You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@druid.apache.org by GitBox <gi...@apache.org> on 2020/09/22 06:41:19 UTC
[GitHub] [druid] vogievetsky opened a new pull request #10417: Web console: compaction dialog update
vogievetsky opened a new pull request #10417:
URL: https://github.com/apache/druid/pull/10417
This PR updates the compaction dialog form to be better. Adds a JSON tab to make it possible to edit the raw JSON
Adds partition UI:
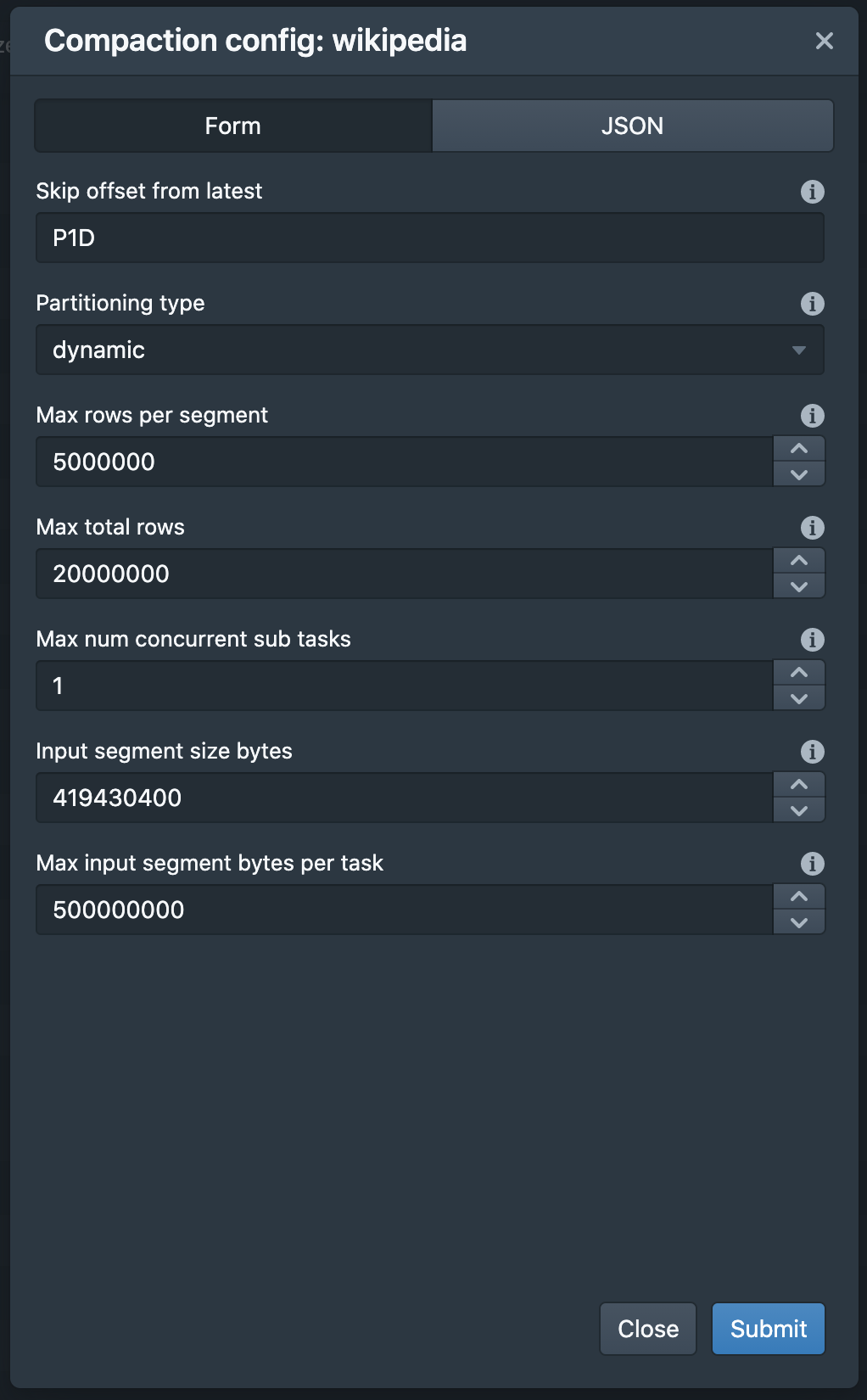
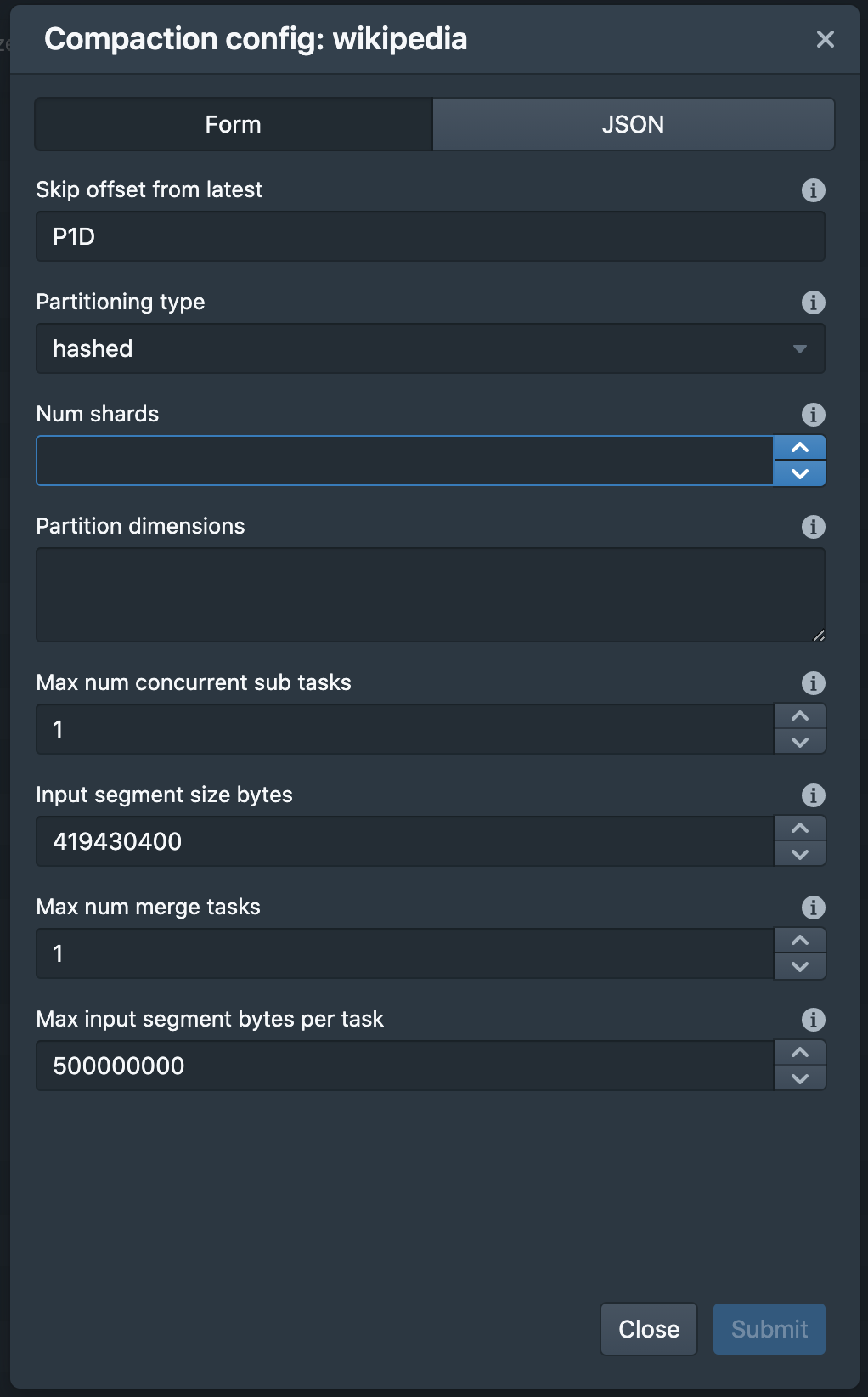
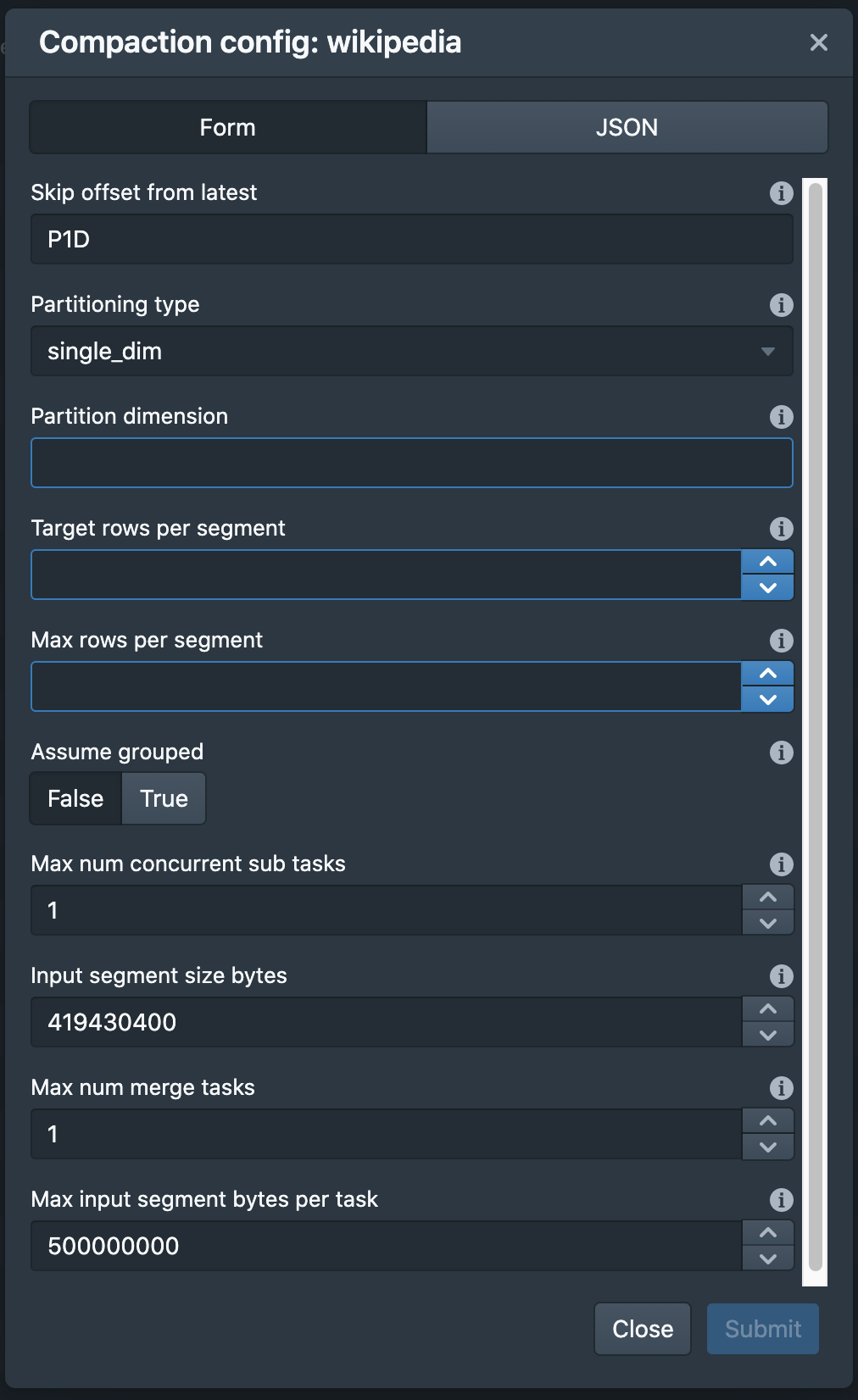
Raw JSON UI
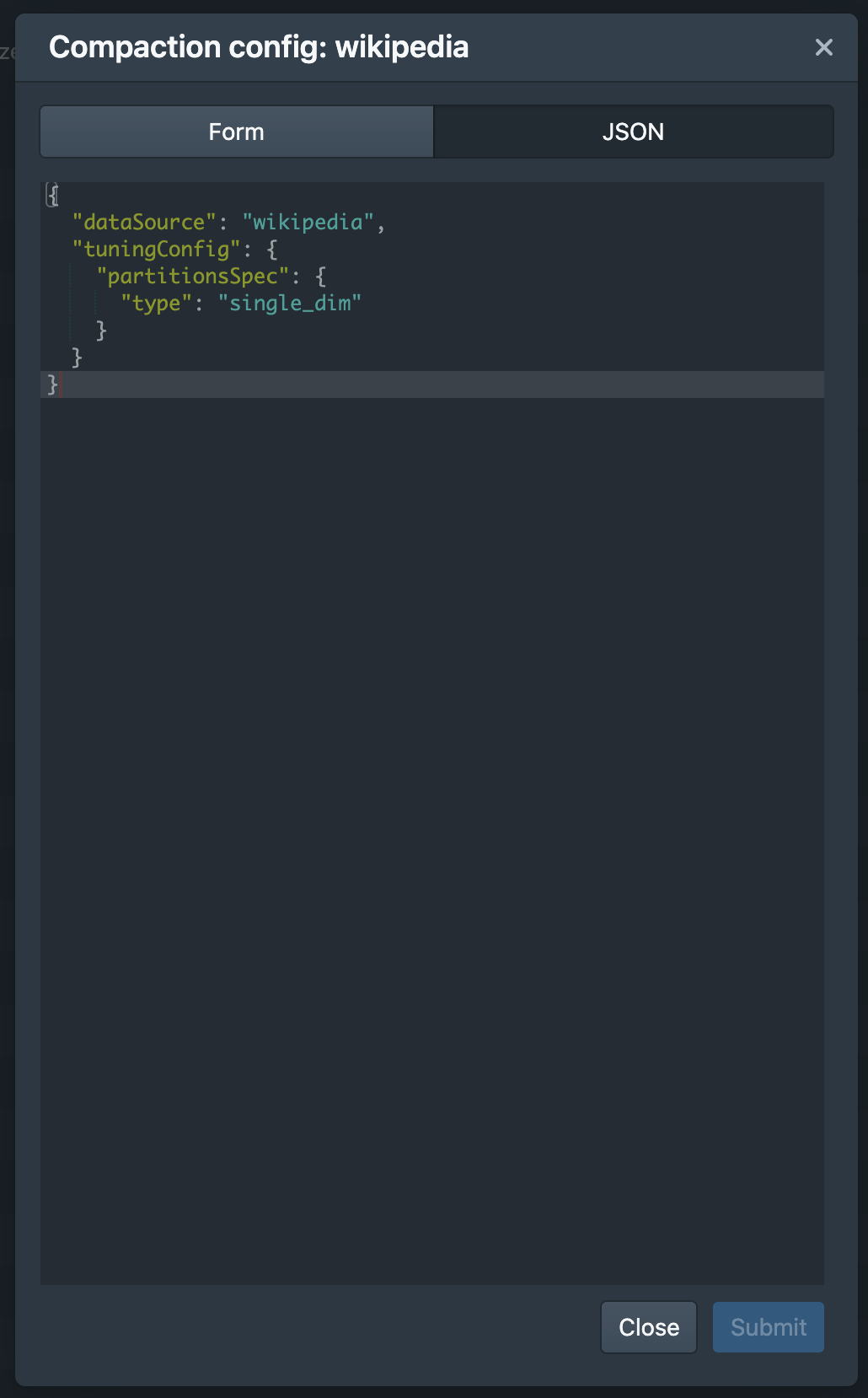
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493152095
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
info: (
<p>
- <ExternalLink href={`${getLink('DOCS')}/ingestion/tasks.html#task-context`}>
- Task context
- </ExternalLink>{' '}
- for compaction tasks.
+ Target number of rows to include in a partition, should be a number that targets segments of
+ 500MB~1GB.
</p>
),
},
{
- name: 'taskPriority',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: 25,
- info: <p>Priority of the compaction task.</p>,
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
+ info: <p>Maximum number of rows to include in a partition.</p>,
},
{
- name: 'tuningConfig',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.assumeGrouped',
+ label: 'Assume grouped',
+ type: 'boolean',
+ defaultValue: false,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
info: (
<p>
- <ExternalLink
- href={`${getLink('DOCS')}/configuration/index.html#compact-task-tuningconfig`}
- >
- Tuning config
- </ExternalLink>{' '}
- for compaction tasks.
+ Assume that input data has already been grouped on time and dimensions. Ingestion will run
+ faster, but may choose sub-optimal partitions if this assumption is violated.
</p>
),
},
+ {
+ name: 'tuningConfig.maxNumConcurrentSubTasks',
+ label: 'Max num concurrent sub tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ info: (
+ <>
+ Maximum number of tasks which can be run at the same time. The supervisor task would spawn
+ worker tasks up to maxNumConcurrentSubTasks regardless of the available task slots. If this
+ value is set to 1, the supervisor task processes data ingestion on its own instead of
+ spawning worker tasks. If this value is set to too large, too many worker tasks can be
+ created which might block other ingestion.
+ </>
+ ),
+ },
+ {
+ name: 'inputSegmentSizeBytes',
+ type: 'number',
+ defaultValue: 419430400,
+ info: (
+ <p>
+ Maximum number of total segment bytes processed per compaction task. Since a time chunk must
+ be processed in its entirety, if the segments for a particular time chunk have a total size
+ in bytes greater than this parameter, compaction will not run for that time chunk. Because
+ each compaction task runs with a single thread, setting this value too far above 1–2GB will
+ result in compaction tasks taking an excessive amount of time.
+ </p>
+ ),
+ },
+ {
+ name: 'tuningConfig.maxNumMergeTasks',
+ label: 'Max num merge tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ defined: (t: CompactionConfig) =>
+ ['hashed', 'single_dim'].includes(deepGet(t, 'tuningConfig.partitionsSpec.type')),
+ info: <>Maximum number of merge tasks which can be run at the same time.</>,
+ },
+ {
+ name: 'tuningConfig.splitHintSpec.maxInputSegmentBytesPerTask',
+ label: 'Max input segment bytes per task',
+ type: 'number',
+ defaultValue: 500000000,
+ min: 1000000,
+ adjustment: (t: CompactionConfig) => deepSet(t, 'tuningConfig.splitHintSpec.type', 'segments'),
+ info: (
+ <>
+ Maximum number of bytes of input segments to process in a single task. If a single segment
+ is larger than this number, it will be processed by itself in a single task (input segments
+ are never split across tasks).
+ </>
+ ),
+ },
];
+function validCompactionConfig(compactionConfig: CompactionConfig): boolean {
+ const partitionsSpecType =
+ deepGet(compactionConfig, 'tuningConfig.partitionsSpec.type') || 'dynamic';
+ switch (partitionsSpecType) {
+ // case 'dynamic': // Nothing to check for dynamic
+ case 'hashed':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.numShards')) {
+ return false;
+ }
+ break;
+
+ case 'single_dim':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.partitionDimension')) {
+ return false;
+ }
+ if (
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.maxRowsPerSegment')
Review comment:
gotcha... I did not understand that at first. Thank you for clarifying
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
Review comment:
will note
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
Review comment:
FWIW that was (originally) copy pasted from https://druid.apache.org/docs/latest/ingestion/native-batch.html - should that be updated also?
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.spec.tsx
##########
@@ -21,15 +21,28 @@ import React from 'react';
import { CompactionDialog } from './compaction-dialog';
-describe('compaction dialog', () => {
- it('matches snapshot', () => {
+describe('CompactionDialog', () => {
+ it('matches snapshot without compactionConfig', () => {
const compactionDialog = shallow(
<CompactionDialog
onClose={() => {}}
onSave={() => {}}
onDelete={() => {}}
- datasource={'test'}
- compactionConfig={{}}
+ datasource={'test1'}
+ compactionConfig={undefined}
+ />,
+ );
+ expect(compactionDialog).toMatchSnapshot();
+ });
+
+ it('matches snapshot with compactionConfig', () => {
Review comment:
👍
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
info: (
<p>
- <ExternalLink href={`${getLink('DOCS')}/ingestion/tasks.html#task-context`}>
- Task context
- </ExternalLink>{' '}
- for compaction tasks.
+ Target number of rows to include in a partition, should be a number that targets segments of
+ 500MB~1GB.
</p>
),
},
{
- name: 'taskPriority',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: 25,
- info: <p>Priority of the compaction task.</p>,
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
+ info: <p>Maximum number of rows to include in a partition.</p>,
},
{
- name: 'tuningConfig',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.assumeGrouped',
+ label: 'Assume grouped',
+ type: 'boolean',
+ defaultValue: false,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
info: (
<p>
- <ExternalLink
- href={`${getLink('DOCS')}/configuration/index.html#compact-task-tuningconfig`}
- >
- Tuning config
- </ExternalLink>{' '}
- for compaction tasks.
+ Assume that input data has already been grouped on time and dimensions. Ingestion will run
+ faster, but may choose sub-optimal partitions if this assumption is violated.
</p>
),
},
+ {
+ name: 'tuningConfig.maxNumConcurrentSubTasks',
+ label: 'Max num concurrent sub tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ info: (
+ <>
+ Maximum number of tasks which can be run at the same time. The supervisor task would spawn
+ worker tasks up to maxNumConcurrentSubTasks regardless of the available task slots. If this
+ value is set to 1, the supervisor task processes data ingestion on its own instead of
+ spawning worker tasks. If this value is set to too large, too many worker tasks can be
+ created which might block other ingestion.
+ </>
+ ),
+ },
+ {
+ name: 'inputSegmentSizeBytes',
+ type: 'number',
+ defaultValue: 419430400,
+ info: (
+ <p>
+ Maximum number of total segment bytes processed per compaction task. Since a time chunk must
+ be processed in its entirety, if the segments for a particular time chunk have a total size
+ in bytes greater than this parameter, compaction will not run for that time chunk. Because
+ each compaction task runs with a single thread, setting this value too far above 1–2GB will
+ result in compaction tasks taking an excessive amount of time.
+ </p>
+ ),
+ },
+ {
+ name: 'tuningConfig.maxNumMergeTasks',
+ label: 'Max num merge tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ defined: (t: CompactionConfig) =>
+ ['hashed', 'single_dim'].includes(deepGet(t, 'tuningConfig.partitionsSpec.type')),
+ info: <>Maximum number of merge tasks which can be run at the same time.</>,
+ },
+ {
+ name: 'tuningConfig.splitHintSpec.maxInputSegmentBytesPerTask',
+ label: 'Max input segment bytes per task',
+ type: 'number',
+ defaultValue: 500000000,
+ min: 1000000,
+ adjustment: (t: CompactionConfig) => deepSet(t, 'tuningConfig.splitHintSpec.type', 'segments'),
+ info: (
+ <>
+ Maximum number of bytes of input segments to process in a single task. If a single segment
+ is larger than this number, it will be processed by itself in a single task (input segments
+ are never split across tasks).
+ </>
+ ),
+ },
];
+function validCompactionConfig(compactionConfig: CompactionConfig): boolean {
+ const partitionsSpecType =
+ deepGet(compactionConfig, 'tuningConfig.partitionsSpec.type') || 'dynamic';
+ switch (partitionsSpecType) {
+ // case 'dynamic': // Nothing to check for dynamic
+ case 'hashed':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.numShards')) {
+ return false;
+ }
+ break;
+
+ case 'single_dim':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.partitionDimension')) {
+ return false;
+ }
+ if (
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.maxRowsPerSegment')
Review comment:
The UI should be adjusted to disappear the other box if one is set. I assume the same applies for the partition spec form un the data loader
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] ccaominh commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
ccaominh commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493683325
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
info: (
<p>
- <ExternalLink href={`${getLink('DOCS')}/ingestion/tasks.html#task-context`}>
- Task context
- </ExternalLink>{' '}
- for compaction tasks.
+ Target number of rows to include in a partition, should be a number that targets segments of
+ 500MB~1GB.
</p>
),
},
{
- name: 'taskPriority',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: 25,
- info: <p>Priority of the compaction task.</p>,
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
+ info: <p>Maximum number of rows to include in a partition.</p>,
},
{
- name: 'tuningConfig',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.assumeGrouped',
+ label: 'Assume grouped',
+ type: 'boolean',
+ defaultValue: false,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
info: (
<p>
- <ExternalLink
- href={`${getLink('DOCS')}/configuration/index.html#compact-task-tuningconfig`}
- >
- Tuning config
- </ExternalLink>{' '}
- for compaction tasks.
+ Assume that input data has already been grouped on time and dimensions. Ingestion will run
+ faster, but may choose sub-optimal partitions if this assumption is violated.
</p>
),
},
+ {
+ name: 'tuningConfig.maxNumConcurrentSubTasks',
+ label: 'Max num concurrent sub tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ info: (
+ <>
+ Maximum number of tasks which can be run at the same time. The supervisor task would spawn
+ worker tasks up to maxNumConcurrentSubTasks regardless of the available task slots. If this
+ value is set to 1, the supervisor task processes data ingestion on its own instead of
+ spawning worker tasks. If this value is set to too large, too many worker tasks can be
+ created which might block other ingestion.
+ </>
+ ),
+ },
+ {
+ name: 'inputSegmentSizeBytes',
+ type: 'number',
+ defaultValue: 419430400,
+ info: (
+ <p>
+ Maximum number of total segment bytes processed per compaction task. Since a time chunk must
+ be processed in its entirety, if the segments for a particular time chunk have a total size
+ in bytes greater than this parameter, compaction will not run for that time chunk. Because
+ each compaction task runs with a single thread, setting this value too far above 1–2GB will
+ result in compaction tasks taking an excessive amount of time.
+ </p>
+ ),
+ },
+ {
+ name: 'tuningConfig.maxNumMergeTasks',
+ label: 'Max num merge tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ defined: (t: CompactionConfig) =>
+ ['hashed', 'single_dim'].includes(deepGet(t, 'tuningConfig.partitionsSpec.type')),
+ info: <>Maximum number of merge tasks which can be run at the same time.</>,
+ },
+ {
+ name: 'tuningConfig.splitHintSpec.maxInputSegmentBytesPerTask',
+ label: 'Max input segment bytes per task',
+ type: 'number',
+ defaultValue: 500000000,
+ min: 1000000,
+ adjustment: (t: CompactionConfig) => deepSet(t, 'tuningConfig.splitHintSpec.type', 'segments'),
+ info: (
+ <>
+ Maximum number of bytes of input segments to process in a single task. If a single segment
+ is larger than this number, it will be processed by itself in a single task (input segments
+ are never split across tasks).
+ </>
+ ),
+ },
];
+function validCompactionConfig(compactionConfig: CompactionConfig): boolean {
+ const partitionsSpecType =
+ deepGet(compactionConfig, 'tuningConfig.partitionsSpec.type') || 'dynamic';
+ switch (partitionsSpecType) {
+ // case 'dynamic': // Nothing to check for dynamic
+ case 'hashed':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.numShards')) {
+ return false;
+ }
+ break;
+
+ case 'single_dim':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.partitionDimension')) {
+ return false;
+ }
+ if (
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.maxRowsPerSegment')
Review comment:
Yeah, the same applies to the data loader.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493152095
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
info: (
<p>
- <ExternalLink href={`${getLink('DOCS')}/ingestion/tasks.html#task-context`}>
- Task context
- </ExternalLink>{' '}
- for compaction tasks.
+ Target number of rows to include in a partition, should be a number that targets segments of
+ 500MB~1GB.
</p>
),
},
{
- name: 'taskPriority',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: 25,
- info: <p>Priority of the compaction task.</p>,
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
+ info: <p>Maximum number of rows to include in a partition.</p>,
},
{
- name: 'tuningConfig',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.assumeGrouped',
+ label: 'Assume grouped',
+ type: 'boolean',
+ defaultValue: false,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
info: (
<p>
- <ExternalLink
- href={`${getLink('DOCS')}/configuration/index.html#compact-task-tuningconfig`}
- >
- Tuning config
- </ExternalLink>{' '}
- for compaction tasks.
+ Assume that input data has already been grouped on time and dimensions. Ingestion will run
+ faster, but may choose sub-optimal partitions if this assumption is violated.
</p>
),
},
+ {
+ name: 'tuningConfig.maxNumConcurrentSubTasks',
+ label: 'Max num concurrent sub tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ info: (
+ <>
+ Maximum number of tasks which can be run at the same time. The supervisor task would spawn
+ worker tasks up to maxNumConcurrentSubTasks regardless of the available task slots. If this
+ value is set to 1, the supervisor task processes data ingestion on its own instead of
+ spawning worker tasks. If this value is set to too large, too many worker tasks can be
+ created which might block other ingestion.
+ </>
+ ),
+ },
+ {
+ name: 'inputSegmentSizeBytes',
+ type: 'number',
+ defaultValue: 419430400,
+ info: (
+ <p>
+ Maximum number of total segment bytes processed per compaction task. Since a time chunk must
+ be processed in its entirety, if the segments for a particular time chunk have a total size
+ in bytes greater than this parameter, compaction will not run for that time chunk. Because
+ each compaction task runs with a single thread, setting this value too far above 1–2GB will
+ result in compaction tasks taking an excessive amount of time.
+ </p>
+ ),
+ },
+ {
+ name: 'tuningConfig.maxNumMergeTasks',
+ label: 'Max num merge tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ defined: (t: CompactionConfig) =>
+ ['hashed', 'single_dim'].includes(deepGet(t, 'tuningConfig.partitionsSpec.type')),
+ info: <>Maximum number of merge tasks which can be run at the same time.</>,
+ },
+ {
+ name: 'tuningConfig.splitHintSpec.maxInputSegmentBytesPerTask',
+ label: 'Max input segment bytes per task',
+ type: 'number',
+ defaultValue: 500000000,
+ min: 1000000,
+ adjustment: (t: CompactionConfig) => deepSet(t, 'tuningConfig.splitHintSpec.type', 'segments'),
+ info: (
+ <>
+ Maximum number of bytes of input segments to process in a single task. If a single segment
+ is larger than this number, it will be processed by itself in a single task (input segments
+ are never split across tasks).
+ </>
+ ),
+ },
];
+function validCompactionConfig(compactionConfig: CompactionConfig): boolean {
+ const partitionsSpecType =
+ deepGet(compactionConfig, 'tuningConfig.partitionsSpec.type') || 'dynamic';
+ switch (partitionsSpecType) {
+ // case 'dynamic': // Nothing to check for dynamic
+ case 'hashed':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.numShards')) {
+ return false;
+ }
+ break;
+
+ case 'single_dim':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.partitionDimension')) {
+ return false;
+ }
+ if (
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.maxRowsPerSegment')
Review comment:
gotcha... I did not understand that at first. Thank you for clarifying
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] ccaominh commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
ccaominh commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493043987
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
Review comment:
```suggestion
dimension). For best-effort rollup, you should use <Code>dynamic</Code>.
```
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
Review comment:
For reference, https://github.com/apache/druid/pull/10419 will make this optional
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
Review comment:
```suggestion
pass through the data.
```
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
info: (
<p>
- <ExternalLink href={`${getLink('DOCS')}/ingestion/tasks.html#task-context`}>
- Task context
- </ExternalLink>{' '}
- for compaction tasks.
+ Target number of rows to include in a partition, should be a number that targets segments of
+ 500MB~1GB.
</p>
),
},
{
- name: 'taskPriority',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: 25,
- info: <p>Priority of the compaction task.</p>,
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
+ info: <p>Maximum number of rows to include in a partition.</p>,
},
{
- name: 'tuningConfig',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.assumeGrouped',
+ label: 'Assume grouped',
+ type: 'boolean',
+ defaultValue: false,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
info: (
<p>
- <ExternalLink
- href={`${getLink('DOCS')}/configuration/index.html#compact-task-tuningconfig`}
- >
- Tuning config
- </ExternalLink>{' '}
- for compaction tasks.
+ Assume that input data has already been grouped on time and dimensions. Ingestion will run
+ faster, but may choose sub-optimal partitions if this assumption is violated.
</p>
),
},
+ {
+ name: 'tuningConfig.maxNumConcurrentSubTasks',
+ label: 'Max num concurrent sub tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ info: (
+ <>
+ Maximum number of tasks which can be run at the same time. The supervisor task would spawn
+ worker tasks up to maxNumConcurrentSubTasks regardless of the available task slots. If this
+ value is set to 1, the supervisor task processes data ingestion on its own instead of
+ spawning worker tasks. If this value is set to too large, too many worker tasks can be
+ created which might block other ingestion.
+ </>
+ ),
+ },
+ {
+ name: 'inputSegmentSizeBytes',
+ type: 'number',
+ defaultValue: 419430400,
+ info: (
+ <p>
+ Maximum number of total segment bytes processed per compaction task. Since a time chunk must
+ be processed in its entirety, if the segments for a particular time chunk have a total size
+ in bytes greater than this parameter, compaction will not run for that time chunk. Because
+ each compaction task runs with a single thread, setting this value too far above 1–2GB will
+ result in compaction tasks taking an excessive amount of time.
+ </p>
+ ),
+ },
+ {
+ name: 'tuningConfig.maxNumMergeTasks',
+ label: 'Max num merge tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ defined: (t: CompactionConfig) =>
+ ['hashed', 'single_dim'].includes(deepGet(t, 'tuningConfig.partitionsSpec.type')),
+ info: <>Maximum number of merge tasks which can be run at the same time.</>,
+ },
+ {
+ name: 'tuningConfig.splitHintSpec.maxInputSegmentBytesPerTask',
+ label: 'Max input segment bytes per task',
+ type: 'number',
+ defaultValue: 500000000,
+ min: 1000000,
+ adjustment: (t: CompactionConfig) => deepSet(t, 'tuningConfig.splitHintSpec.type', 'segments'),
+ info: (
+ <>
+ Maximum number of bytes of input segments to process in a single task. If a single segment
+ is larger than this number, it will be processed by itself in a single task (input segments
+ are never split across tasks).
+ </>
+ ),
+ },
];
+function validCompactionConfig(compactionConfig: CompactionConfig): boolean {
+ const partitionsSpecType =
+ deepGet(compactionConfig, 'tuningConfig.partitionsSpec.type') || 'dynamic';
+ switch (partitionsSpecType) {
+ // case 'dynamic': // Nothing to check for dynamic
+ case 'hashed':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.numShards')) {
+ return false;
+ }
+ break;
+
+ case 'single_dim':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.partitionDimension')) {
+ return false;
+ }
+ if (
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.maxRowsPerSegment')
Review comment:
I noticed when I tried `single_dim` with `partitionDimension`, `targetRowsPerSegment` and `maxRowsPerSegment` all set, that the `Submit` button was not disabled even though it's an invalid partitionsSpec (and results in an error response from the server). The logic here should be changed to return `false` if exactly one of `targetRowsPerSegment` or `maxRowsPerSegment` is not set.
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
Review comment:
See the comment I left on `validCompactionConfig()`.
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -122,25 +263,40 @@ export const CompactionDialog = React.memo(function CompactionDialog(props: Comp
canOutsideClickClose={false}
title={`Compaction config: ${datasource}`}
>
- <AutoForm
- fields={COMPACTION_CONFIG_FIELDS}
- model={currentConfig}
- onChange={m => setCurrentConfig(m)}
- />
- <div className={Classes.DIALOG_FOOTER}>
- <div className={Classes.DIALOG_FOOTER_ACTIONS}>
+ <FormGroup className="tabs">
+ <ButtonGroup fill>
+ <Button
+ text="Form"
+ active={currentTab === 'form'}
+ onClick={() => setCurrentTab('form')}
+ />
<Button
- text="Delete"
- intent={Intent.DANGER}
- onClick={onDelete}
- disabled={!compactionConfig}
+ text="JSON"
+ active={currentTab === 'json'}
+ onClick={() => setCurrentTab('json')}
/>
+ </ButtonGroup>
+ </FormGroup>
+ <div className="content">
+ {currentTab === 'form' ? (
+ <AutoForm
+ fields={COMPACTION_CONFIG_FIELDS}
+ model={currentConfig}
+ onChange={m => setCurrentConfig(m)}
+ />
+ ) : (
+ <JsonInput value={currentConfig} onChange={setCurrentConfig} height="100%" />
+ )}
Review comment:
I really like the new `Form` vs `JSON` tabs and the binding between the two views. Nice work!
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
Review comment:
The sentence "numShards cannot be specified if maxRowsPerSegment is set" can be removed since `numShards` is required.
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.spec.tsx
##########
@@ -21,15 +21,28 @@ import React from 'react';
import { CompactionDialog } from './compaction-dialog';
-describe('compaction dialog', () => {
- it('matches snapshot', () => {
+describe('CompactionDialog', () => {
+ it('matches snapshot without compactionConfig', () => {
const compactionDialog = shallow(
<CompactionDialog
onClose={() => {}}
onSave={() => {}}
onDelete={() => {}}
- datasource={'test'}
- compactionConfig={{}}
+ datasource={'test1'}
+ compactionConfig={undefined}
+ />,
+ );
+ expect(compactionDialog).toMatchSnapshot();
+ });
+
+ it('matches snapshot with compactionConfig', () => {
Review comment:
What do you think about having 3 variants of this test: `dynamic`, `hashed`, and `single_dim` partitions. For example, the snapshot would verify that the "Max num merge tasks" field should only show up for `hashed` and `single_dim`. Also, for `single_dim` we could have a test to verify that the spec is valid (see the comment I left on `validCompactionConfig()`).
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
info: (
<p>
- <ExternalLink href={`${getLink('DOCS')}/ingestion/tasks.html#task-context`}>
- Task context
- </ExternalLink>{' '}
- for compaction tasks.
+ Target number of rows to include in a partition, should be a number that targets segments of
+ 500MB~1GB.
</p>
),
},
{
- name: 'taskPriority',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: 25,
- info: <p>Priority of the compaction task.</p>,
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
Review comment:
See the comment I left on `validCompactionConfig()`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky commented on pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky commented on pull request #10417:
URL: https://github.com/apache/druid/pull/10417#issuecomment-697655004
Thank you for all the review!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky merged pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky merged pull request #10417:
URL: https://github.com/apache/druid/pull/10417
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] ccaominh commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
ccaominh commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493683047
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
Review comment:
Yeah, there's some inconsistency in the docs because on that page the `numShards` description in the `tuningConfig` section has that sentence, but later in the `partitionsSpec` section, the sentence is missing.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky commented on pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky commented on pull request #10417:
URL: https://github.com/apache/druid/pull/10417#issuecomment-697104647
I think I addressed all the feedback, thank you for the review!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493164458
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
info: (
<p>
- <ExternalLink href={`${getLink('DOCS')}/ingestion/tasks.html#task-context`}>
- Task context
- </ExternalLink>{' '}
- for compaction tasks.
+ Target number of rows to include in a partition, should be a number that targets segments of
+ 500MB~1GB.
</p>
),
},
{
- name: 'taskPriority',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: 25,
- info: <p>Priority of the compaction task.</p>,
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
+ info: <p>Maximum number of rows to include in a partition.</p>,
},
{
- name: 'tuningConfig',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.assumeGrouped',
+ label: 'Assume grouped',
+ type: 'boolean',
+ defaultValue: false,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
info: (
<p>
- <ExternalLink
- href={`${getLink('DOCS')}/configuration/index.html#compact-task-tuningconfig`}
- >
- Tuning config
- </ExternalLink>{' '}
- for compaction tasks.
+ Assume that input data has already been grouped on time and dimensions. Ingestion will run
+ faster, but may choose sub-optimal partitions if this assumption is violated.
</p>
),
},
+ {
+ name: 'tuningConfig.maxNumConcurrentSubTasks',
+ label: 'Max num concurrent sub tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ info: (
+ <>
+ Maximum number of tasks which can be run at the same time. The supervisor task would spawn
+ worker tasks up to maxNumConcurrentSubTasks regardless of the available task slots. If this
+ value is set to 1, the supervisor task processes data ingestion on its own instead of
+ spawning worker tasks. If this value is set to too large, too many worker tasks can be
+ created which might block other ingestion.
+ </>
+ ),
+ },
+ {
+ name: 'inputSegmentSizeBytes',
+ type: 'number',
+ defaultValue: 419430400,
+ info: (
+ <p>
+ Maximum number of total segment bytes processed per compaction task. Since a time chunk must
+ be processed in its entirety, if the segments for a particular time chunk have a total size
+ in bytes greater than this parameter, compaction will not run for that time chunk. Because
+ each compaction task runs with a single thread, setting this value too far above 1–2GB will
+ result in compaction tasks taking an excessive amount of time.
+ </p>
+ ),
+ },
+ {
+ name: 'tuningConfig.maxNumMergeTasks',
+ label: 'Max num merge tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ defined: (t: CompactionConfig) =>
+ ['hashed', 'single_dim'].includes(deepGet(t, 'tuningConfig.partitionsSpec.type')),
+ info: <>Maximum number of merge tasks which can be run at the same time.</>,
+ },
+ {
+ name: 'tuningConfig.splitHintSpec.maxInputSegmentBytesPerTask',
+ label: 'Max input segment bytes per task',
+ type: 'number',
+ defaultValue: 500000000,
+ min: 1000000,
+ adjustment: (t: CompactionConfig) => deepSet(t, 'tuningConfig.splitHintSpec.type', 'segments'),
+ info: (
+ <>
+ Maximum number of bytes of input segments to process in a single task. If a single segment
+ is larger than this number, it will be processed by itself in a single task (input segments
+ are never split across tasks).
+ </>
+ ),
+ },
];
+function validCompactionConfig(compactionConfig: CompactionConfig): boolean {
+ const partitionsSpecType =
+ deepGet(compactionConfig, 'tuningConfig.partitionsSpec.type') || 'dynamic';
+ switch (partitionsSpecType) {
+ // case 'dynamic': // Nothing to check for dynamic
+ case 'hashed':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.numShards')) {
+ return false;
+ }
+ break;
+
+ case 'single_dim':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.partitionDimension')) {
+ return false;
+ }
+ if (
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.maxRowsPerSegment')
Review comment:
The UI should be adjusted to disappear the other box if one is set. I assume the same applies for the partition spec form un the data loader
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493162624
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
Review comment:
FWIW that was (originally) copy pasted from https://druid.apache.org/docs/latest/ingestion/native-batch.html - should that be updated also?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky commented on pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky commented on pull request #10417:
URL: https://github.com/apache/druid/pull/10417#issuecomment-697104647
I think I addressed all the feedback, thank you for the review!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493162680
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.spec.tsx
##########
@@ -21,15 +21,28 @@ import React from 'react';
import { CompactionDialog } from './compaction-dialog';
-describe('compaction dialog', () => {
- it('matches snapshot', () => {
+describe('CompactionDialog', () => {
+ it('matches snapshot without compactionConfig', () => {
const compactionDialog = shallow(
<CompactionDialog
onClose={() => {}}
onSave={() => {}}
onDelete={() => {}}
- datasource={'test'}
- compactionConfig={{}}
+ datasource={'test1'}
+ compactionConfig={undefined}
+ />,
+ );
+ expect(compactionDialog).toMatchSnapshot();
+ });
+
+ it('matches snapshot with compactionConfig', () => {
Review comment:
👍
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] ccaominh commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
ccaominh commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493043987
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
Review comment:
```suggestion
dimension). For best-effort rollup, you should use <Code>dynamic</Code>.
```
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
Review comment:
For reference, https://github.com/apache/druid/pull/10419 will make this optional
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
Review comment:
```suggestion
pass through the data.
```
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
info: (
<p>
- <ExternalLink href={`${getLink('DOCS')}/ingestion/tasks.html#task-context`}>
- Task context
- </ExternalLink>{' '}
- for compaction tasks.
+ Target number of rows to include in a partition, should be a number that targets segments of
+ 500MB~1GB.
</p>
),
},
{
- name: 'taskPriority',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: 25,
- info: <p>Priority of the compaction task.</p>,
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
+ info: <p>Maximum number of rows to include in a partition.</p>,
},
{
- name: 'tuningConfig',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.assumeGrouped',
+ label: 'Assume grouped',
+ type: 'boolean',
+ defaultValue: false,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
info: (
<p>
- <ExternalLink
- href={`${getLink('DOCS')}/configuration/index.html#compact-task-tuningconfig`}
- >
- Tuning config
- </ExternalLink>{' '}
- for compaction tasks.
+ Assume that input data has already been grouped on time and dimensions. Ingestion will run
+ faster, but may choose sub-optimal partitions if this assumption is violated.
</p>
),
},
+ {
+ name: 'tuningConfig.maxNumConcurrentSubTasks',
+ label: 'Max num concurrent sub tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ info: (
+ <>
+ Maximum number of tasks which can be run at the same time. The supervisor task would spawn
+ worker tasks up to maxNumConcurrentSubTasks regardless of the available task slots. If this
+ value is set to 1, the supervisor task processes data ingestion on its own instead of
+ spawning worker tasks. If this value is set to too large, too many worker tasks can be
+ created which might block other ingestion.
+ </>
+ ),
+ },
+ {
+ name: 'inputSegmentSizeBytes',
+ type: 'number',
+ defaultValue: 419430400,
+ info: (
+ <p>
+ Maximum number of total segment bytes processed per compaction task. Since a time chunk must
+ be processed in its entirety, if the segments for a particular time chunk have a total size
+ in bytes greater than this parameter, compaction will not run for that time chunk. Because
+ each compaction task runs with a single thread, setting this value too far above 1–2GB will
+ result in compaction tasks taking an excessive amount of time.
+ </p>
+ ),
+ },
+ {
+ name: 'tuningConfig.maxNumMergeTasks',
+ label: 'Max num merge tasks',
+ type: 'number',
+ defaultValue: 1,
+ min: 1,
+ defined: (t: CompactionConfig) =>
+ ['hashed', 'single_dim'].includes(deepGet(t, 'tuningConfig.partitionsSpec.type')),
+ info: <>Maximum number of merge tasks which can be run at the same time.</>,
+ },
+ {
+ name: 'tuningConfig.splitHintSpec.maxInputSegmentBytesPerTask',
+ label: 'Max input segment bytes per task',
+ type: 'number',
+ defaultValue: 500000000,
+ min: 1000000,
+ adjustment: (t: CompactionConfig) => deepSet(t, 'tuningConfig.splitHintSpec.type', 'segments'),
+ info: (
+ <>
+ Maximum number of bytes of input segments to process in a single task. If a single segment
+ is larger than this number, it will be processed by itself in a single task (input segments
+ are never split across tasks).
+ </>
+ ),
+ },
];
+function validCompactionConfig(compactionConfig: CompactionConfig): boolean {
+ const partitionsSpecType =
+ deepGet(compactionConfig, 'tuningConfig.partitionsSpec.type') || 'dynamic';
+ switch (partitionsSpecType) {
+ // case 'dynamic': // Nothing to check for dynamic
+ case 'hashed':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.numShards')) {
+ return false;
+ }
+ break;
+
+ case 'single_dim':
+ if (!deepGet(compactionConfig, 'tuningConfig.partitionsSpec.partitionDimension')) {
+ return false;
+ }
+ if (
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(compactionConfig, 'tuningConfig.partitionsSpec.maxRowsPerSegment')
Review comment:
I noticed when I tried `single_dim` with `partitionDimension`, `targetRowsPerSegment` and `maxRowsPerSegment` all set, that the `Submit` button was not disabled even though it's an invalid partitionsSpec (and results in an error response from the server). The logic here should be changed to return `false` if exactly one of `targetRowsPerSegment` or `maxRowsPerSegment` is not set.
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
Review comment:
See the comment I left on `validCompactionConfig()`.
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -122,25 +263,40 @@ export const CompactionDialog = React.memo(function CompactionDialog(props: Comp
canOutsideClickClose={false}
title={`Compaction config: ${datasource}`}
>
- <AutoForm
- fields={COMPACTION_CONFIG_FIELDS}
- model={currentConfig}
- onChange={m => setCurrentConfig(m)}
- />
- <div className={Classes.DIALOG_FOOTER}>
- <div className={Classes.DIALOG_FOOTER_ACTIONS}>
+ <FormGroup className="tabs">
+ <ButtonGroup fill>
+ <Button
+ text="Form"
+ active={currentTab === 'form'}
+ onClick={() => setCurrentTab('form')}
+ />
<Button
- text="Delete"
- intent={Intent.DANGER}
- onClick={onDelete}
- disabled={!compactionConfig}
+ text="JSON"
+ active={currentTab === 'json'}
+ onClick={() => setCurrentTab('json')}
/>
+ </ButtonGroup>
+ </FormGroup>
+ <div className="content">
+ {currentTab === 'form' ? (
+ <AutoForm
+ fields={COMPACTION_CONFIG_FIELDS}
+ model={currentConfig}
+ onChange={m => setCurrentConfig(m)}
+ />
+ ) : (
+ <JsonInput value={currentConfig} onChange={setCurrentConfig} height="100%" />
+ )}
Review comment:
I really like the new `Form` vs `JSON` tabs and the binding between the two views. Nice work!
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
Review comment:
The sentence "numShards cannot be specified if maxRowsPerSegment is set" can be removed since `numShards` is required.
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.spec.tsx
##########
@@ -21,15 +21,28 @@ import React from 'react';
import { CompactionDialog } from './compaction-dialog';
-describe('compaction dialog', () => {
- it('matches snapshot', () => {
+describe('CompactionDialog', () => {
+ it('matches snapshot without compactionConfig', () => {
const compactionDialog = shallow(
<CompactionDialog
onClose={() => {}}
onSave={() => {}}
onDelete={() => {}}
- datasource={'test'}
- compactionConfig={{}}
+ datasource={'test1'}
+ compactionConfig={undefined}
+ />,
+ );
+ expect(compactionDialog).toMatchSnapshot();
+ });
+
+ it('matches snapshot with compactionConfig', () => {
Review comment:
What do you think about having 3 variants of this test: `dynamic`, `hashed`, and `single_dim` partitions. For example, the snapshot would verify that the "Max num merge tasks" field should only show up for `hashed` and `single_dim`. Also, for `single_dim` we could have a test to verify that the spec is valid (see the comment I left on `validCompactionConfig()`).
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: (
+ <>
+ Directly specify the number of shards to create. If this is specified and 'intervals' is
+ specified in the granularitySpec, the index task can skip the determine intervals/partitions
+ pass through the data. numShards cannot be specified if maxRowsPerSegment is set.
+ </>
+ ),
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimensions',
+ label: 'Partition dimensions',
+ type: 'string-array',
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'hashed',
+ info: <p>The dimensions to partition on. Leave blank to select all dimensions.</p>,
+ },
+ // partitionsSpec type: single_dim
+ {
+ name: 'tuningConfig.partitionsSpec.partitionDimension',
+ label: 'Partition dimension',
+ type: 'string',
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: true,
+ info: <p>The dimension to partition on.</p>,
+ },
+ {
+ name: 'tuningConfig.partitionsSpec.targetRowsPerSegment',
+ label: 'Target rows per segment',
+ type: 'number',
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
info: (
<p>
- <ExternalLink href={`${getLink('DOCS')}/ingestion/tasks.html#task-context`}>
- Task context
- </ExternalLink>{' '}
- for compaction tasks.
+ Target number of rows to include in a partition, should be a number that targets segments of
+ 500MB~1GB.
</p>
),
},
{
- name: 'taskPriority',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: 25,
- info: <p>Priority of the compaction task.</p>,
+ zeroMeansUndefined: true,
+ defined: (t: CompactionConfig) =>
+ deepGet(t, 'tuningConfig.partitionsSpec.type') === 'single_dim',
+ required: (t: CompactionConfig) =>
+ !deepGet(t, 'tuningConfig.partitionsSpec.targetRowsPerSegment') &&
+ !deepGet(t, 'tuningConfig.partitionsSpec.maxRowsPerSegment'),
Review comment:
See the comment I left on `validCompactionConfig()`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] vogievetsky commented on a change in pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
vogievetsky commented on a change in pull request #10417:
URL: https://github.com/apache/druid/pull/10417#discussion_r493162211
##########
File path: web-console/src/dialogs/compaction-dialog/compaction-dialog.tsx
##########
@@ -16,101 +16,242 @@
* limitations under the License.
*/
-import { Button, Classes, Dialog, Intent } from '@blueprintjs/core';
+import { Button, ButtonGroup, Classes, Code, Dialog, FormGroup, Intent } from '@blueprintjs/core';
import React, { useState } from 'react';
-import { AutoForm, ExternalLink, Field } from '../../components';
-import { getLink } from '../../links';
+import { AutoForm, Field, JsonInput } from '../../components';
+import { deepGet, deepSet } from '../../utils/object-change';
import './compaction-dialog.scss';
export const DEFAULT_MAX_ROWS_PER_SEGMENT = 5000000;
-const COMPACTION_CONFIG_FIELDS: Field<Record<string, any>>[] = [
+type Tabs = 'form' | 'json';
+
+type CompactionConfig = Record<string, any>;
+
+const COMPACTION_CONFIG_FIELDS: Field<CompactionConfig>[] = [
{
- name: 'inputSegmentSizeBytes',
- type: 'number',
- defaultValue: 419430400,
+ name: 'skipOffsetFromLatest',
+ type: 'string',
+ defaultValue: 'P1D',
info: (
<p>
- Maximum number of total segment bytes processed per compaction task. Since a time chunk must
- be processed in its entirety, if the segments for a particular time chunk have a total size
- in bytes greater than this parameter, compaction will not run for that time chunk. Because
- each compaction task runs with a single thread, setting this value too far above 1–2GB will
- result in compaction tasks taking an excessive amount of time.
+ The offset for searching segments to be compacted. Strongly recommended to set for realtime
+ dataSources.
</p>
),
},
{
- name: 'skipOffsetFromLatest',
+ name: 'tuningConfig.partitionsSpec.type',
+ label: 'Partitioning type',
type: 'string',
- defaultValue: 'P1D',
+ suggestions: ['dynamic', 'hashed', 'single_dim'],
info: (
<p>
- The offset for searching segments to be compacted. Strongly recommended to set for realtime
- dataSources.
+ For perfect rollup, you should use either <Code>hashed</Code> (partitioning based on the
+ hash of dimensions in each row) or <Code>single_dim</Code> (based on ranges of a single
+ dimension. For best-effort rollup, you should use dynamic.
</p>
),
},
+ // partitionsSpec type: dynamic
{
- name: 'maxRowsPerSegment',
+ name: 'tuningConfig.partitionsSpec.maxRowsPerSegment',
+ label: 'Max rows per segment',
type: 'number',
- defaultValue: DEFAULT_MAX_ROWS_PER_SEGMENT,
- info: <p>Determines how many rows are in each segment.</p>,
+ defaultValue: 5000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Determines how many rows are in each segment.</>,
},
{
- name: 'taskContext',
- type: 'json',
+ name: 'tuningConfig.partitionsSpec.maxTotalRows',
+ label: 'Max total rows',
+ type: 'number',
+ defaultValue: 20000000,
+ defined: (t: CompactionConfig) => deepGet(t, 'tuningConfig.partitionsSpec.type') === 'dynamic',
+ info: <>Total number of rows in segments waiting for being pushed.</>,
+ },
+ // partitionsSpec type: hashed
+ {
+ name: 'tuningConfig.partitionsSpec.numShards',
+ label: 'Num shards',
+ type: 'number',
+ required: true, // ToDo: this will no longer be required soon
Review comment:
will note
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] ccaominh commented on pull request #10417: Web console: compaction dialog update
Posted by GitBox <gi...@apache.org>.
ccaominh commented on pull request #10417:
URL: https://github.com/apache/druid/pull/10417#issuecomment-697540499
I retriggered `(Compile=openjdk8, Run=openjdk11) query integration test` since `ITWikipediaQueryTest.testWikipediaQueriesFromFile` failed, which is unrelated to this PR.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org