You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by "JnaneshwarikTR (via GitHub)" <gi...@apache.org> on 2023/02/09 12:50:18 UTC
[GitHub] [hudi] JnaneshwarikTR opened a new issue, #7910: [SUPPORT]
JnaneshwarikTR opened a new issue, #7910:
URL: https://github.com/apache/hudi/issues/7910
Hi,
* Hudi version :0.11.1
* Spark version :3.2.1
* Hive version : NA
* Hadoop version : NA
* Storage (HDFS/S3/GCS..) :S3
* Running on Docker? (yes/no) : no
We have spark streaming application running with batch interval of 5 min. We added below configs to avoid small file creation.
HoodieCompactionConfig.PARQUET_SMALL_FILE_LIMIT.key() -> String.valueOf(104857600)
HoodieStorageConfig.PARQUET_MAX_FILE_SIZE.key() -> String.valueOf(125829120)
However when i run my application i see my parquet file are created with lesser than the mentioned small file limit.
here is the complete hudi config we are using in application.
HoodieCompactionConfig.PARQUET_SMALL_FILE_LIMIT.key() -> String.valueOf(104857600),
HoodieStorageConfig.PARQUET_MAX_FILE_SIZE.key() -> String.valueOf(125829120),
HoodieCompactionConfig.INLINE_COMPACT_TRIGGER_STRATEGY.key() -> CompactionTriggerStrategy.TIME_ELAPSED.name,
HoodieCompactionConfig.INLINE_COMPACT_TIME_DELTA_SECONDS.key() -> String.valueOf(60 * 60),
HoodieCompactionConfig.CLEANER_POLICY.key() -> HoodieCleaningPolicy.KEEP_LATEST_COMMITS.name(),
HoodieCompactionConfig.CLEANER_COMMITS_RETAINED.key() -> "936",
HoodieCompactionConfig.MIN_COMMITS_TO_KEEP.key() -> "937",
HoodieCompactionConfig.MAX_COMMITS_TO_KEEP.key() -> "960",
HoodieCompactionConfig.ASYNC_CLEAN.key() -> "false",
HoodieCompactionConfig.INLINE_COMPACT.key() -> "true",
HoodieMetricsConfig.TURN_METRICS_ON.key() -> "true",
HoodieMetricsConfig.METRICS_REPORTER_TYPE_VALUE.key() -> MetricsReporterType.DATADOG.name(),
HoodieMetricsDatadogConfig.API_SITE_VALUE.key() -> "US",
HoodieMetricsDatadogConfig.METRIC_PREFIX_VALUE.key() -> "tacticalnovusingest.hudi",
HoodieMetricsDatadogConfig.API_KEY_SUPPLIER.key() -> "com.tr.indigo.tacticalnovusingest.utils.DatadogKeySupplier",
HoodieMetadataConfig.ENABLE.key() -> "false",
HoodieWriteConfig.ROLLBACK_USING_MARKERS_ENABLE.key() -> "false",
Parquet files which created are as below.
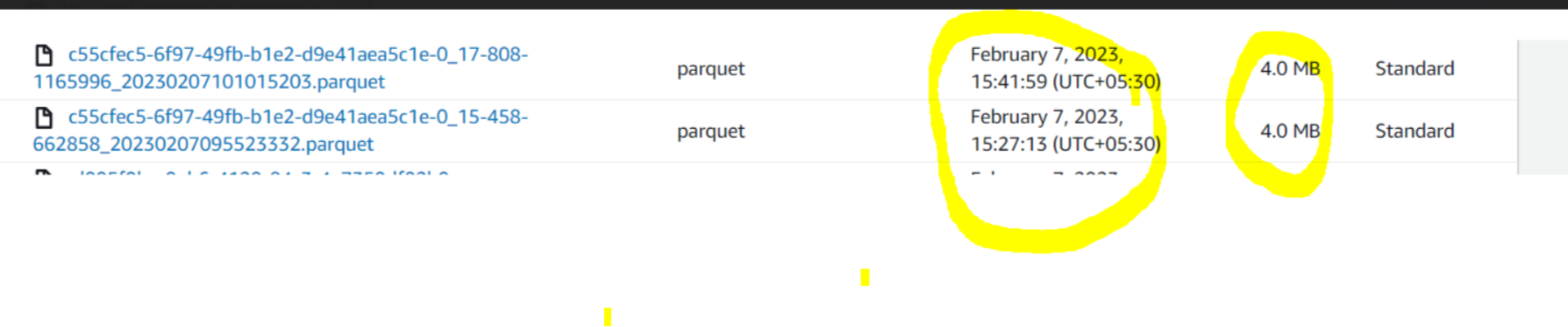
how can we avoid small file creations?
@koochiswathiTR my teammate in case need more info.
Appreciate all the help you guys do.
Thanks,JK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #7910: [SUPPORT]
Posted by "nsivabalan (via GitHub)" <gi...@apache.org>.
nsivabalan commented on issue #7910:
URL: https://github.com/apache/hudi/issues/7910#issuecomment-1454046187
Is its a COW or MOR table?
COW:
if you look at S3 directly, you might find older files too. Hudi after rewriting to a newer version of the base file, will not delete the older file immediately. Cleaner will take care of it. But your queries/reader will only read the latest version of the data file.
But if you w/ MOR table, its more nuanced.
By default only one file group (w/o any log files) are considered for small file bin packing.
If you wish more files to be picked up, you can try tweaking https://hudi.apache.org/docs/configurations/#hoodiemergesmallfilegroupcandidateslimit
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #7910: [SUPPORT]
Posted by "danny0405 (via GitHub)" <gi...@apache.org>.
danny0405 commented on issue #7910:
URL: https://github.com/apache/hudi/issues/7910#issuecomment-1426630077
One reason I can think of is for MOR table, when there are pending compaction on the FileSlice, the FileSlice is then ignored for being the target small files, that is somehow where we can improve, cc @jonvex to see if you have some interests for this patch.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #7910: [SUPPORT] How can we avoid small file creations for spark streaming
Posted by "ad1happy2go (via GitHub)" <gi...@apache.org>.
ad1happy2go commented on issue #7910:
URL: https://github.com/apache/hudi/issues/7910#issuecomment-1569782383
@JnaneshwarikTR Closing out this issue. Please reopen in case of any more queries.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #7910: [SUPPORT]
Posted by "ad1happy2go (via GitHub)" <gi...@apache.org>.
ad1happy2go commented on issue #7910:
URL: https://github.com/apache/hudi/issues/7910#issuecomment-1558741227
@JnaneshwarikTR Hope above information helped. Do you still have any questions/issue on this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] jonvex commented on issue #7910: [SUPPORT]
Posted by "jonvex (via GitHub)" <gi...@apache.org>.
jonvex commented on issue #7910:
URL: https://github.com/apache/hudi/issues/7910#issuecomment-1428221207
@nsivabalan We have recently seen some questions in the slack about small file sizes. Do you think something bigger at play than configuration?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #7910: [SUPPORT]
Posted by "nsivabalan (via GitHub)" <gi...@apache.org>.
nsivabalan commented on issue #7910:
URL: https://github.com/apache/hudi/issues/7910#issuecomment-1454046650
You can also check https://medium.com/@simpsons/apache-hudis-small-file-management-17d8c61b20e6 for reference.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan closed issue #7910: [SUPPORT] How can we avoid small file creations for spark streaming
Posted by "xushiyan (via GitHub)" <gi...@apache.org>.
xushiyan closed issue #7910: [SUPPORT] How can we avoid small file creations for spark streaming
URL: https://github.com/apache/hudi/issues/7910
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org