You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2020/10/23 05:53:02 UTC
[GitHub] [iceberg] liukun4515 opened a new issue #1652: Spark Action: `table` with the catalog with the exception `Invalid table identifier`
liukun4515 opened a new issue #1652:
URL: https://github.com/apache/iceberg/issues/1652
If load the iceberg table from the spark catalog, the `toString` of the spark table will have the catalog name.
For example, `spark_catalog.default.tablename`, the catalog name is `testhive`.
But executing the spark action will producer error.
```
org.apache.iceberg.exceptions.NoSuchTableException: Invalid table identifier: spark_catalog.default.table.ALL_MANIFESTS
at org.apache.iceberg.BaseMetastoreCatalog.loadTable(BaseMetastoreCatalog.java:119)
at org.apache.iceberg.spark.source.IcebergSource.findTable(IcebergSource.java:79)
at org.apache.iceberg.spark.source.IcebergSource.getTableAndResolveHadoopConfiguration(IcebergSource.java:87)
at org.apache.iceberg.spark.source.IcebergSource.getTable(IcebergSource.java:62)
at org.apache.iceberg.spark.source.IcebergSource.inferPartitioning(IcebergSource.java:50)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2Utils$.getTableFromProvider(DataSourceV2Utils.scala:82)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$1(DataFrameReader.scala:256)
at scala.Option.map(Option.scala:230)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:230)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:214)
at org.apache.iceberg.actions.BaseAction.buildValidDataFileDF(BaseAction.java:110)
at org.apache.iceberg.actions.BaseAction.buildValidDataFileDF(BaseAction.java:102)
at org.apache.iceberg.actions.RemoveOrphanFilesAction.execute(RemoveOrphanFilesAction.java:148)
at org.apache.iceberg.spark.procedures.RemoveOrphanFilesProcedure.lambda$removeOrphanFiles$1(RemoveOrphanFilesProcedure.java:86)
at org.apache.iceberg.spark.procedures.BaseProcedure.modifyIcebergTable(BaseProcedure.java:54)
at org.apache.iceberg.spark.procedures.RemoveOrphanFilesProcedure.removeOrphanFiles(RemoveOrphanFilesProcedure.java:79)
at java.lang.invoke.MethodHandle.invokeWithArguments(MethodHandle.java:627)
at org.apache.spark.sql.execution.datasources.v2.CallExec.run(CallExec.scala:33)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:39)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:45)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:229)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3616)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-721184762
Ok I can put up a PR for this, the answer is when using Spark3 we should be calling
return spark.table(allManifestsMetadataTable).selectExpr("path as file_path");
Instead of spark.load..blahblah, I need to think for a second if this breaks compatibility with anything ...
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-716578015
@liukun4515 since we can't read the Metadata table through the catalog you'll have to not use the "hive identifier" or "spark identifier" to lookup the table. I think we may need to set it to always use the table location or split out the logic in Base action.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 edited a comment on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 edited a comment on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-715238022
The code is
```
protected Dataset<Row> buildValidDataFileDF(SparkSession spark, String tableName) {
JavaSparkContext context = new JavaSparkContext(spark.sparkContext());
Broadcast<FileIO> ioBroadcast = context.broadcast(SparkUtil.serializableFileIO(table()));
String allManifestsMetadataTable = metadataTableName(tableName, MetadataTableType.ALL_MANIFESTS);
Dataset<ManifestFileBean> allManifests = spark.read().format("iceberg").load(allManifestsMetadataTable)
.selectExpr("path", "length", "partition_spec_id as partitionSpecId", "added_snapshot_id as addedSnapshotId")
.dropDuplicates("path")
.repartition(spark.sessionState().conf().numShufflePartitions()) // avoid adaptive execution combining tasks
.as(Encoders.bean(ManifestFileBean.class));
return allManifests.flatMap(new ReadManifest(ioBroadcast), Encoders.STRING()).toDF("file_path");
}
```
if the table is loaded by spark catalog, the format of the table name is `catalog.database.tablename` which is not suitable for [inspect by DF](https://iceberg.apache.org/spark/#inspecting-with-dataframes)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-715238022
The code is
```
protected Dataset<Row> buildValidDataFileDF(SparkSession spark, String tableName) {
JavaSparkContext context = new JavaSparkContext(spark.sparkContext());
Broadcast<FileIO> ioBroadcast = context.broadcast(SparkUtil.serializableFileIO(table()));
String allManifestsMetadataTable = metadataTableName(tableName, MetadataTableType.ALL_MANIFESTS);
Dataset<ManifestFileBean> allManifests = spark.read().format("iceberg").load(allManifestsMetadataTable)
.selectExpr("path", "length", "partition_spec_id as partitionSpecId", "added_snapshot_id as addedSnapshotId")
.dropDuplicates("path")
.repartition(spark.sessionState().conf().numShufflePartitions()) // avoid adaptive execution combining tasks
.as(Encoders.bean(ManifestFileBean.class));
return allManifests.flatMap(new ReadManifest(ioBroadcast), Encoders.STRING()).toDF("file_path");
}
```
if the table is loaded by spark catalog, the format of the table name is `catalog.database.tablename`.
[inspect by DF](https://iceberg.apache.org/spark/#inspecting-with-dataframes)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 edited a comment on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 edited a comment on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-715235196
I implement the spark sql extension (remove orphan files) using the spark action.
The pr is [sql remove orphan files](https://github.com/aokolnychyi/incubator-iceberg/pull/2)
When running the test, the corresponding error will be generated.
The configuration is :
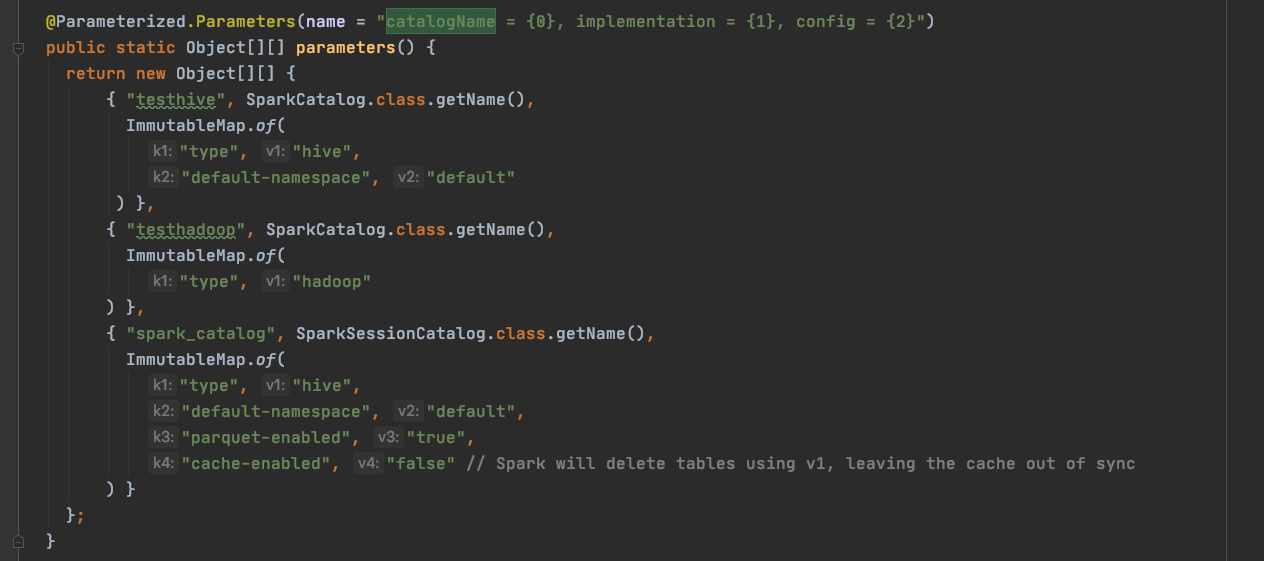
The exception is
```
org.apache.iceberg.exceptions.NoSuchTableException: Invalid table identifier: testhive.default.table.ALL_MANIFESTS
at org.apache.iceberg.BaseMetastoreCatalog.loadTable(BaseMetastoreCatalog.java:119)
at org.apache.iceberg.spark.source.IcebergSource.findTable(IcebergSource.java:79)
at org.apache.iceberg.spark.source.IcebergSource.getTableAndResolveHadoopConfiguration(IcebergSource.java:87)
at org.apache.iceberg.spark.source.IcebergSource.getTable(IcebergSource.java:62)
at org.apache.iceberg.spark.source.IcebergSource.inferPartitioning(IcebergSource.java:50)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2Utils$.getTableFromProvider(DataSourceV2Utils.scala:82)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$1(DataFrameReader.scala:256)
at scala.Option.map(Option.scala:230)
```
@HeartSaVioR
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-714932966
It's a known issue and we've documented into Iceberg-Spark guide doc.
https://iceberg.apache.org/spark/#inspecting-tables
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-715264529
@HeartSaVioR
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR edited a comment on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
HeartSaVioR edited a comment on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-714932966
It's a known issue and we've documented into Iceberg-Spark guide doc.
https://iceberg.apache.org/spark/#inspecting-tables
```
Note
As of Spark 3.0, the format of the table name for inspection (catalog.database.table.metadata) doesn’t work with Spark’s default catalog (spark_catalog). If you’ve replaced the default catalog, you may want to use DataFrameReader API to inspect the table.
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR edited a comment on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
HeartSaVioR edited a comment on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-714932966
It's a known issue and we've documented into Iceberg-Spark guide doc.
https://iceberg.apache.org/spark/#inspecting-tables
> Note
>
> As of Spark 3.0, the format of the table name for inspection (catalog.database.table.metadata) doesn’t work with Spark’s default catalog (spark_catalog). If you’ve replaced the default catalog, you may want to use DataFrameReader API to inspect the table.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-715223620
Could you please provide the query you ran, and how you provide the configuration to setup catalog?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-715219096
There is also an error when the name of the catalog is not `spark_catalog`.
```
org.apache.iceberg.exceptions.NoSuchTableException: Invalid table identifier: testhive.default.table.ALL_MANIFESTS
at org.apache.iceberg.BaseMetastoreCatalog.loadTable(BaseMetastoreCatalog.java:119)
at org.apache.iceberg.spark.source.IcebergSource.findTable(IcebergSource.java:79)
at org.apache.iceberg.spark.source.IcebergSource.getTableAndResolveHadoopConfiguration(IcebergSource.java:87)
at org.apache.iceberg.spark.source.IcebergSource.getTable(IcebergSource.java:62)
at org.apache.iceberg.spark.source.IcebergSource.inferPartitioning(IcebergSource.java:50)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2Utils$.getTableFromProvider(DataSourceV2Utils.scala:82)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$1(DataFrameReader.scala:256)
at scala.Option.map(Option.scala:230)
```
@HeartSaVioR
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-715235196
I implement the spark sql extension (remove orphan files) using the spark action.
The pr is [sql remove orphan files](https://github.com/apache/iceberg/issues/1652)
When running the test, the corresponding error will be generated.
The configuration is :

The exception is
```
org.apache.iceberg.exceptions.NoSuchTableException: Invalid table identifier: testhive.default.table.ALL_MANIFESTS
at org.apache.iceberg.BaseMetastoreCatalog.loadTable(BaseMetastoreCatalog.java:119)
at org.apache.iceberg.spark.source.IcebergSource.findTable(IcebergSource.java:79)
at org.apache.iceberg.spark.source.IcebergSource.getTableAndResolveHadoopConfiguration(IcebergSource.java:87)
at org.apache.iceberg.spark.source.IcebergSource.getTable(IcebergSource.java:62)
at org.apache.iceberg.spark.source.IcebergSource.inferPartitioning(IcebergSource.java:50)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2Utils$.getTableFromProvider(DataSourceV2Utils.scala:82)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$1(DataFrameReader.scala:256)
at scala.Option.map(Option.scala:230)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-720882605
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-721178340
Ah so the error is that the current code uses the non-catalog based Spark
dataframe pathway through spark.read.format.load. Which triggers
IcebergSource as a datasource register which can't handle catalogs since it
is the "non-catalog" path.
On Tue, Nov 3, 2020 at 1:04 AM Kun Liu <no...@github.com> wrote:
> @RussellSpitzer <https://github.com/RussellSpitzer> you can load spark
> table from customer catalog where the name is neither hadoop nor hive and
> execute the RemoveOrphanFilesAction action.
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/apache/iceberg/issues/1652#issuecomment-720943002>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AADE2YINZSR3VCZJIMGUYZDSN6TP5ANCNFSM4S4DNVQA>
> .
>
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 edited a comment on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 edited a comment on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-715235196
I implement the spark sql extension (remove orphan files) using the spark action.
The pr is [sql remove orphan files](https://github.com/apache/iceberg/issues/1652)
When running the test, the corresponding error will be generated.
The configuration is :

The exception is
```
org.apache.iceberg.exceptions.NoSuchTableException: Invalid table identifier: testhive.default.table.ALL_MANIFESTS
at org.apache.iceberg.BaseMetastoreCatalog.loadTable(BaseMetastoreCatalog.java:119)
at org.apache.iceberg.spark.source.IcebergSource.findTable(IcebergSource.java:79)
at org.apache.iceberg.spark.source.IcebergSource.getTableAndResolveHadoopConfiguration(IcebergSource.java:87)
at org.apache.iceberg.spark.source.IcebergSource.getTable(IcebergSource.java:62)
at org.apache.iceberg.spark.source.IcebergSource.inferPartitioning(IcebergSource.java:50)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2Utils$.getTableFromProvider(DataSourceV2Utils.scala:82)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$1(DataFrameReader.scala:256)
at scala.Option.map(Option.scala:230)
```
@HeartSaVioR
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] HeartSaVioR commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
HeartSaVioR commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-715655711
Ah OK, I thought you're asking about "actual usage", but you seem to share the issue on Iceberg development.
One thing you need to be aware is, if you use DataFrameReader API or deal with Iceberg code, you no longer use Spark's catalog functionality. Spark would provide table identifier "without catalog name" when calling methods in catalog, but I'm not aware of how Spark extension would work, so not sure whether table identifier contains catalog name or not.
One more, if the catalog type is Hadoop, you'll need to construct a root "path" in table to provide instead of "table name", as once table name is presented Iceberg will find it from HMS which wouldn't be correct location to check.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-716287658
@rdblue @RussellSpitzer
I have a question about the implementation of the spark actions.
If I want to use the customer catalog(the catalog name is `test_catalog`) to do some spark actions, the spark dataframev1 not support the customer catalog.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] liukun4515 edited a comment on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
liukun4515 edited a comment on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-720882605
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #1652: Spark Action: `table` with the catalog will get the exception `Invalid table identifier`
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #1652:
URL: https://github.com/apache/iceberg/issues/1652#issuecomment-720746878
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org