You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@tvm.apache.org by tq...@apache.org on 2020/11/03 17:04:27 UTC
[incubator-tvm-site] branch main updated: Fix
This is an automated email from the ASF dual-hosted git repository.
tqchen pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/incubator-tvm-site.git
The following commit(s) were added to refs/heads/main by this push:
new d42aba8 Fix
d42aba8 is described below
commit d42aba8542dd6d7ca4235d481ad75e3d40b5ed84
Author: tqchen <ti...@gmail.com>
AuthorDate: Tue Nov 3 12:04:16 2020 -0500
Fix
---
_posts/2019-05-30-pytorch-frontend.md | 4 ++--
_posts/2020-07-15-how-to-bring-your-own-codegen-to-tvm.md | 2 +-
vta.md | 2 +-
3 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/_posts/2019-05-30-pytorch-frontend.md b/_posts/2019-05-30-pytorch-frontend.md
index b32b708..583fb2c 100644
--- a/_posts/2019-05-30-pytorch-frontend.md
+++ b/_posts/2019-05-30-pytorch-frontend.md
@@ -33,7 +33,7 @@ To support Relay, two features were added to the PyTorch JIT: custom transformat
When `torch_tvm` is enabled, subgraphs of PyTorch IR that can be converted to Relay `Expr`s will be marked as Relay-compatible. Since PyTorch IR does not always contain shape information, none of the subgraphs can be compiled in a useful way before invocation.
-During user invocation, the PyTorch JIT runtime will determine input shape information and compile the previously marked subgraphs with the new Relay C++ [build system](https://github.com/pytorch/tvm/blob/master/torch_tvm/compiler.cpp#L226-L246). The compilation is cached based on input shapes for subsequent runs. More details can be found in the [README](https://github.com/pytorch/tvm/blob/master/README.md).
+During user invocation, the PyTorch JIT runtime will determine input shape information and compile the previously marked subgraphs with the new Relay C++ [build system](https://github.com/pytorch/tvm/blob/main/torch_tvm/compiler.cpp#L226-L246). The compilation is cached based on input shapes for subsequent runs. More details can be found in the [README](https://github.com/pytorch/tvm/blob/main/README.md).
`torch_tvm` has a continuous benchmark system set up, which is monitoring the performance of ResNet18 on CPU.
Out of the box TVM provides over two times the performance of the default PyTorch JIT backend for various ResNet models.
@@ -85,7 +85,7 @@ with torch.no_grad():
print("Took {}s to run {} iters".format(tvm_time, iters))
```
-Much of this code comes from [benchmarks.py](https://github.com/pytorch/tvm/blob/master/test/benchmarks.py). Note that tuned parameters for AVX2 LLVM compilation is in the `test/` folder of the repo.
+Much of this code comes from [benchmarks.py](https://github.com/pytorch/tvm/blob/main/test/benchmarks.py). Note that tuned parameters for AVX2 LLVM compilation is in the `test/` folder of the repo.
If you are more comfortable using Relay directly, it is possible to simply extract the expression directly from a
PyTorch function either via (implicit) tracing or TorchScript:
diff --git a/_posts/2020-07-15-how-to-bring-your-own-codegen-to-tvm.md b/_posts/2020-07-15-how-to-bring-your-own-codegen-to-tvm.md
index cb3a79e..26a016f 100644
--- a/_posts/2020-07-15-how-to-bring-your-own-codegen-to-tvm.md
+++ b/_posts/2020-07-15-how-to-bring-your-own-codegen-to-tvm.md
@@ -131,7 +131,7 @@ _register_external_op_helper("multiply")
In the above example, we specify a list of operators that can be supported by DNNL codegen.
### Rules for graph patterns
-Your accelerator or compiler may have optimized some patterns (e.g., Conv2D + add + ReLU) to be a single instruction or an API. In this case, you can specify a mapping from a graph pattern to your instruction/API. For the case of the DNNL, its Conv2D API already includes bias addition and it allows the next ReLU to be attached, so we can call DNNL as the following code snippet (the complete implementation can be found [here]([https://github.com/apache/incubator-tvm/blob/master/src/runtim [...]
+Your accelerator or compiler may have optimized some patterns (e.g., Conv2D + add + ReLU) to be a single instruction or an API. In this case, you can specify a mapping from a graph pattern to your instruction/API. For the case of the DNNL, its Conv2D API already includes bias addition and it allows the next ReLU to be attached, so we can call DNNL as the following code snippet (the complete implementation can be found [here]([https://github.com/apache/incubator-tvm/blob/main/src/runtime/ [...]
```c
DNNLConv2d(const bool has_bias = false, const bool has_relu = false) {
diff --git a/vta.md b/vta.md
index dfd02e5..37aa9e5 100644
--- a/vta.md
+++ b/vta.md
@@ -18,7 +18,7 @@ By extending the TVM stack with a customizable, and open source deep learning ha
This forms a truly end-to-end, from software-to-hardware open source stack for deep learning systems.
{:center: style="text-align: center"}
-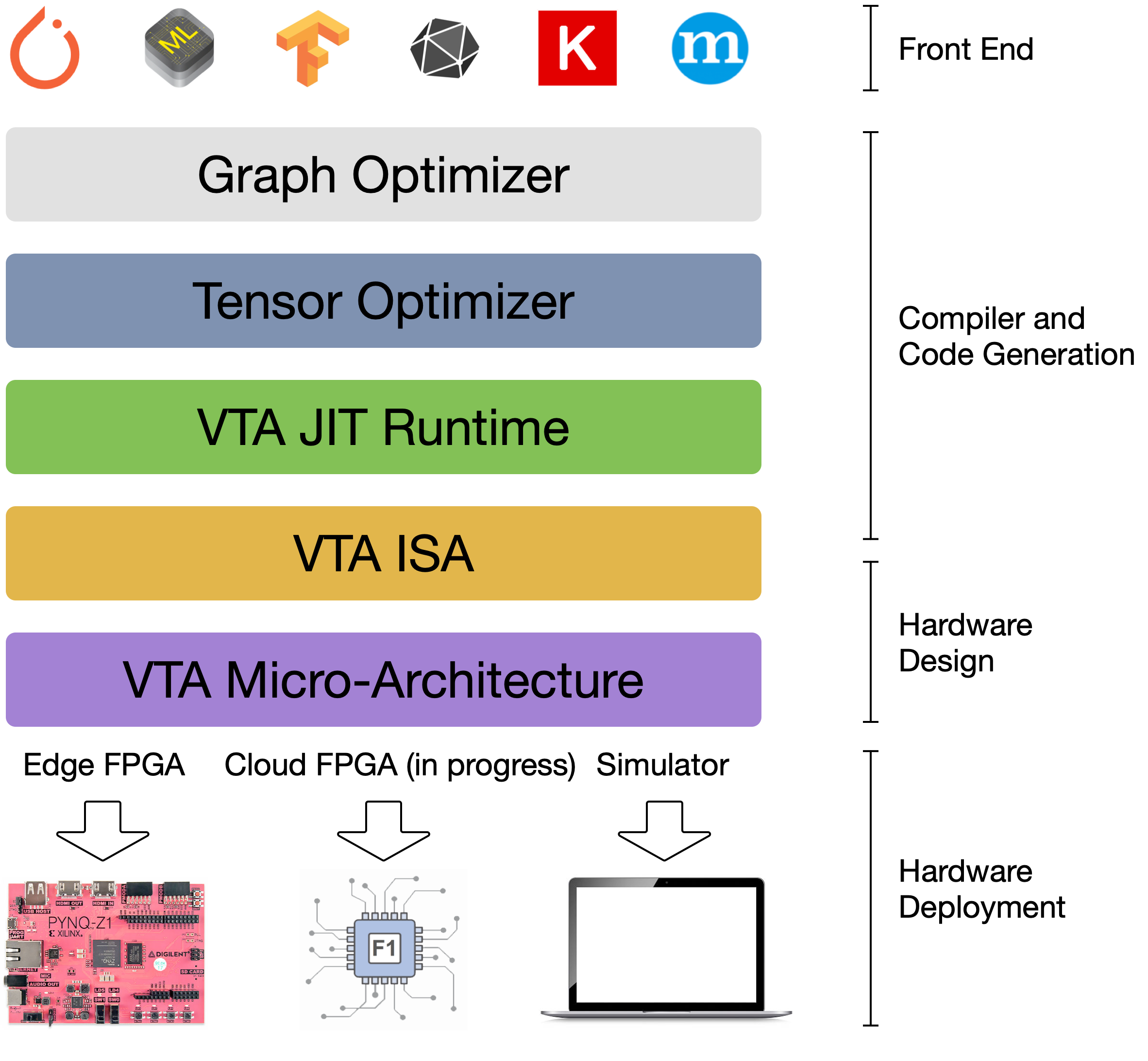{: width="50%"}
+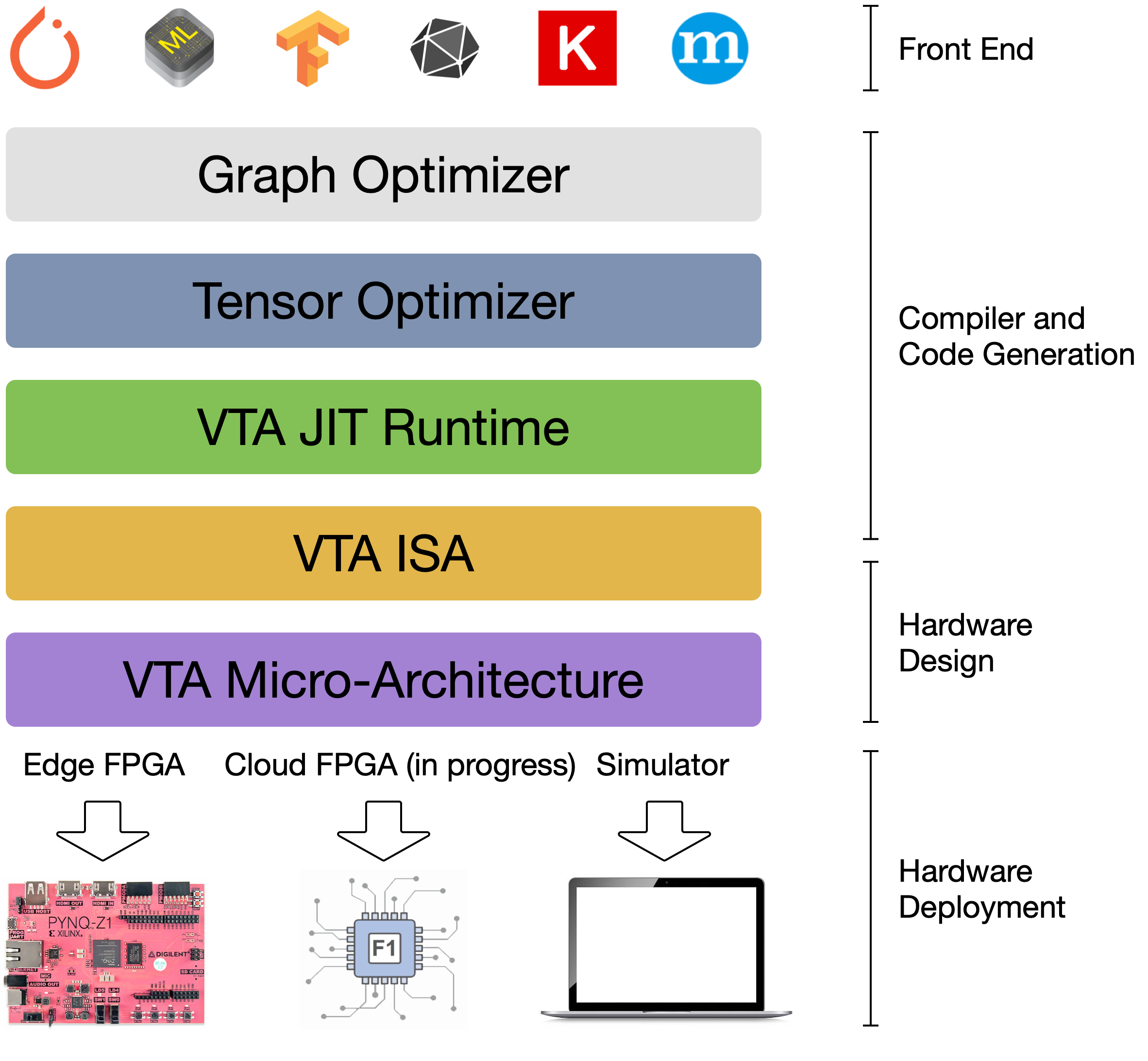{: width="50%"}
{:center}
The VTA and TVM stack together constitute a blueprint for end-to-end, accelerator-centric deep learning system that can: