You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@airflow.apache.org by GitBox <gi...@apache.org> on 2022/01/17 04:05:00 UTC
[GitHub] [airflow] danmactough edited a comment on issue #13542: Task stuck in "scheduled" or "queued" state, pool has all slots queued, nothing is executing
danmactough edited a comment on issue #13542:
URL: https://github.com/apache/airflow/issues/13542#issuecomment-1011598836
Airflow 2.0.2+e494306fb01f3a026e7e2832ca94902e96b526fa (MWAA on AWS)
This happens to us a LOT: a DAG will be running, task instances will be marked as "queued", but nothing gets moved to "running".
When this happened today (the first time today), I was able to track down the following error in the scheduler logs:
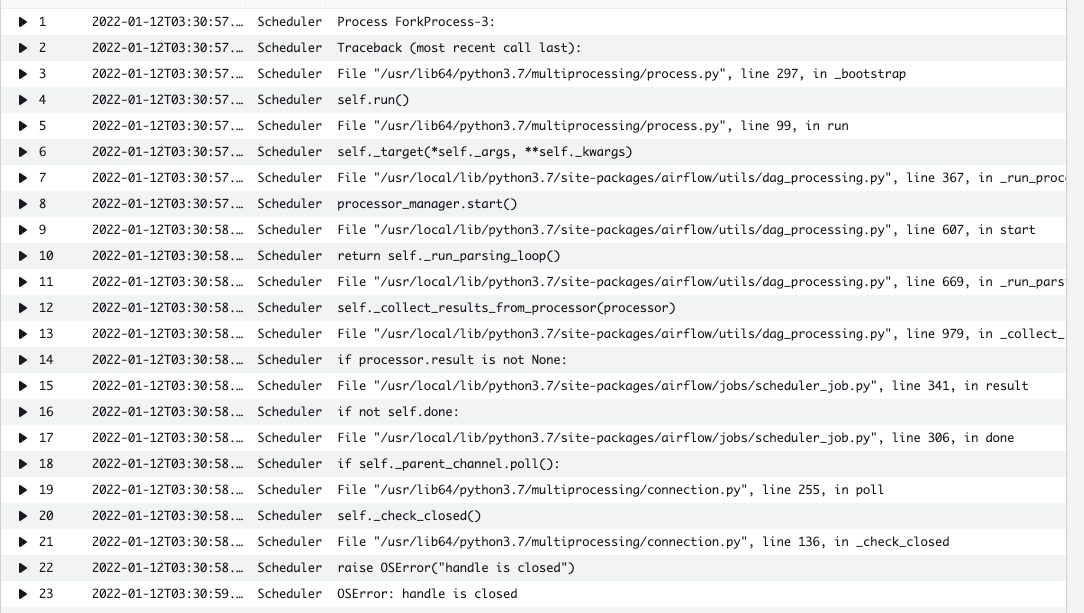
At some point after the scheduler had that exception, I tried to clear the state of the queued task instances to get them to run. That resulting in the following logs:
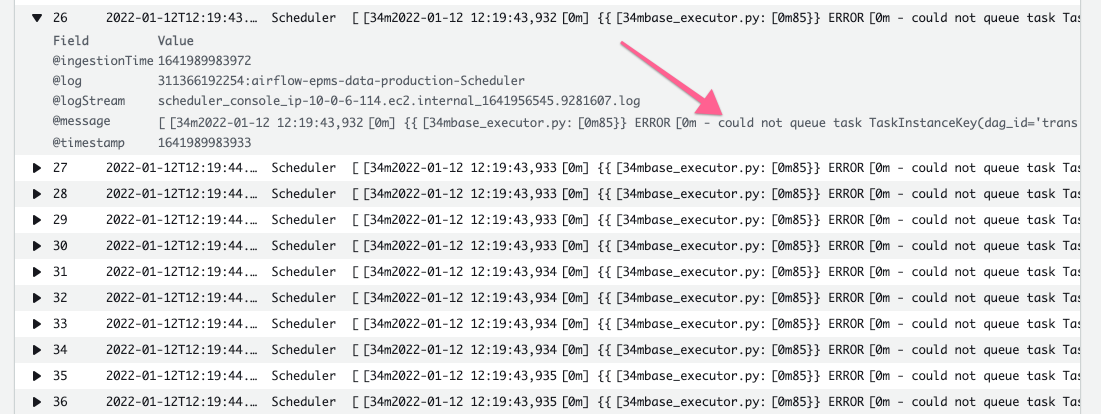
This corresponds to this [section of code](https://github.com/apache/airflow/blob/2.0.2/airflow/executors/base_executor.py#L73-L85):
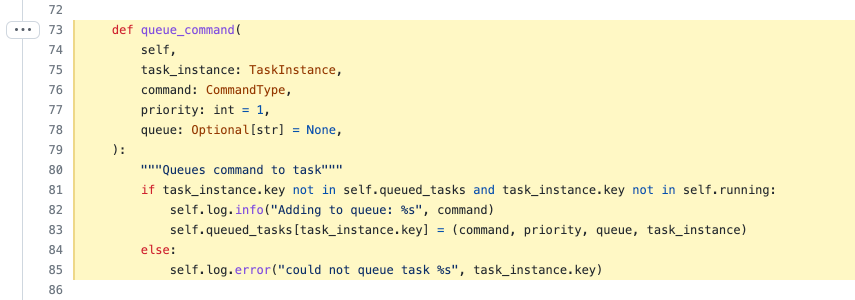
My conclusion is that when the scheduler experienced that error, it entered a pathological state: it was running but had bad state in memory. Specifically, the queued task instances were in the `queued_tasks` or `running` in-memory cache, and thus any attempts to re-queue those tasks would fail as long as that scheduler process was running because the tasks would appear to already have been queued and/or running.
Both caches use the [`TaskInstanceKey`](https://github.com/apache/airflow/blob/10023fdd65fa78033e7125d3d8103b63c127056e/airflow/models/taskinstance.py#L224-L230), which is made up of `dag_id` (which we can't change), `task_id` (which we can't change), `execution_date` (nope, can't change), and `try_number` (🎉 we can change this!!).
So to work around this, I created a utility DAG that will find all task instances in a "queued" or "None" state and increment the `try_number` field.
The DAG runs as a single `PythonOperator`:
```python
import os
from datetime import datetime, timedelta
from pprint import pprint
from airflow import DAG
from airflow.models.dagrun import DagRun
from airflow.models.taskinstance import TaskInstance
from airflow.operators.python import PythonOperator
from airflow.utils import timezone
from airflow.utils.db import provide_session
from airflow.utils.state import State
from dateutil.parser import parse
from sqlalchemy.sql.expression import or_
DAG_NAME = os.path.splitext(os.path.basename(__file__))[0]
DEFAULT_ARGS = {
"owner": "airflow",
"depends_on_past": False,
"email_on_failure": False,
"email_on_retry": False,
"execution_timeout": timedelta(minutes=10),
"retries": 0,
}
@provide_session
def unstick_dag_callable(dag_run, session, **kwargs):
dag_id = dag_run.conf.get("dag_id")
if not dag_id:
raise AssertionError("dag_id was not provided")
execution_date = dag_run.conf.get("execution_date")
if not execution_date:
raise AssertionError("execution_date was not provided")
execution_date = parse(execution_date)
filter = [
or_(TaskInstance.state == State.QUEUED, TaskInstance.state == State.NONE),
TaskInstance.dag_id == dag_id,
TaskInstance.execution_date == execution_date,
]
print(
(
f"DAG id: {dag_id}, Execution Date: {execution_date}, State: "
f"""{dag_run.conf.get("state", f"{State.QUEUED} or {State.NONE}")}, """
f"Filter: {[str(f) for f in filter]}"
)
)
tis = session.query(TaskInstance).filter(*filter).all()
dr = (
session.query(DagRun)
.filter(DagRun.dag_id == dag_id, DagRun.execution_date == execution_date)
.first()
)
dagrun = (
dict(
id=dr.id,
dag_id=dr.dag_id,
execution_date=dr.execution_date,
start_date=dr.start_date,
end_date=dr.end_date,
_state=dr._state,
run_id=dr.run_id,
creating_job_id=dr.creating_job_id,
external_trigger=dr.external_trigger,
run_type=dr.run_type,
conf=dr.conf,
last_scheduling_decision=dr.last_scheduling_decision,
dag_hash=dr.dag_hash,
)
if dr
else {}
)
print(f"Updating {len(tis)} task instances")
print("Here are the task instances we're going to update")
# Print no more than 100 tis so we don't lock up the session too long
for ti in tis[:100]:
pprint(
dict(
task_id=ti.task_id,
job_id=ti.job_id,
key=ti.key,
dag_id=ti.dag_id,
execution_date=ti.execution_date,
state=ti.state,
dag_run={**dagrun},
)
)
if len(tis) > 100:
print("Output truncated after 100 task instances")
for ti in tis:
ti.try_number = ti.next_try_number
ti.state = State.NONE
session.merge(ti)
if dag_run.conf.get("activate_dag_runs", True):
dr.state = State.RUNNING
dr.start_date = timezone.utcnow()
print("Done")
with DAG(
DAG_NAME,
description="Utility DAG to fix TaskInstances stuck in queued or None state",
default_args=DEFAULT_ARGS,
schedule_interval=None,
start_date=datetime(year=2021, month=8, day=1),
max_active_runs=1,
catchup=False,
default_view="graph",
is_paused_upon_creation=False,
) as dag:
PythonOperator(task_id="unstick_dag", python_callable=unstick_dag_callable)
```
To use the DAG, trigger a DAG run with a `dag_id` and `execution_date` like:
```json
{
"dag_id": "my_stuck_dag",
"execution_date": "2022-01-01T00:00:00Z"
}
```
Moments after I shipped this DAG, another DAG got stuck, and I had a chance to see if this utility DAG worked -- it did! 😅
-----
Couple of thoughts:
- I don't think my error is exactly the same as OP, as some very key conditions are not applicable to my case, but this issue appears to have many different and probably not at all related bugs that kind of manifest as "stuck DAGs" and this issue has pretty good Google juice -- I just hope my explanation and/or work-around help someone else.
- The MWAA product from AWS is using an older version of Airflow, so the combination of factors that leads to this pathological state may no longer be possible in the current version of Airflow.
- MWAA uses the CeleryExecutor, which I suspect is where the pathological state is coming from, not BaseExecutor directly.
- All that being said, I'm surprised to see this critical state being kept in memory (`queued_tasks` and `running`), but I don't have a complete mental model of how the executor and the scheduler are distinct or not. My understanding is that this is scheduler code, but with the scheduler being high-availability (we're running 3 schedulers), in-memory state seems like something we should be using very judiciously and be flushing and rehydrating from the database regularly.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@airflow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org