You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@mxnet.apache.org by GitBox <gi...@apache.org> on 2020/07/17 23:58:35 UTC
[GitHub] [incubator-mxnet] gilbertfrancois opened a new issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
gilbertfrancois opened a new issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751
## Description
The implementation of `gluon.nn.BatchNorm` behaves different on CPU and GPU context. I suspect that during the update of running_mean and running_var, the updated values are swapped on GPU context.
Erroneous behaviour of the BatchNorm layer has been reported before in the forum and here in the issue tracker. It might be related to this observation.
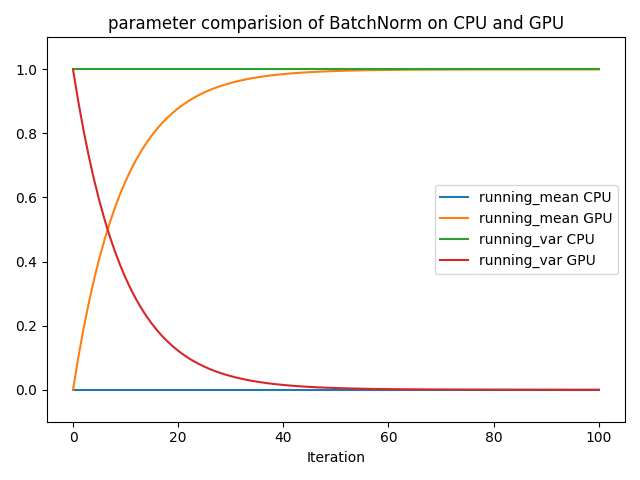
I made a minimal script to show the error. Let _f(X)_ = BatchNorm(_X_). When feeding all-ones matrix _X_, the _running_mean_ should be constant 1 and _running_var_ should be constant 0.
On **CPU**, the behaviour of `gluon.nn.BatchNorm` seems correct.
On **GPU**, the running mean goes to 0 and _running_var_ goes to 1 during iterations. (see plot).
When training e.g. a ResNet with custom output layers, e.g. [ResNet-Features -> Flatten -> BatchNorm -> Dropout -> Dense -> BatchNorm ->Dense], it results in NaN outputs on validation after a few training steps. Computing on CPU only solves the issue.
As a reference, I include some posts from the mxnet forum that might be related to this same issue:
https://discuss.mxnet.io/t/batchnorm-running-var-value-depends-on-context/3401
https://discuss.mxnet.io/t/hw-9-how-to-prevent-overflow-to-nan/3853
## To Reproduce
Run the script from the gist below:
```
curl --retry 10 -s https://gist.githubusercontent.com/gilbertfrancois/11474ff67466067bfee51c96da1bc6f6/raw/0f0659a3c832b346745704cc7ec7168d7f0a3587/bn_test.py | python
```
The script will create a "network" with 1 BatchNorm layer and run 100 times a forward pass with an all-ones matrix as input. At the end, the script will generate the plot shown on this page.
(Partial) output:
```
...
gamma on CPU and GPU are (almost) equal: True, err: 0.00000+-0.00000
beta on CPU and GPU are (almost) equal: True, err: 0.00000+-0.00000
running_mean on CPU and GPU are (almost) equal: False, err: 0.90099+-0.20569
running_var on CPU and GPU are (almost) equal: False, err: 0.90099+-0.20569
```
## Environment
This is tested on the following systems (note that the 1.7.0b version still has this bug)
- AWS p2.xlarge (Nvidia Tesla K80), aws-mxnet-cu101mkl v1.6.0, Deep Learning AMI (Ubuntu 18.04) Version 30.0
- PC Intel x86_64 with 2 x Nvidia GTX 1070 Ti, Ubuntu 18.04, mxnet-cu102 **v1.6.0**
- PC Intel x86_64 with 2 x Nvidia GTX 1070 Ti, Ubuntu 18.04, mxnet-cu102 **v1.7.0b20200716**
## Environment
```
curl --retry 10 -s https://raw.githubusercontent.com/dmlc/gluon-nlp/master/tools/diagnose.py | python
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) Core(TM) i9-9900K CPU @ 3.60GHz
Stepping: 13
CPU MHz: 4998.280
CPU max MHz: 5000.0000
CPU min MHz: 800.0000
BogoMIPS: 7200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 16384K
NUMA node0 CPU(s): 0-15
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant
_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1
sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi fl
expriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp
hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
----------Python Info----------
Version : 3.7.4
Compiler : GCC 7.4.0
Build : ('default', 'Dec 13 2019 13:00:24')
Arch : ('64bit', '')
------------Pip Info-----------
Version : 19.0.3
Directory : /tmp/test/.venv/lib/python3.7/site-packages/pip
----------MXNet Info-----------
Version : 1.7.0
Directory : /tmp/test/.venv/lib/python3.7/site-packages/mxnet
Num GPUs : 2
Hashtag not found. Not installed from pre-built package.
----------System Info----------
Platform : Linux-5.3.0-51-generic-x86_64-with-debian-buster-sid
system : Linux
release : 5.3.0-51-generic
version : #44~18.04.2-Ubuntu SMP Thu Apr 23 14:27:18 UTC 2020
----------Hardware Info----------
machine : x86_64
processor : x86_64
----------Network Test----------
Setting timeout: 10
Timing for MXNet: https://github.com/apache/incubator-mxnet, DNS: 0.0005 sec, LOAD: 0.0568 sec.
Timing for GluonNLP GitHub: https://github.com/dmlc/gluon-nlp, DNS: 0.0002 sec, LOAD: 0.0515 sec.
Timing for GluonNLP: http://gluon-nlp.mxnet.io, DNS: 0.0009 sec, LOAD: 0.0294 sec.
Timing for D2L: http://d2l.ai, DNS: 0.0007 sec, LOAD: 0.0098 sec.
Timing for D2L (zh-cn): http://zh.d2l.ai, DNS: 0.0007 sec, LOAD: 0.0192 sec.
Timing for FashionMNIST: https://repo.mxnet.io/gluon/dataset/fashion-mnist/train-labels-idx1-ubyte.gz, DNS: 0.0006 sec, LOAD: 0.0224 sec.
Timing for PYPI: https://pypi.python.org/pypi/pip, DNS: 0.0007 sec, LOAD: 0.2457 sec.
Error open Conda: https://repo.continuum.io/pkgs/free/, HTTP Error 403: Forbidden, DNS finished in 0.0007281303405761719 sec.
```
If you need more information, I'm happy to help.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-661225937
The CPU version updated running mean and running var in backward path. And there are some nuance difference there between CPU and GPUs. @gilbertfrancois, could you try to add y.backward() after y.net(x) during the iteration.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662730136
After nn.Flatten(), the batch norm is actually performed on a 1xCx1x1 Tensor, where C is 9408 for the first batch norm layer in tail, and it is 32 for the second batch morm layer. And then it will have C running means and C running vars, which might not be expected. And the BN is done on a single value when the batch size is 1.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662687910
@gilbertfrancois I did a quick test, to answer your question:
> I don't understand why y_out from MyNet with BatchNorm on GPU still contains real numbers, given that the layer before outputs NaNs?
The y_out and y_embedding actually came two separate forward runs. And y_embedding came at the second run. The first run was done with training mode( with autograd.record(train_mode=True), and the second run was done without recording. The first run should get both y_out and y_embeddings correctly. Unfortunately, the first run got the first BatchNorm's running var in tail into NaN, so the second run will get NaN for both y_embedding and y_out (did not print out). I have not figured out why the NaN's happened in tail only, as there are also many more BN in the features. Will dig more. BTW, if you print your embedding before y_out, you will get both without NaN's. Non-training mode will get your answer correct.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] wkcn commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
wkcn commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660600872
The values of moving_mean and moving_var are not consistent between CPU and GPU.
The values on CPU is population variance (v / n), but that on GPU CUDNN is sample variance (v / (n - 1)).
Refer: https://github.com/apache/incubator-mxnet/pull/18694/files#diff-cb652780258e73a9cd08568f38929aa2R1554
The line 1554 in tests/python/unittest/test_operator.py
```# cudnn uses m-1 in the denominator of its sample variance calculation, not m```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-665436383
@gilbertfrancois What is the BN suppose to do for your model in the tail? Is it suppose to do batch normalize every single value?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-661225937
The CPU version updates running mean and running var in backward path. And there are some nuance difference there between CPU and GPUs. @gilbertfrancois, could you try to add y.backward() after y.net(x) during the iteration.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662721253
It looks like there is a bug there for doing batch norm with 1D array, when the batch size is 1. For example, in this case, after flat, there vector size is 9408, which make the batch data shape as (1, 9408). I suspect that the batch norm views it as shape (9408, 1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662687910
@gilbertfrancois I did a quick test, to answer your question:
> I don't understand why y_out from MyNet with BatchNorm on GPU still contains real numbers, given that the layer before outputs NaNs?
The y_out and y_embedding actually came two separate forward runs. And y_embedding came at the second run. The first run was done with training mode( with autograd.record(train_mode=True), and the second run was done without recording. The first run should get both y_out and y_embeddings correctly. Unfortunately, the first run got the first BatchNorm's running var in tail into NaN, so the second run will get NaN for both y_embedding and y_out (did not print out). I have not figured out why the NaN's happened in tail only, as there are also many more BN in the features. Will dig more. BTW, if you print your embedding before y_out, you will get both without NaN's. Non-training mode will get your answer correct.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662756717
I suspect that the behaviour is corrected when the update of moving_mean and moving_var on GPU is done in the backward pass, like it is on CPU. It will solve the NaN values and will most likely make the quantitative output between CPU and GPU more consistent.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662730136
After nn.Flatten(), the batch norm is actually performed on a 1xCx1x1 Tensor, where C is 9408 for the first batch norm layer in tail, and it is 32 for the second batch morm layer. And then it will have C running means and C running vars, which might not be expected. And the BN is done on a single value when the batch size is 1. Then what @wkcn mentioned makes sense for a explanation.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662755383
Coming back to mxnet: it looks like it is possible to do a forward pass (inference mode) on cpu when the BatchNorm is placed with Dense layers. Because on CPU, the BatchNorm values are updated on the backward pass. But on GPU, it tries to update some values on the forward pass already, instead of the backward pass, resulting in NaN when the batch size = 1.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-661442792
In case anyone want to do a PyTorch comparison for CPU version:
```python
import torch
import torch.nn as nn
bn = nn.BatchNorm2d(3)
for _ in range(3):
x = torch.ones(8, 3, 32, 32)
out = bn(x)
print(bn.running_mean, bn.running_var)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-661448168
@szha It may not affect real training for either CPU or GPU version as CPU version does update the running mean and running var in the backward path. Should we unify the behaviors to make it consistent?
@gilbertfrancois Do you have a repro script of running into nans during training?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662687910
@gilbertfrancois I did a quick test, to answer your question:
> I don't understand why y_out from MyNet with BatchNorm on GPU still contains real numbers, given that the layer before outputs NaNs?
The y_out and y_embedding actually came from two separate forward runs. And y_embedding came at the second run. The first run was done with training mode(with autograd.record(train_mode=True), and the second run was done without recording (not training). The first run should get both y_out and y_embeddings correctly. Unfortunately, the first run got the first BatchNorm's running var in tail into NaN, so the second run will get NaN for both y_embedding and y_out (did not print out). I have not figured out why the NaN's happened in tail only, as there are also many more BN in the features (and seem those are OK). Will dig more. BTW, if you print the embedding before y_out, you will get both without NaN's. Non-training mode will get your answer correct.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662750082
Ok, I see that. But I guess it is the same intended behaviour as pyTorch nn.BatchNorm1d for Dense layers, which takes as input (N, C). The normalization is done over C features. E.g.:
```
>>> import torch
>>> import torch.nn as nn
>>> bn = nn.BatchNorm1d(32)
>>> x = torch.randn(2, 32)
>>> y = bn(x)
>>> bn.running_mean.shape
torch.Size([32])
>>> bn.running_var.shape
torch.Size([32])
```
This proofs that the BN layer has C running means and C running vars.
When defining `x = torch.randn(1, 32)` and do a forward pass in train mode, it gives an error, like expected. Same as @TristonC mentioned in https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662730136.
When running in eval mode, it does a forward pass:
```
>>> bn.eval()
>>> x = torch.randn(1, 32)
>>> bn(x)
tensor([[-0.6506, 0.9170, -0.8054, 1.4432, -0.2060, -0.5880, -0.0175, -0.8634,
1.0829, 1.1367, 0.6461, 1.1443, -2.3419, 0.0311, -1.2087, 0.1624,
-1.4499, -1.2504, -0.0466, 1.5738, 1.3166, 0.7299, 0.0930, 2.1064,
-0.0726, 1.6979, -0.9420, -0.1544, 0.8395, 1.9348, 0.1931, 0.9253]],
grad_fn=<NativeBatchNormBackward>)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-665976180
Apologies for the delay in answering. I was offline for a few days.
@TristonC https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-665436383 Yes, that is correct. It is part of research I'm doing, where BatchNorm layers are placed in the tail between Dense layers to equalise the "importance" or "amplitude" of features. I noticed that when comparing feature vectors by computing the distance of similar objects with e.g. cosine distance or euclidian distance, the is_similar vs is_not_similar accuracy is slightly higher when the features are balanced with (N, C) BatchNorm layers, especially when objects are partially occluded.
Whether or not this will lead to _generic_ higher accuracy, is still under research. It is too early to say if it will be useful in the end. What I noticed as an issue during experimenting and using Gluon, is that I see different results on CPU and GPU and NaN on GPU when doing a validation step with batch size = 1, which is in fact an inference step, not training. On CPU however, the inference or validation step goes well.
As you mentioned in https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-663168367 I believe that NaN is a valid result when training a network with 1D BatchNorm with a batch size of 1, but I don't think it should occur on inference, where moving mean/var are fixed, which is similar to the outcome of pyTorch, shown in https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662750082.
Please let me know if there is anything I can do to help.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-663168367
I am not sure that putting the running mean and running var into the backward pass is the solution. It can be achieved by setting autograd.record(train_mode=False). The problem here (NaN) is the way of computing running var, be it un-biased (divided by m -1 and as shown in the BN paper) or biased (by m). This is a corner case while m is 1 when the batch size is one and BN is after dense (or flatten) layer. My question is whether having 9408 or 32 running means and running vars really the network trying to do. BTW, the NaN is something frustrating for end users, we need to find a way to solve it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662687910
@gilbertfrancois I did a quick test, to answer your question:
> I don't understand why y_out from MyNet with BatchNorm on GPU still contains real numbers, given that the layer before outputs NaNs?
The y_out and y_embedding actually came from two separate forward runs. And y_embedding came at the second run. The first run was done with training mode(with autograd.record(train_mode=True), and the second run was done without recording (not training). The first run should get both y_out and y_embeddings correctly. Unfortunately, the first run got the first BatchNorm's running var in tail into NaN, so the second run will get NaN for both y_embedding and y_out (did not print out). I have not figured out why the NaN's happened in tail only, as there are also many more BN in the features. Will dig more. BTW, if you print your embedding before y_out, you will get both without NaN's. Non-training mode will get your answer correct.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660583673
Great repro script @gilbertfrancois. The CPU result seems wrong, while the GPU result seems reasonable. On your plot, the GPU running mean actually goes to 1 and running_var goes to 1 during iterations as expected.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC removed a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC removed a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660586280
On GPU, the first running mean is 0, while the following 3 running means are 0.1, 0.19 and 0.271, which can be explained as
running_mean = 0.1 * running_mean + 0.9 * previous running_mean
Not sure why the running mean does not change on CPU context. We need to figure it out.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-661225937
The CPU version updates running mean and running var in backward path. And there are some nuance differences there between CPU and GPU implementations. @gilbertfrancois, could you try to add y.backward() after y.net(x) during the iteration.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC removed a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC removed a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662721253
It looks like there is a bug there for doing batch norm with 1D array, when the batch size is 1. For example, in this case, after flat, there vector size is 9408, which make the batch data shape as (1, 9408). I suspect that the batch norm views it as shape (9408, 1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-661442792
In case anyone want to do a PyTorch comparison for CPU version:
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662750082
Ok, I see that. But I guess it is the same intended behaviour as pyTorch nn.BatchNorm1d, which takes as input (N, C). The normalization is done over C features. E.g.:
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662755383
Coming back to mxnet: it looks like it is possible to do a forward pass (inference mode) on cpu when the BatchNorm is placed with Dense layers. Because on CPU, the BatchNorm parameters are updated on the backward pass. But on GPU, it tries to update some parameters on the forward pass already, instead of the backward pass, resulting in NaN when the batch size = 1.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662729925
Hi @TristonC, the project is for training. I adapted the script. It It does now one training step, with forward - backward pass and a validation step.
The hybrid_forward function of MyNet returns the logits for the softmax function during training, inside a autograd.record() context and returns the embeddings when doing inference (training=False). This is the behaviour I intend to have. Is this not correct to program it like that, with the `if autograd.is_recording()` statement in the `hybrid_forward(self, F, x, *args, **kwargs)` function?
After training I intent to strip the `output` layer and only do inference until the end of MyNet.tail to get `y_embeddings`. That is why I want to use that already during training for validation.
---
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660583673
The CPU result seems wrong, while the GPU result seems more resonable.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660447079
@szha I've just tested it against **mxnet-cu102 v2.0.0b20200716** and it has the same problem. See below:
```
gamma on CPU and GPU are (almost) equal: True, err: 0.00000+-0.00000
beta on CPU and GPU are (almost) equal: True, err: 0.00000+-0.00000
running_mean on CPU and GPU are (almost) equal: False, err: 0.90099+-0.20569
running_var on CPU and GPU are (almost) equal: False, err: 0.90099+-0.20569
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660583673
Great repro script @gilbertfrancois. The CPU result seems wrong, while the GPU result seems reasonable. On your plot, the GPU running mean actually goes to 1 and running_var goes to 0 during iterations as expected.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660586280
On GPU, the first running mean is 0, while the following 3 running means are 0.1, 0.19 and 0.271, which can be explained as
running_mean = 0.1 * running_mean + 0.9 * previous running_mean
Not sure why the running mean does not change on CPU context. We need to figure it out.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662179530
Many thanks for all the help and the swift responses.
TL;DR
Adding BatchNorm at the end of a feature extractor, and computing on GPU, and having a batch size of 1, results in a NaN.
---
## Description
I've created a small test file, which does the following:
It creates a network with a Conv2D feature extractor, followed by a **tail** (HybridSequential). The tail is used to create a custom sized embeddings output. For training, an additional Dense layer is used with N_CLASSES output units.
First variant has BatchNorm layers in the tail:
```
MyNet(
(features): HybridSequential(
...some layers...
)
(tail): HybridSequential(
(0): Flatten
(1): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=2048)
(2): Dense(2048 -> 128, linear)
(3): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=32)
)
(output): Dense(128 -> 10, linear)
)
```
Second variant has no BatchNorm layers in the tail:
```
MyNet2(
(features): HybridSequential(
...some layers...
)
(tail): HybridSequential(
(0): Flatten
(1): Dense(2048 -> 128, linear)
)
(output): Dense(128 -> 10, linear)
)
```
The script tests 8 cases:
- MyNet with and without BN layers in the tail
- On CPU and GPU
- Feed forward with batch of shape _(1, 3, 224, 224)_ and _(2, 3, 224, 224)_, computing `y_out` and `y_embeddings`.
The output of the test is as follows:
```
ctx with_batchnorm y_out y_embeddings input_shape
0 cpu(0) True [[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,... [[-0.15872642, -0.21955031, -0.9183478, -0.140... (1, 3, 224, 224)
1 gpu(0) True [[-2.9428682e-12, 1.359429e-13, -3.246836e-12,... [[nan, nan, nan, nan, nan, nan, nan, nan, nan,... (1, 3, 224, 224)
2 cpu(0) False [[-0.027459817, -0.032691482, -0.060781483, 0.... [[0.045531094, 0.22243185, -0.8400582, 0.12976... (1, 3, 224, 224)
3 gpu(0) False [[-0.027459746, -0.03269219, -0.06078052, 0.01... [[0.08575564, -0.0057277326, -0.027809529, 0.0... (1, 3, 224, 224)
4 cpu(0) True [[0.020913437, -0.03557911, -0.03905518, -0.21... [[0.63409245, -0.15498748, 0.5944583, 0.206986... (2, 3, 224, 224)
5 gpu(0) True [[0.02108069, -0.035640452, -0.038803764, -0.2... [[0.09521756, -0.050475493, 0.0824465, -0.0377... (2, 3, 224, 224)
6 cpu(0) False [[-0.13125925, 0.023433281, 0.0269559, -0.0618... [[-0.90178394, 0.27470633, -0.19833195, 0.5378... (2, 3, 224, 224)
7 gpu(0) False [[-0.1312578, 0.023436725, 0.026953252, -0.061... [[-0.09999961, 0.0913848, -0.11836913, 0.03843... (2, 3, 224, 224)
```
There are a few observations:
- MyNet with BatchNorm layers on GPU gives NaN for `y_embeddings` when _n-samples = 1_.
- MyNet with BatchNorm layers on GPU gives a matrix with real numbers for `y_embeddings` when _n-samples > 1_.
- The results for `y_train` on CPU and GPU are all close for similar test cases.
- The results for `y_embeddings` on CPU and GPU are never close.
- Removing layer (3) in MyNet1 does not help to avoid the NaN in `y_embeddings`.
- I don't understand why `y_out` from MyNet with BatchNorm on GPU still contains real numbers, given that the layer before outputs NaNs?
It can very well be that @wkcn has a point. If m-1 is used in the denominator for the computation of the sample variance, that might explain why we see NaN for a batch with a single sample and real numbers for larger batches.
## To reproduce
Install: `mxnet-cu102` (or one that matches your cuda version), `gluoncv`, `pandas`. Then run:
```
curl --retry 10 -s https://gist.githubusercontent.com/gilbertfrancois/888f81042f5edaa42b1011d28264cff4/raw/d6e2609e4132d21a8bbd318265e007f94418b84e/bn_test_2.py | python
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662750082
Ok, I see that. But I guess it is the same intended behaviour as pyTorch nn.BatchNorm1d for Dense layers, which takes as input (N, C). The normalization is done over C features. E.g.:
```
>>> import torch
>>> import torch.nn as nn
>>> bn = nn.BatchNorm1d(32)
>>> x = torch.randn(2, 32)
>>> y = bn(x)
>>> bn.running_mean.shape
torch.Size([32])
>>> bn.running_var.shape
torch.Size([32])
```
This proofs that the BN layer has C running means and C running vars.
When defining `x = torch.randn(1, 32)` and do a forward pass, it gives an error, like expected. Same as @TristonC mentioned in https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662730136.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-663168367
I am not sure that putting the running mean and running var into the backward pass is the solution. It can be achieved by setting autograd.record(train_mode=False). The problem here (NaN) is the way of computing running var, be it un-biased (divided by m -1 and as shown in the BN paper) or biased (by m). This is a corner case while m is 1 when the batch size is one and BN is after dense (or flatten) lay84er. My question goes is whether having 9408 or 32 running means and running vars really the network trying to do. BTW, the NaN is something frustrating for end users, we need to find a way to solve it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660583673
Great repro script @gilbertfrancois. The CPU result seems wrong, while the GPU result seems reasonable.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660583673
Great repro script @gilbertfrancois. The CPU result seems wrong, while the GPU result seems reasonable. On your plot, the GPU running mean actually goes to 1 and running_var goes to 0 during iterations as expected.
On GPU, the first running mean is 0, while the following 3 running means are 0.1, 0.19 and 0.271, which can be explained as
running_mean = 0.1 * running_mean + 0.9 * previous running_mean
Not sure why the running mean does not change on CPU context. We need to figure it out.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-661884869
@TristonC Yes, I have a project. Let me adapt it with an open dataset, so that I can make it public.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] gilbertfrancois commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
gilbertfrancois commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662755383
Coming back to mxnet: it looks like it is possible to do a forward pass (inference mode) on cpu when the BatchNorm is placed with Dense layers. But on gpu, it tries to update the values on the forward pass, instead of the backward pass, resulting in NaN when the batch size = 1.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662547038
@gilbertfrancois Is your project for training or inference? In your script, it uses autograd, but it does not do backward(). The reason I asked this, is BatchNorm behave differently for these two cases.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662687910
@gilbertfrancois I did a quick test, to answer your question:
> I don't understand why y_out from MyNet with BatchNorm on GPU still contains real numbers, given that the layer before outputs NaNs?
The logged y_out and y_embedding actually came from two separate forward runs. And y_embedding came at the second run. The first run was done with training mode(with autograd.record(train_mode=True), and the second run was done without recording (not training). The first run should get both y_out and y_embeddings correctly. Unfortunately, the first run got the first BatchNorm's running var in tail into NaN, so the second run will get NaN for both y_embedding and y_out (did not print out). I have not figured out why the NaN's happened in tail only, as there are also many more BN in the features (and seem those are OK). Will dig more. BTW, if you print the embedding before y_out, you will get both without NaN's. Non-training mode will get your answer correct.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] TristonC edited a comment on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
TristonC edited a comment on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-662687910
@gilbertfrancois I did a quick test, to answer your question:
> I don't understand why y_out from MyNet with BatchNorm on GPU still contains real numbers, given that the layer before outputs NaNs?
The y_out and y_embedding actually came from two separate forward runs. And y_embedding came at the second run. The first run was done with training mode(with autograd.record(train_mode=True), and the second run was done without recording (not training). The first run should get both y_out and y_embeddings correctly. Unfortunately, the first run got the first BatchNorm's running var in tail into NaN, so the second run will get NaN for both y_embedding and y_out (did not print out). I have not figured out why the NaN's happened in tail only, as there are also many more BN in the features (and seem those are OK). Will dig more. BTW, if you print your embedding before y_out, you will get both without NaN's. Non-training mode will get your answer correct.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] szha commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
szha commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-661554824
Yes I think we definitely should. Otherwise we'd expect the same confusion as in this issue.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] szha commented on issue #18751: gluon.nn.BatchNorm seems to swap updated values of moving_mean and moving_var on GPU.
Posted by GitBox <gi...@apache.org>.
szha commented on issue #18751:
URL: https://github.com/apache/incubator-mxnet/issues/18751#issuecomment-660421440
@gilbertfrancois thanks for the report. Does it also happen with the 2.0 on master branch? You can install mxnet-cu102 v2.0.0b20200716 from https://dist.mxnet.io/python
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org