You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@doris.apache.org by ji...@apache.org on 2023/01/29 00:49:23 UTC
[doris-website] branch master updated: summit 2022
This is an automated email from the ASF dual-hosted git repository.
jiafengzheng pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/doris-website.git
The following commit(s) were added to refs/heads/master by this push:
new 936f811ca10 summit 2022
936f811ca10 is described below
commit 936f811ca10860aecbb2e2357e95cfbd3716c28a
Author: jiafeng.zhang <zh...@gmail.com>
AuthorDate: Sat Jan 28 17:32:25 2023 +0800
summit 2022
---
blog/summit.md | 186 +++++++++++++++++++
.../zh-CN/docusaurus-plugin-content-blog/summit.md | 200 +++++++++++++++++++++
static/images/summit/en/2022.png | Bin 0 -> 91151 bytes
static/images/summit/en/community 2.png | Bin 0 -> 338535 bytes
static/images/summit/en/community.png | Bin 0 -> 100164 bytes
static/images/summit/en/flow.png | Bin 0 -> 261111 bytes
static/images/summit/en/lakehouse.png | Bin 0 -> 213817 bytes
static/images/summit/en/logo wall.png | Bin 0 -> 497511 bytes
static/images/summit/en/performance.png | Bin 0 -> 472871 bytes
static/images/summit/en/realtime.png | Bin 0 -> 175481 bytes
static/images/summit/en/roadmap.png | Bin 0 -> 278317 bytes
static/images/summit/en/semi.png | Bin 0 -> 280851 bytes
static/images/summit/en/top level.png | Bin 0 -> 67342 bytes
13 files changed, 386 insertions(+)
diff --git a/blog/summit.md b/blog/summit.md
new file mode 100644
index 00000000000..7723d7fc1d2
--- /dev/null
+++ b/blog/summit.md
@@ -0,0 +1,186 @@
+---
+{
+ 'title': 'A Glimpse of the Next-generation Analytical Database',
+ 'language": "en'
+ 'summary': "My name is Mingyu Chen and I am the PMC Chair of the Apache Doris.In this lecture, you will go through the development of Doris in 2022 and look into the new trends that Doris is exploring in 2023.",
+ 'date': '2023-01-19',
+ 'author': 'Mingyu Chen',
+ 'tags': ['Top News'],
+}
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+# Self-Intro
+
+Hello everyone, welcome to the Doris Summit 2022, the first summit of Apache Doris since it was open-sourced. In this lecture, you will go through the development of Doris in 2022 and look into the new trends that Doris is exploring in 2023. My name is Mingyu Chen and I am the PMC Chair of the Apache Doris. I have been developing for Doris since 2014, and witnessed its whole process from open-source to graduation from Apache. My sharing will cover the following aspects. Let's get started.
+
+As the beginning, I will briefly introduce what Doris is and why we should choose Doris in case you are new to Apache Doris. In 2022, Doris has became one of the most active open-sourced big data analysis engine projects in the world while the Doris community became one of the most active open-source communities in China, which you may get interested in. Moreover, the cutting-edge features, such as vectorized execution engine, cloud-native and efficient semi-structured data analysis, rea [...]
+
+# About Doris
+
+Briefly speaking, Apache Doris is an easy-to-use, high-performance and unified analytical database. As shown in this enterprise data flow chart, you may have a clear vision of where Apache Doris stands. Data from various upstream data sources, such as transactional databases, log systems, event tracking, etc., as well as data from ETL components, such as Flink, Spark and Hive is ingested into Doris through data processing and integration tools.
+
+
+
+As a fully-complete database system, Doris can provide various direct query functions including report analysis, multi-dimensional analysis, log analysis, user portrait and lakehouse, etc. Thanks to Doris' MPP SQL distributed query engine. Doris can also be used to query external data sources from Hive, Iceberg, Hudi, Elasticsearch and various transactional database systems connected through JDBC, without data import and maintaining the schema of other data sources. There are several cor [...]
+
+- NO.1 is the ease of use. It supports ANSI SQL syntax, including single table aggregation, sorting, filtering and multi table join, sub query, etc. It also supports complex SQL syntax such as window function and grouping sets. At the same time, users can expand system functions through UDF, UDAF. In addition, Apache Doris is also compatible with MySQL protocol, which allows users access Doris through various BI tools.
+- NO.2 is high performance. Doris is equipped with an efficient column storage engine, which not only reduces the amount of data scanning, but also implements an ultra-high data compression ratio. At the same time, Doris also uses various index technology to speed up data reading and filtering. Using the partition and bucket pruning function, Doris can support ultra-high concurrency of online service business, and a single node can support up to thousands of QPS. Further, Apache Doris co [...]
+- NO.3 is unified data warehouse. Thanks to the well-designed architecture, Doris can easily handle both low-latency, high-concurrency scenarios and high-throughput scenarios .
+- NO.4 is the federated query analysis. With the help of Doris's complete distributed query engine, Doris can access data lake such as Hive, Iceberg and Hudi, as well as high-speed queries to external data sources such as Elasticsearch and MySQL.
+- NO.5 is ecological enrichment. Doris provides rich data ingest methods, supports fast loading of data from localhost, Hadoop, Flink, Spark, Kafka, SeaTunnel and other systems, and can also directly access data in MySQL, PostgreSQL, Oracle, S3, Hive, Iceberg, Elasticsearch and other systems without data replication. At the same time, the data stored in Doris can also be read by Spark and Flink, and can be output to the upstream data application for display and analysis.
+
+Next, we will review what remarkable achievements the Doris community has achieved in 2022.
+
+# How should we look back on 2022?
+
+In 2022, the world has witnessed unprecedented changes, and countless magical moments are happening in reality. Thankfully, the power of technology and open source has navigated us to the right path. And 2022 is absolutely a fruitful year for Apache Doris. Let's review the development of Apache Doris in the past year from several angles:
+
+## Important Indicators of the Community
+
+
+In the past year:
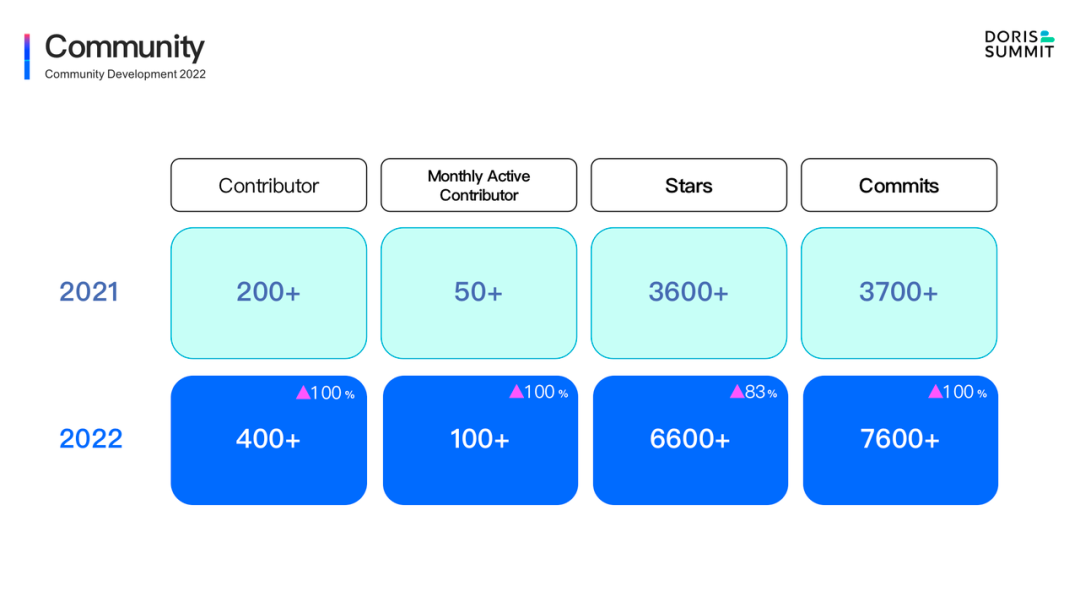
+- The number of cumulative community contributors has increased from 200 to nearly 420, a year-on-year increase of more than 100%, which is still rising.
+- The number of monthly active contributors has doubled from 50 to 100.
+- The number of GitHub Stars has increased from 3.6k to 6.8k, and has been on the daily/weekly/monthly GitHub Trending list many times.
+- The number of all Commits increased from 3.7k to 7.6k. The amount of newly submitted code in the past year exceeded the total of previous years.
+
+
+
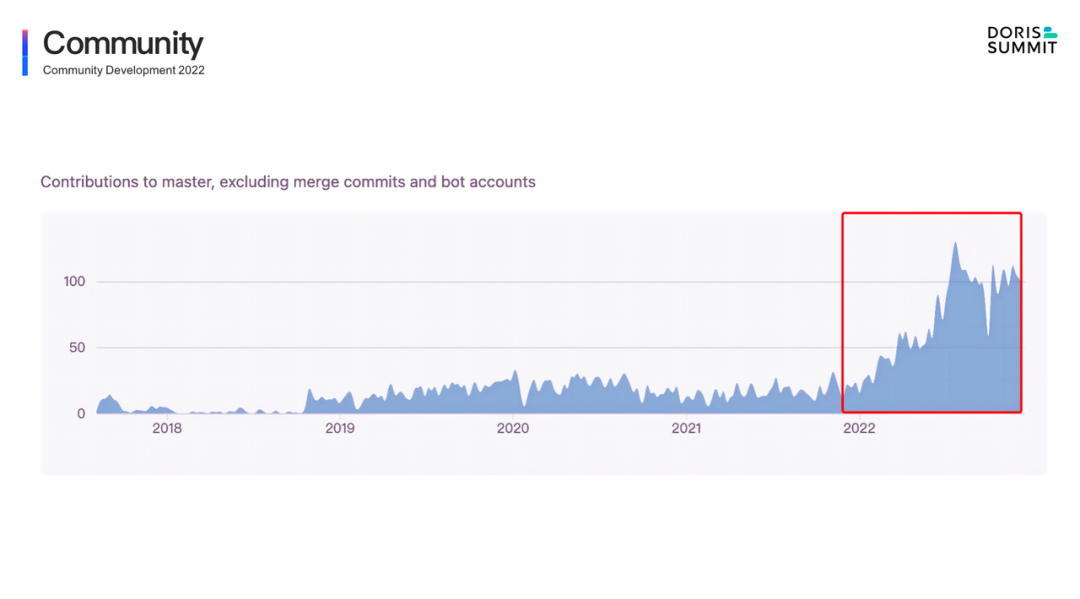
+From these data, we can see that in 2022, there was an explosive growth in Apache Doris. The data indicators of all dimensions are grown by nearly 100%. The great effort has also made Apache Doris one of the most active open-source communities in the big data and database world. As is the growth shown in the trending of GitHub Contribution above, users and developers have made tremendous contribution to the community .
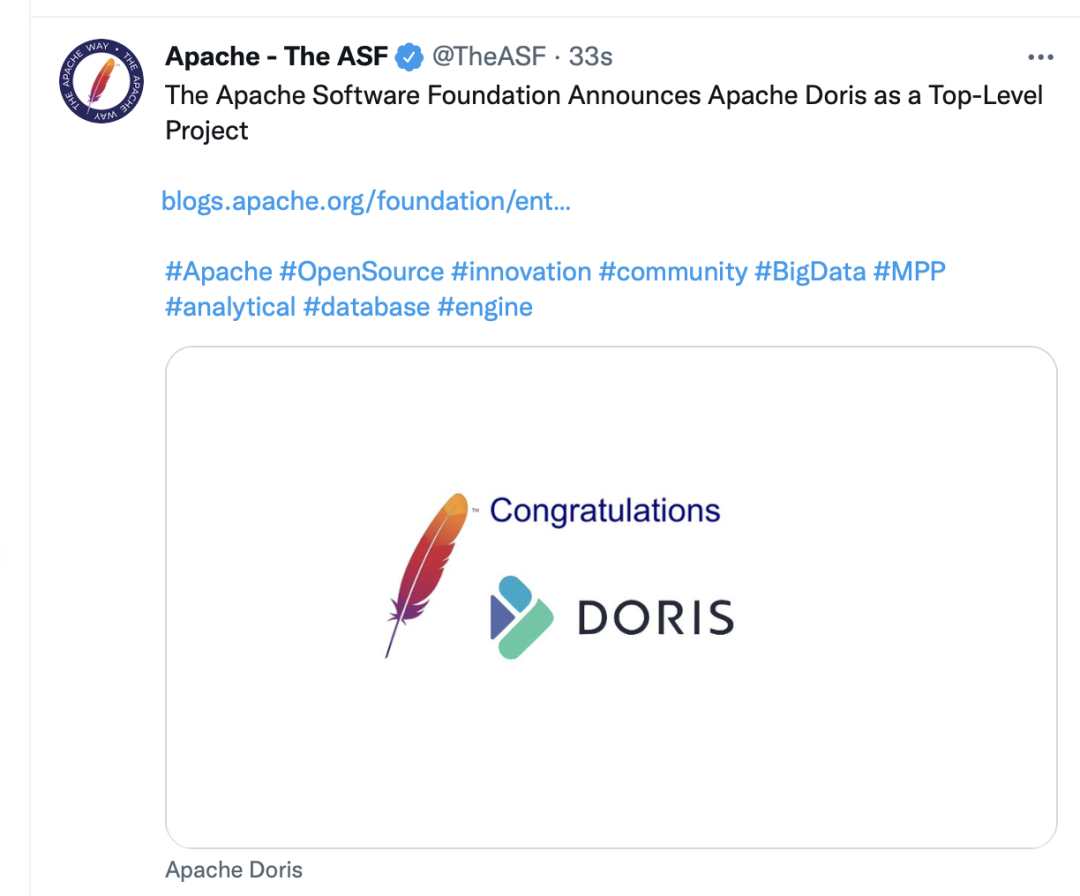
+It is memorable that in June 2022, Apache Doris graduated from the Apache incubator and became a Top-Level Project, which is the biggest milestone since open-souced.
+
+
+
+## Open Source User Scale
+
+Thanks to the voluntary technical support from the developers of SelectDB, a commercial company funding Apache Doris. In 2022 Doris became smoother in user connection and communication, and we were able to interact with users more directly and listen to their real voices.
+Last year, Apache Doris was applied in dozens of industries, such as the Internet, fintech, telecommunications, education, automobiles, manufacturing, logistics, energy, and government affairs, and especially in the Internet industry, which is known for massive data. 80% of the TOP 50 Chinese Internet companies have been using Apache Doris for a long time to solve data analysis problems in their own business, including Baidu, Meituan, Xiaomi, Tencent, JD.com, ByteDance , NetEase, Sina, 3 [...]
+
+
+
+Globally, Apache Doris has served thousands of enterprise users, and this number is still growing rapidly. Most enterprise users are glad to contact the community and participate in community building through various means. Moreover, many of the enterprise users participated in Doris Summit, giving a lecture of their own practical experience based on real business.
+
+## Releases
+
+In the early versions, ease of use has been frequently emphasized. The versions released in 2022 mainly focus on performance, stability, ease of use, which is a comprehensive evolution.
+- In April, the community released Apache Doris V1.0.0, whose major version first changed from 0 to 1(V0.1.5 to V1.0.0) since open-sourced. In version 1.0, the extraordinary vectorized execution engine was first published, marking the beginning of Apache Doris to the era of ultra-high speed data analysis.
+- In version 1.1 released in June, we further improved and optimized the vectorized engine, and set it as default. Simultaneously, the community has also prepared LTS(Long-Term-Support) versions released to quickly fix bugs and optimize functions for version 1.1 on a monthly basis, aiming to ensure higher stability required by the growing community users.
+- Launched in early December, Version 1.2 not only introduces many important functions, such as Merge-on-Write for Unique Key model, Multi-Catalog, Java UDF, Array type, JSONB type, etc., but also improves the query performance by nearly ten times. These features allow Apache Doris to be more adaptable and possible for more data analysis.
+- In version 1.2, stability and quality assurance were strongly stressed. On the one hand, using automated testing tools such as SQL Smith and test cases from various well-known open source projects, we have built millions of test case sets; On the other hand, the community access pipeline and perfect regression testing framework ensure the quality of code-merge.
+
+## Evolution of Core Features
+
+In 2022, the community's research and development was mainly focused on four aspects, high performance, real-time processing, semi-structured data support and Lakehouse.
+
+
+
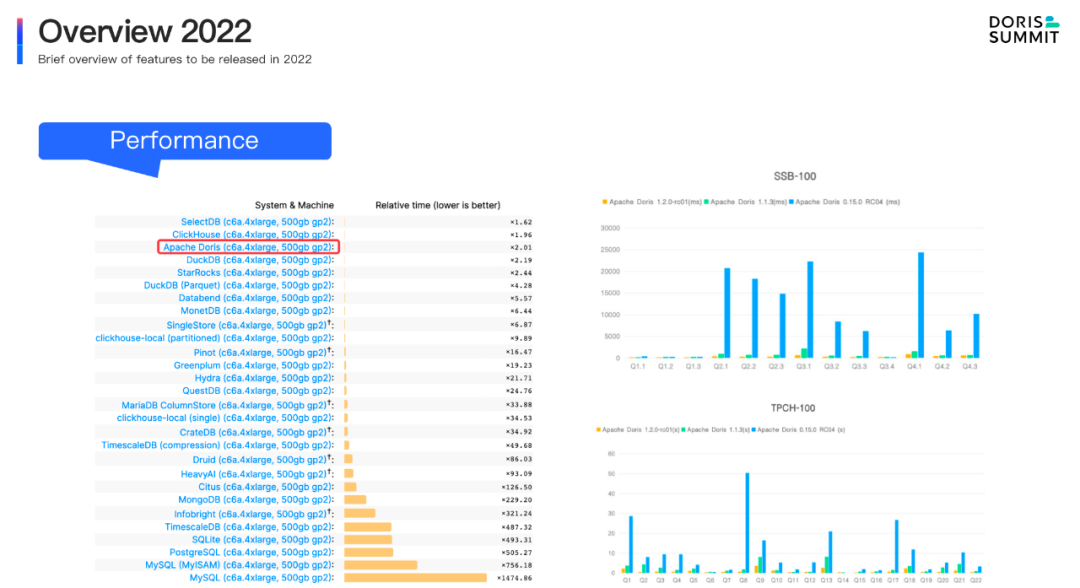
+- Query performance improvement. From the released version 1.0 to 1.2, Apache Doris has made remarkable achievement in performance. In the single-table test, Apache Doris won 3rd place in Clickbench database performance list launched by Clickhouse. In the multi-table association, thanks to the vectorized execution engine and various query optimization, compared to the released version 0.15 at the end of 2021, Apache Doris was 10 times faster in standard test data sets under SSB and TPC-H [...]
+
+
+
+- Real-time processing optimization. In version 1.2, we have implemented the Merge-On-Write data update method on the original Unique Key, with a query performance improved by 5-10 times during high-frequency updates and low latency on updateable data in real-time analytics. In addition, the lightweight Schema Change enables easier column adding and substraction of data, which is unecessary for users to convert historical data any more. Tools such as Flink CDC can be used instantly to sy [...]
+
+
+
+- Semi-structured data analysis. At present, Apache Doris supports Array and JSONB types. The Array type can not only store complex data structures, but also support user behavior analysis through Array functions. JSONB is a binary JSON storage type, which not only has 4 times faster access performance than Text JSON, but has lower memory consumption as well. Various log data structures in JSON format can be easily ingested through JSONB efficiently.
+
+
+
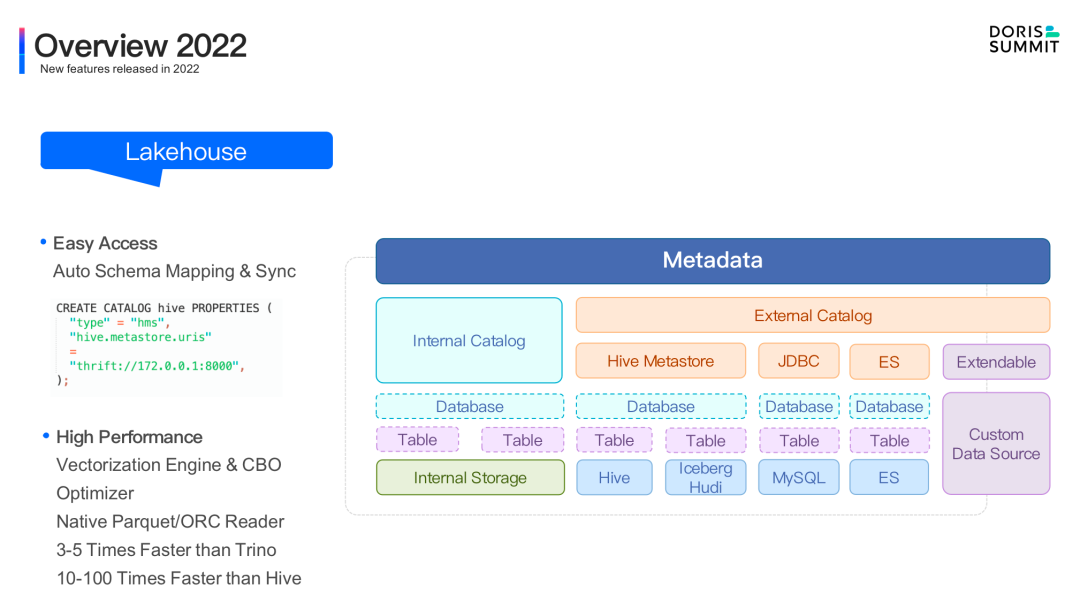
+- Lakehouse. In version 1.2.0, through multiple performance optimizations for external data sources such as Native Format Reader, late materialization, asynchronous IO, data prefetching, high-performance execution engine and query optimizer, Apache Doris can easily access external data sources, for instance, Hive, Iceberg and Hudi. And the speed of access is 3-5 times faster than Trino/Presto and 10-100 times faster than Hive.
+
+
+
+# 2023 RoadMap
+
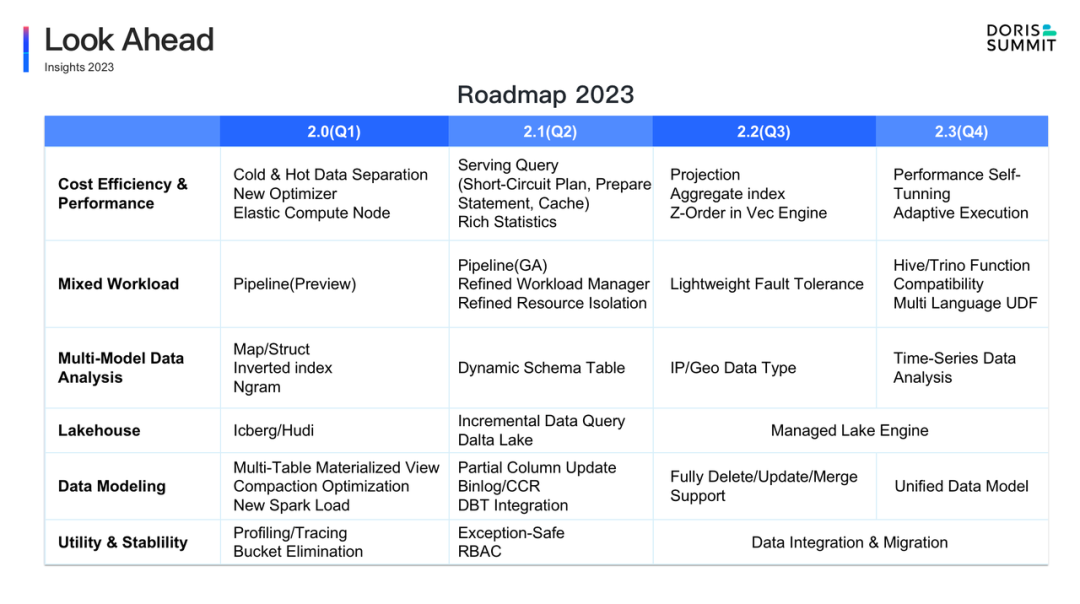
+In 2023, the Apache Doris community will deep dive into new features development, as you can refer to the 2023 RoadMap and the specific plan for next year below:
+
+
+
+In 2023, we will start the iteration of Apache Doris 2.x version on a quarterly basis . At the same time, for each 2-bit version, bug fixes and upgrades will be done on a monthly basis.
+From a functional point of view, the follow-up research and development will focus on the following main directions:
+
+## High Performance
+
+High performance is the goal that Apache Doris is constantly pursuing. Doris' excellent performance on public test datasets such as Clickbench and TPC-H has proved that it has become industry-leading. In the future, we will further enhance performance, including:
+- More complex SQL: The new query optimizer will be available in the first quarter of 2023. The new query optimizer supports the strategy of combining RBO and CBO, and it can support complex queries more efficiently and fully execute all 99 SQLs of TPC-DS.
+- Higher concurrency point query: High concurrency is always what Apache Doris is good at. And in 2023 we will further strengthen this capability through a series of features such as Short-Circuit Plan, Prepare Statement, Query Cache, etc., to support ultra-high concurrency of 10,000 QPS with single node and has higher-concurrency scaling out.
+- More flexible multi-table materialized views: In previous versions, Apache Doris accelerated the analysis efficiency of fixed-dimensional data through strengthen single-table materialized views. The new multi-table materialized view will decouple the lifecycle of Base table and the MV table. In this way, Doris can easily deal with the multi-table JOINs and the pre-calculation acceleration of more complex SQL queries. And Doris is capable of asynchronous refresh and flexible incremental [...]
+
+## Cost-effective
+
+Cost efficiency is the key to winning market competition for enterprises, which is true for databases as well. In the past, Apache Doris helped users greatly save the cost in computing and storage resources with many designs of ease of use. In the future, we will introduce a series of cloud-native capabilities to further reduce costs without affecting business efficiency, including:
+- Lower storage costs: We will explore the combination of object storage systems and file systems on the cloud to help users further reduce storage costs, including better separation of hot and cold data, and migrate cold data to cheaper object storage or file system. Combining technologies such as a single remote replica, cold data cache, and hot & cold data conversion, we can ensure that query efficiency is not affected while saving up storage costs. This feature will be released in th [...]
+- More elastic computing resources: We plan to separate storage and computing state and adopt Elastic Compute Node for computing. Since no data is stored, Elastic Computing Nodes have faster elastic scaling capabilities, which is convenient for users to quickly scale out during peak business periods, and further improve the analysis efficiency in massive data computing, such as lakehouse analysis. This function will be released shortly.
+
+## Hybrid Workload
+
+Lots of users nowadays are building a unified analysis platform within the enterprise based on Apache Doris. On the one hand, Apache Doris is required to execute larger-scale data processing and analysis. On the other hand, Apache Doris is also required to deal with more analytical load challenges, such as real-time reports and Ad-hoc to ELT/ETL, log retrieval and more unified analysis. In order to better adapt to these cases, new features are about to be released in 2023, which include:
+- Pipeline execution engine: Compared with the traditional volcano model, the Pipeline model does not need to set the concurrency manually, but instead, it can do parallel computing between different pipelines, making full usage of CPUs and is more flexible in execution scheduling, which improves the overall performance under mixed load cases.
+- Workload Manager: It is also urgent to improve resource isolation and division capabilities. Based on the Pipeline execution engine, we will launch features such as flexible load management, resource queues, and isolation in shared services to balance query performance and stability in various mixed load cases.
+- Lightweight fault tolerance: It can not only take advantage of the high efficiency of MPP structure but also tolerate errors to better adapt to the challenges of users in ETL/ELT.
+- Function compatibility and UDF in multiple languages: At the same time, we will be more compatible with Hive/Trino/Spark function and support multiple UDF in the future to help users process data more flexibly. And data migration to Apache Doris will be easier than before.
+
+## Multi-model Data Analysis
+
+In the past, Apache Doris was quite good at structured data analysis. As the demand for semi-structured and unstructured data analysis increased, we added Array and JSONB types from version 1.2 to support these data types naturally. In the future release, we will continue providing more cost-effective and better-performance solutions for log analysis cases, including:
+- Richer complex data types: In addition to Array/JSONB types, we will increase support for Map/Struct types in the first quarter of 2023, including efficient writing, storage, analysis functions to better perform multi-model data analysis. In the future, more data types will be supported, such as IP and GEO geographic information, and more time series data.
+- More efficient text analysis algorithms: For text data, we will introduce text analysis algorithms, including adaptive Like, high-performance substring matching, high-performance regular matching, predicate pushdown of Like statements, Ngram Bloomfilter, etc. The full-text search is based on the inverted index and it provides higher performance and is more cost-effective in analysis compared with that of Elasticsearch in the log analysis. These features will come out in early 2023.
+-Dynamic Schema table: In other databases, the schema is relatively static and DDL needs to be executed manually when the schema is changed. In recent cases, the table structure changes all the time, so we plan to launch Dynamic Table, which can automatically adapt to the Schema according to data writing without DDL execution, replacing manual adjusting. This feature will be released in the first quarter of 2023.
+
+## Lakehouse
+
+With the development of data lake technology, analysis performance has become the biggest constraint to data-mining. Building analysis services on top of data lakes based on an easy-to-use and high-performance query analysis engine has become a new trend. In the last year, through many performance optimizations on the data lake, high-performance execution engine and query optimizer, Apache Doris has become extremely fast in analysis and easy-to-use on the data lake with a performance 3-5 [...]
+- Easier data access: In version 1.2, we released Multi-Catalog, which supports automatic metadata mapping and synchronization of multiple heterogeneous data sources and is used for accessing data lakes. Delta Lake, Iceberg and Hudi will be better supported.
+- More complete data lake capabilities: We provide incremental update and query of data on the data lake. Analysis result will be sent to data lake and the data from external tables will be ingested into internal tables. At the same time, Doris will also support multi-version Snapshot's read & delete and materialized views.
+
+## Real-time and storage engine optimization
+
+The value of data will decrease over time, so real-time performance is very important for users. The Merge-on-Write data update in version 1.2 allows Apache Doris to be fast in both real-time updating and query. In 2023, we will upgrade the storage engine with the following:
+- More stable data writing: Through a series of compaction operations and optimization of batch processing, resource cost is able to be saved. And through a new memory management framework, stability of the writing process will be improved.
+- More mature data-updating mechanism: In the past, column updates were implemented through Replace_if_not_null on the Agg model. In the future, we will increase support for partial column updates with the Unique Key model, and data updates such as Delete, Update, and Merge.
+- A unified data model: Currently, the three data models of Apache Doris are widely used in various cases. In the future, we will try to unify the existing data models to provide a better user experience.
+
+## Ease of use and stability
+
+In addition to improving functions, simplicity, ease of use and stability is also the goal that Apache Doris has been pursuing. In 2023, we will dive deeper in the following:
+- Simplified table creation: Currently, Apache Doris already supports time functions in table partitioning. In the future, we will further simplify Bucket settings to help users build models easily.
+- Security: At present, a permission management mechanism based on the RBAC model has been launched, which makes user permissions more secure and reliable. Functions such as ID-federation, Row&Column-level permissions, data desensitization will be further improved in the future.
+- Observability: Profile is an important means of locating query performance problems. In the future, we will strengthen the monitoring of Profile and provide visualized Profile tools to help users locate problems faster.
+- Better BI compatibility and data migration solution: Currently, various BI tools can be connected with Apache Doris through MySQL protocol, and we will further adapt mainstream BI software in the future to ensure a better query experience. With the rise of emerging data integration and migration tools such as DBT and Airbyte, more and more users synchronize data to Apache Doris in this way. So we should provide support for these users in the future.
+
+# How to join the community
+
+Last but not the least, we hope that more developers can participate in the community to jointly create a powerful database. There are 3 ways to participate in the community. First of all, users can subscribe to our developer mailing group through this address: dev@doris.apache.org, which is recommended by the Apache Way as well. You can send any related topics that you want to discuss with the community. Secondly, you can reach out to us virtually on developer's biweekly meeting. The bi [...]
+
+## Links:
+
+Apache Doris Repository
+
+https://github.com/apache/doris
+
+Apache Doris Website
+
+https://doris.apache.org
+
+# The END
+
+It is the end of my sharing. Thank you for listening.
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md b/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md
new file mode 100644
index 00000000000..58267cb5e5a
--- /dev/null
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md
@@ -0,0 +1,200 @@
+---
+{
+ 'title': '十年对于数据库意味着什么?',
+ 'summary': '十年对于数据库而言,可能是一段从诞生到消逝的完整软件生命周期,也可能是迈过里程碑之后的全新旅程。',
+ 'date': '2022-01-06',
+ 'author': '陈明雨',
+ 'tags': ['重大新闻'],
+}
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+# **十年对于数据库意味着什么?**
+
+身处在日新月异的时代,我们见惯了技术的兴起与繁荣、变迁与衰落,甚至是朝荣夕灭。信息技术以前所未有的速度更迭,给周遭事物带来了颠覆性地变化。数据库亦是如此,无数数据库悄然湮没在技术更迭的浪潮里,直到在浩渺如海的代码片段中都找不到些许印记。而有的则历久而弥新,经受了时间的考验,彰显出强大的生命力,并以更加繁茂的姿态扎根生长。
+
+十年对于数据库而言,可能是一段从诞生到消逝的完整软件生命周期,也可能是迈过里程碑之后的全新旅程。
+
+所以从 MySQL 1.0 版本诞生,到具备颠覆性意义的 MySQL 5.7 版本正式发布,时间跨度刚好是十年,而十年之后的故事,大家已经都知道了。
+
+所以从 Benoit、Thierry、Marcin 联合创建 Snowflake,到在纽交所成功上市、成为软件行业有史以来最大规模的IPO,再到全面开启云数据仓库时代,时间跨度也差不多十年。
+
+**而对于 Apache Doris,十年意味着什么?**
+
+留个悬念,在回答这个问题之前,我们不妨来回顾下社区发展历程。
+
+尽管最早的历史可以追溯到 2008 年的百度凤巢广告系统,但彼时非 SQL 的单机查询引擎加 KV 存储系统在产品形态上与 OLAP 还有着较大的差异。
+
+**正式确立 OLAP 数据库这一形态是在 2013 年**。通过自研全列式存储引擎 OLAP Engine 并基于 Apache Impala 改造了全新的 MPP 查询引擎,自此,Doris 真正成为了具备大数据量下高效支持数据分析能力的 OLAP 数据库,并在百度内部大规模应用,成为了百度内部统一的 OLAP 分析平台。
+
+往往一个内部项目的发展会有两种演进模式,一种是随着需求的增加系统架构日益臃肿,当面对较为灵活的需求,常因改动成本过大而被彻底重构。另一种则是长期服务某一固定场景、需求逐渐收敛乃至停滞,最终被快速革新的外部技术彻底取代。而开源则是内部项目的一场新生,在更广阔的应用场景、更多样的开发者群体以及更高效的研发模式加持下开启新的篇章。
+
+于是在数个版本的迭代与优化后,2017年 Doris 的前身在 GitHub 上开源,2018 年进入 Apache 基金会孵化,并正式更名为 Apache Doris。(GitHub 地址:<https://github.com/apache/doris>)
+
+**时至 2022 年,正是 Apache Doris 在 OLAP 领域深耕的十年之际。**
+
+**# 我们该如何回顾过去的 2022 年?**
+
+2022 年,外部世界正处在前所未有的变化之中,无数魔幻时刻在现实中发生。需要庆幸的是,技术和开源的力量帮助我们穿越了许多不确定性。而这一年势必成为 Apache Doris 发展历程中有着浓墨重彩的一年,我们从几个角度来回顾一下 Apache Doris 过去一年的发展:
+
+### **社区重要指标**
+
+
+
+**过去一年中:**
+
+- 社区累计贡献者的数量从 200 余位增长至近 420 位,同比增长**超过 100%** ,目前仍在持续上升中。
+- 每月活跃贡献者的数量从 50 位增长至 100 位,同样呈现**翻倍**增长的趋势。
+- GitHub Star 数量从 3.6k 增长至 6.8k,多次登上 GitHub Trengding 日/周/月度**榜单前列**。
+- 全部 Commits 数量从 3.7k 增长至 7.6k,过去一年新提交代码量超越了以往多年累加总和。
+
+
+
+从这些数据中,我们可以感受到 2022 年是 Apache Doris 全面爆发的一年,各个维度数据指标几乎都有了 100% 的增长。这一年的努力也使 **Apache Doris 成为了全球大数据和数据库领域最为活跃的开源社区之一**,上方 GitHub Contribution 增长趋势图更是证明了这一点。而这一切,正是由社区所有的用户和开发者共同创造的。
+
+另外值得纪念的是,在 2022 年 6 月, Apache Doris 迎来了开源以来最重要的里程碑之一,正式从 Apache 孵化器毕业、成为了 **Apache 顶级项目**。
+
+
+
+### **开源用户规模**
+
+得益于社区成立的专职工程师团队,为 Apache Doris 社区用户提供义务的技术支持,2022 年我们在用户连接与沟通方面变得更加顺畅,可以更直面用户、去倾听用户真实的声音。
+
+在过去的一年里,Apache Doris 已经在互联网、金融、电信、教育、汽车、制造、物流、能源、政务等数十个行业应用落地,尤其是在以海量数据著称的互联网行业。在中国市值或估值排行前 50 的互联网公司中,有 80% 企业在长期使用 Apache Doris 来解决自身业务中的数据分析问题,其中包含了百度、美团、小米、腾讯、京东、字节跳动、网易、新浪、360、 米哈游、知乎等头部知名企业。
+
+
+
+在全球范围内,**Apache Doris 已经得到了超过 1000 家企业用户的认可**,并且这一数字仍在快速增长中。这 1000 多家企业用户中,绝大多数与社区有着直接联系,并通过各种方式参与到社区建设中来。他们中的许多企业用户也参与到本次 Doris Summit 的议题分享中,将自身基于真实业务场景的实践经验分享给大家。
+
+### **版本更新迭代**
+
+如果说过去版本将使用和运维的简易性作为第一追求的话,那么 2022 年发布版本则是在**性能、稳定性、易用性**等多方面特性的全面进化。
+
+- 4 月份社区发布了自开源以来的首个 1 位版本—— Apache Doris 1.0,在 1.0 版本中,意义非凡的向量化执行初次与大家见面,标志着 Apache Doris 开始迈入极速数据分析时代。
+- 6 月份发布的 1.1 版本,我们对向量化引擎进行了进一步完善和优化,并将其作为正式功能默认开启。与此同时,社区建立了 LTS 版本发布机制,以每月发布一个 3 位版本的速度,对 1.1 版本进行快速地 Bug 修复和功能优化,力求满足更多社区用户在稳定性方面的高要求。
+- 在综合考虑版本迭代节奏和用户需求后,我们决定将众多新特性在 1.2 版本中发布。同时期社区的稳定性和质量保障工作也取得了显著的成效,测试 Case 得到了极大程度地丰富,并在 Master 分支上构建了流水线。通过一系列质量手段,Apache Doris 的代码质量和稳定性得到进一步提升,这也使得版本发布有着更加严格的准出标准。
+- 12 月初 1.2 版本正式面世。这一版本的发布不仅使查询性能有了近十倍的提升,同时我们还推出了过去半年时间里研发的诸多重磅功能,包括 Unique Key 模型 Merge-on-Write 的数据更新模式、支持无缝对接多种数据湖的 Multi-Catalog 多源数据目录、Java UDF 、Array 数组类型和 JSONB 类型等,让 Apache Doris 在更多数据分析场景具备了更强的适应性和可能性。
+- 我们也针对系统稳定性进行了大量的工作,一方面,利用 SQL Smith 等自动化测试工具以及各个知名开源项目的测试用例,构建了数以百万计的测试用例集;另一方面,通过社区准入流水线和完善的回归测试框架,保证了代码合入的质量。因此1.2 版本不论从功能、性能还是稳定性方面,都是一次厚积薄发后的全面进化,也是对所有开发者在 2022 年辛苦付出的最好回报。
+
+### **核心特性演进**
+
+核心特性方面,社区的研发力量主要围绕四个方面开展工作,分别是**性能、实时性、半结构化数据支持与 Lakehouse**。
+
+- **查询性能提升**。从 1.0 版本面世到 1.2 版本发布,Apache Doris 在性能方面取得了极为显著的成绩。在单表场景上,Apache Doris 荣登 Clickhouse 公司推出的 Clickbench 数据库性能榜单,并取得了**前三名**的优秀成绩。在多表关联场景上,得益于向量化执行引擎及各种查询优化技术,相对 2021 年底发布的 0.15 版本 ,Apache Doris 在 SSB 和 TPC-H 等标准测试数据集下均**取得了数倍乃至数十倍的性能提升**。这一系列性能方面的优化,已经成功让 Apache Doris 跻身全球数据库性能最优阵列中!
+
+
+
+- **实时场景优化。** 在 1.2 版本中,我们在原有 Unique Key 数据模型上实现了Merge-On-Write 的数据更新方式,查询性能在高频更新时有 **5-10 倍的提升**,实现了在可更新数据上的低延迟实时分析体验。另外还实现了轻量 Schema Change 功能,对于数据的加减列不再需要转换历史数据,可通过 Flink CDC 等工具快速便捷地同步上游事务数据库中的 DML 或 DDL 操作,使数据同步工作能够更加流畅统一。
+- **半结构化数据支持。** 目前 Apache Doris 支持了 Array 和 JSONB 类型,其中 Array 类型不仅能更方便地存储复杂的数据结构,还可以通过 Array 函数满足用户行为分析等场景的业务需求。而 JSONB 是一种二进制 JSON 存储方式,它不但比纯文本 Text JSON 的访问性能快 4 倍,同时也有更低的内存消耗。通过 JSONB 可以方便地导入各种 JSON 格式的日志数据结构,并能取得优异的查询效率。这也是 Apache Doris 在日志分析领域所做的探索之一。
+
+
+
+- **Lakehouse**。在最新发布的 1. 2 版本中,我们引入了全新的 Catalog 概念,正式将 Apache Doris 迈入湖仓一体时代。通过简单的命令便可以方便地连接到各自外部数据源并自动同步元数据,实现统一的分析体验。通过 Native Format Reader、延迟物化、异步 IO、数据预取等多项针对外部数据源的性能优化,并充分利用自身的高性能执行引擎和查询优化器,在对外表访问性能上,Apache Doris 可以达到 Trino/Presto 的 **3- 5 倍**、Hive 的 **10-100 倍**。
+
+
+
+## **2023 RoadMap**
+
+承前而启后,2023 年,Apache Doris 社区在以上几方面特性持续完善的同时,也将开启更多有意义的工作。**全年的 RoadMap 以及明年 Q1 的具体计划,可以参考以下的全景图:**
+
+
+
+稳定的版本发布和迭代速度对于开源软件至关重要。在 2023 年,我们将以每季度一个 2 位版本的节奏,开始 Apache Doris 2.x 版本的迭代。同时,针对每个 2 位版本,我们也将以每月一个 3 位版本的速度进行功能维护和优化。
+
+**从功能角度来看,后续研发工作将会围绕以下几个主要方向展开:**
+
+### **高性能**
+
+高性能是 Apache Doris 不断追求的目标,过去一年在 Clickbench、TPC-H 等公开测试数据集上的优异表现,已经证明了其在执行层以及算子优化方面做到了业界领先。未来我们也会不断优化各个场景下的性能表现,回馈用户极速的数据分析体验,具体包括:
+
+- **更复杂SQL性能提升:** 2022 年我们已经启动全新查询优化器的设计与开发,而这一成果在 2023 年一季度就将与大家见面。全新查询优化器提供了丰富的规则模型,实现了更智能的代价选择,可以更高效地支撑复杂查询,能够完整执行 TPC-DS 全部 99 个SQL。同时全新查询优化器还具备全查询场景的自适应优化,便于用户在面对不同分析负载和业务场景时都获得一致性的使用体验。
+- **更高的点查询并发:** 高并发一直是 Apache Doris 所擅长的场景,而 2023 年我们将会进一步加强这一能力,通过 Short-Circuit Plan、Prepare Statement、Query Cache 等一系列技术,实现单机数万 QPS 的超高并发支持,并具备随集群规模的拓展进而线性提升并发的能力。
+- **更灵活的多表物化视图:** 在过去版本中,通过强一致的单表物化视图,Apache Doris 加速了固定维度数据的分析效率。而全新的多表物化视图将会解耦 Base 表与 MV 表的生命周期,通过异步刷新和灵活的增量计算方式,满足多表关联以及更复杂 SQL 的预计算加速需求,这一特性将在接下来的 2023 年第一季度与大家见面!
+
+### **高性价比**
+
+成本和效率对企业而言是赢得市场竞争的关键,对数据库而言亦是如此。过去 Apache Doris 凭借在易用性方面的诸多设计帮助用户大幅节约了计算与存储资源成本,后续我们也会引入一系列云原生能力,在不影响业务效率的同时进一步降低成本,具体包括:
+
+- **更低的存储成本:** 我们将探索与云上对象存储系统和文件系统的结合,帮助用户进一步降低存储成本,包括更完善的冷热数据分离能力,将冷数据智能转移至更廉价的对象存储或文件系统中。结合单一远程副本、冷数据 Cache 以及冷热智能转换等技术,保证业务查询效率不受影响的同时实现存储成本大幅降低,这一功能将于 2023 年第一季度发布。
+- **更弹性的计算资源:** 剥离存储与计算状态,引入仅用于计算的 Elastic Compute Node 。由于不存储数据,弹性计算节点具备更加快速的弹性伸缩能力,便于用户在业务高峰期进行快速扩容,进一步提升在海量数据计算场景(如数据湖分析)的分析效率,这一功能已经处于最终调试阶段,即将与大家见面。后续我们还将通过对集群内存和 CPU 运行指标的监控和自动策略配置,实现自动的节点扩缩容(Auto-scaling)。
+
+### **混合负载**
+
+随着用户规模的极速扩张,越来越多的用户将 Apache Doris 用于构建企业内部的统一分析平台。这一方面需要 Apache Doris 去承担更大规模的数据处理和分析,另一方面也需要 Apache Doris 同时去应对更多分析负载的挑战,从过去的实时报表和 Ad-hoc 等典型 OLAP 场景,扩展到 ELT/ETL 、日志检索与分析等更多场景的统一。为了能更好适配这些场景,许多工作已经进入紧锣密鼓的研发中,并将于 2023 年陆续与大家见面,具体包括:
+
+- **更灵活的 Pipeline 执行引擎*** *:**与传统的火山模型相比,Pipeline 模型无需手动设置并发度,可以实现不同管道之间的并行计算,充分利用多核的计算能力,实现更灵活的执行调度,提升在混合负载场景下的综合性能表现。
+- **Workload Manager:** 在性能提升的同时,也亟需完善的资源隔离和划分的能力。我们将会基于 Pipeline 执行引擎实现更细粒度和更灵活的负载管理、资源队列以及共享隔离等功能,兼顾多种混合负载场景下的查询性能与稳定性。
+- **轻量级容错:** 轻量级容错能力也是我们后续持续完善的地方,既能利用 MPP 的高效率又能对错误进行容忍,以更好适应用户在 ETL/ELT 场景的挑战。
+- **函数兼容与多语言UDF:** 与此同时,后续也将支持 Hive/Trino/Spark 函数的兼容性以及多语言的 UDF,来帮助用户更灵活地进行数据加工,也可以更方便地从其他数据库系统迁移到 Apache Doris。
+
+### **多模数据分析**
+
+在过去 Apache Doris 更多是是擅长于结构化数据分析,随着对半结构化、非结构化数据分析需求的增加,从 1.2 版本起我们增加了 Array 和 JSONB 类型以实现数据的 Native 支持,后续版本仍将持续加强这一能力,为日志分析场景提供性价比更高、性能更强的解决方案,**具体包括:**
+
+- **更丰富的复杂数据类型*** *:**除 Array/JSONB 类型以外,2023 年第一季度我们将增加对 Map/Struct 类型的支持,包括高效写入、存储、分析函数以及类型之间的相互嵌套,以更好满足多模态数据分析的支持。后续将支持更加丰富的数据类型,包括 IP、GEO 地理信息等数据类型,并会探索在时序数据场景的高效数据分析。
+- **更高效的文本分析算法:** 对于文本数据,我们将引入更多的文本分析算法,包括自适应 Like、高性能子串匹配、高性能正则匹配,Like 语句的谓词下推、Ngram Bloomfilter 等,同时基于倒排索引实现全文检索能力,在日志分析场景提供比 ES 更高性能和性价比的分析能力。这些功能都已经处于就绪阶段,将在 2023 年初与大家见面。
+- **动态 Schema 表:** 传统数据库在设计之初 Schema 是静态的,Schema 变更时需要执行 DDL ,而这一操作往往具有阻塞性。在越来越多的现代数据分析场景中,表结构会随时间推移而变化,因此我们引入了 Dynamic Table,可以根据数据写入自动适应 Schema ,不再需要执行 DDL,由过去的人工干预数据结构进化为数据自驱动,极大提升了灵活数据分析的便捷性。这一功能将在 2022 年第一季度正式发布。
+
+### **Lakehouse**
+
+随着数据湖技术的发展,分析性能成为发挥数据湖效用、挖掘数据价值最大的掣肘。基于一款简单易用和高性能的查询分析引擎在数据湖之上构建分析服务,成为新的技术趋势。在过去一年,通过在数据湖上的诸多性能优化、结合自身的高性能执行引擎和查询优化器以及,Apache Doris 实现了数据湖上极速易用的分析体验,性能较 Presto/Trino 有 3-5 倍的提升。在 2023 年,我们将会继续完善这一能力,具体包括:
+
+- **更简易的数据对接:** 在 1.2 版本中我们发布了 Multi-Catalog,支持了多种异构数据源的元数据自动映射与同步,实现了数据湖的无缝对接,后续将对 Delta Lake 的支持以及 Iceberg、Hudi 等更多数据格式的支持。
+- **更完整的数据湖能力支持:** 提供数据湖上数据的增量更新与查询,还会支持将分析结果写回数据湖、外表写入内表,实现数据分析流程的全闭环。同时还将支持多版本 Snapshot 读取和删除,并进一步在 Apache Doris 为数据湖数据提供物化视图。
+
+### **实时性与存储引擎优化**
+
+数据价值会随着时间推移而降低,因此实时性对于高时效性要求的用户而言至关重要。在 1.1 版本中我们在 Compaction 和 Flink 实时写入方面进行了诸多优化,同时 1.2 版本的 Merge-on-Write 数据更新模式进一步使 Apache Doris 在实时更新与极速查询得以统一。2023 年我们将会持续强化对存储引擎的优化,具体包括:
+
+- **更稳定的数据写入:** 通过一系列 Compaction 操作和批量数据写入方面的优化,节省资源开销,降低写放大问题,并结合全新的内存管理框架提升写入过程的内存稳定性,进而提升系统稳定性。
+- **更完善的数据更新支持:** 过去部分列更新是通过 Agg 模型上的 Replace_if_not_null 来实现的,后续我们将会增加 Unique Key 模型上的部分列更新支持,并完整实现 Delete、Update、 Merge 等数据更新的操作。
+- **更统一的数据模型:** 当前 Apache Doris 的三种数据模型在各个场景均有丰富的应用,后续我们将尝试统一现有几种数据模型,使用户在使用体验上更加统一。
+
+### **易用性和稳定性**
+
+除了功能方面的丰富与完善,更简单、更易用、更稳定同样也是 Apache Doris 一直追求的目标,2023 年我们将在以下几方面出发,让用户具有更简易和放心的使用体验:
+
+- **简化建表:** 目前 Apache Doris 在建表时分区已经支持了时间函数,后续我们将进一步消除 Bucket 设置,帮助用户最大程度简化建表建模。
+- **安全性:** 目前已经实现基于 RBAC 模型的权限管理机制,使用户权限更安全可靠;并对 ID-federation、行列级别权限,数据脱敏等进行了优化,后续将进一步完善。
+- **可观测性:** Profile 是定位查询性能问题的重要手段,后续我们将加强对 Profile 的监控并提供可视化 Profile 工具,帮助用户更快定位问题。
+- **更好的 BI 兼容性和更完善的数据集成迁移方案:** 当前各 BI 工具可以通过 MySQL 协议连接到 Apache Doris,后续我们将对主流 BI 软件进一步适配,保证更佳的查询体验。随着 DBT、Airbyte 等新兴数据集成和迁移工具的兴起,越来越多用户使用此类系统将数据同步至 Apache Doris ,后续我们也会提供对此些系统的官方支持。
+
+## **开启下一个十年!**
+
+###### 或许有读者或听众还记得我在开头提的问题,对于 Apache Doris,十年意味着什么?
+
+有两层含义,上一个十年和下一个十年。
+
+**上一个十年,是 Apache Doris 起源的十年**。从诞生到开源、从默默无闻到被越来越多人熟知和使用,开源赋予了 Apache Doris 更加旺盛的生命力和创造力。
+
+**而下一个十年,则是一场新的旅程**。
+
+正如我在本次 Doris Summit 分享的主题,New Journey of Apache Doris。如果说过去 Apache Doris 更多是服务于在线报表场景和 Ad-hoc 分析的 OLAP 引擎的话,那么在所有社区和开发者的努力下,当前 Apache Doris 已经具备了更为广阔的定位,即极速、易用、实时、统一的多模分析型数据库。
+
+这其中的统一,既包含了架构的统一、也包含了业务和数据的统一。用户可以通过 Apache Doris 构建多种不同场景的数据分析服务、同时支撑在线与离线的业务负载、高吞吐的交互式分析与高并发的点查询;通过一套架构实现湖和仓的统一、在数据湖和多种异构存储之上提供无缝且极速的分析服务;也可通过对日志/文本等半结构化乃至非结构化的多模数据进行统一管理和分析、来满足更多样化数据分析的需求。
+
+这是我们希望 Apache Doris 能够带给用户的价值,**不再让用户在多套系统之间权衡,仅通过一个系统解决绝大部分问题,降低复杂技术栈带来的开发、运维和使用成本,最大化提升生产力。**
+
+“我们已经出发了太久,以至于忘记了为什么出发。”
+
+希望通过这一定位的转变迎接下一个十年的挑战,或许技术趋势会有变化,架构将会革新,但我们解决用户数据分析问题的初衷不会改变。
+
+希望继续带着上一个十年出发的初心,开启下一个十年的旅程。
\ No newline at end of file
diff --git a/static/images/summit/en/2022.png b/static/images/summit/en/2022.png
new file mode 100644
index 00000000000..0893090d1cb
Binary files /dev/null and b/static/images/summit/en/2022.png differ
diff --git a/static/images/summit/en/community 2.png b/static/images/summit/en/community 2.png
new file mode 100644
index 00000000000..be028814d79
Binary files /dev/null and b/static/images/summit/en/community 2.png differ
diff --git a/static/images/summit/en/community.png b/static/images/summit/en/community.png
new file mode 100644
index 00000000000..f84305a0db7
Binary files /dev/null and b/static/images/summit/en/community.png differ
diff --git a/static/images/summit/en/flow.png b/static/images/summit/en/flow.png
new file mode 100644
index 00000000000..cc1bec3ad86
Binary files /dev/null and b/static/images/summit/en/flow.png differ
diff --git a/static/images/summit/en/lakehouse.png b/static/images/summit/en/lakehouse.png
new file mode 100644
index 00000000000..cafbaa95db7
Binary files /dev/null and b/static/images/summit/en/lakehouse.png differ
diff --git a/static/images/summit/en/logo wall.png b/static/images/summit/en/logo wall.png
new file mode 100644
index 00000000000..61194c3c530
Binary files /dev/null and b/static/images/summit/en/logo wall.png differ
diff --git a/static/images/summit/en/performance.png b/static/images/summit/en/performance.png
new file mode 100644
index 00000000000..f8d1770d4d5
Binary files /dev/null and b/static/images/summit/en/performance.png differ
diff --git a/static/images/summit/en/realtime.png b/static/images/summit/en/realtime.png
new file mode 100644
index 00000000000..20434651295
Binary files /dev/null and b/static/images/summit/en/realtime.png differ
diff --git a/static/images/summit/en/roadmap.png b/static/images/summit/en/roadmap.png
new file mode 100644
index 00000000000..b5f9d7757b7
Binary files /dev/null and b/static/images/summit/en/roadmap.png differ
diff --git a/static/images/summit/en/semi.png b/static/images/summit/en/semi.png
new file mode 100644
index 00000000000..d75946e9011
Binary files /dev/null and b/static/images/summit/en/semi.png differ
diff --git a/static/images/summit/en/top level.png b/static/images/summit/en/top level.png
new file mode 100644
index 00000000000..df52cf767d1
Binary files /dev/null and b/static/images/summit/en/top level.png differ
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org