You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2022/05/30 16:24:55 UTC
[GitHub] [iceberg] hililiwei opened a new pull request, #4904: Flink: new sink base on the unified sink API
hililiwei opened a new pull request, #4904:
URL: https://github.com/apache/iceberg/pull/4904
## What is the purpose of the change
The following is the background and basis for this PR:
- [FLIP-143: Unified Sink API](https://cwiki.apache.org/confluence/display/FLINK/FLIP-143%3A+Unified+Sink+API)
- [FLIP-191: Extend unified Sink interface to support small file compaction](https://cwiki.apache.org/confluence/display/FLINK/FLIP-191%3A+Extend+unified+Sink+interface+to+support+small+file+compaction)
1. FLIP-143: Unified Sink API
The Unified Sink API was introduced by FLink in version 1.12, and its motivation is mainly as follows:
> As discussed in FLIP-131, Flink will deprecate the DataSet API in favor of DataStream API and Table API. Users should be able to use DataStream API to write jobs that support both bounded and unbounded execution modes. However Flink does not provide a sink API to guarantee the exactly once semantics in both bounded and unbounded scenarios, which blocks the unification.
>
> So we want to introduce a new unified sink API which could let the user develop sink once and run it everywhere. Specifically Flink allows the user to
>
> Choose the different SDK(SQL/Table/DataStream)
Choose the different execution mode(Batch/Stream) according to the scenarios(bounded/unbounded)
We hope these things(SDK/Execution mode) are transparent to the sink API.
This is the main change point of this PR. It retains most of the underlying logic, provides a V2 version of FlinkSink externally, and tries to minimize the impact of this change on users' experience.
After this PR is completed, we can try to contact Flink community to see if it is possible to directly include this new Sink into Flink repo and exist as a separate Connector.
For the above two FLIP and some other reasons, I think we should implement our Sink based on the latest API, which is clearer in structure, and this helps keep us in line with Flink..
2. FLIP-191: Extend unified Sink interface to support small file compaction
I think this illustration is very clear.
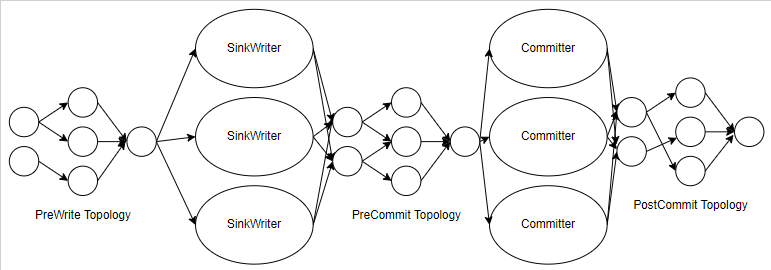
I'm going to do this in a separate PR because it's a bit of a performance bottleneck when we're dealing with a lot of data in production. If possible, I would like to raise PR after those issues are resolved.
## Brief change log
1. Add new flink sink base on [FLIP-143: Unified Sink API](https://cwiki.apache.org/confluence/display/FLINK/FLIP-143%3A+Unified+Sink+API) and [FLIP-191: Extend unified Sink interface to support small file compaction](https://cwiki.apache.org/confluence/display/FLINK/FLIP-191%3A+Extend+unified+Sink+interface+to+support+small+file+compaction)
2. `Iceberg Table Sink` uses the new sink instead of the old one.
## Verifying this change
1. Use existing unit tests.
2. Add some new
## To do
1. Unit tests to cover more case
2. Small file merge
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925805888
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,603 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
+ this.overwrite = flinkWriteConf.overwriteMode();
+ this.distributionMode = flinkWriteConf.distributionMode();
+ this.workerPoolSize = flinkWriteConf.workerPoolSize();
+ this.targetDataFileSize = flinkWriteConf.targetDataFileSize();
+ this.dataFileFormat = flinkWriteConf.dataFileFormat();
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, targetDataFileSize, dataFileFormat, upsertMode,
+ flinkRowType, equalityFieldIds, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ long targetDataFileSize,
+ FileFormat dataFileFormat,
+ boolean upsertMode,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetDataFileSize, dataFileFormat, equalityFieldIds, upsertMode);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private Integer writeParallelism = null;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+ private final Map<String, String> writeOptions = Maps.newHashMap();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ /**
+ * Set the write properties for Flink sink.
+ * View the supported properties in {@link FlinkWriteOptions}
+ */
+ public Builder set(String property, String value) {
+ writeOptions.put(property, value);
+ return this;
+ }
+
+ /**
+ * Set the write properties for Flink sink.
+ * View the supported properties in {@link FlinkWriteOptions}
+ */
+ public Builder setAll(Map<String, String> properties) {
+ writeOptions.putAll(properties);
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ writeOptions.put(FlinkWriteOptions.OVERWRITE_MODE.key(), Boolean.toString(newOverwrite));
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ if (mode != null) {
+ writeOptions.put(FlinkWriteOptions.DISTRIBUTION_MODE.key(), mode.modeName());
+ }
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ writeOptions.put(FlinkWriteOptions.WRITE_UPSERT_ENABLED.key(), Boolean.toString(enabled));
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
Review Comment:
I think we can add some topology diagrams on top?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925812879
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(),
+ MAX_CONTINUOUS_EMPTY_COMMITS,
+ MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<IcebergFlinkCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<IcebergFlinkCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<IcebergFlinkCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<IcebergFlinkCommittable> request : requests) {
+ checkpointId = request.getCommittable().checkpointId();
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ }
+ } else {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
Review Comment:
Not necessarily. When we have no data to commit, we increase the number of empty commits by one. When it is greater than the threshold, we also make a commit.
```java
private void commitResult(int dataFilesNum, int deleteFilesNum,
Collection<CommitRequest<FilesCommittable>> committableCollection) {
int totalFiles = dataFilesNum + deleteFilesNum;
continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
if (totalFiles != 0 || continuousEmptyCheckpoints % maxContinuousEmptyCommits == 0) {
if (replacePartitions) {
replacePartitions(committableCollection, deleteFilesNum);
} else {
commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
}
continuousEmptyCheckpoints = 0;
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925860958
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,603 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
+ this.overwrite = flinkWriteConf.overwriteMode();
+ this.distributionMode = flinkWriteConf.distributionMode();
+ this.workerPoolSize = flinkWriteConf.workerPoolSize();
+ this.targetDataFileSize = flinkWriteConf.targetDataFileSize();
+ this.dataFileFormat = flinkWriteConf.dataFileFormat();
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, targetDataFileSize, dataFileFormat, upsertMode,
+ flinkRowType, equalityFieldIds, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ long targetDataFileSize,
+ FileFormat dataFileFormat,
+ boolean upsertMode,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetDataFileSize, dataFileFormat, equalityFieldIds, upsertMode);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private Integer writeParallelism = null;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+ private final Map<String, String> writeOptions = Maps.newHashMap();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ /**
+ * Set the write properties for Flink sink.
+ * View the supported properties in {@link FlinkWriteOptions}
+ */
+ public Builder set(String property, String value) {
+ writeOptions.put(property, value);
+ return this;
+ }
+
+ /**
+ * Set the write properties for Flink sink.
+ * View the supported properties in {@link FlinkWriteOptions}
+ */
+ public Builder setAll(Map<String, String> properties) {
+ writeOptions.putAll(properties);
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ writeOptions.put(FlinkWriteOptions.OVERWRITE_MODE.key(), Boolean.toString(newOverwrite));
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ if (mode != null) {
+ writeOptions.put(FlinkWriteOptions.DISTRIBUTION_MODE.key(), mode.modeName());
+ }
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ writeOptions.put(FlinkWriteOptions.WRITE_UPSERT_ENABLED.key(), Boolean.toString(enabled));
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
Review Comment:
That would be nice! 😄
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925864835
##########
flink/v1.15/flink/src/test/java/org/apache/iceberg/flink/sink/v2/TestStreamWriter.java:
##########
@@ -0,0 +1,338 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.metrics.testutils.MetricListener;
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.GenericRowData;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableProperties;
+import org.apache.iceberg.data.GenericRecord;
+import org.apache.iceberg.data.Record;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.SimpleDataUtil;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.hadoop.HadoopTables;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.types.Types;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.Rule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+@RunWith(Parameterized.class)
+public class TestStreamWriter {
+ @Rule
+ public TemporaryFolder tempFolder = new TemporaryFolder();
+ private MetricListener metricListener;
+ private Table table;
+
+ private final FileFormat format;
+ private final boolean partitioned;
+
+ @Parameterized.Parameters(name = "format = {0}, partitioned = {1}")
+ public static Object[][] parameters() {
+ return new Object[][] {
+ {"avro", true},
+ {"avro", false},
+ {"orc", true},
+ {"orc", false},
+ {"parquet", true},
+ {"parquet", false}
+ };
+ }
+
+ public TestStreamWriter(String format, boolean partitioned) {
+ this.format = FileFormat.valueOf(format.toUpperCase(Locale.ENGLISH));
+ this.partitioned = partitioned;
+ }
+
+ @Before
+ public void before() throws IOException {
+ metricListener = new MetricListener();
+ File folder = tempFolder.newFolder();
+ // Construct the iceberg table.
+ Map<String, String> props = ImmutableMap.of(TableProperties.DEFAULT_FILE_FORMAT, format.name());
+ table = SimpleDataUtil.createTable(folder.getAbsolutePath(), props, partitioned);
+ }
+
+ @Test
+ public void testPreCommit() throws Exception {
+ StreamWriter streamWriter = createIcebergStreamWriter();
+ streamWriter.write(SimpleDataUtil.createRowData(1, "hello"), new ContextImpl());
+ streamWriter.write(SimpleDataUtil.createRowData(2, "hello"), new ContextImpl());
+ streamWriter.write(SimpleDataUtil.createRowData(3, "hello"), new ContextImpl());
+ streamWriter.write(SimpleDataUtil.createRowData(4, "hello"), new ContextImpl());
+ streamWriter.write(SimpleDataUtil.createRowData(5, "hello"), new ContextImpl());
+
+ Collection<FilesCommittable> filesCommittables = streamWriter.prepareCommit();
+ Assert.assertEquals(filesCommittables.size(), 1);
+ }
+
+ @Test
+ public void testWritingTable() throws Exception {
+ StreamWriter streamWriter = createIcebergStreamWriter();
+ // The first checkpoint
+ streamWriter.write(SimpleDataUtil.createRowData(1, "hello"), new ContextImpl());
+ streamWriter.write(SimpleDataUtil.createRowData(2, "world"), new ContextImpl());
+ streamWriter.write(SimpleDataUtil.createRowData(3, "hello"), new ContextImpl());
+
+ Collection<FilesCommittable> filesCommittables = streamWriter.prepareCommit();
+ Assert.assertEquals(filesCommittables.size(), 1);
+
+ AppendFiles appendFiles = table.newAppend();
+
+ WriteResult result = null;
+ for (FilesCommittable filesCommittable : filesCommittables) {
+ result = filesCommittable.committable();
+ }
+ long expectedDataFiles = partitioned ? 2 : 1;
Review Comment:
nit: newline?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910557828
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ }
+
+ case RANGE:
+ if (equalityFieldIds.isEmpty()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and {}=range is not supported yet in flink", WRITE_DISTRIBUTION_MODE);
+ return input;
Review Comment:
I'm in favor of throwing exceptions more cleanly, but should we maintain consistency with the old Sink behavior?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910929465
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergStreamWriter.java:
##########
@@ -0,0 +1,135 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class IcebergStreamWriter implements
+ StatefulSinkWriter<RowData, IcebergStreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, IcebergFlinkCommittable> {
+
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient String jobId;
+ private transient int subTaskId;
+ private transient long attemptId;
+ private List<IcebergFlinkCommittable> writeResultsRestore = Lists.newArrayList();
+
+ public IcebergStreamWriter(String fullTableName, TaskWriter<RowData> writer, int subTaskId,
+ long attemptId) {
+ this.fullTableName = fullTableName;
+ this.writer = writer;
+ this.subTaskId = subTaskId;
+ this.attemptId = attemptId;
+ }
+
+ public IcebergStreamWriter(String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ String jobId, int subTaskId,
+ long attemptId) {
+ this.fullTableName = fullTableName;
+ this.jobId = jobId;
+ this.subTaskId = subTaskId;
+ this.attemptId = attemptId;
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(subTaskId, attemptId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ public void writeResults(List<IcebergFlinkCommittable> newWriteResults) {
+ this.writeResultsRestore = newWriteResults;
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {
Review Comment:
`prepareCommit` will be called whether checkpoint is enabled or not, so I'm not calling it manually like V1.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r909641002
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
Review Comment:
nit: add an empty line after the control block.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937361970
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
`FlinkWriteConf` doesn't have to keep the `FlinkConfParser` as class members. Instead, `FlinkWriteConf` can use a local `FlinkConfParser` variable to extract the individual config values (similar to what you did here) and only save the individual config values (not `FlinkConfParser`) as class members
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r933083980
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
Review Comment:
We might use the `commitRequest.signalAlreadyCommitted()` to signal that these are already committed, so if Flink is able to filter them out, then they should not be replayed later.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936150001
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
Review Comment:
In the new version, I've given up using it only to reflect commit status. As mentioned above, I relied a little too much on Flink's fault-tolerance mechanism, and I went back to the latest way of using metadata information from iceberg table.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r933635772
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
Review Comment:
Are we sure that the `numberOfRetries` always reflect the state of the Iceberg table?
I think in both cases (retries or not) we should depend on the status of the Iceberg table, and only use the state of the Flink commits as a guide. If Flink says that something is committed, or the commit is failed, then we could be sure that the commit happened, but depending on missing information (no commit yet / no tries yet) could be erroneous.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925871614
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(),
+ MAX_CONTINUOUS_EMPTY_COMMITS,
+ MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<IcebergFlinkCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<IcebergFlinkCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<IcebergFlinkCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<IcebergFlinkCommittable> request : requests) {
+ checkpointId = request.getCommittable().checkpointId();
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ }
+ } else {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
Review Comment:
We will have a new snapshot with the same manifests as the old snapshot.
Nice catch!
The reason for this logic is to refresh the latest `max-committed-checkpoint-id`, so that it can correctly recover from state. Now we change state to `FilesCommittable` and leave it to the Flink itself. So it looks like we don't need that logic anymore.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926481297
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
Review Comment:
nit: It is really not that important, but why not initialize the value with `null`? `""` just an unnecessary constant
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925805130
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,603 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
+ this.overwrite = flinkWriteConf.overwriteMode();
+ this.distributionMode = flinkWriteConf.distributionMode();
+ this.workerPoolSize = flinkWriteConf.workerPoolSize();
+ this.targetDataFileSize = flinkWriteConf.targetDataFileSize();
+ this.dataFileFormat = flinkWriteConf.dataFileFormat();
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, targetDataFileSize, dataFileFormat, upsertMode,
+ flinkRowType, equalityFieldIds, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ long targetDataFileSize,
+ FileFormat dataFileFormat,
+ boolean upsertMode,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
Review Comment:
I removed this method.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910078664
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final transient Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private final transient int maxContinuousEmptyCommits;
+
+
+ private final transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(), MAX_CONTINUOUS_EMPTY_COMMITS, 10);
Review Comment:
10 is hard code
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927769011
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
I am afraid, that we can not base our decisions on what Flink tells us at this point. It might be that the commit is successful, but the system fails, and we do not mark the commit as finished, or we mark it, but the state is restored from an older backup. So even if we call the method, and it does more than documented, we still can not be sure that we do not see this particular commit again in case of a retry.
Again, it is only based on my limited understanding.
Thanks for the patience,
Peter
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
kbendick commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947028378
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
+ }
+
+ @Override
+ public Committer<FilesCommittable> createCommitter() {
+ return committer != null
+ ? committer
+ : new FilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ public void setCommitter(Committer<FilesCommittable> committer) {
Review Comment:
We don’t usually use `set` for our own function names. Is this to make this serializable? If not, I’d skip the `set` verb.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946343370
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommittable.java:
##########
@@ -0,0 +1,79 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.Serializable;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+
+public class FilesCommittable implements Serializable {
+ private final WriteResult committable;
+ private String jobId = "";
+ private long checkpointId;
+ private int subtaskId;
+
+ public FilesCommittable(WriteResult committable) {
Review Comment:
I also found it weird that we have two different constructors. if `prepareCommit` skip other fields in the `FilesCommittable`, will they ever be set? We only use the 2nd constructor in the deserializer path.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936138809
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
We probably should make `FlinkWriteConf` serializable to avoid copying the config values.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936143532
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
Review Comment:
looking at the usage of the `table` object. This probably should be defined as a `SerializableTable`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936160928
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
Review Comment:
good
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937283272
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ } catch (Exception e) {
+ LOG.error("Unable to process the committable: {}.", commitRequest.getCommittable(), e);
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(dynamicOverwrite, dataFilesNum, 0, "dynamic partition overwrite", flinkJobId, checkpointId);
Review Comment:
First, for each checkpoint, all data is committed in a single commiter operation.
Second, when we commit, we will first try to commit data with retry times greater than 0.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937293983
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
Review Comment:
https://github.com/apache/iceberg/blob/be11b2f3b6441ddbddc694bfe24fd307bec0a808/flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java#L644-L655
Thank you. When assigning the value of table, I changed it to this way. The return type of `SerializableTable.copyOfSerializableTable.copyOf()` is `Table`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937401025
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
These config values are retrieved from `Table\Config\...` each time they are used. Do I assign all of them in advance at creation time?? I don't recommend doing that.
For example, if we did that and the user changed the value of the table or config after initializing FlinkWriteConfig, then we would get the wrong value.(Of course, in our case, it doesn't happen, it's read-only.)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936158884
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ } catch (Exception e) {
+ LOG.error("Unable to process the committable: {}.", commitRequest.getCommittable(), e);
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(dynamicOverwrite, dataFilesNum, 0, "dynamic partition overwrite", flinkJobId, checkpointId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
I've removed it here and will use it only in the case of an exception that still thinks it's committed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936159119
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ } catch (Exception e) {
+ LOG.error("Unable to process the committable: {}.", commitRequest.getCommittable(), e);
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(dynamicOverwrite, dataFilesNum, 0, "dynamic partition overwrite", flinkJobId, checkpointId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
I've removed it here and will use it only for case where an exception occurs and still think it's committed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r990881356
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
+
+ @Override
+ public void close() throws Exception {
+ if (writer != null) {
+ writer.close();
+ writer = null;
+ }
+ }
+
+ @Override
+ public String toString() {
+ return MoreObjects.toStringHelper(this)
+ .add("table_name", fullTableName)
+ .add("subtask_id", subTaskId)
+ .toString();
+ }
+
+ @Override
+ public Collection<FilesCommittable> prepareCommit() throws IOException {
+ writeResultsState.add(new FilesCommittable(writer.complete()));
+ this.writer = taskWriterFactory.create();
+ return writeResultsState;
+ }
+
+ @Override
+ public List<StreamWriterState> snapshotState(long checkpointId) {
+ List<StreamWriterState> state = Lists.newArrayList();
+ state.add(new StreamWriterState(Lists.newArrayList(writeResultsState)));
Review Comment:
To adapt to the new architecture, I've made a compromise here. Serialize the WriteResult sent by the StreamWriter into a Manifest file as CommT and deserialize the file in the Committer.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910555869
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
Review Comment:
we'll have multiple sinks with multiple writes and globally one committer.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r906790721
##########
flink/v1.15/flink/src/test/java/org/apache/iceberg/flink/sink/v2/TestFlinkIcebergSinkV2.java:
##########
@@ -0,0 +1,508 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.functions.KeySelector;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.test.util.MiniClusterWithClientResource;
+import org.apache.flink.types.Row;
+import org.apache.flink.types.RowKind;
+import org.apache.iceberg.AssertHelpers;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableProperties;
+import org.apache.iceberg.TableTestBase;
+import org.apache.iceberg.data.IcebergGenerics;
+import org.apache.iceberg.data.Record;
+import org.apache.iceberg.flink.MiniClusterResource;
+import org.apache.iceberg.flink.SimpleDataUtil;
+import org.apache.iceberg.flink.TestTableLoader;
+import org.apache.iceberg.flink.source.BoundedTestSource;
+import org.apache.iceberg.io.CloseableIterable;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableList;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.Types;
+import org.apache.iceberg.util.StructLikeSet;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.ClassRule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+@RunWith(Parameterized.class)
+public class TestFlinkIcebergSinkV2 extends TableTestBase {
+
+ @ClassRule
+ public static final MiniClusterWithClientResource MINI_CLUSTER_RESOURCE =
+ MiniClusterResource.createWithClassloaderCheckDisabled();
+
+ @ClassRule
+ public static final TemporaryFolder TEMPORARY_FOLDER = new TemporaryFolder();
+
+ private static final int FORMAT_V2 = 2;
+ private static final TypeInformation<Row> ROW_TYPE_INFO =
+ new RowTypeInfo(SimpleDataUtil.FLINK_SCHEMA.getFieldTypes());
+
+ private static final Map<String, RowKind> ROW_KIND_MAP = ImmutableMap.of(
+ "+I", RowKind.INSERT,
+ "-D", RowKind.DELETE,
+ "-U", RowKind.UPDATE_BEFORE,
+ "+U", RowKind.UPDATE_AFTER);
+
+ private static final int ROW_ID_POS = 0;
+ private static final int ROW_DATA_POS = 1;
+
+ private final FileFormat format;
+ private final int parallelism;
+ private final boolean partitioned;
+ private final String writeDistributionMode;
+
+ private StreamExecutionEnvironment env;
+ private TestTableLoader tableLoader;
+
+ @Parameterized.Parameters(name = "FileFormat = {0}, Parallelism = {1}, Partitioned={2}, WriteDistributionMode ={3}")
+ public static Object[][] parameters() {
+ return new Object[][] {
+ new Object[] {"avro", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+
+ new Object[] {"orc", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+
+ new Object[] {"parquet", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE}
+ };
+ }
+
+ public TestFlinkIcebergSinkV2(String format, int parallelism, boolean partitioned, String writeDistributionMode) {
+ super(FORMAT_V2);
+ this.format = FileFormat.valueOf(format.toUpperCase(Locale.ENGLISH));
+ this.parallelism = parallelism;
+ this.partitioned = partitioned;
+ this.writeDistributionMode = writeDistributionMode;
+ }
+
+ @Before
+ public void setupTable() throws IOException {
+ this.tableDir = temp.newFolder();
+ this.metadataDir = new File(tableDir, "metadata");
+ Assert.assertTrue(tableDir.delete());
+
+ if (!partitioned) {
+ table = create(SimpleDataUtil.SCHEMA, PartitionSpec.unpartitioned());
+ } else {
+ table = create(SimpleDataUtil.SCHEMA, PartitionSpec.builderFor(SimpleDataUtil.SCHEMA).identity("data").build());
+ }
+
+ table.updateProperties()
+ .set(TableProperties.DEFAULT_FILE_FORMAT, format.name())
+ .set(TableProperties.WRITE_DISTRIBUTION_MODE, writeDistributionMode)
+ .commit();
+
+ env = StreamExecutionEnvironment.getExecutionEnvironment(MiniClusterResource.DISABLE_CLASSLOADER_CHECK_CONFIG)
+ .enableCheckpointing(100L)
+ .setParallelism(parallelism)
+ .setMaxParallelism(parallelism);
+
+ tableLoader = new TestTableLoader(tableDir.getAbsolutePath());
+ }
+
+ private List<Snapshot> findValidSnapshots(Table table) {
+ List<Snapshot> validSnapshots = Lists.newArrayList();
+ for (Snapshot snapshot : table.snapshots()) {
+ if (snapshot.allManifests(table.io()).stream().anyMatch(m -> snapshot.snapshotId() == m.snapshotId())) {
+ validSnapshots.add(snapshot);
+ }
+ }
+ return validSnapshots;
+ }
+
+ private void testChangeLogs(List<String> equalityFieldColumns,
+ KeySelector<Row, Object> keySelector,
+ boolean insertAsUpsert,
+ List<List<Row>> elementsPerCheckpoint,
+ List<List<Record>> expectedRecordsPerCheckpoint) throws Exception {
+ DataStream<Row> dataStream = env.addSource(new BoundedTestSource<>(elementsPerCheckpoint), ROW_TYPE_INFO);
+
+ FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA)
+ .tableLoader(tableLoader)
+ .tableSchema(SimpleDataUtil.FLINK_SCHEMA)
+ .writeParallelism(parallelism)
+ .equalityFieldColumns(equalityFieldColumns)
+ .upsert(insertAsUpsert)
+ .append();
+
+ // Execute the program.
+ env.execute("Test Iceberg Change-Log DataStream.");
+
+ table.refresh();
+ List<Snapshot> snapshots = findValidSnapshots(table);
+ int expectedSnapshotNum = expectedRecordsPerCheckpoint.size();
+ Assert.assertEquals("Should have the expected snapshot number", expectedSnapshotNum, snapshots.size());
+
+ for (int i = 0; i < expectedSnapshotNum; i++) {
+ long snapshotId = snapshots.get(i).snapshotId();
+ List<Record> expectedRecords = expectedRecordsPerCheckpoint.get(i);
+ Assert.assertEquals("Should have the expected records for the checkpoint#" + i,
+ expectedRowSet(expectedRecords.toArray(new Record[0])), actualRowSet(snapshotId, "*"));
+ }
+ }
+
+ private Row row(String rowKind, int id, String data) {
+ RowKind kind = ROW_KIND_MAP.get(rowKind);
+ if (kind == null) {
+ throw new IllegalArgumentException("Unknown row kind: " + rowKind);
+ }
+
+ return Row.ofKind(kind, id, data);
+ }
+
+ private Record record(int id, String data) {
+ return SimpleDataUtil.createRecord(id, data);
+ }
+
+ @Test
+ public void testCheckAndGetEqualityFieldIds() {
+ table.updateSchema()
+ .allowIncompatibleChanges()
+ .addRequiredColumn("type", Types.StringType.get())
+ .setIdentifierFields("type")
+ .commit();
+
+ DataStream<Row> dataStream = env.addSource(new BoundedTestSource<>(ImmutableList.of()), ROW_TYPE_INFO);
+ FlinkSink.Builder builder = FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA).table(table);
+
+ // Use schema identifier field IDs as equality field id list by default
+ Assert.assertEquals(
+ table.schema().identifierFieldIds(),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+
+ // Use user-provided equality field column as equality field id list
+ builder.equalityFieldColumns(Lists.newArrayList("id"));
+ Assert.assertEquals(
+ Sets.newHashSet(table.schema().findField("id").fieldId()),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+
+ builder.equalityFieldColumns(Lists.newArrayList("type"));
+ Assert.assertEquals(
+ Sets.newHashSet(table.schema().findField("type").fieldId()),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+ }
+
+ @Test
+ public void testChangeLogOnIdKey() throws Exception {
+ List<List<Row>> elementsPerCheckpoint = ImmutableList.of(
+ ImmutableList.of(
+ row("+I", 1, "aaa"),
+ row("-D", 1, "aaa"),
+ row("+I", 1, "bbb"),
+ row("+I", 2, "aaa"),
+ row("-D", 2, "aaa"),
+ row("+I", 2, "bbb")
+ ),
+ ImmutableList.of(
+ row("-U", 2, "bbb"),
+ row("+U", 2, "ccc"),
+ row("-D", 2, "ccc"),
+ row("+I", 2, "ddd")
+ ),
+ ImmutableList.of(
+ row("-D", 1, "bbb"),
+ row("+I", 1, "ccc"),
+ row("-D", 1, "ccc"),
+ row("+I", 1, "ddd")
+ )
+ );
+
+ List<List<Record>> expectedRecords = ImmutableList.of(
+ ImmutableList.of(record(1, "bbb"), record(2, "bbb")),
+ ImmutableList.of(record(1, "bbb"), record(2, "ddd")),
+ ImmutableList.of(record(1, "ddd"), record(2, "ddd"))
+ );
+
+ if (partitioned && writeDistributionMode.equals(TableProperties.WRITE_DISTRIBUTION_MODE_HASH)) {
Review Comment:
And why do we check distribution mode in the `if`? Does that impact the the result?
##########
flink/v1.15/flink/src/test/java/org/apache/iceberg/flink/sink/v2/TestFlinkIcebergSinkV2.java:
##########
@@ -0,0 +1,508 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.functions.KeySelector;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.test.util.MiniClusterWithClientResource;
+import org.apache.flink.types.Row;
+import org.apache.flink.types.RowKind;
+import org.apache.iceberg.AssertHelpers;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableProperties;
+import org.apache.iceberg.TableTestBase;
+import org.apache.iceberg.data.IcebergGenerics;
+import org.apache.iceberg.data.Record;
+import org.apache.iceberg.flink.MiniClusterResource;
+import org.apache.iceberg.flink.SimpleDataUtil;
+import org.apache.iceberg.flink.TestTableLoader;
+import org.apache.iceberg.flink.source.BoundedTestSource;
+import org.apache.iceberg.io.CloseableIterable;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableList;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.Types;
+import org.apache.iceberg.util.StructLikeSet;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.ClassRule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+@RunWith(Parameterized.class)
+public class TestFlinkIcebergSinkV2 extends TableTestBase {
+
+ @ClassRule
+ public static final MiniClusterWithClientResource MINI_CLUSTER_RESOURCE =
+ MiniClusterResource.createWithClassloaderCheckDisabled();
+
+ @ClassRule
+ public static final TemporaryFolder TEMPORARY_FOLDER = new TemporaryFolder();
+
+ private static final int FORMAT_V2 = 2;
+ private static final TypeInformation<Row> ROW_TYPE_INFO =
+ new RowTypeInfo(SimpleDataUtil.FLINK_SCHEMA.getFieldTypes());
+
+ private static final Map<String, RowKind> ROW_KIND_MAP = ImmutableMap.of(
+ "+I", RowKind.INSERT,
+ "-D", RowKind.DELETE,
+ "-U", RowKind.UPDATE_BEFORE,
+ "+U", RowKind.UPDATE_AFTER);
+
+ private static final int ROW_ID_POS = 0;
+ private static final int ROW_DATA_POS = 1;
+
+ private final FileFormat format;
+ private final int parallelism;
+ private final boolean partitioned;
+ private final String writeDistributionMode;
+
+ private StreamExecutionEnvironment env;
+ private TestTableLoader tableLoader;
+
+ @Parameterized.Parameters(name = "FileFormat = {0}, Parallelism = {1}, Partitioned={2}, WriteDistributionMode ={3}")
+ public static Object[][] parameters() {
+ return new Object[][] {
+ new Object[] {"avro", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+
+ new Object[] {"orc", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+
+ new Object[] {"parquet", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE}
+ };
+ }
+
+ public TestFlinkIcebergSinkV2(String format, int parallelism, boolean partitioned, String writeDistributionMode) {
+ super(FORMAT_V2);
+ this.format = FileFormat.valueOf(format.toUpperCase(Locale.ENGLISH));
+ this.parallelism = parallelism;
+ this.partitioned = partitioned;
+ this.writeDistributionMode = writeDistributionMode;
+ }
+
+ @Before
+ public void setupTable() throws IOException {
+ this.tableDir = temp.newFolder();
+ this.metadataDir = new File(tableDir, "metadata");
+ Assert.assertTrue(tableDir.delete());
+
+ if (!partitioned) {
+ table = create(SimpleDataUtil.SCHEMA, PartitionSpec.unpartitioned());
+ } else {
+ table = create(SimpleDataUtil.SCHEMA, PartitionSpec.builderFor(SimpleDataUtil.SCHEMA).identity("data").build());
+ }
+
+ table.updateProperties()
+ .set(TableProperties.DEFAULT_FILE_FORMAT, format.name())
+ .set(TableProperties.WRITE_DISTRIBUTION_MODE, writeDistributionMode)
+ .commit();
+
+ env = StreamExecutionEnvironment.getExecutionEnvironment(MiniClusterResource.DISABLE_CLASSLOADER_CHECK_CONFIG)
+ .enableCheckpointing(100L)
+ .setParallelism(parallelism)
+ .setMaxParallelism(parallelism);
+
+ tableLoader = new TestTableLoader(tableDir.getAbsolutePath());
+ }
+
+ private List<Snapshot> findValidSnapshots(Table table) {
+ List<Snapshot> validSnapshots = Lists.newArrayList();
+ for (Snapshot snapshot : table.snapshots()) {
+ if (snapshot.allManifests(table.io()).stream().anyMatch(m -> snapshot.snapshotId() == m.snapshotId())) {
+ validSnapshots.add(snapshot);
+ }
+ }
+ return validSnapshots;
+ }
+
+ private void testChangeLogs(List<String> equalityFieldColumns,
+ KeySelector<Row, Object> keySelector,
+ boolean insertAsUpsert,
+ List<List<Row>> elementsPerCheckpoint,
+ List<List<Record>> expectedRecordsPerCheckpoint) throws Exception {
+ DataStream<Row> dataStream = env.addSource(new BoundedTestSource<>(elementsPerCheckpoint), ROW_TYPE_INFO);
+
+ FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA)
+ .tableLoader(tableLoader)
+ .tableSchema(SimpleDataUtil.FLINK_SCHEMA)
+ .writeParallelism(parallelism)
+ .equalityFieldColumns(equalityFieldColumns)
+ .upsert(insertAsUpsert)
+ .append();
+
+ // Execute the program.
+ env.execute("Test Iceberg Change-Log DataStream.");
+
+ table.refresh();
+ List<Snapshot> snapshots = findValidSnapshots(table);
+ int expectedSnapshotNum = expectedRecordsPerCheckpoint.size();
+ Assert.assertEquals("Should have the expected snapshot number", expectedSnapshotNum, snapshots.size());
+
+ for (int i = 0; i < expectedSnapshotNum; i++) {
+ long snapshotId = snapshots.get(i).snapshotId();
+ List<Record> expectedRecords = expectedRecordsPerCheckpoint.get(i);
+ Assert.assertEquals("Should have the expected records for the checkpoint#" + i,
+ expectedRowSet(expectedRecords.toArray(new Record[0])), actualRowSet(snapshotId, "*"));
+ }
+ }
+
+ private Row row(String rowKind, int id, String data) {
+ RowKind kind = ROW_KIND_MAP.get(rowKind);
+ if (kind == null) {
+ throw new IllegalArgumentException("Unknown row kind: " + rowKind);
+ }
+
+ return Row.ofKind(kind, id, data);
+ }
+
+ private Record record(int id, String data) {
+ return SimpleDataUtil.createRecord(id, data);
+ }
+
+ @Test
+ public void testCheckAndGetEqualityFieldIds() {
+ table.updateSchema()
+ .allowIncompatibleChanges()
+ .addRequiredColumn("type", Types.StringType.get())
+ .setIdentifierFields("type")
+ .commit();
+
+ DataStream<Row> dataStream = env.addSource(new BoundedTestSource<>(ImmutableList.of()), ROW_TYPE_INFO);
+ FlinkSink.Builder builder = FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA).table(table);
+
+ // Use schema identifier field IDs as equality field id list by default
+ Assert.assertEquals(
+ table.schema().identifierFieldIds(),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+
+ // Use user-provided equality field column as equality field id list
+ builder.equalityFieldColumns(Lists.newArrayList("id"));
+ Assert.assertEquals(
+ Sets.newHashSet(table.schema().findField("id").fieldId()),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+
+ builder.equalityFieldColumns(Lists.newArrayList("type"));
+ Assert.assertEquals(
+ Sets.newHashSet(table.schema().findField("type").fieldId()),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+ }
+
+ @Test
+ public void testChangeLogOnIdKey() throws Exception {
+ List<List<Row>> elementsPerCheckpoint = ImmutableList.of(
+ ImmutableList.of(
+ row("+I", 1, "aaa"),
+ row("-D", 1, "aaa"),
+ row("+I", 1, "bbb"),
+ row("+I", 2, "aaa"),
+ row("-D", 2, "aaa"),
+ row("+I", 2, "bbb")
+ ),
+ ImmutableList.of(
+ row("-U", 2, "bbb"),
+ row("+U", 2, "ccc"),
+ row("-D", 2, "ccc"),
+ row("+I", 2, "ddd")
+ ),
+ ImmutableList.of(
+ row("-D", 1, "bbb"),
+ row("+I", 1, "ccc"),
+ row("-D", 1, "ccc"),
+ row("+I", 1, "ddd")
+ )
+ );
+
+ List<List<Record>> expectedRecords = ImmutableList.of(
+ ImmutableList.of(record(1, "bbb"), record(2, "bbb")),
+ ImmutableList.of(record(1, "bbb"), record(2, "ddd")),
+ ImmutableList.of(record(1, "ddd"), record(2, "ddd"))
+ );
+
+ if (partitioned && writeDistributionMode.equals(TableProperties.WRITE_DISTRIBUTION_MODE_HASH)) {
Review Comment:
And why do we check distribution mode in the `if`? Does that impact the result?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r912335560
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
> > If equality keys are not the source of partition keys, then the data with the same equal column value may be divided into different partitions, which is not allowed.
>
> The check above states that _"In 'hash' distribution mode with equality fields set, partition field '%s' " + "should be included in equality fields: '%s'"_. It contradicts what you said.
Sorry for the confusion, I got sidetracked.
The reason we used EqualityFieldKeySelector, because we need to ensure all the same primary key record will be distributed to the same IcebergStreamWriter to ensure result correctness, . But when users set HASH distribution, the intention is to cluster data by partition columns. If we can use partition to to guarantee correctness, then we can use it, Otherwise, it should use the equality distribution. The key point here, then, in which case the partition distribution guarantees the correctness of the results without violating the user's intent? Requiring all of the partition source fields are identifier fields.
refer to: #2898 https://github.com/apache/iceberg/pull/2898#discussion_r810411948
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910552417
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final transient Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private final transient int maxContinuousEmptyCommits;
Review Comment:
nice catch. This is a mistake. thx.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925835175
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,259 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(),
+ MAX_CONTINUOUS_EMPTY_COMMITS,
+ MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ checkpointId = request.getCommittable().checkpointId();
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ }
+ } else {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0 || continuousEmptyCheckpoints % maxContinuousEmptyCommits == 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ continuousEmptyCheckpoints = 0;
Review Comment:
nit: empty line
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#issuecomment-1188973318
@hililiwei: New to the Flink part, but read through the changes and left some comments. Feel free to correct me anywhere if I do not yet understand some of the Flink stuff. Thanks, Peter
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926540313
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommittableSerializer.java:
##########
@@ -0,0 +1,90 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.core.memory.DataInputDeserializer;
+import org.apache.flink.core.memory.DataOutputViewStreamWrapper;
+import org.apache.flink.util.InstantiationUtil;
+import org.apache.iceberg.io.WriteResult;
+
+class FilesCommittableSerializer implements SimpleVersionedSerializer<FilesCommittable> {
+ private static final int SERIALIZER_VERSION = 1;
+
+ @Override
+ public int getVersion() {
+ return SERIALIZER_VERSION;
+ }
+
+ @Override
+ public byte[] serialize(FilesCommittable committable) throws IOException {
+ ByteArrayOutputStream out = new ByteArrayOutputStream();
+ DataOutputViewStreamWrapper view = new DataOutputViewStreamWrapper(out);
+ byte[] serialize = writeResultSerializer.serialize(committable.committable());
+ view.writeUTF(committable.jobID());
+ view.writeLong(committable.checkpointId());
+ view.writeInt(committable.subtaskId());
+ view.writeInt(serialize.length);
+ view.write(serialize);
+ return out.toByteArray();
+ }
+
+ @Override
+ public FilesCommittable deserialize(int version, byte[] serialized) throws IOException {
+ switch (version) {
+ case SERIALIZER_VERSION:
+ DataInputDeserializer view = new DataInputDeserializer(serialized);
+ String jobID = view.readUTF();
+ long checkpointId = view.readLong();
+ int subtaskId = view.readInt();
+ int len = view.readInt();
+ byte[] buf = new byte[len];
+ view.read(buf);
+ WriteResult writeResult = writeResultSerializer.deserialize(writeResultSerializer.getVersion(), buf);
+ return new FilesCommittable(writeResult, jobID, checkpointId, subtaskId);
+ default:
+ throw new IOException("Unrecognized version or corrupt state: " + version);
+ }
+ }
+
+ private final SimpleVersionedSerializer<WriteResult> writeResultSerializer =
+ new SimpleVersionedSerializer<WriteResult>() {
+ @Override
+ public int getVersion() {
+ return 1;
Review Comment:
rename to `VERSION_1`. thx.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925864221
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/StreamWriter.java:
##########
@@ -0,0 +1,123 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+class StreamWriter implements
+ StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient String jobId;
+ private transient int subTaskId;
+ private transient long attemptId;
+ private List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ StreamWriter(String fullTableName, TaskWriter<RowData> writer, int subTaskId,
+ long attemptId) {
+ this.fullTableName = fullTableName;
+ this.writer = writer;
+ this.subTaskId = subTaskId;
+ this.attemptId = attemptId;
+ }
+
+ StreamWriter(String fullTableName, TaskWriterFactory<RowData> taskWriterFactory,
+ String jobId, int subTaskId, long attemptId) {
+ this.fullTableName = fullTableName;
+ this.jobId = jobId;
+ this.subTaskId = subTaskId;
+ this.attemptId = attemptId;
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(subTaskId, attemptId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ public void writeResults(List<FilesCommittable> newWriteResults) {
+ this.writeResultsState = newWriteResults;
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (writer != null) {
+ writer.close();
+ writer = null;
+ }
+ }
+
+ @Override
+ public String toString() {
+ return MoreObjects.toStringHelper(this)
+ .add("table_name", fullTableName)
+ .add("subtask_id", subTaskId)
+ .add("attempt_id", attemptId)
+ .toString();
+ }
+
+ @Override
+ public Collection<FilesCommittable> prepareCommit() throws IOException {
+ writeResultsState.add(new FilesCommittable(writer.complete(), jobId));
+ this.writer = taskWriterFactory.create();
+ return writeResultsState;
+ }
+
+ @Override
+ public List<StreamWriterState> snapshotState(long checkpointId) {
+ List<StreamWriterState> state = Lists.newArrayList();
+ state.add(new StreamWriterState(Lists.newArrayList(writeResultsState)));
+ writeResultsState.clear();
+ return state;
+ }
+
+ public StreamWriter restoreWriter(Collection<StreamWriterState> recoveredState) {
+ List<FilesCommittable> filesCommittables = Lists.newArrayList();
+ for (StreamWriterState streamWriterState : recoveredState) {
+ filesCommittables.addAll(streamWriterState.writeResults());
+ }
+ this.writeResultsState.addAll(filesCommittables);
Review Comment:
nit: newline?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#issuecomment-1190553613
@hililiwei: I am getting second thoughts about this newline stuff. We usually try to add a newline after every block. I see that in several places we do not really adhere to it. Still might worth to check if you think the code would look better.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926500331
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
+ } else {
+ // To be compatible with iceberg format V2.
+ RowDelta rowDelta = table.newRowDelta().scanManifestsWith(workerPool);
+ int numDataFiles = 0;
+ int numDeleteFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ // We don't commit the merged result into a single transaction because for the sequential transaction txn1 and
+ // txn2, the equality-delete files of txn2 are required to be applied to data files from txn1. Committing the
+ // merged one will lead to the incorrect delete semantic.
+
+ // Row delta validations are not needed for streaming changes that write equality deletes. Equality deletes
+ // are applied to data in all previous sequence numbers, so retries may push deletes further in the future,
+ // but do not affect correctness. Position deletes committed to the table in this path are used only to delete
+ // rows from data files that are being added in this commit. There is no way for data files added along with
+ // the delete files to be concurrently removed, so there is no need to validate the files referenced by the
+ // position delete files that are being committed.
+
+ numDataFiles = numDataFiles + result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(rowDelta::addRows);
+
+ numDeleteFiles = numDeleteFiles + result.deleteFiles().length;
+ Arrays.stream(result.deleteFiles()).forEach(rowDelta::addDeletes);
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(rowDelta, numDataFiles, numDeleteFiles, "rowDelta", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
+ }
+ }
+
+ private void commitOperation(SnapshotUpdate<?> operation, int numDataFiles, int numDeleteFiles, String description,
+ String newFlinkJobId) {
+ LOG.info("Committing {} with {} data files and {} delete files to table {}", description, numDataFiles,
+ numDeleteFiles, table);
+ snapshotProperties.forEach(operation::set);
+ // custom snapshot metadata properties will be overridden if they conflict with internal ones used by the sink.
+ operation.set(FLINK_JOB_ID, newFlinkJobId);
+
+ long start = System.currentTimeMillis();
+ operation.commit(); // abort is automatically called if this fails.
Review Comment:
Maybe we should handle `CommitStateUnknownException` differently, as in this case we do not know if the commit was successful, or not. If we retry to commit in this case we might end up with duplicated data.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925742166
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
Review Comment:
`workerPoolSize` comes from `FlinkWriteConf`, which has a default value.
```
public int workerPoolSize() {
return confParser.intConf()
.flinkConfig(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE)
.defaultValue(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE.defaultValue())
.parse();
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r951004617
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
+
+ @Override
+ public void close() throws Exception {
+ if (writer != null) {
+ writer.close();
+ writer = null;
+ }
+ }
+
+ @Override
+ public String toString() {
+ return MoreObjects.toStringHelper(this)
+ .add("table_name", fullTableName)
+ .add("subtask_id", subTaskId)
+ .toString();
+ }
+
+ @Override
+ public Collection<FilesCommittable> prepareCommit() throws IOException {
+ writeResultsState.add(new FilesCommittable(writer.complete()));
+ this.writer = taskWriterFactory.create();
+ return writeResultsState;
+ }
+
+ @Override
+ public List<StreamWriterState> snapshotState(long checkpointId) {
+ List<StreamWriterState> state = Lists.newArrayList();
+ state.add(new StreamWriterState(Lists.newArrayList(writeResultsState)));
Review Comment:
Here is the how that Iceberg sink works today and how I hope that it should continue to work with v2 sink interface. Writers flushed the data files and send `WriteResult` to the global committer. The global committer checkpoints the `Manifest` file for fault tolerance/exactly-once.
I understand that `WriteResult` only contains the metadata. It can still be substantial in certain use cases. E.g.,
- writer parallelism is 1,000
- Each writer writes to 100 files (e.g. bucketing or hourly partition by event time)
- table has many columns. with column-level stats (min, max, count, null etc.). it would be significant metadata bytes per data file. say there are 200 columns, and each columns stats take up 100 bytes. that is 20 KB per file.
- each checkpoint would have size of 20 KB x 100 x 1,000. that is 2 GB.
- if checkpoint interval is 5 minutes and commit can't succeed for 10 hours, we are talking about 120 checkpoints. Then Iceberg sink would accumulate 240 GB of state.
I know this is the worst-case scenario, but it is the motivation behind the current IcebergSink design where the global committer only checkpoint one `ManifestFile` per checkpoint cycle.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927823486
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
Thank you very much for your question. It made me realize that I seemed to be relying too much on Flink's own fault-tolerant mechanism. We should go back to using `max-checkpoint-id`.
Multiple `FilesCommittable` are committed simultaneously, but marking as committed is serial. It is not atomic with the data submission action, which leads to the above problems. As you said above, we have to deduce that from reading the Iceberg table metadata.
When the commit is successful, We need to record `max-checkpoint-id` in the table. When the FilesCommittable re-try , we should check whether its checkpoint id is greater than the max.
Besides, we don't need `signalAlreadyCommitted` anymore.
So let me rewrite this logic.
Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946347938
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
+ }
+
+ @Override
+ public Committer<FilesCommittable> createCommitter() {
+ return committer != null
+ ? committer
+ : new FilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ public void setCommitter(Committer<FilesCommittable> committer) {
Review Comment:
why is this method needed?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947090137
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
Review Comment:
yes, it is a typo. I meant `initializeState` (with the d)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936330321
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
I tried it once, bug `FlinkConfParser` `ReadableConfig` ... blocked me, I didn't go that way. Or we could migrate it inside the `Builder`, as SparkWriberBuilder does?
https://github.com/apache/iceberg/blob/263441752393834c384a04d861cda1b8cb136a63/spark/v3.3/spark/src/main/java/org/apache/iceberg/spark/source/SparkWriteBuilder.java#L76-L86
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937269718
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
FlinkWriteConf uses `FlinkConfParser` and `ReadableConfig` internally, serializing `FlinkWriteConf` is not enough.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937293983
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
Review Comment:
https://github.com/apache/iceberg/blob/be11b2f3b6441ddbddc694bfe24fd307bec0a808/flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java#L644-L655
Thank you. When assigning the value of table, I changed it to this way. The return type of `SerializableTable.copyOf()` is `Table`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r884975720
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java:
##########
@@ -31,7 +31,7 @@
import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
-import org.apache.iceberg.flink.sink.FlinkSink;
+import org.apache.iceberg.flink.sink.v2.FlinkSink;
Review Comment:
**Key points**: Use new Sink
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926537302
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java:
##########
@@ -31,7 +31,7 @@
import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
-import org.apache.iceberg.flink.sink.FlinkSink;
+import org.apache.iceberg.flink.sink.v2.FlinkSink;
Review Comment:
Done, but I don't think `iceberg-sink` is a good name. Do you have a better suggestion?
```
// enable iceberg new sink
public static final ConfigOption<Boolean> ICEBERG_SINK =
ConfigOptions.key("iceberg-sink")
.booleanType().defaultValue(false);
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927013125
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java:
##########
@@ -63,6 +64,16 @@ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
.map(UniqueConstraint::getColumns)
.orElseGet(ImmutableList::of);
+ if (readableConfig.getOptional(FlinkConfigOptions.TABLE_EXEC_ICEBERG_USE_FLIP143_SINK).orElse(false)) {
Review Comment:
there is no need for `getOptional` and `orElse`. Flink configuration already handles default value.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926505819
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
Review Comment:
I am not sure what happens in the Iceberg code, if we want to add already existing files to the table.
Based on the Flink doc, the commit should be idempotent, so if the previous Iceberg commit failed with `CommitStateUnknownException` because there were some communication error with the Catalog then we should be able to commit the changes again (even if the commit was successful previously, or even if it was unsuccessful).
Do we have test for this case?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r906923672
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
Review Comment:
>Providing a table would avoid so many table loading from each separate task.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r924371212
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,603 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
+ this.overwrite = flinkWriteConf.overwriteMode();
+ this.distributionMode = flinkWriteConf.distributionMode();
+ this.workerPoolSize = flinkWriteConf.workerPoolSize();
+ this.targetDataFileSize = flinkWriteConf.targetDataFileSize();
+ this.dataFileFormat = flinkWriteConf.dataFileFormat();
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, targetDataFileSize, dataFileFormat, upsertMode,
+ flinkRowType, equalityFieldIds, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ long targetDataFileSize,
+ FileFormat dataFileFormat,
+ boolean upsertMode,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
Review Comment:
Having this many parameters are confusing. Can we change this to `private`? Or is this expected to be overwritten?
If we need to keep this, would a javadoc provide some more context?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936396544
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
Review Comment:
I did not call it again when successfully committed. It is called only if an exception has occurred but we believe that we no longer need to retry.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r938570916
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
> your current implementation also only retrieve the config values once during job startup/initialization. there is no difference
Yes, I've assigned all the values here, but at this stage, we've entered the job parsing phase, and we can assume that we're no longer receiving changes.
However, we do not provide the same guarantees when initializing FlinkWriteConf. We only get the necessary values when needed, and it ensure that the value is ultimately correct.
It's my considered opinion that we'd better not serialize them. In fact, when we created them, we mentioned in doc that these classes would not be serialized.
https://github.com/apache/iceberg/blob/af4b39555374e1d1ab966278c5bc94ea41ba91af/flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/FlinkWriteConf.java#L43-L49
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937685530
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommittable.java:
##########
@@ -0,0 +1,79 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.Serializable;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+
+public class FilesCommittable implements Serializable {
+ private final WriteResult committable;
+ private String jobID = "";
+ private long checkpointId;
+ private int subtaskId;
+
+ public FilesCommittable(WriteResult committable) {
+ this.committable = committable;
+ }
+
+ public FilesCommittable(WriteResult committable, String jobID, long checkpointId, int subtaskId) {
+ this.committable = committable;
+ this.jobID = jobID;
+ this.checkpointId = checkpointId;
+ this.subtaskId = subtaskId;
+ }
+
+ public WriteResult committable() {
+ return committable;
+ }
+
+ public Long checkpointId() {
+ return checkpointId;
+ }
+
+ public String jobID() {
Review Comment:
Let me modify it. It is also ok to use `jobId`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r938365229
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ RowDelta rowDelta = table.newRowDelta().scanManifestsWith(workerPool);
+ Arrays.stream(result.dataFiles()).forEach(rowDelta::addRows);
+ Arrays.stream(result.deleteFiles()).forEach(rowDelta::addDeletes);
+
+ String flinkJobId = commitRequest.getCommittable().jobID();
+ long checkpointId = commitRequest.getCommittable().checkpointId();
+ commitOperation(
+ commitRequest,
+ rowDelta,
+ dataFilesNum,
+ deleteFilesNum,
+ "rowDelta",
+ flinkJobId,
+ checkpointId);
+ }
+ }
+ }
+
+ private void commitOperation(
+ CommitRequest<FilesCommittable> commitRequest,
+ SnapshotUpdate<?> operation,
+ int numDataFiles,
+ int numDeleteFiles,
+ String description,
+ String newFlinkJobId,
+ long checkpointId) {
+ commitOperation(
+ Lists.newArrayList(commitRequest),
+ operation,
+ numDataFiles,
+ numDeleteFiles,
+ description,
+ newFlinkJobId,
+ checkpointId);
+ }
+
+ private void commitOperation(
+ Collection<CommitRequest<FilesCommittable>> commitRequests,
+ SnapshotUpdate<?> operation,
+ int numDataFiles,
+ int numDeleteFiles,
+ String description,
+ String newFlinkJobId,
+ long checkpointId) {
+ try {
+ commitOperation(
+ operation, numDataFiles, numDeleteFiles, description, newFlinkJobId, checkpointId);
+ } catch (AlreadyExistsException | UnsupportedOperationException e) {
+ commitRequests.forEach(request -> request.signalFailedWithKnownReason(e));
+ } catch (Exception e) {
+ commitRequests.forEach(request -> request.signalFailedWithUnknownReason(e));
+ }
+ }
+
+ private void commitOperation(
+ SnapshotUpdate<?> operation,
+ int numDataFiles,
+ int numDeleteFiles,
+ String description,
+ String newFlinkJobId,
+ long checkpointId) {
+ LOG.info(
+ "Committing {} with {} data files and {} delete files to table {}",
+ description,
+ numDataFiles,
+ numDeleteFiles,
+ table);
+ // custom snapshot metadata properties will be overridden if they conflict with internal ones
+ // used by the sink.
+ snapshotProperties.forEach(operation::set);
+ operation.set(MAX_COMMITTED_CHECKPOINT_ID, Long.toString(checkpointId));
+ operation.set(FLINK_JOB_ID, newFlinkJobId);
+
+ long start = System.currentTimeMillis();
+ operation.commit(); // abort is automatically called if this fails.
+ long duration = System.currentTimeMillis() - start;
+ LOG.info("Committed in {} ms", duration);
+ }
+
+ static long getMaxCommittedCheckpointId(Table table, String flinkJobId) {
+ Snapshot snapshot = table.currentSnapshot();
+ long lastCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
Review Comment:
https://github.com/apache/iceberg/blob/c7ce6bbafe476391807694c65f242c53a334ba0c/flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java#L266-L273
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r933082633
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
Review Comment:
Why do we differentiate between the `restored` and the first time commits?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r951007769
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
The lack of GlobalCommitter in the v2 sink interface makes it not a good fit for Iceberg sink. I added a few more comment in the writer class: https://github.com/apache/iceberg/pull/4904/files#r951000248.
I think we need to address this high-level design question first with the Flink community before we can really adopt the v2 sink interface. So far, we haven't heard back anything on the email thread. We will have to figure out who can we work with from the Flink community.
cc @hililiwei @pvary @kbendick @rdblue
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936682692
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
Review Comment:
since we are using the `Table` interface here, it is better not to assume implementation class are serializable. Let's just use `SerializableTable` interface which is introduced for this purpose. As long as we make sure it is used for read-only path. Once `table` is serialized (when shipping to taskmanager), I believe it becomes a `SerializableTable` anyway.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910560368
##########
flink/v1.15/flink/src/test/java/org/apache/iceberg/flink/sink/v2/TestFlinkIcebergSinkV2.java:
##########
@@ -0,0 +1,508 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.functions.KeySelector;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.test.util.MiniClusterWithClientResource;
+import org.apache.flink.types.Row;
+import org.apache.flink.types.RowKind;
+import org.apache.iceberg.AssertHelpers;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableProperties;
+import org.apache.iceberg.TableTestBase;
+import org.apache.iceberg.data.IcebergGenerics;
+import org.apache.iceberg.data.Record;
+import org.apache.iceberg.flink.MiniClusterResource;
+import org.apache.iceberg.flink.SimpleDataUtil;
+import org.apache.iceberg.flink.TestTableLoader;
+import org.apache.iceberg.flink.source.BoundedTestSource;
+import org.apache.iceberg.io.CloseableIterable;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableList;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.Types;
+import org.apache.iceberg.util.StructLikeSet;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.ClassRule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+@RunWith(Parameterized.class)
+public class TestFlinkIcebergSinkV2 extends TableTestBase {
+
+ @ClassRule
+ public static final MiniClusterWithClientResource MINI_CLUSTER_RESOURCE =
+ MiniClusterResource.createWithClassloaderCheckDisabled();
+
+ @ClassRule
+ public static final TemporaryFolder TEMPORARY_FOLDER = new TemporaryFolder();
+
+ private static final int FORMAT_V2 = 2;
+ private static final TypeInformation<Row> ROW_TYPE_INFO =
+ new RowTypeInfo(SimpleDataUtil.FLINK_SCHEMA.getFieldTypes());
+
+ private static final Map<String, RowKind> ROW_KIND_MAP = ImmutableMap.of(
+ "+I", RowKind.INSERT,
+ "-D", RowKind.DELETE,
+ "-U", RowKind.UPDATE_BEFORE,
+ "+U", RowKind.UPDATE_AFTER);
+
+ private static final int ROW_ID_POS = 0;
+ private static final int ROW_DATA_POS = 1;
+
+ private final FileFormat format;
+ private final int parallelism;
+ private final boolean partitioned;
+ private final String writeDistributionMode;
+
+ private StreamExecutionEnvironment env;
+ private TestTableLoader tableLoader;
+
+ @Parameterized.Parameters(name = "FileFormat = {0}, Parallelism = {1}, Partitioned={2}, WriteDistributionMode ={3}")
+ public static Object[][] parameters() {
+ return new Object[][] {
+ new Object[] {"avro", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+
+ new Object[] {"orc", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+
+ new Object[] {"parquet", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE}
+ };
+ }
+
+ public TestFlinkIcebergSinkV2(String format, int parallelism, boolean partitioned, String writeDistributionMode) {
+ super(FORMAT_V2);
+ this.format = FileFormat.valueOf(format.toUpperCase(Locale.ENGLISH));
+ this.parallelism = parallelism;
+ this.partitioned = partitioned;
+ this.writeDistributionMode = writeDistributionMode;
+ }
+
+ @Before
+ public void setupTable() throws IOException {
+ this.tableDir = temp.newFolder();
+ this.metadataDir = new File(tableDir, "metadata");
+ Assert.assertTrue(tableDir.delete());
+
+ if (!partitioned) {
+ table = create(SimpleDataUtil.SCHEMA, PartitionSpec.unpartitioned());
+ } else {
+ table = create(SimpleDataUtil.SCHEMA, PartitionSpec.builderFor(SimpleDataUtil.SCHEMA).identity("data").build());
+ }
+
+ table.updateProperties()
+ .set(TableProperties.DEFAULT_FILE_FORMAT, format.name())
+ .set(TableProperties.WRITE_DISTRIBUTION_MODE, writeDistributionMode)
+ .commit();
+
+ env = StreamExecutionEnvironment.getExecutionEnvironment(MiniClusterResource.DISABLE_CLASSLOADER_CHECK_CONFIG)
+ .enableCheckpointing(100L)
+ .setParallelism(parallelism)
+ .setMaxParallelism(parallelism);
+
+ tableLoader = new TestTableLoader(tableDir.getAbsolutePath());
+ }
+
+ private List<Snapshot> findValidSnapshots(Table table) {
+ List<Snapshot> validSnapshots = Lists.newArrayList();
+ for (Snapshot snapshot : table.snapshots()) {
+ if (snapshot.allManifests(table.io()).stream().anyMatch(m -> snapshot.snapshotId() == m.snapshotId())) {
+ validSnapshots.add(snapshot);
+ }
+ }
+ return validSnapshots;
+ }
+
+ private void testChangeLogs(List<String> equalityFieldColumns,
+ KeySelector<Row, Object> keySelector,
+ boolean insertAsUpsert,
+ List<List<Row>> elementsPerCheckpoint,
+ List<List<Record>> expectedRecordsPerCheckpoint) throws Exception {
+ DataStream<Row> dataStream = env.addSource(new BoundedTestSource<>(elementsPerCheckpoint), ROW_TYPE_INFO);
+
+ FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA)
+ .tableLoader(tableLoader)
+ .tableSchema(SimpleDataUtil.FLINK_SCHEMA)
+ .writeParallelism(parallelism)
+ .equalityFieldColumns(equalityFieldColumns)
+ .upsert(insertAsUpsert)
+ .append();
+
+ // Execute the program.
+ env.execute("Test Iceberg Change-Log DataStream.");
+
+ table.refresh();
+ List<Snapshot> snapshots = findValidSnapshots(table);
+ int expectedSnapshotNum = expectedRecordsPerCheckpoint.size();
+ Assert.assertEquals("Should have the expected snapshot number", expectedSnapshotNum, snapshots.size());
+
+ for (int i = 0; i < expectedSnapshotNum; i++) {
+ long snapshotId = snapshots.get(i).snapshotId();
+ List<Record> expectedRecords = expectedRecordsPerCheckpoint.get(i);
+ Assert.assertEquals("Should have the expected records for the checkpoint#" + i,
+ expectedRowSet(expectedRecords.toArray(new Record[0])), actualRowSet(snapshotId, "*"));
+ }
+ }
+
+ private Row row(String rowKind, int id, String data) {
+ RowKind kind = ROW_KIND_MAP.get(rowKind);
+ if (kind == null) {
+ throw new IllegalArgumentException("Unknown row kind: " + rowKind);
+ }
+
+ return Row.ofKind(kind, id, data);
+ }
+
+ private Record record(int id, String data) {
+ return SimpleDataUtil.createRecord(id, data);
+ }
+
+ @Test
+ public void testCheckAndGetEqualityFieldIds() {
+ table.updateSchema()
+ .allowIncompatibleChanges()
+ .addRequiredColumn("type", Types.StringType.get())
+ .setIdentifierFields("type")
+ .commit();
+
+ DataStream<Row> dataStream = env.addSource(new BoundedTestSource<>(ImmutableList.of()), ROW_TYPE_INFO);
+ FlinkSink.Builder builder = FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA).table(table);
+
+ // Use schema identifier field IDs as equality field id list by default
+ Assert.assertEquals(
+ table.schema().identifierFieldIds(),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+
+ // Use user-provided equality field column as equality field id list
+ builder.equalityFieldColumns(Lists.newArrayList("id"));
+ Assert.assertEquals(
+ Sets.newHashSet(table.schema().findField("id").fieldId()),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+
+ builder.equalityFieldColumns(Lists.newArrayList("type"));
+ Assert.assertEquals(
+ Sets.newHashSet(table.schema().findField("type").fieldId()),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+ }
+
+ @Test
+ public void testChangeLogOnIdKey() throws Exception {
+ List<List<Row>> elementsPerCheckpoint = ImmutableList.of(
+ ImmutableList.of(
+ row("+I", 1, "aaa"),
+ row("-D", 1, "aaa"),
+ row("+I", 1, "bbb"),
+ row("+I", 2, "aaa"),
+ row("-D", 2, "aaa"),
+ row("+I", 2, "bbb")
+ ),
+ ImmutableList.of(
+ row("-U", 2, "bbb"),
+ row("+U", 2, "ccc"),
+ row("-D", 2, "ccc"),
+ row("+I", 2, "ddd")
+ ),
+ ImmutableList.of(
+ row("-D", 1, "bbb"),
+ row("+I", 1, "ccc"),
+ row("-D", 1, "ccc"),
+ row("+I", 1, "ddd")
+ )
+ );
+
+ List<List<Record>> expectedRecords = ImmutableList.of(
+ ImmutableList.of(record(1, "bbb"), record(2, "bbb")),
+ ImmutableList.of(record(1, "bbb"), record(2, "ddd")),
+ ImmutableList.of(record(1, "ddd"), record(2, "ddd"))
+ );
+
+ if (partitioned && writeDistributionMode.equals(TableProperties.WRITE_DISTRIBUTION_MODE_HASH)) {
Review Comment:
This is a redundant unit test, and I have removed it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r990932968
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
> Yeah agreed that the lack of global committer presents a problem for us. Even the post-commit topology sounds like possibly not the right place (based on name alone even). Plus we lose access to using that for doing small file merging etc
post-commit topology is one cycle behind Commiter, so it is currently fine to use it for small file merges and index generation, and we use it internally as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947381333
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
+ }
+
+ @Override
+ public Committer<FilesCommittable> createCommitter() {
+ return committer != null
+ ? committer
+ : new FilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ public void setCommitter(Committer<FilesCommittable> committer) {
Review Comment:
Just for ut. Maybe add `@VisibleForTesting` for it?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946975047
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
I am not a fan of using global partitioner to achieve essentially single parallelism behavior with parallel downstream committer operators. if we only need a single-parallelism committer, why don't we make it explicitly so. having parallel committers tasks and only route committables to task 0 is weird. It can also lead to more questions from users why other committer sutasks have zero input. Sink V1 interface from Flink has `GlobalCommitter` interface, which would work well for Iceberg use case. It seems that in sink V2 has no equivalent replacement. Javadoc mentioned `WithPostCommitTopology`.
Are we supposed to do sth like this for global committer?
```
private class GlobalCommittingSinkAdapter extends TwoPhaseCommittingSinkAdapter
implements WithPostCommitTopology<InputT, CommT> {
@Override
public void addPostCommitTopology(DataStream<CommittableMessage<CommT>> committables) {
StandardSinkTopologies.addGlobalCommitter(
committables,
GlobalCommitterAdapter::new,
() -> sink.getCommittableSerializer().get());
}
}
```
But they what is the purpose of the regular committer from `TwoPhaseCommittingSink#createCommitter`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927760168
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
>So the Iceberg table commit is not idempotent
We are of one mind on this point.
When flink recovers from a pre-checkpoint, it will retrieve the state data of the checkpoint(When a CommitterOperator receives a CommittableMessage, it stores it in the state.), which contain all `FilesCommittable`, regardless of whether the `FilesCommittable` was committed at the last checkpoint. When the current checkpoint fires, it excludes `FilesCommittable` marked as committed. So, if we don't mark it as committed after a `FilesCommittable` commit, it will be committed again.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936142713
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
Review Comment:
nit: can we move this to the first line?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936158511
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
Review Comment:
I think there are four types of checkpoint data in the for loop:
1. The data of the current checkpoint of the current job, not restored from the checkpoint-data.
2. The data of the current checkpoint of the current job, restored from the checkpoint-data.
Check whether the current checkpoint-id is larger than the checkpoint-id committed last time(From the memory cache, because the checkpointid of the current task is incremented.). If yes, continue to commite. If no, skip.
3. The data of the current checkpoint of the current job, but try to commit again
We determine the number of getNumberOfRetries. If the number is greater than 0, try to retry commit.
4. Pre job, must be recovered from the checkpoint-data.
Check whether the data of the checkpoint has been committed based on the jobID (from iceberg table metadata).
Therefore, the checkpoingid in the for loop is not strictly incremental. It contains the current checkpointid and restore checkpointid, which is come from the previous checkpoint of the current task(triggered when the job is automatically retried due to an error), and which is recovered from the previous job.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936143204
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
Review Comment:
nit: can we move the upsert validation to a separate method. might looks a little cleaner that way.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936199011
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
Review Comment:
In addition, if a job is restore from the previous job checkpoint, its checkpoint id will be incremented from the pre.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#issuecomment-1199117002
@hililiwei: I think commit failure handling is a key here, and we should create several test cases to cover partially failing and retried commits so we can later check that the code written here is able to handle the failures correctly.
Thanks,
Peter
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r933636131
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
Review Comment:
And it is monotonically increasing in our `for` loop as well?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926468115
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
Review Comment:
Should we do the error handling here too, like in the `commitDeltaTxn`?
```
} catch (Exception e) {
commitRequest.signalFailedWithUnknownReason(e);
}
}
commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
writeResults.forEach(CommitRequest::signalAlreadyCommitted);
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926537643
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,616 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes writers that can write
+ * data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log after the
+ * compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class FlinkSink implements StatefulSink<RowData, StreamWriterState>,
Review Comment:
done. rename to `IcebergSink`. thx.
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/FlinkSink.java:
##########
@@ -64,6 +64,10 @@
import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+/**
+ * @deprecated use {@link org.apache.iceberg.flink.sink.v2.FlinkSink}
+ **/
+@Deprecated
Review Comment:
done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926825888
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java:
##########
@@ -31,7 +31,7 @@
import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
-import org.apache.iceberg.flink.sink.FlinkSink;
+import org.apache.iceberg.flink.sink.v2.FlinkSink;
Review Comment:
Maybe `table.exec.iceberg.use-flip143-sink`.
Here is the source config from my r[ecently opened PR](https://github.com/apache/iceberg/pull/5318/files#diff-dcbfb695653a4eb40200eef1889e2526122c3748c6846ef40d90987bdf0a7563).
```
public static final ConfigOption<Boolean> TABLE_EXEC_ICEBERG_USE_FLIP27_SOURCE =
ConfigOptions.key("table.exec.iceberg.use-flip27-source")
.booleanType()
.defaultValue(false)
.withDescription("Use the FLIP-27 based Iceberg source implementation.");
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937570148
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommittable.java:
##########
@@ -0,0 +1,79 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.Serializable;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+
+public class FilesCommittable implements Serializable {
+ private final WriteResult committable;
+ private String jobID = "";
+ private long checkpointId;
+ private int subtaskId;
+
+ public FilesCommittable(WriteResult committable) {
+ this.committable = committable;
+ }
+
+ public FilesCommittable(WriteResult committable, String jobID, long checkpointId, int subtaskId) {
+ this.committable = committable;
+ this.jobID = jobID;
+ this.checkpointId = checkpointId;
+ this.subtaskId = subtaskId;
+ }
+
+ public WriteResult committable() {
+ return committable;
+ }
+
+ public Long checkpointId() {
+ return checkpointId;
+ }
+
+ public String jobID() {
Review Comment:
Do we always use capital letters for `jobID`, and different capitalisation for other id-s, like `checkpointId` - not really important, but strange to see it handled differently with other id-s
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910704230
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
Why do we need `EqualityFieldKeySelector`? Will the requirement be lost if we use `PartitionKeyFieldSelector`? Do we need another `KeyBy` operator to handle the case that equality keys are not the source of partition keys?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910986374
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
If equality keys are not the source of partition keys, then the data with the same equal column value may be divided into different partitions, which is not allowed.
use PartitionKeyFieldSelector, the data is written to the correct partition, and because the partitioned fields is part of the equal fields, it does not cause data results to be abnormal.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937647610
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
Review Comment:
Why do we commit these separately?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r909628196
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
Review Comment:
What do you mean by each separated task? We usually have only one sink in the Flink job. Or you mean the table is loaded previously and here can be skipped?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r944699913
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,278 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNum = 0;
+ int deleteFilesNum = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ // The job id has never written data to the table.
+ store.add(request);
+ dataFilesNum = dataFilesNum + committable.dataFiles().length;
+ deleteFilesNum = deleteFilesNum + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ // committable is restored from the previous job that committed data to the table.
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNum, deleteFilesNum, store);
+ // Since flink's checkpoint id will start from the max-committed-checkpoint-id + 1 in the new
+ // flink job even if it's restored from a snapshot created by another different flink job, so
+ // it's safe to assign the max committed checkpoint id from restored flink job to the current
+ // flink job.
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
Review Comment:
The order of the `CommitRequests` are important, so the `commitRequest` object should be a `List`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946330008
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
Review Comment:
I found the `StreamWriter#restoreWrite` method name a little confusing. `initializedState` seems more accurate to me.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r990934356
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
> The lack of GlobalCommitter in the v2 sink interface makes it not a good fit for Iceberg sink. I added a few more comment in the writer class: https://github.com/apache/iceberg/pull/4904/files#r951000248.
>
> I think we need to address this high-level design question first with the Flink community before we can really adopt the v2 sink interface. So far, we haven't heard back anything on the email thread. We will have to figure out who can we work with from the Flink community.
>
> cc @hililiwei @pvary @kbendick @rdblue
As discussed in the mail thread, the ability to customize Commiter parallelism is what we need. This capability does not seem to be available until at least >flink 1.17, and for now, there are no obvious blocking issues that require us to use the new sink right away. So it looks like we might be able to wait until flink provides this capability before going back and optimizing it.
But maybe one thing we need to consider is that the auto-compacting of small files is a good thing for the user. Maybe we can consider using it the current way (using global), because it doesn't have a problem with functionality, just commiters that won't do anything. Adaptation comes after flink provides the ability to customize Commiter parallelism.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937584112
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ RowDelta rowDelta = table.newRowDelta().scanManifestsWith(workerPool);
+ Arrays.stream(result.dataFiles()).forEach(rowDelta::addRows);
+ Arrays.stream(result.deleteFiles()).forEach(rowDelta::addDeletes);
+
+ String flinkJobId = commitRequest.getCommittable().jobID();
+ long checkpointId = commitRequest.getCommittable().checkpointId();
+ commitOperation(
+ commitRequest,
+ rowDelta,
+ dataFilesNum,
+ deleteFilesNum,
+ "rowDelta",
+ flinkJobId,
+ checkpointId);
+ }
+ }
+ }
+
+ private void commitOperation(
Review Comment:
Could we decrease the number of the `commitOperation` methods? They make the code hard to read
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937757605
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
> Do I assign all of them in advance at creation time
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925807046
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
Review Comment:
Good advice. Prefixes really mean nothing. Let me get rid of it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925868426
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
Review Comment:
Seems nice!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926458933
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
Review Comment:
Do we still need this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926493533
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
Based on the Flink documentation:
```
/**
* Signals that a committable is skipped as it was committed already in a previous run.
* Using this method is optional but eases bookkeeping and debugging. It also serves as a
* code documentation for the branches dealing with recovery.
*/
```
You know more about Flink than me, but this javadoc tells me that we should only call this when we skipped the commit, because it was committed in a previous run. Here it seems to be we are using it as signalling that the commit was successful. Or simply, I just misunderstand something.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926205984
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,616 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes writers that can write
+ * data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log after the
+ * compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class FlinkSink implements StatefulSink<RowData, StreamWriterState>,
Review Comment:
I would suggest not using `v2` in the package name, instead we can name the new sink impl as `IcebergSink`. That is also consistent with the FLIP-27 source `IcebergSource` vs the current `FlinkSource`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926442923
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommittableSerializer.java:
##########
@@ -0,0 +1,90 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.core.memory.DataInputDeserializer;
+import org.apache.flink.core.memory.DataOutputViewStreamWrapper;
+import org.apache.flink.util.InstantiationUtil;
+import org.apache.iceberg.io.WriteResult;
+
+class FilesCommittableSerializer implements SimpleVersionedSerializer<FilesCommittable> {
+ private static final int SERIALIZER_VERSION = 1;
+
+ @Override
+ public int getVersion() {
+ return SERIALIZER_VERSION;
+ }
+
+ @Override
+ public byte[] serialize(FilesCommittable committable) throws IOException {
+ ByteArrayOutputStream out = new ByteArrayOutputStream();
+ DataOutputViewStreamWrapper view = new DataOutputViewStreamWrapper(out);
+ byte[] serialize = writeResultSerializer.serialize(committable.committable());
+ view.writeUTF(committable.jobID());
+ view.writeLong(committable.checkpointId());
+ view.writeInt(committable.subtaskId());
+ view.writeInt(serialize.length);
+ view.write(serialize);
+ return out.toByteArray();
+ }
+
+ @Override
+ public FilesCommittable deserialize(int version, byte[] serialized) throws IOException {
+ switch (version) {
+ case SERIALIZER_VERSION:
+ DataInputDeserializer view = new DataInputDeserializer(serialized);
+ String jobID = view.readUTF();
+ long checkpointId = view.readLong();
+ int subtaskId = view.readInt();
+ int len = view.readInt();
+ byte[] buf = new byte[len];
+ view.read(buf);
+ WriteResult writeResult = writeResultSerializer.deserialize(writeResultSerializer.getVersion(), buf);
+ return new FilesCommittable(writeResult, jobID, checkpointId, subtaskId);
+ default:
+ throw new IOException("Unrecognized version or corrupt state: " + version);
+ }
+ }
+
+ private final SimpleVersionedSerializer<WriteResult> writeResultSerializer =
+ new SimpleVersionedSerializer<WriteResult>() {
+ @Override
+ public int getVersion() {
+ return 1;
Review Comment:
Was it a conscious decision that the `writeResultSerializer` version is different than the `FilesCommittableSerializer`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r929491263
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/TaskWriterFactory.java:
##########
@@ -35,7 +35,7 @@
* @param taskId the identifier of task.
* @param attemptId the attempt id of this task.
*/
- void initialize(int taskId, int attemptId);
+ void initialize(int taskId, long attemptId);
Review Comment:
Undo the change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r933123422
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
Review Comment:
In the restored case, this request may be from the pre task, it may be submitted successfully or failed. We use the flink job ID to obtain the checkpointid of the last successful commite and compare it with the checkpointid carried by the request to determine whether the data is successfully submitted.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#issuecomment-1199122123
> @hililiwei: I think commit failure handling is a key here, and we should create several test cases to cover partially failing and retried commits so we can later check that the code written here is able to handle the failures correctly.
>
> Thanks, Peter
Indeed, let me try to add some unit tests for these case. thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r912335560
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
> > If equality keys are not the source of partition keys, then the data with the same equal column value may be divided into different partitions, which is not allowed.
>
> The check above states that _"In 'hash' distribution mode with equality fields set, partition field '%s' " + "should be included in equality fields: '%s'"_. It contradicts what you said.
Sorry for the confusion, I got sidetracked.
The reason we used EqualityFieldKeySelector, because we need to ensure all the same primary key record will be distributed to the same IcebergStreamWriter to ensure result correctness, . Bug when users set HASH distribution, the intention is to cluster data by partition columns. If the partition distribution satisfies the equality distribution, then this should use the partition distribution. Otherwise, it should use the equality distribution to guarantee correctness. The key point here, then, is that when the partition distribution is equal, we can use the partition distribution without violating the user's intent. So what is `satisfies the equality distribution`? Requiring all of the partition source fields are identifier fields.
refer to: #2898 https://github.com/apache/iceberg/pull/2898#discussion_r810411948
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r912335560
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
> > If equality keys are not the source of partition keys, then the data with the same equal column value may be divided into different partitions, which is not allowed.
>
> The check above states that _"In 'hash' distribution mode with equality fields set, partition field '%s' " + "should be included in equality fields: '%s'"_. It contradicts what you said.
Sorry for the confusion, I got sidetracked.
The reason we used EqualityFieldKeySelector, because we need to ensure all the same primary key record will be distributed to the same IcebergStreamWriter to ensure result correctness, . But when users set HASH distribution, the intention is to cluster data by partition columns. If we can use partition to to guarantee correctness, then we can use it, Otherwise, it should use the equality distribution. The key point here, In which case does partitioning distribution guarantee correctness of the results without violating user intent? Requiring all of the partition source fields are identifier fields.
refer to: #2898 https://github.com/apache/iceberg/pull/2898#discussion_r810411948
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r911663972
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
For example, if we have a composite key `(id, grade)` and a partition field `(grade)`, the `PartitionKeyFieldSelector` distribute data according to `grade` field which is apparently not enough. Or do you mean that we should build `PartitionSpec` upon both `id` and `grade`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910552417
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final transient Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private final transient int maxContinuousEmptyCommits;
Review Comment:
nich catch. This is a mistake. thx.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937695613
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
Review Comment:
Yes, I did deliberately separate the two.
Before I start to commit new data, I try to commit the data that needs to be retried in the last time. The main reason for doing this is that if I put it together with the current new data to be submitted, would it cause an unknowing error? I haven't thought of a use case like this yet. But if we are sure there is no problem, then this branch of judgment can be omitted.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937684728
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommittable.java:
##########
@@ -0,0 +1,79 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.Serializable;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+
+public class FilesCommittable implements Serializable {
+ private final WriteResult committable;
+ private String jobID = "";
+ private long checkpointId;
+ private int subtaskId;
+
+ public FilesCommittable(WriteResult committable) {
+ this.committable = committable;
+ }
+
+ public FilesCommittable(WriteResult committable, String jobID, long checkpointId, int subtaskId) {
+ this.committable = committable;
+ this.jobID = jobID;
+ this.checkpointId = checkpointId;
+ this.subtaskId = subtaskId;
+ }
+
+ public WriteResult committable() {
+ return committable;
+ }
+
+ public Long checkpointId() {
+ return checkpointId;
+ }
+
+ public String jobID() {
Review Comment:
The usage of Flink is followed here. 😄
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947380756
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
Review Comment:
Nice catch. Honestly, this is one of the things that puzzled me. So let's talk about it.
There is only one implementation of `initialize`:
```
@Override
public void initialize(int taskId, int attemptId) {
this.outputFileFactory =
OutputFileFactory.builderFor(table, taskId, attemptId).format(format).build();
}
```
And the signature of `OutputFileFactory.builderFor` goes like this:
```
public static Builder builderFor(Table table, int partitionId, long taskId) {
return new Builder(table, partitionId, taskId);
}
```
so, in the `initialize` method, the pass-through relationship is as follows:
```
initialize:taskId -> builderFor.partitionId
initialize:attemptId -> builderFor.taskId
```
It makes me feel a little confused.
I'm trying to reestablish this relationship here:
```
numberOfParallelSubtasks -> builderFor.partitionId
subTaskId -> builderFor.taskId
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947671199
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,278 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
Review Comment:
Are you worried that the `FilesCommittable` of two(or more) commit action will be put into one collection?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
kbendick commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947026504
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
+1 to avoiding having subtasks that don’t process any input. Even if it’s correct, it will look strange when monitoring. Being more explicit by using the code @stevenzwu mentioned or somehow repartitioning to 1 would make the user experience better as seeing many tasks where only one gets input would be the first thing I’d start investigating upon too much backpressure etc.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
kbendick commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947022791
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
Review Comment:
Nit: I would go with `initializeState` (without the d) but I agree with @stevenzwu . It matches the argument name, and in the case of using an empty collection to avoid the `if` block to return early it also reads a bit more fluently to me.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936136723
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
Review Comment:
sink needs to be serializable. Iceberg `Table` is not serializable. There is a read-only `SerializableTable`.
Does this work in a distributed runtime? wondering if I miss sth.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936388794
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r951000248
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
+
+ @Override
+ public void close() throws Exception {
+ if (writer != null) {
+ writer.close();
+ writer = null;
+ }
+ }
+
+ @Override
+ public String toString() {
+ return MoreObjects.toStringHelper(this)
+ .add("table_name", fullTableName)
+ .add("subtask_id", subTaskId)
+ .toString();
+ }
+
+ @Override
+ public Collection<FilesCommittable> prepareCommit() throws IOException {
+ writeResultsState.add(new FilesCommittable(writer.complete()));
+ this.writer = taskWriterFactory.create();
+ return writeResultsState;
+ }
+
+ @Override
+ public List<StreamWriterState> snapshotState(long checkpointId) {
+ List<StreamWriterState> state = Lists.newArrayList();
+ state.add(new StreamWriterState(Lists.newArrayList(writeResultsState)));
Review Comment:
I am not saying with should use `Manifest` as `CommT`. Again, this is where I feel the v2 sink interface is not a good fit for Iceberg. In the v1 sink interface, we have `GlobalCommT` for `GlobalCommitter`. That will be the ideal interface for Iceberg sink. `WriteResult` would be `CommT` and `Manifest` will be `GlobalCommT`.
```
public interface GlobalCommitter<CommT, GlobalCommT>
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r951000248
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
+
+ @Override
+ public void close() throws Exception {
+ if (writer != null) {
+ writer.close();
+ writer = null;
+ }
+ }
+
+ @Override
+ public String toString() {
+ return MoreObjects.toStringHelper(this)
+ .add("table_name", fullTableName)
+ .add("subtask_id", subTaskId)
+ .toString();
+ }
+
+ @Override
+ public Collection<FilesCommittable> prepareCommit() throws IOException {
+ writeResultsState.add(new FilesCommittable(writer.complete()));
+ this.writer = taskWriterFactory.create();
+ return writeResultsState;
+ }
+
+ @Override
+ public List<StreamWriterState> snapshotState(long checkpointId) {
+ List<StreamWriterState> state = Lists.newArrayList();
+ state.add(new StreamWriterState(Lists.newArrayList(writeResultsState)));
Review Comment:
I am not saying with should use `Manifest` as `CommT`. Again, this is where I feel the v2 sink interface is not a good fit for Iceberg. In the v1 sink interface, we have `GlobalCommT` for `GlobalCommitter`. That will be the ideal interface for Iceberg sink. `WriteResult` would be `CommT` and `Manifest` will be `GlobalCommT`.
```
public interface GlobalCommitter<CommT, GlobalCommT>
```
Here is the how that Iceberg sink works today and how I hope that it should continue to work with v2 sink interface. Writers flushed the data files and send `WriteResult` to the global committer. The global committer checkpoints the `Manifest` file for fault tolerance/exactly-once.
I understand that `WriteResult` only contains the metadata. It can still be substantial in certain use cases. E.g.,
- writer parallelism is 1,000
- Each writer writes to 100 files (e.g. bucketing or hourly partition by event time)
- table has many columns. with column-level stats (min, max, count, null etc.). it would be significant metadata bytes per data file. say there are 200 columns, and each columns stats take up 100 bytes. that is 20 KB per file.
- each checkpoint would have size of 20 KB x 100 x 1,000. that is 2 GB.
- if checkpoint interval is 5 minutes and commit can't succeed for 10 hours, we are talking about 120 checkpoints. Then Iceberg sink would accumulate 240 GB of state.
I know this is the worst-case scenario, but it is the motivation behind the current IcebergSink design where the global committer only checkpoint one `ManifestFile` per checkpoint cycle.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r933085239
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
Review Comment:
Are we sure that the `checkpointId` is monotonously increasing?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r942150770
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
Review Comment:
> Reading your code I had to change my mental model a bit, because I understand now, that commits with deletes should be committed separately, so we need to order the commits by commitId, and collect the commits until we find a commit with delete files. In this case, we have to commit the previous batch, and then commit to current one, and then we can continue going through the rest.
👍 Because of the particularity of the v2 row-level delete, it is processed separately.
> The other part of my review comment was referring to the ways how Iceberg handles commits atomicity and retries.
If Iceberg fails to commit the request, we do not retry it. So, I've streamlined the code here, and when a commit fails, we `signalFailedWithKnownReason` or `signalFailedWithUnknownReason`. This way, when Iceberg fails to commit. If iceberg itself tries again and still fails, it makes no sense for us to retry the commit again and may produce errors.
In the recovery case, when the job is recovered from the pre, it immediately attempts to commit the data of the pre-job. Therefore, the data of the current job does not coexist with the pre.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936680198
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
we can extract the config inside the `FlinkWriteConf`, which can be serializable. we don't have to make `FlinkConfParser` serializable, as `ReadableConfig` is not serializable.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947307158
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
+
+ @Override
+ public void close() throws Exception {
+ if (writer != null) {
+ writer.close();
+ writer = null;
+ }
+ }
+
+ @Override
+ public String toString() {
+ return MoreObjects.toStringHelper(this)
+ .add("table_name", fullTableName)
+ .add("subtask_id", subTaskId)
+ .toString();
+ }
+
+ @Override
+ public Collection<FilesCommittable> prepareCommit() throws IOException {
+ writeResultsState.add(new FilesCommittable(writer.complete()));
+ this.writer = taskWriterFactory.create();
+ return writeResultsState;
+ }
+
+ @Override
+ public List<StreamWriterState> snapshotState(long checkpointId) {
+ List<StreamWriterState> state = Lists.newArrayList();
+ state.add(new StreamWriterState(Lists.newArrayList(writeResultsState)));
Review Comment:
Checkpoint individual data files as writer state can be expensive. E.g., if one checkpoint cycle produces a lot of files with many columns, the amount of metadata can be very significant.
I am also think we shouldn't checkpoint the flushed files here. What does it help?
In the current `FlinkSink` implementation, `IcebergFilesCommitter` checkpoint a staging `ManifestFile` object per checkpoint sync. Here we only need to checkpoint a single manifest file per cycle, which is very small in size. Upon successful commit, committer clears the committed manifest files. Upon commit failure, manifest files are accumulate and attempted for commit in the next checkpoint cycle.
Checkpoint the flushed data files here doesn't bring fault tolerance in my understanding.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946975047
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
I am not a fan of this API from Flink. if we only need a single-parallelism committer, why don't we make it explicitly so. having parallel committers tasks and only route committables to task 0 is weird and can lead to more questions.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947377245
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
Review Comment:
Nice. Thx.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947377137
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
Review Comment:
Yes, it's not strictly necessary, and I'm trying to make it more clear about its inheritance. Removed. Thx.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937631836
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ RowDelta rowDelta = table.newRowDelta().scanManifestsWith(workerPool);
+ Arrays.stream(result.dataFiles()).forEach(rowDelta::addRows);
+ Arrays.stream(result.deleteFiles()).forEach(rowDelta::addDeletes);
+
+ String flinkJobId = commitRequest.getCommittable().jobID();
+ long checkpointId = commitRequest.getCommittable().checkpointId();
+ commitOperation(
+ commitRequest,
+ rowDelta,
+ dataFilesNum,
+ deleteFilesNum,
+ "rowDelta",
+ flinkJobId,
+ checkpointId);
+ }
+ }
+ }
+
+ private void commitOperation(
+ CommitRequest<FilesCommittable> commitRequest,
+ SnapshotUpdate<?> operation,
+ int numDataFiles,
+ int numDeleteFiles,
+ String description,
+ String newFlinkJobId,
+ long checkpointId) {
+ commitOperation(
+ Lists.newArrayList(commitRequest),
+ operation,
+ numDataFiles,
+ numDeleteFiles,
+ description,
+ newFlinkJobId,
+ checkpointId);
+ }
+
+ private void commitOperation(
+ Collection<CommitRequest<FilesCommittable>> commitRequests,
+ SnapshotUpdate<?> operation,
+ int numDataFiles,
+ int numDeleteFiles,
+ String description,
+ String newFlinkJobId,
+ long checkpointId) {
+ try {
+ commitOperation(
+ operation, numDataFiles, numDeleteFiles, description, newFlinkJobId, checkpointId);
+ } catch (AlreadyExistsException | UnsupportedOperationException e) {
+ commitRequests.forEach(request -> request.signalFailedWithKnownReason(e));
+ } catch (Exception e) {
+ commitRequests.forEach(request -> request.signalFailedWithUnknownReason(e));
+ }
+ }
+
+ private void commitOperation(
+ SnapshotUpdate<?> operation,
+ int numDataFiles,
+ int numDeleteFiles,
+ String description,
+ String newFlinkJobId,
+ long checkpointId) {
+ LOG.info(
+ "Committing {} with {} data files and {} delete files to table {}",
+ description,
+ numDataFiles,
+ numDeleteFiles,
+ table);
+ // custom snapshot metadata properties will be overridden if they conflict with internal ones
+ // used by the sink.
+ snapshotProperties.forEach(operation::set);
+ operation.set(MAX_COMMITTED_CHECKPOINT_ID, Long.toString(checkpointId));
+ operation.set(FLINK_JOB_ID, newFlinkJobId);
+
+ long start = System.currentTimeMillis();
+ operation.commit(); // abort is automatically called if this fails.
+ long duration = System.currentTimeMillis() - start;
+ LOG.info("Committed in {} ms", duration);
+ }
+
+ static long getMaxCommittedCheckpointId(Table table, String flinkJobId) {
+ Snapshot snapshot = table.currentSnapshot();
+ long lastCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
Review Comment:
Is the table.history ordered by the time?
Do we commit anything without `MAX_COMMITTED_CHECKPOINT_ID` with the given `FLINK_JOB_ID`?
We might be able to use the things above to get a smaller, more readable method.
Also we usually avoid `get`. Either use `find`, or just use `maxCommittedCheckpointId`
```
private static long maxCommittedCheckpointId(Table table, String flinkJobId) {
for (HistoryEntry history : table.history()) {
Map<String, String> summary = table.snapshot(history.snapshotId()).summary();
if (flinkJobId.equals(summary..get(FLINK_JOB_ID))) {
return Long.parseLong(summary..get(MAX_COMMITTED_CHECKPOINT_ID));
}
}
return INITIAL_CHECKPOINT_ID;
}
```
Or:
```
private static long maxCommittedCheckpointId(org.apache.iceberg.Table table, String flinkJobId) {
return table.history().stream()
.map(history -> table.snapshot(history.snapshotId()).summary())
.filter(summary -> summary.containsKey(FLINK_JOB_ID))
.findFirst()
.map(summary -> Long.parseLong(summary.get(MAX_COMMITTED_CHECKPOINT_ID)))
.orElse(INITIAL_CHECKPOINT_ID);
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937714161
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
Review Comment:
The reason for this is the same as committing data for `request.getNumberOfRetries() > 0` separately. `committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)` means data is restore from the previous job, i will try to commit them first.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r945109271
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommittable.java:
##########
@@ -0,0 +1,79 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.Serializable;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+
+public class FilesCommittable implements Serializable {
+ private final WriteResult committable;
+ private String jobId = "";
+ private long checkpointId;
+ private int subtaskId;
+
+ public FilesCommittable(WriteResult committable) {
Review Comment:
yes.
https://github.com/apache/iceberg/blob/1b3feee3172bcde54670ca76db53d6c4507d83e8/flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java#L96-L100
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946331892
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
Review Comment:
this line is not needed, right? `StatefulSinkWriter` already extends `SinkWriter`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r959093861
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
Review Comment:
Copy that. Let me fix it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r950997554
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
+ }
+
+ @Override
+ public Committer<FilesCommittable> createCommitter() {
+ return committer != null
+ ? committer
+ : new FilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ public void setCommitter(Committer<FilesCommittable> committer) {
Review Comment:
yeah. adding the annotation would help. also if the unit test is in the same package, we can also make it package private.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910696588
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergStreamWriter.java:
##########
@@ -0,0 +1,135 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class IcebergStreamWriter implements
+ StatefulSinkWriter<RowData, IcebergStreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, IcebergFlinkCommittable> {
+
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient String jobId;
+ private transient int subTaskId;
+ private transient long attemptId;
+ private List<IcebergFlinkCommittable> writeResultsRestore = Lists.newArrayList();
+
+ public IcebergStreamWriter(String fullTableName, TaskWriter<RowData> writer, int subTaskId,
+ long attemptId) {
+ this.fullTableName = fullTableName;
+ this.writer = writer;
+ this.subTaskId = subTaskId;
+ this.attemptId = attemptId;
+ }
+
+ public IcebergStreamWriter(String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ String jobId, int subTaskId,
+ long attemptId) {
+ this.fullTableName = fullTableName;
+ this.jobId = jobId;
+ this.subTaskId = subTaskId;
+ this.attemptId = attemptId;
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(subTaskId, attemptId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ public void writeResults(List<IcebergFlinkCommittable> newWriteResults) {
+ this.writeResultsRestore = newWriteResults;
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {
Review Comment:
Do we need to emit the pending data like v1 sink?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910056864
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
Since the partition fields are included in equality fields, should we use `EqualityFieldKeySelector`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r924376982
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,603 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
+ this.overwrite = flinkWriteConf.overwriteMode();
+ this.distributionMode = flinkWriteConf.distributionMode();
+ this.workerPoolSize = flinkWriteConf.workerPoolSize();
+ this.targetDataFileSize = flinkWriteConf.targetDataFileSize();
+ this.dataFileFormat = flinkWriteConf.dataFileFormat();
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, targetDataFileSize, dataFileFormat, upsertMode,
+ flinkRowType, equalityFieldIds, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ long targetDataFileSize,
+ FileFormat dataFileFormat,
+ boolean upsertMode,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetDataFileSize, dataFileFormat, equalityFieldIds, upsertMode);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private Integer writeParallelism = null;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+ private final Map<String, String> writeOptions = Maps.newHashMap();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ /**
+ * Set the write properties for Flink sink.
+ * View the supported properties in {@link FlinkWriteOptions}
+ */
+ public Builder set(String property, String value) {
+ writeOptions.put(property, value);
+ return this;
+ }
+
+ /**
+ * Set the write properties for Flink sink.
+ * View the supported properties in {@link FlinkWriteOptions}
+ */
+ public Builder setAll(Map<String, String> properties) {
+ writeOptions.putAll(properties);
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ writeOptions.put(FlinkWriteOptions.OVERWRITE_MODE.key(), Boolean.toString(newOverwrite));
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ if (mode != null) {
+ writeOptions.put(FlinkWriteOptions.DISTRIBUTION_MODE.key(), mode.modeName());
+ }
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ writeOptions.put(FlinkWriteOptions.WRITE_UPSERT_ENABLED.key(), Boolean.toString(enabled));
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
Review Comment:
Should we change this comment to match the new topology?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r924399071
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
Review Comment:
Why `Integer` and not `int`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927797880
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
Review Comment:
Sorry for the late reply. I've been thinking about what you said.
The goal should be to avoid writing duplicate data. So our best bet was to come up with a mechanism that would allow us to submit the data exactly once.
I will test the failed commit case again soon.
Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925745898
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
Review Comment:
Thanks!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926205113
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java:
##########
@@ -31,7 +31,7 @@
import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
-import org.apache.iceberg.flink.sink.FlinkSink;
+import org.apache.iceberg.flink.sink.v2.FlinkSink;
Review Comment:
I would recommend let's not switch to the new impl in the first release as we are still learning the behaviors of new sink interface. it is better to provide a config for users to the new sink impl
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937581651
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
Review Comment:
Are we sure in this case that some parallel retries or anything has not committed this request to the table concurrently?
I have to check the other `if` branches too, but I think we always should check the current `maxCommittedCheckpointId` from the table.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937744501
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
Review Comment:
`spotlessJava` formatted it automatically. 😂
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r938457365
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
Review Comment:
I would go with the simpler code first, and add new checks only if we find a specific case for it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910099579
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final transient Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private final transient int maxContinuousEmptyCommits;
+
+
+ private final transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(), MAX_CONTINUOUS_EMPTY_COMMITS, 10);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<IcebergFlinkCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<IcebergFlinkCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<IcebergFlinkCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<IcebergFlinkCommittable> request : requests) {
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ checkpointId = request.getCommittable().checkpointId();
+ restored.add(request);
+ WriteResult committable = request.getCommittable().committable();
Review Comment:
We can extract the same code out of if/else block.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r906920689
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFlinkCommittableSerializer.java:
##########
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.core.memory.DataInputDeserializer;
+import org.apache.flink.core.memory.DataOutputViewStreamWrapper;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.util.SerializationUtil;
+
+public class IcebergFlinkCommittableSerializer implements SimpleVersionedSerializer<IcebergFlinkCommittable> {
+
+ @Override
+ public int getVersion() {
+ return 1;
Review Comment:
done.thx.
##########
flink/v1.15/flink/src/test/java/org/apache/iceberg/flink/sink/v2/TestFlinkIcebergSink.java:
##########
@@ -0,0 +1,330 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Collections;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.stream.Collectors;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.test.util.MiniClusterWithClientResource;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.AssertHelpers;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableProperties;
+import org.apache.iceberg.flink.MiniClusterResource;
+import org.apache.iceberg.flink.SimpleDataUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.source.BoundedTestSource;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.ClassRule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+@RunWith(Parameterized.class)
+public class TestFlinkIcebergSink {
+
+ @ClassRule
+ public static final MiniClusterWithClientResource MINI_CLUSTER_RESOURCE =
+ MiniClusterResource.createWithClassloaderCheckDisabled();
+
+ @ClassRule
+ public static final TemporaryFolder TEMPORARY_FOLDER = new TemporaryFolder();
+
+ private static final TypeInformation<Row> ROW_TYPE_INFO = new RowTypeInfo(
+ SimpleDataUtil.FLINK_SCHEMA.getFieldTypes());
+ private static final DataFormatConverters.RowConverter CONVERTER = new DataFormatConverters.RowConverter(
+ SimpleDataUtil.FLINK_SCHEMA.getFieldDataTypes());
+
+ private Table table;
+ private StreamExecutionEnvironment env;
+ private TableLoader tableLoader;
+
+ private final FileFormat format;
+ private final int parallelism;
+ private final boolean partitioned;
+
+ @Parameterized.Parameters(name = "format={0}, parallelism = {1}, partitioned = {2}")
+ public static Object[][] parameters() {
+ return new Object[][] {
+ {"avro", 1, true},
+ {"avro", 1, false},
+ {"avro", 2, true},
+ {"avro", 2, false},
+
+ {"orc", 1, true},
+ {"orc", 1, false},
+ {"orc", 2, true},
+ {"orc", 2, false},
+
+ {"parquet", 1, true},
+ {"parquet", 1, false},
+ {"parquet", 2, true},
+ {"parquet", 2, false}
+ };
+ }
+
+ public TestFlinkIcebergSink(String format, int parallelism, boolean partitioned) {
+ this.format = FileFormat.valueOf(format.toUpperCase(Locale.ENGLISH));
+ this.parallelism = parallelism;
+ this.partitioned = partitioned;
+ }
+
+ @Before
+ public void before() throws IOException {
+ File folder = TEMPORARY_FOLDER.newFolder();
+ String warehouse = folder.getAbsolutePath();
+
+ String tablePath = warehouse.concat("/test");
+ Assert.assertTrue("Should create the table path correctly.", new File(tablePath).mkdir());
+
+ Map<String, String> props = ImmutableMap.of(TableProperties.DEFAULT_FILE_FORMAT, format.name());
+ table = SimpleDataUtil.createTable(tablePath, props, partitioned);
+
+ env = StreamExecutionEnvironment.getExecutionEnvironment(MiniClusterResource.DISABLE_CLASSLOADER_CHECK_CONFIG)
+ .enableCheckpointing(100)
+ .setParallelism(parallelism)
+ .setMaxParallelism(parallelism);
+
+ tableLoader = TableLoader.fromHadoopTable(tablePath);
+ }
+
+ private List<RowData> convertToRowData(List<Row> rows) {
+ return rows.stream().map(CONVERTER::toInternal).collect(Collectors.toList());
+ }
+
+ private BoundedTestSource<Row> createBoundedSource(List<Row> rows) {
+ return new BoundedTestSource<>(rows.toArray(new Row[0]));
+ }
+
+ @Test
+ public void testWriteRowData() throws Exception {
+ List<Row> rows = Lists.newArrayList(
+ Row.of(1, "hello"),
+ Row.of(2, "world"),
+ Row.of(3, "foo")
+ );
+ DataStream<RowData> dataStream = env.addSource(createBoundedSource(rows), ROW_TYPE_INFO)
+ .map(CONVERTER::toInternal, FlinkCompatibilityUtil.toTypeInfo(SimpleDataUtil.ROW_TYPE));
+
+ FlinkSink.forRowData(dataStream)
+ .table(table)
+ .tableLoader(tableLoader)
+ .writeParallelism(parallelism)
+ .append();
+
+ // Execute the program.
+ env.execute("Test Iceberg DataStream");
+
+ // Assert the iceberg table's records.
+ SimpleDataUtil.assertTableRows(table, convertToRowData(rows));
+ }
+
+ private List<Row> createRows(String prefix) {
+ return Lists.newArrayList(
+ Row.of(1, prefix + "aaa"),
+ Row.of(1, prefix + "bbb"),
+ Row.of(1, prefix + "ccc"),
+ Row.of(2, prefix + "aaa"),
+ Row.of(2, prefix + "bbb"),
+ Row.of(2, prefix + "ccc"),
+ Row.of(3, prefix + "aaa"),
+ Row.of(3, prefix + "bbb"),
+ Row.of(3, prefix + "ccc")
+ );
+ }
+
+ private void testWriteRow(TableSchema tableSchema, DistributionMode distributionMode) throws Exception {
+ List<Row> rows = createRows("");
+ DataStream<Row> dataStream = env.addSource(createBoundedSource(rows), ROW_TYPE_INFO);
+
+ FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA)
+ .table(table)
+ .tableLoader(tableLoader)
+ .tableSchema(tableSchema)
+ .writeParallelism(parallelism)
+ .distributionMode(distributionMode)
+ .append();
+
+ // Execute the program.
+ env.execute("Test Iceberg DataStream.");
+
+ SimpleDataUtil.assertTableRows(table, convertToRowData(rows));
+ }
+
+ private int partitionFiles(String partition) throws IOException {
+ return SimpleDataUtil.partitionDataFiles(table, ImmutableMap.of("data", partition)).size();
+ }
+
+ @Test
+ public void testWriteRow() throws Exception {
+ testWriteRow(null, DistributionMode.NONE);
+ }
+
+ @Test
+ public void testWriteRowWithTableSchema() throws Exception {
+ testWriteRow(SimpleDataUtil.FLINK_SCHEMA, DistributionMode.NONE);
+ }
+
+ @Test
+ public void testJobNoneDistributeMode() throws Exception {
+ table.updateProperties()
+ .set(TableProperties.WRITE_DISTRIBUTION_MODE, DistributionMode.HASH.modeName())
+ .commit();
+
+ testWriteRow(null, DistributionMode.NONE);
+
+ if (parallelism > 1) {
+ if (partitioned) {
+ int files = partitionFiles("aaa") + partitionFiles("bbb") + partitionFiles("ccc");
+ Assert.assertTrue("Should have more than 3 files in iceberg table.", files > 3);
+ }
+ }
+ }
+
+ @Test
+ public void testJobHashDistributionMode() {
Review Comment:
It seems to test both overwrite props and the inability to use Range in Flink sink.
This is from the org.apache.iceberg.flink.sink.TestFlinkIcebergSink
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910559643
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
Good question. When we have more equality fields than the partition fields, will it cause data distribution errors if we use EqualityFieldKeySelector?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r906770017
##########
flink/v1.15/flink/src/test/java/org/apache/iceberg/flink/sink/v2/TestFlinkIcebergSink.java:
##########
@@ -0,0 +1,330 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.Collections;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.stream.Collectors;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.test.util.MiniClusterWithClientResource;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.AssertHelpers;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableProperties;
+import org.apache.iceberg.flink.MiniClusterResource;
+import org.apache.iceberg.flink.SimpleDataUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.source.BoundedTestSource;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.ClassRule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+@RunWith(Parameterized.class)
+public class TestFlinkIcebergSink {
+
+ @ClassRule
+ public static final MiniClusterWithClientResource MINI_CLUSTER_RESOURCE =
+ MiniClusterResource.createWithClassloaderCheckDisabled();
+
+ @ClassRule
+ public static final TemporaryFolder TEMPORARY_FOLDER = new TemporaryFolder();
+
+ private static final TypeInformation<Row> ROW_TYPE_INFO = new RowTypeInfo(
+ SimpleDataUtil.FLINK_SCHEMA.getFieldTypes());
+ private static final DataFormatConverters.RowConverter CONVERTER = new DataFormatConverters.RowConverter(
+ SimpleDataUtil.FLINK_SCHEMA.getFieldDataTypes());
+
+ private Table table;
+ private StreamExecutionEnvironment env;
+ private TableLoader tableLoader;
+
+ private final FileFormat format;
+ private final int parallelism;
+ private final boolean partitioned;
+
+ @Parameterized.Parameters(name = "format={0}, parallelism = {1}, partitioned = {2}")
+ public static Object[][] parameters() {
+ return new Object[][] {
+ {"avro", 1, true},
+ {"avro", 1, false},
+ {"avro", 2, true},
+ {"avro", 2, false},
+
+ {"orc", 1, true},
+ {"orc", 1, false},
+ {"orc", 2, true},
+ {"orc", 2, false},
+
+ {"parquet", 1, true},
+ {"parquet", 1, false},
+ {"parquet", 2, true},
+ {"parquet", 2, false}
+ };
+ }
+
+ public TestFlinkIcebergSink(String format, int parallelism, boolean partitioned) {
+ this.format = FileFormat.valueOf(format.toUpperCase(Locale.ENGLISH));
+ this.parallelism = parallelism;
+ this.partitioned = partitioned;
+ }
+
+ @Before
+ public void before() throws IOException {
+ File folder = TEMPORARY_FOLDER.newFolder();
+ String warehouse = folder.getAbsolutePath();
+
+ String tablePath = warehouse.concat("/test");
+ Assert.assertTrue("Should create the table path correctly.", new File(tablePath).mkdir());
+
+ Map<String, String> props = ImmutableMap.of(TableProperties.DEFAULT_FILE_FORMAT, format.name());
+ table = SimpleDataUtil.createTable(tablePath, props, partitioned);
+
+ env = StreamExecutionEnvironment.getExecutionEnvironment(MiniClusterResource.DISABLE_CLASSLOADER_CHECK_CONFIG)
+ .enableCheckpointing(100)
+ .setParallelism(parallelism)
+ .setMaxParallelism(parallelism);
+
+ tableLoader = TableLoader.fromHadoopTable(tablePath);
+ }
+
+ private List<RowData> convertToRowData(List<Row> rows) {
+ return rows.stream().map(CONVERTER::toInternal).collect(Collectors.toList());
+ }
+
+ private BoundedTestSource<Row> createBoundedSource(List<Row> rows) {
+ return new BoundedTestSource<>(rows.toArray(new Row[0]));
+ }
+
+ @Test
+ public void testWriteRowData() throws Exception {
+ List<Row> rows = Lists.newArrayList(
+ Row.of(1, "hello"),
+ Row.of(2, "world"),
+ Row.of(3, "foo")
+ );
+ DataStream<RowData> dataStream = env.addSource(createBoundedSource(rows), ROW_TYPE_INFO)
+ .map(CONVERTER::toInternal, FlinkCompatibilityUtil.toTypeInfo(SimpleDataUtil.ROW_TYPE));
+
+ FlinkSink.forRowData(dataStream)
+ .table(table)
+ .tableLoader(tableLoader)
+ .writeParallelism(parallelism)
+ .append();
+
+ // Execute the program.
+ env.execute("Test Iceberg DataStream");
+
+ // Assert the iceberg table's records.
+ SimpleDataUtil.assertTableRows(table, convertToRowData(rows));
+ }
+
+ private List<Row> createRows(String prefix) {
+ return Lists.newArrayList(
+ Row.of(1, prefix + "aaa"),
+ Row.of(1, prefix + "bbb"),
+ Row.of(1, prefix + "ccc"),
+ Row.of(2, prefix + "aaa"),
+ Row.of(2, prefix + "bbb"),
+ Row.of(2, prefix + "ccc"),
+ Row.of(3, prefix + "aaa"),
+ Row.of(3, prefix + "bbb"),
+ Row.of(3, prefix + "ccc")
+ );
+ }
+
+ private void testWriteRow(TableSchema tableSchema, DistributionMode distributionMode) throws Exception {
+ List<Row> rows = createRows("");
+ DataStream<Row> dataStream = env.addSource(createBoundedSource(rows), ROW_TYPE_INFO);
+
+ FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA)
+ .table(table)
+ .tableLoader(tableLoader)
+ .tableSchema(tableSchema)
+ .writeParallelism(parallelism)
+ .distributionMode(distributionMode)
+ .append();
+
+ // Execute the program.
+ env.execute("Test Iceberg DataStream.");
+
+ SimpleDataUtil.assertTableRows(table, convertToRowData(rows));
+ }
+
+ private int partitionFiles(String partition) throws IOException {
+ return SimpleDataUtil.partitionDataFiles(table, ImmutableMap.of("data", partition)).size();
+ }
+
+ @Test
+ public void testWriteRow() throws Exception {
+ testWriteRow(null, DistributionMode.NONE);
+ }
+
+ @Test
+ public void testWriteRowWithTableSchema() throws Exception {
+ testWriteRow(SimpleDataUtil.FLINK_SCHEMA, DistributionMode.NONE);
+ }
+
+ @Test
+ public void testJobNoneDistributeMode() throws Exception {
+ table.updateProperties()
+ .set(TableProperties.WRITE_DISTRIBUTION_MODE, DistributionMode.HASH.modeName())
+ .commit();
+
+ testWriteRow(null, DistributionMode.NONE);
+
+ if (parallelism > 1) {
+ if (partitioned) {
+ int files = partitionFiles("aaa") + partitionFiles("bbb") + partitionFiles("ccc");
+ Assert.assertTrue("Should have more than 3 files in iceberg table.", files > 3);
+ }
+ }
+ }
+
+ @Test
+ public void testJobHashDistributionMode() {
Review Comment:
This is test overwrite table properties with range mode, right?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r906791371
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
Review Comment:
if the table loader can not be null, why do we need to pass in the table and not just call `loadTable`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r912335560
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
> > If equality keys are not the source of partition keys, then the data with the same equal column value may be divided into different partitions, which is not allowed.
>
> The check above states that _"In 'hash' distribution mode with equality fields set, partition field '%s' " + "should be included in equality fields: '%s'"_. It contradicts what you said.
Sorry for the confusion, I got sidetracked.
The reason we used EqualityFieldKeySelector, because we need to ensure all the same primary key record will be distributed to the same IcebergStreamWriter to ensure result correctness, . Bug when users set HASH distribution, the intention is to cluster data by partition columns. If the partition distribution satisfies the equality distribution, then this should use the partition distribution. Otherwise, it should use the equality distribution to guarantee correctness. The key point here, then, is that when the partition distribution is satisfies the equal, we can use the partition distribution without violating the user's intent. So what is `satisfies the equality distribution`? Requiring all of the partition source fields are identifier fields.
refer to: #2898 https://github.com/apache/iceberg/pull/2898#discussion_r810411948
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925812879
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(),
+ MAX_CONTINUOUS_EMPTY_COMMITS,
+ MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<IcebergFlinkCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<IcebergFlinkCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<IcebergFlinkCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<IcebergFlinkCommittable> request : requests) {
+ checkpointId = request.getCommittable().checkpointId();
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ }
+ } else {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
Review Comment:
Not necessarily. When we have no data to commit, we increase the number of empty commits by one. When it fires the condition, we also make a commit.
```java
private void commitResult(int dataFilesNum, int deleteFilesNum,
Collection<CommitRequest<FilesCommittable>> committableCollection) {
int totalFiles = dataFilesNum + deleteFilesNum;
continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
if (totalFiles != 0 || continuousEmptyCheckpoints % maxContinuousEmptyCommits == 0) {
if (replacePartitions) {
replacePartitions(committableCollection, deleteFilesNum);
} else {
commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
}
continuousEmptyCheckpoints = 0;
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#issuecomment-1190567116
> @hililiwei: I am getting second thoughts about this newline stuff. We usually try to add a newline after every block. I see that in several places we do not really adhere to it. Still might worth to check if you think the code would look better.
Thank you for your review. I'll check it as soon as possible.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r924400194
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
Review Comment:
Shall we check the `workerPoolSize` value, or it is already done somewhere else?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925829493
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(),
+ MAX_CONTINUOUS_EMPTY_COMMITS,
+ MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<IcebergFlinkCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<IcebergFlinkCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<IcebergFlinkCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<IcebergFlinkCommittable> request : requests) {
+ checkpointId = request.getCommittable().checkpointId();
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ }
+ } else {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
Review Comment:
If I understand correctly we count the empty checkpoints, but why do we need to create a new commit after 10 checkpoints, even if we did not write anything? Is this something like a liveliness check? Does this update some metadata on the table, even if no new files are added?
Thanks!
Peter
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925838744
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,591 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+public class FlinkSink implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
Review Comment:
nit: newline after block
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926205984
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,616 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes writers that can write
+ * data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log after the
+ * compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class FlinkSink implements StatefulSink<RowData, StreamWriterState>,
Review Comment:
I would suggest not using `v2` in the package name, instead we can name the new sink impl as `IcebergSink`. That is also consistent with the FLIP-27 source `IcebergSource` vs the current `FlinkSource`.
This can also avoid making some of the classes public in this PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927222316
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
Review Comment:
done. thx.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927823486
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
Thank you very much for your question. It made me realize that I seemed to be relying too much on Flink's own fault-tolerant mechanism. We should go back to using `max-checkpoint-id`.
Multiple `FilesCommittable` are committed simultaneously, but marking as committed is serial. It is not atomic with the data commite action, which leads to the above problems. As you said above, we have to deduce that from reading the Iceberg table metadata.
When the commit is successful, We need to record `max-checkpoint-id` in the table. When the FilesCommittable re-try , we should check whether its checkpoint id is greater than the max.
Besides, we don't need `signalAlreadyCommitted` anymore.
So let me rewrite this logic.
Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926827105
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/FlinkWriteOptions.java:
##########
@@ -54,4 +54,8 @@ private FlinkWriteOptions() {
ConfigOptions.key("distribution-mode")
.stringType().noDefaultValue();
+ // enable iceberg new sink
+ public static final ConfigOption<Boolean> ICEBERG_SINK =
Review Comment:
this should be defined in `FlinkConfigOptions` as the central place.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926508430
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,616 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes writers that can write
+ * data to files in parallel and route commit info globally to one Committer.
Review Comment:
maybe reword it to: a single Committer?
maybe remove keep only a single Committer instance on the graph.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r938582635
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
Review Comment:
Then I may need to change the data structure to a linked list, and put the data that restored from checkpoint to the head, let me try.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936199011
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
Review Comment:
In addition, if a job is restore from the previous job checkpoint, its checkpoint id will be incremented from the pre job.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936317838
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937637330
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
Review Comment:
Do we want to try to commit a previously unsuccessful commit without considering the new data? Was this a conscious decision to do this separately? Wouldn't it be better to try to commit as few times as possible and try to commit this together with the other requests?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937704969
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ RowDelta rowDelta = table.newRowDelta().scanManifestsWith(workerPool);
+ Arrays.stream(result.dataFiles()).forEach(rowDelta::addRows);
+ Arrays.stream(result.deleteFiles()).forEach(rowDelta::addDeletes);
+
+ String flinkJobId = commitRequest.getCommittable().jobID();
+ long checkpointId = commitRequest.getCommittable().checkpointId();
+ commitOperation(
+ commitRequest,
+ rowDelta,
+ dataFilesNum,
+ deleteFilesNum,
+ "rowDelta",
+ flinkJobId,
+ checkpointId);
+ }
+ }
+ }
+
+ private void commitOperation(
+ CommitRequest<FilesCommittable> commitRequest,
+ SnapshotUpdate<?> operation,
+ int numDataFiles,
+ int numDeleteFiles,
+ String description,
+ String newFlinkJobId,
+ long checkpointId) {
+ commitOperation(
+ Lists.newArrayList(commitRequest),
+ operation,
+ numDataFiles,
+ numDeleteFiles,
+ description,
+ newFlinkJobId,
+ checkpointId);
+ }
+
+ private void commitOperation(
+ Collection<CommitRequest<FilesCommittable>> commitRequests,
+ SnapshotUpdate<?> operation,
+ int numDataFiles,
+ int numDeleteFiles,
+ String description,
+ String newFlinkJobId,
+ long checkpointId) {
+ try {
+ commitOperation(
+ operation, numDataFiles, numDeleteFiles, description, newFlinkJobId, checkpointId);
+ } catch (AlreadyExistsException | UnsupportedOperationException e) {
+ commitRequests.forEach(request -> request.signalFailedWithKnownReason(e));
+ } catch (Exception e) {
+ commitRequests.forEach(request -> request.signalFailedWithUnknownReason(e));
+ }
+ }
+
+ private void commitOperation(
+ SnapshotUpdate<?> operation,
+ int numDataFiles,
+ int numDeleteFiles,
+ String description,
+ String newFlinkJobId,
+ long checkpointId) {
+ LOG.info(
+ "Committing {} with {} data files and {} delete files to table {}",
+ description,
+ numDataFiles,
+ numDeleteFiles,
+ table);
+ // custom snapshot metadata properties will be overridden if they conflict with internal ones
+ // used by the sink.
+ snapshotProperties.forEach(operation::set);
+ operation.set(MAX_COMMITTED_CHECKPOINT_ID, Long.toString(checkpointId));
+ operation.set(FLINK_JOB_ID, newFlinkJobId);
+
+ long start = System.currentTimeMillis();
+ operation.commit(); // abort is automatically called if this fails.
+ long duration = System.currentTimeMillis() - start;
+ LOG.info("Committed in {} ms", duration);
+ }
+
+ static long getMaxCommittedCheckpointId(Table table, String flinkJobId) {
+ Snapshot snapshot = table.currentSnapshot();
+ long lastCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
Review Comment:
That is great! Thank you. 👏
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r950999210
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
Review Comment:
maybe add a short javadoc to explain why this is empty.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r944698889
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,278 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNum = 0;
+ int deleteFilesNum = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ // The job id has never written data to the table.
+ store.add(request);
+ dataFilesNum = dataFilesNum + committable.dataFiles().length;
+ deleteFilesNum = deleteFilesNum + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ // committable is restored from the previous job that committed data to the table.
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNum, deleteFilesNum, store);
+ // Since flink's checkpoint id will start from the max-committed-checkpoint-id + 1 in the new
+ // flink job even if it's restored from a snapshot created by another different flink job, so
+ // it's safe to assign the max committed checkpoint id from restored flink job to the current
+ // flink job.
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ // We don't commit the merged result into a single transaction because for the sequential
+ // transaction txn1 and txn2, the equality-delete files of txn2 are required to be applied
+ // to data files from txn1. Committing the merged one will lead to the incorrect delete
+ // semantic.
+ WriteResult result = commitRequest.getCommittable().committable();
+
+ // Row delta validations are not needed for streaming changes that write equality deletes.
+ // Equality deletes are applied to data in all previous sequence numbers, so retries may
+ // push deletes further in the future, but do not affect correctness. Position deletes
+ // committed to the table in this path are used only to delete rows from data files that are
+ // being added in this commit. There is no way for data files added along with the delete
+ // files to be concurrently removed, so there is no need to validate the files referenced by
+ // the position delete files that are being committed.
+ RowDelta rowDelta = table.newRowDelta().scanManifestsWith(workerPool);
+ Arrays.stream(result.dataFiles()).forEach(rowDelta::addRows);
+ Arrays.stream(result.deleteFiles()).forEach(rowDelta::addDeletes);
+
+ String flinkJobId = commitRequest.getCommittable().jobID();
+ long checkpointId = commitRequest.getCommittable().checkpointId();
+ commitOperation(
+ Lists.newArrayList(commitRequest),
+ rowDelta,
+ dataFilesNum,
+ deleteFilesNum,
+ "rowDelta",
+ flinkJobId,
+ checkpointId);
+ }
+ }
+ }
+
+ private void commitOperation(
+ Collection<CommitRequest<FilesCommittable>> commitRequests,
Review Comment:
The order of the `CommitRequests` are important, so this should be a `List`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r944702884
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommittable.java:
##########
@@ -0,0 +1,79 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.Serializable;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+
+public class FilesCommittable implements Serializable {
+ private final WriteResult committable;
+ private String jobId = "";
+ private long checkpointId;
+ private int subtaskId;
+
+ public FilesCommittable(WriteResult committable) {
Review Comment:
nit: is this constructor used?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
kbendick commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947030108
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
+ }
+
+ @Override
+ public Committer<FilesCommittable> createCommitter() {
+ return committer != null
+ ? committer
+ : new FilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ public void setCommitter(Committer<FilesCommittable> committer) {
+ this.committer = committer;
+ }
+
+ @Override
+ public SimpleVersionedSerializer<FilesCommittable> getCommittableSerializer() {
+ return new FilesCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<FilesCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg
+ * table. We use {@link RowData} inside the sink connector, so users need to provide a mapper
+ * function and a {@link TypeInformation} to convert those generic records to a RowData
+ * DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(
+ DataStream<T> input, MapFunction<T, RowData> mapper, TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into
+ * iceberg table. We use {@link RowData} inside the sink connector, so users need to provide a
+ * {@link TableSchema} for builder to convert those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter =
+ new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s
+ * into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s
+ * into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private FlinkWriteConf flinkWriteConf;
+ private TableSchema tableSchema;
+ private Integer writeParallelism = null;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+ private final Map<String, String> writeOptions = Maps.newHashMap();
+
+ private Builder() {}
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(
+ DataStream<T> input, MapFunction<T, RowData> mapper, TypeInformation<RowData> outputType) {
+ this.inputCreator =
+ newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
Review Comment:
Nit: missing space before `(in cdc case)`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946975047
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
I am not a fan of using global partitioner to achieve effectively global committer behavior with parallel downstream committer operators. if we only need a single-parallelism committer, why don't we make it explicitly so. having parallel committers tasks and only route committables to task 0 is weird. It can also lead to more questions from users why other committer subtasks have zero input. Sink V1 interface from Flink has `GlobalCommitter` interface, which would work well for Iceberg use case. It seems that in sink V2 has no equivalent replacement. Javadoc mentioned `WithPostCommitTopology`.
Are we supposed to do sth like this for global committer?
```
private class GlobalCommittingSinkAdapter extends TwoPhaseCommittingSinkAdapter
implements WithPostCommitTopology<InputT, CommT> {
@Override
public void addPostCommitTopology(DataStream<CommittableMessage<CommT>> committables) {
StandardSinkTopologies.addGlobalCommitter(
committables,
GlobalCommitterAdapter::new,
() -> sink.getCommittableSerializer().get());
}
}
```
But they what is the purpose of the regular committer from `TwoPhaseCommittingSink#createCommitter`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947036575
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
@hililiwei @pvary @kbendick FYI, I started a discussion thread in dev@flink. subject is `Sink V2 interface replacement for GlobalCommitter`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#issuecomment-1163052891
Thanks for ping me, I will take a look this week.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r924392482
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
Review Comment:
Just a question: With Hive we started to add `Iceberg` for the class names, even though the package name already contain the info. It seemed like a good idea at the time. Later I regretted this decision since all of the classes start with the same "meaningless" name. Do we need all class names here to start with Iceberg?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925867589
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,603 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
+ this.overwrite = flinkWriteConf.overwriteMode();
+ this.distributionMode = flinkWriteConf.distributionMode();
+ this.workerPoolSize = flinkWriteConf.workerPoolSize();
+ this.targetDataFileSize = flinkWriteConf.targetDataFileSize();
+ this.dataFileFormat = flinkWriteConf.dataFileFormat();
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, targetDataFileSize, dataFileFormat, upsertMode,
+ flinkRowType, equalityFieldIds, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ long targetDataFileSize,
+ FileFormat dataFileFormat,
+ boolean upsertMode,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
Review Comment:
Thanks!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927797880
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
Review Comment:
Sorry for the late reply. I've been thinking about what you said.
The goal should be to avoid writing duplicate data. So our best bet was to come up with a mechanism that would allow us to submit the data exactly one way.
I will test the failed commit case again soon.
Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947088976
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
Review Comment:
this if check is a little weird. The problem seems to be that `CommittableMessage` interface doesn't expose `getCommittable`, which I think we probably should add in Flink upstream.
It is also weird that Flink interface has the `CommT` generic type, but it is not used or exposed in the interface.
```
public interface CommittableMessage<CommT> {
/** The subtask that created this committable. */
int getSubtaskId();
/**
* Returns the checkpoint id or empty if the message does not belong to a checkpoint. In that
* case, the committable was created at the end of input (e.g., in batch mode).
*/
OptionalLong getCheckpointId();
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926387727
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,259 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(),
+ MAX_CONTINUOUS_EMPTY_COMMITS,
+ MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ checkpointId = request.getCommittable().checkpointId();
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
Review Comment:
removed this logic.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926478401
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
Review Comment:
Should we log the exception here, or it will be logged later by the infra anyway?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926676747
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,616 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes writers that can write
+ * data to files in parallel and route commit info globally to one Committer.
Review Comment:
Ahh... Thanks for the info! This absolutely makes sense for fault tolerance 😄
Then your wording and the graph is absolutely correct! Maybe a bit of improvement could be and route commit info globally to one of the Committers.`, but this is not too important.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925834889
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,259 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(),
+ MAX_CONTINUOUS_EMPTY_COMMITS,
+ MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ checkpointId = request.getCommittable().checkpointId();
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ }
+ } else {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
Review Comment:
nit: In Iceberg code we usually try to add an empty line after blocks
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926687910
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
A commit must be idempotent: If some failure occurs in Flink during commit phase, Flink will restart from previous checkpoint and re-attempt to commit all committables. Thus, some or all committables may have already been committed. These Committer.CommitRequests must not change the external system and implementers are asked to signal Committer.CommitRequest.signalAlreadyCommitted().
I call it mainly to avoid double commits.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927013385
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java:
##########
@@ -63,6 +64,16 @@ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
.map(UniqueConstraint::getColumns)
.orElseGet(ImmutableList::of);
+ if (readableConfig.getOptional(FlinkConfigOptions.TABLE_EXEC_ICEBERG_USE_FLIP143_SINK).orElse(false)) {
+ return (DataStreamSinkProvider) (providerContext, dataStream) -> IcebergSink.forRowData(dataStream)
+ .tableLoader(tableLoader)
+ .tableSchema(tableSchema)
+ .equalityFieldColumns(equalityColumns)
+ .overwrite(overwrite)
+ .flinkConf(readableConfig)
+ .append();
+ }
+
Review Comment:
nit: is if-else more symmetric here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927012348
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/FlinkConfigOptions.java:
##########
@@ -81,4 +81,11 @@ private FlinkConfigOptions() {
.intType()
.defaultValue(ThreadPools.WORKER_THREAD_POOL_SIZE)
.withDescription("The size of workers pool used to plan or scan manifests.");
+
+ // enable iceberg new sink
Review Comment:
nit: remove unnecessary comment
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926646529
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,616 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes writers that can write
+ * data to files in parallel and route commit info globally to one Committer.
Review Comment:
In fact, we have multiple Commiters, but all filesCommittables are sent to one of them.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925804706
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,603 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
+ this.overwrite = flinkWriteConf.overwriteMode();
+ this.distributionMode = flinkWriteConf.distributionMode();
+ this.workerPoolSize = flinkWriteConf.workerPoolSize();
+ this.targetDataFileSize = flinkWriteConf.targetDataFileSize();
+ this.dataFileFormat = flinkWriteConf.dataFileFormat();
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
Review Comment:
Yes, I agree with you. Let me see if there's a better way.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926665927
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
Review Comment:
done. thx.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927512380
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
I have tested the following sequence (slightly modified TestIcebergInputFormats.testFilterExp):
```java
[..]
helper = new TestHelper(conf, tables, location.toString(), SCHEMA, SPEC, fileFormat, temp);
[..]
helper.createTable();
List<Record> expectedRecords = helper.generateRandomRecords(2, 0L);
expectedRecords.get(0).set(2, "2020-03-20");
expectedRecords.get(1).set(2, "2020-03-20");
DataFile dataFile1 = helper.writeFile(Row.of("2020-03-20", 0), expectedRecords);
DataFile dataFile2 = helper.writeFile(Row.of("2020-03-21", 0), helper.generateRandomRecords(2, 0L));
helper.appendToTable(dataFile1, dataFile2); // This creates a transaction and adds the data files to it using 'table.newAppend()'
helper.appendToTable(dataFile1, dataFile2);
```
The resulting table contained the expected records twice. So the Iceberg table commit is not idempotent, adding the same file twice will duplicate the record. For me this means that we have to make sure that the `FilesCommitter.commit` is idempotent ourselves.
Reading only the FlinkSink documentation, I think that calling `commitRequest.signalAlreadyCommitted` does not guarantee that the commit operation will not be called again. I think we can not rely on any of the Flink variables / objects to know if a commit happened or not. I think we have to deduce that from reading the Iceberg table data / metadata for the current snapshot, as our only reliable source of information.
@hililiwei: Does this make sense? Do I miss something?
Thanks,
Peter
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927780519
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,224 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient int continuousEmptyCheckpoints;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ continuousEmptyCheckpoints = totalFiles == 0 ? continuousEmptyCheckpoints + 1 : 0;
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+
+ continuousEmptyCheckpoints = 0;
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ int numFiles = 0;
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> writeResult : writeResults) {
+ WriteResult result = writeResult.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = writeResult.getCommittable().jobID();
+ numFiles += result.dataFiles().length;
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(dynamicOverwrite, numFiles, 0, "dynamic partition overwrite", flinkJobId);
+ }
+
+ private void commitDeltaTxn(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = "";
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0,
+ "Should have no referenced data files.");
+
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ } catch (Exception e) {
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(appendFiles, dataFilesNum, 0, "append", flinkJobId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
Yes, what you said is right. If we have committed it, but haven't had time to mark it as committed, and the system fails, it will still re-commit when it recover from checkpoint.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925834143
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FilesCommitter.java:
##########
@@ -0,0 +1,259 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(),
+ MAX_CONTINUOUS_EMPTY_COMMITS,
+ MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ checkpointId = request.getCommittable().checkpointId();
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
Review Comment:
nit: we might do this check immediately after this:
```
checkpointId = request.getCommittable().checkpointId();
```
Not sure how much do you like using `continue`, but it could be a good candidate for this too.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946333565
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
Review Comment:
this is not correct.
```
void initialize(int taskId, int attemptId);
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946975047
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
I am not a fan of using global partitioner to achieve essentially single parallelism behavior with parallel downstream committer operators. if we only need a single-parallelism committer, why don't we make it explicitly so. having parallel committers tasks and only route committables to task 0 is weird and can lead to more questions. Sink V1 has `GlobalCommitter` interface, which would work well for Iceberg use case.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946981673
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
Review Comment:
is there any action needed during flush for batch execution?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
kbendick commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947020925
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
Review Comment:
+1 keeps things simpler.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910092450
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final transient Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private final transient int maxContinuousEmptyCommits;
Review Comment:
Why use final and trasient together?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910001167
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ }
+
+ case RANGE:
+ if (equalityFieldIds.isEmpty()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and {}=range is not supported yet in flink", WRITE_DISTRIBUTION_MODE);
+ return input;
Review Comment:
I think it would be better to throw an exception if we don't support it. Otherwise, the different behavior may confuse users.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910560717
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final transient Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private final transient int maxContinuousEmptyCommits;
+
+
+ private final transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(), MAX_CONTINUOUS_EMPTY_COMMITS, 10);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<IcebergFlinkCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<IcebergFlinkCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<IcebergFlinkCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<IcebergFlinkCommittable> request : requests) {
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ checkpointId = request.getCommittable().checkpointId();
+ restored.add(request);
+ WriteResult committable = request.getCommittable().committable();
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910696939
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergStreamWriterState.java:
##########
@@ -0,0 +1,45 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.Serializable;
+import java.util.List;
+
+public class IcebergStreamWriterState implements Serializable {
+
+ private final long checkpointId;
+
+ private List<IcebergFlinkCommittable> writeResults;
+
+ public IcebergStreamWriterState(long checkpointId, List<IcebergFlinkCommittable> writeResults) {
+ this.checkpointId = checkpointId;
+ this.writeResults = writeResults;
+ }
+
+ public List<IcebergFlinkCommittable> writeResults() {
+ return writeResults;
+ }
+
+ public void writeResults(List<IcebergFlinkCommittable> newWriteResults) {
+ this.writeResults = newWriteResults;
+ }
+
Review Comment:
nit: extra empty line.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r912335560
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
> > If equality keys are not the source of partition keys, then the data with the same equal column value may be divided into different partitions, which is not allowed.
>
> The check above states that _"In 'hash' distribution mode with equality fields set, partition field '%s' " + "should be included in equality fields: '%s'"_. It contradicts what you said.
Sorry for the confusion, I got sidetracked.
The reason we used EqualityFieldKeySelector, because we need to ensure all the same primary key record will be distributed to the same IcebergStreamWriter to ensure result correctness, . Bug when users set HASH distribution, the intention is to cluster data by partition columns. If we can use partition to to guarantee correctness, then we can use it, Otherwise, it should use the equality distribution. The key point here, then, in which case the partition distribution guarantees the correctness of the results without violating the user's intent. Requiring all of the partition source fields are identifier fields.
refer to: #2898 https://github.com/apache/iceberg/pull/2898#discussion_r810411948
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r951004617
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
+
+ @Override
+ public void close() throws Exception {
+ if (writer != null) {
+ writer.close();
+ writer = null;
+ }
+ }
+
+ @Override
+ public String toString() {
+ return MoreObjects.toStringHelper(this)
+ .add("table_name", fullTableName)
+ .add("subtask_id", subTaskId)
+ .toString();
+ }
+
+ @Override
+ public Collection<FilesCommittable> prepareCommit() throws IOException {
+ writeResultsState.add(new FilesCommittable(writer.complete()));
+ this.writer = taskWriterFactory.create();
+ return writeResultsState;
+ }
+
+ @Override
+ public List<StreamWriterState> snapshotState(long checkpointId) {
+ List<StreamWriterState> state = Lists.newArrayList();
+ state.add(new StreamWriterState(Lists.newArrayList(writeResultsState)));
Review Comment:
Here is the how that Iceberg sink works today and how I hope that it should continue to work with v2 sink interface. Writers flushed the data files and send `WriteResult` to the global committer. The global committer checkpoints the `Manifest` file for fault tolerance/exactly-once.
I understand that `WriteResult` only contains the metadata. It can still be substantial in certain use cases. E.g.,
- writer parallelism is 1,000
- Each writer writes to 100 files (e.g. bucketing or hourly partition by event time)
- table has many columns. with column-level stats (min, max, count, null etc.). it would be significant metadata bytes per data file. say there are 200 columns, and each columns stats take up 100 bytes. that is 20 KB per file.
- each checkpoint would have size of 20 KB x 100 x 1,000. that is 2 GB.
- if checkpoint interval is 5 minutes and commit can't succeed for 10 hours, we are talking about 120 checkpoints. Then Iceberg sink would accumulate 240 GB of state.
I know this is the worst-case scenario, but it is the motivation behind the current IcebergSink design where the global committer only checkpoint one `ManifestFile` per checkpoint cycle.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947386817
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
Review Comment:
`prepareCommit` is still called in batch mode, so I'm not doing any action here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947588607
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
+
+ @Override
+ public void close() throws Exception {
+ if (writer != null) {
+ writer.close();
+ writer = null;
+ }
+ }
+
+ @Override
+ public String toString() {
+ return MoreObjects.toStringHelper(this)
+ .add("table_name", fullTableName)
+ .add("subtask_id", subTaskId)
+ .toString();
+ }
+
+ @Override
+ public Collection<FilesCommittable> prepareCommit() throws IOException {
+ writeResultsState.add(new FilesCommittable(writer.complete()));
+ this.writer = taskWriterFactory.create();
+ return writeResultsState;
+ }
+
+ @Override
+ public List<StreamWriterState> snapshotState(long checkpointId) {
+ List<StreamWriterState> state = Lists.newArrayList();
+ state.add(new StreamWriterState(Lists.newArrayList(writeResultsState)));
Review Comment:
`writeResultsState` contains only the metadata of the data file. We don't really put data into the state.
If we remove the state here, this part of the data may be lost if the task fails after the file is closed and before it is sent to the committer.
The more important reason is, in the v2 Sink , `CommT` is transferred between the Writer and Commiter, flink automatically processes its state. If we're going to use `Manifest` instread of `WriteResult` as `CommT`, it means need to generate it in the every writer operator, so that it can be passed to the commiter, i think that's not reasonable. If we generate it in Commiter, as the `IcebergFilesCommitter` did, because the `CommT` still is `WriteResult`, the new version of Commiter doesn't put it in the state, so there is no practical point in generating it. Given the differences between the v1 and v2 versions, I currently feel it would be better to use WriterResult directly.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r948762700
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
Review Comment:
In fact, if we can directly getcheckpointid\jobid\subtaskId in `prepareCommit`, we do not need to assign them here.
The following is the Committable design document for reference.
>We also introduce two common wrappers around the Sink Committables to ease the implementation of the topologies based on committables.
>In these topologies, the committable will always be part of the CommittableWithLinage to have a notion to which checkpoint it belongs and from which subtask it was sent. In this case, it can be either the SinkWriter or Committer depending on which topology is used (pre- or post-commit). Moreover, we introduce the CommittableSummary that is sent once as the last message of this checkpoint. Down-stream operators receiving this message can be sure that the subtask the message was coming from does not send more messages in this checkpoint.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r944702639
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,278 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
Review Comment:
I think that Flink guarantees the order of the `requests`. OTOH I think we need these to be committed by the order of the commitId, before going through the loop.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r933091083
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ } catch (Exception e) {
+ LOG.error("Unable to process the committable: {}.", commitRequest.getCommittable(), e);
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(dynamicOverwrite, dataFilesNum, 0, "dynamic partition overwrite", flinkJobId, checkpointId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
I still think it is not correct to call this method here, since based on the documentation it will write logs that we tried to recommit the same change again (even if this is only the first time when we try to commit this specific change)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936320622
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
Review Comment:
The implementation classes of `Table` are all serializable.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936120650
##########
flink/v1.15/flink/src/test/java/org/apache/iceberg/flink/TestFlinkUpsert.java:
##########
@@ -51,31 +51,40 @@ public class TestFlinkUpsert extends FlinkCatalogTestBase {
@ClassRule public static final TemporaryFolder TEMPORARY_FOLDER = new TemporaryFolder();
private final boolean isStreamingJob;
+ private final boolean useNewSink;
private final Map<String, String> tableUpsertProps = Maps.newHashMap();
private TableEnvironment tEnv;
public TestFlinkUpsert(
- String catalogName, Namespace baseNamespace, FileFormat format, Boolean isStreamingJob) {
+ String catalogName,
+ Namespace baseNamespace,
+ FileFormat format,
+ Boolean isStreamingJob,
+ Boolean useNewSink) {
super(catalogName, baseNamespace);
this.isStreamingJob = isStreamingJob;
+ this.useNewSink = useNewSink;
tableUpsertProps.put(TableProperties.FORMAT_VERSION, "2");
tableUpsertProps.put(TableProperties.UPSERT_ENABLED, "true");
tableUpsertProps.put(TableProperties.DEFAULT_FILE_FORMAT, format.name());
}
@Parameterized.Parameters(
- name = "catalogName={0}, baseNamespace={1}, format={2}, isStreaming={3}")
+ name = "catalogName={0}, baseNamespace={1}, format={2}, isStreaming={3}, useNewSink={4}")
public static Iterable<Object[]> parameters() {
List<Object[]> parameters = Lists.newArrayList();
for (FileFormat format :
new FileFormat[] {FileFormat.PARQUET, FileFormat.AVRO, FileFormat.ORC}) {
for (Boolean isStreaming : new Boolean[] {true, false}) {
- // Only test with one catalog as this is a file operation concern.
- // FlinkCatalogTestBase requires the catalog name start with testhadoop if using hadoop
- // catalog.
- String catalogName = "testhadoop";
- Namespace baseNamespace = Namespace.of("default");
- parameters.add(new Object[] {catalogName, baseNamespace, format, isStreaming});
+ for (Boolean useNewSink : new Boolean[] {true, false}) {
Review Comment:
nit: inconsistent style with the TestFlinkTableSink, where we use two lines of `add` (rather a for loop like here).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r938782673
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ RowDelta rowDelta = table.newRowDelta().scanManifestsWith(workerPool);
+ Arrays.stream(result.dataFiles()).forEach(rowDelta::addRows);
+ Arrays.stream(result.deleteFiles()).forEach(rowDelta::addDeletes);
+
+ String flinkJobId = commitRequest.getCommittable().jobID();
+ long checkpointId = commitRequest.getCommittable().checkpointId();
+ commitOperation(
Review Comment:
Added some comment & UT
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937575751
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
Review Comment:
nit: formatting is different from the 2 other cases where we call this method
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r950997381
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
Review Comment:
Looks like Ryan answered it here: https://github.com/apache/iceberg/pull/5586#event-7223184134
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
kbendick commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r951045444
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
Yeah agreed that the lack of global committer presents a problem for us. Even the post-commit topology sounds like possibly not the right place (based on name alone even). Plus we lose access to using that for doing small file merging etc
The Flink community has a Slack now. Maybe we can go fishing for support / people to discuss with over there? I’m gonna look for the invite link but if anybody needs an invite now, I think I can do it if you send me your email.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r933093400
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ } catch (Exception e) {
+ LOG.error("Unable to process the committable: {}.", commitRequest.getCommittable(), e);
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(dynamicOverwrite, dataFilesNum, 0, "dynamic partition overwrite", flinkJobId, checkpointId);
Review Comment:
Should we try to commit partial changes if any of the previous calculations are thrown an `Exception`? I think it could cause issues, especially if some of the older changes are throwing an exception but a newer change commit is successful. The `checkpointId` is increased, and we will not try to commit the previously failed change. again
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937643558
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
Review Comment:
Maybe we want to calculate the `getMaxCommittedCheckpointId(table, jobId)` once per loop.
Also we have to make sure that the transaction is only committed if the Table has not been changed since between the time we get the `maxCommitterCheckpointId` and the commit. We have to make sure that commit is not automatically retried by some mechanism if there is a conflict
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r938469393
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
Review Comment:
Is it possible to commit some files in the pre-job, and commit some files in the actual job?
My previous understanding was, that we commit only in the committer, and we just collect all of the written files, calculate the min and the max commitId, check that it is not in conflict with the current Iceberg table data, and if everything is ok, then we commit them in one Iceberg commit.
Reading your code I had to change my mental model a bit, because I understand now, that commits with deletes should be committed separately, so we need to order the commits by commitId, and collect the commits until we find a commit with delete files. In this case, we have to commit the previous batch, and then commit to current one, and then we can continue going through the rest.
The other part of my review comment was referring to the ways how Iceberg handles commits atomicity and retries. Iceberg detects conflicts. When we start an Iceberg transaction we lock on an Iceberg snapshot (the actual snapshot of the table object we use to create the change), and if the table is changed before the Iceberg commit call, we will see a different current snapshotId for the table, and have an error.
So that is why we have to be careful when we refresh the table and when we retrieve the maxCommitId.
Also there are ways for Iceberg where the code tries to automatically recover conflicts. If the files does not conflict, then it tries to commit the changes with new metadata without notifying the caller (at least I have read about this somewhere). This retry logic might not be desirable for us. We have to check if this conflict handling will cause issues with our maxCommitId handing, or not
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937577512
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ RowDelta rowDelta = table.newRowDelta().scanManifestsWith(workerPool);
+ Arrays.stream(result.dataFiles()).forEach(rowDelta::addRows);
+ Arrays.stream(result.deleteFiles()).forEach(rowDelta::addDeletes);
+
+ String flinkJobId = commitRequest.getCommittable().jobID();
+ long checkpointId = commitRequest.getCommittable().checkpointId();
+ commitOperation(
Review Comment:
I think it is intentional to commit the changes one-by-one, so we know which delete file applies to which data file, but it would be good to leave a comment here to describe why we do this, so the developers reading this code later will not "fix" this issue - even better if we have a test for this as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937738811
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
Review Comment:
Maybe I didn't quite catch what you mean.
But one thing, I think, is that the table can be changed by other job between the time we get the `maxCommitterCheckpointId` and the commit. For a flink job, the JobId is unique, parallel jobs do not use the same jobid for writing.
When multiple Flink tasks are written in parallel, Iceberg itself ensures the transactional for commit actions. When it commits a conflict, it tries again.
For `committableCheckpointId> maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
|| getMaxCommittedCheckpointId(table, jobId) == -1`:
In theory, `maxCommittedCheckpointIdForJob` it will contain only at most two key, one is the job id of the current job, one is the `pre-job-id` of the pre-job.
No other task will have the same pre-job-id at the same time. So, we think that if `maxCommittedCheckpointIdForJob` does not contain the jobid of this request , and also no corresponding records in the table, then, that means
The jobid has never written data to the table. At this point, whether we are restore from the pre-job or it is the first time of this job, will accumulate the data and commit them all at once later.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937757605
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
> Do I assign all of them in advance at creation time
Yes
> the user changed the value of the table or config after initializing FlinkWriteConfig, then we would get the wrong value
your current implementation also only retrieve the config values once during job startup/initialization. there is no difference
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException(
+ "Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(
+ equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField,
+ equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
Review Comment:
> Do I assign all of them in advance at creation time
Yes
> the user changed the value of the table or config after initializing FlinkWriteConfig, then we would get the wrong value
your current implementation also only retrieve the config values once during job startup/initialization. there is no difference
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r937754593
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,314 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+ private static final int MAX_RECOMMIT_TIMES = 3;
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (request.getNumberOfRetries() > MAX_RECOMMIT_TIMES) {
+ String message =
+ String.format(
+ "Failed to commit transaction %s after retrying %d times",
+ request.getCommittable(), MAX_RECOMMIT_TIMES);
+ request.signalFailedWithUnknownReason(new RuntimeException(message));
+ } else if (request.getNumberOfRetries() > 0) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ } else if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ RowDelta rowDelta = table.newRowDelta().scanManifestsWith(workerPool);
+ Arrays.stream(result.dataFiles()).forEach(rowDelta::addRows);
+ Arrays.stream(result.deleteFiles()).forEach(rowDelta::addDeletes);
+
+ String flinkJobId = commitRequest.getCommittable().jobID();
+ long checkpointId = commitRequest.getCommittable().checkpointId();
+ commitOperation(
+ commitRequest,
+ rowDelta,
+ dataFilesNum,
+ deleteFilesNum,
+ "rowDelta",
+ flinkJobId,
+ checkpointId);
+ }
+ }
+ }
+
+ private void commitOperation(
Review Comment:
Reduced to one
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r933097644
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
Review Comment:
yes , monotonically increasing in one taks.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936135397
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,672 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ public IcebergSink(
Review Comment:
the constructor should be private
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925807649
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
Review Comment:
modified. thx.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927276571
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/TaskWriterFactory.java:
##########
@@ -35,7 +35,7 @@
* @param taskId the identifier of task.
* @param attemptId the attempt id of this task.
*/
- void initialize(int taskId, int attemptId);
+ void initialize(int taskId, long attemptId);
Review Comment:
why is this changed to `long`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r924369106
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,603 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> writeOptions,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+ FlinkWriteConf flinkWriteConf = new FlinkWriteConf(table, writeOptions, readableConfig);
+
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (flinkWriteConf.upsertMode()) {
+ Preconditions.checkState(
+ !flinkWriteConf.overwriteMode(),
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+
+ this.upsertMode = flinkWriteConf.upsertMode();
+ this.overwrite = flinkWriteConf.overwriteMode();
+ this.distributionMode = flinkWriteConf.distributionMode();
+ this.workerPoolSize = flinkWriteConf.workerPoolSize();
+ this.targetDataFileSize = flinkWriteConf.targetDataFileSize();
+ this.dataFileFormat = flinkWriteConf.dataFileFormat();
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
Review Comment:
This seems quite ugly. Are we reasonably sure that we have the correct objects here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r925868805
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
Review Comment:
Thx!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926207024
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/FlinkSink.java:
##########
@@ -64,6 +64,10 @@
import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+/**
+ * @deprecated use {@link org.apache.iceberg.flink.sink.v2.FlinkSink}
+ **/
+@Deprecated
Review Comment:
let's not mark the current sink impl as deprecated. Once we have gain enough confidence of the new sink impl, we can deprecate this class and switch the SQL to the new sink impl
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] pvary commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
pvary commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r924402754
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+ static final int MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT = 10;
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private transient int maxContinuousEmptyCommits;
+
+ private transient ExecutorService workerPool;
+
+ public IcebergFilesCommitter(TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ Integer workerPoolSize) {
+
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+
+ maxContinuousEmptyCommits = PropertyUtil.propertyAsInt(table.properties(),
+ MAX_CONTINUOUS_EMPTY_COMMITS,
+ MAX_CONTINUOUS_EMPTY_COMMITS_DEFAULT);
+ Preconditions.checkArgument(
+ maxContinuousEmptyCommits > 0,
+ MAX_CONTINUOUS_EMPTY_COMMITS + " must be positive");
+ this.maxCommittedCheckpointId = INITIAL_CHECKPOINT_ID;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<IcebergFlinkCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ long checkpointId = 0;
+ Collection<CommitRequest<IcebergFlinkCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<IcebergFlinkCommittable>> store = Lists.newArrayList();
+
+ for (CommitRequest<IcebergFlinkCommittable> request : requests) {
+ checkpointId = request.getCommittable().checkpointId();
+ WriteResult committable = request.getCommittable().committable();
+ if (request.getNumberOfRetries() > 0) {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ }
+ } else {
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
Review Comment:
Do we always have new stuff to store? Are the retries handled separately?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r936158884
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,238 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient long maxCommittedCheckpointId;
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(TableLoader tableLoader, boolean replacePartitions, Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool("iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ this.maxCommittedCheckpointId = -1L;
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNumRestored = 0;
+ int deleteFilesNumRestored = 0;
+
+ int dataFilesNumStored = 0;
+ int deleteFilesNumStored = 0;
+
+ Collection<CommitRequest<FilesCommittable>> restored = Lists.newArrayList();
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ long checkpointId = 0;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+
+ if (request.getCommittable().checkpointId() > maxCommittedCheckpointId) {
+ if (request.getNumberOfRetries() > 0) {
+ restored.add(request);
+ dataFilesNumRestored = dataFilesNumRestored + committable.dataFiles().length;
+ deleteFilesNumRestored = deleteFilesNumRestored + committable.deleteFiles().length;
+ } else {
+ store.add(request);
+ dataFilesNumStored = dataFilesNumStored + committable.dataFiles().length;
+ deleteFilesNumStored = deleteFilesNumStored + committable.deleteFiles().length;
+ }
+ checkpointId = Math.max(checkpointId, request.getCommittable().checkpointId());
+ }
+ }
+
+ if (restored.size() > 0) {
+ commitResult(dataFilesNumRestored, deleteFilesNumRestored, restored);
+ }
+
+ commitResult(dataFilesNumStored, deleteFilesNumStored, store);
+ this.maxCommittedCheckpointId = checkpointId;
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(int dataFilesNum, int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(Collection<CommitRequest<FilesCommittable>> writeResults, int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ try {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ } catch (Exception e) {
+ LOG.error("Unable to process the committable: {}.", commitRequest.getCommittable(), e);
+ commitRequest.signalFailedWithUnknownReason(e);
+ }
+ }
+
+ commitOperation(dynamicOverwrite, dataFilesNum, 0, "dynamic partition overwrite", flinkJobId, checkpointId);
+ writeResults.forEach(CommitRequest::signalAlreadyCommitted);
Review Comment:
~~I've removed it here and will use it only in the case of an exception that still thinks it's committed.~~
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r912414232
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
I see. Thanks for the explanation!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r926833617
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java:
##########
@@ -31,7 +31,7 @@
import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
-import org.apache.iceberg.flink.sink.FlinkSink;
+import org.apache.iceberg.flink.sink.v2.FlinkSink;
Review Comment:
nice.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r927012093
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/FlinkWriteOptions.java:
##########
@@ -53,5 +53,4 @@ private FlinkWriteOptions() {
public static final ConfigOption<String> DISTRIBUTION_MODE =
ConfigOptions.key("distribution-mode")
.stringType().noDefaultValue();
-
Review Comment:
revert unnecessary whitespace change
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946347503
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
+ }
+
+ @Override
+ public Committer<FilesCommittable> createCommitter() {
Review Comment:
Does this create parallel committers or single-parallelism committer?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947036575
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
Review Comment:
@hililiwei @pvary FYI, I started a discussion thread in dev@flink. subject is `Sink V2 interface replacement for GlobalCommitter`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r947307158
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/writer/StreamWriter.java:
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.writer;
+
+import java.io.IOException;
+import java.util.Collection;
+import java.util.List;
+import org.apache.flink.api.connector.sink2.SinkWriter;
+import org.apache.flink.api.connector.sink2.StatefulSink.StatefulSinkWriter;
+import org.apache.flink.api.connector.sink2.TwoPhaseCommittingSink;
+import org.apache.flink.table.data.RowData;
+import org.apache.iceberg.flink.sink.TaskWriterFactory;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.io.TaskWriter;
+import org.apache.iceberg.relocated.com.google.common.base.MoreObjects;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+
+public class StreamWriter
+ implements StatefulSinkWriter<RowData, StreamWriterState>,
+ SinkWriter<RowData>,
+ TwoPhaseCommittingSink.PrecommittingSinkWriter<RowData, FilesCommittable> {
+ private static final long serialVersionUID = 1L;
+
+ private final String fullTableName;
+ private final TaskWriterFactory<RowData> taskWriterFactory;
+ private transient TaskWriter<RowData> writer;
+ private transient int subTaskId;
+ private final List<FilesCommittable> writeResultsState = Lists.newArrayList();
+
+ public StreamWriter(
+ String fullTableName,
+ TaskWriterFactory<RowData> taskWriterFactory,
+ int subTaskId,
+ int numberOfParallelSubtasks) {
+ this.fullTableName = fullTableName;
+ this.subTaskId = subTaskId;
+
+ this.taskWriterFactory = taskWriterFactory;
+ // Initialize the task writer factory.
+ taskWriterFactory.initialize(numberOfParallelSubtasks, subTaskId);
+ // Initialize the task writer.
+ this.writer = taskWriterFactory.create();
+ }
+
+ @Override
+ public void write(RowData element, Context context) throws IOException, InterruptedException {
+ writer.write(element);
+ }
+
+ @Override
+ public void flush(boolean endOfInput) throws IOException {}
+
+ @Override
+ public void close() throws Exception {
+ if (writer != null) {
+ writer.close();
+ writer = null;
+ }
+ }
+
+ @Override
+ public String toString() {
+ return MoreObjects.toStringHelper(this)
+ .add("table_name", fullTableName)
+ .add("subtask_id", subTaskId)
+ .toString();
+ }
+
+ @Override
+ public Collection<FilesCommittable> prepareCommit() throws IOException {
+ writeResultsState.add(new FilesCommittable(writer.complete()));
+ this.writer = taskWriterFactory.create();
+ return writeResultsState;
+ }
+
+ @Override
+ public List<StreamWriterState> snapshotState(long checkpointId) {
+ List<StreamWriterState> state = Lists.newArrayList();
+ state.add(new StreamWriterState(Lists.newArrayList(writeResultsState)));
Review Comment:
Checkpoint individual data files as writer state can be expensive. E.g., if one checkpoint cycle produces a lot of files with many columns, the amount of metadata can be very significant.
I am also think we shouldn't checkpoint the flushed files as writer state. How does it help with fault tolerance? The current FlinkSink writer only flush the data files and emit them to the downstream committer operator.
In the current `FlinkSink` implementation, `IcebergFilesCommitter` checkpoint a staging `ManifestFile` object per checkpoint sync. Here we only need to checkpoint a single manifest file per cycle, which is very small in size. Upon successful commit, committer clears the committed manifest files. Upon commit failure, manifest files are accumulate and attempted for commit in the next checkpoint cycle.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946347503
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() {
+ return new StreamWriterStateSerializer();
+ }
+
+ @Override
+ public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<FilesCommittable>> writeResults) {
+ return writeResults
+ .map(
+ new RichMapFunction<
+ CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() {
+ @Override
+ public CommittableMessage<FilesCommittable> map(
+ CommittableMessage<FilesCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<FilesCommittable> committableWithLineage =
+ (CommittableWithLineage<FilesCommittable>) message;
+ FilesCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(-1));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ })
+ .uid(uidPrefix + "-pre-commit-topology")
+ .global();
+ }
+
+ @Override
+ public Committer<FilesCommittable> createCommitter() {
Review Comment:
Does this create parallel committers or single-parallelism committer?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r946329656
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java:
##########
@@ -0,0 +1,696 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink;
+
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.FlinkWriteConf;
+import org.apache.iceberg.flink.FlinkWriteOptions;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.committer.FilesCommittable;
+import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer;
+import org.apache.iceberg.flink.sink.committer.FilesCommitter;
+import org.apache.iceberg.flink.sink.writer.StreamWriter;
+import org.apache.iceberg.flink.sink.writer.StreamWriterState;
+import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+/**
+ * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes
+ * writers that can write data to files in parallel and route commit info globally to one Committer.
+ * Post commit topology will take of compacting the already written files and updating the file log
+ * after the compaction.
+ *
+ * <pre>{@code
+ * Flink sink
+ * +------------------------------------------------------------------+
+ * | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | Map 1 | ==> | | writer 1 | =| | committer 1 | |
+ * +-------+ | +-------------+ +---------------+ |
+ * | \ |
+ * | \ |
+ * | \ |
+ * +-------+ | +-------------+ \ +---------------+ +---------------+ |
+ * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | |
+ * +-------+ | +-------------+ +---------------+ +---------------+ |
+ * | |
+ * +------------------------------------------------------------------+
+ * }</pre>
+ */
+public class IcebergSink
+ implements StatefulSink<RowData, StreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, FilesCommittable>,
+ WithPostCommitTopology<RowData, FilesCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final FileFormat dataFileFormat;
+ private final int workerPoolSize;
+ private final long targetDataFileSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+ private Committer<FilesCommittable> committer;
+
+ private IcebergSink(
+ TableLoader tableLoader,
+ @Nullable Table table,
+ List<Integer> equalityFieldIds,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ Map<String, String> snapshotProperties,
+ boolean upsertMode,
+ boolean overwrite,
+ TableSchema tableSchema,
+ DistributionMode distributionMode,
+ int workerPoolSize,
+ long targetDataFileSize,
+ FileFormat dataFileFormat) {
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+ Preconditions.checkNotNull(table, "Table shouldn't be null");
+
+ this.tableLoader = tableLoader;
+ this.table = table;
+ this.equalityFieldIds = equalityFieldIds;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+ this.upsertMode = upsertMode;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.workerPoolSize = workerPoolSize;
+ this.targetDataFileSize = targetDataFileSize;
+ this.dataFileFormat = dataFileFormat;
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(
+ inputDataStream,
+ equalityFieldIds,
+ table.spec(),
+ table.schema(),
+ flinkRowType,
+ distributionMode,
+ equalityFieldColumns);
+ }
+
+ @Override
+ public StreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public StreamWriter restoreWriter(
+ InitContext context, Collection<StreamWriterState> recoveredState) {
+ RowDataTaskWriterFactory taskWriterFactory =
+ new RowDataTaskWriterFactory(
+ SerializableTable.copyOf(table),
+ flinkRowType,
+ targetDataFileSize,
+ dataFileFormat,
+ equalityFieldIds,
+ upsertMode);
+ StreamWriter streamWriter =
+ new StreamWriter(
+ table.name(),
+ taskWriterFactory,
+ context.getSubtaskId(),
+ context.getNumberOfParallelSubtasks());
+ if (recoveredState == null) {
Review Comment:
nit: if we pass in an empty collection for the non-restore case, we don't need the if block.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r945123759
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/committer/FilesCommitter.java:
##########
@@ -0,0 +1,278 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.iceberg.flink.sink.committer;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.exceptions.AlreadyExistsException;
+import org.apache.iceberg.exceptions.CommitFailedException;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class FilesCommitter implements Committer<FilesCommittable>, Serializable {
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+ private static final Logger LOG = LoggerFactory.getLogger(FilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final Table table;
+ private transient Map<String, Long> maxCommittedCheckpointIdForJob = Maps.newHashMap();
+
+ private transient ExecutorService workerPool;
+
+ public FilesCommitter(
+ TableLoader tableLoader,
+ boolean replacePartitions,
+ Map<String, String> snapshotProperties,
+ int workerPoolSize) {
+ this.tableLoader = tableLoader;
+ this.replacePartitions = replacePartitions;
+ this.snapshotProperties = snapshotProperties;
+
+ this.workerPool =
+ ThreadPools.newWorkerPool(
+ "iceberg-worker-pool-" + Thread.currentThread().getName(), workerPoolSize);
+
+ // Open the table loader and load the table.
+ this.tableLoader.open();
+ this.table = tableLoader.loadTable();
+ }
+
+ @Override
+ public void commit(Collection<CommitRequest<FilesCommittable>> requests)
+ throws IOException, InterruptedException {
+ int dataFilesNum = 0;
+ int deleteFilesNum = 0;
+
+ Collection<CommitRequest<FilesCommittable>> store = Lists.newArrayList();
+ String jobId = null;
+ long maxCommittableCheckpointId = INITIAL_CHECKPOINT_ID;
+
+ for (CommitRequest<FilesCommittable> request : requests) {
+ WriteResult committable = request.getCommittable().committable();
+ Long committableCheckpointId = request.getCommittable().checkpointId();
+ jobId = request.getCommittable().jobID();
+ if (committableCheckpointId
+ > maxCommittedCheckpointIdForJob.getOrDefault(jobId, Long.MAX_VALUE)
+ || getMaxCommittedCheckpointId(table, jobId) == -1) {
+ // The job id has never written data to the table.
+ store.add(request);
+ dataFilesNum = dataFilesNum + committable.dataFiles().length;
+ deleteFilesNum = deleteFilesNum + committable.deleteFiles().length;
+ maxCommittableCheckpointId = committableCheckpointId;
+ } else if (committableCheckpointId > getMaxCommittedCheckpointId(table, jobId)) {
+ // committable is restored from the previous job that committed data to the table.
+ commitResult(
+ committable.dataFiles().length,
+ committable.deleteFiles().length,
+ Lists.newArrayList(request));
+ maxCommittedCheckpointIdForJob.put(jobId, committableCheckpointId);
+ } else {
+ request.signalFailedWithKnownReason(
+ new CommitFailedException(
+ "The data could not be committed, perhaps because the data was committed."));
+ }
+ }
+
+ commitResult(dataFilesNum, deleteFilesNum, store);
+ // Since flink's checkpoint id will start from the max-committed-checkpoint-id + 1 in the new
+ // flink job even if it's restored from a snapshot created by another different flink job, so
+ // it's safe to assign the max committed checkpoint id from restored flink job to the current
+ // flink job.
+ maxCommittedCheckpointIdForJob.put(jobId, maxCommittableCheckpointId);
+ }
+
+ @Override
+ public void close() throws Exception {
+ if (tableLoader != null) {
+ tableLoader.close();
+ }
+
+ if (workerPool != null) {
+ workerPool.shutdown();
+ }
+ }
+
+ private void commitResult(
+ int dataFilesNum,
+ int deleteFilesNum,
+ Collection<CommitRequest<FilesCommittable>> committableCollection) {
+ int totalFiles = dataFilesNum + deleteFilesNum;
+
+ if (totalFiles != 0) {
+ if (replacePartitions) {
+ replacePartitions(committableCollection, dataFilesNum, deleteFilesNum);
+ } else {
+ commitDeltaTxn(committableCollection, dataFilesNum, deleteFilesNum);
+ }
+ }
+ }
+
+ private void replacePartitions(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ // Partition overwrite does not support delete files.
+ Preconditions.checkState(deleteFilesNum == 0, "Cannot overwrite partitions with delete files.");
+
+ // Commit the overwrite transaction.
+ ReplacePartitions dynamicOverwrite = table.newReplacePartitions().scanManifestsWith(workerPool);
+
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ Arrays.stream(result.dataFiles()).forEach(dynamicOverwrite::addFile);
+ }
+
+ commitOperation(
+ writeResults,
+ dynamicOverwrite,
+ dataFilesNum,
+ 0,
+ "dynamic partition overwrite",
+ flinkJobId,
+ checkpointId);
+ }
+
+ private void commitDeltaTxn(
+ Collection<CommitRequest<FilesCommittable>> writeResults,
+ int dataFilesNum,
+ int deleteFilesNum) {
+ if (deleteFilesNum == 0) {
+ // To be compatible with iceberg format V1.
+ AppendFiles appendFiles = table.newAppend().scanManifestsWith(workerPool);
+ String flinkJobId = null;
+ long checkpointId = -1;
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
+ WriteResult result = commitRequest.getCommittable().committable();
+ Preconditions.checkState(
+ result.referencedDataFiles().length == 0, "Should have no referenced data files.");
+ Arrays.stream(result.dataFiles()).forEach(appendFiles::appendFile);
+ flinkJobId = commitRequest.getCommittable().jobID();
+ checkpointId = commitRequest.getCommittable().checkpointId();
+ }
+
+ commitOperation(
+ writeResults, appendFiles, dataFilesNum, 0, "append", flinkJobId, checkpointId);
+
+ } else {
+ // To be compatible with iceberg format V2.
+ for (CommitRequest<FilesCommittable> commitRequest : writeResults) {
Review Comment:
It's a `List` instance, just not declared as a `List`. I've changed its type.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r906790554
##########
flink/v1.15/flink/src/test/java/org/apache/iceberg/flink/sink/v2/TestFlinkIcebergSinkV2.java:
##########
@@ -0,0 +1,508 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.java.functions.KeySelector;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.test.util.MiniClusterWithClientResource;
+import org.apache.flink.types.Row;
+import org.apache.flink.types.RowKind;
+import org.apache.iceberg.AssertHelpers;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Snapshot;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.TableProperties;
+import org.apache.iceberg.TableTestBase;
+import org.apache.iceberg.data.IcebergGenerics;
+import org.apache.iceberg.data.Record;
+import org.apache.iceberg.flink.MiniClusterResource;
+import org.apache.iceberg.flink.SimpleDataUtil;
+import org.apache.iceberg.flink.TestTableLoader;
+import org.apache.iceberg.flink.source.BoundedTestSource;
+import org.apache.iceberg.io.CloseableIterable;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableList;
+import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.Types;
+import org.apache.iceberg.util.StructLikeSet;
+import org.junit.Assert;
+import org.junit.Before;
+import org.junit.ClassRule;
+import org.junit.Test;
+import org.junit.rules.TemporaryFolder;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+@RunWith(Parameterized.class)
+public class TestFlinkIcebergSinkV2 extends TableTestBase {
+
+ @ClassRule
+ public static final MiniClusterWithClientResource MINI_CLUSTER_RESOURCE =
+ MiniClusterResource.createWithClassloaderCheckDisabled();
+
+ @ClassRule
+ public static final TemporaryFolder TEMPORARY_FOLDER = new TemporaryFolder();
+
+ private static final int FORMAT_V2 = 2;
+ private static final TypeInformation<Row> ROW_TYPE_INFO =
+ new RowTypeInfo(SimpleDataUtil.FLINK_SCHEMA.getFieldTypes());
+
+ private static final Map<String, RowKind> ROW_KIND_MAP = ImmutableMap.of(
+ "+I", RowKind.INSERT,
+ "-D", RowKind.DELETE,
+ "-U", RowKind.UPDATE_BEFORE,
+ "+U", RowKind.UPDATE_AFTER);
+
+ private static final int ROW_ID_POS = 0;
+ private static final int ROW_DATA_POS = 1;
+
+ private final FileFormat format;
+ private final int parallelism;
+ private final boolean partitioned;
+ private final String writeDistributionMode;
+
+ private StreamExecutionEnvironment env;
+ private TestTableLoader tableLoader;
+
+ @Parameterized.Parameters(name = "FileFormat = {0}, Parallelism = {1}, Partitioned={2}, WriteDistributionMode ={3}")
+ public static Object[][] parameters() {
+ return new Object[][] {
+ new Object[] {"avro", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+ new Object[] {"avro", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_NONE},
+
+ new Object[] {"orc", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+ new Object[] {"orc", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_HASH},
+
+ new Object[] {"parquet", 1, true, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 1, false, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 4, true, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE},
+ new Object[] {"parquet", 4, false, TableProperties.WRITE_DISTRIBUTION_MODE_RANGE}
+ };
+ }
+
+ public TestFlinkIcebergSinkV2(String format, int parallelism, boolean partitioned, String writeDistributionMode) {
+ super(FORMAT_V2);
+ this.format = FileFormat.valueOf(format.toUpperCase(Locale.ENGLISH));
+ this.parallelism = parallelism;
+ this.partitioned = partitioned;
+ this.writeDistributionMode = writeDistributionMode;
+ }
+
+ @Before
+ public void setupTable() throws IOException {
+ this.tableDir = temp.newFolder();
+ this.metadataDir = new File(tableDir, "metadata");
+ Assert.assertTrue(tableDir.delete());
+
+ if (!partitioned) {
+ table = create(SimpleDataUtil.SCHEMA, PartitionSpec.unpartitioned());
+ } else {
+ table = create(SimpleDataUtil.SCHEMA, PartitionSpec.builderFor(SimpleDataUtil.SCHEMA).identity("data").build());
+ }
+
+ table.updateProperties()
+ .set(TableProperties.DEFAULT_FILE_FORMAT, format.name())
+ .set(TableProperties.WRITE_DISTRIBUTION_MODE, writeDistributionMode)
+ .commit();
+
+ env = StreamExecutionEnvironment.getExecutionEnvironment(MiniClusterResource.DISABLE_CLASSLOADER_CHECK_CONFIG)
+ .enableCheckpointing(100L)
+ .setParallelism(parallelism)
+ .setMaxParallelism(parallelism);
+
+ tableLoader = new TestTableLoader(tableDir.getAbsolutePath());
+ }
+
+ private List<Snapshot> findValidSnapshots(Table table) {
+ List<Snapshot> validSnapshots = Lists.newArrayList();
+ for (Snapshot snapshot : table.snapshots()) {
+ if (snapshot.allManifests(table.io()).stream().anyMatch(m -> snapshot.snapshotId() == m.snapshotId())) {
+ validSnapshots.add(snapshot);
+ }
+ }
+ return validSnapshots;
+ }
+
+ private void testChangeLogs(List<String> equalityFieldColumns,
+ KeySelector<Row, Object> keySelector,
+ boolean insertAsUpsert,
+ List<List<Row>> elementsPerCheckpoint,
+ List<List<Record>> expectedRecordsPerCheckpoint) throws Exception {
+ DataStream<Row> dataStream = env.addSource(new BoundedTestSource<>(elementsPerCheckpoint), ROW_TYPE_INFO);
+
+ FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA)
+ .tableLoader(tableLoader)
+ .tableSchema(SimpleDataUtil.FLINK_SCHEMA)
+ .writeParallelism(parallelism)
+ .equalityFieldColumns(equalityFieldColumns)
+ .upsert(insertAsUpsert)
+ .append();
+
+ // Execute the program.
+ env.execute("Test Iceberg Change-Log DataStream.");
+
+ table.refresh();
+ List<Snapshot> snapshots = findValidSnapshots(table);
+ int expectedSnapshotNum = expectedRecordsPerCheckpoint.size();
+ Assert.assertEquals("Should have the expected snapshot number", expectedSnapshotNum, snapshots.size());
+
+ for (int i = 0; i < expectedSnapshotNum; i++) {
+ long snapshotId = snapshots.get(i).snapshotId();
+ List<Record> expectedRecords = expectedRecordsPerCheckpoint.get(i);
+ Assert.assertEquals("Should have the expected records for the checkpoint#" + i,
+ expectedRowSet(expectedRecords.toArray(new Record[0])), actualRowSet(snapshotId, "*"));
+ }
+ }
+
+ private Row row(String rowKind, int id, String data) {
+ RowKind kind = ROW_KIND_MAP.get(rowKind);
+ if (kind == null) {
+ throw new IllegalArgumentException("Unknown row kind: " + rowKind);
+ }
+
+ return Row.ofKind(kind, id, data);
+ }
+
+ private Record record(int id, String data) {
+ return SimpleDataUtil.createRecord(id, data);
+ }
+
+ @Test
+ public void testCheckAndGetEqualityFieldIds() {
+ table.updateSchema()
+ .allowIncompatibleChanges()
+ .addRequiredColumn("type", Types.StringType.get())
+ .setIdentifierFields("type")
+ .commit();
+
+ DataStream<Row> dataStream = env.addSource(new BoundedTestSource<>(ImmutableList.of()), ROW_TYPE_INFO);
+ FlinkSink.Builder builder = FlinkSink.forRow(dataStream, SimpleDataUtil.FLINK_SCHEMA).table(table);
+
+ // Use schema identifier field IDs as equality field id list by default
+ Assert.assertEquals(
+ table.schema().identifierFieldIds(),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+
+ // Use user-provided equality field column as equality field id list
+ builder.equalityFieldColumns(Lists.newArrayList("id"));
+ Assert.assertEquals(
+ Sets.newHashSet(table.schema().findField("id").fieldId()),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+
+ builder.equalityFieldColumns(Lists.newArrayList("type"));
+ Assert.assertEquals(
+ Sets.newHashSet(table.schema().findField("type").fieldId()),
+ Sets.newHashSet(builder.checkAndGetEqualityFieldIds())
+ );
+ }
+
+ @Test
+ public void testChangeLogOnIdKey() throws Exception {
+ List<List<Row>> elementsPerCheckpoint = ImmutableList.of(
+ ImmutableList.of(
+ row("+I", 1, "aaa"),
+ row("-D", 1, "aaa"),
+ row("+I", 1, "bbb"),
+ row("+I", 2, "aaa"),
+ row("-D", 2, "aaa"),
+ row("+I", 2, "bbb")
+ ),
+ ImmutableList.of(
+ row("-U", 2, "bbb"),
+ row("+U", 2, "ccc"),
+ row("-D", 2, "ccc"),
+ row("+I", 2, "ddd")
+ ),
+ ImmutableList.of(
+ row("-D", 1, "bbb"),
+ row("+I", 1, "ccc"),
+ row("-D", 1, "ccc"),
+ row("+I", 1, "ddd")
+ )
+ );
+
+ List<List<Record>> expectedRecords = ImmutableList.of(
+ ImmutableList.of(record(1, "bbb"), record(2, "bbb")),
+ ImmutableList.of(record(1, "bbb"), record(2, "ddd")),
+ ImmutableList.of(record(1, "ddd"), record(2, "ddd"))
+ );
+
+ if (partitioned && writeDistributionMode.equals(TableProperties.WRITE_DISTRIBUTION_MODE_HASH)) {
Review Comment:
I think we can put all checks in `testUpsertModeCheck` and here just test the valid cases.
```java
List<String> equalityFields = partitioned ? ImmutableList.of("id", "data") : ImmutableList.of("id");
testChangeLogs(....);
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r906760110
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFlinkCommittableSerializer.java:
##########
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.core.memory.DataInputDeserializer;
+import org.apache.flink.core.memory.DataOutputViewStreamWrapper;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.util.SerializationUtil;
+
+public class IcebergFlinkCommittableSerializer implements SimpleVersionedSerializer<IcebergFlinkCommittable> {
+
+ @Override
+ public int getVersion() {
+ return 1;
Review Comment:
Should we define a constant in this class to avoid hard code?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r912335560
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
> > If equality keys are not the source of partition keys, then the data with the same equal column value may be divided into different partitions, which is not allowed.
>
> The check above states that _"In 'hash' distribution mode with equality fields set, partition field '%s' " + "should be included in equality fields: '%s'"_. It contradicts what you said.
Sorry for the confusion, I got sidetracked.
The reason we used EqualityFieldKeySelector, because we need to ensure all the same primary key record will be distributed to the same IcebergStreamWriter to ensure result correctness, . But when users set HASH distribution, the intention is to cluster data by partition columns. If we can use partition to to guarantee correctness, then we can use it, Otherwise, it should use the equality distribution. The key point here, then, in which case the partition distribution guarantees the correctness of the results without violating the user's intent. Requiring all of the partition source fields are identifier fields.
refer to: #2898 https://github.com/apache/iceberg/pull/2898#discussion_r810411948
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r910069553
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/IcebergFilesCommitter.java:
##########
@@ -0,0 +1,261 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.Serializable;
+import java.util.Arrays;
+import java.util.Collection;
+import java.util.Map;
+import java.util.concurrent.ExecutorService;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.iceberg.AppendFiles;
+import org.apache.iceberg.ReplacePartitions;
+import org.apache.iceberg.RowDelta;
+import org.apache.iceberg.SnapshotUpdate;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.io.WriteResult;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.util.PropertyUtil;
+import org.apache.iceberg.util.ThreadPools;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+public class IcebergFilesCommitter implements Committer<IcebergFlinkCommittable>, Serializable {
+
+ private static final long serialVersionUID = 1L;
+ private static final long INITIAL_CHECKPOINT_ID = -1L;
+
+ private static final Logger LOG = LoggerFactory.getLogger(IcebergFilesCommitter.class);
+ private static final String FLINK_JOB_ID = "flink.job-id";
+
+ // The max checkpoint id we've committed to iceberg table. As the flink's checkpoint is always increasing, so we could
+ // correctly commit all the data files whose checkpoint id is greater than the max committed one to iceberg table, for
+ // avoiding committing the same data files twice. This id will be attached to iceberg's meta when committing the
+ // iceberg transaction.
+ private static final String MAX_COMMITTED_CHECKPOINT_ID = "flink.max-committed-checkpoint-id";
+ static final String MAX_CONTINUOUS_EMPTY_COMMITS = "flink.max-continuous-empty-commits";
+
+ // TableLoader to load iceberg table lazily.
+ private final TableLoader tableLoader;
+ private final boolean replacePartitions;
+ private final Map<String, String> snapshotProperties;
+
+ // It will have an unique identifier for one job.
+ private final transient Table table;
+ private transient long maxCommittedCheckpointId;
+ private transient int continuousEmptyCheckpoints;
+ private final transient int maxContinuousEmptyCommits;
+
Review Comment:
nit: extra empty line
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] chenjunjiedada commented on a diff in pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
chenjunjiedada commented on code in PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#discussion_r911658682
##########
flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/v2/FlinkSink.java:
##########
@@ -0,0 +1,635 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iceberg.flink.sink.v2;
+
+import java.io.IOException;
+import java.io.UncheckedIOException;
+import java.util.Collection;
+import java.util.List;
+import java.util.Locale;
+import java.util.Map;
+import java.util.Set;
+import java.util.function.Function;
+import javax.annotation.Nullable;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.functions.RichMapFunction;
+import org.apache.flink.api.common.typeinfo.TypeInformation;
+import org.apache.flink.api.connector.sink2.Committer;
+import org.apache.flink.api.connector.sink2.StatefulSink;
+import org.apache.flink.configuration.Configuration;
+import org.apache.flink.configuration.ReadableConfig;
+import org.apache.flink.core.io.SimpleVersionedSerializer;
+import org.apache.flink.streaming.api.connector.sink2.CommittableMessage;
+import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage;
+import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology;
+import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology;
+import org.apache.flink.streaming.api.datastream.DataStream;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.operators.StreamingRuntimeContext;
+import org.apache.flink.table.api.TableSchema;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.data.util.DataFormatConverters;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.types.Row;
+import org.apache.iceberg.DataFile;
+import org.apache.iceberg.DistributionMode;
+import org.apache.iceberg.FileFormat;
+import org.apache.iceberg.PartitionField;
+import org.apache.iceberg.PartitionSpec;
+import org.apache.iceberg.Schema;
+import org.apache.iceberg.SerializableTable;
+import org.apache.iceberg.Table;
+import org.apache.iceberg.common.DynFields;
+import org.apache.iceberg.flink.FlinkConfigOptions;
+import org.apache.iceberg.flink.FlinkSchemaUtil;
+import org.apache.iceberg.flink.TableLoader;
+import org.apache.iceberg.flink.sink.EqualityFieldKeySelector;
+import org.apache.iceberg.flink.sink.PartitionKeySelector;
+import org.apache.iceberg.flink.sink.RowDataTaskWriterFactory;
+import org.apache.iceberg.flink.util.FlinkCompatibilityUtil;
+import org.apache.iceberg.relocated.com.google.common.annotations.VisibleForTesting;
+import org.apache.iceberg.relocated.com.google.common.base.Preconditions;
+import org.apache.iceberg.relocated.com.google.common.collect.Lists;
+import org.apache.iceberg.relocated.com.google.common.collect.Maps;
+import org.apache.iceberg.relocated.com.google.common.collect.Sets;
+import org.apache.iceberg.types.TypeUtil;
+import org.apache.iceberg.util.PropertyUtil;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT;
+import static org.apache.iceberg.TableProperties.DEFAULT_FILE_FORMAT_DEFAULT;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED;
+import static org.apache.iceberg.TableProperties.UPSERT_ENABLED_DEFAULT;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE;
+import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE_NONE;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES;
+import static org.apache.iceberg.TableProperties.WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT;
+
+public class FlinkSink implements StatefulSink<RowData, IcebergStreamWriterState>,
+ WithPreWriteTopology<RowData>,
+ WithPreCommitTopology<RowData, IcebergFlinkCommittable>,
+ WithPostCommitTopology<RowData, IcebergFlinkCommittable> {
+ private static final Logger LOG = LoggerFactory.getLogger(FlinkSink.class);
+
+ private final TableLoader tableLoader;
+ private final Table table;
+ private final boolean overwrite;
+ private final boolean upsertMode;
+ private final DistributionMode distributionMode;
+ private final List<String> equalityFieldColumns;
+ private final List<Integer> equalityFieldIds;
+ private final int workerPoolSize;
+ private final String uidPrefix;
+ private final Map<String, String> snapshotProperties;
+ private final RowType flinkRowType;
+
+ public FlinkSink(TableLoader tableLoader,
+ @Nullable Table newTable,
+ TableSchema tableSchema,
+ boolean overwrite,
+ DistributionMode distributionMode,
+ boolean upsert,
+ List<String> equalityFieldColumns,
+ @Nullable String uidPrefix,
+ ReadableConfig readableConfig,
+ Map<String, String> snapshotProperties) {
+ this.tableLoader = tableLoader;
+ this.overwrite = overwrite;
+ this.distributionMode = distributionMode;
+ this.equalityFieldColumns = equalityFieldColumns;
+ this.uidPrefix = uidPrefix == null ? "" : uidPrefix;
+ this.snapshotProperties = snapshotProperties;
+
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ if (newTable == null) {
+ tableLoader.open();
+ try (TableLoader loader = tableLoader) {
+ this.table = loader.loadTable();
+ } catch (IOException e) {
+ throw new UncheckedIOException("Failed to load iceberg table from table loader: " + tableLoader, e);
+ }
+ } else {
+ this.table = newTable;
+ }
+
+ this.workerPoolSize = readableConfig.get(FlinkConfigOptions.TABLE_EXEC_ICEBERG_WORKER_POOL_SIZE);
+ this.equalityFieldIds = checkAndGetEqualityFieldIds(table, equalityFieldColumns);
+
+ this.flinkRowType = toFlinkRowType(table.schema(), tableSchema);
+
+ // Fallback to use upsert mode parsed from table properties if don't specify in job level.
+ this.upsertMode = upsert || PropertyUtil.propertyAsBoolean(table.properties(),
+ UPSERT_ENABLED, UPSERT_ENABLED_DEFAULT);
+
+ // Validate the equality fields and partition fields if we enable the upsert mode.
+ if (upsertMode) {
+ Preconditions.checkState(
+ !overwrite,
+ "OVERWRITE mode shouldn't be enable when configuring to use UPSERT data stream.");
+ Preconditions.checkState(
+ !equalityFieldIds.isEmpty(),
+ "Equality field columns shouldn't be empty when configuring to use UPSERT data stream.");
+ if (!table.spec().isUnpartitioned()) {
+ for (PartitionField partitionField : table.spec().fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In UPSERT mode, partition field '%s' should be included in equality fields: '%s'",
+ partitionField, equalityFieldColumns);
+ }
+ }
+ }
+ }
+
+ @Override
+ public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) {
+ return distributeDataStream(inputDataStream, table.properties(), equalityFieldIds, table.spec(),
+ table.schema(), flinkRowType, distributionMode, equalityFieldColumns);
+ }
+
+ @Override
+ public IcebergStreamWriter createWriter(InitContext context) {
+ return restoreWriter(context, null);
+ }
+
+ @Override
+ public IcebergStreamWriter restoreWriter(InitContext context,
+ Collection<IcebergStreamWriterState> recoveredState) {
+ StreamingRuntimeContext runtimeContext = runtimeContextHidden(context);
+ int attemptNumber = runtimeContext.getAttemptNumber();
+ String jobId = runtimeContext.getJobId().toString();
+ IcebergStreamWriter streamWriter = createStreamWriter(table, flinkRowType, equalityFieldIds,
+ upsertMode, jobId, context.getSubtaskId(), attemptNumber);
+ if (recoveredState == null) {
+ return streamWriter;
+ }
+ return streamWriter.restoreWriter(recoveredState);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergStreamWriterState> getWriterStateSerializer() {
+ return new IcebergStreamWriterStateSerializer<>();
+ }
+
+ static IcebergStreamWriter createStreamWriter(Table table,
+ RowType flinkRowType,
+ List<Integer> equalityFieldIds,
+ boolean upsert,
+ String jobId,
+ int subTaskId,
+ long attemptId) {
+ Map<String, String> props = table.properties();
+ long targetFileSize = PropertyUtil.propertyAsLong(props, WRITE_TARGET_FILE_SIZE_BYTES,
+ WRITE_TARGET_FILE_SIZE_BYTES_DEFAULT);
+
+ RowDataTaskWriterFactory taskWriterFactory = new RowDataTaskWriterFactory(SerializableTable.copyOf(table),
+ flinkRowType, targetFileSize, getFileFormat(props), equalityFieldIds, upsert);
+
+ return new IcebergStreamWriter(table.name(), taskWriterFactory, jobId, subTaskId, attemptId);
+ }
+
+ @Override
+ public DataStream<CommittableMessage<IcebergFlinkCommittable>> addPreCommitTopology(
+ DataStream<CommittableMessage<IcebergFlinkCommittable>> writeResults) {
+ return writeResults.map(new RichMapFunction<CommittableMessage<IcebergFlinkCommittable>,
+ CommittableMessage<IcebergFlinkCommittable>>() {
+ @Override
+ public CommittableMessage<IcebergFlinkCommittable> map(CommittableMessage<IcebergFlinkCommittable> message) {
+ if (message instanceof CommittableWithLineage) {
+ CommittableWithLineage<IcebergFlinkCommittable> committableWithLineage =
+ (CommittableWithLineage<IcebergFlinkCommittable>) message;
+ IcebergFlinkCommittable committable = committableWithLineage.getCommittable();
+ committable.checkpointId(committableWithLineage.getCheckpointId().orElse(0));
+ committable.subtaskId(committableWithLineage.getSubtaskId());
+ committable.jobID(getRuntimeContext().getJobId().toString());
+ }
+ return message;
+ }
+ }).uid(uidPrefix + "pre-commit-topology").global();
+ }
+
+ @Override
+ public Committer<IcebergFlinkCommittable> createCommitter() {
+ return new IcebergFilesCommitter(tableLoader, overwrite, snapshotProperties, workerPoolSize);
+ }
+
+ @Override
+ public SimpleVersionedSerializer<IcebergFlinkCommittable> getCommittableSerializer() {
+ return new IcebergFlinkCommittableSerializer();
+ }
+
+ @Override
+ public void addPostCommitTopology(DataStream<CommittableMessage<IcebergFlinkCommittable>> committables) {
+ // TODO Support small file compaction
+ }
+
+ private StreamingRuntimeContext runtimeContextHidden(InitContext context) {
+ DynFields.BoundField<StreamingRuntimeContext> runtimeContextBoundField =
+ DynFields.builder().hiddenImpl(context.getClass(), "runtimeContext").build(context);
+ return runtimeContextBoundField.get();
+ }
+
+ private static FileFormat getFileFormat(Map<String, String> properties) {
+ String formatString = properties.getOrDefault(DEFAULT_FILE_FORMAT, DEFAULT_FILE_FORMAT_DEFAULT);
+ return FileFormat.valueOf(formatString.toUpperCase(Locale.ENGLISH));
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from generic input data stream into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a mapper function and a
+ * {@link TypeInformation} to convert those generic records to a RowData DataStream.
+ *
+ * @param input the generic source input data stream.
+ * @param mapper function to convert the generic data to {@link RowData}
+ * @param outputType to define the {@link TypeInformation} for the input data.
+ * @param <T> the data type of records.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static <T> Builder builderFor(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ return new Builder().forMapperOutputType(input, mapper, outputType);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link Row}s into iceberg table. We use
+ * {@link RowData} inside the sink connector, so users need to provide a {@link TableSchema} for builder to convert
+ * those {@link Row}s to a {@link RowData} DataStream.
+ *
+ * @param input the source input data stream with {@link Row}s.
+ * @param tableSchema defines the {@link TypeInformation} for input data.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRow(DataStream<Row> input, TableSchema tableSchema) {
+ RowType rowType = (RowType) tableSchema.toRowDataType().getLogicalType();
+ DataType[] fieldDataTypes = tableSchema.getFieldDataTypes();
+
+ DataFormatConverters.RowConverter rowConverter = new DataFormatConverters.RowConverter(fieldDataTypes);
+ return builderFor(input, rowConverter::toInternal, FlinkCompatibilityUtil.toTypeInfo(rowType))
+ .tableSchema(tableSchema);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @param input the source input data stream with {@link RowData}s.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder forRowData(DataStream<RowData> input) {
+ return new Builder().forRowData(input);
+ }
+
+ /**
+ * Initialize a {@link Builder} to export the data from input data stream with {@link RowData}s into iceberg table.
+ *
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public static Builder builder() {
+ return new Builder();
+ }
+
+ public static class Builder {
+ private Function<String, DataStream<RowData>> inputCreator = null;
+ private TableLoader tableLoader;
+ private Table table;
+ private TableSchema tableSchema;
+ private boolean overwrite = false;
+ private DistributionMode distributionMode = null;
+ private Integer writeParallelism = null;
+ private boolean upsert = false;
+ private List<String> equalityFieldColumns = null;
+ private String uidPrefix = "iceberg-flink-job";
+ private final Map<String, String> snapshotProperties = Maps.newHashMap();
+ private ReadableConfig readableConfig = new Configuration();
+
+ private Builder() {
+ }
+
+ private Builder forRowData(DataStream<RowData> newRowDataInput) {
+ this.inputCreator = ignored -> newRowDataInput;
+ return this;
+ }
+
+ private <T> Builder forMapperOutputType(DataStream<T> input,
+ MapFunction<T, RowData> mapper,
+ TypeInformation<RowData> outputType) {
+ this.inputCreator = newUidPrefix -> {
+ // Input stream order is crucial for some situation(e.g. in cdc case).
+ // Therefore, we need to set the parallelismof map operator same as its input to keep map operator
+ // chaining its input, and avoid rebalanced by default.
+ SingleOutputStreamOperator<RowData> inputStream = input.map(mapper, outputType)
+ .setParallelism(input.getParallelism());
+ if (newUidPrefix != null) {
+ inputStream.name(Builder.this.operatorName(newUidPrefix)).uid(newUidPrefix + "-mapper");
+ }
+ return inputStream;
+ };
+ return this;
+ }
+
+ /**
+ * This iceberg {@link Table} instance is used for initializing {@link IcebergStreamWriter} which will write all
+ * the records into {@link DataFile}s and emit them to downstream operator. Providing a table would avoid so many
+ * table loading from each separate task.
+ *
+ * @param newTable the loaded iceberg table instance.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder table(Table newTable) {
+ this.table = newTable;
+ return this;
+ }
+
+ /**
+ * The table loader is used for loading tables in {@link IcebergFilesCommitter} lazily, we need this loader because
+ * {@link Table} is not serializable and could not just use the loaded table from Builder#table in the remote task
+ * manager.
+ *
+ * @param newTableLoader to load iceberg table inside tasks.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder tableLoader(TableLoader newTableLoader) {
+ this.tableLoader = newTableLoader;
+ return this;
+ }
+
+ public Builder tableSchema(TableSchema newTableSchema) {
+ this.tableSchema = newTableSchema;
+ return this;
+ }
+
+ public Builder overwrite(boolean newOverwrite) {
+ this.overwrite = newOverwrite;
+ return this;
+ }
+
+ public Builder flinkConf(ReadableConfig config) {
+ this.readableConfig = config;
+ return this;
+ }
+
+ /**
+ * Configure the write {@link DistributionMode} that the flink sink will use. Currently, flink support
+ * {@link DistributionMode#NONE} and {@link DistributionMode#HASH}.
+ *
+ * @param mode to specify the write distribution mode.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder distributionMode(DistributionMode mode) {
+ Preconditions.checkArgument(
+ !DistributionMode.RANGE.equals(mode),
+ "Flink does not support 'range' write distribution mode now.");
+ this.distributionMode = mode;
+ return this;
+ }
+
+ /**
+ * Configuring the write parallel number for iceberg stream writer.
+ *
+ * @param newWriteParallelism the number of parallel iceberg stream writer.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder writeParallelism(int newWriteParallelism) {
+ this.writeParallelism = newWriteParallelism;
+ return this;
+ }
+
+ /**
+ * All INSERT/UPDATE_AFTER events from input stream will be transformed to UPSERT events, which means it will
+ * DELETE the old records and then INSERT the new records. In partitioned table, the partition fields should be
+ * a subset of equality fields, otherwise the old row that located in partition-A could not be deleted by the
+ * new row that located in partition-B.
+ *
+ * @param enabled indicate whether it should transform all INSERT/UPDATE_AFTER events to UPSERT.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder upsert(boolean enabled) {
+ this.upsert = enabled;
+ return this;
+ }
+
+ /**
+ * Configuring the equality field columns for iceberg table that accept CDC or UPSERT events.
+ *
+ * @param columns defines the iceberg table's key.
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder equalityFieldColumns(List<String> columns) {
+ this.equalityFieldColumns = columns;
+ return this;
+ }
+
+ /**
+ * Set the uid prefix for FlinkSink operators. Note that FlinkSink internally consists of multiple operators (like
+ * writer, committer, dummy sink etc.) Actually operator uid will be appended with a suffix like "uidPrefix-writer".
+ * <br><br>
+ * If provided, this prefix is also applied to operator names.
+ * <br><br>
+ * Flink auto generates operator uid if not set explicitly. It is a recommended
+ * <a href="https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/production_ready/">
+ * best-practice to set uid for all operators</a> before deploying to production. Flink has an option to {@code
+ * pipeline.auto-generate-uid=false} to disable auto-generation and force explicit setting of all operator uid.
+ * <br><br>
+ * Be careful with setting this for an existing job, because now we are changing the operator uid from an
+ * auto-generated one to this new value. When deploying the change with a checkpoint, Flink won't be able to restore
+ * the previous Flink sink operator state (more specifically the committer operator state). You need to use {@code
+ * --allowNonRestoredState} to ignore the previous sink state. During restore Flink sink state is used to check if
+ * last commit was actually successful or not. {@code --allowNonRestoredState} can lead to data loss if the
+ * Iceberg commit failed in the last completed checkpoint.
+ *
+ * @param newPrefix prefix for Flink sink operator uid and name
+ * @return {@link Builder} to connect the iceberg table.
+ */
+ public Builder uidPrefix(String newPrefix) {
+ this.uidPrefix = newPrefix;
+ return this;
+ }
+
+ public Builder setSnapshotProperties(Map<String, String> properties) {
+ snapshotProperties.putAll(properties);
+ return this;
+ }
+
+ public Builder setSnapshotProperty(String property, String value) {
+ snapshotProperties.put(property, value);
+ return this;
+ }
+
+ /**
+ * Append the iceberg sink operators to write records to iceberg table.
+ */
+ @SuppressWarnings("unchecked")
+ public DataStreamSink<Void> append() {
+ Preconditions.checkArgument(
+ inputCreator != null,
+ "Please use forRowData() or forMapperOutputType() to initialize the input DataStream.");
+ Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null");
+
+ DataStream<RowData> rowDataInput = inputCreator.apply(uidPrefix);
+ DataStreamSink rowDataDataStreamSink = rowDataInput.sinkTo(build()).uid(uidPrefix + "-sink");
+ if (writeParallelism != null) {
+ rowDataDataStreamSink.setParallelism(writeParallelism);
+ }
+ return rowDataDataStreamSink;
+ }
+
+ public FlinkSink build() {
+ return new FlinkSink(tableLoader, table, tableSchema, overwrite, distributionMode, upsert, equalityFieldColumns,
+ uidPrefix, readableConfig, snapshotProperties);
+ }
+
+ private String operatorName(String suffix) {
+ return uidPrefix != null ? uidPrefix + "-" + suffix : suffix;
+ }
+
+ @VisibleForTesting
+ List<Integer> checkAndGetEqualityFieldIds() {
+ List<Integer> equalityFieldIds = Lists.newArrayList(table.schema().identifierFieldIds());
+ if (equalityFieldColumns != null && equalityFieldColumns.size() > 0) {
+ Set<Integer> equalityFieldSet = Sets.newHashSetWithExpectedSize(equalityFieldColumns.size());
+ for (String column : equalityFieldColumns) {
+ org.apache.iceberg.types.Types.NestedField field = table.schema().findField(column);
+ Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s",
+ column, table.schema());
+ equalityFieldSet.add(field.fieldId());
+ }
+
+ if (!equalityFieldSet.equals(table.schema().identifierFieldIds())) {
+ LOG.warn("The configured equality field column IDs {} are not matched with the schema identifier field IDs" +
+ " {}, use job specified equality field columns as the equality fields by default.",
+ equalityFieldSet, table.schema().identifierFieldIds());
+ }
+ equalityFieldIds = Lists.newArrayList(equalityFieldSet);
+ }
+ return equalityFieldIds;
+ }
+ }
+
+ static RowType toFlinkRowType(Schema schema, TableSchema requestedSchema) {
+ if (requestedSchema != null) {
+ // Convert the flink schema to iceberg schema firstly, then reassign ids to match the existing iceberg schema.
+ Schema writeSchema = TypeUtil.reassignIds(FlinkSchemaUtil.convert(requestedSchema), schema);
+ TypeUtil.validateWriteSchema(schema, writeSchema, true, true);
+
+ // We use this flink schema to read values from RowData. The flink's TINYINT and SMALLINT will be promoted to
+ // iceberg INTEGER, that means if we use iceberg's table schema to read TINYINT (backend by 1 'byte'), we will
+ // read 4 bytes rather than 1 byte, it will mess up the byte array in BinaryRowData. So here we must use flink
+ // schema.
+ return (RowType) requestedSchema.toRowDataType().getLogicalType();
+ } else {
+ return FlinkSchemaUtil.convert(schema);
+ }
+ }
+
+ static DataStream<RowData> distributeDataStream(DataStream<RowData> input,
+ Map<String, String> properties,
+ List<Integer> equalityFieldIds,
+ PartitionSpec partitionSpec,
+ Schema iSchema,
+ RowType flinkRowType,
+ DistributionMode distributionMode,
+ List<String> equalityFieldColumns) {
+ DistributionMode writeMode;
+ if (distributionMode == null) {
+ // Fallback to use distribution mode parsed from table properties if don't specify in job level.
+ String modeName = PropertyUtil.propertyAsString(
+ properties,
+ WRITE_DISTRIBUTION_MODE,
+ WRITE_DISTRIBUTION_MODE_NONE);
+
+ writeMode = DistributionMode.fromName(modeName);
+ } else {
+ writeMode = distributionMode;
+ }
+
+ LOG.info("Write distribution mode is '{}'", writeMode.modeName());
+ switch (writeMode) {
+ case NONE:
+ if (equalityFieldIds.isEmpty()) {
+ return input;
+ } else {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ }
+
+ case HASH:
+ if (equalityFieldIds.isEmpty()) {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.warn("Fallback to use 'none' distribution mode, because there are no equality fields set " +
+ "and table is unpartitioned");
+ return input;
+ } else {
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
+ }
+ } else {
+ if (partitionSpec.isUnpartitioned()) {
+ LOG.info("Distribute rows by equality fields, because there are equality fields set " +
+ "and table is unpartitioned");
+ return input.keyBy(new EqualityFieldKeySelector(iSchema, flinkRowType, equalityFieldIds));
+ } else {
+ for (PartitionField partitionField : partitionSpec.fields()) {
+ Preconditions.checkState(equalityFieldIds.contains(partitionField.sourceId()),
+ "In 'hash' distribution mode with equality fields set, partition field '%s' " +
+ "should be included in equality fields: '%s'", partitionField, equalityFieldColumns);
+ }
+ return input.keyBy(new PartitionKeySelector(partitionSpec, iSchema, flinkRowType));
Review Comment:
> If equality keys are not the source of partition keys, then the data with the same equal column value may be divided into different partitions, which is not allowed.
The check above states that _"In 'hash' distribution mode with equality fields set, partition field '%s' " +
"should be included in equality fields: '%s'"_. It contradicts what you said.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] hililiwei commented on pull request #4904: Flink: new sink base on the unified sink API
Posted by GitBox <gi...@apache.org>.
hililiwei commented on PR #4904:
URL: https://github.com/apache/iceberg/pull/4904#issuecomment-1142236067
cc @chenjunjiedada @stevenzwu @kbendick , PTAL , thx.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org