You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2022/07/18 01:34:22 UTC
[GitHub] [hudi] jiangbiao910 opened a new issue, #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
jiangbiao910 opened a new issue, #6127:
URL: https://github.com/apache/hudi/issues/6127
Hudi has recently released the latest version of Hudi, 0.11.1, which is pulled from Github and modified as follows for our Hadoop environment CDH6.3.2。
Upgrading to 0.11.1 resulting use sparksql:
`
create table if not exists zone_test.hudi_spark_table0718_mor_0111
(
id string,
brand_id int,
name string,
model_id int,
model_name string,
etl_update_time string,
dt string,
hh string
) using hudi
options (
type = 'mor',
primaryKey = 'brand_id,vehicle_model_id',
preCombineField = 'etl_update_time',
hoodie.cleaner.commits.retained = '2',
hoodie.compact.inline=true
)
partitioned by (dt,hh)
;
insert into zone_test.hudi_spark_table0718_mor_0111 partition (dt,hh)
select id,
brand_id,
name,
model_id,
model_name,
CAST(current_timestamp AS string) as etl_update_time,
'20220718',
'10'
from zone_test.test_vehicle_status_2_hi
;
`
now I can see **3 tables** in the Hive
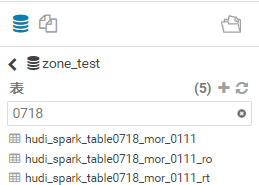
But,there is **zero result** in the table **zone_test.hudi_spark_table0718_mor_0111** and **hudi_spark_table0718_mor_0111_ro
hudi_spark_table0718_mor_0111_rt** has **2 records**。this is a bug?
However when I run this SQL:
`set hoodie.datasource.hive_sync.skip_ro_suffix=true;
create table if not exists zone_test.hudi_spark_table0718_mor_0111_skip
(
id string,
brand_id int,
name string,
model_id int,
model_name string,
etl_update_time string,
dt string,
hh string
) using hudi
options (
type = 'mor',
primaryKey = 'brand_id,vehicle_model_id',
preCombineField = 'etl_update_time',
hoodie.cleaner.commits.retained = '2',
hoodie.compact.inline=true
)
partitioned by (dt,hh)
;
insert into zone_test.hudi_spark_table0718_mor_0111_skip partition (dt,hh)
select id,
brand_id,
name,
model_id,
model_name,
CAST(current_timestamp AS string) as etl_update_time,
'20220715',
'10'
from zone_test.test_vehicle_status_2_hi
;
`
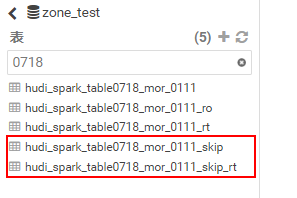
now I can see 2 tables in the Hive,both
**hudi_spark_table0718_mor_0111_skip and hudi_spark_table0718_mor_0111_skip_rt** has **2recoreds**。
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] jiangbiao910 commented on issue #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
Posted by GitBox <gi...@apache.org>.
jiangbiao910 commented on issue #6127:
URL: https://github.com/apache/hudi/issues/6127#issuecomment-1186878898
> only _ro and _rt table will sync partition info to metastore, when I use presto to query raw table, cannot query the data, but _ro or _rt success. Depending on the implementation of the engine. When you `set hoodie.datasource.hive_sync.skip_ro_suffix=true`, it will take raw table as _ro to sync
So,I think it is normal from my tests; thank you very much!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] KnightChess commented on issue #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
Posted by GitBox <gi...@apache.org>.
KnightChess commented on issue #6127:
URL: https://github.com/apache/hudi/issues/6127#issuecomment-1186739851
only _ro and _rt table will sync partition info to metastore, when I use presto to query raw table, cannot query the data, but _ro or _rt success. Depending on the implementation of the engine. When you `set hoodie.datasource.hive_sync.skip_ro_suffix=true`, it will take raw table as _ro to sync
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #6127:
URL: https://github.com/apache/hudi/issues/6127#issuecomment-1188593205
@KnightChess @fengjian428 thanks!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #6127:
URL: https://github.com/apache/hudi/issues/6127#issuecomment-1186696783
cc @fengjian428
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] jiangbiao910 commented on issue #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
Posted by GitBox <gi...@apache.org>.
jiangbiao910 commented on issue #6127:
URL: https://github.com/apache/hudi/issues/6127#issuecomment-1186877890
> hen I use presto to q
> @jiangbiao910 which query engine do you use to query data? make sure `hudi_spark_table0718_mor_0111` has no partition info in hive metastore
I use hive and trino to query data,
**show PARTITIONS hudi_spark_table0718_mor_0111** --》 0
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] KnightChess commented on issue #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
Posted by GitBox <gi...@apache.org>.
KnightChess commented on issue #6127:
URL: https://github.com/apache/hudi/issues/6127#issuecomment-1186737362
@jiangbiao910 which query engine do you use to query data? make sure `hudi_spark_table0718_mor_0111` has no partition info in hive metastore
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] fengjian428 commented on issue #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
Posted by GitBox <gi...@apache.org>.
fengjian428 commented on issue #6127:
URL: https://github.com/apache/hudi/issues/6127#issuecomment-1186775480
Yeah, KnightChess is right, I think this can answer this question
> only _ro and _rt table will sync partition info to metastore, when I use presto to query raw table, cannot query the data, but _ro or _rt success. Depending on the implementation of the engine. When you `set hoodie.datasource.hive_sync.skip_ro_suffix=true`, it will take raw table as _ro to sync
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan closed issue #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
Posted by GitBox <gi...@apache.org>.
xushiyan closed issue #6127: [SUPPORT] Upgrading to 0.11.1 resulting use sparksql and Sync Hive
URL: https://github.com/apache/hudi/issues/6127
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org