You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/03/08 10:09:24 UTC
[GitHub] [iceberg] zhangjun0x01 opened a new pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
zhangjun0x01 opened a new pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229
Now, the `IcebergTableSink` only implement the `AppendStreamTableSink` interface, so we can not write the CDC data into iceberg table by flink sql , but the `AppendStreamTableSink`,`UpsertStreamTableSink`,`RetractStreamTableSink` have deprecated,so I refactor the `IcebergTableSink` and `IcebergTableSource` use the new interface ,so that we can write the CDC data into iceberg by flink sql .
I test that in my machine ,after the refactor, I can write the cdc data into iceberg (v2 format) by flink sql.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r591990219
##########
File path: flink/src/test/java/org/apache/iceberg/flink/actions/TestRewriteDataFilesAction.java
##########
@@ -280,15 +280,15 @@ public void testRewriteLargeTableHasResiduals() throws IOException {
Assert.assertEquals("Residuals must be ignored", Expressions.alwaysTrue(), task.residual());
}
List<DataFile> dataFiles = Lists.newArrayList(CloseableIterable.transform(tasks, FileScanTask::file));
- Assert.assertEquals("Should have 2 data files before rewrite", 2, dataFiles.size());
Review comment:
I updated it
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r588852975
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
Review comment:
yes , I also think the remainingFilters is the filters which could not be applied by the source.
but when I do that, there were a lot of errors in `TestFlinkTableSource` .
So I change the `remainingFilters` to origin `flinkFilters `
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r572633976
##########
File path: flink/src/test/java/org/apache/iceberg/flink/FlinkTestBase.java
##########
@@ -78,7 +79,9 @@ protected TableEnvironment getTableEnv() {
.build();
TableEnvironment env = TableEnvironment.create(settings);
- env.getConfig().getConfiguration().set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
the default parallelism of the new interface is not 1, It seems to be the number of cores of the current machine,If our current machine is multi-core, some test case will go wrong,for example.
there is a sql :
`
INSERT INTO mytest VALUES (1,'iceberg',10),(2,'b',20),(3,CAST(NULL AS VARCHAR),30)
`
it will write multiple files,if we use the sql `SELECT * FROM mytest LIMIT 1` to query the table , the result is random ,not the first record , we will can not do the assertion, so I set the parallelism is 1.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r588850653
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
}
@Override
- public boolean isLimitPushedDown() {
- return isLimitPushDown;
+ public boolean supportsNestedProjection() {
+ return false;
Review comment:
ok.I will submit a new PR to address this issue
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r589361898
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
}
@Override
- public boolean isLimitPushedDown() {
- return isLimitPushDown;
+ public boolean supportsNestedProjection() {
+ return false;
Review comment:
I change the `supportsNestedProjection` to true, I think we could add some test case for nested projection assertion later,what do your think?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r573328104
##########
File path: flink/src/test/java/org/apache/iceberg/flink/FlinkTestBase.java
##########
@@ -78,7 +79,9 @@ protected TableEnvironment getTableEnv() {
.build();
TableEnvironment env = TableEnvironment.create(settings);
- env.getConfig().getConfiguration().set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
how many tests are affected by the ordering issue? for `LIMIT 1` tests, maybe we shouldn't assert on the actual record that depends on order. just assert on the counts.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r589907001
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +104,72 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
Review comment:
I think we will need to refactor this method if we plan to support nested projection in future patch.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r591210866
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
}
@Override
- public boolean isLimitPushedDown() {
- return isLimitPushDown;
+ public boolean supportsNestedProjection() {
+ return false;
Review comment:
Filed TODO issue: https://github.com/apache/iceberg/issues/2312
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r589893045
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java
##########
@@ -20,66 +20,68 @@
package org.apache.iceberg.flink;
import java.util.Map;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.streaming.api.datastream.DataStream;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.table.api.TableSchema;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.sinks.AppendStreamTableSink;
-import org.apache.flink.table.sinks.OverwritableTableSink;
-import org.apache.flink.table.sinks.PartitionableTableSink;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.sink.DataStreamSinkProvider;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.abilities.SupportsOverwrite;
+import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
+import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
import org.apache.iceberg.flink.sink.FlinkSink;
-public class IcebergTableSink implements AppendStreamTableSink<RowData>, OverwritableTableSink, PartitionableTableSink {
- private final boolean isBounded;
+public class IcebergTableSink implements DynamicTableSink, SupportsPartitioning, SupportsOverwrite {
private final TableLoader tableLoader;
private final TableSchema tableSchema;
private boolean overwrite = false;
- public IcebergTableSink(boolean isBounded, TableLoader tableLoader, TableSchema tableSchema) {
- this.isBounded = isBounded;
+ public IcebergTableSink(TableLoader tableLoader, TableSchema tableSchema) {
this.tableLoader = tableLoader;
this.tableSchema = tableSchema;
}
@Override
- public DataStreamSink<?> consumeDataStream(DataStream<RowData> dataStream) {
- Preconditions.checkState(!overwrite || isBounded, "Unbounded data stream doesn't support overwrite operation.");
+ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
+ Preconditions
+ .checkState(!overwrite || context.isBounded(), "Unbounded data stream doesn't support overwrite operation.");
- return FlinkSink.forRowData(dataStream)
+ return (DataStreamSinkProvider) dataStream -> FlinkSink.forRowData(dataStream)
.tableLoader(tableLoader)
.tableSchema(tableSchema)
.overwrite(overwrite)
Review comment:
I mean we will need an integration test case to verify that the whole path would work as expected. We will create a CDC source table, then create an iceberg sink table, finally execute the `INSERT INTO` streaming job. In the end, both the source table and sink table should have the consistent results. That could be future PRs.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r575039399
##########
File path: flink/src/test/java/org/apache/iceberg/flink/FlinkTestBase.java
##########
@@ -78,7 +79,9 @@ protected TableEnvironment getTableEnv() {
.build();
TableEnvironment env = TableEnvironment.create(settings);
- env.getConfig().getConfiguration().set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
In my test, all test methods in `org.apache.iceberg.flink.TestFlinkTableSource` that return more than one record of filter push down will be affected. We need to sort the returned results to do assertion.
In addition, in `TestRewriteDataFilesAction#testRewriteLargeTableHasResiduals` , ([link](https://github.com/apache/iceberg/blob/master/flink/src/test/java/org/apache/iceberg/flink/actions/TestRewriteDataFilesAction.java#L251)),I have two `INSERT INTO`, but it generated 8 data files. I haven't look up the reason yet.
I haven't checked whether there are similar problems in other methods. I think set the parallelism to 1, it is consistent with the original state , it can avoid unknown and unstable results.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r588847716
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java
##########
@@ -20,66 +20,68 @@
package org.apache.iceberg.flink;
import java.util.Map;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.streaming.api.datastream.DataStream;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.table.api.TableSchema;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.sinks.AppendStreamTableSink;
-import org.apache.flink.table.sinks.OverwritableTableSink;
-import org.apache.flink.table.sinks.PartitionableTableSink;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.sink.DataStreamSinkProvider;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.abilities.SupportsOverwrite;
+import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
+import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
import org.apache.iceberg.flink.sink.FlinkSink;
-public class IcebergTableSink implements AppendStreamTableSink<RowData>, OverwritableTableSink, PartitionableTableSink {
- private final boolean isBounded;
+public class IcebergTableSink implements DynamicTableSink, SupportsPartitioning, SupportsOverwrite {
private final TableLoader tableLoader;
private final TableSchema tableSchema;
private boolean overwrite = false;
- public IcebergTableSink(boolean isBounded, TableLoader tableLoader, TableSchema tableSchema) {
- this.isBounded = isBounded;
+ public IcebergTableSink(TableLoader tableLoader, TableSchema tableSchema) {
this.tableLoader = tableLoader;
this.tableSchema = tableSchema;
}
@Override
- public DataStreamSink<?> consumeDataStream(DataStream<RowData> dataStream) {
- Preconditions.checkState(!overwrite || isBounded, "Unbounded data stream doesn't support overwrite operation.");
+ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
+ Preconditions
+ .checkState(!overwrite || context.isBounded(), "Unbounded data stream doesn't support overwrite operation.");
- return FlinkSink.forRowData(dataStream)
+ return (DataStreamSinkProvider) dataStream -> FlinkSink.forRowData(dataStream)
.tableLoader(tableLoader)
.tableSchema(tableSchema)
.overwrite(overwrite)
Review comment:
> We might need a fully covered SQL unit tests to ensure the whole flow work in future PR.
yes, I think all data types of mysql should be covered.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r578306094
##########
File path: flink/src/test/java/org/apache/iceberg/flink/FlinkTestBase.java
##########
@@ -78,7 +79,9 @@ protected TableEnvironment getTableEnv() {
.build();
TableEnvironment env = TableEnvironment.create(settings);
- env.getConfig().getConfiguration().set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
I debug the code , found that the test case will use the parallelism of the `MiniClusterResource` (default 4),In order not to affect more test case, I did not update the parallelism in `FlinkTestBase`.
In [TestFlinkTableSource](https://github.com/apache/iceberg/blob/master/flink/src/test/java/org/apache/iceberg/flink/TestFlinkTableSource.java) ,many test case will generate multiple files so that the query result is unordered or random, so I override the `getTableEnv` method and set the parallelism to 1 instead of modifying a lot of code to change the logic of the assertion,because in the test class, we just judge whether limit or filter is push down, the number of parallelism has no effect on this
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r588849640
##########
File path: flink/src/test/java/org/apache/iceberg/flink/actions/TestRewriteDataFilesAction.java
##########
@@ -280,15 +280,15 @@ public void testRewriteLargeTableHasResiduals() throws IOException {
Assert.assertEquals("Residuals must be ignored", Expressions.alwaysTrue(), task.residual());
}
List<DataFile> dataFiles = Lists.newArrayList(CloseableIterable.transform(tasks, FileScanTask::file));
- Assert.assertEquals("Should have 2 data files before rewrite", 2, dataFiles.size());
Review comment:
when I debug in flink 1.12 source code ,it seem that use this value to override the default parallelism
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r572633976
##########
File path: flink/src/test/java/org/apache/iceberg/flink/FlinkTestBase.java
##########
@@ -78,7 +79,9 @@ protected TableEnvironment getTableEnv() {
.build();
TableEnvironment env = TableEnvironment.create(settings);
- env.getConfig().getConfiguration().set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
It seems that the default parallelism is not 1,for example.
there is a sql :
`
INSERT INTO mytest VALUES (1,'iceberg',10),(2,'b',20),(3,CAST(NULL AS VARCHAR),30)
`
it will write multiple files,if we use the sql `SELECT * FROM mytest LIMIT 1` to query the table , the result is random ,not the first record , we will can not do the assertion, so I set the parallelism is 1 so that we don’t need to change too much code
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r572630207
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +96,67 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<org.apache.iceberg.expressions.Expression> expressions = Lists.newArrayList();
+ for (Expression predicate : flinkFilters) {
+ FlinkFilters.convert(predicate).ifPresent(expressions::add);
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(flinkFilters, flinkFilters);
}
@Override
- public boolean isLimitPushedDown() {
- return isLimitPushDown;
+ public boolean supportsNestedProjection() {
+ return false;
}
@Override
- public TableSource<RowData> applyLimit(long newLimit) {
- return new IcebergTableSource(loader, schema, properties, projectedFields, true, newLimit, filters, readableConfig);
+ public ChangelogMode getChangelogMode() {
Review comment:
now ,flink read only support `INSERT-only`, if we add other mode , it will throw an exception ,like this:
`
Querying a table in batch mode is currently only possible for INSERT-only table sources. But the source for table 'iceberg_catalog.default.t' produces other changelog messages than just INSERT.
`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#issuecomment-775719820
@stevenzwu @openinx could you help me review it ? thanks
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r591267913
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
Review comment:
OK, after read the flink runtime & iceberg filter pushdown code carefully, I found that we iceberg's AVRO file reader did not push down the filters, so it will always return the row that are not filtered by `acceptedFilters` .
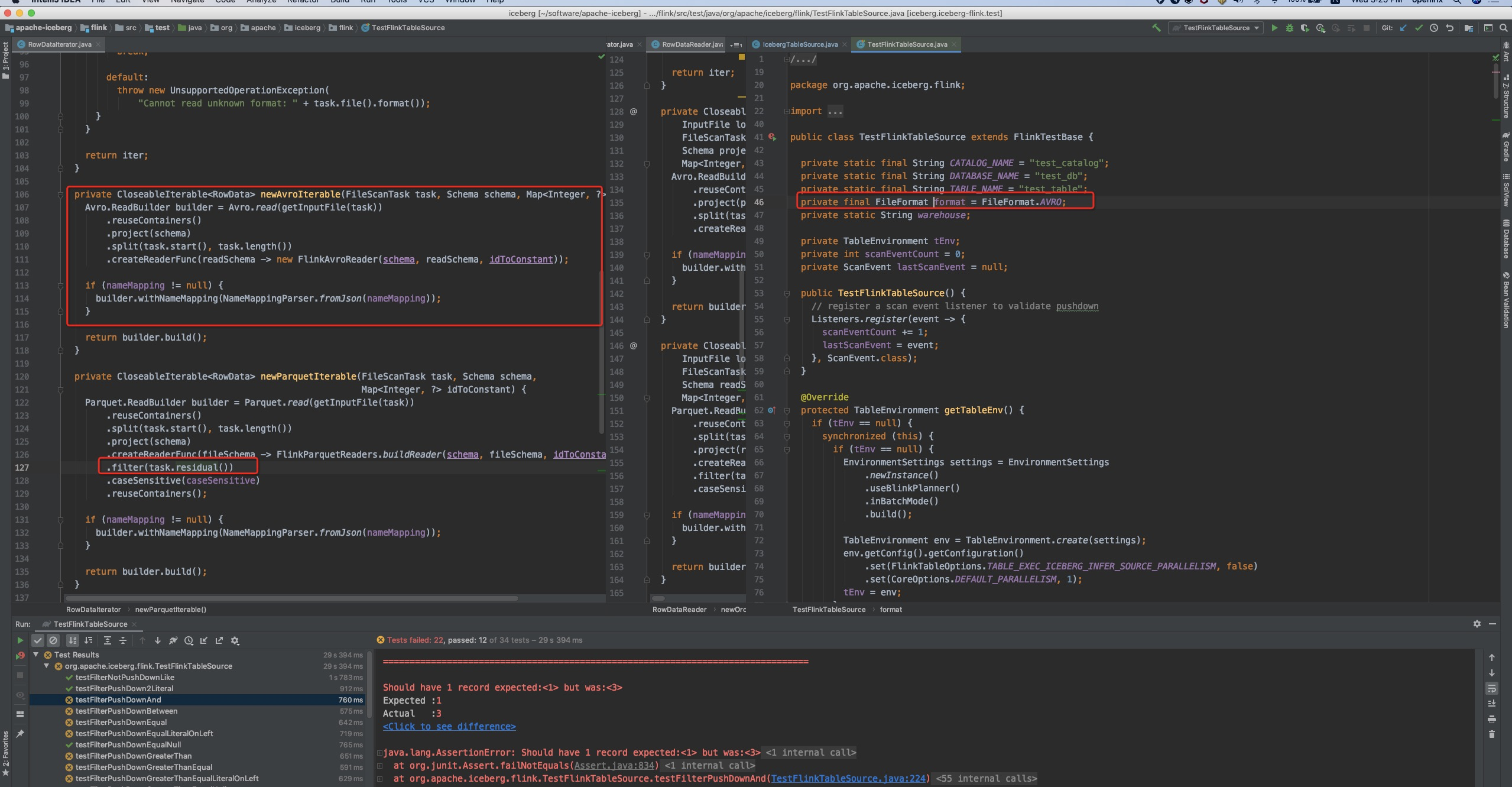
So here we could only pass the `flinkFilters` as the `remainingFilters`. Let me resolve this comment.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r578307131
##########
File path: flink/src/test/java/org/apache/iceberg/flink/actions/TestRewriteDataFilesAction.java
##########
@@ -280,15 +280,15 @@ public void testRewriteLargeTableHasResiduals() throws IOException {
Assert.assertEquals("Residuals must be ignored", Expressions.alwaysTrue(), task.residual());
}
List<DataFile> dataFiles = Lists.newArrayList(CloseableIterable.transform(tasks, FileScanTask::file));
- Assert.assertEquals("Should have 2 data files before rewrite", 2, dataFiles.size());
Review comment:
the default parallelism is 4 ,we have 2 `insert into` ,so it will generate 8 datafiles
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r572636688
##########
File path: flink/src/test/java/org/apache/iceberg/flink/TestFlinkTableSource.java
##########
@@ -40,14 +40,12 @@
private static final String CATALOG_NAME = "test_catalog";
private static final String DATABASE_NAME = "test_db";
private static final String TABLE_NAME = "test_table";
- private final String expectedFilterPushDownExplain = "FilterPushDown";
Review comment:
the new table source interface remove the method `explainSource` so that we can not override the method to rewrite the explain, so I remove the explain assertion, only use the scan event listener to do the assertion,I think it is enough to assert filter push down and verify correctness, and it will also make the code simpler.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r572633976
##########
File path: flink/src/test/java/org/apache/iceberg/flink/FlinkTestBase.java
##########
@@ -78,7 +79,9 @@ protected TableEnvironment getTableEnv() {
.build();
TableEnvironment env = TableEnvironment.create(settings);
- env.getConfig().getConfiguration().set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
the default parallelism of the new interface is not 1, It seems to be the number of cores of the current machine,If our current machine is multi-core, some test case will go wrong,for example.
there is a sql :
`
INSERT INTO mytest VALUES (1,'iceberg',10),(2,'b',20),(3,CAST(NULL AS VARCHAR),30)
`
it will write multiple files,if we use the sql `SELECT * FROM mytest LIMIT 1` to query the table , the result is random ,not the first record , we will can not do the assertion, so I set the parallelism is 1 so that we don’t need to change too much code
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r591402726
##########
File path: flink/src/test/java/org/apache/iceberg/flink/actions/TestRewriteDataFilesAction.java
##########
@@ -280,15 +280,15 @@ public void testRewriteLargeTableHasResiduals() throws IOException {
Assert.assertEquals("Residuals must be ignored", Expressions.alwaysTrue(), task.residual());
}
List<DataFile> dataFiles = Lists.newArrayList(CloseableIterable.transform(tasks, FileScanTask::file));
- Assert.assertEquals("Should have 2 data files before rewrite", 2, dataFiles.size());
Review comment:
Here, I think we'd better to set the parallelism to the default value 1.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r588847602
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java
##########
@@ -20,66 +20,68 @@
package org.apache.iceberg.flink;
import java.util.Map;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.streaming.api.datastream.DataStream;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.table.api.TableSchema;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.sinks.AppendStreamTableSink;
-import org.apache.flink.table.sinks.OverwritableTableSink;
-import org.apache.flink.table.sinks.PartitionableTableSink;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.sink.DataStreamSinkProvider;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.abilities.SupportsOverwrite;
+import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
+import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
import org.apache.iceberg.flink.sink.FlinkSink;
-public class IcebergTableSink implements AppendStreamTableSink<RowData>, OverwritableTableSink, PartitionableTableSink {
- private final boolean isBounded;
+public class IcebergTableSink implements DynamicTableSink, SupportsPartitioning, SupportsOverwrite {
private final TableLoader tableLoader;
private final TableSchema tableSchema;
private boolean overwrite = false;
- public IcebergTableSink(boolean isBounded, TableLoader tableLoader, TableSchema tableSchema) {
- this.isBounded = isBounded;
+ public IcebergTableSink(TableLoader tableLoader, TableSchema tableSchema) {
this.tableLoader = tableLoader;
this.tableSchema = tableSchema;
}
@Override
- public DataStreamSink<?> consumeDataStream(DataStream<RowData> dataStream) {
- Preconditions.checkState(!overwrite || isBounded, "Unbounded data stream doesn't support overwrite operation.");
+ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
+ Preconditions
+ .checkState(!overwrite || context.isBounded(), "Unbounded data stream doesn't support overwrite operation.");
- return FlinkSink.forRowData(dataStream)
+ return (DataStreamSinkProvider) dataStream -> FlinkSink.forRowData(dataStream)
.tableLoader(tableLoader)
.tableSchema(tableSchema)
.overwrite(overwrite)
Review comment:
> did you provide the `equalityColumns` in the builder
yes,we need to provide the `equalityColumns`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r588846221
##########
File path: flink/src/test/java/org/apache/iceberg/flink/actions/TestRewriteDataFilesAction.java
##########
@@ -280,15 +280,15 @@ public void testRewriteLargeTableHasResiduals() throws IOException {
Assert.assertEquals("Residuals must be ignored", Expressions.alwaysTrue(), task.residual());
}
List<DataFile> dataFiles = Lists.newArrayList(CloseableIterable.transform(tasks, FileScanTask::file));
- Assert.assertEquals("Should have 2 data files before rewrite", 2, dataFiles.size());
Review comment:
It is [here](https://github.com/apache/iceberg/blob/master/flink/src/test/java/org/apache/iceberg/flink/MiniClusterResource.java#L30)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r589887920
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
}
@Override
- public boolean isLimitPushedDown() {
- return isLimitPushDown;
+ public boolean supportsNestedProjection() {
+ return false;
Review comment:
I think it's better to enable the switch when we have fully covered unit tests for the nested projection feature because we could ensure that it would work as expected behavior. If we can not guarantee the expected behavior then I prefer to disable it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r591402005
##########
File path: flink/src/test/java/org/apache/iceberg/flink/TestFlinkTableSource.java
##########
@@ -56,6 +58,28 @@ public TestFlinkTableSource() {
}, ScanEvent.class);
}
+ @Override
+ protected TableEnvironment getTableEnv() {
+ if (tEnv == null) {
Review comment:
Nit: we could simplify this as:
```java
@Override
protected TableEnvironment getTableEnv() {
super.getTableEnv()
.getConfig()
.getConfiguration()
.set(CoreOptions.DEFAULT_PARALLELISM, 1);
return super.getTableEnv();
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#issuecomment-792700408
@openinx thanks for your review ,I updated all
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r575478962
##########
File path: flink/src/test/java/org/apache/iceberg/flink/FlinkTestBase.java
##########
@@ -78,7 +79,9 @@ protected TableEnvironment getTableEnv() {
.build();
TableEnvironment env = TableEnvironment.create(settings);
- env.getConfig().getConfiguration().set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
my only small concern is if forcing parallelism of 1 can hide some race condition problem.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r575482464
##########
File path: flink/src/main/java/org/apache/iceberg/flink/FlinkTableFactory.java
##########
@@ -19,51 +19,57 @@
package org.apache.iceberg.flink;
-import java.util.List;
-import java.util.Map;
+import java.util.Set;
+import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.catalog.ObjectPath;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.factories.TableSinkFactory;
-import org.apache.flink.table.factories.TableSourceFactory;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.sources.TableSource;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.source.DynamicTableSource;
+import org.apache.flink.table.factories.DynamicTableFactory;
+import org.apache.flink.table.factories.DynamicTableSinkFactory;
+import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.utils.TableSchemaUtils;
-public class FlinkTableFactory implements TableSinkFactory<RowData>, TableSourceFactory<RowData> {
+public class FlinkTableFactory implements DynamicTableSinkFactory, DynamicTableSourceFactory {
+ public static final String IDENTIFIER = "iceberg";
private final FlinkCatalog catalog;
public FlinkTableFactory(FlinkCatalog catalog) {
this.catalog = catalog;
}
@Override
- public TableSource<RowData> createTableSource(TableSourceFactory.Context context) {
+ public DynamicTableSource createDynamicTableSource(DynamicTableFactory.Context context) {
ObjectPath objectPath = context.getObjectIdentifier().toObjectPath();
TableLoader tableLoader = createTableLoader(objectPath);
- TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getTable().getSchema());
- return new IcebergTableSource(tableLoader, tableSchema, context.getTable().getOptions(),
+ TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());
+ return new IcebergTableSource(tableLoader, tableSchema, context.getCatalogTable().getOptions(),
context.getConfiguration());
}
@Override
- public TableSink<RowData> createTableSink(TableSinkFactory.Context context) {
+ public DynamicTableSink createDynamicTableSink(Context context) {
ObjectPath objectPath = context.getObjectIdentifier().toObjectPath();
TableLoader tableLoader = createTableLoader(objectPath);
- TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getTable().getSchema());
- return new IcebergTableSink(context.isBounded(), tableLoader, tableSchema);
+ TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());
+ return new IcebergTableSink(tableLoader, tableSchema);
}
@Override
- public Map<String, String> requiredContext() {
+ public Set<ConfigOption<?>> requiredOptions() {
Review comment:
`TableFactory` link is for the old interface that we are moving away from here. So it is not relevant here.
For the new `Factory` interface, here is the javadoc. there are some impls (like `ParquetFileFormatFactory`) return an empty set
```
* <p>Every factory declares a set of required and optional options. This information will not be
* used during discovery but is helpful when generating documentation and performing validation. A
* factory may discover further (nested) factories, the options of the nested factories must not be
* declared in the sets of this factory.
```
You linked `HiveDynamicTableFactory` that throws exception for those options method. Error msg suggests that the catalog code path won't call these methods. and there should be no non-catalog usage for Hive. I am fine with keeping the same behavior for Iceberg.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#issuecomment-786990730
@rdblue could you help me review it ? thanks
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r588850653
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
}
@Override
- public boolean isLimitPushedDown() {
- return isLimitPushDown;
+ public boolean supportsNestedProjection() {
+ return false;
Review comment:
ok.I will submit a new PR to address this issue
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r575478962
##########
File path: flink/src/test/java/org/apache/iceberg/flink/FlinkTestBase.java
##########
@@ -78,7 +79,9 @@ protected TableEnvironment getTableEnv() {
.build();
TableEnvironment env = TableEnvironment.create(settings);
- env.getConfig().getConfiguration().set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
I am just a little concerned if forcing parallelism of 1 will hide any race condition or not.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r589910388
##########
File path: flink/src/test/java/org/apache/iceberg/flink/actions/TestRewriteDataFilesAction.java
##########
@@ -280,15 +280,15 @@ public void testRewriteLargeTableHasResiduals() throws IOException {
Assert.assertEquals("Residuals must be ignored", Expressions.alwaysTrue(), task.residual());
}
List<DataFile> dataFiles = Lists.newArrayList(CloseableIterable.transform(tasks, FileScanTask::file));
- Assert.assertEquals("Should have 2 data files before rewrite", 2, dataFiles.size());
Review comment:
That looks strange because when we tested this patch (https://github.com/apache/iceberg/commit/c5e67915b01c2cbf2eea40a412c2765f0c8278e8) in travis ci, it did not report the parallelism issue, but in this DynamicTable refactor issue, the parallelism issue happen. That don't make sense for me.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx merged pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx merged pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r589905537
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java
##########
@@ -20,66 +20,72 @@
package org.apache.iceberg.flink;
import java.util.Map;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.streaming.api.datastream.DataStream;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.table.api.TableSchema;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.sinks.AppendStreamTableSink;
-import org.apache.flink.table.sinks.OverwritableTableSink;
-import org.apache.flink.table.sinks.PartitionableTableSink;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.sink.DataStreamSinkProvider;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.abilities.SupportsOverwrite;
+import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
+import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
import org.apache.iceberg.flink.sink.FlinkSink;
-public class IcebergTableSink implements AppendStreamTableSink<RowData>, OverwritableTableSink, PartitionableTableSink {
- private final boolean isBounded;
+public class IcebergTableSink implements DynamicTableSink, SupportsPartitioning, SupportsOverwrite {
private final TableLoader tableLoader;
private final TableSchema tableSchema;
private boolean overwrite = false;
- public IcebergTableSink(boolean isBounded, TableLoader tableLoader, TableSchema tableSchema) {
- this.isBounded = isBounded;
+ private IcebergTableSink(IcebergTableSink toCopy) {
+ this.tableLoader = toCopy.tableLoader;
+ this.tableSchema = toCopy.tableSchema;
+ this.overwrite = toCopy.overwrite;
+ }
+
+ public IcebergTableSink(TableLoader tableLoader, TableSchema tableSchema) {
this.tableLoader = tableLoader;
this.tableSchema = tableSchema;
}
@Override
- public DataStreamSink<?> consumeDataStream(DataStream<RowData> dataStream) {
- Preconditions.checkState(!overwrite || isBounded, "Unbounded data stream doesn't support overwrite operation.");
+ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
+ Preconditions.checkState(!overwrite || context.isBounded(),
+ "Unbounded data stream doesn't support overwrite operation.");
- return FlinkSink.forRowData(dataStream)
+ return (DataStreamSinkProvider) dataStream -> FlinkSink.forRowData(dataStream)
.tableLoader(tableLoader)
.tableSchema(tableSchema)
.overwrite(overwrite)
.build();
}
@Override
- public DataType getConsumedDataType() {
- return tableSchema.toRowDataType().bridgedTo(RowData.class);
+ public void applyStaticPartition(Map<String, String> partition) {
+ // The flink's PartitionFanoutWriter will handle the static partition write policy automatically.
}
@Override
- public TableSchema getTableSchema() {
- return this.tableSchema;
+ public ChangelogMode getChangelogMode(ChangelogMode requestedMode) {
+ return ChangelogMode.newBuilder()
Review comment:
As the javadoc said:
```java
@PublicEvolving
public interface DynamicTableSink {
/**
* Returns the set of changes that the sink accepts during runtime.
*
* <p>The planner can make suggestions but the sink has the final decision what it requires. If
* the planner does not support this mode, it will throw an error. For example, the sink can
* return that it only supports {@link ChangelogMode#insertOnly()}.
*
* @param requestedMode expected set of changes by the current plan
*/
ChangelogMode getChangelogMode(ChangelogMode requestedMode);
```
We need to ensure that the returned changelogMode is a subset of `requestedMode`. The correct one should be:
```java
@Override
public ChangelogMode getChangelogMode(ChangelogMode requestedMode) {
ChangelogMode.Builder builder = ChangelogMode.newBuilder();
for (RowKind kind : requestedMode.getContainedKinds()) {
builder.addContainedKind(kind);
}
return builder.build();
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r575750653
##########
File path: flink/src/test/java/org/apache/iceberg/flink/FlinkTestBase.java
##########
@@ -78,7 +79,9 @@ protected TableEnvironment getTableEnv() {
.build();
TableEnvironment env = TableEnvironment.create(settings);
- env.getConfig().getConfiguration().set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
Let me take a closer look at the default parallelism in the new interface
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r586179283
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java
##########
@@ -20,66 +20,68 @@
package org.apache.iceberg.flink;
import java.util.Map;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.streaming.api.datastream.DataStream;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.table.api.TableSchema;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.sinks.AppendStreamTableSink;
-import org.apache.flink.table.sinks.OverwritableTableSink;
-import org.apache.flink.table.sinks.PartitionableTableSink;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.sink.DataStreamSinkProvider;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.abilities.SupportsOverwrite;
+import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
+import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
import org.apache.iceberg.flink.sink.FlinkSink;
-public class IcebergTableSink implements AppendStreamTableSink<RowData>, OverwritableTableSink, PartitionableTableSink {
- private final boolean isBounded;
+public class IcebergTableSink implements DynamicTableSink, SupportsPartitioning, SupportsOverwrite {
private final TableLoader tableLoader;
private final TableSchema tableSchema;
private boolean overwrite = false;
- public IcebergTableSink(boolean isBounded, TableLoader tableLoader, TableSchema tableSchema) {
- this.isBounded = isBounded;
+ public IcebergTableSink(TableLoader tableLoader, TableSchema tableSchema) {
this.tableLoader = tableLoader;
this.tableSchema = tableSchema;
}
@Override
- public DataStreamSink<?> consumeDataStream(DataStream<RowData> dataStream) {
- Preconditions.checkState(!overwrite || isBounded, "Unbounded data stream doesn't support overwrite operation.");
+ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
+ Preconditions
Review comment:
Nit: It's better to format this code like this:
```java
Preconditions.checkState(!overwrite || context.isBounded(),
"Unbounded data stream doesn't support overwrite operation.");
```
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java
##########
@@ -20,66 +20,68 @@
package org.apache.iceberg.flink;
import java.util.Map;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.streaming.api.datastream.DataStream;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.table.api.TableSchema;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.sinks.AppendStreamTableSink;
-import org.apache.flink.table.sinks.OverwritableTableSink;
-import org.apache.flink.table.sinks.PartitionableTableSink;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.sink.DataStreamSinkProvider;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.abilities.SupportsOverwrite;
+import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
+import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
import org.apache.iceberg.flink.sink.FlinkSink;
-public class IcebergTableSink implements AppendStreamTableSink<RowData>, OverwritableTableSink, PartitionableTableSink {
- private final boolean isBounded;
+public class IcebergTableSink implements DynamicTableSink, SupportsPartitioning, SupportsOverwrite {
private final TableLoader tableLoader;
private final TableSchema tableSchema;
private boolean overwrite = false;
- public IcebergTableSink(boolean isBounded, TableLoader tableLoader, TableSchema tableSchema) {
- this.isBounded = isBounded;
+ public IcebergTableSink(TableLoader tableLoader, TableSchema tableSchema) {
this.tableLoader = tableLoader;
this.tableSchema = tableSchema;
}
@Override
- public DataStreamSink<?> consumeDataStream(DataStream<RowData> dataStream) {
- Preconditions.checkState(!overwrite || isBounded, "Unbounded data stream doesn't support overwrite operation.");
+ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
+ Preconditions
+ .checkState(!overwrite || context.isBounded(), "Unbounded data stream doesn't support overwrite operation.");
- return FlinkSink.forRowData(dataStream)
+ return (DataStreamSinkProvider) dataStream -> FlinkSink.forRowData(dataStream)
.tableLoader(tableLoader)
.tableSchema(tableSchema)
.overwrite(overwrite)
Review comment:
In you MySQL CDC -> iceberg test, did you provide the `equalityColumns` in the builder ? I think if make this whole workflow work , we will need the equalityColumns. We might need a fully covered SQL unit tests to ensure the whole flow work in future PR.
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java
##########
@@ -20,66 +20,68 @@
package org.apache.iceberg.flink;
import java.util.Map;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.streaming.api.datastream.DataStream;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.table.api.TableSchema;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.sinks.AppendStreamTableSink;
-import org.apache.flink.table.sinks.OverwritableTableSink;
-import org.apache.flink.table.sinks.PartitionableTableSink;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.sink.DataStreamSinkProvider;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.abilities.SupportsOverwrite;
+import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
+import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
import org.apache.iceberg.flink.sink.FlinkSink;
-public class IcebergTableSink implements AppendStreamTableSink<RowData>, OverwritableTableSink, PartitionableTableSink {
- private final boolean isBounded;
+public class IcebergTableSink implements DynamicTableSink, SupportsPartitioning, SupportsOverwrite {
private final TableLoader tableLoader;
private final TableSchema tableSchema;
private boolean overwrite = false;
- public IcebergTableSink(boolean isBounded, TableLoader tableLoader, TableSchema tableSchema) {
- this.isBounded = isBounded;
+ public IcebergTableSink(TableLoader tableLoader, TableSchema tableSchema) {
this.tableLoader = tableLoader;
this.tableSchema = tableSchema;
}
@Override
- public DataStreamSink<?> consumeDataStream(DataStream<RowData> dataStream) {
- Preconditions.checkState(!overwrite || isBounded, "Unbounded data stream doesn't support overwrite operation.");
+ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
+ Preconditions
+ .checkState(!overwrite || context.isBounded(), "Unbounded data stream doesn't support overwrite operation.");
- return FlinkSink.forRowData(dataStream)
+ return (DataStreamSinkProvider) dataStream -> FlinkSink.forRowData(dataStream)
.tableLoader(tableLoader)
.tableSchema(tableSchema)
.overwrite(overwrite)
.build();
}
@Override
- public DataType getConsumedDataType() {
- return tableSchema.toRowDataType().bridgedTo(RowData.class);
+ public void applyStaticPartition(Map<String, String> partition) {
+ // The flink's PartitionFanoutWriter will handle the static partition write policy automatically.
}
@Override
- public TableSchema getTableSchema() {
- return this.tableSchema;
+ public ChangelogMode getChangelogMode(ChangelogMode requestedMode) {
+ return ChangelogMode.newBuilder()
+ .addContainedKind(RowKind.INSERT)
+ .addContainedKind(RowKind.UPDATE_BEFORE)
+ .addContainedKind(RowKind.UPDATE_AFTER)
+ .addContainedKind(RowKind.DELETE)
+ .build();
}
@Override
- public TableSink<RowData> configure(String[] fieldNames, TypeInformation<?>[] fieldTypes) {
- // This method has been deprecated and it will be removed in future version, so left the empty implementation here.
- return this;
+ public DynamicTableSink copy() {
+ IcebergTableSink icebergTableSink = new IcebergTableSink(tableLoader, tableSchema);
+ icebergTableSink.overwrite = overwrite;
+ return icebergTableSink;
}
@Override
- public void setOverwrite(boolean overwrite) {
- this.overwrite = overwrite;
+ public String asSummaryString() {
+ return "iceberg table sink";
Review comment:
Nit: It's better to use "Iceberg table sink" here ( to align with other flink table sink ).
##########
File path: flink/src/test/java/org/apache/iceberg/flink/TestFlinkTableSource.java
##########
@@ -40,14 +40,12 @@
private static final String CATALOG_NAME = "test_catalog";
private static final String DATABASE_NAME = "test_db";
private static final String TABLE_NAME = "test_table";
- private final String expectedFilterPushDownExplain = "FilterPushDown";
Review comment:
Yeah, that sounds reasonable. the `lastScanEvent.filter().toString()` is enough to validate the pushed down filters.
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -78,17 +77,11 @@ private IcebergTableSource(TableLoader loader, TableSchema schema, Map<String, S
}
@Override
- public boolean isBounded() {
- return FlinkSource.isBounded(properties);
+ public void applyProjection(int[][] projectFields) {
Review comment:
As we don't implement nested projection in iceberg source, here I think we could add a check here to ensure that the projections are not nested:
```java
@Override
public void applyProjection(int[][] projectFields) {
this.projectedFields = new int[projectFields.length];
for (int i = 0; i < projectFields.length; i++) {
Preconditions.checkArgument(projectFields[i].length == 0,
"Don't support nested projection in iceberg source now.");
this.projectedFields[i] = projectFields[i][0];
}
}
```
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -78,17 +77,11 @@ private IcebergTableSource(TableLoader loader, TableSchema schema, Map<String, S
}
@Override
- public boolean isBounded() {
- return FlinkSource.isBounded(properties);
+ public void applyProjection(int[][] projectFields) {
+ this.projectedFields = Arrays.stream(projectFields).mapToInt(value -> value[0]).toArray();
}
- @Override
- public TableSource<RowData> projectFields(int[] fields) {
- return new IcebergTableSource(loader, schema, properties, fields, isLimitPushDown, limit, filters, readableConfig);
- }
-
- @Override
- public DataStream<RowData> getDataStream(StreamExecutionEnvironment execEnv) {
+ private DataStream<RowData> getDataStream(StreamExecutionEnvironment execEnv) {
Review comment:
Nit: It's better to rename it as `createDataStream`
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java
##########
@@ -20,66 +20,68 @@
package org.apache.iceberg.flink;
import java.util.Map;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.streaming.api.datastream.DataStream;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.table.api.TableSchema;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.sinks.AppendStreamTableSink;
-import org.apache.flink.table.sinks.OverwritableTableSink;
-import org.apache.flink.table.sinks.PartitionableTableSink;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.sink.DataStreamSinkProvider;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.abilities.SupportsOverwrite;
+import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
+import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
import org.apache.iceberg.flink.sink.FlinkSink;
-public class IcebergTableSink implements AppendStreamTableSink<RowData>, OverwritableTableSink, PartitionableTableSink {
- private final boolean isBounded;
+public class IcebergTableSink implements DynamicTableSink, SupportsPartitioning, SupportsOverwrite {
private final TableLoader tableLoader;
private final TableSchema tableSchema;
private boolean overwrite = false;
- public IcebergTableSink(boolean isBounded, TableLoader tableLoader, TableSchema tableSchema) {
- this.isBounded = isBounded;
+ public IcebergTableSink(TableLoader tableLoader, TableSchema tableSchema) {
this.tableLoader = tableLoader;
this.tableSchema = tableSchema;
}
@Override
- public DataStreamSink<?> consumeDataStream(DataStream<RowData> dataStream) {
- Preconditions.checkState(!overwrite || isBounded, "Unbounded data stream doesn't support overwrite operation.");
+ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
+ Preconditions
+ .checkState(!overwrite || context.isBounded(), "Unbounded data stream doesn't support overwrite operation.");
- return FlinkSink.forRowData(dataStream)
+ return (DataStreamSinkProvider) dataStream -> FlinkSink.forRowData(dataStream)
.tableLoader(tableLoader)
.tableSchema(tableSchema)
.overwrite(overwrite)
.build();
}
@Override
- public DataType getConsumedDataType() {
- return tableSchema.toRowDataType().bridgedTo(RowData.class);
+ public void applyStaticPartition(Map<String, String> partition) {
+ // The flink's PartitionFanoutWriter will handle the static partition write policy automatically.
}
@Override
- public TableSchema getTableSchema() {
- return this.tableSchema;
+ public ChangelogMode getChangelogMode(ChangelogMode requestedMode) {
+ return ChangelogMode.newBuilder()
+ .addContainedKind(RowKind.INSERT)
+ .addContainedKind(RowKind.UPDATE_BEFORE)
+ .addContainedKind(RowKind.UPDATE_AFTER)
+ .addContainedKind(RowKind.DELETE)
+ .build();
}
@Override
- public TableSink<RowData> configure(String[] fieldNames, TypeInformation<?>[] fieldTypes) {
- // This method has been deprecated and it will be removed in future version, so left the empty implementation here.
- return this;
+ public DynamicTableSink copy() {
+ IcebergTableSink icebergTableSink = new IcebergTableSink(tableLoader, tableSchema);
Review comment:
How about introducing a new IcebergTableSink constructor like the following ?
```java
private IcebergTableSink(IcebergTableSink toCopy) {
this.tableLoader = toCopy.tableLoader;
this.tableSchema = toCopy.tableSchema;
this.overwrite = toCopy.overwrite;
}
```
Then, here we could just return the `new IcebergTableSink(this)` here. We usually use this pattern in iceberg to copy an object , you could also see the [StructCopy](https://github.com/apache/iceberg/blob/cde7ec33a075bba95583eb1a5d393880d141b04f/core/src/main/java/org/apache/iceberg/io/StructCopy.java#L28).
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
}
@Override
- public boolean isLimitPushedDown() {
- return isLimitPushDown;
+ public boolean supportsNestedProjection() {
+ return false;
}
@Override
- public TableSource<RowData> applyLimit(long newLimit) {
- return new IcebergTableSource(loader, schema, properties, projectedFields, true, newLimit, filters, readableConfig);
+ public ChangelogMode getChangelogMode() {
+ return ChangelogMode.insertOnly();
}
@Override
- public TableSource<RowData> applyPredicate(List<Expression> predicates) {
- List<org.apache.iceberg.expressions.Expression> expressions = Lists.newArrayList();
- for (Expression predicate : predicates) {
- FlinkFilters.convert(predicate).ifPresent(expressions::add);
- }
+ public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
+ return new DataStreamScanProvider() {
+ @Override
+ public DataStream<RowData> produceDataStream(StreamExecutionEnvironment execEnv) {
+ return getDataStream(execEnv);
+ }
+
+ @Override
+ public boolean isBounded() {
+ return FlinkSource.isBounded(properties);
+ }
+ };
+ }
- return new IcebergTableSource(loader, schema, properties, projectedFields, isLimitPushDown, limit, expressions,
+ @Override
+ public DynamicTableSource copy() {
+ return new IcebergTableSource(loader, schema, properties, projectedFields, isLimitPushDown, limit, filters,
Review comment:
Nit: we could use the similar `IcebergTableSource(toCopy)` to copy the object.
##########
File path: flink/src/main/java/org/apache/iceberg/flink/FlinkDynamicTableFactory.java
##########
@@ -19,48 +19,53 @@
package org.apache.iceberg.flink;
-import java.util.List;
-import java.util.Map;
+import java.util.Set;
+import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.catalog.ObjectPath;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.factories.TableSinkFactory;
-import org.apache.flink.table.factories.TableSourceFactory;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.sources.TableSource;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.source.DynamicTableSource;
+import org.apache.flink.table.factories.DynamicTableFactory;
+import org.apache.flink.table.factories.DynamicTableSinkFactory;
+import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.utils.TableSchemaUtils;
-public class FlinkTableFactory implements TableSinkFactory<RowData>, TableSourceFactory<RowData> {
+public class FlinkDynamicTableFactory implements DynamicTableSinkFactory, DynamicTableSourceFactory {
private final FlinkCatalog catalog;
- public FlinkTableFactory(FlinkCatalog catalog) {
+ public FlinkDynamicTableFactory(FlinkCatalog catalog) {
this.catalog = catalog;
}
@Override
- public TableSource<RowData> createTableSource(TableSourceFactory.Context context) {
+ public DynamicTableSource createDynamicTableSource(DynamicTableFactory.Context context) {
Review comment:
Nit: Here we could just use the `Context` to replace the `DynamicTableFactory.Context` ?
##########
File path: flink/src/test/java/org/apache/iceberg/flink/TestFlinkTableSource.java
##########
@@ -56,6 +58,28 @@ public TestFlinkTableSource() {
}, ScanEvent.class);
}
+ @Override
+ protected TableEnvironment getTableEnv() {
+ if (tEnv == null) {
+ synchronized (this) {
+ if (tEnv == null) {
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .useBlinkPlanner()
+ .inBatchMode()
+ .build();
+
+ TableEnvironment env = TableEnvironment.create(settings);
+ env.getConfig().getConfiguration()
+ .set(FlinkTableOptions.TABLE_EXEC_ICEBERG_INFER_SOURCE_PARALLELISM, false)
+ .set(CoreOptions.DEFAULT_PARALLELISM, 1);
Review comment:
The default parallelism is 1, so why do we need to implement the getTableEnv with setting the DEFAULT_PARALLELISM to 1 again ?
```java
public static final ConfigOption<Integer> DEFAULT_PARALLELISM =
ConfigOptions.key("parallelism.default")
.defaultValue(1)
.withDescription("Default parallelism for jobs.");
```
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
Review comment:
I read the javadoc of [SupportsFilterPushDown](https://github.com/apache/flink/blob/97bfd049951f8d52a2e0aed14265074c4255ead0/flink-table/flink-table-common/src/main/java/org/apache/flink/table/connector/source/abilities/SupportsFilterPushDown.java#L63), the remanningFilters don't have to be the full list of origin `flinkFilters`, it could be the list of filters that did push down for iceberg source.
Although it will be surely correct if pass the complete list as `remainingFilters`, but that seems will introduce extra resources to apply the `acceptedFilters` twice.
##########
File path: flink/src/test/java/org/apache/iceberg/flink/actions/TestRewriteDataFilesAction.java
##########
@@ -280,15 +280,15 @@ public void testRewriteLargeTableHasResiduals() throws IOException {
Assert.assertEquals("Residuals must be ignored", Expressions.alwaysTrue(), task.residual());
}
List<DataFile> dataFiles = Lists.newArrayList(CloseableIterable.transform(tasks, FileScanTask::file));
- Assert.assertEquals("Should have 2 data files before rewrite", 2, dataFiles.size());
Review comment:
Where did we have change the default parallelism from 1 to 4 ? I did not find the changes .
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
}
@Override
- public boolean isLimitPushedDown() {
- return isLimitPushDown;
+ public boolean supportsNestedProjection() {
+ return false;
Review comment:
Could you pls add a TODO indicate that need to support nested projection in future PR, actually we iceberg has the ability to support nested projection now. We could add next PR to address this issue.
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
}
@Override
- public boolean isLimitPushedDown() {
- return isLimitPushDown;
+ public boolean supportsNestedProjection() {
+ return false;
}
@Override
- public TableSource<RowData> applyLimit(long newLimit) {
- return new IcebergTableSource(loader, schema, properties, projectedFields, true, newLimit, filters, readableConfig);
+ public ChangelogMode getChangelogMode() {
+ return ChangelogMode.insertOnly();
}
@Override
- public TableSource<RowData> applyPredicate(List<Expression> predicates) {
- List<org.apache.iceberg.expressions.Expression> expressions = Lists.newArrayList();
- for (Expression predicate : predicates) {
- FlinkFilters.convert(predicate).ifPresent(expressions::add);
- }
+ public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
+ return new DataStreamScanProvider() {
+ @Override
+ public DataStream<RowData> produceDataStream(StreamExecutionEnvironment execEnv) {
+ return getDataStream(execEnv);
+ }
+
+ @Override
+ public boolean isBounded() {
+ return FlinkSource.isBounded(properties);
+ }
+ };
+ }
- return new IcebergTableSource(loader, schema, properties, projectedFields, isLimitPushDown, limit, expressions,
+ @Override
+ public DynamicTableSource copy() {
+ return new IcebergTableSource(loader, schema, properties, projectedFields, isLimitPushDown, limit, filters,
readableConfig);
}
@Override
- public boolean isFilterPushedDown() {
- return this.filters != null && this.filters.size() > 0;
+ public String asSummaryString() {
+ return "iceberg table source";
Review comment:
Nit: use `Iceberg table source` ( to align with other existing flink table source ).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r591237327
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
Review comment:
I tried to apply the following patch, all unit tests could be passed:
```diff
diff --git a/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java b/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
index 79cb17c22..1c2df292b 100644
--- a/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
+++ b/flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
@@ -124,17 +124,20 @@ public class IcebergTableSource
@Override
public Result applyFilters(List<ResolvedExpression> flinkFilters) {
List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
- List<Expression> expressions = Lists.newArrayList();
-
- for (ResolvedExpression resolvedExpression : flinkFilters) {
- Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
- if (icebergExpression.isPresent()) {
- expressions.add(icebergExpression.get());
- acceptedFilters.add(resolvedExpression);
+ List<ResolvedExpression> remainingFilters = Lists.newArrayList();
+ List<Expression> acceptedExpressions = Lists.newArrayList();
+
+ for (ResolvedExpression flinkFilter : flinkFilters) {
+ Optional<Expression> pushedDownFilter = FlinkFilters.convert(flinkFilter);
+ if (pushedDownFilter.isPresent()) {
+ acceptedFilters.add(flinkFilter);
+ acceptedExpressions.add(pushedDownFilter.get());
+ } else {
+ remainingFilters.add(flinkFilter);
}
}
- this.filters = expressions;
+ this.filters = acceptedExpressions;
return Result.of(acceptedFilters, flinkFilters);
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r575033143
##########
File path: flink/src/main/java/org/apache/iceberg/flink/FlinkTableFactory.java
##########
@@ -19,51 +19,57 @@
package org.apache.iceberg.flink;
-import java.util.List;
-import java.util.Map;
+import java.util.Set;
+import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.catalog.ObjectPath;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.factories.TableSinkFactory;
-import org.apache.flink.table.factories.TableSourceFactory;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.sources.TableSource;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.source.DynamicTableSource;
+import org.apache.flink.table.factories.DynamicTableFactory;
+import org.apache.flink.table.factories.DynamicTableSinkFactory;
+import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.utils.TableSchemaUtils;
-public class FlinkTableFactory implements TableSinkFactory<RowData>, TableSourceFactory<RowData> {
+public class FlinkTableFactory implements DynamicTableSinkFactory, DynamicTableSourceFactory {
+ public static final String IDENTIFIER = "iceberg";
private final FlinkCatalog catalog;
public FlinkTableFactory(FlinkCatalog catalog) {
this.catalog = catalog;
}
@Override
- public TableSource<RowData> createTableSource(TableSourceFactory.Context context) {
+ public DynamicTableSource createDynamicTableSource(DynamicTableFactory.Context context) {
ObjectPath objectPath = context.getObjectIdentifier().toObjectPath();
TableLoader tableLoader = createTableLoader(objectPath);
- TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getTable().getSchema());
- return new IcebergTableSource(tableLoader, tableSchema, context.getTable().getOptions(),
+ TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());
+ return new IcebergTableSource(tableLoader, tableSchema, context.getCatalogTable().getOptions(),
context.getConfiguration());
}
@Override
- public TableSink<RowData> createTableSink(TableSinkFactory.Context context) {
+ public DynamicTableSink createDynamicTableSink(Context context) {
ObjectPath objectPath = context.getObjectIdentifier().toObjectPath();
TableLoader tableLoader = createTableLoader(objectPath);
- TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getTable().getSchema());
- return new IcebergTableSink(context.isBounded(), tableLoader, tableSchema);
+ TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());
+ return new IcebergTableSink(tableLoader, tableSchema);
}
@Override
- public Map<String, String> requiredContext() {
+ public Set<ConfigOption<?>> requiredOptions() {
Review comment:
From the comments of `TableFactory`, we learned that ,`An empty context means that the factory matches for all requests `, [link](https://github.com/apache/flink/blob/master/flink-table/flink-table-common/src/main/java/org/apache/flink/table/factories/TableFactory.java#L50)
We can refer to [HiveDynamicTableFactory](https://github.com/apache/flink/blob/master/flink-connectors/flink-connector-hive/src/main/java/org/apache/flink/connectors/hive/HiveDynamicTableFactory.java#L59)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r591279196
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSink.java
##########
@@ -20,66 +20,68 @@
package org.apache.iceberg.flink;
import java.util.Map;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.streaming.api.datastream.DataStream;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.table.api.TableSchema;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.sinks.AppendStreamTableSink;
-import org.apache.flink.table.sinks.OverwritableTableSink;
-import org.apache.flink.table.sinks.PartitionableTableSink;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.types.DataType;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.sink.DataStreamSinkProvider;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.abilities.SupportsOverwrite;
+import org.apache.flink.table.connector.sink.abilities.SupportsPartitioning;
+import org.apache.flink.types.RowKind;
import org.apache.flink.util.Preconditions;
import org.apache.iceberg.flink.sink.FlinkSink;
-public class IcebergTableSink implements AppendStreamTableSink<RowData>, OverwritableTableSink, PartitionableTableSink {
- private final boolean isBounded;
+public class IcebergTableSink implements DynamicTableSink, SupportsPartitioning, SupportsOverwrite {
private final TableLoader tableLoader;
private final TableSchema tableSchema;
private boolean overwrite = false;
- public IcebergTableSink(boolean isBounded, TableLoader tableLoader, TableSchema tableSchema) {
- this.isBounded = isBounded;
+ public IcebergTableSink(TableLoader tableLoader, TableSchema tableSchema) {
this.tableLoader = tableLoader;
this.tableSchema = tableSchema;
}
@Override
- public DataStreamSink<?> consumeDataStream(DataStream<RowData> dataStream) {
- Preconditions.checkState(!overwrite || isBounded, "Unbounded data stream doesn't support overwrite operation.");
+ public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
+ Preconditions
+ .checkState(!overwrite || context.isBounded(), "Unbounded data stream doesn't support overwrite operation.");
- return FlinkSink.forRowData(dataStream)
+ return (DataStreamSinkProvider) dataStream -> FlinkSink.forRowData(dataStream)
.tableLoader(tableLoader)
.tableSchema(tableSchema)
.overwrite(overwrite)
Review comment:
Filed an issue for this: https://github.com/apache/iceberg/issues/2313
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on a change in pull request #2229: Flink : refactor iceberg table source and sink use flink new interface
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r573310539
##########
File path: flink/src/main/java/org/apache/iceberg/flink/FlinkTableFactory.java
##########
@@ -19,51 +19,57 @@
package org.apache.iceberg.flink;
-import java.util.List;
-import java.util.Map;
+import java.util.Set;
+import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.catalog.ObjectPath;
-import org.apache.flink.table.data.RowData;
-import org.apache.flink.table.factories.TableSinkFactory;
-import org.apache.flink.table.factories.TableSourceFactory;
-import org.apache.flink.table.sinks.TableSink;
-import org.apache.flink.table.sources.TableSource;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.source.DynamicTableSource;
+import org.apache.flink.table.factories.DynamicTableFactory;
+import org.apache.flink.table.factories.DynamicTableSinkFactory;
+import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.utils.TableSchemaUtils;
-public class FlinkTableFactory implements TableSinkFactory<RowData>, TableSourceFactory<RowData> {
+public class FlinkTableFactory implements DynamicTableSinkFactory, DynamicTableSourceFactory {
+ public static final String IDENTIFIER = "iceberg";
private final FlinkCatalog catalog;
public FlinkTableFactory(FlinkCatalog catalog) {
this.catalog = catalog;
}
@Override
- public TableSource<RowData> createTableSource(TableSourceFactory.Context context) {
+ public DynamicTableSource createDynamicTableSource(DynamicTableFactory.Context context) {
ObjectPath objectPath = context.getObjectIdentifier().toObjectPath();
TableLoader tableLoader = createTableLoader(objectPath);
- TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getTable().getSchema());
- return new IcebergTableSource(tableLoader, tableSchema, context.getTable().getOptions(),
+ TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());
+ return new IcebergTableSource(tableLoader, tableSchema, context.getCatalogTable().getOptions(),
context.getConfiguration());
}
@Override
- public TableSink<RowData> createTableSink(TableSinkFactory.Context context) {
+ public DynamicTableSink createDynamicTableSink(Context context) {
ObjectPath objectPath = context.getObjectIdentifier().toObjectPath();
TableLoader tableLoader = createTableLoader(objectPath);
- TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getTable().getSchema());
- return new IcebergTableSink(context.isBounded(), tableLoader, tableSchema);
+ TableSchema tableSchema = TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());
+ return new IcebergTableSink(tableLoader, tableSchema);
}
@Override
- public Map<String, String> requiredContext() {
+ public Set<ConfigOption<?>> requiredOptions() {
Review comment:
why throw exception here? if there are no required or optional configs, we should just return empty sets, right?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangjun0x01 closed pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
zhangjun0x01 closed pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on a change in pull request #2229: Flink : Refactor FlinkTableFactory to implement DynamicTableSinkFactory and DynamicTableSourceFactory
Posted by GitBox <gi...@apache.org>.
openinx commented on a change in pull request #2229:
URL: https://github.com/apache/iceberg/pull/2229#discussion_r589889113
##########
File path: flink/src/main/java/org/apache/iceberg/flink/IcebergTableSource.java
##########
@@ -100,70 +93,73 @@ public boolean isBounded() {
.build();
}
- @Override
- public TableSchema getTableSchema() {
- return schema;
- }
-
- @Override
- public DataType getProducedDataType() {
- return getProjectedSchema().toRowDataType().bridgedTo(RowData.class);
- }
-
private TableSchema getProjectedSchema() {
- TableSchema fullSchema = getTableSchema();
if (projectedFields == null) {
- return fullSchema;
+ return schema;
} else {
- String[] fullNames = fullSchema.getFieldNames();
- DataType[] fullTypes = fullSchema.getFieldDataTypes();
+ String[] fullNames = schema.getFieldNames();
+ DataType[] fullTypes = schema.getFieldDataTypes();
return TableSchema.builder().fields(
Arrays.stream(projectedFields).mapToObj(i -> fullNames[i]).toArray(String[]::new),
Arrays.stream(projectedFields).mapToObj(i -> fullTypes[i]).toArray(DataType[]::new)).build();
}
}
@Override
- public String explainSource() {
- String explain = "Iceberg table: " + loader.toString();
- if (projectedFields != null) {
- explain += ", ProjectedFields: " + Arrays.toString(projectedFields);
- }
-
- if (isLimitPushDown) {
- explain += String.format(", LimitPushDown : %d", limit);
- }
+ public void applyLimit(long newLimit) {
+ this.limit = newLimit;
+ }
- if (isFilterPushedDown()) {
- explain += String.format(", FilterPushDown: %s", COMMA.join(filters));
+ @Override
+ public Result applyFilters(List<ResolvedExpression> flinkFilters) {
+ List<ResolvedExpression> acceptedFilters = Lists.newArrayList();
+ List<Expression> expressions = Lists.newArrayList();
+
+ for (ResolvedExpression resolvedExpression : flinkFilters) {
+ Optional<Expression> icebergExpression = FlinkFilters.convert(resolvedExpression);
+ if (icebergExpression.isPresent()) {
+ expressions.add(icebergExpression.get());
+ acceptedFilters.add(resolvedExpression);
+ }
}
- return TableConnectorUtils.generateRuntimeName(getClass(), getTableSchema().getFieldNames()) + explain;
+ this.filters = expressions;
+ return Result.of(acceptedFilters, flinkFilters);
Review comment:
What's the reason that fails the unit tests ? I think we need to have a clear understanding about the semantics of `acceptedFilters` and `remainingFilters` before we change the code to make unit tests pass.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org