You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@tvm.apache.org by GitBox <gi...@apache.org> on 2021/03/09 11:34:02 UTC
[GitHub] [tvm] zhuwenxi opened a new pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
zhuwenxi opened a new pull request #7619:
URL: https://github.com/apache/tvm/pull/7619
For details, please refer to https://github.com/apache/tvm/issues/7246
Note currently there is some issues in the c backend: https://github.com/apache/tvm/issues/7596, so the fix is target for llvm and stackvm for now.
@tqchen Please review this PR if you have time.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r593020891
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -155,6 +166,25 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitExpr_(op);
}
}
+ std::string GetUniqueName(std::string prefix) {
+ for (size_t i = 0; i < prefix.size(); ++i) {
+ if (prefix[i] == '.') prefix[i] = '_';
+ }
Review comment:
The idea to use "std::replace" is perfect. But just to clarify, the whole "GetUniqueName()" function is copied from https://github.com/apache/tvm/blob/main/src/target/source/codegen_source_base.cc#L35. I searched over the whole tvm codebase and found a lot components have the "GetUniqueName()" function, which have pretty much the same functionality. What about we make the "GetUniqueName()" a utility function, which could be shared by all the components, to avoid the duplication?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r593020891
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -155,6 +166,25 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitExpr_(op);
}
}
+ std::string GetUniqueName(std::string prefix) {
+ for (size_t i = 0; i < prefix.size(); ++i) {
+ if (prefix[i] == '.') prefix[i] = '_';
+ }
Review comment:
The idea to use "std::replace" is perfect. But just to clarify, the whole "GetUniqueName()" function is copied from https://github.com/apache/tvm/blob/main/src/target/source/codegen_source_base.cc#L35. I searched over the whole tvm codebase and I found a lot components implement the "GetUniqueName()" function, which have pretty much the same functionality. What about we make the "GetUniqueName()" a utility function, which could be shared by all the components, to avoid the duplication?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-811592846
@tqchen How to assert stack alloca with ir_builder? I suppose you mean there are special assertion facilities in ir_builder which TOPI doesn't have?
Or what you meant is to use ir_builder to create a peace of IR, pass it to tvm.build() to create a IRModule, then we check the IRModule (by recursively visit its nodes)? If so, I don't see it has any differences comparing with the existing test case.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r594922540
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -307,19 +393,37 @@ class BuiltinLower : public StmtExprMutator {
std::vector<Stmt> prep_seq_;
PrimExpr device_type_;
PrimExpr device_id_;
- // Var handle for each stack.
Var stack_shape_;
Var stack_array_;
Var stack_tcode_;
Var stack_value_;
+
+ // Mark the occurence of tvm_stack_make_shape of current stmt:
+ // 1. Set to true when the first tvm_stack_make_shape is met;
+ // 2. Reset to false at the end of VisitStmt();
+ bool emit_stack_shape_{false};
+
+ // Mark the occurence of tvm_stack_make_array of current stmt:
+ // 1. Set to true when the first tvm_stack_make_array is met;
+ // 2. Reset to false at the end of VisitStmt().
+ bool emit_stack_array_{false};
+
+ // Mark the occurence of tvm_call_packed of current stmt:
+ // 1. Set to true when tvm_call_packed intrinsic is met;
+ // 2. Reset to false at the end of VisitStmt().
+ bool emit_stack_value_tcode_{false};
+
// The running statistics
int64_t run_shape_stack_{-1};
uint64_t run_array_stack_{0};
uint64_t run_arg_stack_{0};
// statistics of stacks
int64_t max_shape_stack_{-1};
uint64_t max_array_stack_{0};
- uint64_t max_arg_stack_{0};
Review comment:
And for a non-parallel loop, we still need to provide a shared stack at root, so anyway "max_arg_stack" should be kept, right?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-797486821
Thanks @zhuwenxi , I looked at the code, I think we can do a even smaller amount of changes here to achieve the goal:
- keep most of the original logic of the max_shape, and max_arg_stack logic
- Create a function "RealizeAllocaScope(Stmt body)" that will create new instance of stack values,backs up the statistics in the parent scope, visit its body, and create the alloca at its current scope(similaer to Build function)
- Call RealizeAllocaScope in a ParallelFor(so we make sure alloca is only lifted there) and root
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-812285513
Great, I will have a try.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r602713478
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -48,30 +48,54 @@ inline PrimExpr StackAlloca(std::string type, size_t num) {
// These information are needed during codegen.
class BuiltinLower : public StmtExprMutator {
public:
- Stmt Build(Stmt stmt) {
- stack_shape_ = Var("stack_shape", DataType::Handle());
- stack_array_ = Var("stack_array", DataType::Handle());
- stack_value_ = Var("stack_value", DataType::Handle());
- stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ // Record stack frame for existing scope.
+ struct AllocaScope {
+ Var stack_shape_ = Var("stack_shape", DataType::Handle());
+ Var stack_array_ = Var("stack_array", DataType::Handle());
+ Var stack_value_ = Var("stack_value", DataType::Handle());
+ Var stack_tcode_ = Var("stack_tcode", DataType::Handle());
+
+ int64_t max_shape_stack_{-1};
+ uint64_t max_array_stack_{0};
+ uint64_t max_arg_stack_{0};
+
+ int64_t run_shape_stack_{-1};
+ uint64_t run_array_stack_{0};
+ uint64_t run_arg_stack_{0};
+ };
+
+ Stmt Build(Stmt stmt) { return this->RealizeAlloca(stmt); }
+
+ // Allcoate stack frames, only at parallel-for or root.
+ Stmt RealizeAlloca(Stmt stmt) {
+ alloca_scope_.emplace_back();
stmt = this->VisitStmt(stmt);
- // create a shape var if any shape is made (including scalar shapes)
- if (max_shape_stack_ != -1) {
- stmt = LetStmt(stack_shape_, StackAlloca("shape", max_shape_stack_), stmt);
+ auto& scope = alloca_scope_.back();
Review comment:
you want to copy or std::move instead. Pop back will de-allocate the scope. This is the reason of segfault
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -158,64 +199,67 @@ class BuiltinLower : public StmtExprMutator {
// call shape
PrimExpr MakeShape(const CallNode* op) {
// if args.size() == 0, it represents a scalar shape ()
- if (run_shape_stack_ == -1) {
- run_shape_stack_ = 0;
+ auto& scope = alloca_scope_.back();
+ if (scope.run_shape_stack_ == -1) {
+ scope.run_shape_stack_ = 0;
}
- int64_t stack_begin = run_shape_stack_;
- run_shape_stack_ += op->args.size();
+ int64_t stack_begin = scope.run_shape_stack_;
+ scope.run_shape_stack_ += op->args.size();
PrimExpr expr = StmtExprMutator::VisitExpr_(op);
op = expr.as<CallNode>();
// no need to perform any store for a scalar shape
for (size_t i = 0; i < op->args.size(); ++i) {
- prep_seq_.emplace_back(Store(stack_shape_, cast(DataType::Int(64), op->args[i]),
+ prep_seq_.emplace_back(Store(scope.stack_shape_, cast(DataType::Int(64), op->args[i]),
ConstInt32(stack_begin + i), const_true(1)));
}
- return AddressOffset(stack_shape_, DataType::Int(64), stack_begin);
+ return AddressOffset(scope.stack_shape_, DataType::Int(64), stack_begin);
}
// make array
PrimExpr MakeArray(const CallNode* op) {
- size_t idx = run_array_stack_;
- run_array_stack_ += 1;
+ auto& scope = alloca_scope_.back();
Review comment:
ICHECK(!alloca_scope_.empty());
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -140,6 +164,23 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitStmt_(op);
}
}
+ Stmt VisitStmt_(const ForNode* op) final {
+ PrimExpr min = this->VisitExpr(op->min);
+ PrimExpr extent = this->VisitExpr(op->extent);
+ Stmt body;
+
+ if (op->kind == ForKind::kParallel) {
+ body = this->RealizeAlloca(op->body);
+ } else {
+ body = this->VisitStmt(op->body);
+ }
+ auto n = CopyOnWrite(op);
+ n->min = std::move(min);
+ n->extent = std::move(extent);
+ n->body = std::move(body);
+ Stmt stmt(n);
Review comment:
return Stmt(n);
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -48,30 +48,54 @@ inline PrimExpr StackAlloca(std::string type, size_t num) {
// These information are needed during codegen.
class BuiltinLower : public StmtExprMutator {
public:
- Stmt Build(Stmt stmt) {
- stack_shape_ = Var("stack_shape", DataType::Handle());
- stack_array_ = Var("stack_array", DataType::Handle());
- stack_value_ = Var("stack_value", DataType::Handle());
- stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ // Record stack frame for existing scope.
+ struct AllocaScope {
+ Var stack_shape_ = Var("stack_shape", DataType::Handle());
+ Var stack_array_ = Var("stack_array", DataType::Handle());
+ Var stack_value_ = Var("stack_value", DataType::Handle());
+ Var stack_tcode_ = Var("stack_tcode", DataType::Handle());
+
+ int64_t max_shape_stack_{-1};
+ uint64_t max_array_stack_{0};
+ uint64_t max_arg_stack_{0};
+
+ int64_t run_shape_stack_{-1};
+ uint64_t run_array_stack_{0};
+ uint64_t run_arg_stack_{0};
+ };
+
+ Stmt Build(Stmt stmt) { return this->RealizeAlloca(stmt); }
+
+ // Allcoate stack frames, only at parallel-for or root.
+ Stmt RealizeAlloca(Stmt stmt) {
+ alloca_scope_.emplace_back();
stmt = this->VisitStmt(stmt);
- // create a shape var if any shape is made (including scalar shapes)
- if (max_shape_stack_ != -1) {
- stmt = LetStmt(stack_shape_, StackAlloca("shape", max_shape_stack_), stmt);
+ auto& scope = alloca_scope_.back();
+ alloca_scope_.pop_back();
+ if (scope.max_shape_stack_ != -1) {
+ // scope.stack_shape_ = Var("stack_shape", DataType::Handle());
+ stmt = LetStmt(scope.stack_shape_, StackAlloca("shape", scope.max_shape_stack_), stmt);
}
- if (max_array_stack_ != 0) {
- stmt = LetStmt(stack_array_, StackAlloca("array", max_array_stack_), stmt);
+
+ if (scope.max_array_stack_ != 0) {
+ // scope.stack_array_ = Var("stack_array", DataType::Handle());
+ stmt = LetStmt(scope.stack_array_, StackAlloca("array", scope.max_array_stack_), stmt);
}
- if (max_arg_stack_ != 0) {
- stmt = LetStmt(stack_value_, StackAlloca("arg_value", max_arg_stack_), stmt);
- stmt = LetStmt(stack_tcode_, StackAlloca("arg_tcode", max_arg_stack_), stmt);
+ if (scope.max_arg_stack_ != 0) {
+ // scope.stack_value_ = Var("stack_value", DataType::Handle());
+ // scope.stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ stmt = LetStmt(scope.stack_value_, StackAlloca("arg_value", scope.max_arg_stack_), stmt);
+ stmt = LetStmt(scope.stack_tcode_, StackAlloca("arg_tcode", scope.max_arg_stack_), stmt);
}
+
return stmt;
}
Stmt VisitStmt(const Stmt& s) final {
auto stmt = StmtExprMutator::VisitStmt(s);
- ICHECK_EQ(run_shape_stack_, -1);
- ICHECK_EQ(run_array_stack_, 0);
+ auto& scope = alloca_scope_.back();
Review comment:
ICHECK(!alloca_scope_.empty());
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -140,6 +164,23 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitStmt_(op);
}
}
+ Stmt VisitStmt_(const ForNode* op) final {
+ PrimExpr min = this->VisitExpr(op->min);
+ PrimExpr extent = this->VisitExpr(op->extent);
+ Stmt body;
+
+ if (op->kind == ForKind::kParallel) {
+ body = this->RealizeAlloca(op->body);
+ } else {
+ body = this->VisitStmt(op->body);
+ }
+ auto n = CopyOnWrite(op);
Review comment:
if (min.same_as(op->min) && extent.same_as(op->extent) && body.same_as(body)) {
return GetRef<Stmt>(op);
} else {
// the following logic
}
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -227,34 +271,36 @@ class BuiltinLower : public StmtExprMutator {
if (t != api_type) {
arg = Cast(api_type, arg);
}
- prep_seq_.emplace_back(TVMStructSet(stack_value_, static_cast<int>(arg_stack_begin + i - 1),
+ prep_seq_.emplace_back(TVMStructSet(scope.stack_value_,
+ static_cast<int>(arg_stack_begin + i - 1),
builtin::kTVMValueContent, arg));
int arg_tcode = api_type.code();
if (api_type.is_handle() && arg.as<StringImmNode>()) {
arg_tcode = kTVMStr;
}
if (IsArrayHandle(arg)) arg_tcode = kTVMDLTensorHandle;
prep_seq_.emplace_back(
- Store(stack_tcode_, ConstInt32(arg_tcode), stack_index, const_true(1)));
+ Store(scope.stack_tcode_, ConstInt32(arg_tcode), stack_index, const_true(1)));
}
// UPDATE stack value
- max_arg_stack_ = std::max(run_arg_stack_, max_arg_stack_);
- max_shape_stack_ = std::max(run_shape_stack_, max_shape_stack_);
- max_array_stack_ = std::max(run_array_stack_, max_array_stack_);
- run_shape_stack_ = restore_shape_stack;
- run_array_stack_ = restore_array_stack;
- run_arg_stack_ = arg_stack_begin;
- Array<PrimExpr> packed_args = {op->args[0], stack_value_, stack_tcode_,
+ scope.max_arg_stack_ = std::max(scope.run_arg_stack_, scope.max_arg_stack_);
+ scope.max_shape_stack_ = std::max(scope.run_shape_stack_, scope.max_shape_stack_);
+ scope.max_array_stack_ = std::max(scope.run_array_stack_, scope.max_array_stack_);
+ scope.run_shape_stack_ = restore_shape_stack;
+ scope.run_array_stack_ = restore_array_stack;
+ scope.run_arg_stack_ = arg_stack_begin;
+ Array<PrimExpr> packed_args = {op->args[0], scope.stack_value_, scope.stack_tcode_,
ConstInt32(arg_stack_begin),
ConstInt32(arg_stack_begin + op->args.size() - 1)};
return Call(DataType::Int(32), builtin::tvm_call_packed_lowered(), packed_args);
}
PrimExpr MakeCallTracePacked(const CallNode* op) {
- int64_t restore_shape_stack = run_shape_stack_;
- size_t restore_array_stack = run_array_stack_;
- size_t arg_stack_begin = run_arg_stack_;
- run_arg_stack_ += op->args.size();
+ auto& scope = alloca_scope_.back();
Review comment:
ICHECK(!alloca_scope_.empty());
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -48,30 +48,54 @@ inline PrimExpr StackAlloca(std::string type, size_t num) {
// These information are needed during codegen.
class BuiltinLower : public StmtExprMutator {
public:
- Stmt Build(Stmt stmt) {
- stack_shape_ = Var("stack_shape", DataType::Handle());
- stack_array_ = Var("stack_array", DataType::Handle());
- stack_value_ = Var("stack_value", DataType::Handle());
- stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ // Record stack frame for existing scope.
+ struct AllocaScope {
+ Var stack_shape_ = Var("stack_shape", DataType::Handle());
Review comment:
we do not need underscore here as it is public member now.
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -158,64 +199,67 @@ class BuiltinLower : public StmtExprMutator {
// call shape
PrimExpr MakeShape(const CallNode* op) {
// if args.size() == 0, it represents a scalar shape ()
- if (run_shape_stack_ == -1) {
- run_shape_stack_ = 0;
+ auto& scope = alloca_scope_.back();
Review comment:
ICHECK(!alloca_scope_.empty());
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -48,30 +48,54 @@ inline PrimExpr StackAlloca(std::string type, size_t num) {
// These information are needed during codegen.
class BuiltinLower : public StmtExprMutator {
public:
- Stmt Build(Stmt stmt) {
- stack_shape_ = Var("stack_shape", DataType::Handle());
- stack_array_ = Var("stack_array", DataType::Handle());
- stack_value_ = Var("stack_value", DataType::Handle());
- stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ // Record stack frame for existing scope.
+ struct AllocaScope {
+ Var stack_shape_ = Var("stack_shape", DataType::Handle());
+ Var stack_array_ = Var("stack_array", DataType::Handle());
+ Var stack_value_ = Var("stack_value", DataType::Handle());
+ Var stack_tcode_ = Var("stack_tcode", DataType::Handle());
+
+ int64_t max_shape_stack_{-1};
+ uint64_t max_array_stack_{0};
+ uint64_t max_arg_stack_{0};
+
+ int64_t run_shape_stack_{-1};
+ uint64_t run_array_stack_{0};
+ uint64_t run_arg_stack_{0};
+ };
+
+ Stmt Build(Stmt stmt) { return this->RealizeAlloca(stmt); }
+
+ // Allcoate stack frames, only at parallel-for or root.
+ Stmt RealizeAlloca(Stmt stmt) {
Review comment:
`VisitBodyAndRealizeAlloca(Stmt body)`
for readability
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] huajsj commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
huajsj commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r593322682
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -155,6 +166,25 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitExpr_(op);
}
}
+ std::string GetUniqueName(std::string prefix) {
+ for (size_t i = 0; i < prefix.size(); ++i) {
+ if (prefix[i] == '.') prefix[i] = '_';
+ }
Review comment:
@zhuwenxi, thanks for the clarify, the idea make GetUniqueName to a utility function is a great, I also understand this code style is existing issue, either keep it on this patch or make a utility function and fix is ok to me.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] huajsj commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
huajsj commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r593322682
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -155,6 +166,25 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitExpr_(op);
}
}
+ std::string GetUniqueName(std::string prefix) {
+ for (size_t i = 0; i < prefix.size(); ++i) {
+ if (prefix[i] == '.') prefix[i] = '_';
+ }
Review comment:
@zhuwenxi, thanks for the clarify, the idea make GetUniqueName to a utility function is a great idea, I also understand this code style is existing issue, either keep it on this patch or make a utility function and fix is ok to me.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-800751749
@tqchen I don't quite follow your idea that parent statistics are necessary. Could you explain a little bit more about why there will be problems for "packed calls inside and outside the parallel for loop"? Specifically, what exactly the tir look like when the problem occurs?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r594924614
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -155,6 +166,25 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitExpr_(op);
}
}
+ std::string GetUniqueName(std::string prefix) {
+ for (size_t i = 0; i < prefix.size(); ++i) {
+ if (prefix[i] == '.') prefix[i] = '_';
+ }
Review comment:
Thank you @huajsj , let's keep it on this patch and wait for a total "sweep-up" PR to fix all these code style problems later. I will leave a "TODO" comment here, to mark up the requirement for this function.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r603074923
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -227,34 +271,36 @@ class BuiltinLower : public StmtExprMutator {
if (t != api_type) {
arg = Cast(api_type, arg);
}
- prep_seq_.emplace_back(TVMStructSet(stack_value_, static_cast<int>(arg_stack_begin + i - 1),
+ prep_seq_.emplace_back(TVMStructSet(scope.stack_value_,
+ static_cast<int>(arg_stack_begin + i - 1),
builtin::kTVMValueContent, arg));
int arg_tcode = api_type.code();
if (api_type.is_handle() && arg.as<StringImmNode>()) {
arg_tcode = kTVMStr;
}
if (IsArrayHandle(arg)) arg_tcode = kTVMDLTensorHandle;
prep_seq_.emplace_back(
- Store(stack_tcode_, ConstInt32(arg_tcode), stack_index, const_true(1)));
+ Store(scope.stack_tcode_, ConstInt32(arg_tcode), stack_index, const_true(1)));
}
// UPDATE stack value
- max_arg_stack_ = std::max(run_arg_stack_, max_arg_stack_);
- max_shape_stack_ = std::max(run_shape_stack_, max_shape_stack_);
- max_array_stack_ = std::max(run_array_stack_, max_array_stack_);
- run_shape_stack_ = restore_shape_stack;
- run_array_stack_ = restore_array_stack;
- run_arg_stack_ = arg_stack_begin;
- Array<PrimExpr> packed_args = {op->args[0], stack_value_, stack_tcode_,
+ scope.max_arg_stack_ = std::max(scope.run_arg_stack_, scope.max_arg_stack_);
+ scope.max_shape_stack_ = std::max(scope.run_shape_stack_, scope.max_shape_stack_);
+ scope.max_array_stack_ = std::max(scope.run_array_stack_, scope.max_array_stack_);
+ scope.run_shape_stack_ = restore_shape_stack;
+ scope.run_array_stack_ = restore_array_stack;
+ scope.run_arg_stack_ = arg_stack_begin;
+ Array<PrimExpr> packed_args = {op->args[0], scope.stack_value_, scope.stack_tcode_,
ConstInt32(arg_stack_begin),
ConstInt32(arg_stack_begin + op->args.size() - 1)};
return Call(DataType::Int(32), builtin::tvm_call_packed_lowered(), packed_args);
}
PrimExpr MakeCallTracePacked(const CallNode* op) {
- int64_t restore_shape_stack = run_shape_stack_;
- size_t restore_array_stack = run_array_stack_;
- size_t arg_stack_begin = run_arg_stack_;
- run_arg_stack_ += op->args.size();
+ auto& scope = alloca_scope_.back();
Review comment:
Done.
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -158,64 +199,67 @@ class BuiltinLower : public StmtExprMutator {
// call shape
PrimExpr MakeShape(const CallNode* op) {
// if args.size() == 0, it represents a scalar shape ()
- if (run_shape_stack_ == -1) {
- run_shape_stack_ = 0;
+ auto& scope = alloca_scope_.back();
+ if (scope.run_shape_stack_ == -1) {
+ scope.run_shape_stack_ = 0;
}
- int64_t stack_begin = run_shape_stack_;
- run_shape_stack_ += op->args.size();
+ int64_t stack_begin = scope.run_shape_stack_;
+ scope.run_shape_stack_ += op->args.size();
PrimExpr expr = StmtExprMutator::VisitExpr_(op);
op = expr.as<CallNode>();
// no need to perform any store for a scalar shape
for (size_t i = 0; i < op->args.size(); ++i) {
- prep_seq_.emplace_back(Store(stack_shape_, cast(DataType::Int(64), op->args[i]),
+ prep_seq_.emplace_back(Store(scope.stack_shape_, cast(DataType::Int(64), op->args[i]),
ConstInt32(stack_begin + i), const_true(1)));
}
- return AddressOffset(stack_shape_, DataType::Int(64), stack_begin);
+ return AddressOffset(scope.stack_shape_, DataType::Int(64), stack_begin);
}
// make array
PrimExpr MakeArray(const CallNode* op) {
- size_t idx = run_array_stack_;
- run_array_stack_ += 1;
+ auto& scope = alloca_scope_.back();
Review comment:
Done.
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -48,30 +48,54 @@ inline PrimExpr StackAlloca(std::string type, size_t num) {
// These information are needed during codegen.
class BuiltinLower : public StmtExprMutator {
public:
- Stmt Build(Stmt stmt) {
- stack_shape_ = Var("stack_shape", DataType::Handle());
- stack_array_ = Var("stack_array", DataType::Handle());
- stack_value_ = Var("stack_value", DataType::Handle());
- stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ // Record stack frame for existing scope.
+ struct AllocaScope {
+ Var stack_shape_ = Var("stack_shape", DataType::Handle());
Review comment:
Fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r611307709
##########
File path: tests/python/unittest/test_packed_func.py
##########
@@ -0,0 +1,139 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+import tvm
+from tvm import te
+import numpy as np
+from tvm import testing
+
+
+@tvm.register_func("tvm.test_matmul")
+def my_matmul(a, b, c):
+ c.copyfrom(np.dot(a.asnumpy(), b.asnumpy()))
+
+
+def test_packed_func(target="llvm"):
Review comment:
Done.
##########
File path: tests/python/unittest/test_packed_func.py
##########
@@ -0,0 +1,139 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+import tvm
+from tvm import te
+import numpy as np
+from tvm import testing
+
+
+@tvm.register_func("tvm.test_matmul")
+def my_matmul(a, b, c):
+ c.copyfrom(np.dot(a.asnumpy(), b.asnumpy()))
+
+
+def test_packed_func(target="llvm"):
+ ib = tvm.tir.ir_builder.create()
+
+ m = n = k = 16
+
+ #
+ # Prepare buffer for a, b and c:
Review comment:
Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r610584450
##########
File path: tests/python/unittest/test_packed_func.py
##########
@@ -0,0 +1,139 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+import tvm
+from tvm import te
+import numpy as np
+from tvm import testing
+
+
+@tvm.register_func("tvm.test_matmul")
+def my_matmul(a, b, c):
+ c.copyfrom(np.dot(a.asnumpy(), b.asnumpy()))
+
+
+def test_packed_func(target="llvm"):
+ ib = tvm.tir.ir_builder.create()
+
+ m = n = k = 16
+
+ #
+ # Prepare buffer for a, b and c:
Review comment:
rename this file to test_tir_transform_lower_tvm_builtin.py
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] huajsj commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
huajsj commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-797641411
> @huajsj @tqchen There is a UT "test_te_tesnor.py" failed for this PR, which is a "SegmentFault" in the generated code. Since tvm llvm backend code is generated on the fly (JIT), no binary generated, I couldn't debug it with gdb. Do you have any suggestions? What is the best practice to debug such kind of problems? use lldb?
@zhuwenxi , besides of using export_library, sometime I use "python -m pdb" and gdb together to debug generate code issue, hope this information is useful for you.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] huajsj commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
huajsj commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r592919413
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -155,6 +166,25 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitExpr_(op);
}
}
+ std::string GetUniqueName(std::string prefix) {
+ for (size_t i = 0; i < prefix.size(); ++i) {
+ if (prefix[i] == '.') prefix[i] = '_';
+ }
Review comment:
how about use STL style code "std::replace(prefix.begin(), prefix.end(), '.', '_');" to simple this part logic?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-809154100
@tqchen Thank you, always my pleasure! A bunch of commits I just pushed upstream to fix those problems you figured, including the UT issue, now it doesn't rely on blas anymore. Hope I didn't miss any of your comments.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-802890021
@zhuwenxi in your case, if we have
```
func() {
parallel for () {
packed_call1
}
}
```
Then we will still allocate the same amount of stack at the root of the function(which is un-necessary). Essentially we need local statistics and stack var for each of the local scope( those in parallel for, and those in the func excluding parallel for)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-814079009
All tvm IR nodes can be constructed via python, we can use Evaluate and call_intrin to construct the IR Node. related functions are:
- https://tvm.apache.org/docs/api/python/tir.html#tvm.tir.LetStmt
- https://tvm.apache.org/docs/api/python/tir.html#tvm.tir.call_intrin
IR builder seems to lack the ability to construct a let stmt, and we can patch that to support ib.let() just like the ib.scope_attr
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r594921470
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -74,12 +59,38 @@ class BuiltinLower : public StmtExprMutator {
ICHECK_EQ(run_array_stack_, 0);
if (prep_seq_.size() != 0) {
- Stmt ret = SeqStmt::Flatten(prep_seq_, stmt);
+ stmt = SeqStmt::Flatten(prep_seq_, stmt);
prep_seq_.clear();
- return ret;
- } else {
- return stmt;
}
+
+ // Always generated "tvm_stack_alloca" intrincis next to the "tvm_packed_func",
+ // which makes the stacks allocated thread-local and every tvm_packed_func will have
+ // it's own stack, rather than a shared one. This could help resolve the race
+ // -condition issue in parallel execution.
+
+ if (emit_stack_shape_) {
+ ICHECK_NE(max_shape_stack_, -1);
Review comment:
Looks good to me, actually it's quite like the approach I proposed, "re-allocate stack only in a parallel for loop": https://github.com/apache/tvm/issues/7246#issuecomment-759976432
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-800052394
> > @huajsj @tqchen There is a UT "test_te_tesnor.py" failed for this PR, which is a "SegmentFault" in the generated code. Since tvm llvm backend code is generated on the fly (JIT), no binary generated, I couldn't debug it with gdb. Do you have any suggestions? What is the best practice to debug such kind of problems? use lldb?
>
> @zhuwenxi , besides of using export_library, sometime I use "python -m pdb" and gdb together to debug generate code issue, hope this information is useful for you.
Great! It works, I've found the crash point. (Though it crashes in ndarray.h, rather than llvm ir itself directly)
Just curious, if crash happens in the llvm generated code, is gdb still able to report the crash point, exactly which ir crashed?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-808726535
@zhuwenxi Some more reviews. There is a bug which might be the cause of UT failure. We do want to not rely on blas though because we want UT to run fast, please change that as well
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-797348695
@huajsj @tqchen There is a UT "test_te_tesnor.py" failed for this PR, which is a "SegmentFault" in the generated code. Since tvm llvm backend code is generated on the fly (JIT), no binary generated, I couldn't debug it with gdb. Do you have any suggestions? What is the best practice to debug such kind of problems? use lldb?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen edited a comment on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-793943991
cc @ZihengJiang @areusch @vinx13 please help to review this PR. @zhuwenxi please fix the lint error
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-817455567
@tqchen Changes applied, please check my latest commit.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-801098089
First of all, the statistics is not about parent, but the statistics about its body. The main thing is that if we have
```
func() {
parallel for () {
packed_call1
}
packed_call2
}
```
We need two separate allocations, one for packed call1 and another for the packed_call2(the root scope). Each of the scope would need their own set of statistics and vars for running the alloca
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r593163883
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -74,12 +59,38 @@ class BuiltinLower : public StmtExprMutator {
ICHECK_EQ(run_array_stack_, 0);
if (prep_seq_.size() != 0) {
- Stmt ret = SeqStmt::Flatten(prep_seq_, stmt);
+ stmt = SeqStmt::Flatten(prep_seq_, stmt);
prep_seq_.clear();
- return ret;
- } else {
- return stmt;
}
+
+ // Always generated "tvm_stack_alloca" intrincis next to the "tvm_packed_func",
+ // which makes the stacks allocated thread-local and every tvm_packed_func will have
+ // it's own stack, rather than a shared one. This could help resolve the race
+ // -condition issue in parallel execution.
+
+ if (emit_stack_shape_) {
+ ICHECK_NE(max_shape_stack_, -1);
Review comment:
Thanks @zhuwenxi , I guess we do not need to trigger after every statement visits. Instead, we can check ForNode and see if there is a parallel, if there is, we emit immediately. Otherwise, we emit at root.
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -307,19 +393,37 @@ class BuiltinLower : public StmtExprMutator {
std::vector<Stmt> prep_seq_;
PrimExpr device_type_;
PrimExpr device_id_;
- // Var handle for each stack.
Var stack_shape_;
Var stack_array_;
Var stack_tcode_;
Var stack_value_;
+
+ // Mark the occurence of tvm_stack_make_shape of current stmt:
+ // 1. Set to true when the first tvm_stack_make_shape is met;
+ // 2. Reset to false at the end of VisitStmt();
+ bool emit_stack_shape_{false};
+
+ // Mark the occurence of tvm_stack_make_array of current stmt:
+ // 1. Set to true when the first tvm_stack_make_array is met;
+ // 2. Reset to false at the end of VisitStmt().
+ bool emit_stack_array_{false};
+
+ // Mark the occurence of tvm_call_packed of current stmt:
+ // 1. Set to true when tvm_call_packed intrinsic is met;
+ // 2. Reset to false at the end of VisitStmt().
+ bool emit_stack_value_tcode_{false};
+
// The running statistics
int64_t run_shape_stack_{-1};
uint64_t run_array_stack_{0};
uint64_t run_arg_stack_{0};
// statistics of stacks
int64_t max_shape_stack_{-1};
uint64_t max_array_stack_{0};
- uint64_t max_arg_stack_{0};
Review comment:
let us keep max_arg_stack as it is, and use its value (0 or not) to check whether or not we need emission.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-814055145
@tqchen , I met some problems when I was trying to reconstruct the UT with ir_builder and assert_structural_equal(). This is my code:
<pre>
def assert_packed_func(target="llvm", parallel=True):
ib = tvm.tir.ir_builder.create()
m = n = k = 16
#
# Prepare buffer for a, b and c:
#
a = te.placeholder((m, k), name="a", dtype="float64")
b = te.placeholder((k, n), name="b", dtype="float64")
k = te.reduce_axis((0, k), name="k")
c = te.compute((m, n), lambda i, j: te.sum(a[i, k] * b[k, j], axis=k), name="c")
a_buffer = tvm.tir.decl_buffer(
a.shape, a.dtype, name="a_buffer", offset_factor=1, strides=[te.var("s1"), 1]
)
b_buffer = tvm.tir.decl_buffer(
b.shape, b.dtype, name="b_buffer", offset_factor=1, strides=[te.var("s2"), 1]
)
c_buffer = tvm.tir.decl_buffer(
c.shape, c.dtype, name="c_buffer", offset_factor=1, strides=[te.var("s3"), 1]
)
# Use ir_buider to create a packed call in the parallel loop:
with ib.for_range(0, 10, "i", kind="parallel"):
ib.emit(tvm.tir.call_packed("tvm.test_matmul", a_buffer, b_buffer, c_buffer))
stmt = ib.get()
# Construct a valid IRModule to be lowered:
mod = tvm.IRModule.from_expr(tvm.tir.PrimFunc([a_buffer, b_buffer, c_buffer], stmt))
target = tvm.target.Target(target)
mod = tvm.tir.transform.Apply(lambda f: f.with_attr("target", target))(mod)
mod = tvm.tir.transform.Apply(lambda f: f.with_attr("global_symbol", "main"))(mod)
mod = tvm.tir.transform.MakePackedAPI()(mod)
# Do the lowering:
mod = tvm.tir.transform.LowerTVMBuiltin()(mod)
# Get the PrimFunc from module:
prim_func = mod.functions.items()[0][1]
# Recursively visit PrimFunc until we meet the for-loop
node = prim_func.body
while isinstance(node, (tvm.tir.AssertStmt, tvm.tir.LetStmt, tvm.tir.AttrStmt)):
node = node.body
# For-loop met
assert isinstance(node, tvm.tir.stmt.For)
alloca_tcode = node.body
assert isinstance(alloca_tcode, tvm.tir.LetStmt)
...
</pre>
I suppose I should use assert_structural_equal() to assert the "alloca_tcode" here, but I don't know how to construct the "expected" stmt. The expected stmt here should be `let stack_tcode = tir.tvm_stack_alloca("arg_tcode", 4)`, but seems TVM doesn't have python APIs to create a `tir.tvm_stack_alloca` stmt. (This intrinsic can only be generated by C++ API?)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] huajsj commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
huajsj commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r592919413
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -155,6 +166,25 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitExpr_(op);
}
}
+ std::string GetUniqueName(std::string prefix) {
+ for (size_t i = 0; i < prefix.size(); ++i) {
+ if (prefix[i] == '.') prefix[i] = '_';
+ }
Review comment:
how about use STL style code "std::replace(prefix.begin(), prefix.end(), '.', '-');" to simple this part logic?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r594921470
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -74,12 +59,38 @@ class BuiltinLower : public StmtExprMutator {
ICHECK_EQ(run_array_stack_, 0);
if (prep_seq_.size() != 0) {
- Stmt ret = SeqStmt::Flatten(prep_seq_, stmt);
+ stmt = SeqStmt::Flatten(prep_seq_, stmt);
prep_seq_.clear();
- return ret;
- } else {
- return stmt;
}
+
+ // Always generated "tvm_stack_alloca" intrincis next to the "tvm_packed_func",
+ // which makes the stacks allocated thread-local and every tvm_packed_func will have
+ // it's own stack, rather than a shared one. This could help resolve the race
+ // -condition issue in parallel execution.
+
+ if (emit_stack_shape_) {
+ ICHECK_NE(max_shape_stack_, -1);
Review comment:
Looks good to me, actually it's quite like the approach I proposed, "allocate stack only in a parallel for loop": https://github.com/apache/tvm/issues/7246#issuecomment-759976432
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen edited a comment on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-797486821
Thanks @zhuwenxi , I looked at the code, I think we can do a even smaller amount of changes here to achieve the goal:
- keep most of the original logic of the max_shape, and max_arg_stack logic
- Introduce a AllocaScope stack frame data structure that contains the necessary fields
- Create a function "RealizeAllocaScope(Stmt body)" that will create new instance of stack values,backs up the statistics in the parent scope, visit its body, and create the alloca at its current scope(similaer to Build function)
- Call RealizeAllocaScope in a ParallelFor(so we make sure alloca is only lifted there) and root
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-797490251
```
struct AllocaScope {
// tvm use pointer uniqueness so same name is fine
Var stack_shape_ = Var("stack_shape", DataType::Handle());
Var stack_array_ = Var("stack_array", DataType::Handle());
Var stack_value_ = Var("stack_value", DataType::Handle());
Var stack_tcode_ = Var("stack_tcode", DataType::Handle());
int64_t max_shape_stack_{-1};
uint64_t max_array_stack_{0};
uint64_t max_arg_stack_{0};
};
Stmt RealizeAlloca(Stmt body) {
alloca_scope_.emplace_back(AllocaScope());
stmt = this->VisitStmt(stmt);
auto scope = alloca_scope_.back();
alloca_scope_.pop_back();
// create a shape var if any shape is made (including scalar shapes)
if (scope.max_shape_stack_ != -1) {
stmt = LetStmt(scope.stack_shape_, StackAlloca("shape", max_shape_stack_), stmt);
}
if (scope.max_array_stack_ != 0) {
stmt = LetStmt(scope.stack_array_, StackAlloca("array", max_array_stack_), stmt);
}
if (scope.max_arg_stack_ != 0) {
stmt = LetStmt(scope.stack_value_, StackAlloca("arg_value", max_arg_stack_), stmt);
stmt = LetStmt(scope.stack_tcode_, StackAlloca("arg_tcode", max_arg_stack_), stmt);
}
return stmt;
}
```
And in the functions, update the value using `alloca_scope_.back()`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-797348695
@huajsj @tqchen There is a UT "test_te_tesnor.py" failed for this PR, which is a "SegmentFault" in the generated code. Since tvm llvm backend code is generated on the fly (JIT), no binary generated, so I couldn't debug it with gdb. Do you have any suggestions? What is the best practice to debug such kind of problems, use lldb?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-811023123
NOTE, the CI error was due to timeout. It may have things todo with race condition in the current parallel testcase.
@zhuwenxi can you consider add a unit test instead? We can use IR builder to build a low level IR that contains a parallel for and packed call, then we assert that the stack alloca happens at the right location. Thank you!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r610583633
##########
File path: tests/python/unittest/test_packed_func.py
##########
@@ -0,0 +1,139 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+import tvm
+from tvm import te
+import numpy as np
+from tvm import testing
+
+
+@tvm.register_func("tvm.test_matmul")
+def my_matmul(a, b, c):
+ c.copyfrom(np.dot(a.asnumpy(), b.asnumpy()))
+
+
+def test_packed_func(target="llvm"):
Review comment:
in pytest, we only invoke the functions with default parameters, test_packed_func() instead of looking at main.
Please change to `check_packed_func()`
then add another test_packed_func() that invokes the check for both stackvm and llvm.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-809855345
@tqchen CI was aborted for no reason?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-810711113
@tqchen Looks like the CI was aborted for no reasons? How can I restart it?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-800048875
> @zhuwenxi , you can try to call export_library to export to a shared lib and load it back.
OK, I see.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-797481134
@zhuwenxi , you can try to call export_library to export to a shared lib and load it back.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen edited a comment on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-793943991
cc @ZihengJiang @areusch please help to review this PR. @zhuwenxi please fix the lint error
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-811020992
@zhuwenxi you can push a new dummy commit to do so. I have retriggered it for you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r603074708
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -140,6 +164,23 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitStmt_(op);
}
}
+ Stmt VisitStmt_(const ForNode* op) final {
+ PrimExpr min = this->VisitExpr(op->min);
+ PrimExpr extent = this->VisitExpr(op->extent);
+ Stmt body;
+
+ if (op->kind == ForKind::kParallel) {
+ body = this->RealizeAlloca(op->body);
+ } else {
+ body = this->VisitStmt(op->body);
+ }
+ auto n = CopyOnWrite(op);
Review comment:
Done.
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -140,6 +164,23 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitStmt_(op);
}
}
+ Stmt VisitStmt_(const ForNode* op) final {
+ PrimExpr min = this->VisitExpr(op->min);
+ PrimExpr extent = this->VisitExpr(op->extent);
+ Stmt body;
+
+ if (op->kind == ForKind::kParallel) {
+ body = this->RealizeAlloca(op->body);
+ } else {
+ body = this->VisitStmt(op->body);
+ }
+ auto n = CopyOnWrite(op);
+ n->min = std::move(min);
+ n->extent = std::move(extent);
+ n->body = std::move(body);
+ Stmt stmt(n);
Review comment:
Done.
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -158,64 +199,67 @@ class BuiltinLower : public StmtExprMutator {
// call shape
PrimExpr MakeShape(const CallNode* op) {
// if args.size() == 0, it represents a scalar shape ()
- if (run_shape_stack_ == -1) {
- run_shape_stack_ = 0;
+ auto& scope = alloca_scope_.back();
Review comment:
Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r603074292
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -48,30 +48,54 @@ inline PrimExpr StackAlloca(std::string type, size_t num) {
// These information are needed during codegen.
class BuiltinLower : public StmtExprMutator {
public:
- Stmt Build(Stmt stmt) {
- stack_shape_ = Var("stack_shape", DataType::Handle());
- stack_array_ = Var("stack_array", DataType::Handle());
- stack_value_ = Var("stack_value", DataType::Handle());
- stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ // Record stack frame for existing scope.
+ struct AllocaScope {
+ Var stack_shape_ = Var("stack_shape", DataType::Handle());
+ Var stack_array_ = Var("stack_array", DataType::Handle());
+ Var stack_value_ = Var("stack_value", DataType::Handle());
+ Var stack_tcode_ = Var("stack_tcode", DataType::Handle());
+
+ int64_t max_shape_stack_{-1};
+ uint64_t max_array_stack_{0};
+ uint64_t max_arg_stack_{0};
+
+ int64_t run_shape_stack_{-1};
+ uint64_t run_array_stack_{0};
+ uint64_t run_arg_stack_{0};
+ };
+
+ Stmt Build(Stmt stmt) { return this->RealizeAlloca(stmt); }
+
+ // Allcoate stack frames, only at parallel-for or root.
+ Stmt RealizeAlloca(Stmt stmt) {
Review comment:
Done.
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -48,30 +48,54 @@ inline PrimExpr StackAlloca(std::string type, size_t num) {
// These information are needed during codegen.
class BuiltinLower : public StmtExprMutator {
public:
- Stmt Build(Stmt stmt) {
- stack_shape_ = Var("stack_shape", DataType::Handle());
- stack_array_ = Var("stack_array", DataType::Handle());
- stack_value_ = Var("stack_value", DataType::Handle());
- stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ // Record stack frame for existing scope.
+ struct AllocaScope {
+ Var stack_shape_ = Var("stack_shape", DataType::Handle());
+ Var stack_array_ = Var("stack_array", DataType::Handle());
+ Var stack_value_ = Var("stack_value", DataType::Handle());
+ Var stack_tcode_ = Var("stack_tcode", DataType::Handle());
+
+ int64_t max_shape_stack_{-1};
+ uint64_t max_array_stack_{0};
+ uint64_t max_arg_stack_{0};
+
+ int64_t run_shape_stack_{-1};
+ uint64_t run_array_stack_{0};
+ uint64_t run_arg_stack_{0};
+ };
+
+ Stmt Build(Stmt stmt) { return this->RealizeAlloca(stmt); }
+
+ // Allcoate stack frames, only at parallel-for or root.
+ Stmt RealizeAlloca(Stmt stmt) {
+ alloca_scope_.emplace_back();
stmt = this->VisitStmt(stmt);
- // create a shape var if any shape is made (including scalar shapes)
- if (max_shape_stack_ != -1) {
- stmt = LetStmt(stack_shape_, StackAlloca("shape", max_shape_stack_), stmt);
+ auto& scope = alloca_scope_.back();
Review comment:
Fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen edited a comment on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-808726535
@zhuwenxi Some more reviews. There is a bug which might be the cause of UT failure. We do want to not rely on blas though because we want UT to run fast, please change that as well. Thanks for keeping improving the PR!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-817875288
Thank you @zhuwenxi for keep improving the PR! Thanks @huajsj for review. This PR is now merged
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-800751749
@tqchen Could you explain a little bit more about why there will be problems for "packed calls inside and outside the parallel for loop"? Specifically, what exactly the tir look like when the problem occurs?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-803729265
I see. I will upstream a commit soon.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-795067549
Lint error fixed. There are still some UT failures, I'm will fix them soon.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r602713730
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -140,6 +164,23 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitStmt_(op);
}
}
+ Stmt VisitStmt_(const ForNode* op) final {
+ PrimExpr min = this->VisitExpr(op->min);
+ PrimExpr extent = this->VisitExpr(op->extent);
+ Stmt body;
+
+ if (op->kind == ForKind::kParallel) {
+ body = this->RealizeAlloca(op->body);
+ } else {
+ body = this->VisitStmt(op->body);
+ }
+ auto n = CopyOnWrite(op);
Review comment:
```
if (min.same_as(op->min) && extent.same_as(op->extent) && body.same_as(body)) {
return GetRef<Stmt>(op);
} else {
// the following logic
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-800235225
@zhuwenxi your fix will have some problem when there are packed calls inside and outside the parallel for loop.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-816445095
@tqchen I've updated the UT with IR builder and assert_structural_equal().
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-805634130
@tqchen Please take a look at my latest commit if you have time, thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r593020891
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -155,6 +166,25 @@ class BuiltinLower : public StmtExprMutator {
return StmtExprMutator::VisitExpr_(op);
}
}
+ std::string GetUniqueName(std::string prefix) {
+ for (size_t i = 0; i < prefix.size(); ++i) {
+ if (prefix[i] == '.') prefix[i] = '_';
+ }
Review comment:
The idea to use "std::replace" is perfect. But just to clarify, the whole "GetUniqueName()" function is copied from https://github.com/apache/tvm/blob/main/src/target/source/codegen_source_base.cc#L35. I searched over the whole tvm codebase and I found there are a lot components implement the "GetUniqueName()" function, which have pretty much the same functionality. What about we could make the "GetUniqueName()" a utility function shared by all the components, to avoid the duplication?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-800048875
> @zhuwenxi , you can try to call export_library to export to a shared lib and load it back.
I see.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-801573912
@tqchen Thanks for the explanation. Actually, there are two separate allocations in my fix, indeed:
1. The original code logic in "lower_tvm_builtin.cc" is revered in my proposal, a shared stack is allocated for packed_call2:
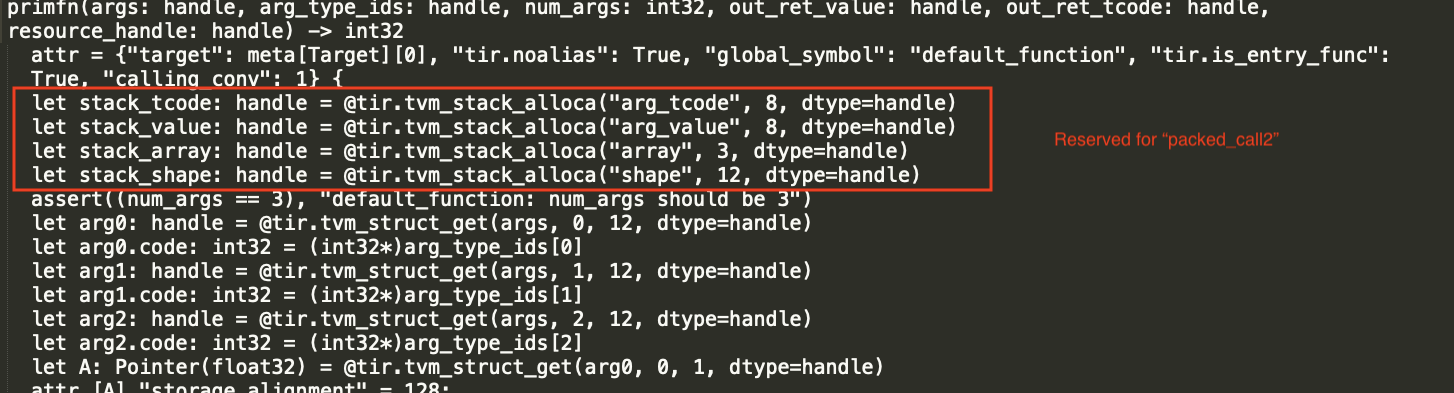
2. The override version of "VisitStmt_(const ForNode *op)" is added to lower_tvm_builtin.cc, to handle the stack (re)allocation of packed_call1:
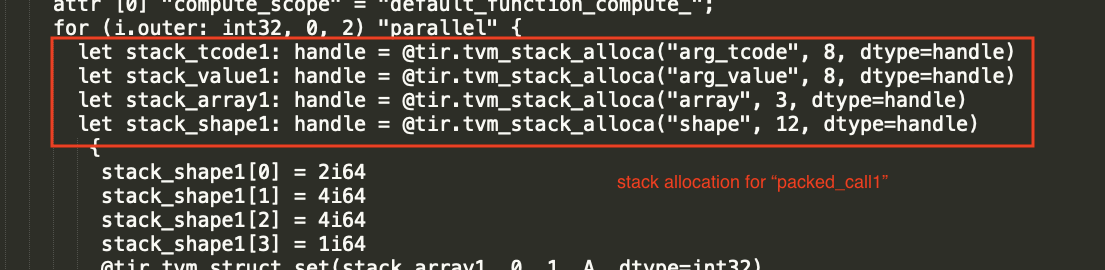
So I don't see any problem in my proposal, for now.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r594922540
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -307,19 +393,37 @@ class BuiltinLower : public StmtExprMutator {
std::vector<Stmt> prep_seq_;
PrimExpr device_type_;
PrimExpr device_id_;
- // Var handle for each stack.
Var stack_shape_;
Var stack_array_;
Var stack_tcode_;
Var stack_value_;
+
+ // Mark the occurence of tvm_stack_make_shape of current stmt:
+ // 1. Set to true when the first tvm_stack_make_shape is met;
+ // 2. Reset to false at the end of VisitStmt();
+ bool emit_stack_shape_{false};
+
+ // Mark the occurence of tvm_stack_make_array of current stmt:
+ // 1. Set to true when the first tvm_stack_make_array is met;
+ // 2. Reset to false at the end of VisitStmt().
+ bool emit_stack_array_{false};
+
+ // Mark the occurence of tvm_call_packed of current stmt:
+ // 1. Set to true when tvm_call_packed intrinsic is met;
+ // 2. Reset to false at the end of VisitStmt().
+ bool emit_stack_value_tcode_{false};
+
// The running statistics
int64_t run_shape_stack_{-1};
uint64_t run_array_stack_{0};
uint64_t run_arg_stack_{0};
// statistics of stacks
int64_t max_shape_stack_{-1};
uint64_t max_array_stack_{0};
- uint64_t max_arg_stack_{0};
Review comment:
And for a non-parallel loops, we still need to provide a shared stack at root, so anyway "max_arg_stack" should be kept, right?
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -307,19 +393,37 @@ class BuiltinLower : public StmtExprMutator {
std::vector<Stmt> prep_seq_;
PrimExpr device_type_;
PrimExpr device_id_;
- // Var handle for each stack.
Var stack_shape_;
Var stack_array_;
Var stack_tcode_;
Var stack_value_;
+
+ // Mark the occurence of tvm_stack_make_shape of current stmt:
+ // 1. Set to true when the first tvm_stack_make_shape is met;
+ // 2. Reset to false at the end of VisitStmt();
+ bool emit_stack_shape_{false};
+
+ // Mark the occurence of tvm_stack_make_array of current stmt:
+ // 1. Set to true when the first tvm_stack_make_array is met;
+ // 2. Reset to false at the end of VisitStmt().
+ bool emit_stack_array_{false};
+
+ // Mark the occurence of tvm_call_packed of current stmt:
+ // 1. Set to true when tvm_call_packed intrinsic is met;
+ // 2. Reset to false at the end of VisitStmt().
+ bool emit_stack_value_tcode_{false};
+
// The running statistics
int64_t run_shape_stack_{-1};
uint64_t run_array_stack_{0};
uint64_t run_arg_stack_{0};
// statistics of stacks
int64_t max_shape_stack_{-1};
uint64_t max_array_stack_{0};
- uint64_t max_arg_stack_{0};
Review comment:
And for non-parallel loops, we still need to provide a shared stack at root, so anyway "max_arg_stack" should be kept, right?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen merged pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen merged pull request #7619:
URL: https://github.com/apache/tvm/pull/7619
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-806641510
@zhuwenxi this could due to the fact that the unittest is not configured with BLAS enabled. Perhaps it is worthwhile to register a test function(e.g. tvm.testing.AddOne) in https://github.com/apache/tvm/blob/main/src/support/ffi_testing.cc that you can try to call into
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-793943991
cc @ZihengJiang @areusch please help to review this PR
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
tqchen commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-811836194
We have https://tvm.apache.org/docs/api/python/ir.html?highlight=structural_equal#tvm.ir.structural_equal that can check structural equality. ir_builder can directly create PrimFunc that put into IRModule without build. See unit tests of other transforms We can also recursively visit the node.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-814055145
@tqchen , I met some problems when I was trying to reconstruct the UT with ir_builder and assert_structural_equal(). This is my code:
<pre>
def assert_packed_func(target="llvm", parallel=True):
ib = tvm.tir.ir_builder.create()
m = n = k = 16
#
# Prepare buffer for a, b and c:
#
a = te.placeholder((m, k), name="a", dtype="float64")
b = te.placeholder((k, n), name="b", dtype="float64")
k = te.reduce_axis((0, k), name="k")
c = te.compute((m, n), lambda i, j: te.sum(a[i, k] * b[k, j], axis=k), name="c")
a_buffer = tvm.tir.decl_buffer(
a.shape, a.dtype, name="a_buffer", offset_factor=1, strides=[te.var("s1"), 1]
)
b_buffer = tvm.tir.decl_buffer(
b.shape, b.dtype, name="b_buffer", offset_factor=1, strides=[te.var("s2"), 1]
)
c_buffer = tvm.tir.decl_buffer(
c.shape, c.dtype, name="c_buffer", offset_factor=1, strides=[te.var("s3"), 1]
)
# Use ir_buider to create a packed call in the parallel loop:
with ib.for_range(0, 10, "i", kind="parallel"):
ib.emit(tvm.tir.call_packed("tvm.test_matmul", a_buffer, b_buffer, c_buffer))
stmt = ib.get()
# Construct a valid IRModule to be lowered:
mod = tvm.IRModule.from_expr(tvm.tir.PrimFunc([a_buffer, b_buffer, c_buffer], stmt))
target = tvm.target.Target(target)
mod = tvm.tir.transform.Apply(lambda f: f.with_attr("target", target))(mod)
mod = tvm.tir.transform.Apply(lambda f: f.with_attr("global_symbol", "main"))(mod)
mod = tvm.tir.transform.MakePackedAPI()(mod)
# Do the lowering:
mod = tvm.tir.transform.LowerTVMBuiltin()(mod)
# Get the PrimFunc from module:
prim_func = mod.functions.items()[0][1]
# Recursively visit PrimFunc until we meet the for-loop
node = prim_func.body
while isinstance(node, (tvm.tir.AssertStmt, tvm.tir.LetStmt, tvm.tir.AttrStmt)):
node = node.body
# For-loop met
assert isinstance(node, tvm.tir.stmt.For)
alloca_tcode = node.body
assert isinstance(alloca_tcode, tvm.tir.LetStmt)
return alloca_tcode
</pre>
I suppose I should use assert_structural_equal() to assert the "alloca_tcode" here, but I don't know how to construct the "expected" stmt. The expected stmt here should be `let stack_tcode = tir.tvm_stack_alloca("arg_tcode", 4)`, but seems TVM doesn't have python APIs to create a `tir.tvm_stack_alloca` stmt. (This intrinsic can only be generated by C++ API?)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#issuecomment-806554991
@tqchen A UT failure was reported for my latest commit, which is exactly the test case I wrote for this fix ("test_packed_func.py"). It's wired because it works properly in my local dev machine (`python tests/python/unittest/test_packed_func.py`). What is the best practice to deal with such kind of issue?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on a change in pull request #7619: [BugFix] Fix the race condition issue of packed func. (#7246).
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on a change in pull request #7619:
URL: https://github.com/apache/tvm/pull/7619#discussion_r603074581
##########
File path: src/tir/transforms/lower_tvm_builtin.cc
##########
@@ -48,30 +48,54 @@ inline PrimExpr StackAlloca(std::string type, size_t num) {
// These information are needed during codegen.
class BuiltinLower : public StmtExprMutator {
public:
- Stmt Build(Stmt stmt) {
- stack_shape_ = Var("stack_shape", DataType::Handle());
- stack_array_ = Var("stack_array", DataType::Handle());
- stack_value_ = Var("stack_value", DataType::Handle());
- stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ // Record stack frame for existing scope.
+ struct AllocaScope {
+ Var stack_shape_ = Var("stack_shape", DataType::Handle());
+ Var stack_array_ = Var("stack_array", DataType::Handle());
+ Var stack_value_ = Var("stack_value", DataType::Handle());
+ Var stack_tcode_ = Var("stack_tcode", DataType::Handle());
+
+ int64_t max_shape_stack_{-1};
+ uint64_t max_array_stack_{0};
+ uint64_t max_arg_stack_{0};
+
+ int64_t run_shape_stack_{-1};
+ uint64_t run_array_stack_{0};
+ uint64_t run_arg_stack_{0};
+ };
+
+ Stmt Build(Stmt stmt) { return this->RealizeAlloca(stmt); }
+
+ // Allcoate stack frames, only at parallel-for or root.
+ Stmt RealizeAlloca(Stmt stmt) {
+ alloca_scope_.emplace_back();
stmt = this->VisitStmt(stmt);
- // create a shape var if any shape is made (including scalar shapes)
- if (max_shape_stack_ != -1) {
- stmt = LetStmt(stack_shape_, StackAlloca("shape", max_shape_stack_), stmt);
+ auto& scope = alloca_scope_.back();
+ alloca_scope_.pop_back();
+ if (scope.max_shape_stack_ != -1) {
+ // scope.stack_shape_ = Var("stack_shape", DataType::Handle());
+ stmt = LetStmt(scope.stack_shape_, StackAlloca("shape", scope.max_shape_stack_), stmt);
}
- if (max_array_stack_ != 0) {
- stmt = LetStmt(stack_array_, StackAlloca("array", max_array_stack_), stmt);
+
+ if (scope.max_array_stack_ != 0) {
+ // scope.stack_array_ = Var("stack_array", DataType::Handle());
+ stmt = LetStmt(scope.stack_array_, StackAlloca("array", scope.max_array_stack_), stmt);
}
- if (max_arg_stack_ != 0) {
- stmt = LetStmt(stack_value_, StackAlloca("arg_value", max_arg_stack_), stmt);
- stmt = LetStmt(stack_tcode_, StackAlloca("arg_tcode", max_arg_stack_), stmt);
+ if (scope.max_arg_stack_ != 0) {
+ // scope.stack_value_ = Var("stack_value", DataType::Handle());
+ // scope.stack_tcode_ = Var("stack_tcode", DataType::Handle());
+ stmt = LetStmt(scope.stack_value_, StackAlloca("arg_value", scope.max_arg_stack_), stmt);
+ stmt = LetStmt(scope.stack_tcode_, StackAlloca("arg_tcode", scope.max_arg_stack_), stmt);
}
+
return stmt;
}
Stmt VisitStmt(const Stmt& s) final {
auto stmt = StmtExprMutator::VisitStmt(s);
- ICHECK_EQ(run_shape_stack_, -1);
- ICHECK_EQ(run_array_stack_, 0);
+ auto& scope = alloca_scope_.back();
Review comment:
Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org