You are viewing a plain text version of this content. The canonical link for it is here.
Posted to notifications@apisix.apache.org by GitBox <gi...@apache.org> on 2022/11/25 08:04:54 UTC
[GitHub] [apisix-website] SylviaBABY commented on a diff in pull request #1421: docs:add two ecosystem blogs
SylviaBABY commented on code in PR #1421:
URL: https://github.com/apache/apisix-website/pull/1421#discussion_r1032092521
##########
blog/zh/blog/2022/11/23/why-is-not-reload-hot-loaded-in-nginx.md:
##########
@@ -0,0 +1,106 @@
+---
+title: "为什么 NGINX 的 reload 不是热加载?"
+author: "刘维"
+authorURL: "https://github.com/monkeyDluffy6017"
+authorImageURL: "https://github.com/monkeyDluffy6017.png"
+keywords:
+- 热加载
+- 开源
+- APISIX
+- NGINX
+description: 本文介绍了 APISIX 如何解决 NGINX 热加载带来的缺陷。
+tags: [Ecosystem]
+---
+
+> 本文介绍了 APISIX 如何解决 NGINX 热加载带来的缺陷。
+
+<!--truncate-->
+
+这段时间在 Reddit 看到一个讨论,为什么 NGINX 不支持热加载?乍看之下很反常识,作为世界第一大 Web 服务器,不支持热加载?难道大家都在使用的 `nginx -s reload` 命令都用错了? 带着这个疑问,让我们开始这次探索之旅,一起聊聊热加载和 NGINX 的故事。
+
+## NGINX 相关介绍
+
+NGINX 是一个跨平台的开源 Web 服务器,使用 C 语言开发。据统计,全世界流量最高的前 1000 名网站中,有超过 40% 的网站都在使用 NGINX 处理海量请求。
+
+NGINX 有什么优势,导致它从众多的 Web 服务器中脱颖而出,并一直保持高使用量呢?
+
+我觉得核心原因在于,NGINX 天生善于处理高并发,能在高并发请求的同时保持高效的服务。相比于同时代的其他竞争对手例如 Apache、Tomcat 等,其领先的事件驱动型设计和全异步的网络 I/O 处理机制,以及极致的内存分配管理等众多优秀设计,将服务器硬件资源压缩到了极致。使得 NGINX 成为高性能 Web 服务器的代名词。
+
+当然,除此之外还有一些其他原因,比如:
+
+- 高度模块化的设计,使得 NGINX 拥有无数个功能丰富的官方模块和第三方拓展模块。
+- 最自由的 BSD 许可协议,使得无数开发者愿意为 NGINX 贡献自己的想法。
+- 支持热加载,能保证 NGINX 提供 7x24h 不间断的服务。
+
+## 关于热加载
+
+大家期望的热加载功能是什么样的?我个人认为,首先应该是用户端无感知的,在保证用户请求正常和连接不断的情况下,实现服务端或上游的动态更新。
+
+那什么情况下需要热加载?在如今云原生时代下,微服务架构盛行,越来越多的应用场景有了更加频繁的服务变更需求。包括反向代理域名上下线、上游地址变更、IP 黑白名单更新等,这些都和热加载息息相关。
+
+那么 NGINX 是如何实现热加载的?
+
+## NGINX 热加载的原理
+
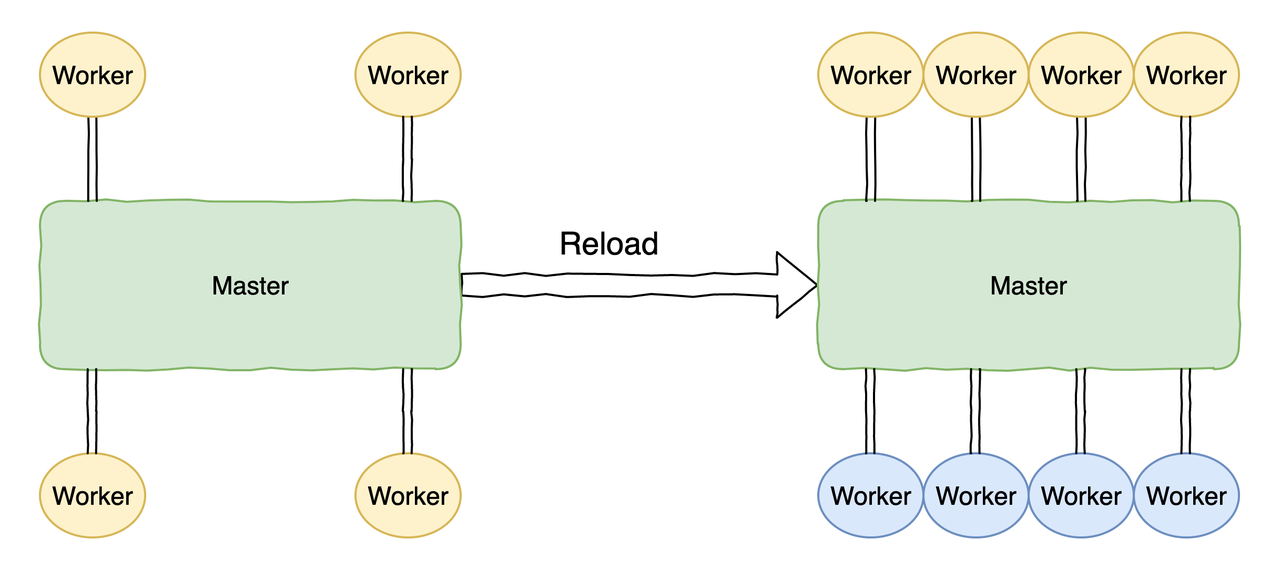
+执行 `nginx -s reload` 热加载命令,就等同于向 NGINX 的 master 进程发送 HUP 信号。在 master 进程收到 HUP 信号后,会依次打开新的监听端口,然后启动新的 worker 进程。
+
+此时会存在新旧两套 worker 进程,在新的 worker 进程起来后,master 会向老的 worker 进程发送 QUIT 信号进行优雅关闭。老的 worker 进程收到 QUIT 信号后,会首先关闭监听句柄,此时新的连接就只会流进到新的 worker 进程中,老的 worker 进程处理完当前连接后就会结束进程。
+
+
+
+从原理上看,NGINX 的热加载能很好地满足我们的需求吗?答案很可能是否定的,让我们来看下 NGINX 的热加载存在哪些问题。
+
+## NGINX 热加载的缺陷
+
+**首先,NGINX 频繁热加载会造成连接不稳定,增加丢失业务的可能性。**
+
+NGINX 在执行 reload 指令时,会在旧的 worker 进程上处理已经存在的连接,处理完连接上的当前请求后,会主动断开连接。此时如果客户端没处理好,就可能会丢失业务,这对于客户端来说明显就不是无感知的了。
+
+**其次,在某些场景下,旧进程回收时间长,进而影响正常业务。**
+
+比如代理 WebSocket 协议时,由于 NGINX 不解析通讯帧,所以无法知道该请求是否为已处理完毕状态。即使 worker 进程收到来自 master 的退出指令,它也无法立刻退出,而是需要等到这些连接出现异常、超时或者某一端主动断开后,才能正常退出。
+
+再比如 NGINX 做 TCP 层和 UDP 层的反向代理时,它也没法知道一个请求究竟要经过多少次请求才算真正地结束。
+
+这就导致旧 worker 进程的回收时间特别长,尤其是在直播、新闻媒体活语音识别等行业。旧 worker 进程的回收时间通常能达到半小时甚至更长,这时如果再频繁 reload,将会导致 shutting down 进程持续增加,最终甚至会导致 NGINX OOM,严重影响业务。
+
+```shell
+# 一直存在旧 worker 进程:
+nobody 6246 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 6247 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 6247 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 6248 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 6249 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 7995 10419 0 10:30 ? 00:20:37 nginx: worker process is shutting down <= here
+nobody 7995 10419 0 10:30 ? 00:20:37 nginx: worker process is shutting down
+nobody 7996 10419 0 10:30 ? 00:20:37 nginx: worker process is shutting down
+```
+
+从上述内容可以看到,通过 `nginx -s reload` 方式支持的“热加载”,虽然在以往的技术场景中够用,但是在微服务和云原生迅速发展的今天,它已经捉襟见肘且不合时宜。
+
+如果你的业务变更频率是每周或者每天,那么 NGINX 这种 reload 还是满足你的需求的。但如果变更频率是每小时、每分钟呢?假设你有 100 个 NGINX 服务,每小时 reload 一次的话,就要 reload 2400 次;如果每分钟 reload 一次,就是 864 万次。这显然是无法接受的。
+
+因此,我们需要一个不需要进程替换的 reload 方案,在现有 NGINX 进程内可以直接完成内容的更新和实时生效。
+
+## 在内存中直接生效的热加载方案
+
+在 Apache APISIX 诞生之初,就是希望来解决 NGINX 热加载这个问题的。
+
+Apache APISIX 是基于 NGINX + Lua 的技术栈,以 ETCD 作为配置中心实现的云原生、高性能、全动态的微服务 API 网关,提供负载均衡、动态上游、灰度发布、精细化路由、限流限速、服务降级、服务熔断、身份认证、可观测性等数百项功能。
+
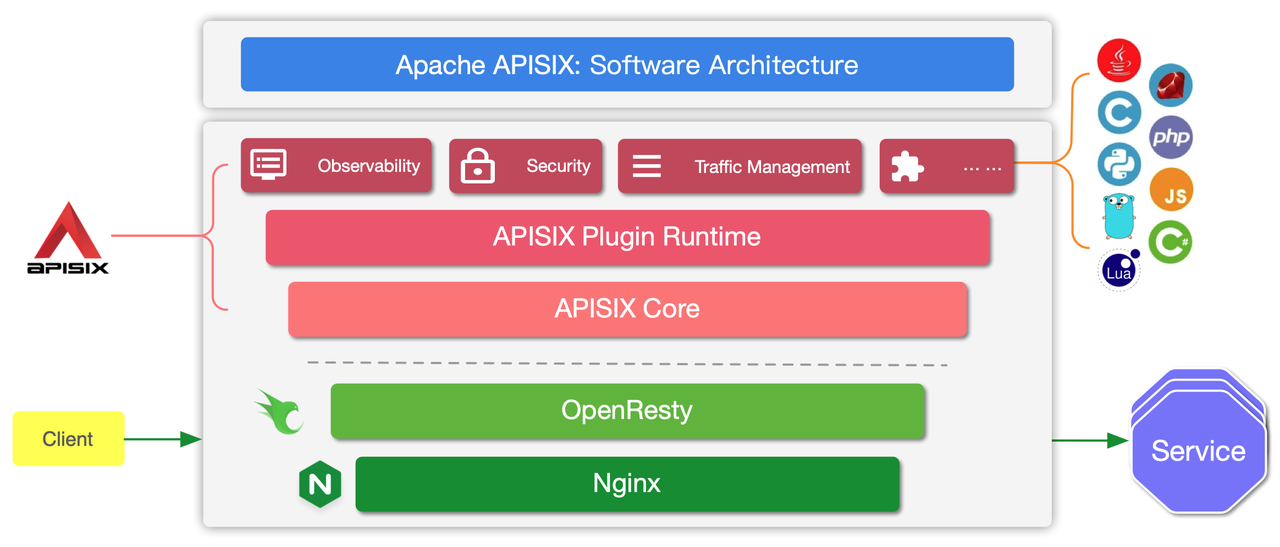
+使用 APISIX 你不需要重启服务就可以更新配置,这意味着修改上游、路由、插件时都不用重启。既然是基于 NGINX,APISIX 又是如何摆脱 NGINX 的限制实现完美热更新?我们先看下 APISIX 的架构。
+
+
+
+通过上述架构图可以看到,之所以 APISIX 能摆脱 NGINX 的限制是因为它把上游等配置全部放到 APISIX Core 和 Plugin Runtime 中动态指定。
+
+以路由为例,NGINX 需要在配置文件内进行配置,每次更改都需要 reload 之后才能生效。而为了实现路由动态配置,Apache APISIX 在 NGINX 配置文件内配置了单个 server,这个 server 中只有一个 location。我们把这个 location 作为主入口,所有的请求都会经过这个 location,再由 APISIX Core 动态指定具体上游。因此 Apache APISIX 的路由模块支持在运行时增减、修改和删除路由,实现了动态加载。所有的这些变化,对客户端都零感知,没有任何影响。
+再来几个典型场景的描述。
+
+比如增加某个新域名的反向代理,在 APISIX 中只需创建上游,并添加新的路由即可,整个过程中不需要 NGINX 进程有任何重启。再比如插件系统,APISIX 可以通过 ip-restriction 插件实现 IP 黑白名单功能,这些能力的更新也是动态方式,同样不需要重启服务。借助架构内的 ETCD,配置策略以增量方式实时推送,最终让所有规则实时、动态的生效,为用户带来极致体验。
Review Comment:
```suggestion
比如增加某个新域名的反向代理,在 APISIX 中只需创建上游,并添加新的路由即可,整个过程中不需要 NGINX 进程有任何重启。再比如插件系统,APISIX 可以通过 `ip-restriction` 插件实现 IP 黑白名单功能,这些能力的更新也是动态方式,同样不需要重启服务。借助架构内的 etcd,配置策略以增量方式实时推送,最终让所有规则实时、动态的生效,为用户带来极致体验。
```
##########
blog/zh/blog/2022/11/23/why-is-not-reload-hot-loaded-in-nginx.md:
##########
@@ -0,0 +1,106 @@
+---
+title: "为什么 NGINX 的 reload 不是热加载?"
+author: "刘维"
+authorURL: "https://github.com/monkeyDluffy6017"
+authorImageURL: "https://github.com/monkeyDluffy6017.png"
+keywords:
+- 热加载
+- 开源
+- APISIX
+- NGINX
+description: 本文介绍了 APISIX 如何解决 NGINX 热加载带来的缺陷。
+tags: [Ecosystem]
+---
+
+> 本文介绍了 APISIX 如何解决 NGINX 热加载带来的缺陷。
+
+<!--truncate-->
+
+这段时间在 Reddit 看到一个讨论,为什么 NGINX 不支持热加载?乍看之下很反常识,作为世界第一大 Web 服务器,不支持热加载?难道大家都在使用的 `nginx -s reload` 命令都用错了? 带着这个疑问,让我们开始这次探索之旅,一起聊聊热加载和 NGINX 的故事。
+
+## NGINX 相关介绍
+
+NGINX 是一个跨平台的开源 Web 服务器,使用 C 语言开发。据统计,全世界流量最高的前 1000 名网站中,有超过 40% 的网站都在使用 NGINX 处理海量请求。
+
+NGINX 有什么优势,导致它从众多的 Web 服务器中脱颖而出,并一直保持高使用量呢?
+
+我觉得核心原因在于,NGINX 天生善于处理高并发,能在高并发请求的同时保持高效的服务。相比于同时代的其他竞争对手例如 Apache、Tomcat 等,其领先的事件驱动型设计和全异步的网络 I/O 处理机制,以及极致的内存分配管理等众多优秀设计,将服务器硬件资源压缩到了极致。使得 NGINX 成为高性能 Web 服务器的代名词。
+
+当然,除此之外还有一些其他原因,比如:
+
+- 高度模块化的设计,使得 NGINX 拥有无数个功能丰富的官方模块和第三方拓展模块。
+- 最自由的 BSD 许可协议,使得无数开发者愿意为 NGINX 贡献自己的想法。
+- 支持热加载,能保证 NGINX 提供 7x24h 不间断的服务。
+
+## 关于热加载
+
+大家期望的热加载功能是什么样的?我个人认为,首先应该是用户端无感知的,在保证用户请求正常和连接不断的情况下,实现服务端或上游的动态更新。
+
+那什么情况下需要热加载?在如今云原生时代下,微服务架构盛行,越来越多的应用场景有了更加频繁的服务变更需求。包括反向代理域名上下线、上游地址变更、IP 黑白名单更新等,这些都和热加载息息相关。
+
+那么 NGINX 是如何实现热加载的?
+
+## NGINX 热加载的原理
+
+执行 `nginx -s reload` 热加载命令,就等同于向 NGINX 的 master 进程发送 HUP 信号。在 master 进程收到 HUP 信号后,会依次打开新的监听端口,然后启动新的 worker 进程。
+
+此时会存在新旧两套 worker 进程,在新的 worker 进程起来后,master 会向老的 worker 进程发送 QUIT 信号进行优雅关闭。老的 worker 进程收到 QUIT 信号后,会首先关闭监听句柄,此时新的连接就只会流进到新的 worker 进程中,老的 worker 进程处理完当前连接后就会结束进程。
+
+
+
+从原理上看,NGINX 的热加载能很好地满足我们的需求吗?答案很可能是否定的,让我们来看下 NGINX 的热加载存在哪些问题。
+
+## NGINX 热加载的缺陷
+
+**首先,NGINX 频繁热加载会造成连接不稳定,增加丢失业务的可能性。**
+
+NGINX 在执行 reload 指令时,会在旧的 worker 进程上处理已经存在的连接,处理完连接上的当前请求后,会主动断开连接。此时如果客户端没处理好,就可能会丢失业务,这对于客户端来说明显就不是无感知的了。
+
+**其次,在某些场景下,旧进程回收时间长,进而影响正常业务。**
+
+比如代理 WebSocket 协议时,由于 NGINX 不解析通讯帧,所以无法知道该请求是否为已处理完毕状态。即使 worker 进程收到来自 master 的退出指令,它也无法立刻退出,而是需要等到这些连接出现异常、超时或者某一端主动断开后,才能正常退出。
+
+再比如 NGINX 做 TCP 层和 UDP 层的反向代理时,它也没法知道一个请求究竟要经过多少次请求才算真正地结束。
+
+这就导致旧 worker 进程的回收时间特别长,尤其是在直播、新闻媒体活语音识别等行业。旧 worker 进程的回收时间通常能达到半小时甚至更长,这时如果再频繁 reload,将会导致 shutting down 进程持续增加,最终甚至会导致 NGINX OOM,严重影响业务。
+
+```shell
+# 一直存在旧 worker 进程:
+nobody 6246 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 6247 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 6247 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 6248 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 6249 6241 0 10:51 ? 00:00:00 nginx: worker process
+nobody 7995 10419 0 10:30 ? 00:20:37 nginx: worker process is shutting down <= here
+nobody 7995 10419 0 10:30 ? 00:20:37 nginx: worker process is shutting down
+nobody 7996 10419 0 10:30 ? 00:20:37 nginx: worker process is shutting down
+```
+
+从上述内容可以看到,通过 `nginx -s reload` 方式支持的“热加载”,虽然在以往的技术场景中够用,但是在微服务和云原生迅速发展的今天,它已经捉襟见肘且不合时宜。
+
+如果你的业务变更频率是每周或者每天,那么 NGINX 这种 reload 还是满足你的需求的。但如果变更频率是每小时、每分钟呢?假设你有 100 个 NGINX 服务,每小时 reload 一次的话,就要 reload 2400 次;如果每分钟 reload 一次,就是 864 万次。这显然是无法接受的。
+
+因此,我们需要一个不需要进程替换的 reload 方案,在现有 NGINX 进程内可以直接完成内容的更新和实时生效。
+
+## 在内存中直接生效的热加载方案
+
+在 Apache APISIX 诞生之初,就是希望来解决 NGINX 热加载这个问题的。
+
+Apache APISIX 是基于 NGINX + Lua 的技术栈,以 ETCD 作为配置中心实现的云原生、高性能、全动态的微服务 API 网关,提供负载均衡、动态上游、灰度发布、精细化路由、限流限速、服务降级、服务熔断、身份认证、可观测性等数百项功能。
Review Comment:
```suggestion
Apache APISIX 是基于 NGINX + Lua 的技术栈,以 etcd 作为配置中心实现的云原生、高性能、全动态的微服务 API 网关,提供负载均衡、动态上游、灰度发布、精细化路由、限流限速、服务降级、服务熔断、身份认证、可观测性等数百项功能。
```
##########
blog/zh/blog/2022/11/25/how-apisix-support-1000-pods.md:
##########
@@ -0,0 +1,409 @@
+---
+title: "APISIX Ingress 是如何支持上千个 Pod 副本的应用"
+author: "容鑫"
+authorURL: "https://github.com/AlinsRan"
+authorImageURL: "https://github.com/AlinsRan.png"
+keywords:
+- Kubernetes
+- APISIX Ingress
+- 开源
+- APISIX
+- Pod
+description: 本文通过介绍 Kubernetes 中上千个 Pod 副本应用场景的解析,提出技术实现的困难。介绍 APISIX Ingress 是如何解决这一难题的。
+tags: [Ecosystem]
+---
+
+> 本文通过介绍 Kubernetes 中上千个 Pod 副本应用场景的解析,提出技术实现的困难。介绍 APISIX Ingress 是如何解决这一难题的。
+
+<!--truncate-->
+
+## 在 Kubernetes 中为什么会遇到上千个 Pod 副本的应用场景?
+
+在 Kubernetes 中,Pod 是最小的调度单元。应用程序实际是以 Pod 在运行的,通常情况下出于可扩展性和降低爆炸半径等方面的考虑,只会给 Pod 设置有限的资源。那么对于大流量的场景,一般都是通过水平扩容的方式进行应对。
+
+例如电商行业在进行促销活动或秒杀抢购活动时,业务流量相对较大。为了应对这种场景,通常会设置弹性扩容。在活动进行时,服务会进行弹性伸缩直到能够承载流量,这时会基于弹性扩容的策略,为业务增加副本数,也就是 Pod 会变多。
+
+每个 Pod 都有各自唯一的 IP ,但同时 Pod 的 IP 也不是固定的。为了及时追踪 Pod IP 的变化,从而进行负载均衡,Endpoints API 提供了在 Kubernetes 中跟踪网络端点的一种简单而直接的方法。
+
+但随着 Kubernetes 集群和服务逐渐开始为更多的后端 Pod 进行处理和发送请求,比如上文提到大流量场景下,Pod 数量会被不断扩容,Endpoints API 也将变得越大。这种情况下,Endpoints API 局限性变得越来越明显,甚至成为性能瓶颈。
+
+为了解决这个局限性问题,在 Kubernetes v1.21 的版本中引入了对 Endpointslice API 的支持,解决了 Endpoints API 处理大量网络端点带来的性能问题,同时提供了可扩展和可伸缩的能力。
+
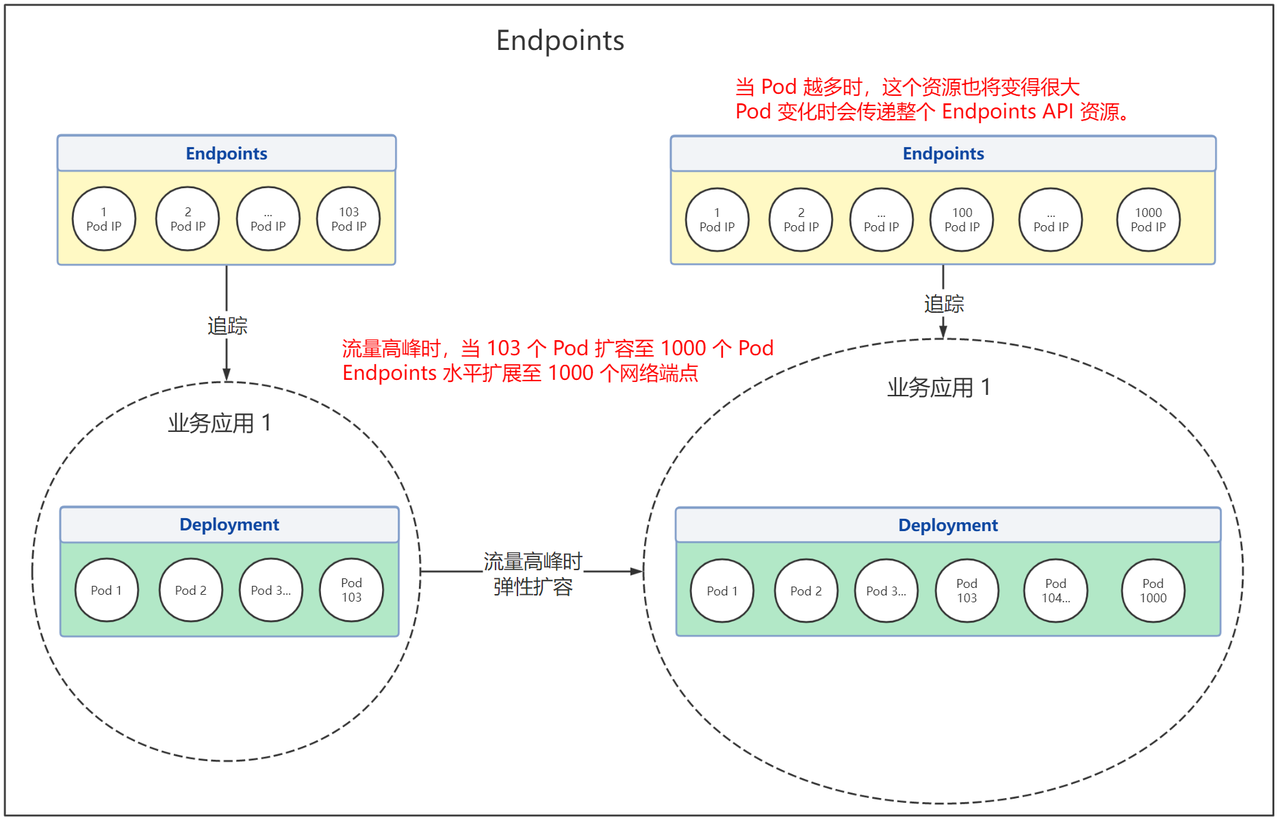
+通过下图我们可以明显看到它们之间的区别:
+
+- Endpoints 在流量高峰时的变化:
+
+
+
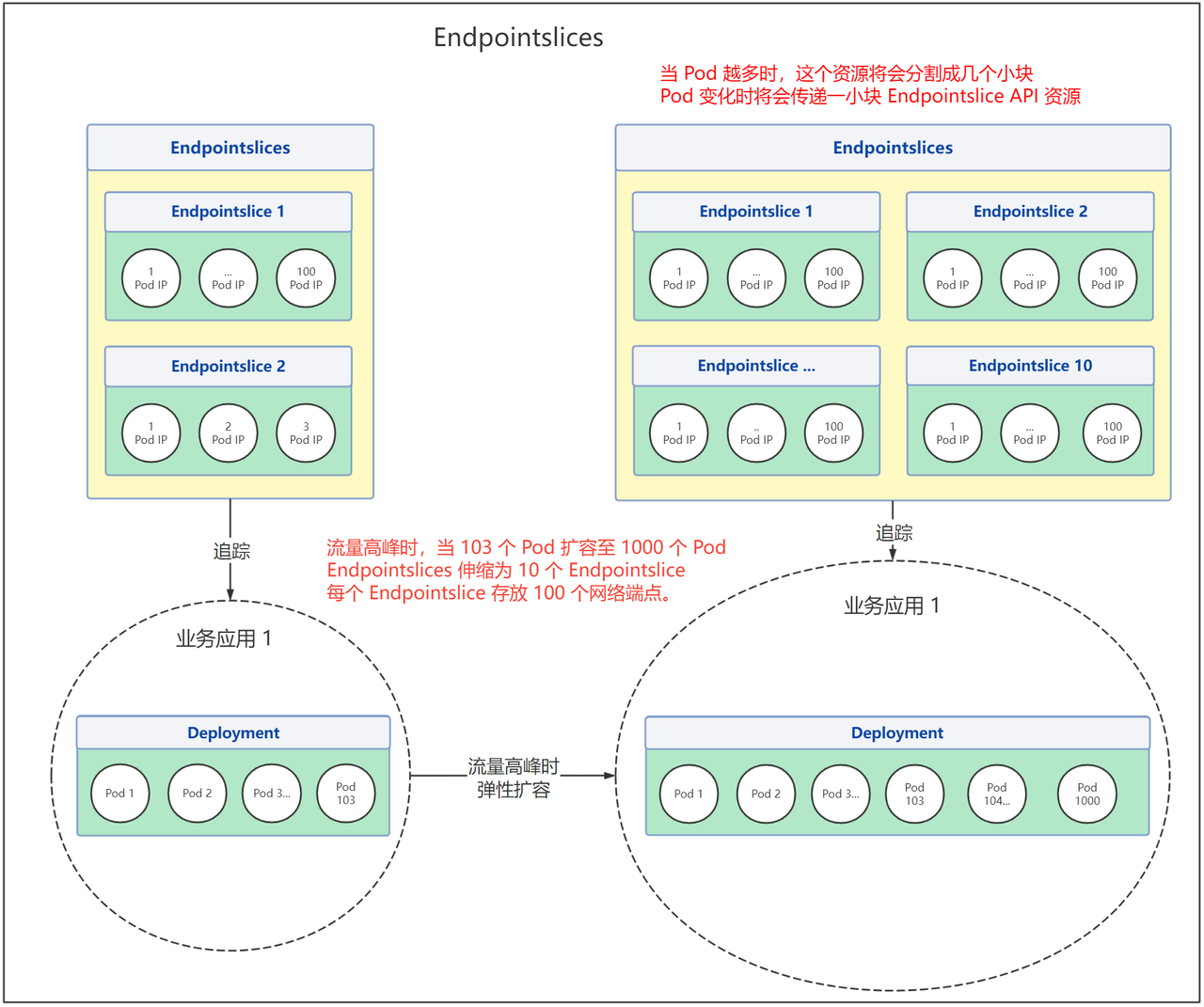
+- Endpointslices 在流量高峰时的变化:
+
+
+
+在 Kubernetes 中,应用之间是如何进行相互访问的呢?Endpoints 和 Endpointslice 具体区别又是什么?和 Pod 有着什么样的关系?APISIX Ingress 中为什么要支持这些特性,以及如何进行安装和使用?本文将着重介绍这些问题。
+
+## Kubernetes 中如何访问应用?
+
+在 Kubernetes 中,每个 Pod 都有其自己唯一的 IP 地址。通常情况下,Service 通过 selector 和一组 Pod 建立关联,并提供了相同的 DNS 名,并可以在它之间进行负载均衡。Kubernetes 集群内不同应用之间可通过 DNS 进行相互访问。
+
+在 Service 创建时,Kubernetes 会根据 Service 关联一个 Endpoints 资源,若 Service 没有定义 selector 字段,将不会自动创建 Endpoints。
+
+### 什么是 Endpoints?
+
+Endpoints 是 Kubernetes 中的一个资源对象,存储在 etcd 中,用来记录一个 Service 对应一组 Pod 的访问地址,一个 Service 只有一个 Endpoints 资源。
+Endpoints 资源会去观测 Pod 集合,只要服务中的某个 Pod 发生变更,Endpoints 就会进行同步更新。
+
+比如部署 3 个 httpbin 副本,查看 Pod 的情况,包括 IP 信息。
+
+```bash
+$ kubectl get pods -o wide
+NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
+httpbin-deployment-fdd7d8dfb-8sxxq 1/1 Running 0 49m 10.1.36.133 docker-desktop <none> <none>
+httpbin-deployment-fdd7d8dfb-bjw99 1/1 Running 4 (5h39m ago) 23d 10.1.36.125 docker-desktop <none> <none>
+httpbin-deployment-fdd7d8dfb-r5nf9 1/1 Running 0 49m 10.1.36.131 docker-desktop <none> <none>
+```
+
+创建 httpbin 服务,并查看应 Endpoints 端点情况。
+
+```shell
+$ kubectl get endpoints httpbin
+NAME ENDPOINTS AGE
+httpbin 10.1.36.125:80,10.1.36.131:80,10.1.36.133:80 23d
+
+```
+
+**从上述示例可以看到,Endpoints 中 httpbin 资源对象的所有网络端点,分别对应了每个 Pod 的 IP 地址。**
+
+当然, Endpoints 也有它的一些不足之处,比如:
+
+1. Endpoints 具有容量限制,如果某个 Endpoints 资源中端口的个数超过 1000,那么 Endpoints 控制器会将其截断为 1000。
+2. 一个 Service 只有一个 Endpoints 资源,这意味着它需要为支持相应服务的每个 Pod 存储 IP 等网络信息。这导致 Endpoints 资源变的十分巨大,其中一个端点发生了变更,将会导致整个 Endpoints 资源更新。当业务需要进行频繁端点更新时,一个巨大的 API 资源被相互传递,而这会影响到 Kubernetes 组件的性能,并且会产生大量的网络流量和额外的处理。
+
+### 什么是 Endpointslices?
+
+Endpointslices 为 Endpoints 提供了一种可扩缩和可拓展的替代方案,缓解处理大量网络端点带来的性能问题,还能为一些诸如拓扑路由的额外功能提供一个可扩展的平台。**该特性在 Kubernetes v1.21+ 的版本中已提供支持。**
+
+EndpointSlice 旨在通过分片的方式来解决此问题,并没有使用单个 Endpoints 资源跟踪服务的所有网络端点,而是将它们拆分为多个较小的 EndpointSlice。
+
+默认情况下,控制面创建和管理的 EndpointSlice 将包含不超过 100 个端点。 你可以使用 [kube-controller-manager](https://kubernetes.io/zh-cn/docs/reference/command-line-tools-reference/kube-controller-manager/) 的 `--max-endpoints-per-slice` 标志设置此值,其最大值为 1000。
+
+### 为什么需要 Endpointslices?
+
+首先,我们考虑具有 2000 个 Pod 的服务它最终可能具有 1.0 MB 的 Endpoints 资源。在生产环境中,如果该服务发生滚动更新或节点迁移,那么 Endpoints 资源将会频繁变更。
+
+想象一下,如果滚动更新会导致全部 Pod 都被替换,[由于 etcd 具有最大请求大小限制](https://etcd.io/docs/v3.3/dev-guide/limit/#request-size-limit),Kubernets 对 Endpoints 最大容量限制为 1000,如果网络端点数量超出了 1000,那么多出来的网络端点,将不会被 Endpoints 资源记录。
+
+当然也可能因为一些需求,需要多次进行滚动更新,那么这个巨大的 API 资源对象将会 Kubernetes 组件中来回传递,极大影响了 Kubernetes 组件的性能。
+如果使用了 Endpointslices,假设一个服务后端有 2000 个 Pod。如果将配置修改为每个 Endpointslices 存储 100 个端点,最终将获得 20 个 Endpointslices。添加或删除 Pod 时,只需要更新其中 1 个 Endpointslice 资源即可,这样操作后,可扩展性和网络可伸缩有了很大的提升。
+
+比起在流量高峰时,服务为了承载流量,扩容出大量的 Pod,Endpoints 资源会被频繁更新,两个使用场景的差异就变得非常明显。更重要的是,既然服务的所有 Pod IP 都不需要存储在单个资源中,那么我们就不必担心 etcd 中存储的对象的大小限制。
+
+### Endpoints VS Endpointslice
+
+> 因为 Endpointslice 是在 Kubernetes v1.21+ 的版本得到支持,所以该结论是基于 Kubernetes v1.21+ 版本。
+
+通过上文的描述我们总结一下两种资源的适用情况。
+
+Endpoints 适用场景:
+
+- 有弹性伸缩需求,Pod 数量较少,传递资源不会造成大量网络流量和额外处理。
+- 无弹性伸缩需求,Pod 数量不会太多。哪怕 Pod 数量是固定,但是总是要滚动更新或者出现故障的。
+
+Endpointslice 适用场景:
+
+- 有弹性需求,且 Pod 数量较多(几百上千)。
+- Pod 数量很多(几百上千),因为 Endpoints 网络端点最大数量限制为 1000,所以超过 1000 的 Pod 必须得用 Endpointslice。
+
+## 在 APISIX Ingress 中的实践
+
+APISIX Ingress Controller 是一个 Ingress 控制器的实现。可以将用户配置的规则转换为 Apache APISIX中的规则,从而使用 APISIX 完成具体的流量承载。
+在具体实现过程中,APISIX Ingress 通过 watch Endpoints 或 Endpointslice 资源的变化,从而让 APISIX 能够对 Pod 进行负载均衡和健康检查等。为了能够支持 Kubernetes v1.16+ 的版本,APISIX Ingress 在安装时,默认使用 Endpoints 的特性。
+
+**如果你的集群版本为 Kubernetes v1.21+,在安装 APISIX Ingress 时,需要指定 `watchEndpointSlice=true` 标志来开启 Endpointslice 特性的支持。**
+
+> 注意:在集群的版本为 Kubernetes v1.21+ 时,我们推荐使用 Endpointslice 特性。否则当服务中 Pod 数量超过 `--max-endpoints-per-slice` 标志设定的值时,由于 APISIX Ingress watch 的是 Endpoints 资源对象,则会导致配置的丢失。开启此特性,就不额外关注 `--max-endpoints-per-slice` 的值。
+
+以下将为你简单介绍如何在 APISIX Ingress 中应用 Endpointslice 特性。
+
+### 创建包含 20 个副本的 Service
+
+使用 `kubectl apply -f httpbin-deploy.yaml` 命令,在 Kuernetes 中部署 httpbin 应用服务,并创建 20 个 Pod 副本。具体 `htppbin-deploy.yaml` 文件配置可参考下方代码。
+
+```YAML
+# htppbin-deploy.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: httpbin-deployment
+spec:
+ replicas: 20
+ selector:
+ matchLabels:
+ app: httpbin-deployment
+ strategy:
+ rollingUpdate:
+ maxSurge: 50%
+ maxUnavailable: 1
+ type: RollingUpdate
+ template:
+ metadata:
+ labels:
+ app: httpbin-deployment
+ spec:
+ terminationGracePeriodSeconds: 0
+ containers:
+ - livenessProbe:
+ failureThreshold: 3
+ initialDelaySeconds: 2
+ periodSeconds: 5
+ successThreshold: 1
+ tcpSocket:
+ port: 80
+ timeoutSeconds: 2
+ readinessProbe:
+ failureThreshold: 3
+ initialDelaySeconds: 2
+ periodSeconds: 5
+ successThreshold: 1
+ tcpSocket:
+ port: 80
+ timeoutSeconds: 2
+ image: "kennethreitz/httpbin:latest"
+ imagePullPolicy: IfNotPresent
+ name: httpbin-deployment
+ ports:
+ - containerPort: 80
+ name: "http"
+ protocol: "TCP"
+
+---
+
+apiVersion: v1
+kind: Service
+metadata:
+ name: httpbin
+spec:
+ selector:
+ app: httpbin-deployment
+ ports:
+ - name: http
+ port: 80
+ protocol: TCP
+ targetPort: 80
+ type: ClusterIP
+```
+
+### 通过 APISIX Ingress 代理
+
+第一步,使用 Helm 安装 APISIX Ingress。
+通过 `--set ingress-controller.config.kubernetes.watchEndpointSlice=true` 开启 Endpointslice 特性的支持。
+
+```YAML
+helm repo add apisix https://charts.apiseven.com
+helm repo add bitnami https://charts.bitnami.com/bitnami
+helm repo update
+
+
+kubectl create ns ingress-apisix
+helm install apisix apisix/apisix \
+ --set gateway.type=NodePort \
+ --set ingress-controller.enabled=true \
+ --namespace ingress-apisix \
+ --set ingress-controller.config.apisix.serviceNamespace=ingress-apisix \
+ --set ingress-controller.config.kubernetes.watchEndpointSlice=true
+```
+
+第二步,使用 CRD 资源进行代理。注意,APISIX Ingress 中对 Endpoints 和 Endpointslice 特性的支持,使用者是感知不到的,它们的配置都是一致的。
+
+```YAML
+apiVersion: apisix.apache.org/v2
+kind: ApisixRoute
+metadata:
+ name: httpbin-route
+spec:
+ http:
+ - name: rule
+ match:
+ hosts:
+ - httpbin.org
+ paths:
+ - /get
+ backends:
+ - serviceName: httpbin
+ servicePort: 80
+```
+
+第三步,进入 APISIX Pod 中查看。可以看到在 APISIX 中的 upstream 对象 nodes 字段包含了 20 个 Pod 的 IP 地址。
+
+```bash
+kubectl exec -it ${Pod for APISIX} -n ingress-apisix -- curl "http://127.0.0.1:9180/apisix/admin/upstreams" -H 'X-API-KEY: edd1c9f034335f136f87ad84b625c8f1'
+```
+
+```JSON
+{
+ "action": "get",
+ "count": 1,
+ "node": {
+ "key": "\/apisix\/upstreams",
+ "nodes": [
+ {
+ "value": {
+ "hash_on": "vars",
+ "desc": "Created by apisix-ingress-controller, DO NOT modify it manually",
+ "pass_host": "pass",
+ "nodes": [
+ {
+ "weight": 100,
+ "host": "10.1.36.100",
+ "priority": 0,
+ "port": 80
+ },
+ {
+ "weight": 100,
+ "host": "10.1.36.101",
+ "priority": 0,
+ "port": 80
+ },
+ {
+ "weight": 100,
+ "host": "10.1.36.102",
+ "priority": 0,
+ "port": 80
+ },
+ {
+ "weight": 100,
+ "host": "10.1.36.103",
+ "priority": 0,
+ "port": 80
+ },
+ {
+ "weight": 100,
+ "host": "10.1.36.104",
+ "priority": 0,
+ "port": 80
+ },
+ {
+ "weight": 100,
+ "host": "10.1.36.109",
+ "priority": 0,
+ "port": 80
+ },
+ {
+ "weight": 100,
+ "host": "10.1.36.92",
+ "priority": 0,
+ "port": 80
+ }
+ ... // 以下省略 13 个节点
+ // 10.1.36.118
+ // 10.1.36.115
+ // 10.1.36.116
+ // 10.1.36.106
+ // 10.1.36.113
+ // 10.1.36.111
+ // 10.1.36.108
+ // 10.1.36.114
+ // 10.1.36.107
+ // 10.1.36.110
+ // 10.1.36.105
+ // 10.1.36.112
+ // 10.1.36.117
+ ],
+ "labels": {
+ "managed-by": "apisix-ingress-controller"
+ },
+ "type": "roundrobin",
+ "name": "default_httpbin_80",
+ "scheme": "http"
+ },
+ "key": "\/apisix\/upstreams\/5ce57b8e"
+ }
+ ],
+ "dir": true
+ }
+}
+```
+
+上述信息与 Endpointslice 中的网络端点相对应。
+
+```YAML
+addressType: IPv4
+apiVersion: discovery.k8s.io/v1
+endpoints:
+- addresses:
+ - 10.1.36.92
+ ...
+- addresses:
+ - 10.1.36.100
+ ...
+- addresses:
+ - 10.1.36.104
+ ...
+- addresses:
+ - 10.1.36.102
+ ...
+- addresses:
+ - 10.1.36.101
+ ...
+- addresses:
+ - 10.1.36.103
+ ...
+- addresses:
+ - 10.1.36.109
+ ...
+- addresses:
+ - 10.1.36.118
+ ...
+- addresses:
+ - 10.1.36.115
+ ...
+- addresses:
+ - 10.1.36.116
+ ...
+- addresses:
+ - 10.1.36.106
+ ...
+- addresses:
+ - 10.1.36.113
+ ...
+- addresses:
+ - 10.1.36.111
+ ...
+- addresses:
+ - 10.1.36.108
+ ...
+- addresses:
+ - 10.1.36.114
+ ...
+- addresses:
+ - 10.1.36.107
+ ...
+- addresses:
+ - 10.1.36.110
+ ...
+- addresses:
+ - 10.1.36.105
+ ...
+- addresses:
+ - 10.1.36.112
+ ...
+- addresses:
+ - 10.1.36.117
+ ...
+kind: EndpointSlice
+metadata:
+ labels:
+ endpointslice.kubernetes.io/managed-by: endpointslice-controller.k8s.io
+ kubernetes.io/service-name: httpbin
+ name: httpbin-dkvtr
+ namespace: default
+ports:
+- name: http
+ port: 80
+ protocol: TCP
+```
+
+## 总结
+
+本文介绍了 Kubnertes 需要部署大量 Pod 的场景和遇到的问题,对比了 Endpoints 和 Endpointslice 之间区别,以及如何安装 APISIX Ingress 来使用 Endpointslice 的特性。
Review Comment:
```suggestion
本文介绍了 Kubernetes 需要部署大量 Pod 的场景和遇到的问题,对比了 Endpoints 和 Endpointslice 之间区别,以及如何安装 APISIX Ingress 来使用 Endpointslice 的特性。
```
##########
blog/zh/blog/2022/11/25/how-apisix-support-1000-pods.md:
##########
@@ -0,0 +1,409 @@
+---
+title: "APISIX Ingress 是如何支持上千个 Pod 副本的应用"
+author: "容鑫"
+authorURL: "https://github.com/AlinsRan"
+authorImageURL: "https://github.com/AlinsRan.png"
+keywords:
+- Kubernetes
+- APISIX Ingress
+- 开源
+- APISIX
+- Pod
+description: 本文通过介绍 Kubernetes 中上千个 Pod 副本应用场景的解析,提出技术实现的困难。介绍 APISIX Ingress 是如何解决这一难题的。
+tags: [Ecosystem]
+---
+
+> 本文通过介绍 Kubernetes 中上千个 Pod 副本应用场景的解析,提出技术实现的困难。介绍 APISIX Ingress 是如何解决这一难题的。
+
+<!--truncate-->
+
+## 在 Kubernetes 中为什么会遇到上千个 Pod 副本的应用场景?
+
+在 Kubernetes 中,Pod 是最小的调度单元。应用程序实际是以 Pod 在运行的,通常情况下出于可扩展性和降低爆炸半径等方面的考虑,只会给 Pod 设置有限的资源。那么对于大流量的场景,一般都是通过水平扩容的方式进行应对。
+
+例如电商行业在进行促销活动或秒杀抢购活动时,业务流量相对较大。为了应对这种场景,通常会设置弹性扩容。在活动进行时,服务会进行弹性伸缩直到能够承载流量,这时会基于弹性扩容的策略,为业务增加副本数,也就是 Pod 会变多。
+
+每个 Pod 都有各自唯一的 IP ,但同时 Pod 的 IP 也不是固定的。为了及时追踪 Pod IP 的变化,从而进行负载均衡,Endpoints API 提供了在 Kubernetes 中跟踪网络端点的一种简单而直接的方法。
+
+但随着 Kubernetes 集群和服务逐渐开始为更多的后端 Pod 进行处理和发送请求,比如上文提到大流量场景下,Pod 数量会被不断扩容,Endpoints API 也将变得越大。这种情况下,Endpoints API 局限性变得越来越明显,甚至成为性能瓶颈。
+
+为了解决这个局限性问题,在 Kubernetes v1.21 的版本中引入了对 Endpointslice API 的支持,解决了 Endpoints API 处理大量网络端点带来的性能问题,同时提供了可扩展和可伸缩的能力。
+
+通过下图我们可以明显看到它们之间的区别:
+
+- Endpoints 在流量高峰时的变化:
+
+
Review Comment:
maybe we can add a [tab] to keep this section indented consistently
<img width="1157" alt="image" src="https://user-images.githubusercontent.com/39793568/203931104-6eff8b4e-c462-4cca-81c9-c6f5ad8b311c.png">
##########
blog/zh/blog/2022/11/25/how-apisix-support-1000-pods.md:
##########
@@ -0,0 +1,409 @@
+---
+title: "APISIX Ingress 是如何支持上千个 Pod 副本的应用"
+author: "容鑫"
+authorURL: "https://github.com/AlinsRan"
+authorImageURL: "https://github.com/AlinsRan.png"
+keywords:
+- Kubernetes
+- APISIX Ingress
+- 开源
+- APISIX
+- Pod
+description: 本文通过介绍 Kubernetes 中上千个 Pod 副本应用场景的解析,提出技术实现的困难。介绍 APISIX Ingress 是如何解决这一难题的。
+tags: [Ecosystem]
+---
+
+> 本文通过介绍 Kubernetes 中上千个 Pod 副本应用场景的解析,提出技术实现的困难。介绍 APISIX Ingress 是如何解决这一难题的。
+
+<!--truncate-->
+
+## 在 Kubernetes 中为什么会遇到上千个 Pod 副本的应用场景?
+
+在 Kubernetes 中,Pod 是最小的调度单元。应用程序实际是以 Pod 在运行的,通常情况下出于可扩展性和降低爆炸半径等方面的考虑,只会给 Pod 设置有限的资源。那么对于大流量的场景,一般都是通过水平扩容的方式进行应对。
+
+例如电商行业在进行促销活动或秒杀抢购活动时,业务流量相对较大。为了应对这种场景,通常会设置弹性扩容。在活动进行时,服务会进行弹性伸缩直到能够承载流量,这时会基于弹性扩容的策略,为业务增加副本数,也就是 Pod 会变多。
+
+每个 Pod 都有各自唯一的 IP ,但同时 Pod 的 IP 也不是固定的。为了及时追踪 Pod IP 的变化,从而进行负载均衡,Endpoints API 提供了在 Kubernetes 中跟踪网络端点的一种简单而直接的方法。
+
+但随着 Kubernetes 集群和服务逐渐开始为更多的后端 Pod 进行处理和发送请求,比如上文提到大流量场景下,Pod 数量会被不断扩容,Endpoints API 也将变得越大。这种情况下,Endpoints API 局限性变得越来越明显,甚至成为性能瓶颈。
+
+为了解决这个局限性问题,在 Kubernetes v1.21 的版本中引入了对 Endpointslice API 的支持,解决了 Endpoints API 处理大量网络端点带来的性能问题,同时提供了可扩展和可伸缩的能力。
+
+通过下图我们可以明显看到它们之间的区别:
+
+- Endpoints 在流量高峰时的变化:
+
+
+
+- Endpointslices 在流量高峰时的变化:
+
+
+
+在 Kubernetes 中,应用之间是如何进行相互访问的呢?Endpoints 和 Endpointslice 具体区别又是什么?和 Pod 有着什么样的关系?APISIX Ingress 中为什么要支持这些特性,以及如何进行安装和使用?本文将着重介绍这些问题。
+
+## Kubernetes 中如何访问应用?
+
+在 Kubernetes 中,每个 Pod 都有其自己唯一的 IP 地址。通常情况下,Service 通过 selector 和一组 Pod 建立关联,并提供了相同的 DNS 名,并可以在它之间进行负载均衡。Kubernetes 集群内不同应用之间可通过 DNS 进行相互访问。
+
+在 Service 创建时,Kubernetes 会根据 Service 关联一个 Endpoints 资源,若 Service 没有定义 selector 字段,将不会自动创建 Endpoints。
+
+### 什么是 Endpoints?
+
+Endpoints 是 Kubernetes 中的一个资源对象,存储在 etcd 中,用来记录一个 Service 对应一组 Pod 的访问地址,一个 Service 只有一个 Endpoints 资源。
+Endpoints 资源会去观测 Pod 集合,只要服务中的某个 Pod 发生变更,Endpoints 就会进行同步更新。
+
+比如部署 3 个 httpbin 副本,查看 Pod 的情况,包括 IP 信息。
+
+```bash
+$ kubectl get pods -o wide
+NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
+httpbin-deployment-fdd7d8dfb-8sxxq 1/1 Running 0 49m 10.1.36.133 docker-desktop <none> <none>
+httpbin-deployment-fdd7d8dfb-bjw99 1/1 Running 4 (5h39m ago) 23d 10.1.36.125 docker-desktop <none> <none>
+httpbin-deployment-fdd7d8dfb-r5nf9 1/1 Running 0 49m 10.1.36.131 docker-desktop <none> <none>
+```
+
+创建 httpbin 服务,并查看应 Endpoints 端点情况。
+
+```shell
+$ kubectl get endpoints httpbin
+NAME ENDPOINTS AGE
+httpbin 10.1.36.125:80,10.1.36.131:80,10.1.36.133:80 23d
+
+```
+
+**从上述示例可以看到,Endpoints 中 httpbin 资源对象的所有网络端点,分别对应了每个 Pod 的 IP 地址。**
+
+当然, Endpoints 也有它的一些不足之处,比如:
+
+1. Endpoints 具有容量限制,如果某个 Endpoints 资源中端口的个数超过 1000,那么 Endpoints 控制器会将其截断为 1000。
+2. 一个 Service 只有一个 Endpoints 资源,这意味着它需要为支持相应服务的每个 Pod 存储 IP 等网络信息。这导致 Endpoints 资源变的十分巨大,其中一个端点发生了变更,将会导致整个 Endpoints 资源更新。当业务需要进行频繁端点更新时,一个巨大的 API 资源被相互传递,而这会影响到 Kubernetes 组件的性能,并且会产生大量的网络流量和额外的处理。
+
+### 什么是 Endpointslices?
+
+Endpointslices 为 Endpoints 提供了一种可扩缩和可拓展的替代方案,缓解处理大量网络端点带来的性能问题,还能为一些诸如拓扑路由的额外功能提供一个可扩展的平台。**该特性在 Kubernetes v1.21+ 的版本中已提供支持。**
+
+EndpointSlice 旨在通过分片的方式来解决此问题,并没有使用单个 Endpoints 资源跟踪服务的所有网络端点,而是将它们拆分为多个较小的 EndpointSlice。
+
+默认情况下,控制面创建和管理的 EndpointSlice 将包含不超过 100 个端点。 你可以使用 [kube-controller-manager](https://kubernetes.io/zh-cn/docs/reference/command-line-tools-reference/kube-controller-manager/) 的 `--max-endpoints-per-slice` 标志设置此值,其最大值为 1000。
+
+### 为什么需要 Endpointslices?
+
+首先,我们考虑具有 2000 个 Pod 的服务它最终可能具有 1.0 MB 的 Endpoints 资源。在生产环境中,如果该服务发生滚动更新或节点迁移,那么 Endpoints 资源将会频繁变更。
+
+想象一下,如果滚动更新会导致全部 Pod 都被替换,[由于 etcd 具有最大请求大小限制](https://etcd.io/docs/v3.3/dev-guide/limit/#request-size-limit),Kubernets 对 Endpoints 最大容量限制为 1000,如果网络端点数量超出了 1000,那么多出来的网络端点,将不会被 Endpoints 资源记录。
Review Comment:
```suggestion
想象一下,如果滚动更新会导致全部 Pod 都被替换,[由于 etcd 具有最大请求大小限制](https://etcd.io/docs/v3.3/dev-guide/limit/#request-size-limit),Kubernetes 对 Endpoints 最大容量限制为 1000,如果网络端点数量超出了 1000,那么多出来的网络端点,将不会被 Endpoints 资源记录。
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@apisix.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org