2-WAL.md
new file mode 100644
index 0000000..08b54c9
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/2-WAL.md
@@ -0,0 +1,26 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 写前日志
+
+## 相关代码
+
+* org.apache.iotdb.db.writelog.*
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/3-FlushManager.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/3-FlushManager.md
new file mode 100644
index 0000000..1850742
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/3-FlushManager.md
@@ -0,0 +1,84 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# Flush Memtable
+
+## 设计思想
+
+内存缓冲区 memtable 达到一定阈值后,会交给 FlushManager 进行异步的持久化,不阻塞正常写入。持久化的过程采用流水线的方式。
+
+## 相关代码
+
+* org.apache.iotdb.db.engine.flush.FlushManager
+
+ Memtable 的 Flush 任务管理器。
+
+* org.apache.iotdb.db.engine.flush.MemtableFlushTask
+
+ 负责持久化一个 Memtable。
+
+## FlushManager: 持久化管理器
+
+FlushManager 可以接受 memtable 的持久化任务,提交者有两个,第一个是 TsFileProcessor,第二个是持久化子线程 FlushThread。
+
+每个 TsFileProcessor 同一时刻只会有一个 flush 任务执行,一个 TsFileProcessor 可能对应多个需要持久化的 memtable
+
+## MemTableFlushTask: 持久化任务
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/73625254-03fe2680-467f-11ea-8197-115f3a749cbd.png">
+
+背景:每个 memtable 可包含多个 device,每个 device 可包含多个 measurement。
+
+### 三个线程
+
+一个 memtable 的持久化的过程有三个线程,只有当所有任务都完成后,主线程工作才结束。
+
+* MemTableFlushTask 所在线程
+
+ 持久化主线程兼排序线程,负责给每个 measurement 对应的 chunk 排序。
+
+* encodingTask 线程
+
+ 编码线程,负责给每个 Chunk 进行编码,编码成字节数组。
+
+* ioTask 线程
+
+ IO线程,负责将编码好的 Chunk 持久化到磁盘的 TsFile 文件上。
+
+### 两个任务队列
+
+三个线程之间通过两个任务队列交互
+
+* encodingTaskQueue: 排序线程->编码线程,包括三种任务
+
+ * StartFlushGroupIOTask:开始持久化一个 device (ChunkGroup), encoding 不处理这个命令,直接发给 IO 线程。
+
+ * Pair\<TVList, MeasurementSchema\>:编码一个 Chunk
+
+ * EndChunkGroupIoTask:结束一个 device (ChunkGroup) 的持久化,encoding 不处理这个命令,直接发给 IO 线程。
+
+* ioTaskQueue: 编码线程->IO线程,包括三种任务
+
+ * StartFlushGroupIOTask:开始持久化一个 device (ChunkGroup)。
+
+ * IChunkWriter:持久化一个 Chunk 到磁盘上
+
+ * EndChunkGroupIoTask:结束一个 device (ChunkGroup) 的持久化。
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/4-MergeManager.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/4-MergeManager.md
new file mode 100644
index 0000000..7e68c4f
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/4-MergeManager.md
@@ -0,0 +1,26 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 文件合并机制
+
+## 相关代码
+
+* org.apache.iotdb.db.engine.merge.*
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/5-DataPartition.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/5-DataPartition.md
new file mode 100644
index 0000000..ae8ede4
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/5-DataPartition.md
@@ -0,0 +1,86 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 数据分区
+
+时间序列数据在存储组和时间范围两个层级上进行分区
+
+## 存储组
+
+存储组由用户显示指定,使用语句"SET STORAGE GROUP TO"来指定存储组,每一个存储组有一个对应的 StorageGroupProcessor
+
+其拥有的主要字段为:
+
+* 一个读写锁: insertLock
+
+* 每个时间分区所对应的未关闭的顺序文件处理器: workSequenceTsFileProcessors
+
+* 每个时间分区所对应的未关闭的乱序文件处理器: workUnsequenceTsFileProcessors
+
+* 该存储组的全部顺序文件列表(按照时间排序): sequenceFileTreeSet
+
+* 该存储组的全部乱序文件列表(无顺序): unSequenceFileList
+
+* 记录每一个设备最后写入时间的map,顺序数据刷盘时会使用该map记录的时间: latestTimeForEachDevice
+
+* 记录每一个设备最后刷盘时间的map,用来区分顺序和乱序数据: latestFlushedTimeForEachDevice
+
+* 每个时间分区所对应的版本生成器map,便于查询时确定不同chunk的优先级: timePartitionIdVersionControllerMap
+
+
+### 相关代码
+
+* src/main/java/org/apache/iotdb/db/engine/StorageEngine.java
+
+
+## 时间范围
+
+同一个存储组中的数据按照用户指定的时间范围进行分区,相关参数为partition_interval,默认为周,也就是不同周的数据会放在不同的分区中
+
+### 实现逻辑
+
+StorageGroupProcessor 对插入的数据进行分区计算,找到指定的 TsFileProcessor,而每一个 TsFileProcessor 对应的 TsFile 会被放置在不同的分区文件夹内
+
+### 文件结构
+
+分区后的文件结构如下:
+
+data
+
+-- sequence
+
+---- [存储组名1]
+
+------ [时间分区ID1]
+
+-------- xxxx.tsfile
+
+-------- xxxx.resource
+
+------ [时间分区ID2]
+
+---- [存储组名2]
+
+-- unsequence
+
+### 相关代码
+
+* src/main/java/org/apache/iotdb/db/engine/storagegroup.StoragetGroupProcessor.java 中的 getOrCreateTsFileProcessorIntern 方法
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/6-DataManipulation.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/6-DataManipulation.md
new file mode 100644
index 0000000..eb689e7
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/4-StorageEngine/6-DataManipulation.md
@@ -0,0 +1,96 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 数据增删改
+
+下面介绍四种常用数据操控操作,分别是插入,更新,删除和TTL设置
+
+## 数据插入
+
+### 单行数据(一个设备一个时间戳多个值)写入
+
+* 对应的接口
+ * JDBC 的 execute 和 executeBatch 接口
+ * Session 的 insert 和 insertInBatch
+
+* 总入口: public void insert(InsertPlan insertPlan) StorageEngine.java
+ * 找到对应的 StorageGroupProcessor
+ * 根据写入数据的时间以及当前设备落盘的最后时间戳,找到对应的 TsFileProcessor
+ * 记录写前日志
+ * 写入 TsFileProcessor 对应的 memtable 中
+ * 如果是乱序文件,则更新tsfileResource中的endTimeMap
+ * 如果tsfile中没有该设备的信息,则更新tsfileResource中的startTimeMap
+ * 根据 memtable 大小,来判断是否触发异步持久化 memtable 操作
+ * 如果是顺序文件且执行了刷盘动作,则更新tsfileResource中的endTimeMap
+ * 根据当前磁盘 TsFile 的大小,判断是否触发文件关闭操作
+
+### 批量数据(一个设备多个时间戳多个值)写入
+
+* 对应的接口
+ * Session 的 insertBatch
+
+* 总入口: public Integer[] insertBatch(BatchInsertPlan batchInsertPlan) StorageEngine.java
+ * 找到对应的 StorageGroupProcessor
+ * 根据这批数据的时间以及当前设备落盘的最后时间戳,将这批数据分成小批,分别对应到一个 TsFileProcessor 中
+ * 记录写前日志
+ * 分别将每小批写入 TsFileProcessor 对应的 memtable 中
+ * 如果是乱序文件,则更新tsfileResource中的endTimeMap
+ * 如果tsfile中没有该设备的信息,则更新tsfileResource中的startTimeMap
+ * 根据 memtable 大小,来判断是否触发异步持久化 memtable 操作
+ * 如果是顺序文件且执行了刷盘动作,则更新tsfileResource中的endTimeMap
+ * 根据当前磁盘 TsFile 的大小,判断是否触发文件关闭操作
+
+
+## 数据更新
+
+目前不支持数据的原地更新操作,即update语句,但用户可以直接插入新的数据,在同一个时间点上的同一个时间序列以最新插入的数据为准
+旧数据会通过合并来自动删除,参见:
+
+* [文件合并机制](/#/SystemDesign/progress/chap4/sec4)
+
+## 数据删除
+
+* 对应的接口
+ * JDBC 的 execute 接口,使用delete SQL语句
+
+* 总入口: public void delete(String deviceId, String measurementId, long timestamp) StorageEngine.java
+ * 找到对应的 StorageGroupProcessor
+ * 找到受影响的所有TsfileProcessor
+ * 写写前日志
+ * 找到受影响的所有TsfileResource
+ * 在mod文件中记录删除的时间点
+ * 如果文件没有关闭(存在对应的TsfileProcessor),则删除内存中的数据
+
+
+## 数据TTL设置
+
+* 对应的接口
+ * JDBC 的 execute 接口,使用SET TTL语句
+
+* 总入口: public void setTTL(String storageGroup, long dataTTL) StorageEngine.java
+ * 找到对应的 StorageGroupProcessor
+ * 在 StorageGroupProcessor 中设置新的data ttl
+ * 对所有TsfileResource进行TTL检查
+ * 如果某个文件在当前TTL下失效,则删除文件
+
+同时,我们在 StorageEngine 中启动了一个定时检查文件TTL的线程,详见
+
+* src/main/java/org/apache/iotdb/db/engine/StorageEngine.java 中的 start 方法
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/1-DataQuery.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/1-DataQuery.md
new file mode 100644
index 0000000..36e2aa8
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/1-DataQuery.md
@@ -0,0 +1,40 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 数据查询
+
+数据查询有如下几种类型
+
+* 原始数据查询
+* 聚合查询
+* 降采样查询
+* 单点补空值查询
+* 最新数据查询
+
+为了实现以上几种查询,IoTDB 查询引擎中设计了针对单个时间序列的基础查询组件,在此基础上,实现了多种查询功能。
+
+## 相关文档
+
+* [基础查询组件](/#/SystemDesign/progress/chap5/sec2)
+* [原始数据查询](/#/SystemDesign/progress/chap5/sec3)
+* [聚合查询](/#/SystemDesign/progress/chap5/sec4)
+* [降采样查询](/#/SystemDesign/progress/chap5/sec5)
+* [最近时间戳查询](/#/SystemDesign/progress/chap5/sec6)
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/2-SeriesReader.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/2-SeriesReader.md
new file mode 100644
index 0000000..bcc59f3
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/2-SeriesReader.md
@@ -0,0 +1,384 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 查询基础组件
+
+## 设计原理
+
+IoTDB server 模块共提供 3 种不同形式的针对单个时间序列的读取接口,以支持不同形式的查询。
+
+* 原始数据查询接口,返回 BatchData,可带时间过滤条件或值过滤条件,两种过滤不可同时存在。
+* 聚合查询接口 (主要用于聚合查询和降采样查询)
+* 按递增时间戳查询对应值的接口(主要用于带值过滤的查询)
+
+## 相关接口
+
+以上三种读取单个时间序列数据的方式对应代码里的三个接口
+
+### org.apache.iotdb.tsfile.read.reader.IBatchReader
+
+#### 主要方法
+
+```
+// 判断是否还有 BatchData
+boolean hasNextBatch() throws IOException;
+
+// 获得下一个 BatchData,并把游标后移
+BatchData nextBatch() throws IOException;
+```
+
+#### 使用流程
+
+```
+while (batchReader.hasNextBatch()) {
+ BatchData batchData = batchReader.nextBatch();
+
+ // use batchData to do some work
+ ...
+}
+```
+
+### org.apache.iotdb.db.query.reader.series.IAggregateReader
+
+#### 主要方法
+
+```
+// 判断是否还有 Chunk
+boolean hasNextChunk() throws IOException;
+
+// 判断是否能够使用当前 Chunk 的统计信息
+boolean canUseCurrentChunkStatistics();
+
+// 获得当前 Chunk 的统计信息
+Statistics currentChunkStatistics();
+
+// 跳过当前 Chunk
+void skipCurrentChunk();
+
+// 判断当前Chunk是否还有下一个 Page
+boolean hasNextPage() throws IOException;
+
+// 判断能否使用当前 Page 的统计信息
+boolean canUseCurrentPageStatistics() throws IOException;
+
+// 获得当前 Page 的统计信息
+Statistics currentPageStatistics() throws IOException;
+
+// 跳过当前的 Page
+void skipCurrentPage();
+
+// 获得当前 Page 的数据
+BatchData nextPage() throws IOException;
+```
+
+#### 一般使用流程
+
+```
+while (aggregateReader.hasNextChunk()) {
+ if (aggregateReader.canUseCurrentChunkStatistics()) {
+ Statistics chunkStatistics = aggregateReader.currentChunkStatistics();
+
+ // 用 chunk 层的统计信息计算
+ ...
+
+ aggregateReader.skipCurrentChunk();
+ continue;
+ }
+
+ // 把当前 chunk 中的 page 消耗完
+ while (aggregateReader.hasNextPage()) {
+ if (aggregateReader.canUseCurrentPageStatistics()) {
+ // 可以用统计信息
+ Statistics pageStatistic = aggregateReader.currentPageStatistics();
+
+ // 用 page 层的统计信息计算
+ ...
+
+ aggregateReader.skipCurrentPage();
+ continue;
+ } else {
+ // 不能用统计信息,需要用数据计算
+ BatchData batchData = aggregateReader.nextOverlappedPage();
+
+ // 用 batchData 计算
+ ...
+ }
+ }
+}
+```
+
+### org.apache.iotdb.db.query.reader.IReaderByTimestamp
+
+#### 主要方法
+
+```
+// 得到给定时间戳的值,如果不存在返回 null(要求传入的 timestamp 是递增的)
+Object getValueInTimestamp(long timestamp) throws IOException;
+
+// 给定一批递增时间戳的值,返回一批结果(减少方法调用次数)
+Object[] getValuesInTimestamps(long[] timestamps) throws IOException;
+```
+
+#### 一般使用流程
+
+该接口在带值过滤的查询中被使用,TimeGenerator生成时间戳后,使用该接口获得该时间戳对应的value
+
+```
+Object value = readerByTimestamp.getValueInTimestamp(timestamp);
+
+or
+
+Object[] values = readerByTimestamp.getValueInTimestamp(timestamps);
+```
+
+## 具体实现类
+
+上述三个接口都有其对应的实现类,由于以上三种查询有共性,我们设计了一个基础的 SeriesReader 工具类,封装了对于一个时间序列读取操作的基本方法,帮助实现以上三种接口。下面首先介绍 SeriesReader 的设计原理,然后再依次介绍三个接口的具体实现。
+
+### org.apache.iotdb.db.query.reader.series.SeriesReader
+
+#### 设计思想
+
+背景知识:TsFile 文件(TsFileResource)解开后可以得到 ChunkMetadata,ChunkMetadata 解开后可以得到一堆 PageReader,PageReader 可以直接返回 BatchData 数据点。
+
+为了支持以上三种接口
+
+数据按照粒度从大到小分成四种:文件,Chunk,Page,相交数据点。在原始数据查询中,最大的数据块返回粒度是一个 page,如果一个 page 和其他 page 由于乱序写入相互覆盖了,就解开成数据点做合并。聚合查询中优先使用 Chunk 的统计信息,其次是 Page 的统计信息,最后是相交数据点。
+
+设计原则是能用粒度大的就不用粒度小的。
+
+首先介绍一下SeriesReader里的几个重要字段
+
+```
+
+/*
+ * 文件层
+ */
+private final List<TsFileResource> seqFileResource;
+ 顺序文件列表,因为顺序文件本身就保证有序,且时间戳互不重叠,只需使用List进行存储
+
+private final PriorityQueue<TsFileResource> unseqFileResource;
+ 乱序文件列表,因为乱序文件互相之间不保证顺序性,且可能有重叠,为了保证顺序,使用优先队列进行存储
+
+/*
+ * chunk 层
+ *
+ * 三个字段之间数据永远不重复,first 永远是第一个(开始时间最小)
+ */
+private ChunkMetaData firstChunkMetaData;
+ 填充 chunk 层时优先填充此字段,保证这个 chunk 具有当前最小开始时间
+
+private final List<ChunkMetaData> seqChunkMetadatas;
+ 顺序文件解开后得到的 ChunkMetaData 存放在此,本身有序且互不重叠,所以使用 List 存储
+
+private final PriorityQueue<ChunkMetaData> unseqChunkMetadatas;
+ 乱序文件解开后得到的 ChunkMetaData 存放在此,互相之间可能有重叠,为了保证顺序,使用优先队列进行存储
+
+/*
+ * page 层
+ *
+ * 两个字段之间数据永远不重复,first 永远是第一个(开始时间最小)
+ */
+private VersionPageReader firstPageReader;
+ 开始时间最小的 page reader
+
+private PriorityQueue<VersionPageReader> cachedPageReaders;
+ 当前获得的所有 page reader,按照每个 page 的起始时间进行排序
+
+/*
+ * 相交数据点层
+ */
+private PriorityMergeReader mergeReader;
+ 本质上是多个带优先级的 page,按时间戳从低到高输出数据点,时间戳相同时,保留优先级高的
+
+/*
+ * 相交数据点产出结果的缓存
+ */
+private boolean hasCachedNextOverlappedPage;
+ 是否缓存了下一个batch
+
+private BatchData cachedBatchData;
+ 缓存的下一个batch的引用
+```
+
+下面介绍一下SeriesReader里的重要方法
+
+#### hasNextChunk()
+
+* 主要功能:判断该时间序列还有没有下一个chunk。
+
+* 约束:在调用这个方法前,需要保证 `SeriesReader` 内已经没有 page 和 数据点 层级的数据了,也就是之前解开的 chunk 都消耗完了。
+
+* 实现:如果 `firstChunkMetaData` 不为空,则代表当前已经缓存了第一个 `ChunkMetaData`,且未被使用,直接返回`true`;
+
+ 尝试去解开第一个顺序文件和第一个乱序文件,填充 chunk 层。并解开与 `firstChunkMetadata` 相重合的所有文件。
+
+#### isChunkOverlapped()
+
+* 主要功能:判断当前的 chunk 有没有与其他 Chunk 有重叠
+
+* 约束:在调用这个方法前,需要保证 chunk 层已经缓存了 `firstChunkMetadata`,也就是调用了 hasNextChunk() 并且为 true。
+
+* 实现:直接把 `firstChunkMetadata` 与 `seqChunkMetadatas` 和 `unseqChunkMetadatas` 相比较。因为此前已经保证所有和 `firstChunkMetadata` 相交的文件都被解开了。
+
+#### currentChunkStatistics()
+
+返回 `firstChunkMetaData` 的统计信息。
+
+#### skipCurrentChunk()
+
+跳过当前 chunk。只需要将`firstChunkMetaData `置为`null`。
+
+#### hasNextPage()
+
+* 主要功能:判断 SeriesReader 中还有没有已经解开的 page,如果有相交的 page,就构造 `cachedBatchData` 并缓存,否则缓存 `firstPageReader`。
+
+* 实现:如果已经缓存了 `cachedBatchData` 就直接返回。如果有相交数据点,就构造 `cachedBatchData`。如果已经缓存了 `firstPageReader`,就直接返回。
+
+ 如果当前的 `firstChunkMetadata` 还没有解开,就解开与之重叠的所有 ChunkMetadata,构造 firstPageReader。
+
+ 判断,如果 `firstPageReader` 和 `cachedPageReaders` 相交,则构造 `cachedBatchData`,否则直接返回。
+
+#### isPageOverlapped()
+
+* 主要功能:判断当前的 page 有没有与其他 page 有重叠
+
+* 约束:在调用这个方法前,需要保证调用了 hasNextPage() 并且为 true。也就是,有可能缓存了一个相交的 `cachedBatchData`,或者缓存了不相交的 `firstPageReader`。
+
+* 实现:先判断有没有 `cachedBatchData`,如果没有,就说明当前 page 不相交,则 `mergeReader` 里没数据。再判断 `firstPageReader` 是否与 `cachedPageReaders` 中的 page 相交。
+
+#### currentPageStatistics()
+
+返回 `firstPageReader` 的统计信息。
+
+#### skipCurrentPage()
+
+跳过当前Page。只需要将 `firstPageReader` 置为 null。
+
+#### nextPage()
+
+* 主要功能:返回下一个相交或不想交的 page
+
+* 约束:在调用这个方法前,需要保证调用了 hasNextPage() 并且为 true。也就是,有可能缓存了一个相交的 `cachedBatchData`,或者缓存了不相交的 `firstPageReader`。
+
+* 实现:如果 `hasCachedNextOverlappedPage` 为 true,说明缓存了一个相交的 page,直接返回 `cachedBatchData`。否则当前 page 不相交,直接从 firstPageReader 里拿当前 page 的数据。
+
+#### hasNextOverlappedPage()
+
+* 主要功能:内部方法,用来判断当前有没有重叠的数据,并且构造相交的 page 并缓存。
+
+* 实现:如果 `hasCachedNextOverlappedPage` 为 `true`,直接返回 `true`。
+
+ 否则,先调用 `tryToPutAllDirectlyOverlappedPageReadersIntoMergeReader()` 方法,将 `cachedPageReaders` 中所有与 `firstPageReader` 有重叠的放进 `mergeReader` 里。`mergeReader` 里维护了一个 `currentLargestEndTime` 变量,每次添加进新的 Reader 时被更新,用以记录当前添加进 `mergeReader` 的 page 的最大结束时间。
+ 然后先从`mergeReader`里取出当前最大的结束时间,作为第一批数据的结束时间,记为`currentPageEndTime`。接着去遍历`mergeReader`,直到当前的时间戳大于`currentPageEndTime`。
+
+ 每从 mergeReader 移出一个点前,我们先要判断是否有与当前时间戳重叠的file或者chunk或者page(这里之所以还要再做一次判断,是因为,比如当前page是1-30,和他直接相交的page是20-50,还有一个page是40-60,每取一个点判断一次是想把40-60解开),如果有,解开相应的file或者chunk或者page,并将其放入`mergeReader`。完成重叠的判断后,从`mergeReader`中取出相应数据。
+
+ 完成迭代后将获得数据缓存在 `cachedBatchData` 中,并将 `hasCachedNextOverlappedPage` 置为 `true`。
+
+#### nextOverlappedPage()
+
+将缓存的`cachedBatchData`返回,并将`hasCachedNextOverlappedPage`置为`false`。
+
+### org.apache.iotdb.db.query.reader.series.SeriesRawDataBatchReader
+
+`SeriesRawDataBatchReader`实现了`IBatchReader`。
+
+其方法`hasNextBatch()`的核心判断流程是
+
+```
+// 有缓存了 batch,直接返回
+if (hasCachedBatchData) {
+ return true;
+}
+
+/*
+ * 如果 SeriesReader 里还有 page,返回 page
+ */
+if (readPageData()) {
+ hasCachedBatchData = true;
+ return true;
+}
+
+/*
+ * 如果有 chunk,并且有 page,返回 page
+ */
+while (seriesReader.hasNextChunk()) {
+ if (readPageData()) {
+ hasCachedBatchData = true;
+ return true;
+ }
+}
+return hasCachedBatchData;
+```
+
+### org.apache.iotdb.db.query.reader.series.SeriesReaderByTimestamp
+
+`SeriesReaderByTimestamp` 实现了 `IReaderByTimestamp`。
+
+设计思想:当给一个时间戳要查询值时,这个时间戳可以转化为一个 time >= x 的过滤条件。不断更新这个过滤条件,并且跳过不满足的文件,chunk 和 page。
+
+实现方式:
+
+```
+/*
+ * 优先判断下一个 page 有没有当前所查时间,能跳过就跳过
+ */
+if (readPageData(timestamp)) {
+ return true;
+}
+
+/*
+ * 判断下一个 chunk 有没有当前所查时间,能跳过就跳过
+ */
+while (seriesReader.hasNextChunk()) {
+ Statistics statistics = seriesReader.currentChunkStatistics();
+ if (!satisfyTimeFilter(statistics)) {
+ seriesReader.skipCurrentChunk();
+ continue;
+ }
+ /*
+ * chunk 不能跳过,继续到 chunk 里检查 page
+ */
+ if (readPageData(timestamp)) {
+ return true;
+ }
+}
+return false;
+```
+
+### org.apache.iotdb.db.query.reader.series.SeriesAggregateReader
+
+`SeriesAggregateReader` 实现了 `IAggregateReader`
+
+`IAggregateReader`的大部分接口方法都在`SeriesReader`有对应实现,除了`canUseCurrentChunkStatistics()`和`canUseCurrentPageStatistics()`两个方法。
+
+#### canUseCurrentChunkStatistics()
+
+设计思想:可以用统计信息的条件是当前 chunk 不重叠,并且满足过滤条件。
+
+先调用`SeriesReader`的`currentChunkStatistics()`方法,获得当前chunk的统计信息,再调用`SeriesReader`的`isChunkOverlapped()`方法判断当前chunk是否重叠,如果当前chunk不重叠,且其统计信息满足过滤条件,则返回`true`,否则返回`false`。
+
+#### canUseCurrentPageStatistics()
+
+设计思想:可以用统计信息的条件是当前 page 不重叠,并且满足过滤条件。
+
+先调用`SeriesReader`的 `currentPageStatistics()` 方法,获得当前page的统计信息,再调用`SeriesReader` 的 `isPageOverlapped()` 方法判断当前 page 是否重叠,如果当前page不重叠,且其统计信息满足过滤条件,则返回`true`,否则返回`false`。
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/3-RawDataQuery.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/3-RawDataQuery.md
new file mode 100644
index 0000000..95c5a0d
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/3-RawDataQuery.md
@@ -0,0 +1,301 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 原始数据查询
+
+## 设计原理
+
+原始数据查询根据是否包含值过滤条件,可以分为两类。不包含值过滤条件时,根据结果集结构又可分为两类。
+
+* 不包含值过滤条件(无过滤条件 or 仅包含时间过滤条件)
+ * 结果集按时间戳对齐(默认原始数据查询)
+ * 结果集不按时间戳对齐(disable align)
+* 包含值过滤条件
+ * 结果集按时间戳对齐
+
+以上三种查询在代码中对应三种不同的 DataSet,封装了这三种查询的执行逻辑。
+
+## 不包含值过滤条件 + 结果集按时间戳对齐
+
+### org.apache.iotdb.db.query.dataset.RawQueryDataSetWithoutValueFilter
+
+`RawQueryDataSetWithoutValueFilter`实现了没有值过滤条件,且需要按照时间戳对齐的查询逻辑。虽然最后的查询结果需要每个时间序列按照时间戳对齐,但是每个时间序列的查询是可以做并行化的。这里借助消费者-生产者队列的思想,将每个时间序列获取数据的操作与最后对所有时间序列进行对齐的操作解耦。每个时间序列对应一个生产者线程,且有其对应的`BlockingQueue`,生产者任务负责读取相应的时间序列的数据放进`BlockingQueue`中;消费者线程只有一个,负责从每个时间序列的`BlockingQueue`中取出数据,进行时间戳对齐之后,将结果组装成`TSQueryDataSet`形式返回。
+
+在具体实现的时候,考虑到机器的资源限制,并非为每个查询的每一个时间序列创建一个线程,而是采用线程池技术,将每一个时间序列的生产者任务当作一个`Runnable`的task提交到线程池中执行。
+
+下面就先介绍生产者的代码,它被封装在是`RawQueryDataSetWithoutValueFilter`的一个内部类`ReadTask`中,实现了`Runnable`接口。
+
+### org.apache.iotdb.db.query.dataset.RawQueryDataSetWithoutValueFilter.ReadTask
+
+`ReadTask`中有两个字段
+
+* private final ManagedSeriesReader reader;
+* private BlockingQueue<BatchData> blockingQueue;
+
+`ManagedSeriesReader`接口继承了`IBatchReader`接口,主要用来读取单个时间序列的数据,并且新增了以下四个方法
+
+```
+boolean isManagedByQueryManager();
+
+void setManagedByQueryManager(boolean managedByQueryManager);
+
+boolean hasRemaining();
+
+void setHasRemaining(boolean hasRemaining);
+```
+
+前两个方法用以表征该时间序列对应的生产者任务有没有被查询管理器所管理,即生产者任务有没有因为阻塞队列满了,而自行退出(后文会解释为什么不阻塞等待,而是直接退出);后两个方法用以表征该时间序列对应的reader里还有没有数据。
+
+`blockingQueue`就是该生产者任务的阻塞队列,实际上该阻塞队列只会在消费者取数据时单边阻塞,生产者放数据时,如果发现队列满了,便会直接退出,不会阻塞。
+
+下面看一下`ReadTask`的`run()`方法,执行流程的解释以注释的形式展现在代码中
+
+#### run()
+
+```
+public void run() {
+ try {
+ // 这里加锁的原因是为了保证对于blockingQueue满不满的判断是正确同步的
+ synchronized (reader) {
+ // 由于每次提交生产者任务时(不论是生产者自己递归的提交自己,还是消费者发现生产者任务自行退出而提交的),都会检查队列是不是满的,如果队列满了,是不会提交生产者任务的
+ // 所以生产者任务一旦被提交,blockingQueue里一定是有空余位置的,我们不需要检查队列是否满
+ // 如果时间序列对应的reader还有数据,进入循环体
+ while (reader.hasNextBatch()) {
+ BatchData batchData = reader.nextBatch();
+ // 由于拿到的BatchData有可能为空,所以需要一直迭代到第一个不为空的BatchData
+ if (batchData.isEmpty()) {
+ continue;
+ }
+ // 将不为空的batchData放进阻塞队列中,此时的阻塞队列一定是不满的,所以不会阻塞
+ blockingQueue.put(batchData);
+ // 如果阻塞队列仍然没有满,生产者任务再次向线程池里递归地提交自己,进行下一个batchData的获取
+ if (blockingQueue.remainingCapacity() > 0) {
+ pool.submit(this);
+ }
+ // 如果阻塞队列满了,生产者任务退出,并将对应reader的managedByQueryManager置为false
+ else {
+ reader.setManagedByQueryManager(false);
+ }
+ return;
+ }
+ // 代码执行到这边,代表之前的while循环条件不满足,即该时间序列对应的reader里没有数据了
+ // 我们往阻塞队列里放入一个SignalBatchData,用以告知消费者,这个时间序列已经没有数据了,不需要再从该时间序列对应的队列里取数据了
+ blockingQueue.put(SignalBatchData.getInstance());
+ // 将reader的hasRemaining字段置为false
+ // 通知消费者不需要再为这个时间序列提交生产者任务
+ reader.setHasRemaining(false);
+ // 将reader的managedByQueryManager字段置为false
+ reader.setManagedByQueryManager(false);
+ }
+ } catch (InterruptedException e) {
+ LOGGER.error("Interrupted while putting into the blocking queue: ", e);
+ Thread.currentThread().interrupt();
+ } catch (IOException e) {
+ LOGGER.error("Something gets wrong while reading from the series reader: ", e);
+ } catch (Exception e) {
+ LOGGER.error("Something gets wrong: ", e);
+ }
+}
+```
+
+接下来介绍消费者的代码,消费者的主要逻辑是从每个时间序列的队列里拿出值,做时间戳对齐,然后拼凑结果集。时间戳的对齐主要通过一个时间戳的最小堆来实现,如果该时间序列的时间戳等于堆顶的时间戳,则取出该值,反之,将该时间戳下该时间序列的值置为`null`。
+
+先介绍消费者任务的一些重要字段
+
+* TreeSet<Long> timeHeap
+
+ 时间戳的最小堆,用以实现时间戳对齐操作
+
+* BlockingQueue<BatchData>[] blockingQueueArray;
+
+ 阻塞队列的数组,用以存储每个时间序列对应的阻塞队列
+
+* boolean[] noMoreDataInQueueArray
+
+ 用以表征某个时间序列的阻塞队列里还有没有值,如果为false,则消费者不会再去调用`take()`方法,以防消费者线程被阻塞。
+
+* BatchData[] cachedBatchDataArray
+
+ 缓存从阻塞队列里取出的一个BatchData,因为阻塞队列里`take()`出的`BatchData`并不能一次性消费完,所以需要做缓存
+
+在消费者`RawQueryDataSetWithoutValueFilter`的构造函数里首先调用了`init()`方法
+
+#### init()
+
+```
+private void init() throws InterruptedException {
+ timeHeap = new TreeSet<>();
+ // 为每个时间序列构建生产者任务
+ for (int i = 0; i < seriesReaderList.size(); i++) {
+ ManagedSeriesReader reader = seriesReaderList.get(i);
+ reader.setHasRemaining(true);
+ reader.setManagedByQueryManager(true);
+ pool.submit(new ReadTask(reader, blockingQueueArray[i]));
+ }
+ // 初始化最小堆,填充每个时间序列对应的缓存
+ for (int i = 0; i < seriesReaderList.size(); i++) {
+ // 调用fillCache(int)方法填充缓存
+ fillCache(i);
+ // 尝试将每个时间序列的当前最小时间戳放进堆中
+ if (cachedBatchDataArray[i] != null && cachedBatchDataArray[i].hasCurrent()) {
+ long time = cachedBatchDataArray[i].currentTime();
+ timeHeap.add(time);
+ }
+ }
+}
+```
+
+#### fillCache(int)
+
+该方法负责从阻塞队列中取出数据,并填充缓存,具体逻辑见下文注释
+
+```
+private void fillCache(int seriesIndex) throws InterruptedException {
+ // 从阻塞队列中拿数据,如果没有数据,则会阻塞等待队列中有数据
+ BatchData batchData = blockingQueueArray[seriesIndex].take();
+ // 如果是一个信号BatchData,则将相应时间序列的oMoreDataInQueue置为false
+ if (batchData instanceof SignalBatchData) {
+ noMoreDataInQueueArray[seriesIndex] = true;
+ }
+ else {
+ // 将取出的BatchData放进cachedBatchDataArray缓存起来
+ cachedBatchDataArray[seriesIndex] = batchData;
+
+ // 这里加锁的原因与生产者任务那边一样,是为了保证对于blockingQueue满不满的判断是正确同步的
+ synchronized (seriesReaderList.get(seriesIndex)) {
+ // 只有当阻塞队列不满的时候,我们才需要判断是不是需要提交生产者任务,这里也保证了生产者任务会被提交,当且仅当阻塞队列不满
+ if (blockingQueueArray[seriesIndex].remainingCapacity() > 0) {
+ ManagedSeriesReader reader = seriesReaderList.get(seriesIndex);、
+ // 如果该时间序列的reader并没有被查询管理器管理(即生产者任务由于队列满了,自行退出),并且该reader里还有数据,我们需要再次提交该时间序列的生产者任务
+ if (!reader.isManagedByQueryManager() && reader.hasRemaining()) {
+ reader.setManagedByQueryManager(true);
+ pool.submit(new ReadTask(reader, blockingQueueArray[seriesIndex]));
+ }
+ }
+ }
+ }
+}
+```
+
+有了每个时间序列的数据,接下来就是将每个时间戳的数据做对齐,并将结果组装成`TSQueryDataSet`返回。这里的逻辑封装在`fillBuffer()`方法中,该方法里还包含了`limit`和`offset`,以及格式化结果集的逻辑,对此我们不作赘述,只分析其中数据读取和时间戳对齐的流程。
+
+```
+// 从最小堆中取出当前时间戳
+long minTime = timeHeap.pollFirst();
+for (int seriesIndex = 0; seriesIndex < seriesNum; seriesIndex++) {
+ if (cachedBatchDataArray[seriesIndex] == null
+ || !cachedBatchDataArray[seriesIndex].hasCurrent()
+ || cachedBatchDataArray[seriesIndex].currentTime() != minTime) {
+ // 该时间序列在当前时间戳没有数据,置为null
+ ...
+
+ } else {
+ // 该时间序列在当前时间戳有数据,将该数据格式化成结果集格式
+ TSDataType type = cachedBatchDataArray[seriesIndex].getDataType();
+ ...
+
+ }
+
+ // 将该时间序列缓存的batchdata游标向后移
+ cachedBatchDataArray[seriesIndex].next();
+
+ // 如果当前缓存的batchdata为空,并且阻塞队列依然有数据,则再次调用fillCache()方法填充缓存
+ if (!cachedBatchDataArray[seriesIndex].hasCurrent()
+ && !noMoreDataInQueueArray[seriesIndex]) {
+ fillCache(seriesIndex);
+ }
+
+ // 尝试将该时间序列的下一个时间戳放进最小堆中
+ if (cachedBatchDataArray[seriesIndex].hasCurrent()) {
+ long time = cachedBatchDataArray[seriesIndex].currentTime();
+ timeHeap.add(time);
+ }
+}
+```
+
+## 不包含值过滤条件 + 结果集不按时间戳对齐
+
+### org.apache.iotdb.db.query.dataset.NonAlignEngineDataSet
+
+`NonAlignEngineDataSet`实现了没有值过滤条件,且不需要按照时间戳对齐的查询逻辑。这里的查询逻辑跟`RawQueryDataSetWithoutValueFilter`很类似,但是它的消费者逻辑更为简单,因为不需要做时间戳对齐的操作。并且每个生产者任务中也可以做更多的工作,不仅可以从Reader中取出BatchData,还可以进一步讲取出的BatchData格式化为结果集需要的输出,从而提高了程序的并行度。如此,消费者只需要从每个阻塞队列里取出数据,set进`TSQueryNonAlignDataSet`相应的位置即可。
+
+具体的查询逻辑,在此就不再赘述了,可以参照`RawQueryDataSetWithoutValueFilter`的查询逻辑分析。
+
+## 包含值过滤条件 + 结果集按时间戳对齐
+
+### org.apache.iotdb.db.query.dataset.EngineDataSetWithValueFilter
+
+`EngineDataSetWithValueFilter`实现了有值过滤条件的查询逻辑。
+
+它的查询逻辑是,首先根据查询条件生成满足过滤条件的时间戳,通过满足条件的时间戳查询投影列的值,然后返回结果集。它有四个字段
+
+* private EngineTimeGenerator timeGenerator;
+
+ 是用来生成满足过滤条件的时间戳的
+
+* private List<IReaderByTimestamp> seriesReaderByTimestampList;
+
+ 每个时间序列对应的reader,用来根据时间戳获取数据
+
+* private boolean hasCachedRowRecord;
+
+ 当前是否缓存了数据行
+
+* private RowRecord cachedRowRecord;
+
+ 当前缓存的数据行
+
+它的主要查询逻辑封装在`cacheRowRecord()`方法中,具体分析见代码中的注释
+
+#### cacheRowRecord()
+
+```
+private boolean cacheRowRecord() throws IOException {
+ // 判断有没有下一个符合条件的时间戳
+ while (timeGenerator.hasNext()) {
+ boolean hasField = false;
+ // 获得当前符合条件的时间戳
+ long timestamp = timeGenerator.next();
+ RowRecord rowRecord = new RowRecord(timestamp);
+ for (int i = 0; i < seriesReaderByTimestampList.size(); i++) {
+ // 根获得每个时间序列当前时间戳下的value
+ IReaderByTimestamp reader = seriesReaderByTimestampList.get(i);
+ Object value = reader.getValueInTimestamp(timestamp);
+ // 如果该时间序列在当前时间戳下没有值,则置null
+ if (value == null) {
+ rowRecord.addField(null);
+ }
+ // 否则将hasField置为true
+ else {
+ hasField = true;
+ rowRecord.addField(value, dataTypes.get(i));
+ }
+ }
+ // 如果该时间戳下,任何一个时间序列有值,则表示该时间戳有效,缓存该数据行
+ if (hasField) {
+ hasCachedRowRecord = true;
+ cachedRowRecord = rowRecord;
+ break;
+ }
+ }
+ return hasCachedRowRecord;
+}
+```
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/4-AggregationQuery.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/4-AggregationQuery.md
new file mode 100644
index 0000000..56b2589
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/4-AggregationQuery.md
@@ -0,0 +1,114 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 聚合查询
+
+聚合查询的主要逻辑在 AggregateExecutor
+
+* org.apache.iotdb.db.query.executor.AggregationExecutor
+
+## 不带值过滤条件的聚合查询
+
+对于不带值过滤条件的聚合查询,通过 `executeWithoutValueFilter()` 方法获得结果并构建 dataSet。首先使用 `mergeSameSeries()` 方法将对于相同时间序列的聚合查询合并,例如:如果需要计算count(s1), sum(s2), count(s3), sum(s1),即需要计算s1的两个聚合值,那么将会得到pathToAggrIndexesMap结果为:s1 -> 0, 3; s2 -> 1; s3 -> 2。
+
+那么将会得到 `pathToAggrIndexesMap`,其中每一个 entry 都是一个 series 的聚合查询,因此可以通过调用 `groupAggregationsBySeries()` 方法计算出其聚合值 `aggregateResults`。在最后创建结果集之前,需要将其顺序还原为用户查询的顺序。最后使用 `constructDataSet()` 方法创建结果集并返回。
+
+下面详细讲解 `groupAggregationsBySeries()` 方法。首先创建一个 `IAggregateReader`:
+```
+IAggregateReader seriesReader = new SeriesAggregateReader(
+ pathToAggrIndexes.getKey(), tsDataType, context, QueryResourceManager.getInstance()
+ .getQueryDataSource(seriesPath, context, timeFilter), timeFilter, null);
+```
+
+对于每一个 entry(即series),首先为其每一种聚合查询创建一个聚合结果 `AggregateResult`,同时维护一个布尔值列表 `isCalculatedList`,对应每一个 `AggregateResult`是否已经计算完成,并记录需要剩余计算的聚合函数数目 `remainingToCalculate`。布尔值列表和这个计数值将会使得某些聚合函数(如 `FIRST_VALUE`)在获得结果后,不需要再继续进行整个循环过程。
+
+接下来,按照5.2节所介绍的 `aggregateReader` 使用方法,更新 `AggregateResult`:
+
+```
+while (aggregateReader.hasNextChunk()) {
+ if (aggregateReader.canUseCurrentChunkStatistics()) {
+ Statistics chunkStatistics = aggregateReader.currentChunkStatistics();
+
+ // do some aggregate calculation using chunk statistics
+ ...
+
+ aggregateReader.skipCurrentChunk();
+ continue;
+ }
+
+ while (aggregateReader.hasNextPage()) {
+ if (aggregateReader.canUseCurrentPageStatistics()) {
+ Statistics pageStatistic = aggregateReader.currentPageStatistics();
+
+ // do some aggregate calculation using page statistics
+ ...
+
+ aggregateReader.skipCurrentPage();
+ continue;
+ } else {
+ BatchData batchData = aggregateReader.nextPage();
+ // do some aggregate calculation using batch data
+ ...
+ }
+ }
+}
+```
+
+需要注意的是,在对于每一个result进行更新之前,需要首先判断其是否已经被计算完(利用 `isCalculatedList` 列表);每一次更新后,调用 `isCalculatedAggregationResult()` 方法同时更新列表中的布尔值。如果列表中所有值均为true,即 `remainingToCalculate` 值为0,证明所有聚合函数结果均已计算完,可以返回。
+```
+if (Boolean.FALSE.equals(isCalculatedList.get(i))) {
+ AggregateResult aggregateResult = aggregateResultList.get(i);
+ ... // 更新
+ if (aggregateResult.isCalculatedAggregationResult()) {
+ isCalculatedList.set(i, true);
+ remainingToCalculate--;
+ if (remainingToCalculate == 0) {
+ return aggregateResultList;
+ }
+ }
+}
+```
+
+在使用 `overlapedPageData` 进行更新时,由于获得每一个聚合函数结果都会遍历这个 batchData,因此需要调用 `resetBatchData()` 方法将指针指向其开始位置,使得下一个函数可以遍历。
+
+## 带值过滤条件的聚合查询
+对于带值过滤条件的聚合查询,通过 `executeWithoutValueFilter()` 方法获得结果并构建 dataSet。首先根据表达式创建 `timestampGenerator`,然后为每一个时间序列创建一个 `SeriesReaderByTimestamp`,放到 `readersOfSelectedSeries`列表中;为每一个查询创建一个创建一个聚合结果 `AggregateResult`,放到 `aggregateResults`列表中。
+
+初始化完成后,调用 `aggregateWithValueFilter()` 方法更新结果:
+```
+while (timestampGenerator.hasNext()) {
+ // 生成timestamps
+ long[] timeArray = new long[aggregateFetchSize];
+ int timeArrayLength = 0;
+ for (int cnt = 0; cnt < aggregateFetchSize; cnt++) {
+ if (!timestampGenerator.hasNext()) {
+ break;
+ }
+ timeArray[timeArrayLength++] = timestampGenerator.next();
+ }
+
+ // 利用timestamps计算聚合结果
+ for (int i = 0; i < readersOfSelectedSeries.size(); i++) {
+ aggregateResults.get(i).updateResultUsingTimestamps(timeArray, timeArrayLength,
+ readersOfSelectedSeries.get(i));
+ }
+ }
+```
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/5-GroupByQuery.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/5-GroupByQuery.md
new file mode 100644
index 0000000..e7fc406
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/5-GroupByQuery.md
@@ -0,0 +1,260 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 降采样查询
+
+* org.apache.iotdb.db.query.dataset.groupby.GroupByEngineDataSet
+
+降采样查询的结果集都会继承 `GroupByEngineDataSet`,该类包含如下字段:
+* protected long queryId
+* private long interval
+* private long slidingStep
+
+以下两个字段针对整个查询,时间段为左闭右开,即 `[startTime, endTime)`:
+* private long startTime
+* private long endTime
+
+以下字段针对当前分段,时间段为左闭右开,即 `[curStartTime, curEndTime)`
+* protected long curStartTime;
+* protected long curEndTime;
+* private int usedIndex;
+* protected boolean hasCachedTimeInterval;
+
+
+`GroupByEngineDataSet` 的核心方法很容易,首先根据是否有缓存的时间段判断是否有下一分段,有则返回 `true`;如果没有就计算分段开始时间,将 `usedIndex` 增加1。如果分段开始时间已经超过了查询结束时间,返回 `false`,否则计算查询结束时间,将 `hasCachedTimeInterval` 置为`true`,并返回 `true`:
+```
+protected boolean hasNextWithoutConstraint() {
+ if (hasCachedTimeInterval) {
+ return true;
+ }
+
+ curStartTime = usedIndex * slidingStep + startTime;
+ usedIndex++;
+ if (curStartTime < endTime) {
+ hasCachedTimeInterval = true;
+ curEndTime = Math.min(curStartTime + interval, endTime);
+ return true;
+ } else {
+ return false;
+ }
+}
+```
+
+## 不带值过滤条件的降采样查询
+
+不带值过滤条件的降采样查询逻辑主要在 `GroupByWithoutValueFilterDataSet` 类中,该类继承了 `GroupByEngineDataSet`。
+
+
+该类有如下关键字段:
+* private Map<Path, GroupByExecutor> pathExecutors 针对于相同 `Path` 的聚合函数进行归类,并封装成 `GroupByExecutor` ,
+`GroupByExecutor` 封装了每个 `Path` 的数据计算逻辑和方法,在后面介绍
+
+* private TimeRange timeRange 将每次计算的时间区间封装成对象,用于判断 `Statistics` 是否可以直接参与计算
+* private Filter timeFilter 将用户定义的查询区间生成为 `Filter` 对象,用来过滤可用的`文件`、`chunk`、`page`
+
+首先,在初始化 `initGroupBy()` 方法中,根据表达式计算出 `timeFilter`,并为每个 `path` 生成 `GroupByExecutor` 。
+
+`nextWithoutConstraint()` 方法通过调用 `GroupByExecutor.calcResult()` 方法计算出每个 `Path` 内的所有聚合方法的聚合值 `aggregateResults`。
+以下方法用于将结果列表转化为 RowRecord,需要注意列表中没有结果时, RowRecord 中添加 `null`:
+```
+for (AggregateResult res : fields) {
+ if (res == null) {
+ record.addField(null);
+ continue;
+ }
+ record.addField(res.getResult(), res.getResultDataType());
+}
+```
+
+
+### GroupByExecutor
+封装了相同 path 下的所有聚合函数的计算方法,该类有如下关键字段:
+* private IAggregateReader reader 读取当前 `Path` 数据用到的 `SeriesAggregateReader`
+* private BatchData preCachedData 每次从 `Reader` 读取的数据是一批,很有可能会超过当前的时间段,那么这个 `BatchData` 就会被缓存留给下一次使用
+* private List<Pair<AggregateResult, Integer>> results 存储了当前 `Path` 里所有的聚合方法,
+例如:`select count(a),sum(a),avg(b)` ,`count` 和 `sum` 方法就被存到一起。
+右侧的 `Integer` 用于结果集转化为RowRecord之前,需要将其顺序还原为用户查询的顺序。
+
+#### 主要方法
+
+```
+//从 reader 中读取数据,并计算,该类的主方法。
+private List<Pair<AggregateResult, Integer>> calcResult() throws IOException, QueryProcessException;
+
+//添加当前 path 的聚合操作
+private void addAggregateResult(AggregateResult aggrResult, int index);
+
+//判断当前 path 是否已经完成了所有的聚合计算
+private boolean isEndCalc();
+
+//从上次计算没有使用完缓存的 BatchData 中计算结果
+private boolean calcFromCacheData() throws IOException;
+
+//使用 BatchData 计算
+private void calcFromBatch(BatchData batchData) throws IOException;
+
+//使用 Page 或 Chunk 的 Statistics 信息直接计算结果
+private void calcFromStatistics(Statistics statistics) throws QueryProcessException;
+
+//清空所有计算结果
+private void resetAggregateResults();
+
+//遍历并计算 page 中的数据
+private boolean readAndCalcFromPage() throws IOException, QueryProcessException;
+
+```
+
+`GroupByExecutor` 中因为相同 `path` 的不同聚合函数使用的数据是相同的,所以在入口方法 `calcResult` 中负责读取该 `Path` 的所有数据,
+取出来的数据再调用 `calcFromBatch` 方法完成遍历所有聚合函数对 `BatchData` 的计算。
+
+`calcResult` 方法返回当前 Path 下的所有AggregateResult,以及当前聚合值在用户查询顺序里的位置,其主要逻辑:
+
+```
+//把上次遗留的数据先做计算,如果能直接获得结果就结束计算
+if (calcFromCacheData()) {
+ return results;
+}
+
+//因为一个chunk是包含多个page的,那么必须先使用完当前chunk的page,再打开下一个chunk
+if (readAndCalcFromPage()) {
+ return results;
+}
+
+//遗留的数据如果计算完了就要打开新的chunk继续计算
+while (reader.hasNextChunk()) {
+ Statistics chunkStatistics = reader.currentChunkStatistics();
+ // 判断能否使用 Statistics,并执行计算
+ ....
+ // 跳过当前chunk
+ reader.skipCurrentChunk();
+ // 如果已经获取到了所有结果就结束计算
+ if (isEndCalc()) {
+ return true;
+ }
+ continue;
+ }
+ //如果不能使用 chunkStatistics 就需要使用page数据计算
+ if (readAndCalcFromPage()) {
+ return results;
+ }
+}
+```
+
+`readAndCalcFromPage` 方法是从当前打开的chunk中获取page的数据,并计算聚合结果。当完成所有计算时返回 true,否则返回 false。主要逻辑:
+
+```
+while (reader.hasNextPage()) {
+ Statistics pageStatistics = reader.currentPageStatistics();
+ //只有page与其它page不相交时,才能使用 pageStatistics
+ if (pageStatistics != null) {
+ // 判断能否使用 Statistics,并执行计算
+ ....
+ // 跳过当前page
+ reader.skipCurrentPage();
+ // 如果已经获取到了所有结果就结束计算
+ if (isEndCalc()) {
+ return true;
+ }
+ continue;
+ }
+ }
+ // 不能使用 Statistics 时,只能取出所有数据进行计算
+ BatchData batchData = reader.nextPage();
+ if (batchData == null || !batchData.hasCurrent()) {
+ continue;
+ }
+ // 如果刚打开的page就超过时间范围,缓存取出来的数据并直接结束计算
+ if (batchData.currentTime() >= curEndTime) {
+ preCachedData = batchData;
+ return true;
+ }
+ //执行计算
+ calcFromBatch(batchData);
+ ...
+}
+
+```
+
+`calcFromBatch` 方法是对于取出的BatchData数据,遍历所有聚合函数进行计算,主要逻辑为:
+
+```
+for (Pair<AggregateResult, Integer> result : results) {
+ //如果某个函数已经完成了计算,就不在进行计算了,比如最小值这种计算
+ if (result.left.isCalculatedAggregationResult()) {
+ continue;
+ }
+ // 执行计算
+ ....
+}
+//判断当前的 batchdata 里的数据是否还能被下次使用,如果能则加到缓存中
+if (batchData.getMaxTimestamp() >= curEndTime) {
+ preCachedData = batchData;
+}
+```
+
+## 带值过滤条件的聚合查询
+带值过滤条件的降采样查询逻辑主要在 `GroupByWithValueFilterDataSet` 类中,该类继承了 `GroupByEngineDataSet`。
+
+该类有如下关键字段:
+* private List<IReaderByTimestamp> allDataReaderList
+* private GroupByPlan groupByPlan
+* private TimeGenerator timestampGenerator
+* private long timestamp 用于为下一个 group by 分区缓存 timestamp
+* private boolean hasCachedTimestamp 用于判断是否有为下一个 group by 分区缓存 timestamp
+* private int timeStampFetchSize 是 group by 计算 batch 的大小
+
+首先,在初始化 `initGroupBy()` 方法中,根据表达式创建 `timestampGenerator`;然后为每一个时间序列创建一个 `SeriesReaderByTimestamp`,放到 `allDataReaderList`列表中
+
+初始化完成后,调用 `nextWithoutConstraint()` 方法更新结果。如果有为下一个 group by 分区缓存 timestamp,且时间符合要求,则将其加入 `timestampArray` 中,否则直接返回 `aggregateResultList` 结果;在没有为下一个 group by 分区缓存 timestamp 的情况下,使用 `timestampGenerator` 进行遍历:
+
+```
+while (timestampGenerator.hasNext()) {
+ // 调用 constructTimeArrayForOneCal() 方法,得到 timestamp 列表
+ timeArrayLength = constructTimeArrayForOneCal(timestampArray, timeArrayLength);
+
+ // 调用 updateResultUsingTimestamps() 方法,使用 timestamp 列表计算聚合结果
+ for (int i = 0; i < paths.size(); i++) {
+ aggregateResultList.get(i).updateResultUsingTimestamps(
+ timestampArray, timeArrayLength, allDataReaderList.get(i));
+ }
+
+ timeArrayLength = 0;
+ // 判断是否到结束
+ if (timestamp >= curEndTime) {
+ hasCachedTimestamp = true;
+ break;
+ }
+}
+```
+
+其中的 `constructTimeArrayForOneCal()` 方法遍历 timestampGenerator 构建 timestamp 列表:
+
+```
+for (int cnt = 1; cnt < timeStampFetchSize && timestampGenerator.hasNext(); cnt++) {
+ timestamp = timestampGenerator.next();
+ if (timestamp < curEndTime) {
+ timestampArray[timeArrayLength++] = timestamp;
+ } else {
+ hasCachedTimestamp = true;
+ break;
+ }
+}
+```
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/6-LastQuery.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/6-LastQuery.md
new file mode 100644
index 0000000..3394442
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/6-LastQuery.md
@@ -0,0 +1,119 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 最近时间戳 Last 查询
+
+Last 查询的主要逻辑在 LastQueryExecutor
+
+* org.apache.iotdb.db.query.executor.LastQueryExecutor
+
+Last查询对每个指定的时间序列执行`calculateLastPairForOneSeries`方法。
+
+## 读取MNode缓存数据
+
+我们在需要查询的时间序列所对应的MNode结构中添加Last数据缓存。`calculateLastPairForOneSeries`方法对于某个时间序列的Last查询,首先尝试读取MNode中的缓存数据。
+```
+try {
+ node = MManager.getInstance().getDeviceNodeWithAutoCreateStorageGroup(seriesPath.toString());
+} catch (MetadataException e) {
+ throw new QueryProcessException(e);
+}
+if (((LeafMNode) node).getCachedLast() != null) {
+ return ((LeafMNode) node).getCachedLast();
+}
+```
+如果发现缓存没有被写入过,则执行下面的标准查询流程读取TsFile数据。
+
+## Last标准查询流程
+
+Last标准查询流程需要遍历所有的顺序文件和乱序文件得到查询结果,最后将查询结果写回到MNode缓存。算法中对顺序文件和乱序文件分别进行处理。
+- 顺序文件由于是对其写入时间已经排好序,因此直接使用`loadChunkMetadataFromTsFileResource`方法取出最后一个`ChunkMetadata`,通过`ChunkMetadata`的统计数据得到最大时间戳和对应的值。
+ ```
+ if (!seqFileResources.isEmpty()) {
+ List<ChunkMetaData> chunkMetadata =
+ FileLoaderUtils.loadChunkMetadataFromTsFileResource(
+ seqFileResources.get(seqFileResources.size() - 1), seriesPath, context);
+ if (!chunkMetadata.isEmpty()) {
+ ChunkMetaData lastChunkMetaData = chunkMetadata.get(chunkMetadata.size() - 1);
+ Statistics chunkStatistics = lastChunkMetaData.getStatistics();
+ resultPair =
+ constructLastPair(
+ chunkStatistics.getEndTime(), chunkStatistics.getLastValue(), tsDataType);
+ }
+ }
+ ```
+- 乱序文件则需要遍历所有的`ChunkMetadata`结构得到最大时间戳数据。需要注意的是当多个`ChunkMetadata`拥有相同的时间戳时,我们取`version`值最大的`ChunkMatadata`中的数据作为Last的结果。
+
+ ```
+ long version = 0;
+ for (TsFileResource resource : unseqFileResources) {
+ if (resource.getEndTimeMap().get(seriesPath.getDevice()) < resultPair.getTimestamp()) {
+ break;
+ }
+ List<ChunkMetaData> chunkMetadata =
+ FileLoaderUtils.loadChunkMetadataFromTsFileResource(resource, seriesPath, context);
+ for (ChunkMetaData chunkMetaData : chunkMetadata) {
+ if (chunkMetaData.getEndTime() == resultPair.getTimestamp()
+ && chunkMetaData.getVersion() > version) {
+ Statistics chunkStatistics = chunkMetaData.getStatistics();
+ resultPair =
+ constructLastPair(
+ chunkStatistics.getEndTime(), chunkStatistics.getLastValue(), tsDataType);
+ version = chunkMetaData.getVersion();
+ }
+ }
+ }
+ ```
+ - 最后将查询结果写入到MNode的Last缓存
+ ```
+ ((LeafMNode) node).updateCachedLast(resultPair, false, Long.MIN_VALUE);
+ ```
+
+## Last 缓存更新策略
+
+Last缓存更新的逻辑位于`LeafMNode`的`updateCachedLast`方法内,这里引入两个额外的参数`highPriorityUpdate`和`latestFlushTime`。`highPriorityUpdate`用来表示本次更新是否是高优先级的,新数据写入而导致的缓存更新都被认为是高优先级更新,而查询时更新缓存默认为低优先级更新。`latestFlushTime`用来记录当前已被写回到磁盘的数据的最大时间戳。
+
+缓存更新的策略如下:
+
+1. 当缓存中没有记录时,对于查询到的Last数据,将查询的结果直接写入到缓存中。
+2. 当缓存中没有记录时,对于写入的最新数据如果时间戳大于或等于`latestFlushTime`,则将写入的数据写入到缓存中。
+3. 当缓存中已有记录时,根据查询或写入的数据时间戳与当前缓存中时间戳作对比。写入的数据具有高优先级,时间戳不小于缓存记录则更新缓存;查询出的数据低优先级,必须大于缓存记录的时间戳才更新缓存。
+
+具体代码如下
+```
+public synchronized void updateCachedLast(
+ TimeValuePair timeValuePair, boolean highPriorityUpdate, Long latestFlushedTime) {
+ if (timeValuePair == null || timeValuePair.getValue() == null) return;
+
+ if (cachedLastValuePair == null) {
+ // If no cached last, (1) a last query (2) an unseq insertion or (3) a seq insertion will update cache.
+ if (!highPriorityUpdate || latestFlushedTime <= timeValuePair.getTimestamp()) {
+ cachedLastValuePair =
+ new TimeValuePair(timeValuePair.getTimestamp(), timeValuePair.getValue());
+ }
+ } else if (timeValuePair.getTimestamp() > cachedLastValuePair.getTimestamp()
+ || (timeValuePair.getTimestamp() == cachedLastValuePair.getTimestamp()
+ && highPriorityUpdate)) {
+ cachedLastValuePair.setTimestamp(timeValuePair.getTimestamp());
+ cachedLastValuePair.setValue(timeValuePair.getValue());
+ }
+}
+```
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/7-AlignByDeviceQuery.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/7-AlignByDeviceQuery.md
new file mode 100644
index 0000000..25042e2
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/5-DataQuery/7-AlignByDeviceQuery.md
@@ -0,0 +1,203 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 按设备对齐查询
+
+AlignByDevicePlan 即按设备对齐查询对应的表结构为:
+
+| Time | Device | sensor1 | sensor2 | sensor3 | ... |
+| ---- | ------ | ------- | ------- | ------- | --- |
+| | | | | | |
+
+## 设计原理
+
+按设备对齐查询其实现原理主要是计算出查询中每个设备对应的测点和过滤条件,然后将查询按设备分别进行,最后将结果集拼装并返回。
+
+### AlignByDevicePlan 中重要字段含义
+
+首先解释一下 AlignByDevicePlan 中一些重要字段的含义:
+- `List<String> measurements`:查询中出现的 measurement 列表。
+- `Map<Path, TSDataType> dataTypeMapping`: 该变量继承自基类 QueryPlan,其主要作用是在计算每个设备的执行路径时,提供此次查询的 paths 对应的数据类型。
+- `Map<String, Set<String>> deviceToMeasurementsMap`, `Map<String, IExpression> deviceToFilterMap`: 这两个字段分别用来存储设备对应的测点和过滤条件。
+- `Map<String, TSDataType> measurementDataTypeMap`:AlignByDevicePlan 要求不同设备的同名 sensor 数据类型一致,该字段是一个 `measurementName -> dataType` 的 Map 结构,用来验证同名 sensor 的数据类型一致性。如 `root.sg.d1.s1` 和 `root.sg.d2.s1` 应该是同一数据类型。
+- `enum MeasurementType`:记录三种 measurement 类型。在任何设备中都不存在的 measurement 为 `NonExist` 类型;有单引号或双引号的 measurement 为 `Constant` 类型;存在的 measurement 为 `Exist` 类型。
+- `Map<String, MeasurementType> measurementTypeMap`: 该字段是一个 `measureName -> measurementType` 的 Map 结构,用来记录查询中所有 measurement 的类型。
+- groupByPlan, fillQueryPlan, aggregationPlan:为了避免冗余,这三个执行计划被设定为 RawDataQueryPlan 的子类,而在 AlignByDevicePlan 中被设置为变量。如果查询计划属于这三个计划中的一种,则该字段会被赋值并保存。
+
+在进行具体实现过程的讲解前,先给出一个覆盖较为完整的例子,下面的解释过程中将结合该示例进行说明。
+
+```sql
+SELECT s1, "1", *, s2, s5 FROM root.sg.d1, root.sg.* WHERE time = 1 AND s1 < 25 ALIGN BY DEVICE
+```
+
+其中,系统中的时间序列为:
+
+- root.sg.d1.s1
+- root.sg.d1.s2
+- root.sg.d2.s1
+
+存储组 `root.sg` 共包含两个设备 d1 和 d2,其中 d1 有两个传感器 s1 和 s2,d2 只有传感器 s1,相同传感器 s1 的数据类型相同。
+
+下面将按具体过程进行分别解释:
+
+### 逻辑计划生成
+
+- org.apache.iotdb.db.qp.Planner
+
+与原始数据查询不同,按设备对齐查询并不在此阶段进行 SELECT 语句和 WHERE 语句中后缀路径的拼接,而将在后续生成物理计划时,计算出每个设备对应的映射值和过滤条件。因此,按设备对齐在此阶段所做的工作只包括对 WHERE 语句中过滤条件的优化。
+
+对过滤条件的优化主要包括三部分:去非、转化析取范式、合并同路径过滤条件。对应的优化器分别为:RemoveNotOptimizer, DnfFilterOptimizer, MergeSingleFilterOptimizer。该部分逻辑可参考:[Planner](/#/SystemDesign/progress/chap2/sec2).
+
+### 物理计划生成
+
+- org.apache.iotdb.db.qp.strategy.PhysicalGenerator
+
+生成逻辑计划后,将调用 PhysicalGenerator 类中的 `transformToPhysicalPlan()` 方法将该逻辑计划转化为物理计划。对于按设备对齐查询,该方法的主要逻辑实现在 `transformQuery()` 方法中。
+
+**该阶段所做的主要工作为生成查询对应的** `AlignByDevicePlan`,**填充其中的变量信息。**
+
+首先解释一下 `transformQuery()` 方法中一些重要字段的含义(与 AlignByDevicePlan 中重复的字段见上文):
+
+- prefixPaths, suffixPaths:前者为 FROM 子句中的前缀路径,示例中为 `[root.sg.d1, root.sg.*]`; 后者为 SELECT 子句中的后缀路径,示例中为 `[s1, "1", *, s2, s5]`.
+- devices:对前缀路径去通配符和设备去重后得到的设备列表,示例中为 `[root.sg.d1, root.sg.d2]`。
+- measurementSetOfGivenSuffix:中间变量,记录某一 suffix 对应的 measurement,示例中,对于后缀 \*, `measurementSetOfGivenSuffix = {s1,s2}`,对于后缀 s1, `measurementSetOfGivenSuffix = {s1}`;
+
+接下来介绍 AlignByDevicePlan 的计算过程:
+
+1. 检查查询类型是否为 groupByPlan, fillQueryPlan, aggregationPlan 这三类查询中的一种,如果是则对相应的变量进行赋值,并更改 `AlignByDevicePlan` 的查询类型。
+2. 遍历 SELECT 后缀路径,对每一个后缀路径设置一个中间变量为 `measurementSetOfGivenSuffix`,用来记录该后缀路径对应的所有 measurement。如果后缀路径以单引号或双引号开头,则直接在 `measurements` 中增加该值,并记录其类型为 `Constant` 类型。
+3. 否则将设备列表与该后缀路径拼接,得到完整的路径,如果拼接后的路径不存在,需要进一步判断该 measurement 是否在其它设备中存在,如果都没有则暂时识别为 `NonExist`,如果后续出现设备存在该 measurement,则覆盖 `NonExist` 值为 `Exist`。
+4. 如果拼接后路径存在,则证明 measurement 是 `Exist` 类型,需要检验数据类型的一致性,不满足返回错误信息,满足则记录下该 Measurement,对 `measurementSetOfGivenSuffix`, `deviceToMeasurementsMap` 等进行更新。
+5. 在一层 suffix 循环结束后,将该层循环中出现的 `measurementSetOfGivenSuffix` 加入 `measurements` 中。在整个循环结束后,将循环中得到的变量信息赋值到 AlignByDevicePlan 中。此处得到的 measurements 列表是未经过去重的,在生成 `ColumnHeader` 时将进行去重。
+6. 最后调用 `concatFilterByDevice()` 方法计算 `deviceToFilterMap`,得到将每个设备分别拼接后对应的 Filter 信息。
+
+```java
+Map<String, IExpression> concatFilterByDevice(List<String> devices,
+ FilterOperator operator)
+输入:去重后的 devices 列表和未拼接的 FilterOperator
+输入:经过拼接后的 deviceToFilterMap,记录了每个设备对应的 Filter 信息
+```
+
+`concatFilterByDevice()` 方法的主要处理逻辑在 `concatFilterPath()` 中:
+
+`concatFilterPath()` 方法遍历未拼接的 FilterOperator 二叉树,判断节点是否为叶子节点,如果是,则取该叶子结点的路径,如果路径以 time 或 root 开头则不做处理,否则将设备名与节点路径进行拼接后返回;如果不是,则对该节点的所有子节点进行迭代处理。示例中,设备1过滤条件拼接后的结果为 `time = 1 AND root.sg.d1.s1 < 25`,设备2为 `time = 1 AND root.sg.d2.s1 < 25`。
+
+下面用示例总结一下通过该阶段计算得到的变量信息:
+
+- measurement 列表 `measurements`:`[s1, "1", s1, s2, s2, s5]`
+- measurement 类型 `measurementTypeMap`:
+ - `s1 -> Exist`
+ - `s2 -> Exist`
+ - `"1" -> Constant`
+ - `s5 -> NonExist`
+- 每个设备的测点 `deviceToMeasurementsMap`:
+ - `root.sg.d1 -> s1, s2`
+ - `root.sg.d2 -> s1`
+- 每个设备的过滤条件 `deviceToFilterMap`:
+ - `root.sg.d1 -> time = 1 AND root.sg.d1.s1 < 25`
+ - `root.sg.d2 -> time = 1 AND root.sg.d2.s1 < 25`
+
+### 构造表头 (ColumnHeader)
+
+- org.apache.iotdb.db.service.TSServiceImpl
+
+在生成物理计划后,则可以执行 TSServiceImpl 中的 executeQueryStatement() 方法生成结果集并返回,其中第一步是构造表头。
+
+按设备对齐查询在调用 `TSServiceImpl.getQueryColumnHeaders()` 方法后,根据查询类型进入 `TSServiceImpl.getAlignByDeviceQueryHeaders()` 来构造表头。
+
+`getAlignByDeviceQueryHeaders()` 方法声明如下:
+
+```java
+private void getAlignByDeviceQueryHeaders(
+ AlignByDevicePlan plan, List<String> respColumns, List<String> columnTypes)
+输入:当前执行的物理计划 AlignByDevicePlan 和需要输出的列名 respColumns 以及其对应的数据类型 columnTypes
+输出:计算得到的列名 respColumns 和数据类型 columnTypes
+```
+
+其具体实现逻辑如下:
+
+1. 首先加入 `Device` 列,其数据类型为 `TEXT`;
+2. 遍历未去重的 measurements 列表,判断当前遍历 measurement 的类型,如果是 `Exist` 类型则从 `measurementTypeMap` 中取得其类型;其余两种类型设其类型为 `TEXT`,然后将 measurement 及其类型加入表头数据结构中。
+3. 根据中间变量 `deduplicatedMeasurements` 对 measurements 进行去重。
+
+最终得到的 Header 为:
+
+| Time | Device | s1 | 1 | s1 | s2 | s2 | s5 |
+| ---- | ------ | --- | --- | --- | --- | --- | --- |
+| | | | | | | | |
+
+去重后的 `measurements` 为 `[s1, "1", s2, s5]`。
+
+### 结果集生成
+
+生成 ColumnHeader 后,最后一步为生成结果集填充结果并返回。
+
+#### 结果集创建
+
+- org.apache.iotdb.db.service.TSServiceImpl
+
+该阶段需要调用 `TSServiceImpl.createQueryDataSet()` 创建一个新的结果集,这部分实现逻辑较为简单,对于 AlignByDeviceQuery 而言,只需要新建一个 `AlignByDeviceDataSet` 即可,在构造函数中将把 AlignByDevicePlan 中的参数赋值到新建的结果集中。
+
+#### 结果集填充
+
+- org.apache.iotdb.db.utils.QueryDataSetUtils
+
+接下来需要填充结果,AlignByDeviceQuery 将调用 `TSServiceImpl.fillRpcReturnData()` 方法,然后根据查询类型进入 `QueryDataSetUtils.convertQueryDataSetByFetchSize()` 方法.
+
+`convertQueryDataSetByFetchSize()` 方法中获取结果的重要方法为 QueryDataSet 的 `hasNext()` 方法。
+
+`hasNext()` 方法的主要逻辑如下:
+
+1. 判断是否有规定行偏移量 `rowOffset`,如果有则跳过需要偏移的行数;如果结果总行数少于规定的偏移量,则返回 false。
+2. 判断是否有规定行数限制 `rowLimit`,如果有则比较当前输出行数,当前输出行数大于行数限制则返回 false。
+3. 进入 `AlignByDeviceDataSet.hasNextWithoutConstraint()` 方法
+
+<br>
+
+- org.apache.iotdb.db.query.dataset.AlignByDeviceDataSet
+
+首先解释一下结果集中重要字段的含义:
+
+- `deviceIterator`:按设备对齐查询本质上是计算出每个设备对应的映射值和过滤条件,然后将查询按设备分别进行,该字段即为设备的迭代器,每次查询获取一个设备进行。
+- `currentDataSet`:该字段代表了本次对某设备查询所获得的结果集。
+
+`hasNextWithoutConstraint()` 方法所做的工作主要是判断当前结果集是否有下一结果,没有则获取下一设备,计算该设备执行查询需要的路径、数据类型及过滤条件,然后按其查询类型执行具体的查询计划后获得结果集,直至没有设备可进行查询。
+
+其具体实现逻辑如下:
+
+1. 首先判断当前结果集是否被初始化且有下一个结果,如果是则直接返回 true,即当前可以调用 `next()` 方法获取下一个 `RowRecord`;否则设置结果集未被初始化进入步骤2.
+2. 迭代 `deviceIterator` 获取本次执行需要的设备,之后 `deviceToMeasurementsMap` 中取得该设备对应的测点,得到 `executeColumns`.
+3. 拼接当前设备名与 measurements,计算当前设备的查询路径、数据类型及过滤条件,得到对应的字段分别为 `executePaths`, `tsDataTypes`, `expression`,如果是聚合查询,则还需要计算 `executeAggregations`。
+4. 判断当前子查询类型为 GroupByQuery, AggregationQuery, FillQuery 或 RawDataQuery 进行对应的查询并返回结果集,实现逻辑可参考[原始数据查询](/#/SystemDesign/progress/chap5/sec3),[聚合查询](/#/SystemDesign/progress/chap5/sec4),[降采样查询](/#/SystemDesign/progress/chap5/sec5)。
+
+通过 `hasNextWithoutConstraint()` 方法初始化结果集并确保有下一结果后,则可调用 `QueryDataSet.next()` 方法获取下一个 `RowRecord`.
+
+`next()` 方法主要实现逻辑为 `AlignByDeviceDataSet.nextWithoutConstraint()` 方法。
+
+`nextWithoutConstraint()` 方法所做的工作主要是**将单个设备查询所得到的按时间对齐的结果集形式变换为按设备对齐的结果集形式**,并返回变换后的 `RowRecord`。
+
+其具体实现逻辑如下:
+
+1. 首先从结果集中取得下一个按时间对齐的 `originRowRecord`。
+2. 新建一个添加了时间戳的 `RowRecord`,向其中加入设备列,先根据 `executeColumns` 与得到的结果建立一个由 `measurementName -> Field` 的 Map 结构 `currentColumnMap`.
+3. 之后只需要遍历去重后的 `measurements` 列表,判断其类型,如果类型为 `Exist` 则根据 measurementName 从 `currentColumnMap` 中取得其对应的结果,如果没有则设为 `null`;如果是 `NonExist`类型,则直接设为 `null`; 如果是 `Constant` 类型,则将 `measureName` 作为该列的值。
+
+再根据变换后的 `RowRecord` 写入输出数据流后,即可将结果集返回。
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/6-Tools/1-Sync.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/6-Tools/1-Sync.md
new file mode 100644
index 0000000..e230f9c
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/6-Tools/1-Sync.md
@@ -0,0 +1,299 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+<!-- TOC -->
+
+- [同步工具](#同步工具)
+ - [概述](#概述)
+ - [场景](#场景)
+ - [目标](#目标)
+ - [目录结构](#目录结构)
+ - [目录结构设计](#目录结构设计)
+ - [目录结构说明](#目录结构说明)
+ - [发送端](#发送端)
+ - [接收端](#接收端)
+ - [其他](#其他)
+ - [同步工具发送端](#同步工具发送端)
+ - [需求说明](#需求说明)
+ - [模块设计](#模块设计)
+ - [文件管理模块](#文件管理模块)
+ - [包](#包)
+ - [文件选择](#文件选择)
+ - [文件清理](#文件清理)
+ - [文件传输模块](#文件传输模块)
+ - [包](#包-1)
+ - [同步schema](#同步schema)
+ - [同步数据文件](#同步数据文件)
+ - [恢复模块](#恢复模块)
+ - [包](#包-2)
+ - [流程](#流程)
+ - [同步工具接收端](#同步工具接收端)
+ - [需求说明](#需求说明-1)
+ - [模块设计](#模块设计-1)
+ - [文件传输模块](#文件传输模块-1)
+ - [包](#包-3)
+ - [流程](#流程-1)
+ - [文件加载模块](#文件加载模块)
+ - [包](#包-4)
+ - [文件删除](#文件删除)
+ - [加载新文件](#加载新文件)
+ - [恢复模块](#恢复模块-1)
+ - [包](#包-5)
+ - [流程](#流程-2)
+
+<!-- /TOC -->
+
+# 同步工具
+
+同步工具是定期将本地磁盘中和新增的已持久化的tsfile文件上传至云端并加载到Apache IoTDB的套件工具。
+
+## 概述
+
+本文档主要介绍了同步工具的需求定义、模块设计等方面。
+
+### 场景
+
+同步工具的需求主要有以下几个方面:
+
+* 在生产环境中,Apache IoTDB会收集数据源(工业设备、移动端等)产生的数据存储到本地。由于数据源可能分布在不同的地方,可能会有多个Apache IoTDB同时负责收集数据。针对每一个IoTDB,它需要将自己本地的数据同步到数据中心中。数据中心负责收集并管理来自多个Apache IoTDB的数据。
+
+* 随着Apache IoTDB系统的广泛应用,用户根据目标业务需求需要将一些Apache IoTDB实例生成的tsfile文件放在另一个Apache IoTDB实例的数据目录下加载并应用,实现数据同步。
+
+* 同步模块在发送端以独立进程的形式存在,在接收端和Apache IoTDB位于同一进程内。
+
+* 支持一个发送端向多个接收端同步数据且一个接收端可同时接收多个发送端的数据,但需要保证多个发送端同步的数据不冲突(即一个设备的数据来源只能有一个),否则需要提示冲突。
+
+### 目标
+
+利用同步工具可以将数据文件在两个Apache IoTDB实例间传输并加载。在网络不稳定或宕机等情况发生时,保证文件能够被完整、正确地传送到数据中心。
+
+## 目录结构
+
+为方便说明,设应用场景为节点`192.168.130.15`向节点`192.168.130.16:5555`同步数据,同时节点`192.168.130.15`接收来自`192.168.130.14`节点同步的数据。由于节点`192.168.130.15`同时作为发送端和接收端,因此下面以节点`192.168.130.15`来说明目录结构。
+
+### 目录结构设计
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/26211279/74145347-849dc380-4c39-11ea-9ef2-e10a3fe2074d.png">
+
+### 目录结构说明
+
+sync-sender文件夹中包含该节点作为发送端时同步数据期间的临时文件、状态日志等。
+
+sync-receiver文件夹中包含该节点作为接收端时接收数据并加载期间的临时文件、状态日志等。
+
+schema/sync文件夹下保存的是需要持久化的同步信息。
+
+#### 发送端
+
+`data/sync-sender`为发送端文件夹,该目录下的文件夹名表示接收端的IP和端口,在该实例中有一个接收端`192.168.130.16:5555`, 每个文件夹下包含以下几个文件:
+
+* last_local_files.txt
+记录同步任务结束后所有已被同步的本地tsfile文件列表,每次同步任务结束后更新。
+
+* snapshot
+在同步数据期间,该文件夹下含有所有的待同步的tsfile文件的硬链接。
+
+* sync.log
+记录同步模块的任务进度日志,用以系统宕机恢复时使用,后文会对该文件的结构进行详细阐述。
+
+#### 接收端
+
+`sync-receiver`为接收端文件夹,该目录下的文件夹名表示发送端的IP和UUID,表示从该发送端接收到的数据文件和文件加载日志情况等,在该实例中有一个发送端`192.168.130.14`,它的UUID为`a45b6e63eb434aad891264b5c08d448e`。 每个文件夹下包含以下几个文件:
+
+* load.log
+该文件是记录tsfile文件加载的任务进度日志,用以系统宕机恢复时使用。
+
+* data
+该文件夹中含有已从发送端接收到的tsfile文件。
+
+#### 其他
+
+`schema/sync`文件夹下包含以下信息:
+
+* 作为发送端时,发送端实例的文件锁`sync.lock`
+ 该文件锁的目的是保证同一个发送端对同一个接收端仅能启动一个发送端实例,即只有一个向该接收端同步数据的进程。图示中目录`192.168.130.16_5555/sync_lock`表示对接收端`192.168.130.16_5555`同步的
+ 实例锁。每次启动时首先会检查该文件是否上锁,如果上锁说明已经有向该接收端同步数据的发送端,则停止本实例。
+
+* 作为发送端时,发送端的唯一标识UUID`uuid.txt`
+ 每个发送端有一个唯一的标识,以供接收端区分不同的发送端
+
+* 作为发送端时,每个接收端的schema同步进度`sync_schema_pos`
+
+ 由于schema日志`mlog.txt`数据是追加的,其中记录了所有元信息的变化过程,因此每次同步完schema后记录下当前位置在下次同步时直接增量同步即可减少重复schema传输。
+
+* 作为接收端,接收端中每个设备的所有信息`device_owner.log`
+ 同步工具的应用中,一个接收端可以同时接收多个发送端的数据,但是不能产生冲突,否则接收端将不能保证数据的正确性。因此需要记录下每个设备是由哪个发送端进行同步的,遵循先到先得原则。
+
+单独将这些信息放在schmea文件夹下的原因是一个Apache IoTDB实例可以拥有多个数据文件目录,也就是data目录可以有多个,但是schema文件夹只有一个,而这些信息是一个发送端实例共享的信息,而data文件夹下的信息表示的是该文件目录下的同步情况,属于子任务信息(每个数据文件目录即为一个子任务)。
+
+## 同步工具发送端
+
+### 需求说明
+
+* 每隔一段时间将发送端收集到的最新数据回传到接收端上。同时,针对历史数据的更新和删除,将这部分信息同步到接收端上。
+
+* 同步数据必须完整,如果在传输的过程中因为网络不稳定、机器故障等因素造成数据文件不完整或者损坏,需要在下一次传输的过程中修复。
+
+### 模块设计
+
+#### 文件管理模块
+
+##### 包
+
+org.apache.iotdb.db.sync.sender.manage
+
+##### 文件选择
+
+文件选择的功能是选出当前Apache IoTDB实例中已封口的tsfile文件(有对应的`.resource`文件, 且不含`.modification`文件和`.merge`文件)列表和上次同步任务结束后记录的tsfile文件列表的差异,共有两部分:删除的tsfile文件列表和新增的tsfile文件列表。并对所有的新增的文件进行硬链接,防止同步期间由于系统运行导致的文件删除等操作。
+
+##### 文件清理
+
+当接收到文件传输模块的任务结束的通知时,执行以下命令:
+
+* 将`last_local_files.txt`文件中的文件名列表加载到内存形成set,并逐行解析`log.sync`对set进行删除和添加
+
+* 将内存中的文件名列表set写入`current_local_files.txt`文件中
+
+* 删除`last_local_files.txt`文件
+
+* 将`current_local_files.txt`重命名为`last_local_files.txt`
+
+* 删除sequence文件夹和`sync.log`文件
+
+#### 文件传输模块
+
+##### 包
+
+org.apache.iotdb.db.sync.sender.transfer
+
+##### 同步schema
+
+在同步数据文件前,首先同步新增的schmea信息,并更新`sync_schema_pos`。
+
+##### 同步数据文件
+
+对于每个文件路径,调用文件管理模块,获得删除的文件列表和新增的文件列表,然后执行以下流程:
+
+1. 开始同步任务,在`sync.log`记录`sync start`
+2. 开始同步删除的文件列表,在`sync.log`记录`sync deleted file names start`
+3. 通知接收端开始同步删除的文件名列表,
+4. 对删除列表中的每一个文件名
+ 4.1. 向接收端传输文件名(示例`1581324718762-101-1.tsfile`)
+ 4.2. 传输成功,在`sync.log`中记录`1581324718762-101-1.tsfile`
+5. 开始同步新增的tsfile文件列表,在`sync.log`记录`sync deleted file names end和 sync tsfile start`
+6. 通知接收端开始同步文件
+7. 对新增列表中的每一个tsfile:
+ 7.1. 将文件按块传输给接收端(示例`1581324718762-101-1.tsfile`)
+ 7.2. 若文件传输失败,则多次尝试,若尝试超过一定次数(可由用户配置,默认为5),放弃该文件的传输;若传输成功,在`sync.log`中记录`1581324718762-101-1.tsfile`
+8. 通知接收端同步任务结束,在`sync.log`记录`sync tsfile end`和`sync end`
+9. 调用文件管理模块清理文件
+10. 结束同步任务
+
+#### 恢复模块
+
+##### 包
+
+org.apache.iotdb.db.sync.sender.recover
+
+##### 流程
+
+同步工具发送端每次启动同步任务时,首先检查发送端文件夹下有没有对应的接收端文件夹,若没有,表示没有和该接收端进行过同步任务,跳过恢复模块;否则,根据该文件夹下的文件执行恢复算法:
+
+1. 若存在`current_local_files.txt`,跳转到步骤2;若不存在,跳转到步骤3
+2. 若存在`last_local_files.txt`,则删除`current_local_files.txt`文件并跳转到步骤
+3;若不存在,跳转到步骤7
+3. 若存在`sync.log`,跳转到步骤4;若不存在,跳转到步骤8
+4. 将`last_local_files.txt`文件中的文件名列表加载到内存形成set,并逐行解析
+`sync.log`对set进行删除和添加
+5. 将内存中的文件名列表set写入`current_local_files.txt`文件中
+6. 删除`last_local_files.txt`文件
+7. 将`current_local_files.txt`重命名为`last_local_files.txt`
+8. 删除sequence文件夹和`sync.log`文件
+9. 算法结束
+
+
+## 同步工具接收端
+
+### 需求说明
+
+* 由于接收端需要同时接收来自多个发送端的文件,需要将不同发送端的文件区分开来,统一管理这些文件。
+
+* 接收端从发送端接收文件并检验文件名、文件数据和该文件的MD5值。文件接收完成后,存储文件到接收端本地,并对接收到的tsfile文件进行MD5值校验和文件尾部检查,若检查通过若未正确接收,则对文件进行重传。
+
+* 针对发送端传来的数据文件(可能包含了对旧数据的更新,新数据的插入等操作),需要将这部分数据合并到接收端本地的文件中。
+
+### 模块设计
+
+#### 文件传输模块
+
+##### 包
+
+org.apache.iotdb.db.sync.receiver.transfer
+
+##### 流程
+
+文件传输模块负责接收从发送端传输的文件名和文件,其流程如下:
+
+1. 接收到发送端的同步开始指令,检查是否存在sync.log文件,若存在则表示上次同步的数据还未加载完毕,拒绝本次同步任务;否则在sync.log中记录sync.start
+2. 接收到发送端的开始同步删除的文件名列表的指令,在sync.log中记录sync deleted file names start
+3. 依次接收发送端传输的删除文件名
+ 3.1. 接收到发送端传输的文件名(示例`1581324718762-101-1.tsfile`)
+ 3.2. 接收成功,在`sync.log`中记录`1581324718762-101-1.tsfile`,并提交给数据加载模块处理
+4. 接收到发送单的开始同步传输的文件的指令,在`sync.log`中记录`sync deleted file names end`和`sync tsfile start`
+5. 依次接收发送端传输的tsfile文件
+ 5.1. 按块接收发送端传输的文件(示例`1581324718762-101-2.tsfile`)
+ 5.2. 对文件进行校验,若检验失败,删除该文件并通知发送端失败;否则,在`sync.log`中记录`1581324718762-101-2.tsfile`,并提交给数据加载模块处理
+6. 接收到发送端的同步任务结束命令,在`sync.log`中记录`sync tsfile end`和`sync end`
+7. 创建sync.end空文件
+
+#### 文件加载模块
+
+##### 包
+
+org.apache.iotdb.db.sync.receiver.load
+
+##### 文件删除
+
+对于需要删除的文件(示例`1581324718762-101-1.tsfile`),在内存中的`sequence tsfile list`中搜索是否有该文件,如有则将该文件从内存中维护的列表中删除并将磁盘中的文件删除。执行成功后在`load.log`中记录`delete 1581324718762-101-1.tsfile`。
+
+##### 加载新文件
+
+对于需要加载的文件(示例`1581324718762-101-1.tsfile`),首先用`device_owner.log`检查该文件是否符合应用场景,即是否和其他发送端传输了相同设备的数据导致了冲突),如果发生了冲突,则拒绝此次加载并向发送端发送错误信息;否则,更新`device_owner.log`信息。
+
+符合应用场景要求后,将该文件插入`sequence tsfile list`中合适的位置并将文件移动到`data/sequence`目录下。执行成功后在`load.log`中记录`load 1581324718762-101-1.tsfile`。每次文件加载完毕后,检查同步的目录下是否含有sync.end文件,如含有该文件且sequence文件夹下为空,则先删除sync.log文件,再删除load.log和sync.end文件。
+
+#### 恢复模块
+
+##### 包
+org.apache.iotdb.db.sync.receiver.recover
+
+##### 流程
+
+ApacheIoTDB系统启动时,依次检查sync文件夹下的各个子文件夹,每个子文件表示由文件夹名所代表的发送端的同步任务。根据每个子文件夹下的文件执行恢复算法:
+
+1. 若不存在`sync.log`文件,跳转到步骤4;若存在,跳转到步骤2
+2. 逐行扫描sync.log的日志,执行对应的删除文件的操作和加载文件的操作,若该操作已在`load.log`文件中记录,则表明已经执行完毕,跳过该操作。跳转到步骤3
+3. 删除`sync.log`文件
+4. 删除`load.log`文件
+5. 删除`sync.end`文件
+6. 算法结束
+
+每一次同步任务开始时,接收端对相应的子文件夹进行检查并恢复。
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/7-Connector/2-Hive-TsFile.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/7-Connector/2-Hive-TsFile.md
new file mode 100644
index 0000000..e8fbacd
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/7-Connector/2-Hive-TsFile.md
@@ -0,0 +1,114 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+## TsFile 的 Hive 连接器
+
+TsFile 的 Hive 连接器实现了通过 Hive 读取外部 TsFile 类型的文件格式的支持,使用户能够通过 Hive 操作 TsFile。
+
+连接器的主要功能:
+
+* 将单个 TsFile 文件加载进 Hive,不论文件是存储在本地文件系统或者是 HDFS 中
+* 将某个特定目录下的所有文件加载进 Hive,不论文件是存储在本地文件系统或者是 HDFS 中
+* 使用 HQL 查询 TsFile
+* 到现在为止, 写操作在 hive-connector 中还不支持. 所以, HQL 中的 insert 操作是不被允许的
+
+### 设计原理
+
+Hive 连接器需要能够解析 TsFile 的文件格式,转化为 Hive 能够识别的按行返回的格式。也需要能够根据用户定义的 Table 的形式,格式化输出。所以,Hive 连接器的功能实现主要分成四个部分
+
+* 将整个 TsFile 文件分片
+* 从分片中读取数据,转化为 Hive 能够识别的数据类型
+* 解析用户自定义的 Table
+* 将数据反序列化为 Hive 的输出格式
+
+### 具体实现类
+
+上述的主要四个功能模块都有其对应的实现类,下面就分别介绍一下这四个实现类。
+
+#### org.apache.iotdb.hive.TSFHiveInputFormat
+
+该类主要负责对输入的 TsFile 文件的格式化操作,它继承了`FileInputFormat<NullWritable, MapWritable>`类,一些通用的格式化操作在`FileInputFormat`中已经有实现,这个类覆写了它的`getSplits(JobConf, int)`方法,自定义了对于 TsFile 文件的分片方式;以及`getRecordReader(InputSpli, JobConf, Reporter)`方法,用于生成具体从一个分片中读取数据的
+`TSFHiveRecordReader`。
+
+#### org.apache.iotdb.hive.TSFHiveRecordReader
+
+该类主要负责从一个分片中读取 TsFile 的数据。
+
+它实现了`IReaderSet`接口,这个接口里是一些设置类内部属性的方法,主要是为了抽出`TSRecordReader`和`TSHiveRecordReader`中重复的代码部分。
+
+```
+public interface IReaderSet {
+
+ void setReader(TsFileSequenceReader reader);
+
+ void setMeasurementIds(List<String> measurementIds);
+
+ void setReadDeviceId(boolean isReadDeviceId);
+
+ void setReadTime(boolean isReadTime);
+}
+```
+
+下面先介绍一下这个类的一些重要字段
+
+* private List<QueryDataSet> dataSetList = new ArrayList<>();
+
+ 这个分片所生成的所有的 QueryDataSet
+
+* private List<String> deviceIdList = new ArrayList<>();
+
+ 设备名列表,这个顺序与 dataSetList 的顺序一致,即 deviceIdList[i] 是 dataSetList[i] 的设备名.
+
+* private int currentIndex = 0;
+
+ 当前正在被处理的 QueryDataSet 的下标
+
+这个类在构造函数里,调用了`TSFRecordReader`的`initialize(TSFInputSplit, Configuration, IReaderSet, List<QueryDataSet>, List<String>)`方法去初始化上面提到的一些类字段。它覆写了`RecordReader`的`next()`方法,用以返回从 TsFile 里读出的数据。
+
+##### next(NullWritable, MapWritable)
+
+我们注意到它从 TsFile 读取出来数据之后,是以`MapWritable`的形式返回的,这里的`MapWritable`其实就是一个`Map`,只不过它的 key 与 value 都做了序列化与反序列化的特殊适配,它的读取流程如下
+
+1. 首先判断`dataSetList`当前位置的`QueryDataSet`还有没有值,如果没有值,则将`currentIndex`递增1,直到找到第一个有值的`QueryDataSet`
+2. 然后调用`QueryDataSet`的`next()`方法获得`RowRecord`
+3. 最后调用`TSFRecordReader`的`getCurrentValue()`方法,将`RowRecord`中的值放入`MapWritable`里
+
+
+#### org.apache.iotdb.hive.TsFileSerDe
+
+这个类继承了`AbstractSerDe`,也是我们实现Hive从自定义输入格式中读取数据所必须的。
+
+它覆写了`AbstractSerDe`的`initialize()`方法,在这个方法里,从用户的建表 sql 里,解析出相应的设备名,传感器名以及传感器对应的类型。还要构建出`ObjectInspector`对象,这个对象主要负责数据类型的转化,由于 TsFile 只支持原始数据类型,所以当出现其他数据类型时,需要抛出异常,具体的构建过程在`createObjectInspectorWorker()`方法中可以看到。
+
+这个类的最主要职责就是序列化和反序列化不同文件格式的数据,由于我们的 Hive 连接器暂时只支持读取操作,并不支持 insert 操作,所以只有反序列化的过程,所以仅覆写了`deserialize(Writable)`方法,该方法里调用了`TsFileDeserializer`的`deserialize()`方法。
+
+
+#### org.apache.iotdb.hive.TsFileDeserializer
+
+这个类就是将数据反序列化为 Hive 的输出格式,仅有一个`deserialize()`方法。
+
+##### public Object deserialize(List<String>, List<TypeInfo>, Writable, String)
+
+这个方法的`Writable`参数就是`TSFHiveRecordReader`的`next()`生成的`MapWritable`。
+
+首先判断`Writable`参数是不是`MapWritable`类型,如果不是,则抛出异常。
+
+接着依次从`MapWritable`中取出该设备的传感器的值,如果遇到类型不匹配则抛异常,最后返回生成的结果集。
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/7-Connector/3-Spark-TsFile.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/7-Connector/3-Spark-TsFile.md
new file mode 100644
index 0000000..1cd1b24
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/7-Connector/3-Spark-TsFile.md
@@ -0,0 +1,101 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# Spark Tsfile 连接器
+
+## 设计目的
+
+* 使用Spark SQL读取指定Tsfile的数据,以Spark DataFrame的形式返回给客户端
+
+* 使用Spark Dataframe中的数据生成Tsfile
+
+## 支持格式
+宽表结构:Tsfile原生格式,IOTDB原生路径格式
+
+| time | root.ln.wf02.wt02.temperature | root.ln.wf02.wt02.status | root.ln.wf02.wt02.hardware | root.ln.wf01.wt01.temperature | root.ln.wf01.wt01.status | root.ln.wf01.wt01.hardware |
+|------|-------------------------------|--------------------------|----------------------------|-------------------------------|--------------------------|----------------------------|
+| 1 | null | true | null | 2.2 | true | null |
+| 2 | null | false | aaa | 2.2 | null | null |
+| 3 | null | null | null | 2.1 | true | null |
+| 4 | null | true | bbb | null | null | null |
+| 5 | null | null | null | null | false | null |
+| 6 | null | null | ccc | null | null | null |
+
+窄表结构: 关系型数据库模式,IOTDB align by device格式
+
+| time | device_name | status | hardware | temperature |
+|------|-------------------------------|--------------------------|----------------------------|-------------------------------|
+| 1 | root.ln.wf02.wt01 | true | null | 2.2 |
+| 1 | root.ln.wf02.wt02 | true | null | null |
+| 2 | root.ln.wf02.wt01 | null | null | 2.2 |
+| 2 | root.ln.wf02.wt02 | false | aaa | null |
+| 3 | root.ln.wf02.wt01 | true | null | 2.1 |
+| 4 | root.ln.wf02.wt02 | true | bbb | null |
+| 5 | root.ln.wf02.wt01 | false | null | null |
+| 6 | root.ln.wf02.wt02 | null | ccc | null |
+
+## 查询流程步骤
+
+#### 1. 表结构推断和生成
+该步骤是为了使DataFrame的表结构与需要查询的Tsfile的表结构匹配
+主要逻辑在src/main/scala/org/apache/iotdb/spark/tsfile/DefaultSource.scala中的inferSchema函数
+
+#### 2. SQL解析
+该步骤目的是为了将用户SQL语句转化为Tsfile原生的查询表达式
+
+主要逻辑在src/main/scala/org/apache/iotdb/spark/tsfile/DefaultSource.scala中的buildReader函数
+
+SQL解析分宽表结构与窄表结构
+
+#### 3. 宽表结构
+宽表结构的SQL解析主要逻辑在src/main/scala/org/apache/iotdb/spark/tsfile/WideConverter.scala中
+
+
+该结构与Tsfile原生查询结构基本相同,不需要特殊处理,直接将SQL语句转化为相应查询表达式即可
+
+#### 4. 窄表结构
+宽表结构的SQL解析主要逻辑在src/main/scala/org/apache/iotdb/spark/tsfile/NarrowConverter.scala中
+
+SQL转化为表达式后,由于窄表结构与Tsfile原生查询结构不同,需要先将表达式转化为与device有关的析取表达式
+,才可以转化为对Tsfile的查询,转化代码在src/main/java/org/apache/iotdb/spark/tsfile/qp中
+
+#### 5. 查询实际执行
+实际数据查询执行由Tsfile原生组件完成,参见:
+
+* [Tsfile原生查询流程](../1-TsFile/4-Read.md)
+
+## 写入步骤流程
+写入主要是将Dataframe结构中的数据转化为Tsfile的RowRecord,使用Tsfile Writer进行写入
+
+#### 宽表结构
+其主要转化代码在如下两个文件中:
+
+* src/main/scala/org/apache/iotdb/spark/tsfile/WideConverter.scala 负责结构转化
+
+* src/main/scala/org/apache/iotdb/spark/tsfile/WideTsFileOutputWriter.scala 负责匹配spark接口与执行写入,会调用上一个文件中的结构转化功能
+
+#### 窄表结构
+其主要转化代码在如下两个文件中:
+
+* src/main/scala/org/apache/iotdb/spark/tsfile/NarrowConverter.scala 负责结构转化
+
+* src/main/scala/org/apache/iotdb/spark/tsfile/NarrowTsFileOutputWriter.scala 负责匹配spark接口与执行写入,会调用上一个文件中的结构转化功能
+
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/7-Connector/4-Spark-IOTDB.md b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/7-Connector/4-Spark-IOTDB.md
new file mode 100644
index 0000000..2224d0a
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/SystemDesign/7-Connector/4-Spark-IOTDB.md
@@ -0,0 +1,89 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# Spark IOTDB 连接器
+
+## 设计目的
+
+* 使用Spark SQL读取IOTDB的数据,以Spark DataFrame的形式返回给客户端
+
+## 核心思想
+由于IOTDB具有解析和执行SQL的能力,故该部分可以直接将SQL转发给IOTDB进程执行,将数据拿到后转换为RDD即可
+
+## 执行流程
+#### 1. 入口
+
+* src/main/scala/org/apache/iotdb/spark/db/DefaultSource.scala
+
+#### 2. 构建Relation
+Relation主要保存了RDD的元信息,比如列名字,分区策略等,调用Relation的buildScan方法可以创建RDD
+
+* src/main/scala/org/apache/iotdb/spark/db/IoTDBRelation.scala
+
+#### 3. 构建RDD
+RDD中执行对IOTDB的SQL请求,保存游标
+
+* src/main/scala/org/apache/iotdb/spark/db/IoTDBRDD.scala中的compute方法
+
+#### 4. 迭代RDD
+由于Spark懒加载机制,用户遍历RDD时才具体调用RDD的迭代,也就是IOTDB的fetch Result
+
+* src/main/scala/org/apache/iotdb/spark/db/IoTDBRDD.scala中的getNext方法
+
+
+## 宽窄表结构转换
+宽表结构:IOTDB原生路径格式
+
+| time | root.ln.wf02.wt02.temperature | root.ln.wf02.wt02.status | root.ln.wf02.wt02.hardware | root.ln.wf01.wt01.temperature | root.ln.wf01.wt01.status | root.ln.wf01.wt01.hardware |
+|------|-------------------------------|--------------------------|----------------------------|-------------------------------|--------------------------|----------------------------|
+| 1 | null | true | null | 2.2 | true | null |
+| 2 | null | false | aaa | 2.2 | null | null |
+| 3 | null | null | null | 2.1 | true | null |
+| 4 | null | true | bbb | null | null | null |
+| 5 | null | null | null | null | false | null |
+| 6 | null | null | ccc | null | null | null |
+
+窄表结构: 关系型数据库模式,IOTDB align by device格式
+
+| time | device_name | status | hardware | temperature |
+|------|-------------------------------|--------------------------|----------------------------|-------------------------------|
+| 1 | root.ln.wf02.wt01 | true | null | 2.2 |
+| 1 | root.ln.wf02.wt02 | true | null | null |
+| 2 | root.ln.wf02.wt01 | null | null | 2.2 |
+| 2 | root.ln.wf02.wt02 | false | aaa | null |
+| 3 | root.ln.wf02.wt01 | true | null | 2.1 |
+| 4 | root.ln.wf02.wt02 | true | bbb | null |
+| 5 | root.ln.wf02.wt01 | false | null | null |
+| 6 | root.ln.wf02.wt02 | null | ccc | null |
+
+由于IOTDB查询到的数据默认为宽表结构,所以需要宽窄表转换,有如下两个实现方法
+
+#### 1. 使用IOTDB的group by device语句
+这种方式可以直接拿到窄表结构,计算由IOTDB完成
+
+#### 2. 使用Transformer
+可以使用Transformer进行宽窄表之间的转换,计算由Spark完成
+
+* src/main/scala/org/apache/iotdb/spark/db/Transformer.scala
+
+宽表转窄表使用了遍历device列表,生成对应的窄表,在union起来的策略,并行性较好(无shuffle)
+
+窄表转宽表使用了基于timestamp的join操作,有shuffle,可能存在潜在的性能问题
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/0-Get Started/1-QuickStart.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/0-Get Started/1-QuickStart.md
new file mode 100644
index 0000000..9cc1f95
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/0-Get Started/1-QuickStart.md
@@ -0,0 +1,293 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+<!-- TOC -->
+
+## 概览
+
+- 快速入门
+ - 安装环境
+ - IoTDB安装
+ - 从源代码生成
+ - 配置文件
+ - IoTDB试用
+ - 启动IoTDB
+ - 操作IoTDB
+ - 使用Cli工具
+ - IoTDB的基本操作
+ - 停止IoTDB
+ - 单独打包服务器
+ - 单独打包客户端
+
+<!-- /TOC -->
+
+# 快速入门
+
+本文将介绍关于IoTDB使用的基本流程,如果需要更多信息,请浏览我们官网的[指引](https://iotdb.apache.org/#/Documents/progress/chap1/sec1).
+
+## 安装环境
+
+安装前需要保证设备上配有JDK>=1.8的运行环境,并配置好JAVA_HOME环境变量。
+
+设置最大文件打开数为65535。
+
+## IoTDB安装
+
+IoTDB支持多种安装途径。用户可以使用三种方式对IoTDB进行安装——下载二进制可运行程序、使用源码、使用docker镜像。
+
+* 使用源码:您可以从代码仓库下载源码并编译,具体编译方法见下方。
+
+* 二进制可运行程序:请从Download页面下载最新的安装包,解压后即完成安装。
+
+* 使用Docker镜像:dockerfile 文件位于 https://github.com/apache/incubator-iotdb/blob/master/docker/src/main
+
+### IoTDB下载
+
+您可以从这里下载程序:[下载](https://iotdb.apache.org/#/Download)
+
+### 配置文件
+
+配置文件在"conf"文件夹下,包括:
+
+ * 环境配置模块 (`iotdb-env.bat`, `iotdb-env.sh`),
+ * 系统配置模块 (`tsfile-format.properties`, `iotdb-engine.properties`)
+ * 日志配置模块 (`logback.xml`).
+
+想要了解更多,请浏览[Chapter3: Server](https://iotdb.apache.org/#/Documents/progress/chap3/sec1)
+
+
+## IoTDB试用
+
+用户可以根据以下操作对IoTDB进行简单的试用,若以下操作均无误,则说明IoTDB安装成功。
+
+
+### 启动IoTDB
+
+用户可以使用sbin文件夹下的start-server脚本启动IoTDB。
+
+Linux系统与MacOS系统启动命令如下:
+
+```
+> sbin/start-server.sh
+```
+
+Windows系统启动命令如下:
+
+```
+> sbin\start-server.bat
+```
+
+
+### 操作IoTDB
+
+#### 使用Cli工具
+
+IoTDB为用户提供多种与服务器交互的方式,在此我们介绍使用Cli工具进行写入、查询数据的基本步骤。
+
+初始安装后的IoTDB中有一个默认用户:root,默认密码为root。用户可以使用该用户运行Cli工具操作IoTDB。Cli工具启动脚本为sbin文件夹下的start-client脚本。启动脚本时需要指定运行ip、port、username和password。若脚本未给定对应参数,则默认参数为"-h 127.0.0.1 -p 6667 -u root -pw -root"
+
+以下启动语句为服务器在本机运行,且用户未更改运行端口号的示例。
+
+Linux系统与MacOS系统启动命令如下:
+
+```
+> sbin/start-client.sh -h 127.0.0.1 -p 6667 -u root -pw root
+```
+
+Windows系统启动命令如下:
+
+```
+> sbin\start-client.bat -h 127.0.0.1 -p 6667 -u root -pw root
+```
+
+启动后出现如图提示即为启动成功。
+
+```
+ _____ _________ ______ ______
+|_ _| | _ _ ||_ _ `.|_ _ \
+ | | .--.|_/ | | \_| | | `. \ | |_) |
+ | | / .'`\ \ | | | | | | | __'.
+ _| |_| \__. | _| |_ _| |_.' /_| |__) |
+|_____|'.__.' |_____| |______.'|_______/ version x.x.x
+
+
+IoTDB> login successfully
+IoTDB>
+```
+
+#### IoTDB的基本操作
+
+在这里,我们首先介绍一下使用Cli工具创建时间序列、插入数据并查看数据的方法。
+
+数据在IoTDB中的组织形式是以时间序列为单位,每一个时间序列中有若干个数据-时间点对,每一个时间序列属于一个存储组。在定义时间序列之前,要首先使用SET STORAGE GROUP语句定义存储组。SQL语句如下:
+
+```
+IoTDB> SET STORAGE GROUP TO root.ln
+```
+
+我们可以使用SHOW STORAGE GROUP语句来查看系统当前所有的存储组,SQL语句如下:
+
+```
+IoTDB> SHOW STORAGE GROUP
+```
+
+执行结果为:
+
+```
++-----------------------------------+
+| Storage Group|
++-----------------------------------+
+| root.ln|
++-----------------------------------+
+storage group number = 1
+```
+
+存储组设定后,使用CREATE TIMESERIES语句可以创建新的时间序列,创建时间序列时需要定义数据的类型和编码方式。此处我们创建两个时间序列,SQL语句如下:
+
+```
+IoTDB> CREATE TIMESERIES root.ln.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN
+IoTDB> CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE
+```
+
+为了查看指定的时间序列,我们可以使用SHOW TIMESERIES <Path>语句,其中<Path>表示时间序列对应的路径,默认值为空,表示查看系统中所有的时间序列。下面是两个例子:
+
+使用SHOW TIMESERIES语句查看系统中存在的所有时间序列,SQL语句如下:
+
+```
+IoTDB> SHOW TIMESERIES
+```
+
+执行结果为:
+
+```
++-------------------------------+---------------+--------+--------+
+| Timeseries| Storage Group|DataType|Encoding|
++-------------------------------+---------------+--------+--------+
+| root.ln.wf01.wt01.status| root.ln| BOOLEAN| PLAIN|
+| root.ln.wf01.wt01.temperature| root.ln| FLOAT| RLE|
++-------------------------------+---------------+--------+--------+
+Total timeseries number = 2
+```
+
+查看具体的时间序列root.ln.wf01.wt01.status的SQL语句如下:
+
+```
+IoTDB> SHOW TIMESERIES root.ln.wf01.wt01.status
+```
+
+执行结果为:
+
+```
++------------------------------+--------------+--------+--------+
+| Timeseries| Storage Group|DataType|Encoding|
++------------------------------+--------------+--------+--------+
+| root.ln.wf01.wt01.status| root.ln| BOOLEAN| PLAIN|
++------------------------------+--------------+--------+--------+
+Total timeseries number = 1
+```
+
+
+接下来,我们使用INSERT语句向root.ln.wf01.wt01.status时间序列中插入数据,在插入数据时需要首先指定时间戳和路径后缀名称:
+
+```
+IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,status) values(100,true);
+```
+
+我们也可以向多个时间序列中同时插入数据,这些时间序列同属于一个时间戳:
+
+```
+IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,status,temperature) values(200,false,20.71)
+```
+
+最后,我们查询之前插入的数据。使用SELECT语句我们可以查询指定的时间序列的数据结果,SQL语句如下:
+
+```
+IoTDB> SELECT status FROM root.ln.wf01.wt01
+```
+
+查询结果如下:
+
+```
++-----------------------+------------------------+
+| Time|root.ln.wf01.wt01.status|
++-----------------------+------------------------+
+|1970-01-01T08:00:00.100| true|
+|1970-01-01T08:00:00.200| false|
++-----------------------+------------------------+
+Total line number = 2
+```
+
+我们也可以查询多个时间序列的数据结果,SQL语句如下:
+
+```
+IoTDB> SELECT * FROM root.ln.wf01.wt01
+```
+
+查询结果如下:
+
+```
++-----------------------+--------------------------+-----------------------------+
+| Time| root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
++-----------------------+--------------------------+-----------------------------+
+|1970-01-01T08:00:00.100| true| null|
+|1970-01-01T08:00:00.200| false| 20.71|
++-----------------------+--------------------------+-----------------------------+
+Total line number = 2
+```
+
+输入quit或exit可退出Cli结束本次会话。
+
+```
+IoTDB> quit
+```
+或
+
+```
+IoTDB> exit
+```
+
+想要浏览更多IoTDB数据库支持的命令,请浏览[SQL Reference](https://iotdb.apache.org/#/Documents/progress/chap5/sec4).
+
+### 停止IoTDB
+
+用户可以使用$IOTDB_HOME/sbin文件夹下的stop-server脚本停止IoTDB。
+
+Linux系统与MacOS系统停止命令如下:
+
+```
+> $sbin/stop-server.sh
+```
+
+Windows系统停止命令如下:
+
+```
+> $sbin\stop-server.bat
+```
+
+## 只建立客户端
+
+在incubator-iotdb的根路径下:
+
+```
+> mvn clean package -pl client -am -DskipTests
+```
+
+构建后,IoTDB客户端将位于文件夹“ client / target / iotdb-client- {project.version}”下。
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/0-Get Started/2-Frequently asked questions.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/0-Get Started/2-Frequently asked questions.md
new file mode 100644
index 0000000..fce7d50
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/0-Get Started/2-Frequently asked questions.md
@@ -0,0 +1,166 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+<!-- TOC -->
+
+## 概览
+
+- 常见问题
+ - 如何查询我的 IoTDB 版本?
+ - 在哪里可以找到 IoTDB 的日志?
+ - 在哪里可以找到 IoTDB 的数据文件?
+ - 如何知道 IoTDB 中存储了多少时间序列?
+ - 可以使用 Hadoop 和 Spark 读取 IoTDB 中的 TsFile 吗?
+ - IoTDB 如何处理重复的数据点?
+ - 我如何知道具体的 timeseries 的类型?
+ - 如何更改 IoTDB 的客户端时间显示格式?
+
+<!-- /TOC -->
+# 常见问题
+
+## 如何查询我的 IoTDB 版本?
+
+有几种方法可以识别您使用的 IoTDB 版本:
+
+*启动 IoTDB 的命令行界面:
+
+```
+> ./start-client.sh -p 6667 -pw root -u root -h localhost
+ _____ _________ ______ ______
+|_ _| | _ _ ||_ _ `.|_ _ \
+ | | .--.|_/ | | \_| | | `. \ | |_) |
+ | | / .'`\ \ | | | | | | | __'.
+ _| |_| \__. | _| |_ _| |_.' /_| |__) |
+|_____|'.__.' |_____| |______.'|_______/ version x.x.x
+```
+
+* 检查 pom.xml 文件:
+
+```
+<version>x.x.x</version>
+```
+
+* 使用 JDBC API:
+
+```
+String iotdbVersion = tsfileDatabaseMetadata.getDatabaseProductVersion();
+```
+
+* 使用命令行接口:
+
+```
+IoTDB> show version
+show version
++---------------+
+|version |
++---------------+
+|x.x.x |
++---------------+
+Total line number = 1
+It costs 0.241s
+```
+
+## 在哪里可以找到 IoTDB 的日志?
+
+假设您的根目录是:
+
+```
+$ pwd
+/workspace/incubator-iotdb
+
+$ ls -l
+server/
+client/
+pom.xml
+Readme.md
+...
+```
+
+假如 `$IOTDB_HOME = /workspace/incubator-iotdb/server/target/iotdb-server-{project.version}`
+
+假如 `$IOTDB_CLI_HOME = /workspace/incubator-iotdb/client/target/iotdb-client-{project.version}`
+
+在默认的设置里,logs 文件夹会被存储在```IOTDB_HOME/logs```。您可以在```IOTDB_HOME/conf```目录下的```logback.xml```文件中修改日志的级别和日志的存储路径。
+
+## 在哪里可以找到 IoTDB 的数据文件?
+
+在默认的设置里,数据文件(包含 TsFile,metadata,WAL)被存储在```IOTDB_HOME/data```文件夹。
+
+## 如何知道 IoTDB 中存储了多少时间序列?
+
+使用 IoTDB 的命令行接口:
+
+```
+IoTDB> show timeseries root
+```
+
+在返回的结果里,会展示`Total timeseries number`,这个数据就是 IoTDB 中 timeseries 的数量。
+
+在当前版本中,IoTDB 支持直接使用命令行接口查询时间序列的数量:
+
+```
+IoTDB> count timeseries root
+```
+
+如果您使用的是 Linux 操作系统,您可以使用以下的 Shell 命令:
+
+```
+> grep "0,root" $IOTDB_HOME/data/system/schema/mlog.txt | wc -l
+> 6
+```
+
+## 可以使用 Hadoop 和 Spark 读取 IoTDB 中的 TsFile 吗?
+
+是的。IoTDB 与开源生态紧密结合。IoTDB 支持 [Hadoop](https://github.com/apache/incubator-iotdb/tree/master/hadoop), [Spark](https://github.com/apache/incubator-iotdb/tree/master/spark) 和 [Grafana](https://github.com/apache/incubator-iotdb/tree/master/grafana) 可视化工具.
+
+## IoTDB如何处理重复的数据点?
+
+一个数据点是由一个完整的时间序列路径(例如:```root.vehicle.d0.s0```)和时间戳唯一标识的。如果您使用与现有点相同的路径和时间戳提交一个新点,那么IoTDB将更新这个点的值,而不是插入一个新点。
+
+## 我如何知道具体的 timeseries 的类型?
+
+在 IoTDB 的命令行接口中使用 SQL ```SHOW TIMESERIES <timeseries path>```:
+
+例如:如果您想知道所有 timeseries 的类型 \<timeseries path> 应该为 `root`。上面的 SQL 应该修改为:
+
+```
+IoTDB> show timeseries root
+```
+
+如果您想查询一个指定的时间序列, 您可以修改 \<timeseries path> 为时间序列的完整路径。比如:
+
+```
+IoTDB> show timeseries root.fit.d1.s1
+```
+
+您还可以在 timeseries 路径中使用通配符:
+
+```
+IoTDB> show timeseries root.fit.d1.*
+```
+
+## 如何更改IoTDB的客户端时间显示格式?
+
+IoTDB 客户端默认显示的时间是人类可读的(比如:```1970-01-01T08:00:00.001```),如果您想显示是时间戳或者其他可读格式, 请在启动命令上添加参数```-disableIS08601```:
+
+```
+> $IOTDB_CLI_HOME/sbin/start-client.sh -h 127.0.0.1 -p 6667 -u root -pw root -disableIS08601
+```
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/0-Get Started/3-Publication.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/0-Get Started/3-Publication.md
new file mode 100644
index 0000000..7b5ce0f
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/0-Get Started/3-Publication.md
@@ -0,0 +1,37 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 研究论文
+
+Apache IoTDB 始于清华大学软件学院。IoTDB是一个用于管理大量时间序列数据的数据库,它采用了列式存储、数据编码、预计算和索引技术,具有类SQL的接口,可支持每秒每节点写入数百万数据点,可以秒级获得超过数万亿个数据点的查询结果。它还可以很容易地与 ApacheHadoop、MapReduce 和 ApacheSpark 集成以进行分析。
+
+相关研究论文如下:
+
+* [PISA: An Index for Aggregating Big Time Series Data](https://dl.acm.org/citation.cfm?id=2983775&dl=ACM&coll=DL), Xiangdong Huang and Jianmin Wang and Raymond K. Wong and Jinrui Zhang and Chen Wang. CIKM 2016.
+* [Matching Consecutive Subpatterns over Streaming Time Series](https://link.springer.com/chapter/10.1007/978-3-319-96893-3_8), Rong Kang and Chen Wang and Peng Wang and Yuting Ding and Jianmin Wang. APWeb/WAIM 2018.
+* [KV-match: A Subsequence Matching Approach Supporting Normalization and Time Warping](https://www.semanticscholar.org/paper/KV-match%3A-A-Subsequence-Matching-Approach-and-Time-Wu-Wang/9ed84cb15b7e5052028fc5b4d667248713ac8592), Jiaye Wu and Peng Wang and Chen Wang and Wei Wang and Jianmin Wang. ICDE 2019.
+* 我们还研发了面向时间序列数据库的Benchmark工具: [https://github.com/thulab/iotdb-benchmark](https://github.com/thulab/iotdb-benchmark)
+
+# Benchmark工具
+
+我们还研发了面向时间序列数据库的Benchmark工具:
+
+https://github.com/thulab/iotdb-benchmark
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/1-What is IoTDB.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/1-What is IoTDB.md
new file mode 100644
index 0000000..1ac6efa
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/1-What is IoTDB.md
@@ -0,0 +1,26 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第1章: IoTDB概述
+
+## 什么是IoTDB
+
+IoTDB是针对时间序列数据收集、存储与分析一体化的数据管理引擎。它具有体量轻、性能高、易使用的特点,完美对接Hadoop与Spark生态,适用于工业物联网应用中海量时间序列数据高速写入和复杂分析查询的需求。
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/2-Architecture.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/2-Architecture.md
new file mode 100644
index 0000000..169370b
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/2-Architecture.md
@@ -0,0 +1,36 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第1章: IoTDB概述
+
+## 架构
+
+IoTDB套件由若干个组件构成,共同形成“数据收集-数据写入-数据存储-数据查询-数据可视化-数据分析”等一系列功能。
+
+图1.1展示了使用IoTDB套件全部组件后形成的整体应用架构。下文称所有组件形成IoTDB套件,而IoTDB特指其中的时间序列数据库组件。
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/25913899/67943956-39c1e800-fc16-11e9-8da2-a662f8246816.png">
+
+在图1.1中,用户可以通过JDBC将来自设备上传感器采集的时序数据、服务器负载和CPU内存等系统状态数据、消息队列中的时序数据、应用程序的时序数据或者其他数据库中的时序数据导入到本地或者远程的IoTDB中。用户还可以将上述数据直接写成本地(或位于HDFS上)的TsFile文件。
+
+对于写入到IoTDB的数据以及本地的TsFile文件,可以通过同步工具TsFileSync将数据文件同步到HDFS上,进而实现在Hadoop或Spark的数据处理平台上的诸如异常检测、机器学习等数据处理任务。对于分析的结果,可以写回成TsFile文件。
+
+IoTDB和TsFile还提供了相应的客户端工具,满足用户查看和写入数据的SQL形式、脚本形式和图形化形式等多种需求。
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/3-Scenario.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/3-Scenario.md
new file mode 100644
index 0000000..79fe86e
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/3-Scenario.md
@@ -0,0 +1,78 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第1章: IoTDB概述
+
+## 应用场景
+
+### 场景1
+
+某公司采用表面贴装技术(SMT)生产芯片:需要首先在芯片上的焊接点处印刷(即涂抹)锡膏,然后将元器件放置在锡膏上,进而通过加热熔化锡膏并冷却,使得元器件被焊接在芯片上。上述流程采用自动化生产线。为了确保产品质量合格,在印刷锡膏后,需要通过光学设备对锡膏印刷的质量进行评估:采用三维锡膏印刷检测(SPI)设备对每个焊接点上的锡膏的体积(v)、高度(h)、面积(a)、水平偏移(px)、竖直偏移(py)进行度量。
+
+为了提升印刷质量,该公司有必要将各个芯片上焊接点的度量值进行存储,以便后续基于这些数据进行分析。
+
+此时可以采用IoTDB套件中的TsFile组件、TsFileSync工具和Hadoop/Spark集成组件对数据进行存储:每新印刷一个芯片,就在SPI设备上使用SDK写一条数据,这些数据最终形成一个TsFile文件。通过TsFileSync工具,生成的TsFile文件将按一定规则(如每天)被同步到Hadoop数据中心,并由数据分析人员对其进行分析。
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51579014-695ef980-1efa-11e9-8cbc-e9e7ee4fa0d8.png">
+
+在场景1中,仅需要TsFile、TsFileSync部署在一台PC上,此外还需要Hadoop/Spark集群。其示意图如图1.2所示。图1.3展示了此时的应用架构。
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51579026-77ad1580-1efa-11e9-8345-564b22d70286.jpg">
+
+### 场景2
+
+某公司拥有多座风力发电机,公司在每个发电机上安装了上百种传感器,分别采集该发电机的工作状态、工作环境中的风速等信息。
+
+为了保证发电机的正常运转并对发电机及时监控和分析,公司需要收集这些传感器信息,在发电机工作环境中进行部分计算和分析,还需要将收集的原始信息上传到数据中心。
+
+此时可以采用IoTDB套件中的IoTDB、TsFileSync工具和Hadoop/Spark集成组件等。需要部署一个场控PC机,其上安装IoTDB和TsFileSync工具,用于支持读写数据、本地计算和分析以及上传数据到数据中心。此外还需要部署Hadoop/Spark集群用于数据中心端的数据存储和分析。如图1.4所示。
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51579033-7ed42380-1efa-11e9-889f-fb4180291a9e.png">
+
+图1.5给出了此时的应用架构。
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51579064-8f849980-1efa-11e9-8cd6-a7339cd0540f.jpg">
+
+### 场景3
+
+某工厂在厂区范围内拥有多种机械手设备,这些机械手设备的硬件配置有限,很难搭载复杂的应用程序。在每个机械手设备上工厂安装了很多种传感器,用以对机械手的工作状态、温度等信息进行监控。由于工厂的网络环境原因,在工厂内部的机械手均处于工厂内部局域网内,无法连接外部网络。同时,工厂中会有少量服务器能够直接连接外部公网。
+
+为了保证机械手的监控数据能够及时监控和分析,公司需要收集这些机械手传感器信息,将其发送至可以连接外部网络的服务器上,而后将原始数据信息上传到数据中心进行复杂的计算和分析。
+
+此时,可以采用IoTDB套件中的IoTDB、IoTDB-Client工具、TsFileSync工具和Hadoop/Spark集成组件等。将IoTDB服务器安装在工厂连接外网的服务器上,用户接收机械手传输的数据并将数据上传到数据中心。将IoTDB-Client工具安装在每一个连接工厂内网的机械手上,用于将传感器产生的实时数据上传到工厂内部服务器。再使用TsFileSync工具将原始数据上传到数据中心。此外还需要部署Hadoop/Spark集群用于数据中心端的数据存储和分析。如图1.6中间场景所示。
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51579080-96aba780-1efa-11e9-87ac-940c45b19dd7.jpg">
+
+图1.7给出了此时的应用架构。
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51579085-9dd2b580-1efa-11e9-97b9-f56bc8d342b0.jpg">
+
+### 场景4
+
+某汽车公司在其下属的汽车上均安装了传感器采集车辆的行驶状态等监控信息。这些汽车设备的硬件配置有限,很难搭载复杂的应用程序。安装传感器的汽车可以通过窄带物联网相互连接,也可以通过窄带物联网将数据发送至外部网络。
+
+为了能够实时接收汽车传感器所采集的物联网数据,公司需要在车辆行驶的过程中将传感器数据通过窄带物联网实时发送至数据中心,而后在数据中心的服务器上进行复杂的计算和分析。
+
+此时,可以采用IoTDB套件中的IoTDB、IoTDB-Client和Hadoop/Spark集成组件等。将IoTDB-Client工具安装在每一辆车联网内的车辆上,使用IoTDB-JDBC工具将数据直接传回数据中心的服务器。
+
+此外还需要部署Hadoop/Spark集群用于数据中心端的数据存储和分析。如图1.8所示。
+
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51579095-a4f9c380-1efa-11e9-9f95-17165ec55568.jpg">
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/4-Features.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/4-Features.md
new file mode 100644
index 0000000..63bf407
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/1-Overview/4-Features.md
@@ -0,0 +1,51 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第1章: IoTDB概述
+
+## 主要功能与特点
+
+IoTDB具有以下特点:
+* 灵活的部署方式
+ * 云端一键部署
+ * 终端解压即用
+ * 终端-云端无缝连接(数据云端同步工具)
+* 低硬件成本的存储解决方案
+ * 高压缩比的磁盘存储(10亿数据点硬盘成本低于1.4元)
+* 目录结构的时间序列组织管理方式
+ * 支持复杂结构的智能网联设备的时间序列组织
+ * 支持大量同类物联网设备的时间序列组织
+ * 可用模糊方式对海量复杂的时间序列目录结构进行检索
+* 高通量的时间序列数据读写
+ * 支持百万级低功耗强连接设备数据接入(海量)
+ * 支持智能网联设备数据高速读写(高速)
+ * 以及同时具备上述特点的混合负载
+* 面向时间序列的丰富查询语义
+ * 跨设备、跨传感器的时间序列时间对齐
+ * 面向时序数据特征的计算
+ * 提供面向时间维度的丰富聚合函数支持
+* 极低的学习门槛
+ * 支持类SQL的数据操作
+ * 提供JDBC的编程接口
+ * 完善的导入导出工具
+* 完美对接开源生态环境
+ * 支持开源数据分析生态系统:Hadoop、Spark
+ * 支持开源可视化工具对接:Grafana
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/1-Data Model and Terminology.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/1-Data Model and Terminology.md
new file mode 100644
index 0000000..00012ef
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/1-Data Model and Terminology.md
@@ -0,0 +1,220 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第2章 IoTDB基本概念
+## 数据模型与技术
+
+我们为您提供一份简化的[样例数据](https://github.com/apache/incubator-iotdb/blob/master/docs/Documentation/OtherMaterial-Sample%20Data.txt)。
+
+下载文件: [IoTDB-SampleData.txt](https://raw.githubusercontent.com/apache/incubator-iotdb/master/docs/Documentation/OtherMaterial-Sample%20Data.txt).
+
+根据本文描述的[数据](https://github.com/apache/incubator-iotdb/blob/master/docs/Documentation/OtherMaterial-Sample%20Data.txt)属性层级,按照属性涵盖范围以及它们之间的从属关系,我们可将其表示为如下图2.1的属性层级组织结构,其层级关系为:集团层-电场层-设备层-传感器层。其中ROOT为根节点,传感器层的每一个节点称为叶子节点。在使用IoTDB的过程中,您可以直接将由ROOT节点到每一个叶子节点路径上的属性用“.”连接,将其作为一个IoTDB的时间序列的名称。图2.1中最左侧的路径可以生成一个名为`ROOT.ln.wf01.wt01.status`的时间序列。
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577327-7aa50780-1ef4-11e9-9d75-cadabb62444e.jpg">
+
+**图2.1 属性层级组织结构**</center>
+
+得到时间序列的名称之后,我们需要根据数据的实际场景和规模设置存储组。由于在本文所述场景中,每次到达的数据通常以集团为单位(即数据可能为跨电场、跨设备的),为了写入数据时避免频繁切换IO降低系统速度,且满足用户以集团为单位进行物理隔离数据的要求,我们将存储组设置在集团层。
+
+根据模型结构,IoTDB中涉及如下基本概念:
+
+* 设备
+
+设备指的是在实际场景中拥有传感器的装置。在IoTDB当中,所有的传感器都应有其对应的归属的设备。
+
+* 传感器
+
+传感器是指在实际场景中的一种检测装置,它能感受到被测量的信息,并能将感受到的信息按一定规律变换成为电信号或其他所需形式的信息输出并发送给IoTDB。在IoTDB当中,存储的所有的数据及路径,都是以传感器为单位进行组织。
+
+* 存储组
+
+用户可以将任意前缀路径设置成存储组。如有4条时间序列`root.vehicle.d1.s1`, `root.vehicle.d1.s2`, `root.vehicle.d2.s1`, `root.vehicle.d2.s2`,路径`root.vehicle`下的两个设备d1,d2可能属于同一个业主,或者同一个厂商,因此关系紧密。这时候就可以将前缀路径`root.vehicle`指定为一个存储组,这将使得IoTDB将其下的所有设备的数据存储在同一个文件夹下。未来`root.vehicle`下增加了新的设备,也将属于该存储组。
+
+> 注意:不允许将一个完整路径(如上例的`root.vehicle.d1.s1`)设置成存储组。
+
+设置合理数量的存储组可以带来性能的提升:既不会因为产生过多的存储文件(夹)导致频繁切换IO降低系统速度(并且会占用大量内存且出现频繁的内存-文件切换),也不会因为过少的存储文件夹(降低了并发度从而)导致写入命令阻塞。
+
+用户应根据自己的数据规模和使用场景,平衡存储文件的存储组设置,以达到更好的系统性能。(未来会有官方提供的存储组规模与性能测试报告)
+
+> 注意:一个时间序列其前缀必须属于某个存储组。在创建时间序列之前,用户必须设定该序列属于哪个存储组(Storage Group)。只有设置了存储组的时间序列才可以被持久化在磁盘上。
+
+一个前缀路径一旦被设定成存储组后就不可以再更改这个存储组的设置。
+
+一个存储组设定后,其对应的前缀路径的所有父层级与子层级也不允许再设置存储组(如,`root.ln`设置存储组后,root层级与`root.ln.wf01`不允许被设置为存储组)。
+
+* 路径
+
+在IoTDB中,路径是指符合以下约束的表达式:
+
+```
+path: LayerName (DOT LayerName)+
+LayerName: Identifier | STAR
+```
+
+其中STAR为“*”,DOT为“.”。
+
+我们称一个路径中在两个“.”中间的部分叫做一个层级,则`root.a.b.c`为一个层级为4的路径。
+
+值得说明的是,在路径中,root为一个保留字符,它只允许出现在下文提到的时间序列的开头,若其他层级出现root,则无法解析,提示报错。
+
+* 时间序列
+
+时间序列是IoTDB中的核心概念。时间序列可以被看作产生时序数据的传感器的所在完整路径,在IoTDB中所有的时间序列必须以root开始、以传感器作为结尾。一个时间序列也可称为一个全路径。
+
+例如,vehicle种类的device1有名为sensor1的传感器,则它的时间序列可以表示为:`root.vehicle.device1.sensor1`。
+
+> 注意:当前IoTDB支持的时间序列必须大于等于四层(之后会更改为两层)。
+
+* 前缀路径
+
+前缀路径是指一个时间序列的前缀所在的路径,一个前缀路径包含以该路径为前缀的所有时间序列。例如当前我们有`root.vehicle.device1.sensor1`, `root.vehicle.device1.sensor2`, `root.vehicle.device2.sensor1`三个传感器,则`root.vehicle.device1`前缀路径包含`root.vehicle.device1.sensor1`、`root.vehicle.device1.sensor2`两个时间序列,而不包含`root.vehicle.device2.sensor1`。
+
+* 3.1.7 带`*`路径
+为了使得在表达多个时间序列或表达前缀路径的时候更加方便快捷,IoTDB为用户提供带`*`路径。`*`可以出现在路径中的任何层。按照`*`出现的位置,带`*`路径可以分为两种:
+
+`*`出现在路径的结尾;
+
+`*`出现在路径的中间;
+
+当`*`出现在路径的结尾时,其代表的是(`*`)+,即为一层或多层`*`。例如`root.vehicle.device1.*`代表的是`root.vehicle.device1.*`, `root.vehicle.device1.*.*`, `root.vehicle.device1.*.*.*`等所有以`root.vehicle.device1`为前缀路径的大于等于4层的路径。
+
+当`*`出现在路径的中间,其代表的是`*`本身,即为一层。例如`root.vehicle.*.sensor1`代表的是以`root.vehicle`为前缀,以`sensor1`为后缀,层次等于4层的路径。
+
+> 注意:`*`不能放在路径开头。
+
+> 注意:`*`放在末尾时与前缀路径表意相同,例如`root.vehicle.*`与`root.vehicle`为相同含义。
+
+* 时间戳
+
+时间戳是一个数据到来的时间点,其中包括绝对时间戳和相对时间戳。
+
+* 绝对时间戳
+
+IOTDB中绝对时间戳分为二种,一种为LONG类型,一种为DATETIME类型(包含DATETIME-INPUT, DATETIME-DISPLAY两个小类)。
+
+在用户在输入时间戳时,可以使用LONG类型的时间戳或DATETIME-INPUT类型的时间戳,其中DATETIME-INPUT类型的时间戳支持格式如表所示:
+
+<center>**DATETIME-INPUT类型支持格式**
+
+|format|
+|:---|
+|yyyy-MM-dd HH:mm:ss|
+|yyyy/MM/dd HH:mm:ss|
+|yyyy.MM.dd HH:mm:ss|
+|yyyy-MM-dd'T'HH:mm:ss|
+|yyyy/MM/dd'T'HH:mm:ss|
+|yyyy.MM.dd'T'HH:mm:ss|
+|yyyy-MM-dd HH:mm:ssZZ|
+|yyyy/MM/dd HH:mm:ssZZ|
+|yyyy.MM.dd HH:mm:ssZZ|
+|yyyy-MM-dd'T'HH:mm:ssZZ|
+|yyyy/MM/dd'T'HH:mm:ssZZ|
+|yyyy.MM.dd'T'HH:mm:ssZZ|
+|yyyy/MM/dd HH:mm:ss.SSS|
+|yyyy-MM-dd HH:mm:ss.SSS|
+|yyyy.MM.dd HH:mm:ss.SSS|
+|yyyy/MM/dd'T'HH:mm:ss.SSS|
+|yyyy-MM-dd'T'HH:mm:ss.SSS|
+|yyyy.MM.dd'T'HH:mm:ss.SSS|
+|yyyy-MM-dd HH:mm:ss.SSSZZ|
+|yyyy/MM/dd HH:mm:ss.SSSZZ|
+|yyyy.MM.dd HH:mm:ss.SSSZZ|
+|yyyy-MM-dd'T'HH:mm:ss.SSSZZ|
+|yyyy/MM/dd'T'HH:mm:ss.SSSZZ|
+|yyyy.MM.dd'T'HH:mm:ss.SSSZZ|
+|ISO8601 standard time format|
+
+</center>
+
+IoTDB在显示时间戳时可以支持LONG类型以及DATETIME-DISPLAY类型,其中DATETIME-DISPLAY类型可以支持用户自定义时间格式。自定义时间格式的语法如表所示:
+
+<center>**DATETIME-DISPLAY自定义时间格式的语法**
+
+|Symbol|Meaning|Presentation|Examples|
+|:---:|:---:|:---:|:---:|
+|G|era|era|era|
+|C|century of era (>=0)| number| 20|
+| Y |year of era (>=0)| year| 1996|
+|||||
+| x |weekyear| year| 1996|
+| w |week of weekyear| number |27|
+| e |day of week |number| 2|
+| E |day of week |text |Tuesday; Tue|
+|||||
+| y| year| year| 1996|
+| D |day of year |number| 189|
+| M |month of year |month| July; Jul; 07|
+| d |day of month |number| 10|
+|||||
+| a |halfday of day |text |PM|
+| K |hour of halfday (0~11) |number| 0|
+| h |clockhour of halfday (1~12) |number| 12|
+|||||
+| H |hour of day (0~23)| number| 0|
+| k |clockhour of day (1~24) |number| 24|
+| m |minute of hour| number| 30|
+| s |second of minute| number| 55|
+| S |fraction of second |millis| 978|
+|||||
+| z |time zone |text |Pacific Standard Time; PST|
+| Z |time zone offset/id| zone| -0800; -08:00; America/Los_Angeles|
+|||||
+| '| escape for text |delimiter| |
+| ''| single quote| literal |'|
+
+</center>
+
+* 相对时间戳
+
+ 相对时间是指与服务器时间```now()```和```DATETIME```类型时间相差一定时间间隔的时间。
+ 形式化定义为:
+ ```
+ Duration = (Digit+ ('Y'|'MO'|'W'|'D'|'H'|'M'|'S'|'MS'|'US'|'NS'))+
+ RelativeTime = (now() | DATETIME) ((+|-) Duration)+
+
+ ```
+
+ <center>**The syntax of the duration unit**
+
+ |Symbol|Meaning|Presentation|Examples|
+ |:---:|:---:|:---:|:---:|
+ |y|year|1y=365 days|1y|
+ |mo|month|1mo=30 days|1mo|
+ |w|week|1w=7 days|1w|
+ |d|day|1d=1 day|1d|
+ |||||
+ |h|hour|1h=3600 seconds|1h|
+ |m|minute|1m=60 seconds|1m|
+ |s|second|1s=1 second|1s|
+ |||||
+ |ms|millisecond|1ms=1000_000 nanoseconds|1ms|
+ |us|microsecond|1us=1000 nanoseconds|1us|
+ |ns|nanosecond|1ns=1 nanosecond|1ns|
+
+ </center>
+
+ 例子:
+ ```
+ now() - 1d2h //比服务器时间早1天2小时的时间
+ now() - 1w //比服务器时间早1周的时间
+ ```
+ > 注意:'+'和'—'的左右两边必须有空格
+
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/2-Data Type.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/2-Data Type.md
new file mode 100644
index 0000000..b5acca4
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/2-Data Type.md
@@ -0,0 +1,42 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第2章 IoTDB基本概念
+
+## 数据类型
+IoTDB支持:
+* BOOLEAN(布尔值)
+* INT32(整型)
+* INT64(长整型)
+* FLOAT(单精度浮点数)
+* DOUBLE(双精度浮点数)
+* TEXT(字符串)
+
+一共六种数据类型。
+
+其中**FLOAT**与**DOUBLE**类型的序列,如果编码方式采用[RLE](/#/Documents/progress/chap2/sec3)或[TS_2DIFF](/#/Documents/progress/chap2/sec3)可以指定MAX_POINT_NUMBER,该项为浮点数的小数点后位数,具体指定方式请参见本文[第5.4节](/#/Documents/progress/chap5/sec4),若不指定则系统会根据配置文件`tsfile-format.properties`文件中的[float_precision项](/#/Documents/progress/chap3/sec4)配置。
+
+当系统中用户输入的数据类型与该时间序列的数据类型不对应时,系统会提醒类型错误,如下所示,二阶差分不支持布尔类型的编码:
+
+```
+IoTDB> create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
+error: encoding TS_2DIFF does not support BOOLEAN
+```
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/3-Encoding.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/3-Encoding.md
new file mode 100644
index 0000000..0fba5db
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/3-Encoding.md
@@ -0,0 +1,67 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第2章 IoTDB基本概念
+
+## 编码方式
+
+为了提高数据的存储效率,需要在数据写入的过程中对数据进行编码,从而减少磁盘空间的使用量。在写数据以及读数据的过程中都能够减少I/O操作的数据量从而提高性能。IoTDB支持四种针对不同类型的数据的编码方法:
+
+* PLAIN编码(PLAIN)
+
+PLAIN编码,默认的编码方式,即不编码,支持多种数据类型,压缩和解压缩的时间效率较高,但空间存储效率较低。
+
+* 二阶差分编码(TS_2DIFF)
+
+二阶差分编码,比较适合编码单调递增或者递减的序列数据,不适合编码波动较大的数据。
+
+* 游程编码(RLE)
+
+游程编码,比较适合存储某些整数值连续出现的序列,不适合编码大部分情况下前后值不一样的序列数据。
+
+游程编码也可用于对浮点数进行编码,但在创建时间序列的时候需指定保留小数位数(MAX_POINT_NUMBER,具体指定方式参见本文本文[第5.4节](/#/Documents/progress/chap5/sec4))。比较适合存储某些浮点数值连续出现的序列数据,不适合存储对小数点后精度要求较高以及前后波动较大的序列数据。
+
+* GORILLA编码(GORILLA)
+
+GORILLA编码,比较适合编码前后值比较接近的浮点数序列,不适合编码前后波动较大的数据。
+
+* 定频数据编码 (REGULAR)
+
+定频数据编码,仅适用于整形(INT32)和长整型(INT64)的定频数据,且允许数据中有一些点缺失,使用此方法编码定频数据优于二阶差分编码(TS_2DIFF)。
+
+定频数据编码无法用于非定频数据,建议使用二阶差分编码(TS_2DIFF)进行处理。
+
+* 数据类型与编码的对应关系
+
+前文介绍的四种编码适用于不同的数据类型,若对应关系错误,则无法正确创建时间序列。数据类型与支持其编码的编码方式对应关系总结如表格2-3。
+
+<center> **表格2-3 数据类型与支持其编码的对应关系**
+
+|数据类型 |支持的编码|
+|:---:|:---:|
+|BOOLEAN| PLAIN, RLE|
+|INT32 |PLAIN, RLE, TS_2DIFF, REGULAR|
+|INT64 |PLAIN, RLE, TS_2DIFF, REGULAR|
+|FLOAT |PLAIN, RLE, TS_2DIFF, GORILLA|
+|DOUBLE |PLAIN, RLE, TS_2DIFF, GORILLA|
+|TEXT |PLAIN|
+
+</center>
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/4-Compression.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/4-Compression.md
new file mode 100644
index 0000000..448576b
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/2-Concept/4-Compression.md
@@ -0,0 +1,33 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第2章 IoTDB基本概念
+
+## 压缩方式
+
+当时间序列写入并按照指定的类型编码为二进制数据后,IoTDB会使用压缩技术对该数据进行压缩,进一步提升空间存储效率。虽然编码和压缩都旨在提升存储效率,但编码技术通常只适合特定的数据类型(如二阶差分编码只适合与INT32或者INT64编码,存储浮点数需要先将他们乘以10m以转换为整数),然后将它们转换为二进制流。压缩方式(SNAPPY)针对二进制流进行压缩,因此压缩方式的使用不再受数据类型的限制。
+
+IoTDB允许在创建一个时间序列的时候指定该列的压缩方式。现阶段IoTDB现在支持的压缩方式有两种:
+
+* UNCOMPRESSED(不压缩)
+* SNAPPY压缩
+
+压缩方式的指定语法详见本文[5.4节](/#/Documents/progress/chap5/sec4)。
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/1-Download.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/1-Download.md
new file mode 100644
index 0000000..c4a1e21
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/1-Download.md
@@ -0,0 +1,122 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第3章 服务器端
+
+## 下载
+
+IoTDB为您提供了两种安装方式,您可以参考下面的建议,任选其中一种:
+
+第一种,从官网下载安装包。这是我们推荐使用的安装方式,通过该方式,您将得到一个可以立即使用的、打包好的二进制可执行文件。
+
+第二种,使用源码编译。若您需要自行修改代码,可以使用该安装方式。
+
+### 安装环境要求
+
+安装前请保证您的电脑上配有JDK>=1.8的运行环境,并配置好JAVA_HOME环境变量。
+
+如果您需要从源码进行编译,还需要安装:
+
+1. Maven>=3.1的运行环境,具体安装方法可以参考以下链接:[https://maven.apache.org/install.html](https://maven.apache.org/install.html)。
+
+> 注: 也可以选择不安装,使用我们提供的'mvnw.sh' 或 'mvnw.cmd' 工具。使用时请用'mvnw.sh' 或 'mvnw.cmd'命令代替下文的'mvn'命令。
+
+### 从官网下载二进制可执行文件
+
+您可以从[http://iotdb.apache.org/#/Download](http://iotdb.apache.org/#/Download)上下载已经编译好的可执行程序iotdb-xxx.tar.gz或者iotdb-xxx.zip,该压缩包包含了IoTDB系统运行所需的所有必要组件。
+
+```
+NOTE:
+iotdb-<version>.tar.gz # For Linux or MacOS
+iotdb-<version>.zip # For Windows
+```
+
+下载后,您可使用以下操作对IoTDB的压缩包进行解压:
+
+如果您使用的操作系统是Windows,则使用解压缩工具解压或使用如下解压命令:
+
+```
+Shell > uzip iotdb-<version>.zip
+```
+
+如果您使用的操作系统是Linux或MacOS,则使用如下解压命令:
+
+```
+Shell > tar -zxf iotdb-<version>.tar.gz # For Linux or MacOS
+```
+
+解压后文件夹内容见图:
+
+```
+server/ <-- root path
+|
++- sbin/ <-- script files
+|
++- conf/ <-- configuration files
+|
++- lib/ <-- project dependencies
+|
++- LICENSE <-- LICENSE
+```
+
+### 使用源码编译
+
+您可以获取已发布的源码https://iotdb.apache.org/#/Download,或者从git仓库获取https://github.com/apache/incubator-iotdb/tree/master
+
+源码克隆后,进入到源码文件夹目录下,使用以下命令进行编译:
+
+```
+> mvn clean package -pl server -am -Dmaven.test.skip=true
+```
+
+成功后,可以在终端看到如下信息:
+
+```
+[INFO] ------------------------------------------------------------------------
+[INFO] Reactor Summary:
+[INFO]
+[INFO] Apache IoTDB (incubating) Project Parent POM ....... SUCCESS [ 6.405 s]
+[INFO] TsFile ............................................. SUCCESS [ 10.435 s]
+[INFO] Service-rpc ........................................ SUCCESS [ 4.170 s]
+[INFO] IoTDB Jdbc ......................................... SUCCESS [ 3.252 s]
+[INFO] IoTDB Server ....................................... SUCCESS [ 8.072 s]
+[INFO] ------------------------------------------------------------------------
+[INFO] BUILD SUCCESS
+[INFO] ------------------------------------------------------------------------
+```
+
+否则,你需要检查错误语句,并修复问题。
+
+编译后,IoTDB项目会在名为iotdb的子文件夹下,该文件夹会包含以下内容:
+
+```
+$IOTDB_HOME/
+|
++- sbin/ <-- script files
+|
++- conf/ <-- configuration files
+|
++- lib/ <-- project dependencies
+```
+
+### 通过Docker安装 (Dockerfile)
+
+你可以通过[这份指南](/#/Documents/progress/chap3/sec3)编译并运行一个IoTDB docker image。
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/2-Single Node Setup.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/2-Single Node Setup.md
new file mode 100644
index 0000000..28913ea
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/2-Single Node Setup.md
@@ -0,0 +1,32 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+# 第3章: 服务器端
+## 单节点安装
+
+用户可以使用 sbin 文件夹下 start-server 脚本启动 IoTDB.
+
+```
+# Unix/OS X
+> sbin/start-server.sh
+
+# Windows
+> sbin\start-server.bat
+```
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/3-Cluster Setup.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/3-Cluster Setup.md
new file mode 100644
index 0000000..4ff45c0
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/3-Cluster Setup.md
@@ -0,0 +1,25 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+# 第3章: 服务器端
+
+## 集群设置
+
+Coming Soon.
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/4-Config Manual.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/4-Config Manual.md
new file mode 100644
index 0000000..5100895
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/4-Config Manual.md
@@ -0,0 +1,442 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第3章 服务器端
+
+## 配置手册
+
+为方便IoTDB Server的配置与管理,IoTDB Server为用户提供三种配置项,使得用户可以在启动服务器或服务器运行时对其进行配置。
+
+三种配置项的配置文件均位于IoTDB安装目录:`$IOTDB_HOME/conf`文件夹下,其中涉及server配置的共有2个文件,分别为:`iotdb-env.sh`, `iotdb-engine.properties`。用户可以通过更改其中的配置项对系统运行的相关配置项进行配置。
+
+配置文件的说明如下:
+
+* `iotdb-env.sh`:环境配置项的默认配置文件。用户可以在文件中配置JAVA-JVM的相关系统配置项。
+
+* `iotdb-engine.properties`:IoTDB引擎层系统配置项的默认配置文件。用户可以在文件中配置IoTDB引擎运行时的相关参数,如JDBC服务监听端口(`rpc_port`)、overflow数据文件存储目录(`overflow_data_dir`)等。此外,用户可以在文件中配置IoTDB存储时TsFile文件的相关信息,如每次将内存中的数据写入到磁盘时的数据大小(`group_size_in_byte`),内存中每个列打一次包的大小(`page_size_in_byte`)等。
+
+### 热修改配置项
+
+为方便用户使用,IoTDB Server为用户提供了热修改功能,即在系统运行过程中修改`iotdb-engine.properties`中部分配置参数并即时应用到系统中。下面介绍的参数中,改后
+生效方式为`触发生效`的均为支持热修改的配置参数。
+
+触发方式:客户端发送```load configuration```命令至IoTDB Server,客户端的使用方式详见第4章
+
+### 环境配置项
+
+环境配置项主要用于对IoTDB Server运行的Java环境相关参数进行配置,如JVM相关配置。IoTDB Server启动时,此部分配置会被传给JVM。用户可以通过查看 `iotdb-env.sh`(或`iotdb-env.bat`)文件查看环境配置项内容。详细配置项说明如下:
+
+* LOCAL\_JMX
+
+|名字|LOCAL\_JMX|
+|:---:|:---|
+|描述|JMX监控模式,配置为yes表示仅允许本地监控,设置为no的时候表示允许远程监控|
+|类型|枚举String : “yes”, “no”|
+|默认值|yes|
+|改后生效方式|重启服务器生效|
+
+
+* JMX\_PORT
+
+|名字|JMX\_PORT|
+|:---:|:---|
+|描述|JMX监听端口。请确认该端口不是系统保留端口并且未被占用。|
+|类型|Short Int: [0,65535]|
+|默认值|31999|
+|改后生效方式|重启服务器生效|
+
+* MAX\_HEAP\_SIZE
+
+|名字|MAX\_HEAP\_SIZE|
+|:---:|:---|
+|描述|IoTDB启动时能使用的最大堆内存大小。|
+|类型|String|
+|默认值|取决于操作系统和机器配置。在Linux或MacOS系统下默认为机器内存的四分之一。在Windows系统下,32位系统的默认值是512M,64位系统默认值是2G。|
+|改后生效方式|重启服务器生效|
+
+* HEAP\_NEWSIZE
+
+|名字|HEAP\_NEWSIZE|
+|:---:|:---|
+|描述|IoTDB启动时能使用的最小堆内存大小。|
+|类型|String|
+|默认值|取决于操作系统和机器配置。在Linux或MacOS系统下默认值为机器CPU核数乘以100M的值与MAX\_HEAP\_SIZE四分之一这二者的最小值。在Windows系统下,32位系统的默认值是512M,64位系统默认值是2G。。|
+|改后生效方式|重启服务器生效|
+
+### 系统配置项
+
+系统配置项是IoTDB Server运行的核心配置,它主要用于设置IoTDB Server文件层和引擎层的参数,便于用户根据自身需求调整Server的相关配置,以达到较好的性能表现。系统配置项可分为两大模块:文件层配置项和引擎层配置项。用户可以通过查看`iotdb-engine.properties`,文件查看和修改两种配置项的内容。在0.7.0版本中字符串类型的配置项大小写敏感。
+
+#### 文件层配置
+
+* compressor
+
+|名字|compressor|
+|:---:|:---|
+|描述|数据压缩方法|
+|类型|枚举String : “UNCOMPRESSED”, “SNAPPY”|
+|默认值| UNCOMPRESSED |
+|改后生效方式|触发生效|
+
+* group\_size\_in\_byte
+
+|名字|group\_size\_in\_byte|
+|:---:|:---|
+|描述|每次将内存中的数据写入到磁盘时的最大写入字节数|
+|类型|Int32|
+|默认值| 134217728 |
+|改后生效方式|触发生效|
+
+* max\_number\_of\_points\_in\_page
+
+|名字| max\_number\_of\_points\_in\_page |
+|:---:|:---|
+|描述|一个页中最多包含的数据点(时间戳-值的二元组)数量|
+|类型|Int32|
+|默认值| 1048576 |
+|改后生效方式|触发生效|
+
+* max\_string\_length
+
+|名字| max\_string\_length |
+|:---:|:---|
+|描述|针对字符串类型的数据,单个字符串最大长度,单位为字符|
+|类型|Int32|
+|默认值| 128 |
+|改后生效方式|触发生效|
+
+* page\_size\_in\_byte
+
+|名字| page\_size\_in\_byte |
+|:---:|:---|
+|描述|内存中每个列写出时,写成的单页最大的大小,单位为字节|
+|类型|Int32|
+|默认值| 65536 |
+|改后生效方式|触发生效|
+
+* time\_series\_data\_type
+
+|名字| time\_series\_data\_type |
+|:---:|:---|
+|描述|时间戳数据类型|
+|类型|枚举String: "INT32", "INT64"|
+|默认值| Int64 |
+|改后生效方式|触发生效|
+
+* time\_encoder
+
+|名字| time\_encoder |
+|:---:|:---|
+|描述| 时间列编码方式|
+|类型|枚举String: “TS_2DIFF”,“PLAIN”,“RLE”|
+|默认值| TS_2DIFF |
+|改后生效方式|触发生效|
+
+* float_precision
+
+|名字| float_precision |
+|:---:|:---|
+|描述| 浮点数精度,为小数点后数字的位数 |
+|类型|Int32|
+|默认值| 默认为2位。注意:32位浮点数的十进制精度为7位,64位浮点数的十进制精度为15位。如果设置超过机器精度将没有实际意义。|
+|改后生效方式|触发生效|
+
+#### 引擎层配置
+
+* back\_loop\_period\_in\_second
+
+|名字| back\_loop\_period\_in\_second |
+|:---:|:---|
+|描述| 系统统计量触发统计的频率,单位为秒。|
+|类型|Int32|
+|默认值| 5 |
+|改后生效方式|重启服务器生效|
+
+* data\_dirs
+
+|名字| data\_dirs |
+|:---:|:---|
+|描述| IoTDB数据存储路径,默认存放在和bin目录同级的data目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。|
+|类型|String|
+|默认值| data |
+|改后生效方式|触发生效|
+
+* enable_wal
+
+|名字| enable_wal |
+|:---:|:---|
+|描述| 是否开启写前日志,默认值为true表示开启,配置成false表示关闭 |
+|类型|Bool|
+|默认值| true |
+|改后生效方式|触发生效|
+
+* fetch_size
+
+|名字| fetch_size |
+|:---:|:---|
+|描述| 批量读取数据的时候,每一次读取数据的数量。单位为数据条数,即不同时间戳的个数。某次会话中,用户可以在使用时自己设定,此时仅在该次会话中生效。|
+|类型|Int32|
+|默认值| 10000 |
+|改后生效方式|重启服务器生效|
+
+* force\_wal\_period\_in\_ms
+
+|名字| force\_wal\_period\_in\_ms |
+|:---:|:---|
+|描述| 写前日志定期刷新到磁盘的周期,单位毫秒,有可能丢失至多flush\_wal\_period\_in\_ms毫秒的操作。 |
+|类型|Int32|
+|默认值| 10 |
+|改后生效方式|触发生效|
+
+* flush\_wal\_threshold
+
+|名字| flush\_wal\_threshold |
+|:---:|:---|
+|描述| 写前日志的条数达到该值之后,刷新到磁盘,有可能丢失至多flush\_wal\_threshold个操作 |
+|类型|Int32|
+|默认值| 10000 |
+|改后生效方式|触发生效|
+
+* merge\_concurrent\_threads
+
+|名字| merge\_concurrent\_threads |
+|:---:|:---|
+|描述| 乱序数据进行合并的时候最多可以用来进行merge的线程数。值越大,对IO和CPU消耗越多。值越小,当乱序数据过多时,磁盘占用量越大,读取会变慢。 |
+|类型|Int32|
+|默认值| 0 |
+|改后生效方式|重启服务器生效|
+
+* partition\_interval
+
+|名字| partition\_interval |
+|:---:|:---|
+|描述| 用于存储组分区的时间段长度,用户指定的存储组下会使用该时间段进行分区,单位:秒 |
+|类型|Int64|
+|默认值| 604800 |
+|改后生效方式|仅允许在第一次启动服务器前修改|
+
+* memtable\_num\_in\_each\_storage\_group
+
+|名字| memtable\_num\_in\_each\_storage\_group|
+|:---:|:---|
+|描述| 每个存储组所控制的memtable的最大数量,这决定了来源于多少个不同时间分区的数据可以并发写入<br>举例来说,你的时间分区为按天分区,想要同时并发写入3天的数据,那么这个值应该被设置为6(3个给顺序写入,3个给乱序写入)|
+|类型|Int32|
+|默认值| 10 |
+|改后生效方式|重启服务器生效|
+
+* multi\_dir\_strategy
+
+|名字| multi\_dir\_strategy |
+|:---:|:---|
+|描述| IoTDB在tsfile\_dir中为TsFile选择目录时采用的策略。可使用简单类名或类名全称。系统提供以下三种策略:<br>1. SequenceStrategy:IoTDB按顺序从tsfile\_dir中选择目录,依次遍历tsfile\_dir中的所有目录,并不断轮循;<br>2. MaxDiskUsableSpaceFirstStrategy:IoTDB优先选择tsfile\_dir中对应磁盘空余空间最大的目录;<br>3. MinFolderOccupiedSpaceFirstStrategy:IoTDB优先选择tsfile\_dir中已使用空间最小的目录;<br>4. <UserDfineStrategyPackage>(用户自定义策略)<br>您可以通过以下方法完成用户自定义策略:<br>1. 继承cn.edu.tsinghua.iotdb.conf.directories.strategy.DirectoryStrategy类并实现自身的Strategy方法;<br>2. 将实现的类的完整类名(包名加类名,UserDfineStrategyPa [...]
+|类型|String|
+|默认值| MaxDiskUsableSpaceFirstStrategy |
+|改后生效方式|触发生效|
+
+* rpc_address
+
+|名字| rpc_address |
+|:---:|:---|
+|描述| |
+|类型|String|
+|默认值| "0.0.0.0" |
+|改后生效方式|重启服务器生效|
+
+* rpc_port
+
+|名字| rpc_port |
+|:---:|:---|
+|描述|jdbc服务监听端口。请确认该端口不是系统保留端口并且未被占用。|
+|类型|Short Int : [0,65535]|
+|默认值| 6667 |
+|改后生效方式|重启服务器生效||
+
+* time\_zone
+
+|名字| time_zone |
+|:---:|:---|
+|描述| 服务器所处的时区,默认为北京时间(东八区) |
+|类型|Time Zone String|
+|默认值| +08:00 |
+|改后生效方式|触发生效|
+
+* enable\_stat\_monitor
+
+|名字| enable\_stat\_monitor |
+|:---:|:---|
+|描述| 选择是否启动后台统计功能|
+|类型| Boolean |
+|默认值| false |
+|改后生效方式|重启服务器生效|
+
+* concurrent\_flush\_thread
+
+|名字| concurrent\_flush\_thread |
+|:---:|:---|
+|描述| 当IoTDB将内存中的数据写入磁盘时,最多启动多少个线程来执行该操作。如果该值小于等于0,那么采用机器所安装的CPU核的数量。默认值为0。|
+|类型| Int32 |
+|默认值| 0 |
+|改后生效方式|重启服务器生效|
+
+
+* stat\_monitor\_detect\_freq\_in\_second
+
+|名字| stat\_monitor\_detect\_freq\_in\_second |
+|:---:|:---|
+|描述| 每隔一段时间(以秒为单位)检测当前记录统计量时间范围是否超过stat_monitor_retain_interval,并进行定时清理。|
+|类型| Int32 |
+|默认值|600 |
+|改后生效方式|重启服务器生效|
+
+
+* stat\_monitor\_retain\_interval\_in\_second
+
+|名字| stat\_monitor\_retain\_interval\_in\_second |
+|:---:|:---|
+|描述| 系统统计信息的保留时间(以秒为单位),超过保留时间范围的统计数据将被定时清理。|
+|类型| Int32 |
+|默认值|600 |
+|改后生效方式|重启服务器生效|
+
+* tsfile\_storage\_fs
+
+|名字| tsfile\_storage\_fs |
+|:---:|:---|
+|描述| Tsfile和相关数据文件的存储文件系统。目前支持LOCAL(本地文件系统)和HDFS两种|
+|类型| String |
+|默认值|LOCAL |
+|改后生效方式|重启服务器生效|
+
+* core\_site\_path
+
+|Name| core\_site\_path |
+|:---:|:---|
+|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置core-site.xml的绝对路径|
+|类型| String |
+|默认值|/etc/hadoop/conf/core-site.xml |
+|改后生效方式|重启服务器生效|
+
+* hdfs\_site\_path
+
+|Name| hdfs\_site\_path |
+|:---:|:---|
+|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置hdfs-site.xml的绝对路径|
+|类型| String |
+|默认值|/etc/hadoop/conf/hdfs-site.xml |
+|改后生效方式|重启服务器生效|
+
+* hdfs\_ip
+
+|名字| hdfs\_ip |
+|:---:|:---|
+|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置HDFS的IP。**如果配置了多于1个hdfs\_ip,则表明启用了Hadoop HA**|
+|类型| String |
+|默认值|localhost |
+|改后生效方式|重启服务器生效|
+
+* hdfs\_port
+
+|名字| hdfs\_port |
+|:---:|:---|
+|描述| 在Tsfile和相关数据文件存储到HDFS的情况下用于配置HDFS的端口|
+|类型| String |
+|默认值|9000 |
+|改后生效方式|重启服务器生效|
+
+* dfs\_nameservices
+
+|名字| hdfs\_nameservices |
+|:---:|:---|
+|描述| 在使用Hadoop HA的情况下用于配置HDFS的nameservices|
+|类型| String |
+|默认值|hdfsnamespace |
+|改后生效方式|重启服务器生效|
+
+* dfs\_ha\_namenodes
+
+|名字| hdfs\_ha\_namenodes |
+|:---:|:---|
+|描述| 在使用Hadoop HA的情况下用于配置HDFS的nameservices下的namenodes|
+|类型| String |
+|默认值|nn1,nn2 |
+|改后生效方式|重启服务器生效|
+
+* dfs\_ha\_automatic\_failover\_enabled
+
+|名字| dfs\_ha\_automatic\_failover\_enabled |
+|:---:|:---|
+|描述| 在使用Hadoop HA的情况下用于配置是否使用失败自动切换|
+|类型| Boolean |
+|默认值|true |
+|改后生效方式|重启服务器生效|
+
+* dfs\_client\_failover\_proxy\_provider
+
+|名字| dfs\_client\_failover\_proxy\_provider |
+|:---:|:---|
+|描述| 在使用Hadoop HA且使用失败自动切换的情况下配置失败自动切换的实现方式|
+|类型| String |
+|默认值|org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider |
+|改后生效方式|重启服务器生效|
+
+* hdfs\_use\_kerberos
+
+|名字| hdfs\_use\_kerberos |
+|:---:|:---|
+|描述| 是否使用kerberos验证访问hdfs|
+|类型| String |
+|默认值|false |
+|改后生效方式|重启服务器生效|
+
+* kerberos\_keytab\_file_path
+
+|名字| kerberos\_keytab\_file_path |
+|:---:|:---|
+|描述| kerberos keytab file 的完整路径|
+|类型| String |
+|默认值|/path |
+|改后生效方式|重启服务器生效|
+
+* kerberos\_principal
+
+|名字| kerberos\_principal |
+|:---:|:---|
+|描述| Kerberos 认证原则|
+|类型| String |
+|默认值|your principal |
+|改后生效方式|重启服务器生效|
+
+
+## 开启GC日志
+GC日志默认是关闭的。为了性能调优,用户可能会需要手机GC信息。
+若要打开GC日志,则需要在启动IoTDB Server的时候加上"printgc"参数:
+
+```bash
+sbin/start-server.sh printgc
+```
+或者
+
+```bash
+sbin\start-server.bat printgc
+```
+
+GC日志会被存储在`IOTDB_HOME/logs/gc.log`. 至多会存储10个gc.log文件,每个文件最多10MB。
+
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/5-Docker Image.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/5-Docker Image.md
new file mode 100644
index 0000000..790d4ff
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/3-Server/5-Docker Image.md
@@ -0,0 +1,89 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第3章 服务器端
+## Docker Image
+Dockerfile 存放在的 docker 工程下的 src/main/Dockerfile 中.
+
+1. 您可以使用下面的命令构建 docker image:
+```
+$ docker build -t iotdb:base git://github.com/apache/incubator-iotdb#master:docker
+```
+或者:
+```
+$ git clone https://github.com/apache/incubator-iotdb
+$ cd incubator-iotdb
+$ cd docker
+$ docker build -t iotdb:base .
+```
+当 docker image 在本地构建完成当时候 (示例中的 tag为 iotdb:base),已经距完成只有一步之遥了!
+
+2. 创建数据文件和日志的 docker 挂载目录(docker volume):
+```
+$ docker volume create mydata
+$ docker volume create mylogs
+```
+3. 运行 docker container:
+```shell
+$ docker run -p 6667:6667 -v mydata:/iotdb/data -v mylogs:/iotdb/logs -d iotdb:base /iotdb/bin/start-server.sh
+```
+您可以使用`docker ps`来检查是否运行成功,当成功时控制台会输出下面的日志:
+```
+CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
+2a68b6944cb5 iotdb:base "/iotdb/bin/start-se…" 4 minutes ago Up 5 minutes 0.0.0.0:6667->6667/tcp laughing_meitner
+```
+您可以使用下面的命令来获取 container 的 ID:
+```
+$ docker container ls
+```
+假设这个 ID 为 <C_ID>.
+
+然后使用下面的命令获取这个 ID 对应的 IP 地址:
+```
+$ docker inspect --format='{{.NetworkSettings.IPAddress}}' <C_ID>
+```
+假设获取的 IP 为 <C_IP>.
+
+4. 如果您想尝试使用 iotdb-cli 命令行, 您可以使用如下命令:
+```
+$ docker exec -it /bin/bash <C_ID>
+$ (now you have enter the container): /cli/sbin/start-client.sh -h localhost -p 6667 -u root -pw root
+```
+
+或者运行一个新的 client docker container,命令如下:
+```
+$ docker run -it iotdb:base /cli/sbin/start-client.sh -h <C_IP> -p 6667 -u root -pw root
+```
+还可以使用本地的 iotdb-cli (比如:您已经使用`mvn package`编译过源码), 假设您的 work_dir 是 cli/bin, 那么您可以直接运行:
+```
+$ start-client.sh -h localhost -p 6667 -u root -pw root
+```
+5. 如果您想写一些代码来插入或者查询数据,您可以在 pom.xml 文件中加入下面的依赖:
+```xml
+ <dependency>
+ <groupId>org.apache.iotdb</groupId>
+ <artifactId>iotdb-jdbc</artifactId>
+ <version>0.8.0</version>
+ </dependency>
+```
+这里是一些使用 IoTDB-JDBC 连接 IoTDB 的示例: https://github.com/apache/incubator-iotdb/tree/master/example/jdbc/src/main/java/org/apache/iotdb
+
+6. 现在已经大功告成了
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/1-Command Line Interface (CLI).md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/1-Command Line Interface (CLI).md
new file mode 100644
index 0000000..b1b41d5
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/1-Command Line Interface (CLI).md
@@ -0,0 +1,148 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+<!-- TOC -->
+# 第4章 客户端
+## 概览
+- Cli / Shell工具
+ - Cli / Shell安装
+ - Cli / Shell运行方式
+ - Cli / Shell运行参数
+ - Cli / Shell的-e参数
+
+<!-- /TOC -->
+
+# 命令行接口(CLI)
+IOTDB为用户提供Client/Shell工具用于启动客户端和服务端程序。下面介绍每个Client/Shell工具的运行方式和相关参数。
+> \$IOTDB\_HOME表示IoTDB的安装目录所在路径。
+
+## Cli / Shell安装
+在incubator-iotdb的根目录下执行
+
+```
+> mvn clean package -pl client -am -DskipTests
+```
+
+在生成完毕之后,IoTDB的cli工具位于文件夹"client/target/iotdb-client-{project.version}"中。
+
+## Cli / Shell运行方式
+安装后的IoTDB中有一个默认用户:`root`,默认密码为`root`。用户可以使用该用户尝试运行IoTDB客户端以测试服务器是否正常启动。客户端启动脚本为$IOTDB_HOME/bin文件夹下的`start-client`脚本。启动脚本时需要指定运行IP和PORT。以下为服务器在本机启动,且用户未更改运行端口号的示例,默认端口为6667。若用户尝试连接远程服务器或更改了服务器运行的端口号,请在-h和-p项处使用服务器的IP和PORT。</br>
+用户也可以在启动脚本的最前方设置自己的环境变量,如JAVA_HOME等 (对于linux用户,脚本路径为:"/sbin/start-client.sh"; 对于windows用户,脚本路径为:"/sbin/start-client.bat")
+
+
+
+Linux系统与MacOS系统启动命令如下:
+
+```
+ Shell > ./sbin/start-client.sh -h 127.0.0.1 -p 6667 -u root -pw root
+```
+Windows系统启动命令如下:
+
+```
+ Shell > \sbin\start-client.bat -h 127.0.0.1 -p 6667 -u root -pw root
+```
+回车后即可成功启动客户端。启动后出现如图提示即为启动成功。
+```
+ _____ _________ ______ ______
+|_ _| | _ _ ||_ _ `.|_ _ \
+ | | .--.|_/ | | \_| | | `. \ | |_) |
+ | | / .'`\ \ | | | | | | | __'.
+ _| |_| \__. | _| |_ _| |_.' /_| |__) |
+|_____|'.__.' |_____| |______.'|_______/ version <version>
+
+
+IoTDB> login successfully
+IoTDB>
+```
+输入`quit`或`exit`可退出Client结束本次会话,Client输出`quit normally`表示退出成功。
+
+## Cli / Shell运行参数
+
+|参数名|参数类型|是否为必需参数| 说明| 例子 |
+|:---|:---|:---|:---|:---|
+|-disableIS08601 |没有参数 | 否 |如果设置了这个参数,IoTDB将以数字的形式打印时间戳(timestamp)。|-disableIS08601|
+|-h <`host`> |string类型,不需要引号|是|IoTDB客户端连接IoTDB服务器的IP地址。|-h 10.129.187.21|
+|-help|没有参数|否|打印IoTDB的帮助信息|-help|
+|-p <`port`>|int类型|是|IoTDB连接服务器的端口号,IoTDB默认运行在6667端口。|-p 6667|
+|-pw <`password`>|string类型,不需要引号|否|IoTDB连接服务器所使用的密码。如果没有输入密码IoTDB会在Cli端提示输入密码。|-pw root|
+|-u <`username`>|string类型,不需要引号|是|IoTDB连接服务器锁使用的用户名。|-u root|
+|-maxPRC <`maxPrintRowCount`>|int类型|否|设置IoTDB返回客户端命令行中所显示的最大行数。|-maxPRC 10|
+|-e <`execute`> |string类型|否|在不进入客户端输入模式的情况下,批量操作IoTDB|-e "show storage group"|
+
+
+下面展示一条客户端命令,功能是连接IP为10.129.187.21的主机,端口为6667 ,用户名为root,密码为root,以数字的形式打印时间戳,IoTDB命令行显示的最大行数为10。
+
+Linux系统与MacOS系统启动命令如下:
+
+```
+ Shell >./sbin/start-client.sh -h 10.129.187.21 -p 6667 -u root -pw root -disableIS08601 -maxPRC 10
+```
+Windows系统启动命令如下:
+
+```
+ Shell > \sbin\start-client.bat -h 10.129.187.21 -p 6667 -u root -pw root -disableIS08601 -maxPRC 10
+```
+## Cli / Shell的-e参数
+当您想要通过脚本的方式通过Cli / Shell对IoTDB进行批量操作时,可以使用-e参数。通过使用该参数,您可以在不进入客户端输入模式的情况下操作IoTDB。
+
+为了避免SQL语句和其他参数混淆,现在只支持-e参数作为最后的参数使用。
+
+针对Client/Shell工具的-e参数用法如下:
+
+```
+ Shell > ./sbin/start-client.sh -h {host} -p {port} -u {user} -pw {password} -e {sql for iotdb}
+```
+
+为了更好的解释-e参数的使用,可以参考下面的例子。
+
+假设用户希望对一个新启动的IoTDB进行如下操作:
+
+1.创建名为root.demo的存储组
+
+2.创建名为root.demo.s1的时间序列
+
+3.向创建的时间序列中插入三个数据点
+
+4.查询验证数据是否插入成功
+
+那么通过使用Client/Shell工具的-e参数,可以采用如下的脚本:
+
+```
+# !/bin/bash
+
+host=127.0.0.1
+port=6667
+user=root
+pass=root
+
+./sbin/start-client.sh -h ${host} -p ${port} -u ${user} -pw ${pass} -e "set storage group to root.demo"
+./sbin/start-client.sh -h ${host} -p ${port} -u ${user} -pw ${pass} -e "create timeseries root.demo.s1 WITH DATATYPE=INT32, ENCODING=RLE"
+./sbin/start-client.sh -h ${host} -p ${port} -u ${user} -pw ${pass} -e "insert into root.demo(timestamp,s1) values(1,10)"
+./sbin/start-client.sh -h ${host} -p ${port} -u ${user} -pw ${pass} -e "insert into root.demo(timestamp,s1) values(2,11)"
+./sbin/start-client.sh -h ${host} -p ${port} -u ${user} -pw ${pass} -e "insert into root.demo(timestamp,s1) values(3,12)"
+./sbin/start-client.sh -h ${host} -p ${port} -u ${user} -pw ${pass} -e "select s1 from root.demo"
+```
+
+打印出来的结果显示在下图,通过这种方式进行的操作与客户端的输入模式以及通过JDBC进行操作结果是一致的。
+
+
+
+需要特别注意的是,在脚本中使用-e参数时要对特殊字符进行转义。
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/2-Programming - Native API.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/2-Programming - Native API.md
new file mode 100644
index 0000000..25bb3ee
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/2-Programming - Native API.md
@@ -0,0 +1,103 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第4章: 客户端
+
+# 编程 - 原生接口
+
+## 使用
+
+## 依赖
+
+* JDK >= 1.8
+* Maven >= 3.1
+
+## 安装到本地 maven 库
+
+在根目录下运行:
+> mvn clean install -pl session -am -Dmaven.test.skip=true
+
+## 在 maven 中使用原生接口
+
+```
+<dependencies>
+ <dependency>
+ <groupId>org.apache.iotdb</groupId>
+ <artifactId>iotdb-session</artifactId>
+ <version>0.10.0</version>
+ </dependency>
+</dependencies>
+```
+
+## 原生接口使用示例
+下面将给出Session对应的接口的简要介绍和对应参数:
+
+### 建立连接
+
+* 初始化Session
+ Session(String host, int port)
+ Session(String host, String port, String username, String password)
+ Session(String host, int port, String username, String password)
+
+* 开启Session
+ Session.open()
+
+* 关闭Session
+ Session.close()
+
+### 数据操作接口
+
+* 设置存储组
+
+ TSStatus setStorageGroup(String storageGroupId)
+
+* 删除单个或多个存储组
+
+ TSStatus deleteStorageGroup(String storageGroup)
+ TSStatus deleteStorageGroups(List<String> storageGroups)
+
+* 创建单个时间序列
+
+ TSStatus createTimeseries(String path, TSDataType dataType, TSEncoding encoding, CompressionType compressor)
+
+* 删除一个或多个时间序列
+
+ TSStatus deleteTimeseries(String path)
+ TSStatus deleteTimeseries(List<String> paths)
+
+* 删除某一特定时间前的时间序列
+
+ TSStatus deleteData(String path, long time)
+ TSStatus deleteData(List<String> paths, long time)
+
+* 插入时序数据
+
+ TSStatus insert(String deviceId, long time, List<String> measurements, List<String> values)
+
+* 批量插入时序数据
+
+ TSExecuteBatchStatementResp insertBatch(RowBatch rowBatch)
+
+### 示例代码
+
+浏览上述接口的详细信息,请参阅代码 ```session/src/main/java/org/apache/iotdb/session/Session.java```
+
+使用上述接口的示例代码在 ```example/session/src/main/java/org/apache/iotdb/SessionExample.java```
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/3-Programming - JDBC.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/3-Programming - JDBC.md
new file mode 100644
index 0000000..123e39e
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/3-Programming - JDBC.md
@@ -0,0 +1,278 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第4章: 客户端
+
+## 编程 - JDBC
+
+## 使用
+
+## 依赖项
+
+* JDK >= 1.8
+* Maven >= 3.1
+
+## 只打包 JDBC 工程
+
+在根目录下执行下面的命令:
+```
+mvn clean package -pl jdbc -am -Dmaven.test.skip=true
+```
+
+## 如何到本地 MAVEN 仓库
+
+在根目录下执行下面的命令:
+```
+mvn clean install -pl jdbc -am -Dmaven.test.skip=true
+```
+
+## 如何在 MAVEN 中使用 IoTDB JDBC
+
+```
+<dependencies>
+ <dependency>
+ <groupId>org.apache.iotdb</groupId>
+ <artifactId>iotdb-jdbc</artifactId>
+ <version>0.8.0</version>
+ </dependency>
+</dependencies>
+```
+
+
+## 示例
+
+本章提供了如何建立数据库连接、执行 SQL 和显示查询结果的示例。
+
+要求您已经在工程中包含了数据库编程所需引入的包和 JDBC class.
+
+**注意:为了更快地插入,建议使用 insertBatch()**
+
+```Java
+import java.sql.*;
+import org.apache.iotdb.jdbc.IoTDBSQLException;
+
+public class JDBCExample {
+ /**
+ * Before executing a SQL statement with a Statement object, you need to create a Statement object using the createStatement() method of the Connection object.
+ * After creating a Statement object, you can use its execute() method to execute a SQL statement
+ * Finally, remember to close the 'statement' and 'connection' objects by using their close() method
+ * For statements with query results, we can use the getResultSet() method of the Statement object to get the result set.
+ */
+ public static void main(String[] args) throws SQLException {
+ Connection connection = getConnection();
+ if (connection == null) {
+ System.out.println("get connection defeat");
+ return;
+ }
+ Statement statement = connection.createStatement();
+ //Create storage group
+ try {
+ statement.execute("SET STORAGE GROUP TO root.demo");
+ }catch (IoTDBSQLException e){
+ System.out.println(e.getMessage());
+ }
+
+
+ //Show storage group
+ statement.execute("SHOW STORAGE GROUP");
+ outputResult(statement.getResultSet());
+
+ //Create time series
+ //Different data type has different encoding methods. Here use INT32 as an example
+ try {
+ statement.execute("CREATE TIMESERIES root.demo.s0 WITH DATATYPE=INT32,ENCODING=RLE;");
+ }catch (IoTDBSQLException e){
+ System.out.println(e.getMessage());
+ }
+ //Show time series
+ statement.execute("SHOW TIMESERIES root.demo");
+ outputResult(statement.getResultSet());
+ //Show devices
+ statement.execute("SHOW DEVICES");
+ outputResult(statement.getResultSet());
+ //Count time series
+ statement.execute("COUNT TIMESERIES root");
+ outputResult(statement.getResultSet());
+ //Count nodes at the given level
+ statement.execute("COUNT NODES root LEVEL=3");
+ outputResult(statement.getResultSet());
+ //Count timeseries group by each node at the given level
+ statement.execute("COUNT TIMESERIES root GROUP BY LEVEL=3");
+ outputResult(statement.getResultSet());
+
+
+ //Execute insert statements in batch
+ statement.addBatch("insert into root.demo(timestamp,s0) values(1,1);");
+ statement.addBatch("insert into root.demo(timestamp,s0) values(1,1);");
+ statement.addBatch("insert into root.demo(timestamp,s0) values(2,15);");
+ statement.addBatch("insert into root.demo(timestamp,s0) values(2,17);");
+ statement.addBatch("insert into root.demo(timestamp,s0) values(4,12);");
+ statement.executeBatch();
+ statement.clearBatch();
+
+ //Full query statement
+ String sql = "select * from root.demo";
+ ResultSet resultSet = statement.executeQuery(sql);
+ System.out.println("sql: " + sql);
+ outputResult(resultSet);
+
+ //Exact query statement
+ sql = "select s0 from root.demo where time = 4;";
+ resultSet= statement.executeQuery(sql);
+ System.out.println("sql: " + sql);
+ outputResult(resultSet);
+
+ //Time range query
+ sql = "select s0 from root.demo where time >= 2 and time < 5;";
+ resultSet = statement.executeQuery(sql);
+ System.out.println("sql: " + sql);
+ outputResult(resultSet);
+
+ //Aggregate query
+ sql = "select count(s0) from root.demo;";
+ resultSet = statement.executeQuery(sql);
+ System.out.println("sql: " + sql);
+ outputResult(resultSet);
+
+ //Delete time series
+ statement.execute("delete timeseries root.demo.s0");
+
+ //close connection
+ statement.close();
+ connection.close();
+ }
+
+ public static Connection getConnection() {
+ // JDBC driver name and database URL
+ String driver = "org.apache.iotdb.jdbc.IoTDBDriver";
+ String url = "jdbc:iotdb://127.0.0.1:6667/";
+
+ // Database credentials
+ String username = "root";
+ String password = "root";
+
+ Connection connection = null;
+ try {
+ Class.forName(driver);
+ connection = DriverManager.getConnection(url, username, password);
+ } catch (ClassNotFoundException e) {
+ e.printStackTrace();
+ } catch (SQLException e) {
+ e.printStackTrace();
+ }
+ return connection;
+ }
+
+ /**
+ * This is an example of outputting the results in the ResultSet
+ */
+ private static void outputResult(ResultSet resultSet) throws SQLException {
+ if (resultSet != null) {
+ System.out.println("--------------------------");
+ final ResultSetMetaData metaData = resultSet.getMetaData();
+ final int columnCount = metaData.getColumnCount();
+ for (int i = 0; i < columnCount; i++) {
+ System.out.print(metaData.getColumnLabel(i + 1) + " ");
+ }
+ System.out.println();
+ while (resultSet.next()) {
+ for (int i = 1; ; i++) {
+ System.out.print(resultSet.getString(i));
+ if (i < columnCount) {
+ System.out.print(", ");
+ } else {
+ System.out.println();
+ break;
+ }
+ }
+ }
+ System.out.println("--------------------------\n");
+ }
+ }
+}
+```
+
+
+## Status Code
+
+在最新版本中引入了**状态码**这一概念。例如,因为IoTDB需要在写入数据之前首先注册时间序列,一种可能的解决方案是:
+
+```
+try {
+ writeData();
+} catch (SQLException e) {
+ // the most case is that the time series does not exist
+ if (e.getMessage().contains("exist")) {
+ //However, using the content of the error message is not so efficient
+ registerTimeSeries();
+ //write data once again
+ writeData();
+ }
+}
+
+```
+
+利用状态码,我们就可以不必写诸如`if (e.getErrorMessage().contains("exist"))`的代码,只需要使用`e.getStatusType().getCode() == TSStatusCode.TIME_SERIES_NOT_EXIST_ERROR.getStatusCode()`。
+
+这里是状态码和相对应信息的列表:
+
+|状态码|状态类型|状态信息|
+|:---|:---|:---|
+|200|SUCCESS_STATUS||
+|201|STILL_EXECUTING_STATUS||
+|202|INVALID_HANDLE_STATUS||
+|300|TIMESERIES_ALREADY_EXIST_ERROR|时间序列已经存在|
+|301|TIMESERIES_NOT_EXIST_ERROR|时间序列不存在|
+|302|UNSUPPORTED_FETCH_METADATA_OPERATION_ERROR|不支持的获取元数据操作|
+|303|METADATA_ERROR|处理元数据错误|
+|305|OUT_OF_TTL_ERROR|插入时间少于TTL时间边界|
+|306|CONFIG_ADJUSTER|IoTDB系统负载过大|
+|307|MERGE_ERROR|合并错误|
+|308|SYSTEM_CHECK_ERROR|系统检查错误|
+|309|SYNC_DEVICE_OWNER_CONFLICT_ERROR|回传设备冲突错误|
+|310|SYNC_CONNECTION_EXCEPTION|回传连接错误|
+|311|STORAGE_GROUP_PROCESSOR_ERROR|存储组处理器相关错误|
+|312|STORAGE_GROUP_ERROR|存储组相关错误|
+|313|STORAGE_ENGINE_ERROR|存储引擎相关错误|
+|400|EXECUTE_STATEMENT_ERROR|执行语句错误|
+|401|SQL_PARSE_ERROR|SQL语句分析错误|
+|402|GENERATE_TIME_ZONE_ERROR|生成时区错误|
+|403|SET_TIME_ZONE_ERROR|设置时区错误|
+|404|NOT_STORAGE_GROUP_ERROR|操作对象不是存储组|
+|405|QUERY_NOT_ALLOWED|查询语句不允许|
+|406|AST_FORMAT_ERROR|AST格式相关错误|
+|407|LOGICAL_OPERATOR_ERROR|逻辑符相关错误|
+|408|LOGICAL_OPTIMIZE_ERROR|逻辑优化相关错误|
+|409|UNSUPPORTED_FILL_TYPE_ERROR|不支持的填充类型|
+|410|PATH_ERROR|路径相关错误|
+|405|READ_ONLY_SYSTEM_ERROR|操作系统只读|
+|500|INTERNAL_SERVER_ERROR|服务器内部错误|
+|501|CLOSE_OPERATION_ERROR|关闭操作错误|
+|502|READ_ONLY_SYSTEM_ERROR|系统只读|
+|503|DISK_SPACE_INSUFFICIENT_ERROR|磁盘空间不足|
+|504|START_UP_ERROR|启动错误|
+|600|WRONG_LOGIN_PASSWORD_ERROR|用户名或密码错误|
+|601|NOT_LOGIN_ERROR|没有登录|
+|602|NO_PERMISSION_ERROR|没有操作权限|
+|603|UNINITIALIZED_AUTH_ERROR|授权人未初始化|
+
+> 在最新版本中,我们重构了IoTDB的异常类。通过将错误信息统一提取到异常类中,并为所有异常添加不同的错误代码,从而当捕获到异常并引发更高级别的异常时,错误代码将保留并传递,以便用户了解详细的错误原因。
+除此之外,我们添加了一个基础异常类“ProcessException”,由所有异常扩展。
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/4-Programming - Other Languages.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/4-Programming - Other Languages.md
new file mode 100644
index 0000000..094d278
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/4-Programming - Other Languages.md
@@ -0,0 +1,66 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+# 第4章: 客户端
+## 其他语言
+
+## Python API
+
+### 1. 介绍
+
+这是一个如何使用thrift rpc接口通过python连接到IoTDB的示例。 在Linux或Windows上情况会有所不同,我们将介绍如何分别在两个系统上进行操作。
+
+### 2. 先决条件
+
+首选python3.7或更高版本。
+
+您必须安装Thrift(0.11.0或更高版本)才能将我们的Thrift文件编译为python代码。
+
+下面是官方安装教程:
+
+```
+http://thrift.apache.org/docs/install/
+```
+
+### 3. 如何获取Python库
+
+#### 方案1: pip install
+
+您可以在https://pypi.org/project/apache-iotdb/上找到Apache IoTDB Python客户端API软件包。
+
+下载命令为:
+
+```
+pip install apache-iotdb
+```
+
+#### 方案2: 使用我们提供的编译脚本
+
+如果你在路径中添加了Thrift可执行文件,则可以运行`client-py/compile.sh`或
+ `client-py \ compile.bat`,或者你必须对其进行修改以将变量`THRIFT_EXE`设置为指向你的可执行文件。 这将在`target`文件夹下生成节俭源,你可以将其添加到你的`PYTHONPATH`,以便你可以在代码中使用该库。 请注意,脚本通过相对路径找到节俭的源文件,因此,如果将脚本移动到其他位置,它们将不再有效。
+
+#### 方案3:thrift的基本用法
+
+或者,如果您了解thrift的基本用法,则只能在以下位置下载Thrift源文件:
+`service-rpc\src\main\thrift\rpc.thrift`,并且只需使用`thrift -gen py -out ./target/iotdb rpc.thrift`生成python库。
+
+### 4. 示例代码
+
+我们在`client-py / src/ client_example.py`中提供了一个示例,说明如何使用Thrift库连接到IoTDB,请先仔细阅读,然后再编写自己的代码。
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/5-Programming - TsFile API.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/5-Programming - TsFile API.md
new file mode 100644
index 0000000..8609380
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/5-Programming - TsFile API.md
@@ -0,0 +1,701 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第4章: 客户端
+## TsFile API
+
+TsFile 是在 IoTDB 中使用的时间序列的文件格式。在这个章节中,我们将介绍这种文件格式的用法。
+
+## 安装 TsFile libaray
+
+
+在您自己的项目中有两种方法使用 TsFile .
+
+* 使用 jar 包:
+ * 编译源码生成 jar 包
+
+ ```
+ git clone https://github.com/apache/incubator-iotdb.git
+ cd tsfile/
+ mvn clean package -Dmaven.test.skip=true
+ ```
+ 命令执行完成之后,所有的 jar 包都可以从 `target/` 目录下找到。之后您可以在自己的工程中倒入 `target/tsfile-0.10.0-jar-with-dependencies.jar`.
+
+* 使用 Maven 依赖:
+
+ 编译源码并且部署到您的本地仓库中需要 3 步:
+
+ * 下载源码
+
+ ```
+ git clone https://github.com/apache/incubator-iotdb.git
+ ```
+ * 编译源码和部署到本地仓库
+
+ ```
+ cd tsfile/
+ mvn clean install -Dmaven.test.skip=true
+ ```
+ * 在您自己的工程中增加依赖:
+
+ ```
+ <dependency>
+ <groupId>org.apache.iotdb</groupId>
+ <artifactId>tsfile</artifactId>
+ <version>0.10.0</version>
+ </dependency>
+ ```
+
+ 或者,您可以直接使用官方的 Maven 仓库:
+
+ * 首先,在`${username}\.m2\settings.xml`目录下的`settings.xml`文件中`<profiles>`
+ 节中增加`<profile>`,内容如下:
+ ```
+ <profile>
+ <id>allow-snapshots</id>
+ <activation><activeByDefault>true</activeByDefault></activation>
+ <repositories>
+ <repository>
+ <id>apache.snapshots</id>
+ <name>Apache Development Snapshot Repository</name>
+ <url>https://repository.apache.org/content/repositories/snapshots/</url>
+ <releases>
+ <enabled>false</enabled>
+ </releases>
+ <snapshots>
+ <enabled>true</enabled>
+ </snapshots>
+ </repository>
+ </repositories>
+ </profile>
+ ```
+ * 之后您可以在您的工程中增加如下依赖:
+
+ ```
+ <dependency>
+ <groupId>org.apache.iotdb</groupId>
+ <artifactId>tsfile</artifactId>
+ <version>0.10.0</version>
+ </dependency>
+ ```
+
+## TSFile 的使用
+本章节演示TsFile的详细用法。
+
+### 时序数据(Time-series Data)
+一个时序是由4个序列组成,分别是 device, measurement, time, value。
+
+* **measurement**: 时间序列描述的是一个物理或者形式的测量(measurement),比如:城市的温度,一些商品的销售数量或者是火车在不同时间的速度。
+传统的传感器(如温度计)也采用单次测量(measurement)并产生时间序列,我们将在下面交替使用测量(measurement)和传感器。
+
+* **device**: 一个设备指的是一个正在进行多次测量(产生多个时间序列)的实体,例如,
+ 一列正在运行的火车监控它的速度、油表、它已经运行的英里数,当前的乘客每个都被传送到一个时间序列。
+
+表1描述了一组时间序列数据。下表中显示的集合包含一个名为 "device\_1" 的设备,它有三个测量值(measurement)分别是
+"sensor\_1", "sensor\_2" 和 "sensor\_3".
+
+<center>
+<table style="text-align:center">
+ <tr><th colspan="6">device_1</th></tr>
+ <tr><th colspan="2">sensor_1</th><th colspan="2">sensor_2</th><th colspan="2">sensor_3</th></tr>
+ <tr><th>time</th><th>value</td><th>time</th><th>value</td><th>time</th><th>value</td>
+ <tr><td>1</td><td>1.2</td><td>1</td><td>20</td><td>2</td><td>50</td></tr>
+ <tr><td>3</td><td>1.4</td><td>2</td><td>20</td><td>4</td><td>51</td></tr>
+ <tr><td>5</td><td>1.1</td><td>3</td><td>21</td><td>6</td><td>52</td></tr>
+ <tr><td>7</td><td>1.8</td><td>4</td><td>20</td><td>8</td><td>53</td></tr>
+</table>
+<span>一组时间序列数据</span>
+</center>
+
+**单行数据**: 在许多工业应用程序中,一个设备通常包含多个传感器,这些传感器可能同时具有多个值,这称为一行数据。
+
+在形式上,一行数据包含一个`device_id`,它是一个时间戳,表示从 1970年1月1日 00:00:00 开始的毫秒数,
+以及由`measurement_id`和相应的`value`组成的几个数据对。一行中的所有数据对都属于这个`device_id`,并且具有相同的时间戳。
+如果其中一个度量值`measurements`在某个时间戳`timestamp`没有值`value`,将使用一个空格表示(实际上 TsFile 并不存储 null 值)。
+其格式如下:
+
+```
+device_id, timestamp, <measurement_id, value>...
+```
+
+示例数据如下所示。在本例中,两个度量值(measurement)的数据类型分别是`INT32`和`FLOAT`。
+
+```
+device_1, 1490860659000, m1, 10, m2, 12.12
+```
+
+
+### 写入 TsFile
+
+#### 生成一个 TsFile 文件
+TsFile可以通过以下三个步骤生成,完整的代码参见"写入 TsFile 示例"章节。
+
+* 首先,构造一个`TsFileWriter`实例。
+
+ 以下是可用的构造函数:
+
+ * 没有预定义 schema
+ ```
+ public TsFileWriter(File file) throws IOException
+ ```
+ * 预定义 schema
+ ```
+ public TsFileWriter(File file, Schema schema) throws IOException
+ ```
+ 这个是用于使用 HDFS 文件系统的。`TsFileOutput`可以是`HDFSOutput`类的一个实例。
+
+ ```
+ public TsFileWriter(TsFileOutput output, Schema schema) throws IOException
+ ```
+
+ 如果你想自己设置一些 TSFile 的配置,你可以使用`config`参数。比如:
+ ```
+ TSFileConfig conf = new TSFileConfig();
+ conf.setTSFileStorageFs("HDFS");
+ TsFileWriter tsFileWriter = new TsFileWriter(file, schema, conf);
+ ```
+ 在上面的例子中,数据文件将存储在 HDFS 中,而不是本地文件系统中。如果你想在本地文件系统中存储数据文件,你可以使用`conf.setTSFileStorageFs("LOCAL")`,这也是默认的配置。
+
+ 您还可以通过`config.setHdfsIp(...)`和`config.setHdfsPort(...)`来配置 HDFS 的 IP 和端口。默认的 IP是`localhost`,默认的端口是`9000`.
+
+ **参数:**
+
+ * file : 写入 TsFile 数据的文件
+
+ * schema : 文件的 schemas,将在下章进行介绍
+
+ * config : TsFile 的一些配置项
+
+* 第二部,添加测量值(measurement)
+
+ 你也可以先创建一个`Schema`类的实例然后把它传递给`TsFileWriter`类的构造函数
+
+ `Schema`类保存的是一个映射关系,key 是一个 measurement 的名字,value 是 measurement schema.
+
+ 下面是一系列接口:
+ ```
+ // Create an empty Schema or from an existing map
+ public Schema()
+ public Schema(Map<String, MeasurementSchema> measurements)
+ // Use this two interfaces to add measurements
+ public void registerMeasurement(MeasurementSchema descriptor)
+ public void registerMeasurements(Map<String, MeasurementSchema> measurements)
+ // Some useful getter and checker
+ public TSDataType getMeasurementDataType(String measurementId)
+ public MeasurementSchema getMeasurementSchema(String measurementId)
+ public Map<String, MeasurementSchema> getAllMeasurementSchema()
+ public boolean hasMeasurement(String measurementId)
+ ```
+
+ 你可以在`TsFileWriter`类中使用以下接口来添加额外的测量(measurement):
+
+ ```
+ public void addMeasurement(MeasurementSchema measurementSchema) throws WriteProcessException
+ ```
+
+ `MeasurementSchema`类保存了一个测量(measurement)的信息,有几个构造函数:
+ ```
+ public MeasurementSchema(String measurementId, TSDataType type, TSEncoding encoding)
+ public MeasurementSchema(String measurementId, TSDataType type, TSEncoding encoding, CompressionType compressionType)
+ public MeasurementSchema(String measurementId, TSDataType type, TSEncoding encoding, CompressionType compressionType,
+ Map<String, String> props)
+ ```
+
+ **参数:**
+
+ * measurementID: 测量的名称,通常是传感器的名称。
+
+ * type: 数据类型,现在支持六种类型: `BOOLEAN`, `INT32`, `INT64`, `FLOAT`, `DOUBLE`, `TEXT`;
+
+ * encoding: 编码类型. 参见 [Chapter 2-3](/#/Documents/progress/chap2/sec3).
+
+ * compression: 压缩方式. 现在支持 `UNCOMPRESSED` 和 `SNAPPY`.
+
+ * props: 特殊数据类型的属性。比如说`FLOAT`和`DOUBLE`可以设置`max_point_number`,`TEXT`可以设置`max_string_length`。
+ 可以使用Map来保存键值对,比如("max_point_number", "3")。
+
+ > **注意:** 虽然一个测量(measurement)的名字可以被用在多个deltaObjects中, 但是它的参数是不允许被修改的。比如:
+ 不允许多次为同一个测量(measurement)名添加不同类型的编码。下面是一个错误示例:
+
+ // The measurement "sensor_1" is float type
+ addMeasurement(new MeasurementSchema("sensor_1", TSDataType.FLOAT, TSEncoding.RLE));
+
+ // This call will throw a WriteProcessException exception
+ addMeasurement(new MeasurementSchema("sensor_1", TSDataType.INT32, TSEncoding.RLE));
+* 第三,插入和写入数据。
+
+ 使用这个接口创建一个新的`TSRecord`(时间戳和设备对)。
+
+ ```
+ public TSRecord(long timestamp, String deviceId)
+ ```
+
+ 然后创建一个`DataPoint`(度量(measurement)和值的对应),并使用 addTuple 方法将数据 DataPoint 添加正确的值到 TsRecord。
+
+ 用下面这种方法写
+ ```
+ public void write(TSRecord record) throws IOException, WriteProcessException
+ ```
+
+* 最后,调用`close`方法来完成写入过程。
+
+ ```
+ public void close() throws IOException
+ ```
+
+#### 写入 TsFile 示例
+
+您需要安装 TsFile 到本地的 Maven 仓库中。
+
+详情参见: [Installation](./1-Installation.md)
+
+如果存在**非对齐**的时序数据(比如:不是所有的传感器都有值),您可以通过构造**TSRecord**来写入。
+
+更详细的例子可以在`/example/tsfile/src/main/java/org/apache/iotdb/tsfile/TsFileWriteWithTSRecord.java`中查看
+
+```java
+package org.apache.iotdb.tsfile;
+
+import java.io.File;
+import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
+import org.apache.iotdb.tsfile.file.metadata.enums.TSEncoding;
+import org.apache.iotdb.tsfile.write.TsFileWriter;
+import org.apache.iotdb.tsfile.write.record.TSRecord;
+import org.apache.iotdb.tsfile.write.record.datapoint.DataPoint;
+import org.apache.iotdb.tsfile.write.record.datapoint.FloatDataPoint;
+import org.apache.iotdb.tsfile.write.record.datapoint.IntDataPoint;
+import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
+/**
+ * An example of writing data to TsFile
+ * It uses the interface:
+ * public void addMeasurement(MeasurementSchema MeasurementSchema) throws WriteProcessException
+ */
+public class TsFileWriteWithTSRecord {
+
+ public static void main(String args[]) {
+ try {
+ String path = "test.tsfile";
+ File f = new File(path);
+ if (f.exists()) {
+ f.delete();
+ }
+ TsFileWriter tsFileWriter = new TsFileWriter(f);
+
+ // add measurements into file schema
+ tsFileWriter
+ .addMeasurement(new MeasurementSchema("sensor_1", TSDataType.INT64, TSEncoding.RLE));
+ tsFileWriter
+ .addMeasurement(new MeasurementSchema("sensor_2", TSDataType.INT64, TSEncoding.RLE));
+ tsFileWriter
+ .addMeasurement(new MeasurementSchema("sensor_3", TSDataType.INT64, TSEncoding.RLE));
+
+ // construct TSRecord
+ TSRecord tsRecord = new TSRecord(1, "device_1");
+ DataPoint dPoint1 = new LongDataPoint("sensor_1", 1);
+ DataPoint dPoint2 = new LongDataPoint("sensor_2", 2);
+ DataPoint dPoint3 = new LongDataPoint("sensor_3", 3);
+ tsRecord.addTuple(dPoint1);
+ tsRecord.addTuple(dPoint2);
+ tsRecord.addTuple(dPoint3);
+
+ // write TSRecord
+ tsFileWriter.write(tsRecord);
+
+ // close TsFile
+ tsFileWriter.close();
+ } catch (Throwable e) {
+ e.printStackTrace();
+ System.out.println(e.getMessage());
+ }
+ }
+}
+
+```
+
+如果所有时序数据都是**对齐**的,您可以通过构造**RowBatch**来写入数据。
+
+更详细的例子可以在`/example/tsfile/src/main/java/org/apache/iotdb/tsfile/TsFileWriteWithRowBatch.java`中查看
+
+```java
+package org.apache.iotdb.tsfile;
+
+import java.io.File;
+import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
+import org.apache.iotdb.tsfile.file.metadata.enums.TSEncoding;
+import org.apache.iotdb.tsfile.write.TsFileWriter;
+import org.apache.iotdb.tsfile.write.schema.Schema;
+import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
+import org.apache.iotdb.tsfile.write.record.RowBatch;
+/**
+ * An example of writing data with RowBatch to TsFile
+ */
+public class TsFileWriteWithRowBatch {
+
+ public static void main(String[] args) {
+ try {
+ String path = "test.tsfile";
+ File f = new File(path);
+ if (f.exists()) {
+ f.delete();
+ }
+
+ Schema schema = new Schema();
+
+ // the number of rows to include in the row batch
+ int rowNum = 1000000;
+ // the number of values to include in the row batch
+ int sensorNum = 10;
+
+ // add measurements into file schema (all with INT64 data type)
+ for (int i = 0; i < sensorNum; i++) {
+ schema.registerMeasurement(
+ new MeasurementSchema("sensor_" + (i + 1), TSDataType.INT64, TSEncoding.TS_2DIFF));
+ }
+
+ // add measurements into TSFileWriter
+ TsFileWriter tsFileWriter = new TsFileWriter(f, schema);
+
+ // construct the row batch
+ RowBatch rowBatch = schema.createRowBatch("device_1");
+
+ long[] timestamps = rowBatch.timestamps;
+ Object[] values = rowBatch.values;
+
+ long timestamp = 1;
+ long value = 1000000L;
+
+ for (int r = 0; r < rowNum; r++, value++) {
+ int row = rowBatch.batchSize++;
+ timestamps[row] = timestamp++;
+ for (int i = 0; i < sensorNum; i++) {
+ long[] sensor = (long[]) values[i];
+ sensor[row] = value;
+ }
+ // write RowBatch to TsFile
+ if (rowBatch.batchSize == rowBatch.getMaxBatchSize()) {
+ tsFileWriter.write(rowBatch);
+ rowBatch.reset();
+ }
+ }
+ // write RowBatch to TsFile
+ if (rowBatch.batchSize != 0) {
+ tsFileWriter.write(rowBatch);
+ rowBatch.reset();
+ }
+
+ // close TsFile
+ tsFileWriter.close();
+ } catch (Throwable e) {
+ e.printStackTrace();
+ System.out.println(e.getMessage());
+ }
+ }
+}
+
+```
+
+### 读取 TsFile 接口
+
+#### 开始之前
+
+"时序数据"章节中的数据集在本章节做具体的介绍。下表中显示的集合包含一个名为"device\_1"的 deltaObject,包含了 3 个名为"sensor\_1","sensor\_2"和"sensor\_3"的测量(measurement)。
+测量值被简化成一个简单的例子,每条数据只包含 4 条时间和值的对应数据。
+
+<center>
+<table style="text-align:center">
+ <tr><th colspan="6">device_1</th></tr>
+ <tr><th colspan="2">sensor_1</th><th colspan="2">sensor_2</th><th colspan="2">sensor_3</th></tr>
+ <tr><th>time</th><th>value</td><th>time</th><th>value</td><th>time</th><th>value</td>
+ <tr><td>1</td><td>1.2</td><td>1</td><td>20</td><td>2</td><td>50</td></tr>
+ <tr><td>3</td><td>1.4</td><td>2</td><td>20</td><td>4</td><td>51</td></tr>
+ <tr><td>5</td><td>1.1</td><td>3</td><td>21</td><td>6</td><td>52</td></tr>
+ <tr><td>7</td><td>1.8</td><td>4</td><td>20</td><td>8</td><td>53</td></tr>
+</table>
+<span>一组时间序列数据</span>
+</center>
+
+#### 路径的定义
+
+路径是一个点(.)分隔的字符串,它唯一地标识 TsFile 中的时间序列,例如:"root.area_1.device_1.sensor_1"。
+最后一部分"sensor_1"称为"measurementId",其余部分"root.area_1.device_1"称为deviceId。
+正如之前提到的,不同设备中的相同测量(measurement)具有相同的数据类型和编码,设备也是唯一的。
+
+在read接口中,参数```paths```表示要选择的测量值(measurement)。
+Path实例可以很容易地通过类```Path```来构造。例如:
+
+```
+Path p = new Path("device_1.sensor_1");
+```
+
+我们可以为查询传递一个 ArrayList 路径,以支持多个路径查询。
+
+```
+List<Path> paths = new ArrayList<Path>();
+paths.add(new Path("device_1.sensor_1"));
+paths.add(new Path("device_1.sensor_3"));
+```
+
+> **注意:** 在构造路径时,参数的格式应该是一个点(.)分隔的字符串,最后一部分是measurement,其余部分确认为deviceId。
+
+
+#### 定义 Filter
+
+##### 使用条件过滤
+在 TsFile 读取过程中使用 Filter 来选择满足一个或多个给定条件的数据。
+
+#### IExpression
+`IExpression`是一个过滤器表达式接口,它将被传递给系统查询时调用。
+我们创建一个或多个筛选器表达式,并且可以使用`Binary Filter Operators`将它们连接形成最终表达式。
+
+* **创建一个Filter表达式**
+
+ 有两种类型的过滤器。
+
+ * TimeFilter: 使用时序数据中的`time`过滤。
+ ```
+ IExpression timeFilterExpr = new GlobalTimeExpression(TimeFilter);
+ ```
+ 使用以下关系获得一个`TimeFilter`对象(值是一个 long 型变量)。
+ <center>
+ <table style="text-align:center">
+ <tr><th>Relationship</th><th>Description</td></tr>
+ <tr><td>TimeFilter.eq(value)</td><td>选择时间等于值的数据</td>
+ <tr><td>TimeFilter.lt(value)</td><td>选择时间小于值的数据</td>
+ <tr><td>TimeFilter.gt(value)</td><td>选择时间大于值的数据</td>
+ <tr><td>TimeFilter.ltEq(value)</td><td>选择时间小于等于值的数据</td>
+ <tr><td>TimeFilter.gtEq(value)</td><td>选择时间大于等于值的数据</td>
+ <tr><td>TimeFilter.notEq(value)</td><td>选择时间不等于值的数据</td>
+ <tr><td>TimeFilter.not(TimeFilter)</td><td>选择时间不满足另一个时间过滤器的数据</td>
+ </table>
+ </center>
+
+ * ValueFilter: 使用时序数据中的`value`过滤。
+
+ ```
+ IExpression valueFilterExpr = new SingleSeriesExpression(Path, ValueFilter);
+ ```
+ `ValueFilter`的用法与`TimeFilter`相同,只是需要确保值的类型等于measurement(在路径中定义)的类型。
+
+* **Binary Filter Operators**
+
+ Binary filter operators 可以用来连接两个单独的表达式。
+
+ * BinaryExpression.and(Expression, Expression): 选择同时满足两个表达式的数据。
+ * BinaryExpression.or(Expression, Expression): 选择满足任意一个表达式值的数据。
+
+
+##### Filter Expression 示例
+
+* **TimeFilterExpression 示例**
+
+ ```
+ IExpression timeFilterExpr = new GlobalTimeExpression(TimeFilter.eq(15)); // series time = 15
+
+ ```
+ ```
+ IExpression timeFilterExpr = new GlobalTimeExpression(TimeFilter.ltEq(15)); // series time <= 15
+
+ ```
+ ```
+ IExpression timeFilterExpr = new GlobalTimeExpression(TimeFilter.lt(15)); // series time < 15
+
+ ```
+ ```
+ IExpression timeFilterExpr = new GlobalTimeExpression(TimeFilter.gtEq(15)); // series time >= 15
+
+ ```
+ ```
+ IExpression timeFilterExpr = new GlobalTimeExpression(TimeFilter.notEq(15)); // series time != 15
+
+ ```
+ ```
+ IExpression timeFilterExpr = BinaryExpression.and(new GlobalTimeExpression(TimeFilter.gtEq(15L)),
+ new GlobalTimeExpression(TimeFilter.lt(25L))); // 15 <= series time < 25
+ ```
+ ```
+ IExpression timeFilterExpr = BinaryExpression.or(new GlobalTimeExpression(TimeFilter.gtEq(15L)),
+ new GlobalTimeExpression(TimeFilter.lt(25L))); // series time >= 15 or series time < 25
+ ```
+#### 读取接口
+
+首先,我们打开 TsFile 并从文件路径`path`中获取一个`ReadOnlyTsFile`实例。
+
+```
+TsFileSequenceReader reader = new TsFileSequenceReader(path);
+
+ReadOnlyTsFile readTsFile = new ReadOnlyTsFile(reader);
+```
+接下来,我们准备路径数组和查询表达式,然后通过这个接口得到最终的`QueryExpression`对象:
+
+```
+QueryExpression queryExpression = QueryExpression.create(paths, statement);
+```
+
+ReadOnlyTsFile类有两个`query`方法来执行查询。
+* **Method 1**
+
+ ```
+ public QueryDataSet query(QueryExpression queryExpression) throws IOException
+ ```
+
+* **Method 2**
+
+ ```
+ public QueryDataSet query(QueryExpression queryExpression, long partitionStartOffset, long partitionEndOffset) throws IOException
+ ```
+
+ 此方法是为高级应用(如 TsFile-Spark 连接器)设计的。
+
+ * **参数** : 对于 method 2,添加了两个额外的参数来支持部分查询(Partial Query):
+ * ```partitionStartOffset```: TsFile 的开始偏移量
+ * ```partitionEndOffset```: TsFile 的结束偏移量
+
+ > **什么是部分查询?**
+ >
+ > 在一些分布式文件系统中(比如:HDFS), 文件被分成几个部分,这些部分被称为"Blocks"并存储在不同的节点中。在涉及的每个节点上并行执行查询可以提高效率。因此需要部分查询(Partial Query)。部分查询(Partial Query)仅支持查询 TsFile 中被```QueryConstant.PARTITION_START_OFFSET```和```QueryConstant.PARTITION_END_OFFSET```分割的部分。
+
+### QueryDataset 接口
+
+上面执行的查询将返回一个`QueryDataset`对象。
+
+下面是一些用户常用的接口:
+
+
+* `bool hasNext();`
+
+ 如果该数据集仍然有数据,则返回true。
+* `List<Path> getPaths()`
+
+ 获取这个数据集中的路径。
+* `List<TSDataType> getDataTypes();`
+
+ 获取数据类型。TSDataType 是一个 enum 类,其值如下:
+
+ BOOLEAN,
+ INT32,
+ INT64,
+ FLOAT,
+ DOUBLE,
+ TEXT;
+ * `RowRecord next() throws IOException;`
+
+ 获取下一条记录。
+
+ `RowRecord`类包含一个`long`类型的时间戳和一个`List<Field>`,用于不同传感器中的数据,我们可以使用两个getter方法来获取它们。
+
+ ```
+ long getTimestamp();
+ List<Field> getFields();
+ ```
+
+ 要从一个字段获取数据,请使用以下方法:
+
+ ```
+ TSDataType getDataType();
+ Object getObjectValue();
+ ```
+
+#### 读取现有 TsFile 示例
+
+
+您需要安装 TsFile 到本地的 Maven 仓库中。
+
+有关查询语句的更详细示例,请参见
+`/tsfile/example/src/main/java/org/apache/iotdb/tsfile/TsFileRead.java`
+
+```java
+package org.apache.iotdb.tsfile;
+import java.io.IOException;
+import java.util.ArrayList;
+import org.apache.iotdb.tsfile.read.ReadOnlyTsFile;
+import org.apache.iotdb.tsfile.read.TsFileSequenceReader;
+import org.apache.iotdb.tsfile.read.common.Path;
+import org.apache.iotdb.tsfile.read.expression.IExpression;
+import org.apache.iotdb.tsfile.read.expression.QueryExpression;
+import org.apache.iotdb.tsfile.read.expression.impl.BinaryExpression;
+import org.apache.iotdb.tsfile.read.expression.impl.GlobalTimeExpression;
+import org.apache.iotdb.tsfile.read.expression.impl.SingleSeriesExpression;
+import org.apache.iotdb.tsfile.read.filter.TimeFilter;
+import org.apache.iotdb.tsfile.read.filter.ValueFilter;
+import org.apache.iotdb.tsfile.read.query.dataset.QueryDataSet;
+
+/**
+ * The class is to show how to read TsFile file named "test.tsfile".
+ * The TsFile file "test.tsfile" is generated from class TsFileWrite.
+ * Run TsFileWrite to generate the test.tsfile first
+ */
+public class TsFileRead {
+ private static void queryAndPrint(ArrayList<Path> paths, ReadOnlyTsFile readTsFile, IExpression statement)
+ throws IOException {
+ QueryExpression queryExpression = QueryExpression.create(paths, statement);
+ QueryDataSet queryDataSet = readTsFile.query(queryExpression);
+ while (queryDataSet.hasNext()) {
+ System.out.println(queryDataSet.next());
+ }
+ System.out.println("------------");
+ }
+
+ public static void main(String[] args) throws IOException {
+
+ // file path
+ String path = "test.tsfile";
+
+ // create reader and get the readTsFile interface
+ TsFileSequenceReader reader = new TsFileSequenceReader(path);
+ ReadOnlyTsFile readTsFile = new ReadOnlyTsFile(reader);
+ // use these paths(all sensors) for all the queries
+ ArrayList<Path> paths = new ArrayList<>();
+ paths.add(new Path("device_1.sensor_1"));
+ paths.add(new Path("device_1.sensor_2"));
+ paths.add(new Path("device_1.sensor_3"));
+
+ // no query statement
+ queryAndPrint(paths, readTsFile, null);
+
+ //close the reader when you left
+ reader.close();
+ }
+}
+
+```
+
+## 指定配置文件路径
+
+默认的配置文件`tsfile-format.properties.template`存放在`/tsfile/src/main/resources`目录下。如果您想使用自定义的路径:
+```
+System.setProperty(TsFileConstant.TSFILE_CONF, "your config file path");
+```
+然后调用:
+```
+TSFileConfig config = TSFileDescriptor.getInstance().getConfig();
+```
+
+## Bloom filter
+
+在加载元数据之前 Bloom filter 可以检查给定的时间序列是否在 TsFile 中。这可以优化加载元数据的性能,并跳过不包含指定时间序列的 TsFile。
+如果你想了解更多关于它的细节,你可以参考: [wiki page of bloom filter](https://en.wikipedia.org/wiki/Bloom_filter).
+
+#### 配置
+您可以通过`/server/src/assembly/resources/conf`目录下的`tsfile-format.properties`配置文件中的以下参数来控制bloom过滤器的误报率:
+```
+# The acceptable error rate of bloom filter, should be in [0.01, 0.1], default is 0.05
+bloom_filter_error_rate=0.05
+```
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/6-Status Codes.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/6-Status Codes.md
new file mode 100644
index 0000000..40d1e28
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/4-Client/6-Status Codes.md
@@ -0,0 +1,65 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# Chapter 4: Client
+# Status codes
+
+对于每个SQL请求,都会返回一个结果码;
+若SQL运行失败,客户端会收到错误码和一段错误消息。
+目前的结果码定义如下:
+
+ SUCCESS_STATUS(200),
+ STILL_EXECUTING_STATUS(201),
+ INVALID_HANDLE_STATUS(202),
+ TIMESERIES_ALREADY_EXIST_ERROR(300),
+ TIMESERIES_NOT_EXIST_ERROR(301),
+ UNSUPPORTED_FETCH_METADATA_OPERATION_ERROR(302),
+ METADATA_ERROR(303),
+ OUT_OF_TTL_ERROR(305),
+ CONFIG_ADJUSTER(306),
+ MERGE_ERROR(307),
+ SYSTEM_CHECK_ERROR(308),
+ SYNC_DEVICE_OWNER_CONFLICT_ERROR(309),
+ SYNC_CONNECTION_EXCEPTION(310),
+ STORAGE_GROUP_PROCESSOR_ERROR(311),
+ STORAGE_GROUP_ERROR(312),
+ STORAGE_ENGINE_ERROR(313),
+ EXECUTE_STATEMENT_ERROR(400),
+ SQL_PARSE_ERROR(401),
+ GENERATE_TIME_ZONE_ERROR(402),
+ SET_TIME_ZONE_ERROR(403),
+ NOT_STORAGE_GROUP_ERROR(404),
+ QUERY_NOT_ALLOWED(405),
+ AST_FORMAT_ERROR(406),
+ LOGICAL_OPERATOR_ERROR(407),
+ LOGICAL_OPTIMIZE_ERROR(408),
+ UNSUPPORTED_FILL_TYPE_ERROR(409),
+ PATH_ERROR(410),
+ INTERNAL_SERVER_ERROR(500),
+ CLOSE_OPERATION_ERROR(501),
+ READ_ONLY_SYSTEM_ERROR(502),
+ DISK_SPACE_INSUFFICIENT_ERROR(503),
+ START_UP_ERROR(504),
+ WRONG_LOGIN_PASSWORD_ERROR(600),
+ NOT_LOGIN_ERROR(601),
+ NO_PERMISSION_ERROR(602),
+ UNINITIALIZED_AUTH_ERROR(603),
+ INCOMPATIBLE_VERSION(203)
\ No newline at end of file
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/1-DDL (Data Definition Language).md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/1-DDL (Data Definition Language).md
new file mode 100644
index 0000000..b0e7eaa
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/1-DDL (Data Definition Language).md
@@ -0,0 +1,181 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第5章 IoTDB操作指南
+## DDL (数据定义语言)
+
+### 创建存储组
+
+我们可以根据存储模型建立相应的存储组。创建存储组的SQL语句如下所示:
+
+```
+IoTDB > set storage group to root.ln
+IoTDB > set storage group to root.sgcc
+```
+
+根据以上两条SQL语句,我们可以创建出两个存储组。
+
+需要注意的是,当系统中已经存在某个存储组或存储组的父亲节点或者孩子节点被设置为存储组的情况下,用户不可创建存储组。例如在已经有`root.ln`和`root.sgcc`这两个存储组的情况下,创建`root.ln.wf01`存储组是不可行的。系统将给出相应的错误提示,如下所示:
+
+```
+IoTDB> set storage group to root.ln.wf01
+Msg: org.apache.iotdb.exception.MetadataErrorException: org.apache.iotdb.exception.PathErrorException: The prefix of root.ln.wf01 has been set to the storage group.
+```
+
+### 查看存储组
+
+在存储组创建后,我们可以使用[SHOW STORAGE GROUP](/#/Documents/progress/chap5/sec4)语句来查看所有的存储组,SQL语句如下所示:
+
+```
+IoTDB> show storage group
+```
+
+执行结果为:
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577338-84c70600-1ef4-11e9-9dab-605b32c02836.jpg"></center>
+
+### 创建时间序列
+
+根据建立的数据模型,我们可以分别在两个存储组中创建相应的时间序列。创建时间序列的SQL语句如下所示:
+
+```
+IoTDB > create timeseries root.ln.wf01.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf01.wt01.temperature with datatype=FLOAT,encoding=RLE
+IoTDB > create timeseries root.ln.wf02.wt02.hardware with datatype=TEXT,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf02.wt02.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.temperature with datatype=FLOAT,encoding=RLE
+```
+
+需要注意的是,当创建时间序列时指定的编码方式与数据类型不对应时,系统会给出相应的错误提示,如下所示:
+```
+IoTDB> create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
+error: encoding TS_2DIFF does not support BOOLEAN
+```
+
+详细的数据类型与编码方式的对应列表请参见[编码方式](/#/Documents/progress/chap2/sec3)。
+
+### 查看时间序列
+
+目前,IoTDB支持两种查看时间序列的方式:
+
+* SHOW TIMESERIES语句以JSON形式展示系统中所有的时间序列信息
+
+* SHOW TIMESERIES <`Path`>语句以表格的形式返回给定路径的下的所有时间序列信息及时间序列总数。时间序列信息具体包括:时间序列路径名,数据类型,编码类型。其中,`Path`需要为一个前缀路径、带星路径或时间序列路径。例如,分别查看`root`路径和`root.ln`路径下的时间序列,SQL语句如下所示:
+
+```
+IoTDB> show timeseries root
+IoTDB> show timeseries root.ln
+```
+
+执行结果分别为:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577347-8db7d780-1ef4-11e9-91d6-764e58c10e94.jpg"></center>
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577359-97413f80-1ef4-11e9-8c10-53b291fc10a5.jpg"></center>
+
+需要注意的是,当查询路径不存在时,系统会返回0条时间序列。
+
+### 统计时间序列总数
+
+IoTDB支持使用`COUNT TIMESERIES<Path>`来统计一条路径中的时间序列个数。SQL语句如下所示:
+```
+IoTDB > COUNT TIMESERIES root
+IoTDB > COUNT TIMESERIES root.ln
+IoTDB > COUNT TIMESERIES root.ln.*.*.status
+IoTDB > COUNT TIMESERIES root.ln.wf01.wt01.status
+```
+
+除此之外,还可以通过定义`LEVEL`来统计指定层级下的时间序列个数。这条语句可以用来统计每一个设备下的传感器数量,语法为:`COUNT TIMESERIES <Path> GROUP BY LEVEL=<INTEGER>`。
+
+例如有如下时间序列(可以使用`show timeseries`展示所有时间序列):
+
+<center><img style="width:100%; max-width:800px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/69792072-cdc8a480-1200-11ea-8cec-321fef618a12.png"></center>
+
+那么Metadata Tree如下所示:
+
+<center><img style="width:100%; max-width:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/69792176-1718f400-1201-11ea-861a-1a83c07ca144.jpg"></center>
+
+可以看到,`root`被定义为`LEVEL=0`。那么当你输入如下语句时:
+
+```
+IoTDB > COUNT TIMESERIES root GROUP BY LEVEL=1
+IoTDB > COUNT TIMESERIES root.ln GROUP BY LEVEL=2
+IoTDB > COUNT TIMESERIES root.ln.wf01 GROUP BY LEVEL=2
+```
+
+你将得到以下结果:
+<center><img style="width:100%; max-width:800px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/69792071-cb664a80-1200-11ea-8386-02dd12046c4b.png"></center>
+
+> 注意:时间序列的路径只是过滤条件,与level的定义无关。
+
+### 统计节点数
+IoTDB支持使用`COUNT NODES <Path> LEVEL=<INTEGER>`来统计当前Metadata树下指定层级的节点个数,这条语句可以用来统计设备数。例如:
+
+```
+IoTDB > COUNT NODES root LEVEL=2
+IoTDB > COUNT NODES root.ln LEVEL=2
+IoTDB > COUNT NODES root.ln.wf01 LEVEL=3
+```
+
+对于上面提到的例子和Metadata Tree,你可以获得如下结果:
+<center><img style="width:100%; max-width:800px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/69792060-c73a2d00-1200-11ea-8ec4-be7145fd6c8c.png"></center>
+
+> 注意:时间序列的路径只是过滤条件,与level的定义无关。
+
+### 删除时间序列
+我们可以使用`DELETE TimeSeries <PrefixPath>`语句来删除我们之前创建的时间序列。SQL语句如下所示:
+```
+IoTDB> delete timeseries root.ln.wf01.wt01.status
+IoTDB> delete timeseries root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware
+IoTDB> delete timeseries root.ln.wf02.*
+```
+
+### 查看设备
+
+与 `Show Timeseries` 相似,IoTDB 目前也支持两种方式查看设备。
+* `SHOW DEVICES` 语句显示当前所有的设备信息,等价于 `SHOW DEVICES root`。
+* `SHOW DEVICES <PrefixPath>` 语句规定了 `PrefixPath`,返回在给定的前缀路径下的设备信息。
+
+SQL语句如下所示:
+```
+IoTDB> show devices
+IoTDB> show devices root.ln
+```
+
+## TTL
+IoTDB支持对存储组级别设置数据存活时间(TTL),这使得IoTDB可以定期、自动地删除一定时间之前的数据。合理使用TTL
+可以帮助您控制IoTDB占用的总磁盘空间以避免出现磁盘写满等异常。并且,随着文件数量的增多,查询性能往往随之下降,
+内存占用也会有所提高。及时地删除一些较老的文件有助于使查询性能维持在一个较高的水平和减少内存资源的占用。
+
+### 设置 TTL
+设置TTL的SQL语句如下所示:
+```
+IoTDB> set ttl to root.ln 3600000
+```
+这个例子表示在`root.ln`存储组中,只有最近一个小时的数据将会保存,旧数据会被移除或不可见。
+
+### 取消 TTL
+取消TTL的SQL语句如下所示:
+```
+IoTDB> unset ttl to root.ln
+```
+取消设置TTL后,存储组`root.ln`中所有的数据都会被保存。
+
+
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/2-DML (Data Manipulation Language).md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/2-DML (Data Manipulation Language).md
new file mode 100644
index 0000000..6b1afd6
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/2-DML (Data Manipulation Language).md
@@ -0,0 +1,726 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第5章 IoTDB操作指南
+
+## DML (数据操作语言)
+
+## 数据接入
+
+IoTDB为用户提供多种插入实时数据的方式,例如在[Cli/Shell工具](/#/Documents/progress/chap4/sec1)中直接输入插入数据的INSERT语句,或使用Java API(标准[Java JDBC](/#/Documents/progress/chap4/sec2)接口)单条或批量执行插入数据的INSERT语句。
+
+本节主要为您介绍实时数据接入的INSERT语句在场景中的实际使用示例,有关INSERT SQL语句的详细语法请参见本文[INSERT语句](/#/Documents/progress/chap5/sec4)节。
+
+### 使用INSERT语句
+
+使用INSERT语句可以向指定的已经创建的一条或多条时间序列中插入数据。对于每一条数据,均由一个时间戳类型的时间戳和一个数值或布尔值、字符串类型的传感器采集值组成。
+
+在本节的场景实例下,以其中的两个时间序列`root.ln.wf02.wt02.status`和`root.ln.wf02.wt02.hardware`为例 ,它们的数据类型分别为BOOLEAN和TEXT。
+
+单列数据插入示例代码如下:
+
+```
+IoTDB > insert into root.ln.wf02.wt02(timestamp,status) values(1,true)
+IoTDB > insert into root.ln.wf02.wt02(timestamp,hardware) values(1, "v1")
+```
+
+以上示例代码将长整型的timestamp以及值为true的数据插入到时间序列`root.ln.wf02.wt02.status`中和将长整型的timestamp以及值为”v1”的数据插入到时间序列`root.ln.wf02.wt02.hardware`中。执行成功后会返回执行时间,代表数据插入已完成。
+
+> 注意:在IoTDB中,TEXT类型的数据单双引号都可以来表示,上面的插入语句是用的是双引号表示TEXT类型数据,下面的示例将使用单引号表示TEXT类型数据。
+
+INSERT语句还可以支持在同一个时间点下多列数据的插入,同时向2时间点插入上述两个时间序列的值,多列数据插入示例代码如下:
+
+```
+IoTDB > insert into root.ln.wf02.wt02(timestamp, status, hardware) VALUES (2, false, 'v2')
+```
+
+插入数据后我们可以使用SELECT语句简单查询已插入的数据。
+
+```
+IoTDB > select * from root.ln.wf02 where time < 3
+```
+
+结果如图所示。由查询结果可以看出,单列、多列数据的插入操作正确执行。
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51605021-c2ee1500-1f48-11e9-8f6b-ba9b48875a41.png"></center>
+
+### INSERT语句的错误处理
+
+若用户向一个不存在的时间序列中插入数据,例如执行以下命令:
+
+```
+IoTDB > insert into root.ln.wf02.wt02(timestamp, temperature) values(1,"v1")
+```
+
+由于`root.ln.wf02.wt02. temperature`时间序列不存在,系统将会返回以下ERROR告知该Timeseries路径不存在:
+
+```
+Msg: The resultDataType or encoding or compression of the last node temperature is conflicting in the storage group root.ln
+```
+
+若用户插入的数据类型与该Timeseries对应的数据类型不一致,例如执行以下命令:
+
+```
+IoTDB > insert into root.ln.wf02.wt02(timestamp,hardware) values(1,100)
+```
+
+系统将会返回以下ERROR告知数据类型有误:
+
+```
+error: The TEXT data type should be covered by " or '
+```
+
+## 数据查询
+
+### 时间切片查询
+
+本节主要介绍时间切片查询的相关示例,主要使用的是[IoTDB SELECT语句](/#/Documents/progress/chap5/sec4)。同时,您也可以使用[Java JDBC](/#/Documents/progress/chap4/sec2)标准接口来执行相关的查询语句。
+
+#### 根据一个时间区间选择一列数据
+
+SQL语句为:
+
+```
+select temperature from root.ln.wf01.wt01 where time < 2017-11-01T00:08:00.000
+```
+
+其含义为:
+
+被选择的设备为ln集团wf01子站wt01设备;被选择的时间序列为温度传感器(temperature);该语句要求选择出该设备在“2017-11-01T00:08:00.000”(此处可以使用多种时间格式,详情可参看[2.1节](/#/Documents/progress/chap2/sec1))时间点以前的所有温度传感器的值。
+
+该SQL语句的执行结果如下:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/23614968/61280074-da1c0a00-a7e9-11e9-8eb8-3809428043a8.png"></center>
+
+#### 根据一个时间区间选择多列数据
+
+SQL语句为:
+
+```
+select status, temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;
+```
+
+其含义为:
+
+被选择的设备为ln集团wf01子站wt01设备;被选择的时间序列为供电状态(status)和温度传感器(temperature);该语句要求选择出“2017-11-01T00:05:00.000”至“2017-11-01T00:12:00.000”之间的所选时间序列的值。
+
+该SQL语句的执行结果如下:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/23614968/61280328-40a12800-a7ea-11e9-85b9-3b8db67673a3.png"></center>
+
+#### 按照多个时间区间选择同一设备的多列数据
+
+IoTDB支持在一次查询中指定多个时间区间条件,用户可以根据需求随意组合时间区间条件。例如,
+
+SQL语句为:
+
+```
+select status,temperature from root.ln.wf01.wt01 where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);
+```
+
+其含义为:
+
+被选择的设备为ln集团wf01子站wt01设备;被选择的时间序列为“供电状态(status)”和“温度传感器(temperature)”;该语句指定了两个不同的时间区间,分别为“2017-11-01T00:05:00.000至2017-11-01T00:12:00.000”和“2017-11-01T16:35:00.000至2017-11-01T16:37:00.000”;该语句要求选择出满足任一时间区间的被选时间序列的值。
+
+该SQL语句的执行结果如下:
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/23614968/61280449-780fd480-a7ea-11e9-8ed0-70fa9dfda80f.png"></center>
+
+
+#### 按照多个时间区间选择不同设备的多列数据
+
+该系统支持在一次查询中选择任意列的数据,也就是说,被选择的列可以来源于不同的设备。例如,SQL语句为:
+
+```
+select wf01.wt01.status,wf02.wt02.hardware from root.ln where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);
+```
+
+其含义为:
+
+被选择的时间序列为“ln集团wf01子站wt01设备的供电状态”以及“ln集团wf02子站wt02设备的硬件版本”;该语句指定了两个时间区间,分别为“2017-11-01T00:05:00.000至2017-11-01T00:12:00.000”和“2017-11-01T16:35:00.000至2017-11-01T16:37:00.000”;该语句要求选择出满足任意时间区间的被选时间序列的值。
+
+该SQL语句的执行结果如下:
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577450-dcfe0800-1ef4-11e9-9399-4ba2b2b7fb73.jpg"></center>
+
+#### 其他结果返回形式
+
+IoTDB支持另外两种结果返回形式: 按设备时间对齐 'align by device' 和 时序不对齐 'disable align'.
+
+'align by device' 对齐方式下,设备ID会单独作为一列出现。在 select 子句中写了多少列,最终结果就会有该列数+2 (时间列和设备名字列)。SQL形如:
+
+```
+select s1,s2 from root.sg1.* GROUP BY DEVICE
+```
+
+更多语法请参照 SQL REFERENCE.
+
+'disable align' 意味着每条时序就有3列存在。更多语法请参照 SQL REFERENCE.
+
+
+### 降频聚合查询
+
+本章节主要介绍降频聚合查询的相关示例,
+主要使用的是IoTDB SELECT语句的[GROUP BY子句](/#/Documents/progress/chap5/sec4),
+该子句是IoTDB中用于根据用户给定划分条件对结果集进行划分,并对已划分的结果集进行聚合计算的语句。
+IoTDB支持根据时间间隔和自定义的滑动步长(默认值与时间间隔相同,自定义的值必须大于等于时间间隔)对结果集进行划分,默认结果按照时间升序排列。
+同时,您也可以使用Java JDBC标准接口来执行相关的查询语句。
+
+Group By 语句不支持 limit 和 offset。
+
+GROUP BY语句为用户提供三类指定参数:
+
+* 参数1:时间轴显示时间窗参数
+* 参数2:划分时间轴的时间间隔参数(必须为正数)
+* 参数3:滑动步长(可选参数,默认值与时间间隔相同,自定义的值必须大于等于时间间隔)
+
+三类参数的实际含义已经在图5.2中指出,这三类参数里,第三个参数是可选的。
+接下来,我们将给出三种典型的降频聚合查询的例子:
+滑动步长未指定,
+指定滑动步长,
+带值过滤条件。
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/16079446/69109512-f808bc80-0ab2-11ea-9e4d-b2b2f58fb474.png">
+
+**图 5.2 三类参数的实际含义**</center>
+
+#### 未指定滑动步长的降频聚合查询
+
+对应的SQL语句是:
+
+```
+select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00],1d);
+```
+这条查询的含义是:
+
+由于用户没有指定滑动步长,滑动步长将会被默认设置为跟时间间隔参数相同,也就是`1d`。
+
+上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是[2017-11-01T00:00:00, 2017-11-07T23:00:00]。
+
+上面这个例子的第二个参数是划分时间轴的时间间隔参数,将`1d`当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[0,1d), [1d, 2d), [2d, 3d)等等。
+
+然后系统将会用WHERE子句中的时间和值过滤条件以及GROUP BY语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在[2017-11-01T00:00:00, 2017-11-07 T23:00:00]这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从2017-11-01T00:00:00到2017-11-07T23:00:00:00的每一天)
+
+每个时间间隔窗口内都有数据,SQL执行后的结果集如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/16079446/69116068-eed51b00-0ac5-11ea-9731-b5a45c5cd224.png"></center>
+
+#### 指定滑动步长的降频聚合查询
+
+对应的SQL语句是:
+
+```
+select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00], 3h, 1d);
+```
+
+这条查询的含义是:
+
+由于用户指定了滑动步长为`1d`,GROUP BY语句执行时将会每次把时间间隔往后移动一天的步长,而不是默认的3小时。
+
+也就意味着,我们想要取从2017-11-01到2017-11-07每一天的凌晨0点到凌晨3点的数据。
+
+上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是[2017-11-01T00:00:00, 2017-11-07T23:00:00]。
+
+上面这个例子的第二个参数是划分时间轴的时间间隔参数,将`3h`当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[2017-11-01T00:00:00, 2017-11-01T03:00:00), [2017-11-02T00:00:00, 2017-11-02T03:00:00), [2017-11-03T00:00:00, 2017-11-03T03:00:00)等等。
+
+上面这个例子的第三个参数是每次时间间隔的滑动步长。
+
+然后系统将会用WHERE子句中的时间和值过滤条件以及GROUP BY语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在[2017-11-01T00:00:00, 2017-11-07 T23:00:00]这个时间范围的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从2017-11-01T00:00:00到2017-11-07T23:00:00:00的每一天的凌晨0点到凌晨3点)
+
+每个时间间隔窗口内都有数据,SQL执行后的结果集如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/16079446/69116083-f85e8300-0ac5-11ea-84f1-59d934eee96e.png"></center>
+
+#### 带值过滤条件的降频聚合查询
+
+对应的SQL语句是:
+
+```
+select count(status), max_value(temperature) from root.ln.wf01.wt01 where time > 2017-11-01T01:00:00 and temperature > 20 group by([2017-11-01T00:00:00, 2017-11-07T23:00:00], 3h, 1d);
+```
+
+这条查询的含义是:
+
+由于用户指定了滑动步长为`1d`,GROUP BY语句执行时将会每次把时间间隔往后移动一天的步长,而不是默认的3小时。
+
+也就意味着,我们想要取从2017-11-01到2017-11-07每一天的凌晨0点到凌晨3点的数据。
+
+上面这个例子的第一个参数是显示窗口参数,决定了最终的显示范围是[2017-11-01T00:00:00, 2017-11-07T23:00:00]。
+
+上面这个例子的第二个参数是划分时间轴的时间间隔参数,将`3h`当作划分间隔,显示窗口参数的起始时间当作分割原点,时间轴即被划分为连续的时间间隔:[2017-11-01T00:00:00, 2017-11-01T03:00:00), [2017-11-02T00:00:00, 2017-11-02T03:00:00), [2017-11-03T00:00:00, 2017-11-03T03:00:00)等等。
+
+上面这个例子的第三个参数是每次时间间隔的滑动步长。
+
+然后系统将会用WHERE子句中的时间和值过滤条件以及GROUP BY语句中的第一个参数作为数据的联合过滤条件,获得满足所有过滤条件的数据(在这个例子里是在[2017-11-01T00:00:00, 2017-11-07 T23:00:00]这个时间范围的并且满足root.ln.wf01.wt01.temperature > 20的数据),并把这些数据映射到之前分割好的时间轴中(这个例子里是从2017-11-01T00:00:00到2017-11-07T23:00:00:00的每一天的凌晨0点到凌晨3点)
+
+每个时间间隔窗口内都有数据,SQL执行后的结果集如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/16079446/69116088-001e2780-0ac6-11ea-9a01-dc45271d1dad.png"></center>
+
+GROUP BY的SELECT子句里的查询路径必须是聚合函数,否则系统将会抛出如下对应的错误。
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/16079446/69116099-0b715300-0ac6-11ea-8074-84e04797b8c7.png"></center>
+
+### 最近时间戳数据查询
+
+对应的SQL语句是:
+
+```
+select last <Path> [COMMA <Path>]* from < PrefixPath > [COMMA < PrefixPath >]* <DISABLE ALIGN>
+```
+其含义是:
+
+查询时间序列prefixPath.path中最近时间戳的数据
+
+下面的例子中查询时间序列root.ln.wf01.wt01.status最近时间戳的数据:
+```
+select last status from root.ln.wf01.wt01 disable align
+```
+结果集为以下的形式返回:
+```
+| Time | Path | Value |
+| --- | ----------------------- | ----- |
+| 5 | root.ln.wf01.wt01.status| 100 |
+```
+
+假设root.ln.wf01.wt01中包含多列数据,如id, status, temperature,下面的例子将会把这几列数据在最近时间戳的记录同时返回:
+```
+select last id, status, temperature from root.ln.wf01 disable align
+
+| Time | Path | Value |
+| --- | ---------------------------- | ----- |
+| 5 | root.ln.wf01.wt01.id | 10 |
+| 7 | root.ln.wf01.wt01.status | true |
+| 9 | root.ln.wf01.wt01.temperature| 35.7 |
+```
+
+### 自动填充
+
+在IoTDB的实际使用中,当进行时间序列的查询操作时,可能会出现在某些时间点值为null的情况,这会妨碍用户进行进一步的分析。 为了更好地反映数据更改的程度,用户希望可以自动填充缺失值。 因此,IoTDB系统引入了自动填充功能。
+
+自动填充功能是指对单列或多列执行时间序列查询时,根据用户指定的方法和有效时间范围填充空值。 如果查询点的值不为null,则填充功能将不起作用。
+
+> 注意:在当前版本中,IoTDB为用户提供两种方法:Previous 和Linear。 Previous 方法用前一个值填充空白。 Linear方法通过线性拟合来填充空白。 并且填充功能只能在执行时间点查询时使用。
+
+#### 填充功能
+
+- Previous功能
+
+当查询的时间戳值为空时,将使用前一个时间戳的值来填充空白。 形式化的先前方法如下(有关详细语法,请参见第7.1.3.6节):
+
+```
+select <path> from <prefixPath> where time = <T> fill(<data_type>[previous, <before_range>], …)
+```
+
+表3-4给出了所有参数的详细说明。
+
+<center>**表3-4previous填充参数列表**
+
+| 参数名称(不区分大小写) | 解释 |
+| :----------------------- | :----------------------------------------------------------- |
+| path, prefixPath | 查询路径; 必填项 |
+| T | 查询时间戳(只能指定一个); 必填项 |
+| data\_type | 填充方法使用的数据类型。 可选值是int32,int64,float,double,boolean,text; 可选字段 |
+| before\_range | 表示前一种方法的有效时间范围。 当[T-before \ _range,T]范围内的值存在时,前一种方法将起作用。 如果未指定before_range,则before_range会使用默认值default_fill_interval; -1表示无穷大; 可选字段 |
+
+</center>
+
+在这里,我们举一个使用先前方法填充空值的示例。 SQL语句如下:
+
+```
+select temperature from root.sgcc.wf03.wt01 where time = 2017-11-01T16:37:50.000 fill(float[previous, 1m])
+```
+
+意思是:
+
+由于时间根目录root.sgcc.wf03.wt01.temperature在2017-11-01T16:37:50.000为空,因此系统使用以前的时间戳2017-11-01T16:37:00.000(且时间戳位于[2017-11-01T16:36:50.000, 2017-11-01T16:37:50.000]范围)进行填充和显示。
+
+在[样例数据中](https://raw.githubusercontent.com/apache/incubator-iotdb/master/docs/Documentation/OtherMaterial-Sample%20Data.txt), 该语句的执行结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577616-67df0280-1ef5-11e9-9dff-2eb8342074eb.jpg"></center>
+
+值得注意的是,如果在指定的有效时间范围内没有值,系统将不会填充空值,如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577679-9f4daf00-1ef5-11e9-8d8b-06a58de6efc1.jpg"></center>
+
+- Linear方法
+
+当查询的时间戳值为空时,将使用前一个和下一个时间戳的值来填充空白。 形式化线性方法如下:
+
+```
+select <path> from <prefixPath> where time = <T> fill(<data_type>[linear, <before_range>, <after_range>]…)
+```
+
+表3-5中给出了所有参数的详细说明。
+
+<center>**表3-5线性填充参数列表**
+
+| 参数名称(不区分大小写) | 解释 |
+| :-------------------------- | :----------------------------------------------------------- |
+| path, prefixPath | 查询路径; 必填项 |
+| T | 查询时间戳(只能指定一个); 必填项 |
+| data_type | 填充方法使用的数据类型。 可选值是int32,int64,float,double,boolean,text; 可选字段 |
+| before\_range, after\_range | 表示线性方法的有效时间范围。 当[T-before_range,T + after_range]范围内的值存在时,前一种方法将起作用。 如果未明确指定before_range和after_range,则使用default\_fill\_interval。 -1表示无穷大; 可选字段 |
+
+</center>
+
+在这里,我们举一个使用线性方法填充空值的示例。 SQL语句如下:
+
+```
+select temperature from root.sgcc.wf03.wt01 where time = 2017-11-01T16:37:50.000 fill(float [linear, 1m, 1m])
+```
+
+意思是:
+
+由于时间根目录root.sgcc.wf03.wt01.temperature在2017-11-01T16:37:50.000为空,因此系统使用以前的时间戳2017-11-01T16:37:00.000(且时间戳位于[2017- 11-01T16:36:50.000,2017-11-01T16:37:50.000]时间范围)及其值21.927326,下一个时间戳记2017-11-01T16:38:00.000(且时间戳记位于[2017-11-11] 01T16:37:50.000、2017-11-01T16:38:50.000]时间范围)及其值25.311783以执行线性拟合计算:
+
+21.927326 +(25.311783-21.927326)/ 60s * 50s = 24.747707
+
+在 [样例数据](https://raw.githubusercontent.com/apache/incubator-iotdb/master/docs/Documentation/OtherMaterial-Sample%20Data.txt), 该语句的执行结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577727-d4f29800-1ef5-11e9-8ff3-3bb519da3993.jpg"></center>
+
+#### 数据类型和填充方法之间的对应关系
+
+数据类型和支持的填充方法如表3-6所示。
+
+<center>**表3-6数据类型和支持的填充方法**
+
+| 数据类型 | 支持的填充方法 |
+| :------- | :--------------- |
+| boolean | previous |
+| int32 | previous, linear |
+| int64 | previous, linear |
+| float | previous, linear |
+| double | previous, linear |
+| text | previous |
+
+</center>
+
+值得注意的是,IoTDB将针对数据类型不支持的填充方法给出错误提示,如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577741-e340b400-1ef5-11e9-9238-a4eaf498ab84.jpg"></center>
+
+如果未指定fill方法,则每种数据类型均具有其自己的默认fill方法和参数。 对应关系如表3-7所示。
+
+<center>**表3-7各种数据类型的默认填充方法和参数**
+
+| 数据类型 | 默认填充方法和参数 |
+| :------- | :--------------------- |
+| boolean | previous, 600000 |
+| int32 | linear, 600000, 600000 |
+| int64 | linear, 600000, 600000 |
+| float | linear, 600000, 600000 |
+| double | linear, 600000, 600000 |
+| text | previous, 600000 |
+
+</center>
+
+> 注意:在版本0.7.0中,应在Fill语句中至少指定一种填充方法。
+
+### 对查询结果的行和列控制
+
+IoTDB提供 [LIMIT/SLIMIT](/#/Documents/progress/chap5/sec4) 子句和 [OFFSET/SOFFSET](/#/Documents/progress/chap5/sec4) 子句,以使用户可以更好地控制查询结果。使用LIMIT和SLIMIT子句可让用户控制查询结果的行数和列数,
+并且使用OFFSET和SOFSET子句允许用户设置结果显示的起始位置。
+
+请注意,按组查询不支持LIMIT和OFFSET。
+
+本章主要介绍查询结果的行和列控制的相关示例。你还可以使用 [Java JDBC](/#/Documents/progress/chap4/sec2) 标准接口执行查询。
+
+#### 查询结果的行控制
+
+通过使用LIMIT和OFFSET子句,用户可以以与行相关的方式控制查询结果。 我们将通过以下示例演示如何使用LIMIT和OFFSET子句。
+
+- 示例1:基本的LIMIT子句
+
+SQL语句是:
+
+```
+select status, temperature from root.ln.wf01.wt01 limit 10
+```
+
+意思是:
+
+所选设备为ln组wf01工厂wt01设备; 选择的时间序列是“状态”和“温度”。 SQL语句要求返回查询结果的前10行。
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577752-efc50c80-1ef5-11e9-9071-da2bbd8b9bdd.jpg"></center>
+
+- 示例2:带OFFSET的LIMIT子句
+
+SQL语句是:
+
+```
+select status, temperature from root.ln.wf01.wt01 limit 5 offset 3
+```
+
+意思是:
+
+所选设备为ln组wf01工厂wt01设备; 选择的时间序列是“状态”和“温度”。 SQL语句要求返回查询结果的第3至7行(第一行编号为0行)。
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577773-08352700-1ef6-11e9-883f-8d353bef2bdc.jpg"></center>
+
+- 示例3:LIMIT子句与WHERE子句结合
+
+SQL语句是:
+
+```
+select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time< 2017-11-01T00:12:00.000 limit 2 offset 3
+```
+
+意思是:
+
+所选设备为ln组wf01工厂wt01设备; 选择的时间序列是“状态”和“温度”。 SQL语句要求返回时间“ 2017-11-01T00:05:00.000”和“ 2017-11-01T00:12:00.000”之间的状态和温度传感器值的第3至4行(第一行) 编号为第0行)。
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577789-15521600-1ef6-11e9-86ca-d7b2c947367f.jpg"></center>
+
+- 示例4:LIMIT子句与GROUP BY子句组合
+
+SQL语句是:
+
+```
+select count(status), max_value(temperature) from root.ln.wf01.wt01 group by (1d,[2017-11-01T00:00:00, 2017-11-07T23:00:00]) limit 5 offset 3
+```
+
+意思是:
+
+SQL语句子句要求返回查询结果的第3至7行(第一行编号为0行)。
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577796-1e42e780-1ef6-11e9-8987-be443000a77e.jpg"></center>
+
+值得注意的是,由于当前的FILL子句只能在某个时间点填充时间序列的缺失值,也就是说,FILL子句的执行结果恰好是一行,因此LIMIT和OFFSET不会是 与FILL子句结合使用,否则将提示错误。 例如,执行以下SQL语句:
+
+```
+select temperature from root.sgcc.wf03.wt01 where time = 2017-11-01T16:37:50.000 fill(float[previous, 1m]) limit 10
+```
+
+SQL语句将不会执行,并且相应的错误提示如下:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/61517266-6e2fe080-aa39-11e9-8015-154a8e8ace30.png"></center>
+
+#### 查询结果的列控制
+
+通过使用LIMIT和OFFSET子句,用户可以以与列相关的方式控制查询结果。 我们将通过以下示例演示如何使用SLIMIT和OFFSET子句。
+
+- 示例1:基本的SLIMIT子句
+
+SQL语句是:
+
+```
+select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1
+```
+
+意思是:
+
+所选设备为ln组wf01工厂wt01设备; 所选时间序列是该设备下的第一列,即电源状态。 SQL语句要求在“ 2017-11-01T00:05:00.000”和“ 2017-11-01T00:12:00.000”的时间点之间选择状态传感器值。
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577813-30bd2100-1ef6-11e9-94ef-dbeb450cf319.jpg"></center>
+
+- 示例2:带OFFSET的LIMIT子句
+
+SQL语句是:
+
+```
+select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1 soffset 1
+```
+
+意思是:
+
+所选设备为ln组wf01工厂wt01设备; 所选时间序列是该设备下的第二列,即温度。 SQL语句要求在“ 2017-11-01T00:05:00.000”和“ 2017-11-01T00:12:00.000”的时间点之间选择温度传感器值。
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577827-39adf280-1ef6-11e9-81b5-876769607cd2.jpg"></center>
+
+- 示例3:SLIMIT子句与GROUP BY子句结合
+
+SQL语句是:
+
+```
+select max_value(*) from root.ln.wf01.wt01 group by (1d, [2017-11-01T00:00:00, 2017-11-07T23:00:00]) slimit 1 soffset 1
+
+```
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577840-44688780-1ef6-11e9-8abc-04ae78efa85b.jpg"></center>
+
+- 示例4:SLIMIT子句与FILL子句结合
+
+SQL语句是:
+
+```
+select * from root.sgcc.wf03.wt01 where time = 2017-11-01T16:37:50.000 fill(float[previous, 1m]) slimit 1 soffset 1
+
+```
+
+意思是:
+
+所选设备为ln组wf01工厂wt01设备; 所选时间序列是该设备下的第二列,即温度。
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577855-4d595900-1ef6-11e9-8541-a4accd714b75.jpg"></center>
+
+值得注意的是,预期SLIMIT子句将与星形路径或前缀路径一起使用,并且当SLIMIT子句与完整路径查询一起使用时,系统将提示错误。 例如,执行以下SQL语句:
+
+```
+select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1
+
+```
+
+SQL语句将不会执行,并且相应的错误提示如下:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577867-577b5780-1ef6-11e9-978c-e02c1294bcc5.jpg"></center>
+
+#### Row and Column Control over Query Results
+
+除了对查询结果进行行或列控制之外,IoTDB还允许用户控制查询结果的行和列。 这是同时包含LIMIT子句和SLIMIT子句的完整示例。
+
+SQL语句是:
+
+```
+select * from root.ln.wf01.wt01 limit 10 offset 100 slimit 2 soffset 0
+
+```
+
+意思是:
+
+所选设备为ln组wf01工厂wt01设备; 所选时间序列是此设备下的第0列至第1列(第一列编号为第0列)。 SQL语句子句要求返回查询结果的第100至109行(第一行编号为0行)。
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51577879-64984680-1ef6-11e9-9d7b-57dd60fab60e.jpg"></center>
+
+#### 其他结果集格式
+
+此外,IoTDB支持两种其他结果集格式:“按设备对齐”和“禁用对齐”。
+
+“按设备对齐”指示将deviceId视为一列。 因此,数据集中的列完全有限。
+
+SQL语句是:
+
+```
+select s1,s2 from root.sg1.* GROUP BY DEVICE
+
+```
+
+有关更多语法描述,请阅读SQL REFERENCE。
+
+“禁用对齐”指示结果集中每个时间序列都有3列。 有关更多语法描述,请阅读SQL REFERENCE。
+
+#### 错误处理
+
+当LIMIT / SLIMIT的参数N / SN超过结果集的大小时,IoTDB将按预期返回所有结果。 例如,原始SQL语句的查询结果由六行组成,我们通过LIMIT子句选择前100行:
+
+```
+select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 limit 100
+
+```
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51578187-ad9cca80-1ef7-11e9-897a-83e66a0f3d94.jpg"></center>
+
+当LIMIT / SLIMIT子句的参数N / SN超过允许的最大值(N / SN的类型为int32)时,系统将提示错误。 例如,执行以下SQL语句:
+
+```
+select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 limit 1234567890123456789
+
+```
+
+SQL语句将不会执行,并且相应的错误提示如下:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/61517469-e696a180-aa39-11e9-8ca5-42ea991d520e.png"></center>
+
+当LIMIT / LIMIT子句的参数N / SN不是正整数时,系统将提示错误。 例如,执行以下SQL语句:
+
+```
+select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 limit 13.1
+
+```
+
+SQL语句将不会执行,并且相应的错误提示如下:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/19167280/61518094-68d39580-aa3b-11e9-993c-fc73c27540f7.png"></center>
+
+当LIMIT子句的参数OFFSET超过结果集的大小时,IoTDB将返回空结果集。 例如,执行以下SQL语句:
+
+```
+select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 limit 2 offset 6
+
+```
+
+结果如下所示:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51578227-c60ce500-1ef7-11e9-98eb-175beb8d4086.jpg"></center>
+
+当SLIMIT子句的参数SOFFSET不小于可用时间序列数时,系统将提示错误。 例如,执行以下SQL语句:
+
+```
+select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1 soffset 2
+
+```
+
+SQL语句将不会执行,并且相应的错误提示如下:
+
+### 数据删除
+
+用户使用[DELETE语句](/#/Documents/progress/chap5/sec4)可以删除指定的时间序列中符合时间删除条件的数据。在删除数据时,用户可以选择需要删除的一个或多个时间序列、时间序列的前缀、时间序列带\*路径对某时间之前的数据进行删除(当前版本暂不支持删除某一闭时间区间范围内的数据)。
+
+在JAVA编程环境中,您可以使用JDBC API单条或批量执行DELETE语句。
+
+#### 单传感器时间序列值删除
+
+以测控ln集团为例,存在这样的使用场景:
+
+wf02子站的wt02设备在2017-11-01 16:26:00之前的供电状态出现多段错误,且无法分析其正确数据,错误数据影响了与其他设备的关联分析。此时,需要将此时间段前的数据删除。进行此操作的SQL语句为:
+
+```
+delete from root.ln.wf02.wt02.status where time<=2017-11-01T16:26:00;
+```
+
+#### 多传感器时间序列值删除
+
+当ln集团wf02子站的wt02设备在2017-11-01 16:26:00之前的供电状态和设备硬件版本都需要删除,此时可以使用含义更广的[前缀路径或带`*`路径](/#/Documents/progress/chap2/sec1)进行删除操作,进行此操作的SQL语句为:
+
+```
+delete from root.ln.wf02.wt02 where time <= 2017-11-01T16:26:00;
+```
+
+或
+
+```
+delete from root.ln.wf02.wt02.* where time <= 2017-11-01T16:26:00;
+```
+
+需要注意的是,当删除的路径不存在时,IoTDB会提示路径不存在,无法删除数据,如下所示。
+
+```
+IoTDB> delete from root.ln.wf03.wt02.status where time < now()
+Msg: TimeSeries does not exist and its data cannot be deleted
+```
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/3-Account Management Statements.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/3-Account Management Statements.md
new file mode 100644
index 0000000..03833c9
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/3-Account Management Statements.md
@@ -0,0 +1,134 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第5章 IoTDB操作指南
+
+## 账户管理语句
+
+IoTDB为用户提供了权限管理操作,从而为用户提供对于数据的权限管理功能,保障数据的安全。
+
+我们将通过以下几个具体的例子为您示范基本的用户权限操作,详细的SQL语句及使用方式详情请参见本文[第5.4节](/#/Documents/progress/chap5/sec4)。同时,在JAVA编程环境中,您可以使用[JDBC API](/#/Documents/progress/chap4/sec2)单条或批量执行权限管理类语句。
+
+### 基本概念
+#### 用户
+
+用户即数据库的合法使用者。一个用户与一个唯一的用户名相对应,并且拥有密码作为身份验证的手段。一个人在使用数据库之前,必须先提供合法的(即存于数据库中的)用户名与密码,使得自己成为用户。
+
+#### 权限
+
+数据库提供多种操作,并不是所有的用户都能执行所有操作。如果一个用户可以执行某项操作,则称该用户有执行该操作的权限。权限可分为数据管理权限(如对数据进行增删改查)以及权限管理权限(用户、角色的创建与删除,权限的赋予与撤销等)。数据管理权限往往需要一个路径来限定其生效范围,它的生效范围是以该路径对应的节点为根的一颗子树(具体请参考IoTDB的数据组织)。
+
+#### 角色
+
+角色是若干权限的集合,并且有一个唯一的角色名作为标识符。用户通常和一个现实身份相对应(例如交通调度员),而一个现实身份可能对应着多个用户。这些具有相同现实身份的用户往往具有相同的一些权限。角色就是为了能对这样的权限进行统一的管理的抽象。
+
+#### 默认用户及其具有的角色
+
+初始安装后的IoTDB中有一个默认用户:root,默认密码为root。该用户为管理员用户,固定拥有所有权限,无法被赋予、撤销权限,也无法被删除。
+
+### 权限操作示例
+
+根据本文中描述的[样例数据](/#/Documents/progress/chap5/sec1)内容,IoTDB的样例数据可能同时属于ln, sgcc等不同发电集团,不同的发电集团不希望其他发电集团获取自己的数据库数据,因此我们需要将不同的数据在集团层进行权限隔离。
+
+#### 创建用户
+
+我们可以为ln和sgcc集团创建两个用户角色,名为ln_write_user, sgcc_write_user,密码均为write_pwd。SQL语句为:
+
+```
+CREATE USER ln_write_user 'write_pwd'
+CREATE USER sgcc_write_user 'write_pwd'
+```
+此时使用展示用户的SQL语句:
+
+```
+LIST USER
+```
+我们可以看到这两个已经被创建的用户,结果如图:
+
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51578263-e2a91d00-1ef7-11e9-94e8-28819b6fea87.jpg"></center>
+
+#### 赋予用户权限
+
+此时,虽然两个用户已经创建,但是他们不具有任何权限,因此他们并不能对数据库进行操作,例如我们使用ln_write_user用户对数据库中的数据进行写入,SQL语句为:
+
+```
+INSERT INTO root.ln.wf01.wt01(timestamp,status) values(1509465600000,true)
+```
+此时,系统不允许用户进行此操作,会提示错误,如图:
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51597609-9af5b600-1f36-11e9-9460-8ab185eb4735.png"></center>
+
+现在,我们分别赋予他们向对应存储组数据的写入权限,并再次尝试向对应的存储组进行数据写入。SQL语句为:
+```
+GRANT USER ln_write_user PRIVILEGES 'INSERT_TIMESERIES' on root.ln
+GRANT USER sgcc_write_user PRIVILEGES 'INSERT_TIMESERIES' on root.sgcc
+INSERT INTO root.ln.wf01.wt01(timestamp, status) values(1509465600000, true)
+```
+执行状态如图所示:
+<center><img style="width:100%; max-width:800px; max-height:600px; margin-left:auto; margin-right:auto; display:block;" src="https://user-images.githubusercontent.com/13203019/51578942-33ba1080-1efa-11e9-891c-09d69791aff1.jpg"></center>
+
+### 其他说明
+#### 用户、权限与角色的关系
+
+角色是权限的集合,而权限和角色都是用户的一种属性。即一个角色可以拥有若干权限。一个用户可以拥有若干角色与权限(称为用户自身权限)。
+
+目前在IoTDB中并不存在相互冲突的权限,因此一个用户真正具有的权限是用户自身权限与其所有的角色的权限的并集。即要判定用户是否能执行某一项操作,就要看用户自身权限或用户的角色的所有权限中是否有一条允许了该操作。用户自身权限与其角色权限,他的多个角色的权限之间可能存在相同的权限,但这并不会产生影响。
+
+需要注意的是:如果一个用户自身有某种权限(对应操作A),而他的某个角色有相同的权限。那么如果仅从该用户撤销该权限无法达到禁止该用户执行操作A的目的,还需要从这个角色中也撤销对应的权限,或者从这个用户将该角色撤销。同样,如果仅从上述角色将权限撤销,也不能禁止该用户执行操作A。
+
+同时,对角色的修改会立即反映到所有拥有该角色的用户上,例如对角色增加某种权限将立即使所有拥有该角色的用户都拥有对应权限,删除某种权限也将使对应用户失去该权限(除非用户本身有该权限)。
+
+#### 系统所含权限列表
+
+<center>**系统所含权限列表**
+
+|权限名称|说明|
+|:---|:---|
+|SET\_STORAGE\_GROUP|创建时间序列。包含设置存储组的权限。路径相关|
+|INSERT\_TIMESERIES|插入数据。路径相关|
+|UPDATE\_TIMESERIES|更新数据。路径相关|
+|READ\_TIMESERIES|查询数据。路径相关|
+|DELETE\_TIMESERIES|删除数据或时间序列。路径相关|
+|CREATE\_USER|创建用户。路径无关|
+|DELETE\_USER|删除用户。路径无关|
+|MODIFY\_PASSWORD|修改所有用户的密码。路径无关。(没有该权限者仍然能够修改自己的密码。)|
+|LIST\_USER|列出所有用户,列出某用户权限,列出某用户具有的角色三种操作的权限。路径无关|
+|GRANT\_USER\_PRIVILEGE|赋予用户权限。路径无关|
+|REVOKE\_USER\_PRIVILEGE|撤销用户权限。路径无关|
+|GRANT\_USER\_ROLE|赋予用户角色。路径无关|
+|REVOKE\_USER\_ROLE|撤销用户角色。路径无关|
+|CREATE\_ROLE|创建角色。路径无关|
+|DELETE\_ROLE|删除角色。路径无关|
+|LIST\_ROLE|列出所有角色,列出某角色拥有的权限,列出拥有某角色的所有用户三种操作的权限。路径无关|
+|GRANT\_ROLE\_PRIVILEGE|grant role priviledges; path independent|
+|REVOKE\_ROLE\_PRIVILEGE|撤销角色权限。路径无关|
+</center>
+
+#### 用户名限制
+
+IoTDB规定用户名的字符长度不小于4,其中用户名不能包含空格。
+
+#### 密码限制
+
+IoTDB规定密码的字符长度不小于4,其中密码不能包含空格,密码采用MD5进行加密。
+
+#### 角色名限制
+
+IoTDB规定角色名的字符长度不小于4,其中角色名不能包含空格。
diff --git a/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/4-SQL Reference.md b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/4-SQL Reference.md
new file mode 100644
index 0000000..240c35f
--- /dev/null
+++ b/incubator-iotdb/master/docs/Documentation-CHN/UserGuide/5-Operation Manual/4-SQL Reference.md
@@ -0,0 +1,885 @@
+<!--
+
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
+
+# 第5章 IoTDB操作指南
+## SQL 参考文档
+
+### 显示版本号
+
+```sql
+show version
+```
+
+```
++---------------+
+| version|
++---------------+
+|0.10.0-SNAPSHOT|
++---------------+
+Total line number = 1
+It costs 0.417s
+```
+
+### Schema语句
+
+* 设置存储组
+
+``` SQL
+SET STORAGE GROUP TO <FullPath>
+Eg: IoTDB > SET STORAGE GROUP TO root.ln.wf01.wt01
+Note: FullPath can not include `*`
+```
+* 删除存储组
+
+```
+DELETE STORAGE GROUP <FullPath> [COMMA <FullPath>]*
+Eg: IoTDB > DELETE STORAGE GROUP root.ln.wf01.wt01
+Eg: IoTDB > DELETE STORAGE GROUP root.ln.wf01.wt01, root.ln.wf01.wt02
+Note: FullPath can not include `*`
+```
+
+* 创建时间序列语句
+
+```
+CREATE TIMESERIES <FullPath> WITH <AttributeClauses>
+AttributeClauses : DATATYPE=<DataTypeValue> COMMA ENCODING=<EncodingValue> [COMMA <ExtraAttributeClause>]*
+DataTypeValue: BOOLEAN | DOUBLE | FLOAT | INT32 | INT64 | TEXT
+EncodingValue: GORILLA | PLAIN | RLE | TS_2DIFF | REGULAR
+ExtraAttributeClause: {
+ COMPRESSOR | COMPRESSION = <CompressorValue>
+ MAX_POINT_NUMBER = Integer
+}
+CompressorValue: UNCOMPRESSED | SNAPPY
+Eg: IoTDB > CREATE TIMESERIES root.ln.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN
+Eg: IoTDB > CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE
+Eg: IoTDB > CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE, COMPRESSOR=SNAPPY, MAX_POINT_NUMBER=3
+Note: Datatype and encoding type must be corresponding. Please check Chapter 3 Encoding Section for details.
+```
+
+* 删除时间序列语句
+
+```
+DELETE TIMESERIES <PrefixPath> [COMMA <PrefixPath>]*
+Eg: IoTDB > DELETE TIMESERIES root.ln.wf01.wt01.status
+Eg: IoTDB > DELETE TIMESERIES root.ln.wf01.wt01.status, root.ln.wf01.wt01.temperature
+Eg: IoTDB > DELETE TIMESERIES root.ln.wf01.wt01.*
+```
+
+* 显示所有时间序列语句
+
+```
+SHOW TIMESERIES
+Eg: IoTDB > SHOW TIMESERIES
+Note: This statement can only be used in IoTDB Client. If you need to show all timeseries in JDBC, please use `DataBaseMetadata` interface.
+```
+
+* 显示特定时间序列语句
+
+```
+SHOW TIMESERIES <Path>
+Eg: IoTDB > SHOW TIMESERIES root
+Eg: IoTDB > SHOW TIMESERIES root.ln
+Eg: IoTDB > SHOW TIMESERIES root.ln.*.*.status
+Eg: IoTDB > SHOW TIMESERIES root.ln.wf01.wt01.status
+Note: The path can be prefix path, star path or timeseries path
+Note: This statement can be used in IoTDB Client and JDBC.
+```
+
+* 显示存储组语句
+
+```
+SHOW STORAGE GROUP
+Eg: IoTDB > SHOW STORAGE GROUP
+Note: This statement can be used in IoTDB Client and JDBC.
+```
+
+* 显示指定路径下时间序列数语句
+
+```
+COUNT TIMESERIES <Path>
+Eg: IoTDB > COUNT TIMESERIES root
+Eg: IoTDB > COUNT TIMESERIES root.ln
+Eg: IoTDB > COUNT TIMESERIES root.ln.*.*.status
+Eg: IoTDB > COUNT TIMESERIES root.ln.wf01.wt01.status
+Note: The path can be prefix path, star path or timeseries path.
+Note: This statement can be used in IoTDB Client and JDBC.
+```
+
+```
+COUNT TIMESERIES <Path> GROUP BY LEVEL=<INTEGER>
+Eg: IoTDB > COUNT TIMESERIES root GROUP BY LEVEL=1
+Eg: IoTDB > COUNT TIMESERIES root.ln GROUP BY LEVEL=2
+Eg: IoTDB > COUNT TIMESERIES root.ln.wf01 GROUP BY LEVEL=3
+Note: The path can be prefix path or timeseries path.
+Note: This statement can be used in IoTDB Client and JDBC.
+```
+
+* 显示指定路径下特定层级的节点数语句
+
+```
+COUNT NODES <Path> LEVEL=<INTEGER>
+Eg: IoTDB > COUNT NODES root LEVEL=2
+Eg: IoTDB > COUNT NODES root.ln LEVEL=2
+Eg: IoTDB > COUNT NODES root.ln.wf01 LEVEL=3
+Note: The path can be prefix path or timeseries path.
+Note: This statement can be used in IoTDB Client and JDBC.
+```
+
+* 显示所有设备语句
+
+```
+SHOW DEVICES
+Eg: IoTDB > SHOW DEVICES
+Note: This statement can be used in IoTDB Client and JDBC.
+```
+
+* 显示特定设备语句
+
+```
+SHOW DEVICES <PrefixPath>
+Eg: IoTDB > SHOW DEVICES root
+Eg: IoTDB > SHOW DEVICES root.ln
+Eg: IoTDB > SHOW DEVICES root.*.wf01
+Note: The path can be prefix path or star path.
+Note: This statement can be used in IoTDB Client and JDBC.
+```
+
+* 显示ROOT节点的子节点名称语句
+
+```
+SHOW CHILD PATHS
+Eg: IoTDB > SHOW CHILD PATHS
+Note: This statement can be used in IoTDB Client and JDBC.
+```
+
+* 显示子节点名称语句
+
+```
+SHOW CHILD PATHS <Path>
+Eg: IoTDB > SHOW CHILD PATHS root
+Eg: IoTDB > SHOW CHILD PATHS root.ln
+Eg: IoTDB > SHOW CHILD PATHS root.*.wf01
+Eg: IoTDB > SHOW CHILD PATHS root.ln.wf*
+Note: The path can be prefix path or star path, the nodes can be in a "prefix + star" format.
+Note: This statement can be used in IoTDB Client and JDBC.
+```
+### 数据管理语句
+
+* 插入记录语句
+
+```
+INSERT INTO <PrefixPath> LPAREN TIMESTAMP COMMA <Sensor> [COMMA <Sensor>]* RPAREN VALUES LPAREN <TimeValue>, <PointValue> [COMMA <PointValue>]* RPAREN
+Sensor : Identifier
+Eg: IoTDB > INSERT INTO root.ln.wf01.wt01(timestamp,status) values(1509465600000,true)
+Eg: IoTDB > INSERT INTO root.ln.wf01.wt01(timestamp,status) VALUES(NOW(), false)
+Eg: IoTDB > INSERT INTO root.ln.wf01.wt01(timestamp,temperature) VALUES(2017-11-01T00:17:00.000+08:00,24.22028)
+Eg: IoTDB > INSERT INTO root.ln.wf01.wt01(timestamp, status, temperature) VALUES (1509466680000, false, 20.060787);
+Note: the statement needs to satisfy this constraint: <PrefixPath> + <Path> = <Timeseries>
+Note: The order of Sensor and PointValue need one-to-one correspondence
+```
+
+* 更新记录语句
+
+```
+UPDATE <UpdateClause> SET <SetClause> WHERE <WhereClause>
+UpdateClause: <prefixPath>
+SetClause: <SetExpression>
+SetExpression: <Path> EQUAL <PointValue>
+WhereClause : <Condition> [(AND | OR) <Condition>]*
+Condition : <Expression> [(AND | OR) <Expression>]*
+Expression : [NOT | !]? TIME PrecedenceEqualOperator <TimeValue>
+Eg: IoTDB > UPDATE root.ln.wf01.wt01 SET temperature = 23 WHERE time < NOW() and time > 2017-11-1T00:15:00+08:00
+Note: the statement needs to satisfy this constraint: <PrefixPath> + <Path> = <Timeseries>
+```
+
+* 删除记录语句
+
+```
+DELETE FROM <PrefixPath> [COMMA <PrefixPath>]* WHERE TIME LESSTHAN <TimeValue>
+Eg: DELETE FROM root.ln.wf01.wt01.temperature WHERE time < 2017-11-1T00:05:00+08:00
+Eg: DELETE FROM root.ln.wf01.wt01.status, root.ln.wf01.wt01.temperature WHERE time < NOW()
+Eg: DELETE FROM root.ln.wf01.wt01.* WHERE time < 1509466140000
+```
+
+* 选择记录语句
+
+```
+SELECT <SelectClause> FROM <FromClause> [WHERE <WhereClause>]?
+SelectClause : <SelectPath> (COMMA <SelectPath>)*
+SelectPath : <FUNCTION> LPAREN <Path> RPAREN | <Path>
+FUNCTION : ‘COUNT’ , ‘MIN_TIME’, ‘MAX_TIME’, ‘MIN_VALUE’, ‘MAX_VALUE’
+FromClause : <PrefixPath> (COMMA <PrefixPath>)?
+WhereClause : <Condition> [(AND | OR) <Condition>]*
+Condition : <Expression> [(AND | OR) <Expression>]*
+Expression : [NOT | !]? <TimeExpr> | [NOT | !]? <SensorExpr>
+TimeExpr : TIME PrecedenceEqualOperator (<TimeValue> | <RelativeTime>)
+RelativeTimeDurationUnit = Integer ('Y'|'MO'|'W'|'D'|'H'|'M'|'S'|'MS'|'US'|'NS')
+RelativeTime : (now() | <TimeValue>) [(+|-) RelativeTimeDurationUnit]+
+SensorExpr : (<Timeseries> | <Path>) PrecedenceEqualOperator <PointValue>
+Eg: IoTDB > SELECT status, temperature FROM root.ln.wf01.wt01 WHERE temperature < 24 and time > 2017-11-1 0:13:00
+Eg. IoTDB > SELECT * FROM root
+Eg. IoTDB > SELECT * FROM root where time > now() - 5m
+Eg. IoTDB > SELECT * FROM root.ln.*.wf*
+Eg. IoTDB > SELECT COUNT(temperature) FROM root.ln.wf01.wt01 WHERE root.ln.wf01.wt01.temperature < 25
+Eg. IoTDB > SELECT MIN_TIME(temperature) FROM root.ln.wf01.wt01 WHERE root.ln.wf01.wt01.temperature < 25
+Eg. IoTDB > SELECT MAX_TIME(temperature) FROM root.ln.wf01.wt01 WHERE root.ln.wf01.wt01.temperature > 24
+Eg. IoTDB > SELECT MIN_VALUE(temperature) FROM root.ln.wf01.wt01 WHERE root.ln.wf01.wt01.temperature > 23
+Eg. IoTDB > SELECT MAX_VALUE(temperature) FROM root.ln.wf01.wt01 WHERE root.ln.wf01.wt01.temperature < 25
+Note: the statement needs to satisfy this constraint: <Path>(SelectClause) + <PrefixPath>(FromClause) = <Timeseries>
+Note: If the <SensorExpr>(WhereClause) is started with <Path> and not with ROOT, the statement needs to satisfy this constraint: <PrefixPath>(FromClause) + <Path>(SensorExpr) = <Timeseries>
+Note: In Version 0.7.0, if <WhereClause> includes `OR`, time filter can not be used.
+Note: There must be a space on both sides of the plus and minus operator appearing in the time expression
+```
+
+* Group By 语句
+
+```
+SELECT <SelectClause> FROM <FromClause> WHERE <WhereClause> GROUP BY <GroupByClause>
+SelectClause : <Function> [COMMA < Function >]*
+Function : <AggregationFunction> LPAREN <Path> RPAREN
+FromClause : <PrefixPath>
+WhereClause : <Condition> [(AND | OR) <Condition>]*
+Condition : <Expression> [(AND | OR) <Expression>]*
+Expression : [NOT | !]? <TimeExpr> | [NOT | !]? <SensorExpr>
+TimeExpr : TIME PrecedenceEqualOperator (<TimeValue> | <RelativeTime>)
+RelativeTimeDurationUnit = Integer ('Y'|'MO'|'W'|'D'|'H'|'M'|'S'|'MS'|'US'|'NS')
+RelativeTime : (now() | <TimeValue>) [(+|-) RelativeTimeDurationUnit]+
+SensorExpr : (<Timeseries> | <Path>) PrecedenceEqualOperator <PointValue>
+GroupByClause : LPAREN <TimeInterval> COMMA <TimeUnit> (COMMA <TimeUnit>)? RPAREN
+TimeInterval: LBRACKET <TimeValue> COMMA <TimeValue> RBRACKET
+TimeUnit : Integer <DurationUnit>
+DurationUnit : "ms" | "s" | "m" | "h" | "d" | "w"
+Eg: SELECT COUNT(status), COUNT(temperature) FROM root.ln.wf01.wt01 where temperature < 24 GROUP BY([1509465720000, 1509466380000], 5m)
+Eg. SELECT COUNT (status), MAX_VALUE(temperature) FROM root.ln.wf01.wt01 WHERE time < 1509466500000 GROUP BY([1509465720000, 1509466380000], 5m, 10m)
+Eg. SELECT MIN_TIME(status), MIN_VALUE(temperature) FROM root.ln.wf01.wt01 WHERE temperature < 25 GROUP BY ([1509466140000, 1509466380000], 3m, 5ms)
+Note: the statement needs to satisfy this constraint: <Path>(SelectClause) + <PrefixPath>(FromClause) = <Timeseries>
+Note: If the <SensorExpr>(WhereClause) is started with <Path> and not with ROOT, the statement needs to satisfy this constraint: <PrefixPath>(FromClause) + <Path>(SensorExpr) = <Timeseries>
+Note: <TimeValue>(TimeInterval) needs to be greater than 0
+Note: First <TimeValue>(TimeInterval) in needs to be smaller than second <TimeValue>(TimeInterval)
+Note: <TimeUnit> needs to be greater than 0
+Note: Third <TimeUnit> if set shouldn't be smaller than second <TimeUnit>
+```
+
+* Fill 语句
+
+```
+SELECT <SelectClause> FROM <FromClause> WHERE <WhereClause> FILL <FillClause>
+SelectClause : <Path> [COMMA <Path>]*
+FromClause : < PrefixPath > [COMMA < PrefixPath >]*
+WhereClause : <WhereExpression>
+WhereExpression : TIME EQUAL <TimeValue>
+FillClause : LPAREN <TypeClause> [COMMA <TypeClause>]* RPAREN
+TypeClause : <Int32Clause> | <Int64Clause> | <FloatClause> | <DoubleClause> | <BoolClause> | <TextClause>
+Int32Clause: INT32 LBRACKET (<LinearClause> | <PreviousClause>) RBRACKET
+Int64Clause: INT64 LBRACKET (<LinearClause> | <PreviousClause>) RBRACKET
+FloatClause: FLOAT LBRACKET (<LinearClause> | <PreviousClause>) RBRACKET
+DoubleClause: DOUBLE LBRACKET (<LinearClause> | <PreviousClause>) RBRACKET
+BoolClause: BOOLEAN LBRACKET (<LinearClause> | <PreviousClause>) RBRACKET
+TextClause: TEXT LBRACKET (<LinearClause> | <PreviousClause>) RBRACKET
+PreviousClause : PREVIOUS [COMMA <ValidPreviousTime>]?
+LinearClause : LINEAR [COMMA <ValidPreviousTime> COMMA <ValidBehindTime>]?
+ValidPreviousTime, ValidBehindTime: <TimeUnit>
+TimeUnit : Integer <DurationUnit>
+DurationUnit : "ms" | "s" | "m" | "h" | "d" | "w"
+Eg: SELECT temperature FROM root.ln.wf01.wt01 WHERE time = 2017-11-01T16:37:50.000 FILL(float[previous, 1m])
+Eg: SELECT temperature,status FROM root.ln.wf01.wt01 WHERE time = 2017-11-01T16:37:50.000 FILL (float[linear, 1m, 1m], boolean[previous, 1m])
+Eg: SELECT temperature,status,hardware FROM root.ln.wf01.wt01 WHERE time = 2017-11-01T16:37:50.000 FILL (float[linear, 1m, 1m], boolean[previous, 1m], text[previous])
+Eg: SELECT temperature,status,hardware FROM root.ln.wf01.wt01 WHERE time = 2017-11-01T16:37:50.000 FILL (float[linear], boolean[previous, 1m], text[previous])
+Note: the statement needs to satisfy this constraint: <PrefixPath>(FromClause) + <Path>(SelectClause) = <Timeseries>
+Note: Integer in <TimeUnit> needs to be greater than 0
+```
+
+* Limit & SLimit 语句
+
+```
+SELECT <SelectClause> FROM <FromClause> [WHERE <WhereClause>] [<LIMITClause>] [<SLIMITClause>]
+SelectClause : [<Path> | Function]+
+Function : <AggregationFunction> LPAREN <Path> RPAREN
+FromClause : <Path>
+WhereClause : <Condition> [(AND | OR) <Condition>]*
+Condition : <Expression> [(AND | OR) <Expression>]*
+Expression: [NOT|!]?<TimeExpr> | [NOT|!]?<SensorExpr>
+TimeExpr : TIME PrecedenceEqualOperator (<TimeValue> | <RelativeTime>)
+RelativeTimeDurationUnit = Integer ('Y'|'MO'|'W'|'D'|'H'|'M'|'S'|'MS'|'US'|'NS')
+RelativeTime : (now() | <TimeValue>) [(+|-) RelativeTimeDurationUnit]+
+SensorExpr : (<Timeseries>|<Path>) PrecedenceEqualOperator <PointValue>
+LIMITClause : LIMIT <N> [OFFSETClause]?
+N : Integer
+OFFSETClause : OFFSET <OFFSETValue>
+OFFSETValue : Integer
+SLIMITClause : SLIMIT <SN> [SOFFSETClause]?
+SN : Integer
+SOFFSETClause : SOFFSET <SOFFSETValue>
+SOFFSETValue : Integer
+Eg: IoTDB > SELECT status, temperature FROM root.ln.wf01.wt01 WHERE temperature < 24 and time > 2017-11-1 0:13:00 LIMIT 3 OFFSET 2
+Eg. IoTDB > SELECT COUNT (status), MAX_VALUE(temperature) FROM root.ln.wf01.wt01 WHERE time < 1509466500000 GROUP BY([1509465720000, 1509466380000], 5m) LIMIT 3
+Note: N, OFFSETValue, SN and SOFFSETValue must be greater than 0.
+Note: The order of <LIMITClause> and <SLIMITClause> does not affect the grammatical correctness.
+Note: <FillClause> can not use <LIMITClause> but not <SLIMITClause>.
+```
+
+* Align by device语句
+
+```
+AlignbyDeviceClause : ALIGN BY DEVICE
+
+规则:
+1. 大小写不敏感.
+正例: select * from root.sg1 align by device
+正例: select * from root.sg1 ALIGN BY DEVICE
+
+2. AlignbyDeviceClause 只能放在末尾.
+正例: select * from root.sg1 where time > 10 align by device
+错例: select * from root.sg1 align by device where time > 10
+
+3. Select子句中的path只能是单层,或者通配符,不允许有path分隔符"."。
+正例: select s0,s1 from root.sg1.* align by device
+正例: select s0,s1 from root.sg1.d0, root.sg1.d1 align by device
+正例: select * from root.sg1.* align by device
+正例: select * from root align by device
+正例: select s0,s1,* from root.*.* align by device
+错例: select d0.s1, d0.s2, d1.s0 from root.sg1 align by device
+错例: select *.s0, *.s1 from root.* align by device
+错例: select *.*.* from root align by device
+
+4.相同measurement的各设备的数据类型必须都相同,
+
+正例: select s0 from root.sg1.d0,root.sg1.d1 align by device
+root.sg1.d0.s0 and root.sg1.d1.s0 are both INT32.
+
+正例: select count(s0) from root.sg1.d0,root.sg1.d1 align by device
+count(root.sg1.d0.s0) and count(root.sg1.d1.s0) are both INT64.
+
+错例: select s0 from root.sg1.d0, root.sg2.d3 align by device
+root.sg1.d0.s0 is INT32 while root.sg2.d3.s0 is FLOAT.
+
+5. 结果集的展示规则:对于select中给出的列,不论是否有数据(是否被注册),均会被显示。此外,select子句中还支持常数列(例如,'a', '123'等等)。
+例如, "select s0,s1,s2,'abc',s1,s2 from root.sg.d0, root.sg.d1, root.sg.d2 align by device". 假设只有下述三列有数据:
+- root.sg.d0.s0
+- root.sg.d0.s1
+- root.sg.d1.s0
+
+结果集形如:
+
+| Time | Device | s0 | s1 | s2 | 'abc' | s1 | s2 |
+| --- | --- | ---| ---| null | 'abc' | ---| null |
+| 1 |root.sg.d0| 20 | 2.5| null | 'abc' | 2.5| null |
+| 2 |root.sg.d0| 23 | 3.1| null | 'abc' | 3.1| null |
+| ... | ... | ...| ...| null | 'abc' | ...| null |
+| 1 |root.sg.d1| 12 |null| null | 'abc' |null| null |
+| 2 |root.sg.d1| 19 |null| null | 'abc' |null| null |
+| ... | ... | ...| ...| null | 'abc' | ...| null |
+
+注意注意 设备'root.sg.d1'的's0'的值全为null
+
+6. 在From中重复写设备名字或者设备前缀是没有任何作用的。
+例如, "select s0,s1 from root.sg.d0,root.sg.d0,root.sg.d1 align by device" 等于 "select s0,s1 from root.sg.d0,root.sg.d1 align by device".
+例如. "select s0,s1 from root.sg.*,root.sg.d0 align by device" 等于 "select s0,s1 from root.sg.* align by device".
+
+7. 在Select子句中重复写列名是生效的。例如, "select s0,s0,s1 from root.sg.* align by device" 不等于 "select s0,s1 from root.sg.* align by device".
+
+8. 更多正例:
+ - select * from root.vehicle align by device
+ - select s0,s0,s1 from root.vehicle.* align by device
+ - select s0,s1 from root.vehicle.* limit 10 offset 1 align by device
+ - select * from root.vehicle slimit 10 soffset 2 align by device
+ - select * from root.vehicle where time > 10 align by device
+ - select * from root.vehicle where root.vehicle.d0.s0>0 align by device
+ - select count(*) from root.vehicle align by device
+ - select sum(*) from root.vehicle GROUP BY (20ms,0,[2,50]) align by device
+ - select * from root.vehicle where time = 3 Fill(int32[previous, 5ms]) align by device
+```
+
+* Disable align 语句
+
+```
+规则:
+1. 大小写均可.
+正例: select * from root.sg1 disable align
+正例: select * from root.sg1 DISABLE ALIGN
+
+2. Disable Align只能用于查询语句句尾.
+正例: select * from root.sg1 where time > 10 disable align
+错例: select * from root.sg1 disable align where time > 10
+
+3. Disable Align 不能用于聚合查询、Fill语句、Group by或Group by device语句,但可用于Limit语句。
+正例: select * from root.sg1 limit 3 offset 2 disable align
+正例: select * from root.sg1 slimit 3 soffset 2 disable align
+错例: select count(s0),count(s1) from root.sg1.d1 disable align
+错例: select * from root.vehicle where root.vehicle.d0.s0>0 disable align
+错例: select * from root.vehicle align by device disable align
+
... 271871 lines suppressed ...