You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@doris.apache.org by lu...@apache.org on 2023/07/26 03:16:05 UTC
[doris-website] branch master updated: [feature](i18n) remove zh_CN (#272)
This is an automated email from the ASF dual-hosted git repository.
luzhijing pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/doris-website.git
The following commit(s) were added to refs/heads/master by this push:
new be1fbfafb97 [feature](i18n) remove zh_CN (#272)
be1fbfafb97 is described below
commit be1fbfafb97be1df40ed3c63c11abc96892e9d19
Author: Jeffrey <co...@gmail.com>
AuthorDate: Wed Jul 26 11:15:59 2023 +0800
[feature](i18n) remove zh_CN (#272)
---
i18n/zh-CN/code.json | 798 -------------------
.../docusaurus-plugin-content-blog/1.1 Release.md | 400 ----------
i18n/zh-CN/docusaurus-plugin-content-blog/360.md | 175 ----
.../docusaurus-plugin-content-blog/Annoucing.md | 74 --
.../BestPractice_Kwai.md | 181 -----
.../docusaurus-plugin-content-blog/Compaction.md | 219 -----
.../Data Lakehouse.md | 290 -------
i18n/zh-CN/docusaurus-plugin-content-blog/Douyu.md | 192 -----
.../docusaurus-plugin-content-blog/Duyansoft.md | 192 -----
.../Flink-realtime-write.md | 159 ----
i18n/zh-CN/docusaurus-plugin-content-blog/HCDS.md | 343 --------
i18n/zh-CN/docusaurus-plugin-content-blog/HYXJ.md | 275 -------
.../High_concurrency.md | 319 --------
.../Inverted Index.md | 281 -------
.../docusaurus-plugin-content-blog/JD_OLAP.md | 88 --
i18n/zh-CN/docusaurus-plugin-content-blog/LY.md | 129 ---
.../Memory_Management.md | 184 -----
.../Midland Realty.md | 249 ------
i18n/zh-CN/docusaurus-plugin-content-blog/Moka.md | 163 ----
i18n/zh-CN/docusaurus-plugin-content-blog/NIO.md | 223 ------
.../docusaurus-plugin-content-blog/Netease.md | 253 ------
.../Tencent Music.md | 312 --------
.../docusaurus-plugin-content-blog/Tianyancha.md | 175 ----
i18n/zh-CN/docusaurus-plugin-content-blog/jd.md | 136 ----
.../docusaurus-plugin-content-blog/linkedcare.md | 259 ------
.../docusaurus-plugin-content-blog/meituan.md | 182 -----
.../docusaurus-plugin-content-blog/options.json | 14 -
.../principle-of-Doris-SQL-parsing.md | 273 -------
.../principle-of-Doris-Stream-Load.md | 131 ---
.../release-1.1.1.md | 83 --
.../release-1.1.2.md | 94 ---
.../release-1.1.3.md | 94 ---
.../release-1.1.4.md | 75 --
.../release-1.1.5.md | 70 --
.../release-1.2.0.md | 624 ---------------
.../release-1.2.1.md | 195 -----
.../release-1.2.3.md | 173 ----
.../release-note-0.15.0.md | 225 ------
.../release-note-1.0.0.md | 254 ------
.../docusaurus-plugin-content-blog/scenario.md | 213 -----
i18n/zh-CN/docusaurus-plugin-content-blog/ssb.md | 616 --------------
.../zh-CN/docusaurus-plugin-content-blog/summit.md | 200 -----
i18n/zh-CN/docusaurus-plugin-content-blog/tpch.md | 884 ---------------------
.../zh-CN/docusaurus-plugin-content-blog/xiaomi.md | 240 ------
.../xiaomi_vector.md | 168 ----
.../current.json | 30 -
i18n/zh-CN/docusaurus-theme-classic/footer.json | 46 --
i18n/zh-CN/docusaurus-theme-classic/navbar.json | 30 -
src/pages/users/index.tsx | 3 +-
src/theme/BlogListPage/index.tsx | 5 +-
src/theme/Footer/Links/MultiColumn/index.tsx | 17 +-
.../NavbarItem/LocaleDropdownNavbarItem/index.tsx | 4 +
userCases/zh_CN.json | 86 --
53 files changed, 9 insertions(+), 11089 deletions(-)
diff --git a/i18n/zh-CN/code.json b/i18n/zh-CN/code.json
deleted file mode 100644
index 9fc5e106da2..00000000000
--- a/i18n/zh-CN/code.json
+++ /dev/null
@@ -1,798 +0,0 @@
-{
- "theme.blog.post.readingTime.plurals": {
- "message": "{readingTime} 分钟阅读",
- "description": "Pluralized label for \"{readingTime} min read\". Use as much plural forms (separated by \"|\") as your language support (see https://www.unicode.org/cldr/cldr-aux/charts/34/supplemental/language_plural_rules.html)"
- },
- "theme.ErrorPageContent.title": {
- "message": "页面已崩溃。",
- "description": "The title of the fallback page when the page crashed"
- },
- "theme.ErrorPageContent.tryAgain": {
- "message": "重试",
- "description": "The label of the button to try again when the page crashed"
- },
- "theme.NotFound.title": {
- "message": "找不到页面",
- "description": "The title of the 404 page"
- },
- "theme.NotFound.p1": {
- "message": "我们找不到您要找的页面。",
- "description": "The first paragraph of the 404 page"
- },
- "theme.NotFound.p2": {
- "message": "请联系原始链接来源网站的所有者,并告知他们链接已损坏。",
- "description": "The 2nd paragraph of the 404 page"
- },
- "theme.AnnouncementBar.closeButtonAriaLabel": {
- "message": "关闭",
- "description": "The ARIA label for close button of announcement bar"
- },
- "theme.BackToTopButton.buttonAriaLabel": {
- "message": "回到顶部",
- "description": "The ARIA label for the back to top button"
- },
- "theme.blog.archive.title": {
- "message": "历史博文",
- "description": "The page & hero title of the blog archive page"
- },
- "theme.blog.archive.description": {
- "message": "历史博文",
- "description": "The page & hero description of the blog archive page"
- },
- "theme.blog.paginator.navAriaLabel": {
- "message": "博文列表分页导航",
- "description": "The ARIA label for the blog pagination"
- },
- "theme.blog.paginator.newerEntries": {
- "message": "较新的博文",
- "description": "The label used to navigate to the newer blog posts page (previous page)"
- },
- "theme.blog.paginator.olderEntries": {
- "message": "较旧的博文",
- "description": "The label used to navigate to the older blog posts page (next page)"
- },
- "theme.blog.post.readMoreLabel": {
- "message": "阅读 {title} 的全文",
- "description": "The ARIA label for the link to full blog posts from excerpts"
- },
- "theme.blog.post.readMore": {
- "message": "阅读更多",
- "description": "The label used in blog post item excerpts to link to full blog posts"
- },
- "theme.blog.post.paginator.navAriaLabel": {
- "message": "博文分页导航",
- "description": "The ARIA label for the blog posts pagination"
- },
- "theme.blog.post.paginator.newerPost": {
- "message": "较新一篇",
- "description": "The blog post button label to navigate to the newer/previous post"
- },
- "theme.blog.post.paginator.olderPost": {
- "message": "较旧一篇",
- "description": "The blog post button label to navigate to the older/next post"
- },
- "theme.blog.post.plurals": {
- "message": "{count} 篇博文",
- "description": "Pluralized label for \"{count} posts\". Use as much plural forms (separated by \"|\") as your language support (see https://www.unicode.org/cldr/cldr-aux/charts/34/supplemental/language_plural_rules.html)"
- },
- "theme.blog.tagTitle": {
- "message": "{nPosts} 含有标签「{tagName}」",
- "description": "The title of the page for a blog tag"
- },
- "theme.tags.tagsPageLink": {
- "message": "查看所有标签",
- "description": "The label of the link targeting the tag list page"
- },
- "theme.colorToggle.ariaLabel": {
- "message": "切换浅色/暗黑模式(当前为{mode})",
- "description": "The ARIA label for the navbar color mode toggle"
- },
- "theme.colorToggle.ariaLabel.mode.dark": {
- "message": "暗黑模式",
- "description": "The name for the dark color mode"
- },
- "theme.colorToggle.ariaLabel.mode.light": {
- "message": "浅色模式",
- "description": "The name for the light color mode"
- },
- "theme.docs.breadcrumbs.home": {
- "message": "主页面",
- "description": "The ARIA label for the home page in the breadcrumbs"
- },
- "theme.docs.breadcrumbs.navAriaLabel": {
- "message": "页面路径",
- "description": "The ARIA label for the breadcrumbs"
- },
- "theme.docs.DocCard.categoryDescription": {
- "message": "{count} 个项目",
- "description": "The default description for a category card in the generated index about how many items this category includes"
- },
- "theme.docs.paginator.navAriaLabel": {
- "message": "文档分页导航",
- "description": "The ARIA label for the docs pagination"
- },
- "theme.docs.paginator.previous": {
- "message": "上一页",
- "description": "The label used to navigate to the previous doc"
- },
- "theme.docs.paginator.next": {
- "message": "下一页",
- "description": "The label used to navigate to the next doc"
- },
- "theme.docs.tagDocListPageTitle.nDocsTagged": {
- "message": "{count} 篇文档带有标签",
- "description": "Pluralized label for \"{count} docs tagged\". Use as much plural forms (separated by \"|\") as your language support (see https://www.unicode.org/cldr/cldr-aux/charts/34/supplemental/language_plural_rules.html)"
- },
- "theme.docs.tagDocListPageTitle": {
- "message": "{nDocsTagged}「{tagName}」",
- "description": "The title of the page for a docs tag"
- },
- "theme.docs.versionBadge.label": {
- "message": "版本:{versionLabel}"
- },
- "theme.docs.versions.unreleasedVersionLabel": {
- "message": "此为 {siteTitle} {versionLabel} 版本的文档。",
- "description": "The label used to tell the user that he's browsing an unreleased doc version"
- },
- "theme.docs.versions.unmaintainedVersionLabel": {
- "message": "此为 {siteTitle} {versionLabel} 版的文档,现已不再积极维护。",
- "description": "The label used to tell the user that he's browsing an unmaintained doc version"
- },
- "theme.docs.versions.latestVersionSuggestionLabel": {
- "message": "最新的文档请参阅 {latestVersionLink} ({versionLabel})。",
- "description": "The label used to tell the user to check the latest version"
- },
- "theme.docs.versions.latestVersionLinkLabel": {
- "message": "最新版本",
- "description": "The label used for the latest version suggestion link label"
- },
- "theme.common.editThisPage": {
- "message": "编辑此页",
- "description": "The link label to edit the current page"
- },
- "theme.common.headingLinkTitle": {
- "message": "标题的直接链接",
- "description": "Title for link to heading"
- },
- "theme.lastUpdated.atDate": {
- "message": "于 {date} ",
- "description": "The words used to describe on which date a page has been last updated"
- },
- "theme.lastUpdated.byUser": {
- "message": "由 {user} ",
- "description": "The words used to describe by who the page has been last updated"
- },
- "theme.lastUpdated.lastUpdatedAtBy": {
- "message": "最后{byUser}{atDate}更新",
- "description": "The sentence used to display when a page has been last updated, and by who"
- },
- "theme.navbar.mobileVersionsDropdown.label": {
- "message": "选择版本",
- "description": "The label for the navbar versions dropdown on mobile view"
- },
- "theme.common.skipToMainContent": {
- "message": "跳到主要内容",
- "description": "The skip to content label used for accessibility, allowing to rapidly navigate to main content with keyboard tab/enter navigation"
- },
- "theme.tags.tagsListLabel": {
- "message": "标签:",
- "description": "The label alongside a tag list"
- },
- "theme.blog.sidebar.navAriaLabel": {
- "message": "最近博文导航",
- "description": "The ARIA label for recent posts in the blog sidebar"
- },
- "theme.CodeBlock.copied": {
- "message": "复制成功",
- "description": "The copied button label on code blocks"
- },
- "theme.CodeBlock.copyButtonAriaLabel": {
- "message": "复制代码到剪贴板",
- "description": "The ARIA label for copy code blocks button"
- },
- "theme.CodeBlock.copy": {
- "message": "复制",
- "description": "The copy button label on code blocks"
- },
- "theme.CodeBlock.wordWrapToggle": {
- "message": "切换自动换行",
- "description": "The title attribute for toggle word wrapping button of code block lines"
- },
- "theme.DocSidebarItem.toggleCollapsedCategoryAriaLabel": {
- "message": "打开/收起侧边栏菜单「{label}」",
- "description": "The ARIA label to toggle the collapsible sidebar category"
- },
- "theme.navbar.mobileLanguageDropdown.label": {
- "message": "选择语言",
- "description": "The label for the mobile language switcher dropdown"
- },
- "theme.TOCCollapsible.toggleButtonLabel": {
- "message": "本页总览",
- "description": "The label used by the button on the collapsible TOC component"
- },
- "theme.docs.sidebar.collapseButtonTitle": {
- "message": "收起侧边栏",
- "description": "The title attribute for collapse button of doc sidebar"
- },
- "theme.docs.sidebar.collapseButtonAriaLabel": {
- "message": "收起侧边栏",
- "description": "The title attribute for collapse button of doc sidebar"
- },
- "theme.navbar.mobileSidebarSecondaryMenu.backButtonLabel": {
- "message": "← 回到主菜单",
- "description": "The label of the back button to return to main menu, inside the mobile navbar sidebar secondary menu (notably used to display the docs sidebar)"
- },
- "theme.docs.sidebar.expandButtonTitle": {
- "message": "展开侧边栏",
- "description": "The ARIA label and title attribute for expand button of doc sidebar"
- },
- "theme.docs.sidebar.expandButtonAriaLabel": {
- "message": "展开侧边栏",
- "description": "The ARIA label and title attribute for expand button of doc sidebar"
- },
- "theme.SearchBar.noResultsText": {
- "message": "没有找到任何文档"
- },
- "theme.SearchBar.seeAll": {
- "message": "查看全部结果"
- },
- "theme.SearchBar.label": {
- "message": "搜索",
- "description": "The ARIA label and placeholder for search button"
- },
- "theme.SearchPage.existingResultsTitle": {
- "message": "“{query}” 的搜索结果",
- "description": "The search page title for non-empty query"
- },
- "theme.SearchPage.emptyResultsTitle": {
- "message": "搜索文档",
- "description": "The search page title for empty query"
- },
- "theme.SearchPage.documentsFound.plurals": {
- "message": "共找到 {count} 篇文档",
- "description": "Pluralized label for \"{count} documents found\". Use as much plural forms (separated by \"|\") as your language support (see https://www.unicode.org/cldr/cldr-aux/charts/34/supplemental/language_plural_rules.html)"
- },
- "theme.SearchPage.noResultsText": {
- "message": "没有找到任何文档",
- "description": "The paragraph for empty search result"
- },
- "homepage.more": {
- "message": "了解更多",
- "description": "more link"
- },
- "coreFeatures.title.f1": {
- "message": "简单易用"
- },
- "coreFeatures.subTitle.f1": {
- "message": "部署只需两个进程,不依赖其他系统;在线集群扩缩容,自动副本修复;兼容 MySQL 协议,并且使用标准 SQL"
- },
- "coreFeatures.title.f2": {
- "message": "高性能"
- },
- "coreFeatures.subTitle.f2": {
- "message": "依托列式存储引擎、现代的 MPP 架构、向量化查询引擎、预聚合物化视图、数据索引的实现,在低延迟和高吞吐查询上, 都达到了极速性能"
- },
- "coreFeatures.title.f3": {
- "message": "统一数仓"
- },
- "coreFeatures.subTitle.f3": {
- "message": "单一系统,可以同时支持实时数据服务、交互数据分析和离线数据处理场景"
- },
- "coreFeatures.title.f4": {
- "message": "联邦查询"
- },
- "coreFeatures.subTitle.f4": {
- "message": "支持对 Hive、Iceberg、Hudi 等数据湖和 MySQL、Elasticsearch 等数据库的联邦查询分析"
- },
- "coreFeatures.title.f5": {
- "message": "多种导入"
- },
- "coreFeatures.subTitle.f5": {
- "message": "支持从 HDFS/S3 等批量拉取导入和 MySQL Binlog/Kafka 等流式拉取导入;支持通过HTTP接口进行微批量推送写入和 JDBC 中使用 Insert 实时推送写入"
- },
- "coreFeatures.title.f6": {
- "message": "生态丰富"
- },
- "coreFeatures.subTitle.f6": {
- "message": "Spark 利用 Spark Doris Connector 读取和写入 Doris;Flink Doris Connector 配合 Flink CDC 实现数据 Exactly Once 写入 Doris;利用 DBT Doris Adapter,可以很容易的在 Doris 中完成数据转化"
- },
- "community.title.c1": {
- "message": "邮件列表"
- },
- "community.title.c2": {
- "message": "讨论区"
- },
- "community.title.c3": {
- "message": "参与贡献"
- },
- "community.title.c4": {
- "message": "源代码"
- },
- "community.title.c5": {
- "message": "改进建议"
- },
- "community.title.c6": {
- "message": "Doris 团队"
- },
- "homepage.news": {
- "message": "1月6日-7日,Doris Summit 2022 于线上全面开启!",
- "description": "The label for the link to homepage news"
- },
- "homepage.what": {
- "message": "Apache Doris 定位",
- "description": "What is Apache Doris"
- },
- "homepage.features": {
- "message": "核心优势",
- "description": "Core Features"
- },
- "homepage.join": {
- "message": "加入社区",
- "description": "Join The Community"
- },
- "homepage.start.title": {
- "message": "准备踏上 Doris 之旅 ?"
- },
- "homepage.start.downloadButton": {
- "message": "下载"
- },
- "homepage.start.docsButton": {
- "message": "文档"
- },
- "learnmore": {
- "message": "了解更多"
- },
- "sotry.summary.meituan": {
- "message": "Apache Doris 可以较好地处理汇总与明细数据查询、变化维的历史回溯、非预设维的灵活应用、准实时的批处理等场景。"
- },
- "sotry.summary.jindong": {
- "message": "Apache Doris 不仅可以应对海量数据的秒级查询,更可以满足实时、准实时的分析需求。"
- },
- "footer.follow": {
- "message": "分享",
- "description": "Footer Follow"
- },
- "download.quick.download": {
- "message": "快速下载",
- "description": "Quick Download"
- },
- "download.release": {
- "message": "所有版本"
- },
- "download.flink.connector": {
- "message": "Flink Doris Connector",
- "description": "Flink Doris Connector"
- },
- "download.maven": {
- "message": "Maven",
- "description": "Maven"
- },
- "download.spark.connector": {
- "message": "Spark Doris Connector",
- "description": "Spark Doris Connector"
- },
- "download.verify": {
- "message": "验证",
- "description": "Verify"
- },
- "doc.version": {
- "message": "版本",
- "description": "Version"
- },
- "footer.language": {
- "message": "语言",
- "description": "Footer Language"
- },
- "download.binary.version": {
- "message": "二进制版本",
- "description": "Binary Version"
- },
- "download.cpu.model": {
- "message": "CPU 型号",
- "description": "CPU Model"
- },
- "download.jdk.version": {
- "message": "JDK 版本",
- "description": "JDK Version"
- },
- "download.download.link": {
- "message": "下载链接",
- "description": "Download"
- },
- "download.quick.download.intr.prefix": {
- "message": "如果 CPU 不支持 avx2 指令集,请选择 noavx2 版本,您可以通过"
- },
- "download.quick.download.intr.suffix": {
- "message": "查看 CPU 是否支持。avx2 指令将会提升 Bloom Filter 等数据结构的计算效率。"
- },
- "download.release.more": {
- "message": "查看更多"
- },
- "download.all.release.version": {
- "message": "版本"
- },
- "download.all.release.date": {
- "message": "发布日期"
- },
- "download.all.release.note": {
- "message": "版本通告"
- },
- "download.flink.connector.version": {
- "message": "版本"
- },
- "download.flink.release.date": {
- "message": "发布日期"
- },
- "download.flink.version": {
- "message": "Flink 版本"
- },
- "download.flink.scala.version": {
- "message": "Scala 版本"
- },
- "download.flink.doris.version": {
- "message": "Doris 版本"
- },
- "download.spark.connector.version": {
- "message": "版本"
- },
- "download.spark.release.date": {
- "message": "发布日期"
- },
- "download.spark.version": {
- "message": "Spark 版本"
- },
- "download.spark.scala.version": {
- "message": "Scala 版本"
- },
- "download.spark.doris.version": {
- "message": "Doris 版本"
- },
- "download.verify.w1": {
- "message": "关于如何校验下载文件,请参阅 "
- },
- "download.verify.w2": {
- "message": "校验下载文件"
- },
- "download.verify.w3": {
- "message": ",并使用这些"
- },
- "download.verify.w4": {
- "message": "KEYS"
- },
- "download.verify.w5": {
- "message": "。校验完成后,可以参阅"
- },
- "download.verify.w6": {
- "message": "编译文档"
- },
- "download.verify.w7": {
- "message": "以及"
- },
- "download.verify.w8": {
- "message": "安装与部署文档"
- },
- "download.verify.w9": {
- "message": "进行 Doris 的编译、安装与部署。"
- },
- "user.companies": {
- "message": "他们都在使用 Apache Doris",
- "description": "Companies That Trust Apache Doris"
- },
- "user.case": {
- "message": "案例研究",
- "description": "Case Studies"
- },
- "user.add..your.company": {
- "message": "添加你的企业信息",
- "description": "Add Your Company"
- },
- "homepage.banner.title": {
- "message": "Apache Doris"
- },
- "homepage.banner.subTitle": {
- "message": "简单易用、高性能和统一的分析数据库"
- },
- "download.all.release.download": {
- "message": "下载"
- },
- "download.source.binary": {
- "message": "源码 / 二进制"
- },
- "download.all.binary": {
- "message": "二进制"
- },
- "download.source": {
- "message": "源码"
- },
- "download": {
- "message": "下载"
- },
- "homepage.banner.button1": {
- "message": "快速开始"
- },
- "sotry.summary.xiaomi": {
- "message": "Apache Doris 在小米得到了广泛的使用,目前已经服务了数十个业务,并形成了一套以 Apache Doris 为核心的数据生态。"
- },
- "navbar.download": {
- "message": "下载"
- },
- "homepage.title": {
- "message": "首页"
- },
- "download.title": {
- "message": "下载"
- },
- "users.title": {
- "message": "用户"
- },
- "sitemap.title": {
- "message": "学习路径"
- },
- "sitemap.subTitle": {
- "message": ""
- },
- "sitemap.page.title": {
- "message": "学习路径"
- },
- "documentation.feedback": {
- "message": "问题反馈"
- },
- "theme.PwaReloadPopup.info": {
- "message": "有可用的新版本",
- "description": "The text for PWA reload popup"
- },
- "theme.PwaReloadPopup.refreshButtonText": {
- "message": "刷新",
- "description": "The text for PWA reload button"
- },
- "theme.PwaReloadPopup.closeButtonAriaLabel": {
- "message": "关闭",
- "description": "The ARIA label for close button of PWA reload popup"
- },
- "Introduction to Apache Doris": {
- "message": "Apache Doris 总体介绍"
- },
- "Get Started": {
- "message": "快速开始"
- },
- "Installation and deployment": {
- "message": "安装部署"
- },
- "Compilation": {
- "message": "源码编译"
- },
- "Table Design": {
- "message": "数据表设计"
- },
- "Data Model": {
- "message": "数据模型"
- },
- "Data Partition": {
- "message": "数据划分"
- },
- "Guidelines for Creating Table": {
- "message": "建表指南"
- },
- "Rollup and Query": {
- "message": "Rollup与查询"
- },
- "Practices of Creating Table": {
- "message": "建表实践"
- },
- "Index": {
- "message": "索引"
- },
- "Data Import": {
- "message": "数据导入"
- },
- "Import Overview": {
- "message": "导入总览"
- },
- "Import Local Data": {
- "message": "导入本地数据"
- },
- "Import External Storage Data": {
- "message": "导入外部存储数据"
- },
- "Subscribe Kafka Data": {
- "message": "订阅 Kafka 日志"
- },
- "Synchronize Data Through External Table": {
- "message": "通过外部表同步数据"
- },
- "Data Export": {
- "message": "数据导出"
- },
- "Export Data": {
- "message": "导出数据"
- },
- "Export Query Result": {
- "message": "导出查询结果集"
- },
- "Export Table Structure or Data": {
- "message": "导出表结构或数据"
- },
- "Data Backup": {
- "message": "数据备份"
- },
- "Update and Delete": {
- "message": "数据更新及删除"
- },
- "Update": {
- "message": "数据更新"
- },
- "Delete": {
- "message": "删除操作"
- },
- "Batch Delete": {
- "message": "批量删除"
- },
- "Sequence Column": {
- "message": "Sequence 列"
- },
- "Advanced Usage": {
- "message": "进阶使用"
- },
- "Schema Change": {
- "message": "表结构变更"
- },
- "Dynamic Partition": {
- "message": "动态分区"
- },
- "Data Cache": {
- "message": "数据缓存"
- },
- "Join Optimization": {
- "message": "Join 优化"
- },
- "Materialized view": {
- "message": "物化视图"
- },
- "BITMAP Precise De-duplication": {
- "message": "BITMAP 精确去重"
- },
- "HLL ApproximateDe-duplication": {
- "message": "HLL 近似去重"
- },
- "Variables": {
- "message": "变量"
- },
- "Time Zone": {
- "message": "时区"
- },
- "File Manager": {
- "message": "文件管理器"
- },
- "Ecosystem": {
- "message": "生态拓展"
- },
- "Doris on ES": {
- "message": "Doris on ES"
- },
- "Doris on Hudi": {
- "message": "Doris on Hudi"
- },
- "Doris on Iceberg": {
- "message": "Doris on Iceberg"
- },
- "Doris on Hive": {
- "message": "Doris on Hive"
- },
- "Doris on ODBC": {
- "message": "Doris on ODBC"
- },
- "Spark Doris Connector": {
- "message": "Spark Doris Connector"
- },
- "Flink Doris Connector": {
- "message": "Flink Doris Connector"
- },
- "Seatunnel Connector": {
- "message": "Seatunnel Connector"
- },
- "DataX doriswriter": {
- "message": "DataX doriswriter"
- },
- "UDF": {
- "message": "UDF"
- },
- "Audit log plugin": {
- "message": "审计日记插件"
- },
- "SQL Manual": {
- "message": "SQL 手册"
- },
- "SQL Function": {
- "message": "SQL 函数"
- },
- "DDL": {
- "message": "DDL"
- },
- "DML": {
- "message": "DML"
- },
- "Data Types": {
- "message": "数据类型"
- },
- "Utility": {
- "message": "辅助命令"
- },
- "Cluster Management": {
- "message": "集群管理"
- },
- "Cluster Upgrade": {
- "message": "集群升级"
- },
- "Elastic scaling": {
- "message": "弹性扩缩容"
- },
- "Statistics of query execution": {
- "message": "查询分析"
- },
- "Maintenance and Monitor": {
- "message": "监控报警"
- },
- "Metadata Operation": {
- "message": "元数据运维"
- },
- "Error Code": {
- "message": "错误码"
- },
- "Config": {
- "message": "配置管理"
- },
- "Authority Management": {
- "message": "权限管理"
- },
- "Multi-tenancy": {
- "message": "多租户与资源管理"
- },
- "FAQ": {
- "message": "常见问题"
- },
- "FAQs of Operation and Maintenance": {
- "message": "运维常见问题"
- },
- "FAQs of Data Operation": {
- "message": "数据操作问题"
- },
- "SQL FAQs": {
- "message": "SQL 问题"
- },
- "sitemap.page.subTitle": {
- "message": "从这里开启您的 Apache Doris 之旅,与 Apache Doris 一起发现无限可能"
- },
- "download.quick.download.version.tips": {
- "message": "apache-doris-1.1.2-bin-x86-noavx2 版本暂不提供下载,我们会在进行更新。"
- },
- "Notice": {
- "message": "注意事项"
- },
- "download.quick.download.notice": {
- "message": "1.2.1 版本暂不支持使用 JDK11 运行,会在后续版本修复。"
- },
- "1.2.6": {
- "message": "Apache Doris 1.2.6 is released now.",
- "description": "Apache Doris 1.2.6 is released now."
- },
- "download.document": {
- "message": "Document",
- "description": "文档"
- },
- "user.logos": {
- "message": "Companies That Trust Apache Doris",
- "description": "Companies That Trust Apache Doris"
- },
- "user.user-case": {
- "message": "Companies Powerd by Apache Doris",
- "description": "Companies Powerd by Apache Doris"
- },
- "user.case-description": {
- "message": "There are more than 1,000 companies worldwide leveraging Apache Doris to build their unified data analytical database. Some of them are listed below:",
- "description": "There are more than 1,000 companies worldwide leveraging Apache Doris to build their unified\n data analytical database. Some of them are listed below:"
- },
- "download.version": {
- "message": "版本",
- "description": "Binary Version"
- }
-}
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/1.1 Release.md b/i18n/zh-CN/docusaurus-plugin-content-blog/1.1 Release.md
deleted file mode 100644
index 94b2882c27b..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/1.1 Release.md
+++ /dev/null
@@ -1,400 +0,0 @@
----
-{
- 'title': 'Apache Doris 1.1 Release 版本正式发布',
- 'summary': '亲爱的社区小伙伴们,我们很高兴地宣布,Apache Doris 在 2022 年 7 月 14 日迎来 1.1 Release 版本的正式发布!这是 Apache Doris 正式从 Apache 孵化器毕业后并成为 Apache 顶级项目后发布的第一个 Release 版本。在 1.1 版本中,有 90 位 Contributor 为 Apache Doris 提交了超过 450 项优化和修复,感谢每一个让 Apache Doris 变得更好的你!',
- 'date': '2022-07-14',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-亲爱的社区小伙伴们,我们很高兴地宣布,Apache Doris 在 2022 年 7 月 14 日迎来 1.1 Release 版本的正式发布!这是 Apache Doris 正式从 Apache 孵化器毕业后并成为 Apache 顶级项目后发布的第一个 Release 版本。在 1.1 版本中,有 90 位 Contributor 为 Apache Doris 提交了超过 450 项优化和修复,感谢每一个让 Apache Doris 变得更好的你!
-
-在 1.1 版本中,**我们实现了计算层和存储层的全面向量化、正式将向量化执行引擎作为稳定功能进行全面启用**,所有查询默认通过向量化执行引擎来执行,**性能较之前版本有 3-5 倍的巨大提升**;增加了直接访问 Apache Iceberg 外部表的能力,支持对 Doris 和 Iceberg 中的数据进行联邦查询,**扩展了 Apache Doris 在数据湖上的分析能力**;在原有的 LZ4 基础上增加了 ZSTD 压缩算法,进一步提升了数据压缩率;**修复了诸多之前版本存在的性能与稳定性问题**,使系统稳定性得到大幅提升。欢迎大家下载使用。
-
-## 升级说明
-
-### 向量化执行引擎默认开启
-
-在 Apache Doris 1.0 版本中,我们引入了向量化执行引擎作为实验性功能。用户需要在执行 SQL 查询手工开启,通过 `set batch_size = 4096` 和 `set enable_vectorized_engine = true `配置 session 变量来开启向量化执行引擎。
-
-在 1.1 版本中,我们正式将向量化执行引擎作为稳定功能进行了全面启用,session 变量`enable_vectorized_engine` 默认设置为 true,无需用户手工开启,所有查询默认通过向量化执行引擎来执行。
-
-### BE 二进制文件更名
-
-BE 二进制文件从原有的 palo_be 更名为 doris_be ,如果您以前依赖进程名称进行集群管理和其他操作,请注意修改相关脚本。
-
-### Segment 存储格式升级
-
-Apache Doris 早期版本的存储格式为 Segment V1,在 0.12 版本中我们实现了新的存储格式 Segment V2 ,引入了 Bitmap 索引、内存表、Page Cache、字典压缩以及延迟物化等诸多特性。从 0.13 版本开始,新建表的默认存储格式为 Segment V2,与此同时也保留了对 Segment V1 格式的兼容。
-
-为了保证代码结构的可维护性、降低冗余历史代码带来的额外学习及开发成本,我们决定从下一个版本起不再支持 Segment v1 存储格式,预计在 Apache Doris 1.2 版本中将删除这部分代码,还请所有仍在使用 Segment V1 存储格式的用户务必在 1.1 版本中完成数据格式的转换,操作手册请参考以下链接:
-
-[https://doris.apache.org/zh-CN/docs/1.0/administrator-guide/segment-v2-usage
-](https://doris.apache.org/zh-CN/docs/1.0/administrator-guide/segment-v2-usage)
-
-### 正常升级
-
-正常升级操作请按照官网上的集群升级文档进行滚动升级即可。
-
-[https://doris.apache.org/zh-CN/docs/admin-manual/cluster-management/upgrade](https://doris.apache.org/zh-CN/docs/admin-manual/cluster-management/upgrade)
-
-## 重要功能
-
-### 支持数据随机分布 [实验性功能] [#8259](https://github.com/apache/doris/pull/8259) [#8041](https://github.com/apache/doris/pull/8041)
-
-在某些场景中(例如日志分析类场景),用户可能无法找到一个合适的分桶键来避免数据倾斜,因此需要由系统提供额外的分布方式来解决数据倾斜的问题。
-
-因此通过在建表时可以不指定具体分桶键,选择使用随机分布对数据进行分桶`DISTRIBUTED BY random BUCKET number`,数据导入时将会随机写入单个 Tablet ,以减少加载过程中的数据扇出,并减少资源开销、提升系统稳定性。
-
-### 支持创建 Iceberg 外部表 [实验性功能] [#7391](https://github.com/apache/doris/pull/7391) [#7981](https://github.com/apache/doris/pull/7981) [#8179](https://github.com/apache/doris/pull/8179)
-
-Iceberg 外部表为 Apache Doris 提供了直接访问存储在 Iceberg 数据的能力。通过 Iceberg 外部表可以实现对本地存储和 Iceberg 存储的数据进行联邦查询,省去繁琐的数据加载工作、简化数据分析的系统架构,并进行更复杂的分析操作。
-
-在 1.1 版本中,Apache Doris 支持了创建 Iceberg 外部表并查询数据,并支持通过 REFRESH 命令实现 Iceberg 数据库中所有表 Schema 的自动同步。
-
-### 增加 ZSTD 压缩算法 [#8923](https://github.com/apache/doris/pull/8923) [#9747](https://github.com/apache/doris/pull/9747)
-
-目前 Apache Doris 中数据压缩方法是系统统一指定的,默认为 LZ4。针对部分对数据存储成本敏感的场景,例如日志类场景,原有的数据压缩率需求无法得到满足。
-
-在 1.1 版本中,用户建表时可以在表属性中设置`"compression"="zstd"` 将压缩方法指定为 ZSTD。在 25GB 1.1 亿行的文本日志测试数据中,**最高获得了近 10 倍的压缩率、较原有压缩率提升了 53%,从磁盘读取数据并进行解压缩的速度提升了 30%** 。
-
-## 功能优化
-
-### **更全面的向量化支持**
-
-在 1.1 版本中,我们实现了计算层和存储层的全面向量化,包括:
-
-- 实现了所有内置函数的向量化
-
-- 存储层实现向量化,并支持了低基数字符串列的字典优化
-
-- 优化并解决了向量化引擎的大量性能和稳定性问题。
-
-我们对 Apache Doris 1.1 版本与 0.15 版本分别在 SSB 和 TPC-H 标准测试数据集上进行了性能测试:
-
-- 在 SSB 测试数据集的全部 13 个 SQL 上,1.1 版本均优于 0.15 版本,整体性能约提升了 3 倍,解决了 1.0 版本中存在的部分场景性能劣化问题;
-
-- 在 TPC-H 测试数据集的全部 22 个 SQL 上,1.1 版本均优于 0.15 版本,整体性能约提升了 4.5 倍,部分场景性能达到了十余倍的提升;
-
-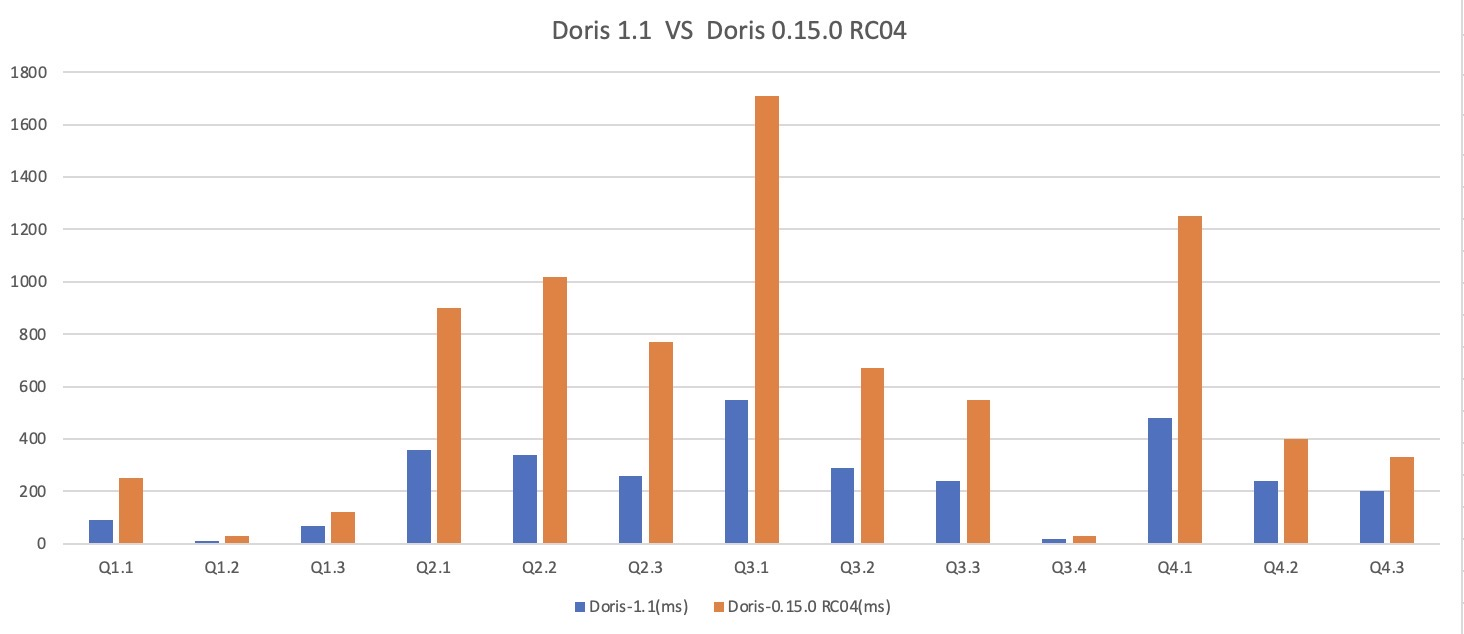
-
-<p align='center'>SSB 测试数据集</p>
-
-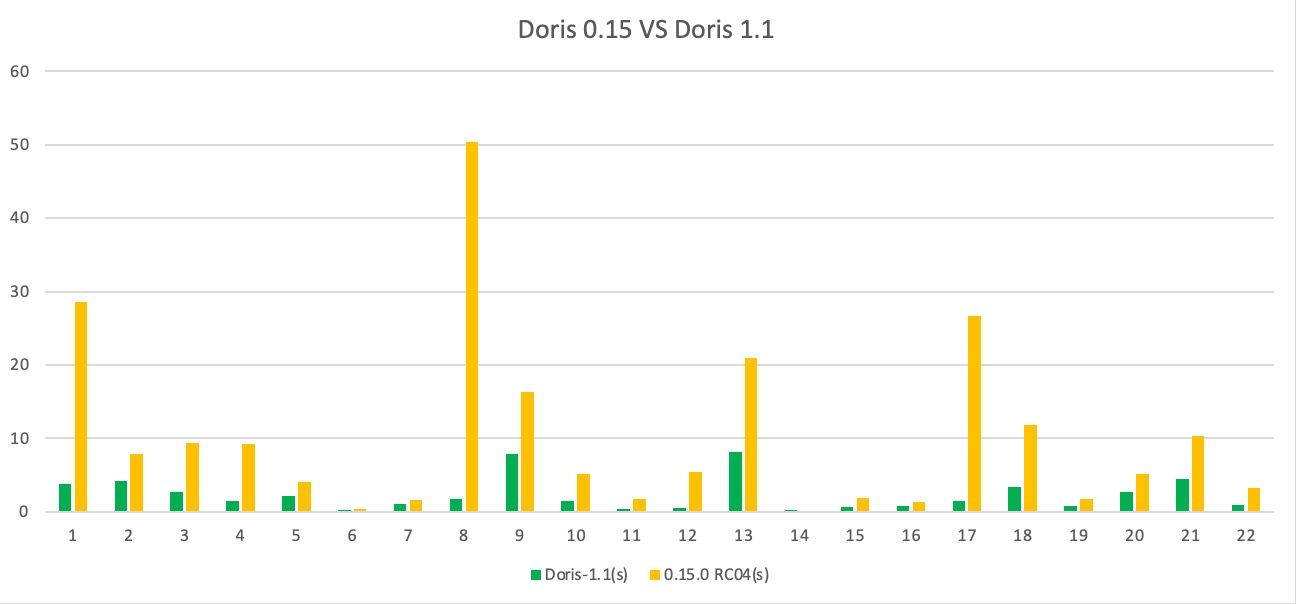
-
-<p align='center'>TPC-H 测试数据集</p>
-
-**性能测试报告:**
-
-[https://doris.apache.org/zh-CN/docs/benchmark/ssb](https://doris.apache.org/zh-CN/docs/benchmark/ssb)
-
-[https://doris.apache.org/zh-CN/docs/benchmark/tpch](https://doris.apache.org/zh-CN/docs/benchmark/tpch)
-
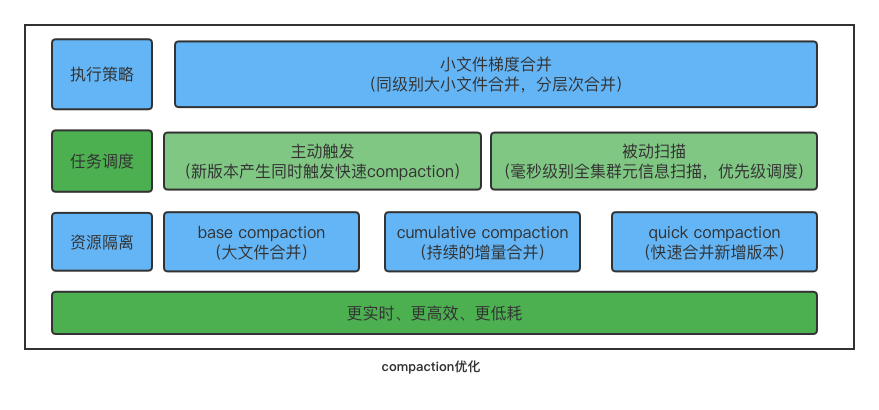
-### Compaction 逻辑优化与实时性保证 [#10153](https://github.com/apache/doris/pull/10153)
-
-在 Apache Doris 中每次 Commit 都会产生一个数据版本,在高并发写入场景下,容易出现因数据版本过多且 Compaction 不及时而导致的 -235 错误,同时查询性能也会随之下降。
-
-在 1.1 版本中我们引入了 QuickCompaction,增加了主动触发式的 Compaction 检查,在数据版本增加的时候主动触发 Compaction,同时通过提升分片元信息扫描的能力,快速发现数据版本过多的分片并触发 Compaction。通过主动式触发加被动式扫描的方式,彻底解决数据合并的实时性问题。
-
-同时,针对高频的小文件 Cumulative Compaction,实现了 Compaction 任务的调度隔离,防止重量级的 Base Compaction 对新增数据的合并造成影响。
-
-最后,针对小文件合并,优化了小文件合并的策略,采用梯度合并的方式,每次参与合并的文件都属于同一个数据量级,防止大小差别很大的版本进行合并,逐渐有层次的合并,减少单个文件参与合并的次数,能够大幅地节省系统的 CPU 消耗。
-
-
-
-在数据上游维持每秒 10w 的写入频率时(20 个并发写入任务、每个作业 5000 行、 Checkpoint 间隔 1s),1.1 版本表现如下:
-
-- 数据快速合并:Tablet 数据版本维持在 50 以下,Compaction Score 稳定。相较于之前版本高并发写入时频繁出现的 -235 问题,**Compaction 合并效率有 10 倍以上的提升**。
-
-<!---->
-
-- CPU 资源消耗显著降低:针对小文件 Compaction 进行了策略优化,在上述高并发写入场景下,**CPU 资源消耗降低 25%** ;
-
-<!---->
-
-- 查询耗时稳定:提升了数据整体有序性,大幅降低查询耗时的波动性,**高并发写入时的查询耗时与仅查询时持平**,查询性能较之前版本**有 3-4 倍提升**。
-
-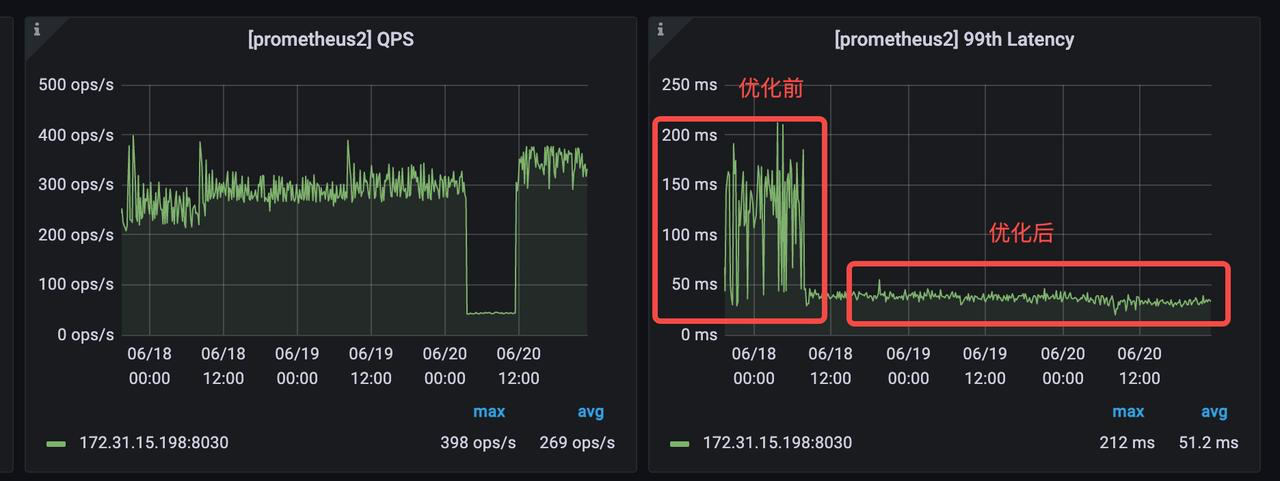
-
-### Parquet 和 ORC 文件的读取效率优化 [#9472](https://github.com/apache/doris/pull/9472)
-
-通过调整 Arrow 参数,利用 Arrow 的多线程读取能力来加速 Arrow 对每个 row_group 的读取,并修改成 SPSC 模型,通过预取来降低等待网络的代价。优化前后对 Parquet 文件导入的性能有 4 ~ 5 倍的提升。
-
-### 更安全的元数据 Checkpoint [#9180](https://github.com/apache/doris/pull/9180) [#9192](https://github.com/apache/doris/pull/9192)
-
-通过对元数据检查点后生成的 image 文件进行双重检查和保留历史 image 文件的功能,解决了 image 文件错误导致的元数据损坏问题。
-
-## Bug 修复
-
-### 修复由于缺少数据版本而无法查询数据的问题。(严重)[#9267](https://github.com/apache/doris/pull/9267) [#9266](https://github.com/apache/doris/pull/9266)
-
-问题描述:`failed to initialize storage reader. tablet=924991.xxxx, res=-214, backend=xxxx`
-
-该问题是在版本 1.0 中引入的,可能会导致多个副本的数据版本丢失。
-
-### 解决了资源隔离对加载任务的资源使用限制无效的问题(中等)[#9492](https://github.com/apache/doris/pull/9492)
-
-在 1.1 版本中, Broker Load 和 Routine Load 将使用具有指定资源标记的 BE 节点进行加载。
-
-### 修复使用 HTTP BRPC 超过 2GB 传输网络数据包导致数据传输错误的问题(中等)[#9770](https://github.com/apache/doris/pull/9770)
-
-在以前的版本中,当通过 BRPC 在后端之间传输的数据超过 2GB 时,可能会导致数据传输错误。
-
-## 其他
-
-### 禁用 Mini Load
-
-Mini Load 与 Stream Load 的导入实现方式完全一致,都是通过 HTTP 协议提交和传输数据,在导入功能支持上 Stream Load 更加完备。
-
-在 1.1 版本中,默认情况下 Mini Load 接口 `/_load` 将处于禁用状态,请统一使用 Stream Load 来替换 Mini Load。您也可以通过关闭 FE 配置项 `disable_mini_load` 来重新启用 Mini Load 接口。在版本 1.2 中,将彻底删除 Mini Load 。
-
-### 完全禁用 SegmentV1 存储格式
-
-在 1.1 版本中将不再允许新创建 SegmentV1 存储格式的数据,现有数据仍可以继续正常访问。
-
-您可以使用 ADMIN SHOW TABLET STORAGE FORMAT 语句检查集群中是否仍然存在 SegmentV1 格式的数据,如果存在请务必通过数据转换命令转换为 SegmentV2。
-
-在 Apache Doris 1.2 版本中不再支持对 Segment V1 数据的访问,同时 Segment V1 代码将被彻底删除。
-
-### 限制 String 类型的最大长度 [#8567](https://github.com/apache/doris/pull/8567)
-
-String 类型是 Apache Doris 在 0.15 版本中引入的新数据类型,在过去 String 类型的最大长度允许为 2GB。
-
-在 1.1 版本中,我们将 String 类型的最大长度限制为 1 MB,超过此长度的字符串无法再写入,同时不再支持将 String 类型用作表的 Key 列、分区列以及分桶列。
-
-已写入的字符串类型可以正常访问。
-
-### 修复 fastjson 相关漏洞 [#9763](https://github.com/apache/doris/pull/9763)
-
-对 Canal 版本进行更新以修复 fastjson 安全漏洞
-
-### 添加了 ADMIN DIAGNOSE TABLET 命令 [#8839](https://github.com/apache/doris/pull/8839)
-
-通过 ADMIN DIAGNOSE TABLET tablet_id 命令可以快速诊断指定 Tablet 的问题。
-
-## 下载使用
-
-### 下载链接
-
-[https://doris.apache.org/zh-CN/download](https://doris.apache.org/zh-CN/download)
-
-### 升级说明
-
-您可以从 Apache Doris 1.0 Release 版本和 1.0.x 发行版本升级到 1.1 Release 版本,升级过程请官网参考文档。如果您当前是 0.15 Release 版本或 0.15.x 发行版本,可跳过 1.0 版本直接升级至 1.1。
-
-[https://doris.apache.org/zh-CN/docs/admin-manual/cluster-management/upgrade](https://doris.apache.org/zh-CN/docs/admin-manual/cluster-management/upgrade
-
-### 意见反馈
-
-如果您遇到任何使用上的问题,欢迎随时通过 GitHub Discussion 论坛或者 Dev 邮件组与我们取得联系。
-
-GitHub 论坛:[https://github.com/apache/incubator-doris/discussions](https://github.com/apache/incubator-doris/discussions)
-
-Dev 邮件组:[dev@doris.apache.org](dev@doris.apache.org)
-
-## 致谢
-
-Apache Doris 1.1 Release 版本的发布离不开所有社区用户的支持,在此向所有参与版本设计、开发、测试、讨论的社区贡献者们表示感谢,他们分别是:
-
-```
-
-@adonis0147
-
-@airborne12
-
-@amosbird
-
-@aopangzi
-
-@arthuryangcs
-
-@awakeljw
-
-@BePPPower
-
-@BiteTheDDDDt
-
-@bridgeDream
-
-@caiconghui
-
-@cambyzju
-
-@ccoffline
-
-@chenlinzhong
-
-@daikon12
-
-@DarvenDuan
-
-@dataalive
-
-@dataroaring
-
-@deardeng
-
-@Doris-Extras
-
-@emerkfu
-
-@EmmyMiao87
-
-@englefly
-
-@Gabriel39
-
-@GoGoWen
-
-@gtchaos
-
-@HappenLee
-
-@hello-stephen
-
-@Henry2SS
-
-@hewei-nju
-
-@hf200012
-
-@jacktengg
-
-@jackwener
-
-@Jibing-Li
-
-@JNSimba
-
-@kangshisen
-
-@Kikyou1997
-
-@kylinmac
-
-@Lchangliang
-
-@leo65535
-
-@liaoxin01
-
-@liutang123
-
-@lovingfeel
-
-@luozenglin
-
-@luwei16
-
-@luzhijing
-
-@mklzl
-
-@morningman
-
-@morrySnow
-
-@nextdreamblue
-
-@Nivane
-
-@pengxiangyu
-
-@qidaye
-
-@qzsee
-
-@SaintBacchus
-
-@SleepyBear96
-
-@smallhibiscus
-
-@spaces-X
-
-@stalary
-
-@starocean999
-
-@steadyBoy
-
-@SWJTU-ZhangLei
-
-@Tanya-W
-
-@tarepanda1024
-
-@tianhui5
-
-@Userwhite
-
-@wangbo
-
-@wangyf0555
-
-@weizuo93
-
-@whutpencil
-
-@wsjz
-
-@wunan1210
-
-@xiaokang
-
-@xinyiZzz
-
-@xlwh
-
-@xy720
-
-@yangzhg
-
-@Yankee24
-
-@yiguolei
-
-@yinzhijian
-
-@yixiutt
-
-@zbtzbtzbt
-
-@zenoyang
-
-@zhangstar333
-
-@zhangyifan27
-
-@zhannngchen
-
-@zhengshengjun
-
-@zhengshiJ
-
-@zingdle
-
-@zuochunwei
-
-@zy-kkk
-```
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/360.md b/i18n/zh-CN/docusaurus-plugin-content-blog/360.md
deleted file mode 100644
index b38178a5c4e..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/360.md
+++ /dev/null
@@ -1,175 +0,0 @@
----
-{
- 'title': '日增百亿数据,查询结果秒出, Apache Doris 在 360商业化的统一 OLAP 应用实践',
- 'summary': "360商业化为助力业务团队更好推进商业化增长,实时数仓共经历了三种模式的演进,分别是 Storm + Druid + MySQL 模式、Flink + Druid + TiDB 的模式 以及 Flink + Doris 的模式,基于 Apache Doris 的新一代架构的成功落地使得 360商业化团队完成了实时数仓在 OLAP 引擎上的统一,成功实现广泛实时场景下的秒级查询响应。本文将为大家进行详细介绍演进过程以及新一代实时数仓在广告业务场景中的具体落地实践。",
- 'date': '2023-06-01',
- 'author': '360商业化数据团队',
- 'tags': ['最佳实践'],
-}
-
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-**导读**:360商业化为助力业务团队更好推进商业化增长,实时数仓共经历了三种模式的演进,分别是 Storm + Druid + MySQL 模式、Flink + Druid + TIDB 的模式 以及 Flink + Doris 的模式,基于 [Apache Doris](https://doris.apache.org/) 的新一代架构的成功落地使得 360商业化团队完成了实时数仓在 OLAP 引擎上的统一,成功实现广泛实时场景下的秒级查询响应。本文将为大家进行详细介绍演进过程以及新一代实时数仓在广告业务场景中的具体落地实践。
-
-作者|360商业化数据团队 窦和雨、王新新
-
-360 公司致力于成为互联网和安全服务提供商,是互联网免费安全的倡导者,先后推出 360安全卫士、360手机卫士、360安全浏览器等安全产品以及 360导航、360搜索等用户产品。
-
-360商业化依托 360产品庞大的用户覆盖能力和超强的用户粘性,通过专业数据处理和算法实现广告精准投放,助力数十万中小企业和 KA 企业实现价值增长。360商业化数据团队主要是对整个广告投放链路中所产生的数据进行计算处理,为产品运营团队提供策略调整的分析数据,为算法团队提供模型训练的优化数据,为广告主提供广告投放的效果数据。
-
-## 业务场景
-
-在正式介绍 Apache Doris 在 360 商业化的应用之前,我们先对广告业务中的典型使用场景进行简要介绍:
-
-- **实时大盘:** 实时大盘场景是我们对外呈现数据的关键载体,需要从多个维度监控商业化大盘的指标情况,包括流量指标、消费指标、转化指标和变现指标,因此其对数据的准确性要求非常高(保证数据不丢不重),同时对数据的时效性和稳定性要求也很高,要求实现秒级延迟、分钟级数据恢复。
-- **广告账户的实时消费数据场景:** 通过监控账户粒度下的多维度指标数据,及时发现账户的消费变化,便于产品团队根据实时消费情况推动运营团队对账户预算进行调整。在该场景下数据一旦出现问题,就可能导致账户预算的错误调整,从而影响广告的投放,这对公司和广告主将造成不可估量的损失,因此在该场景中,同样对数据准确性有很高的要求。目前在该场景下遇到的困难是如何在数据量比较大、查询交叉的粒度比较细的前提下,实现秒级别查询响应。
-- **AB 实验平台:** 在广告业务中,算法和策略同学会针对不同的场景进行实验,在该场景下,具有报表维度不固定、多种维度灵活组合、数据分析比较复杂、数据量较大等特点,这就需要可以在百万级 QPS 下保证数据写入存储引擎的性能,因此我们需要针对业务场景进行特定的模型设计和处理上的优化,提高实时数据处理的性能以及数据查询分析的效率,只有这样才能满足算法和策略同学对实验报表的查询分析需求。
-
-
-## 实时数仓演进
-
-为提升各场景下数据服务的效率,助力相关业务团队更好推进商业化增长,截至目前实时数仓共经历了三种模式的演进,分别是 Storm + Druid + MySQL 模式、Flink + Druid + TIDB 的模式 以及 Flink + Doris 的模式,本文将为大家进行详细介绍实时数仓演进过程以及新一代实时数仓在广告业务场景中的具体落地。
-
-### 第一代架构
-
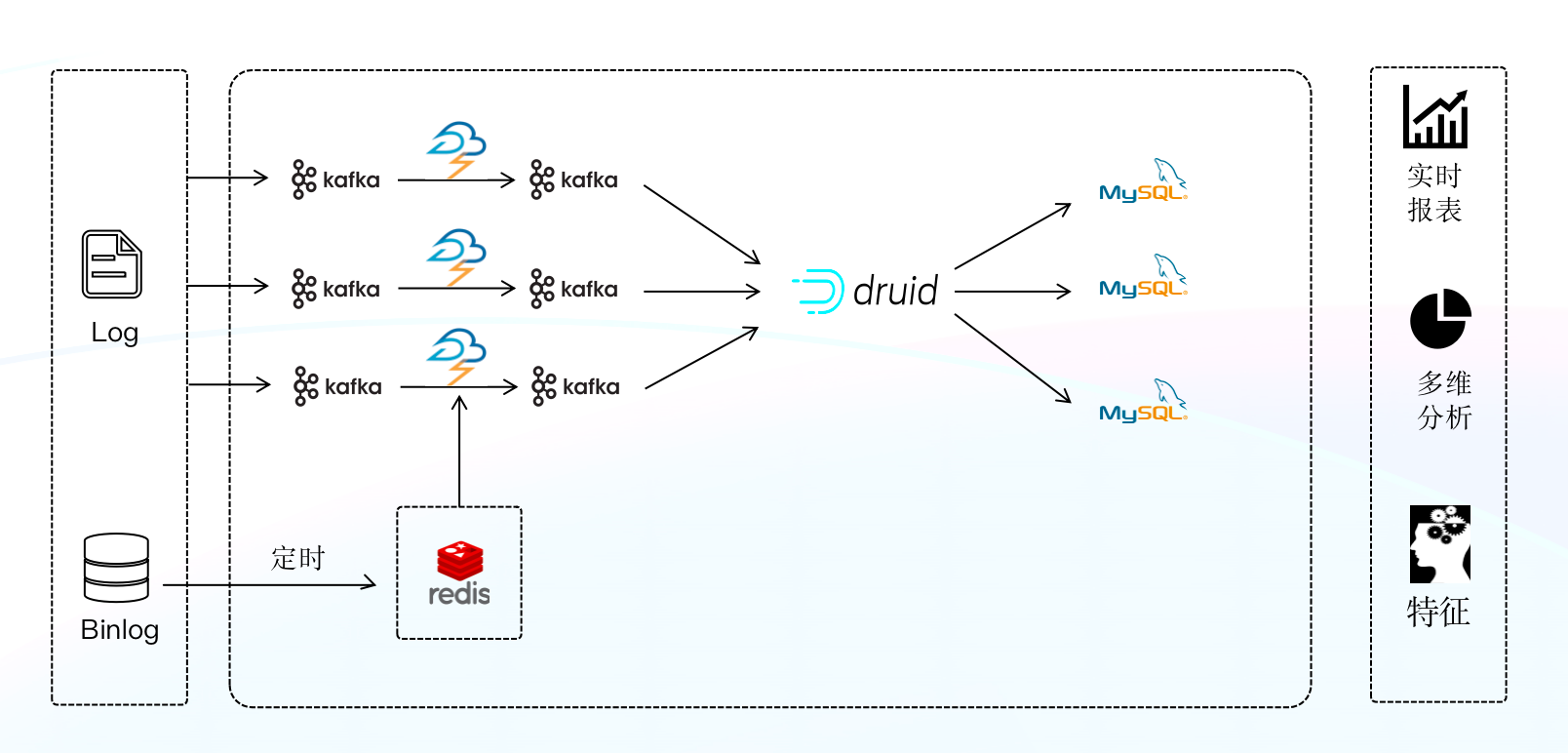
-该阶段的实时数仓是基于 Storm + Druid + MySQL 来构建的,Storm 为实时处理引擎,数据经 Storm 处理后,将数据写入 Druid ,利用 Druid 的预聚合能力对写入数据进行聚合。
-
-
-
-**架构痛点:**
-
-最初我们试图依靠该架构解决业务上所有的实时问题,经由 Druid 统一对外提供数据查询服务,但是在实际的落地过程中我们发现 Druid 是无法满足某些分页查询和 Join 场景的,为解决该问题,我们只能利用 MySQL 定时任务的方式将数据定时从 Druid 写入 MySQL 中(类似于将 MySQL 作为 Druid 的物化视图),再通过 Druid + MySQL 的模式对外提供服务。通过这种方式暂时可以满足某些场景需求,但随着业务规模的逐步扩大,当面对更大规模数据下的查询分析需求时,该架构已难以为继,架构的缺陷也越发明显:
-
-- 面对数据量的持续增长,数据仓库压力空前剧增,已无法满足实时数据的时效性要求。
-- MySQL 的分库分表维护难度高、投入成本大,且 MySQL 表之间的数据一致性无法保障。
-
-
-### 第二代架构
-
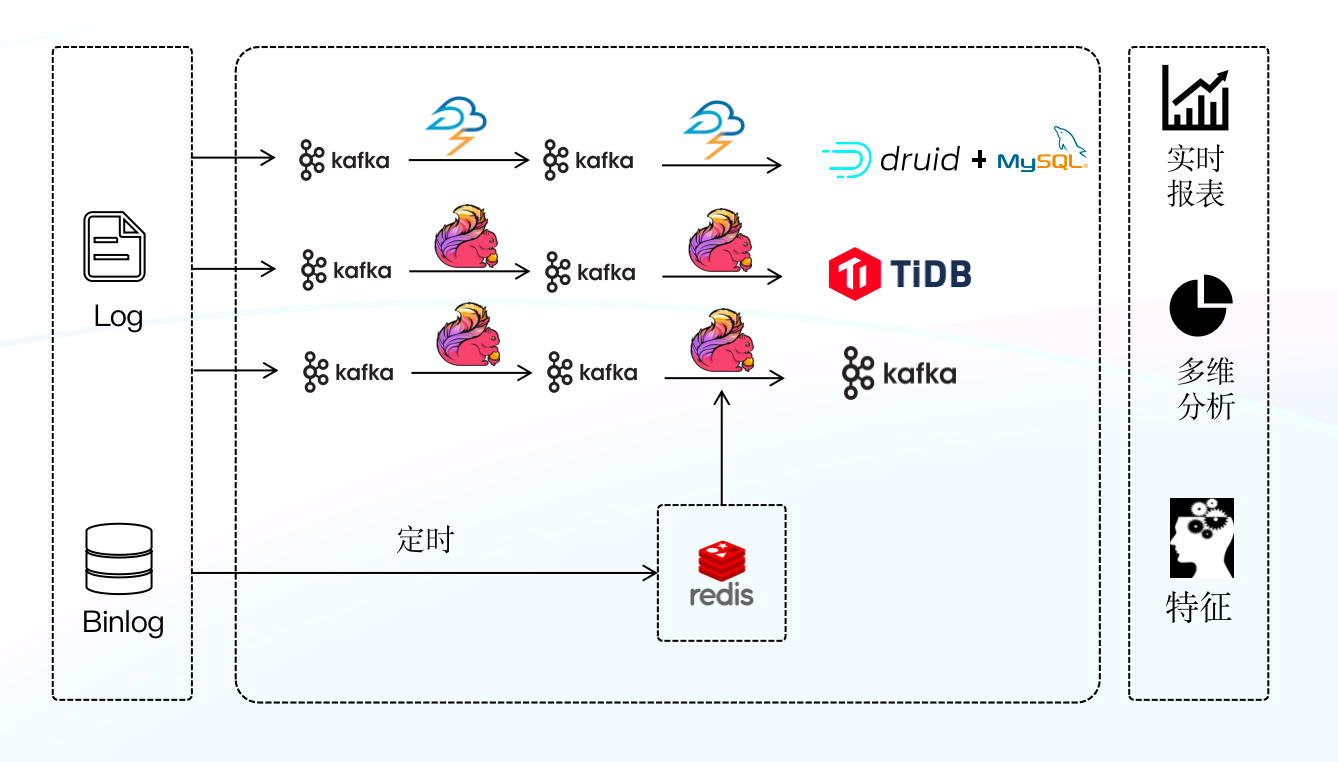
-
-
-基于第一套架构存在的问题,我们进行了首次升级,这次升级的主要变化是将 Storm 替换成新的实时数据处理引擎 Flink ,Flink 相较于 Storm 不仅在许多语义和功能上进行了扩展,还对数据的一致性做了保证,这些特性使得报表的时效性大幅提升;其次我们使用 TiDB 替换了 MySQL ,利用 TIDB 分布式的特性,一定程度上解决了 MySQL 分库分表难以维护的问题(TiDB 在一定程度上比 MySQL 能够承载更大数据量,可以拆分更少表)。在升级完成后,我们按照不同业务场景的需求,将 Flink 处理完的数据分别写入 Druid 和 TiDB ,由 Druid 和 TIDB 对外提供数据查询服务。
-
-
-**架构痛点:**
-
-虽然该阶段的实时数仓架构有效提升了数据的时效性、降低了 MySQL 分库分表维护的难度,但在一段时间的使用之后又暴露出了新的问题,也迫使我们进行了第二次升级:
-
-- Flink + TIDB 无法实现端到端的一致性,原因是当其面对大规模的数据时,开启事务将对 TiDB 写入性能造成很大的影响,该场景下 TiDB 的事务形同虚设,心有余而力不足。
-- Druid 不支持标准 SQL ,使用有一定的门槛,相关团队使用数据时十分不便,这也直接导致了工作效率的下降。
-- 维护成本较高,需要维护两套引擎和两套查询逻辑,极大增加了维护和开发成本的投入。
-
-
-### 新一代实时数仓架构
-
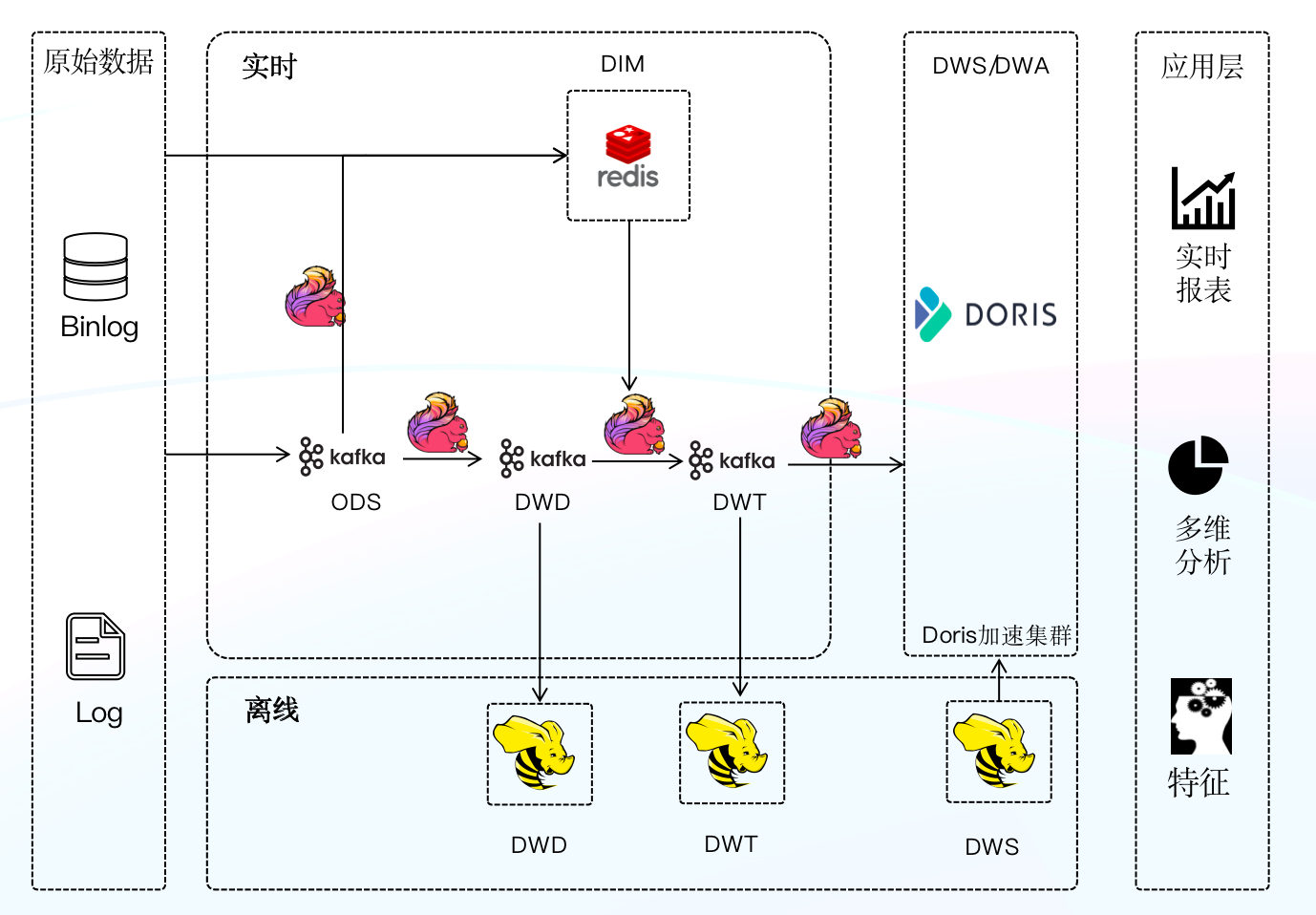
-第二次升级我们引入 Apache Doris 结合 Flink 构建了新一代实时数仓架构,借鉴离线数仓分层理念对实时数仓进行分层构建,并统一 Apache Doris 作为数仓 OLAP 引擎,由 Doris 统一对外提供服务。
-
-
-
-我们的数据主要源自于维表物料数据和业务打点日志。维表物料数据会定时全量同步到 Redis 或者 Aerospike (类似于 Redis 的 KV 存储)中,通过 Binlog 变更进行增量同步。业务数据由各个团队将日志收集到 Kafka,内部称为 ODS 原始数据(ODS 原始数据不做任何处理),我们对 ODS 层的数据进行归一化处理,包括字段命名、字段类型等,并对一些无效字段进行删减,并根据业务场景拆分生成 DWD 层数据,DWD 层的数据通过业务逻辑加工以及关联 Redis 中维表数据或者多流 Join,最后生成面向具体业务的大宽表(即 DWT 层数据),我们将 DWT 层数据经过聚合、经由 Stream Load 写入 Doris 中,由 Doris 对外提供数据查询服务。在离线数仓部分,同样也有一些场景需要每日将加工完的 DWS 数据经由 Broker Load 写入到 Doris 集群中,并利用 Doris 进行查询加速,以提升我们对外�
��供服务的效率。
-
-
-## 选择 Doris 的原因
-
-基于 Apache Doris 高性能、极简易用、实时统一等诸多特性,助力 360商业化成功构建了新一代实时数仓架构,本次升级不仅提升了实时数据的复用性、实现了 OLAP 引擎的统一,而且满足了各大业务场景严苛的数据查询分析需求,使得整体实时数据流程架构变得简单,大大降低了其维护和使用的成本。我们选择 Doris 作为统一 OLAP 引擎的重要原因大致可归结为以下几点:
-
-- **物化视图:** Doris 的物化视图与广告业务场景的特点契合度非常高,比如广告业务中大部分报表的查询维度相对比较固定,利用物化视图的特性可以提升查询的效率,同时 Doris 可以保证物化视图和底层数据的一致性,该特性可帮助我们降低维护成本的投入。
-- **数据一致性:** Doris 提供了 Stream Load Label 机制,我们可通过事务的方式与 Flink 二阶段提交进行结合,以保证幂等写入数据,另外我们通过自研 Flink Sink Doris 组件,实现了数据的端到端的一致性,保证了数据的准确性。
-- **SQL 协议兼容**:Doris 兼容 MySQL 协议,支持标准 SQL,这无论是对于开发同学,还是数据分析、产品同学,都可以实现无成本衔接,相关同学直接使用 SQL 就可以进行查询,使用门槛很低,为公司节省了大量培训和使用成本,同时也提升了工作效率。
-- **优秀的查询性能:** Apache Doris 已全面实现向量化查询引擎,使 Doris 的 OLAP 性能表现更加强悍,在多种查询场景下都有非常明显的性能提升,可极大优化了报表的询速度。同时依托列式存储引擎、现代的 MPP 架构、预聚合物化视图、数据索引的实现,在低延迟和高吞吐查询上,都达到了极速性能
-- **运维难度低:** Doris 对于集群和和数据副本管理上做了很多自动化工作,这些投入使得集群运维起来非常的简单,近乎于实现零门槛运维。
-
-## 在 AB 实验平台的具体落地
-
-Apache Doris 目前广泛应用于 360商业化内部的多个业务场景。比如在实时大盘场景中,我们利用 Doris 的 Aggregate 模型对请求、曝光、点击、转化等多个实时流进行事实表的 Join ;依靠 Doris 事务特性保证数据的一致性;通过多个物化视图,提前根据报表维度聚合数据、提升查询速度,由于物化视图和 Base 表的一致关系由 Doris 来维护保证,这也极大的降低了使用复杂度。比如在账户实时消费场景中,我们主要借助 Doris 优秀的查询优化器,通过 Join 来计算同环比......
-
-**接下来仅以 AB 实验平台这一典型业务场景为例,详尽的为大家介绍 Doris 在该场景下的落地实践,在上述所举场景中的应用将不再赘述。**
-
-
-AB 实验在广告场景中的应用非常广泛,是衡量设计、算法、模型、策略对产品指标提升的重要工具,也是精细化运营的重要手段,我们可以通过 AB实验平台对迭代方案进行测试,并结合数据进行分析和验证,从而优化产品方案、提升广告效果。
-
-在文章开头也有简单介绍,AB 实验场景所承载的业务相对比较复杂,这里再详细说明一下:
-
-- 各维度之间组合灵活度很高,例如需要对从 DSP 到流量类型再到广告位置等十几个维度进行分析,完成从请求、竞价、曝光、点击、转化等几十个指标的完整流量漏斗。
-- 数据量巨大,日均流量可以达到**百亿级别**,峰值可达**百万OPS**(Operations Per Second),一条流量可能包含**几十个实验标签 ID**。
-
-基于以上特点,我们在 AB实验场景中一方面需要保证数据算的快、数据延迟低、用户查询数据快,另一方面也要保证数据的准确性,保障数据不丢不重。
-
-
-
-
-### 数据落地
-
-当面对一条流量可能包含几十个实验标签 ID 的情况时,从分析角度出发,只需要选中一个实验标签和一个对照实验标签进行分析;而如果通过`like`的方式在几十个实验标签中去匹配选中的实验标签,实现效率就会非常低。
-
-最初我们期望从数据入口处将实验标签打散,将一条包含 20 个实验标签的流量拆分为 20 条只包含一个实验标签的流量,再导入 Doris 的聚合模型中进行数据分析。而在这个过程中我们遇到一个明显的问题,当数据被打散之后会膨胀数十倍,百亿级数据将膨胀为千亿级数据,即便 Doris 聚合模型会对数据再次压缩,但这个过程会对集群造成极大的压力。因此我们放弃该实现方式,开始尝试将压力分摊一部分到计算引擎,这里需要注意的是,如果将数据直接在 Flink 中打散,当 Job 全局 Hash 的窗口来 Merge 数据时,膨胀数十倍的数据也会带来几十倍的网络和 CPU 消耗。
-
-
-接着我们开始第三次尝试,这次尝试我们考虑在 Flink 端将数据拆分后立刻进行 Local Merge,在同一个算子的内存中开一个窗口,先将拆分的数据进行一层聚合,再通过 Job 全局 Hash 窗口进行第二层聚合,因为 Chain 在一起的两个算子在同一个线程内,因此可以大幅降低膨胀后数据在不同算子之间传输的网络消耗。该方式**通过两层窗口的聚合,再结合 Doris 的聚合模型,有效降低了数据的膨胀程度**,其次我们也同步推动实业务方定期清理已下线的实验,减少计算资源的浪费。
-
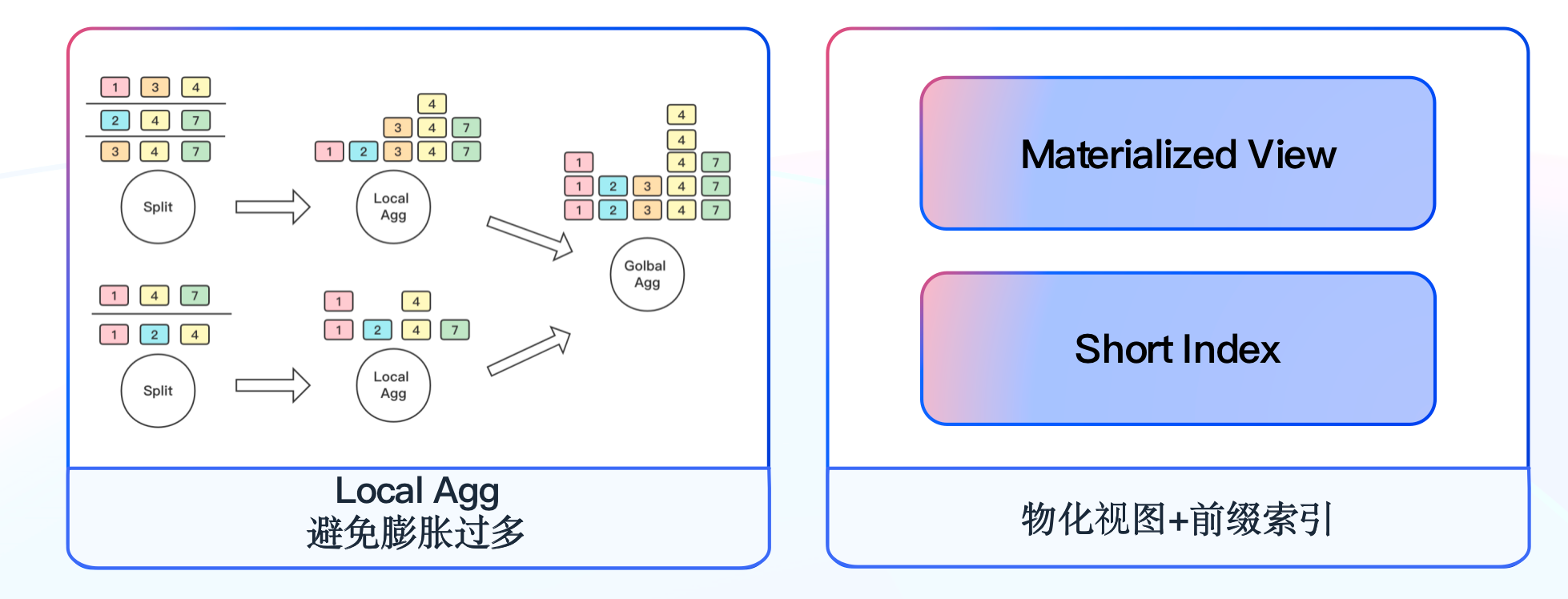
-
-
-考虑到 AB实验分析场景的特点,我们将实验 ID 作为 Doris 的第一个排序字段,利用前缀索引可以很快定位到目标查询的数据。另外根据常用的维度组合建立物化视图,进一步缩小查询的数据量,**Doris 物化视图基本能够覆盖 80% 的查询场景**,我们会定期分析查询 SQL 来调整物化视图。**最终我们通过模型的设计、前缀索引的应用,结合物化视图能力,使大部分实验查询结果能够实现秒级返回。**
-
-
-### 数据一致性保障
-
-数据的准确性是 AB实验平台的基础,当算法团队呕心沥血优化的模型使广告效果提升了几个百分点,却因数据丢失看不出实验效果,这样的结果确实无法令人接受,同时这也是我们内部不允许出现的问题。那么我们该如何避免数据丢失、保障数据的一致性呢?
-
-#### **自研 Flink Sink Doris 组件**
-
-我们内部已有一套 Flink Stream API 脚手架,因此借助 Doris 的幂等写特性和 Flink 的二阶段提交特性,自研了 Sink To Doris 组件,保证了数据端到端的一致性,并在此基础上新增了异常情况的数据保障机制。
-
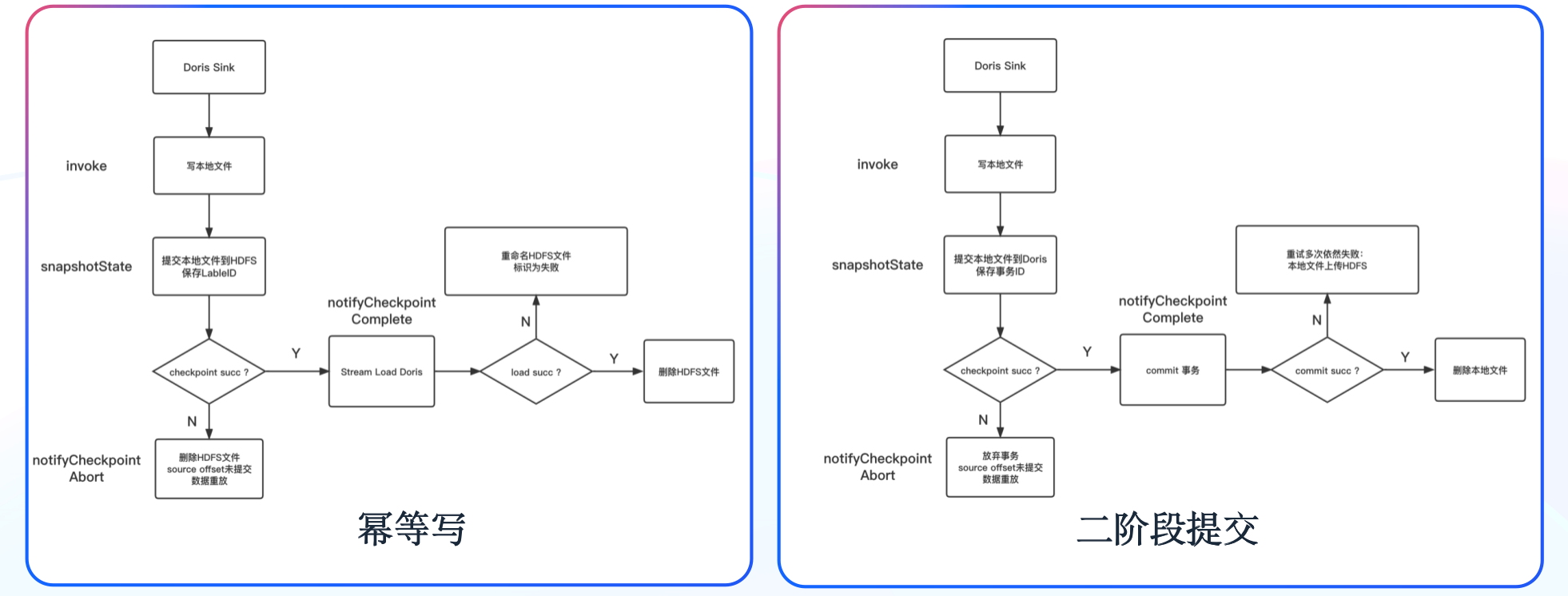
-
-
-在 Doris 0.14 版本中(初期使用的版本),我们一般通过“同一个 Label ID 只会被写入一次”的机制来保证数据的一致性;在 Doris 1.0 版本之后,通过 “Doris 的事务结合 Flink 二阶段提交”的机制来保证数据的一致性。这里详细分享使用 Doris 1.0 版本之后,通过 “Doris 的事务结合 Flink 二阶段提交”机制保证数据的一致性的原理与实现。
-
-> 在 Flink 中做到数据端到端的一致性有两种方式,一种为通过至少一次结合幂等写,一种为通过恰好一次的二阶段事务。
-
-如右图所示,我们首先在数据写入阶段先将数据写入本地文件,一阶段过程中将数据预提交到 Doris,并保存事务 ID 到状态,如果 Checkpoint 失败,则手动放弃 Doris 事务;如果 Checkpoint 成功,则在二阶段进行事务提交。对于二阶段提交重试多次仍然失败的数据,将提供数据以及事务 ID 保存到 HDFS 的选项,通过 Broker Load 进行手动恢复。为了避免单次提交数据量过大,而导致 Stream Load 时长超过 Flink Checkpoint 时间的情况,我们提供了将单次 Checkpoint 拆分为多个事务的选项。**最终成功通过二阶段提交的机制实现了对数据一致性的保障。**
-
-
-**应用展示**
-
-下图为 Sink To Doris 的具体应用,整体工具屏蔽了 API 调用以及拓扑流的组装,只需要通过简单的配置即可完成 Stream Load 到 Doris 的数据写入 。
-
-
-
-
-### 集群监控
-
-在集群监控层面,我们采用了社区提供的监控模板,从集群指标监控、主机指标监控、数据处理监控三个方面出发来搭建 Doris 监控体系。其中集群指标监控和主机指标监控主要根据社区监控说明文档进行监控,以便我们查看集群整体运行的情况。除社区提供的模板之外,我们还新增了有关 Stream Load 的监控指标,比如对当前 Stream Load 数量以及写入数据量的监控,如下图所示:
-
-
-
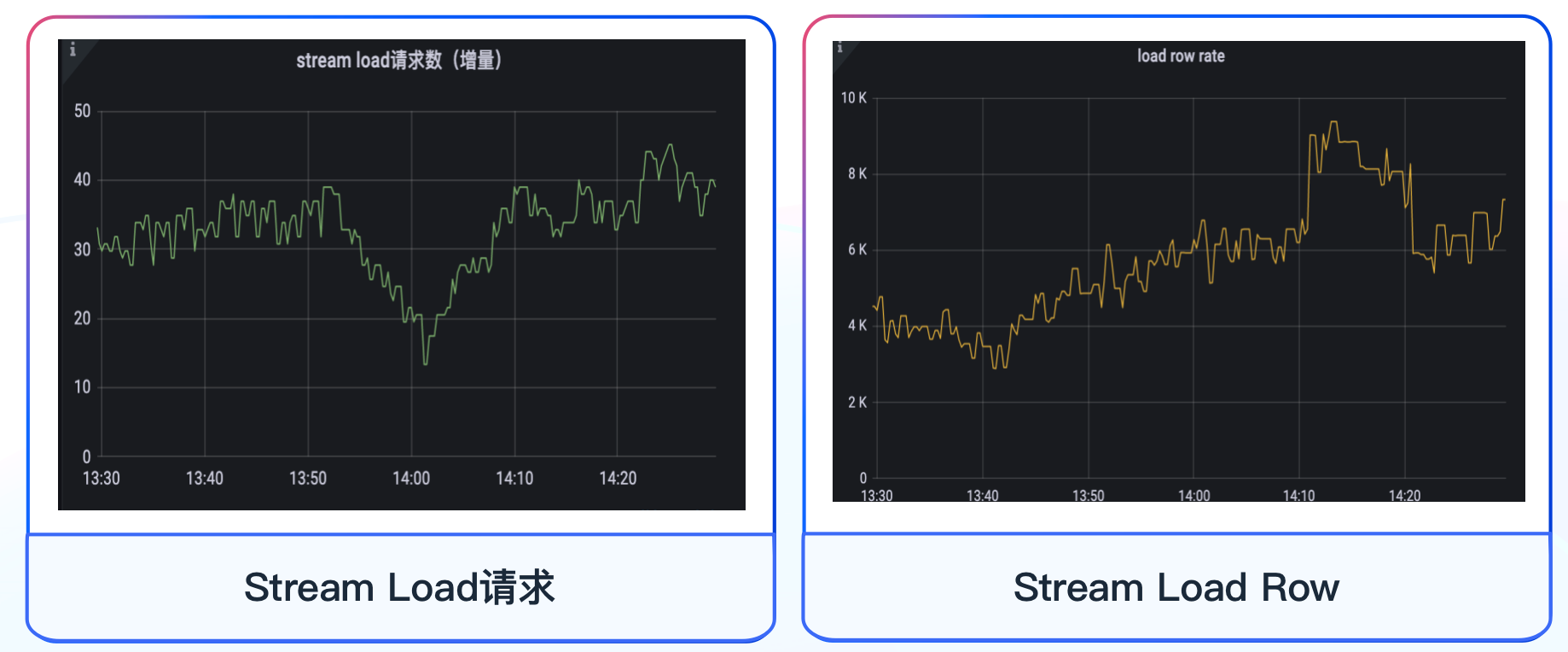
-除此之外,我们对数据写入 Doris 的时长以及写入的速度也比较关注,根据自身业务的需求,我们对任务写入数据速度、处理数据耗时等数据处理相关指标进行监控,帮助我们及时发现数据写入和读取的异常情况,借助公司内部的报警平台进行监控告警,报警方式支持电话、短信、推推、邮件等
-
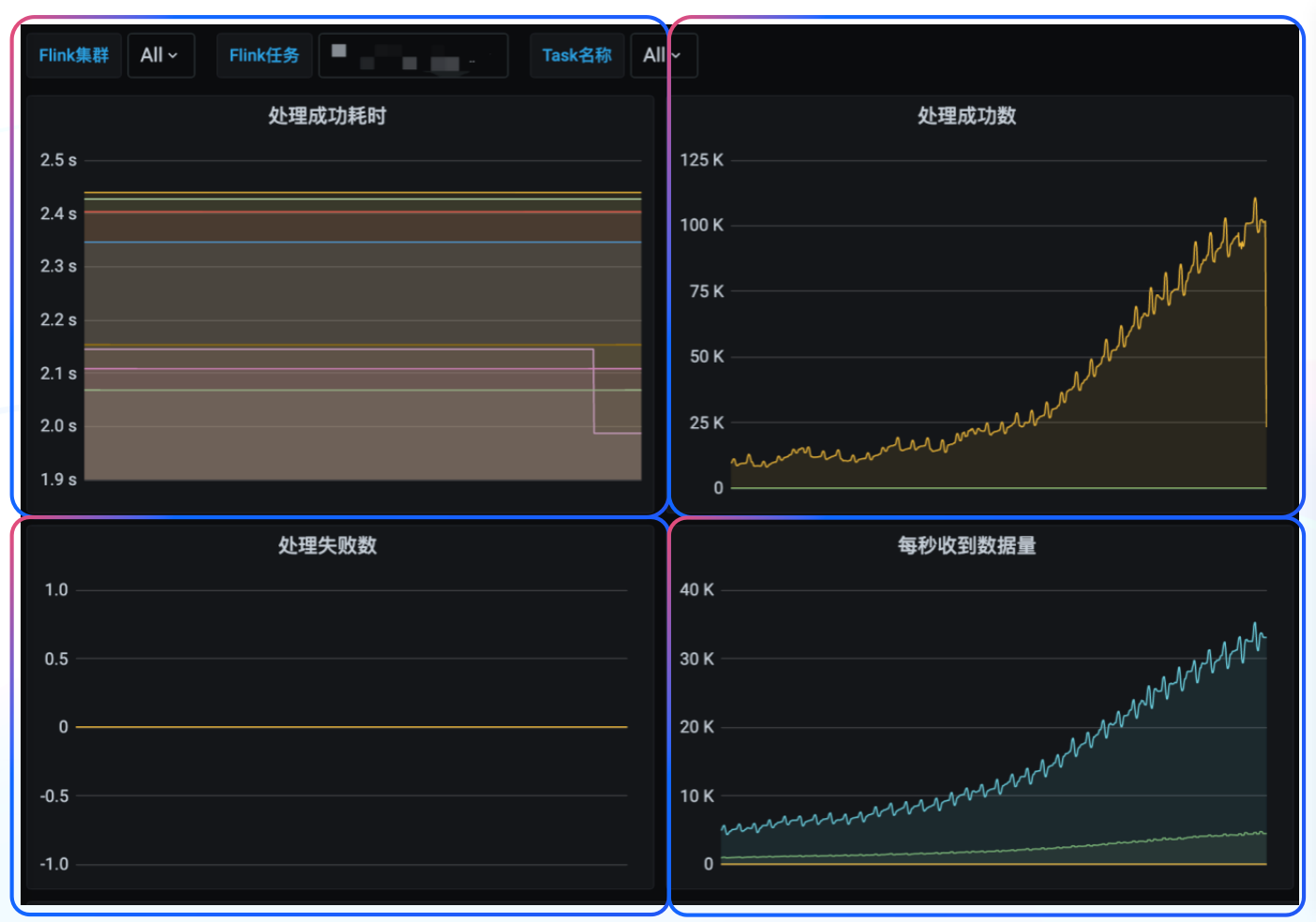
-
-
-
-
-## 总结与规划
-
-目前 Apache Doris 主要应用于广告业务场景,**已有数十台集群机器,覆盖近 70% 的实时数据分析场景,实现了全量离线实验平台以及部分离线 DWS 层数据查询加速。当前日均新增数据规模可以达到百亿级别,在大部分实时场景中,其查询延迟在 1s 内**。同时,Apache Doris 的成功落地使得我们完成了实时数仓在 OLAP 引擎上的统一。Doris 优异的分析性能及简单易用的特点,也使得数仓架构更加简洁。
-
-未来我们将对 Doris 集群进行扩展,根据业务优先级进行资源隔离,完善资源管理机制,并计划将 Doris 应用到 360商业化内部更广泛的业务场景中,充分发挥 Doris 在 OLAP 场景的优势。最后我们将更加深入的参与到 Doris 社区中来,积极回馈社区,与 Doris 并肩同行,共同进步!
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Annoucing.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Annoucing.md
deleted file mode 100644
index 29e78a6902c..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Annoucing.md
+++ /dev/null
@@ -1,74 +0,0 @@
----
-{
- 'title': '开源实时分析型数据库 Apache Doris 正式成为顶级项目',
- 'summary': 'Apache Doris 是一个基于 MPP 的现代化、高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 在多维报表、用户画像、即席查询、实时大屏等诸多业务领域都能得到很好应用。',
- 'date': '2022-06-16',
- 'author': '陈明雨',
- 'tags': ['重大新闻'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-Apache Doris 是一个基于 MPP 的现代化、高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 在多维报表、用户画像、即席查询、实时大屏等诸多业务领域都能得到很好应用。
-
-Apache Doris 最早是诞生于百度内部广告报表业务的 Palo 项目,2017 年正式对外开源,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化,之后在 Apache 导师的指导下由孵化器项目管理委员会成员进行孵化和运营。
-
-我们很自豪 Doris 能够顺利从 Apache 孵化器毕业,这是一个重要的里程碑。在整个孵化阶段,依靠 Apache 理念的指导和孵化器导师的帮助,我们学会了如何以 Apache 的方式去发展我们的项目与社区,也在这一进程中获得了巨大的成长。
-
-目前 Apache Doris 社区已经聚集了来自不同行业近百家企业的 300 余位贡献者,并且每月活跃贡献者人数也接近 100 位。在孵化期间,Apache Doris 一共发布了 8 个重要版本,完成了包括存储引擎升级、向量化执行引擎等诸多重大功能,并正式发布了 1.0 版本。正是依靠这些来自开源贡献者的力量,才使得 Apache Doris 取得了今天的成绩。
-
-与此同时,Apache Doris 如今在中国乃至全球范围内都拥有着极为广泛的用户群体,截止目前, Apache Doris 已经在全球超过 500 家企业的生产环境中得到应用,在中国市值或估值排行前 50 的互联网公司中,有超过 80% 长期使用 Apache Doris,包括百度、美团、小米、京东、字节跳动、腾讯、快手、网易、微博、新浪、360 等知名公司。同时在一些传统行业如金融、能源、制造、电信等领域也有着丰富的应用。
-
-你可以基于 Apache Doris 快速构建一个简单易用并且性能强大的数据分析平台,非常易于上手,所需要付出的学习成本非常低。并且 Apache Doris 的分布式架构非常简洁,可以极大降低系统运维的工作量,这也是越来越多用户选择 Apache Doris 的关键因素。
-
-作为一款成熟的分析型数据库项目,Apache Doris 有以下优势:
-
-- 性能优异:自带高效的列式存储引擎,减少数据扫描量的同时还实现了超高的数据压缩比。同时 Doris 还提供了丰富的索引结构来加速数据读取与过滤,利用分区分桶裁剪功能,Doris 可以支持在线服务业务的超高并发,单节点最高可支持上千 QPS。更进一步,Apache Doris 结合了向量化执行引擎来充分发挥现代化 CPU 并行计算能力,辅以智能物化视图技术实现预聚合加速,并可以通过查询优化器同时进行基于规划和基于代价的查询优化。通过上述多种方式,实现了极致的查询性能。
-
-- 简单易用:支持标准 ANSI SQL 语法,包括单表聚合、排序、过滤和多表 Join、子查询等,还支持窗口函数、Grouping Set 等复杂 SQL 语法,同时用户可以通过 UDF 和 UDAF 等自定义函数来拓展系统功能。除此以外,Apache Doris 还实现了 MySQL 协议兼容,用户可以通过各类客户端工具来访问 Doris,并支持与 BI 工具的无缝对接。
-
-- 架构精简:系统只有两个 Frontend(FE)和 Backend(BE)两个模块,其中 FE 节点负责用户请求的接入、查询计划的解析、元数据存储及集群管理等工作,BE 节点负责数据存储和查询计划的执行,自身就是一个完备的分布式数据库管理系统,用户无需安装任何第三方管控组件即可运行起 Apache Doris 集群,并且部署和升级过程都非常简易。同时,任一模块都可以支持横向拓展,集群最高可以拓展到数百个节点,支持存储超过 10PB 的超大规模数据。
-
-- 稳定可靠:支持数据多副本存储,集群具备自愈功能,自身的分布式管理框架可以自动管理数据副本的分布、修复和均衡,副本损坏时系统可以自动感知并进行修复。节点扩容时,仅需一条 SQL 命令即可完成,数据分片会自动在节点间均衡,无需人工干预或操作。无论是扩容、缩容、单节点故障还是在升级过程中,系统都无需停止运行,可正常提供稳定可靠的在线服务。
-
-- 生态丰富:提供丰富的数据同步方式,支持快速加载来自本地、Hadoop、Flink、Spark、Kafka、SeaTunnel 等系统中的数据,也可以直接访问 MySQL、PostgreSQL、Oracle、S3、Hive、Iceberg、Elasticsearch 等系统中的数据而无需数据复制。同时存储在 Doris 中的数据也可以被 Spark、Flink 读取,并且可以输出给上游数据应用进行展示分析。
-
-毕业不是最终目标,它是新征程的起点。在过去,我们发起 Doris 的目标是为更多人提供体验更佳的数据分析工具、解决他们数据分析的难题。成为 Apache 顶级项目一方面是对 Apache Doris 社区过去所有贡献者一直以来辛勤工作的肯定,另一方面也意味着我们在 Apache Way 的指引下建立了一个强大的、繁荣的、可持续发展的开源社区。未来我们将会继续以 Apache 方式运作社区,相信会吸引到更多优秀的开源贡献者参与社区中来,社区也会在所有贡献者的帮助下得到进一步成长。
-
-Apache Doris 后续将开展更多富有挑战且有意义的工作,包括新的查询优化器、对湖仓一体化的支持,以及面向云上基础设施的架构演进等等。欢迎更多的开源技术爱好者加入 Apache Doris 的社区,携手共成长。
-
-我们再次由衷地感谢所有参与建设 Apache Doris 社区的贡献者们,以及所有使用 Apache Doris 并不断提出改进建议的用户们。同时也感谢一路走来,不断鼓励、支持和帮助过我们的孵化器导师、IPMC 成员以及各个开源项目社区的朋友们。
-
-**Apache Doris GitHub:**
-
-[https://github.com/apache/doris](https://github.com/apache/doris)
-
-**Apache Doris website:**
-
-[http://doris.apache.org](http://doris.apache.org)
-
-**Please contact us via:**
-
-[dev@doris.apache.org.](dev@doris.apache.org.)
-
-**See How to subscribe:**
-
-[https://doris.apache.org/zh-CN/community/subscribe-mail-list](https://doris.apache.org/zh-CN/community/subscribe-mail-list/)
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/BestPractice_Kwai.md b/i18n/zh-CN/docusaurus-plugin-content-blog/BestPractice_Kwai.md
deleted file mode 100644
index 69f57c1d457..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/BestPractice_Kwai.md
+++ /dev/null
@@ -1,181 +0,0 @@
----
-{
- 'title': 'Doris on Es在快手商业化的最佳实践',
- 'language": "zh',
- 'summary': "快手商业化报表引擎为外部广告主提供广告投放效果的实时多维分析报表在线查询服务,以及为内部各商业化系统提供多维分析报表查询服务,致力于解决多维分析报表场景的高性能、高并发、高稳定的查询问题。早期Druid on Es的架构含有诸多弊端,通过调研我们选择了Doris on Es的数仓解决方案。使用Doris 之后,查询变得简单。我们仅需要按天同步事实表和维表,在查询的同时 Join即可。通过Doris替代Druid、Clickhouse的方案,基本覆盖了我们使用Druid 时的所有场景,大大提高了海量数据的聚合分析能力。在Apache Doris的使用过程中,我们还发现了一些意想不到的收益:例如,Routine Load和 Broker Load的导入方式较为简单,提升了查询速度;数据占用空间大幅降低;Doris支持MySQL协议,方便了数据分析师自助取数绘图等。",
- 'date': '2022-12-14',
- 'author': '贺祥',
- 'tags': ['最佳实践']
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-> 作者:贺祥,数据架构高级工程师,快手商业化团队
-
-
-
-# 1 关于快手
-
-## 1.1 快手
-
-快手(HKG: 1024)是一个短视频和潮流社交网络。发现有趣的短片,通过生活中的录音、视频、玩日常挑战或喜欢最好的动效模版和视频来为虚拟社区做出贡献。用短视频分享生活,并从数十种神奇的效果和滤镜中选择喜欢的方式。
-
-## 1.2 快手商业化报表引擎
-
-快手商业化报表引擎为外部广告主提供广告投放效果的实时多维分析报表在线查询服务,以及为内部各商业化系统提供多维分析报表查询服务,致力于解决多维分析报表场景的高性能、高并发、高稳定的查询问题。
-
-# 2 初期架构
-
-## 2.1 需求背景
-
-传统 OLAP 引擎应对多维分析时更多是以预建模的方式,通过构建数据立方体(Cube)对事实数据进行下钻、上卷、切片、切块等操作。现代 OLAP 分析引入了关系模型的理念,在二维关系表中描绘数据。而在建模过程中,往往有两种建模方式,一是采用宽表模型、将多张表的数据通过 Join 写入进一张宽表中,另一种方式是采用星型模型、将数据表区分为事实表和维度表、查询时对事实表与维度表进行 Join 。
-以上两种方案各有部分优缺点:
-
-宽表模型:
-
-采取空间换时间的思路,理论上都是维表主键为唯一 ID 来填充所有维度,冗余存储了多条维度数据。其优势在于查询时非常方便,无需关联额外维表,性能表现更佳。其弊端在于如果有维度数据变化,需要对全表数据进行重刷,无法支撑高频的 Update。
-
-星型模型:
-
-维度数据与事实数据完全分离,维度数据往往用专门的引擎存储 (如 MySQL、Elasticsearch 等),查询时通过主键关联查询维度数据,其优势在于维度数据变化不影响事实数据、可支持高频 Update 操作。其弊端在于查询逻辑相对更复杂,且多表 Join 可能导致性能受损。
-
-## 2.2 业务需求
-
-在快手的业务场景中,商业化报表引擎承载了外部广告主实时查询广告投放效果的需求,在构建报表引擎时,我们期望可以满足如下要求:
-- 超大数据量:单表原始数据每天增量百亿
-- 查询高 QPS:平均 QPS千级别
-- 高稳定性要求:在线服务要求稳定性4个9
-最为重要的是,由于维度数据经常发生变更,维度表需要支持高达上千 QPS 的 Update 操作,同时还要进一步支持模糊匹配、分词检索等需求。
-基于以上需求,我们选择了星型模型来建模,并以 Apache Druid 和 Elasticsearch 为核心构建了早期的报表引擎架构。
-
-## 2.3 初期架构:基于Apache Druid的架构
-
-我们选择了引擎结合的方式,用Elasticsearch适配Druid引擎来实现。在数据写入阶段,我们通过Flink对数据进行分钟级预聚合,利用Kafka对数据进行小时级别的数据预聚合。在数据查询中,App端发起查询需求,对RE Front统一接口进行查询,Re Query根据引擎适配,向维表引擎(Elasticsearch和MySQL)及扩展引擎分别发起查询。
-
-Druid则是一款基于时序的查询引擎,支持数据实时摄入,用来存储和查询大量的事实数据。而选用Elasticsearch作为维度数据存储引擎,主要是因为如下原因:
-- 支持高频实时更新,可以支撑上千 QPS的 Update操作
-- 支持分词模糊检索,适用于快手的业务
-- 支持量级较高的维表数据,不用像MySQL数据库一样做分库分表才能满足
-- 支持数据同步监控,同时拥有检查和恢复的服务
-
-## 2.4 报表引擎
-
-报表引擎架构整体分为REFront 和 REQuery两层,REMeta为独立的元数据管理模块。报表引擎在REQuery内部实现MEM Join。支持Druid引擎中的事实数据与ES引擎中的维度数据做关联查询。为上层业务提供虚拟的cube表查询。屏蔽复杂的跨引擎管理查询逻辑。
-
-
-
-## 3 基于Apache Doris的架构
-
-## 3.1 架构遗留的问题
-
-首先,我们在使用报表引擎时,发现了这样的一个问题。Mem Join是单机实现与串行执行,到单次从ES中拉取的数据量超过10W时,响应时间已经接近10s,用户体验差。而且单节点实现大规模数据Join处理,内存消耗大,有Full GC风险。
-
-其次,Druid的Lookup Join了功能不够完善是一个较大的问题,不能完全满足真实业务需求。
-
-## 3.2 选型调研
-
-于是我们对业界常见的 OLAP 数据库进行了调研,其中最具代表性的为 Apache Doris和 Clickhouse。在进一步的调研中我们发现,Apache Doris在大宽表Join的能力更强。ClickHouse能够支持 Broadcast 基于内存的Join,但是对于大数据量千万级以上大宽表的Join,ClickHouse 的性能表现不好。Doris 和 Clickhouse 都支持明细数据存储,但Clickhouse支持的并发度较低,相反Doris支持高并发低延时的查询服务,单机最高支持上千QPS。在并发增加时,线性扩充FE和BE即可支持。而Clickhouse的数据导入没有事务支持功能,无法实现exactly once语义,对标准sql的支持也是有限的。相比之下,Doris提供了数据导入的事务支持和原子性,Doris 自身能够保证不丢不重的订阅 Kafka 中的消息,即 Exactly-Once 消费语义。ClickHouse使用门槛高、运维成本高和分布式能力弱,需要较多的定制化和较深的技术实力也
是另一个难题,Doris则不同,只有FE、BE两个核心组件,外 [...]
-
-由此看来Doris可以比较好的提升Join的性能,在迁移成本、横向扩容、并发程度等其他方面也比较优秀。不过在高频Update上,Elasticsearch具有先天的优势。
-
-通过 Doris 创建 ES 外表的方式来同时应对高频Upate和Join性能问题,会是比较理想的解决方案。
-
-## 3.3 Doris+Doris on ES完美配合
-
-Doris on ES 的查询性能究竟如何呢?
-
-首先,Apache Doris 是一个基于MPP 架构的实时分析型数据库,性能强劲、横向扩展能力能力强。Doris on ES构建在这个能力之上,并且对查询做了大量的优化。其次,在这些之上,融合Elasticsearch的能力之后,我们还对查询功能做出了大量的优化:
-- Shard级别并发
-- 行列扫描自动适配,优先列式扫描
-- 顺序读取,提前终止
-- 两阶段查询变为一阶段查询
-- Join场景使用Broadcast Join,对于小批量数据Join特别友好
-
-
-
-## 3.4 基于Doris on Elasticsearch的架构实现
-
-### 3.4.1 数据链路升级
-
-数据链路的升级适配比较简单。第一步,由Doris构建新的Olap表,配置好物化视图。第二步,基于之前事实数据的kafka topic启动routine load,导入实时数据。第三步,从Hive中通broker load导入离线数据。最后一步,通过Doris创建Es外表。
-
-
-
-### 3.4.2 报表引擎适配升级
-
-
-
-注:上图关联的mysql维表是基于未来规划,目前主要是ES做维表引擎
-
-报表引擎适配
-- 抽象基于Doris的星型模型虚拟cube表
-- 适配cube表查询解析,智能下推
-- 支持灰度上线
-
-# 4 线上表现
-
-## 4.1 查询响应时间
-
-### 4.1.1 事实表查询表现对比
-
-Druid
-
-
-
-Doris
-
-
-
-99分位耗时Druid大概为270ms,Doris为150ms,延时下降45%
-
-### 4.1.2 Join场景下cube表查询表现对比
-
-Druid
-
-
-
-Doris
-
-
-
-99分位耗时Druid大概为660ms,Doris为440ms,延时下降33%
-
-### 4.1.3 收益总结
-
-- P99整体耗时下降35%左右
-- 资源节省50%左右
-- 去除报表引擎内部Mem Join的复杂逻辑,下沉至Doris通过DOE实现,在大查询场景下(维表结果超过10W,性能提升超过10倍,10s->1s)
-- 更丰富的查询语义(原本Mem Join实现比较简单,不支持复杂的查询)
-
-# 5 总结与未来规划
-
-在快手商业化业务里面,维度数据与事实数据Join查询是非常普遍的。使用Doris 之后,查询变得简单。我们仅需要按天同步事实表和维表,在查询的同时 Join即可。通过Doris替代Druid、Clickhouse的方案,基本覆盖了我们使用Druid 时的所有场景,大大提高了海量数据的聚合分析能力。在Apache Doris的使用过程中,我们还发现了一些意想不到的收益:例如,Routine Load和 Broker Load的导入方式较为简单,提升了查询速度;数据占用空间大幅降低;Doris支持MySQL协议,方便了数据分析师自助取数绘图等。
-
-尽管Doris on ES的解决方案比较成功的满足了我们的报表业务,ES外表映射仍然需要手工建表。但Apache Doris于近日完成了最新版本V1.2.0的发布,新版本功能新增了Multi-Catlog,提供了无缝接入Hive、ES、Hudi、Iceberg 等外部数据源的能力。用户可以通过 CREATE CATALOG 命令连接到外部数据源,Doris 会自动映射外部数据源的库、表信息。如此一来,以后我们就不需要再手动创建Es外表完成映射,大大节省了开发的时间成本,提升了研发效率。而全面向量化、Ligt Schema Change、Merge-on-Write、Java UDF等其他新功能的实现,也让我们对Apache Doris有了全新的期待。祝福Apache Doris!
-
-
-# 联系我们
-
-官网:http://doris.apache.org
-
-Github:https://github.com/apache/doris
-
-dev邮件组:dev@doris.apache.org
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Compaction.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Compaction.md
deleted file mode 100644
index 277aeb9a3d7..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Compaction.md
+++ /dev/null
@@ -1,219 +0,0 @@
----
-{
- 'title': '资源消耗降低 90%,速度提升 50%,解读 Apache Doris Compaction 最新优化与实现',
- 'summary': "在 Apache Doris 最新的 1.2.2 版本和即将发布的 2.0.0 版本中,我们对系统 Compaction 能力进行了全方位增强,在触发策略、执行方式、工程实现以及参数配置上都进行了大幅优化,在实时性、易用性与稳定性得到提升的同时更是彻底解决了查询效率问题。",
- 'date': '2023-06-09',
- 'author': 'Apache Doris',
- 'tags': ['技术解析'],
-}
-
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-# 背景
-
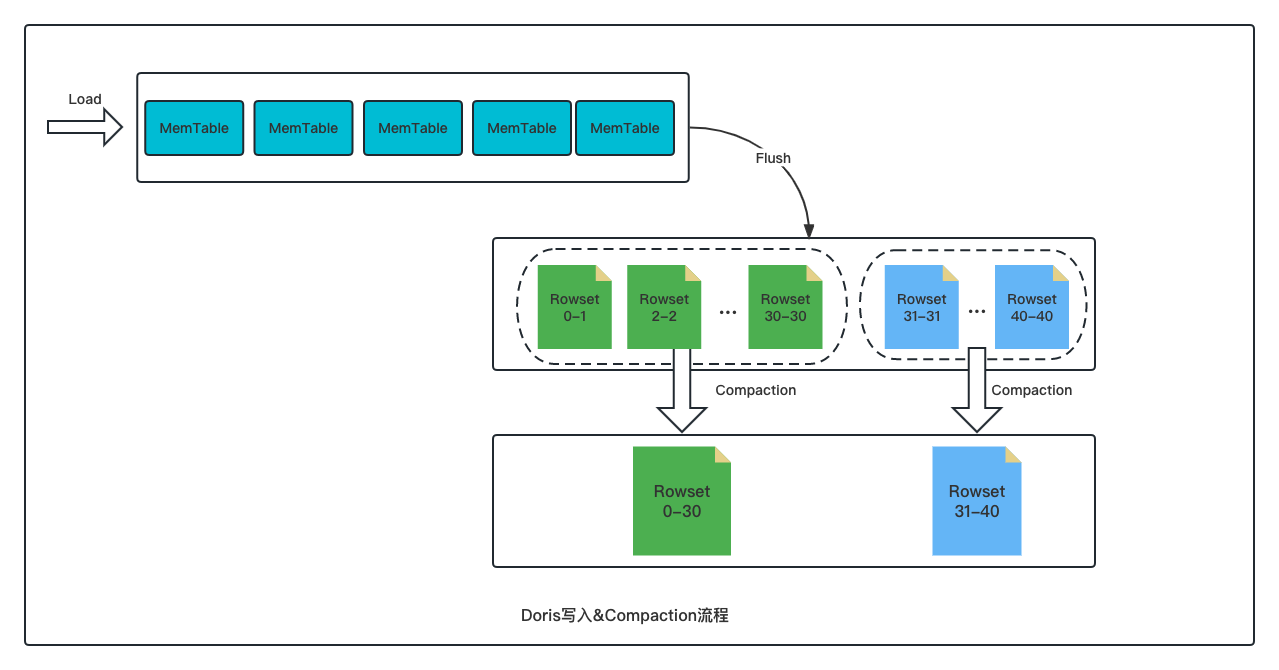
-LSM-Tree( Log Structured-Merge Tree)是数据库中最为常见的存储结构之一,其核心思想在于充分发挥磁盘连续读写的性能优势、以短时间的内存与 IO 的开销换取最大的写入性能,数据以 Append-only 的方式写入 Memtable、达到阈值后冻结 Memtable 并 Flush 为磁盘文件、再结合 Compaction 机制将多个小文件进行多路归并排序形成新的文件,最终实现数据的高效写入。
-
-[Apache Doris](https://github.com/apache/doris) 的存储模型也是采用类似的 LSM-Tree 数据模型。用户不同批次导入的数据会先写入内存结构,随后在磁盘上形成一个个的 Rowset 文件,每个 Rowset 文件对应一次数据导入版本。而 Doris 的 Compaction 则是负责将这些 Rowset 文件进行合并,将多个 Rowset 小文件合并成一个 Rowset 大文件。
-
-
-
-在此过程中 Compaction 发挥着以下作用:
-
-- 每个 Rowset 内的数据是按主键有序的,但 Rowset 与 Rowset 之间数据是无序的,Compaction 会将多个 Rowset 的数据从无序变为有序,提升数据在读取时的效率;
-- 数据以 Append-only 的方式进行写入,因此 Delete、Update 等操作都是标记写入,Compaction 会将标记的数据进行真正删除或更新,避免数据在读取时进行额外的扫描及过滤;
-- 在 Aggregate 模型上,Compaction 还可以将不同 Rowset 中相同 Key 的数据进行预聚合,减少数据读取时的聚合计算,进一步提升读取效率。
-
-# 问题与思考
-
-尽管 Compaction 在写入和查询性能方面发挥着十分关键的作用,但 Compaction 任务执行期间的写放大问题以及随之而来的磁盘 I/O 和 CPU 资源开销,也为系统稳定性和性能的充分发挥带来了新的挑战。
-
-在用户真实场景中,往往面临着各式各样的数据写入需求,并行写入任务的多少、单次提交数据量的大小、提交频次的高低等,各种场景可能需要搭配不同的 Compaction 策略。而不合理的 Compaction 策略则会带来一系列问题:
-
-- Compaction 任务调度不及时导致大量版本堆积、Compaction Score 过高,最终导致写入失败(-235/-238);
-- Compaction 任务执行速度慢,CPU 消耗高;
-- Compaction 任务内存占用高,影响查询性能甚至导致 BE OOM;
-
-与此同时,尽管 Apache Doris 提供了多个参数供用户进行调整,但相关参数众多且语义复杂,用户理解成本过高,也为人工调优增加了难度。
-
-
-
-
-基于以上问题,从 Apache Doris 1.1.0 版本开始,我们增加了主动触发式 QuickCompaction、引入了 Cumulative Compaction 任务的隔离调度并增加了小文件合并的梯度合并策略,对高并发写入和数据实时可见等场景都进行了针对性优化。
-
-而在 Apache Doris 最新的 1.2.2 版本和即将发布的 2.0.0 版本中,我们对系统 Compaction 能力进行了全方位增强,**在触发策略、执行方式 、 工程实现以及参数配置上都进行了大幅优化,** **在实时性、易用性与稳定性得到提升的同时更是彻底解决了查询效率问题**。
-
-# Compaction 优化与实现
-
-在设计和评估 Compaction 策略之时,我们需要综合权衡 Compaction 的任务模型和用户真实使用场景,核心优化思路包含以下几点:
-
-- **实时性和高效性**。Compaction 任务触发策略的实时性和任务执行方式的高效性直接影响到了查询执行的速度,版本堆积将导致 Compaction Score 过高且触发自我保护机制,导致后续数据写入失败。
-- **稳定性**。Compaction 任务对系统资源的消耗可控,不会因 Compaction 任务带来过多的内存与 CPU 开销造成系统不稳定。
-- **易用性**。由于 Compaction 任务涉及调度、策略、执行多个逻辑单元,部分特殊场景需要对 Compaction 进行调优,因此需要 Compaction 涉及的参数能够精简明了,指导用户快速进行场景化的调优。
-
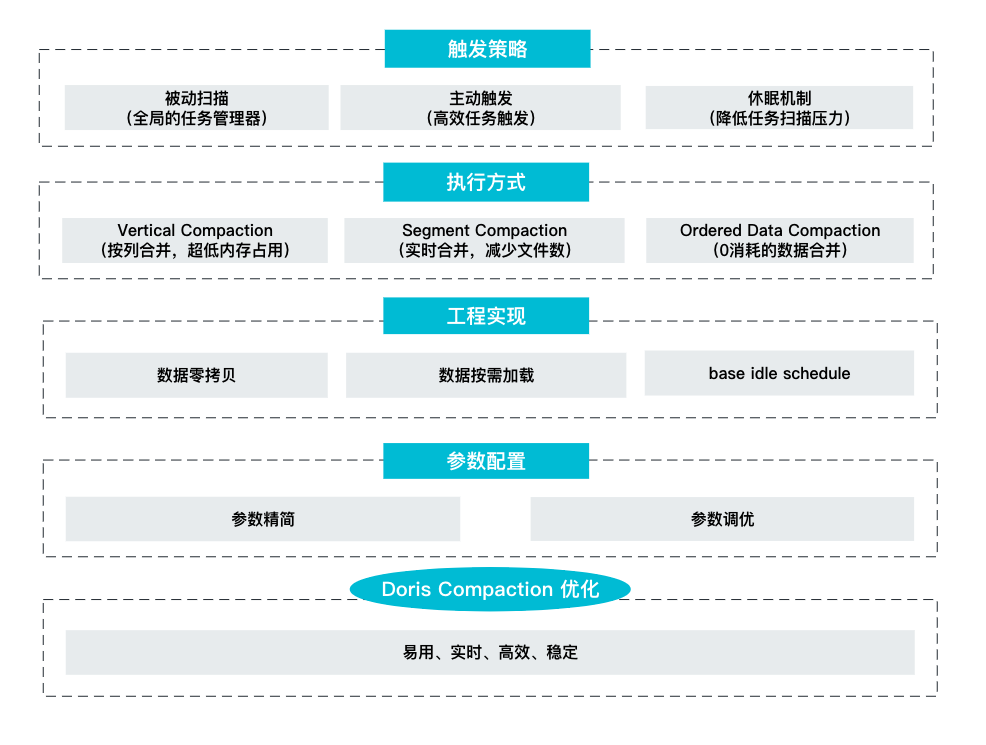
-具体在实现过程中,包含了触发策略、执行方式、工程实现以及参数配置这四个方面的优化。
-
-
-
-### Compaction 触发策略
-
-调度策略决定着 Compaction 任务的实时性。在 Apache Doris 2.0.0 版本中,我们在主动触发和被动扫描这两种方式的基础之上引入了 Tablet 休眠机制,力求在各类场景均能以最低的消耗保障最高的实时性。
-
-#### 主动触发
-
-主动触发是一种最为实时的方式,在数据导入的阶段就检查 Tablet 是否有待触发的 Compaction 任务,这样的方式保证了 Compaction 任务与数据导入任务同步进行,在新版本产生的同时就能够立即触发数据合并,能够让 Tablet 版本数维持在一个非常稳定的状态。主动触发主要针对增量数据的 Compaction (Cumulative Compaction),存量数据则依赖被动扫描完成。
-
-#### 被动扫描
-
-与主动触发不同,被动扫描主要负责触发大数据量的 Base Compaction 任务。Doris 通过启动一个后台线程,对该节点上所有的 Tablet 元数据进行扫描,根据 Tablet Compaction 任务的紧迫程度进行打分,选择得分最高的 Tablet 触发 Compaction 任务。这样的全局扫描模式能够选出最紧急的 Tablet 进行 Compaction,但一般其执行周期较长,所以需要配合主动触发策略实施。
-
-#### 休眠机制
-
-频繁的元信息扫描会导致大量的 CPU 资源浪费。因此在 Doris 2.0.0 版本中我们引入了 Tablet 休眠机制,来降低元数据扫描带来的 CPU 开销。通过对长时间没有 Compaction 任务的 Tablet 设置休眠时间,一段时间内不再对该 Tablet 进行扫描,能够大幅降低任务扫描的压力。同时如果休眠的 Tablet 有突发的导入,通过主动触发的方式也能顾唤醒 Compaction 任务,不会对任务的实时性有任何影响。
-
-通过上述的主动扫描+被动触发+休眠机制,使用最小的资源消耗,保证了 Compaction 任务触发的实时性。
-
-### Compaction 执行方式
-
-在 Doris 1.2.2 版本中中,我们引入了两种全新的 Compaction 执行方式:
-
-- Vertical Compaction,用以彻底解决 Compaction 的内存问题以及大宽表场景下的数据合并;
-- Segment Compaction,用以彻底解决上传过程中的 Segment 文件过多问题;
-
-而在即将发布的 Doris 2.0.0 版本,我们引入了 Ordered Data Compaction 以提升时序数据场景的数据合并能力。
-
-#### Vertical Compaction
-
-在之前的版本中,Compaction 通常采用行的方式进行,每次合并的基本单元为整行数据。由于存储引擎采用列式存储,行 Compaction 的方式对数据读取极其不友好,每次 Compaction 都需要加载所有列的数据,内存消耗极大,而这样的方式在宽表场景下也将带来内存的极大消耗。
-
-针对上述问题,我们在 Doris 1.2.2 版本中实现了对列式存储更加友好的 Vertical Compaction,具体执行流程如下图:
-
-
-
-整体分为如下几个步骤:
-
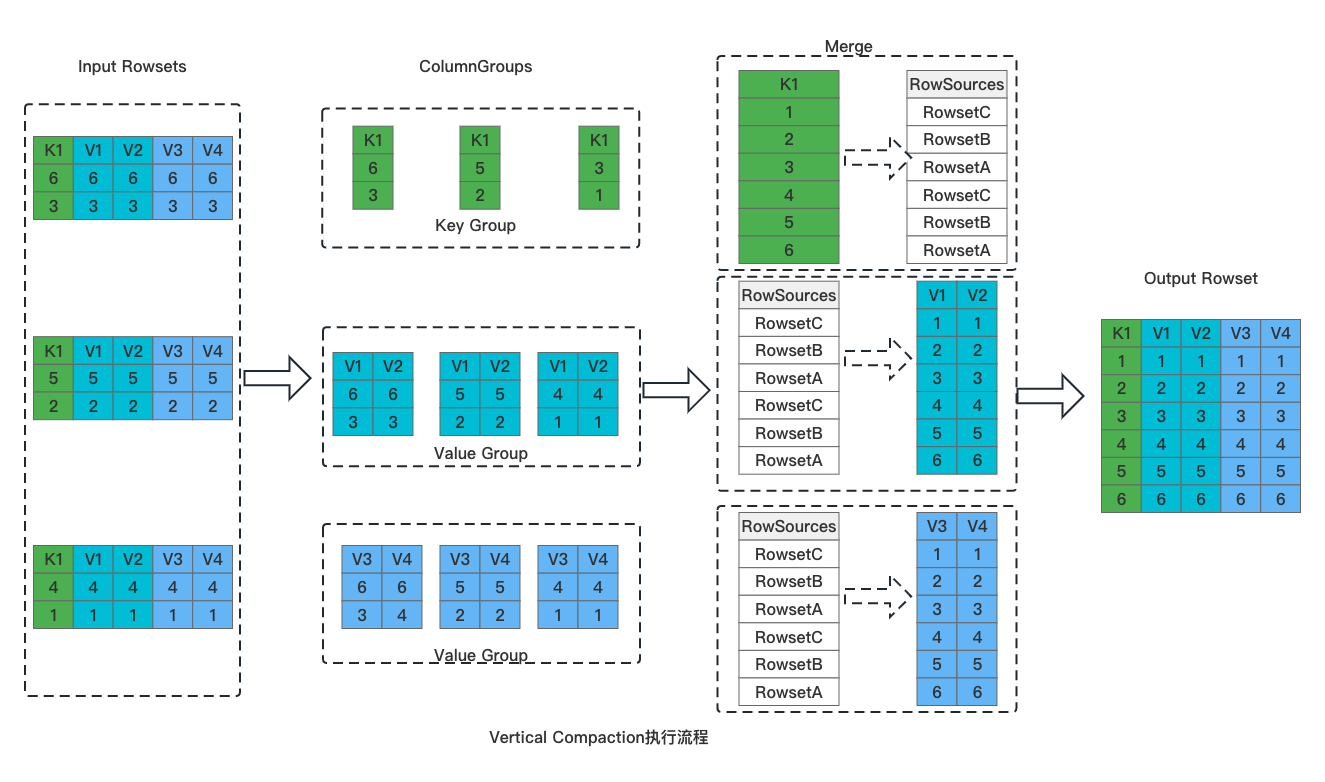
-1. 切分列组。将输入 Rowset 按照列进行切分,所有的 Key 列一组、Value 列按 N 个一组,切分成多个 Column Group;
-1. Key 列合并。Key 列的顺序就是最终数据的顺序,多个 Rowset 的 Key 列采用堆排序进行合并,产生最终有序的 Key 列数据。在产生 Key 列数据的同时,会同时产生用于标记全局序 RowSources。
-1. Value 列的合并。逐一合并 Column Group 中的 Value 列,以 Key 列合并时产生的 RowSources 为依据对数据进行排序。
-1. 数据写入。数据按列写入,形成最终的 Rowset 文件。
-
-由于采用了按列组的方式进行数据合并,Vertical Compaction 天然与列式存储更加贴合,使用列组的方式进行数据合并,单次合并只需要加载部分列的数据,因此能够极大减少合并过程中的内存占用。在实际测试中,**Vertical** **C** **ompaction 使用内存仅为原有 Compaction 算法的 1/10,同时 Compaction 速率提升 15%。**
-
-Vertical Compaction 在 1.2.2 版本中默认关闭状态,需要在 BE 配置项中设置 `enable_vertical_compaction=true` 开启该功能。
-
-相关PR:https://github.com/apache/doris/pull/14524
-
-
-
-
-
-
-
-#### Segment Compaction
-
-在数据导入阶段,Doris 会在内存中积攒数据,到达一定大小时 Flush 到磁盘形成一个个的 Segment 文件。大批量数据导入时会形成大量的 Segment 文件进而影响后续查询性能,基于此 Doris 对一次导入的 Segment 文件数量做了限制。当用户导入大量数据时,可能会触发这个限制,此时系统将反馈 -238 (TOO_MANY_SEGMENTS) 同时终止对应的导入任务。Segment compaction 允许我们在导入数据的同时进行数据的实时合并,以有效控制 Segment 文件的数量,增加系统所能承载的导入数据量,同时优化后续查询效率。具体流程如下所示:
-
-
-
-在新增的 Segment 数量超过一定阈值(例如 10)时即触发该任务执行,由专门的合并线程异步执行。通过将每组 10个 Segment 合并成一个新的 Segment 并删除旧 Segment,导入完成后的实际 Segment 文件数量将下降 10 倍。Segment Compaction 会伴随导入的过程并行执行,在大数据量导入的场景下,能够在不显著增加导入时间的前提下大幅降低文件个数,提升查询效率。
-
-Segment Compaction 在 1.2.2 版本中默认关闭状态,需要在 BE 配置项中设置 ` enable_segcompaction = true `开启该功能。
-
-相关 PR : https://github.com/apache/doris/pull/12866
-
-
-#### Ordered Data Compaction
-
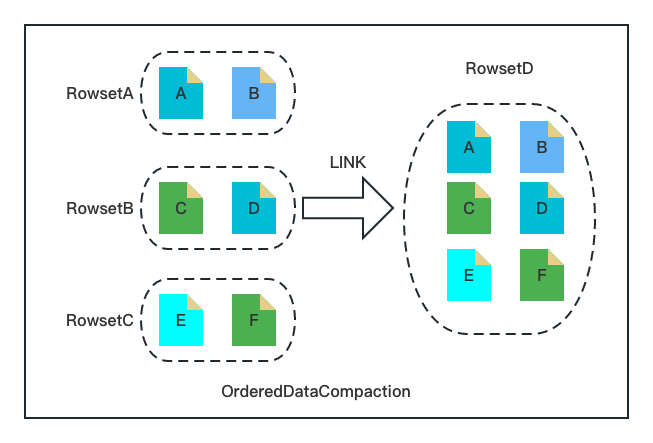
-随着越来越多用户在时序数据分析场景应用 Apache Doris,我们在 Apache Doris 2.0.0 版本实现了全新的 Ordered Data Compaction。
-
-时序数据分析场景一般具备如下特点:数据整体有序、写入速率恒定、单次导入文件大小相对平均。针对如上特点,Ordered Data Compaction 无需遍历数据,跳过了传统 Compaction 复杂的读数据、排序、聚合、输出的流程,通过文件 Link 的方式直接操作底层文件生成 Compaction 的目标文件。
-
-
-
-
-Ordered Data Compaction 执行流程包含如下几个关键阶段:
-
-1. 数据上传阶段。记录 Rowset 文件的 Min/Max Key,用于后续合并 Rowset 数据交叉性的判断;
-1. 数据检查阶段。检查参与 Compaction 的 Rowset 文件的有序性与整齐度,主要通过数据上传阶段的 Min /Max Key 以及文件大小进行判断。
-1. 数据合并阶段。将输入 Rowset 的文件硬链接到新 Rowset,然后构建新 Rowset 的元数据(包括行数,Size,Min/Max Key 等)。
-
-可以看到上述阶段与传统的 Compaction 流程完全不一样,只需要文件的 Link 以及内存元信息的构建,极其简洁、轻量。**针对时序场景设计的 Ordered Data Compaction 能够在毫秒级别完成大规模的 Compaction 任务,其内存消耗几乎为** ******0,对用户极其友好。**
-
-Ordered Data Compaction 在 2.0.0 版本中默认开启状态,如需调整在 BE 配置项中修改 ` enable_segcompaction `即可。
-
-使用方式:BE 配置 `enable_ordered_data_compaction=true`
-
-### Compaction 工程实现
-
-除了上述在触发策略和 Compaction 算法上的优化之外,Apache Doris 2.0.0 版本还对 Compaction 的工程实现进行了大量细节上的优化,包括数据零拷贝、按需加载、Idle Schedule 等。
-
-#### **数据零拷贝**
-
-Doris 采用分层的数据存储模型,数据在 BE 上可以分为如下几层:Tablet -> Rowset -> Segment -> Column -> Page,数据需要经过逐层处理。由于 Compaction 每次参与的数据量大,数据在各层之间的流转会带来大量的 CPU 消耗,在新版本中我们设计并实现了全流程无拷贝的 Compaction 逻辑,Block 从文件加载到内存中后,后续无序再进行拷贝,各个组件的使用都通过一个 BlockView 的数据结构完成,这样彻底的解决了数据逐层拷贝的问题,将 Compaction 的效率再次提升了 5%。
-
-#### **按需加载**
-
-Compaction 的逻辑本质上是要将多个无序的 Rowset 合并成一个有序的 Rowset,在大部分场景中,Rowset 内或者 Rowset 间的数据并不是完全无序的,可以充分利用局部有序性进行数据合并,在同一时间仅需加载有序文件中的第一个,这样随着合并的进行再逐渐加载。利用数据的局部有序性按需加载,能够极大减少数据合并过程中的内存消耗。
-
-#### **Idle schedule**
-
-在实际运行过程中,由于部分 Compaction 任务占用资源多、耗时长,经常出现因为 Compaction 任务影响查询性能的 Case。这类 Compaction 任务一般存在于 Base compaction 中,具备数据量大、执行时间长、版本合并少的特点,对任务执行的实时性要求不高。在新版本中,针对此类任务开启了线程 Idle Schedule 特性,降低此类任务的执行优先级,避免 Compaction 任务造成线上查询的性能波动。
-
-### 易用性
-
-在 Compaction 的易用性方面,Doris 2.0.0 版本进行了系统性优化。结合长期以来 Compaction 调优的一些经验数据,默认配置了一套通用环境下表现最优的参数,同时大幅精简了 Compaction 相关参数及语义,方便用户在特殊场景下的 Compaction 调优。
-
-
-
-# 总结规划
-
-通过上述一系列的优化方式, 全新版本在 Compaction 过程中取得了极为显著的改进效果。在 ClickBench 性能测试中,**新版本 Compaction 执行速度** **达到 30w row/s,相较于旧版本** **提升** **了** **50** **%** **;资源消耗降幅巨大,** **内存占用仅为原先的 10%** 。高并发数据导入场景下,Compaction Score 始终保持在 50 左右,且系统表现极为平稳。同时在时序数据场景中,Compaction 写放大系数降低 90%,极大提升了可承载的写入吞吐量。
-
-后续我们仍将进一步探索迭代优化的空间,主要的工作方向将聚焦在自动化、可观测性以及执行效率等方向上:
-
-1. 自动化调优。针对不同的用户场景,无需人工干预,系统支持进行自动化的 Compaction 调优;
-1. 可观测性增强。收集统计 Compaction 任务的各项指标,用于指导自动化以及手动调优;
-1. 并行 Vertical Compaction。通过 Value 列并发执行,进一步提升 Vertical Compaction 效率。
-
-以上方向的工作都已处于规划或开发中,如果有小伙伴对以上方向感兴趣,也欢迎参与到社区中的开发来。期待有更多人参与到 Apache Doris 社区的建设中 ,欢迎你的加入!
-
-# 作者介绍:
-
-一休,Apache Doris contributor,SelectDB 资深研发工程师
-
-张正宇,Apache Doris contributor,SelectDB 资深研发工程师
-
-
-
-**# 相关链接:**
-
-**SelectDB 官网**:
-
-https://selectdb.com
-
-**Apache Doris 官网**:
-
-http://doris.apache.org
-
-**Apache Doris Github**:
-
-https://github.com/apache/doris
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Data Lakehouse.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Data Lakehouse.md
deleted file mode 100644
index 2d23d8c2c12..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Data Lakehouse.md
+++ /dev/null
@@ -1,290 +0,0 @@
----
-{
- 'title': '查询性能较 Trino:Presto 3-10 倍提升!Apache Doris 极速数据湖分析深度解读',
- 'summary': "Apache Doris 已经完全具备了构建极速易用的 Lakehouse 架构的能力,并且也已在多个用户的真实业务场景中得到验证和推广,希望为用户带来湖仓查询加速
-统一数据分析网关、统一数据集成和更加开放的数据生态。",
- 'date': '2023-03-14',
- 'author': 'Apache Doris',
- 'tags': ['技术解析'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-从上世纪 90 年代初 Bill Inmon 在《building the Data Warehouse》一书中正式提出数据仓库这一概念,至今已有超过三十年的时间。在最初的概念里,数据仓库被定义为「一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策」,而数据湖最初是为了解决数仓无法存储海量且异构的数据而构建的集中式存储系统。
-
-时代的发展与用户数据应用诉求的演进,催生了数据架构的不断革新,也衍生了更复杂的技术形态。可以清晰看到现代数据架构从计算到存储都在向着融合统一的方向发展,新的数据湖范式被提出,这也是 Lakehouse 诞生的背景。作为一种全新的、开放式的数据管理架构,Lakehouse 提供了更强的数据分析能力与更好的数据治理能力,也保留了数据湖的灵活性与开放式存储,为用户带来更多价值:
-
-- 从存储的角度:统一数据集成,避免冗余存储以及跨系统间 ETL 带来的繁重工程和失败风险;
-- 从治理的角度:支持 ACID、Schema Evolution 与 Snapshot,数据与元数据皆可治理;
-- 从应用的角度:多引擎访问支持、可插拔,通过统一接口进行数据访问,同时适用于多种工作负载 Workload;
-- ……
-
-如果我们把 Lakehouse 从系统层面进行解构,会发现除了需要 Apache Iceberg、Apache Hudi 以及 Delta Lake 等数据湖表格式(Table Format)以外,**高性能分析引擎更是充分发挥湖上数据价值的关键**。
-
-作为一款极速易用的开源实时 OLAP 数据库,Apache Doris 自 0.15 版本即开始尝试在 Apache Iceberg 之上探索与数据湖的能力结合。而经过多个版本的优化迭代,Apache Doris 在数据湖分析已经取得了长足的进展,一方面在数据读取、查询执行以及优化器方面做了诸多优化,另一方面则是重构了整体的元数据连接框架并支持了更多外部存储系统。因此 Apache Doris 已经完全具备了构建极速易用的 Lakehouse 架构的能力,并且也已在多个用户的真实业务场景中得到验证和推广,我们希望通过 Apache Doris 能为用户在更多场景中带来价值:
-
-1. **湖仓查询加速**
-
- 利用 Apache Doris 优秀的分布式执行引擎以及本地文件缓存,结合数据湖开放格式提供的多种索引能力,对湖上数据及文件提供优秀的查询加速能力,相比 Hive、Presto、Spark 等查询引擎实现数倍的性能提升。
-
-1. **统一数据分析网关**
-
- 利用 Apache Doris 构建完善可扩展的数据源连接框架,便于快速接入多类数据源,包括各种主流关系型数据库、数据仓库以及数据湖引擎(例如 Hive、Iceberg、Hudi、Delta Lake、Flink Table Store 等),提供基于各种异构数据源的快速查询和写入能力,将 Apache Doris 打造成统一的数据分析网关。
-
-1. **统一数据集成**
-
- 基于可扩展的连接框架,增强 Doris 在数据集成方面的能力,让数据更便捷的被消费和处理。用户可以通过 Doris 对上游的多种数据源进行统一的增量、全量同步,并利用 Doris 的数据处理能力对数据进行加工和展示,也可以将加工后的数据写回到数据源,或提供给下游系统进行消费。该能力使得 Apache Doris 能够成为业务的统一数据枢纽,降低数据流转成本。
-
-1. **更加开放的数据生态**
-
- 通过对 Parquet/ORC 等数据格式以及开放的元数据管理机制的支持,用户不用再担心数据被特定数据库引擎锁定,无法被其他引擎访问,也不用再为数据的迁移和格式转换付出高昂的时间和算力成本,降低用户的数据迁移成本和对数据流通性的顾虑,更便捷、放心地享受 Apache Doris 带来的极速数据分析体验。
-
-
-
-
-基于以上的场景定位,我们需要进一步去思考在构建 Lakehouse 过程中需要如何去设计和改造系统,具体包括:
-
-- 如何支持更丰富的数据源访问以及更便捷的元数据获取方式;
-- 如何提升湖上数据的查询执行性能;
-- 如何实现更灵活的资源调度与负载管理;
-
-因此本文将重点介绍 Apache Doris 在 Lakehouse 上的设计思路和技术细节,同时会为大家介绍后续的发展规划。
-
-# 元数据连接与数据访问
-
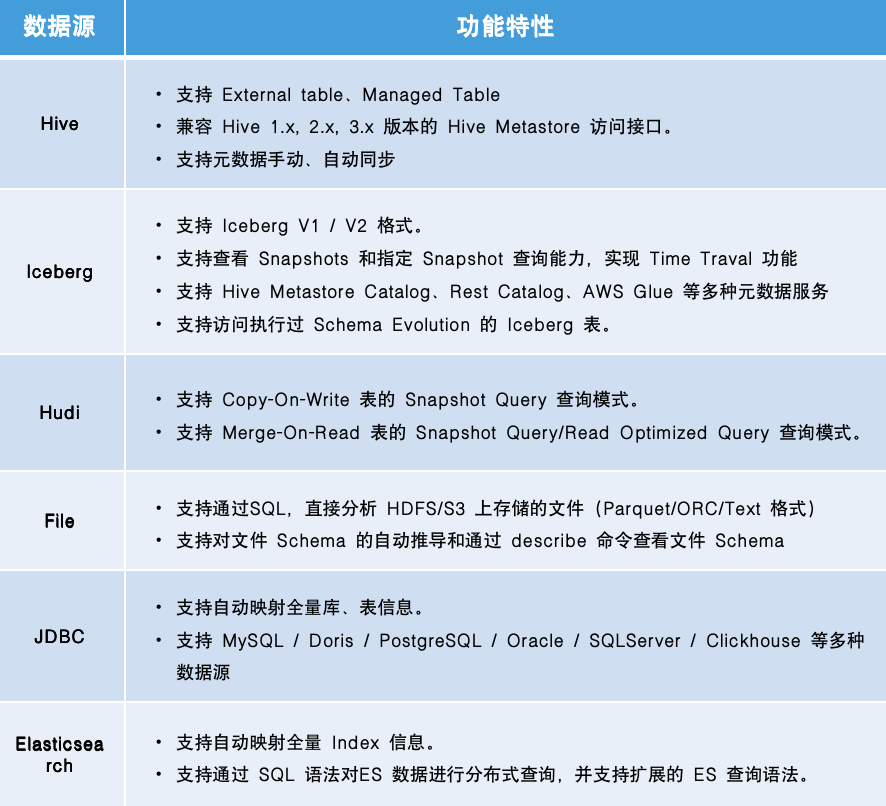
-截至最新的 1.2.2 版本,Apache Doris 已经提供了十余种的数据湖格式和外部数据源的访问支持。同时也支持通过 Table Value Function 直接对文件进行分析。
-
-
-
-
-
-
-为了支持这些数据源,Apache Doris 分别在**元数据连接**和**数据访问**两方面做了大量的架构调整和性能优化 **。**
-
-## 元数据连接
-
-元数据包括数据源的库、表信息、分区信息、索引信息、文件信息等。不同数据源的元信息格式、组织方式各有不同,对于元数据的连接需要解决以下问题:
-
-1. **统一的元数据结构**:屏蔽不同数据源的元数据差异。
-1. **可扩展的元数据连接框架**:低成本、快速地接入数据源。
-1. **高效的元数据访问能力**:提供可靠、高效的元数据访问性能,并支持实时同步元数据变更。
-1. **自定义鉴权服务**:能够灵活对接外部的权限管理系统,降低业务迁移成本。
-
-### **统一的元数据结构**
-
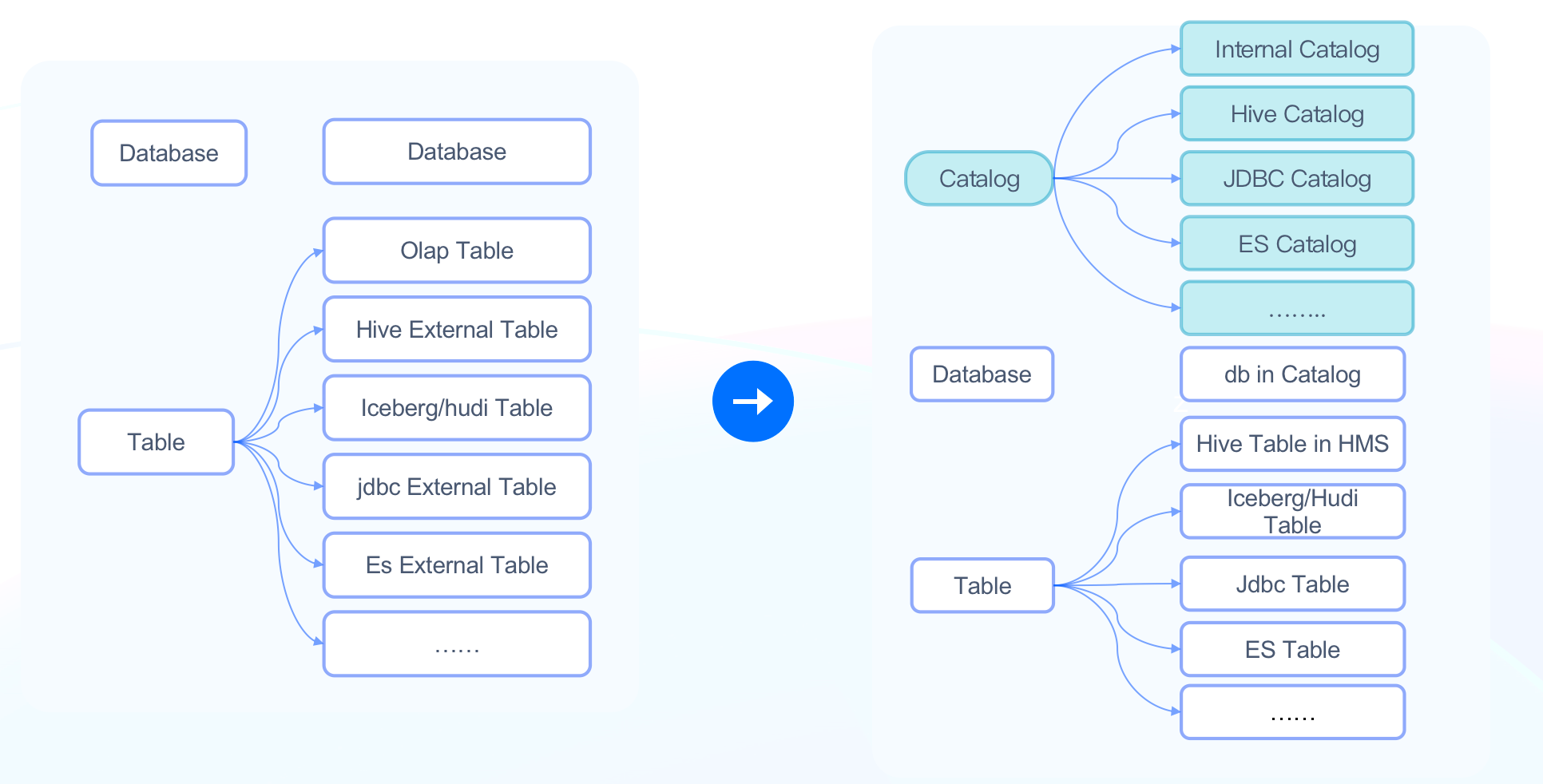
-在过去 Apache Doris 的元数据只有 Database(数据库) 和 Table(表)两个层级,当外部数据目录 Schema 发生变化或者外部数据目录的 Database 或 Table 非常多时,需要用户手工进行一一映射,维护量非常大。因此在 Apache Doris 1.2.0 版本中新增了 Catalog(数据目录)层级,提供了快速接入外部数据源的能力。
-
-
-
-Catalog 层级的引入解决以下问题:
-
-1. **数据源层级的映射**:用户不再需要在 Database、Table 层级进行一一映射,可以通过 Catalog 直接映射整个数据源,自动同步其中的所有元信息,简化元数据映射逻辑
-1. **数据源统一信息管理**:在 Catalog 层级统一维护指定数据源的属性,如连接信息、权限信息、同步方式等,更方便的管理多个数据源。
-
-引入 Catalog 层级后,我们也对 Doris 的元数据进行调整和划分:
-
-1. Internal Catalog:原有的自管理的 Table 和 Database 都归属于 Internal Catalog。
-1. External Catalog:用于对接其他非自管理的外部数据源。比如 HMS External Catalog 可以连接到一个 Hive Metastore 管理的集群、Iceberg External Cataog 可以连接到 Iceberg 集群等。
-
-用户可以使用 `SWITCH`语句切换不同的 Catalog,也可以通过全限定名方便的进行**跨数据源的联邦查询**,如:
-
-```
-SELECT * FROM hive.db1.tbl1 a JOIN iceberg.db2.tbl2 b
-ON a.k1 = b.k1;
-```
-
-相关文档:https://doris.apache.org/zh-CN/docs/dev/lakehouse/multi-catalog
-
-### 可扩展的元数据连接框架
-
-基于新的元数据层级,用户可以通过 `CREATE CATALOG`语句方便的添加新的数据源:
-
-```
-CREATE CATALOG hive PROPERTIES (
- 'type'='hms',
- 'hive.metastore.uris' = 'thrift://172.21.0.1:7004',
-);
-```
-
-在数据湖场景下,目前 Doris 支持的元数据服务包括:
-
-- Hive Metastore 兼容的元数据服务
-- Aliyun Data Lake Formation
-- AWS Glue
-
-同时,开发者也可以自行扩展 External Catalog,只需要实现对应的访问接口,即可在 Doris 中快速接入新的元数据服务。
-
-### **高效的元数据访问**
-
-元数据存储在外部数据源中,而对外部数据源的访问受到网络、数据源资源等限制,性能和可靠性是不可控的。所以 Doris 需要提供高效、可靠的元数据服务以保证线上服务的稳定运行,同时 Doris 也需要实时感知元数据的变更,提升数据访问的实时性。
-
-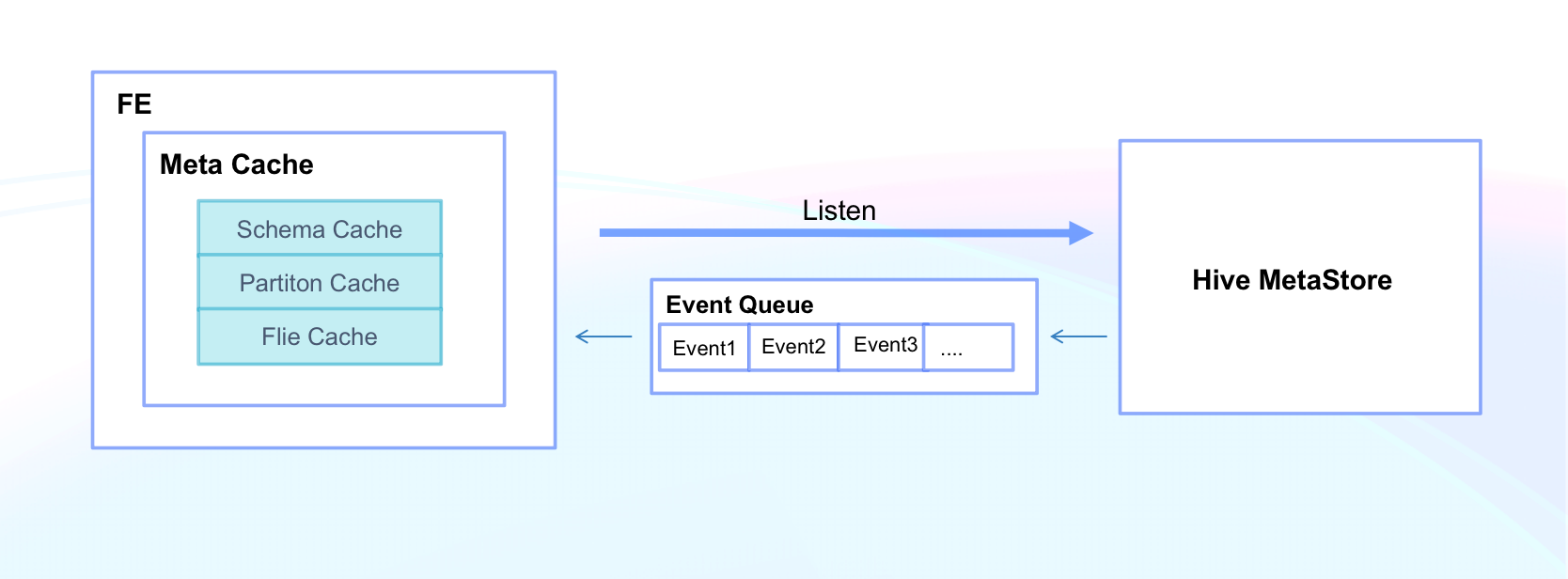
-
-Doris 通过内存中的**元数据缓存**提供高效的元数据服务。元数据缓存包括**列信息缓存**,**分区缓存**,**文件缓存。** 通过元信息缓存,可以显著提升元数据访问性能并降低对外部元数据服务的请求压力,**使得Doris 可以应对数千张表,数十万分区场景下,毫秒级别的元数据查询响应。**
-
-Doris 支持在 Catalog/Database/Table 级别,对元数据缓存进行手动刷新。同时,针对 Hive Metastore,Doris还支持通过监听 Hive Metastore Event 自动同步元数据,提供元数据秒级实时更新能力。
-
-### **自定义鉴权服务**
-
-外部数据源通常拥有自己的权限管理服务,而很多企业也会使用统一的权限管理系统(例如 Apache Ranger)来管理多套数据系统。Doris支持通过自定义鉴权插件对接企业内部已有的权限管理系统,从而可以低成本的接入现有业务,完成授权、审计、数据加密等操作。
-
-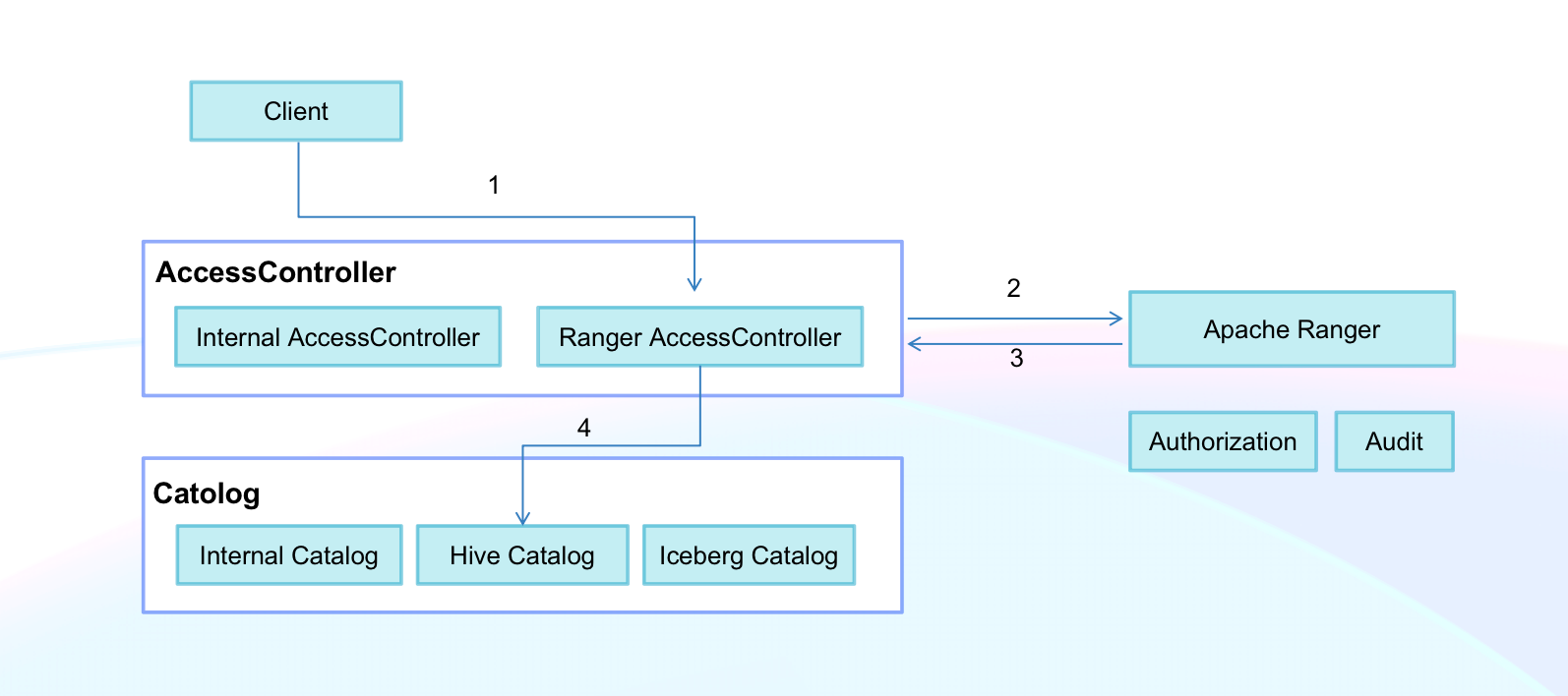
-
-具体实现上,用户可以基于 Doris 的 AccessController 接口实现插件对接相应的权限管理系统,并在创建 Catalog 时,指定对应的鉴权插件。通过这种机制,所有通过 Doris 对外部数据源的访问,都将统一使用自定义的插件完成鉴权、审计等操作。
-
-## 数据访问
-
-外部数据源的数据访问,主要集中在对存储系统的访问支持上。在数据湖场景下,主要是对 HDFS 以及各种 S3 兼容的对象存储的支持。目前 Apache Doris 支持的存储系统如下,并且仍在不断增加中:
-
-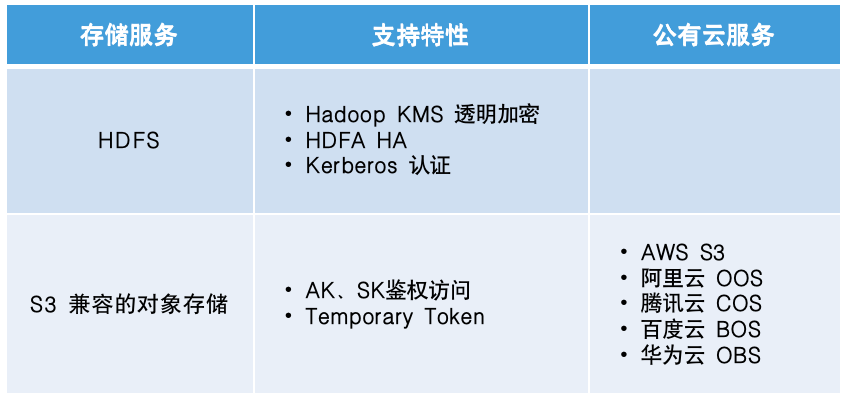
-
-# 性能优化
-
-在实现数据源的连接和访问后,下一个问题是我们如何结合 Apache Doris 自身优异的查询性能以及各类存储系统的特性,进行针对性的查询性能优化,这也是在 构建 Lakehouse 过程中最需要解决的问题和权衡的因素。在具体实现过程中,Apache Doris 分别在**数据读取、执行引擎、优化器**方面进行了诸多优化。
-
-## 数据读取
-
-湖上数据通常存储在远端存储系统上,相较于本地存储,在数据的访问延迟、并发能力、IO 带宽上天然存在一定劣势。因此,在数据读取上,Apache Doris 从减少远端读取频率,降低读取量等方面出发进行了细致的优化。
-
-### Native File Format Reader
-
-Parquet 和 ORC 是最常见的开放数据格式,这些数据格式本身提供了包括索引、编码、统计信息在内的多种特性,如何针对格式特性来提升文件读取效率是性能优化的关键一步。在早期的实现中,Apache Doris 是通过 Apache Arrow 来读取 Parquet/ORC 数据文件的,但这种方式存在以下问题:
-
-1. **数据格式转换的开销**:Arrow Reader 需要先将文件读取成 Arrow 的内存格式,再转换到 Doris 自己的内存格式,两次数据转换带来额外的开销。
-1. **无法支持高级文件格式特性**。如不支持 Parquet 的 Page Index,不支持 Bloom Fitler,无法实现谓词下推、延迟物化等功能。
-
-基于以上问题,我们对 Flile reader 进行了重构,实现了全新的 Native File Format Reader。这里我们以 Parquet Reader 为例,介绍 Doris 的文件格式读取方面所做的优化:
-
-1. **减少格式转换**。新的 File Reader 直接将文件格式转换成 Doris 的内存格式,并可以直接利用字典编码等功能转换到对应的更高性能的内存格式,以提升数据转换和处理的效率。
-1. **细粒度的智能索引**。支持了 Parquet 的 Page Index,可以利用 Page 级别的智能索引对 Page 进行过滤。相比之前只能在 Row Group 级别过滤,Page Index 过滤粒度更细、过滤效果更好。
-1. **谓词下推和延迟物化**。延迟物化的基本逻辑是先读取有过滤条件的列,再使用过滤后的行号读取其他列。这种方式能显著降低文件的读取量。这一点在远程文件读取场景下尤为重要,可以最大限度减少不必要的数据读取。
-1. **数据预读。** 将多次文件读取合并成一次,充分利用远端存储高吞吐、低并发的特性,提高数据的总体吞吐效率。
-
-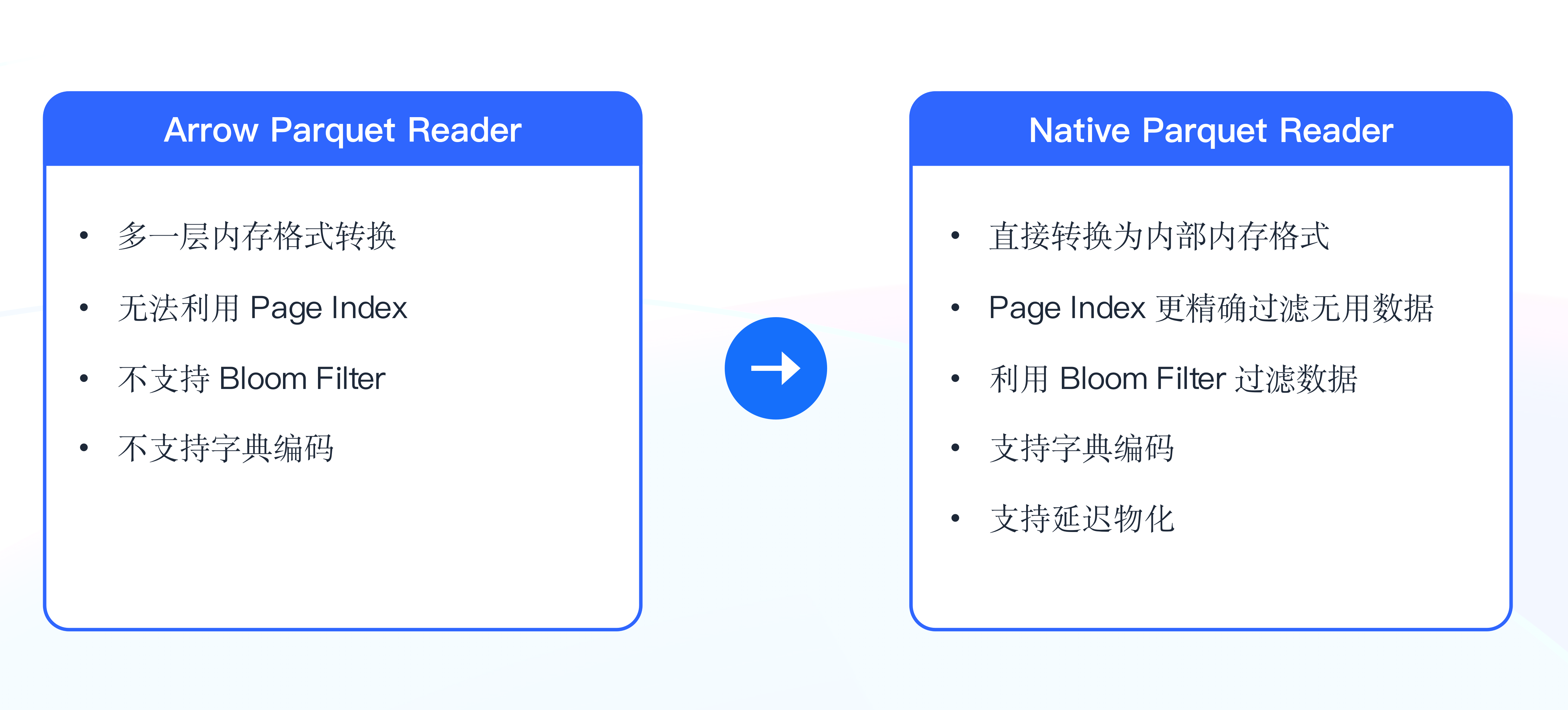
-
-### File Cache
-
-利用本地高性能磁盘对远端存储系统中的文件进行本地缓存,能最大限度的减少远程数据读取的开销,同时可以提供接近 Doris 内部表数据的访问性能。在本地文件缓存方面 Doris 进行了如下优化:
-
-1. **文件块缓存(Block Cache)** 。支持对远端文件进行 Block 级别的缓存。Block 的大小会根据读取请求自动调整,从 4KB 到 4MB 不等。Block 级别的缓存能有效减少缓存导致的读写放大问题,优化缓存冷启动场景下的数据读取延迟。
-1. **缓存一致性哈希**。通过一致性哈希算法对缓存位置和数据扫描任务进行管理和调度,充分利用已缓存的数据提供服务,并避免节点上下线导致缓存大面积失效的问题,提升缓存命中率和查询服务的稳定性。
-
-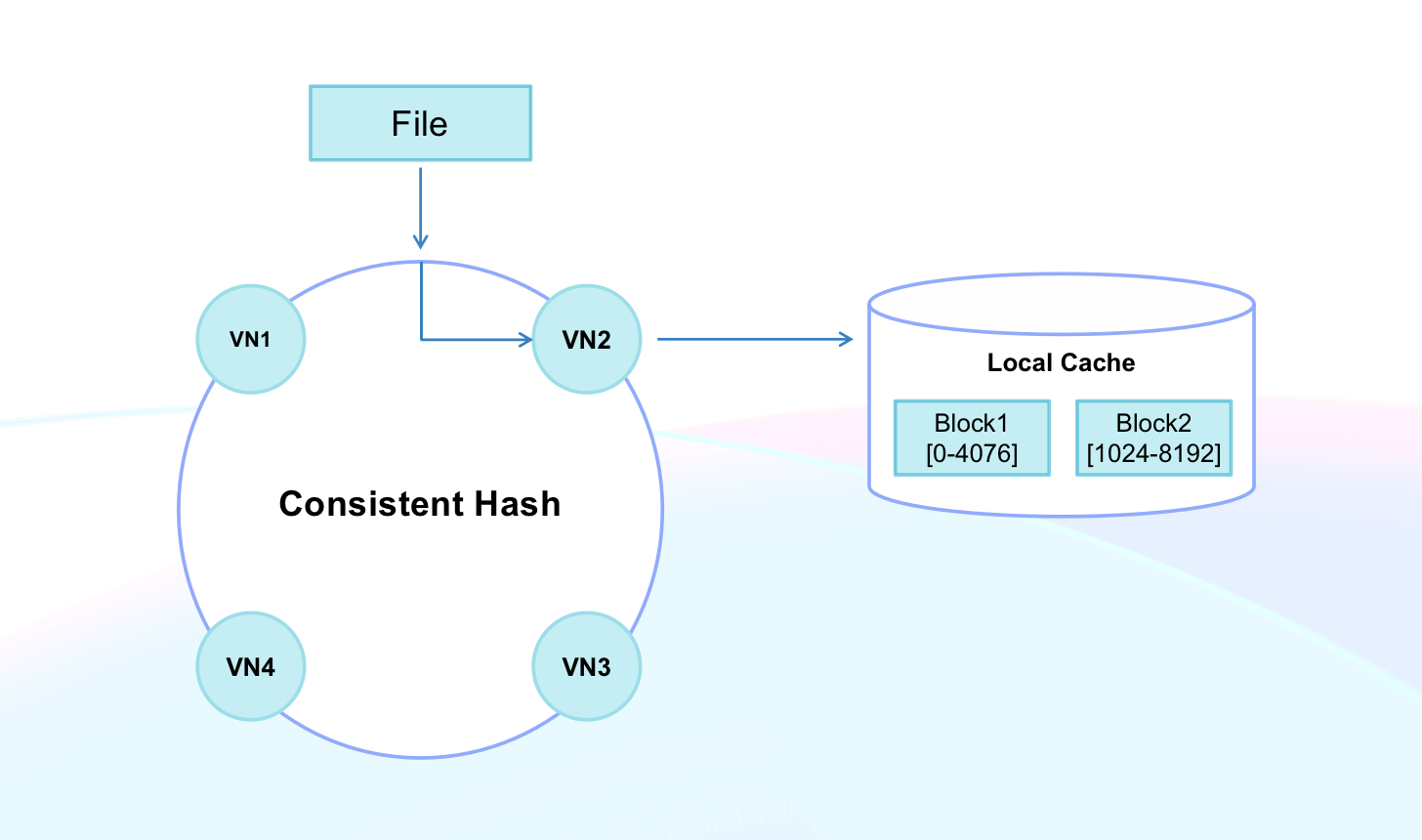
-
-通过 Flie Cache,在命中缓存的情况下,Apache Doris 可以提供和本地表一致的查询性能。
-
-## 执行引擎
-
-在执行引擎层面,我们希望能够完全复用 Apache Doris 的向量化执行引擎以及各类执行层面的算子优化,为数据湖提供极速的查询体验。因此,Apache Doris 对数据扫描(Scan)节点进行了重构,使得每一种新的数据源的接入,开发者只需要关注数据源本身的访问逻辑,无需重复地开发通用功能。
-
-1. **通用查询能力的分层**
-
-包括内表在内的所有数据查询,都会使用相同的 Join、Sort、Agg 等算子。唯一不同在于数据源的访问方式上,例如对本地内部格式数据的读取,或存储在 S3 上的 Parquet 格式数据的读取。因此 Doris 将不同数据源的查询逻辑差异下推到最底层的 Scan 节点上。Scan 节点之上,所有查询逻辑统一,Scan 节点之下,由具体的实现类负责不同数据源的访问逻辑。
-
-2. **Scan 算子的通用框架**
-
-对于 Scan 节点,不同数据源也有很多共性的方面,如子任务的拆分逻辑、子任务的调度、IO 的调度、谓词下推以及 Runtime Filter 的处理等。因此我们也对这一部分架构进行了重构。首先,将共性部分都以接口的形式对外暴露,如子任务的拆分、下推谓词的处理等;其次,对子任务实现了统一的调度管理逻辑,可以由统一的调度器管理整个节点 Scan 任务的执行。调度器拥有节点全局的信息,可以方便的实现更细粒度的Scan 任务调度策略。在这样的统一的数据查询框架下,**大约 1 人周就可以完成一种新数据源接入**。
-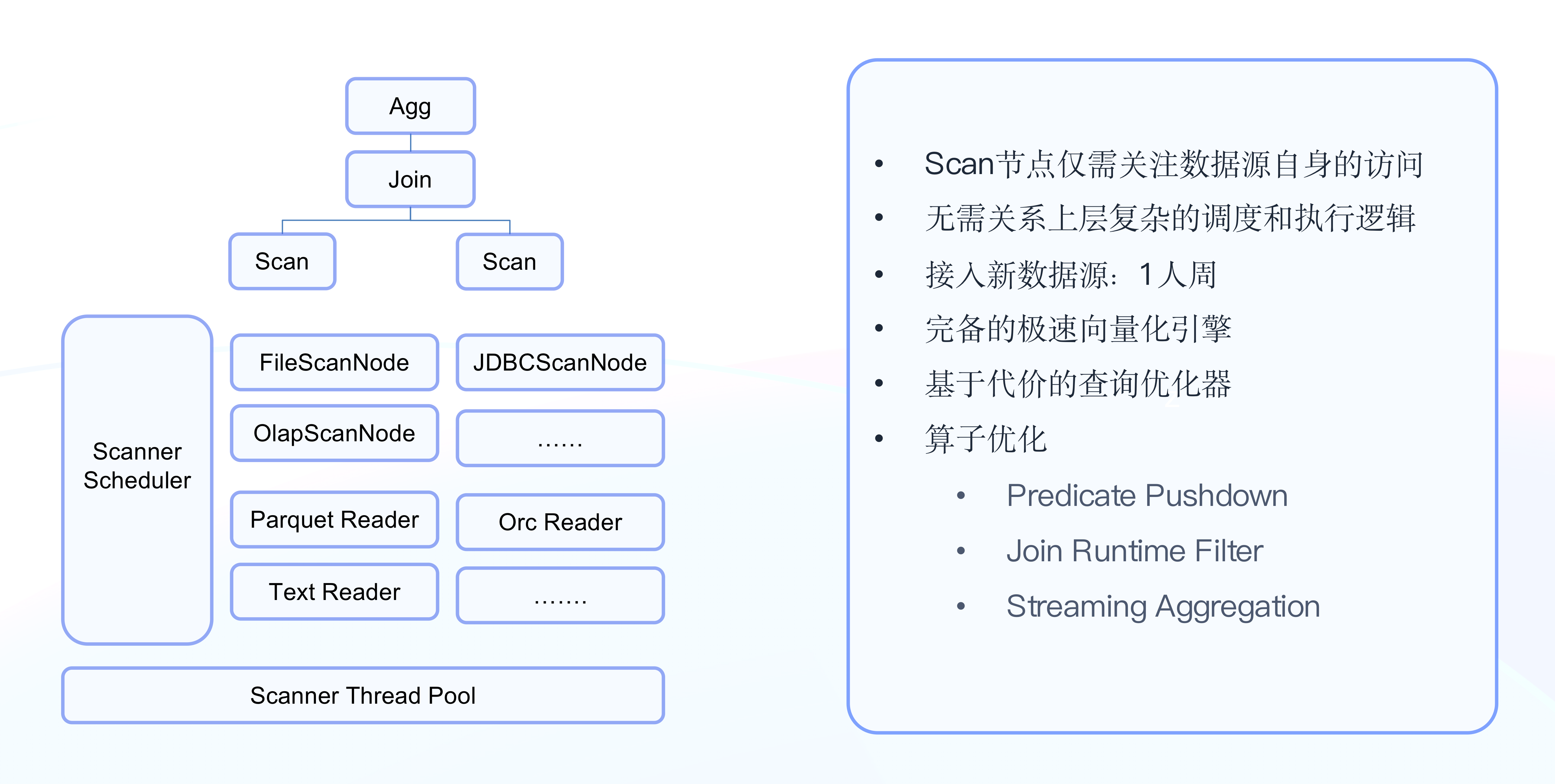
-
-## 查询优化器
-
-查询优化器层面的优化集中在**统计信息收集**和**代价模型的推导**方面。
-
-Apache Doris 支持对不同数据源的统计信息收集,如 Hive Metastore、Iceberg Metafile、Hudi MetaTable 中存储的统计信息等。同时在代价模型推导方面,我们也针对外部数据源的特性做了细致的调整。基于这些优化,Doris 可以为复杂的外表查询提供更优的查询规划。
-
-## 性能对比
-
-以上优先项,我们分别在**宽表场景**(Clickbench)和**多表关联场景**(TPC-H)下与 Presto/Trino 进行了 Hive 数据集的查询性能对比。
-
-
-
-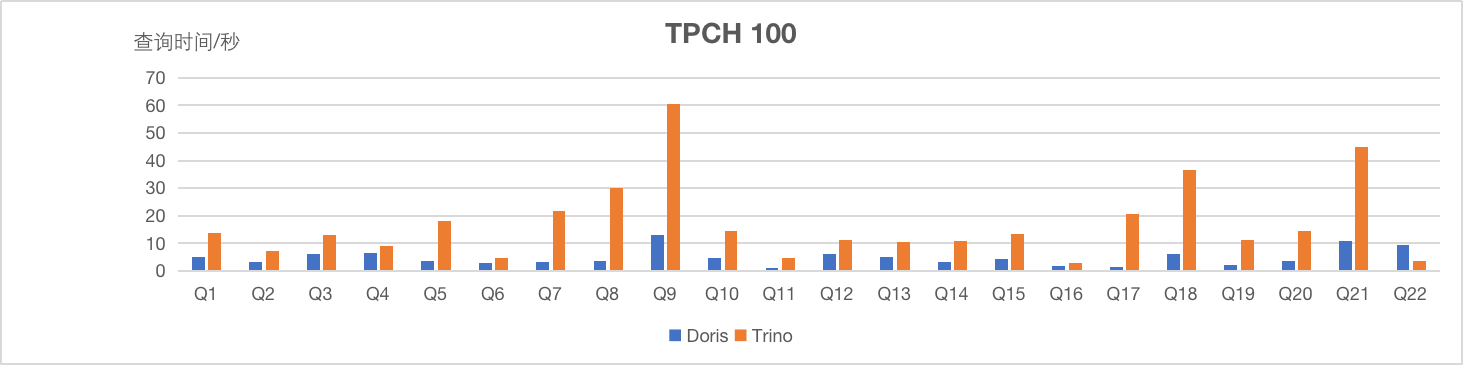
-
-可以看到,在相同计算资源和数据集下,无论是宽表场景或多表关联场景,绝大多数 SQL Apache Doris 的查询耗时都是大幅低于 Presto/Trino **,整体性能** **相比** **Presto/** **Trino 有 3-10 倍的提升**。
-
-# 负载管理与弹性计算
-
-对外部数据源的查询并不依赖 Doris 的数据存储能力,这也为 Doris 实现弹性的无状态计算节点成为可能。在即将发布的 2.0 版本中,Apache Doris 还实现了弹性计算节点功能(Elastic Compute Node),可以专门用于支持外部数据源的查询负载。
-
-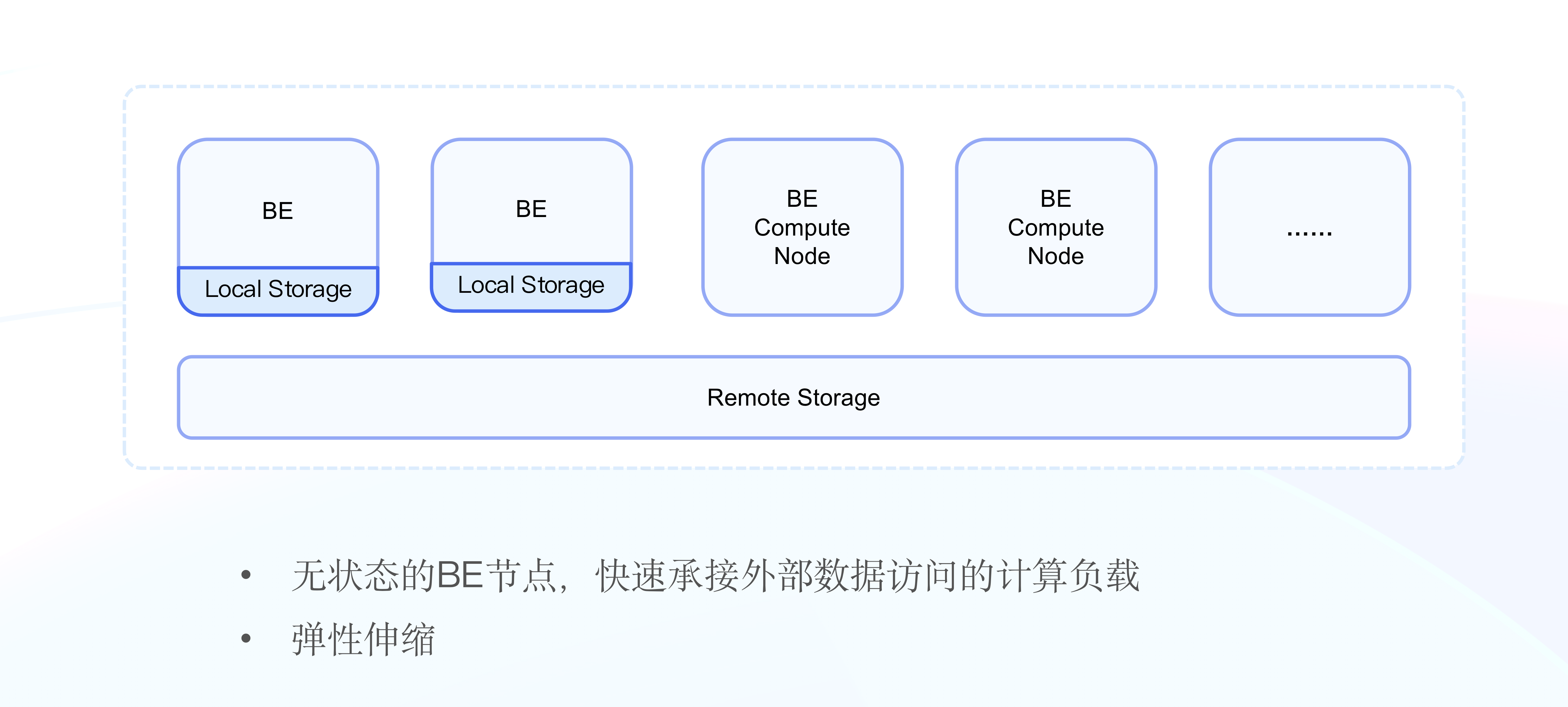
-
-由于计算节点是无状态的,因此我们可以对这类节点进行快速扩缩容,以灵活地应对峰谷期的查询负载,在查询性能与成本消耗之间取得更好的平衡。
-
-同时,Doris 也针对 k8s 场景下的集群管理和节点调度进行了优化,Master 节点可以自动管理弹性计算节点的上下线,方便业务在云原生场景、混合云场景下都能便捷的管理集群负载。
-
-# 案例实践
-
-随着以上功能的完善与性能的提升,Apache Doris 已经被多家社区用户应用于数据湖分析,在真实业务中发挥着重要的作用,在此以某金融企业的风控场景为例。
-
-金融风控场景往往对数据的实时性有着更高的要求,早期基于 Greenplum 和 CDH 搭建的风控数据集市已经无法满足其高时效性的需求,T+1 的数据生产模式成为业务迅速发展的掣肘,因此该企业于 2022 年引入 Apache Doris 并改造了整个数据生产和应用流程,实现对 Elasticsearch、Greenplum 以及 Hive 的联邦分析,整体效果包括:
-
-- 只需创建一个 Hive Catalog 即可对现存的数万张 Hive 表进行查询分析,查询性能得到极大幅度提升;
-- 利用 Elasticsearch Catalog 实现对 ES 实时数据的联邦分析,数据时效性从过去的分钟级提升至秒级甚至毫秒级,满足了风控策略的实时性要求;
-- 将日常跑批与统计分析进行解耦,降低资源消耗的同时使系统稳定性得到进一步增强。
-
-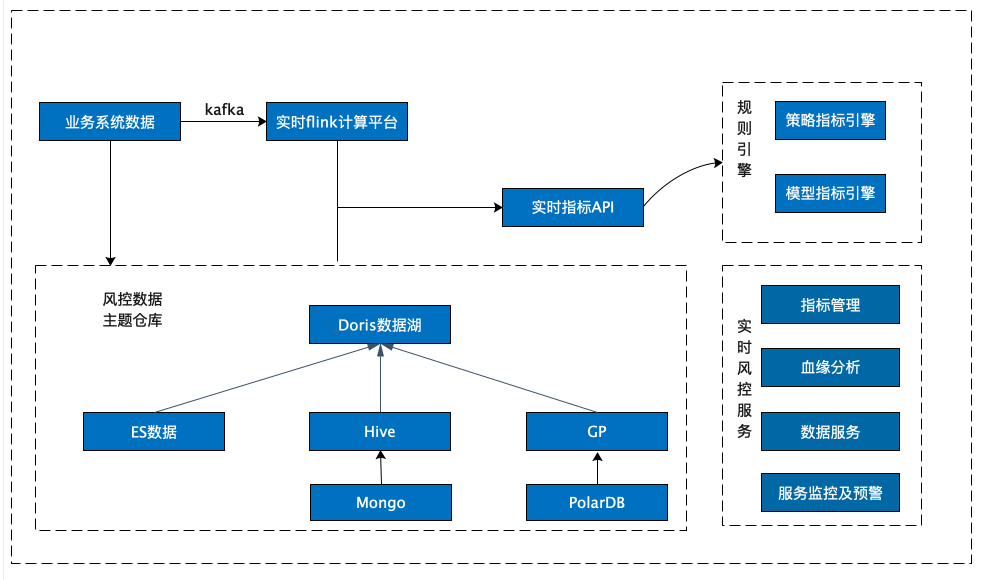
-
-# 未来规划
-
-后续 Apache Doris 将持续在 Lakehouse 方向进行迭代和升级,下一步的工作将围绕在**更丰富的数据源支持**、**数据集成**和**资源隔离与调度**等方面:
-
-## 更丰富的数据源支持
-
-随着数据湖在各种业务场景中的不断落地,数据湖本身的功能也在不断迭代以满足越来越多样的业务需求。Doris也将和各个开源社区紧密合作,提供更完善的数据湖分析支持。
-
-- Hudi Merge-On-Read 表的 Incremental Query 支持
-- 利用 Iceberg/Hudi 丰富的索引功能,结合查询优化器提供更低延迟的分析性能。
-- 支持包括 Delta Lake、Flink Table Store 等更多数据湖格式。
-
-## 数据集成
-
-具体到功能层面,数据集成可以分为数据的**读取**和**写回**两部分。
-
-**数据读取方面**,Doris 将进一步整合数据湖的数据访问特性,包括:
-
-- 数据湖 CDC 的接入以及增量物化视图的支持,为用户提供近实时的数据视图。
-- 支持 Git-Like 的数据访问模式,通过多版本、Branch 等机制,在数据安全、数据质量等方面为用户提供更便捷的数据管理模式。
-
-**数据写回功能的支持**,帮助 Doris 进一步完善统一数据分析网关的生态闭环。用户可以使用 Doris 作为统一数据管理入口,管理各个数据源中的数据,包括加工后数据的写回、数据导出等,对业务提供统一的数据视图。
-
-## 资源隔离与调度
-
-随着越来越多数据源的接入,Doris 也在逐步承接不同的工作负载,比如在提供低延迟的在线服务的同时,对 Hive 中 T-1 的数据进行批量处理。所以同集群内的资源隔离会愈发重要。
-
-Doris 会持续优化弹性计算节点在不同场景下的调度管理逻辑,同时会支持更细粒度的节点内资源隔离,如 CPU、IO、内存等,帮助 Doris 支持多样且稳定的工作负载。
-
-# 加入我们
-
-目前社区已成立 Lakehouse SIG(湖仓兴趣小组),汇集了来自多家企业的开发者,旨在共同打造 Apache Doris 的 Lakehouse 场景支持,欢迎感兴趣的同学加入我们。
-
-**# 相关链接:**
-
-**SelectDB 官网**:
-
-https://selectdb.com
-
-**Apache Doris 官网**:
-
-http://doris.apache.org
-
-**Apache Doris Github**:
-
-https://github.com/apache/doris
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Douyu.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Douyu.md
deleted file mode 100644
index e535d6e426d..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Douyu.md
+++ /dev/null
@@ -1,192 +0,0 @@
----
-{
- 'title': '赋能直播行业精细化运营,斗鱼基于 Apache Doris 的应用实践',
- 'summary': "在目标驱动下,斗鱼在原有架构的基础上进行升级改造、引入 Apache Doris 构建了实时数仓体系,并在该基础上成功构建了标签平台以及多维分析平台",
- 'date': '2023-05-05',
- 'author': '韩同阳',
- 'tags': ['最佳实践'],
-}
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-**导读:** 斗鱼是一家弹幕式直播分享网站,为用户提供视频直播和赛事直播服务。随着斗鱼直播、视频等业务的高速发展,用户增长和营收两大主营业务线对精细化运营的需求越发地迫切,各个细分业务场景对用户的差异化分析诉求也越发的强烈。为更好满足业务需求,斗鱼在 2022 年引入了 [Apache Doris](http://doris.apache.org) 构建了一套比较相对完整的实时数仓架构,并在该基础上成功构建了标签平台以及多维分析平台,在此期间积累了一些建设及实践经验通过本文分享给大家。
-
-
-
-
-作者**|**斗鱼资深大数据工程师、OLAP 平台负责人 韩同阳
-
-斗鱼是一家弹幕式直播分享网站,为用户提供视频直播和赛事直播服务。斗鱼以游戏直播为主,也涵盖了娱乐、综艺、体育、户外等多种直播内容。随着斗鱼直播、视频等业务的高速发展,用户增长和营收两大主营业务线对精细化运营的需求越发地迫切,各个细分业务场景对用户的差异化分析诉求也越发的强烈,例如增长业务线需要在各个活动(赛事、专题、拉新、招募等)中针对不同人群进行差异化投放,营收业务线需要根据差异化投放的效果及时调整投放策略。
-
-
-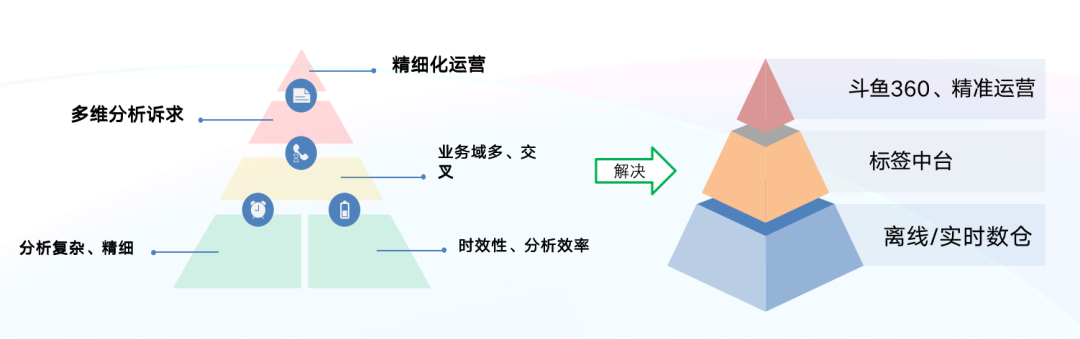
-
-根据业务场景的诉求和精细化运营的要求,我们从金字塔自下而上来看,需求大致可以分为以下几点:
-
-- 分析需求更加复杂、精细化,不再满足简单的聚合分析;数据时效性要求更高,不满足于 T+1 的分析效率,期望实现近实时、实时的分析效率。
-- 业务场景多,细分业务场景既存在独立性、又存在交叉性,例如:针对某款游戏进行专题活动投放(主播、用户),进行人群圈选、AB 实验等,需要标签/用户画像平台支持。
-- 多维数据分析的诉求强烈,需要精细化运营的数据产品支持。
-
-**为更好解决上述需求,我们的初步目标是:**
-
-- 构建离线/实时数仓,斗鱼的离线数仓体系已成熟,希望此基础上构建一套实时数仓体系;
-- 基于离线/实时数仓构建通用的标签中台(用户画像平台),为业务场景提供人群圈选、AB实验等服务;
-- 在标签平台的基础上构建适用于特定业务场景的多维分析和精细化运营的数据产品。
-
-在目标驱动下,斗鱼在原有架构的基础上进行升级改造、**引入 [Apache Doris](https://github.com/apache/doris) 构建了实时数仓体系,并在该基础上成功构建了标签平台以及多维分析平台**,在此期间积累了一些建设及实践经验通过本文分享给大家。
-
-
-
-# 原有实时数仓架构
-
-斗鱼从 2018 年开始探索实时数仓的建设,并尝试在某些垂直业务领域应用,但受制于人力的配置及流计算组件发展的成熟度,直到 2020 年第一版实时数据架构才构建完成,架构图如下图所示:
-
-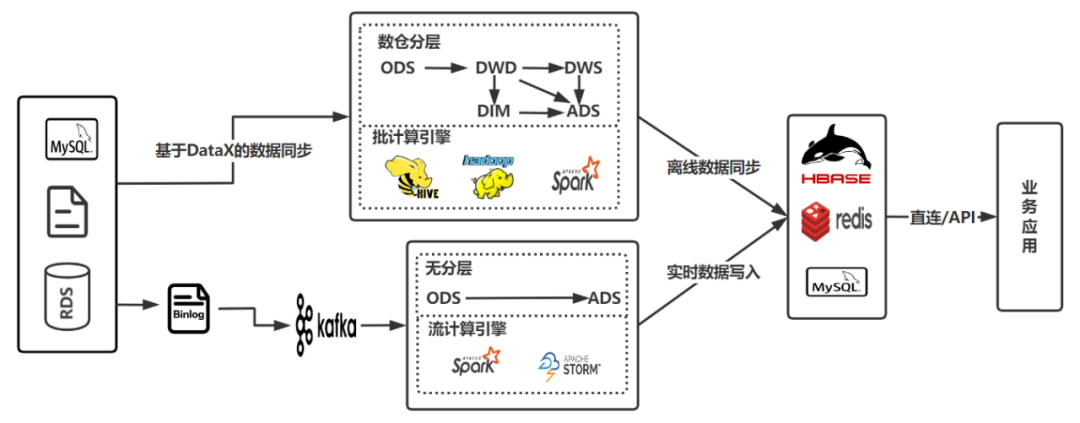
-
-原有实时数仓架构是一个典型的 Lambda 架构,上方链路为离线数仓架构,下方链路为实时数据仓架构。鉴于当时离线数仓体系已经非常成熟,使用 Lambda 架构足够支撑实时分析需求,但随着业务的高速发展和数据需求的不断提升,**原有架构凸显出几个问题**:
-
-- 在实际的流式作业开发中,缺乏对实时数据源的管理,在极端情况下接近于烟囱式接入实时数据流,无法关注数据是否有重复接入,也无法辨别数据是否可以复用。
-- 离线、实时数仓完全割裂,实时数仓没有进行数仓分层,无法像离线数仓按层复用,只能面向业务定制化开发。
-- 数据仓库数据服务于业务平台需要多次中转,且涉及到多个技术组件,ToB 应用亟需引入 OLAP 引擎缓解压力。
-- 计算引擎和存储引擎涉及技术栈多,学习成本和运维难度也很大,无法进行合理有效管理。
-
-
-
-# 新实时数仓架构
-
-### **技术选型**
-
-带着以上的问题,我们希望引入一款成熟的、在业内有大规模落地经验的 OLAP 引擎来帮助我们解决原有架构的痛点。我们希望该 OLAP 引擎不仅要具备传统 OLAP 的优势(即 Data Analytics),还能更好地支持数据服务(Data Serving)场景,比如标签数据需要明细级的查询、实时业务数据需要支持点更新、高并发以及大数据量的复杂 Join 。除此之外,我们希望该 OLAP 引擎可以便捷、低成本的的集成到 Lambda 架构下的离线/实时数仓架构中。**立足于此,我们在技术选型时对比了市面上的几款 OLAP 引擎,如下图所示**:
-
-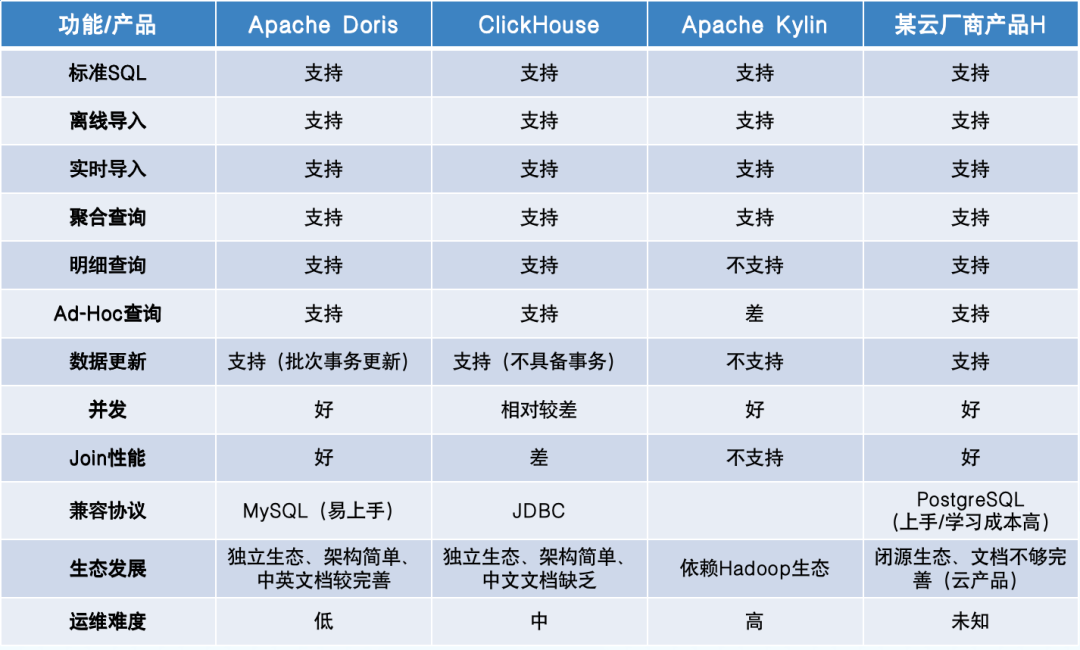
-
-根据对选型的要求,**我们发现 Apache Doris 可以很好地满足当前业务场景及诉求,同时也兼顾了低成本的要求,因此决定引入 Doris 进行升级尝试**。
-
-### **架构设计**
-
-我们在 2022 年引入了 Apache Doris ,并基于 Apache Doris 构建了一套比较相对完整的实时数仓架构,如下图所示。
-
-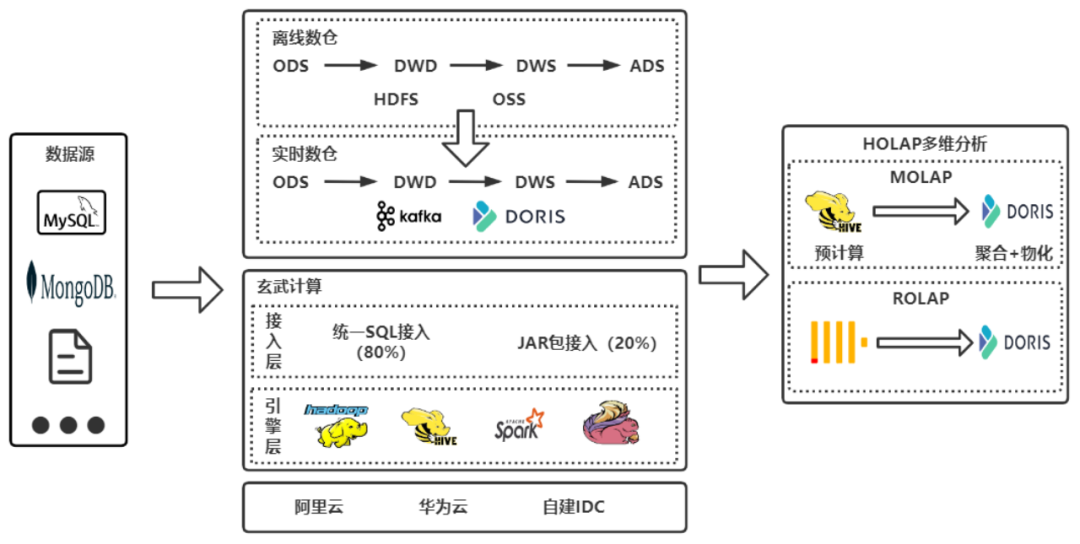
-
-总的来说,引入 Doris 后为整体架构带来几大变化:
-
-- 统一了计算平台(玄武计算),底层引擎支持 Flink、Spark 等组件,接入层支持统一 SQL 和 JAR 包接入。
-- 引入 Doris 后,我们将实时数仓分为 ODS、DWD、DWS、ADS 层,部分中间层实时数据直接使用 Doris 进行存储;
-- 构建了基于 Doris 的 HOLAP 多维分析平台,直接服务于业务;简化了原来需要通过 Hive 进行预计算的加工链路,逐步替换使用难度和运维难度相对较高的 ClickHouse;
-- 下游应用的数据存储从之前的 MySQL 和 HBase 更换为 Doris,可以在数据集市和大宽表的数据服务场景下直接查询 Doris。
-- 支持混合 IDC(自建和云厂商)。
-
-### Overwrite 语义实现
-
-Apache Doris 支持原子替换表和分区,我们在计算平台(玄武平台)整合 Doris Spark Connector 时进行了定制,且在 Connector 配置参数上进行扩展、增加了“Overwrite”模式。
-
-当 Spark 作业提交后会调用 Doris 的接口,获取表的 Schema 信息和分区信息。
-
-- 如果为非分区表:先创建目标表对应的临时表,将数据导入到临时表中,导入后进行原子替换,如导入失败则清理临时表;
-- 如果是动态分区表:先创建目标分区对应的临时分区,将数据导入临时分区,导入后进行原子替换,如导入失败则清理临时分区;
-- 如果是非动态分区:需要扩展 Doris Spark Connector 参数配置分区表达式,配完成后先创建正式目标分区、再创建其临时分区,将数据导入到临时分区中,导入后进行原子替换,如导入失败则清理临时分区。
-
-### 架构收益
-
-通过架构升级及二次开发,我们获得了 3 个明显的收益:
-
-- 构建了规范、完善、计算统一的实时数仓平台
-- 构建了统一混合 OLAP 平台,既支持 MOLAP,又支持 ROLAP,大部分多维分析需求均由该平台实现。
-- 面对大批量数据导入的场景,任务吞入率和成功率提升了 50%。
-
-
-
-# Doris 在标签中台的应用
-
-标签中台(也称用户画像平台)是斗鱼进行精准运营的重要平台之一,承担了各业务线人群圈选、规则匹配、A/B 实验、活动投放等需求。接下来看下 Doris 在标签中台是如何应用的。
-
-### 原标签中台架构
-
-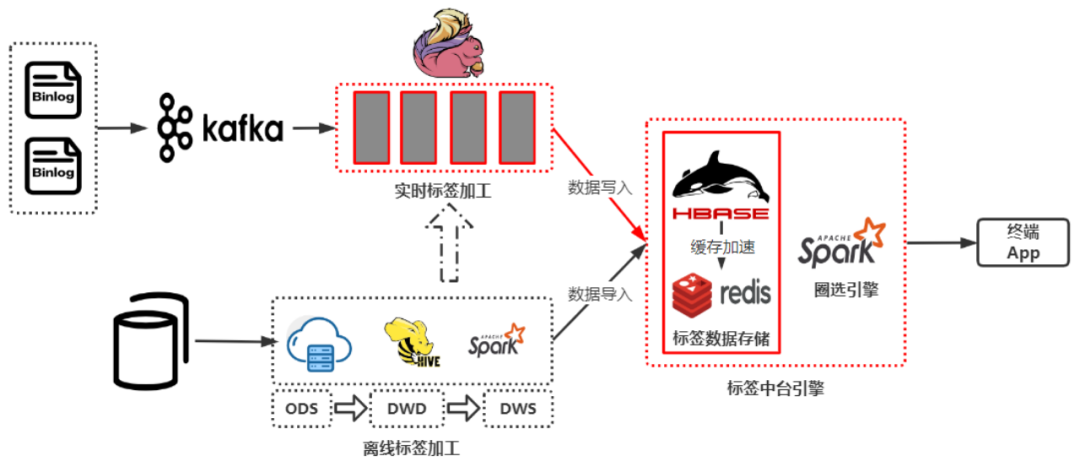
-
-上图为斗鱼原来的标签中台架构,离线标签在数仓中加工完成后合入宽表,将最终数据写入 HBase 中,实时标签使用 Flink 加工,加工完直接写入到 HBase 中。
-
-终端 APP 在使用标签中台时,主要解决两种业务需求:
-
-- 人群圈选,即通过标签和规则找到符合条件的人。
-- 规则匹配,即当有一个用户,找出该用户在指定的业务场景下符合哪些已配置的规则,也可以理解是“人群圈选“的逆方向。
-
-在应对这两种场需求中,原标签中台架构出现了两个问题:
-
-- 实时标签链路:Flink 计算长周期实时指标时稳定性较差且耗费资源较高,任务挂掉之后由于数据周期较长,导致 Checkpoint 恢复很慢;
-- 人群圈选:Spark 人群圈选效率较低,特别是在实时标签的时效性上。
-
-### 新标签中台架构
-
-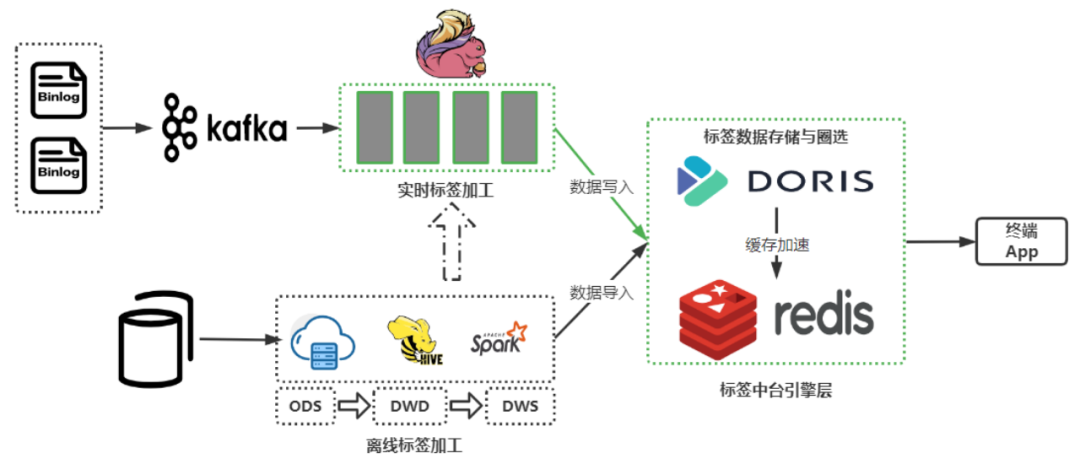
-
-引入 Apache Doris 之后,我们对标签中台架构的进行了改进,主要改进集中在实时链路和标签数据存储这两个部分:
-
-- 实时标签链路:仍然是通过实时数据源到 Kafka 中,通过 Flink 进行实时加工;不同的是,我们将一部分加工逻辑迁移到 Doris 中进行计算,长周期实时指标的计算从单一的 Flink 计算转移到了 Flink + Doris 中进行;
-- 标签数据存储:从 HBase 改成了 Doris,利用 Doris 聚合模型的部分更新特性,将离线标签和实时标签加工完之后直接写入到 Doris 中。
-
-#### **1. 离线/实时标签混合圈人**
-
-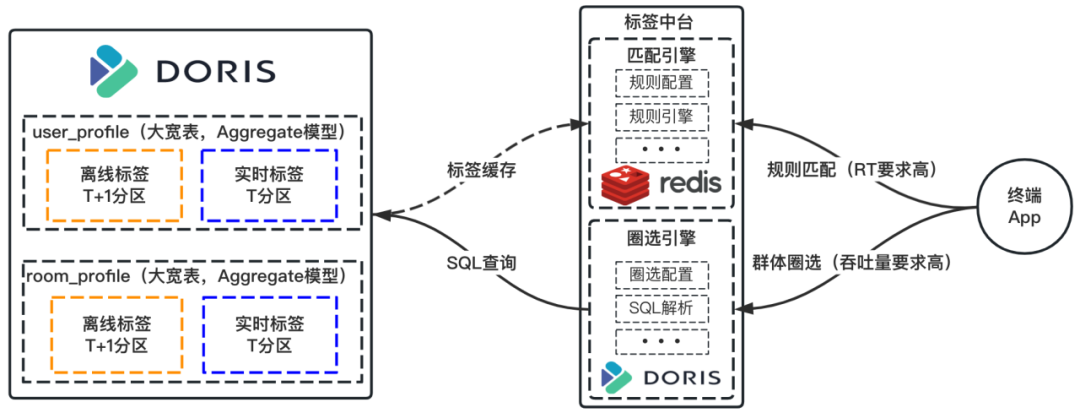
-
-- 简化存储:原存储在 HBase 中的大宽表,改为在 Doris 中分区存储,其中离线标签 T+1 更新,实时标签 T 更新、T+1 采用离线数据覆盖矫正。
-- 查询简化:**面对人群圈选场景**,无需利用 Spark 引擎,可直接在标签中台查询服务层,将圈选规则配置解析成 SQL 在 Doris 中执行、并获得最终的人群,大大提高了人群圈选的效率。**面对规则匹配场景**,使用 Redis 缓存 Doris 中的热点数据,以降低响应时间。
-
-#### **2. 长周期实时标签计算原链路**
-
-长周期实时标签:计算实时标签时所需的数据周期较长,部分标签还需要采用历史数据(离线)合并实时数据流一起进行计算的场景。
-
-**使用前:**
-
-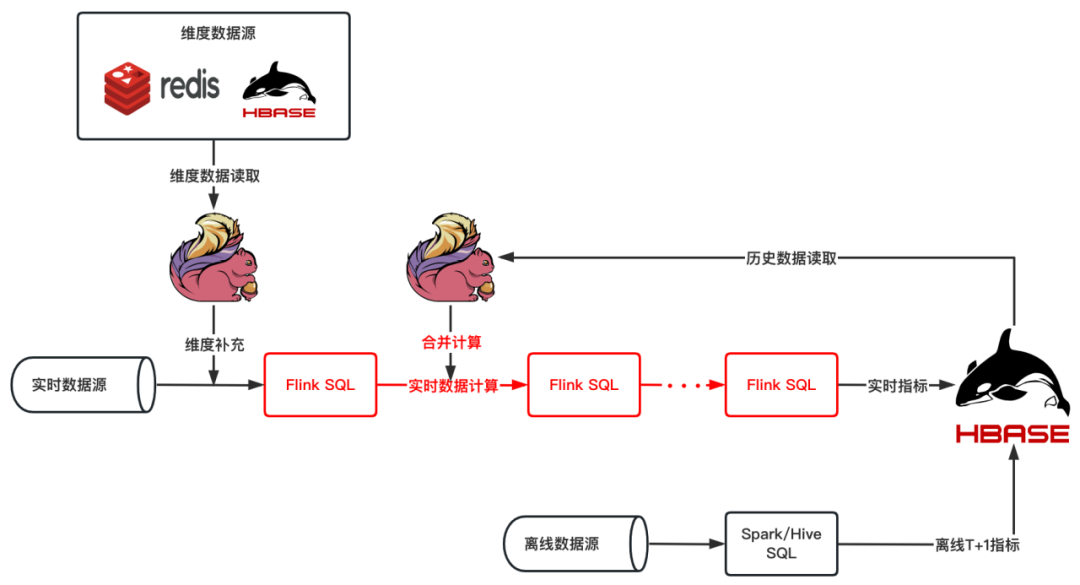
-
-从原来的计算链路中可知,计算长周期的实时标签时会涉及到维度补充、历史数据 Merge,在经过几步加工最终将数据写入到 HBase 中。
-
-在实际使用中发现,在这个过程中 Merge 离线聚合的数据会使链路变得很复杂,往往一个实时标签需要多个任务参与才能完成计算;另外聚合逻辑复杂的实时标签一般需要多次聚合计算,任意一个中间聚合资源分配不够或者不合理,都有可能出现反压或资源浪费的问题,从而使整个任务调试起来特别困难,同时链路过长运维管理也很麻烦,稳定性也比较低。
-
-**使用后:**
-
-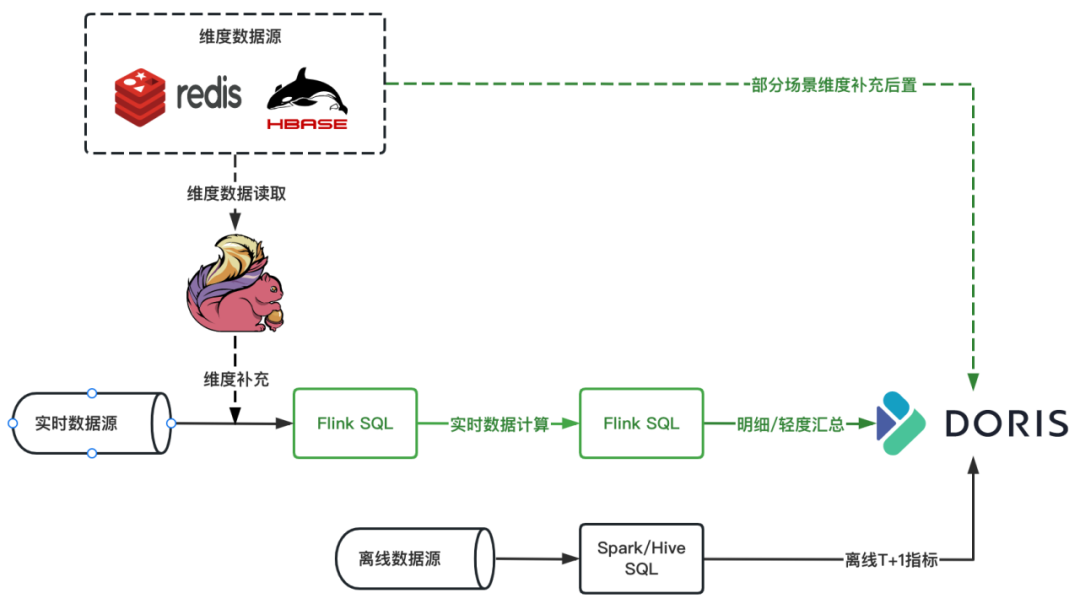
-
-我们在长周期指标计算实时链路中加入了 Apache Doris,在 Flink 中只做维度补充和轻度加工汇总,只关注短的实时数据流,对于需要 Merge 的离线数据,Merge 的计算逻辑转移到 Doris 中进行计算,另外 Doris 中的轻度汇总/明细数据有助于问题排查,同时任务稳定性也能提升。
-
-### 使用收益
-
-目前标签中台底层有近 4 亿+条用户标签,每个用户标签 300+,已有 1W+ 用户规则人群,每天定时更新的人群数量达到 5K+。标签中台引入 Apache Doris 之后,**单个人群平均圈选时间实现了分钟级到秒级的跨越**,实时标签任务稳定性有所提高,实时标签任务的产出时间相较于之前约有 **40% 的提升**,资源使用成本大大降低。
-
-
-
-
-
-# Doris 在多维数据分析平台的应用
-
-除以上所述应用及收益之外,Apache Doris 也助力内部多维数据分析平台——斗鱼 360 取得了较大的发展,受益于 Apache Doris 的 Rollup、物化视图以及向量化执行引擎,使原来需要预计算的场景可以直接导入明细数据到 Doris 中,简化了业务数据开发流程,提升了分析效率;Doris 兼容 MySQL 协议,并具有独立简单的分布式架构,使得业务开发人员入门使用也更容易,缩短了业务开发周期,有效降低了开发成本;同时我们原来基于 ClickHouse 的查询目前也全部切换到了 Doris 中进行。
-
-目前我们用于多维分析场景的 Doris 集群共有两个,节点规模约 120 个,存储数据量达 90~100 TB,每天增量写入到 Doris 的数据约 900GB,其中查询 QPS 在 120 左右,Apache Doris 应对起来毫不费力,轻松自如。
-
-*因文章篇幅限制,该部分应用不再赘述,后续有机会与大家进行详细分享。*
-
-
-
-# 未来展望
-
-未来随着 Apache Doris 在斗鱼更广泛业务场景的落地,我们将在可视化运维、问题快速定位排查等方面进行更多实践和深耕。我们关注到, Apache Doris 1.2.0 版本已经对 Multi Catalog 功能进行了支持,我们也计划对其进行探索、解锁更多使用场景,同时也期待即将发布 Apache Doris 2.x 版本的行列混存功能,更好的支持 Data Serving 场景。
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Duyansoft.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Duyansoft.md
deleted file mode 100644
index 340017575e3..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Duyansoft.md
+++ /dev/null
@@ -1,192 +0,0 @@
----
-{
- 'title': '复杂查询响应速度提升10+倍,度言软件基于 Apache Doris 实时数仓建设实践',
- 'summary': '度言软件使用 Doris 替换了部分业务使用场景后,用户的产品使用体验有了进一步提升,页面打开更加流畅,原本因为查询慢而不能实现的功能,当前已经实现并上线使用。同时在资源成本上也减轻了 MySQL 和 MongoDB 数据库的压力,不需要频繁进行升配和磁盘升级。',
- 'date': '2023-02-27',
- 'author': '杭州度言软件大数据团队',
- 'tags': ['最佳实践'],
-}
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-作者 | 杭州度言软件大数据团队
-
-编辑整理:SelectDB
-
-杭州度言软件有限公司(度言软件)成立于2014年,是信贷不良资产处置技术服务供应商,以“智能科技赋能不良资产处置,推动贷后行业合规高效发展”为使命,运用云通讯、大数据、人工智能等智能科技为信贷不良资产处置业务赋能,提供贷后管理通信能力支撑,实现了催收作业的智能化管理,客户群体为银行、消费金融公司、AMC 等金融机构和为这些机构提供人力资源外包服务的相关公司,目前已拥有 2000 多家企业客户。
-
-度言软件以围绕信贷不良资产案件高效流转管理为目的核心,从机构管理、团队管理、坐席管理、外呼作业、调解法诉等环节入手,帮助客户构建数智化的业务管理体系,以数字化系统提升管理效能、以智能化工具赋能处置作业,打通金融机构、外包服务公司、司法系统等多方的业务系统,并按照监管要求**对外呼行为、录音文件、沟通记录等案件相关数据进行记录、汇集、稽核、统计和分析,具有海量账号同时登陆、数据请求高并发、多来源数据汇总接入的特点要求。**
-
-# 业务需求
-
-2021 年之前,度言软件旗下产品的数据需求主要由传统数据库 MySQL,MongoDB,ElasticSearch 为主的技术架构来实现,近两年随着业务不断发展带而来数据量的高速增长,传统的数仓技术架构已初显瓶颈,难以满足客户日益丰富多样化的数据及分析需求。为了给客户提供更优质的服务体验,度言软件亟需对现有的技术架构做出优化和重构。
-
-# 早期架构及痛点
-
-## 数仓架构 1.0 版本
-
-初创期间,由于公司业务量相对较少,主要还是以 OLTP 业务和少量的业务报表服务为主,并且对于数据分析方面的需求也很少,仅通过传统的数据库基本就能满足早期的业务数据需求。**数仓** **架构 1.0 如下图所示:**
-
-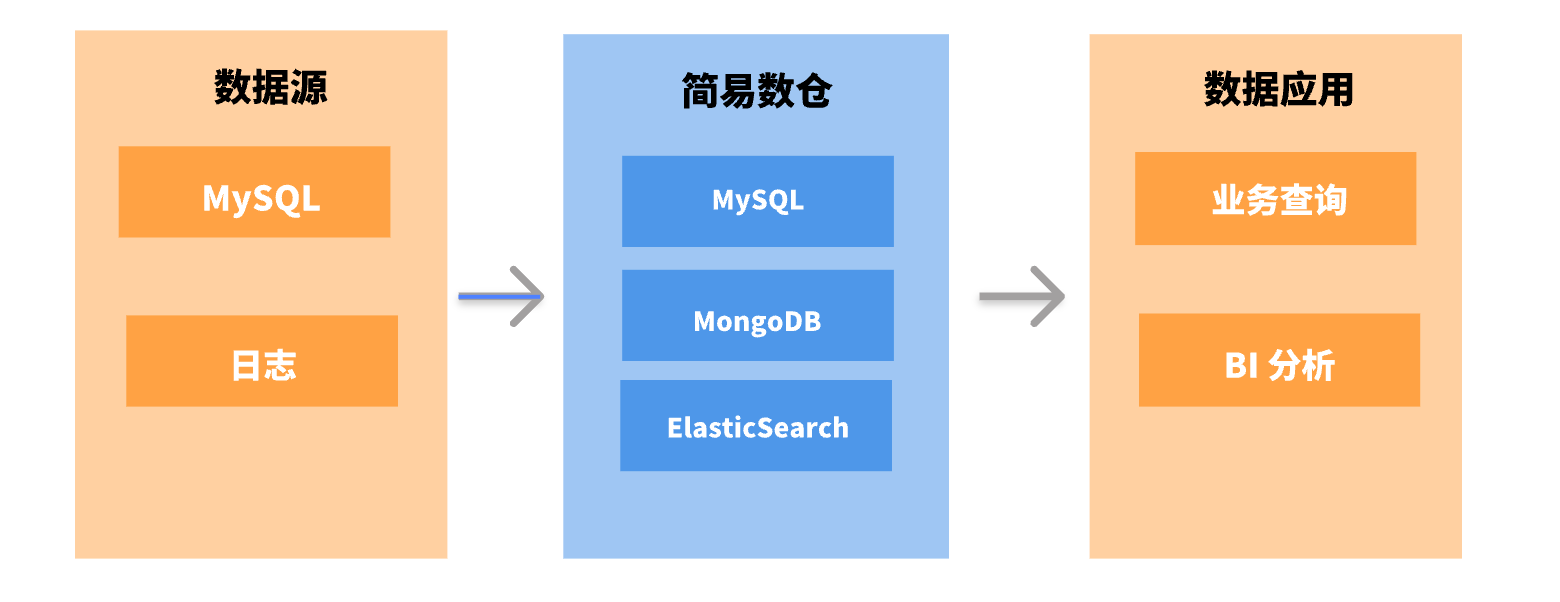
-
-## 数仓架构 2.0 版本
-
-随着公司业务的不断扩展,数据体量也出现极速增长的态势,业务侧对于数据分析方面的需求也逐渐多了起来,为此我们成立了专门的大数据团队,为搭建新的数仓及业务数据分析需求进行服务。**如下图所示为数仓架构 2.0** :
-
-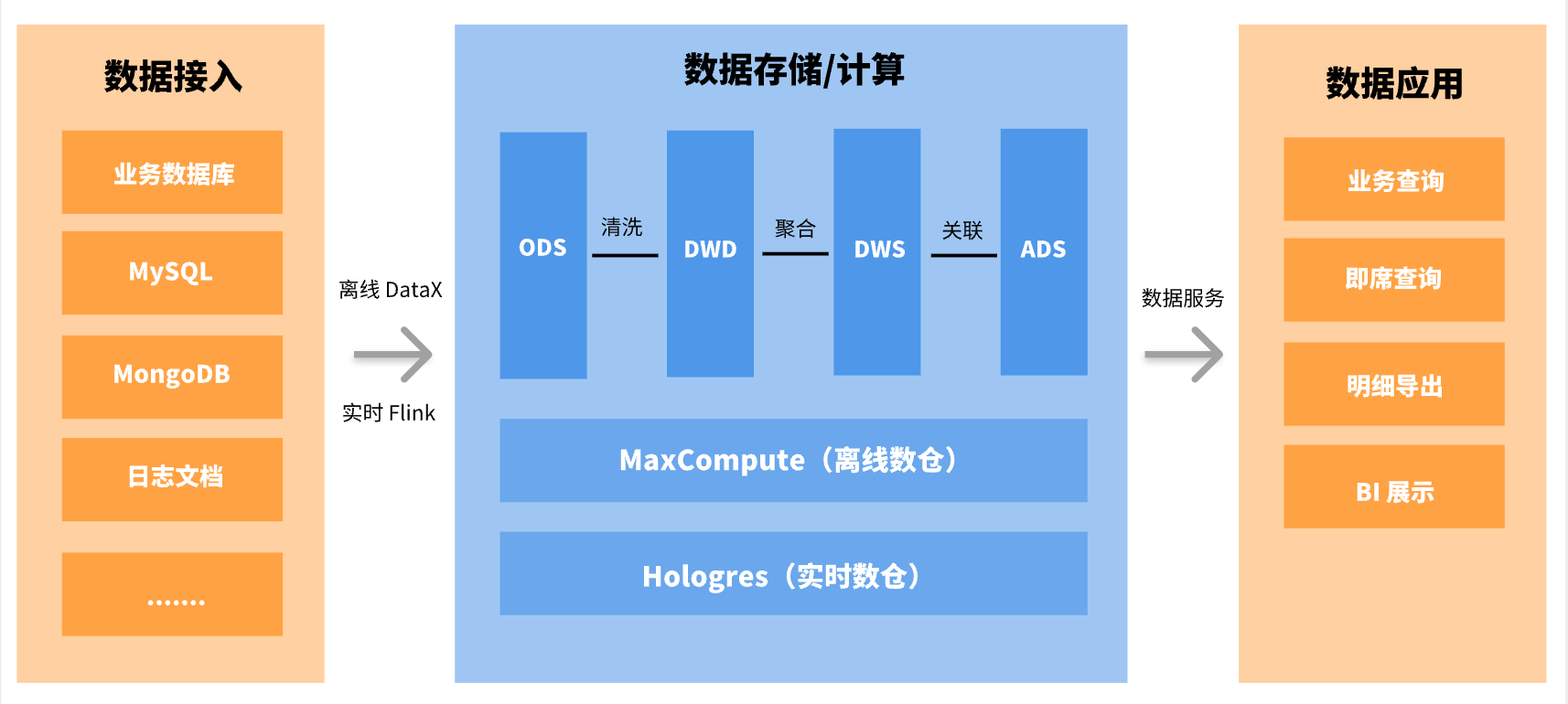
-
-数仓架构 2.0 版本是基于 MaxCompute + Hologres/MySQL 来搭建的。数据来源主要有 MySQL 和 MongoDB 的业务数据以及埋点日志数据;数据首先采集到数据总线 DataHub 中,后经过 DataHub 直接导入到 MaxCompute,MaxCompute 作为一个离线数仓,我们将其进行了传统的数仓分层;数据的加工处理和分析计算主要在离线数仓中进行,并将计算好的结果导出到 MySQL中,来对接 QuickBI 展示报表。此外,我们还尝试了将 Hologres 用作实时数仓,作为 MongoDB 的替换方案,用于业务上的查询系统。
-
-## 早期架构存在的问题:
-
-1. **响应速度较慢**。MySQL 对于大表的聚合计算并不友好,响应速度较慢。产品侧要求数据查询响应时间在 5 秒以内,虽然我们也基于 MySQL 进行了许多优化,但优化效果十分有限,仍无法达到 5s 的响应要求;我们甚至尝试了直接用 MaxCompute 对接 QuickBI,希望基于 MaxCompute 的查询加速和 QuickBI 的缓存来帮助我们解决问题,然而结果并不理想。
-1. **维系维度表成本高、难度大。** 离线数仓在数据同步的时效性上并不占优势(每 5 分钟进行一次批量同步),因此不太适合数据频繁更新和删除的场景,同时也给维度表的维护带来了额外的工作量。在数据更新和删除场景中,我们需要定期通过过滤和去重来保持数据的一致性,而事实上,大多时候需要报表数据实时关联维度表,这让我们直接放弃了在离线数仓中维系维度表的方案。
-1. **不支持高并发点查询场景。** 原实时数仓虽然可以满足我们对数据分析的部分性能要求,但其对高并发的点查场景并不太友好,不管是采用列式存储还是行级存储建表,优化之后的响应时长在 500 毫秒左右,综合来看性价比不算太高。
-
-# 解决思路
-
-为了解决上述问题,我们希望理想数仓能具有如下特性:
-
-1. 实现一站式实时数仓,能同时满足多种不同业务数据需求,大大简化大数据架构体系;
-1. 可同时支持 OLAP,Ad-hoc 和高 QPS 点查场景;
-1. 数据接入友好,写入即可见,对数据增删改和聚合等都有较好的支持;
-1. 架构简单,运维部署和维护简单,有较好的监控体系。
-
-# 技术选型
-
-在 2022 年 3 月份,我们对市场上主流的的几款即席查询数据库进行了调研,调研中我们发现每个产品只能满足某 1 个或几个特定的使用场景,没有一个产品可以完全满足所有的选型要求,而同时采用多个产品,将大大增加开发运维成本,同时也会使架构变得更加庞大复杂,这并不符合我们对理想数仓的要求。
-
-正在这时,我们从开源社区、技术媒体等渠道了解到了[ Apache Doris](https://github.com/apache/doris) ,经初步调研,我们发现 Doris 基本可以满足我们对理想数仓的所有要求。接着我们对 Doris 展开了深入调研,并使我们最终决定使用 Doris:Doris 架构非常简单,只有 FE 和 BE 两类进程,这两类进程都可以进行横向扩展,单集群可以支持到数百台机器、数十 PB 的存储容量,并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了分布式系统的运维成本,同时也不需要依赖于 Hadoop,避免了我们需要投入成本来额外部署 Hadoop 集群。
-
-# 基于 Doris 的新数仓架构设计
-
-最初使用 Doris 的初衷是替换部分 MySQL 数据量较大的报表,基于 MySQL 的查询约需要几十秒的响应时间,在替换为 Doris 后,查询性能有了显著提升,几秒内即可返回结果,最长的 SQL 执行时间大概在 8 秒左右,速度相较于之前提升了8 倍。Doris 的初步应用就给了我们一个意外的惊喜,因此我们决定使用 Doris 完全替换掉早期数仓中的 MySQL,在这使用过程中,我们又发现 Doris 远比我们想象的要强大,目前已将客户报表及公司内部运营决策数据全部迁移至 Apache Doris,并计划用 Apache Doris 来替换 MongoDB 和 ElasticSearch,用于业务上高 QPS 的点查场景。**以下是基于 Doris 的新数仓架构设计及使用情况:**
-
-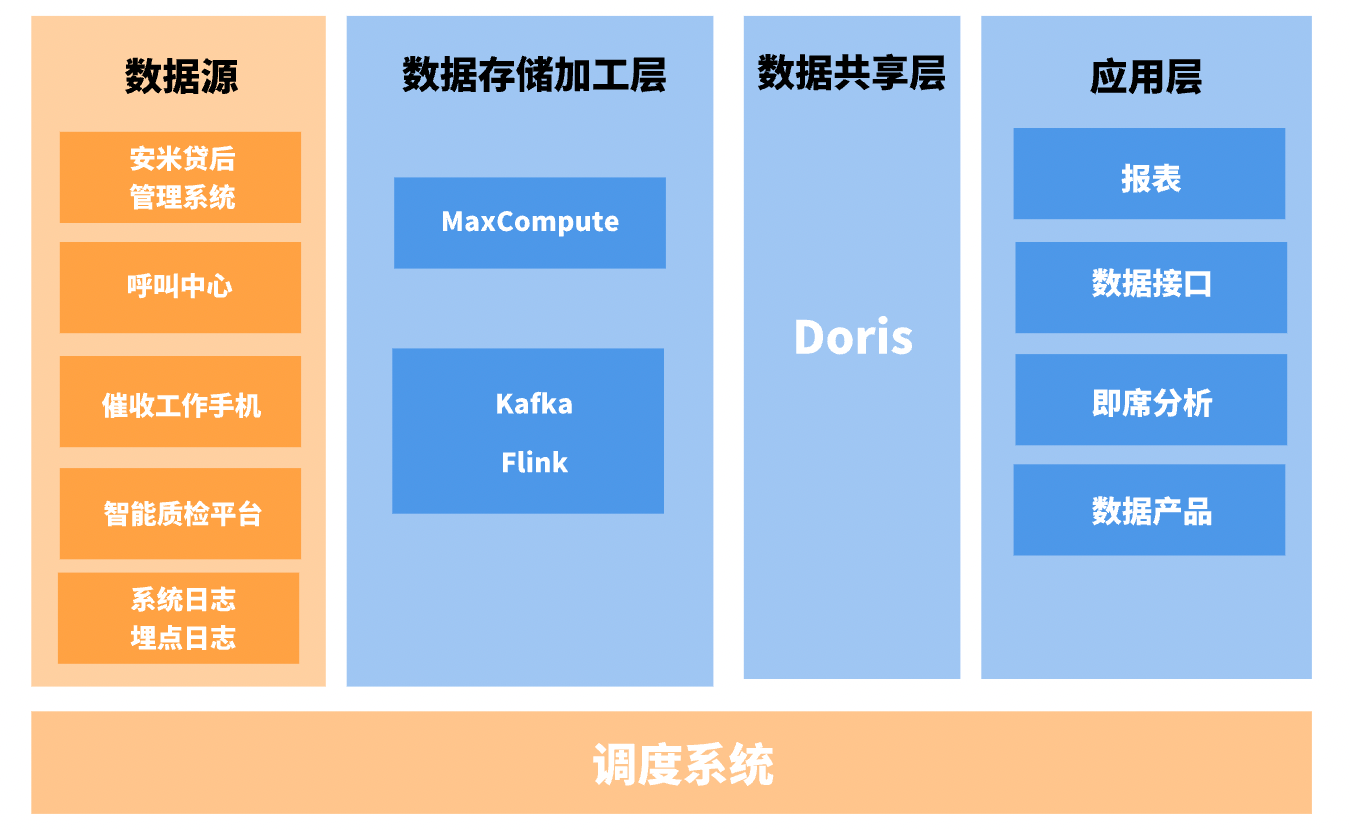
-
-## **数据建模:**
-
-我们在业务上使用最多的是 Unique 模型和 Aggregate 模型,这两种模型基本能够满足业务需求。
-
-- Unique 模型主要用于维度表和业务表(原始表)的接入,确保数据导入过程中的一致性。
-- Aggregate主要用于报表数据的导入,Aggregate 分为 Key (维度列) 和 Value(指标列),Value 列支持四种聚合方式:`sum` ,`replace`,`max`,`min`。当前主要以`replace` 聚合方式为主,方便统计数据重复导入和修正结果,后续也会尝试更多的方式来充分发挥 Doris 的性能。
-
-### **数据接入:**
-
-1. 使用 Flink-Doris-Connector 进行实时导入:主要用于业务数据的导入,基于MySQL 的 Binlog 日志写入到 Kafka 后,通过 Flink 解析加工后准实时写入 Doris。
-1. 使用 DataX 进行离线导入:主要用于对接离线数仓已计算后的报表数据。
-
-### **数据开发:**
-
-目前 Doris 主要以提供终端查询为主,复杂的 SQL 开发任务运行比较少,为尽可能减少 Doris 在数据加工方面的资源消耗,当前仅有报表集群在凌晨执行少量的 SQL 任务,主要以 Doris SQL 通过 insert into 的方式来导入。
-
-### **数据管理:**
-
-Doris 支持将当前数据以文件的形式通过 Broker 备份到远端存储系统中,后可以通过恢复命令从远端存储系统中将数据恢复到任意 Doris 集群。通过该功能,Doris 可支持定期对数据进行快照备份,也可以通过该功能在不同集群间进行数据迁移。我们也会定期将集群数据备份到阿里云 OSS 上,作为备用数据恢复方案。另外,在这期间我们对 Doris 集群进行了一次拆分,将报表集群和业务上的高并发查询集群分开,采用了 Doris 的数据备份和迁移功能。
-
-### **监控和报警:**
-
-我们使用官网推荐的 Prometheus 和 Grafana 进行监控项的采集和展示,Doris 本身提供了丰富的监控指标和标准监控模版,可以非常便捷地对 Doris 集群使用情况进行监控和报警。
-
-另外,为了进一步对慢 SQL 进行优化,我们还部署了审计日志插件,对于特定用户和特定的慢 SQL 进行优化和资源限制。如下是我们日常使用中的一些指标:
-
-**慢 SQL 查询:**
-
-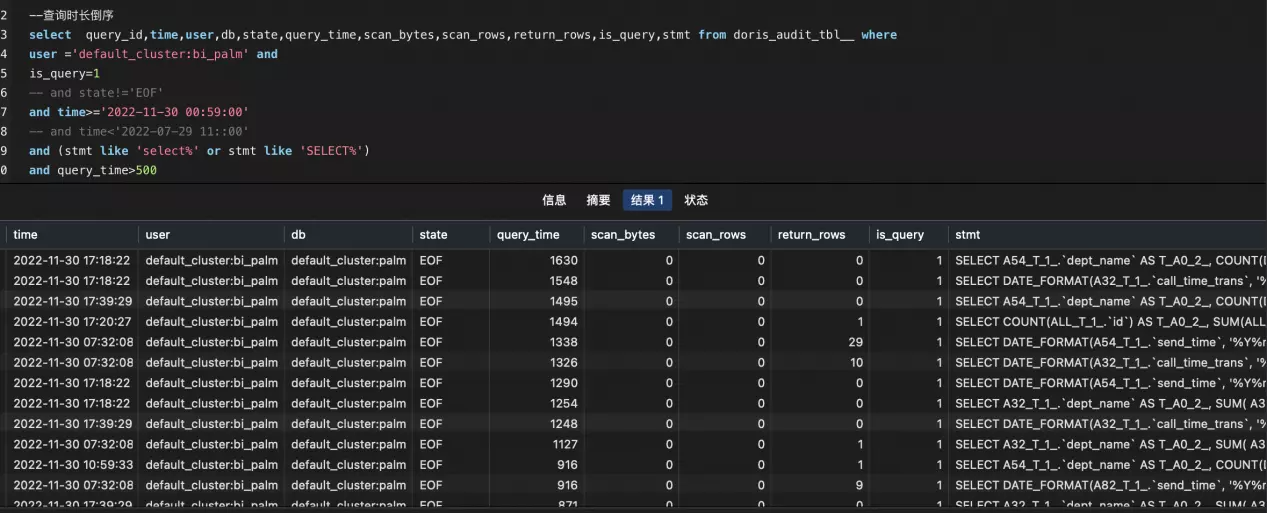
-
-对于一些长文本 SQL,无法完全展示,可以进一步查看`fe.audit.log`。
-
-**主要查询统计指标:**
-
-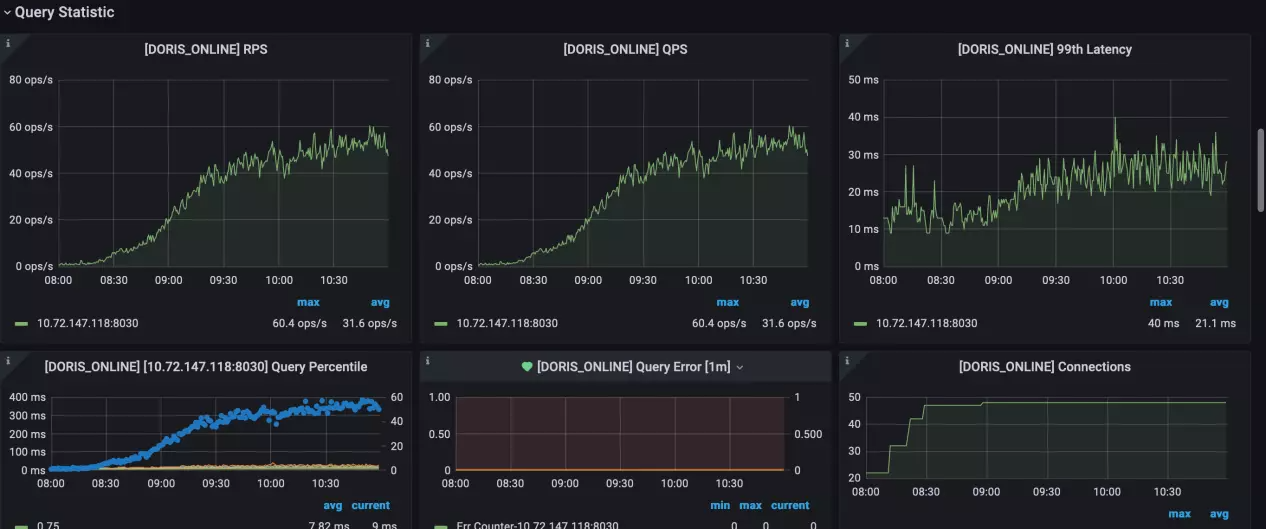
-
-# 优化实践:
-
-## 提高并发
-
-我们考虑在资源给定的情况下,如何最大程度地提高并发。刚开始引入 Doris 集群的时候,我们尝试对复杂 SQL 进行压测(SQL 层面优化已完成),但始终无法达到预期的压测效果。后来我们尝试**调低** `parallel_fragment_exec_instance_num` **的值**,顺利完成了压测目标。
-
-> **需要说明的是:**
->
-> ` parallel_fragment_exec_instance_num `指的是 Scan Node 在每个 BE 节点上执行实例的个数,相当于在整个查询计划执行过程中的并发度,调高该参数可以提升查询效率,但同时也会增加更多机器资源的消耗。因此在资源有限且查询耗时满足业务需求的情况下,通过调低参数来节省单个 SQL 的资源消耗,有助于提高并发表现。另外,我们通过 Doris 社区了解到,在即将发布的新版本中将实现参数自动设置,无需进行手动调整。
-
-如下图,我们可以看到,在参数设置为 16 的时候,异常率高达 82.84%,并且期间还出现了 BE 宕机重启,将参数调低至 8 后,异常率也同步降低到了 27.66%。最后我们将参数设置为最小值 1 后,异常率为 0,查询响应也能达到预期目标。
-
-说明:测试环境已重新取数,配置较低,数据仅用来说明 `parallel_fragment_exec_instance_num` 变动所带来的效果。
-
-当参数调整为 1:`parallel_fragment_exec_instance_num = 1`
-
-
-
-当参数调整为 8:`parallel_fragment_exec_instance_num = 8`
-
-
-
-
-
-当参数调整为 16:`parallel_fragment_exec_instance_num = 16`
-
-
-
-## BE 内存问题
-
-最初我们使用的是 Doris 0.15 的版本。由于刚开始处于测试阶段,Doris 集群配置比较低或参数配置的不合理,当某些 SQL 扫描数据量较大时,就可能因为内存问题导致 BE 宕机。
-
-在向社区咨询后,了解到 Supervisor 是用 Python 开发的一套通用的进程管理程序,能将一个普通的命令行进程变为后台 Daemon,并监控进程状态,异常退出时能自动重启,因此我们参照官网给出的例子直接用 Supervisor 对 Doris 的 FE 和 BE 进程进行管理。
-
-但是在运行了一段时间后,新的问题又出现了(已升级到 1.1.0 版本)。Doris 的 BE 节点内存一直在缓慢上升状态,并且达到了设置的最大内存参数 80% 后仍在继续上涨。后经分析发现 BE 存在内存泄漏问题,因此设置的参数并未生效。为此,我们将 Supervisor 切换为 Systemd 来守护 FE、BE 进程,限制整个节点的内存使用上限。不过在 Doris 1.1.3 推出之后,此问题已得到彻底的修复。
-
-## 资源占用
-
-在迁移完新集群后,我们发现通过 Flink-Doris-Connector 数据导入占用非常高的集群资源,虽然设置了按批次写入(每 3s 写入一次 ),以限制数据的导入频率,但集群资源的占用仍未得到较大改善。因此我们在集群资源和数据实时可见性方面做了权衡,介于我们对数据实时性的要求相对不是太高,所以我们将每 3s 写入一次改为每 10s 或 20s 写入一次,调整写入时间后,集群的 CPU 资源占用下降明显,得到改善。
-
-# 应用现状
-
-目前度言软件有 2 个 Doris 集群,1 个集群用作线上业务的查询系统,主要是应对高 QPS 的点查场景,我们将原先基于业务库 MySQL 和 MongoDB 的查询迁移至 Doris,一方面减少了业务库的读写压力,同时也提高了用户查询服务的使用体验。在 Doris 中,最复杂的查询在 1 秒以内即可响应,响应速度提升了十几倍;另外 1 个集群主要用作即席查询(AD-Hoc Query)和报表分析,具体包括公司内部使用的所有报表和一些临时查询、客户报表、数据实时大屏。
-
-总而言之,使用 Doris 替换了部分业务使用场景后,用户在产品上的使用体验有了进一步得到提升,页面打开更加流畅,原本因为查询慢而不能实现的功能,当前已经实现并上线使用。同时在资源成本上也减轻了 MySQL 和 MongoDB 数据库的压力,不需要频繁进行升配和磁盘升级。
-
-# 总结规划
-
-## 效果总结
-
-1. Doris 完美覆盖了原本需要多个技术栈才能实现的业务场景,极大地简化了大数据的架构体系。
-1. Doris 对 Join 支持较好,因此我们选择了将维度表放到 Doris 中进行维护,相较于之前在离线数仓中进行维护,明显地提高了开发的效率,并降低了数据出错的可能性,满足了业务上对维度表近实时更新的需求。
-1. Doris 支持 MySQL 协议和标准 SQL,开发人员学习成本低,上手简单,可以快速将原先的业务迁移至 Doris 上来。
-1. Doris 社区活跃,版本迭代速度快。在遇到任何问题时,都可以向社区求助,[SelectDB](https://cn.selectdb.com/) 为 Apache Doris 组建了一支全职专业的技术支持入队,24H 内即可得到社区的响应回复。
-
-## 未来规划
-
-到目前为止,基于 Doris 的实时数仓搭建已基本完成,但我们对 Doris 的进一步尝试才刚刚开始,比如 BE 的多磁盘部署,物化视图的使用,Doris-On-ES,Doris 多租户和资源划分等。
-
-**此外,我们也希望 Doris 未来能对以下功能进行进一步优化:**
-
-1. Flink-Doris-Connector 能支持单 Sink 同时写入多张表,不需要再通过分流后多个 Sink 写入。
-1. 物化视图能够支持多表 Join,不再局限于单表。
-1. 进一步优化数据的底层 Compaction,在保证数据可见性的同时能够尽可能降低资源消耗。
-1. Doris-Manager 提供对慢 SQL 的优化建议以及表信息收集,对于不合理的建表进行一定的提示。
-
-
-
-
-从 3 月份使用 Doris 以来,我们一直都和 Doris 社区保持着密切的联系,后续我们也将继续围绕 Doris 作为实时数仓应用到更多的业务使用场景中,对于使用中遇到的问题和优化的方案,我们也会持续和社区保持热切联系,为社区进步贡献我们的一份力量。
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Flink-realtime-write.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Flink-realtime-write.md
deleted file mode 100644
index 734fd7703ec..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Flink-realtime-write.md
+++ /dev/null
@@ -1,159 +0,0 @@
----
-{
- 'title': 'Apache Doris 1.1 特性揭秘:Flink 实时写入如何兼顾高吞吐和低延时',
- 'summary': "随着数据实时化需求的日益增多,数据的时效性对企业的精细化运营越来越重要,使得实时数仓在这一过程中起到了不可替代的作用。本文将基于用户遇到的问题与挑战,揭秘 Apache Doris 1.1 特性,对 Flink 实时写入 Apache Doris 的优化实现与未来规划进行详细的介绍。",
- 'date': '2022-07-29',
- 'author': 'Apache Doris',
- 'tags': ['技术解析'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-
-
-# 背景
-随着数据实时化需求的日益增多,数据的时效性对企业的精细化运营越来越重要,在海量数据中,如何能实时有效的挖掘出有价值的信息,快速的获取数据反馈,协助公司更快的做出决策,更好的进行产品迭代,**实时数仓在这一过程中起到了不可替代的作用**。
-
-在这种形势下,**Apache Doris 作为一款实时 MPP 分析型数据库脱颖而出**,同时具备高性能、简单易用等特性,具有丰富的数据接入方式,结合 Flink 流式计算,可以让用户快速将 Kafka 中的非结构化数据以及 MySQL 等上游业务库中的变更数据,快速同步到 Doris 实时数仓中,同时 Doris 提供亚秒级分析查询的能力,可以有效地满足实时 OLAP、实时数据看板以及实时数据服务等场景的需求。
-
-# 挑战
-
-通常实时数仓要保证端到端高并发以及低延迟,往往面临诸多挑战,比如:
-
-- 如何保证端到端的**秒级别数据同步**?
-- 如何快速保证**数据可见性**?
-- 在高并发大压力下,如何解决**大量小文件写入**的问题?
-- 如何确保端到端的 **Exactly Once** 语义?
-
-结合这些挑战,同时对用户使用 Flink+Doris 构建实时数仓的业务场景进行深入调研,在掌握了用户使用的痛点之后,**我们在 Doris 1.1 版本中进行了针对性的优化,大幅提升实时数仓构建的用户体验,同时提升系统的稳定性,系统资源消耗也得到了大幅的优化。**
-
-# 优化
-
-## 流式写入
-Flink Doris Connector 最初的做法是在接收到数据后,缓存到内存 Batch 中,通过攒批的方式进行写入,同时使用 batch.size、batch.interval 等参数来控制 Stream Load 写入的时机。这种方式通常在参数合理的情况下可以稳定运行,一旦参数不合理导致频繁的 Stream Load,便会引发 Compaction 不及时,从而导致 version 过多的错误(-235);其次,当数据过多时,为了减少 Stream Load 的写入时机,batch.size 过大的设置还可能会引发 Flink 任务的 OOM。为了解决这个问题,**我们引入了流式写入** **:** 
-
-1. Flink 任务启动后,会异步发起一个 Stream Load 的 Http 请求。
-
-2. 接收到实时数据后,通过 Http 的分块传输编码(Chunked transfer encoding)机制持续向 Doris 传输数据。
-
-3. 在 Checkpoint 时结束 Http 请求,完成本次 Stream Load 写入,同时异步发起下一次 Stream Load 的请求。
-
-4. 继续接收实时数据,后续流程同上。
-
-**由于采用 Chunked 机制传输数据,就避免了攒批对内存的压力,同时将写入的时机和 Checkpoint 绑定起来,使得 Stream Load 的时机可控,并且为下面的 Exactly-Once 语义提供了基础。**
-
-## Exactly-Once
-
-Exactly-Once 语义是指即使在机器或应用出现故障的情况下,也不会重复处理数据或者丢失数据。Flink 很早就支持 End-to-End 的 Exactly-Once 场景,主要是通过两阶段提交协议来实现 Sink 算子的 Exactly-Once 语义。在 Flink 两阶段提交的基础上,同时借助 Doris 1.0 的 Stream Load 两阶段提交,**Flink Doris Connector 实现了 Exactly Once 语义,具体原理如下:**
-
-1. Flink 任务在启动的时候,会发起一个 Stream Load 的 PreCommit 请求,此时会先开启一个事务,同时会通过 Http 的 Chunked 机制将数据持续发送到 Doris。
-
-
-
-2. 在 Checkpoint 时,结束数据写入,同时完成 Http 请求,并且将事务状态设置为预提交(PreCommitted),此时数据已经写入 BE,对用户不可见。
-
-
-
-3. Checkpoint 完成后,发起 Commit 请求,并且将事务状态设置为提交(Committed),完成后数据对用户可见。
-
-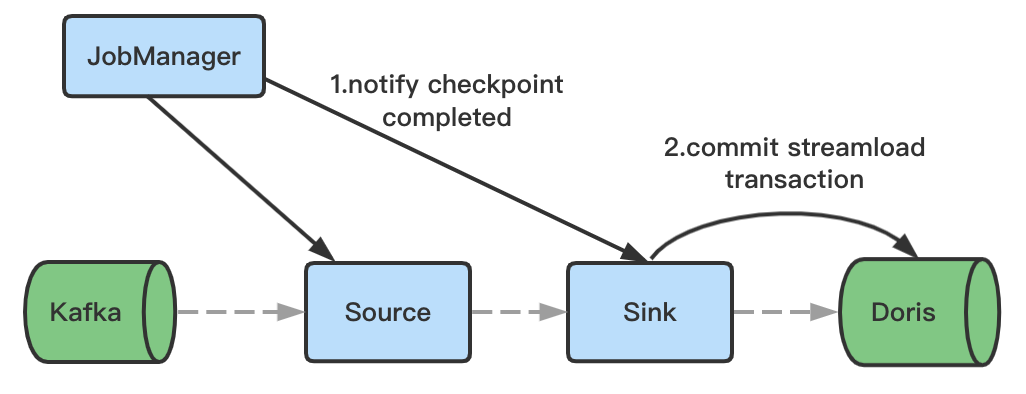
-
-4. Flink 应用意外挂掉后,从 Checkpoint 重启时,若上次事务为预提交(PreCommitted)状态,则会发起回滚请求,并且将事务状态设置为 Aborted。
-
-**基于此,可以借助 Flink Doris Connector 实现数据实时入库时数据不丢不重。**
-
-## 秒级别数据同步
-
-高并发写入场景下的端到端秒级别数据同步以及数据的实时可见能力,**需要 Doris 具备如下几方面的能力:**
-
-**事务处理能力**
-
-Flink 实时写入以 Stream Load 2PC 的方式与 Doris 进行交互,需要 Doris 具备对应的事务处理能力,保障事务基本的 ACID 特性,在高并发场景下支撑 Flink 秒级别的数据同步。
-
-## 数据版本的快速聚合能力
-
-Doris 里面一次导入会产生一个数据版本,在高并发写入场景下必然带来的一个影响是数据版本过多,且单次导入的数据量不会太大。持续的高并发小文件写入场景对 Doris 并不友好,极其考验 Doris 数据合并的实时性以及性能,进而会影响到查询的性能。**Doris 在 1.1 中大幅增强了数据 Compaction 能力,对于新增数据能够快速完成聚合,避免分片数据中的版本过多导致的 -235 错误以及带来的查询效率问题。**
-
-**首先**,在 Doris 1.1 版本中,引入了 QuickCompaction,增加了主动触发式的 Compaction 检查,在数据版本增加的时候主动触发 Compaction。同时通过提升分片元信息扫描的能力,快速的发现数据版本多的分片,触发 Compaction。通过主动式触发加被动式扫描的方式,彻底解决数据合并的实时性问题。
-
-**同时**,针对高频的小文件 Cumulative Compaction,实现了 Compaction 任务的调度隔离,防止重量级的 Base Compaction 对新增数据的合并造成影响。
-
-**最后**,针对小文件合并,优化了小文件合并的策略,采用梯度合并的方式,每次参与合并的文件都属于同一个数据量级,防止大小差别很大的版本进行合并,逐渐有层次的合并,减少单个文件参与合并的次数,能够大幅的节省系统的 CPU 消耗。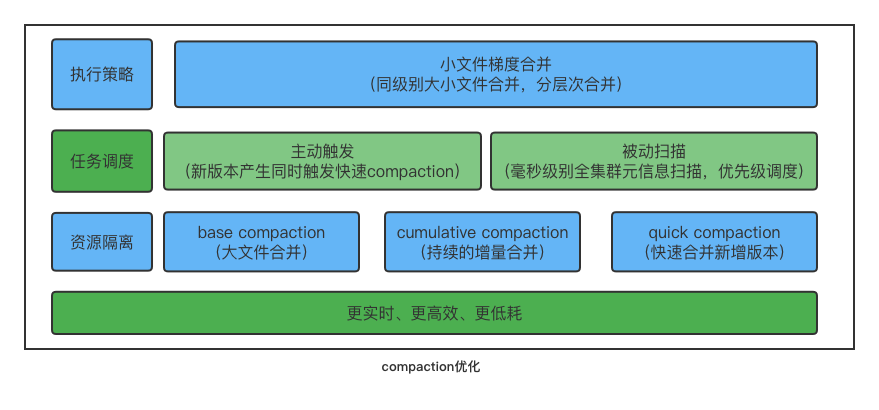
-
-**Doris 1.1 对高并发导入、秒级别数据同步、数据实时可见等场景都做了针对性优化,大大增加了 Flink + Doris 系统的易用性以及稳定性,节省了集群整体资源。**
-
-
-# 效果
-
-## 通用 Flink 高并发场景
-
-在调研的通用场景中,使用 Flink 同步上游 Kafka 中的非结构化数据,经过 ETL 后使用 Flink Doris Connector 将数据实时写入 Doris 中。这里客户场景极其严苛,上游维持以每秒 10w 的超高频率写入,需要数据能够在 5s 内完成上下游同步,实现秒级别的数据可见。这里 Flink 配置为 20 并发,Checkpoint 间隔 5s,Doris 1.1 的表现相当优异。**具体体现在如下几个方面:**
-
-**Compaction 实时性**
-
-数据能快速合并,Tablet 数据版本个数维持在 50 以下, Compaction Score 稳定。相比于之前高并发导入频出的 -235 问题,**Compaction 合并效率有 10+ 倍提升**。
-
-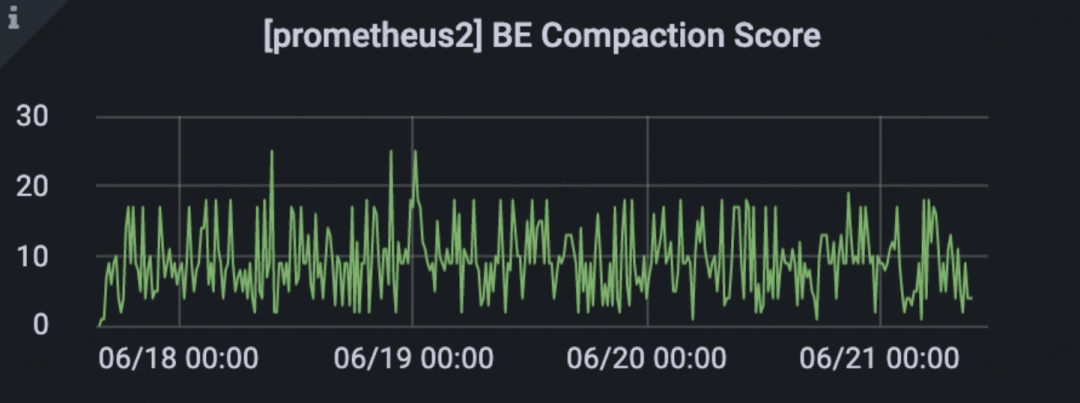
-
-**CPU 资源消耗**
-
-Doris 1.1 针对小文件的 Compaction 进行了策略优化,在上述高并发导入场景,**CPU 资源消耗下降 25%。** 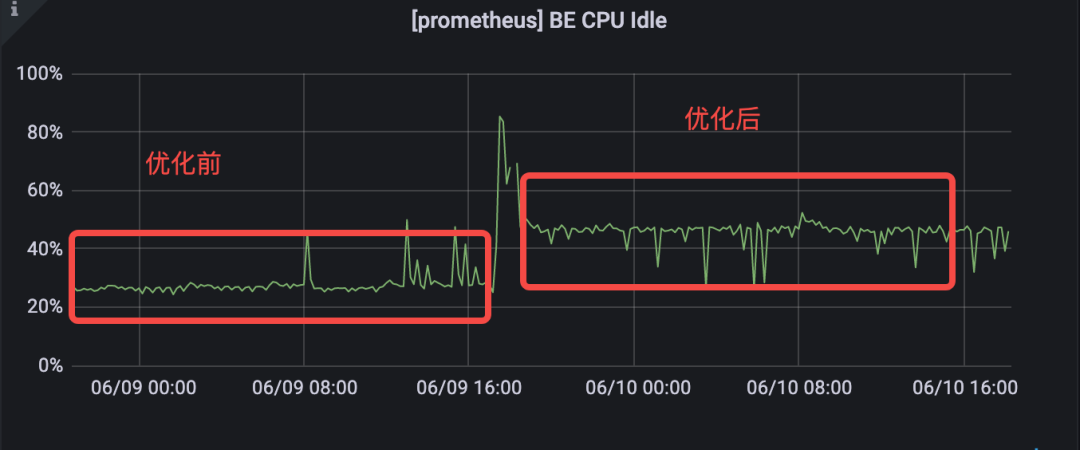
-
-**QPS 查询延迟稳定**
-
-通过降低 CPU 使用率,减少数据版本的个数,提升了数据整体有序性,从而减少了 SQL 查询的延迟。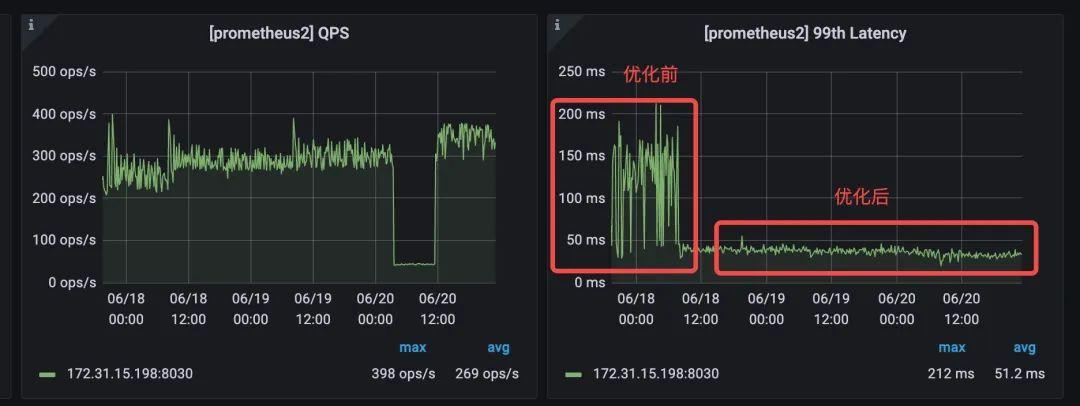
-
-## 秒级别数据同步场景(极限大压力)
-
-单 BE 单 Tablet,客户端 30 并发极限 Stream Load 压测,数据在实时性<1s,Compaction Score 优化前后对比
-
-
-
-# 使用建议
-
-## 数据实时可见场景
-
-对延迟要求特别严格的场景,比如秒级别数据同步,通常意味着单次导入文件较小,此时建议调小 cumulative_size_based_promotion_min_size_mbytes,单位是 MB,默认 64,可以设置成 8,能够很大程度提升 Compaction 的实时性。
-
-## 高并发场景
-
-对于高并发的写入场景,可以通过增加 Checkpoint 的间隔来减少 Stream Load 的频率,比如 Checkpoint 可以设置为 5-10s,不仅可以增加 Flink 任务的吞吐,也可以减少小文件的产生,避免给 Compaction 造成更多压力。
-
-此外,对数据实时性要求不高的场景,比如分钟级别的数据同步,可以增加 Checkpoint 的间隔,比如 5-10 分钟,此时 Flink Doris Connector 依然能够通过两阶段提交 +checkpoint 机制来保证数据的完整性。
-
-# 未来规划
-
-**实时 Schema Change**
-
-目前通过 Flink CDC 实时接入数据时,当上游业务表进行 Schema Change 操作时,必须先手动修改 Doris 中的 Schema 和 Flink 任务中的 Schema,最后再重启任务,新的 Schema 的数据才可以同步过来。这样使用方式需要人为的介入,会给用户带来极大的运维负担。**后续会针对 CDC 场景做到支持 Schema 实时变更,上游的 Schema Change 实时同步到下游,全面提升 Schema Change 的效率。**
-
-**Doris 多表写入**
-
-目前 Doris Sink 算子仅支持同步单张表,所以对于整库同步的操作,需要手动在 Flink 层面进行分流,写到多个 Doris Sink 中,这无疑增加了开发者的难度,**在后续版本中我们也将支持单个 Doris Sink 同步多张表,这样就大大的简化了用户的操作。**
-
-**自适应的 Compaction 参数调优**
-
-目前 Compaction 策略参数较多,在大部分通用场景能发挥较好的效果,但是在一些特殊场景下并不能高效的发挥作用。**我们将在后续版本中持续优化,针对不同的场景,进行自适应的 Compaction 调优,在各类场景下提高数据合并效率,提升实时性。**
-
-**单副本 Compaction**
-
-目前的 Compaction 策略是各 BE 单独进行,**在后续版本中我们将实现单副本 Compaction,通过克隆快照的方式实现 Compaction 任务,减少集群 2/3 的 Compaction 任务,降低系统的负载,把更多的系统资源留给用户侧。**
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/HCDS.md b/i18n/zh-CN/docusaurus-plugin-content-blog/HCDS.md
deleted file mode 100644
index 89e9297df9e..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/HCDS.md
+++ /dev/null
@@ -1,343 +0,0 @@
----
-{
- 'title': 'Apache Doris 冷热分层技术如何实现存储成本降低 70%?',
- 'summary': "冷热数据分层技术的诞生是为了更好地满足企业降本增效的趋势。顾名思义,冷热分层是将冷热数据分别存储在成本不同的存储介质上,例如热数据存储在成本更高的 SSD 盘上、以提高时效数据的查询速度和响应能力,而冷数据则存储在相对低成本的 HDD 盘甚至更为廉价的对象存储上,以降低存储成本。",
- 'date': '2023-06-23',
- 'author': 'Apache Doris',
- 'tags': ['技术解析'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-在数据分析的实际场景中,冷热数据往往面临着不同的查询频次及响应速度要求。例如在电商订单场景中,用户经常访问近 6 个月的订单,时间较久远的订单访问次数非常少;在行为分析场景中,需支持近期流量数据的高频查询且时效性要求高,但为了保证历史数据随时可查,往往要求数据保存周期更为久远;在日志分析场景中,历史数据的访问频次很低,但需长时间备份以保证后续的审计和回溯的工作...往往历史数据的应用价值会随着时间推移而降低,且需要应对的查询需求也会随之锐减。而随着历史数据的不断增多,如果我们将所有数据存储在本地,将造成大量的资源浪费。
-
-为了解决满足以上问题,冷热数据分层技术应运而生,以更好满足企业降本增效的趋势。顾名思义,**冷热分层是将冷热数据分别存储在成本不同的存储介质上**,例如热数据存储在成本更高的 SSD 盘上、以提高时效数据的查询速度和响应能力,而冷数据则存储在相对低成本的 HDD 盘甚至更为廉价的对象存储上,以降低存储成本。我们还可以根据实际业务需求进行灵活的配置和调整,以满足不同场景的要求。
-
-**冷热分层一般适用于以下需求场景:**
-
-* 数据存储周期长:面对历史数据的不断增加,存储成本也随之增加;
-
-* 冷热数据访问频率及性能要求不同:热数据访问频率高且需要快速响应,而冷数据访问频率低且响应速度要求不高;
-
-* 数据备份和恢复成本高:备份和恢复大量数据需要消耗大量的时间和资源。
-
-* ......
-
-# 更高存储效率的冷热分层技术
-
-自 Apache Doris 0.12 版本引入动态分区功能,开始支持对表分区进行生命周期管理,可以设置热数据转冷时间以及存储介质标识,通过后台任务将热数据从 SSD 自动冷却到 HDD,以帮助用户较大程度地降低存储成本。用户可以在建表属性中配置参数 `storage_cooldown_time` 或者 `dynamic_partition.hot_partition_num` 来控制数据从 SSD 冷却到 HDD,当分区满足冷却条件时,Doris 会自动执行任务。而 HDD 上的数据是以多副本的方式存储的,并没有做到最大程度的成本节约,因此对于冷数据存储成本仍然有较大的优化空间。
-
-为了帮助用户进一步降低存储成本,社区在已有功能上进行了优化,并在 Apache Doris 2.0 版本中推出了**冷热** **数据** **分层的功能**。冷热数据分层功能使 Apache Doris 可以将冷数据下沉到存储成本更加低廉的对象存储中,同时冷数据在对象存储上的保存方式也从多副本变为单副本,存储成本进一步降至原先的三分之一,同时也减少了因存储附加的计算资源成本和网络开销成本。
-
-如下图所示,在 Apache Doris 2.0 版本中支持三级存储,分别是 SSD、HDD 和对象存储。用户可以配置使数据从 SSD 下沉到 HDD,并使用冷热分层功能将数据从 SSD 或者 HDD 下沉到对象存储中。
-
-
-
-以公有云价格为例,云磁盘的价格通常是对象存储的 5-10 倍,如果可以将 80% 的冷数据保存到对象存储中,存储成本至少可降低 70%。
-
-我们使用以下公式计算节约的成本,设冷数据比率为 rate,对象存储价格为 OSS,云磁盘价格为 CloudDisk
-
-$1 - \frac{rate * 100 * OSS + (1 - rate) * 100 * CloudDisk}{100 * CloudDisk}$
-
-这里我们假设用户有 100TB 的数据,我们按照不同比例将冷数据迁移到对象存储,来计算一下**如果使用冷热分层之后,相较于全量使用普通云盘、SSD 云盘** **可节约** **多少** **成本**。
-
-* 阿里云 OSS 标准存储成本是 120 元/ T /月
-* 阿里云普通云盘的价格是 300 元/ T /月
-* 阿里云 SSD 云盘的价格是 1000 元/ T /月
-
-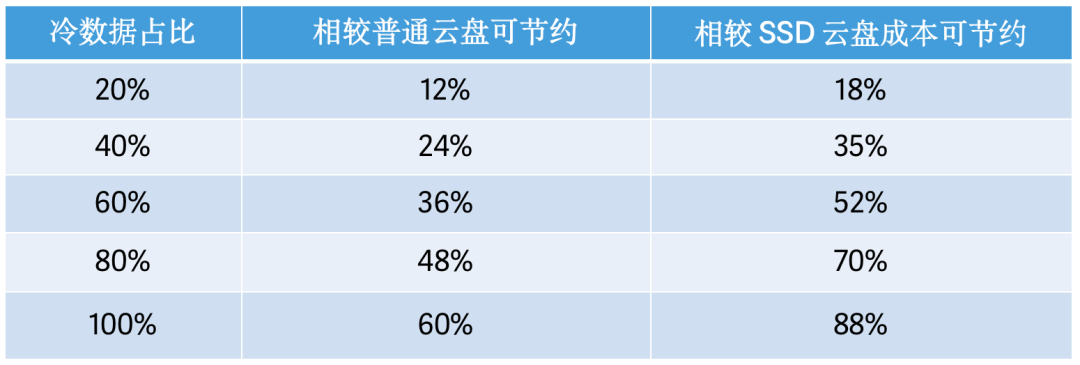
-
-例如在 80% 冷数据占比的情况下,剩余 20% 使用普通云盘每月仅花费 80T*120 + 20T \* 300 = 15600元,而全量使用普通云盘则需要花费 30000 元,通过冷热数据分层节省了 48% 的存储成本。如果用户使用的是 SSD 云盘,那么花费则会从全量使用需花费的 100000 元降低到 80T*120 + 20T \* 1000 = 29600元,存储成本最高降低超过 70%!
-
-# 使用指南
-
-若要使用 Doris 的冷热分层功能,首先需要准备一个对象存储的 Bucket 并获取对应的 AK/SK。当准备就绪之后,下面为具体的使用步骤:
-
-**1. 创建 Resource**
-
-可以使用对象存储的 Bucket 以及 AK/SK 创建 Resource,目前支持 AWS、Azure、阿里云、华为云、腾讯云、百度云等多个云的对象存储。
-
- CREATE RESOURCE IF NOT EXISTS "${resource_name}"
- PROPERTIES(
- "type"="s3",
- "s3.endpoint" = "${S3Endpoint}",
- "s3.region" = "${S3Region}",
- "s3.root.path" = "path/to/root",
- "s3.access_key" = "${S3AK}",
- "s3.secret_key" = "${S3SK}",
- "s3.connection.maximum" = "50",
- "s3.connection.request.timeout" = "3000",
- "s3.connection.timeout" = "1000",
- "s3.bucket" = "${S3BucketName}"
- );
-
-**2. 创建 Storage Policy**
-
-可以通过 Storage Policy 控制数据冷却时间,目前支持相对和绝对两种冷却时间的设置。
-
- CREATE STORAGE POLICY testPolicy
- PROPERTIES(
- "storage_resource" = "remote_s3",
- "cooldown_ttl" = "1d"
- );
-
-例如上方代码中名为 `testPolicy` 的 `storage policy `设置了新导入的数据将在一天后开始冷却,并且冷却后的冷数据会存放到 `remote_s3 `所表示的对象存储的 `root path` 下。除了设置 TTL 以外,在 Policy 中也支持设置冷却的时间点,可以直接设置为:
-
-```sql
-CREATE STORAGE POLICY testPolicyForTTlDatatime
-PROPERTIES(
- "storage_resource" = "remote_s3",
- "cooldown_datetime" = "2023-06-07 21:00:00"
-);
-```
-
-**3. 给表或者分区设置 Storage Policy**
-
-在创建出对应的 Resource 和 Storage Policy 之后,我们可以在建表的时候对整张表设置 Cooldown Policy,也可以针对某个 Partition 设置 Cooldown Policy。这里以 TPCH 测试数据集中的 lineitem 表举例。如果需要将整张表都设置冷却的策略,则可以直接在整张表的 properties 中设置:
-
- CREATE TABLE IF NOT EXISTS lineitem1 (
- L_ORDERKEY INTEGER NOT NULL,
- L_PARTKEY INTEGER NOT NULL,
- L_SUPPKEY INTEGER NOT NULL,
- L_LINENUMBER INTEGER NOT NULL,
- L_QUANTITY DECIMAL(15,2) NOT NULL,
- L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
- L_DISCOUNT DECIMAL(15,2) NOT NULL,
- L_TAX DECIMAL(15,2) NOT NULL,
- L_RETURNFLAG CHAR(1) NOT NULL,
- L_LINESTATUS CHAR(1) NOT NULL,
- L_SHIPDATE DATEV2 NOT NULL,
- L_COMMITDATE DATEV2 NOT NULL,
- L_RECEIPTDATE DATEV2 NOT NULL,
- L_SHIPINSTRUCT CHAR(25) NOT NULL,
- L_SHIPMODE CHAR(10) NOT NULL,
- L_COMMENT VARCHAR(44) NOT NULL
- )
- DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
- PARTITION BY RANGE(`L_SHIPDATE`)
- (
- PARTITION `p202301` VALUES LESS THAN ("2017-02-01"),
- PARTITION `p202302` VALUES LESS THAN ("2017-03-01")
- )
- DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3
- PROPERTIES (
- "replication_num" = "3",
- "storage_policy" = "${policy_name}"
- )
-
-用户可以通过 show tablets 获得每个 Tablet 的信息,其中 CooldownReplicaId 不为 -1 并且 CooldownMetaId 不为空的 Tablet 说明使用了 Storage Policy。如下方代码,通过 show tablets 可以看到上面的 Table 的所有 Tablet 都设置了 CooldownReplicaId 和 CooldownMetaId,这说明整张表都是使用了 Storage Policy。
-
- TabletId: 3674797
- ReplicaId: 3674799
- BackendId: 10162
- SchemaHash: 513232100
- Version: 1
- LstSuccessVersion: 1
- LstFailedVersion: -1
- LstFailedTime: NULL
- LocalDataSize: 0
- RemoteDataSize: 0
- RowCount: 0
- State: NORMAL
- LstConsistencyCheckTime: NULL
- CheckVersion: -1
- VersionCount: 1
- QueryHits: 0
- PathHash: 8030511811695924097
- MetaUrl: http://172.16.0.16:6781/api/meta/header/3674797
- CompactionStatus: http://172.16.0.16:6781/api/compaction/show?tablet_id=3674797
- CooldownReplicaId: 3674799
- CooldownMetaId: TUniqueId(hi:-8987737979209762207, lo:-2847426088899160152)
-
-我们也可以对某个具体的 Partition 设置 Storage Policy,只需要在 Partition 的 Properties 中加上具体的 Policy Name 即可:
-
- CREATE TABLE IF NOT EXISTS lineitem1 (
- L_ORDERKEY INTEGER NOT NULL,
- L_PARTKEY INTEGER NOT NULL,
- L_SUPPKEY INTEGER NOT NULL,
- L_LINENUMBER INTEGER NOT NULL,
- L_QUANTITY DECIMAL(15,2) NOT NULL,
- L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
- L_DISCOUNT DECIMAL(15,2) NOT NULL,
- L_TAX DECIMAL(15,2) NOT NULL,
- L_RETURNFLAG CHAR(1) NOT NULL,
- L_LINESTATUS CHAR(1) NOT NULL,
- L_SHIPDATE DATEV2 NOT NULL,
- L_COMMITDATE DATEV2 NOT NULL,
- L_RECEIPTDATE DATEV2 NOT NULL,
- L_SHIPINSTRUCT CHAR(25) NOT NULL,
- L_SHIPMODE CHAR(10) NOT NULL,
- L_COMMENT VARCHAR(44) NOT NULL
- )
- DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
- PARTITION BY RANGE(`L_SHIPDATE`)
- (
- PARTITION `p202301` VALUES LESS THAN ("2017-02-01") ("storage_policy" = "${policy_name}"),
- PARTITION `p202302` VALUES LESS THAN ("2017-03-01")
- )
- DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3
- PROPERTIES (
- "replication_num" = "3"
- )
-
-这张 Lineitem1 设置了两个分区,每个分区 3 个 Bucket,另外副本数设置为 3,可以计算出一共有 2*3 = 6 个 Tablet,那么副本数一共是 6*3 = 18 个 Replica,通过 `show tablets` 命令可以查看到所有的 Tablet 以及 Replica 的信息,可以看到只有部分 Tablet 的 Replica 是设置了CooldownReplicaId 和 CooldownMetaId 。用户可以通过 A`DMIN SHOW REPLICA STATUS FROM TABLE PARTITION(PARTITION)`` `查看 Partition 下的 Tablet 以及Replica,通过对比可以发现其中只有属于 p202301 这个 Partition 的 Tablet 的 Replica 设置了CooldownReplicaId 和 CooldownMetaId,而属于 p202302 这个 Partition 下的数据没有设置,所以依旧会全部存放到本地磁盘。 以上表的 Tablet 3691990 为例,该 Tab [...]
-
- *****************************************************************
- TabletId: 3691990
- ReplicaId: 3691991
- CooldownReplicaId: 3691993
- CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
- *****************************************************************
- TabletId: 3691990
- ReplicaId: 3691992
- CooldownReplicaId: 3691993
- CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
- *****************************************************************
- TabletId: 3691990
- ReplicaId: 3691993
- CooldownReplicaId: 3691993
- CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
-
-可以观察到 3691990 的 3 个副本都选择了 3691993 副本作为 CooldownReplica,在用户指定的 Resource 上也只会保存这个副本的数据。
-
-**4. 查看数据信息**
-
-我们可以按照上述 3 中的 Linetem1 来演示如何查看是使用冷热数据分层策略的 Table 的数据信息,一般可以通过 `show tablets from lineitem1 `直接查看这张表的 Tablet 信息。Tablet 信息中区分了 LocalDataSize 和 RemoteDataSize,前者表示存储在本地的数据,后者表示已经冷却并移动到对象存储上的数据。具体信息可见下方代码:
-
-下方为数据刚导入到 BE 时的数据信息,可以看到数据还全部存储在本地。
-
- *************************** 1. row ***************************
- TabletId: 2749703
- ReplicaId: 2749704
- BackendId: 10090
- SchemaHash: 1159194262
- Version: 3
- LstSuccessVersion: 3
- LstFailedVersion: -1
- LstFailedTime: NULL
- LocalDataSize: 73001235
- RemoteDataSize: 0
- RowCount: 1996567
- State: NORMAL
- LstConsistencyCheckTime: NULL
- CheckVersion: -1
- VersionCount: 3
- QueryHits: 0
- PathHash: -8567514893400420464
- MetaUrl: http://172.16.0.8:6781/api/meta/header/2749703
- CompactionStatus: http://172.16.0.8:6781/api/compaction/show?tablet_id=2749703
- CooldownReplicaId: 2749704
- CooldownMetaId:
-
-当数据到达冷却时间后,再次进行 `show tablets from table` 可以看到对应的数据变化。
-
- *************************** 1. row ***************************
- TabletId: 2749703
- ReplicaId: 2749704
- BackendId: 10090
- SchemaHash: 1159194262
- Version: 3
- LstSuccessVersion: 3
- LstFailedVersion: -1
- LstFailedTime: NULL
- LocalDataSize: 0
- RemoteDataSize: 73001235
- RowCount: 1996567
- State: NORMAL
- LstConsistencyCheckTime: NULL
- CheckVersion: -1
- VersionCount: 3
- QueryHits: 0
- PathHash: -8567514893400420464
- MetaUrl: http://172.16.0.8:6781/api/meta/header/2749703
- CompactionStatus: http://172.16.0.8:6781/api/compaction/show?tablet_id=2749703
- CooldownReplicaId: 2749704
- CooldownMetaId: TUniqueId(hi:-8697097432131255833, lo:9213158865768502666)
-
-除了通过上述命令查看数据信息之外,我们也可以在对象存储上查看冷数据的信息。以腾讯云为例,可以在 Policy 指定的 Bucket 的 Path 下可以查看冷却过后的数据的信息:
-
-
-
-进入对应文件后可以看到数据和元数据文件
-
-
-
-我们可以看到在对象存储上数据是单副本。
-
-
-
-**5. 查询**
-
-假设 Table Lineitem1 中的所有数据都已经冷却并且上传到对象存储中,如果用户在 Lineitem1 上进行对应的查询,Doris 会根据对应 Partition 使用的 Policy 信息找到对应的 Bucket 的 Root Path,并根据不同 Tablet 下的 Rowset 信息下载查询所需的数据到本地进行运算。
-
-Doris 2.0 在查询上进行了优化,冷数据第一次查询会进行完整的 S3 网络 IO,并将 Remote Rowset 的数据下载到本地后,存放到对应的 Cache 之中,后续的查询将自动命中 Cache,以此来保证查询效率。(性能对比可见后文评测部分)。
-
-**6. 冷却后继续导入数据**
-
-在某些场景下,用户需要对历史数据进行数据的修正或补充数据,而新数据会按照分区列信息导入到对应的 Partition中。在 Doris 中,每次数据导入都会产生一个新的 Rowset,以保证冷数据的 Rowset 在不会影响新导入数据的 Rowset 的前提下,满足冷热数据同时存储的需求。Doris 2.0 的冷热分层粒度是基于 Rowset 的,当到达冷却时间时会将当前满足条件的 Rowset 全部上传到 S3 上并删除本地数据,之后新导入的数据生成的新 Rowset 会在到达冷却时间后也上传到 S3。
-
-# 查询性能测试
-
-为了测试使用冷热分层功能之后,查询对象存储中的数据是否占用会较大网络 I/O,从而影响查询性能,因此我们以 SSB SF100 标准集为例,对冷热分层表和非冷热分层表进行了查询耗时的对比测试。
-
-配置:均在 3 台 16C 64G 的机器上部署 1FE、3BE 的集群
-
-暂时无法在飞书文档外展示此内容
-
-如上图所示,在充分预热之后(数据已经缓存在 Cache 中),冷热分层表共耗时 5.799s,非冷热分层表共耗时 5.822s,由此可知,使用冷热分层查询表和非冷热分层表的查询性能几乎相同。这表明,使用 Doris 2.0 提供的冷热分层功能,不会对查询性能造成的影响。
-
-# 冷热分层技术的具体实现
-
-## **存储方式的优化**
-
-在 Doris 之前的版本中,数据从 SSD 冷却到 HDD 后,为了保证数据的高可用和可靠性,通常会将一个 Tablet 存储多份副本在不同 BE 上,为了进一步降低成本,我们在 Apache Doris 2.0 版本引入了对象存储,推出了冷热分层功能。由于对象存储本身具有高可靠高可用性,冷数据在对象存储上只需要一份即可,元数据以及热数据仍然保存在 BE,我们称之为本地副本,本地副本同步冷数据的元数据,这样就可以实现多个本地副本共用一份冷却数据的目的,有效避免冷数据占用过多的存储空间,从而降低数据存储成本。
-
-具体而言,Doris 的 FE 会从 Tablet 的所有可用本地副本中选择一个本地副本作为上传数据的 Leader,并通过 Doris 的周期汇报机制同步 Leader 的信息给其它本地副本。在 Leader 上传冷却数据时,也会将冷却数据的元数据上传到对象存储,以便其他副本同步元数据。因此,任何本地副本都可以提供查询所需的数据,同时也保证了数据的高可用性和可靠性。
-
-
-
-## **冷数据 Compaction**
-
-在一些场景下会有大量修补数据的需求,在大量补数据的场景下往往需要删除历史数据,删除可以通过 `delete where`实现,Doris 在 Compaction 时会对符合删除条件的数据做物理删除。基于这些场景,冷热分层也必须实现对冷数据进行 Compaction,因此在 Doris 2.0 版本中我们支持了对冷却到对象存储的冷数据进行 Compaction(ColdDataCompaction)的能力,用户可以通过冷数据 Compaction,将分散的冷数据重新组织并压缩成更紧凑的格式,从而减少存储空间的占用,提高存储效率。
-
-Doris 对于本地副本是各自进行 Compaction,在后续版本中会优化为单副本进行 Compaction。由于冷数据只有一份,因此天然的单副本做 Compaction 是最优秀方案,同时也会简化处理数据冲突的操作。BE 后台线程会定期从冷却的 Tablet 按照一定规则选出 N 个 Tablet 发起 ColdDataCompaction。与数据冷却流程类似,只有 CooldownReplica 能执行该 Tablet 的 ColdDataCompaction。Compaction下刷数据时每积累一定大小(默认5MB)的数据,就会上传一个 Part 到对象,而不会占用大量本地存储空间。Compaction 完成后,CooldownReplica 将冷却数据的元数据更新到对象存储,其他 Replica 只需从对象存储同步元数据,从而大量减少对象存储的 IO 和节点自身的 CPU 开销。
-
-## **冷数据 Cache**
-
-冷数据 Cache 在数据查询中具有重要的作用。冷数据通常是数据量较大、使用频率较低的数据,如果每次查询都需要从对象中读取,会导致查询效率低下。通过冷数据 Cache 技术,可以将冷数据缓存在本地磁盘中,提高数据读取速度,从而提高查询效率。而 Cache 的粒度大小直接影响 Cache 的效率,比较大的粒度会导致 Cache 空间以及带宽的浪费,过小粒度的 Cache 会导致对象存储 IO 效率低下,Apache Doris 采用了以 Block 为粒度的 Cache 实现。
-
-如前文所述,Apache Doris 的冷热分层会将冷数据上传到对象存储上,上传成功后本地的数据将会被删除。因此,后续涉及到冷数据的查询均需要对对象存储发起 IO 。为了优化性能,Apache Doris 实现了基于了 Block 粒度的 Cache 功能,当远程数据被访问时会先将数据按照 Block 的粒度下载到本地的 Block Cache 中存储,且 Block Cache 中的数据访问性能和非冷热分层表的数据性能一致(可见后文查询性能测试)。
-
-具体来讲,前文提到 Doris 的冷热分层是在 Rowset 级别进行的,当某个 Rowset 在冷却后其所有的数据都会上传到对象存储上。而 Doris 在进行查询的时候会读取涉及到的 Tablet 的 Rowset 进行数据聚合和运算,当读取到冷却的 Rowset 时,会把查询需要的冷数据下载到本地 Block Cache 之中。基于性能考量,Doris 的 Cache 按照 Block 对数据进行划分。Block Cache 本身采用的是简单的 LRU 策略,可以保证越是使用程度较高数据越能在 Block Cache 中存放的久。
-
-# 结束语
-
-Apache Doris 2.0 版本实现了基于对象存储的冷热数据分层,该功能可以帮助我们有效降低存储成本、提高存储效率,并提高数据查询和处理效率。未来,Apache Doris 将会基于冷热数据分层以及弹性计算节点,为用户提供更好的资源弹性、更低的使用成本以及更灵活的负载隔离服务。
-
-在前段时间推出的 [Apache Doris 2.0 Alpha 版本](https://github.com/apache/doris/releases/tag/2.0.0-alpha1)中,已经实现了[单节点数万 QPS 的高并发点查询能力](http://mp.weixin.qq.com/s?__biz=Mzg3Njc2NDAwOA==\&mid=2247516978\&idx=1\&sn=eb3f1f74eedd2306ca0180b8076fe773\&chksm=cf2f8d35f85804238fd680c18b7ab2bc4c53d62adfa271cb31811bd6139404cc8d2222b9d561\&scene=21#wechat_redirect)、[高性能的倒排索引](http://mp.weixin.qq.com/s?__biz=Mzg3Njc2NDAwOA==\&mid=2247519079\&idx=1\&sn=a232a72695ff93eea0ffe79635936dcb\&chksm=cf2f8560f8580c768bbde [...]
-
-为了让用户可以体验社区开发的最新特性,同时保证最新功能可以收获到更广范围的使用反馈,我们建立了 2.0 版本的专项支持群,[请大家填写申请](https://wenjuan.feishu.cn/m?t=sF2FZOL1KXKi-m73g),欢迎广大社区用户在使用最新版本过程中多多反馈使用意见,帮助 Apache Doris 持续改进。
-
-# **作者介绍:**
-
-杨勇强,SelectDB 联合创始人、技术副总裁
-
-岳靖、程宇轩,SelectDB 存储层研发工程师
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/HYXJ.md b/i18n/zh-CN/docusaurus-plugin-content-blog/HYXJ.md
deleted file mode 100644
index 05d3ae5eaaa..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/HYXJ.md
+++ /dev/null
@@ -1,275 +0,0 @@
----
-{
- 'title': '杭银消金基于 Apache Doris 的统一数据查询网关改造',
- 'summary': "杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风控数据集市进行了升级改造,利用 Multi Catalog 功能统一了 ES、Hive、GP 等数据源出口,实现了联邦查询,为未来统一数据查询网关奠定了基础;同时,基于 Apache Doris 高性能、简单易用、部署成本低等诸多优势,也使得各大业务场景的查询分析响应实现了从分钟级到秒级的跨越。",
- 'date': '2023-04-20',
- 'author': '杭银消金大数据团队',
- 'tags': ['最佳实践'],
-}
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-**导读:** 随着业务量快速增长,数据规模的不断扩大,杭银消金早期的大数据平台在应对实时性更强、复杂度更高的的业务需求时存在瓶颈。为了更好的应对未来的数据规模增长,杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风控数据集市进行了升级改造,利用 Multi Catalog 功能统一了 ES、Hive、GP 等数据源出口,实现了联邦查询,为未来统一数据查询网关奠定了基础;同时,基于 [Apache Doris](https://github.com/apache/doris) 高性能、简单易用、部署成本低等诸多优势,也使得各大业务场景的查询分析响应实现了从分钟级到秒级的跨越。
-
-
-杭银消费金融股份有限公司,成立于 2015 年 12 月,是杭州银行牵头组建的浙江省首家持牌消费金融公司,经过这几年的发展,在 2022 年底资产规模突破 400 亿,服务客户数超千万。公司秉承“数字普惠金融”初心,坚持服务传统金融覆盖不充分的、具有消费信贷需求的客户群体,以“**数据、场景、风控、技术**”为核心,依托大数据、人工智能、云计算等互联网科技,为全国消费者提供专业、高效、便捷、可信赖的金融服务。
-
-# **业务需求**
-
-杭银消金业务模式是线上业务结合线下业务的双引擎驱动模式。为更好的服务用户,运用数据驱动实现精细化管理,基于当前业务模式衍生出了四大类的业务数据需求:
-
-- 预警类:实现业务流量监控,主要是对信贷流程的用户数量与金额进行实时监控,出现问题自动告警。
-- 分析类:支持查询统计与临时取数,对信贷各环节进行分析,对审批、授信、支用等环节的用户数量与额度情况查询分析。
-- 看板类:打造业务实时驾驶舱与 T+1 业务看板,提供内部管理层与运营部门使用,更好辅助管理进行决策。
-- 建模类:支持多维模型变量的建模,通过算法模型回溯用户的金融表现,提升审批、授信、支用等环节的模型能力。
-
-# 数据架构 1.0
-
-为满足以上需求,我们采用 Greenplum + CDH 融合的架构体系创建了大数据平台 1.0 ,如下图所示,大数据平台的数据源均来自于业务系统,我们可以从数据源的 3 个流向出发,了解大数据平台的组成及分工:
-
-- 业务系统的核心系统数据通过 CloudCanal 实时同步进入 Greenplum 数仓进行数据实时分析,为 BI 报表,数据大屏等应用提供服务,部分数据进入风控集市 Hive 中,提供查询分析和建模服务。
-- 业务系统的实时数据推送到 Kafka 消息队列,经 Flink 实时消费写入 ES,通过风控变量提供数据服务,而 ES 中的部分数据也可以流入 Hive 中,进行相关分析处理。
-- 业务系统的风控数据会落在 MongoDB,经过离线同步进入风控集市 Hive,Hive 数仓支撑了查询平台和建模平台,提供风控分析和建模服务。
-
-
-
-**我们将 ES 和** **Hive** **共同组成了风控数据集市**,从上述介绍也可知,四大类的业务需求基本都是由风控数据集市来满足的,因此我们后续的改造升级主要基于风控数据集市来进行。在这之前,我们先了解一下风控数据集市 1.0 是如何来运转的。
-
-**风控数据集市 1.0**
-
-风控数据集市原有架构是基于 CDH 搭建的,由实时写入和离线统计分析两部分组成,整个架构包含了 ES、Hive、Greenplum 等核心组件,风控数据集市的数据源主要有三种:通过 Greenplum 数仓同步的业务系统数据、通过 MongoDB 同步的风控决策数据,以及通过 ES 写入的实时风控变量数据。
-
-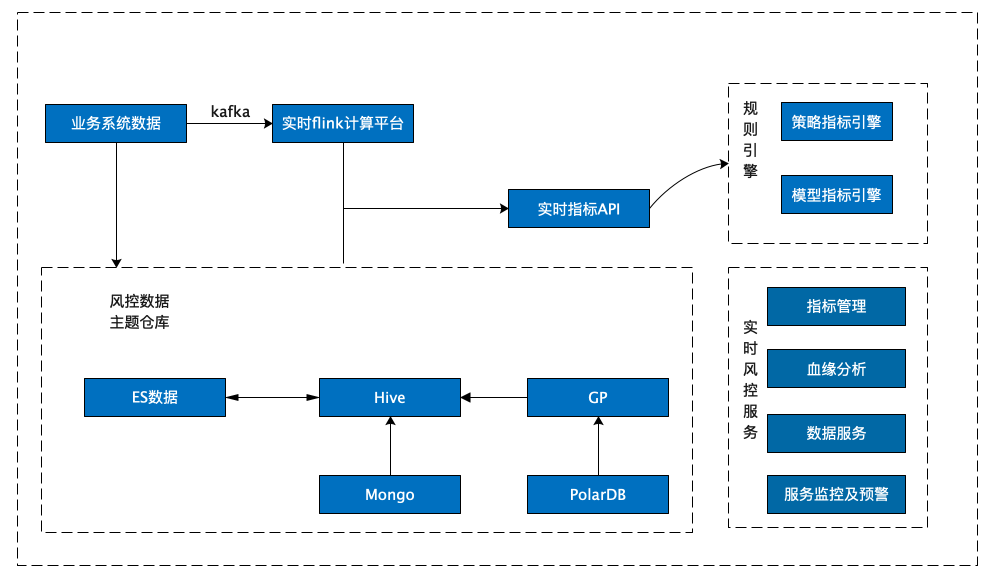
-
-**实时流数据:** 采用了 Kafka + Flink + ES 的实时流处理方式,利用 Flink 对 Kafka 的实时数据进行清洗,实时写入ES,并对部分结果进行汇总计算,通过接口提供给风控决策使用。
-
-**离线风控数据:** 采用基于 CDH 的方案实现,通过 Sqoop 离线同步核心数仓 GP 上的数据,结合实时数据与落在 MongoDB 上的三方数据,经数据清洗后统一汇总到 Hive 数仓进行日常的跑批与查询分析。
-
-**需求满足情况:**
-
-在大数据平台 1.0 的的支持下,我们的业务需求得到了初步的实现:
-
-- 预警类:基于 ES + Hive 的外表查询,实现了实时业务流量监控;
-- 分析类:基于 Hive 实现数据查询分析和临时取数;
-- 看板类:基于 Tableau +Hive 搭建了业务管理驾驶舱以及T+1 业务看板;
-- 建模类:基于 Spark+Hive 实现了多维模型变量的建模分析;
-
-受限于 Hive 的执行效率,以上需求均在分钟级别返回结果,仅可以满足我们最基本的诉求,而面对秒级甚至毫秒级的分析场景,Hive 则稍显吃力。
-
-**存在的问题:**
-
-- **单表宽度过大,影响查询性能**。风控数据集市的下游业务主要以规则引擎与实时风控服务为主,因规则引擎的特殊性,公司在数据变量衍生方面资源投入较多,某些维度上的衍生变量会达到几千甚至上万的规模,这将导致 Hive 中存储的数据表字段非常多,部分经常使用的大宽表字段数量甚至超过上千,过宽的大宽表非常影响实际使用中查询性能。
-- **数据规模庞大,维护成本高。** 目前 Hive 上的风控数据集市已经有存量数据在百 T 以上,面对如此庞大的数据规模,使用外表的方式进行维护成本非常高,数据的接入也成为一大难题。
-- **接口服务不稳定。** 由风控数据集市离线跑批产生的变量指标还兼顾为其他业务应用提供数据服务的职责,目前 Hive 离线跑批后的结果会定时推送到 ES 集群(每天更新的数据集比较庞大,接口调用具有时效性),推送时会因为 IO 过高触发 ES 集群的 GC 抖动,导致接口服务不稳定。
-
-除此之外,风控分析师与建模人员一般通过 Hive & Spark 方式进行数据分析建模,这导致随着业务规模的进一步增大,T+1 跑批与日常分析的效率越来越低,风控数据集市改造升级的需求越发强烈。
-
-# 技术选型
-
-基于业务对架构提出的更高要求,我们期望引入一款强劲的 OLAP 引擎来改善架构,因此我们于 2022 年 9 月份对 ClickHouse 和 Apache Doris 进行了调研,调研中发现 Apache Doris 具有高性能、简单易用、实现成本低等诸多优势,而且 Apache Doris 1.2 版本非常符合我们的诉求,原因如下:
-
-**宽表查询性能优异**:从官方公布的测试结果来看,1.2 Preview 版本在 SSB-Flat 宽表场景上相对 1.1.3 版本整体性能提升了近 4 倍、相对于 0.15.0 版本性能提升了近 10 倍,在 TPC-H 多表关联场景上较 1.1.3 版本上有近 3 倍的提升、较 0.15.0 版本性能提升了 11 倍以上,多个场景性能得到飞跃性提升。
-
-**便捷的数据接入框架以及联邦数据分析能力:** Apache Doris 1.2 版本推出的 Multi Catalog 功能可以构建完善可扩展的数据源连接框架,**便于快速接入多类数据源,提供基于各种异构数据源的联邦查询和写入能力。** 目前 Multi-Catalog 已经支持了 Hive、Iceberg、Hudi 等数据湖以及 MySQL、Elasticsearch、Greenplum 等数据库,全面覆盖了我们现有的组件栈,基于此能力有希望通过 Apache Doris 来打造统一数据查询网关。
-
-**生态丰富:** 支持 Spark Doris Connector、Flink Doris Connector,方便离线与实时数据的处理,缩短了数据处理链路耗费的时间。
-
-**社区活跃:** Apache Doris 社区非常活跃,响应迅速,并且 SelectDB 为社区提供了一支专职的工程师团队,为用户提供技术支持服务。
-
-# 数据架构 2.0
-
-**风控数据集市 2.0**
-
-基于对 Apache Doris 的初步的了解与验证,22 年 10 月在社区的支持下我们正式引入 Apache Doris 1.2.0 Preview 版本作为风控数据集市的核心组件,Apache Doris 的 Multi Catalog 功能助力大数据平台统一了 ES、Hive、Greenplum 等数据源出口,通过 Hive Catalog 和 ES Catalog 实现了对 Hive & ES 等多数据源的联邦查询,并且支持 Spark-Doris-Connector,可以实现数据 Hive 与 Doris 的双向流动,与现有建模分析体系完美集成,在短期内实现了性能的快速提升。
-
-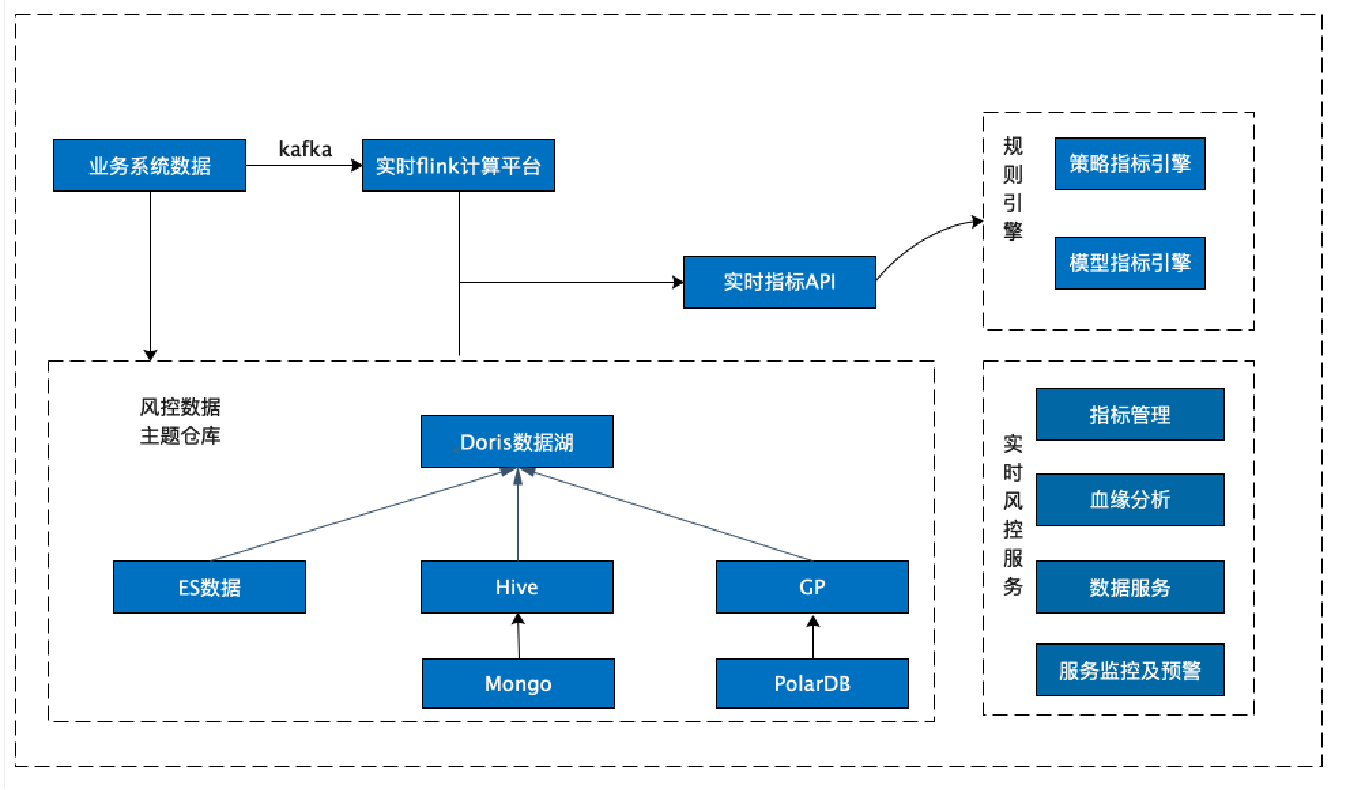
-
-**大数据平台 2.0**
-
-风控数据集市调整优化之后,大数据平台架构也相应的发生了变化,如下图所示,仅通过 Doris 一个组件即可为数据服务、分析平台、建模平台提供数据服务。
-
-在最初进行联调适配的时候,Doris 社区和 SelectDB 支持团队针对我们提出的问题和疑惑一直保持高效的反馈效率,给于积极的帮助和支持,快速帮助我们解决在生产上遇到的问题。
-
-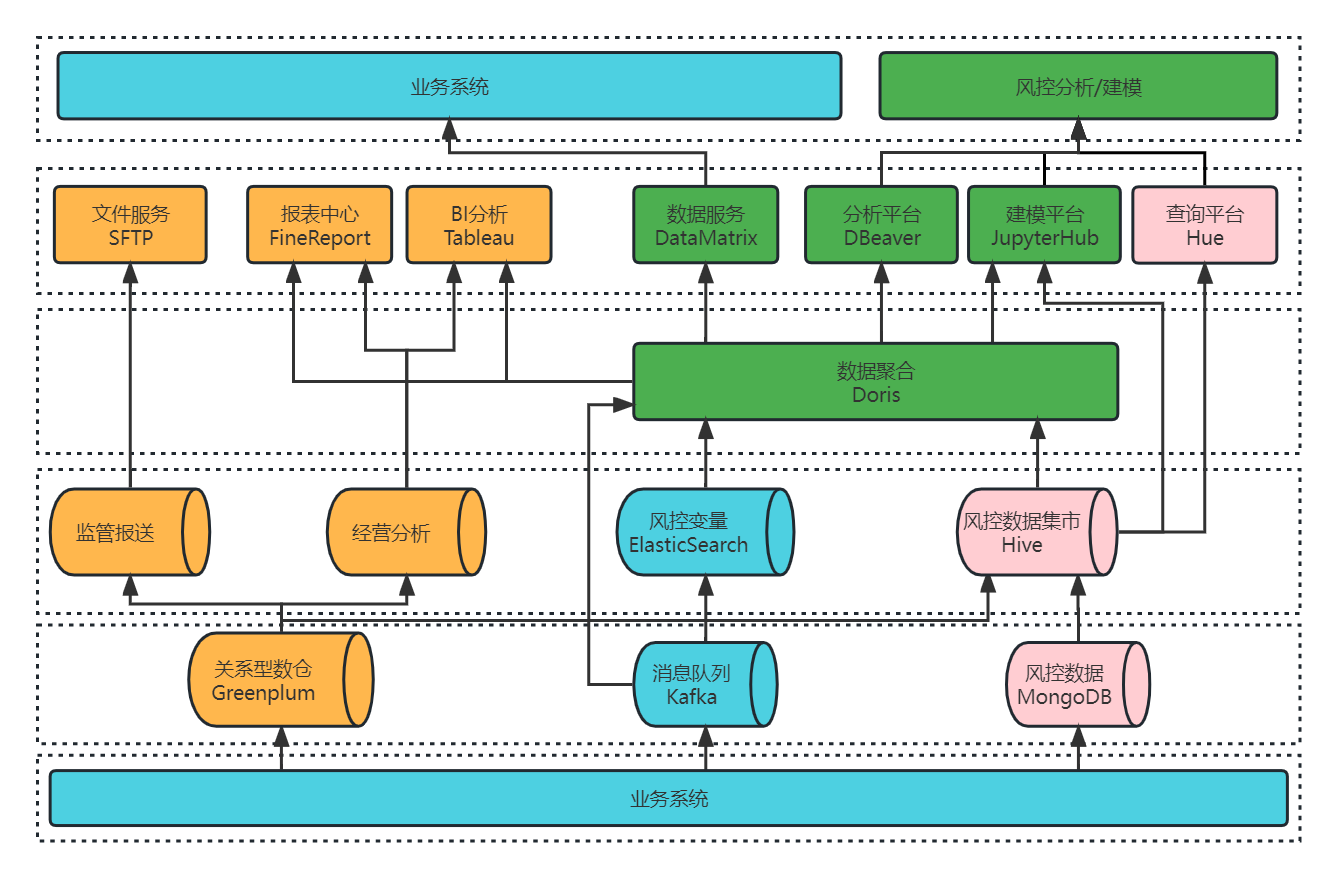
-
-**需求实现情况:**
-
-在大数据平台 2.0 的加持下,业务需求实现的方式也发生了变更,主要变化如下所示
-
-- 预警类:基于 ES Catalog+ Doris 实现了对实时数据的查询分析。在架构 1.0 中,实时数据落在 ES 集群上,通过 Hive 外表进行查询分析,查询结果以分钟级别返回;而在 Doris 1.2 集成之后, 使用 ES Catalog 访问 ES,可以实现对 ES 数据秒级统计分析。
-- 分析类:基于 Hive Catalog + Doris 实现了对现有风控数据集市的快速查询。目前 Hive 数据集市存量表在两万张左右,如果通过直接创建 Hive 外部表的方式,表结构映射关系的维护难度与数据同步成本使这一方式几乎不可能实现。而 Doris 1.2 的 Multi Catalog 功能则完美解决了这个问题,只需要创建一个 Hive Catalog,就能对现有风控数据集市进行查询分析,既能提升查询性能,还减少了日常查询分析对跑批任务的资源影响。
-- 看板类:基于 Tableau + Doris 聚合展示业务实时驾驶舱和 T+1 业务看板,最初使用 Hive 时,报表查询需要几分钟才能返回结果,而 Apache Doris 则是秒级甚至是毫秒级的响应速度。
-- 建模类:基于 Spark+Doris 进行聚合建模。利用 Doris1.2 的 Spark-Doris-Connector功 能,实现了 Hive 与 Doris 数据双向同步,满足了 Spark 建模平台的功能复用。同时增加了 Doris 数据源,基础数据查询分析的效率得到了明显提升,建模分析能力的也得到了增强。
-
-在 Apache Doris 引入之后,以上四个业务场景的查询耗时基本都实现了从分钟级到秒级响应的跨越,性能提升十分巨大。
-
-**生产环境集群监控**
-
-为了快速验证新版本的效果,我们在生产环境上搭建了两个集群,目前生产集群的配置是 4 个 FE + 8个 BE,单个节点是配置为 64 核+ 256G+4T,备用集群为 4 个 FE + 4 个 BE 的配置,单个节点配置保持一致。
-
-集群监控如下图所示:
-
-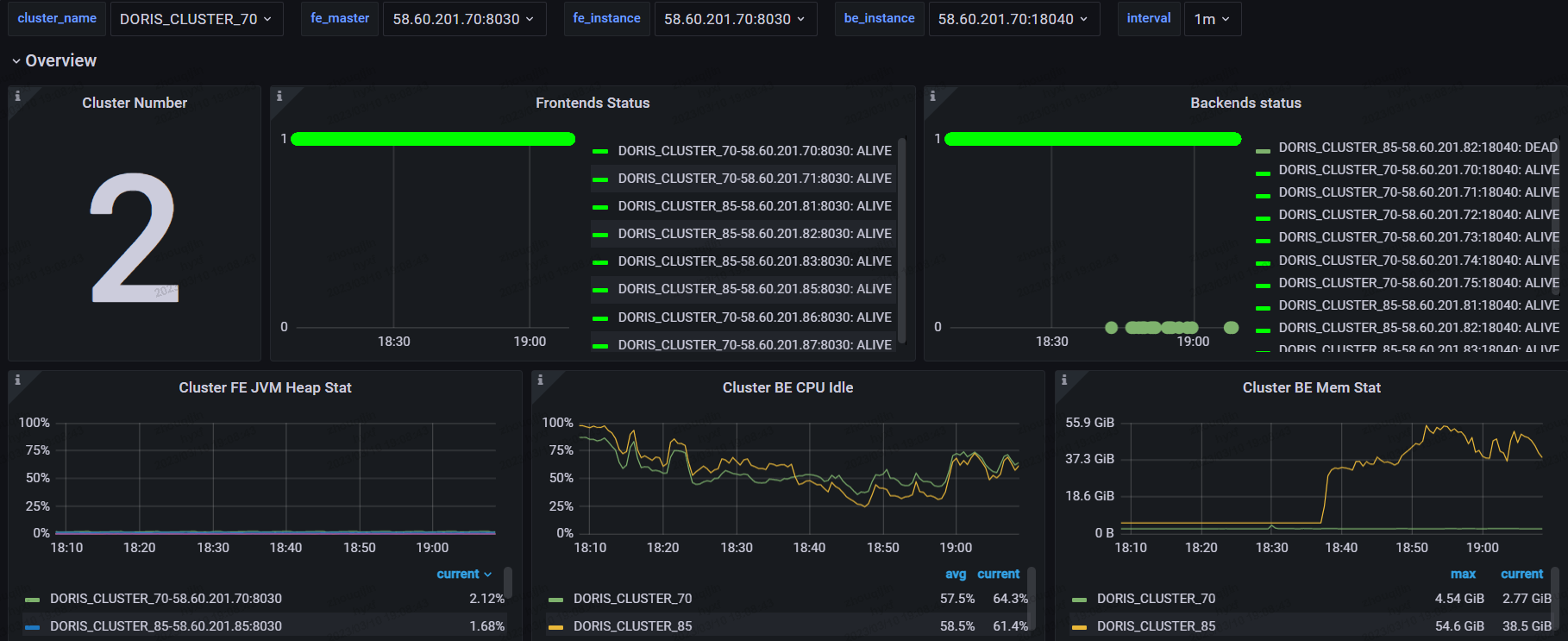
-
-可以看出,Apache Doris 1.2 的查询效率非常高,原计划至少要上 10 个节点,而在实际使用下来,我们发现当前主要使用的场景均是以 Catalog 的方式查询,因此集群规模可以相对较小就可以快速上线,也不会破坏当前的系统架构,兼容性非常好。
-
-## 数据集成方案
-
-前段时间,Apache Doris 1.2.2 版本已经发布,为了更好的支撑应用服务,我们使用 Apache Doris 1.2.2 与 DolphinScheduler 3.1.4 调度器、SeaTunnel 2.1.3 数据同步平台等开源软件实现了集成,以便于数据定时从 Hive 抽取到 Doris 中。整体的数据集成方案如下:
-
-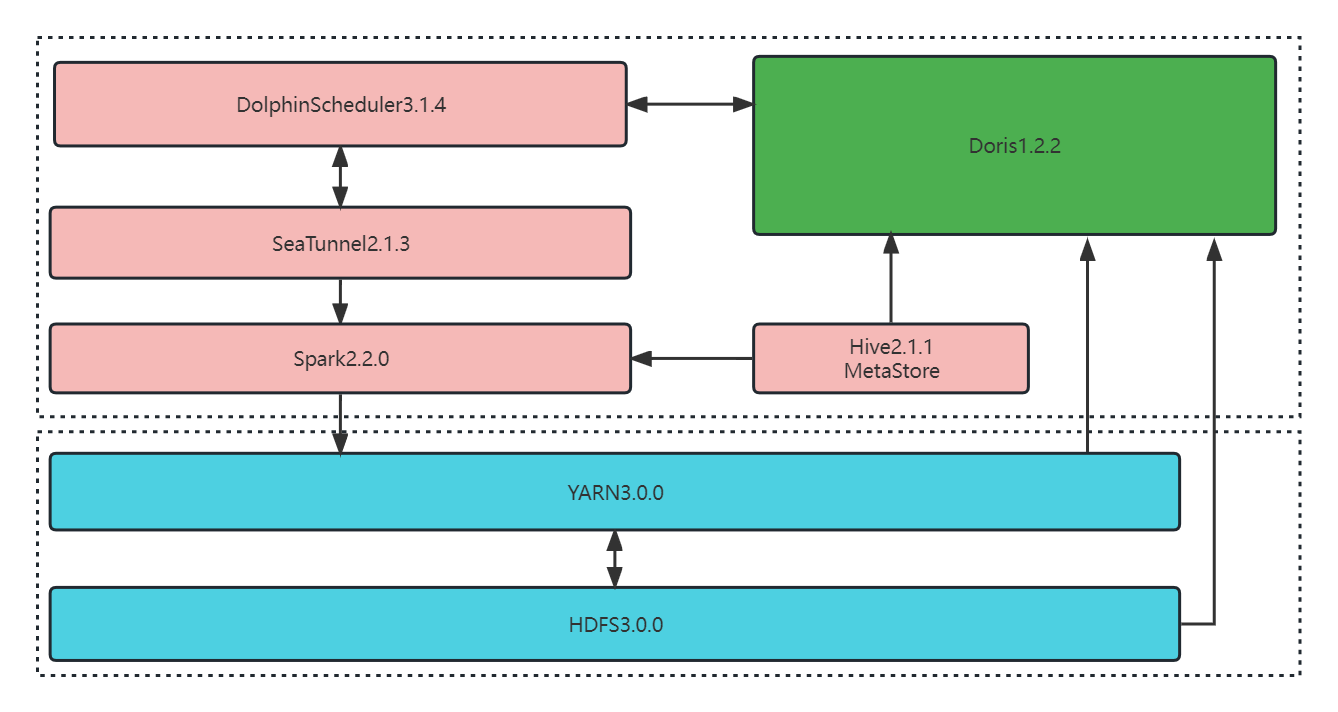
-
-在当前的硬件配置下,数据同步采用的是 DolphinScheduler 的 Shell 脚本模式,定时调起 SeaTunnel 的脚本,数据同步任务的配置文件如下:
-
-```sql
- env{
- spark.app.name = "hive2doris-template"
- spark.executor.instances = 10
- spark.executor.cores = 5
- spark.executor.memory = "20g"
-}
-spark {
- spark.sql.catalogImplementation = "hive"
-}
-source {
- hive {
- pre_sql = "select * from ods.demo_tbl where dt='2023-03-09'"
- result_table_name = "ods_demo_tbl"
- }
-}
-
-transform {
-}
-
-sink {
- doris {
- fenodes = "192.168.0.10:8030,192.168.0.11:8030,192.168.0.12:8030,192.168.0.13:8030"
- user = root
- password = "XXX"
- database = ods
- table = ods_demo_tbl
- batch_size = 500000
- max_retries = 1
- interval = 10000
- doris.column_separator = "\t"
- }
-}
-```
-
-**该方案成功实施后,资源占用、计算内存占用有了明显的降低,查询性能、导入性能有了大幅提升:**
-
-1. 存储成本降低
-
-使用前:Hive 原始表包含 500 个字段,单个分区数据量为 1.5 亿/天,在 HDFS 上占用约 810G 的空间。
-
-使用后:我们通过 SeaTunnel 调起 Spark on YARN 的方式进行数据同步,可以在 **40 分钟左右**完成数据同步,同步后数据占用 **270G 空间,存储资源仅占之前的 1/3**。
-
-2. 计算内存占用降低,性能提升显著
-
-使用前:上述表在 Hive 上进行 Group By 时,占用 YARN 资源 720 核 1.44T 内存,需要 **162 秒**才可返回结果;
-
-使用后:
-
-- 通过 Doris 调用 Hive Catalog 进行聚合查询,在设置 `set exec_mem_limit=16G` 情况下用时 **58.531 秒,查询耗时较之前减少了近 2/3;**
-- 在同等条件下,在 Doris 中执行相同的的操作可以在 **0.828 秒**就能返回查询结果,性能增幅巨大。
-
-具体效果如下:
-
-(1)Hive 查询语句,用时 162 秒。
-
-```sql
-select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
-group by product_no;
-```
-
-(2)Doris 上 Hive Catalog 查询语句,用时 58.531 秒。
-
-```sql
-set exec_mem_limit=16G;
-select count(*),product_no FROM hive.ods.demo_tbl where dt='2023-03-09'
-group by product_no;
-```
-
-(3)Doris 上本地表查询语句,**仅用时0.828秒**。
-
-```sql
-select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
-group by product_no;
-```
-
-3. 导入性能提升
-
-使用前:Hive 原始表包含 40 个字段,单个分区数据量 11 亿/天,在 HDFS 上占用约 806G 的空间
-
-使用后:通过 SeaTunnel 调起 Spark on YARN 方式进行数据同步,可以在 11 分钟左右完成数据同步,即 **1 分钟同步约一亿条数据**,同步后占用 378G 空间。
-
-可以看出,在数据导入性能的提升的同时,资源也有了较大的节省,主要得益于对以下几个参数进行了调整:
-
-`push_write_mbytes_per_sec`:BE 磁盘写入限速,300M
-
-`push_worker_count_high_priority:` 同时执行的 push 任务个数,15
-
-`push_worker_count_normal_priority`: 同时执行的 push 任务个数,15
-
-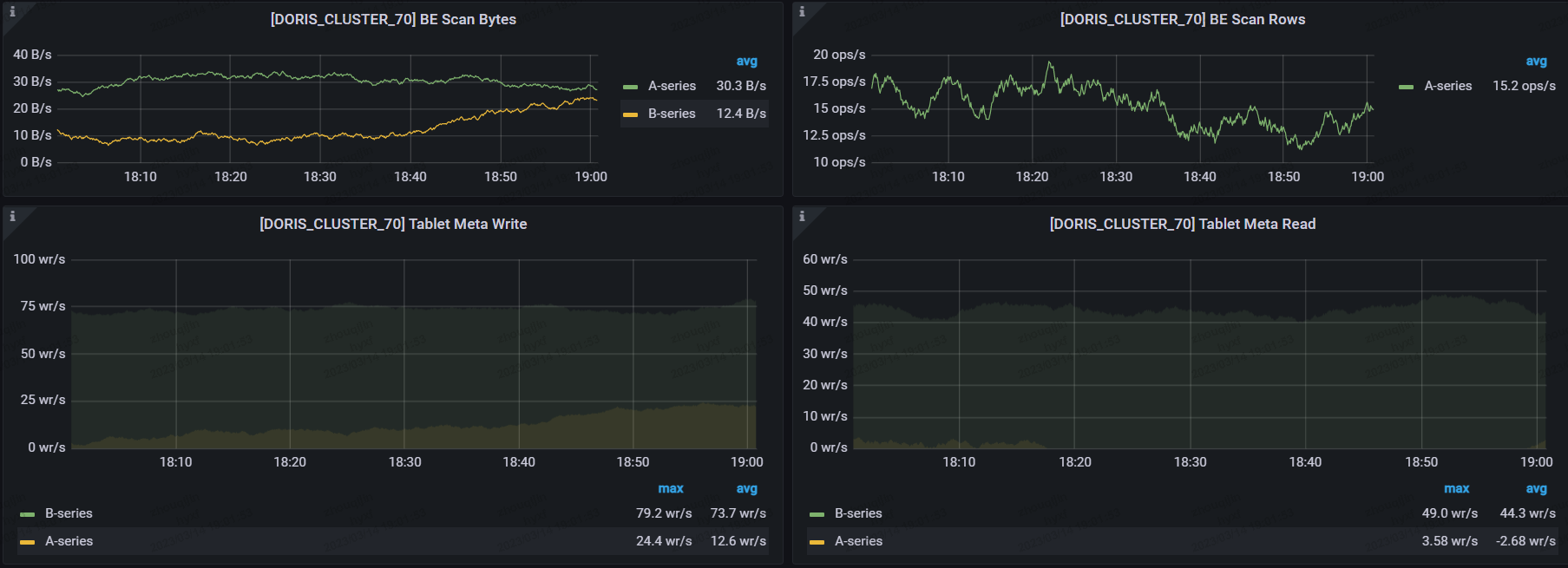
-
-## **架构收益**
-
-**(1)统一数据源出口,查询效率显著提升**
-
-风控数据集市采用的是异构存储的方式来存储数据,Apache Doris 的 Multi Catalog 功能成功统一了 ES、Hive、GP 等数据源出口,实现了联邦查询。 同时,Doris 本身具有存储能力,可支持其他数据源中的数据通过外表插入内容的方式快速进行数据同步,真正实现了数据门户。此外,Apache Doris 可支持聚合查询,在向量化引擎的加持下,查询效率得到显著提升。
-
-**(2)** **Hive** **任务拆分,提升集群资源利用率**
-
-我们将原有的 Hive 跑批任务跟日常的查询统计进行了隔离,以提升集群资源的利用效率。目前 YARN 集群上的任务数量是几千的规模,跑批任务占比约 60%,临时查询分析占比 40%,由于资源限制导致日常跑批任务经常会因为资源等待而延误,临时分析也因资源未及时分配而导致任务无法完成。当部署了 Doris 1.2 之后,对资源进行了划分,完全摆脱 YARN 集群的资源限制,跑批与日常的查询统计均有了明显的改善,**基本可以在秒级得到分析结果**,同时也减轻了数据分析师的工作压力,提升了用户对平台的满意度。
-
-**(3)提升了数据接口的稳定性,数据写入性能大幅提升**
-
-之前数据接口是基于 ES 集群的,当进行大批量离线数据推送时会导致 ES 集群的 GC 抖动,影响了接口稳定性,经过调整之后,我们将接口服务的数据集存储在 Doris 上,Doris 节点并未出现抖动,实现数据快速写入,成功提升了接口的稳定性,同时 Doris 查询在数据写入时影响较小,数据写入性能较之前也有了非常大的提升,**千万级别的数据可在十分钟内推送成功**。
-
-**(4)Doris 生态丰富,迁移方便成本较低。**
-
-Spark-Doris-Connector 在过渡期为我们减轻了不少的压力,当数据在 Hive 与 Doris 共存时,部分 Doris 分析结果通过 Spark 回写到 Hive 非常方便,当 Spark 调用 Doris 时只需要进行简单改造就能完成原有脚本的复用,迁移方便、成本较低。
-
-**(5)支持横向热部署,集群扩容、运维简单。**
-
-Apache Doris 支持横向热部署,集群扩容方便,节点重启可以在在秒级实现,可实现无缝对接,减少了该过程对业务的影响; 在架构 1.0 中,当 Hive 集群与 GP 集群需要扩容更新时,配置修改后一般需要较长时间集群才可恢复,用户感知比较明显。而 Doris 很好的解决了这个问题,实现用户无感知扩容,也降低了集群运维的投入。
-
-# **未来与展望**
-
-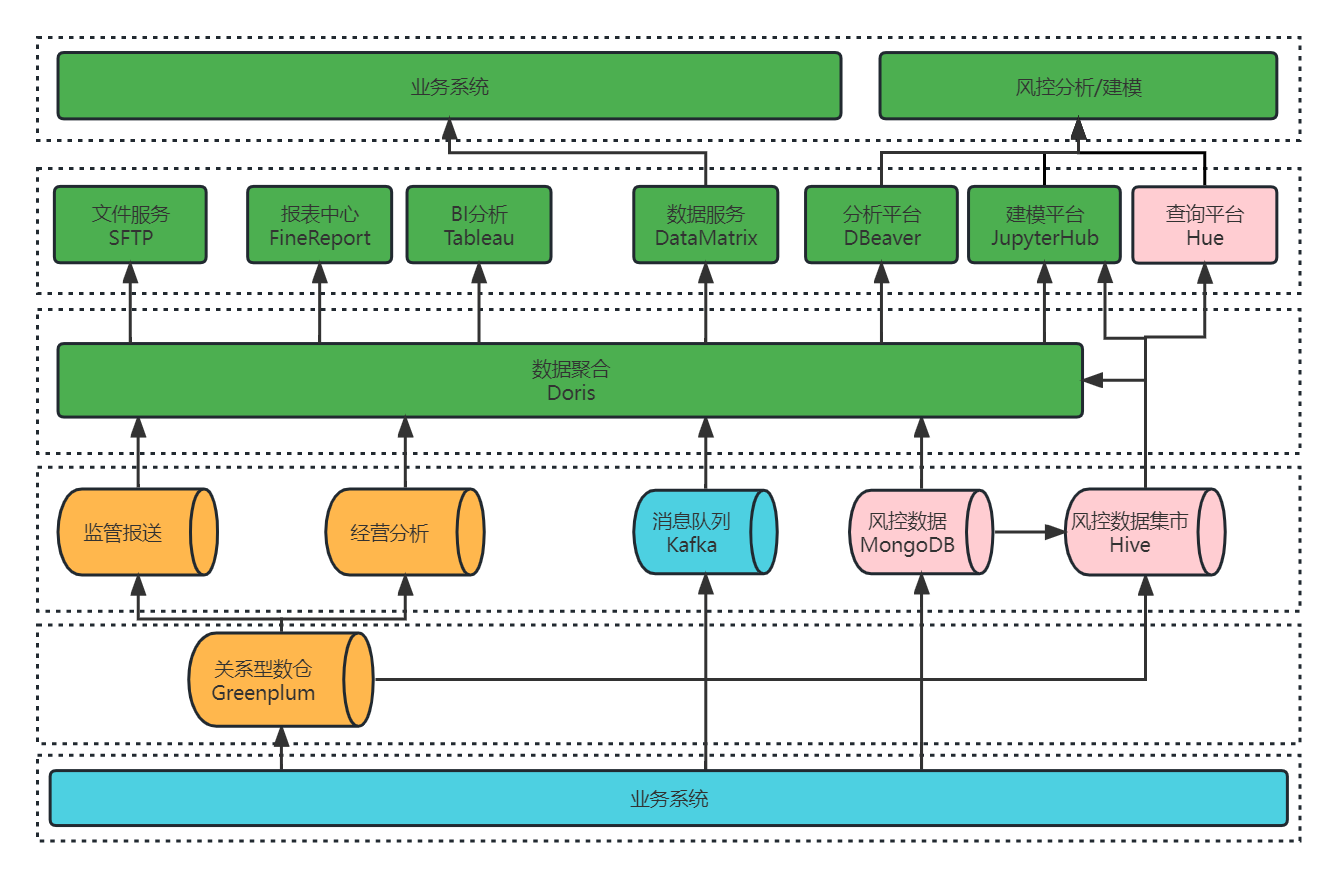
-
-当前在架构 2.0 中的 Doris 集群在大数据平台中的角色更倾向于查询优化,大部分数据还集中维护在 Hive 集群上,未来我们计划在升级架构 3.0 的时候,完成以下改造:
-
-- 实时全量数据接入:利用 Flink 将所有的实时数据直接接入 Doris,不再经过 ES 存储;
-- 数据集数据完整性:利用 Doris 构建实时数据集市的原始层,利用 FlinkCDC 等同步工具将业务库 MySQL与决策过程中产生的 MongoDB 数据实时同步到 Doris,最大限度将现有数据都接入 Doris 的统一平台,保证数据集数据完整性。
-- 离线跑批任务迁移:将现有 Hive&Spark 中大部分跑批任务迁移至 Doris,提升跑批效率;
-- 统一查询分析出口:将所有的查询分析统一集中到 Doris,完全统一数据出口,实现统一数据查询网关,使数据的管理更加规范化;
-- 强化集群稳定扩容:引入可视化运维管理工具对集群进行维护和管理,使 Doris 集群能够更加稳定支撑业务扩展。
-
-# 总结与致谢
-
-Apache Doris1.2 是社区在版本迭代中的重大升级,借助 Multi Catalog 等优异功能能让 Doris 在 Hadoop 相关的大数据体系中快速落地,实现联邦查询;同时可以将日常跑批与统计分析进行解耦,有效提升大数据平台的的查询性能。
-
-作为第一批 Apache Doris1.2 的用户,我们深感荣幸,同时也十分感谢 Doris 团队的全力配合和付出,可以让 Apache Doris 快速落地、上线生产,并为后续的迭代优化提供了可能。
-
-Apache Doris 1.2 值得大力推荐,希望大家都能从中受益,祝愿 Apache Doris 生态越来越繁荣,越来越好!
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/High_concurrency.md b/i18n/zh-CN/docusaurus-plugin-content-blog/High_concurrency.md
deleted file mode 100644
index 761db4f90d9..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/High_concurrency.md
+++ /dev/null
@@ -1,319 +0,0 @@
----
-{
- 'title': '并发提升 20+ 倍、单节点数万 QPS,Apache Doris 高并发特性解读',
- 'summary': "在即将发布的 2.0 版本中,我们在原有功能基础上引入了一系列面向点查询的优化手段,单节点可达数万 QPS 的超高并发,极大拓宽了适用场景的能力边界。",
- 'date': '2023-04-14',
- 'author': 'Apache Doris',
- 'tags': ['技术解析'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-随着用户规模的极速扩张,越来越多用户将 Apache Doris 用于构建企业内部的统一分析平台,这一方面需要 [Apache Doris](https://github.com/apache/doris) 去承担更大业务规模的处理和分析——既包含了更大规模的数据量、也包含了更高的并发承载,而另一方面,也意味着需要应对企业更加多样化的数据分析诉求,从过去的统计报表、即席查询、交互式分析等典型 OLAP 场景,拓展到推荐、风控、标签画像以及 IoT 等更多业务场景中,而数据服务(Data Serving)就是其中具有代表性的一类需求。Data Serving 通常指的是向用户或企业客户提供数据访问服务,用户使用较为频繁的查询模式一般是按照 Key 查询一行或多行数据,例如:
-
-- 订单详情查询
-- 商品详情查询
-- 物流状态查询
-- 交易详情查询
-- 用户信息查询
-- 用户画像属性查询
-- ...
-
-与面向大规模数据扫描与计算的 Adhoc 不同,**Data Serving 在实际业务中通常呈现为高并发的点查询——** **查询返回的数据量较少、通常只需返回一行或者少量行数据,但对于查询耗时极为敏感、期望在毫秒内返回查询结果,并且面临着超高并发的挑战。**
-
-在过去面对此类业务需求时,通常采取不同的系统组件分别承载对应的查询访问。OLAP 数据库一般是基于列式存储引擎构建,且是针对大数据场景设计的查询框架,通常以数据吞吐量来衡量系统能力,因此在 Data Serving 高并发点查场景的表现往往不及用户预期。基于此,用户一般引入 Apache HBase 等 KV 系统来应对点查询、Redis 作为缓存层来分担高并发带来的系统压力。而这样的架构往往比较复杂,存在冗余存储、维护成本高的问题。融合统一的分析范式为 Apache Doris 能承载的工作负载带来了挑战,也让我们更加系统化地去思考如何更好地满足用户在此类场景的业务需求。基于以上思考,**在即将发布的 2.0 版本中,我们在原有功能基础上引入了一系列面向点查询的优化手段,单节点可达数万 QPS 的超高并发,极大拓宽了适用场景的能力边界。**
-
-# **# 如何应对高并发查询?**
-
-一直以来高并发就是 Apache Doris 的优势之一。对于高并发查询,其核心在于如何平衡有限的系统资源消耗与并发执行带来的高负载。换而言之,需要最大化降低单个 SQL 执行时的 CPU、内存和 IO 开销,其关键在于减少底层数据的 Scan 以及随后的数据计算,其主要优化方式有如下几种:
-
-### 分区分桶裁剪
-
-Apache Doris 采用两级分区,第一级是 Partition,通常可以将时间作为分区键。第二级为 Bucket,通过 Hash 将数据打散至各个节点中,以此提升读取并行度并进一步提高读取吞吐。通过合理地划分区分桶,可以提高查询性能,以下列查询语句为例:
-
-```
-select * from user_table where id = 5122 and create_date = '2022-01-01'
-```
-
-用户以`create_time`作为分区键、ID 作为分桶键,并设置了 10 个 Bucket, 经过分区分桶裁剪后可快速过滤非必要的分区数据,最终只需读取极少数据,比如 1 个分区的 1 个 Bucket 即可快速定位到查询结果,最大限度减少了数据的扫描量、降低了单个查询的延时。
-
-### 索引
-
-除了分区分桶裁剪, Doris 还提供了丰富的索引结构来加速数据的读取和过滤。索引的类型大体可以分为智能索引和二级索引两种,其中智能索引是在 Doris 数据写入时自动生成的,无需用户干预。智能索引包括前缀索引和 ZoneMap 索引两类:
-
-- **前缀稀疏索引(Sorted Index)** 是建立在排序结构上的一种索引。Doris 存储在文件中的数据,是按照排序列有序存储的,Doris 会在排序数据上每 1024 行创建一个稀疏索引项。索引的 Key 即当前这 1024 行中第一行的前缀排序列的值,当用户的查询条件包含这些排序列时,可以通过前缀稀疏索引快速定位到起始行。
-- **ZoneMap 索引**是建立在 Segment 和 Page 级别的索引。对于 Page 中的每一列,都会记录在这个 Page 中的最大值和最小值,同样,在 Segment 级别也会对每一列的最大值和最小值进行记录。这样当进行等值或范围查询时,可以通过 MinMax 索引快速过滤掉不需要读取的行。
-
-二级索引是需要用手动创建的索引,包括 Bloom Filter 索引、Bitmap 索引,以及 2.0 版本新增的 Inverted 倒排索引和 NGram Bloom Filter 索引,在此不细述,可从官网文档先行了解,后续将有系列文章进行解读。
-
-**官网文档:**
-
-- 倒排索引:https://doris.apache.org/zh-CN/docs/dev/data-table/index/inverted-index
-- NGram BloomFilter 索引:https://doris.apache.org/zh-CN/docs/dev/data-table/index/ngram-bloomfilter-index
-
-我们以下列查询语句为例:
-
-```
-select * from user_table where id > 10 and id < 1024
-```
-
-假设按照 ID 作为建表时指定的 Key, 那么在 Memtable 以及磁盘上按照 ID 有序的方式进行组织,查询时如果过滤条件包含前缀字段时,则可以使用前缀索引快速过滤。Key 查询条件在存储层会被划分为多个 Range,按照前缀索引做二分查找获取到对应的行号范围,由于前缀索引是稀疏的,所以只能大致定位出行的范围。随后过一遍 ZoneMap、Bloom Filter、Bitmap 等索引,进一步缩小需要 Scan 的行数。**通过索引,大大减少了需要扫描的行数,减少 CPU 和 IO 的压力,整体大幅提升了系统的并发能力。**
-
-### 物化视图
-
-物化视图是一种典型的空间换时间的思路,其本质是根据预定义的 SQL 分析语句执⾏预计算,并将计算结果持久化到另一张对用户透明但有实际存储的表中。在需要同时查询聚合数据和明细数据以及匹配不同前缀索引的场景,**命中物化视图时可以获得更快的查询相应,同时也避免了大量的现场计算,因此可以提高性能表现并降低资源消耗**。
-
-```
-// 对于聚合操作, 直接读物化视图预聚合的列
-create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id;
-SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
-
-// 对于查询, k3满足物化视图前缀列条件, 走物化视图加速查询
-CREATE MATERIALIZED VIEW mv_1 as SELECT k3, k2, k1 FROM tableA ORDER BY k3;
-select k1, k2, k3 from table A where k3=3;
-```
-
-### Runtime Filter
-
-除了前文提到的用索引来加速过滤查询的数据, Doris 中还额外加入了动态过滤机制,即 Runtime Filter。在多表关联查询时,我们通常将右表称为 BuildTable、左表称为 ProbeTable,左表的数据量会大于右表的数据。在实现上,会首先读取右表的数据,在内存中构建一个 HashTable(Build)。之后开始读取左表的每一行数据,并在 HashTable 中进行连接匹配,来返回符合连接条件的数据(Probe)。而 Runtime Filter 是在右表构建 HashTable 的同时,为连接列生成一个过滤结构,可以是 Min/Max、IN 等过滤条件。之后把这个过滤列结构下推给左表。这样一来,左表就可以利用这个过滤结构,对数据进行过滤,从而减少 Probe 节点需要传输和比对的数据量。在大多数 Join 场景中,Runtime Filter 可以实现节点的自动穿透,将 Filter 穿透下推到最底层的扫描节点或者分布式 Shuffle Join 中
。**大多数的关联查询 Runtime Filter 都可以起到大幅减少数据读取的效果,从而加速整个查询的速度。**
-
-### OPN 优化技术
-
-在数据库中查询最大或最小几条数据的应用场景非常广泛,比如查询满足某种条件的时间最近 100 条数据、查询价格最高或者最低的几个商品等,此类查询的性能对于实时分析非常重要。在 Doris 中引入了 TOPN 优化来解决大数据场景下较高的 IO、CPU、内存资源消耗:
-
-- 首先从 Scanner 层读取排序字段和查询字段,利用堆排序保留 TOPN 条数据,实时更新当前已知的最大或最小的数据范围, 并动态下推至 Scanner
-
-- Scanner 层根据范围条件,利用索引等加速跳过文件和数据块,大幅减少读取的数据量。
-
-- 在宽表中用户通常需要查询字段数较多, 在 TOPN 场景实际有效的数据仅 N 条, 通过将读取拆分成两阶段, 第一阶段根据少量的排序列、条件列来定位行号并排序,第二阶段根据排序后并取 TOPN 的结果得到行号反向查询数据,这样可以大大降低 Scan 的开销
-
-
-
-
-**通过以上一系列优化手段,可以将不必要的数据剪枝掉,减少读取、排序的数据量,显著降低系统 IO、CPU 以及内存资源消耗**。此外,还可以利用包括 SQL Cache、Partition Cache 在内的缓存机制以及 Join 优化手段来进一步提升并发,由于篇幅原因不在此详述。
-
-# **# Apache Doris 2.0 新特性揭秘**
-
-通过上一段中所介绍的内容,Apache Doris 实现了单节点上千 QPS 的并发支持。但在一些超高并发要求(例如数万 QPS)的 Data Serving 场景中,仍然存在瓶颈:
-
-- 列式存储引擎对于行级数据的读取不友好,宽表模型上列存格式将大大放大随机读取 IO;
-- OLAP 数据库的执行引擎和查询优化器对于某些简单的查询(如点查询)来说太重,需要在查询规划中规划短路径来处理此类查询;
-- SQL 请求的接入以及查询计划的解析与生成由 FE 模块负责,使用的是 Java 语言,在高并发场景下解析和生成大量的查询执行计划会导致高 CPU 开销;
-- ……
-
-带着以上问题,Apache Doris 在分别从降低 SQL 内存 IO 开销、提升点查执行效率以及降低 SQL 解析开销这三个设计点出发,进行一系列优化。
-
-### 行式存储格式(Row Store Format)
-
-与列式存储格式不同,行式存储格式在数据服务场景会更加友好,数据按行存储、应对单次检索整行数据时效率更高,可以极大减少磁盘访问次数。**因此在 Apache Doris 2.0 版本中,我们引入了行式存储格式,将行存编码后存在单独的一列中,通过额外的空间来存储**。用户可以在建表语句的 Property 中指定如下属性来开启行存:
-
-```
-"store_row_column" = "true"
-```
-
-我们选择以 JSONB 作为行存的编码格式,主要出于以下考虑:
-
-- Schema 变更灵活:随着数据的变化、变更,表的 Schema 也可能发生相应变化。行存储格式提供灵活性以处理这些变化是很重要的,例如用户删减字段、修改字段类型,数据变更需要及时同步到行存中。通过使用 JSONB 作为编码方式,将列作为 JSONB 的字段进行编码, 可以非常方便地进行字段扩展以及更改属性。
-- 性能更高:在行存储格式中访问行可以比在列存储格式中访问行更快,因为数据存储在单个行中。这可以在高并发场景下显著减少磁盘访问开销。此外,通过将每个列 ID 映射到 JSONB其对应的值,可以实现对个别列的快速访问。
-- 存储空间:将 JSONB 作为行存储格式的编解码器也可以帮助减少磁盘存储成本。紧凑的二进制格式可以减少存储在磁盘上的数据总大小,使其更具成本效益。
-
-使用 JSONB 编解码行存储格式,可以帮助解决高并发场景下面临的性能和存储问题。行存在存储引擎中会作为一个隐藏列(`DORIS_ROW_STORE_COL`)来进行存储,在 Memtable Flush 时,将各个列按照 JSONB 进行编码并缓存到这个隐藏列里。在数据读取时, 通过该隐藏列的 Column ID 来定位该列, 通过其行号定位到某一具体的行,并反序列化各列。
-
-相关PR:https://github.com/apache/doris/pull/15491
-
-### 点查询短路径优化(Short-Circuit)
-
-通常情况下,一条 SQL 语句的执行需要经过三个步骤:首先通过 SQL Parser 解析语句,生成抽象语法树(AST),随后通过 Query Optimizer 生成可执行计划(Plan),最终通过执行该计划得到计算结果。对于大数据量下的复杂查询,经由查询优化器生成的执行计划无疑具有更高效的执行效果,但对于低延时和高并发要求的点查询,则不适宜走整个查询优化器的优化流程,会带来不必要的额外开销。为了解决这个问题,我们实现了点查询的短路径优化,绕过查询优化器以及 PlanFragment 来简化 SQL 执行流程,直接使用快速高效的读路径来检索所需的数据。
-
-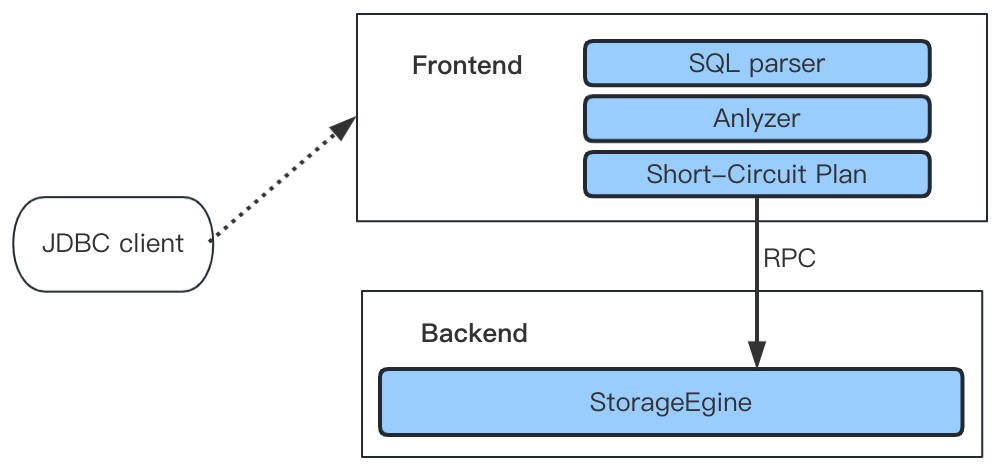
-
-
-当查询被 FE 接收后,它将由规划器生成适当的 Short-Circuit Plan 作为点查询的物理计划。该 Plan 非常轻量级,不需要任何等效变换、逻辑优化或物理优化,仅对 AST 树进行一些基本分析、构建相应的固定计划并减少优化器的开销。对于简单的主键点查询,如`select * from tbl where pk1 = 123 and pk2 = 456`,因为其只涉及单个 Tablet,因此可以使用轻量的 RPC 接口来直接与 StorageEngine 进行交互,以此避免生成复杂的Fragment Plan 并消除了在 MPP 查询框架下执行调度的性能开销。RPC 接口的详细信息如下:
-
-```
-message PTabletKeyLookupRequest {
- required int64 tablet_id = 1;
- repeated KeyTuple key_tuples = 2;
- optional Descriptor desc_tbl = 4;
- optional ExprList output_expr = 5;
-}
-
-message PTabletKeyLookupResponse {
- required PStatus status = 1;
- optional bytes row_batch = 5;
- optional bool empty_batch = 6;
-}
-rpc tablet_fetch_data(PTabletKeyLookupRequest) returns (PTabletKeyLookupResponse);
-```
-
-以上 tablet_id 是从主键条件列计算得出的,`key_tuples`是主键的字符串格式,在上面的示例中,`key_tuples`类似于 ['123', '456'],在 BE 收到请求后`key_tuples`将被编码为主键存储格式,并根据主键索引来识别 Key 在 Segment File 中的行号,并查看对应的行是否在`delete bitmap`中,如果存在则返回其行号,否则返回`NotFound`。然后使用该行号直对`__DORIS_ROW_STORE_COL__`列进行点查询,因此我们只需在该列中定位一行并获取 JSONB 格式的原始值,并对其进行反序列化作为后续输出函数计算的值。
-
-相关PR:https://github.com/apache/doris/pull/15491
-
-### 预处理语句优化(PreparedStatement)
-
-高并发查询中的 CPU 开销可以部分归因于 FE 层分析和解析 SQL 的 CPU 计算,为了解决这个问题,我们在 FE 端提供了与 MySQL 协议完全兼容的预处理语句(Prepared Statement)。当 CPU 成为主键点查的性能瓶颈时,**Prepared Statement 可以有效发挥作用,实现 4 倍以上的性能提升**。
-
-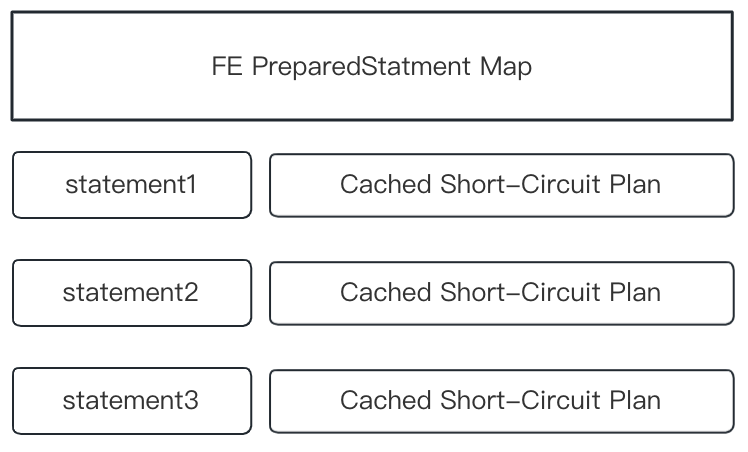
-
-Prepared Statement 的工作原理是通过在 Session 内存 HashMap 中缓存预先计算好的 SQL 和表达式,在后续查询时直接复用缓存对象即可。Prepared Statement 使用 [MySQL 二进制协议](https://dev.mysql.com/doc/dev/mysqlserver/latest/page_protocol_binary_resultset.html#sect_protocol_binary_resultset_row)作为传输协议。该协议在文件`mysql_row_buffer.[h|cpp] `中实现,符合标准 MySQL 二进制编码, 通过该协议客户端例如 JDBC Client, 第一阶段发送`PREPARE`MySQL Command 将预编译语句发送给 FE 并由 FE 解析、Analyze 该语句并缓存到上图的 HashMap 中,接着客户端通过`EXECUTE`MySQL Command 将占位符替换并编码成二进制的格式发送给 FE, 此时 FE 按照 MySQL 协议反序列化后得到占位符中的值,生 [...]
-
-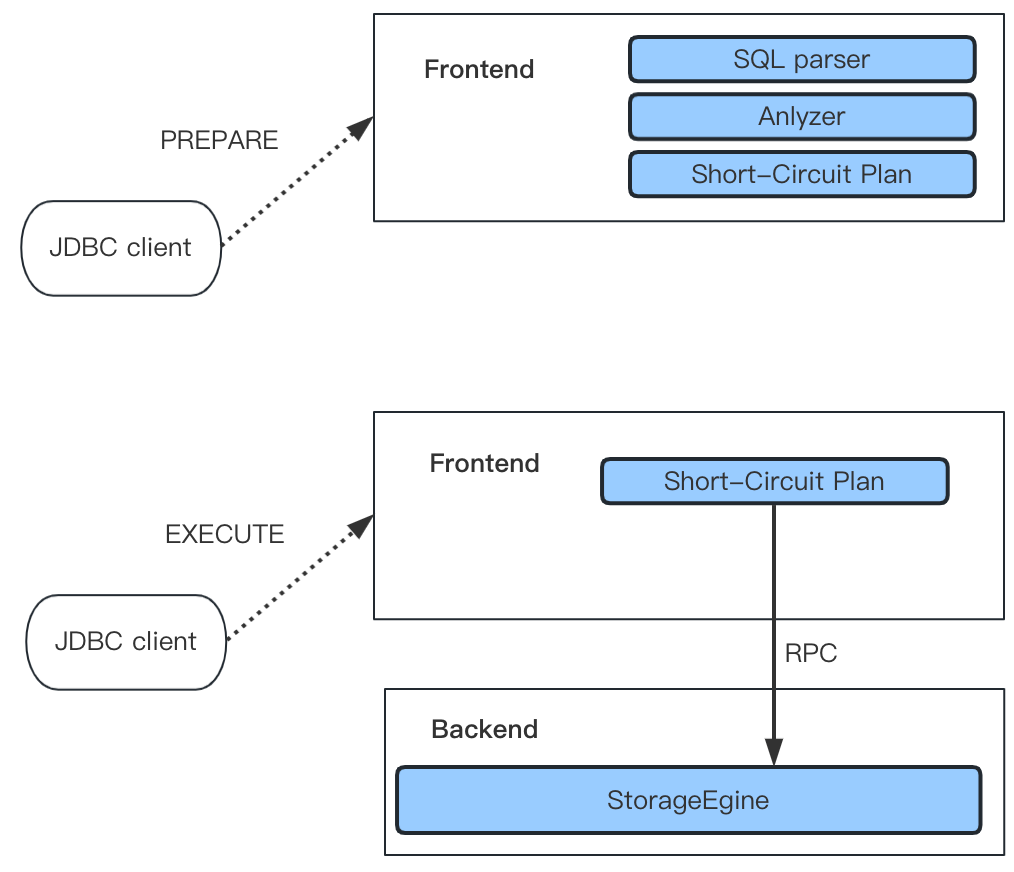
-
-
-除了在 FE 缓存 Statement,我们还需要在 BE 中缓存被重复使用的结构,包括预先分配的计算 Block,查询描述符和输出表达式,由于这些结构在序列化和反序列化时会造成 CPU 热点, 所以需要将这些结构缓存下来。对于每个查询的 PreparedStatement,都会附带一个名为 CacheID 的 UUID。当 BE 执行点查询时,根据相关的 CacheID 找到对应的复用类, 并在 BE 中表达式计算、执行时重复使用上述结构。下面是在 JDBC 中使用 PreparedStatement 的示例:1. 设置 JDBC URL 并在 Server 端开启 PreparedStatement
-
-```
-url = jdbc:mysql://127.0.0.1:9030/ycsb?useServerPrepStmts=true
-```
-
-2. 使用 Prepared Statement
-
-```
-// use `?` for placement holders, readStatement should be reused
-PreparedStatement readStatement = conn.prepareStatement("select * from tbl_point_query where key = ?");
-...
-readStatement.setInt(1234);
-ResultSet resultSet = readStatement.executeQuery();
-...
-readStatement.setInt(1235);
-resultSet = readStatement.executeQuery();
-...
-
-相关 PR:https://github.com/apache/doris/pull/15491
-```
-
-### 行存缓存
-
-Doris 中有针对 Page 级别的 Cache,每个 Page 中存的是某一列的数据,所以 Page Cache 是针对列的缓存。
-
-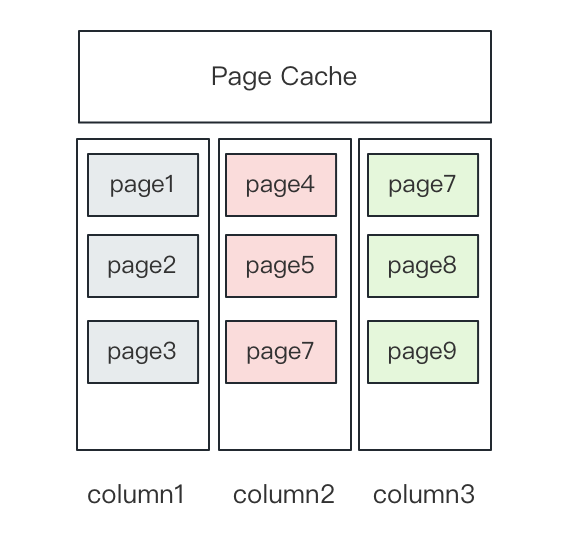
-
-
-对于前面提到的行存,一行里包括了多列数据,缓存可能被大查询给刷掉,为了增加行缓存命中率,就需要单独引入行存缓存(Row Cache)。行存 Cache 复用了 Doris 中的 LRU Cache 机制, 启动时会初始化一个内存阈值, 当超过内存阈值后会淘汰掉陈旧的缓存行。对于一条主键查询语句,在存储层上命中行缓存和不命中行缓存可能有数十倍的性能差距(磁盘 IO 与内存的访问差距),**因此行缓存的引入可以极大提升点查询的性能,特别是缓存命中高的场景下。**
-
-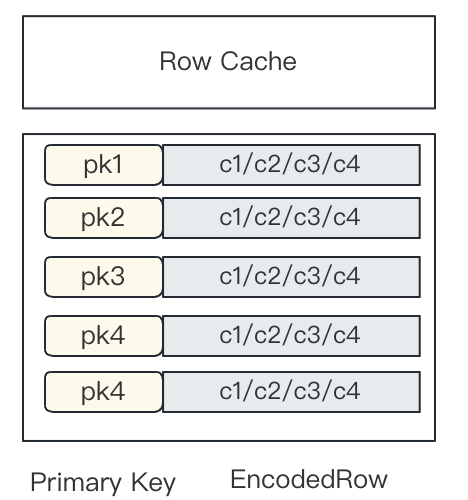
-
-开启行存缓存可以在 BE 中设置以下配置项来开启:
-
-```
-disable_storage_row_cache=false //是否开启行缓存, 默认不开启
-row_cache_mem_limit=20% // 指定row cache占用内存的百分比, 默认20%内存
-```
-
-相关 PR:https://github.com/apache/doris/pull/15491
-
-# **# Benchmark**
-
-基于以上一系列优化,帮助 Apache Doris 在 Data Serving 场景的性能得到进一步提升。我们基于 Yahoo! Cloud Serving Benchmark (YCSB)标准性能测试工具进行了基准测试,其中环境配置与数据规模如下:
-
-- 机器环境:单台 16 Core 64G 内存 4*1T 硬盘的云服务器
-- 集群规模:1 FE + 3 BE
-- 数据规模:一共 1 亿条数据,平均每行在 1K 左右,测试前进行了预热。
-- 对应测试表结构与查询语句如下:
-
-
-```
-// 建表语句如下:
-
-CREATE TABLE `usertable` (
- `YCSB_KEY` varchar(255) NULL,
- `FIELD0` text NULL,
- `FIELD1` text NULL,
- `FIELD2` text NULL,
- `FIELD3` text NULL,
- `FIELD4` text NULL,
- `FIELD5` text NULL,
- `FIELD6` text NULL,
- `FIELD7` text NULL,
- `FIELD8` text NULL,
- `FIELD9` text NULL
-) ENGINE=OLAP
-UNIQUE KEY(`YCSB_KEY`)
-COMMENT 'OLAP'
-DISTRIBUTED BY HASH(`YCSB_KEY`) BUCKETS 16
-PROPERTIES (
-"replication_allocation" = "tag.location.default: 1",
-"in_memory" = "false",
-"persistent" = "false",
-"storage_format" = "V2",
-"enable_unique_key_merge_on_write" = "true",
-"light_schema_change" = "true",
-"store_row_column" = "true",
-"disable_auto_compaction" = "false"
-);
-
-// 查询语句如下:
-
-SELECT * from usertable WHERE YCSB_KEY = ?
-```
-
-开启优化(即同时开启行存、点查短路径以及 PreparedStatement)与未开启的测试结果如下:
-
-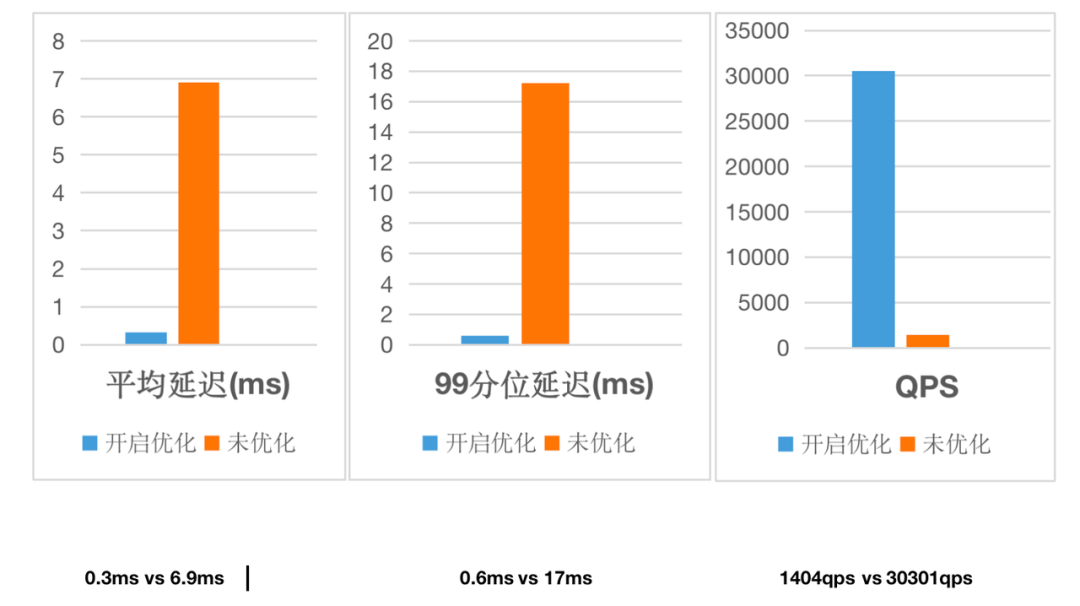
-
-开启以上优化项后平均**查询耗时降低了 96%** ,99 分位的**查询耗时仅之前的 1/28**,QPS 并发**从 1400 增至 3w、提升了超过 20 倍**,整体性能表现和并发承载实现数据量级的飞跃!
-
-# **# 最佳实践**
-
-需要注意的是,在当前阶段实现的点查询优化均是在 Unique Key 主键模型进行的,同时需要开启 Merge-on-Write 以及 Light Schema Change 后使用,以下是点查询场景的建表语句示例:
-
-```
-CREATE TABLE `usertable` (
- `USER_KEY` BIGINT NULL,
- `FIELD0` text NULL,
- `FIELD1` text NULL,
- `FIELD2` text NULL,
- `FIELD3` text NULL
-) ENGINE=OLAP
-UNIQUE KEY(`USER_KEY`)
-COMMENT 'OLAP'
-DISTRIBUTED BY HASH(`USER_KEY`) BUCKETS 16
-PROPERTIES (
-"enable_unique_key_merge_on_write" = "true",
-"light_schema_change" = "true",
-"store_row_column" = "true",
-);
-```
-
-**注意:**
-
-- 开启`light_schema_change`来支持 JSONB 行存编码 ColumnID
-
-- 开启`store_row_column`来存储行存格式
-
-完成建表操作后,类似如下基于主键的点查 SQL 可通过行式存储格式和短路径执行得到性能的大幅提升:
-
-```
-select * from usertable where USER_KEY = xxx;
-```
-
-与此同时,可以通过 JDBC 中的 Prepared Statement 来进一步提升点查询性能。如果有充足的内存, 还可以在 BE 配置文件中开启行存 Cache,上文中均已给出使用示例,在此不再赘述。
-
-# **# 总结**
-
-通过引入行式存储格式、点查询短路径优化、预处理语句以及行存缓存,Apache Doris 实现了单节点上万 QPS 的超高并发,实现了数十倍的性能飞跃。而随着集群规模的横向拓展、机器配置的提升,Apache Doris 还可以利用硬件资源实现计算加速,自身的 MPP 架构也具备横向线性拓展的能力。**因此 Apache Doris 真正具备了在** **一套架构下同时** **满足高吞吐的 OLAP 分析和高并发的 Data Serving 在线服务的能力,大大简化了混合工作负载下的技术架构,为用户提供了多场景下的统一分析体验**。
-
-以上功能的实现得益于 Apache Doris 社区开发者共同努力以及 SelectDB 工程师的的持续贡献,当前已处于紧锣密鼓的发版流程中,在不久后的 2.0 版本就会发布出来。如果对于以上功能有强烈需求,**[欢迎填写问卷提交申请](https://wenjuan.feishu.cn/m?t=sF2FZOL1KXKi-m73g),或者与 SelectDB 技术团队直接联系,提前获得 2.0-alpha 版本的体验机会**,也欢迎随时向我们反馈使用意见。
-
-**作者介绍:**
-
-李航宇,Apache Doris Contributor,SelectDB 半结构化研发工程师。
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Inverted Index.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Inverted Index.md
deleted file mode 100644
index 3df7abb207c..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Inverted Index.md
+++ /dev/null
@@ -1,281 +0,0 @@
----
-{
- 'title': '从 Elasticsearch 到 Apache Doris,10 倍性价比的新一代日志存储分析平台',
- 'summary': "Apache Doris 借鉴了信息检索的核心技术,在存储引擎上实现了面向 AP 场景优化的高性能倒排索引,对于字符串类型的全文检索和普通数值、日期等类型的等值、范围检索具有更高效的支持,相较于 Elasticsearch 实现性价比 10 余倍的提升,以此为日志存储与分析场景提供了更优的选择。",
- 'date': '2023-05-26',
- 'author': '肖康',
- 'tags': ['技术解析'],
-}
-
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-
-
-
-
-**作者介绍**:肖康,[SelectDB](https://cn.selectdb.com/) 技术副总裁
-
-# 导语
-
-日志数据的处理与分析是最典型的大数据分析场景之一,过去业内以 Elasticsearch 和 Grafana Loki 为代表的两类架构难以同时兼顾高吞吐实时写入、低成本海量存储、实时文本检索的需求。Apache Doris 借鉴了信息检索的核心技术,在存储引擎上实现了面向 AP 场景优化的高性能倒排索引,对于字符串类型的全文检索和普通数值、日期等类型的等值、范围检索具有更高效的支持,相较于 Elasticsearch 实现性价比 10 余倍的提升,以此为日志存储与分析场景提供了更优的选择。
-
-
-# 日志数据分析的需求与特点
-
-日志数据在企业大数据中非常普遍,其体量往往在企业大数据体系中占据非常高的比重,包括服务器、数据库、网络设备、IoT 物联网设备产生的系统运维日志,与此同时还包含了用户行为埋点等业务日志。
-
-日志数据对于保障系统稳定运行和业务发展至关重要:基于日志的监控告警可以发现系统运行风险,及时预警;在故障排查过程中,实时日志检索能帮助工程师快速定位到问题,尽快恢复服务;日志报表能通过长历史统计发现潜在趋势。而用户埋点日志数据则是用户行为分析以及智能推荐业务所依赖的决策基础,有助于用户需求洞察与体验优化以及后续的业务流程改进。
-
-由于其在业务中能发挥的重要意义,因此构建统一的日志分析平台,提供对日志数据的存储、高效检索以及快速分析能力,成为企业挖掘日志数据价值的关键一环。而日志数据和应用场景往往呈现如下的特点:
-
-- 数据增长快:每一次用户操作、系统事件都会触发新的日志产生,很多企业每天新增日志达到几十甚至几百亿条,对日志平台的写入吞吐要求很高;
-- 数据总量大:由于自身业务和监管等需要,日志数据经常要存储较长的周期,因此累积的数据量经常达到几百 TB 甚至 PB 级,而较老的历史数据访问频率又比较低,面临沉重的存储成本压力;
-- 时效性要求高:在故障排查等场景需要能快速查询到最新的日志,分钟级的数据延迟往往无法满足业务极高的时效性要求,因此需要实现日志数据的实时写入与实时查询。
-
-这些日志数据和应用场景的特点,为承载存储和分析需求的日志平台提出了如下挑战:
-
-- 高吞吐实时写入:既需要保证日志流量的大规模写入,又要支持低延迟可见;
-- 低成本大规模存储:既要存储大量的数据,又要降低存储成本;
-- 支持文本检索的实时查询:既要能支持日志文本的全文检索,又要做到实时查询响应;
-
-
-# 业界日志存储分析解决方案
-
-当前业界有两种比较典型的日志存储与分析架构,分别是以 Elasticsearch 为代表的倒排索引检索架构以及以 Loki 为代表的轻量索引/无索引架构,如果我们从实时写入吞吐、存储成本、实时交互式查询性能等几方面进行对比,不难发现以下结论:
-
-- 以 ES 为代表的倒排索引检索架构,支持全文检索、查询性能好,因此在日志场景中被业内大规模应用,但其仍存在一些不足,包括实时写入吞吐低、消耗大量资源构建索引,且需要消耗巨大存储成本;
-- 以 Loki 为代表的轻量索引或无索引架构,实时写入吞吐高、存储成本较低,但是检索性能慢、关键时候查询响应跟不上,性能成为制约业务分析的最大掣肘。
-
-
-
-ES 在日志场景的优势在于全文检索能力,能快速从海量日志中检索出匹配关键字的日志,其底层核心技术是倒排索引(Inverted Index)。
-
-倒排索引是一种用于快速查找文档中包含特定单词或短语的数据结构,最早应用于信息检索领域。如下图所示,在数据写入时,倒排索引可以将每一行文本进行分词,变成一个个词(Term),然后构建词(Term) -> 行号列表(Posting List) 的映射关系,将映射关系按照词进行排序存储。当需要查询某个词在哪些行出现的时候,先在 词 -> 行号列表 的有序映射关系中查找词对应的行号列表,然后用行号列表中的行号去取出对应行的内容。这样的查询方式,可以避免遍历对每一行数据进行扫描和匹配,只需要访问包含查找词的行,在海量数据下性能有数量级的提升。
-
-
-
-图:倒排索引原理示意
-
-
-
-倒排索引为 ES 带来快速检索能力的同时,也付出了写入速度吞吐低和存储空间占用高的代价——由于数据写入时倒排索引需要进行分词、词典排序、构建倒排表等 CPU 和内存密集型操作,导致写入吞吐大幅下降。而从存储成本角度考虑,ES 会存储原始数据和倒排索引,为了加速分析可能还需要额外存储一份列存数据,因此 3 份冗余也会导致更高的存储空间占用。
-
-Loki 则放弃了倒排索引,虽然带来来写入吞吐和存储空间的优势,但是损失了日志检索的用户体验,在关键时刻不能发挥快速查日志的作用。成本虽然有所降低,但是没有真正解决用户的问题。
-
-# 更高性价比的日志存储分析解决方案
-
-从以上方案对比可知,以 Elasticsearch 为代表的倒排索引检索架构以及以 Loki 为代表的轻量索引/无索引架构无法同时兼顾 高吞吐、低存储成本和实时高性能的要求,只能在某一方面或某几方面做权衡取舍。如果在保持倒排索引的文本检索性能优势的同时,大幅提升系统的写入速度与吞吐量并降低存储资源成本,是否日志场景所面临的困境就迎刃而解呢?答案是肯定的。
-
-如果我们希望使用 Apache Doris 来更好解决日志存储与分析场景的痛点,其实现路径也非常清晰——**在数据库内部增加倒排索引、以满足字符串类型的全文检索和普通数值/日期等类型的等值、范围检索,同时进一步优化倒排索引的查询性能、使其更加契合日志数据分析的场景需求**。
-
-在同样实现倒排索引的情况下,相较于 ES, Apache Doris 怎么做到更高的性能表现呢?或者说现有倒排索引的优化空间有哪些呢?
-
-- ES 基于 Apache Lucene 构建倒排索引,Apache Lucene 自 2000 年开源至今已有超过 20 年的历史,设计之初主要面向信息检索领域、功能丰富且复杂,而日志和大多数 OLAP 场景只需要其核心功能,包括分词、倒排表等,而相关度排序等并非强需求,因此存在进一步功能简化和性能提升的空间;
-- ES 和 Apache Lucene 均采用 Java 实现,而 Apache Doris 存储引擎和执行引擎采用 C++ 开发并且实现了全面向量化,相对于 Java 实现具有更好的性能;
-- 倒排索引并不能决定性能表现的全部,作为一个高性能、实时的 OLAP 数据库,Apache Doris 的列式存储引擎、MPP 分布式查询框架、向量化执行引擎以及智能 CBO 查询优化器,相较于 ES 更为高效。
-
-通过在 [Apache Doris 2.0.0 最新版本](https://github.com/apache/doris/releases/tag/2.0.0-alpha1)的探索与持续优化,在相同硬件配置和数据集的测试表现上,Apache Doris 在数据库内核实现高性能倒排索引后,相对于 ES 实现了日志数据写入速度提升 4 倍、存储空间降低 80%、查询性能提升 2 倍,再结合 Apache Doris 2.0.0 版本引入的冷热数据分离特性,整体性价比提升 10 倍以上!
-
-接下来我们进一步介绍设计与实现细节。
-
-# 高性能倒排索引的设计与实现
-
-业界各类系统为了支持全文检索和任意列索引,往往有两种实现方式:一是通过外接索引系统来实现,原始数据存储在原系统中、索引存储在独立的索引系统中,两个系统通过数据的 ID 进行关联。数据写入时会同步写入到原系统和索引系统,索引系统构建索引后不存储完整数据只保留索引。查询时先从索引系统查出满足过滤条件的数据 ID 集合,然后用 ID 集合去原系统查原始数据。
-
-这种架构的优势是实现简单,借力外部索引系统,对原有系统改动小。但是问题也很明显:
-
-- 数据写入两个系统,异常有数据不一致的问题,也存在一定冗余存储;
-- 查询需在两个系统进行网络交互有额外开销,数据量大时用 ID 集合去原系统查性能比较低;
-- 维护两套系统的复杂度高,将系统的复杂性从开发测转移到运维测;
-
-而另一种方式则是直接在系统中内置倒排索引,尽管技术难度更高,但性能更好、且无需花费额外的系统维护成本,对用户更加友好,这也是 Apache Doris 所选择的方式。
-
-### 数据库内置倒排索引
-
-在选择了在数据库内核中内置倒排索引后,我们需要进一步对 Apache Doris 索引结构进行分析,判断能否通过在已有索引基础上进行拓展来实现。
-
-Apache Doris 现有的索引存储在 Segment 文件的 Index Region 中,按照适用场景可以分为跳数索引和点查索引两类:
-
-- 跳数索引:包括 ZoneMap 索引和 Bloom Filter 索引。
-
- - ZoneMap 索引对每一个数据块和文件保存 Min/Max/isnull 等汇总信息,可以用于等值、范围查询的粗粒度过滤,只能排除不满足查询条件的数据块和文件,不能定位到行,也不支持文本分词。
- - BloomFilter 索引也是数据块和文件级别的索引,通过 Bloom Filter 判断某个值是否在数据块和文件中,同样不能定位到行、不支持文本分词;
-
-- 点查索引:包括 ShortKey 前缀排序索引和 Bitmap 索引。
-
- - ShortKey 在排序的基础上,根据给定的前缀列实现快速查询数据的索引方式,能够对前缀索引的列进行等值、范围查询,但不支持文本分词,另外由于数据要按前缀索引排序、因此一个表只允许一组前缀索引。
- - Bitmap 索引记录数据值 -> 行号 Bitmap 的有序映射,是一种很基础的倒排索引,但是索引结构比较简单、查询效率不高、不支持文本分词。
-
-原有索引结构很难满足日志场景实时文本检索的需求,因此设计了全新的倒排索引。倒排索引在设计和实现上我们采取了无侵入的方式、不改变 Segment 数据文件格式,而是增加了新的 Inverted Index File,逻辑上在 Table 的 Column 级别。具体流程如下:
-
-- 数据写入和 Compaction 阶段:在写 Segment 文件的同时,同步写入一个 Inverted Index 文件,文件路径由 Segment ID + Index ID 决定。写入 Segment 的 Row 和 Index 中的 Doc 一一对应,由于同步顺序写入,Segment 中的 Rowid 和 Index 中的 Docid 完全对应。
-- 查询阶段:如果查询 Where 条件中有建了倒排索引的列,会自动去 Index 文件中查询,返回满足条件的 Docid List,将 Docid List 一一对应的转成 Rowid Bitmap,然后走 Doris 通用的 Rowid 过滤机制只读取满足条件的行,达到查询加速的效果。
-
-
-
-图:Doris倒排索引架构图
-
-
-这个设计的好处是已有的数据文件无需修改,可以做到兼容升级,而且增减索引不影响数据文件和其他索引,用户增建索引没有负担。
-
-### 通用倒排索引优化
-
-**C++和向量化实现**
-
-Apache Doris 使用 [CLucene](https://clucene.sourceforge.net/) 作为底层的倒排索引库,CLucene 是一个用 C++ 实现的高性能、稳定的 Lucene 倒排索引库,它的功能比较完整,支持分词和自定义分词算法,支持全文检索查询和等值、范围查询。
-
-Apache Doris 的存储模块和 CLucene 都用 C++ 实现,避免了Java Lucene 的 JVM GC 等开销,同样的计算 C++ 实现相对于 Java 性能优势明显,而且更利于做向量化加速。Doris 倒排索引进行了向量化优化,包括分词、倒排表构建、查询等,性能得到进一步提升。整体来看 Doris 的倒排索引写入速度可以超过单核 20MB/s,而 ES 的单核写入速度不到 5MB/s,有 4 倍的性能优势。
-
-**列式存储和压缩**
-
-Lucene 本身是文档存储模型,主数据采用行存,而 Doris 中不同列的倒排索引是相互独立的,因此倒排索引文件也采用列式存储,有利于向量化构建索引和提高压缩率。
-
-采用压缩比高且速度快的 ZSTD,通常可以达到 5 ~10倍的压缩比,与常用的GZIP压缩相比有50%以上的空间节省且速度更快。
-
-**BKD 索引与** **数值、日期类型** **列优化**
-
-针对数值、日期类型的列,我们还实现了 BKD 索引,可以对范围查询提高性能,存储空间也相对于转成定长字符串更加高效,具有以下主要特性和优势:
-
-1. 高效范围查询:BKD 索引采用多维数据结构,为范围查询带来高效率。它能迅速定位数值或日期类型列中所需的数据范围,降低查询时间复杂度。
-1. 存储空间优化:与其他索引方法相比,BKD 索引在存储空间使用上更高效。通过聚合并压缩相邻数据块,减少索引所需存储空间,降低存储成本。
-1. 多维数据支持:BKD 索引具备良好扩展性,支持多维数据类型,如地理坐标(GEO point)和范围(Range),使其在处理复杂数据类型时具有高适应性。
-
-此外,我们在原有 BKD 索引能力基础上进行了进一步拓展:
-
-1. 优化低基数场景:针对数值分布集中、单个数值倒排列表较多的低基数场景,我们调整了针对性的压缩算法,降低大量倒排表解压缩和反序列化所带来的CPU性能消耗。
-1. 预查询技术:针对查询结果命中数较高的场景,我们采用预查询技术进行命中数预估。若命中数显著超过阈值,可跳过索引查询,直接利用Doris在大数据量查询下的技术优势进行数据过滤。
-
-
-### 面向 OLAP 的倒排索引优化
-
-日志存储和分析场景对检索的需求很简单,不需要特别复杂的功能(比如相关性排序),更需要降低存储成本和快速按照条件查出数据。因此,在面对海量数据的写入和查询时,Apache Doris 还针对 OLAP 数据库的特点优化了倒排索引的结构,使其更加简洁高效。例如:
-
-- 在写入流程保证不会多个线程写入一个索引,从而避免写入时多线程锁竞争的开销;
-- 在存储结构上去掉了不必要的正排、norm 等文件,减少写入 IO 开销和存储空间占用;
-- 查询过程中简化相关性打分和排序逻辑,降低不必要的开销,提升查询性能。
-
-
-针对日志等数据有按时间分区、历史数据访问频度低的特点,基于独立的索引文件设计,Apache Doris 还将在后续的版本中提供更细粒度、更灵活的索引管理功能:
-
-- 指定分区构建倒排索引,比如新增一个索引的时候指定最近7天的日志构建索引,历史数据不建索引
-- 指定分区删除倒排索引,比如删除超过1个月的日志的索引,释放访问频度低的索引存储空间
-
-
-# 性能测试
-
-高性能是 Apache Doris 倒排索引设计和实现的首要出发点,我们通过公开的测试数据集分别与 ES 以及 Clickhouse 进行性能测试,测试效果如下:
-
-### vs Elasticsearch
-
-我们采用了 ES 官方的性能测试 Benchmark esrally 并使用其中的 HTTP Logs 日志,在同样的硬件资源、数据、测试Case 以及测试工具下,记录并对比各自的数据写入时间、吞吐以及查询延迟。
-
-- 测试数据:esrally HTTP Logs track 中自带测试数据集,1998 年 World Cup HTTP Server Logs,未压缩前 32G、共 2.47 亿行、单行平均长度 134 字节;
-- 测试查询:esrally HTTP Logs 测试关键词检索、范围查询、聚合、排序等 11 个 Query,所有查询跑 100 次串行执行;
-- 测试环境:3 台 16C 64G 云主机组成的集群。
-
-在最终的测试结果中,**Doris 写入速度是 ES 的 4.2 倍**、达到 550 MB/s,写入后的数据压缩比接近 1:10、**存储空间** **节省** **超** ******80%** **,查询耗时下降 57%、查询性能是 ES 的 2.3 倍。加上冷热数据分离降低冷数据存储成本,整体相较 ES 实现 10倍以上的性价比提升。**
-
-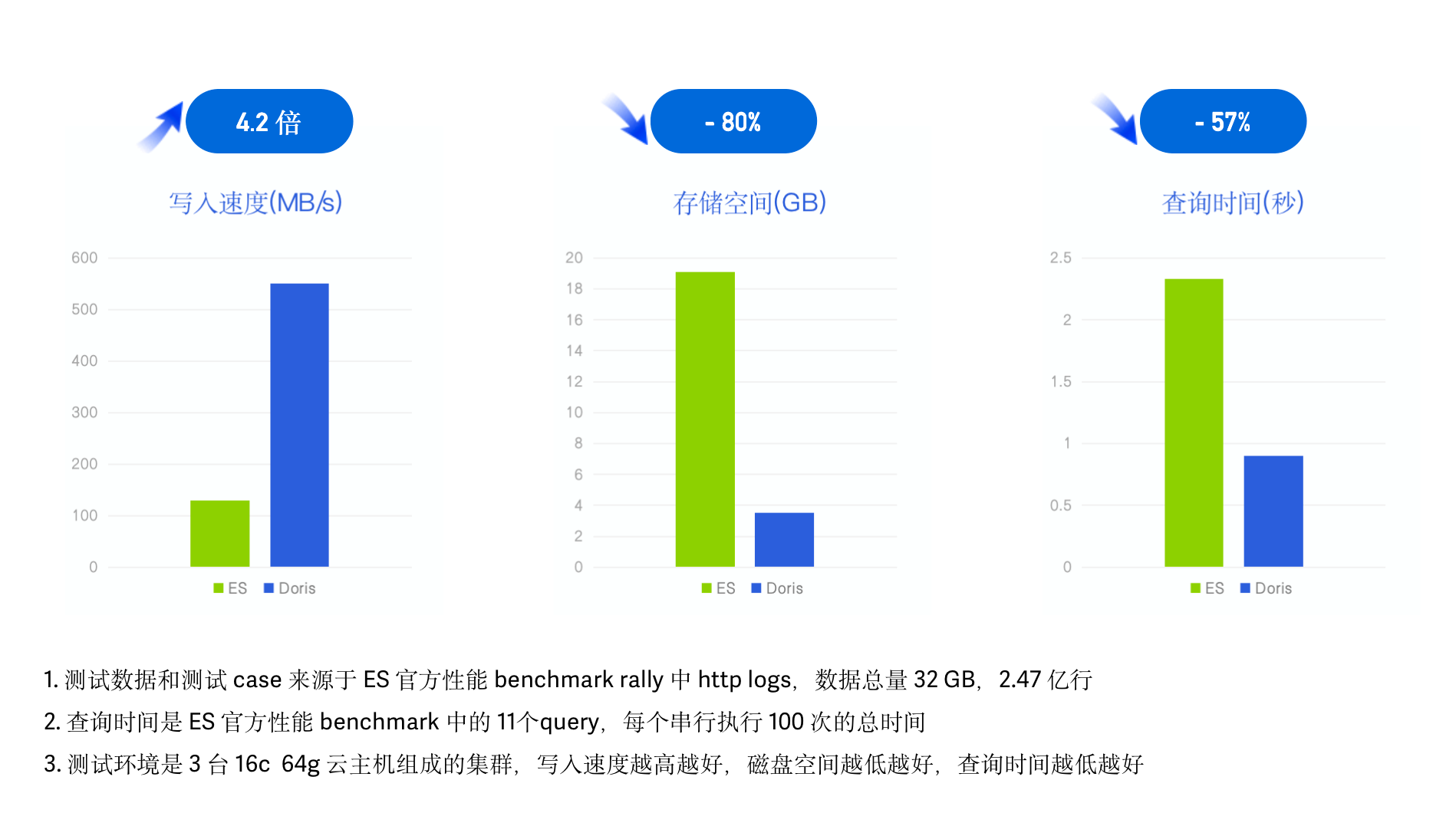
-
-### vs Clickhouse
-
-Clickhouse 近期的 v23.1 版本也引入了类似 Feature,将倒排索引作为实验性功能发布,因此我们同样进行了跟 Clickhouse 倒排索引的性能对比。在本次测试中,我们采用了 Clickhouse 官方 Inverted Index 介绍博客中使用的 Hacker News 样例数据以及查询 SQL ,同样保持相同的物理资源、数据、测试 Case 以及测试工具。
-
-(参考文章:https://clickhouse.com/blog/clickhouse-search-with-inverted-indices)
-
-- 测试数据:Hacker News 2873 万条数据,6.7G,Parquet 格式;
-- 测试查询:3 个查询,分别查询 'clickhouse'、'olap' OR 'oltp'、'avx' AND 'sve' 等关键字出现的次数;
-- 测试机器:1 台 16C 64G 云主机
-
-在最终的测试结果中,3 个 SQL **Apache Doris 的查询性能分别是 Clickhouse 的 4.7 倍、12.0 倍以及 18.5 倍**,有明显的性能优势。
-
-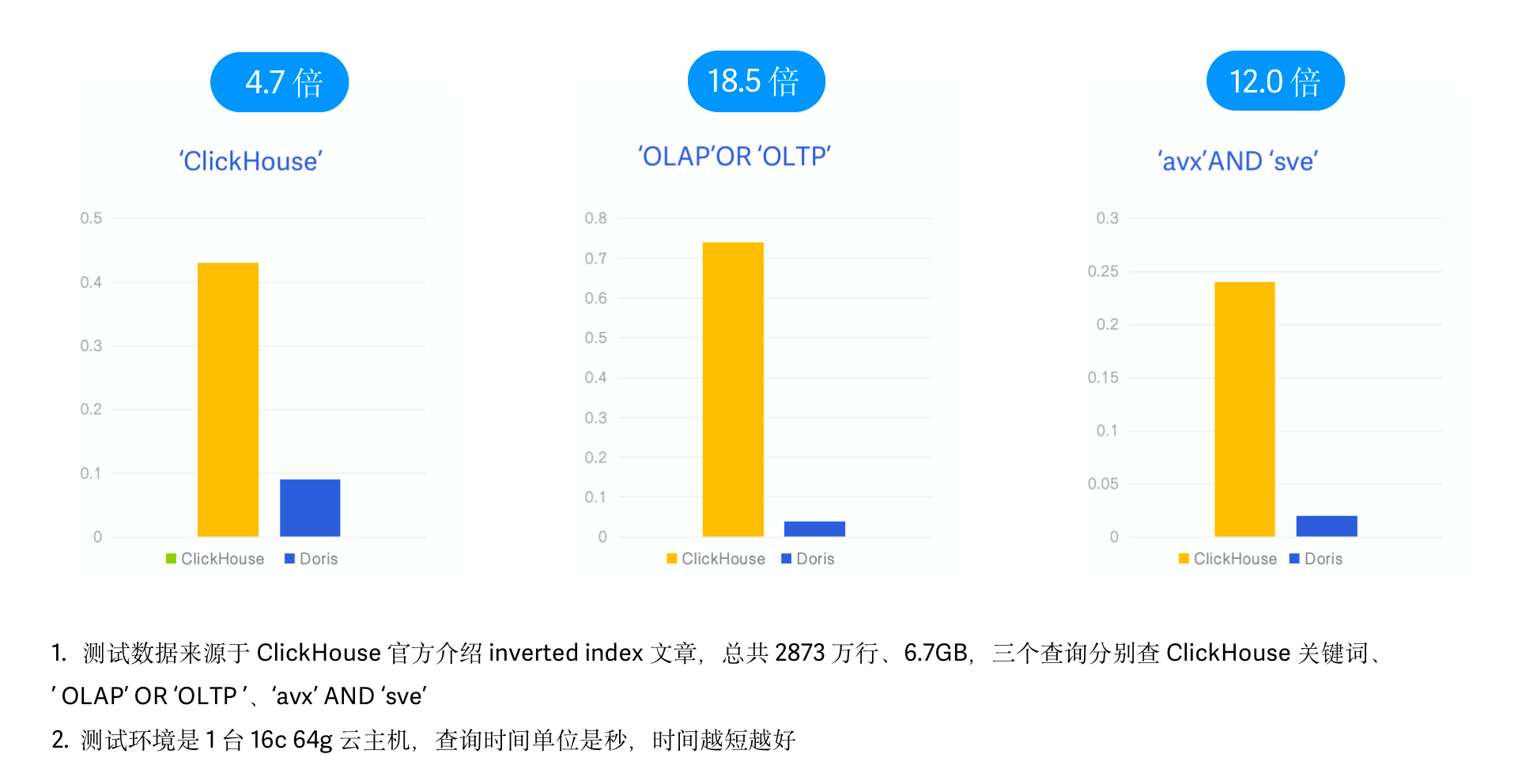
-
-# 如何使用
-
-下面以一个 Hacker News 100 万条测试数据的示例展示 Doris 如何利用倒排索引实现高效的日志分析。
-
-1. 建表时指定索引
-
- 1. INDEX idx_comment (`comment`) 指定对 comment 列建一个名为 idx_comment 的索引
- 1. USING INVERTED 指定索引类型为倒排索引
- 1. PROPERTIES("parser" = "english") 指定分词类型为英文分词
-
-```
-CREATE TABLE hackernews_1m
-(
- `id` BIGINT,
- `deleted` TINYINT,
- `type` String,
- `author` String,
- `timestamp` DateTimeV2,
- `comment` String,
- `dead` TINYINT,
- `parent` BIGINT,
- `poll` BIGINT,
- `children` Array<BIGINT>,
- `url` String,
- `score` INT,
- `title` String,
- `parts` Array<INT>,
- `descendants` INT,
- INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
-)
-DUPLICATE KEY(`id`)
-DISTRIBUTED BY HASH(`id`) BUCKETS 10
-PROPERTIES ("replication_num" = "1");
-```
-
-注:对于已经存在的表,也可以通过 `` ADD INDEX idx_comment ON hackernews_1m(`comment`) USING INVERTED PROPERTIES("parser" = "english") ``来增加索引。值得一提的是,和 Doris 原先存储在 Segment 数据文件中的智能索引和二级索引相比,增加倒排索引的过程只会读 comment 列构建新的倒排索引文件,不会读写原有的其他数据,效率有明显提升。
-
-2. 导入数据后查询,使用 `MATCH_ALL` 在 comment 这一列上匹配 OLAP 和 OLTP 两个词,和 LIKE 扫描硬匹配相比,查询性能有十余倍的提升。(这仅是 100 万条数据下的测试效果,而随着数据量增大、性能提升越明显)
-
-```
-mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
-+---------+
-| count() |
-+---------+
-| 15 |
-+---------+
-1 row in set (0.13 sec)
-
-mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
-+---------+
-| count() |
-+---------+
-| 15 |
-+---------+
-1 row in set (0.01 sec)
-```
-
-更多详细功能介绍和测试步骤可以参考Apache Doris [倒排索引官方文档](https://doris.apache.org/zh-CN/docs/dev/data-table/index/inverted-index) 。
-
-# 总结
-
-通过内置高性能倒排索引,Apache Doris 对于字符串类型的全文检索和普通数值、日期等类型的等值、范围检索具有更高效的支持,进一步提升了数据查询的效率和准确性,对于大规模日志数据查询分析有了更好的性能表现,为需要检索能力的用户提供了更高性价比的选择。
-
-目前倒排索引已经支持了 String、Int、Decimal、Datetime 等常用 Scalar 数据类型和 Array 数组类型,后续还会增加对 JSONB、Map 等复杂数据类型的支持。而 BKD 索引可以支持多维度类型的索引,为未来 Doris 增加 GEO 地理位置数据类型和索引打下了基础。与此同时 Apache Doris 在半结构化数据分析方面还有更多能力扩展,比如自动根据导入数据扩展表结构的 Dynamic Table、丰富的复杂数据类型(Array、Map、Struct、JSONB)以及高性能字符串匹配算法等。
-
-除倒排索引以外,[Apache Doris 在 2.0.0 Alpha 版本](https://github.com/apache/doris/releases/tag/2.0.0-alpha1)中还实现了单节点数万 QPS 的高并发点查询能力、基于对象存储的冷热数据分离、基于代价模型的全新查询优化器以及 Pipeline 执行引擎等,欢迎大家下载体验。高并发点查询的详细介绍可以查看 SelectDB 技术团队过往发布的技术博客,其他功能的使用介绍请参考社区官方文档,同时也敬请持续关注我们后续发布的特性解读系列文章。
-
-为了让用户可以体验社区开发的最新特性,同时保证最新功能可以收获到更广范围的使用反馈,我们建立了 2.0.0 版本的专项支持群,欢迎广大社区用户在使用最新版本过程中多多反馈使用意见,帮助 Apache Doris 持续改进,[通过此处填写申请加入专项支持群。](https://wenjuan.feishu.cn/m/cfm?t=sF2FZOL1KXKi-m73g)
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/JD_OLAP.md b/i18n/zh-CN/docusaurus-plugin-content-blog/JD_OLAP.md
deleted file mode 100644
index 94bbfc196ab..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/JD_OLAP.md
+++ /dev/null
@@ -1,88 +0,0 @@
----
-{
- 'title': 'Apache Doris 在京东搜索实时 OLAP 探索与实践',
- 'summary': '本文讨论了京东搜索在实时流量数据分析方面,利用Apache Flink和Apache Doris进行的探索和实践。流式计算在近些年的热度与日俱增:从Google Dataflow论文的发表,到Apache Flink计算引擎逐渐站到舞台中央,再到Apache Druid等实时分析型数据库的广泛应用,流式计算引擎百花齐放。但不同的业务场景,面临着不同的问题,没有哪一种引擎是万能的。我们希望京东搜索业务在流计算的应用实践,能够给到大家一些启发,也欢迎大家多多交流,给我们提出宝贵的建议.',
- 'date': '2022-12-02',
- 'author': '李哲',
- 'tags': ['最佳实践'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-# 京东搜索实时 OLAP 探索与实践
-
-
-
-> 前言
-本文讨论了京东搜索在实时流量数据分析方面,利用Apache Flink和Apache Doris进行的探索和实践。流式计算在近些年的热度与日俱增:从Google Dataflow论文的发表,到Apache Flink计算引擎逐渐站到舞台中央,再到Apache Druid等实时分析型数据库的广泛应用,流式计算引擎百花齐放。但不同的业务场景,面临着不同的问题,没有哪一种引擎是万能的。我们希望京东搜索业务在流计算的应用实践,能够给到大家一些启发,也欢迎大家多多交流,给我们提出宝贵的建议。
-
-> 作者:李哲,京东搜推数据开发工程师,曾就职于美团点评,主要从事离线数据开发、流计算开发以及OLAP多维查询引擎的应用开发。
-
-## 京东与京东搜索
-京东集团(NASDAQ:JD)中国领先的电商企业,2021年全年净收入达到9516亿元人民币。京东集团旗下设有京东零售、京东国际、京东科技、京东物流、京东云等。 京东集团于2014年5月在美国纳斯达克证券交易所正式挂牌上市。
-
-## 搜索业务对实时数据分析的需求
-京东搜索作为电商平台的入口,为众多商家与用户提供连接的纽带。京东搜索发挥着导流的作用,给用户提供表达需求的入口;为了正确理解用户意图,将用户的需求进行高效的转化,线上同时运行着多个AB实验算法,遍及POP形态与自营形态的多个商品。而这些商品所属的品类、所在的组织架构以及品牌店铺等属性,都需要在线进行监控,以衡量转化的效果和承接的能力。目前搜索上层应用业务对实时数据的需求,主要包含三部分内容:
-1、 搜索整体数据的实时分析。
-2、 AB实验效果的实时监控。
-3、 热搜词的Top榜单以反映舆情的变化。
-这三部分数据需求,都需要进行深度的下钻,维度细化需要到SKU粒度。同时我们也承担着搜索实时数据平台的建设任务,为下游用户输出不同层次的实时流数据。
-我们的用户包括搜索的运营、产品、算法以及采销人员。虽然不同用户关心的数据粒度不同、时间频率不同、维度也不同,但是我们希望能够建立统一的实时OLAP数据仓库,并提供一套安全、可靠的、灵活的实时数据服务。
-目前每日新增的曝光日志达到几亿条记录,而拆分到SKU粒度的日志则要翻10倍,再细拆到AB实验的SKU粒度时,数据量则多达上百亿记录,多维数据组合下的聚合查询要求秒级响应时间,这样的数据量也给团队带来了不小的挑战。
-
-## 实时技术架构演进
-我们之前的方案是以Apache Storm引擎进行点对点的数据处理,这种方式在业务需求快速增长的阶段,可以快速的满足实时报表的需求。但是随着业务的不断发展、数据量逐渐增加以及需求逐渐多样化,弊端随之产生。例如灵活性差、数据一致性无法满足、开发效率较低、资源成本增加等。
-
-
-
-为解决之前架构出现的问题,我们首先进行了架构升级,将storm引擎替换为Apache Flink,用以实现高吞吐、exactly once的处理语义。同时根据搜索数据的特点,将实时数据进行分层处理,构建出PV流明细层、SKU流明细层和AB实验流明细层,期望基于不同明细层的实时流,构建上层的实时OLAP层。
-OLAP层的在技术选型时,需要满足以下几点:
-1:数据延迟在分钟级,查询响应时间在秒级
-2:标准SQL交互引擎,降低使用成本
-3:支持join操作,方便以维度级别增加属性信息
-4:流量数据可以近似去重,但订单行要精准去重
-5:高吞吐,每分钟数据量在千万级记录,每天数百亿条新增记录
-6:前端业务较多,查询并发度不能太低
-通过对比目前业界广泛使用的支持实时导入的OLAP引擎,我们在druid、ES、clickhouse和doris之间做了横向比较:
-
-
-
-通过对比开源的几款实时OLAP引擎,我们发现doris和clickhouse能够满足我们的需求,但是clickhouse的并发度太低是个潜在的风险,而且clickhouse的数据导入没有事务支持,无法实现exactly once语义,对标准sql的支持也是有限的。
-最终,我们选定doris作为聚合层,用于实时OLAP分析。对于流量数据,使用聚合模型建表;对于订单行,我们使用Uniq模型,保证同一个订单最终只会存储一条记录,从而达到订单行精准去重的目的。在flink处理时,我们也将之前的任务拆解,将反复加工的逻辑封装,每一次处理都生成新的topic流,明细层细分了不同粒度的实时流。新方案如下:
-
-
-
-目前的技术架构中,flink的任务是非常轻的。基于生产的数据明细层,我们直接使用了doris来充当聚合层的功能,将原本可以在flink中实现的窗口计算,下沉到doris中完成。利用doris的routine load消费实时数据,虽然数据在导入前是明细粒度,但是基于聚合模型,导入后自动进行异步聚合。而聚合度的高低,完全根据维度的个数与维度的基数决定。通过在base表上建立rollup,在导入时双写或多写并进行预聚合操作,这有点类似于物化视图的功能,可以将数据进行高度的汇总,以提升查询性能。
-在明细层采用kafka直接对接到doris,还有一个好处就是这种方式天然的支持数据回溯。数据回溯简单说就是当遇到实时数据的乱序问题时,可以将“迟到”的数据进行重新计算,更新之前的结果。这是因为我们导入的是明细数据,延迟的数据无论何时到达都可以被写入到表中,而查询接口只需要再次进行查询即可获得最新的计算结果。最终方案的数据流图如下:
-
-
-
-## Doris在大促期间的优化
-上文提到我们在doris中建立了不同粒度的聚合模型,包括PV粒度、SKU粒度以及AB实验粒度。我们这里以每日生产数据量最大的曝光AB实验模型为例,阐述在doris中如何支持大促期间每日新增百亿条记录的查询的。
-AB实验的效果监控,业务上需要10分钟、30分钟、60分钟以及全天累计等四个时间段,同时需要根据渠道、平台和一二三级品类等维度进行下钻分析,观测的指标则包含曝光PV、UV、曝光SKU件次、点击PV、点击UV等基础指标,以及CTR等衍生指标。
-在数据建模阶段,我们将曝光实时数据建立聚合模型,其中K空间包含日期字段、分钟粒度的时间字段、渠道、平台、一二三级品类等,V空间则包含上述的指标列,其中UV和PV进行HLL近似计算,而SKU件次则采用SUM函数,每到来一条新记录则加1。由于AB实验数据都是以AB实验位作为过滤条件,因此将实验位字段设置为分桶字段,查询时能够快速定位tablet分片。值得注意的是,HLL的近似度在目前PV和UV的基数下,实际情况误差在0.8%左右,符合预期。
-目前doris的集群共30+台BE,存储采用的是支持NVMe协议的SSD硬盘。AB实验曝光topic的分区数为40+,每日新增百亿条数据。在数据导入阶段,我们主要针对导入任务的三个参数进行优化:最大时间间隔、最大数据量以及最大记录数。当这3个指标中任何一个达到设置的阈值时,任务都会触发导入操作。为了更好的了解任务每次触发的条件,达到10分钟消费6亿条记录的压测目标,我们通过间隔采样的方法,每隔3分钟采样一次任务的情况,获取Statistic信息中的receivedBytes、cimmittedTaskNum、loadedRows以及taskExecuteTimeMs数值。通过对上述数值在前后2个时间段的差值计算,确定每个任务触发的条件,并调整参数,以在吞吐和延迟之间进行平衡,最终达到压测的要求。
-为了实现快速的多维数据查询,基于base表建立了不同的rollup,同时每个rollup的字段顺序,也要遵循过滤的字段尽可能放到前面的原则,充分利用前缀索引的特性。这里并不是rollup越多越好,因为每个rollup都会有相应的物理存储,每增加一个rollup,在写入时就会增加一份IO。最终我们在此表上建立了2个rollup,在要求的响应时间内尽可能多的满足查询需求。
-
-## 总结与展望
-京东搜索是在2020年5月份引入doris的,规模是30+台BE,线上同时运行着10+个routine load任务,每日新增数据条数在200亿+,已经成为京东体量最大的doris用户。从结果看,用doris替换flink的窗口计算,既可以提高开发效率,适应维度的变化,同时也可以降低计算资源,用doris充当实时数据仓库的聚合层,并提供统一的接口服务,保证了数据的一致性和安全性。
-我们在使用中也遇到了查询相关的、任务调度相关的bug,也在推动京东OLAP平台升级到最新版本。接下来待版本升级后,我们计划使用bitmap功能来支持UV等指标的精准去重操作,并将推荐实时业务应用doris实现。除此之外,为了完善实时数仓的分层结构,为更多业务提供数据输入,我们也计划使用适当的flink窗口开发聚合层的实时流,增加数据的丰富度和完整度。
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/LY.md b/i18n/zh-CN/docusaurus-plugin-content-blog/LY.md
deleted file mode 100644
index 2271dcf4e4f..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/LY.md
+++ /dev/null
@@ -1,129 +0,0 @@
----
-{
- 'title': '应用实践:数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设',
- 'language': "zh",
- 'summary': "同程数科成立于 2015 年,是同程集团旗下的旅游产业金融服务平台。2020 年,同程数科由于看到了 Apache Doris 丰富的数据接入方式、优异的并行运算能力和极简运维的特性,引入了Apache Doris 进行数仓架构改造。本文详细讲述了同程数科数仓架构从1.0 到 2.0 的演进过程及使用Doris过程中的应用实践。",
- 'date': '2022-12-19',
- 'author': '王星',
- 'tags': ['最佳实践']
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-> 导读:同程数科成立于 2015 年,是同程集团旗下的旅游产业金融服务平台。2020 年,同程数科由于看到了 Apache Doris 丰富的数据接入方式、优异的并行运算能力和极简运维的特性,引入了Apache Doris 进行数仓架构改造。本文详细讲述了同程数科数仓架构从1.0 到 2.0 的演进过程及使用Doris过程中的应用实践。希望对大家有所帮助。
-
-> 作者|同程数科大数据高级工程师 王星
-
-
-
-# 业务背景
-
-## 业务介绍
-同程数科是同程集团旗下的旅游金融服务平台,其前身是同程金服。正式成立于 2015 年,同程数科以“数字科技引领旅游产业”为愿景,坚持以科技的力量,赋能我国旅游产业。
-目前,同程数科的业务涵盖金融服务、消费金融服务、金融科技及数字科技等板块,累计服务覆盖超过千万用户和 76 座城市。
-
-## 业务需求
-
-包含四大类:
-- 看板类:包括实时驾驶舱以及 T+1 业务看板等。
-- 预警类:包括风控熔断、资金异常以及流量监控等。
-- 分析类:包括及时性数据查询分析以及临时取数等。
-- 财务类:包括清算以及支付对账需求。
-
-# 架构演进之 1.0
-
-## 工作流程
-
-
-
-我们最初的数仓架构沿袭了前几年非常流行的SteamSets 和 Apache Kudu 组合的第一代架构。该架构中,Binlog 通过StreamSets后,通过实时采集后写入 Apache Kudu 中,最后通过 Apache Impala 和可视化工具进行查询和使用。
-
-不足:
-- 组件引入过多,维护成本随之增加
-- 多种技术架构和过长的开发链路,提高了数仓研发人员的学习成本,数仓人员需要在不同组件之间进行开发,导致开发效率降低。
-- Apache Kudu 在大表关联 Join 方面性能差强人意。
-- 由于数仓使用了 CDH组件搭建,离线和实时集群并未进行分离,形成资源之间的相互竞争;在离线数据批量处理时对 IO 或磁盘消耗较大,无法保证实时数据的及时性。
-- 虽然 SteamSets 配备了预警能力,但作业恢复能力仍相对欠缺。在配置多个任务时, JVM 的消耗较大,导致恢复速度较慢。
-
-# 架构演进之 2.0
-
-## 调研过程
-
-由于缺点众多,我们不得不放弃了数仓1.0的架构。在 2020年中,我们对市面上流行的数仓进行了深度调研。
-
-在调研过程中,我们集中对比了Click house和Apache Doris。ClickHouse 对 CPU 的利用率较高,所以在单表查询时表现比较优秀,但是在多查询高 QPS 的情况下则表现欠佳。反观Doris不仅单节点最高可支持上千QPS,而且得益于分区分桶裁剪的功能,可以支持QPS万级别的高并发查询;再者,ClickHouse的扩容缩容复杂且繁琐,目前做不到自动在线操作,需要自研工具支持。Doris支持集群的在线动态扩缩容,且可以随着业务的发展水平扩展。
-
-在调研中,ApacheDoris脱颖而出。Doris高并发的查询能力非常吸引我们,而且灵活的扩缩容能力也也更适合我们灵活多变的广告业务。因此我们选择了 Apache Doris。
-
-
-
-引入 Apache Doris 后,我们对整个数仓进行了改造:
-- 通过Canal 采集MySQL Binlog 进入 Kafka中。因为Apache Doris 与 Kafka 的契合度较高,可以便捷地使用 Routine Load 对数据加载和导入。
-- 我们对原有离线计算的数据链路进行了细微调整。对于存储在 Hive 中的数据,Apahce Doris 可以通过 Broker Load 将 Hive 中的数据导入。这样一来离线集群的数据就可以直接加载到 Doris。
-
-## 选择 Doris
-
-
-
-Apache Doris 整体表现令人深刻:
-- 数据接入:提供了丰富的数据导入方式,能够支持众多数据源的接入。
-- 数据连接:Doris 支持 JDBC 与 ODBC 等方式连接。Doris对 BI 工具的可视化展示比较友好,能够便捷地与 BI 工具进行连接。另外Doris 采用MySQL 协议进行通信,用户可以通过各类 Client 工具直接访问 Doris。
-- SQL 语法:Doris 采用MySQL 协议,高度兼容MySQL 语法,支持标准SQL,对于数仓开发人员来说学习成本较低;
-- MPP 并行计算:Doris 基于 MPP 架构,提供了非常优秀的并行计算能力。在复杂Join和大表Join的场景下Doris优势非常明显;
-- 文档健全:Doris 官方文档非常健全,对于新用户上手非常友好。(我们最看重的一点)
-
-## Doris 实时系统架构
-
-
-
-- 数据源:在实时系统架构中,数据源来自产业金融、消费金融、风控数据等业务线,通过 Canal 和 API 接口进行采集。
-
-- 数据采集:通过 Canal- Admin 进行数据采集后,Canal将数据发送到 Kafka 消息队列之中。之后,数据再通过 Routine Load 接入到 Doris 集群。
-
-- Doris 数仓:由Doris 集群组成了了数据仓库的三级分层,分别是:使用了 Unique 模型的 DWD 明细层 、 Aggregate 模型的 DWS 汇总层以及 ADS 应用层。
-
-- 数据应用:数据应用于实时看板、数据及时性分析以及数据服务三方面。
-
-## Doris 新数仓特点
-
-数据导入方式简便,根据不同场景采用 3 种不同的导入方式:
-- Routine Load:当我们提交 Rountine Load 任务时,Doris 内部会有一个常驻进程实时消费 Kafka ,不断从 Kafka 中读取数据并导入进 Doris中。
-- Broker Load:维度表及历史数据等离线数据有序地导入Doris。
-- Insert Into:用于定时批式计算任务,负责处理DWD 层数据,从而形成 DWS 层以及 ADS 层。
-Doris 的良好数据模型,提升了我们的开发效率:
-- Unique 模型在 DWD 层接入时使用,可以有效防止重复消费数据。
-- Aggregate 模型用作聚合。在 Doris 中,Aggregate 支持如 Sum、Replace、Min 、Max 4 种方式的聚合模型,聚合的过程中使用 Aggregate 底层模型可以减少很大部分 SQL 代码量,不再人工手写Sum、Min、Max 等代码。
-Doris 查询效率高:
-- 支持物化视图与 Rollup 物化索引。物化视图底层类似 Cube 的概念与预计算的过程,与 Kylin 中以空间换时间的方式类似,均是在底层生成特殊的表,在查询中命中物化视图并快速响应。
-
-# 新架构的收益
-
-- 数据接入:在最初的架构中,通过 SteamSets 进行数据接入的过程中需要手动建立 Kudu 表。由于缺乏工具,整个建表和创建任务的过程需要 20-30 分钟。如今可以通过平台与快速构建语句实现数据快速接入,每张表的接入过程从之前的20-30分钟缩短到现在的 3-5 分钟,性能提升了 5-6 倍。
-- 数据开发:使用 Doris之后,我们可以直接使用 Doris 中自带的 Unique、Aggregate 等数据模型及可以很好支持日志类场景的 Duplicate 模型,在 ETL 过程中大幅度加快开发过程。
-- 查询分析:Doris 底层带有物化视图及 Rollup 物化索引等功能。物化视图底层类似 Cube 的概念与预计算的过程,与 Kylin 中以空间换时间的方式类似,均是在底层生成特殊的表,在查询中命中物化视图并快速响应。同时 Doris 底层对于大表关联进行了诸多优化,如 Runtime Filter 以及其他 Join 和自定义优化。相较于 Doris,Apache Kudu 则需要经过更为深入和复杂的优化才能更好地使用。
-- 数据报表:我们最初使用 Kudu 报表查询需要 1-2 分钟才能够完成渲染,而 Doris 则是秒级甚至是毫秒级的响应速度。
-- 便捷运维:Doris 没有 Hadoop 生态系统的复杂度,维护成本远低于 Hadoop。尤其是在集群迁移过程中,Doris 的运维便捷性尤为突出。3 月份,我们的机房进行了搬迁,12 台 Doris 节点机器在三天内全部迁移完成。整体操作较为简单,除了机器上架下架和搬移外,FE 扩容与缩容时只运用了 Add 与 Drop 等简单指令,并未消耗太长时间。
-
-# 未来展望
-
-- 实现基于 Flink CDC 的数据接入:当前,优化后的数据库架构中并没有没有引入 Flink CDC ,而是继续沿用了 数据经Canal 采集到 Kafka 后再采集到 Doris 中的模式,链路相对来说较长。使用Flink CDC 虽然可以继续精简整体架构,但是还需要写一定量的代码,这对于数据分析师直接使用感受并不友好。我们希望数据分析师只需要写简单SQL 或在页面上直接操作。在未来的规划中,我们计划引入 Flink CDC 功能并对上层应用进行扩充。
-- 紧跟社区迭代计划:我们正在使用的 Doris 版本相对较老,现在的最新版本 Apache Doris V1.2.0在全面向量化、multi-catalog多元数据目录、light schema change轻量表结构变更方面有了较大幅度的提升。我们将紧跟社区迭代节奏对集群进行升级并充分利用新特性。
-- 强化建设相关体系:我们现在的指标体系管理如报表元数据、业务元数据等维护与管理水平依旧有待提高。在数据质量监控方面,虽然目前包含了数据质量监控功能,但对于整个平台监控与数据自动化监控方面还需要强化与改善。
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Memory_Management.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Memory_Management.md
deleted file mode 100644
index fc250d7f0c4..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Memory_Management.md
+++ /dev/null
@@ -1,184 +0,0 @@
----
-{
- 'title': '一文揭秘高效稳定的 Apache Doris 内存管理机制',
- 'summary': "在面临内存资源消耗巨大的复杂计算和大规模作业时,有效的内存分配、统计、管控对于系统的稳定性起着十分关键的作用——更快的内存分配速度将有效提升查询性能,通过对内存的分配、跟踪与限制可以保证不存在内存热点,及时准确地响应内存不足并尽可能规避 OOM 和查询失败,这一系列机制都将显著提高系统稳定性;更精确的内存统计,也是大查询落盘的基础。",
- 'date': '2023-06-16',
- 'author': 'Apache Doris',
- 'tags': ['技术解析'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-
-
-作者:SelectDB 高级研发工程师、Apache Doris Committer 邹新一
-
-# 背景
-
-[Apache Doris](https://github.com/apache/doris) 作为基于 MPP 架构的 OLAP 数据库,数据从磁盘加载到内存后,会在算子间流式传递并计算,在内存中存储计算的中间结果,这种方式减少了频繁的磁盘 I/O 操作,充分利用多机多核的并行计算能力,可在性能上呈现巨大优势。
-
-在面临内存资源消耗巨大的复杂计算和大规模作业时,**有效的内存分配** **、统计、** **管控对于系统的稳定性起着十分关键的作用**——更快的内存分配速度将有效提升查询性能,通过对内存的分配、跟踪与限制可以保证不存在内存热点,及时准确地响应内存不足并尽可能规避 OOM 和查询失败,这一系列机制都将显著提高系统稳定性;更精确的内存统计,也是大查询落盘的基础。
-
-
-
-# 问题和思考
-
-- 在内存充足时内存管理通常对用户是无感的,但真实场景中往往面临着各式各样的极端 Case ,这些都将为内存性能和稳定性带来挑战,在过去版本中,用户在使用 Apache Doris 时在内存管理方面遭遇了以下挑战:
-- - OOM 导致 BE 进程崩溃。内存不足时,用户可以接受执行性能稍慢一些,或是让后到的任务排队,或是让少量任务失败,总之希望有效限制进程的内存使用而不是宕机;
- - BE 进程占用内存较高。用户反馈 BE 进程占用了较多内存,但很难找到对应内存消耗大的查询或导入任务,也无法有效限制单个查询的内存使用;
- - 用户很难合理的设置每个query的内存大小,所以经常出现内存还很充足,但是query 被cancel了;
- - 高并发性能下降严重,也无法快速定位到内存热点;
- - 构建 HashTable 的中间数据不支持落盘,两个大表的 Join 由于内存超限无法完成。
-
-针对开发者而言又存在另外一些问题,比如内存数据结构功能重叠且使用混乱,MemTracker 的结构难以理解且手动统计易出错等。
-
-针对以上问题,我们经历了过去多个版本的迭代与优化。从 Apache Doris 1.1.0 版本开始,我们逐渐统一内存数据结构、重构 MemTracker、开始支持查询内存软限,并引入进程内存超限后的 GC 机制,同时优化了高并发的查询性能等。在 Apache Doris 1.2.4 版本中,Apache Doris 内存管理机制已趋于完善,在 Benchmark、压力测试和真实用户业务场景的反馈中,基本消除了内存热点以及 OOM 导致 BE 宕机的问题,同时可定位内存 Top 的查询、支持查询内存灵活限制。**而在最新的 Doris 2.0 alpha 版本中,我们实现了查询的异常安全,并将逐步配合 Pipeline 执行引擎和中间数据落盘** **,** **让用户不再受内存不足困扰。**
-
-在此我们将系统介绍 Apache Doris 在内存管理部分的实现与优化。
-
-# 内存管理优化与实现
-
-
-
-Allocator 作为系统中大块内存申请的统一的入口从系统申请内存,并在申请过程中使用 MemTracker 跟踪内存申请和释放的大小,执行算子所需批量申请的大内存将交由不同的数据结构管理,并在合适的时机干预限制内存分配的过程,确保内存申请的高效可控。
-
-## 内存分配
-
-早期 Apache Doris 内存分配的核心理念是尽可能接管系统内存自己管理,使用通用的全局缓存满足大内存申请的性能要求,并在 LRU Cache 中缓存 Data Page、Index Page、RowSet Segment、Segment Index 等数据。
-
-随着 Doris 使用 Jemalloc 替换 TCMalloc,Jemalloc 的并发性能已足够优秀,所以不在 Doris 内部继续全面接管系统内存,转而针对内存热点位置的特点,使用多种内存数据结构并接入统一的系统内存接口,实现内存统一管理和局部的内存复用。
-
-
-
-### 内存数据结构
-
-查询执行过程中大块内存的分配主要使用 Arena、HashTable、PODArray 这三个数据结构管理。
-
-1. **Arena**
-
-Arena 是一个内存池,维护一个内存块列表,并从中分配内存以响应 alloc 请求,从而减少从系统申请内存的次数以提升性能,内存块被称为 Chunk,在内存池的整个生命周期内存在,在析构时统一释放,这通常和查询生命周期相同,并支持内存对齐,主要用于保存 Shuffle 过程中序列化/反序列化数据、HashTable 中序列化 Key 等。
-
-Chunk 初始 4096 字节,内部使用游标记录分配过的内存位置,如果当前 Chunk 剩余大小无法满足当前内存申请,则申请一个新的 Chunk 添加到列表中,为减少从系统申请内存的次数,在当前 Chunk 小于 128M 时,每次新申请的 Chunk 大小加倍,在当前 Chunk 大于 128M 时,新申请的 Chunk 大小在满足本次内存申请的前提下至多额外分配 128M ,避免浪费过多内存,默认之前的 Chunk 不会再参与后续 alloc。
-
-2. **HashTable**
-
-Doris 中的 HashTable 主要在 Hash Join、聚合、集合运算、窗口函数中应用,主要使用的 PartitionedHashTable 最多包含 16 个子 HashTable,支持两个 HashTable 的并行化合并,每个子 Hash Join 独立扩容,预期可减少总内存的使用,扩容期间的延迟也将被分摊。
-
-在 HashTable 小于 8M 时将以 4 的倍数扩容,在 HashTable 大于 8M 时将以 2 的倍数扩容,在 HashTable 小于 2G 时扩容因子为 50%,即在 HashTable 被填充到 50% 时触发扩容,在 HashTable 大于 2G 后扩容因子被调整为 75%,为了避免浪费过多内存,在构建 HashTable 前通常会依据数据量预扩容。此外 Doris 为不同场景设计了不同的 HashTable,比如聚合场景使用 PHmap 优化并发性能。
-
-3. **PODArray**
-
-PODArray 是一个 POD 类型的动态数组,与 std::vector 的区别在于不会初始化元素,支持部分 std::vector 的接口,同样支持内存对齐并以 2 的倍数扩容,PODArray 析构时不会调用每个元素的析构函数,而是直接释放掉整块内存,主要用于保存 String 等 Column 中的数据,此外在函数计算和表达式过滤中也被大量使用。
-
-### 统一的内存接口
-
-Allocator 作为 Arena、PODArray、HashTable 的统一内存接口,对大于 64M 的内存使用 MMAP 申请,并通过预取加速性能,对小于 4K 的内存直接 malloc/free 从系统申请,对大于 4K 小于 64M 的内存,使用一个通用的缓存 ChunkAllocator 加速,在 Benchmark 测试中这可带来 10% 的性能提升,ChunkAllocator 会优先从当前 Core 的 FreeList 中无锁的获取一个指定大小的 Chunk,若不存在则有锁的从其他 Core 的 FreeList 中获取,若仍不存在则从系统申请指定内存大小封装为 Chunk 后返回。
-
-Allocator 使用通用内存分配器申请内存,在 Jemalloc 和 TCMalloc 的选择上,Doris 之前在高并发测试时 TCMalloc 中 CentralFreeList 的 Spin Lock 能占到查询总耗时的 40%,虽然关闭aggressive memory decommit能有效提升性能,但这会浪费非常多的内存,为此不得不单独用一个线程定期回收 TCMalloc 的缓存。Jemalloc 在高并发下性能优于 TCMalloc 且成熟稳定,在 Doris 1.2.2 版本中我们切换为 Jemalloc,调优后在大多数场景下性能和 TCMalloc 持平,并使用更少的内存,高并发场景的性能也有明显提升。
-
-### 内存复用
-
-Doris 在执行层做了大量内存复用,可见的内存热点基本都被屏蔽。比如对数据块 Block 的复用贯穿 Query 执行的始终;比如 Shuffle 的 Sender 端始终保持一个 Block 接收数据,一个 Block 在 RPC 传输中,两个 Block 交替使用;还有存储层在读一个 Tablet 时复用谓词列循环读数、过滤、拷贝到上层 Block、Clear;导入 Aggregate Key 表时缓存数据的 MemTable 到达一定大小预聚合收缩后继续写入,等等。
-
-此外 Doris 会在数据 Scan 开始前依据 Scanner 个数和线程数预分配一批 Free Block,每次调度 Scanner 时会从中获取一个 Block 并传递到存储层读取数据,读取完成后会将 Block 放到生产者队列中,供上层算子消费并进行后续计算,上层算子将数据拷走后会将 Block 重新放回 Free Block 中,用于下次 Scanner 调度,从而实现内存复用,数据 Scan 完成后 Free Block 会在之前预分配的线程统一释放,避免内存申请和释放不在同一个线程而导致的额外开销,Free Block 的个数一定程度上还控制着数据 Scan 的并发。
-
-## 内存跟踪
-
-Doris 使用 MemTracker 跟踪内存的申请和释放来实时分析进程和查询的内存热点位置,MemTracker 记录着每一个查询、导入、Compaction 等任务以及Cache、TabletMeta等全局对象的内存大小,支持手动统计或 MemHook 自动跟踪,支持在 Web 页面查看实时的 Doris BE 内存统计。
-
-### MemTracker 结构
-
-过去 Doris MemTracker 是具有层次关系的树状结构,自上而下包含 process、query pool、query、fragment instance、exec node、exprs/hash table/etc.等多层,上一层 MemTracker是下一层的 Parent,开发者使用时需理清它们之间的父子关系,然后手动计算内存申请和释放的大小并消费 MemTracker,此时会同时消费这个 MemTracker 的所有 Parent。这依赖开发者时刻关注内存使用,后续迭代过程中若 MemTracker 统计错误将产生连锁反应,对 Child MemTracker 的统计误差会不断累积到他的 Parent MemTracker 中,导致整体结果不可信。
-
-
-
-在 Doris 1.2.0 中引入了新的 MemTracker 结构,去掉了 Fragment、Instance 等不必要的层级,根据使用方式分为两类,第一类 Memtracker Limiter,在每个查询、导入、Compaction 等任务和全局 Cache、TabletMeta 唯一,用于观测和控制内存使用;第二类 MemTracker,主要用于跟踪查询执行过程中的内存热点,如 Join/Aggregation/Sort/窗口函数中的 HashTable、序列化的中间数据等,来分析查询中不同算子的内存使用情况,以及用于导入数据下刷的内存控制。后文没单独指明的地方,统称二者为 MemTracker。
-
-二者之间的父子关系只用于快照的打印,使用Lable名称关联,相当于一层软链接,不再依赖父子关系同时消费,生命周期互不影响,减少开发者理解和使用的成本。所有 MemTracker 存放在一组 Map 中,并提供打印所有 MemTracker Type 的快照、打印 Query/Load/Compaction 等 Task 的快照、获取当前使用内存最多的一组 Query/Load、获取当前过量使用内存最多的一组 Query/Load 等方法。
-
-
-
-### MemTracker 统计方式
-
-为统计某一段执行过程的内存,将一个 MemTracker 添加到当前线程 Thread Local 的一个栈中,使用 MemHook 重载 Jemalloc 或 TCMalloc 的 malloc/free/realloc 等方法,获取本次申请或释放内存的实际大小并记录在当前线程的 Thread Local 中,在当前线程内存使用量累计到一定值时消费栈中的所有 MemTracker,这段执行过程结束时会将这个 MemTracker 从栈中弹出,栈底通常是整个查询或导入唯一的 Memtracker,记录整个查询执行过程的内存。
-
-下面以一个简化的查询执行过程为例:
-
-- Doris BE 启动后所有线程的内存将默认记录在 Process MemTracker 中。
-- Query 提交后,将 Query MemTracker 添加到 Fragment 执行线程的 Thread Local Storage(TLS) Stack 中。
-- ScanNode 被调度后,将 ScanNode MemTracker 继续添加到 Fragment 执行线程的 TLS Stack 中,此时线程申请和释放的内存会同时记录到 Query MemTracker 和 ScanNode MemTracker。
-- Scanner 被调度后,将 Query MemTracker 和 Scanner MemTracker 同时添加到 Scanner 线程的 TLS Stack 中。
-- Scanner 结束后,将 Scanner 线程 TLS Stack 中的 MemTracker 全部移除,随后 ScanNode 调度结束,将ScanNode MemTracker 从 Fragment 执行线程中移除。随后 AggregationNode 被调度时同样将 MemTracker 添加到 Fragment 执行线程中,并在调度结束后将自己的 MemTracker 从 Fragment 执行线程移除。
-- 后续 Query 结束后,将 Query MemTracker 从 Fragment 执行线程 TLS Stack 中移除,此时 Stack 应为空,在 QueryProfile 中即可看到 Query 整体、ScanNode、AggregationNode 等执行期间内存的峰值。
-
-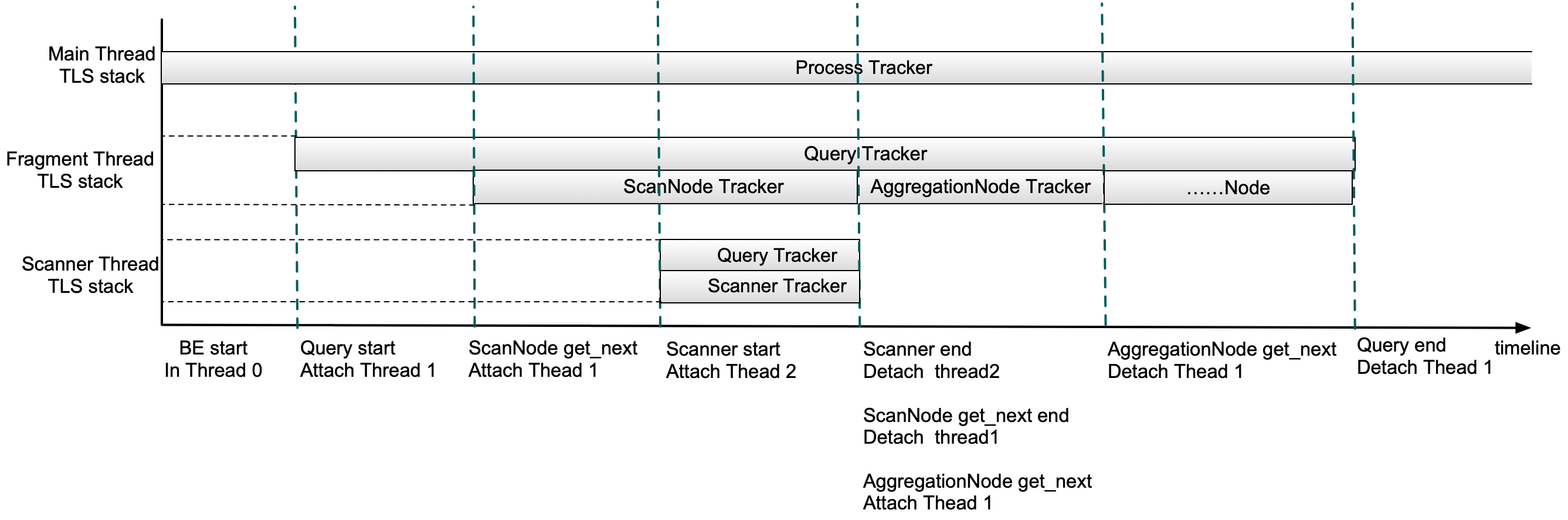
-
-可见为跟踪一个查询的内存使用,在查询所有线程启动时将 Query MemTracker 绑定到线程 Thread Local,在算子执行的代码区间内,将算子 MemTracker 同样绑定到线程 Thread Local,此后这些线程所有的内存申请和释放都将记录在这个查询中,在算子调度结束和查询结束时分别解除绑定,从而统计一个查询生命周期内各个算子和查询整体的内存使用。
-
-期待开发者能将 Doris 执行过程中长时间持有的内存尽可能多地统计到 MemTracker 中,这有助于内存问题的分析,不必担心统计误差,这不会影响查询整体统计的准确性,也不必担心影响性能,在 ThreadLocal 中按批消费 MemTracker 对性能的影响微乎其微。
-
-### MemTracker 使用
-
-通过 Doris BE 的 Web 页面可以看到实时的内存统计结果,将 Doris BE 内存分为了 Query/Load/Compaction/Global 等几部分,并分别展示它们当前使用的内存和历史的峰值内存,具体使用方法和字段含义可参考 Doris 管理手册:
-
-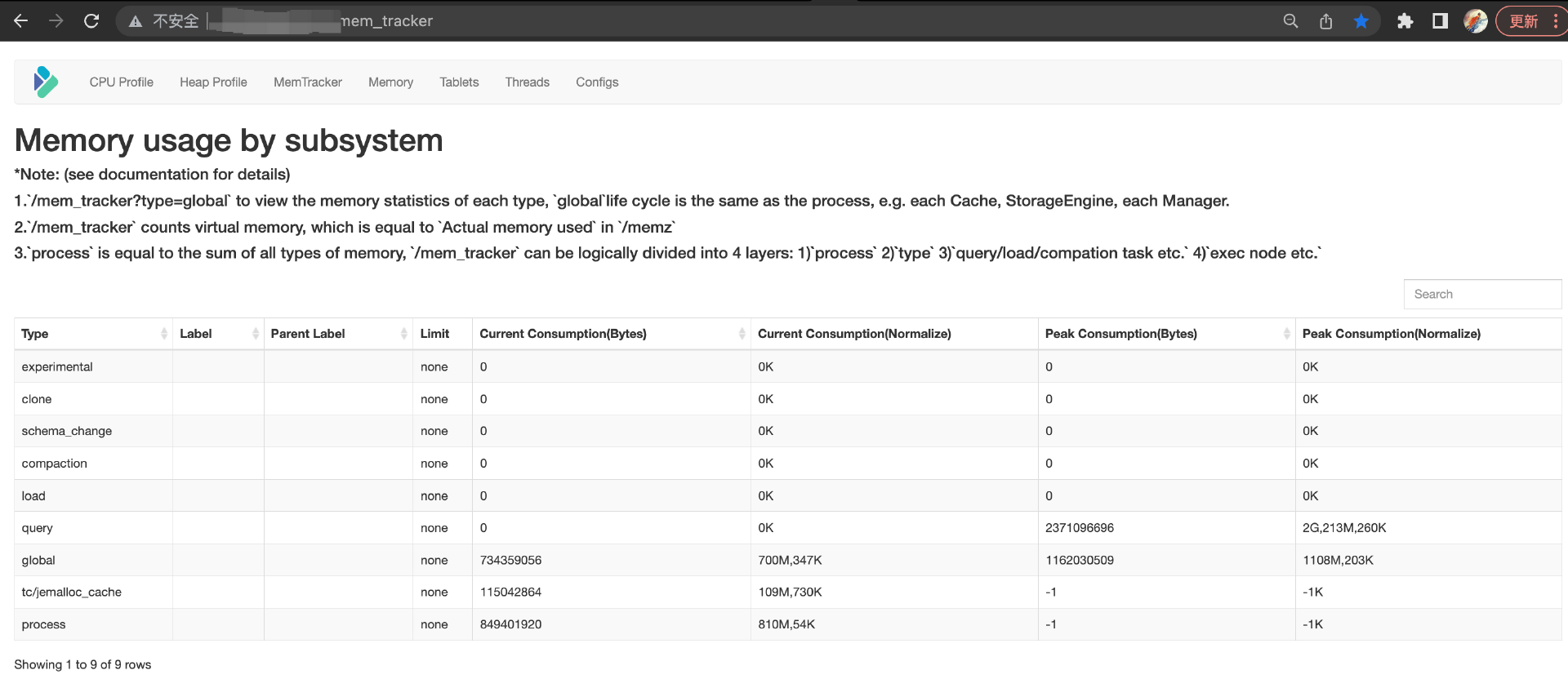
-
-Global 类型的 MemTracker 中,包括全局的 Cache、TabletMeta 等。
-
-
-
-Query 类型的 MemTracker 中,可以看到 Query 和其算子当前使用的内存和峰值内存,通过 Label 将他们关联,历史查询的内存统计可以查看 FE 审计日志或 BE INFO 日志。
-
-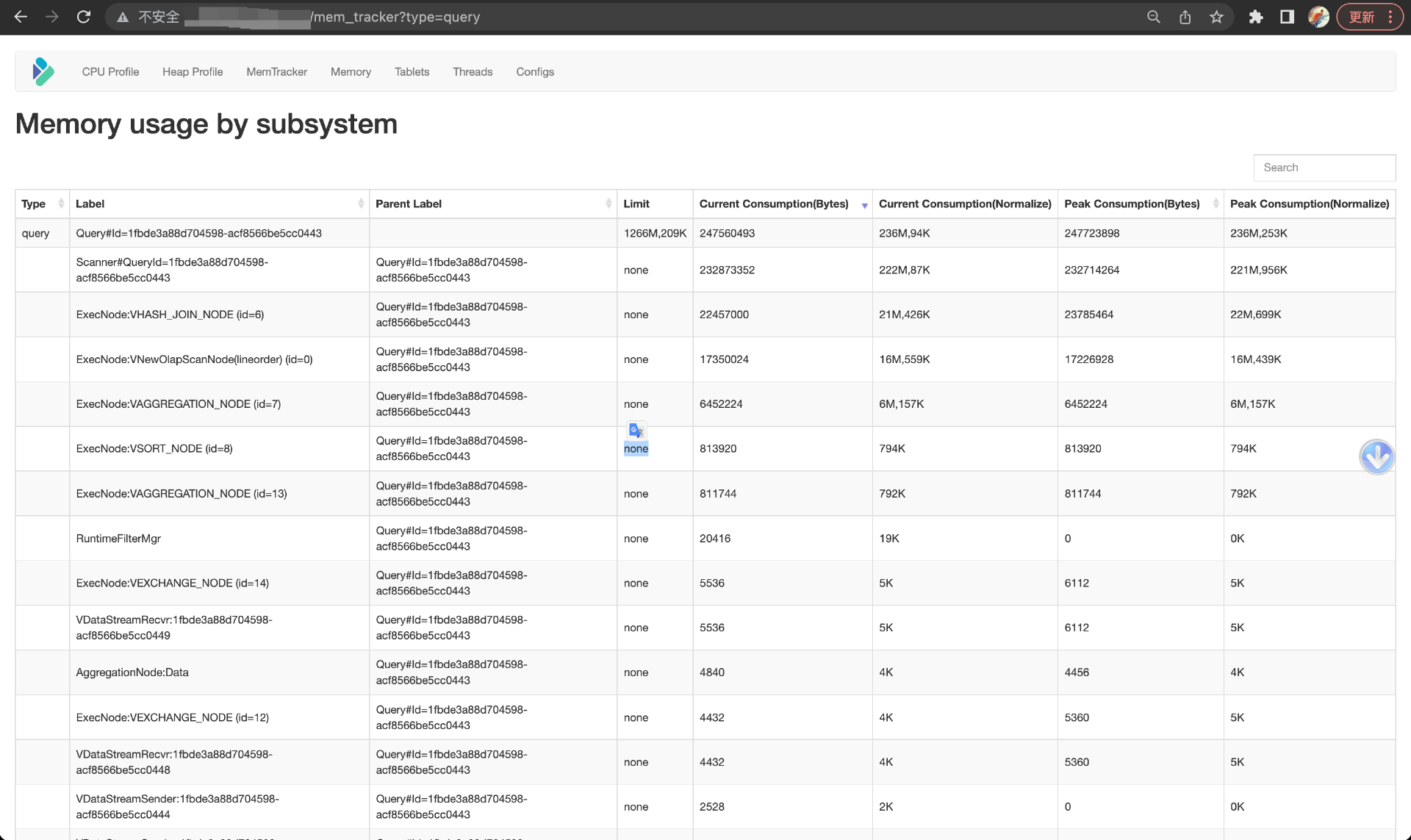
-
-## 内存限制
-
-内存不足导致 OOM 引起 BE 宕机或查询大量失败一直是用户的痛点,为此在 Doris BE 大多数内存被跟踪后,开始着手改进查询和进程的内存限制,在关键内存分配时检测内存限制来保证内存可控。
-
-### 查询内存限制
-
-每个查询都可以指定内存上限,查询运行过程中内存超过上限会触发 Cancel。从 Doris 1.2 开始查询支持内存超发(overcommit),旨在允许查询设置更灵活的内存限制,内存充足时即使查询内存超过上限也不会被 Cancel,所以通常用户无需关注查询内存使用。内存不足时,任何查询都会在尝试分配新内存时等待一段时间,如果等待过程中内存释放的大小满足需求,查询将继续执行, 否则将抛出异常并终止查询。
-
-Doris 2.0 初步实现了查询的异常安全,这使得任何位置在发现内存不足时随时可抛出异常并终止查询,而无需依赖后续执行过程中异步的检查 Cancel 状态,这将使查询终止的速度更快。
-
-### 进程内存限制
-
-Doris BE 会定时从系统获取进程的物理内存和系统当前剩余可用内存,并收集所有查询、导入、Compaction 任务 MemTracker 的快照,当 BE 进程内存超限或系统剩余可用内存不足时,Doris 将释放 Cache 和终止部分查询或导入来释放内存,这个过程由一个单独的 GC 线程定时执行。
-
-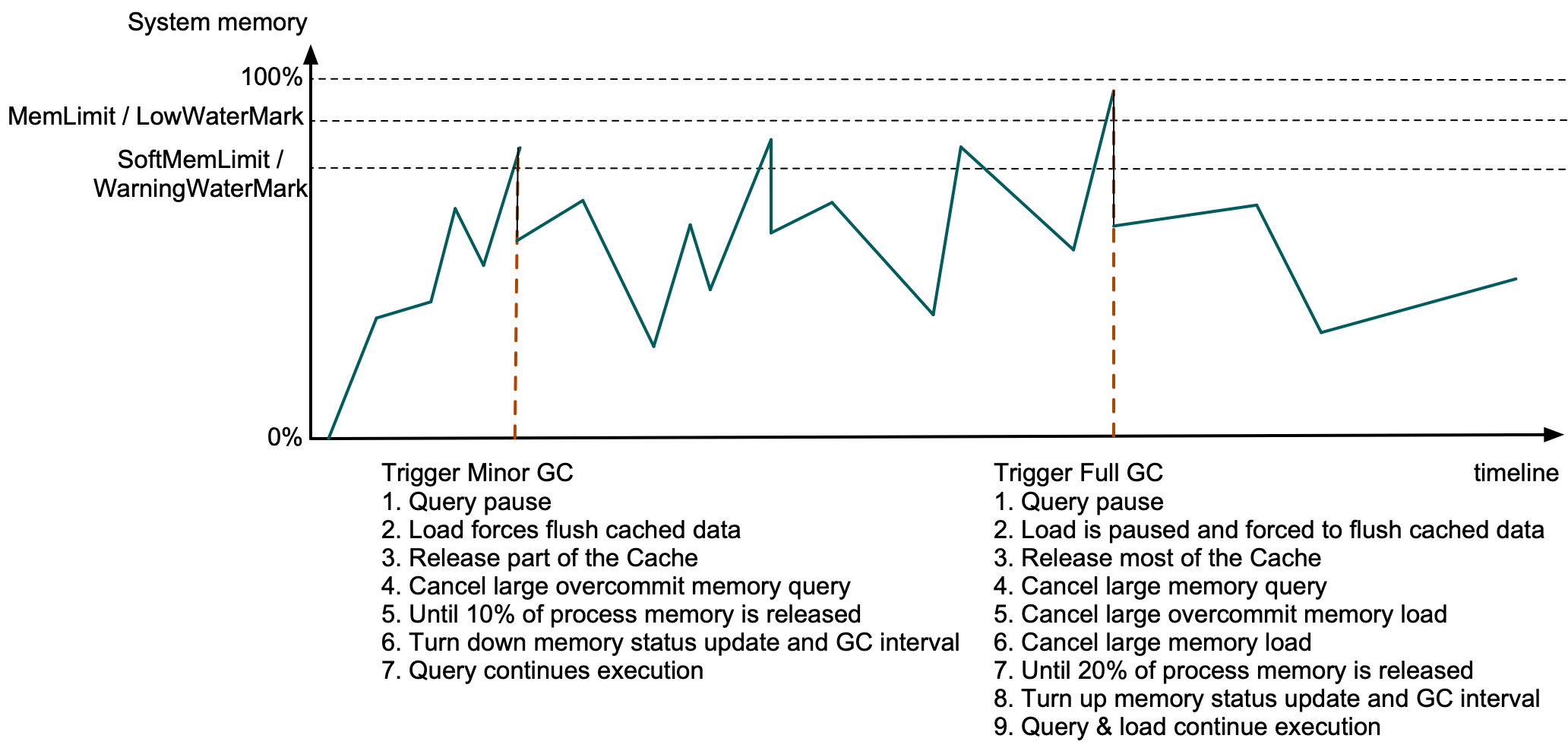
-
-若 Doris BE 进程内存超过 SoftMemLimit(默认系统总内存的 81%)或系统剩余可用内存低于 Warning 水位线(通常不大于 3.2GB)时触发 Minor GC,此时查询会在 Allocator 分配内存时暂停,同时导入强制下刷缓存中的数据,并释放部分 Data Page Cache 以及过期的 Segment Cache 等,若释放的内存不足进程内存的 10%,若启用了查询内存超发,则从内存超发比例大的查询开始 Cancel,直到释放 10% 的进程内存或没有查询可被 Cancel,然后调低系统内存状态获取间隔和 GC 间隔,其他查询在发现剩余内存后将继续执行。
-
-若 BE 进程内存超过 MemLimit(默认系统总内存的 90%)或系统剩余可用内存低于 Low 水位线(通常不大于1.6GB)时触发 Full GC,此时除上述操作外,导入在强制下刷缓存数据时也将暂停,并释放全部 Data Page Cache 和大部分其他 Cache,如果释放的内存不足 20%,将开始按一定策略在所有查询和导入的 MemTracker 列表中查找,依次 Cancel 内存占用大的查询、内存超发比例大的导入、内存占用大的导入,直到释放 20% 的进程内存后,调高系统内存状态获取间隔和 GC 间隔,其他查询和导入也将继续执行,GC 的耗时通常在几百 us 到几十 ms 之间。
-
-# 总结规划
-
-通过上述一系列的优化,高并发性能和稳定性有明显改善,OOM 导致 BE 宕机的次数也明显降低,即使发生 OOM 通常也可依据日志定位内存位置,并针对性调优,从而让集群恢复稳定,对查询和导入的内存限制也更加灵活,在内存充足时让用户无需感知内存使用。
-
-为了让用户可以体验社区开发的最新特性,同时保证最新功能可以收获到更广范围的使用反馈,我们建立了 [2.0 Alpha 版本的专项支持群](https://wenjuan.feishu.cn/m?t=sF2FZOL1KXKi-m73g),欢迎广大社区用户在使用最新版本过程中多多反馈使用意见,帮助 Apache Doris 持续改进。
-
-后续我们将让 Apache Doris 从“能有效限制内存”转为“内存超限时能完成计算”,尽可能减少查询因内存不足被 Cancel,主要工作将聚焦在异常安全、资源组内存隔离、中间数据落盘上:
-
-1. 查询和导入支持异常安全,从而可以随时随地的抛出内存分配失败的 Exception,外部捕获后触发异常处理或释放内存,而不是在内存超限后单纯依赖异步 Cancel。
-1. Pipeline 调度中将支持资源组内存隔离,用户可以划分资源组并指定优先级,从而更灵活的管理不同类型任务使用的内存,资源组内部和资源组之间同样支持内存的“硬限”和“软限”,并在内存不足时支持排队机制。
-1. Doris 将实现统一的落盘机制,支持 Sort,Hash Join,Agg 等算子的落盘,在内存紧张时将中间数据临时写入磁盘并释放内存,从而在有限的内存空间下,对数据分批处理,支持超大数据量的计算,在避免 Cancel 让查询能跑出来的前提下尽可能保证性能。
-
-以上方向的工作都已处于规划或开发中,如果有小伙伴对以上方向感兴趣,也欢迎参与到社区中的开发来。期待有更多人参与到 Apache Doris 社区的建设中 ,欢迎你的加入!
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Midland Realty.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Midland Realty.md
deleted file mode 100644
index 1fe4cd26cbb..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Midland Realty.md
+++ /dev/null
@@ -1,249 +0,0 @@
----
-{
- 'title': 'Apache Doris 在美联物业的数据仓库应用实践,助力传统行业数字化革新',
- 'summary': "本文主要介绍美联物业基于 Apache Doris 在数据体系方面的建设,以及对数据仓库搭建经验进行的分享和介绍,旨在为数据量不大的传统企业提供一些数仓思路,实现数据驱动业务,低成本、高效的进行数仓改造。",
- 'date': '2023-05-12',
- 'author': '谢帮桂',
- 'tags': ['最佳实践'],
-}
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-
-
-**导读:** 传统行业面对数字化转型往往会遇到很多困难,比如缺乏数据管理体系、数据需求开发流程冗长、烟囱式开发、过于依赖纸质化办公等,美联物业也有遇到类似的问题。本文主要介绍美联物业基于 [Apache Doris](https://github.com/apache/doris) 在数据体系方面的建设,以及对数据仓库搭建经验进行的分享和介绍,旨在为数据量不大的传统企业提供一些数仓思路,实现数据驱动业务,低成本、高效的进行数仓改造。
-
-作者|美联物业数仓负责人 谢帮桂
-
-美联物业属于香港美联集团成员,于 1973 年成立,并于 1995 年在香港联合交易所挂牌上市(香港联交所编号:1200),2008 年美联工商铺于主板上市(香港联交所编号:459), 成为拥有两家上市公司的地产代理企业。拥有 40 余载房地产销售行业经验,业务涵盖中、小型住宅、豪宅及工商铺,提供移民顾问、金融、测量、按揭转介等服务,业务遍布中国香港地区、中国澳门地区和中国内地等多个重要城市。
-
-本文主要介绍关于美联物业在数据体系方面的建设,以及对数据仓库搭建经验进行的分享和介绍,旨在为数据量不大的传统企业提供一些数仓思路,实现数据驱动业务,低成本、高效的进行数仓改造。
-
-*考虑隐私政策,本文不涉及公司任何具体业务数据。*
-
-# 业务背景
-
-美联物业早在十多年前就已深入各城市开展房地产中介业务,数据体系的建设和发展与大多数传统服务型公司类似,经历过几个阶段时期,如下图所示。
-
-
-
-我们的数据来源于大大小小的子业务系统和部门手工报表数据等,存在历史存量数据庞大,数据结构多样复杂,数据质量差等普遍性问题。此外,早期业务逻辑处理多数是使用关系型数据库 SQL Server 的存储过程来实现,当业务流程稍作变更,就需要投入大量精力排查存储过程并进行修改,使用及维护成本都比较高。
-
-**基于此背景,我们面临的挑战可以大致归纳为以下几点:**
-
-- 缺乏数据管理体系,统计口径统一,已有数据无法降本复用。多部门、多系统、多字段,命名随意、表违反范式结构混乱;对同一业务来源数据无法做到多份报表复用,反复在不同报表编写同一套计算逻辑。
-- 海量数据下性能不足,查询响应慢。历史大多数业务数据存储在关系型数据库中,分表分库已无法做到上亿数据秒级分析查询。
-- 数据需求开发流程冗长、烟囱式开发。每当业务部门提出一个数据需求,数据开发就需要在多个系统之间进行数据兼容编写存储过程,从而导致存储过程的可移植性和可读性都非常差。
-- 部门之间严重依赖文本文档处理工作,效率低下。由于长期的手工统计,用户已形成习惯,导致对信息系统的信任程度也比较低。
-
-# 早期架构
-
-针对上述的⼏个需求,我们在平台建设的初期选⽤了 Hadoop、Hive、Spark 构建最初的离线数仓架构,也是比较普遍、常见的架构,运作原理不进行过多赘述。
-
-
-
-我们数据体系主要服务对象以内部员工为主,如房产经纪人、后勤人员、行政人事、计算机部门,房产经纪在全国范围内分布广泛,也是我们的主要服务对象。当前数据体系还无需面向 C 端用户,因此在数据计算和资源方面的压力并不大,早期基于 Hadoop 的架构可以满足一部分基本的需求。但是随着业务的不断发展、内部人员对于数据分析的复杂性、分析的效率也越来越高,该架构的弊端日益越发的明显,主要体现为以下几点:
-
-- 过于笨重:传统公司的计算量和数据量并不大,使用 Hadoop 过于浪费。
-- 效率低下:T+1 的调度时效和脚本,动辄需要花费 1 小时的计算时间导入导出,效率低、影响数据的开发工作。
-- 维护成本高:组件过多,排查故障链路过长,运维成本也很高,且部门同事之间熟悉各个组件需要大量学习和沟通成本。
-
-# 新数仓架构
-
-基于上述业务需求及痛点,我们开始了架构升级,并希望在这次升级中实现几个目标:
-
-- 初步建立数据管理体系,搭建数据仓库。
-- 搭建报表平台和报表快速开发流程体系。
-- 实现数据需求能够快速反应和交付(1小时内),查询延迟不超过 10s。
-- 最小成本原则构建架构,支持滚动扩容。
-
-## 技术选型
-
-经过调研了解以及朋友推荐,我们了解到了 Apache Doris ,并很快与社区取得了联系,Apache Doris 的几大优势吸引了我们:
-
-**足够简单**
-
-美联物业及大部分传统公司的数据人员除了需要完成数据开发工作之外,还需要兼顾运维和架构规划的工作。因此我们选择数仓组件的第一原则就是"简单",简单主要包括两个方面:
-
-- 使用简单:Apache Doris 兼容 MySQL 协议,支持标准 SQL,有利于开发效率和共识统一,此外,Doris 的 ETL 编写脚本主要使用 SQL进行开发,使用 MySQL 协议登陆使用,兼容多数 MySQL 语法,提供丰富的数据分析函数,省去了 UDF 开发工作。
-- 架构简单:Doris 的组件架构由 FE+BE 两类进程组成,不依赖其他系统,升级扩容非常方便,故障排查链路非常清晰,有利于运维成本的降低。
-
-**极速性能**
-
-Doris 依托于列式存储引擎、自动分区分桶、向量计算、多方面 Join 优化和物化视图等功能的实现,可以覆盖众多场景的查询优化,海量数据也能可以保证低延迟查询,实现分钟级或秒级响应。
-
-**极低成本**
-
-降本提效已经成为现如今企业发展的常态,免费的开源软件就比较满足我们的条件,另外基于 Doris 极简的架构、语言的兼容、丰富的生态等,为我们节省了不少的资源和人力的投入。并且 Doris 支持 PB 级别的存储和分析,对于存量历史数据较大、增量数据较少的公司来说,仅用 5-8 个节点就足以支撑上线使用。
-
-**社区活跃**
-
-截止目前,Apache Doris 已开源数年,并已支持全国超 1500 企业生产使用,其健壮性、稳定性不可否认。另外社区非常活跃,SelectDB 为社区组建了专职的技术支持团队,任何问题均能快速反馈,提供无偿技术支持,使用起来没有后顾之忧。
-
-## **运行架构**
-
-
-
-在对 Apache Doris 进一步测试验证之后,我们完全摒弃了之前使用 Hadoop、Hive、Spark 体系建立的数仓,决定基于 Doris 对架构进行重构,以 Apache Doris 作为数仓主体进行开发:
-
-- 数据集成:利用 DataX、Flink CDC 和 Apache Doris 的 Multi Catalog 功能等进行数据集成。
-- 数据管理:利用 Apache Dolphinscheduler 进行脚本开发的生命周期管理、多租户人员的权限管理、数据质量监察等。
-- 监控告警:采用 Grafana + Prometheus + Loki 进行监控告警,Doris 的各项监控指标可以在上面运行,解决了对组件资源和日志的监控问题。
-- 数据服务:使用帆软 Report 为用户提供数据查询和分析服务,帆软支持表单制作和数据填报等功能,支持自助取数和自助分析。
-
-### **数据模型**
-
-**1)纵向分域**
-
-房地产中介行业的大数据主题大致如下,一般会根据这些主题进行数仓建模。建模主题域核心围绕"企业用户"、"客户"、"房源"、"组织"等几个业务实体展开,进行维度表和事实表的创建。
-
-
-
-我们从前线到后勤,对业务数据总线进行了梳理,旨在整理业务实体和业务活动相关数据,如多个系统之间存在同一个业务实体,应统一为一个字段。梳理业务总线有助于掌握公司整体数据结构,便于维度建模等工作。
-
-下图为我们简单的梳理部分房地产中介行业的业务总线:
-
-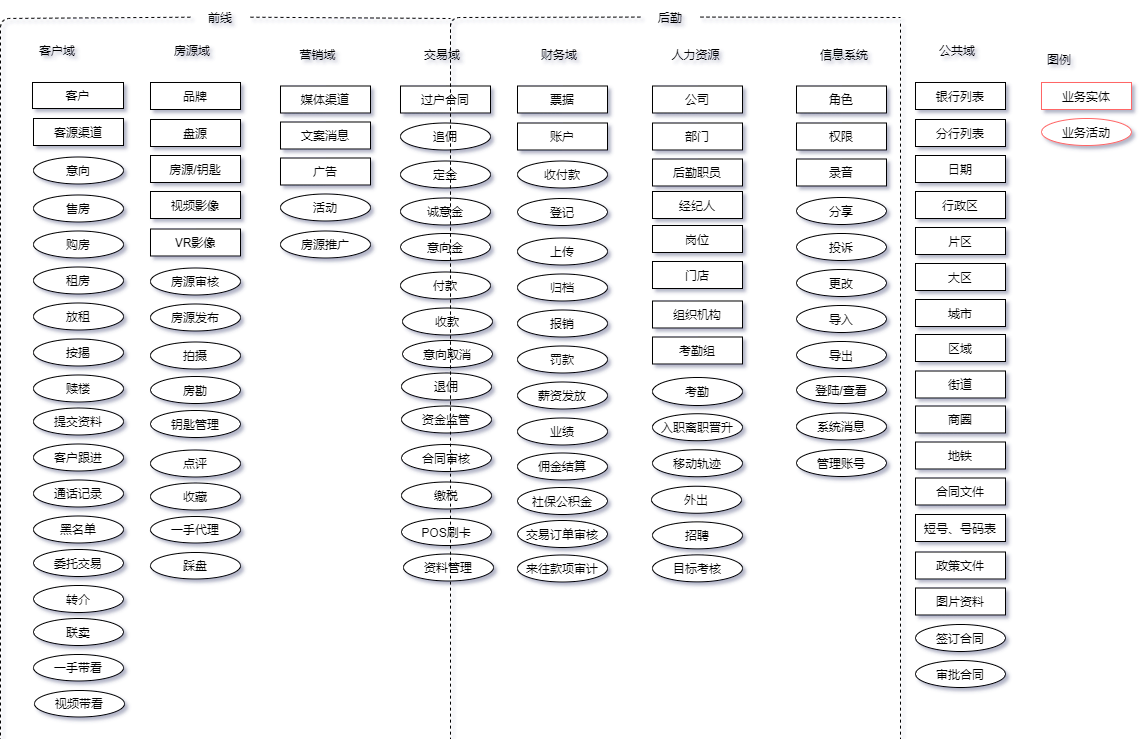
-
-**2)横向分层**
-
-数据分层是最常见的 5 层结构主要是利用 Apache Doris + Apache DolphinScheduler 进行层级数据之间 DAG 脚本调度。
-
-**存储策略:** 我们在 8 点到 24 点之间采用增量策略,0 点到 8 点执行全量策略。采用增量 + 全量的方式是为了在ODS 表因为记录的历史状态字段变更或者 CDC 出现数据未完全同步的情况下,可以及时进行全量补数修正。
-
-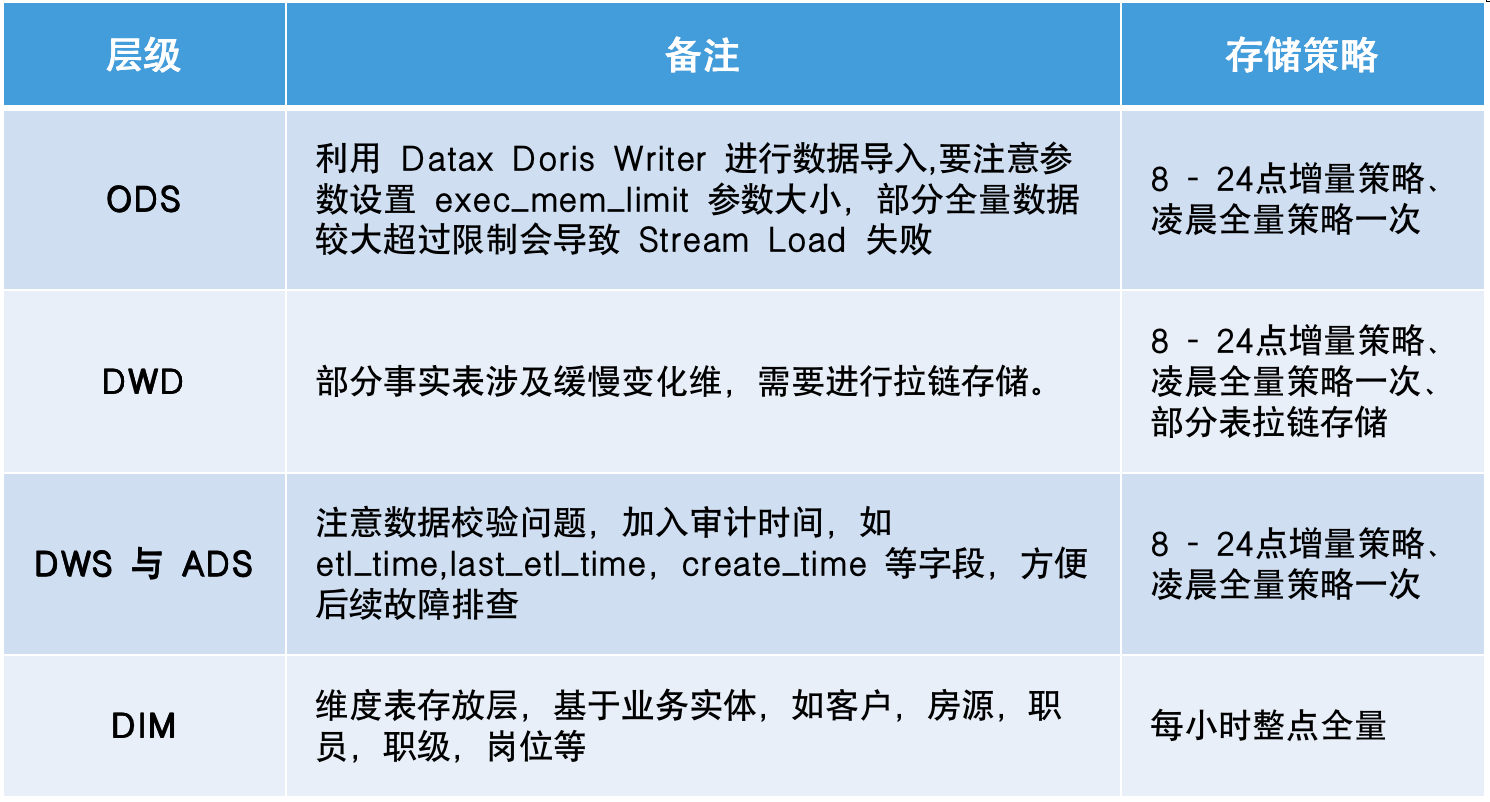
-
-**3)增量策略**
-
-1. where >= "业务时间-1天或-1小时"
-
-增量的 SQL 语句不使用 `where="业务时间当天"`的原因是为了避免数据漂移情况发生,换言之,调度脚本之间存在时间差,如 23:58:00 执行了脚本,脚本的执行周期是 10 分钟/次,但是源库最后一条数据 23:59:00 才进来,这时候 ` where="业务时间当天" `就会将该数据漏掉。
-
-2. 每次跑增量脚本前获取表中最大的主键 ID 存入辅助表,`where >= "辅助表记录ID"`
-
-如果 Doris 表使用的是 Unique Key 模型,且恰好为组合主键,当主键组合在源表发生了变化,这时候 `where >=" 业务时间-1天"`会记录该变化,把主键发生变化的数据 Load 进来,从而造成数据重复。而使用这种自增策略可有效避免该情况发生,且自增策略只适用于源表自带业务自增主键的情况。
-
-3. 表分区
-
-如面对日志表等基于时间的自增数据,且历史数据和状态基本不会变更,数据量非常大,全量或快照计算压力非常大的场景,这种场景需要对 Doris 表进行建表分区,每次增量进行分区替换操作即可,同时需要注意数据漂移情况。
-
-**4)全量策略**
-
-1. Truncate Table 清空表插入
-
-先清空表格后再把源表数据全量导入,该方式适用于数据量较小的表格和凌晨没有用户使用系统的场景。
-
-2. ` ALTER TABLE tbl1 REPLACE WITH TABLE tbl2 `表替换
-
-这种方式是一种原子操作,适合数据量大的全量表。每次执行脚本前先 Create 一张数据结构相同的临时表,把全量数据 Load 到临时表,再执行表替换操作,可以进行无缝衔接。
-
-# **应用实践**
-
-## 业务模型
-
-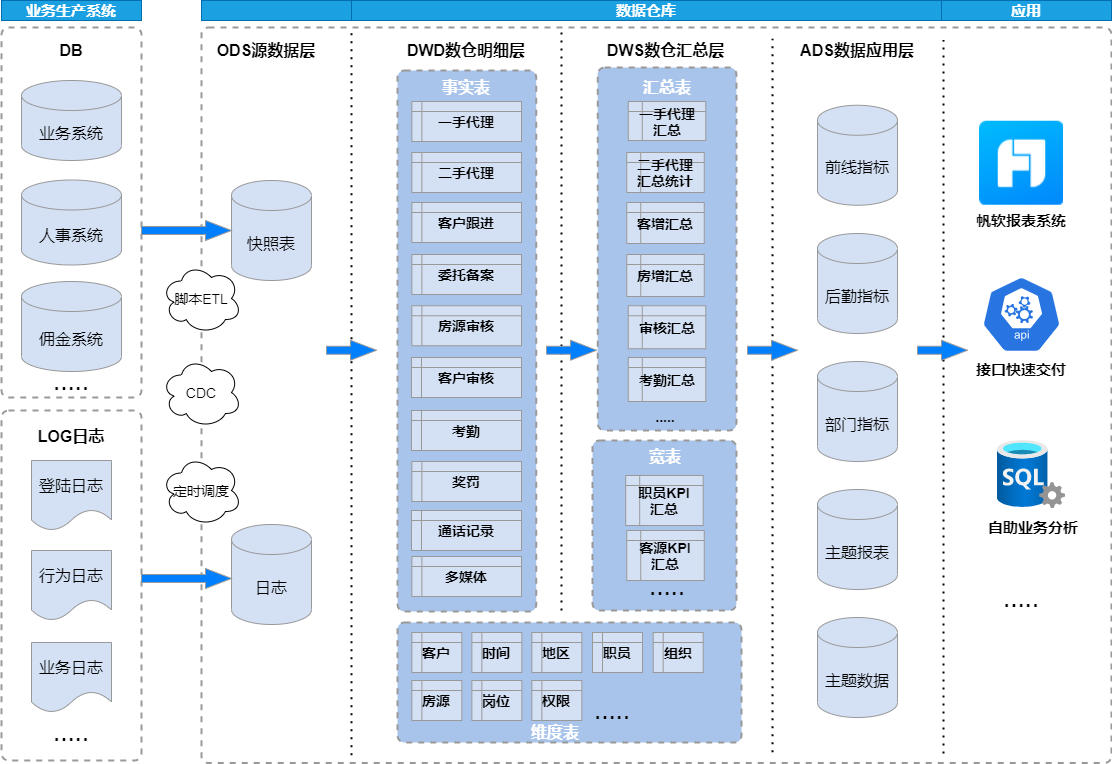
-
-- 业务模型是分钟级调度 ETL
-- 初次部署建议配置:8 节点 2FE * 8BE 混合部署
-- 节点配置:32C * 60GB * 2TB SSD
-- 对于存量数据 TB 级、增量数据 GB 级的场景完全够用,如有需要可以进行滚动扩容。
-
-## **具体应用**
-
-1. 离线数据和日志数据集成利用 DataX 进行增量和全量调度,Datax 支持 CSV 格式和多种关系型数据库的Redear,而 Doris 在很早之前就提供了 DataX Doris writer 连接器。
-
-
-
-2. 实时统计部分借助了 Flink CDC 对源表进行实时同步,利用 Doris 的物化视图或者 Aggregate 模型表进行实时指标的汇总处理,因我们只有部分指标需要实时处理,不希望产生过多的数据库连接和 Flink Job,因此我们使用 Dinky 的多源合并和整库同步功能,也可以自己简单实现一个Flink DataStream 多源合并任务,只通过一个 Job 可对多个 CDC 源表进行维护。值得一提的是, Flink CDC 和 Apache Doris 新版本支持 Schema Change 实时同步,在成本允许的前提下,可完全使用 CDC 的方式对 ODS 层进行改造。
-
-```
-EXECUTE CDCSOURCE demo_doris WITH (
- 'connector' = 'mysql-cdc',
- 'hostname' = '127.0.0.1',
- 'port' = '3306',
- 'username' = 'root',
- 'password' = '123456',
- 'checkpoint' = '10000',
- 'scan.startup.mode' = 'initial',
- 'parallelism' = '1',
- 'table-name' = 'ods.ods_*,ods.ods_*',
- 'sink.connector' = 'doris',
- 'sink.fenodes' = '127.0.0.1:8030',
- 'sink.username' = 'root',
- 'sink.password' = '123456',
- 'sink.doris.batch.size' = '1000',
- 'sink.sink.max-retries' = '1',
- 'sink.sink.batch.interval' = '60000',
- 'sink.sink.db' = 'test',
- 'sink.sink.properties.format' ='json',
- 'sink.sink.properties.read_json_by_line' ='true',
- 'sink.table.identifier' = '${schemaName}.${tableName}',
- 'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
-);
-```
-
-3. 脚本语言采用 Shell + SQL 或纯 SQL 的形式,我们在 Apache DolphinScheduler 上进行脚本生命周期管理和发布,如 ODS 层,可以编写通用的 DataX Job 文件,通过传参的方式将 DataX Job 文件传参执行源表导入,无需在每一个源表编写不同的DataX Job ,支持统一配置参数和代码内容,维护起来非常方便。另外我们在 DolphinsSheduler 上对 Doris 的 ETL 脚本进行管理,还可以进行版本控制,能有效控制生产环境错误的发生,进行及时回滚。
-
-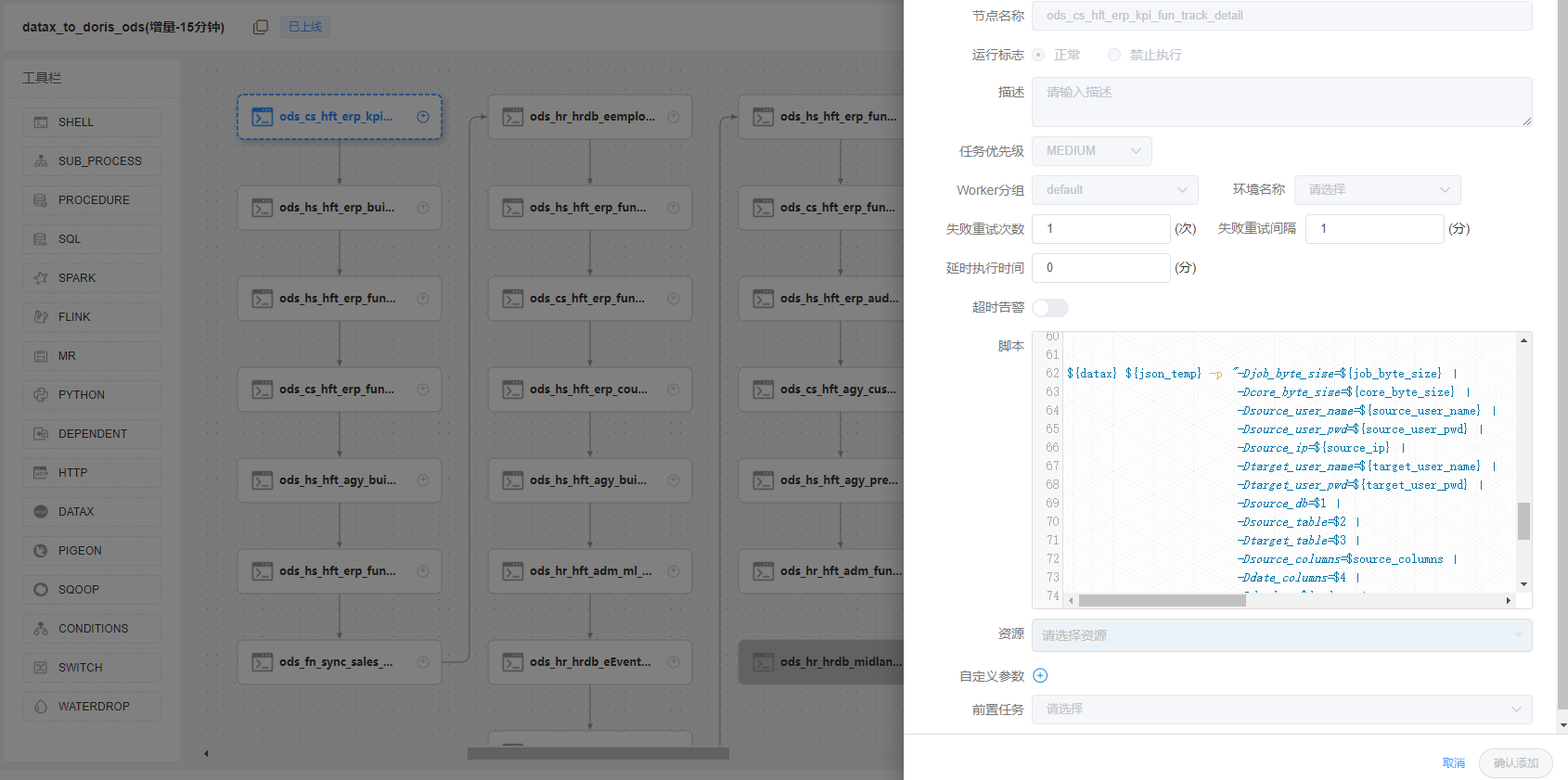
-
-4. 发布 ETL 脚本后导入数据,可直接在帆软 Report 进行页面制作,基于登陆账号来控制页面权限,如需控制行级别、字段级别权限,可以制作全局字典,利用 SQL 方式进行控制。Doris 完全支持对账号的库表权限控制,这一点和 MySQL 的设置完全一样,使用起来非常便捷。
-
-
-
-除以上之外,在容灾恢复、集群监控、数据安全等方面也有应用,比如利用 Doris 备份实现容灾恢复、Grafana+Loki 对集群进行指标规则告警、Supervisor 对节点组件进行守护进程监控,开启 Doris 审计日志对执行 SQL 效率进行监控等,因篇幅限制,此处不进行详细说明。
-
-## 优化经验
-
-1. **数据导入**
-
-我们使用 DataX 进行离线数据导入,DataX 采用的是 Stream Load 方式导入,该方式可以通过参数控制导入批次流量,DataX 导入不需要借助计算引擎,开箱即用的特点非常方便。另外,Stream Load 导入是同步返回结果的,其他导入方式一般是异步返回结果,针对我们的架构来说,在 Dolphinscheduler上执行异步导入数据会误以为该脚本已经执行成功,影响其正常运行。如采用其他异步导入方式,建议在 Shell 脚本中 执行` show load ` 再利用正则过滤状态进行判断。
-
-2. **数据模型**
-
-我们所有层级的表模型大部分采用 Unique Key 模型,该模型可有效保证数据脚本的结果幂等性,Unique Key 模型可以完美解决上游数据重复的问题,大家可以根据业务模式来选择不同的模型建表。
-
-3. **外部数据源读取**
-
-Catalog 方式可以使用 JDBC 外表连接,还可以对 Doris 生产集群数据进行读取,便于生产数据直接 Load 进测试服务器进行测试。另外,新版支持多数据源的 Catalog,可以基于 Catalog 对 ODS 层进行改造,无需使用 DataX 对ODS 层进行导入。
-
-4. **查询优化**
-
-尽量把非字符类型(如 int 类型、where 条件)中最常用的字段放在前排 36 个字节内,在点查表过程中可以快速过滤这些字段(毫秒级别),可以充分利用该特性进行数据表输出。
-
-5. **数据字典**
-
-利用 Doris 自带的 `information_schema` 元数据制作简单的数据字典,这在还未建立数据治理体系前非常重要,当部门人数较多的时候,沟通成本成为发展过程中最大的“拦路虎”,利用数据字典可快速对表格和字段的全局查找和释义,最低成本形成数仓人员的数据规范,减少人员沟通成本,提高开发效率。
-
-# 架构收益
-
-- 自动取数导数:数据仓库的明细表可以定时进行取数、导数,自助组合维度进行分析。
-- 效率提升:T+1 的离线时效从小时计降低至分钟级
-- 查询延迟降低:面对上亿行数据的表,利用 Doris 在索引和点查方面的能力,实现即席查询 1 秒内响应,复杂查询 5 秒内响应。
-- 运维成本降低:从数据集成到数据服务,只需维护少数组件就可以实现整体链路高效管理。
-- 数据管理体系:Doris 数仓的搭建,使得数据管理体系初步形成,数据资产得以规范化的沉淀。
-- 资源节省:只用了少数服务器,快速搭建起一套数据仓库,成功实现降本赋能。同时 Doris 超高的压缩比,将数据压缩了 70%,相较于 Hadoop 来说,存储资源的消耗大幅降低。
-
-# 总结与规划
-
-目前我们已经完成数仓建设的初期目标,未来我们有计划基于 Apache Doris 进行中台化的改造,同时 Apache Doris在用户画像和人群圈选场景的能力十分强悍,支持 Bitmap 等格式进行导入和转换,提供了丰富的 Bitmap 分析函数等,后续我们也将利用这部分能力进行客户群体分析,加快数字化转型。
-
-最后,感谢 Apache Doris 社区和 SelectDB 团队对美联物业的快速响应和无偿支持,希望 Doris 发展越来越好,也希望更多的企业可以尝试使用 Apache Doris。
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Moka.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Moka.md
deleted file mode 100644
index 733c5bd64f8..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Moka.md
+++ /dev/null
@@ -1,163 +0,0 @@
----
-{
- 'title': '查询提速 20 倍,Apache Doris 在 Moka BI SaaS 服务场景下的应用实践',
- 'summary': "为了提供更完备的数据支持,助力企业提升招聘竞争力,MOKA 引入性能强悍的 Apache Doris 对早期架构进行升级转型,成就了 Moka BI 强大的性能与优秀的用户体验。",
- 'date': '2023-07-10',
- 'author': '张宝铭',
- 'tags': ['最佳实践'],
-}
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-**导读:** MOKA 主要有两大业务线 MOKA 招聘(智能化招聘管理系统)和 MOKA People(智能化人力资源管理系统),MOKA BI 通过全方位数据统计和可灵活配置的实时报表,赋能于智能化招聘管理系统和人力资源管理系统。为了提供更完备的数据支持,助力企业提升招聘竞争力,MOKA 引入性能强悍的 [Apache Doris](https://github.com/apache/doris) 对早期架构进行升级转型,成就了 Moka BI 强大的性能与优秀的用户体验。
-
-
-
-作者**|**Moka 数据架构师 张宝铭
-
-
-# 业务需求
-
-MOKA 主要有两大业务线 MOKA 招聘(智能化招聘管理系统)和 MOKA People(智能化人力资源管理系统)。
-
-- MOKA 招聘系统覆盖社招、校招、内推、猎头管理等场景,让 HR 获得更高效的招聘体验,更便捷的协作体验,让管理者获得招聘数据洞见,让招聘降本增效的同时,树立企业在候选人心目中的专业形象。
-- MOKA People 覆盖企业所需要的组织人事、假期考勤、薪酬、绩效、审批等高频业务场景,打通从招聘到人力资源管理的全流程,为 HR 工作提效赋能。通过多维度数据洞见,助力管理者高效科学决策。全生态对接,更加注重全员体验,是一款工作体验更愉悦的人力资源管理系统。
-
-而 MOKA BI 通过全方位数据统计和可灵活配置的实时报表,赋能于智能化招聘管理系统和人力资源管理系统。通过 PC 端和移动端的多样化报表展示,为企业改善招聘业务提供数据支持,全面提升招聘竞争力,从而助力科学决策。
-
-
-
-# MOKA BI 早期架构
-
-
-
-Moka BI 数仓早期架构是类 Lambda 架构,实时处理和离线处理并存。
-
-- 实时部分数据主要来源为结构化的数据,Canal 采集 MySQL 或 DBLE(基于 MySQL 的分布式中间件)的 Binlog 输出至 Kafka 中;未建模的数据按照公司分库,存储在业务 DBLE 中,通过 Flink 进行实时建模,将计算后的数据实时写入业务 DBLE 库,通过 DBLE 提供报表查询能力,支持数据大屏和实时报表统计。
-- 离线部分涵盖了实时部分数据,其结构化数据来源于 DBLE 的 Binlog,明细数据在 Hbase 中实时更新,并映射成 Hive 表,非结构化数据通过 ETL 流程,存储至 Hive 中,通过 Spark 进行进行离线部分建模计算,离线数仓 ADS 层数据输出至 MySQL 和 Redis 支持离线报表统计,明细数据又为指标预测和搜索等外部应用提供数据支持。
-
-
-
-
-## **现状与问题**
-
-在早期数仓架构中,为了实现实时建模以及实时报表查询功能,就必须要求底层数据库能够承载业务数据的频繁插入、更新及删除操作,并要求支持标准 SQL,因此当时我们选择 DBLE 作为数据存储、建模、查询的底层库。早期 Moka BI 灰度期用户较少,业务数据量以及报表的使用量都比较低,DBLE 尚能满足业务需求,但随着 Moka BI 逐渐面向所有用户开放,DBLE 逐渐无法适应 BI 报表的查询分析性能要求,同时实时与离线架构分离、存储成本高且数据不易维护,亟需进行升级转型。
-
-
-
-
-# 技术选型
-
-为匹配业务飞速增长的要求、满足更复杂的查询需求,我们决定引入一款性能突出的 OLAP 引擎对 Moka BI 进行升级改造。同时出于多样化分析场景的考虑,我们希望其能够支撑更广泛的应用场景。调研的主要方向包括 报表的实时查询能力、数据的更新能力、标准的查询 SQL 以及数据库的可维护性、扩展性、稳定性等。
-
-
-
-确定调研方向后,我们首先对 Greenplum 展开了调研,其特点主要是数据加载和批量 DML 处理快,但受限于主从双层架构设计、存在性能瓶颈,且并发能力很有限、性能随着并发量增加而快速下降,同时其使用的是 PG 语法、不支持 MySQL 语法,在进行引擎切换时成本较高,因此在基本功能调研结束后便不再考虑使用。
-
-随后我们对 ClickHouse 进行了调研,ClickHouse 在单表查询场景下性能表现非常优异的,但是在多表 Join 场景中性能表现不尽如人意,另外 ClickHouse 缺少数据实时更新和删除的能力,仅适用于批量删除或修改数据,同时 ClickHouse 对 SQL 的支持也比较有限,使用起来需要一定的学习成本。
-
-紧接着我们对近几年势如破竹的 Apache Doris 进行了调研,在调研中发现,Doris 支持实时导入,同时也支持数据的实时更新与删除,可以实现 Exactly-Once 语义;其次,在实时查询方面,Doris 可以实现秒级查询,且在多表 Join 能力的支持上更加强劲;除此之外,Doris 简单易用,部署只需两个进程,不依赖其他系统,兼容 MySQL 协议,并且使用标准 SQL ,可快速上手,部署及学习成本投入均比较低。
-
-## **Benchmark**
-
-在初步调研的基础之上,我们进一步将 Apache Doris 、Clickhouse 与当下使用的 DBLE 在查询性能上进行了多轮测试对比,查询耗时如下:
-
-
-
-- **多表 Join**:随着 SQL Join 数量的增多,Doris 和 ClickHouse 性能表现差距越来越大,Doris 的查询延迟相对比较稳定,最长耗时仅为 3.2s;而 ClickHouse 的查询延迟呈现指数增长,最长耗时甚至达到 17.8s,二者性能最高相差 5 倍,DBLE 的查询性能则远不如这两款产品。
-- **慢查询:** 在线上慢查询 SQL 的对比测试中,Doris 的性能同样非常稳定,不同的 SQL 查询基本都能在 1s 内返回查询结果,ClickHouse 与之对比查询延迟波动较大、性能表现很不稳定,二者相同 SQL 性能差距最大超过 10 余倍。
-
-
-
-
-**通过以上调研对比,可以看出 Apache Doris 不管是在基本功能上、还是查询性能上表现都更胜一筹,因此我们将目标锁定了 Doris,并决定尽快引入 Apache Doris 作为 Moka** **BI** **新一代** **数仓** **架构的查询引擎。**
-
-
-
-
-# 新版架构
-
-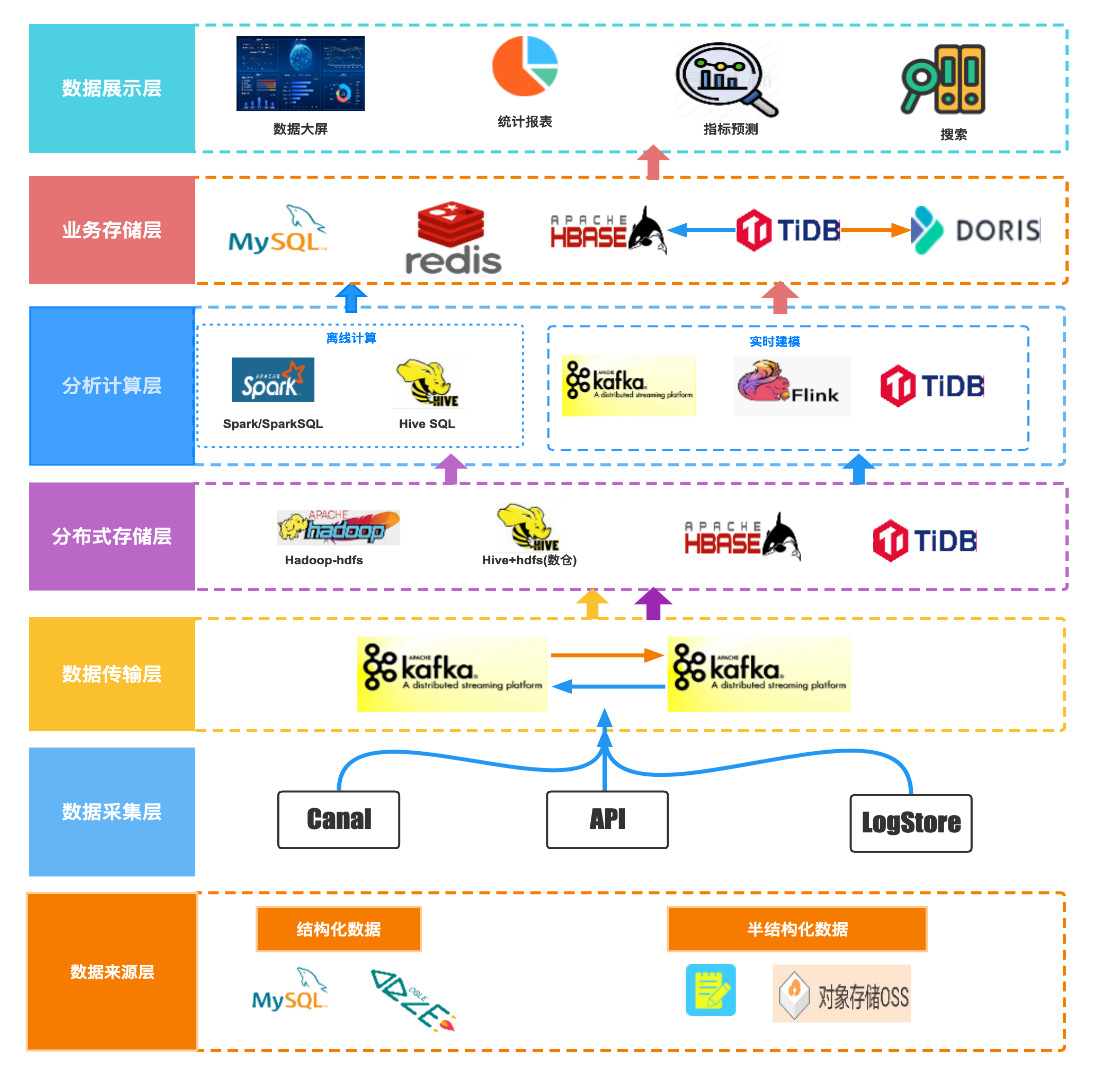
-
-在引入 Doris 之后,Moka BI 数仓架构的主要变化是将 OLAP 和 OLTP 进行分离,即使用 DBLE 支持数据的实时建模,数据来源于 Moka 系统的业务数据,包含了结构化和半结构化的数据,通过 Flink 读取 DBLE Binlog,完成数据去重、合并后写入 Kafka,Doris 通过 Routine Load 读取 Kafka 完成数据写入,此时 DBLE 仅作为数据建模合成使用,由 Doris 提供报表查询能力。
-
-
-
-
-基于 Doris 列存储、高并发、高性能等特性,Moka BI 报表采用自助方式构建完成,支撑客户根据需求灵活配置行、列、筛选的场景。与传统报表按需求定制开发方式对比,这种自助式报表构建非常灵活,平台开发与需求开发完全独立,需求完成速度得到极大的提升。
-
-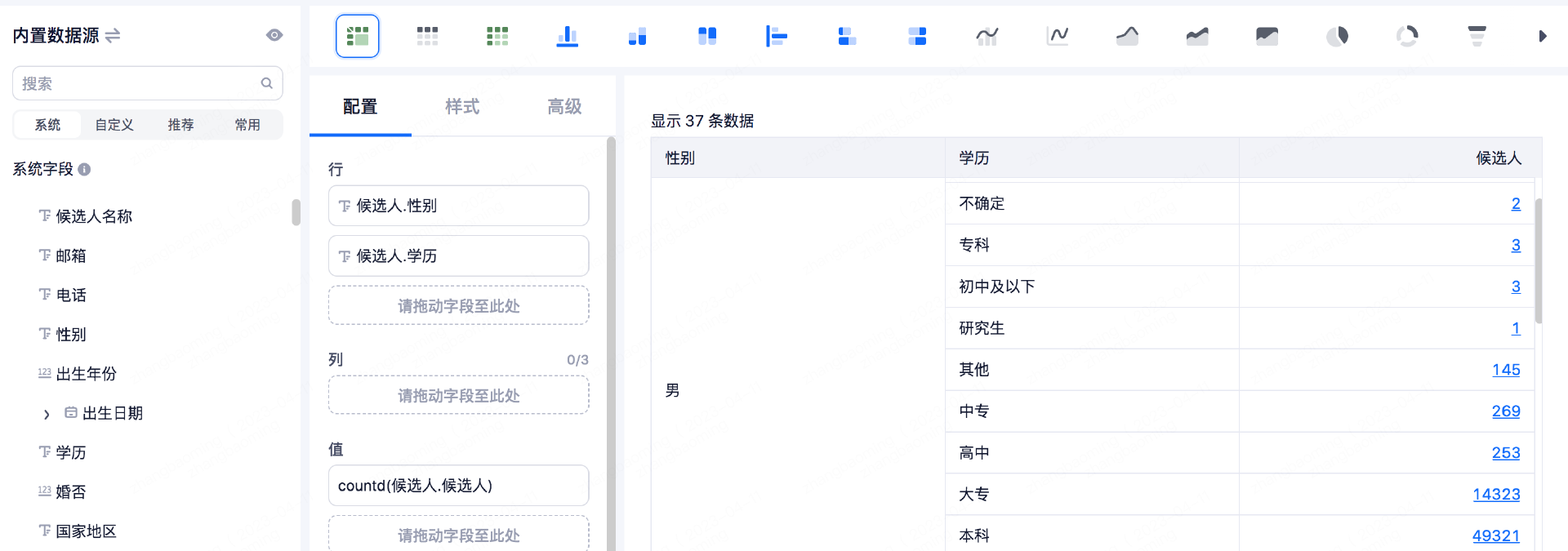
-
-数据导入方面,数据通过 Routine Load 定期批量导入到 Doris 数据仓库中,保证了数据的准实时同步。通过对系统数据收集与建模,及时向客户提供最新的业务数据,以帮助客户快速了解招聘情况,并做出有效的调整。
-
-数据更新方面,Doris 在大数据量(单表几十亿)的场景下,表现出了突出的数据更新和删除能力,Moka BI 读取的是业务库的 Binlog 数据,其中有大量的更新以及删除操作,Doris 可以通过 Routine Load 的 Delete 配置实现实时删除,根据 Key 实现幂等性写入,配合 Flink 可以做到真正的 Exactly-Once。在架构中增加了 Routine Load 后,数仓可以实现 1 分钟级别的准实时 **,** 同时结合 Routine load + Kafka 可以实现流量的削峰,保证集群稳定,并且可以通过重置 Kafka 偏移量来实现间数据重写,通过 Kafka 实现多点消费等。
-
-数据查询方面,充分利用 Doris 的多表 Join 能力,使得系统能够实现实时查询。我们将不同的数据表按照关联字段进行连接,形成一个完整的数据集,基于数据集可进行各种数据分析和可视化操作,同时可高效应对任意条件组合的查询场景以及需要灵活定制需求的查询分析场景,**在某些报表中,需要 Join 的表可能达到几十张,Doris 强大的 Join 性能,使 Moka** **BI** **的报表查询可以达到秒级响应。**
-
-运维管理方面,Doris 部署运维简单方便,不依赖第三方组件,无损弹性扩缩容,自动数据均衡,集群高可用。Doris 集群仅有 FE 和 BE 两个组件,不依赖 Zookeeper 等组件即可实现高可用,部署、运维方便,相比传统的 Hadoop 组件,非常友好,支持弹性扩容,只需简单配置即可实现无损扩容,并且可以自动负载数据到扩容的节点,大大降低了我们引入新技术栈的难度和运维压力。
-
-
-
-
-# 调优实践
-
-新架构实际的落地使用中,我们总结了一些调优的经验,在此分享给大家。
-
-在 Moka BI 报表查询权限场景中,同样配置的报表,**有权限认证**时查询速度比**没有权限认证**时慢 30% 左右,甚至出现查询超时,而**超管权限**查询时则正常,这一现象在数据量较大的客户报表中尤为明显。
-
-人力资源管理业务的数据权限有着极为严格和精细的管控需求,除了 SaaS 业务自身对于不同租户间的数据隔离要求外,还需要针对业务人员的身份角色、管理部门范畴以及被管理人员的信息敏感程度对可见数据的范围进行进一步细分,因此在 Moka BI 权限功能模块的设计之时就考虑并实现了极为灵活的自定义配置化方案。例如 HRBP 与 PayRoll、HRIS 等角色的可见字段不同、不同职级或部门但角色一致用户的可见数据区间不同,同时针对部分敏感的人员信息还需要做数据过滤,或者出于管理授权的需求临时开通某一权限,甚至以上权限要求还会进行多重的交叉组合,以保证每一用户可查看的数据、报表、信息均被限制在权限范围以内。
-
-因此当用户需要对数据报表进行查询时,会先在 Moka BI 的权限管理模块进行多重验证,验证信息会通过` in `的方式拼接在查询 SQL 中并传递给 OLAP 系统。随着客户业务体量的增大,对于权限管控的要求越精细、最终所产生的 SQL 就越复杂,部分业务规模比较大的客户报表会出现上千甚至更多的权限限制,因此造成 OLAP 系统的 id 过滤时间变长,导致报表查询延迟增加,给大客户造成了体验不佳。
-
-
-
-**解决方案:**
-
-为适配该业务场景,我们通过查看官方的文档发现 Doris Bloom Filter 索引的特性可以很好的解决该问题
-
-
-
-Doris BloomFilter 索引使用场景:
-
-- BloomFilter 适用于非前缀过滤。
-- 查询会根据该列高频过滤,而且查询条件大多是` in `和` = `过滤。
-- 不同于 Bitmap,BloomFilter 适用于高基数列,比如 UserID。因为如果创建在低基数的列上,比如 “性别” 列,则每个 Block 几乎都会包含所有取值,导致 BloomFilter 索引失去意义。
-
-
-
-经过验证,可以通过上方对比报表看到,**将相关 ID 字段增加 BloomFilter 索引后** **,权限验证场景查询速度提升约 30% ,有权限验证的报表超时的问题也得到了改善。**
-
-
-
-
-# 收益与总结
-
-**目前 Moka** **BI** **Doris 有两个集群,** **共 40 台服务器,** **数仓** **共维护了 400 多张表** **,其中 50 多张表数据量超过 1 亿,总数据量为 T** **B** **级别。**
-
-引入 Apache Doris 改造了新的数据仓库之后,满足了日益增长的分析需求以及对数据实时性的要求,总体收益包含以下几点:
-
-1. **高性能数据查询:** Doris 基于列存储技术,能够快速处理大量的数据,并支持高并发的在线查询,解决了关系型数据库无法支持的复杂查询问题,复杂 SQL 查询的速度上升了一个数据量级。
-1. **数据仓库** **的可扩展性:** Doris 采用分布式集群架构,可以通过增加节点来线性提升存储和查询瓶颈,打破了关系型数据库数据单点限制问题,查询性能得以显著提升。
-1. **更广泛的应用:** 基于 Doris 构建了统一的数据查询平台,应用不再局限于报表服务,对于离线的查询也有很好的支撑,可以说 Doris 的引入是构建数仓一体化的前奏。
-1. **实现自助式分析:** 基于 Doris 强大的查询能力,我们引入了全新的报表构建方式,通过用户自助构建报表方式,能够快速满足用户的各种灵活需求。
-
-在使用 Doris 的两年多时间里,Moka BI 与 Apache Doris 共同成长、共同进步,可以说 Doris 成就了 Moka BI 强大的性能与优秀的用户体验;也正是 Moka BI 特殊的使用场景,也丰富了 Doris 的优化方向,我们提的很多 Issue 与建议,经过版本更新迭代后使其更具竞争力。在未来的时间里,Moka BI 也会紧跟社区脚步,不断优化、回馈社区,希望 [Apache Doris](https://github.com/apache/doris) 和 [SelectDB](https://cn.selectdb.com/) 发展越来越好、越来越强大。
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/NIO.md b/i18n/zh-CN/docusaurus-plugin-content-blog/NIO.md
deleted file mode 100644
index 86072037c01..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/NIO.md
+++ /dev/null
@@ -1,223 +0,0 @@
----
-{
- 'title': 'Apache Doris 在蔚来汽车的应用',
- 'summary': '蔚来(纽约证券交易所代码:NIO)是设计高端智能电动汽车市场的领先公司. NIO 成立于 2014 年 11 月,设计、开发、联合制造和销售高端智能电动汽车,并不断推动自动驾驶、数字技术、电动动力总成和电池领域的创新,Doris作为统一OLAP数仓,Doris在运营平台上的实践',
- 'date': '2022-11-28',
- 'author': '唐怀东',
- 'tags': ['最佳实践'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-
-# Apache Doris 在蔚来汽车的应用
-
-
-
->导读:本次分享的题目是Apache Doris在蔚来汽车的应用,主要包括以下几大部分:
->1. 蔚来
->2. OLAP在蔚来的发展
->3. Doris作为统一OLAP数仓
->4. Doris在运营平台上的实践
->5. 经验总结
-
-作者:唐怀东,蔚来汽车 数据团队负责人
-
-## 蔚来
-
-蔚来(纽约证券交易所代码:NIO)是设计高端智能电动汽车市场的领先公司。 NIO 成立于 2014 年 11 月,设计、开发、联合制造和销售高端智能电动汽车,并不断推动自动驾驶、数字技术、电动动力总成和电池领域的创新。
-
-## OLAP在蔚来的发展
-
-首先,让我们来一起回顾OLAP在蔚来汽车的发展。
-
-### 1. 2017年引入Apache Druid
-
-在当时可选择的OLAP存储和查询引擎并不多,比较常见的有Apache Druid、Apache Kylin。我们优先引入Druid的原因是以前有使用经验,而Kylin预计算虽然具有极高的查询效率优势,但是:
-
-- Kylin底层最合适和最优的存储是HBase,之前公司并未引入,会额外增加运维的工作。
-
-- Kylin对各种维度和指标进行预计算,如果维度和维度取值非常多,会有维度爆炸的问题,对存储造成非常大的压力。
-
-Druid的优势很明显,支持实时和离线数据接入,列式存储,高并发,查询效率非常高。其缺点也比较明显:
-
-- 未使用标准协议例如JDBC,使用门槛高
-- Join的支持较弱
-- 精确去重的效率低,性能会随之下降。整体性能要分场景去考虑,这也是我们后期去选型其他OLAP的原因
-- 运维成本高,不同的组件有不同的安装方式和不同的依赖;数据导入还要考虑和Hadoop集成以及JAR包的依赖
-
-### 2. 2019年引入TiDB
-
-**TiDB是一个OLTP+OLAP的成熟引擎,同样是优点、缺点分明:**
-
-优势:
-
-- OLTP数据库,更新友好。
-- 支持明细和聚合,有指标计算和数据看板展示,还支持明细数据查询
-- 支持标准SQL,使用成本低
-- 运维成本低
-
-劣势:
-- 它不是一个独立的OLAP。TiFlash依赖于OLTP,会增加存储。其OLAP能力稍显不足
-- 整体性能要分场景去衡量
-
-### 3. 2021年引入Doris
-
-自2021年起,我们正式引入了Apache Doris。在系统选型过程中,产品的性能、SQL语法、系统兼容性、学习以及运维成本等多方面因素是我们最为关心的部分。经过深入调研、层层对比以下几个系统后,我们得出了如下结论:
-
-**我们重点关注的Doris,其优点完全满足我们的诉求:**
-
-- 支持高并发查询(我们最关心的一点)
-- 同时支持实时和离线数据
-- 支持明细和聚合
-- Uniq模型支持更新
-- 物化视图的能力能极大的加速查询效率
-- 兼容MySQL协议,所以开发和使用成本比较低
-- 性能完全满足我们的要求
-- 运维成本比较低
-
-**Clickhouse,我们之前也调研过,也尝试想去使用它。其单机性能极强,但是缺点明显:**
-
-- 我们明确需要的场景下,它的多表join支持的稍微差一些
-- 并发度比较低
-- 运维成本极高
-
-凭借多种性能优势,Apache Doris比较理想地替代了Druid和TiDB。而Clickhouse在我们的业务上并不能很好的适配,让我们最终走向了Apache Doris。
-
-## Doris作为统一OLAP数仓
-
-
-
-这张图基本上就是从数据源到数据接入、数据计算、数据仓库、数据服务以及应用。
-
-### 1. 数据源
-
-蔚来的场景下,数据源不仅仅指业务系统的数据,还有埋点数据、设备数据、车辆数据等等。数据会通过一种接入方式接入到大数据平台。
-
-### 2. 数据接入
-
-对于一些业务系统的数据,可以开启CDC捕捉变化的数据,然后转换成一个数据流存储到Kafka,接续再进行流式的计算。某些只能通过批量的方式的数据会直接进入到我们的分布式存储。
-
-### 3. 数据计算
-
-我们没有采用流批一体,采用的是Lambda架构。
-我们本身的业务决定了我们的Lambda架构是离线和实时分成了两条路径:
-- 部分数据是流式的。
-- 部分数据能够存储到数据流里,一些历史数据不会存储到Kafka。
-- 有些场景数据要求高精准度。为了保证数据的准确性,一个离线的pipeline将会把整个数据重新计算和刷新。
-
-### 4. 数据仓库
-
-数据计算到数仓,这两条线路我们没有采用Flink或Spark Doris Connector。我们用Routine Load来连接Apache Doris和Flink,用Broker Load连接Doris和Spark。 由Spark批量生成的数据,会备份到Hive供其他场景使用。这样每计算一次,就同时供多个场景去使用,大大提升了效率。Flink的情况也诸如此类。
-
-### 5. 数据服务
-
-Doris后面是One Service。通过注册数据源或灵活配置的方式,自动生成API,对API进行流量的控制和权限的控制,灵活性大大提高。并借助于k8s serverless方案,整个服务非常灵活和丰富。
-
-### 6. 数据应用
-
-应用层中我们主要是部署一些报表应用和其他的一些服务。
-
-我们主要有两类使用场景:
-- 面向用户,类似于互联网,我们有很多用户的场景,包括看板和指标
-- 面向车,车的数据通过这种方式进入到Doris,通过一定的聚合之后,Doris数据体量在几十亿级别。但总体性能仍然可以满足我们的要求。
-
-## Doris在运营平台上的实践
-
-### 1. CDP Architecture
-
-
-
-接下来我来介绍Doris在运营平台上的实践。这是我们的真实使用场景。如今互联网公司普遍会做自己的CDP,它一般包括几个模块:
-- 标签,是最基础的部分。
-- 圈人,基于标签,按照一定逻辑将人圈选出来。
-- 洞察,针对圈定的人群,了解人群分布、特点。
-- 触达,利用例如短信、电话、声音、APP通知、IM等方式触达到用户,并配合流量控制。
-- 效果分析,提升运营平台的完整性,有动作、有效果、有反馈。
-
-Doris在这里面起到了最重要的作用,包括:标签存储、人群存储、效果分析。
-标签分为基础标签和用户行为的基础数据,在此基础之上,我们可以灵活自定义其他标签。从实效性来看,标签还分为实时的标签和离线的标签。
-
-### 2. CDP存储选型的考量点
-我们从5个维度去考量CDP存储的选型。
-
-**(1) 离线和实时统一
-如前所述标签有离线标签,有实时标签。目前我们是准实时的场景。对于有些数据,准实时已足够满足我们的需求,大量的标签还是离线的标签,采用的方式就是Doris的Routine Load和Broker Load。
-
-| **场景** | **需求** | **Apache Doris功能点** |
-| --- | --- | --- |
-| 实时标签 | 数据实时更新 | Routine Load |
-| 离线标签 | 高效大批量导入 | Broker Load |
-| 流批统一 | 实时历险数据存储统一 | Routine Load 和 Broker Load 更新同一张表的不同列 |
-
-另外同一张表上,不同列更新的频率也是不一样的。例如用户的基础标签,我们对用户的身份需要实时的更新,因为用户的身份是时刻变化的。T+1的更新不能满足我们的需求。有些标签离线,例如用户的性别、年龄等基础标签,T+1更新足以满足我们的标准。基础用户的原子标签放在一张表中带来的维护成本很低。当后期自定义标签时,表的数量会大大减少,这样对于整体性能的提升有极大好处。
-
-**(2) 高效圈选**
-
-用户运营有了标签,第二步就是圈人,圈选就是根据标签的不同组合,把符合标签条件的所有人筛选出来,这时会有不同标签条件组合的查询、这个查询在Doris引入向量化之后有比较明显的提升。
-
-| **场景** | **需求** | **Apache Doris功能点** |
-| --- | --- | --- |
-| 复杂条件圈选 | 高效的支持多条件圈选 | SIMD的优化 |
-
-**(3) 高效聚合**
-
-前面提到的用户洞察或群体洞察以及效果分析统计,需要对数据做统计分析,并不是单一的按用户ID获取标签的这种简单场景。其读取的数据量和查询效率,对我们这个标签的分布、群体的分布、效果分析的统计都有很大的影响。在这里,体现到的Doris的功能特点是:
-- 第一是数据分片,我们按时间把数据分片,分析统计就会极大的减少数据量,可以极大的加速查询和分析的效率。
-- 第二是节点聚合,然后再收集做统一的聚合。
-- 第三是向量化加速,向量化引擎对性能提升非常显著。
-
-| **场景** | **需求** | **Apache Doris功能点** |
-| --- | --- | --- |
-| 标签值的分布 | 每天都需要更新所有标签,需要快速高效统计 | 数据分片,减少数据传输和计算 |
-| 群体的分布 | 同上 | 存算统一,每个节点先聚合 |
-| 效果分析的统计值 | 同上 | SIMD提速 |
-
-**(4) 多表关联**
-
-我们的CDP可能和业内常见的CDP场景不太一样,因为有些场景的CDP标签是提前预估完成的,不存在自定义标签。只做原子标签,或者说用户基础行为数据的统计,这样可以把灵活性留给使用CDP的用户,根据自己的业务场景去自定义标签。底层的数据是分散在不同的数据库表里,如果做自定义的标签的建设,势必需要做表的关联。
-我们选择Doris一个非常重要的原因,就是多表关联的能力。通过性能测试,Doris目前能够满足我们的要求。而且Doris为用户提供了非常强大的能力。因为标签是动态的。
-
-| **场景** | **需求** | **Apache Doris功能点** |
-| --- | --- | --- |
-| 群体的特征分布 | 统计群体在某个特征下的分布 | 多表关联 |
-| Single Tag | Display tags | |
-
-**(5) 联邦查询**
-
-用户触达成功与否我们会记录到TiDB。用户运营中的通知,可能只影响用户体验,如果涉及到钱例如发放积分或优惠券,任务执行就要做到不重不漏,这种OLTP场景用TiDB比较合适。
-做效果分析,需要了解运营计划执行到什么程度,是否达成目标,其分布情况等等。需要把任务执行情况和人群圈选相结合才能进行分析,就会用到Doris和TiDB的关联,外表关联进行查询。
-我们设想标签体量比较小,保存到es可能比较合适,然而ES不能满足我们的需求,后面会解释其原因。
-
-| **场景** | **需求** | **Apache Doris功能点** |
-| --- | --- | --- |
-| 效果分析关联任务执行明细 | Doris数据关联TiDB数据 | 关联外表进行查询 |
-| 人群标签关联行为聚合数据 | Doris数据关联Elasticsearch数据 |
-
-## 经验和总结
-
-1. **bitmap**. 我们的体量无法充分发挥其效率。如果体量达到一定程度,用bitmap会有很好的性能提升。例如计算UV场景,Id全集大于5000万,可以考虑bitmap聚合。
-
-2. **ES外表。单表查询下效率比较理想。**
-
-3. **分批更新列**. 为了减少表的数量和提升join表的性能,设计表尽量精简尽量聚合,相同类型的事实都放在一起。但相同类型的字段可能更新频率不同,有些字段需要天级更新,有些字段可能需要小时级更新,单独更新某一列就是一个明显的诉求。Doris聚合模型单独更新某些列的解决方案是使用REPLACE_IF_NOT_NULL。注意:用null替换原来的非null值是做不到的,可以把所有的null替换成有意义的默认值,例如unknown。
-
-4. **在线服务**. Doris同一份数据同时服务在线离线场景,对资源隔离的要求比较高,目前还存在进一步优化的空间。
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Netease.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Netease.md
deleted file mode 100644
index 8e21e639a13..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Netease.md
+++ /dev/null
@@ -1,253 +0,0 @@
----
-{
- 'title': 'Apache Doris 助力网易严选打造精细化运营 DMP 标签系统',
- 'summary': '如果说互联网的上半场是粗狂运营,那么在下半场,精细化运营将是长久的主题,有数据分析能力才能让用户得到更好的体验。当下比较典型的分析方式是构建用户标签系统,本文将由网易严选分享 DMP 标签系统的建设以及 Apache Doris 在其中的应用实践.',
- 'date': '2022-11-30',
- 'author': '刘晓东',
- 'tags': ['最佳实践'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-# 应用实践|Apache Doris 助力网易严选打造精细化运营 DMP 标签系统
-
-
-
-**导读**:如果说互联网的上半场是粗狂运营,那么在下半场,精细化运营将是长久的主题,有数据分析能力才能让用户得到更好的体验。当下比较典型的分析方式是构建用户标签系统,本文将由网易严选分享 DMP 标签系统的建设以及 Apache Doris 在其中的应用实践。
-
-作者**|**刘晓东 网易严选资深开发工程师
-
-
-
-如果说互联网的上半场是粗狂运营,因为有流量红利不需要考虑细节。那么在下半场,精细化运营将是长久的主题,有数据分析能力才能让用户得到更好的体验。当下比较典型的分析方式是构建用户标签系统,从而精准地生成用户画像,提升用户体验。今天分享的主题是网易严选 DMP 标签系统建设实践,**主要围绕下面五点展开:**
-
-- 平台总览
-- 标签生产 :标签圈选&生产链路
-- 标签存储:存储方式&存储架构演进
-- 高性能查询
-- 未来规划
-
-# 平台总览
-
-DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务,承担着非常重要的基石角色。
-
-**DMP 的数据来源主要包括三大部分:**
-
-- 自营平台的 APP、小程序、PC 端等各端的业务日志
-- 网易集团内部共建的一些基础数据
-- 京东、淘宝、抖音等第三方渠道店铺的数据
-
-通过收集、清洗,将以上数据形成数据资产沉淀下来。DMP 在数据资产基础上形成了一套自己的标签产出、人群圈选和用户画像分析体系,从而为业务提供支撑,包括:智能化的选品、精准触达以及用户洞察等。总的来说,**DMP 系统就是构建以数据为核心的标签体系和画像体系,从而辅助业务做一系列精细化的运营。**
-
-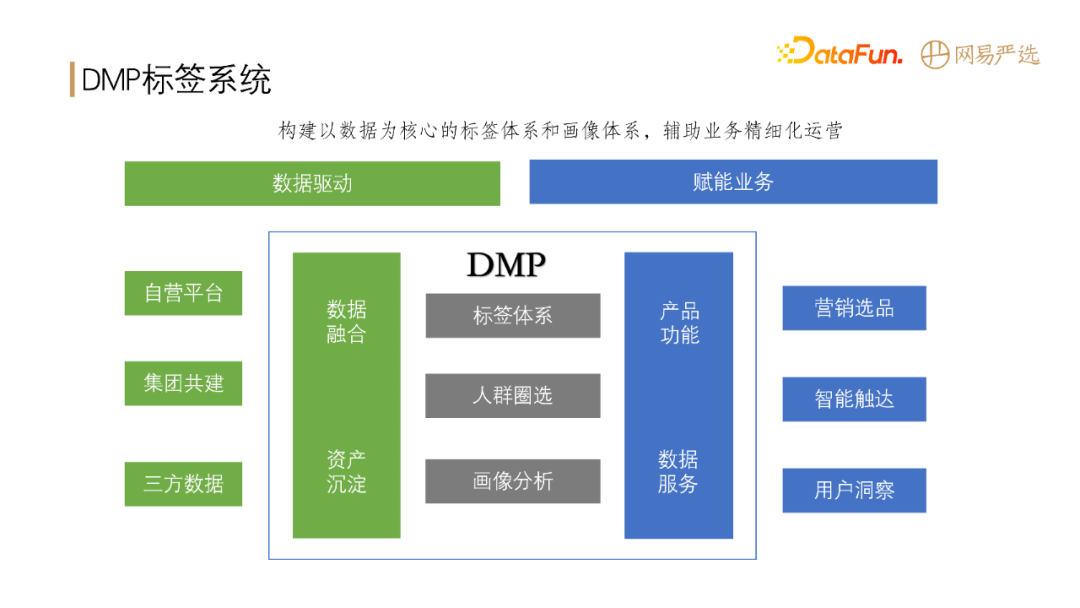
-
-了解 DMP 系统,先从以下几个概念开始。
-
-- **标签**: 对于实体(用户、设备、手机号等)特征的描述,是一种面向业务的数据组织形式,比如使用:年龄段、地址、偏好类目等对用户实体进行刻画。
-- **人群圈选**: 通过条件组合从全体用户中圈选出一部分用户,具体就是指定一组用户标签和其对应的标签值,得到符合条件的用户人群。
-- **画像分析**: 对于人群圈选结果,查看该人群的行为情况、标签分布。例如查看【城市为杭州,且性别为女性】的用户在严选 APP 上的行为路径、消费模型等。
-
-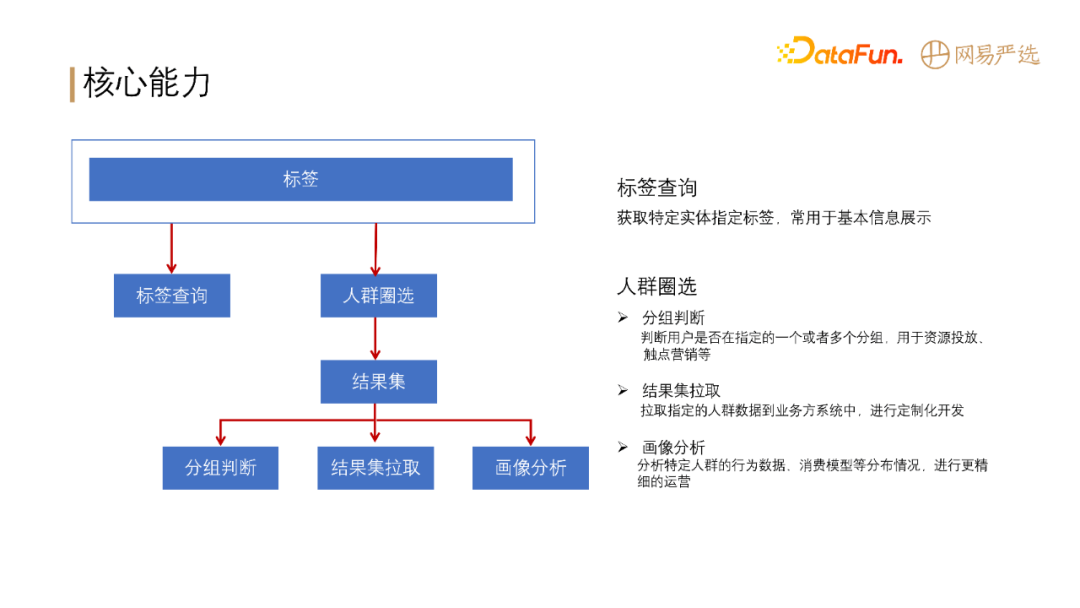
-
-严选标签系统对外主要提供两大核心能力:
-
-1. 标签查询:查询特定实体指定标签的能力,常用于基本信息的展示。
-
-2. 人群圈选:分为实时和离线圈选。**圈选结果主要用于:**
-
-- 分组判断:判读用户是否在指定的一个或多个分组,资源投放、触点营销等场景使用较多。
-- 结果集拉取:拉取指定的人群数据到业务方系统中,进行定制化开发。
-- 画像分析:分析特定人群的行为数据,消费模型等,进行更精细的运营。
-
-**整体的业务流程如下:**
-
-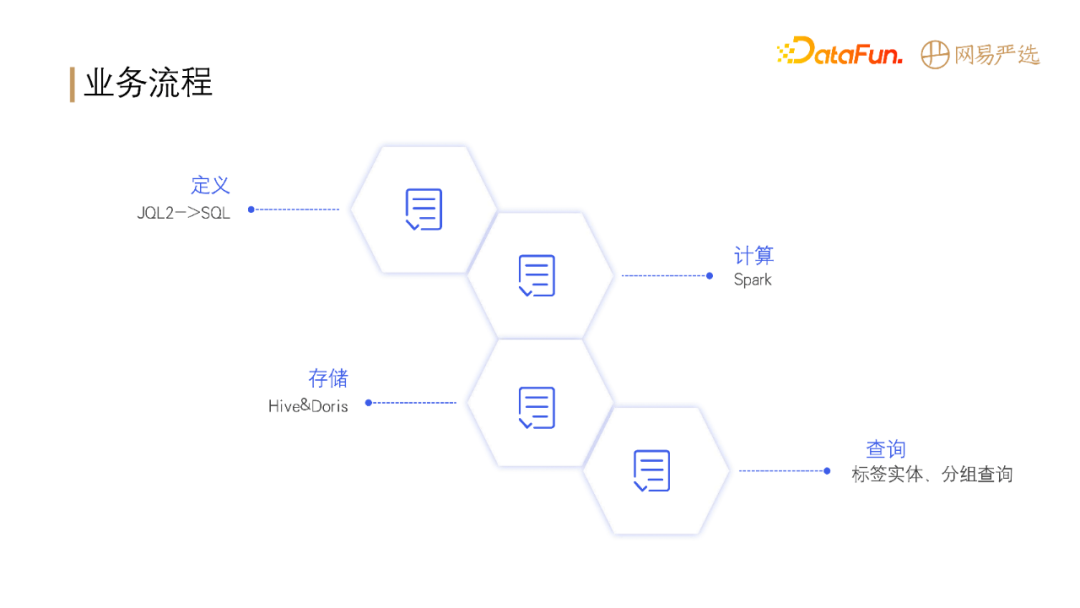
-
-- 首先定义标签和人群圈选的规则;
-- 定义出描述业务的 DSL 之后,便可以将任务提交到 Spark 进行计算;
-- 计算完成之后,**将计算结果存储到 Hive 和 Doris**;
-- 之后业务方便可以根据实际业务需求**从 Hive 或** **Doris** **中查询使用数据**。
-
-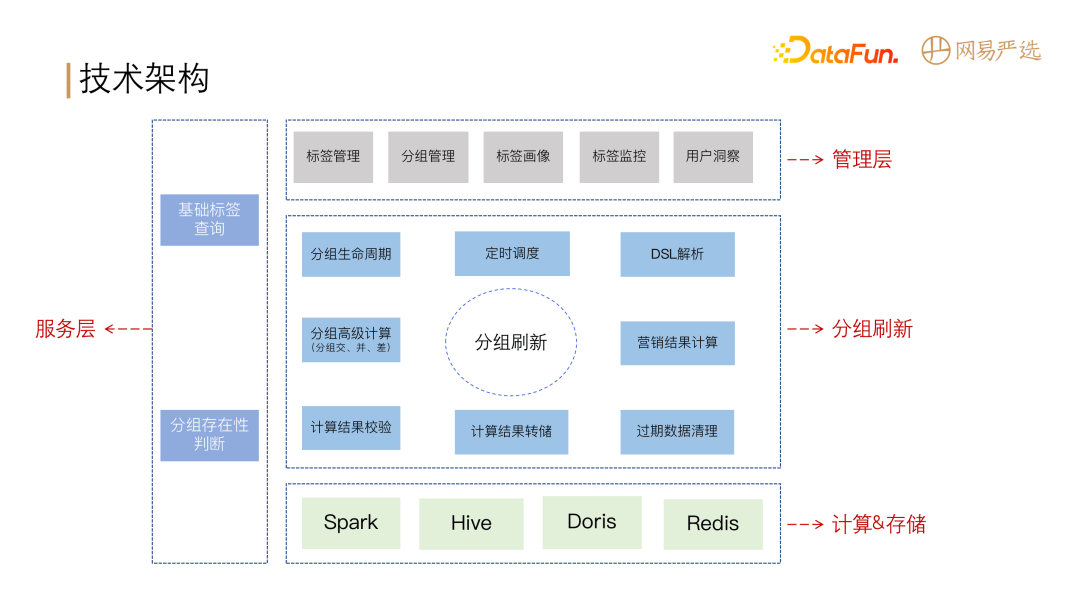
-
-**DMP 平台整体分为计算存储层、调度层、服务层、和元数据管理四大模块。**
-
-所有的标签元信息存储在源数据表中;调度层对业务的整个流程进行任务调度:数据处理、聚合转化为基础标签,基础标签和源表中的数据通过 DSL 规则转化为可用于数据查询的 SQL 语义,由调度层将任务调度到计算存储层的 Spark 进行计算,**并将计算结果存储到 Hive 和 Doris 中。**服务层由标签服务、实体分组服务、基础标签数据服务、画像分析服务四部分组成。
-
-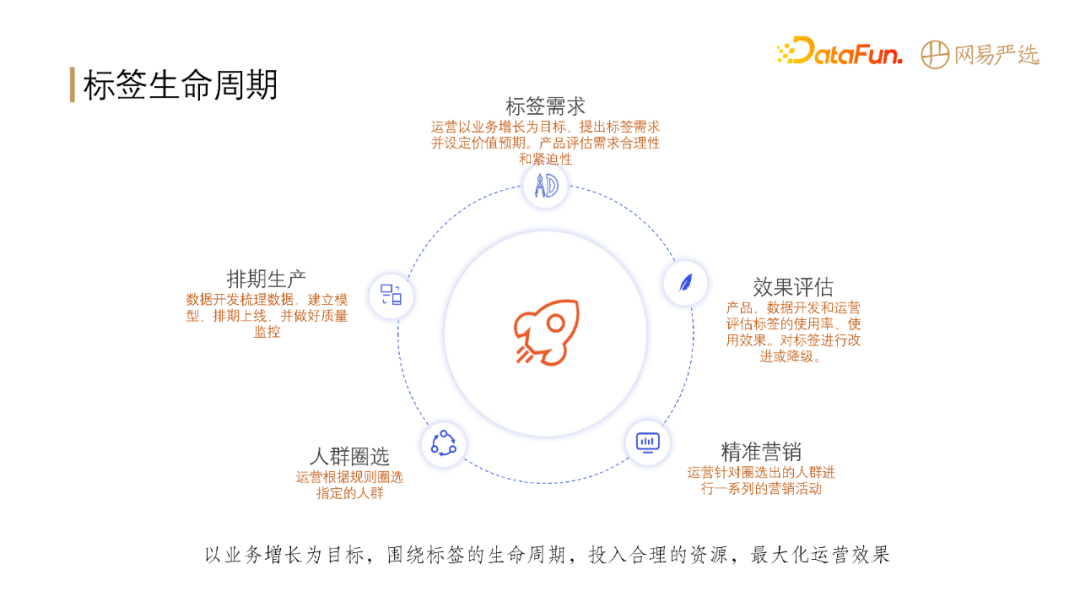
-
-**标签的生命周期包含5个阶段:**
-
-- **标签需求**: 在此阶段,运营提出标签的需求和价值预期,产品评估需求合理性以及紧迫性。
-- **排期生产**: 此阶段需要数据开发梳理数据,从 ods 到 dwd 到 dm 层整个链路,根据数据建立模型,同时数据开发需要做好质量监控。
-- **人群圈选**: 标签生产出来之后进行应用,圈选出标签对应的人群。
-- **精准营销**: 对圈选出来的人群进行精准化营销。
-- **效果评估**: 最后产品、数据开发和运营对标签使用率、使用效果进行效果评估来决定后续对标签进行改进或降级。
-
-总的来说,就是以业务增长为目标,围绕标签的生命周期,投入合理的资源,最大化运营效果。
-
-
-
-# 标签生产
-
-**接下来介绍标签生产的整个过程。**
-
-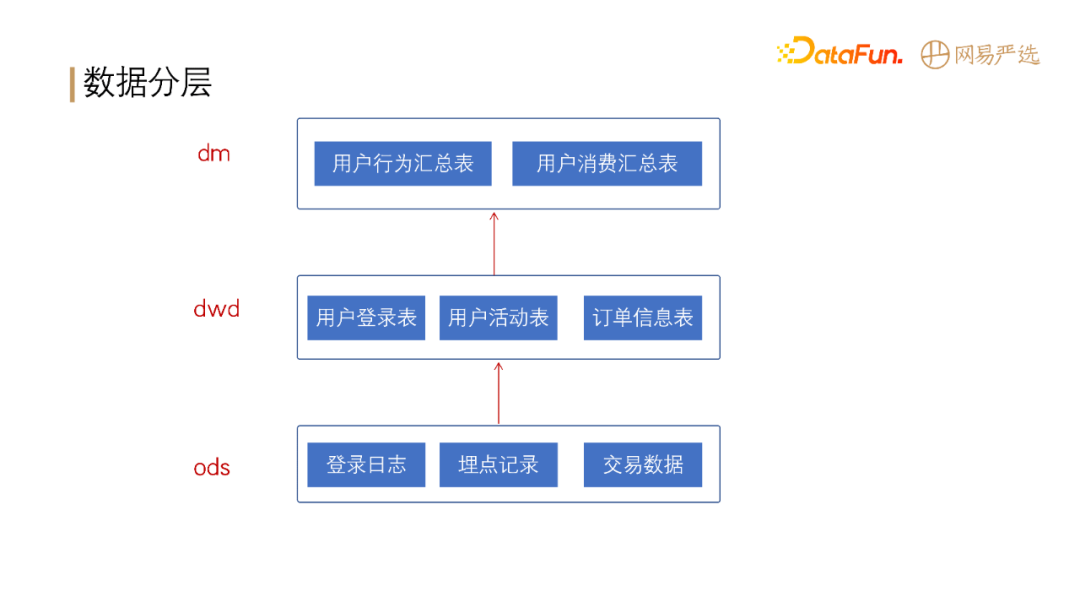
-
-**标签的数据分层:**
-
-- 最下层是 ods 层,包括用户登录日志、埋点记录日志、交易数据以及各种数据库的 Binlog 数据。
-- 对 ods 层处理后的数据到达 dwd 明细层,包括用户登录表、用户活动表、订单信息表等。
-- dwd 层数据聚合后到 dm 层,标签全部基于 dm 层数据实现。
-
-目前我们从原始数据库到 ods 层数据产出已经完全自动化,从 ods 层到 dwd 层实现了部分自动化,从 dwd 到 dm 层有一部分自动化操作,但自动化程度还不高,这部分的自动化操作是我们接下来的工作重点。
-
-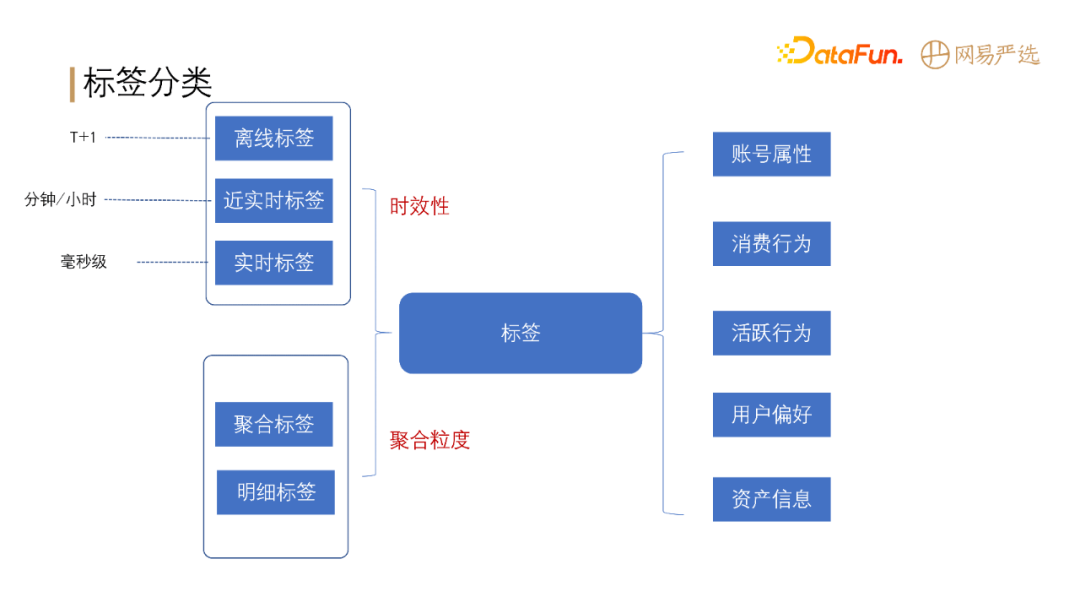
-
-**标签根据时效性分为**:离线标签、近实时标签和实时标签。
-
-**根据聚合粒度分为**:聚合标签和明细标签。
-
-通过类别维度可将标签分为:账号属性标签、消费行为标签、活跃行为标签、用户偏好标签、资产信息标签等。
-
-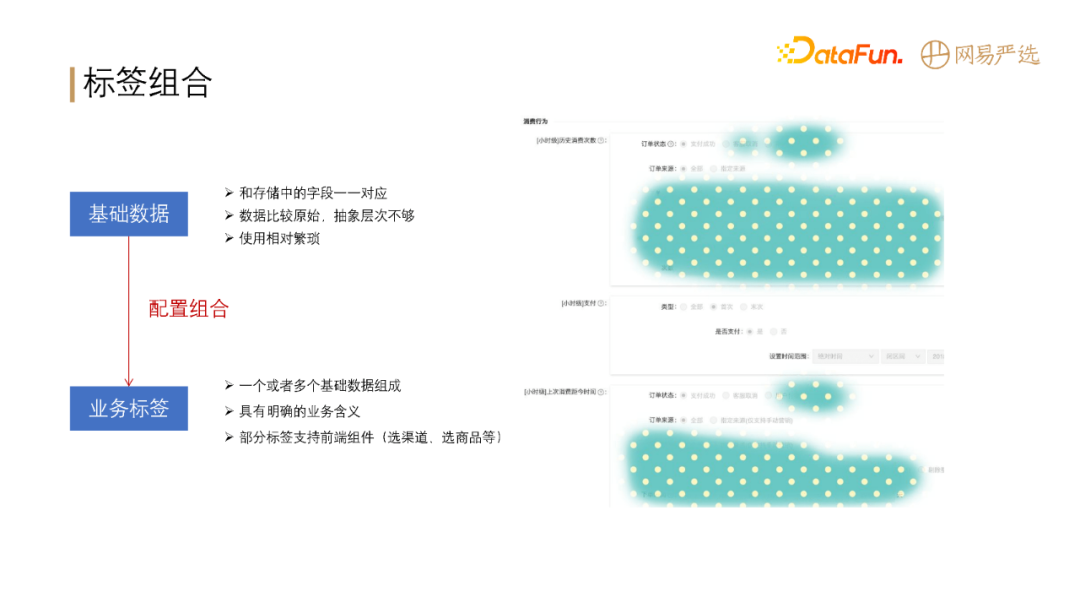
-
-**直接将 dm 层的数据不太方便拿来用,原因在于:**
-
-基础数据比较原始,抽象层次有所欠缺、使用相对繁琐。通过对基础数据进行与、或、非的组合,形成业务标签供业务方使用,可以降低运营的理解成本,降低使用难度。
-
-
-
-标签组合之后需要对标签进行具体业务场景应用,如人群圈选。配置如上图左侧所示,支持离线人群包和实时行为(需要分开配置)。
-
-配置完后,生成上图右侧所示的 DSL 规则,以 Json 格式表达,对前端比较友好,也可以转成存储引擎的查询语句。
-
-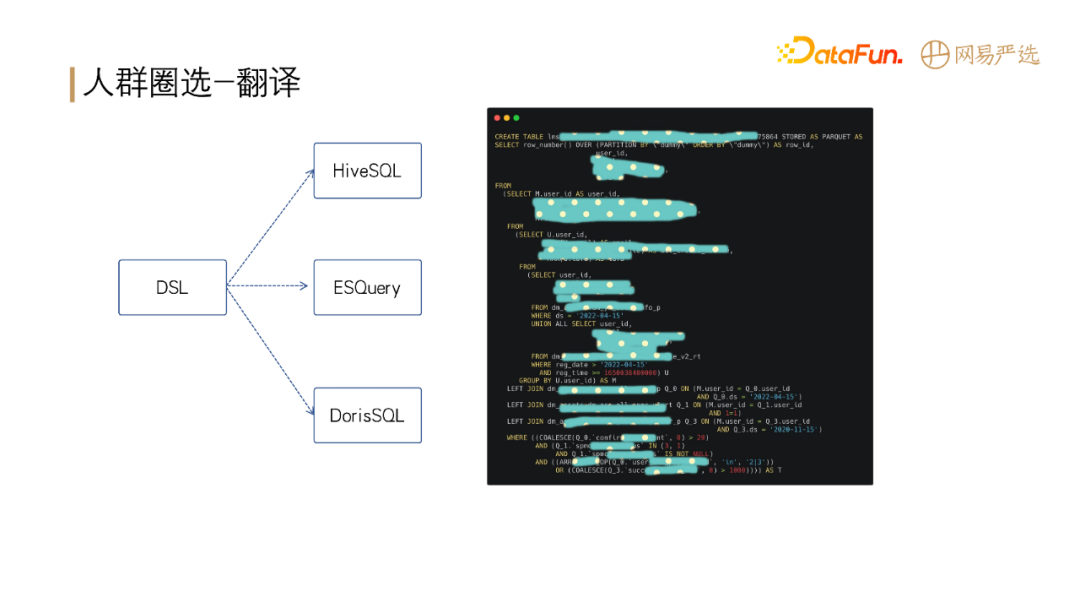
-
-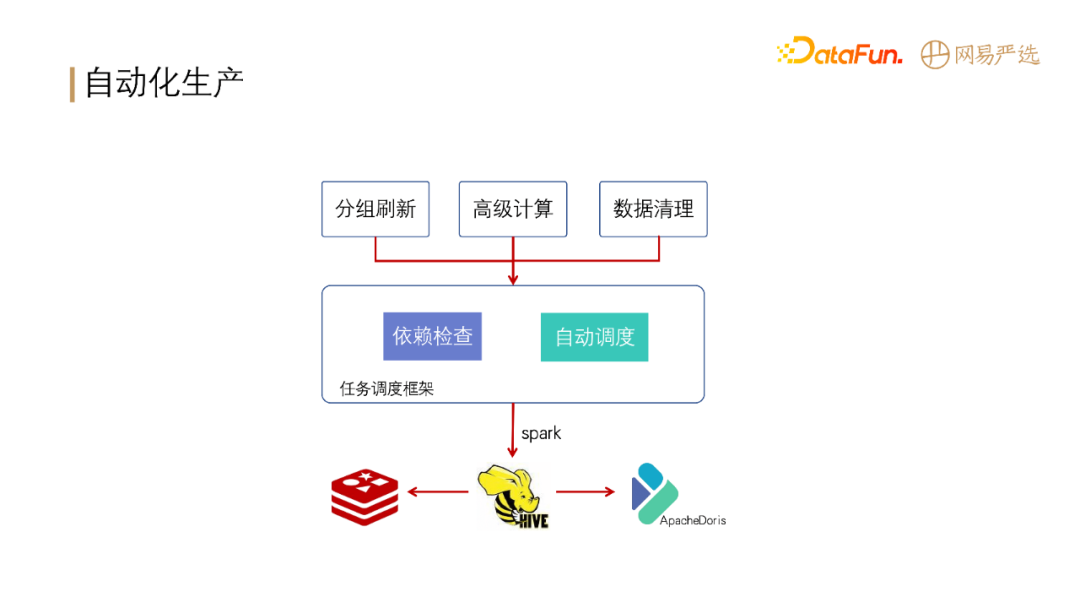
-
-标签有一部分实现了自动化。在人群圈选部分自动化程度比较高。比如分组刷新,每天定时刷新;高级计算,如分组与分组间的交/并/差集;数据清理,及时清理过期失效的实体集。
-
-# 标签存储
-
-**下面介绍一下我们在标签存储方面的实践。**
-
-严选 DMP 标签系统需要承载比较大的 C端流量,对实时性要求也比较高。
-
-我们对存储的要求包括:
-
-- 支持高性能查询,以应对大规模 C端流量
-- 支持 SQL,便于应对数据分析场景
-- 支持数据更新机制
-- 可存储大数据量
-- 支持扩展函数,以便处理自定义数据结构
-- 和大数据生态结合紧密
-
-目前还没有一款存储能够完全满足要求。
-
-**我们第一版的存储架构如下图所示:**
-
-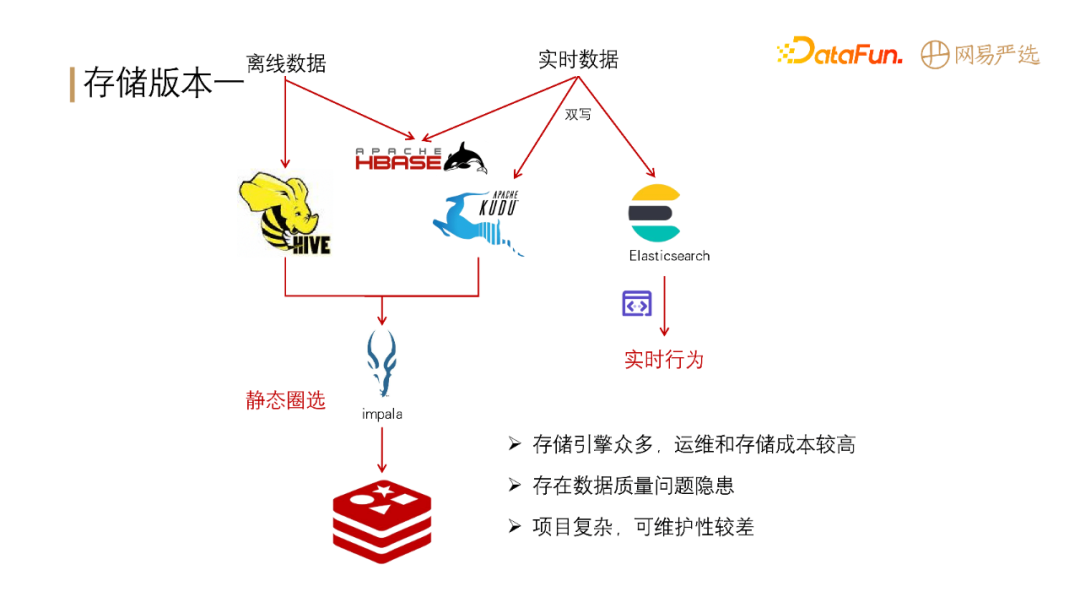
-
-离线数据大部分存储在 Hive 中,小部分存储在 Hbase(主要用于基础标签的查询)。实时数据一部分存储在 Hbase 中用于基础标签的查询,部分双写到 KUDU 和 ES 中,用于实时分组圈选和数据查询。离线圈选的数据通过 impala 计算出来缓存在 Redis 中。
-
-**这一版本的缺点包括:**
-
-- 存储引擎过多。
-- 双写有数据质量隐患,可能一方成功一方失败,导致数据不一致。
-- 项目复杂,可维护性较差。
-
-为了减少引擎和存储的使用量,提高项目可维护性,在版本一的基础上改进实现了版本二。
-
-**我们第二版的存储架构如下图所示:**
-
-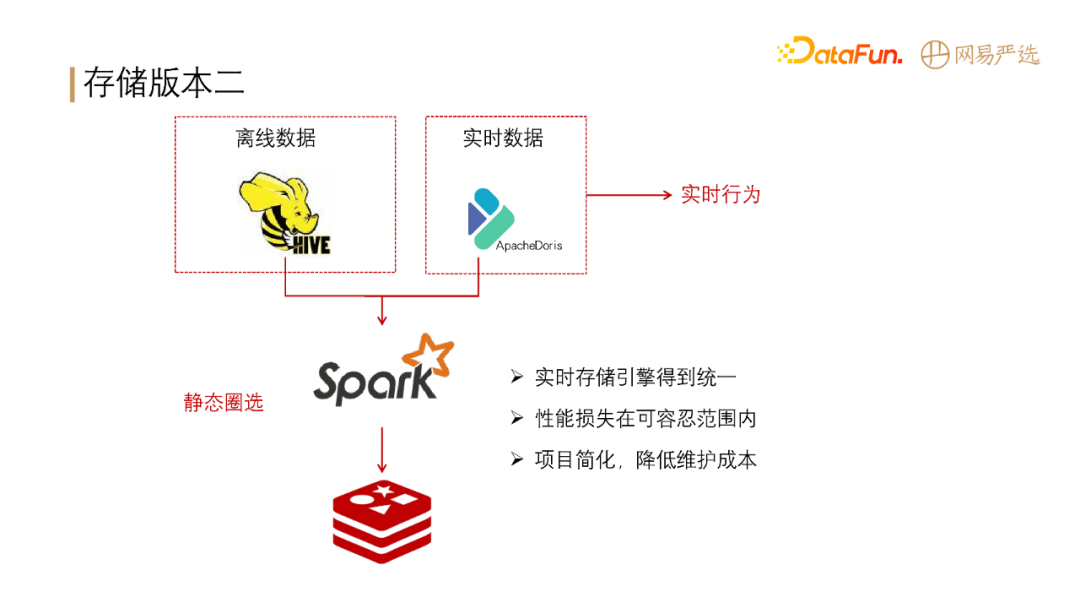
-
-**存储架构版本二引入了 Apache Doris**,离线数据主要存储在 Hive 中,同时将基础标签导入到 Doris,实时数据也存储在 Doris,基于 Spark 做 Hive 加 Doris 的联合查询,并将计算出来的结果存储在 Redis 中。经过此版改进后,实时离线引擎存储得到了统一,性能损失在可容忍范围内(Hbase 的查询性能比 Doris 好一些,能控制在 10ms 以内,Doris 目前是 1.0 版本,p99,查询性能能控制在 20ms 以内,p999,能控制在 50ms 以内);**项目简化,降低了运维成本。**
-
-**在大数据领域,各种存储计算引擎有各自的适用场景,如下表所示:**
-
-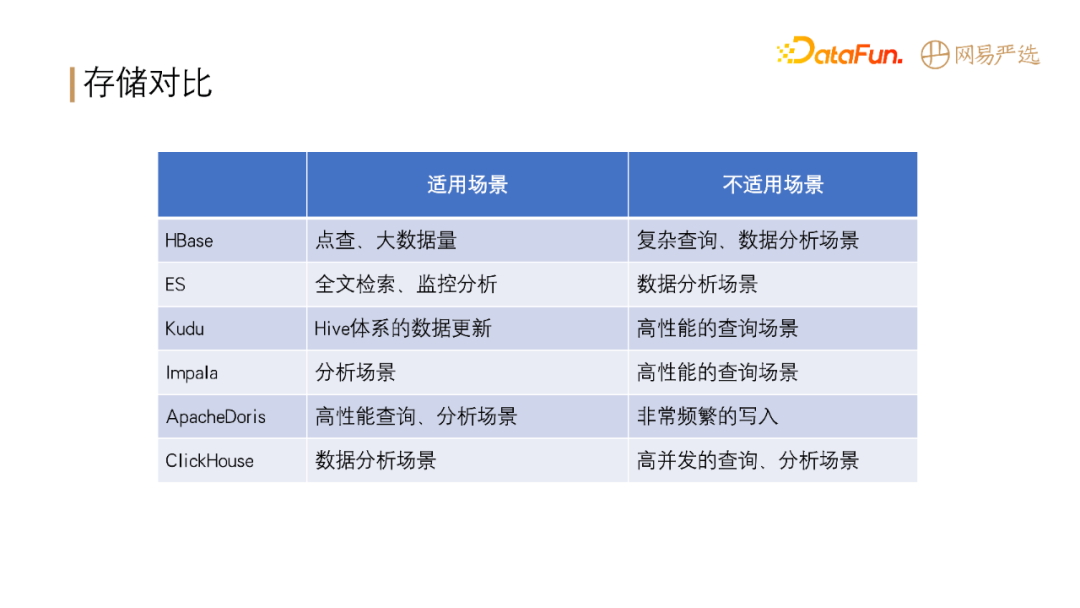
-
-# 高性能查询
-
-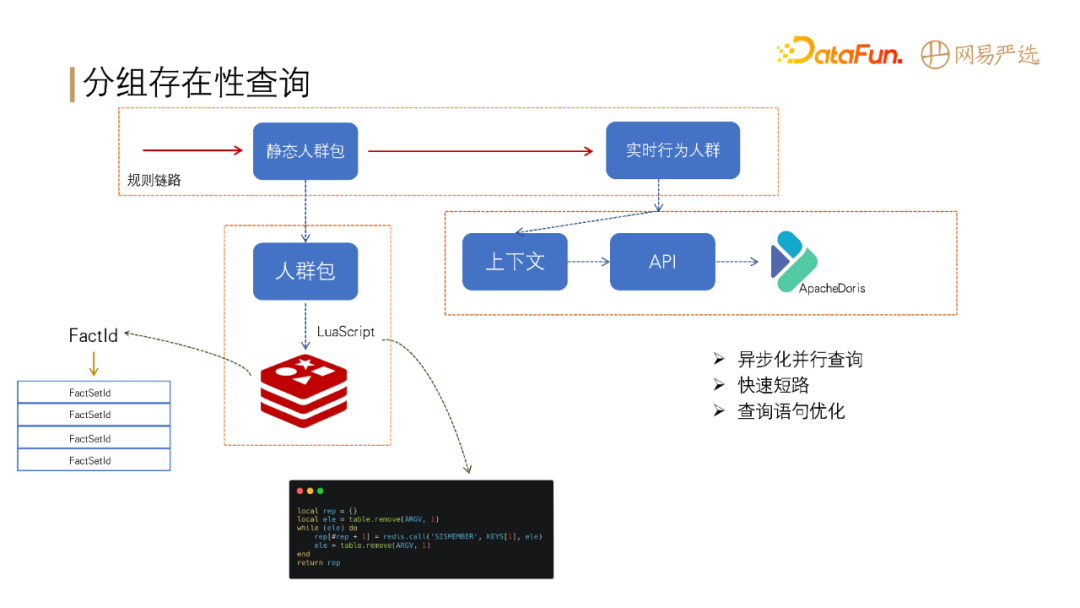
-
-分组存在性判断:判断用户是否在指定的一个分组或者多个分组。包括两大部分:
-
-- 第一部分为静态人群包,提前进行预计算,存入 Redis 中(Key 为实体的 ID,Value 为结果集 ID),采用 Lua 脚本进行批量判断,提升性能;
-- 第二部分为实时行为人群,需要从上下文、API 和 Apache Doris 中提取数据进行规则判断。性能提升方案包括,异步化查询、快速短路、查询语句优化、控制 Join表数量等。
-
-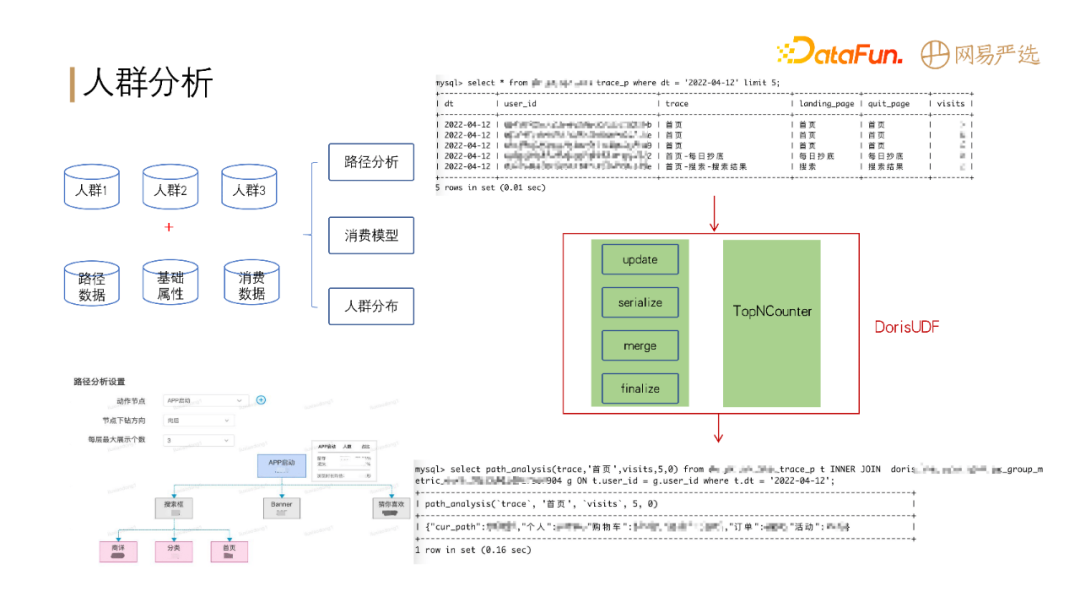
-
-还有一个场景是人群分析:人群分析需要将人群包数据同多个表进行联合查询,分析行为路径。目前 Doris 还不支持路径分析函数,因此我们开发了 DorisUDF 来支持此业务。**Doris 的计算模型对自定义函数的开发还是很友好的,能够比较好地满足我们的性能需要。**
-
-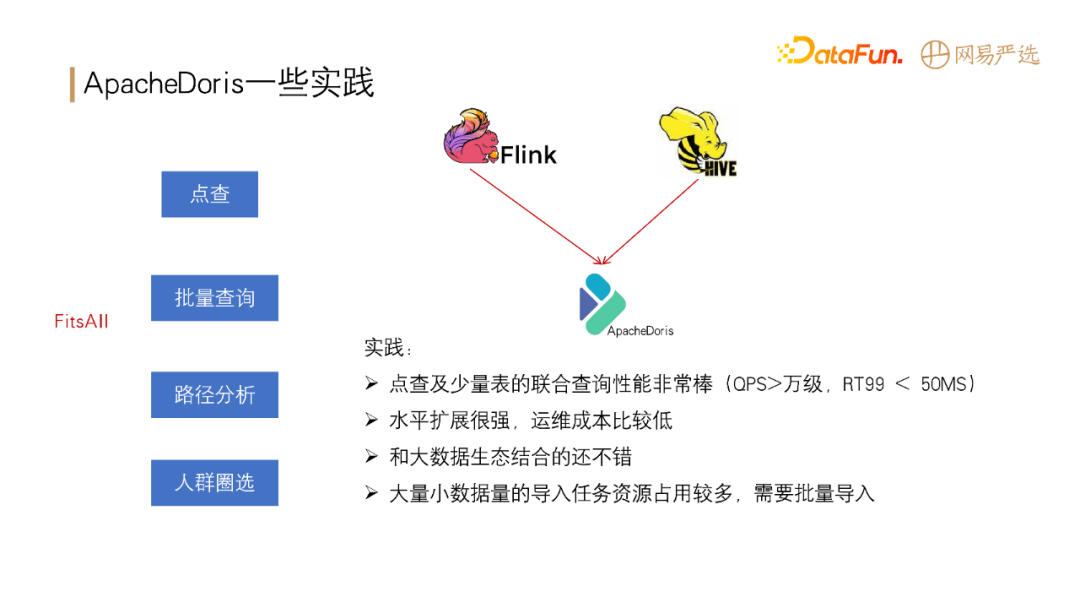
-
-**Apache Doris 在网易严选中已应用于点查、批量查询、路径分析、人群圈选等场景。在实践中具备以下优势:**
-
-- 在点查和少量表的联合查询性能 QPS 超过万级,RT99<50MS。
-- 水平扩展能力很强,运维成本相对比较低。
-- 离线数据和实时数据相统一,降低标签模型复杂度。
-
-不足之处在于大量小数据量的导入任务资源占用较多,待 Doris 1.1.2 版本正式发布后我们也会及时同步升级。不过此问题已经在 Doris 1.1 版本中进行了优化,**Doris 在 1.1 中大幅增强了数据 Compaction 能力,对于新增数据能够快速完成聚合,避免分片数据中的版本过多导致的 -235 错误以及带来的查询效率问题。**
-
-**具体可以参考:**[Apache Doris 1.1 特性揭秘:Flink 实时写入如何兼顾高吞吐和低延时](http://mp.weixin.qq.com/s?__biz=Mzg3Njc2NDAwOA==&mid=2247500848&idx=1&sn=a667665ed4ccf4cf807a47be7c264f69&chksm=cf2fca37f85843219e2f74d856478d4aa24d381c1d6e7f9f6a64b65f3344ce8451ad91c5af97&scene=21#wechat_redirect)
-
-# 未来规划
-
-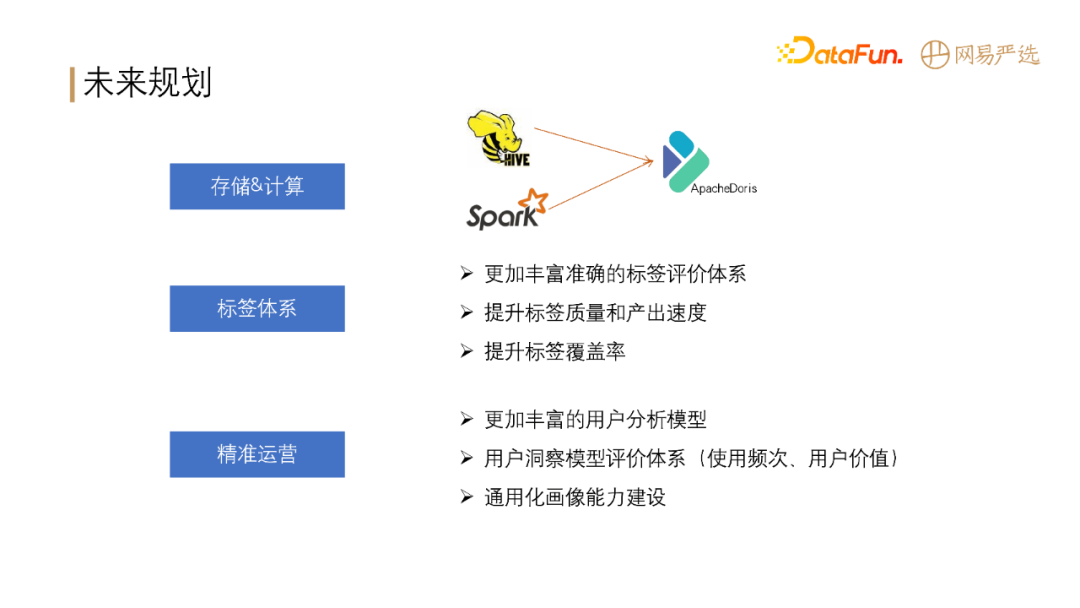
-
-**提升存储&计算性能**: Hive 和 Spark 逐渐全部转向 Apache Doris。
-
-**优化标签体系:**
-
-- 建立丰富准确的标签评价体系
-- 提升标签质量和产出速度
-- 提升标签覆盖率
-
-**更精准的运营**
-
-- 建立丰富的用户分析模型
-- 从使用频次和用户价值两个方面提升用户洞察模型评价体系
-- 建立通用化画像分析能力,辅助运营智能化决策
-
-
-
-# 资料下载
-
-关注公众号「**SelectDB**」,后台回复【**网易严选**】获取本次演讲 **PPT 资料**!
-
-
-**相关链接:**
-
-
-Apache Doris 官方网站:
-
-http://doris.apache.org
-
-Apache Doris Github:
-
-https://github.com/apache/doris
-
-Apache Doris 开发者邮件组:
-
-dev@doris.apache.org
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Tencent Music.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Tencent Music.md
deleted file mode 100644
index 9a4ebac2d19..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Tencent Music.md
+++ /dev/null
@@ -1,312 +0,0 @@
----
-{
- 'title': '从 ClickHouse 到 Apache Doris,腾讯音乐内容库数据平台架构演进实践',
- 'summary': "腾讯音乐内容库数据平台旨在为应用层提供库存盘点、分群画像、指标分析、标签圈选等内容分析服务,高效为业务赋能。目前,内容库数据平台的数据架构已经从 1.0 演进到了 4.0 ,经历了分析引擎从 ClickHouse 到 [Apache Doris](https://github.com/apache/doris) 的替换、经历了数据架构语义层的初步引入到深度应用,有效提高了数据时效性、降低了运维成本、解决了数据管理割裂等问题,收益显著。本文将为大家分享腾讯音乐内容库数据平台的数据架构演进历程与实践思考,希望所有读者从文章中有所启发。",
- 'date': '2023-03-07',
- 'author': '张俊 & 代凯',
- 'tags': ['最佳实践'],
-}
----
-
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-
-
-作者:腾讯音乐内容库数据平台 张俊、代凯
-
-腾讯音乐娱乐集团(简称“腾讯音乐娱乐”)是中国在线音乐娱乐服务开拓者,提供在线音乐和以音乐为核心的社交娱乐两大服务。腾讯音乐娱乐在中国有着广泛的用户基础,拥有目前国内市场知名的四大移动音乐产品:QQ音乐、酷狗音乐、酷我音乐和全民K歌,总月活用户数超过8亿。
-
-
-
-# 业务需求
-
-腾讯音乐娱乐拥有海量的内容曲库,包括录制音乐、现场音乐、音频和视频等多种形式。通过技术和数据的赋能,腾讯音乐娱乐持续创新产品,为用户带来更好的产品体验,提高用户参与度,也为音乐人和合作伙伴在音乐的制作、发行和销售方面提供更大的支持。
-
-在业务运营过程中我们需要对包括歌曲、词曲、专辑、艺人在内的内容对象进行全方位分析,高效为业务赋能,**内容库数据平台旨在集成各数据源的数据,整合形成内容数据资产(以指标和标签体系为载体),为应用层提供库存盘点、分群画像、指标分析、标签圈选等内容分析服务。**
-
-
-
-# 数据架构演进
-
-TDW 是腾讯最大的离线数据处理平台,公司内大多数业务的产品报表、运营分析、数据挖掘等的存储和计算都是在TDW中进行,内容库数据平台的数据加工链路同样是在腾讯数据仓库 TDW 上构建的。截止目前,内容库数据平台的数据架构已经从 1.0 演进到了 4.0 ,**经历了分析引擎从 ClickHouse 到 Apache Doris 的替换、经历了数据架构语义层的初步引入到深度应用**,有效提高了数据时效性、降低了运维成本、解决了数据管理割裂等问题,收益显著。接下来将为大家分享腾讯音乐内容库数据平台的数据架构演进历程与实践思考。
-
-## 数据架构 1.0
-
-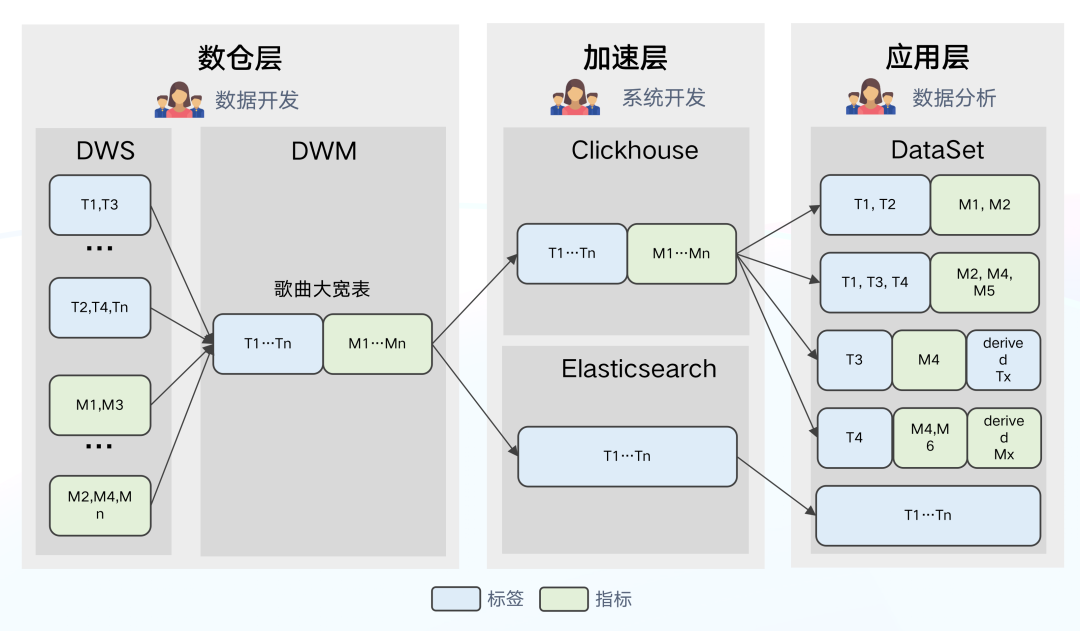
-
-如图所示为数据架构 1.0 架构图,分为数仓层、加速层、应用层三部分,数据架构 1.0 是一个相对主流的架构,简单介绍一下各层的作用及工作原理:
-
-- 数仓层:通过 ODS-DWD-DWS 三层将数据整合为不同主题的标签和指标体系, DWM 集市层围绕内容对象构建大宽表,从不同主题域 DWS 表中抽取字段。
-- 加速层:在数仓中构建的大宽表导入到加速层中,Clickhouse 作为分析引擎,Elasticsearch 作为搜索/圈选引擎。
-- 应用层:根据场景创建 DataSet,作为逻辑视图从大宽表选取所需的标签与指标,同时可以二次定义衍生的标签与指标。
-
-**存在的问题:**
-
-- 数仓层:不支持部分列更新,当上游任一来源表产生延迟,均会造成大宽表延迟,进而导致数据时效性下降。
-- 加速层:不同的标签跟指标特性不同、更新频率也各不相同。由于 ClickHouse 目前更擅长处理宽表场景,无区别将所有数据导入大宽表生成天的分区将造成存储资源的浪费,维护成本也将随之升高。
-- 应用层:ClickHouse 采用的是计算和存储节点强耦合的架构,架构复杂,组件依赖严重,牵一发而动全身,容易出现集群稳定性问题,对于我们来说,同时维护 ClickHouse 和 Elasticsearch 两套引擎的连接与查询,成本和难度都比较高。
-
-除此之外,ClickHouse 由国外开源,交流具有一定的语言学习成本,遇到问题无法准确反馈、无法快速获得解决,与社区沟通上的阻塞也是促进我们进行架构升级的因素之一。
-
-
-## 数据架构 2.0
-
-
-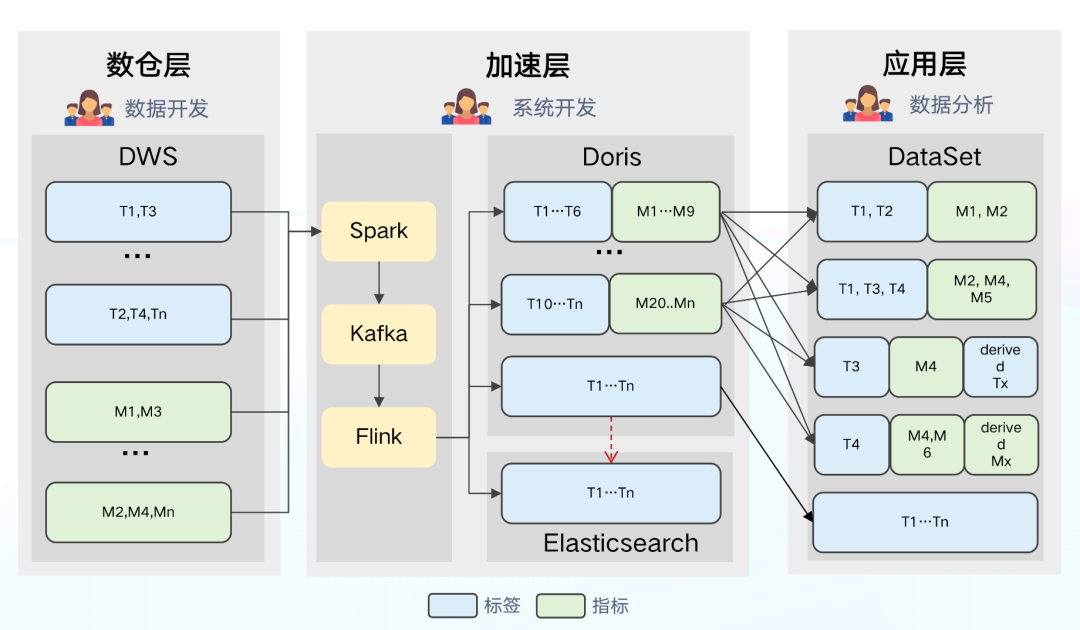
-
-
-基于架构 1.0 存在的问题和 ClickHouse 的局限性,我们尝试对架构进行优化升级,**将分析引擎 ClickHouse 切换为 Doris**,Doris 具有以下的优势:
-
-**Apache Doris 的优势:**
-
-- Doris 架构极简易用,部署只需两个进程,不依赖其他系统,运维简单;兼容 MySQL 协议,并且使用标准 SQL。
-- 支持丰富的数据模型,可满足多种数据更新方式,支持部分列更新。
-- 支持对 Hive、Iceberg、Hudi 等数据湖和 MySQL、Elasticsearch 等数据库的联邦查询分析。
-- 导入方式多样,支持从 HDFS/S3 等远端存储批量导入,也支持读取 MySQL Binlog 以及订阅消息队列 Kafka 中的数据,还可以通过 Flink Connector 实时/批次同步数据源(MySQL,Oracle,PostgreSQL 等)到 Doris。
-- 社区目前 Apache Doris 社区活跃、技术交流更多,SelectDB 针对社区有专职的技术支持团队,在使用过程中遇到问题均能快速得到响应解决。
-
-**同时我们也利用 Doris 的特性,解决了架构 1.0 中较为突出的问题。**
-
-- 数仓层:Apache Doris 的 Aggregate 数据模型可支持部分列实时更新,因此我们去掉了 DWM 集市层的构建,直接增量到 Doris / ES 中构建宽表,**解决了架构 1.0 中上游数据更新延迟导致整个宽表延迟的问题,进而提升了数据的时效性**。数据(指标、标签等)通过 Spark 统一离线加载到 Kafka 中,使用 Flink 将数据增量更新到 Doris 和 ES 中(利用 Flink 实现进一步的聚合,减轻了 Doris 和 ES 的更新压力)。
-- 加速层:该层主要将大宽表拆为小宽表,根据更新频率配置不同的分区策略,减小数据冗余带来的存储压力,提高查询吞吐量。**Doris 具备多表查询和联邦查询性能特性,可以利用多表关联特性实现组合查询。**
-- 应用层:DataSet 统一指向 Doris,**Doris 支持外表查询**,利用该特性可对 ES 引擎直接查询。
-
-**架构 2.0 存在的问题:**
-
-- DataSet 灵活度较高,数据分析师可对指标和标签自由组合和定义,但是不同的分析师对同一数据的定义不尽相同、定义口径不一致,导致指标和标签缺乏统一管理,这使得数据管理和使用的难度都变高。
-- Dataset 与物理位置绑定,应用层无法进行透明优化,如果 Doris 引擎出现负载较高的情况,无法通过降低用户查询避免集群负载过高报错的问题。
-
-## 数据架构 3.0
-
-针对指标和标签定义口径不统一,数据使用和管理难度较高的问题,我们继续对架构进行升级。数据架构 3.0 主要的变化是引入了专门的语义层,语义层的主要作用是将技术语言转换为业务部门更容易理解的概念,目的是将标签 (tag)与指标(metric)变为“一等公民”,作为数据定义与管理的基本对象。
-
-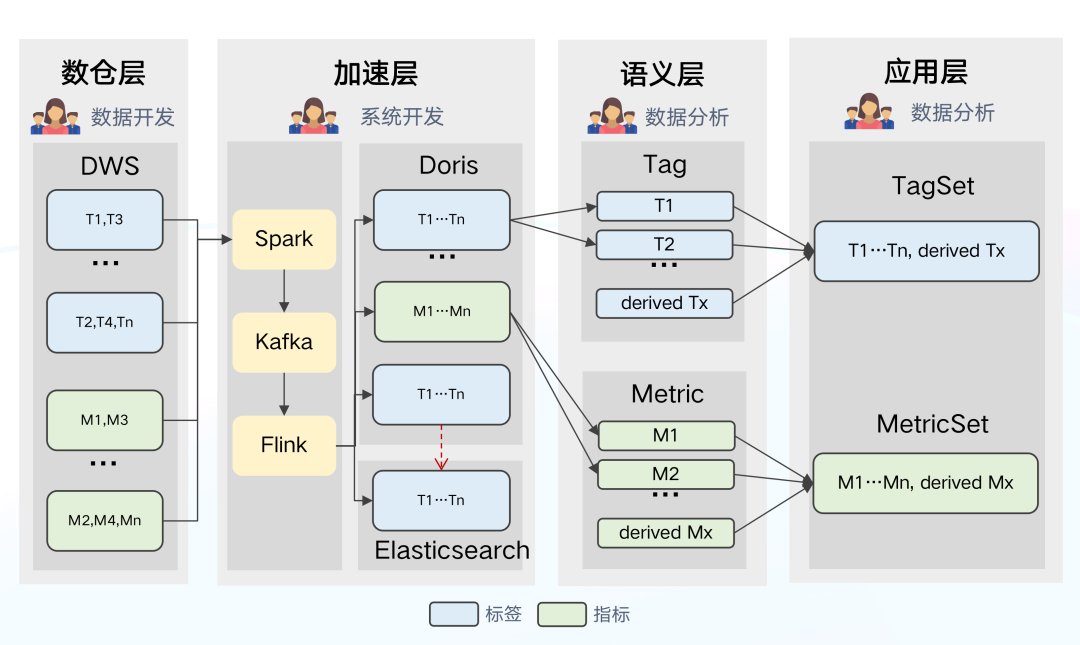
-
-**引入语义层的优势有:**
-
-- 对于技术来说,应用层不再需要创建 DataSet,从语义层可直接获取特定内容对象的标签集 (tagset)和指标集(metricset) 来发起查询。
-- 对于数据分析师来说,可统一在语义层定义和创建衍生的指标和标签,解决了定义口径不一致、管理和使用难度较高的问题。
-- 对于业务来说,无需耗费过长时间考虑什么场景应选择哪个数据集使用,语义层对标签和指标透明统一的定义提升了工作效率、降低了使用成本。
-
-**存在的问题:**
-
-从架构图可知,标签和指标等数据均处于下游位置,虽然标签与指标在语义层被显式定义,但仍然无法影响上游链路,数仓层有自己的语义逻辑,加速层有自己的导入配置,**这样就造成了数据管理机制的割裂**。
-
-## 数据架构 4.0
-
-在数据架构 3.0 的基础上,我们对语义层进行更深层次的应用,在数据架构 4.0 中,我们将语义层变为架构的中枢节点,目标是对所有的指标和标签统一定义,从计算-加速-查询实现中心化、标准化管理,解决数据管理机制割裂的问题。
-
-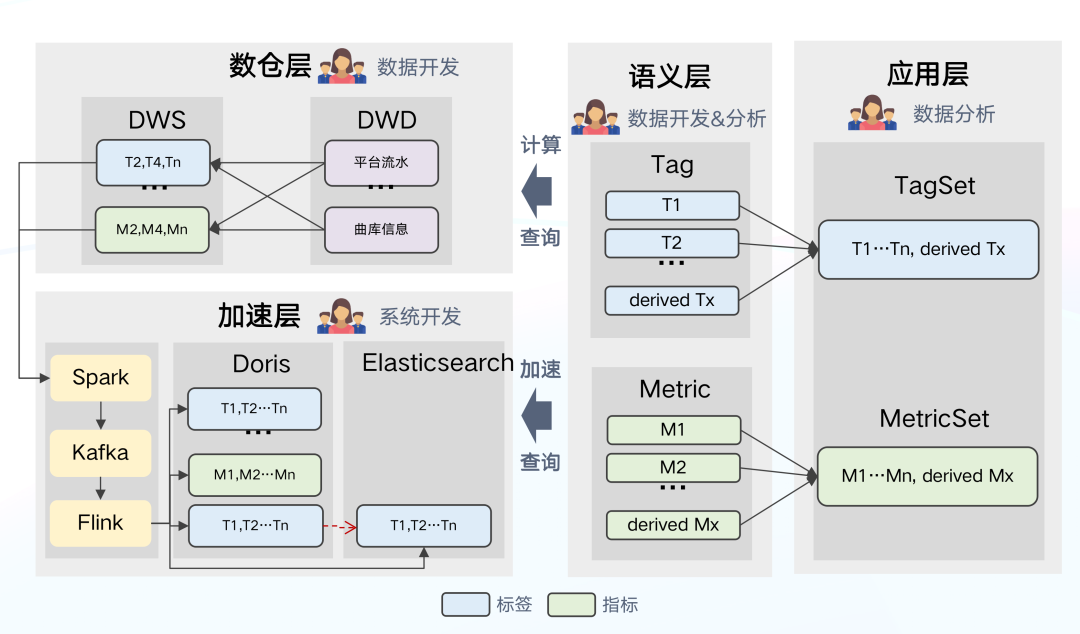
-
-语义层作为架构中枢节点所带来的变化:
-
-- 数仓层:语义层接收 SQL 触发计算或查询任务。数仓从 DWD 到 DWS 的计算逻辑将在语义层中进行定义,且以单个指标和标签的形式进行定义,之后由语义层来发送命令,生成 SQL 命令给数仓层执行计算。
-- 加速层:从语义层接收配置、触发导入任务,比如加速哪些指标与标签均由语义层指导。
-- 应用层:向语义层发起逻辑查询,由语义层选择引擎,生成物理 SQL。
-
-**架构优势:**
-
-- 可以形成统一视图,对于核心指标和标签的定义进行统一查看及管理。
-- 应用层与物理引擎完成解耦,可进一步对更加灵活易用的架构进行探索:如何对相关指标和标签进行加速,如何在时效性和集群的稳定性之间平衡等。
-
-**存在的问题:**
-
-因为当前架构是对单个标签和指标进行了定义,因此如何在查询计算时自动生成一个准确有效的 SQL 语句是非常有难度的。如果你有相关的经验,期待有机会可以一起探索交流。
-
-
-# 优化经验
-
-从上文已知,为更好地实现业务需求,数据架构演进到 4.0 版本,其中 **Apache Doris 作为分析加速场景的解决方案在整个系统中发挥着重要的作用**。接下来将从场景需求、数据导入、查询优化以及成本优化四个方面出发,分享基于 Doris 的读写优化经验,希望给读者带来一些参考。
-
-## 场景需求
-
-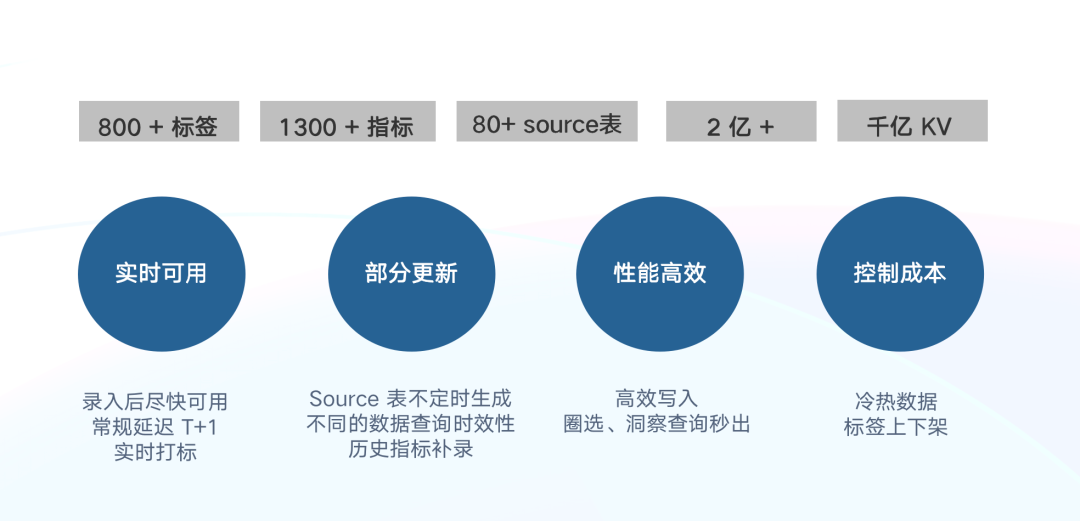
-
-目前我们有 800+ 标签, 1300+ 指标,对应 TDW 中有 80 + Source 表,单个标签、指标的最大基数达到了 2 亿+。我们希望将这些数据从 TDW 加速到 Doris 中完成标签画像和指标的分析。**从业务的角度,需要满足以下要求:**
-
-- **实时可用**:标签/指标导入以后,需实现数据尽快可用。不仅要支持常规离线导入 T+1 ,同时也要支持实时打标场景。
-- **部分更新**:因每个 Source 表由各自 ETL 任务产出对应的数据,其产出时间不一致,并且每个表只涉及部分指标或标签,不同数据查询对时效性要求也不同,因此架构需要支持部分列更新。
-- **性能高效**:具备高效的写入能力,且在圈选、洞察、报表等场景可以实现秒级响应。
-- **控制成本**:在满足业务需求的前提下,最大程度地降低成本;支持冷热数据精细化管理,支持标签灵活上下架。
-
-## 数据导入方案
-
-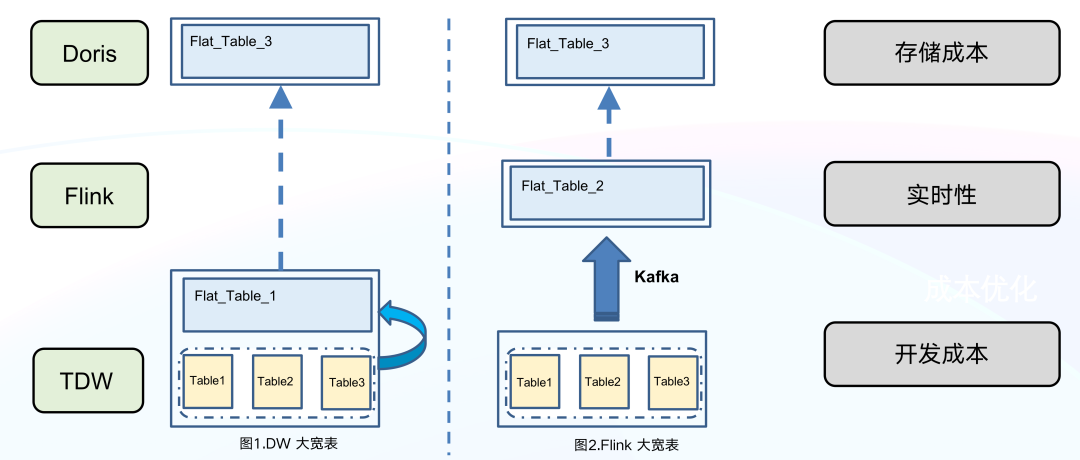
-
-为了减轻 Doris 写入压力,我们考虑在数据写入 Doris 之前,尽量将数据生成宽表,再写入到 Doris 中。**针对宽表的生成,我们有两个实现思路**:第一个是在 TDW 数仓中生成宽表;第二个是 Flink 中生成宽表。我们对这两个实现思路进行了实践对比,最终决定选择第二个实现思路,原因如下:
-
-在 TDW 中生成宽表,虽然链路简单,但是弊端也比较明显。
-
-- 存储成本较高, TDW 除了要维护离散的 80 +个 Source 表外,还需维护 1 个大宽表、2 份冗余的数据。
-- 实时性比较差,由于每个 Source 表产出的时间不一样,往往会因为某些延迟比较大的 Source 表导致整个数据链路延迟增大。
-- 开发成本较高,该方案只能作为离线方式,若想实现实时方式则需要投入开发资源进行额外的开发。
-
-而**在 Flink 中生成宽表,链路简单、成本低也容易实现**,主要流程是:首先用 Spark 将相关 Source 表最新数据离线导入到 Kafka 中, 接着使用 Flink 来消费 Kafka,并通过主键 ID 构建出一张大宽表,最后将大宽表导入到 Doris 中。如下图所示,来自数仓 N 个表中 ID=1 的 5 条数据,经过 Flink 处理以后,只有一条 ID=1 的数据写入 Doris 中,大大减少 Doris 写入压力。
-
-
-
-通过以上导入优化方案,**极大地降低了存储成本**, TDW 无需维护两份冗余的数据,Kafka 也只需保存最新待导入的数据。同时该方案**整体实时性更好且可控**,并且大宽表聚合在 Flink 中执行,可灵活加入各种 ETL 逻辑,离线和实时可对多个开发逻辑进行复用,**灵活度较高**。
-
-### **数据模型选择**
-
-目前我们生产环境所使用的版本为 Apache Doris 1.1.3,我们对其所支持的 Unique 主键模型、Aggregate 聚合模型和 Duplicate 明细模型进行了对比 ,相较于 Unique 模型和 Duplicate 模型,**Aggregate 聚合模型满足我们部分列更新的场景需求**:
-
-Aggregate 聚合模型可以支持多种预聚合模式,可以通过`REPLACE_IF_NOT_NULL`的方式实现部分列更新。数据写入过程中,Doris 会将多次写入的数据进行聚合,最终用户查询时,返回一份聚合后的完整且正确的数据。
-
-另外两种数据模型适用的场景,这里也进行简单的介绍:
-
-- Unique 模型适用于需要保证 Key 唯一性场景,同一个主键 ID 多次导入之后,会以 append 的方式进行行级数据更新,仅保留最后一次导入的数据。在与社区进行沟通后,确定**后续版本 Unique 模型也将支持部分列更新**。
-- Duplicate 模型区别于 Aggregate 和 Unique 模型,数据完全按照导入的明细数据进行存储,不会有任何预聚合或去重操作,即使两行数据完全相同也都会保留,因此 Duplicate 模型适用于既没有聚合需求,又没有主键唯一性约束的原始数据存储。
-
-确定数据模型之后,我们在建表时如何对列进行命名呢?可以直接使用指标或者是标签的名称吗?
-
-在使用场景中通常会有以下几个需求:
-
-- 为了更好地表达数据的意义,业务方会有少量修改标签、指标名称的需求。
-- 随着业务需求的变动,标签经常存在上架、下架的情况。
-- 实时新增的标签和指标,用户希望数据尽快可用。
-
-Doris 1.1.3 是不支持对列名进行修改的,如果直接使用指标/标签名称作为列名,则无法满足上述标签或指标更名的需求。而对于上下架标签的需求,如果直接以 drop/add column 的方式实现,则会涉及数据文件的更改,该操作耗时耗力,甚至会影响线上查询的性能。
-
-那么,有没有更轻量级的方式来满足需求呢?接下来将为大家分享相关解决方案及收益:****
-
-- **为了实现少量标签、指标名称修改**,我们用 MySQL 表存储相应的元数据,包括名称、全局唯一的 ID 和上下架状态等信息,比如标签歌曲名称`song_name`的 ID 为 4,在 Doris 中存储命名为 a4,用户使用更具有业务含义`song_name`进行查询。在查询 Doris 前,我们会在查询层将 SQL 改写成具体的列名 a4。这样名称的修改只是修改其元数据,底层 Doris 的表结构可以保持不变。
-- **为了实现标签灵活上下架**,我们通过统计标签的使用情况来分析标签的价值,将低价值的标签进入下架流程。下架指的是对元信息进行状态标注,在下架标签重新上架之前,不会继续导入其数据,元信息中数据可用时间也不会发生变化。
-- **对于实时新增标签/指标**,我们基于名称 ID 的映射在 Doris 表中预先创建适量 ID 列,当标签/指标完成元信息录入后,直接将预留的 ID 分配给新录入的标签/指标,避免在查询高峰期因新增标签/指标所引起的 Schema Change 开销对集群产生的影响。经测试,用户在元信息录入后 10 分钟内就可以使用相应的数据。
-
-值得关注的是,**在社区近期发布的 1.2.0 版本中,增加了 Light Schema Change 功能, 对于增减列的操作不需要修改数据文件,只需要修改 FE 中的元数据,从而可以实现毫秒级的 Schame Change 操作**。同时开启 Light Schema Change 功能的数据表也可以支持列名的修改,这与我们的需求十分匹配,后续我们也会及时升级到最新版本。
-
-### **写入优化**
-
-接着我们在数据写入方面也进行了调整优化,这里几点小经验与大家分享:
-
-- Flink 预聚合:通过主键 ID 预聚合,减少写入压力。(前文已说明,此处不再赘述)
-- 写入 Batch 大小自适应变更:为了不占用过多 Flink 资源,我们实现了从同一个 Kafka Topic 中消费数据写入到不同 Doris 表中的功能,并且可以根据数据的大小自动调整写入的批次,尽量做到攒批低频写入。
-- Doris 写入调优:针对- 235 报错进行相关参数的调优。比如设置合理的分区和分桶(Tablet 建议1-10G),同时结合场景对 Compaction 参数调优:
-
-```
-max_XXXX_compaction_thread
-max_cumulative_compaction_num_singleton_deltas
-```
-
-- 优化 BE 提交逻辑:定期缓存 BE 列表,按批次随机提交到 BE 节点,细化负载均衡粒度。
-
-> 优化背景:在写入时发现某一个 BE负载会远远高于其他的 BE,甚至出现 OOM。结合源码发现:作业启动后会获取一次 BE 地址列表,从中随机选出一个 BE 作为 Coordinator 协调者,该节点主要负责接收数据、并分发到其他的 BE 节点,除非作业异常报错,否则该节点不会发生切换。
->
-> 对于少量 Flink 作业大数据场景会导致选中的 BE 节点负载较高,因此我们尝试对 BE 提交逻辑进行优化,设置每 1 小时缓存一次 BE 列表,每写入一个批次都随机从 BE 缓存列表中获取一个进行提交,这样负载均衡的粒度就从 job 级别细化到每次提交的批次,使得 BE 间负载更加的均衡,这部分实现我们已经贡献到社区,欢迎大家一起使用并反馈。
->
-> - https://github.com/apache/doris-spark-connector/pull/59
-> - https://github.com/apache/doris-spark-connector/pull/60
-> - https://github.com/apache/doris-spark-connector/pull/61
-
-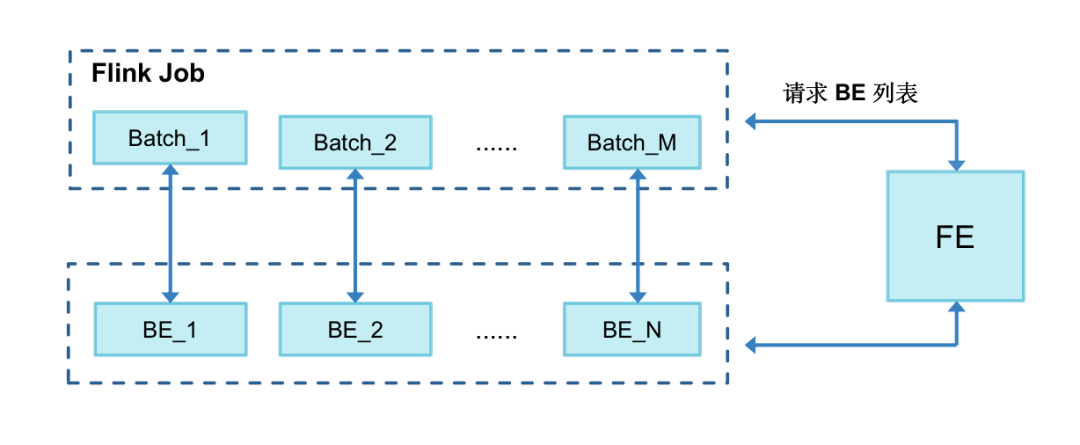
-
-通过以上数据导入的优化措施,使得整体导入链路更加稳定,每日离线**导入时长下降了 75%** ,数据版本累积情况也有所改善,其中 cumu compaction 的**合并分数更是从 600+直降到 100 左右**,优化效果十分明显。
-
-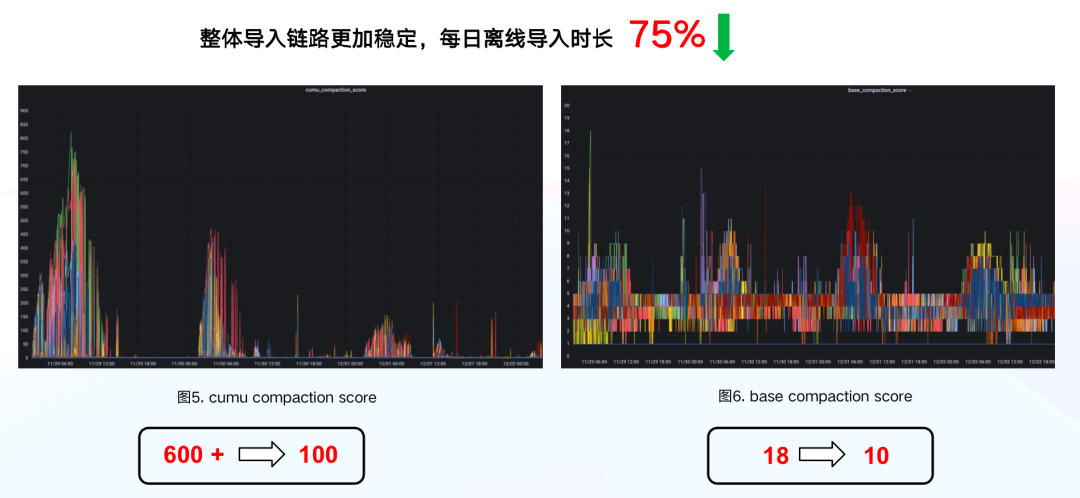
-
-## 查询优化
-
-目前我们的场景指标数据是以分区表的形式存储在 Doris 中, ES 保留一份全量的标签数据。在我们的使用场景中,标签圈选的使用率很高,大约有 60% 的使用场景中用到了标签圈选,在标签圈选场景中,通常需要满足以下几个要求:
-
-- 用户圈选逻辑比较复杂,数据架构需要支持同时有上百个标签做圈选过滤条件。
-- 大部分圈选场景只需要最新标签数据,但是在指标查询时需要支持历史的数据的查询。
-- 基于圈选结果,需要进行指标数据的聚合分析。
-- 基于圈选结果,需要支持标签和指标的明细查询。
-
-经过调研,我们最终采用了 **Doris on ES 的解决方案**来实现以上要求,将 Doris 的分布式查询规划能力和 ES 的全文检索能力相结合。Doris on ES 主要查询模式如下所示:
-
-```
-SELECT tag, agg(metric)
- FROM Doris
- WHERE id in (select id from Es where tagFilter)
- GROUP BY tag
-```
-
-在 ES 中圈选查询出的 ID 数据,以子查询方式在 Doris 中进行指标分析。
-
-我们在实践中发现,查询时长跟圈选的群体大小相关。如果从 ES 中圈选的群体规模超过 100 万时,查询时长会达到 60 秒,圈选群体再次增大甚至会出现超时报错。经排查分析,主要的耗时包括两方面:
-
-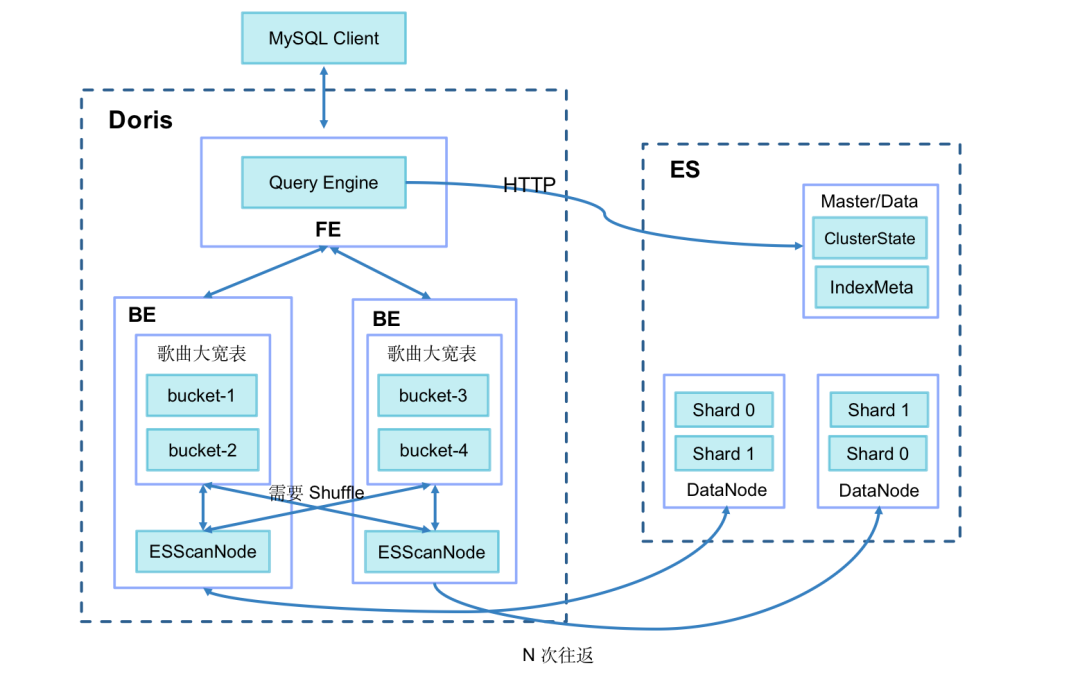
-
-- BE 从 ES 中拉取数据(默认一次拉取 1024 行),对于 100 万以上的群体,网络 IO 开销会很大。
-- BE 数据拉取完成以后,需要和本地的指标表做 Join,一般以 SHUFFLE/BROADCAST 的方式,成本较高。
-
-**针对这两点,我们进行了以下优化:**
-
-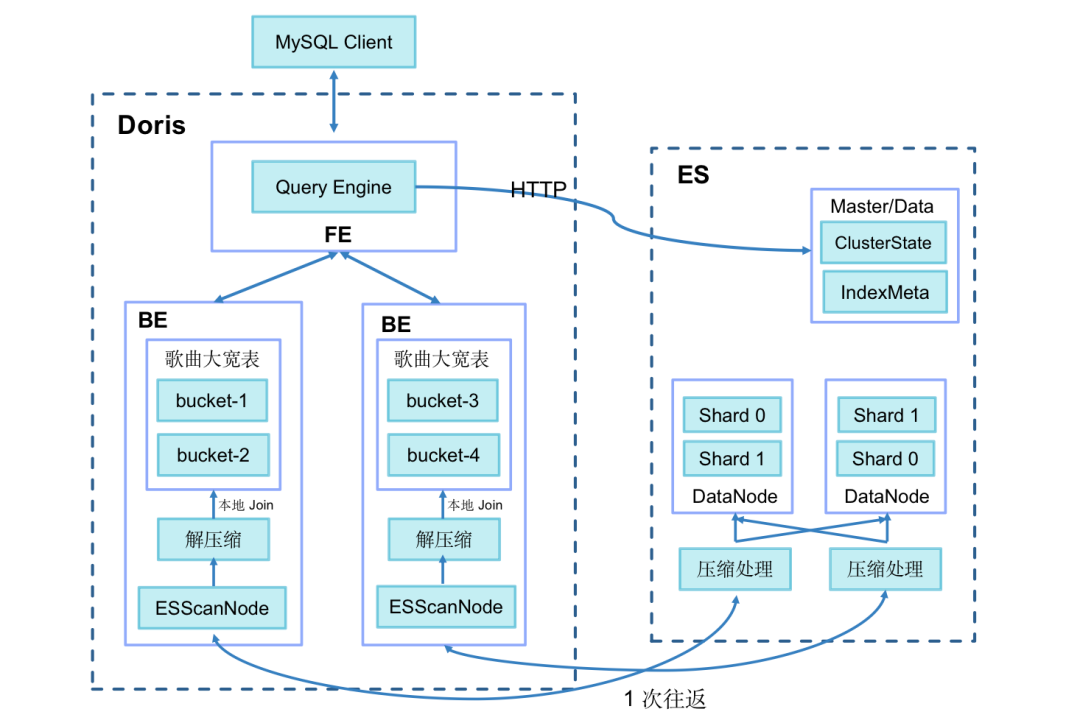
-
-- 增加了查询会话变量`es_optimize`,以开启优化开关;
-- 数据写入 ES 时,新增 BK 列用来存储主键 ID Hash 后的分桶序号,算法和 Doris 的分桶算法相同(CRC32);
-- BE 生成 Bucket Join 执行计划,将分桶序号下发到 BE ScanNode 节点,并下推到 ES;
-- ES 对查询出的数据进行 Bitmap 压缩,并将数据的多批次获取优化为一次获取,减少网络 IO 开销;
-- Doris BE 只拉取和本地 Doris 指标表相关 Bucket 的数据,直接进行本地 Join,避免 Doris BE 间数据再 Shuffle 的过程。
-
-通过以上优化措施,**百万分群圈选洞察查询时间从最初的 60 秒缩短到 3.7 秒**,性能显著提升!
-
-经过与社区沟通交流,**Apache Doris 从 2.0.0 版本开始,将支持倒排索引**。可进行文本类型的全文检索;支持中文、英文分词;支持文本、数值日期类型的等值和范围过滤;倒排索引对数组类型也提供了支持,多个过滤条件可以任意进行 AND OR NOT 逻辑组合。由于高性能的向量化实现和面向 AP 数据库的精简优化,**Doris 的倒排索引相较于 ES 会有 3~5 倍性价比提升**,即将在 2 月底发布的 2.0 preview 版本中可用于功能评估和性能测试,相信在这个场景使用后会有进一步的性能提升。
-
-## 成本优化
-
-在当前大环境下,降本提效成为了企业的热门话题,**如何在保证服务质量的同时降低成本开销**,是我们一直在思考的问题。在我们的场景中,**成本优化主要得益于 Doris 自身优秀的能力**,这里为大家分享两点:
-
-**1、冷热数据进行精细化管理。**
-
-- 利用 Doris TTL 机制,在 Doris 中只存储近一年的数据,更早的数据放到存储代价更低的 TDW 中;
-- 支持分区级副本设置,3 个月以内的数据高频使用,分区设置为 3 副本 ;3-6 个月数据分区调整为 2 副本;6 个月之前的数据分区调整为1 副本;
-- 支持数据转冷, 在 SSD 中仅存储最近 7 天的数据,并将 7 天之前的数据转存到到 HDD 中,以降低存储成本;
-- 标签上下线,将低价值标签和指标下线处理后,后续数据不再写入,减少写入和存储代价。
-
-**2、降低数据链路成本。**
-
-Doris 架构非常简单,只有FE 和 BE 两类进程,不依赖其他组件,并通过一致性协议来保证服务的高可用和数据的高可靠,自动故障修复,运维起来比较容易;
-
-- 高度兼容 MySQL 语法,支持标准 SQL,极大降低开发人员接入使用成本;
-- 支持多种联邦查询方式,支持对 Hive、MySQL、Elasticsearch 、Iceberg 等组件的联邦查询分析,降低多数据源查询复杂度。
-
-通过以上的方式,**使得存储成本降低 42%,开发与时间成本降低了 40%** ,成功实现降本提效,后续我们将继续探索!
-
-
-# 未来规划
-
-未来我们还将继续进行迭代和优化,我们计划在以下几个方向进行探索:
-
-- 实现自动识别冷热数据,用 Apache Doris 存储热数据,Iceberg 存储冷数据,利用 Doris 湖仓一体化能力简化查询。
-- 对高频出现的标签/指标组合,通过 Doris 的物化视图进行预计算,提升查询的性能。
-- 探索 Doris 应用于数仓计算任务,利用物化视图简化代码逻辑,并提升核心数据的时效性。
-
-最后,感谢 Apache Doris 社区和 [SelectDB](https://selectdb.com) 的同学,感谢其快速响应和积极支持,未来我们也会持续将相关成果贡献到社区,希望 Apache Doris 飞速发展,越来越好!
-
-**# 相关链接:**
-
-**SelectDB 官网**:
-
-https://selectdb.com
-
-**Apache Doris 官网**:
-
-http://doris.apache.org
-
-**Apache Doris Github**:
-
-https://github.com/apache/doris
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Tianyancha.md b/i18n/zh-CN/docusaurus-plugin-content-blog/Tianyancha.md
deleted file mode 100644
index 15244d407d9..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Tianyancha.md
+++ /dev/null
@@ -1,175 +0,0 @@
----
-{
- 'title': '秒级数据写入,毫秒查询响应,天眼查基于 Apache Doris 构建统一实时数仓',
- 'summary': "天眼查引入 Apache Doris 对数仓架构进行升级改造,实现了数据门户的统一,大大缩短了数据处理链路,数据导入速率提升 75 %,500 万及以下人群圈选可以实现毫秒级响应,收获了公司内部数据部门、业务方的一致好评",
- 'date': '2023-07-01',
- 'author': '王涛',
- 'tags': ['最佳实践'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-**导读:** 随着天眼查近年来对产品的持续深耕和迭代,用户数量也在不断攀升,业务的突破更加依赖于数据赋能,精细化的用户/客户运营也成为提升体验、促进消费的重要动力。在这样的背景下正式引入 Apache Doris 对数仓架构进行升级改造,实现了数据门户的统一,大大缩短了数据处理链路,数据导入速率提升 75 %,500 万及以下人群圈选可以实现毫秒级响应,收获了公司内部数据部门、业务方的一致好评。
-
-**作者:** 王涛,天眼查实时计算负责人
-
-# 业务需求
-
-天眼查的数据仓库主要服务于三个业务场景,每个场景都有其特点和需求,具体如下:
-
-1. **亿级用户人群圈选:** 人群圈选场景中目前有 100+ 人群包,我们需要根据 SQL 条件圈选人群包,来支持人群包的交并差、人群包实时圈选和人群包更新通知下游等需求。例如:圈选出下单未支付超过 5 分钟的用户,我们通过用户标签可以直观掌握用户支付状态,为运营 & 营销团队提供更精细化的人群管理服务,从而提高转化率。
-1. **多元活动支撑的精准营销:** 该场景目前支持了 1000 多个指标,可支持即席查询,根据活动效果及时调整运营策略。例如在“开工季”活动中,需要为数据分析 & 运营团队提供数据支持,从而生成可视化的活动驾驶舱。
-1. **高并发的 C 端分析数据:** 该场景承载了 3 亿+实体(多种维度)的数据体量,同时要求实时更新,以供用户进行数据分析。
-
-# 原有架构及痛点
-
-为满足各业务场景提出的需求,我们开始搭建第一代数据仓库,即原有数仓:
-
-
-
-在原有数仓架构中, Hive 作为数据计算层,MySQL、ES、PG 作为数据存储层,我们简单介绍一下架构的运行原理:
-
-- **数据源层和数据接入层:** MySQL 通过 Canal 将 BinLog 接入 Kafka、埋点日志通过 Flume 接入 Kafka,最后由 DataX 把 Kafka 中的数据接入数据计算层 Hive 中;
-- **数据计算层:** 该层使用 Hive 中的传统的数仓模型,并利用海豚调度使数据通过 ODS -> DWD -> DWS 分层,最后通过 DataX 将 T+1 把数据导入到数据存储层的 MySQL 和 ES 中。
-- **数据存储层:** MySQL 主要为 DataBank、Tableau、C 端提供分析数据,ES 用于存储用户画像数据,PG 用于人群包的存储(PG 安装的插件具有 Bitmap 交并差功能),ES、PG 两者均服务于 DMP人群圈选系统。
-
-**问题与挑战:**
-
-依托于原有架构的投入使用,初步解决了业务方的需求,但随着天眼查近年来对产品的持续深耕和迭代,用户数量也在不断攀升,业务的突破更加依赖于数据赋能。精细化的用户/客户运营也成为提升体验、促进消费的重要动力。在这样的背景下,原有架构的缺点逐渐暴露:
-
-1. 开发流程冗长:体现在数据处理链路上,比如当面对一个简单的开发需求,需要先拉取数据,再经过 Hive 计算,然后通过 T+1更新导入数据等,数据处理链路较长且复杂,非常影响开发效率。
-1. 不支持即席查询:体现在报表服务和人群圈选场景中,所用的指标无法根据条件直接查询,必须提前进行定义和开发。
-1. T+1 更新延迟高:T+1 数据时效性已经无法提供精确的线索,主要体现在报表和人群圈选场景上。
-1. 运维难度高:原有架构具有多条数据处理链路、多组件耦合的特点,运维和管理难度都很高。
-
-# 理想架构
-
-基于以上问题,我们决定对架构进行升级改进,在正式升级之前,我们希望未来的架构可以做到以下几点:
-
-- 原架构涉及 MySQL 、PG、ES 等多个组件,并为不同应用提供服务;我们希望未来的架构可以兼容 MySQL 协议,实现低成本替换、无缝衔接以上组件。
-- 支持即席查询且性能优异,即席查询能够给业务方提供更灵活的表达方式,业务方可以从多个角度、多个维度对数据进行查询和分析,更好地发现数据的规律和趋势,帮助业务方更精准备地做出决策。
-- 支持实时聚合,以减轻开发负担并保证计算结果的准确性。
-- 统一数据出口,原架构中数据出口不唯一,我们希望未来的架构能更统一数据出口,缩短链路维护成本,提升数据的可复用性。
-- 支持高并发, C 端的实时分析数据需要较高的并发能力,我们希望未来的架构可以高并发性能优异。
-
-# 技术选型
-
-考虑到和需求的匹配度,我们重点对 OLAP 引擎进行了调研,并快速定位到 ClickHouse 和 [Apache Doris](https://doris.apache.org/zh-CN/) 这两款产品,在深入调研中发现 Doris 在以下几个方面优势明显,更符合我们的诉求:
-
-- 标准 SQL:ClickHouse 对标准 SQL 支持有限,使用中需要对多表 Join 语法进行改写;而 Doris 兼容 MySQL 协议,支持标准 SQL ,可以直接运行,同时 Doris 的 Join 性能远优于 ClickHouse。
-- 降本增效:Doris 部署简单,只有 FE 和 BE 两个组件,不依赖其他系统;生态内导数功能较为完备,可针对数据源/数据格式选择导入方式;还可以直接使用命令行操作弹性伸缩,无需额外投入人力;运维简单,问题排查难度低。相比之下,ClickHouse 需要投入较多的开发人力来实现类似的功能,使用难度高;同时 ClickHouse 运维难度很高,需要研发一个运维系统来支持处理大部分的日常运维工作。
-- 并发能力:ClickHouse 的并发能力较弱是一个潜在风险,而 Doris 并发能力更占优势,并且刚刚发布的 2.0 版本支持了[更高并发的点查](https://mp.weixin.qq.com/s?__biz=Mzg3Njc2NDAwOA==&mid=2247516978&idx=1&sn=eb3f1f74eedd2306ca0180b8076fe773&chksm=cf2f8d35f85804238fd680c18b7ab2bc4c53d62adfa271cb31811bd6139404cc8d2222b9d561&token=699376670&lang=zh_CN#rd)。
-- 导入事务:ClickHouse 的数据导入没有事务支持,无法实现 Exactly Once 语义,如导数失败需要删除重导,流程比较复杂;而 Doris 导入数据支持事务,可以保证一批次内的数据原子生效,不会出现部分数据写入的情况,降低了判断的成本。
-- 丰富的使用场景:ClickHouse 支持场景单一,Doris 支持场景更加丰富,用户基于 Doris 可以构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
-- 丰富的数据模型:Doris 提供了Unique、Duplicate、Aggregate 三种数据模型,可以针对不同场景灵活应用不同的数据模型。
-- 社区响应速度快:Doris 社区的响应速度是其独有特色,SelectDB 为社区组建了一直完备的社区支持团队,社区的快速响应让我们少走了很多歪路,帮助我们解决了许多问题。
-
-# 新数仓架构
-
-经过对 Doris 进行综合评估,我们最终决定采用 Doris 对原有架构进行升级优化,并在架构层级进行了压缩。新的架构图如下所示:
-
-
-
-在新架构中,数据源层和数据接入层与原有架构保持一致,**主要变化是将 Doris 作为新架构的数据服务层,统一了原有架构中的数据计算层和存储层,这样实现了数据门户的统一,大大缩短了数据处理链路,解决了开发流程冗长的问题。** 同时,基于 Doris 的高性能,实现了即席查询能力,提高了数据查询效率。另外,Flink 与 Doris 的结合实现了实时数据快速写入,解决了 T+1 数据更新延迟较高的问题。除此之外,借助于 Doris 精简的架构,大幅降低了架构维护的难度。
-
-**数据流图**
-
-缩短数据处理链路直接或间接地带来了许多收益。接下来,我们将具体介绍引入 Doris 后的数据流图。
-
-
-
-总体而言,数据源由 MySQL 和日志文件组成,数据在 Kafka 中进行分层操作(ODS、DWD、DWS),Apache Doris 作为数据终点统一进行存储和计算。应用层包含 C 端、Tableau 和 DMP 系统,通过网关服务从 Doris 中获取相应的数据。
-
-具体来看,MySQL 通过 Canal 把 Binlog 接入 Kafka,日志文件通过 Flume 接入 Kafka 作为 ODS 层。然后经过 Flink SQL 进行清洗、关联维表,形成 DWD 层的宽表,并生成聚合表。为了节省空间,我们将 ODS 层存储在 Kafka 中,DWD 层和 DWS 层主要与 Doris 进行交互。DWD 层的数据一般通过 Flink SQL 写入 Doris。针对不同的场景,我们应用了不同的数据模型进行数据导入。MySQL 数据使用 Unique 模型,日志数据使用 Duplicate 模型,DWS 层采用 Aggregate 模型,可进行实时聚合,从而减少开发成本。
-
-# 应用场景优化
-
-在应用新的架构之后,我们必须对业务场景的数据处理流程进行优化以匹配新架构,从而达到最佳应用效果。接下来我们以人群圈选、C端分析数据及精准营销线索为主要场景,分享相关场景流程优化的实践与经验。
-
-## 人群圈选
-
-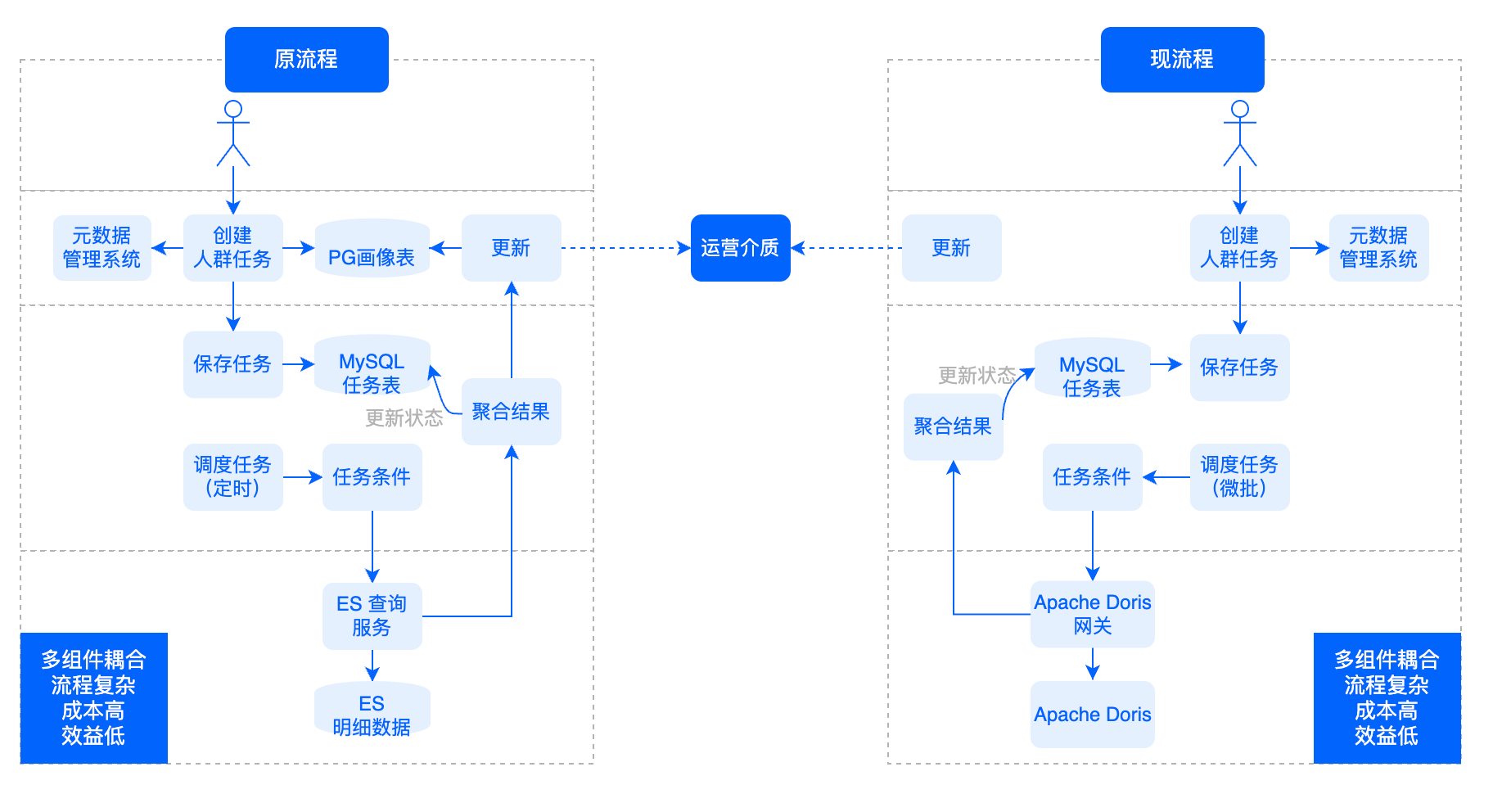
-
-**原流程(左)中**,业务人员在画像平台页面上利用表的元数据创建人群圈选任务,任务创建后进行人群 ID 分配,写入到 PG 画像表和 MySQL 任务表中。接着根据任务条件定时在 ES 中查询结果,获取结果后更新任务表的状态,并把 Bitmap 人群包写入 PG。利用 PG 插件提供的 Bitmap 交并差能力操作人群包,最后下游运营介质从 PG 取相应人群包。
-
-然而,该流程处理方式非常复杂,ES 和 PG 中的表无法复用,造成成本高、效益低。同时,原流程中的数据为 T+1 更新,标签必须提前进行定义及计算,这非常影响查询效率。
-
-**现流程(右)中**,业务人员在画像平台创建人群圈选任务,后台分配人群 ID,并将其写入 MySQL 任务表中。首次圈选时,根据任务条件在 Doris 中进行即席查询,获取结果后对任务表状态进行更新,并将人群包写入 Doris。后续根据时间进行微批轮询,利用 Doris Bitmap 函数提供的交并差功能与上一次的人群包做差集,如果有人群包更新会主动通知下游。
-
-引入 Doris 后,原有流程的问题得到了解决,新流程以 Doris 为核心构建了人群圈选服务,支持人群包实时更新,新标签无需提前定义,可通过条件配置自助生成,减少了开发时间。新流程表达方式更加灵活,为人群包 AB 实验提供了便捷的条件。流程中采用 Doris 统一了明细数据和人群包的存储介质,实现业务聚焦,无需处理多组件数据之间的读写问题,达到了降本增效的终极目标。
-
-## C端分析数据及精准营销线索场景
-
-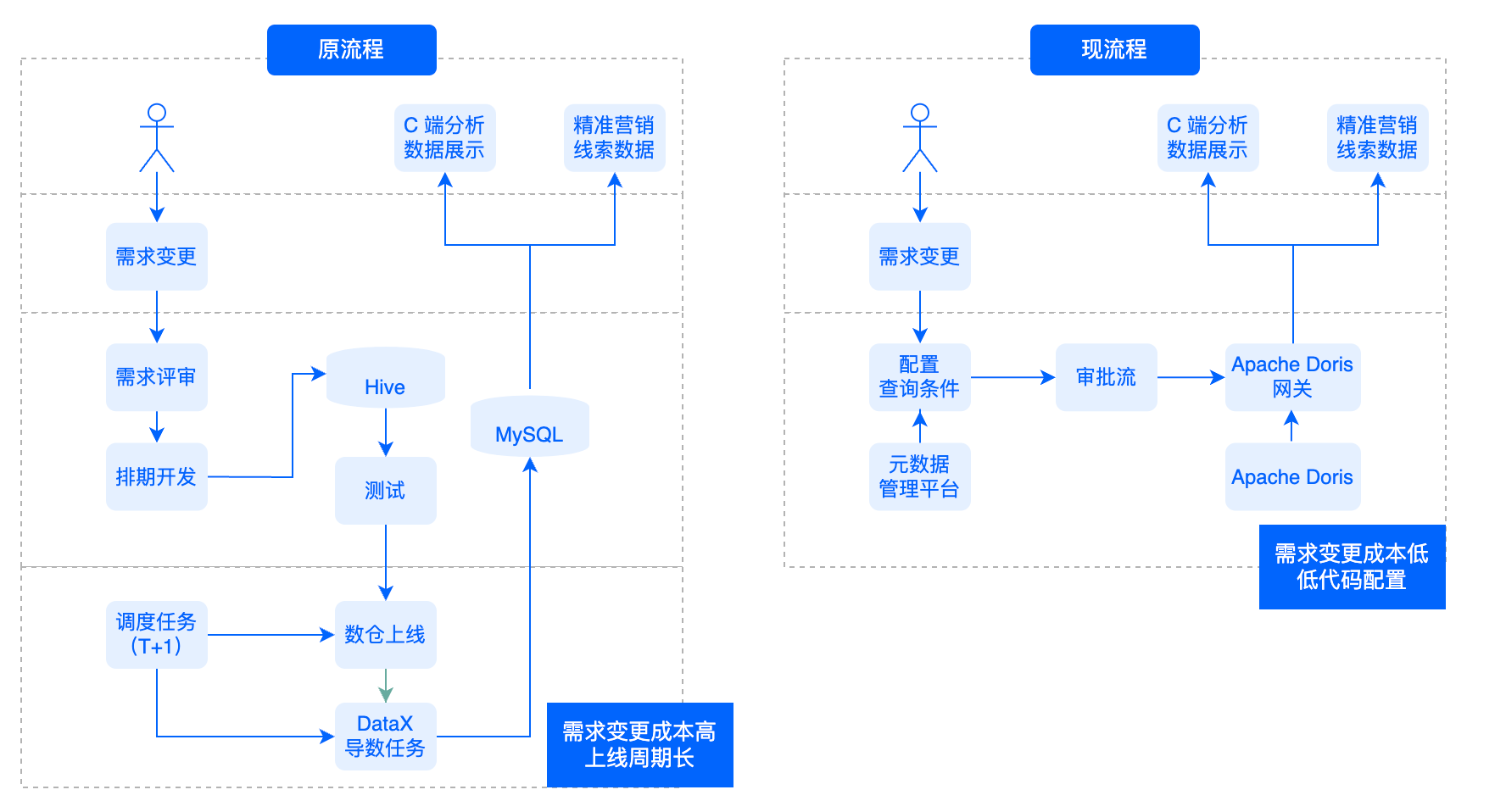
-
-**原流程:** 在原流程中,如果业务提出新需求,需要先发起需求变更,再经过评审、排期开发,然后开始对 Hive 中的数据模型进行开发并进行测试,测试完成后进行数仓上线,配置 T+1 调度任务写入 MySQL,最后 C端和精准营销系统对 MySQL 数据进行读取。原流程链路复杂,主要体现在流程长、成本高、上线周期长。
-
-**现流程:** 当前明细数据已经在 Doris 上线,当业务方发起需求变更时,只需要拉取元数据管理平台元数据信息,配置查询条件,审批完成后即可上线,上线 SQL 可直接在 Doris 中进行即席查询。相比原流程,现在的流程大幅缩短了需求变更流程,只需进行低代码配置,成功降低了开发成本,缩短了上线周期。
-
-# 优化经验
-
-为了规避风险,许多公司的人群包`user_id`是随机生成的,这些`user_id`相差很大且是非连续的。然而,使用非连续的`user_id`进行人群圈选时,会导致 Bitmap 生成速度较慢。因此,我们生成了映射表,并生成了连续稠密的`user_id`。当使用连续 `user_id` 圈选人群时,**速度较之前提升了 70%** 。
-
-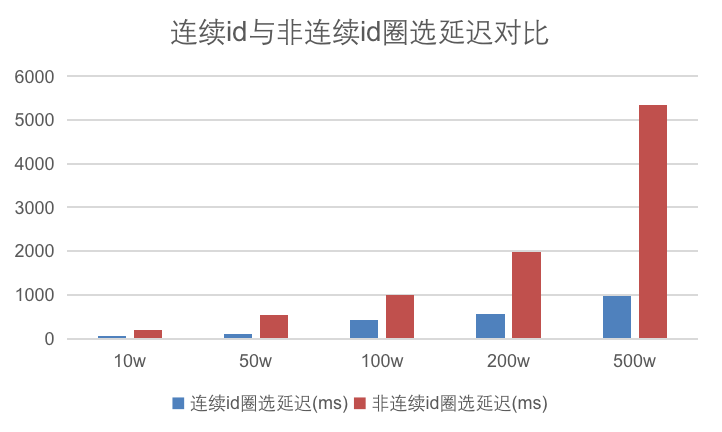
-
-用户 ID 映射表样例数据:从图可知原始用户 ID 由多位数字组合,并且 ID 很稀疏(用户 ID 间相差很大),而连续用户 ID 则 从1开始,且 ID 很稠密。
-
-
-
-**案例展示:**
-
-1. 用户 ID 映射表:
-
-用户 ID 映射表将用户 ID 作为唯一键模型,而连续用户 ID 则通过用户 ID 来生成,一般从 1 开始,严格保持单调递增。需要注意的是,因为该表使用频繁,因此将 `in_memory` 设置为`true`,直接将其缓存在内存中:
-
-
-
-2. 人群包表
-
-人群包表是以用户标签作聚合键的模型,假设以 `user_id` 大于 0、小于 2000000 作为圈选条件,使用原始 `user_id` 进行圈选耗费的时间远远远大于连续稠密 `user_id` 圈选所耗时间。
-
-
-
-如下图所示,左侧使用 `tyc_user_id`圈选生成人群包响应时间:1843ms,右侧使用使`tyc_user_id_continuous`圈选生成人群包响应时间:543ms。消耗时间大幅缩短
-
-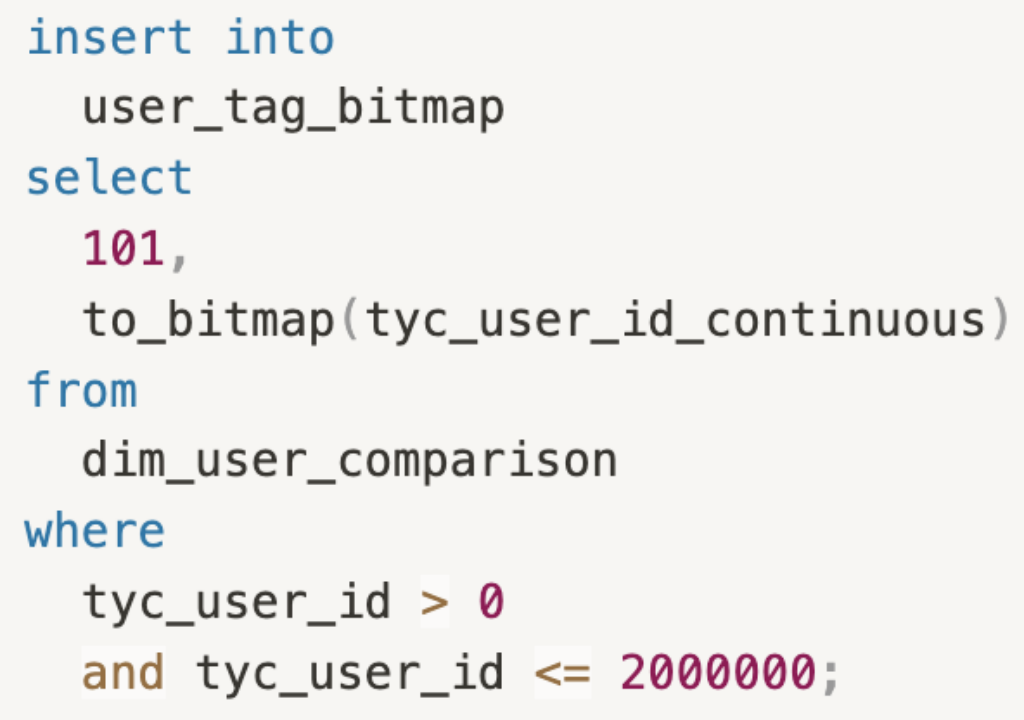
-
-# 规模与收益:
-
-引入 Doris 后,我们已经搭建了 2 个集群,承载的数据规模正随着迁移的推进而持续增大。目前,**我们已经处理的数据总量已经达到了数十TB,单日新增数据量已经达到了 数亿条**,而数据体量还在持续增长中。此外,我们在 Doris 上运行的指标和人群包数量已经超过了 500,分别涵盖了商查、搜索、运营、用户和营收五大类指标。
-
-Doris 的引入满足了业务上的新需求,解决了原有架构的痛点问题,具体表现为以下几点:
-
-- **降本增效:** Doris 统一了数据的门户,实现了存储和计算的统一,提高了数据/表的复用率,降低了资源消耗。同时,新架构优化了数据到 MySQL、ES 的流程,开发效率得到有效提升。
-- **导入速率提升:** 原有数据流程中,数据处理流程过长,数据的导入速度随着业务体量的增长和数据量的不断上升而急剧下降。引入 Doris 后,我们依赖 Broker Load 优秀的写入能力,使得**导入速率提升了 75%以上**。
-- **响应速度**:Doris 的使用提高了各业务场景中的查询响应速度。例如,在人群圈选场景中,对于 **500 万及以下的人群包进行圈选时,能够做到毫秒级响应**。
-
-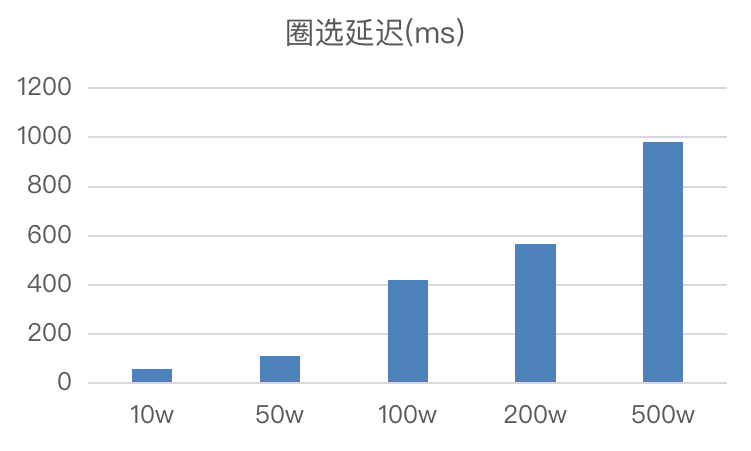
-
-# 未来规划
-
-正如前文所讲,Apache Doris 的引入解决了许多架构及业务上的难题,初见成效,同时也收获了公司内部数据部门、业务方的一致好评,未来我们将继续探索,基于 Doris 展开更深度的应用,不久的将来,我们将重点推进以下几个方面工作:
-
-- 离线指标实时化:将更多的指标从离线转为实时,提供更及时的数据服务。
-- 搭建数据血缘系统:将代码中的血缘关系重新定义为可视,全面构建数据血缘关系,为问题排查、链路报警等提供有效支持。
-- 探索批流一体路线:从使用者的角度思考设计,实现语义开发层的统一,使数据开发更便捷、更低门槛、更高效率。
-
-在此特别感谢 [SelectDB 团队](https://cn.selectdb.com/),作为基于 [Apache Doris](https://doris.apache.org/zh-CN/) 的商业化公司,为社区投入了大量的研发和用户支持力量,在使用过程中遇到任何问题都能及时响应,为我们降低了许多试错成本。未来,我们也会更积极参与社区贡献及活动中来,与社区共同进步和成长,欢迎大家选择和使用 Doris,相信 Doris 一定不会让你失望。
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/jd.md b/i18n/zh-CN/docusaurus-plugin-content-blog/jd.md
deleted file mode 100644
index 279c94ebcfd..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/jd.md
+++ /dev/null
@@ -1,136 +0,0 @@
----
-{
- 'title': 'Apache Doris 在京东客服 OLAP 中的应用实践',
- 'summary': '本文主要讨论京东客服在人工咨询、客户事件单、售后服务单等专题的实时大屏,在实时和离线数据多维分析方面,如何利用 Doris 进行业务探索与实践。近些年来,随着数据量爆炸式的增长,以及海量数据联机分析需求的出现,MySQL、Oracle 等传统的关系型数据库在大数据量下遇到瓶颈,而 Hive、Kylin 等数据库缺乏时效性。于是 Apache Doris、Apache Druid、ClickHouse 等实时分析型数据库开始出现,不仅可以应对海量数据的秒级查询,更满足实时、准实时的分析需求。离线、实时计算引擎百花齐放。但是针对不同的场景,面临不同的问题,没有哪一种引擎是万能的。我们希望通过本文,对京东客服业务在离线与实时分析的应用与实践,能够给到大家一些启发,也希望大家多多交流,给我们提出宝贵的建议',
- 'date': '2022-07-20',
- 'author': 'Apache Doris',
- 'tags': ['最佳实践'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-# **引言**
-
-Apache Doris 是一款开源的 MPP 分析型数据库产品,不仅能够在亚秒级响应时间即可获得查询结果,有效的支持实时数据分析,而且支持 10PB 以上的超大的数据集。相较于其他业界比较火的 OLAP 数据库系统,Doris 的分布式架构非常简洁,支持弹性伸缩,易于运维,节省大量人力和时间成本。目前国内社区火热,也有美团、小米等大厂在使用。
-
-本文主要讨论京东客服在人工咨询、客户事件单、售后服务单等专题的实时大屏,在实时和离线数据多维分析方面,如何利用 Doris 进行业务探索与实践。近些年来,随着数据量爆炸式的增长,以及海量数据联机分析需求的出现,MySQL、Oracle 等传统的关系型数据库在大数据量下遇到瓶颈,而 Hive、Kylin 等数据库缺乏时效性。于是 Apache Doris、Apache Druid、ClickHouse 等实时分析型数据库开始出现,不仅可以应对海量数据的秒级查询,更满足实时、准实时的分析需求。离线、实时计算引擎百花齐放。但是针对不同的场景,面临不同的问题,没有哪一种引擎是万能的。我们希望通过本文,对京东客服业务在离线与实时分析的应用与实践,能够给到大家一些启发,也希望大家多多交流,给我们提出宝贵的建议。
-
-# **京东客服业务形态**
-
-京东客服作为集团服务的入口,为用户和商家提供了高效、可靠的保障。京东客服肩负着及时解决用户问题的重任,给用户提供详细易懂的说明与解释;为更好的了解用户的反馈以及产品的状况,需要实时的监控咨询量、接起率、投诉量等一系列指标,通过环比和同比,及时发现存在的问题,以更好的适应用户的购物方式,提高服务质量与效率,进而提高京东品牌的影响力。
-
-# **Easy OLAP 设计**
-
-### **01 EasyOLAP Doris 数据导入链路**
-
-EasyOLAP Doris 数据源主要是实时 Kafka 和离线 HDFS 文件。实时数据的导入依赖于 Routine Load 的方式;离线数据主要使用 Broker Load 和 Stream Load 的方式导入。
-
-
-
-EasyOLAP Doris 数据导入链路
-
-### **02 EasyOLAP Doris 全链路监控**
-
-目前 EasyOLAP Doris 项目的监控,使用的是 Prometheus + Grafana 框架。其中 node_exporter 负责采集机器层面的指标,Doris 也会自动以 Prometheus 格式吐出 FE、BE 的服务层面的指标。另外,部署了 OLAP Exporter 服务用于采集 Routine Load 相关的指标,旨在第一时间发现实时数据流导入的情况,确保实时数据的时效性。
-
-
-
-EasyOLAP Doris 监控链路
-
-
-
-EasyOLAP Doris 监控面板展示
-
-### **03 EasyOLAP Doris 主备双流设计**
-
-EasyOLAP Doris 为了保障 0 级业务在大促期间服务的稳定性,采取了主备集群双写的方式。当其中一个集群出现抖动或者数据存在延迟的情况,用户可以自主地快速切换到另一个集群,尽可能的减少集群抖动给业务带来的影响。
-
-
-
-EasyOLAP Doris 主备双流设计
-
-### **04 EasyOLAP Doris 动态分区管理**
-
-京东 OLAP 团队分析需求之后,对 Doris 做了一定的定制化开发,其中就涉及到动态分区管理功能。尽管社区版本已经拥有动态分区的功能,但是该功能无法保留指定时间的分区。针对京东集团的特点,我们对指定时间的历史数据进行了留存,比如 618 和 11.11 期间的数据,不会因为动态分区而被删除。
-
-动态分区管理功能能够控制集群中存储的数据量,而且方便了业务方的使用,无需手动或使用额外代码来管理分区信息。
-
-# **Doris 缓存机制**
-
-### **01 需求场景**
-
-致力于不断提升用户体验,京东客服的数据分析追求极致的时效性。离线数据分析场景是写少读多,数据写入一次,多次频繁读取;实时数据分析场景,一部分数据是不更新的历史分区,一部分数据是处于更新的分区。在大部分的分析应用中,存在下述几种场景:
-
-- 高并发场景:Doris 较好的支持高并发,但是过高的 QPS 会引起集群抖动,且单个节点无法承载太高的 QPS ;
-- 复杂查询:京东客服实时运营平台监控根据业务场景需展示多维复杂指标,丰富指标展示对应多种不同的查询,且数据源来自于多张表,虽然单个查询的响应时间在毫秒级别,但是整体的响应时间可能会到秒级别;
-- 重复查询:如果没有防重刷机制,由于延迟或手误,重复刷新页面会导致提交大量重复的查询;
-
-针对上述场景,在应用层有解决方案——将查询结果放入到 Redis 中,缓存会周期性的刷新或者由用户手动刷新,但是也会存在一些问题:
-
-- 数据不一致:无法立即对数据的更新作出响应,用户接收到的结果可能是旧数据;
-- 命中率低:如果数据实时性强,缓存频繁失效,则缓存的命中率低且系统的负载无法得缓解;
-- 额外成本:引入外部组件,增加系统复杂度,增加额外成本。
-
-### **02 缓存机制简介**
-
-在 EasyOLAP Doris 中,一共有三种不同类型 Cache。根据适用场景的不同,分别为 Result Cache、SQL Cache 和 Partition Cache 。三种缓存都可以通过 MySQL 客户端指令控制开关。
-
-这三种缓存机制是可以共存的,即可以同时开启。查询时,查询分析器首先会判断是否开启了 Result Cache ,在 Result Cache 开启的情况下先从 Result Cache 中查找该查询是否存在缓存,如果存在缓存,直接取缓存的值返回给客户端;如果缓存失效或者不存在,则直接进行查询并将结果写入到缓存。缓存放在各个 FE 节点的内存中,以便快速读取。
-
-SQL Cache 按照 SQL 的签名、查询的表的分区的 ID 和分区最新版本号来存储和获取缓存。这三者一起作为缓存的条件,其中一者发生变化,如 SQL 语句变化、数据更新之后分区版本号变化,都会无法命中缓存。在多表 Join 的情况下,其中一张表的分区更新,也会导致无法命中缓存。SQL Cache 更适合 T+1 更新的场景。
-
-Partition Cache 是更细粒度的缓存机制。Partition Cache 主要是将一个查询根据分区并行拆分,拆分为只读分区和可更新分区,只读分区缓存,更新分区不缓存,相应的结果集也会生成 n 个,然后再将各个拆分后的子查询的结果合并。因此,如果查询 N 天的数据,数据更新最近的 D 天,每天只是日期范围不一样但相似的查询,就可以利用 Partition Cache ,只需要查询 D 个分区即可,其他部分都来自缓存,可以有效降低集群负载,缩短查询响应时间。
-
-一个查询进入到 Doris,系统先会处理查询语句,并将该查询语句作为 Key,在执行查询语句之前,查询分析器能够自动选择最适合的缓存机制,以确保在最优的情况下,利用缓存机制来缩短查询相应时间。然后检查 Cache 中是否存在该查询结果,如果存在就获取缓存中的数据返回给客户端;如果没有缓存,则正常查询,并将该查询结果以 Value 的形式和该查询语句 Key 存储到缓存中。Result Cache 可以在高并发场景下发挥其作用,也可以保护集群资源不受重复的大查询的侵占。SQL Cache 更加适合 T+1 的场景,在分区更新不频繁以及 SQL 语句重复的情况下,效果很好。Partition Cache 是粒度最小的缓存。在查询语句查询一个时间段的数据时,查询语句会被拆分成多个子查询。在数据只写一个分区或者部分分区的情况下,能够缩短查询时间,节省集群资源。
-
-为了更好的观察缓存的效果,相关指标已经加入到 Doris 的服务指标中,通过 Prometheus 和 Grafana 监控系统获取直观的监控数据。指标有不同种类的 Cache 的命中数量、不同种类的 Cache 命中率、 Cache 的内存大小等指标。
-
-### **03 缓存机制效果**
-
-京东客服 Doris 主集群,11.11 期间在没有开启缓存时,部分业务就导致 CPU 的使用率达到 100% ;在开启 Result Cache 的情况下,CPU 使用率在 30%-40% 之间。缓存机制确保业务在高并发场景下,能够快速的得到查询结果,并很好的保护了集群资源。
-
-# **Doris 在 2020 年 11.11 大促期间的优化**
-
-### **01 导入任务优化**
-
-实时数据的导入一直是一个挑战。其中,保证数据实时性和导入稳定性是最重要的。为了能够更加直观的观察实时数据导入的情况,京东 OLAP 团队自主开发了 OLAP Exporter ,用于采集实时数据导入相关的指标,如导入速度、导入积压和暂停的任务等。通过导入速度和导入积压,可以判断一个实时导入任务的状态,如发现任务有积压的趋势,可以使用自主开发的采样工具,对实时任务进行采样分析。实时任务主要有三个阈值来控制任务的提交,分别是每批次最大处理时间间隔、每批次最大处理条数和每批次最大处理数据量,一个任务只要达到其中一个阈值,该任务就会被提交。通过增加日志,发现 FE 中的任务队列比较繁忙,所以,参数的调整主要都是将每批次最大处理条数和每批次最大处理数据量调大,然后根据业务的需求,调整每批次最大处理时
间间隔,以保证数据的延迟在每批次最大处理时间间隔的两倍之内。通过采样工具,分析任务,不仅保证了数据的实时性,也保证了导入的稳定性。另外,我们也设置了告警,可以及时发现实时导入任务的积压以及导入任务的暂停等异常情况。
-
-### **02 监控指标优化**
-
-监控指标主要分为两个部分,一个是机器层面指标部分,一个是业务层面指标部分。在整个监控面板里,详细的指标带来了全面的数据的同时,也增加了获取重要指标的难度。所以,为了更好的观察所有集群的重要指标,单独设立一个板块—— 11.11 重要指标汇总板块。板块中有 BE CPU 使用率、实时任务消费积压行数、TP99、QPS 等指标。指标数量不多,但是可以观测到所有集群的情况,这样可以免去在监控中频繁切换的麻烦。
-
-### **03 周边工具支持**
-
-除了上述说到的采样工具和 OLAP Exporter ,京东 OLAP 团队还开发了一系列的 Doris 维护工具。
-
-1. 导入采样工具:导入采样工具不仅可以采集实时导入的数据,而且还支持调整实时导入任务的参数,或者在实时导入任务暂停状态下,生成创建语句(包括最新的位点等信息)用于任务的迁移等操作。
-
-2. 大查询工具:大查询不仅会造成集群 BE CPU 使用率的抖动,还会导致其他查询响应时间变长。在有大查询工具之前,发现集群 CPU 出现抖动,需要去检查所有 FE 上的审计日志,然后再做统计,不仅浪费时间,而且不够直观。大查询工具就是为了解决上述的问题。当监控侧发现集群有抖动,就可以使用大查询工具,输入集群名和时间点,就可以得到该时间点下,不同业务的查询总数,时间超过 5 秒、 10 秒、 20 秒的查询个数,扫描量巨大的查询个数等,方便我们从不同的维度分析大查询。大查询的详细情况也将被保存在中间文件中,可以直接获取不同业务的大查询。整个过程只需要几十秒到一分钟就可以定位到正在发生的大查询并获取相应的查询语句,大大节约了时间和运维成本。
-
-3. 降级与恢复工具:为了确保 11.11 大促期间, 0 级业务的稳定性,在集群压力超过安全位的时候,需要对其他非 0 级业务做降级处理,待度过高峰期后,再一键恢复到降级前的设置。降级主要是降低业务的最大连接数、暂停非 0 级的实时导入任务等。这大大增加了操作的便捷性,提高了效率。
-
-4. 集群巡检工具:在 11.11 期间,集群的健康巡检是极其重要的。常规巡检包括双流业务的主备集群一致性检查,为了确保业务在一个集群出现问题的时候可以快速切换到另一个集群,就需要保证两个集群上的库表一致、数据量差异不大等;检查库表的副本数是否为 3 且检查集群是否存在不健康的 Tablet ;检查机器磁盘使用率、内存等机器层面的指标等。
-
-# **总结与展望**
-
-京东客服是在 2020 年年初开始引入 Doris 的,目前拥有一个独立集群,一个共享集群,是京东 OLAP 的资深用户。
-
-在业务使用中也遇到了例如任务调度相关的、导入任务配置相关的和查询相关等问题,这也在推动京东 OLAP 团队更深入的了解 Doris 。我们计划推广使用物化视图来进一步提升查询的效率;使用 Bitmap 来支持 UV 等指标的精确去重操作;使用审计日志,更方便的统计大查询、慢查询;解决实时导入任务的调度问题,使导入任务更加高效稳定。除此之外,我们也计划优化建表、创建优质 Rollup 或物化视图以提升应用的流畅性,加速更多业务向 OLAP 平台靠拢,以提升应用的影响力。
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/linkedcare.md b/i18n/zh-CN/docusaurus-plugin-content-blog/linkedcare.md
deleted file mode 100644
index a1686a58dc9..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/linkedcare.md
+++ /dev/null
@@ -1,259 +0,0 @@
----
-{
- 'title': '并发提升 10 倍,运算延时降低 70%,领健从 ClickHouse 和 Kudu 到 Apache Doris 数仓升级实践',
- 'summary': 'Doris 在领健的发展历程。最初 Doris 替代 ClickHouse 被应用到数据服务项目中,该项目是领健为旗下客户提供的增值报表服务;后在项目服务中发掘出 Doris 查询性能优异、简单易用、部署成本低等诸多优势,在 2021 年10月,我们决定扩大 Doris 应用范围,将 Doris 引入到公司的数仓中,在 Doris 社区及 SelectDB 专业技术团队的支持下,业务逐步从 Kudu 迁移到 Doris,并在最近升级到 1.1.4 向量化版本',
- 'date': '2023-01-28',
- 'author': '杨鷖',
- 'tags': ['最佳实践'],
-}
----
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-作者|杨鷖 资深大数据开发工程师
-
-领健是健康科技行业 SaaS 软件的引领者,专注于消费医疗口腔和医美行业,为口腔诊所、医美机构、生美机构提供经营管理一体化系统,提供了覆盖单店管理、连锁管理、健康档案/电子病历、客户关系管理、智能营销、B2B交易平台、进销存、保险支付、影像集成、BI商业智能等覆盖机构业务全流程的一体化SaaS软件。 同时通过开放平台连接产业上下游,与优质的第三方平台合作,为机构提供完整配套的一站式服务。 截止当前,领健已经在全国设立了 20 余个分支机构,超过 30000 多家中高端以及连锁机构正在使用其服务。
-
-
-
-# Doris 在领健的演进历程
-
-在进入正文之前,简单了解一下 Doris 在领健的发展历程。最初 Doris 替代 ClickHouse 被应用到数据服务项目中,该项目是领健为旗下客户提供的增值报表服务;后在项目服务中发掘出 Doris 查询性能优异、简单易用、部署成本低等诸多优势,在 2021 年10月,我们决定扩大 Doris 应用范围,将 Doris 引入到公司的数仓中,在 Doris 社区及 SelectDB 专业技术团队的支持下,业务逐步从 Kudu 迁移到 Doris,并在最近升级到 1.1.4 向量化版本。我们将通过本文为大家详细介绍领健基于 Doris 的演进实践及数仓构建的经验。
-
-
-
-# 数据服务架构演进
-
-## 项目需求
-
-领健致力于为医疗行业客户提供精细化门店运营平台,为客户提供了数据报表工具,该工具可实现自助式拖拽设计图表、支持多种自带函数自建、数据实时更新等功能,可以支持门店订单查询、客户管理、收入分析等,以推动门店数字化转型,辅助门店科学决策。为更好实现以上功能,数据报表工具需满足以下特点:
-
-- 支持复杂查询:客户进行自助拖拽设计图表时,将生成一段复杂的 SQL 查询语句直查数据库,且语句复杂度未知,这将对数据库带来不小的压力,从而影响查询性能。
-
-- 高并发低延时:至少可以支撑 **100 个**并发,并在**1 秒内**得到查询结果;
-
-- 数据实时同步: 报表数据源自于 SaaS 系统,当客户对系统中的历史数据进行修改后,报表数据也要进行同步更改,保持一致,这就要求报表数据要与系统实现实时同步。
-
-- 低成本易部署:SaaS 业务存在私有云客户,为降低私有化部署的人员及成本投入,这要求**架构部署及运维要足够简单。**
-
-## **ClickHouse 遭遇并发宕机**
-
-最初项目选用 ClickHouse 来提供数据查询服务,但在运行过程中 ClickHouse 遭遇了严重的并发问题,即 10 个并发就会导致 ClickHouse 宕机,这使其无法正常为客户提供服务,这是迫使我们寻找可以替代 ClickHouse 产品的关键因素。
-
-**除此之外还有几个较为棘手的问题:**
-
-1. 云上 ClickHouse 服务成本非常高,且 ClickHouse 组件依赖性较高,数据同步时 ClickHouse 和 Zookeeper 的频繁交互,会对稳定性产生较大的压力。
-1. 如何进行无缝迁移,不影响客户正常使用。
-
-## 技术选型
-
-针对存在的问题及需求,我们决定进行技术选型,分别对 Doris(0.14)、Clickhous、Kudu 这 3 个产品展开的调研测试。
-
-
-
-如上表所示,我们对这 3 个产品进行了横向比较,可以看出 Doris 在多方面表现优异:
-
-- 高并发:Doris 并发性好,可支持上百甚至上千并发,轻松解决 10 并发导致 ClickHouse 宕机问题。
-
-- 查询性能:Doris 可实现毫秒级查询响应,在单表查询中,虽 Doris 与 ClickHouse 查询性能基本持平,但在多表查询中,Doris 远胜于 ClickHouse ,Doris 可以实现在较高的并发下,QPS 不下降。
-
-- 数据更新:Doris 的数据模型可以满足我们对数据更新的需求,以保障系统数据和业务数据的一致性,下文将详细介绍。
-
-- 使用成本:Doris 架构简单,整体部署简单快速,具有完备的导入功能,很好的弹性伸缩能力;同时, Doris 内部可以自动做副本平衡,运维成本极低。而 ClickHouse 及 Kudu 对组件依赖较高,在使用上需要做许多准备工作,这就要求具备一支专业的运维支持团队来处理大量的日常运维工作。
-
-- 标准 SQL:Doris 兼容 MySQL 协议,使用标准 SQL,开发人员上手简单,不需要付出额外的学习成本。
-
-- 分布式 Join :Doris 支持分布式 Join,而 ClickHouse 由于 Join 查询限制、函数局限性、以及可维护性较差等原因,不满足我们当前的业务需求。
-
-- 社区活跃:Apache Doris 是国内自研数据库,开源社区相当活跃,同时 SelectDB 为 Doris 社区提供了专业且全职团队做技术支持,遇到问题可以直接与社区联系沟通,并能得到快速解决,这对于国外的项目,很大的降低与社区沟通的语言与时间成本。
-
-从以上调研中可以发现,Doris 各方面能力优秀,十分符合我们对选型产品的需求,因此我们使用 Doris 替代了 ClickHouse ,很好解决了ClickHouse 并发性能差、宕机等问题,很好的支撑了数据报表查询服务。
-
-# 数仓架构演进
-
-在数据报表的使用过程中,我们逐渐发掘出 Doris 诸多优势,因此决定扩大 Doris 应用范围,将 Doris 引入到公司的数仓中来。**接下来将为大家介绍公司数仓从 Kudu 到 Doris 的演进历程,以及在搭建过程中的优化实践分享。**
-
-## 早期公司数仓架构
-
-早期的公司数仓架构使用 Kudu、Impala 来作为运算存储引擎,整体架构如下图所示。
-
-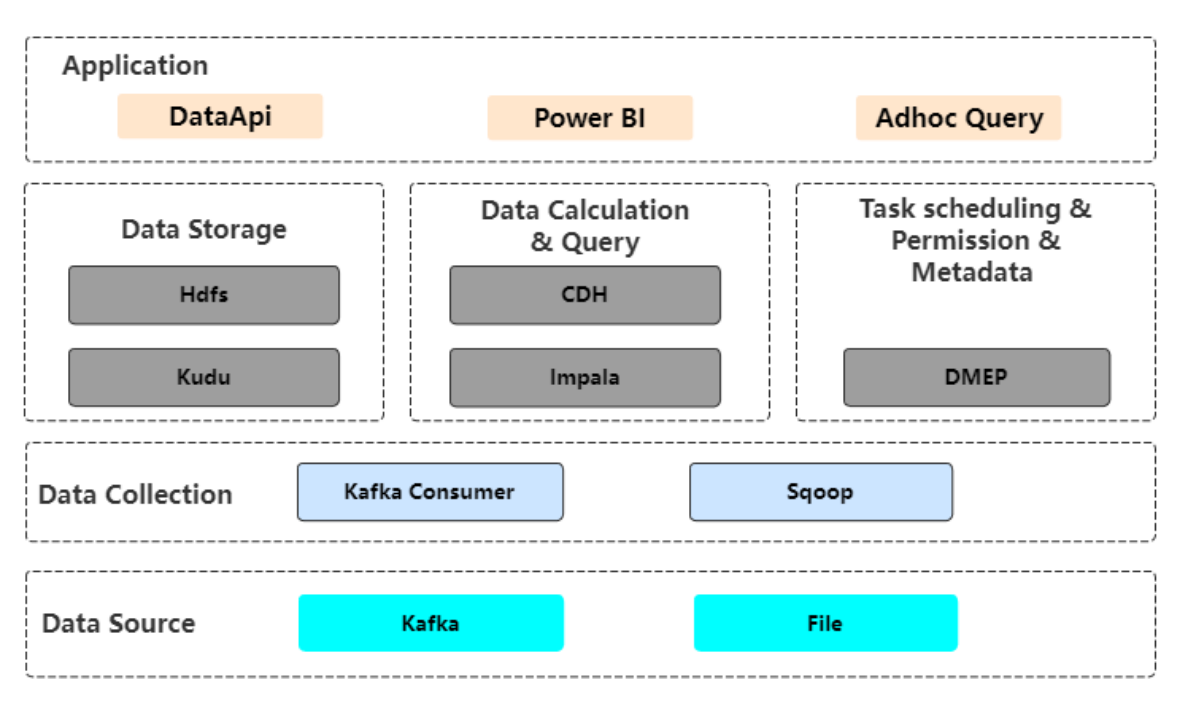
-
-从上图可知,数据通过 Kafka Consumer 进入 ODS 层;通过 Kudu 层满足数据更新需要;运用 Impala 来执行数据运算和查询;通过自研平台 DMEP 进行任务调度。 在 ETL 代码中会使用大量的 Upsert 对数据进行 Merge 操作,那么引入 Doris 的首要问题就是要如何实现 Merge 操作,支持业务数据更新,下文中将进行介绍。
-
-## 基于 Doris 的新数仓架构设计
-
-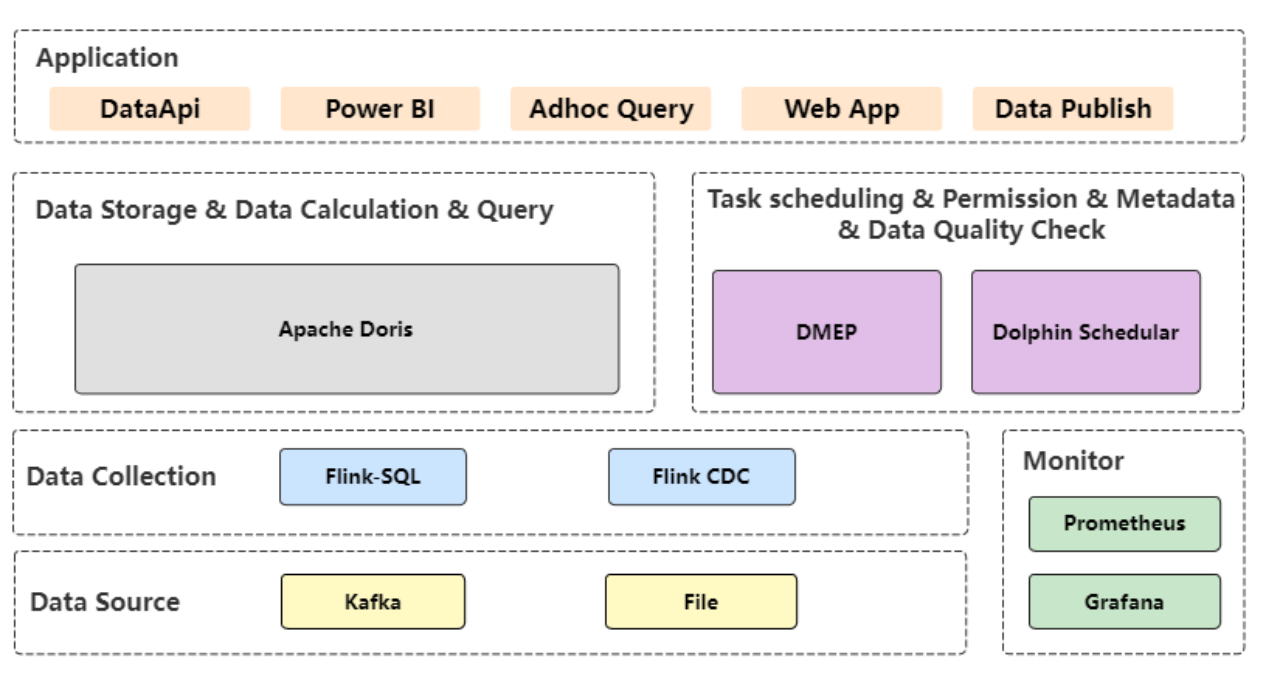
-
-如上图所示,在新架构设计中使用 Apache Doris 负责数仓存储及数据运算;实时数据、 ODS数据的同步从 Kafka Consumter 改为 Flink ;流计算平台使用团队自研的 Duckula;任务调度则引入最新 的 DolphinSchedular,Dolphin schedule 几乎涵盖了自研 DMEP 的大部分功能,同时可以很方便拓展 ETL 的方式,可调度很多不同的任务。
-
-# 优化实践
-
-## **数据模型选择**
-
-上文中提到,当客户对系统中的历史数据修改后,报表数据也要进行同步更改,同时,客户有时只更改某一列的数值,这要求我们需要选择合适的 Doris 模型来满足这些需求。我们在测试中发现,**通过 Aggregate 聚合模型`Replace_if_not_null` 方式进行数据更新时,可以实现单独更新一列,代码如下:**
-
-```
-drop table test.expamle_tbl2
-
-CREATE TABLE IF NOT EXISTS test.expamle_tbl2
-(
- `user_id` LARGEINT NOT NULL COMMENT "用户id",
- `date` DATE NOT NULL COMMENT "数据灌入日期时间",
- `city` VARCHAR(20) COMMENT "用户所在城市",
- `age` SMALLINT COMMENT "用户年龄",
- `sex` TINYINT COMMENT "用户性别",
- `last_visit_date` DATETIME REPLACE_IF_NOT_NULL COMMENT "用户最后一次访问时间",
- `cost` BIGINT REPLACE_IF_NOT_NULL COMMENT "用户总消费",
- `max_dwell_time` INT REPLACE_IF_NOT_NULL COMMENT "用户最大停留时间",
- `min_dwell_time` INT REPLACE_IF_NOT_NULL COMMENT "用户最小停留时间"
-)
-AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
-DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
-PROPERTIES (
-"replication_allocation" = "tag.location.default: 1"
-);
-
-insert into test.expamle_tbl2
-values(10000,'2017-10-01','北京',20,0,'017-10-01 06:00:00',20,10,10);
-select * from test.expamle_tbl ;
-
-insert into test.expamle_tbl2 (user_id,date,city,age,sex,cost)
-values(10000,'2017-10-01','北京',20,0,50);
-select * from test.expamle_tbl ;
-```
-
-如下图所示,当写 50 进去,可以实现只覆盖`Cost`列,其他列保持不变。
-
-
-
-
-
-## Doris Compaction 优化
-
-当 Flink 抽取业务库全量数据、持续不断高频写入 Doris 时,将产生了大量数据版本,Doris 的 Compaction 合并版本速度跟不上新版本生成速度,从而造成数据版本堆积。从下图可看出,BE Compaction Score 分数很高,最高可以达到 400,而健康状态分数应在 100 以下。
-
-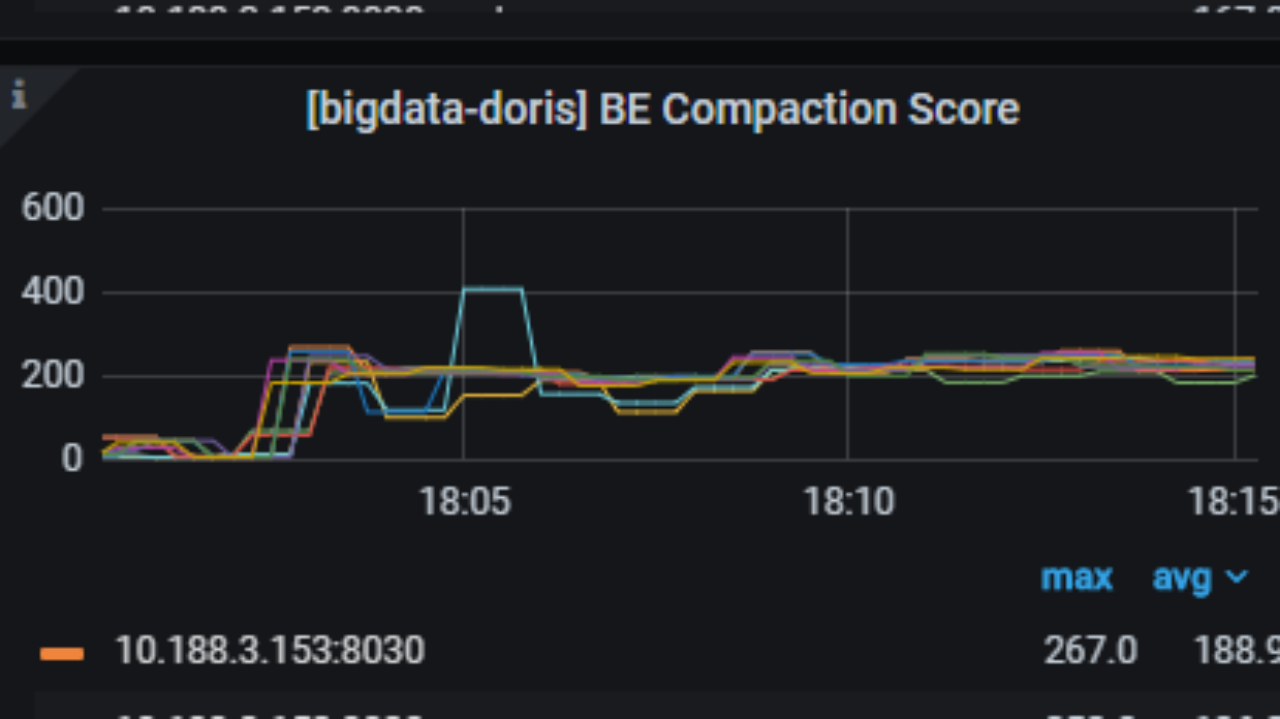
-
-针对以上我们做了以下调整:
-
-- 全量数据不使用实时写入的方式,先导出到 CSV,再通过 Stream Load 写入 Doris;
-
-- 降低 Flink 写入频率,增大 Flink 单一批次数据量;该调整会降低数据的实时性,需与业务侧进行沟通,根据业务方对实时性的要求调整相关数值,最大程度的降低写入压力。
-
-- 调节 Doris BE 参数,使更多 CPU 资源参与到 Compaction 操作中;
-
- - `compaction_task_num_per_disk` 单磁盘 Compaction 任务线程数默认值 2,提升后会大量占用CPU资源,阿里云 16 核,提升 1 个线程多占用 6% 左右 CPU。
- - `max_compaction_threads compaction`线程总数默认为10。
- - `max_cumulative_compaction_num_singleton_deltas` 参数控制一个 CC 任务最多合并 1000 个数据版本,适当改小后单个 Compaction 任务的执行时间变短,执行频率变高,集群整体版本数会更加稳定。
-
-通过调整集群, Compaction Score 稳定在了**50-100,有效解决了版本堆积问题**。
-
-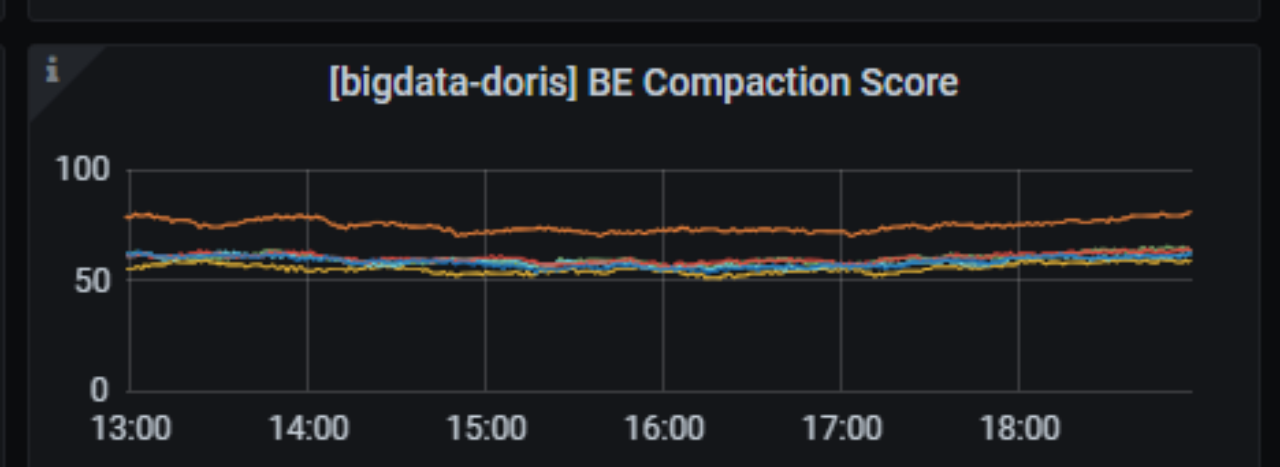
-
-值得关注的是,在 Doris 1.1 版本中对 Compaction 进行了一系列的优化,**在任务调度层面**,增加了主动触发式的 Compaction 任务调度,结合原有的被动式扫描,高效的感知数据版本的变化,主动触发Compaction。**在任务执行层面**,对资源进行隔离,将重量级的 Base Compaction 和轻量级的Cumulative Compaction 进行了物理分离,防止任务的互相影响。同时,**针对高频小文件的导入**,优化文件合并策略,采用梯度合并的方式,保证单次合并的文件都属于同一数量级,逐渐有层次的进行数据合并,减少单个文件参与合并的次数,大幅节省系统消耗。
-
-## 负载隔离
-
-最初我们只有 1 个 Doris 集群,Doris 集群要同时支持高频实时写、 高并发查询、ETL 处理以及Adhoc 查询等功能。其中高频实时写对 CPU 的占用很高,而 CPU 的上限决定高并发查询的能力,另外 Adhoc 查询无法预知 SQL 的复杂度,当复杂度过高时也会占用较高的内存资源。这就导致了资源竞争,业务之前互相影响的问题。为解决这些问题,我们进行了以下探索优化。
-
-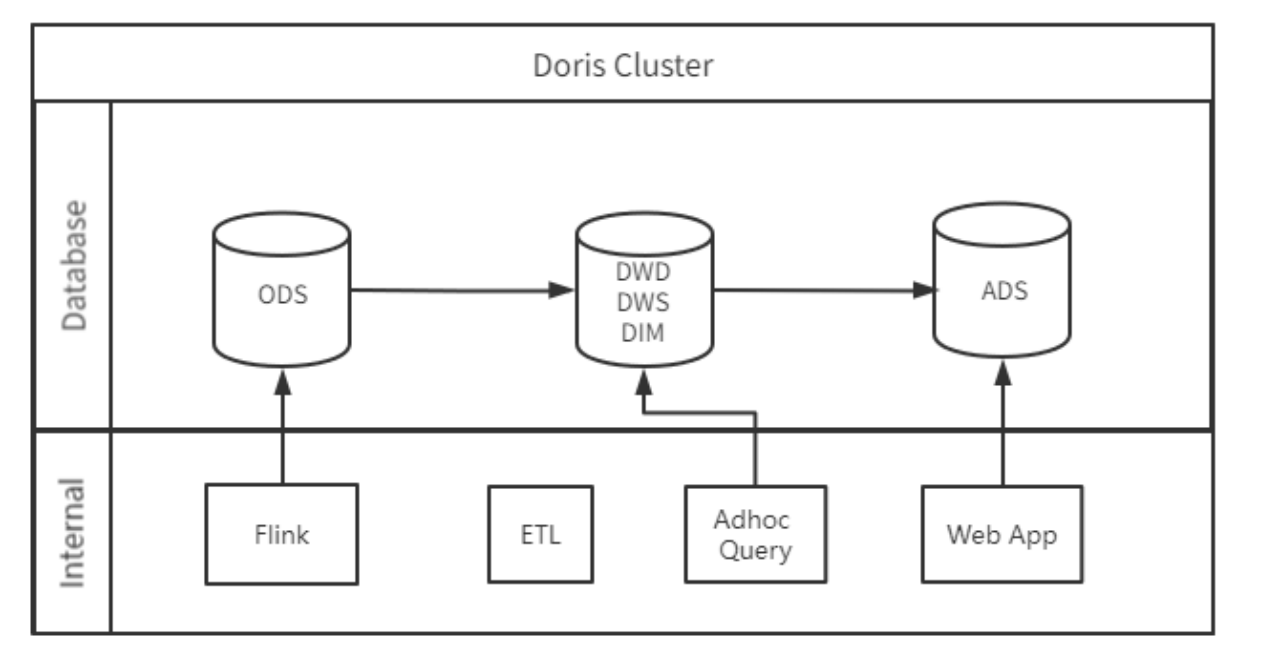
-
-1. **Doris 集群拆分**
-
-最初我们尝试对 Doris 集群进行拆分,我们把 1 个集群拆分为 3 个集群,分别为 ODS 集群、DW 集群、ADS 集群。我们将 CPU 负载最高的 ODS 层分离出去, ETL 时,通过 Doris 外表连接另一个 Doris 集群抽取数据;同时也将 BI 应用访问的集群分离出去,独立为业务提供数据查询。如下所示为各集群负责的任务:
-
-- ODS 集群:数仓 ODS 层,Flink 写数据集中在此层进行。
-
-- DW 集群:数仓 DW 层,DIM 层,主要负责 ETL 处理,Adhoc 查询任务。
-
-- ADS 集群:数仓 ADS 层,主要支持 Web 应用的数据查询
-
-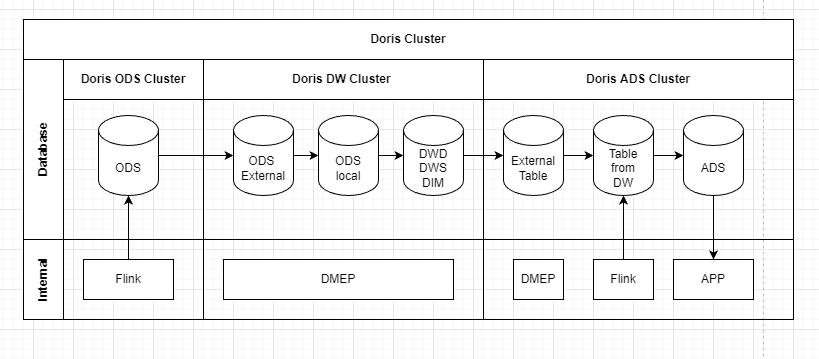
-
-通过集群拆分,有效降低各个资源间的相互影响,保证每个业务运转都有较充足的资源。但是集群的拆分也存在集群之间数据同步 ETL 时间较长、从 ADS 到 ODS 跨3个集群的数据校验复杂度较高等问题。直到 Doris 0.15 发布后,这些问题也得到了相对有效的解决。
-
-2. **资源隔离优化集群资源**
-
-Doris 0.15 版本新增了资源标签功能以及查询 Block 功能,资源标签功能允许 Doris 集群实现资源隔离,该功能有效减少集群之间同步数据的时间,降低了跨集群数据校验复杂度。其次查询 Block 功能的上线,可以对 SQL 进行查询审计,阻塞简单/不合规的查询语句,降低资源占用率,提升查询性能。除此之外,通过资源隔离的方式,我们将 3 个集群合并成 1 个集群,被合并的 6 个入口节点 FE 被释放掉,将节省的资源加到核心的运算节点上来。
-
-升级到 Doris 0.15 后,我们将 ODS 表的副本修改为 `group_ods`3份,`default`3份。 Flink 写入时只写 `group_ods` 资源组的节点,数据写入后,得益于 Doris 内部的副本同步机制,数据会自动实时同步到 `default`资源组。ETL 则可以使用 `default` 资源组的节点资源取用 ODS 数据,进行查询和数据处理。同理 ADS 也做了相同处理,原先需要通过外表进行数据抽取同步的表,均被做成了副本跨资源组的形式。此方式有效缩短了跨集群数据同步的 ETL 时长 。
-
-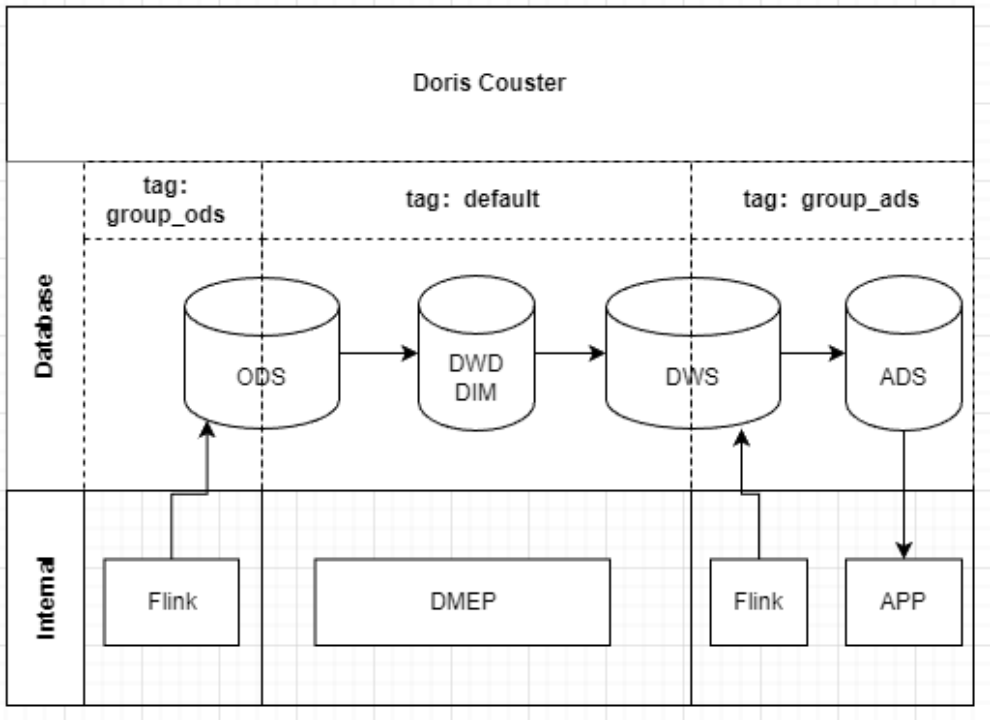
-
-## 离线 ETL 内存高
-
-我们使用的是离线 ETL 方式直接在 Doris 上做 ETL 操作,在 Join 时,如果右表数据量比较大的情况下会消耗大量的内存,从而造成 OOM。在 1.0 版本之前内存跟踪能力较弱,容易造成 BE 节点超出 Linux 限制,导致进程被关闭 ,这时候会收到以下报错信息:`Host is down`或者 `Fail to initialize storage reader`。在1.0 及更高版本中, Doris 由于优化了内存跟踪,则容易见到以下报错:`Memory exceed limit. Used: XXXX ,Limit XXXX.`
-
-**针对内存受限问题,我们开始寻找优化方案,另外由于公司内部资源受限,优化方案必须在不增加集群成本的情况下把超出集群负荷的任务跑通。这里为大家介绍 2 个解决方法:**
-
-1. 优化调整 Join 的方式:
-
-Doris 内部 Join 分为 4 种,其内存开销以及优先级如下图所示:
-
-
-
-从上图可知,Join 类型优先级从左往右依次变低,Shuffle 的优先级最低,排在 Broadcast 之后。值得注意的是, Broadcast 内存开销非常大,它将右表广播到所有 BE 节点,这相当于每个 BE 节点会消耗一个右表的内存,这将造成很大的内存开销。**针对 Broadcast 比较大的内存开销,我们通过 Hint 条件强制 Join 类型的方式,使 Join 语句跳过 Broadcast 到 Shuffle Join ,从而降低内存消耗**。
-
-```
-select * from a join [shuffle] b on a.k1 = b.k1;
-```
-
-2. **数据分批处理**
-
-我们尝试将数据按照时间分批,每批涵盖某一个或某几个时间段的数据,分批进行 ETL,有效降低内存消耗,避免 OOM 。分批须知:需要将分批的标记列放在主键中,最大程度提升搜索数据的效率;注意分桶和分区的设置方式,保证每个分区的数据量都比较均衡,避免个别分区内存占用较高的问题。
-
-# 总结
-
-## **新架构收益:**
-
-- 基于 Doris 的新数仓架构不再依赖 Hadoop 生态组件,运维简单,维护成本低。
-
-- 具有更高性能,使用更少的服务器资源,提供更强的数据处理能力。
-
-- 支持高并发,能直接支持 WebApp 的查询服务。
-
-- 支持外表,可以很方便的进行数据发布,将数据推送其他数据库中。
-
-- 支持动态扩容,数据自动平衡。
-
-- 支持多种联邦查询方式,支持 Hive、ES、MySQL 等
-
-得益于新架构的优异能力,我们所用集群从 **18 台 16C128G 减少到 12 台 16C128G**,集群资源较之前**节省了33%** ,大大降低了投入成本;并且运算性能得到大幅提升,在 Kudu 上 **3 小时**即可完成的 ETL 任务, Doris 只需要 **1 小时**即可完成 。除此之外,高频更新的场景下,Kudu 内部数据碎片文件不能进行自动合并,表的性能会越来越差,需要定期重建;而Doris 内部的 Compaction 机制可以有效避免此问题。
-
-## 社区寄语:
-
-首先,Doris 的使用成本很低,仅需要 3 台低配服务器、甚至是台式机,就能相对容易的部署一套基于 Doris 的数仓作为数据中台基础;我认为对于想要进行数字化,但介于资源投入有限而又不想落后于市场的企业来说,非常建议尝试使用 Apache Doris ,Doris 可以助力企业低成本跑通整个数据中台。
-
-其次,Doris 是一款国人自研的的 MPP 架构分析型数据库,这令我感到很自豪,同时其社区十分活跃、便于沟通,Doris 背后的商业化公司 SelectDB 为社区组建了一支专职技术团队,任何问题都能在 1 小时内得到响应,近 1 年社区更是在 SelectDB 的持续推动下,推出了一系列十分抗打的新特性。另外社区在版本迭代时会认真考虑中国人的使用习惯,这些会为我们的使用带来很多便利。
-
-最后,感谢 Doris 社区和 SelectDB 团队的全力支持,也欢迎开发者以及各企业多多了解 Doris、使用 Doris,支持国产数据!
-
-# 1.2.0 版本传送门
-
-Apache Doris 于 2022 年 12 月 7 日迎来 1.2.0 Release 版本的正式发布!新版本中**实现了全面的向量化、实现多场景查询性能 3-11 倍的提升**,在 Unique Key 模型上**实现了 Merge-on-Write 的数据更新模式、数据高频更新时查询性能提升达 3-6 倍**,增加了 Multi-Catalog 多源数据目录、**提供了无缝接入** **Hive**、ES、Hudi、Iceberg 等外部数据源的能力 **,引入了 Light Schema Change 轻量表结构变更、** 实现毫秒级的 Schema Change 操作**并可以借助 Flink CDC** 自动同步上游数据库的 DML 和 **DDL** **操作**,以 JDBC 外部表替换了过去的 ODBC 外部表,支持了 Java UDF 和 Romote UDF 以及 Array 数组类型和 JSONB 类型,修复了诸多之前版本的性能和稳定性问题,推荐大家下载和使用!
-
-## 下载安装
-
-GitHub下载:[https://github.com/apache/doris/releases](https://www.oschina.net/action/GoToLink?url=https%3A%2F%2Fgithub.com%2Fapache%2Fdoris%2Freleases)
-
-官网下载页:[https://doris.apache.org/download](https://www.oschina.net/action/GoToLink?url=https%3A%2F%2Fdoris.apache.org%2Fdownload)
-
-源码地址:[https://github.com/apache/doris/releases/tag/1.2.0-rc04](https://www.oschina.net/action/GoToLink?url=https%3A%2F%2Fgithub.com%2Fapache%2Fdoris%2Freleases%2Ftag%2F1.1.3-rc024)
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/meituan.md b/i18n/zh-CN/docusaurus-plugin-content-blog/meituan.md
deleted file mode 100644
index e938a70e313..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/meituan.md
+++ /dev/null
@@ -1,182 +0,0 @@
----
-{
- 'title': 'Apache Doris 在美团外卖实时数仓建设中的实践',
- 'summary': '本文主要介绍一种通用的实时数仓构建的方法与实践。实时数仓以端到端低延迟、SQL标准化、快速响应变化、数据统一为目标。在实践中,我们总结的最佳实践是:一个通用的实时生产平台 + 一个通用交互式实时分析引擎相互配合同时满足实时和准实时业务场景。两者合理分工,互相补充,形成易于开发、易于维护、效率最高的流水线,兼顾开发效率与生产成本,以较好的投入产出比满足业务多样需求.',
- 'date': '2022-07-20',
- 'author': 'Apache Doris',
- 'tags': ['最佳实践'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-**导读:**本文主要介绍一种通用的实时数仓构建的方法与实践。实时数仓以端到端低延迟、SQL 标准化、快速响应变化、数据统一为目标。在实践中,我们总结的最佳实践是:一个通用的实时生产平台 + 一个通用交互式实时分析引擎相互配合同时满足实时和准实时业务场景。两者合理分工,互相补充,形成易于开发、易于维护、效率最高的流水线,兼顾开发效率与生产成本,以较好的投入产出比满足业务多样需求。
-
-# **实时场景**
-
-实时数据在美团外卖的场景是非常多的,主要有以下几点:
-
-- 运营层面:比如实时业务变化,实时营销效果,当日营业情况以及当日实时业务趋势分析等。
-
-- 生产层面:比如实时系统是否可靠,系统是否稳定,实时监控系统的健康状况等。
-
-- C 端用户:比如搜索推荐排序,需要实时了解用户的想法,行为、特点,给用户推荐更加关注的内容。
-
-- 风控侧:在外卖以及金融科技用的是非常多的,实时风险识别,反欺诈,异常交易等,都是大量应用实时数据的场景
-
-# **实时技术及架构**
-
-### **1.实时计算技术选型**
-
-目前开源的实时技术比较多,比较通用的是 Storm、Spark Streaming 以及 Flink,具体要根据不同公司的业务情况进行选型。
-
-美团外卖是依托美团整体的基础数据体系建设,从技术成熟度来讲,前几年用的是 Storm,Storm 当时在性能稳定性、可靠性以及扩展性上是无可替代的,随着 Flink 越来越成熟,从技术性能上以及框架设计优势上已经超越 Storm,从趋势来讲就像 Spark 替代 MR 一样,Storm 也会慢慢被 Flink 替代,当然从 Storm 迁移到 Flink 会有一个过程,我们目前有一些老的任务仍然在 Storm 上,也在不断推进任务迁移。
-
-具体 Storm 和 Flink 的对比可以参考上图表格。
-
-### 2.**实时架构**
-
-**① Lambda 架构**
-
-Lambda 架构是比较经典的架构,以前实时的场景不是很多,以离线为主,当附加了实时场景后,由于离线和实时的时效性不同,导致技术生态是不一样的。Lambda 架构相当于附加了一条实时生产链路,在应用层面进行一个整合,双路生产,各自独立。这在业务应用中也是顺理成章采用的一种方式。
-
-双路生产会存在一些问题,比如加工逻辑 double,开发运维也会 double,资源同样会变成两个资源链路。因为存在以上问题,所以又演进了一个 Kappa 架构。
-
-**② Kappa 架构**
-
-Kappa 架构从架构设计来讲比较简单,生产统一,一套逻辑同时生产离线和实时。但是在实际应用场景有比较大的局限性,在业内直接用 Kappa 架构生产落地的案例不多见,且场景比较单一。这些问题在我们这边同样会遇到,我们也会有自己的一些思考,在后面会讲到。
-
-# **业务痛点**
-
-在外卖业务上,我们也遇到了一些问题。
-
-业务早期,为了满足业务需要,一般是拿到需求后 case by case 的先把需求完成,业务对于实时性要求是很高的,从时效性来说,没有进行中间层沉淀的机会,在这种场景下,一般是拿到业务逻辑直接嵌入,这是能想到的简单有效的方法,在业务发展初期这种开发模式比较常见。
-
-如上图所示,拿到数据源后,会经过数据清洗,扩维,通过 Storm 或 Flink 进行业务逻辑处理,最后直接进行业务输出。把这个环节拆开来看,数据源端会重复引用相同的数据源,后面进行清洗、过滤、扩维等操作,都要重复做一遍,唯一不同的是业务的代码逻辑是不一样的,如果业务较少,这种模式还可以接受,但当后续业务量上去后,会出现谁开发谁运维的情况,维护工作量会越来越大,作业无法形成统一管理。而且所有人都在申请资源,导致资源成本急速膨胀,资源不能集约有效利用,因此要思考如何从整体来进行实时数据的建设。
-
-# **数据特点与应用场景**
-
-那么如何来构建实时数仓呢?
-
-首先要进行拆解,有哪些数据,有哪些场景,这些场景有哪些共同特点,对于外卖场景来说一共有两大类,日志类和业务类。
-
-- 日志类:数据量特别大,半结构化,嵌套比较深。日志类的数据有个很大的特点,日志流一旦形成是不会变的,通过埋点的方式收集平台所有的日志,统一进行采集分发,就像一颗树,树根非常大,推到前端应用的时候,相当于从树根到树枝分叉的过程(从 1 到 n 的分解过程),如果所有的业务都从根上找数据,看起来路径最短,但包袱太重,数据检索效率低。日志类数据一般用于生产监控和用户行为分析,时效性要求比较高,时间窗口一般是 5min 或 10min 或截止到当前的一个状态,主要的应用是实时大屏和实时特征,例如用户每一次点击行为都能够立刻感知到等需求。
-
-- 业务类:主要是业务交易数据,业务系统一般是自成体系的,以 Binlog 日志的形式往下分发,业务系统都是事务型的,主要采用范式建模方式,特点是结构化的,主体非常清晰,但数据表较多,需要多表关联才能表达完整业务,因此是一个 n 到 1 的集成加工过程。
-
-业务类实时处理面临的几个难点:
-
-- 业务的多状态性:业务过程从开始到结束是不断变化的,比如从下单->支付->配送,业务库是在原始基础上进行变更的,Binlog 会产生很多变化的日志。而业务分析更加关注最终状态,由此产生数据回撤计算的问题,例如 10 点下单,13 点取消,但希望在 10 点减掉取消单。
-
-- 业务集成:业务分析数据一般无法通过单一主体表达,往往是很多表进行关联,才能得到想要的信息,在实时流中进行数据的合流对齐,往往需要较大的缓存处理且复杂。
-
-- 分析是批量的,处理过程是流式的:对单一数据,无法形成分析,因此分析对象一定是批量的,而数据加工是逐条的。
-
-日志类和业务类的场景一般是同时存在的,交织在一起,无论是 Lambda 架构还是 Kappa 架构,单一的应用都会有一些问题。因此针对场景来选择架构与实践才更有意义。
-
-# **实时**数仓架构设计
-
-### **1. 实时架构:流批结合的探索**
-
-基于以上问题,我们有自己的思考。通过流批结合的方式来应对不同的业务场景。
-
-如上图所示,数据从日志统一采集到消息队列,再到数据流的 ETL 过程,作为基础数据流的建设是统一的。之后对于日志类实时特征,实时大屏类应用走实时流计算。对于 Binlog 类业务分析走实时 OLAP 批处理。
-
-流式处理分析业务的痛点?对于范式业务,Storm 和 Flink 都需要很大的外存,来实现数据流之间的业务对齐,需要大量的计算资源。且由于外存的限制,必须进行窗口的限定策略,最终可能放弃一些数据。计算之后,一般是存到 Redis 里做查询支撑,且 KV 存储在应对分析类查询场景中也有较多局限。
-
-实时 OLAP 怎么实现?有没有一种自带存储的实时计算引擎,当实时数据来了之后,可以灵活的在一定范围内自由计算,并且有一定的数据承载能力,同时支持分析查询响应呢?随着技术的发展,目前 MPP 引擎发展非常迅速,性能也在飞快提升,所以在这种场景下就有了一种新的可能。这里我们使用的是 Doris 引擎。
-
-这种想法在业内也已经有实践,且成为一个重要探索方向。阿里基于 ADB 的实时 OLAP 方案等。
-
-### **2. 实时数仓架构设计**
-
-从整个实时数仓架构来看,首先考虑的是如何管理所有的实时数据,资源如何有效整合,数据如何进行建设。
-
-从方法论来讲,实时和离线是非常相似的,离线数仓早期的时候也是 case by case,当数据规模涨到一定量的时候才会考虑如何治理。分层是一种非常有效的数据治理方式,所以在实时数仓如何进行管理的问题上,首先考虑的也是分层的处理逻辑,具体如下:
-
-- 数据源:在数据源的层面,离线和实时在数据源是一致的,主要分为日志类和业务类,日志类又包括用户日志,DB 日志以及服务器日志等。
-
-- 实时明细层:在明细层,为了解决重复建设的问题,要进行统一构建,利用离线数仓的模式,建设统一的基础明细数据层,按照主题进行管理,明细层的目的是给下游提供直接可用的数据,因此要对基础层进行统一的加工,比如清洗、过滤、扩维等。
-
-- 汇总层:汇总层通过 Flink 或 Storm 的简洁算子直接可以算出结果,并且形成汇总指标池,所有的指标都统一在汇总层加工,所有人按照统一的规范管理建设,形成可复用的汇总结果。
-
-总结起来,从整个实时数仓的建设角度来讲,首先数据建设的层次化要先建出来,先搭框架,然后定规范,每一层加工到什么程度,每一层用什么样的方式,当规范定义出来后,便于在生产上进行标准化的加工。由于要保证时效性,设计的时候,层次不能太多,对于实时性要求比较高的场景,基本可以走上图左侧的数据流,对于批量处理的需求,可以从实时明细层导入到实时 OLAP 引擎里,基于 OLAP 引擎自身的计算和查询能力进行快速的回撤计算,如上图右侧的数据流。
-
-# **实时平台化建设**
-
-架构确定之后,后面考虑的是如何进行平台化的建设,实时平台化建设完全附加于实时数仓管理之上进行的。
-
-首先进行功能的抽象,把功能抽象成组件,这样就可以达到标准化的生产,系统化的保障就可以更深入的建设,对于基础加工层的清洗、过滤、合流、扩维、转换、加密、筛选等功能都可以抽象出来,基础层通过这种组件化的方式构建直接可用的数据结果流。这其中会有一个问题,用户的需求多样,满足了这个用户,如何兼容其他的用户,因此可能会出现冗余加工的情况,从存储来讲,实时数据不存历史,不会消耗过多的存储,这种冗余是可以接受的,通过冗余的方式可以提高生产效率,是一种空间换时间的思想应用。
-
-通过基础层的加工,数据全部沉淀到 IDL 层,同时写到 OLAP 引擎的基础层,再往上是实时汇总层计算,基于 Storm、Flink 或 Doris,生产多维度的汇总指标,形成统一的汇总层,进行统一的存储分发。
-
-当这些功能都有了以后,元数据管理,指标管理,数据安全性、SLA、数据质量等系统能力也会逐渐构建起来。
-
-### 1.实时基础层功能
-
-实时基础层的建设要解决一些问题。
-
-首先是一条流重复读的问题,一条 Binlog 打过来,是以 DB 包的形式存在的,用户可能只用其中一张表,如果大家都要用,可能存在所有人都要接这个流的问题。解决方案是可以按照不同的业务解构出来,还原到基础数据流层,根据业务的需要做成范式结构,按照数仓的建模方式进行集成化的主题建设。
-
-其次要进行组件的封装,比如基础层的清洗、过滤、扩维等功能,通过一个很简单的表达入口,让用户将逻辑写出来。trans 环节是比较灵活的,比如从一个值转换成另外一个值,对于这种自定义逻辑表达,我们也开放了自定义组件,可以通过 Java 或 Python 开发自定义脚本,进行数据加工。
-
-### 2.**实时特征生产功能**
-
-特征生产可以通过 SQL 语法进行逻辑表达,底层进行逻辑的适配,透传到计算引擎,屏蔽用户对计算引擎的依赖。就像对于离线场景,目前大公司很少通过代码的方式开发,除非一些特别的 case,所以基本上可以通过 SQL 化的方式表达。
-
-在功能层面,把指标管理的思想融合进去,原子指标、派生指标,标准计算口径,维度选择,窗口设置等操作都可以通过配置化的方式,这样可以统一解析生产逻辑,进行统一封装。
-
-还有一个问题,同一个源,写了很多 SQL,每一次提交都会起一个数据流,比较浪费资源,我们的解决方案是,通过同一条流实现动态指标的生产,在不停服务的情况下可以动态添加指标。
-
-所以在实时平台建设过程中,更多考虑的是如何更有效的利用资源,在哪些环节更能节约化的使用资源,这是在工程方面更多考虑的事情。
-
-### 3.SLA 建设
-
-SLA 主要解决两个问题,一个是端到端的 SLA,一个是作业生产效率的 SLA,我们采用埋点+上报的方式,由于实时流比较大,埋点要尽量简单,不能埋太多的东西,能表达业务即可,每个作业的输出统一上报到 SLA 监控平台,通过统一接口的形式,在每一个作业点上报所需要的信息,最后能够统计到端到端的 SLA。
-
-在实时生产中,由于链路非常长,无法控制所有链路,但是可以控制自己作业的效率,所以作业 SLA 也是必不可少的。
-
-### 4. 实时 OLAP 方案
-
-问题:
-
-- Binlog 业务还原复杂:业务变化很多,需要某个时间点的变化,因此需要进行排序,并且数据要存起来,这对于内存和 CPU 的资源消耗都是非常大的。
-
-- Binlog 业务关联复杂:流式计算里,流和流之间的关联,对于业务逻辑的表达是非常困难的。
-
-解决方案:
-
-通过带计算能力的 OLAP 引擎来解决,不需要把一个流进行逻辑化映射,只需要解决数据实时稳定的入库问题。
-
-我们这边采用的是 Doris 作为高性能的 OLAP 引擎,由于业务数据产生的结果和结果之间还需要进行衍生计算,Doris 可以利用 unique 模型或聚合模型快速还原业务,还原业务的同时还可以进行汇总层的聚合,也是为了复用而设计。应用层可以是物理的,也可以是逻辑化视图。
-
-这种模式重在解决业务回撤计算,比如业务状态改变,需要在历史的某个点将值变更,这种场景用流计算的成本非常大,OLAP 模式可以很好的解决这个问题。
-
-# 实时应用案例
-
-最后通过一个案例说明,比如商家要根据用户历史下单数给用户优惠,商家需要看到历史下了多少单,历史 T+1 的数据要有,今天实时的数据也要有,这种场景是典型的 Lambda 架构,可以在 Doris 里设计一个分区表,一个是历史分区,一个是今日分区,历史分区可以通过离线的方式生产,今日指标可以通过实时的方式计算,写到今日分区里,查询的时候进行一个简单的汇总。
-
-这种场景看起来比较简单,难点在于商家的量上来之后,很多简单的问题都会变的复杂,因此后面我们也会通过更多的业务输入,沉淀出更多的业务场景,抽象出来形成统一的生产方案和功能,以最小化的实时计算资源支撑多样化的业务需求,这也是未来需要达到的目的。
-
-今天的分享就到这里,谢谢大家。
-
-### 嘉宾介绍:
-
-朱良,5 年以上传统行业数仓建设经验,6 年互联网数仓经验,技术方向涉及离线,实时数仓治理,系统化能力建设,OLAP 系统及引擎,大数据相关技术,重点跟进 OLAP,实时技术前沿发展趋势。业务方向涉及即席查询,运营分析,策略报告产品,用户画像,人群推荐,实验评估等。
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/options.json b/i18n/zh-CN/docusaurus-plugin-content-blog/options.json
deleted file mode 100644
index e009426f48d..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/options.json
+++ /dev/null
@@ -1,14 +0,0 @@
-{
- "title": {
- "message": "博客",
- "description": "The title for the blog used in SEO"
- },
- "description": {
- "message": "Apache Doris 博客",
- "description": "The description for the blog used in SEO"
- },
- "sidebar.title": {
- "message": "Recent posts",
- "description": "The label for the left sidebar"
- }
-}
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/principle-of-Doris-SQL-parsing.md b/i18n/zh-CN/docusaurus-plugin-content-blog/principle-of-Doris-SQL-parsing.md
deleted file mode 100644
index 4a405895ba2..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/principle-of-Doris-SQL-parsing.md
+++ /dev/null
@@ -1,273 +0,0 @@
----
-{
-'title': 'Doris全面解析:Doris SQL 原理解析',
-'summary': "本文主要介绍了Doris SQL解析的原理。由于SQL类型有很多,本文侧重介绍查询SQL的解析,从算法原理和代码实现上深入讲解了Doris的SQL解析原理。",
-'date': '2022-08-25',
-'author': 'Apache Doris',
-'tags': ['技术解析'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-**导读:**
-本文主要介绍了Doris SQL解析的原理。
-
-重点讲述了生成单机逻辑计划,生成分布式逻辑计划,生成分布式物理计划的过程。对应于代码实现是Analyze,SinglePlan,DistributedPlan,Schedule四个部分。
-
-Analyze负责对AST进行前期的一些处理,SinglePlan根据AST进行优化生成单机查询计划,DistributedPlan将单机的查询计划拆成分布式的查询计划,Schedule阶段负责决定查询计划下发到哪些机器上执行。
-
-由于SQL类型有很多,本文侧重介绍查询SQL的解析,从算法原理和代码实现上深入讲解了Doris的SQL解析原理。
-
-# 1 Doris简介
-Doris是基于MPP架构的交互式SQL数据仓库,主要用于解决近实时的报表和多维分析。
-
-Doris分成两部分FE和BE,FE 负责存储以及维护集群元数据、接收、解析、查询、设计规划整体查询流程,BE 负责数据存储和具体的实施过程。
-
-在 Doris 的存储引擎中,用户数据被水平划分为若干个数据分片(Tablet,也称作数据分桶)。每个 Tablet 包含若干数据行。多个 Tablet 在逻辑上归属于不同的分区Partition。一个 Tablet 只属于一个 Partition。而一个 Partition 包含若干个 Tablet。Tablet 是数据移动、复制等操作的最小物理存储单元。
-
-# 2 SQL解析简介
-SQL解析在这篇文章中指的是**将一条sql语句经过一系列的解析最后生成一个完整的物理执行计划的过程**。
-
-这个过程包括以下四个步骤:词法分析,语法分析,生成逻辑计划,生成物理计划。 如图1所示:
-
-
-
-## 2.1 词法分析
-
-词法分析主要负责将字符串形式的sql识别成一个个token,为语法分析做准备。
-```undefined
-select ...... from ...... where ....... group by ..... order by ......
-
-SQL 的 Token 可以分为如下几类:
-○ 关键字(select、from、where)
-○ 操作符(+、-、>=)
-○ 开闭合标志((、CASE)
-○ 占位符(?)
-○ 注释
-○ 空格
-......
-```
-## 2.2 语法分析
-语法分析主要负责根据语法规则,将词法分析生成的token转成抽象语法树(Abstract Syntax Tree),如图2所示。
-
-
-
-
-## 2.3 逻辑计划
-逻辑计划负责将抽象语法树转成代数关系。代数关系是一棵算子树,每个节点代表一种对数据的计算方式,整棵树代表了数据的计算方式以及流动方向,如图3所示。
-
-
-
-## 2.4 物理计划
-物理计划是在逻辑计划的基础上,根据机器的分布,数据的分布,决定去哪些机器上执行哪些计算操作。
-
-Doris系统的SQL解析也是采用这些步骤,只不过根据Doris系统结构的特点和数据的存储方式,进行了细化和优化,最大化发挥机器的计算能力。
-
-# 3 设计目标
-Doris SQL解析架构的设计有以下目标:
-
-1. 最大化计算的并行性
-
-2. 最小化数据的网络传输
-
-3. 最大化减少需要扫描的数据
-
-# 4 总体架构
-Doris SQL解析具体包括了五个步骤:词法分析,语法分析,生成单机逻辑计划,生成分布式逻辑计划,生成物理执行计划。
-
-具体代码实现上包含以下五个步骤:Parse, Analyze, SinglePlan, DistributedPlan, Schedule。
-
-
-
-如图4所示,Parse阶段本文不详细讲,Analyze负责对AST进行前期的一些处理,SinglePlan根据AST进行优化生成单机查询计划,DistributedPlan将单机的查询计划拆成分布式的查询计划,Schedule阶段负责决定查询计划下发到哪些机器上执行。
-
-**由于SQL类型有很多,本文侧重介绍查询SQL的解析。**
-
-图5展示了一个简单的查询SQL在Doris的解析实现
-
-
-
-# 5 Parse阶段
-词法分析采用jflex技术,语法分析采用java cup parser技术,最后生成抽象语法树(Abstract Syntax Tree)AST,这些都是现有的、成熟的技术,在这里不进行详细介绍。
-
-AST是一种树状结构,代表着一条SQL。不同类型的查询select, insert, show, set, alter table, create table等经过Parse阶段后生成不同的数据结构(SelectStmt, InsertStmt, ShowStmt, SetStmt, AlterStmt, AlterTableStmt, CreateTableStmt等),但他们都继承自Statement,并根据自己的语法规则进行一些特定的处理。例如:对于select类型的sql, Parse之后生成了SelectStmt结构。
-
-SelectStmt结构包含了SelectList,FromClause,WhereClause,GroupByClause,SortInfo等结构。这些结构又包含了更基础的一些数据结构,如WhereClause包含了BetweenPredicate(between表达式), BinaryPredicate(二元表达式), CompoundPredicate(and or组合表达式), InPredicate(in表达式)等。
-
-AST中所有结构都是由基本结构表达式Expr通过多种组合而成,如图6所示。
-
-
-
-# 6 Analyze阶段
-Analyze主要是对Parse阶段生成的抽象语法树AST进行一些前期的处理和语义分析,为生成单机逻辑计划做准备。
-
-抽象语法树是由StatementBase这个抽象类表示。这个抽象类包含一个最重要的成员函数analyze(),用来执行Analyze阶段要做的事。
-
-不同类型的查询select, insert, show, set, alter table, create table等经过Parse阶段后生成不同的数据结构(SelectStmt, InsertStmt, ShowStmt, SetStmt, AlterStmt, AlterTableStmt, CreateTableStmt等),这些数据结构继承自StatementBase,并实现analyze()函数,对特定类型的SQL进行特定的Analyze。
-
-例如:select类型的查询,会转成对select sql的子语句SelectList, FromClause, GroupByClause, HavingClause, WhereClause, SortInfo等的analyze()。然后这些子语句再各自对自己的子结构进行进一步的analyze(),通过层层迭代,把各种类型的sql的各种情景都分析完毕。例如:WhereClause进一步分析其包含的BetweenPredicate(between表达式), BinaryPredicate(二元表达式), CompoundPredicate(and or组合表达式), InPredicate(in表达式)等。
-
-**对于查询类型的SQL,包含以下几项重要工作:**
-
-- **元信息的识别和解析**:识别和解析sql中涉及的 Cluster, Database, Table, Column 等元信息,确定需要对哪个集群的哪个数据库的哪些表的哪些列进行计算。
-
-- **SQL 的合法性检查**:窗口函数不能 DISTINCT,投影列是否有歧义,where语句中不能含有grouping操作等。
-
-- **SQL 简单重写**:比如将 select * 扩展成 select 所有列,count distinct转成bitmap或者hll函数等。
-
-- **函数处理**:检查sql中包含的函数和系统定义的函数是否一致,包括参数类型,参数个数等。
-
-- **Table 和 Column 的别名处理**
-
-- **类型检查和转换**:例如二元表达式两边的类型不一致时,需要对其中一个类型进行转换(BIGINT 和 DECIMAL 比较,BIGINT 类型需要 Cast 成 DECIMAL)。
-
-对AST 进行analyze后,会再进行一次rewrite操作,进行精简或者是转成统一的处理方式。目前rewrite的算法是基于规则的方式,针对AST的树状结构,自底向上,应用每一条规则进行重写。如果重写后,AST有变化,则再次进行analyze和rewrite,直到AST无变化为止。
-
-例如:常量表达式的化简:1 + 1 + 1 重写成 3,1 > 2 重写成 Flase 等。将一些语句转成统一的处理方式,比如将 where in, where exists 重写成 semi join, where not in, where not exists 重写成 anti join。
-
-# 7 生成单机逻辑Plan阶段
-这部分工作主要是根据AST抽象语法树生成代数关系,也就是俗称的算子数。树上的每个节点都是一个算子,代表着一种操作。
-
-如图7所示,ScanNode代表着对一个表的扫描操作,将一个表的数据读出来。HashJoinNode代表着join操作,小表在内存中构建哈希表,遍历大表找到连接键相同的值。Project表示投影操作,代表着最后需要输出的列,图7表示只用输出citycode这一列。
-
-
-
-如果不进行优化,生成的关系代数下发到存储中执行的代价非常高。
-
-对于查询:
-```undefined
-select a.siteid, a.pv from table1 a join table2 b on a.siteid = b.siteid where a.citycode=122216 and b.username="test" order by a.pv limit 10
-```
-未优化的关系代数,如图8所示,需要将所有列读出来进行一系列的计算,在最后选择输出siteid, pv两列,大量无用的列数据浪费了计算资源。
-
-Doris在生成代数关系时,进行了大量的优化,将投影列和查询条件尽可能放到扫描操作时执行。
-
-
-
-**具体来说这个阶段主要做了如下几项工作:**
-
-- **Slot 物化**:指确定一个表达式对应的列需要 Scan 和计算,比如聚合节点的聚合函数表达式和 Group By 表达式需要进行物化。
-
-- **投影下推**:BE 在 Scan 时只会 Scan 必须读取的列。
-
-- **谓词下推**:在满足语义正确的前提下将过滤条件尽可能下推到 Scan 节点。
-
-- **分区,分桶裁剪**:根据过滤条件中的信息,确定需要扫描哪些分区,哪些桶的tablet。
-
-- **Join Reorder**:对于 Inner Join, Doris 会根据行数调整表的顺序,将大表放在前面。
-
-- **Sort + Limit 优化成 TopN**:对于order by limit语句会转换成TopN的操作节点,方便统一处理。
-
-- **MaterializedView 选择**:会根据查询需要的列,过滤,排序和 Join 的列,行数,列数等因素选择最佳的物化视图。
-
-图9展示了优化的示例,Doris是在生成关系代数的过程中优化,边生成边优化。
-
-
-
-# 8 生成分布式Plan阶段
-
-有了单机的PlanNode树之后,就需要进一步根据分布式环境,拆成分布式PlanFragment树(PlanFragment用来表示独立的执行单元),毕竟一个表的数据分散地存储在多台主机上,完全可以让一些计算并行起来。
-
-这个步骤的主要目标是最大化并行度和数据本地化。主要方法是将能够并行执行的节点拆分出去单独建立一个PlanFragment,用ExchangeNode代替被拆分出去的节点,用来接收数据。拆分出去的节点增加一个DataSinkNode,用来将计算之后的数据传送到ExchangeNode中,做进一步的处理。
-
-这一步采用递归的方法,自底向上,遍历整个PlanNode树,然后给树上的每个叶子节点创建一个PlanFragment,如果碰到父节点,则考虑将其中能够并行执行的子节点拆分出去,父节点和保留下来的子节点组成一个parent PlanFragment。拆分出去的子节点增加一个父节点DataSinkNode组成一个child PlanFragment,child PlanFragment指向parent PlanFragment。这样就确定了数据的流动方向。
-
-对于查询操作来说,join操作是最常见的一种操作。
-
-**Doris目前支持4种join算法**:broadcast join,hash partition join,colocate join,bucket shuffle join。
-
-**broadcast join**:将小表发送到大表所在的每台机器,然后进行hash join操作。当一个表扫描出的数据量较少时,计算broadcast join的cost,通过计算比较hash partition的cost,来选择cost最小的方式。
-
-**hash partition join**:当两张表扫描出的数据都很大时,一般采用hash partition join。它遍历表中的所有数据,计算key的哈希值,然后对集群数取模,选到哪台机器,就将数据发送到这台机器进行hash join操作。
-
-**colocate join**:两个表在创建的时候就指定了数据分布保持一致,那么当两个表的join key与分桶的key一致时,就会采用colocate join算法。由于两个表的数据分布是一样的,那么hash join操作就相当于在本地,不涉及到数据的传输,极大提高查询性能。
-
-**bucket shuffle join**:当join key是分桶key,并且只涉及到一个分区时,就会优先采用bucket shuffle join算法。由于分桶本身就代表了数据的一种切分方式,所以可以利用这一特点,只需将右表对左表的分桶数hash取模,这样只需网络传输一份右表数据,极大减少了数据的网络传输,如图10所示。
-
-
-
-如图11展示了带有HashJoinNode的单机逻辑计划创建分布式逻辑计划的核心流程。
-
-- 对PlanNode,自底向上创建PlanFragment。
-
-- 如果是ScanNode,则直接创建一个PlanFragment,PlanFragment的RootPlanNode是这个ScanNode。
-
-- 如果是HashJoinNode,则首先计算下broadcastCost,为选择boracast join还是hash partition join提供参考。
-
-- 根据不同的条件判断选择哪种Join算法
-
-- 如果使用colocate join,由于join操作都在本地,就不需要拆分。设置HashJoinNode的左子节点为leftFragment的RootPlanNode,右子节点为rightFragment的RootPlanNode,与leftFragment共用一个PlanFragment,删除掉rightFragment。
-
-- 如果使用bucket shuffle join,需要将右表的数据发送给左表。所以先创建了一个ExchangeNode,设置HashJoinNode的左子节点为leftFragment的RootPlanNode,右子节点为这个ExchangeNode,与leftFragment共用一个PlanFragment,并且指定rightFragment数据发送的目的地为这个ExchangeNode。
-
-- 如果使用broadcast join,需要将右表的数据发送给左表。所以先创建了一个ExchangeNode,设置HashJoinNode的左子节点为leftFragment的RootPlanNode,右子节点为这个ExchangeNode,与leftFragment共用一个PlanFragment,并且指定rightFragment数据发送的目的地为这个ExchangeNode。
-
-- 如果使用hash partition join,左表和右边的数据都要切分,需要将左右节点都拆分出去,分别创建left ExchangeNode, right ExchangeNode,HashJoinNode指定左右节点为left ExchangeNode和 right ExchangeNode。单独创建一个PlanFragment,指定RootPlanNode为这个HashJoinNode。最后指定leftFragment, rightFragment的数据发送目的地为left ExchangeNode, right ExchangeNode。
-
-
-
-图12是两个表的join操作转换成PlanFragment树之后的示例,一共生成了3个PlanFragment。最终数据的输出通过ResultSinkNode节点。
-
-
-
-# 9 Schedule阶段
-
-这一步是根据分布式逻辑计划,创建分布式物理计划。主要解决以下问题:
-
-- 哪个 BE 执行哪个 PlanFragment
-
-- 每个 Tablet 选择哪个副本去查询
-
-- 如何进行多实例并发
-
-**图13展示了创建分布式物理计划的核心流程:**
-
-**a. prepare阶段**:给每个PlanFragment创建一个FragmentExecParams结构,用来表示PlanFragment执行时所需的所有参数;如果一个PlanFragment包含有DataSinkNode,则找到数据发送的目的PlanFragment,然后指定目的PlanFragment的FragmentExecParams的输入为该PlanFragment的FragmentExecParams。
-
-**b. computeScanRangeAssignment阶段**:针对不同类型的join进行不同的处理。
-
-- computeScanRangeAssignmentByColocate:针对colocate join进行处理,由于join的两个表桶中的数据分布都是一样的,他们是基于桶的join操作,所以在这里是确定每个桶选择哪个host。在给host分配桶时,尽量保证每个host分配到的桶基本平均。
-
-- computeScanRangeAssignmentByBucket:针对bucket shuffle join进行处理,也只是基于桶的操作,所以在这里是确定每个桶选择哪个host。在给host分配桶时,同样需要尽量保证每个host分配到的桶基本平均。
-
-- computeScanRangeAssignmentByScheduler:针对其他类型的join进行处理。确定每个scanNode读取tablet哪个副本。一个scanNode会读取多个tablet,每个tablet有多个副本。为了使scan操作尽可能分散到多台机器上执行,提高并发性能,减少IO压力,Doris采用了Round-Robin算法,使tablet的扫描尽可能地分散到多台机器上去。例如100个tablet需要扫描,每个tablet 3个副本,一共10台机器,在分配时,保障每台机器扫描10个tablet。
-
-**c. computeFragmentExecParams阶段**:这个阶段解决PlanFragment下发到哪个BE上执行,以及如何处理实例并发问题。确定了每个tablet的扫描地址之后,就可以以地址为维度,将FragmentExecParams生成多个实例,也就是FragmentExecParams中包含的地址有多个,就生成多个实例FInstanceExecParam。如果设置了并发度,那么一个地址的执行实例再进一步的拆成多个FInstanceExecParam。针对bucket shuffle join和colocate join会有一些特殊处理,但是基本思想一样。FInstanceExecParam创建完成后,会分配一个唯一的ID,方便追踪信息。如果FragmentExecParams中包含有ExchangeNode,需要计算有多少senders,以便知道需要接受多少个发送方的数据。最后FragmentExecParams确定destinations,并把目的地址填充上去。
-
-**d. create result receiver阶段**:result receiver是查询完成后,最终数据需要输出的地方。
-
-**e. to thrift阶段**:根据所有PlanFragment的FInstanceExecParam创建rpc请求,然后下发到BE端执行。这样一个完整的SQL解析过程完成了。
-
-
-
-
-如图14所示是一个简单示例,图中的PlanFrament包含了一个ScanNode,ScanNode扫描3个tablet,每个tablet有2副本,集群假设有2台host。
-
-computeScanRangeAssignment阶段确定了需要扫描replica 1,3,5,8,10,12,其中replica 1,3,5位于host1上,replica 8,10,12位于host2上。
-
-如果全局并发度设置为1时,则创建2个实例FInstanceExecParam,下发到host1和host2上去执行,如果如果全局并发度设置为3,这个host1上创建3个实例FInstanceExecParam,host2上创建3个实例FInstanceExecParam,每个实例扫描一个replica,相当于发起6个rpc请求。
-
-
-
-# 10 总结
-本文首先简单介绍了Doris,然后介绍SQL解析的通用流程:词法分析,语法分析,生成逻辑计划,生成物理计划,接着从总体上介绍了Doris在SQL解析这块的总体架构,最后详细讲解了Parse,Analyze,SinglePlan,DistributedPlan,Schedule等5个过程,从算法原理和代码实现上进行了深入的讲解。
-
-Doris遵守了SQL解析的常用方法,但根据底层存储架构,以及分布式的特点,在SQL解析这块进行了大量的优化,实现了最大并行度和最小化网络传输,给SQL执行层面减少很多负担。
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/principle-of-Doris-Stream-Load.md b/i18n/zh-CN/docusaurus-plugin-content-blog/principle-of-Doris-Stream-Load.md
deleted file mode 100644
index b2fd6958456..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/principle-of-Doris-Stream-Load.md
+++ /dev/null
@@ -1,131 +0,0 @@
----
-{
-'title': 'Doris Stream Load原理解析',
-'summary': "Stream Load是Doris用户最常用的数据导入方式之一,它是一种同步的导入方式, 允许用户通过Http访问的方式批量地将数据导入Doris,并返回数据导入的结果。",
-'date': '2022-09-08',
-'author': 'Apache Doris',
-'tags': ['技术解析'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-**导读:**
-
-Stream Load是Doris用户最常用的数据导入方式之一,它是一种同步的导入方式, 允许用户通过Http访问的方式批量地将数据导入Doris,并返回数据导入的结果。用户可以直接通过Http请求的返回体判断数据导入是否成功,也可以通过在客户端执行查询SQL来查询历史任务的结果。
-
-# **Stream Load简介**
-
-Doris的导入(Load)功能就是将用户的原始数据导入到 Doris表中。Doris底层实现了统一的流式导入框架,在这个框架之上,Doris提供了非常丰富的导入方式以适应不同的数据源和数据导入需求。Stream Load是Doris用户最常用的数据导入方式之一,它是一种同步的导入方式, 允许用户通过Http访问的方式批量地将CSV格式或JSON格式的数据导入Doris,并返回数据导入的结果。用户可以直接通过Http请求的返回体判断数据导入是否成功,也可以通过在客户端执行查询SQL来查询历史任务的结果。另外,Doris还为Stream Load提供了操作审计功能,可以通过审计日志对历史的Stream Load任务信息进行审计。本文将从Stream Load的执行流程、事务管理、导入计划的执行、数据写入以及操作审计等方面对Stream Load的实现原理进行深入地解析。
-
-# 1 **执行流程**
-
-用户将Stream Load的Http请求提交给FE,FE会通过 Http 重定向(Redirect)将数据导入请求转发给某一个BE节点,该BE节点将作为本次Stream Load任务的Coordinator。在这个过程中,接收请求的FE节点仅仅提供转发服务,由作为 Coordinator的BE节点实际负责整个导入作业,比如负责向Master FE发送事务请求、从FE获取导入执行计划、接收实时数据、分发数据到其他Executor BE节点以及数据导入结束后返回结果给用户。用户也可以将Stream Load的Http请求直接提交给某一个指定的BE节点,并由该节点作为本次Stream Load任务的Coordinator。在Stream Load过程中,Executor BE节点负责将数据写入存储层。
-
-在Coordinator BE中,通过一个线程池来处理所有的Http请求,其中包括Stream Load请求。一次Stream Load任务通过导入的Label唯一标识。Stream Load的原理框图如图1所示。
-
-
-
-Stream Load完整执行流程如图2所示:
-
-(1)用户提交Stream Load的Http请求到FE(用户也可以直接提交Stream Load的Http请求到Coordinator BE)。
-
-(2)FE接收到用户提交的Stream Load请求后,会进行Http的Header解析(其中包括解析数据导入的库、表、Label等信息),然后进行用户鉴权。如果Http的Header解析成功并且用户鉴权通过,FE会将Stream Load的Http请求转发到一台BE节点,该BE节点将作为本次Stream Load的Coordinator;否则,FE会直接向用户返回Stream Load的失败信息。
-
-(3)Coordinator BE接收到Stream Load的Http请求后,会首先进行Http的Header解析和数据校验,其中包括解析数据的文件格式、数据body的大小、Http超时时间、进行用户鉴权等。如果Header数据校验失败,会直接向用户返回Stream Load的失败信息。
-
-(4)Http Header数据校验通过之后,Coordinator BE会通过Thrift RPC向FE发送Begin Transaction的请求。
-
-(5)FE收到Coordinator BE发送的Begin Transaction的请求之后,会开启一个事务,并向Coordinator BE返回Transaction Id。
-
-(6)Coordinator BE收到Begin Transaction成功信息之后,会通过Thrift RPC向 FE发送获取导入计划的请求。
-
-(7)FE收到Coordinator BE发送的获取导入计划的请求之后,会为Stream Load任务生成导入计划,并返回给Coordinator BE。
-
-(8)Coordinator BE接收到导入计划之后,开始执行导入计划,其中包括接收Http传来的实时数据以及将实时数据通过BRPC分发到其他Executor BE。
-
-(9)Executor BE接收到Coordinator BE分发的实时数据之后,负责将数据写入存储层。
-
-(10)Executor BE完成数据写入之后,Coordinator BE通过Thrift RPC 向FE发送Commit Transaction的请求。
-
-(11)FE收到Coordinator BE发送的Commit Transaction的请求之后,会对事务进行提交, 并向Executor BE发送 Publish Version的任务,同时等待Executor BE执行Publish Version完成。
-
-(12)Executor BE异步执行Publish Version,将数据导入生成的Rowset变为可见数据版本。
-
-(13)Publish Version正常完成或执行超时之后,FE向Coordinator BE返回Commit Transaction和Publish Version的结果。
-
-(14)Coordinator BE向用户返回Stream Load的最终结果。
-
-
-
-# 2 事务管理
-
-Doris通过事务(Transaction)来保证数据导入的原子性,一次Stream Load任务对应一个事务。Stream Load的事务管理由FE负责,FE通过FrontendService接收Coordinator BE节点发送来的Thrift RPC事务请求,事务请求类型包括Begin Transaction、Commit Transaction和Rollback Transaction。Doris的事务状态包括:PREPARE、COMMITTED、VISIBLE和ABORTED。Stream Load事务的状态流转过程如图3所示。
-
-
-
-数据导入开始之前,Coordinator BE节点会向FE发送Begin Transaction请求,FE会检查本次Begin Transaction请求的label是否已经存在,如果label在系统中不存在,则会为当前label开启一个新的事务,并为事务分配Transaction Id,同时将事务状态设置为PREPARE,然后将Transaction Id以及Begin Transaction成功的信息返回给Coordinator BE;否则,本次事务可能是一次重复的数据导入,FE向Coordinator BE返回Begin Transaction失败的信息,Stream Load任务退出。
-
-当数据在所有Executor BE节点完成写入之后,Coordinator BE节点会向FE发送Commit Transaction请求,FE收到Commit Transaction请求之后会执行Commit Transaction以及Publish Version两个操作。首先,FE会判断每一个Tablet成功写入数据的副本数量是否超过了Tablet副本总数的一半,如果每一个Tablet成功写入数据的副本数量都超过Tablet副本总数的一半(多数成功),则Commit Transaction成功,并将事务状态设置为COMMITTED;否则,向Coordinator BE返回Commit Transaction失败的信息。COMMITTED状态表示数据已经成功写入,但是数据还不可见,需要继续执行Publish Version任务,此后,事务不可被回滚。
-
-FE会有一个单独的线程对Commit成功的Transaction执行Publish Version,FE执行Publish Version时会通过Thrift RPC向Transaction相关的所有Executor BE节点下发Publish Version请求,Publish Version任务在各个Executor BE节点异步执行,将数据导入生成的Rowset变为可见的数据版本。当Executor BE上所有的Publish Version任务执行成功,FE会将事务状态设置为VISIBLE,并向Coordinator BE返回Commit Transaction以及Publish Version成功的信息。如果存在某些Publish Version任务失败,FE会向Executor BE节点重复下发Publish Version请求直到之前失败的Publish Version任务成功。如果在一定超时时间之后,事务状态还没有被设置为VISIBLE,FE就会向Coordinator BE返回Commit Transaction成功但Publish Version超时 [...]
-
-当从FE获取导入计划失败、执行数据导入失败或Commit Transaction失败时,Coordinator BE节点会向FE发送Rollback Transaction请求,执行事务回滚。FE收到事务回滚的请求之后,会将事务的状态设置为ABORTED,并通过Thrift RPC向Executor BE发送Clear Transaction的请求,Clear Transaction任务在BE节点异步执行,将数据导入生成的Rowset标记为不可用,这些Rowset在之后会从BE上被删除。状态为COMMITTED的事务(Commit Transaction成功但Publish Version超时的事务)不能被回滚。
-
-# 3 导入计划的执行
-在Doris的BE中,所有执行计划由FragmentMgr管理,每一个导入计划的执行由PlanFragmentExecutor负责。BE从FE获取到导入执行计划之后,会将导入计划提交到FragmentMgr的线程池执行。Stream Load 的导入执行计划只有一个Fragment, 其中包含一个BrokerScanNode 和 一个 OlapTableSink。BrokerScanNode负责实时读取流式数据,并将 CSV 格式或JSON格式的数据行转为 Doris 的Tuple格式;OlapTableSink 负责将实时数据发送到对应的Executor BE节点,每个数据行对应哪个Executor BE节点是由数据行所在的Tablet存储在哪些BE上决定的,可以根据数据行的 PartitionKey和DistributionKey确定该行数据所在的Partition和Tablet,每个Tablet及其副本存储在哪台BE节点上是在Table或Partition创建时就已经确定的。
-
-导入执行计划提交到FragmentMgr的线程池之后,Stream Load线程会按块(chunk)接收通过Http传输的实时数据并写入StreamLoadPipe中,BrokerScanNode会从StreamLoadPipe中批量读取实时数据,OlapTableSink会将BrokerScanNode读取的批量数据通过BRPC发送到Executor BE进行数据写入。所有实时数据都写入StreamLoadPipe之后,Stream Load线程会等待导入计划执行结束。
-
-PlanFragmentExecutor执行一个具体的导入计划过程由Prepare、Open和Close三个阶段组成。在Prepare阶段,主要对来自FE的导入执行计划进行解析;在Open阶段,会打开BrokerScanNode和OlapTableSink,BrokerScanNode负责每次读取一个Batch的实时数据,OlapTableSink负责调用BRPC将每一个Batch的数据发送到其他Executor BE节点;在Close阶段,负责等待数据导入结束,并关闭BrokerScanNode和OlapTableSink。Stream Load的导入执行计划如图4所示。
-
-
-
-OlapTableSink负责Stream Load任务的数据分发。Doris中的Table可能会有Rollup或物化视图,每一个Table及其Rollup、物化视图都称为一个Index。数据分发过程中,IndexChannel会维护一个Index的数据分发通道,Index下的Tablet可能会有多个副本(Replica),并分布在不同的BE节点上,NodeChannel会在IndexChannel下维护一个Executor BE节点的数据分发通道,因此,OlapTableSink下包含多个IndexChannel,每一个IndexChannel下包含多个NodeChannel,如图5所示。
-
-
-
-OlapTableSink分发数据时,会逐行读取BrokerScanNode获取到的数据Batch,并将数据行添加到每一个Index的IndexChannel中。可以根据 PartitionKey和DistributionKey确定数据行所在的Partition和Tablet,进而根据Tablet在Partition中的顺序计算出数据行在其他Index中对应的Tablet。每一个Tablet可能会有多个副本,并分布在不同的BE节点上,因此,在IndexChannel中会将每一个数据行添加到其所在Tablet的每一个副本对应的NodeChannel中。每一个NodeChannel中都会有一个发送队列,当NodeChannel中新增的数据行累积到一定的大小就会作为一个数据Batch被添加到发送队列中。OlapTableSink中会有一个固定的线程依次轮训每一个IndexChannel下的每一个NodeChannel,并调用BRPC将发送队列中的一个数据Batch发送到对应的Executor BE上。Stream Load任务的数据分发过程如图6所示。
-
-
-
-# 4 **数据写入**
-
-Executor BE的BRPC server接收到Coordinator BE发送来的数据Batch之后,会将数据写入任务提交到线程池来异步执行。在Doris的BE中,数据采用分层的方式写入存储层,每一个Stream Load任务在每个Executor BE上都对应一个LoadChannel,LoadChannel维护一次Stream Load任务的数据写入通道,负责一次Stream Load任务在当前Executor BE节点的数据写入,LoadChannel可以将一次Stream Load任务在当前BE节点的数据分批写入存储层,直到Stream Load任务完成。每一个LoadChannel由Load Id唯一标识,BE节点上的所有LoadChannel由LoadChannelMgr进行管理。一次Stream Load任务对应的Table可能会有多个Index,每一个Index对应一个TabletsChannel,由Index Id唯一标识,因此,每一个LoadChannel下会有多个TabletsChannel。TabletsChannel维护一个Index的数 [...]
-
-
-
-MemTable的刷写操作由MemtableFlushExecutor异步执行,当MemTable的刷写任务提交到线程池之后,会生成一个新的MemTable来接收当前Tablet的后续数据写入。MemtableFlushExecutor执行数据刷写时,RowsetWriter会读出MemTable中的所有数据,并通过SegmentWriter刷写出多个Segment文件,每个Segment文件大小不超过256MB。对于一个Tablet,每次Stream Load任务都会生成一个新的Rowset,生成的Rowset中可以包含多个Segment文件。Stream Load任务的数据写入过程如图8所示。
-
-
-
-Executor BE节点上的TxnManager负责Tablet级别数据导入的事务管理,DeltaWriter初始化时,会执行Prepare Transaction将对应Tablet在本次Stream Load任务中的数据写入事务添加到TxnManager中进行管理;数据写入Tablet完成并关闭DeltaWriter时,会执行Commit Transaction将数据导入生成的新的Rowset添加到TxnManager中进行管理。注意,这里的TxnManager只是负责单个BE上的事务,而FE中的事务管理是负责整体导入事务的。
-
-数据导入结束之后,Executor BE执行FE下发的Publish Version任务时,会执行Publish Transaction将数据导入生成的新的Rowset变为可见版本,并从TxnManager中将对应Tablet在本次Stream Load任务中的数据写入事务删除,这意味着Tablet在本次Stream Load任务中的数据写入事务结束。
-
-# 5 **Stream Load操作审计**
-
-Doris为Stream Load增加了操作审计功能,每一次Stream Load任务结束并将结果返回给用户之后,Coordinator BE会将本次Stream Load任务的详细信息持久化地存储在本地RocksDB上。Master FE定时地通过Thrift RPC从集群的各个BE节点上拉取已经结束的Stream Load任务的信息,每次从一个BE节点上拉取一个批次的Stream Load操作记录,并将拉取到的Stream Load任务信息写入审计日志(fe.audit.log)中。存储在BE上的每一条Stream Load任务信息会设有过期时间(TTL),RocksDB执行Compaction时会将过期的Stream Load任务信息进行删除。用户可以通过FE的审计日志对历史的Stream Load任务信息进行审计。
-
-FE将拉取的Stream Load任务信息写入Audit日志的同时,会在内存中保留一份。为防止内存膨胀,内存中会保留固定数量的Stream Load任务的信息,随着后续拉取数据地持续进行,会从FE内存中逐渐淘汰掉早期的Stream Load任务信息。用户可以通过客户端执行SHOW STREAM LOAD命令来查询最近的Stream Load任务信息。
-
-# 总结
-
-本文从Stream Load的执行流程、事务管理、导入计划的执行、数据写入以及操作审计等方面对Stream Load的实现原理进行了深入地解析。Stream Load是Doris用户最常用的数据导入方式之一,它是一种同步的导入方式, 允许用户通过Http访问的方式批量地将数据导入Doris,并返回数据导入的结果。用户可以直接通过Http请求的返回体判断数据导入是否成功,也可以通过在客户端执行查询SQL来查询历史任务的结果。另外,Doris还为Stream Load提供了结果审计功能,可以通过审计日志对历史的Stream Load任务信息进行审计。
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.1.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.1.md
deleted file mode 100644
index 5eb6f5cc132..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.1.md
+++ /dev/null
@@ -1,83 +0,0 @@
----
-{
- 'title': '[Doris 发版通告] Apache Doris 1.1.1 Release',
- 'summary': '[Doris 发版通告] Apache Doris 1.1.1 Release',
- 'date': '2022-07-29',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-## 新增功能
-
-### 向量化执行引擎支持 ODBC Sink。
-
-在 1.1.0 版本的向量化执行引擎中 ODBC Sink 是不支持的,而这一功能在之前版本的行存引擎是支持的,因此在 1.1.1 版本中我们重新完善了这一功能。
-
-### 增加简易版 MemTracker
-
-MemTracker 是一个用于分析内存使用情况的统计工具,在 1.1.0 版本的向量化执行引擎中,由于 BE 侧没有 MemTracker,可能出现因内存失控导致的 OOM 问题。在 1.1.1 版本中,BE 侧增加了一个简易版 MemTracker,可以帮助控制内存,并在内存超出时取消查询。
-
-完整版 MemTracker 将在 1.1.2 版本中正式发布。
-
-
-## 改进
-
-### 支持在 Page Cache 中缓存解压后数据。
-
-在 Page Cache 中有些数据是用 bitshuffle 编码方式压缩的,在查询过程中需要花费大量的时间来解压。在 1.1.1 版本中,Doris 将缓存解压由 bitshuffle 编码的数据以加速查询,我们发现在 ssb-flat 的一些查询中,可以减少 30% 的延时。
-
-## Bug 修复
-
-### 修复无法从 1.0 版本进行滚动升级的问题。
-
-这个问题是在 1.1.0 版本中出现的,当升级 BE 而不升级 FE 时,可能会导致 BE Core。
-
-如果你遇到这个问题,你可以尝试用 [#10833](https://github.com/apache/doris/pull/10833) 来修复它。
-
-### 修复某些查询不能回退到非向量化引擎的问题,并导致 BE Core。
-
-目前,向量化执行引擎不能处理所有的 SQL 查询,一些查询(如 left outer join)将使用非向量化引擎来运行。但部分场景在 1.1.0 版本中未被覆盖到,这可能导致 BE 挂掉。
-
-### 修复 Compaction 不能正常工作导致的 -235 错误。
-
-在 Unique Key 模型中,当一个 Rowset 有多个 Segment 时,在做 Compaction 过程中由于没有正确的统计行数,会导致Compaction 失败并且产生 Tablet 版本过多而导致的 -235 错误。
-
-### 修复查询过程中出现的部分 Segment fault。
-
-[#10961](https://github.com/apache/doris/pull/10961)
-[#10954](https://github.com/apache/doris/pull/10954)
-[#10962](https://github.com/apache/doris/pull/10962)
-
-# 致谢
-
-感谢所有参与贡献 1.1.1 版本的开发者:
-
-```
-@jacktengg
-@mrhhsg
-@xinyiZzz
-@yixiutt
-@starocean999
-@morrySnow
-@morningman
-@HappenLee
-```
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.2.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.2.md
deleted file mode 100644
index 51db2beccc4..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.2.md
+++ /dev/null
@@ -1,94 +0,0 @@
----
-{
- 'title': '[Doris 发版通告] Apache Doris 1.1.2 Release',
- 'summary': '[Doris 发版通告] Apache Doris 1.1.2 Release',
- 'date': '2022-09-13',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-
-在 Apache Doris 1.1.2 版本中,我们引入了新的 Memtracker、极大程度上避免 OOM 类问题的发生,提升了向量化执行引擎在多数查询场景的性能表现,修复了诸多导致 BE 和 FE 发生异常的问题,优化了在湖仓联邦查询场景的部分体验问题并提升访问外部数据的性能。
-
-相较于 1.1.1 版本,在 1.1.2 版本中有超过 170 个 Issue 和性能优化项被合入,系统稳定性和性能都得到进一步加强。与此同时,1.1.2 版本还将作为 Apache Doris 首个 LTS (Long-term Support)长周期支持版本,后续长期维护和支持,推荐所有用户下载和升级。
-
-# 新增功能
-
-### MemTracker
-
-MemTracker 是一个用于分析内存使用情况的统计工具,在 1.1.1 版本中我们引入了简易版 Memtracker 用以控制 BE 侧内存。在 1.1.2 版本中,我们引入了新的 MemTracker,在向量化执行引擎和非向量化执行引擎中都更为准确。
-
-### 增加展示和取消正在执行 Query 的 API
-
-`GET /rest/v2/manager/query/current_queries`
-
-`GET /rest/v2/manager/query/kill/{query_id}`
-
-具体使用参考文档 [Query Profile Action](https://doris.apache.org/zh-CN/docs/dev/admin-manual/http-actions/fe/manager/query-profile-action?_highlight=current&_highlight=query#request)
-
-### 支持读写 Emoji 表情通过 ODBC 外表
-
-
-# 优化改进
-
-### 数据湖相关改进
-
-- 扫描 HDFS ORC 文件时性能提升约 300%。[#11501](https://github.com/apache/doris/pull/11501)
-
-- 查询 Iceberg 表支持 HDFS 的 HA 模式。
-
-- 支持查询由 [Apache Tez](https://tez.apache.org/) 创建的 Hive 数据
-
-- 添加阿里云 OSS 作为 Hive 外部支持
-
-### 在 Spark Load 中增加对 String 字符串类型和 Text 文本类型的支持
-
-
-### 在非向量化引擎支持复用 Block,在某些场景中有 50%性能提升。[#11392](https://github.com/apache/doris/pull/11392)
-
-### 提升 Like 和正则表达式的性能
-
-### 禁用 TCMalloc 的 aggressive_memory_decommit。
-
-在查询或导入时将会有 40% 性能提升,也可以在配置文件中通过 `tc_enable_aggressive_memory_decommit`来修改
-
-# Bug Fix
-
-### 修复部分可能导致 FE 失败或者数据损坏的问题
-
-- 在 HA 环境中,BDBJE 将保留尽可能多的文件,通过增加配置 `bdbje_reserved_disk_bytes `以避免产生太多的 BDBJE 文件,BDBJE 日志只有在接近磁盘限制时才会删除。
-
-- 修复了 BDBJE 中的重要错误,该错误将导致 FE 副本无法正确启动或数据损坏。
-
-### 修复 FE 在查询过程中会在 waitFor_rpc 上 Hang 住以及 BE 在高并发情况下会 Hang 住的问题。
-
-[#12459](https://github.com/apache/doris/pull/12459) [#12458](https://github.com/apache/doris/pull/12458) [#12392](https://github.com/apache/doris/pull/12392)
-
-### 修复向量化执行引擎查询时得到错误结果的问题。
-
-[#11754](https://github.com/apache/doris/pull/11754) [#11694](https://github.com/apache/doris/pull/11694)
-
-### 修复许多 Planner 导致 BE Core 或者处于不正常状态的问题。
-
-[#12080](https://github.com/apache/doris/pull/12080) [#12075](https://github.com/apache/doris/pull/12075) [#12040](https://github.com/apache/doris/pull/12040) [#12003](https://github.com/apache/doris/pull/12003) [#12007](https://github.com/apache/doris/pull/12007) [#11971](https://github.com/apache/doris/pull/11971) [#11933](https://github.com/apache/doris/pull/11933) [#11861](https://github.com/apache/doris/pull/11861) [#11859](https://github.com/apache/doris/pull/11859) [#11855](https: [...]
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.3.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.3.md
deleted file mode 100644
index bbcab405044..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.3.md
+++ /dev/null
@@ -1,94 +0,0 @@
----
-{
- 'title': '[Doris 发版通告] Apache Doris 1.1.3 Release',
- 'summary': '[Doris 发版通告] Apache Doris 1.1.3 Release',
- 'date': '2022-10-17',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-
-
-作为 1.1.2 LTS(Long-term Support,长周期支持)版本基础之上的 Bugfix 版本,在 Apache Doris 1.1.3 版本中,有超过 80 个 Issue 或性能优化项被合入,优化了在导入或查询过程中的内存控制,修复了许多导致 BE Core 以及产生错误查询结果的问题,系统稳定性和性能得以进一步加强,推荐所有用户下载和使用。
-
-# 新增功能
-
-- 在 ODBC 表中支持 SQLServer 和 PostgreSQL 的转义标识符。
-
-- 支持使用 Parquet 作为导出文件格式。
-
-# 优化改进
-
-- 优化了 Flush 策略以及避免过多 Segment 小文件。 [#12706](https://github.com/apache/doris/pull/12706) [#12716](https://github.com/apache/doris/pull/12716)
-
-- 重构 Runtime Filter 以减少初始准备时间。 [#13127](https://github.com/apache/doris/pull/13127)
-
-- 修复了若干个在查询或导入过程中的内存控制问题。 [#12682](https://github.com/apache/doris/pull/12682) [#12688](https://github.com/apache/doris/pull/12688) [#12708](https://github.com/apache/doris/pull/12708) [#12776](https://github.com/apache/doris/pull/12776) [#12782](https://github.com/apache/doris/pull/12782) [#12791](https://github.com/apache/doris/pull/12791) [#12794](https://github.com/apache/doris/pull/12794) [#12820](https://github.com/apache/doris/pull/12820) [#12932](https://github.com/apache/doris/p [...]
-
-# Bug 修复
-
-- 修复了 largeint 类型在 Compaction 过程中导致 Core 的问题。 [#10094](https://github.com/apache/doris/pull/10094)
-
-- 修复了 Grouping set 导致 BE Core 或者返回错误结果的问题。 [#12313](https://github.com/apache/doris/pull/12313)
-
-- 修复了使用 orthogonal_bitmap_union_count 函数时执行计划 PREAGGREGATION 显示错误的问题。 [#12581](https://github.com/apache/doris/pull/12581)
-
-- 修复了 Level1Iterator 未被释放导致的内存泄漏问题。 [#12592](https://github.com/apache/doris/pull/12592)
-
-- 修复了当 2 BE 且存在 Colocation 表时通过 Decommission 下线节点失败的问题。 [#12644](https://github.com/apache/doris/pull/12644)
-
-- 修复了 TBrokerOpenReaderResponse 过大时导致堆栈缓冲区溢出而导致的 BE Core 问题。 [#12658](https://github.com/apache/doris/pull/12658)
-
-- 修复了出现 -238错误时 BE 节点可能 OOM 的问题。 [#12666](https://github.com/apache/doris/pull/12666)
-
-- 修复了 LEAD() 函数错误子表达式的问题。 [#12587](https://github.com/apache/doris/pull/12587)
-
-- 修复了行存代码中相关查询失败的问题。 [#12712](https://github.com/apache/doris/pull/12712)
-
-- 修复了 curdate()/current_date() 函数产生错误结果的问题。 [#12720](https://github.com/apache/doris/pull/12720)
-
-- 修复了 lateral View explode_split 函数出现错误结果的问题。 [#13643](https://github.com/apache/doris/pull/13643)
-
-- 修复了两张相同表中 Bucket Shuffle Join 计划错误的问题。 [#12930](https://github.com/apache/doris/pull/12930)
-
-- 修复了更新或导入过程中 Tablet 版本可能错误的问题。 [#13070](https://github.com/apache/doris/pull/13070)
-
-- 修复了在加密函数下使用 Broker 导入数据时 BE 可能发生 Core 的问题。 [#13009](https://github.com/apache/doris/pull/13009)
-
-# 升级说明
-
-默认情况下禁用 PageCache 和 ChunkAllocator 以减少内存使用,用户可以通过修改配置项 `disable_storage_page_cache` 和 `chunk_reserved_bytes_limit` 来重新启用。
-
-Storage Page Cache 和 Chunk Allocator 分别缓存用户数据块和内存预分配。
-
-这两个功能会占用一定比例的内存,并且不会释放。 这部分内存占用无法灵活调配,导致在某些场景下,因这部分内存占用而导致其他任务内存不足,影响系统稳定性和可用性。因此我们在 1.1.3 版本中默认关闭了这两个功能。
-
-但在某些延迟敏感的报表场景下,关闭该功能可能会导致查询延迟增加。如用户担心升级后该功能对业务造成影响,可以通过在 be.conf 中增加以下参数以保持和之前版本行为一致。
-
-```
-disable_storage_page_cache=false
-chunk_reserved_bytes_limit=10%
-```
-
-* `disable_storage_page_cache`:是否关闭 Storage Page Cache。 1.1.2(含)之前的版本,默认是false,即打开。1.1.3 版本默认为 true,即关闭。
-* `chunk_reserved_bytes_limit`:Chunk allocator 预留内存大小。1.1.2(含)之前的版本,默认是整体内存的 10%。1.1.3 版本默认为 209715200(200MB)。
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.4.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.4.md
deleted file mode 100644
index 80cd751b9fa..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.4.md
+++ /dev/null
@@ -1,75 +0,0 @@
----
-{
- 'title': '[Doris 发版通告] Apache Doris 1.1.4 Release',
- 'summary': '[Doris 发版通告] Apache Doris 1.1.4 Release',
- 'date': '2022-11-11',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-
-
-
-作为 1.1 LTS(Long-term Support,长周期支持)版本基础之上的 Bugfix 版本,在 Apache Doris 1.1.4 版本中,Doris 团队修复了自 1.1.3 版本以来的约 60 个 Issue 或性能优化项。改进了 Spark Load 的使用体验,优化了诸多内存以及 BE 异常宕机的问题,系统稳定性和性能得以进一步加强,推荐所有用户下载和使用。
-
-# 新增功能
-
-- Broker Load 支持 华为云 OBS 对象存储。[#13523](https://github.com/apache/doris/pull/13523)
-
-- Spark Load 支持 Parquet 和 Orc 文件。[#13438](https://github.com/apache/doris/pull/13438)
-
-
-# 优化改进
-
-- 禁用 Metric Hook 中的互斥量,其将影响数据导入过程中的查询性能。 [#10941](https://github.com/apache/doris/pull/10941)
-
-
-# Bug 修复
-
-- 修复了当 Spark Load 加载文件时 Where 条件不生效的问题。 [#13804](https://github.com/apache/doris/pull/13804)
-
-- 修复了 If 函数存在 Nullable 列时开启向量化返回错误结果的问题。 [#13779](https://github.com/apache/doris/pull/13779)
-
-- 修复了在使用 Anti Join 和其他 Join 谓词时产生错误结果的问题。 [#13743](https://github.com/apache/doris/pull/13743)
-
-- 修复了当调用函数 concat(ifnull)时 BE 宕机的问题。 [#13693](https://github.com/apache/doris/pull/13693)
-
-- 修复了 group by 语句中存在函数时 planner 错误的问题。 [#13613](https://github.com/apache/doris/pull/13613)
-
-- 修复了 lateral view 语句不能正确识别表名和列名的问题。 [#13600](https://github.com/apache/doris/pull/13600)
-
-- 修复了使用物化视图和表别名时出现未知列的问题。 [#13605](https://github.com/apache/doris/pull/13605)
-
-- 修复了 JSONReader 无法释放值和解析 allocator 内存的问题。 [#13513](https://github.com/apache/doris/pull/13513)
-
-- 修复了当 enable_vectorized_alter_table 为 true 时允许使用 to_bitmap() 对负值列创建物化视图的问题。 [#13448](https://github.com/apache/doris/pull/13448)
-
-- 修复了函数 from_date_format_str 中微秒数丢失的问题。 [#13446](https://github.com/apache/doris/pull/13446)
-
-- 修复了排序 exprs 的 nullability 属性在使用子 smap 信息进行替换后可能不正确的问题。 [#13328](https://github.com/apache/doris/pull/13328)
-
-- 修复了 case when 有 1000 个条件时出现 Core 的问题。 [#13315](https://github.com/apache/doris/pull/13315)
-
-- 修复了 Stream Load 导入数据时最后一行数据丢失的问题。 [#13066](https://github.com/apache/doris/pull/13066)
-
-- 恢复表或分区的副本数与备份前相同。 [#11942](https://github.com/apache/doris/pull/11942)
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.5.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.5.md
deleted file mode 100644
index 74a61bd2f59..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.1.5.md
+++ /dev/null
@@ -1,70 +0,0 @@
----
-{
- 'title': '[Doris 发版通告] Apache Doris 1.1.5 Release',
- 'summary': '[Doris 发版通告] Apache Doris 1.1.5 Release',
- 'date': '2022-12-19',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-在 1.1.5 版本中,Doris 团队已经修复了自 1.1.4 版本发布以来约 36 个问题或性能改进项。同时,1.1.5 版本也是作为 1.1 LTS 版本的错误修复版本,建议所有用户升级到这个版本。
-
-
-# Behavior Changes
-
-
-当别名与原始列名相同时,例如 "select year(birthday) as birthday",在 group by、order by、having 子句中使用别名时将与 MySQL 中保持一致,Group by 和 having 将首先使用原始列,order by 将首先使用别名。这里可能会对用户带来疑惑,因此建议最好不要使用与原始列名相同的别名。
-
-# Features
-
-支持 Hash 函数 murmur_hash3_64。[#14636](https://github.com/apache/doris/pull/14636)
-
-# Improvements
-
-为日期函数 convert_tz 添加时区缓存以提高性能。[#14616](https://github.com/apache/doris/pull/14616)
-
-当调用 show 子句时,按 tablename 对结果进行排序。 [#14492](https://github.com/apache/doris/pull/14492)
-
-# Bug Fix
-
-修复 if 语句中带有常量时导致 BE 可能 Coredump 的问题。[#14858](https://github.com/apache/doris/pull/14858)
-
-修复 ColumnVector::insert_date_column 可能崩溃的问题 [#14839](https://github.com/apache/doris/pull/14839)
-
-更新 high_priority_flush_thread_num_per_store 默认值为 6,将提高负载性能。 [#14775](https://github.com/apache/doris/pull/14775)
-
-优化 quick compaction core。 [#14731](https://github.com/apache/doris/pull/14731)
-
-修复分区列非 duplicate key 时 Spark Load 抛出 IndexOutOfBounds 错误的问题。
- [#14661](https://github.com/apache/doris/pull/14661)
-
-修正 VCollectorIterator 中的内存泄漏问题。 [#14549](https://github.com/apache/doris/pull/14549)
-
-修复了存在 Sequence 列时可能存在的建表问题。 [#14511](https://github.com/apache/doris/pull/14511)
-
-使用 avg rowset 来计算批量大小,而不是使用 total_bytes,因为它要花费大量的 Cpu。 [#14273](https://github.com/apache/doris/pull/14273)
-
-修复了 right outer join 可能导致 core 的问题。[#14821](https://github.com/apache/doris/pull/14821)
-
-优化了 TCMalloc gc 的策略。 [#14777](https://github.com/apache/doris/pull/14777) [#14738](https://github.com/apache/doris/pull/14738) [#14374](https://github.com/apache/doris/pull/14374)
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.2.0.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.2.0.md
deleted file mode 100644
index 385206ff79d..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.2.0.md
+++ /dev/null
@@ -1,624 +0,0 @@
----
-{
- 'title': '[Doris 发版通告] Apache Doris 1.2.0 Release',
- 'summary': '[Doris 发版通告] Apache Doris 1.2.0 Release',
- 'date': '2022-12-07',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-亲爱的社区小伙伴们,再一次经历数月的等候后,我们很高兴地宣布,Apache Doris 于 2022 年 12 月 7 日迎来 1.2.0 Release 版本的正式发布!有近 118 位 Contributor 为 Apache Doris 提交了超 2400 项优化和修复,感谢每一位让 Apache Doris 更好的你!
-
-自从社区正式确立 LTS 版本管理机制后,在 1.1.x 系列版本中不再合入大的功能,仅提供问题修复和稳定性改进,力求满足更多社区用户在稳定性方面的高要求。而在综合考虑版本迭代节奏和用户需求后,我们决定将众多新特性在 1.2 版本中发布,这无疑承载了众多社区用户和开发者的深切期盼,同时这也是一场厚积而薄发后的全面进化!
-
-在 1.2 版本中,我们实现了全面的向量化、**实现多场景查询性能 3-11 倍的提升**,在 Unique Key 模型上实现了 Merge-on-Write 的数据更新模式、**数据高频更新时查询性能提升达 3-6 倍**,增加了 Multi-Catalog 多源数据目录、**提供了无缝接入 Hive、ES、Hudi、Iceberg 等外部数据源的能力**,引入了 Light Schema Change 轻量表结构变更、**实现毫秒级的 Schema Change 操作并可以借助 Flink CDC 自动同步上游数据库的 DML 和 DDL 操作**,以 JDBC 外部表替换了过去的 ODBC 外部表,支持了 Java UDF 和 Romote UDF 以及 Array 数组类型和 JSONB 类型,修复了诸多之前版本的性能和稳定性问题,推荐大家下载和使用!
-
-# 下载安装
-GitHub下载:[https://github.com/apache/doris/releases](https://github.com/apache/doris/releases)
-
-官网下载页:[https://doris.apache.org/download](https://doris.apache.org/download)
-
-源码地址:[https://github.com/apache/doris/releases/tag/1.2.0-rc04](https://github.com/apache/doris/releases/tag/1.2.0-rc04)
-
-### 下载说明:
-
-由于 Apache 服务器文件大小限制,官网下载页的 1.2.0 版本的二进制程序分为三个包:
-
-1. apache-doris-fe
-
-2. apache-doris-be
-
-3. apache-doris-java-udf-jar-with-dependencies
-
-其中新增的 `apache-doris-java-udf-jar-with-dependencies` 包用于支持 1.2.0 版本中的 JDBC 外表和 JAVA UDF 。下载后,需要将其中的 `java-udf-jar-with-dependencies.jar` 文件放到 `be/lib` 目录下,方可启动 BE,否则无法启动成功。
-
-### 部署说明:
-
-从历史版本升级到 1.2.0 版本,需完整更新 fe、be 下的 bin 和 lib 目录。
-
-其他升级注意事项,请完整阅读本发版通告最后一节“升级注意事项”以及安装部署文档 [https://doris.apache.org/zh-CN/docs/dev/install/install-deploy](https://doris.apache.org/zh-CN/docs/dev/install/install-deploy) 和集群升级文档 [https://doris.apache.org/zh-CN/docs/dev/admin-manual/cluster-management/upgrade](https://doris.apache.org/zh-CN/docs/dev/admin-manual/cluster-management/upgrade)
-
-# 重要更新
-
-### 1. 全面向量化支持,性能大幅提升
-
-在 Apache Doris 1.2.0 版本中,系统所有模块都实现了向量化,包括数据导入、Schema Change、Compaction、数据导出、UDF 等。新版向量化执行引擎具备了完整替换原有非向量化引擎的能力,后续我们也将考虑在未来版本中去除原有非向量化引擎的代码。
-
-与此同时,在全面向量化的基础上,我们对数据扫描、谓词计算、Aggregation 算子、HashJoin 算子、算子之间 Shuffle 效率等进行了全链路的优化,使得查询性能有了大幅提升。
-
-我们对 Apache Doris 1.2.0 新版本进行了多个标准测试集的测试,同时选择了 1.1.3 版本和 0.15.0 版本作为对比参照项。经测,1.2.0 **在 SSB-Flat 宽表场景上相对 1.1.3 版本整体性能提升了近 4 倍、相对于 0.15.0 版本性能提升了近 10 倍,在 TPC-H 多表关联场景上较 1.1.3 版本上有近 3 倍的提升、较 0.15.0 版本性能至少提升了 11 倍。**
-
-
-
-
-
-同时,我们将 1.2.0 版本的测试数据提交到了全球知名的数据库测试排行榜 ClickBench,在最新的排行榜中,Apache Doris 1.2.0 新版本取得了通用机型(c6a.4xlarge, 500gb gp2)下**查询性能 Cold Run 第二和 Hot Run 第三的醒目成绩,共有 8 个 SQL 刷新榜单最佳成绩、成为新的性能标杆**。导入性能方面,1.2.0 新版本数据写入效率在同机型所有产品中位列第一,压缩前 70G 数据写入仅耗时 415s、单节点写入速度超过 170 MB/s,在实现极致查询性能的同时也保证了高效的写入效率!
-
-
-
-
-
-### 2. 在 Unique Key 模型上实现了 Merge-on-Write 的数据更新模式
-
-在过去版本中, Apache Doris 主要是通过 Unique Key 数据模型来实现数据实时更新的。但由于采用的是 Merge-on-Read 的实现方式,查询存在着效率瓶颈,有大量非必要的 CPU 计算资源消耗和 IO 开销,且可能将出现查询性能抖动等问题。
-
-在 1.2.0 版本中,我们在原有的 Unique Key 数据模型上,增加了 Merge-on-Write 的数据更新模式。该模式在数据写入时即对需要删除或更新的数据进行标记,始终保证有效的主键只出现在一个文件中(即在写入的时候保证了主键的唯一性),不需要在读取的时候通过归并排序来对主键进行去重,这对于高频写入的场景来说,大大减少了查询执行时的额外消耗。此外还能够支持谓词下推,并能够很好利用 Doris 丰富的索引,在数据 IO 层面就能够进行充分的数据裁剪,大大减少数据的读取量和计算量,因此在很多场景的查询中都有非常明显的性能提升。
-
-在比较有代表性的 SSB-Flat 数据集上,通过模拟多个持续导入场景,**新版本的大部分查询取得了 3-6 倍的性能提升**。
-
-
-
-使用场景:所有对主键唯一性有需求,需要频繁进行实时 Upsert 更新的用户建议打开。
-
-使用说明:作为新的 Feature 默认关闭,用户可以通过在建表时添加下面的 Property 来开启:
-
-```
-“enable_unique_key_merge_on_write” = “true”
-```
-
-另外新版本 Merge-on-Write 数据更新模式与旧版本 Merge-on-Read 实现方式存在差异,因此已经创建的 Unique Key 表无法直接通过 Alter Table 添加 Property 来支持,只能在新建表的时候指定。如果用户需要将旧表转换到新表,可以使用 `insert into new_table select * from old_table` 的方式来实现。
-
-### 3. Multi Catalog 多源数据目录
-
-Multi-Catalog 多源数据目录功能的目标在于能够帮助用户更方便对接外部数据目录,以增强 Apache Doris 的数据湖分析和联邦数据查询能力。
-
-在过去版本中,当我们需要对接外部数据源时,只能在 Database 或 Table 层级对接。当外部数据目录 Schema 发生变化、或者外部数据目录的 Database 或 Table 非常多时,需要用户手工进行一一映射,维护量非常大。1.2.0 版本新增的多源数据目录功能为 Apache Doris 提供了快速接入外部数据源进行访问的能力,用户可以通过 `CREATE CATALOG` 命令连接到外部数据源,Doris 会自动映射外部数据源的库、表信息。之后,用户就可以像访问普通表一样,对这些外部数据源中的数据进行访问,避免了之前用户需要对每张表手动建立外表映射的复杂操作。
-
-目前能支持以下数据源:
-
-1. Hive Metastore:可以访问包括 Hive、Iceberg、Hudi 在内的数据表,也可对接兼容 Hive Metastore 的数据源,如阿里云的 DataLake Formation,同时支持 HDFS 和对象存储上的数据访问。
-
-2. Elasticsearch:访问 ES 数据源。
-
-3. JDBC:支持通过 JDBC 访问 MySQL 数据源。
-
-注:相应的权限层级也会自动变更,详见“升级注意事项”部分
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/ecosystem/external-table/multi-catalog](https://doris.apache.org/zh-CN/docs/dev/ecosystem/external-table/multi-catalog)
-
-### 4. 轻量表结构变更 Light Schema Change
-
-在过去版本中,Schema Change 是一项相对消耗比较大的工作,需要对数据文件进行修改,在集群规模和表数据量较大时执行效率会明显降低。同时由于是异步作业,当上游 Schema 发生变更时,需要停止数据同步任务并手动执行 Schema Change,增加开发和运维成本的同时还可能造成消费数据的挤压。
-
-在 1.2.0 新版本中,对数据表的加减列操作,不再需要同步更改数据文件,仅需在 FE 中更新元数据即可,从而实现毫秒级的 Schema Change 操作,且存在导入任务时效率的提升更为显著。与此同时,使得 Apache Doris 在面对上游数据表维度变化时,可以更加快速稳定实现表结构同步,保证系统的高效且平稳运转。如用户可以通过 Flink CDC,可实现上游数据库到 Doris 的 DML 和 DDL 同步,进一步提升了实时数仓数据处理和分析链路的时效性与便捷性。
-
-
-
-使用说明:作为新的 Feature 默认关闭,用户可以通过在建表时添加下面的 Property 来开启:
-
-```
-"light_schema_change" = "true"
-```
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE)
-
-### 5. JDBC 外部表
-
-在过去版本中,Apache Doris 提供了 ODBC 外部表的方式来访问 MySQL、Oracle、SQL Server、PostgreSQL 等数据源,但由于 ODBC 驱动版本问题可能造成系统的不稳定。相对于 ODBC,JDBC 接口更为统一且支持数据库众多,因此在 1.2.0 版本中我们实现了 JDBC 外部表以替换原有的 ODBC 外部表。在新版本中,用户可以通过 JDBC 连接支持 JDBC 协议的外部数据源,
-
-当前已适配的数据源包括:
-
-- MySQL
-- PostgreSQL
-- Oracle
-- SQLServer
-- ClickHouse
-
-更多数据源的适配已经在规划之中,原则上任何支持 JDBC 协议访问的数据库均能通过 JDBC 外部表的方式来访问。而之前的 ODBC 外部表功能将会在后续的某个版本中移除,还请尽量切换到 JDBC 外表功能。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/ecosystem/external-table/jdbc-of-doris/](https://doris.apache.org/zh-CN/docs/dev/ecosystem/external-table/jdbc-of-doris/)
-
-### 6. JAVA UDF
-
-在过去版本中,Apache Doris 提供了 C++ 语言的原生 UDF,便于用户通过自己编写自定义函数来满足特定场景的分析需求。但由于原生 UDF 与 Doris 代码耦合度高、当 UDF 出现错误时可能会影响集群稳定性,且只支持 C++ 语言,对于熟悉 Hive、Spark 等大数据技术栈的用户而言存在较高门槛,因此在 1.2.0 新版本我们增加了 Java 语言的自定义函数,支持通过 Java 编写 UDF/UDAF,方便用户在 Java 生态中使用。同时,通过堆外内存、Zero Copy 等技术,使得跨语言的数据访问效率大幅提升。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/ecosystem/udf/java-user-defined-function](https://doris.apache.org/zh-CN/docs/dev/ecosystem/udf/java-user-defined-function)
-
-示例:[https://github.com/apache/doris/tree/master/samples/doris-demo](https://github.com/apache/doris/tree/master/samples/doris-demo)
-
-### 7. Remote UDF
-
-远程 UDF 支持通过 RPC 的方式访问远程用户自定义函数服务,从而彻底消除用户编写 UDF 的语言限制,用户可以使用任意编程语言实现自定义函数,完成复杂的数据分析工作。
-
-文档:[https://doris.apache.org/zh-CN/docs/ecosystem/udf/remote-user-defined-function](https://doris.apache.org/zh-CN/docs/ecosystem/udf/remote-user-defined-function)
-
-示例:[https://github.com/apache/doris/tree/master/samples/doris-demo](https://github.com/apache/doris/tree/master/samples/doris-demo)
-
-### 8. Array/JSONB 复合数据类型
-
-- Array 类型
-
-支持了数组类型,同时也支持多级嵌套的数组类型。在一些用户画像,标签等场景,可以利用 Array 类型更好的适配业务场景。同时在新版本中,我们也实现了大量数组相关的函数,以更好的支持该数据类型在实际场景中的应用。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/ARRAY](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/ARRAY)
-
-相关函数:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/array-functions/array](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/array-functions/array)
-
-- JSONB 类型
-
-支持二进制的 JSON 数据类型 JSONB。该类型提供更紧凑的 JSONB 编码格式,同时提供在编码格式上的数据访问,相比于使用字符串存储的 JSON 数据,有数倍的性能提升。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/JSONB](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/JSONB)
-
-相关函数:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/json-functions/jsonb_parse](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/json-functions/jsonb_parse)
-
-### 9. DateV2/DatatimeV2 新版日期/日期时间数据类型
-
-支持 DataV2 日期类型和 DatatimeV2 日期时间类型,相较于原有的 Data 和 Datatime 效率更高且支持最多到微秒的时间精度,建议使用新版日期类型。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/DATETIMEV2/](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/DATETIMEV2/)
-
- [https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/DATEV2](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/DATEV2)
-
-影响范围:
- 1. 用户需要在建表时指定 DateV2 和 DatetimeV2,原有表的 Date 以及 Datetime 不受影响。
- 2. Datev2 和 Datetimev2 在与原来的 Date 和 Datetime 做计算时(例如等值连接),原有类型会被cast 成新类型做计算
- 3. Example 参考文档中说明
-
-### 10. 全新内存管理框架
-
-在 Apache Doris 1.2.0 版本中我们增加了全新的内存跟踪器(Memory Tracker),用以记录 Doris BE 进程内存使用,包括查询、导入、Compaction、Schema Change 等任务生命周期中使用的内存以及各项缓存。通过 Memory Tracker 实现了更加精细的内存监控和控制,大大减少了因内存超限导致的 OOM 问题,使系统稳定性进一步得到提升。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/admin-manual/maint-monitor/memory-management/memory-tracker](https://doris.apache.org/zh-CN/docs/dev/admin-manual/maint-monitor/memory-management/memory-tracker)
-
-### 11. Table Valued Function 表函数
-
-增加了 Table Valued Function(TVF,表函数),TVF 可以视作一张普通的表,可以出现在 SQL 中所有“表”可以出现的位置,让用户像访问关系表格式数据一样,读取或访问来自 HDFS 或 S3 上的文件内容,
-
-例如使用 S3 TVF 实现对象存储上的数据导入:
-```
-insert into tbl select * from s3("s3://bucket/file.*", "ak" = "xx", "sk" = "xxx") where c1 > 2;
-```
-
-或者直接查询 HDFS 上的数据文件:
-```
-insert into tbl select * from hdfs("hdfs://bucket/file.*") where c1 > 2;
-```
-TVF 可以帮助用户充分利用 SQL 丰富的表达能力,灵活处理各类数据。
-
-文档:
-[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/table-functions/s3](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/table-functions/s3)
-
-[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/table-functions/hdfs](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/table-functions/hdfs)
-
-# 更多功能
-
-### 1. 更便捷的分区创建方式
-
-支持通过 `FROM TO` 命令创建一个时间范围内的多个分区。
-
-文档搜索“MULTI RANGE”:
-[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE)
-
-示例:
-```
-// 根据时间date 创建分区,支持多个批量逻辑和单独创建分区的混合使用
-
-PARTITION BY RANGE(event_day)(
- FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR,
- FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH,
- FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK,
- FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY,
- PARTITION p_20230114 VALUES [('2023-01-14'), ('2023-01-15'))
-)
-```
-```
-// 根据时间datetime 创建分区
-PARTITION BY RANGE(event_time)(
- FROM ("2023-01-03 12") TO ("2023-01-14 22") INTERVAL 1 HOUR
-)
-```
-
-### 2. 列重命名
-
-对于开启了 Light Schema Change 的表,支持对列进行重命名。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Alter/ALTER-TABLE-RENAME ](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Alter/ALTER-TABLE-RENAME )
-
-### 3. 更丰富权限管理
-
-- 支持行级权限
-
-可以通过 `CREATE ROW POLICY` 命令创建行级权限。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-POLICY](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-POLICY)
-
-- 支持指定密码强度、过期时间等。
-
-- 支持在多次失败登录后锁定账户。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Account-Management-Statements/ALTER-USER](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Account-Management-Statements/ALTER-USER)
-
-### 4. 导入相关
-
-- CSV 导入支持带 header 的 CSV 文件。
-
-在文档中搜索 `csv_with_names`:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/STREAM-LOAD/](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/STREAM-LOAD/)
-
-- Stream Load 新增 `hidden_columns`,可以显式指定 delete flag 列和 sequence 列。
-
-在文档中搜索 `hidden_columns`:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/STREAM-LOAD](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/STREAM-LOAD)
-
-- Spark Load 支持 Parquet 和 ORC 文件导入。
-- 支持清理已完成的导入的 Label
- 文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/CLEAN-LABEL](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/CLEAN-LABEL)
-
-- 支持通过状态批量取消导入作业
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/CANCEL-LOAD](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/CANCEL-LOAD)
-
-- Broker Load 新增支持阿里云 OSS,腾讯 CHDFS 和华为云 OBS。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/advanced/broker](https://doris.apache.org/zh-CN/docs/dev/advanced/broker)
-
-- 支持通过 hive-site.xml 文件配置访问 HDFS。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/admin-manual/config/config-dir](https://doris.apache.org/zh-CN/docs/dev/admin-manual/config/config-dir)
-
-### 5. 支持通过 `SHOW CATALOG RECYCLE BIN` 功能查看回收站中的内容。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Show-Statements/SHOW-CATALOG-RECYCLE-BIN](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Show-Statements/SHOW-CATALOG-RECYCLE-BIN)
-
-### 6. 支持 `SELECT * EXCEPT` 语法。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/data-table/basic-usage](https://doris.apache.org/zh-CN/docs/dev/data-table/basic-usage)
-
-### 7. OUTFILE 支持 ORC 格式导出,并且支持多字节分隔符。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/OUTFILE](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/OUTFILE)
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/OUTFILE](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/OUTFILE)
-
-### 8. 支持通过配置修改可保存的 Query Profile 的数量。
-
-文档搜索 FE 配置项:`max_query_profile_num`
-
-### 9. DELETE 语句支持 IN 谓词条件。并且支持分区裁剪。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Manipulation/DELETE](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Manipulation/DELETE)
-
-### 10. 时间列的默认值支持使用 `CURRENT_TIMESTAMP`
-
-文档中搜索 "CURRENT_TIMESTAMP":[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE)
-
-### 11. 添加两张系统表:backends、rowsets
-
-backends 是 Doris 中内置系统表,存放在 information_schema 数据库下,通过该系统表可以查看当前 Doris 集群中的 BE 节点信息。
-
-rowsets 是 Doris 中内置系统表,存放在 information_schema 数据库下,通过该系统表可以查看 Doris 集群中各个 BE 节点当前 rowsets 情况。
-
-文档:
-
-[https://doris.apache.org/zh-CN/docs/dev/admin-manual/system-table/backends](https://doris.apache.org/zh-CN/docs/dev/admin-manual/system-table/backends)
-
-[https://doris.apache.org/zh-CN/docs/dev/admin-manual/system-table/rowsets](https://doris.apache.org/zh-CN/docs/dev/admin-manual/system-table/rowsets)
-
-### 12. 备份恢复
-
- - Restore作业支持 `reserve_replica` 参数,使得恢复后的表的副本数和备份时一致。
- - Restore 作业支持 `reserve_dynamic_partition_enable` 参数,使得恢复后的表保持动态分区开启状态。
-
- 文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Backup-and-Restore/RESTORE](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Backup-and-Restore/RESTORE)
-
- - 支持通过内置的 libhdfs 进行备份恢复操作,不再依赖 broker。
-
- 文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Backup-and-Restore/CREATE-REPOSITORY](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Backup-and-Restore/CREATE-REPOSITORY)
-
-### 13. 支持同机多磁盘之间的数据均衡
-
-文档:
-
-[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Database-Administration-Statements/ADMIN-REBALANCE-DISK](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Database-Administration-Statements/ADMIN-REBALANCE-DISK)
-
-[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Database-Administration-Statements/ADMIN-CANCEL-REBALANCE-DISK](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Database-Administration-Statements/ADMIN-CANCEL-REBALANCE-DISK)
-
-### 14. Routine Load 支持订阅 Kerberos 认证的 Kafka 服务。
-
-文档中搜索 kerberos:[https://doris.apache.org/zh-CN/docs/dev/data-operate/import/import-way/routine-load-manual](https://doris.apache.org/zh-CN/docs/dev/data-operate/import/import-way/routine-load-manual)
-
-### 15. New built-in-function 新增内置函数
-
- 新增以下内置函数:
-
- - cbrt
- - sequence_match/sequence_count
- - mask/mask_first_n/mask_last_n
- - elt
- - any/any_value
- - group_bitmap_xor
- - ntile
- - nvl
- - uuid
- - initcap
- - regexp_replace_one/regexp_extract_all
- - multi_search_all_positions/multi_match_any
- - domain/domain_without_www/protocol
- - running_difference
- - bitmap_hash64
- - murmur_hash3_64
- - to_monday
- - not_null_or_empty
- - window_funnel
- - outer combine
- 以及所有 Array 函数
-
-# 升级注意事项
-
-### FE 元数据版本变更 【重要】
-
-FE Meta Version 由 107 变更为 114,因此从 1.1.x 以及更早版本升级至 1.2.0 版本后,不可回滚到之前版本。
-升级过程中,建议通过灰度升级的方式,先升级部分节点并观察业务运行情况,以降低升级风险,若执行非法的回滚操作将可能导致数据丢失与损坏。
-
-### 行为改变
-
-- 权限层级变更。
-
- 因为引入了 Catalog 层级,所以相应的用户权限层级也会自动变更。规则如下:
-
- - GlobalPrivs 和 ResourcePrivs 保持不变
- - 新增 CatalogPrivs 层级。
- - 原 DatabasePrivs 层级增加 internal 前缀(表示 internal catalog 中的 db)
- - 原 TablePrivs 层级增加 internal 前缀(表示internal catalog中的 tbl)
-- GroupBy 和 Having 子句中,优先使用列名而不是别名进行匹配。
-- 不再支持创建以 "mv_" 开头的列。"mv_" 是物化视图中的保留关键词
-- 移除了 order by 语句默认添加的 65535 行的 Limit 限制,并增加 Session 变量 `default_order_by_limit` 可以自定配置这个限制。
-- "Create Table As Select" 生成的表,所有字符串列统一使用 String类型,不再区分 varchar/char/string
-- audit log 中,移除 db 和 user 名称前的 `default_cluster` 字样。
-- audit log 中增加 sql digest 字段
-- union 子句总 order by 逻辑变动。新版本中,order by 子句将在 union 执行完成后执行,除非通过括号进行显式的关联。
-- 进行 decommission 操作时,会忽略回收站中的 tablet,确保 decomission 能够完成。
-- Decimal 的返回结果将按照原始列中声明的精度进行显示 ,或者按照显式指定的 cast 函数中的精度进行展示。
-- 列名的长度限制由 64 变更为 256
-- FE 配置项变动
- - 默认开启 `enable_vectorized_load` 参数。
- - 增大了 `create_table_timeout` 值。建表操作的默认超时时间将增大。
- - 修改 `stream_load_default_timeout_second` 默认值为 3天。
- - 修改`alter_table_timeout_second` 的默认值为 一个月。
- - 增加参数 `max_replica_count_when_schema_change` 用于限制 alter 作业中涉及的 replica数量,默认为100000。
- - 添加 `disable_iceberg_hudi_table`。默认禁用了 iceberg 和 hudi 外表,推荐使用 multi catalog功能。
-- BE 配置项变动
- - 移除了 `disable_stream_load_2pc` 参数。2PC的stream load可直接使用。
- - 修改`tablet_rowset_stale_sweep_time_sec` ,从1800秒修改为 300 秒。
-- Session变量变动
- - 修改变量 `enable_insert_strict` 默认为 true。这会导致一些之前可以执行,但是插入了非法值的insert操作,不再能够执行。
- - 修改变量 `enable_local_exchange` 默认为 true
- - 默认通过 lz4 压缩进行数据传输,通过变量 `fragment_transmission_compression_codec` 控制
- - 增加 `skip_storage_engine_merge` 变量,用于调试 unique 或 agg 模型的数据
- 文档:https://doris.apache.org/zh-CN/docs/dev/advanced/variables
-- BE 启动脚本会通过 `/proc/sys/vm/max_map_count` 检查数值是否大于200W,否则启动失败。
-- 移除了 mini load 接口
-
-### 升级过程中需注意
-
-1. 升级准备
- - 需替换:lib, bin 目录(start/stop 脚本均有修改)
- - BE 也需要配置 JAVA_HOME,已支持 JDBC Table 和 Java UDF。
- - fe.conf 中默认 JVM Xmx 参数修改为 8GB。
-
-2. 升级过程中可能的错误
- - repeat 函数不可使用并报错:`vectorized repeat function cannot be executed`,可以在升级前先关闭向量化执行引擎。
- - schema change 失败并报错:`desc_tbl is not set. Maybe the FE version is not equal to the BE`
- - 向量化 hash join 不可使用并报错。`vectorized hash join cannot be executed`。可以在升级前先关闭向量化执行引擎。
-
-以上错误在完全升级后会恢复正常。
-
-### 性能影响
-
-- 默认使用 JeMalloc 作为新版本 BE 的内存分配器,替换 TcMalloc 。
-
-JeMalloc 相比 TcMalloc 使用的内存更少、高并发场景性能更高,但在内存充足的性能测试时,TcMalloc 比 JeMalloc 性能高5%-10%,详细测试见: https://github.com/apache/doris/pull/12496
-
-- tablet sink 中的 batch size 修改为至少 8K。
-- 默认关闭 Page Cache 和 减少 Chunk Allocator 预留内存大小
-
-Page Cache 和 Chunk Allocator 分别缓存用户数据块和内存预分配,这两个功能会占用一定比例的内存并且不会释放。由于这部分内存占用无法灵活调配,导致在某些场景下可能因这部分内存占用而导致其他任务内存不足,影响系统稳定性和可用性,因此新版本中默认关闭了这两个功能。
-
-但在某些延迟敏感的报表场景下,关闭该功能可能会导致查询延迟增加。如用户担心升级后该功能对业务造成影响,可以通过在 be.conf 中增加以下参数以保持和之前版本行为一致。
-```
-disable_storage_page_cache=false
-chunk_reserved_bytes_limit=10%
-```
-
-### API 变化
-
-- BE 的 http api 错误返回信息,由 `{"status": "Fail", "msg": "xxx"}` 变更为更具体的 ``{"status": "Not found", "msg": "Tablet not found. tablet_id=1202"}``
-
-- `SHOW CREATE TABLE` 中, comment的内容由双引号包裹变为单引号包裹
-
-- 支持普通用户通过 http 命令获取 query profile。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/admin-manual/http-actions/fe/manager/query-profile-action](https://doris.apache.org/zh-CN/docs/dev/admin-manual/http-actions/fe/manager/query-profile-action)
-
-- 优化了 sequence 列的指定方式,可以直接指定列名。
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/data-operate/update-delete/sequence-column-manual](https://doris.apache.org/zh-CN/docs/dev/data-operate/update-delete/sequence-column-manual)
-
-- `show backends` 和 `show tablets` 返回结果中,增加远端存储的空间使用情况 (#11450)
-- 移除了 Num-Based Compaction 相关代码(#13409)
-- 重构了BE的错误码机制,部分返回的错误信息会发生变化(#8855)
-
-# 其他
-
-- 支持Docker 官方镜像。
-- 支持在 MacOS(x86/M1) 和 ubuntu-22.04 上编译 Doris
-- 支持进行image 文件的校验。
-
-文档搜索“--image”:[https://doris.apache.org/zh-CN/docs/dev/admin-manual/maint-monitor/metadata-operation](https://doris.apache.org/zh-CN/docs/dev/admin-manual/maint-monitor/metadata-operation)
-- 脚本相关
- - FE、BE 的 stop 脚本支持通过 `--grace` 参数退出FE、BE(使用 kill -15 信号代替 kill -9)
- - FE start 脚本支持通过 --version 查看当前FE 版本(#11563)
-- 支持通过 `ADMIN COPY TABLET` 命令获取某个 tablet 的数据和相关建表语句,用于本地问题调试
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Database-Administration-Statements/ADMIN-COPY-TABLET](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Database-Administration-Statements/ADMIN-COPY-TABLET)
-
-- 支持通过 http api,获取一个SQL语句相关的 建表语句,用于本地问题复现
-
-文档:[https://doris.apache.org/zh-CN/docs/dev/admin-manual/http-actions/fe/query-schema-action](https://doris.apache.org/zh-CN/docs/dev/admin-manual/http-actions/fe/query-schema-action)
-
-- 支持建表时关闭这个表的 compaction 功能,用于测试
-
-文档中搜索 "disble_auto_compaction":[https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE)
-
-# 致谢
-
-Apache Doris 1.2.0 版本的发布离不开所有社区用户的支持,在此向所有参与版本设计、开发、测试、讨论的社区贡献者们表示感谢,他们分别是(首字母排序):
-
-```
-@924060929
-@a19920714liou
-@adonis0147
-@Aiden-Dong
-@aiwenmo
-@AshinGau
-@b19mud
-@BePPPower
-@BiteTheDDDDt
-@bridgeDream
-@ByteYue
-@caiconghui
-@CalvinKirs
-@cambyzju
-@caoliang-web
-@carlvinhust2012
-@catpineapple
-@ccoffline
-@chenlinzhong
-@chovy-3012
-@coderjiang
-@cxzl25
-@dataalive
-@dataroaring
-@dependabot
-@dinggege1024
-@DongLiang-0
-@Doris-Extras
-@eldenmoon
-@EmmyMiao87
-@englefly
-@FreeOnePlus
-@Gabriel39
-@gaodayue
-@geniusjoe
-@gj-zhang
-@gnehil
-@GoGoWen
-@HappenLee
-@hello-stephen
-@Henry2SS
-@hf200012
-@huyuanfeng2018
-@jacktengg
-@jackwener
-@jeffreys-cat
-@Jibing-Li
-@JNSimba
-@Kikyou1997
-@Lchangliang
-@LemonLiTree
-@lexoning
-@liaoxin01
-@lide-reed
-@link3280
-@liutang123
-@liuyaolin
-@LOVEGISER
-@lsy3993
-@luozenglin
-@luzhijing
-@madongz
-@morningman
-@morningman-cmy
-@morrySnow
-@mrhhsg
-@Myasuka
-@myfjdthink
-@nextdreamblue
-@pan3793
-@pangzhili
-@pengxiangyu
-@platoneko
-@qidaye
-@qzsee
-@SaintBacchus
-@SeekingYang
-@smallhibiscus
-@sohardforaname
-@song7788q
-@spaces-X
-@ssusieee
-@stalary
-@starocean999
-@SWJTU-ZhangLei
-@TaoZex
-@timelxy
-@Wahno
-@wangbo
-@wangshuo128
-@wangyf0555
-@weizhengte
-@weizuo93
-@wsjz
-@wunan1210
-@xhmz
-@xiaokang
-@xiaokangguo
-@xinyiZzz
-@xy720
-@yangzhg
-@Yankee24
-@yeyudefeng
-@yiguolei
-@yinzhijian
-@yixiutt
-@yuanyuan8983
-@zbtzbtzbt
-@zenoyang
-@zhangboya1
-@zhangstar333
-@zhannngchen
-@ZHbamboo
-@zhengshiJ
-@zhenhb
-@zhqu1148980644
-@zuochunwei
-@zy-kkk
-```
\ No newline at end of file
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.2.1.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.2.1.md
deleted file mode 100644
index ab9f414205c..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.2.1.md
+++ /dev/null
@@ -1,195 +0,0 @@
----
-{
- 'title': '[Doris 发版通告] Apache Doris 1.2.1 Release',
- 'summary': '[Doris 发版通告] Apache Doris 1.2.1 Release',
- 'date': '2023-01-04',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-在 1.2.1 版本中,Doris 团队已经修复了自 1.2.0 版本发布以来约 200 个问题或性能改进项。同时,1.2.1 版本也作为 1.2 LTS 的第一个迭代版本,具备更高的稳定性,建议所有用户升级到这个版本。
-
-
-# 优化改进
-
-### 支持高精度小数 DecimalV3
-
-支持精度更高和性能更好的 DecimalV3,相较于过去版本具有以下优势:
-
-- 可表示范围更大,取值范围都进行了明显扩充,有效数字范围 [1,38]。
-
-- 性能更高,根据不同精度,占用存储空间可自适应调整。
-
-- 支持更完备的精度推演,对于不同的表达式,应用不同的精度推演规则对结果的精度进行推演。
-
-[DecimalV3](https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/DECIMALV3)
-
-### 支持 Iceberg V2
-
-支持 Iceberg V2 (仅支持 Position Delete, Equality Delete 会在后续版本支持),可以通过 Multi-Catalog 功能访问 Iceberg V2 格式的表。
-
-
-### 支持 OR 条件转 IN
-
-支持将 where 条件表达式后的 or 条件转换成 in 条件,在部分场景中可以提升执行效率。 [#15437](https://github.com/apache/doris/pull/15437) [#12872](https://github.com/apache/doris/pull/12872)
-
-
-### 优化 JSONB 类型的导入和查询性能
-
-优化 JSONB 类型的导入和查询性能,在测试数据上约有 70% 的性能提升。 [#15219](https://github.com/apache/doris/pull/15219) [#15219](https://github.com/apache/doris/pull/15219)
-
-### Stream load 支持带引号的 CSV 数据
-
-通过导入任务参数 `trim_double_quotes` 来控制,默认值为 false,为 true 时表示裁剪掉 CSV 文件每个字段最外层的双引号。 [#15241](https://github.com/apache/doris/pull/15241)
-
-### Broker 支持腾讯云 CHDFS 和 百度云 BOS 、AFS
-
-可以通过 Broker 访问存储在腾讯云 CHDFS 和 百度智能云 BOS、AFS 上的数据。 [#15297](https://github.com/apache/doris/pull/15297) [#15448](https://github.com/apache/doris/pull/15448)
-
-### 新增函数
-
-新增函数 `substring_index`。 [#15373](https://github.com/apache/doris/pull/15373)
-
-
-
-# 问题修复
-
-- 修复部分情况下,从 1.1.x 版本升级到 1.2.0 版本后,用户权限信息丢失的问题。 [#15144](https://github.com/apache/doris/pull/15144)
-
-- 修复使用 date/datetimev2 类型进行分区时,分区值错误的问题。 [#15094](https://github.com/apache/doris/pull/15094)
-
-- 修复部分已发布功能的 Bug,具体列表可参阅:[PR List](https://github.com/apache/doris/pulls?q=is%3Apr+label%3Adev%2F1.2.1-merged+is%3Aclosed)
-
-
-# 升级注意事项
-
-### 已知问题
-
-- 请勿使用 JDK11 作为 BE 的运行时 JDK,会导致 BE Crash。
-
-- 该版本对csv格式的读取性能有下降,会影响csv格式的导入和读取效率,我们会在下一个三位版本尽快修复
-
-### 行为改变
-
-- BE 配置项 `high_priority_flush_thread_num_per_store` 默认值由 1 改成 6 ,以提升 Routine Load 的写入效率。[#14775](https://github.com/apache/doris/pull/14775)
-
-- FE 配置项 `enable_new_load_scan_node` 默认值改为 true ,将使用新的 File Scan Node 执行导入任务,对用户无影响。 [#14808](https://github.com/apache/doris/pull/14808)
-
-- 删除 FE 配置项 `enable_multi_catalog`,默认开启 Multi-Catalog 功能。
-
-- 默认强制开启向量化执行引擎。会话变量 `enable_vectorized_engine` 将不再生效,如需重新生效,需将 FE 配置项 `disable_enable_vectorized_engine` 设为 false,并重启 FE。 [#15213](https://github.com/apache/doris/pull/15213)
-
-# 致谢
-
-有 45 位贡献者参与到 1.2.1 版本的开发与完善中,感谢他们的付出,他们分别是:
-
-@adonis0147
-
-@AshinGau
-
-@BePPPower
-
-@BiteTheDDDDt
-
-@ByteYue
-
-@caiconghui
-
-@cambyzju
-
-@chenlinzhong
-
-@dataroaring
-
-@Doris-Extras
-
-@dutyu
-
-@eldenmoon
-
-@englefly
-
-@freemandealer
-
-@Gabriel39
-
-@HappenLee
-
-@Henry2SS
-
-@hf200012
-
-@jacktengg
-
-@Jibing-Li
-
-@Kikyou1997
-
-@liaoxin01
-
-@luozenglin
-
-@morningman
-
-@morrySnow
-
-@mrhhsg
-
-@nextdreamblue
-
-@qidaye
-
-@spaces-X
-
-@starocean999
-
-@wangshuo128
-
-@weizuo93
-
-@wsjz
-
-@xiaokang
-
-@xinyiZzz
-
-@xutaoustc
-
-@yangzhg
-
-@yiguolei
-
-@yixiutt
-
-@Yulei-Yang
-
-@yuxuan-luo
-
-@zenoyang
-
-@zhangstar333
-
-@zhannngchen
-
-@zhengshengjun
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.2.3.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.2.3.md
deleted file mode 100644
index 92861c7f917..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-1.2.3.md
+++ /dev/null
@@ -1,173 +0,0 @@
----
-{
- 'title': 'Apache Doris 1.2.3 Release 版本正式发布',
- 'summary': 'Apache Doris 于 2023 年 3 月 20 日迎来 1.2.3 Release 版本的正式发布!欢迎大家下载使用',
- 'date': '2023-03-20',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-亲爱的社区小伙伴们,我们很高兴地宣布,**Apache Doris 于 2023 年 3 月 20 日迎来 1.2.3 Release 版本的正式发布**!在新版本中包含超过 200 项功能优化和问题修复。同时,1.2.3 版本作为 1.2 LTS 的迭代版本,**更加稳定易用,建议用户升级到这个版本**。
-
-**GitHub下载:**https://github.com/apache/doris/releases/tag/1.2.3-rc02
-
-**官网下载页:**https://doris.apache.org/zh-CN/download
-
-
-# Improvement
-
-### JDBC Catalog
-
-- 支持通过 JDBC Catalog 连接到另一个 Doris 数据库。
-
-参考文档:[https://doris.apache.org/docs/dev/lakehouse/multi-catalog/jdbc/#doris](https://doris.apache.org/docs/dev/lakehouse/multi-catalog/jdbc/#doris)
-
-- 支持通过参数 `only_specified_database` 来同步指定的数据库。
-
-- 支持通过 `lower_case_table_names` 参数控制是否以小写形式同步表名,解决表名区分大小写的问题。
-
-参考文档:[https://doris.apache.org/docs/dev/lakehouse/multi-catalog/jdbc](https://doris.apache.org/docs/dev/lakehouse/multi-catalog/jdbc)
-
-- 优化 JDBC Catalog 的读取性能。
-
-### Elasticsearch Catalog
-
-- 支持 Array 类型映射。
-
-- 支持通过 `like_push_down` 属性下推 like 表达式来控制 ES 集群的 CPU 开销。
-
-参考文档:[https://doris.apache.org/docs/dev/lakehouse/multi-catalog/es](https://doris.apache.org/docs/dev/lakehouse/multi-catalog/es)
-
-### Hive Catalog
-
-- 支持 Hive 表默认分区 `__HIVE_DEFAULT_PARTITION__`。
-
-- Hive Metastore 元数据自动同步支持压缩格式的通知事件。
-
-### 动态分区优化
-
-- 支持通过 storage_medium 参数来控制创建动态分区的默认存储介质。
-
-参考文档:[https://doris.apache.org/docs/dev/advanced/partition/dynamic-partition](https://doris.apache.org/docs/dev/advanced/partition/dynamic-partition)
-
-
-### 优化 BE 的线程模型
-
-- 优化 BE 的线程模型,以避免频繁创建和销毁线程所带来的稳定性问题。
-
-# Bug 修复
-
-- 修复了部分 Unique Key 模型 Merge-on-Write 表的问题;
-
-- 修复了部分 Compaction 相关问题;
-
-- 修复了部分 Delete 语句导致的数据问题;
-
-- 修复了部分 Query 执行问题;
-
-- 修复了在某些操作系统上使用 JDBC Catalog 导致 BE 宕机的问题;
-
-- 修复了部分 Multi-Catalog 的问题;
-
-- 修复了部分内存统计和优化问题;
-
-- 修复了部分 DecimalV3 和 date/datetimev2 的相关问题。
-
-- 修复了部分导入过程中的稳定性问题;
-
-- 修复了部分 Light Schema Change 的问题;
-
-- 修复了使用 `datetime` 类型无法批量创建分区的问题;
-
-- 修复了大量失败的 Broker Load 作业导致 FE 内存使用率过高的问题;
-
-- 修复了删除表后无法取消 Stream Load 的问题;
-
-- 修复了某些情况下查询 `information_schema` 库表超时的问题;
-
-- 修复了使用 `select outfile` 并发数据导出导致 BE 宕机的问题;
-
-- 修复了事务性 Insert 操作导致内存泄漏的问题;
-
-- 修复了 BE Tablet GC 线程导致 IO 负载过高的问题;
-
-- 修复了 Kafka Routine Load 中提交 Offset 不准确的问题。
-
-# 致谢
-
-Apache Doris 1.2.3 版本的发布离不开所有社区用户的支持,在此向所有参与版本设计、开发、测试、讨论的社区 52 位贡献者们表示感谢,他们分别是:
-
-[@zy-kkk](https://github.com/zy-kkk)
-[@zhannngchen](https://github.com/zhannngchen)
-[@ZhangYu0123](https://github.com/ZhangYu0123)
-[@zhangstar333](https://github.com/zhangstar333)
-[@zclllyybb](https://github.com/zclllyybb)
-[@yuxuan-luo](https://github.com/yuxuan-luo)
-[@yixiutt](https://github.com/yixiutt)
-[@yiguolei](https://github.com/yiguolei)
-[@yangzhg](https://github.com/yangzhg)
-[@xinyiZzz](https://github.com/xinyiZzz)
-[@XieJiann](https://github.com/XieJiann)
-[@xiaokang](https://github.com/xiaokang)
-[@WuWQ98](https://github.com/WuWQ98)
-[@WinkerDu](https://github.com/WinkerDu)
-[@wangbo](https://github.com/wangbo)
-[@TangSiyang2001](https://github.com/TangSiyang2001)
-[@SWJTU-ZhangLei](https://github.com/SWJTU-ZhangLei)
-[@starocean999](https://github.com/starocean999)
-[@stalary](https://github.com/stalary)
-[@sohardforaname](https://github.com/sohardforaname)
-[@SaintBacchus](https://github.com/SaintBacchus)
-[@qzsee](https://github.com/qzsee)
-[@qidaye](https://github.com/qidaye)
-[@platoneko](https://github.com/platoneko)
-[@nextdreamblue](https://github.com/nextdreamblue)
-[@mrhhsg](https://github.com/mrhhsg)
-[@morrySnow](https://github.com/morrySnow)
-[@morningman](https://github.com/morningman)
-[@maochongxin](https://github.com/maochongxin)
-[@luwei16](https://github.com/luwei16)
-[@luozenglin](https://github.com/luozenglin)
-[@liaoxin01](https://github.com/liaoxin01)
-[@Kikyou1997](https://github.com/Kikyou1997)
-[@Jibing-Li](https://github.com/Jibing-Li)
-[@jacktengg](https://github.com/jacktengg)
-[@htyoung](https://github.com/htyoung)
-[@HappenLee](https://github.com/HappenLee)
-[@Gabriel39](https://github.com/Gabriel39)
-[@freemandealer](https://github.com/freemandealer)
-[@englefly](https://github.com/englefly)
-[@eldenmoon](https://github.com/eldenmoon)
-[@dutyu](https://github.com/dutyu)
-[@Doris-Extras](https://github.com/Doris-Extras)
-[@chenlinzhong](https://github.com/chenlinzhong)
-[@catpineapple](https://github.com/catpineapple)
-[@Cai-Yao](https://github.com/Cai-Yao)
-[@caiconghui](https://github.com/caiconghui)
-[@ByteYue](https://github.com/ByteYue)
-[@BiteTheDDDDt](https://github.com/BiteTheDDDDt)
-[@Bingandbing](https://github.com/Bingandbing)
-@BePPPower
-@adonis0147
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-note-0.15.0.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-note-0.15.0.md
deleted file mode 100644
index 7f47d9f400d..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-note-0.15.0.md
+++ /dev/null
@@ -1,225 +0,0 @@
----
-{
- 'title': '[Doris 发版通告] Apache Doris(Incubating) 0.15.0 Release',
- 'summary': '[Doris 发版通告] Apache Doris(Incubating) 0.15.0 Release',
- 'date': '2021-11-29',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-# Apache Doris(Incubating) 0.15.0 Release
-
-亲爱的社区小伙伴们,历时数个月精心打磨,我们很高兴地宣布, Apache Doris(incubating) 于 2021 年 11 月 29 日迎来了 0.15.0 Release 版本的正式发布!有 99 位 Contributor 为 Apache Doris 提交了近 700 项优化和修复,在此我们也对所有贡献者表示最真诚的感激!
-
-在 0.15.0 Release 版本中,我们增加了诸多新功能,对 Apache Doris 的查询性能、易用性、稳定性方面等进行了全面优化:新增资源划分和隔离功能,用户可以通过资源标签的方式将集群中的 BE 节点划分为资源组,实现对在线、离线业务的统一管理和资源隔离;增加了 Runtime Filter 及 Join Reorder 功能,对多表 Join 场景的查询效率进行了大幅提升,在 Star Schema Benchmark 测试数据集下有 2-10 倍的性能提升;新增导入方式 Binlog Load ,使 Doris 可以增量同步 MySQL 中对数据更新操作的 CDC ;支持 String 列类型,长度最大支持 2GB ;支持 List 分区功能,可以通过枚举值创建分区;支持 Unique Key 模型上的 Update 语句;Spark-Doris-Connector 支持数据写入 Doris ……还有更多重要特性,欢迎大家下载使用。
-
-我们欢迎大家在使用过程中,有任何问题通过 GitHub Discussion 或者 Dev 邮件组与我们取得联系,也期待大家参与社区讨论和建设中 。
-
-
-## 重要更新
-
-### 资源划分与隔离
-
-用户可以通过资源标签的方式将一个 Doris 集群中的 BE 节点划分成多个资源组,从而可以进行在线、离线业务的统一管理和节点级别的资源隔离。
-同时,还可以通过限制单个查询任务的 CPU、内存开销以及复杂度,来控制单个查询的资源开销,从而降低不同查询之间的资源抢占问题。
-
-### 性能优化
-
-* Runtime Filter 功能通过使用 Join 算子中右表的 Join Key 列条件来过滤左表的数据,在大部分 Join 场景下可以显著提升查询效率。如在 Star Schema Benchmark ( TPCH 的精简测试集) 下可以获得 2-10 倍的性能提升。
-
-* Join Reorder 功能可以通过通过代价模型自动帮助调整 SQL 中 Join 的顺序,以帮助获得最优的 Join 效率。
-可通过会话变量 `set enable_cost_based_join_reorder=true` 开启。
-
-### 新增功能
-
-* 支持直接对接 Canal Server 同步 MySQL binlog 数据。
-* 支持 String 列类型,最大支持 2GB 。
-* 支持 List 分区功能,可以针对枚举值创建分区。
-* 支持事务性 Insert 语句功能。可以通过 begin ; insert ; insert; ,... ; commit ; 的方式批量导入数据。
-* 支持在 Unique Key 模型上的 Update 语句功能。可以在 Unique Key 模型表上执行 Update Set where 语句。
-* 支持 SQL 阻塞名单功能。可以通过正则、Hash 值匹配等方式阻止部分 SQL 的执行。
-* 支持 LDAP 登陆验证。
-
-### 拓展功能
-
-* 支持 Flink-Doris-Connector 。
-* 支持 DataX doriswriter 插件。
-* Spark-Doris-Connector 支持数据写入 Doris 。
-
-
-## 功能优化
-
-### 查询
-
-* 支持在 SQL 查询规划阶段,利用 BE 的函数计算能力计算所有常量表达式。
-
-### 导入
-
-* 支持导入文本格式文件时,指定多字节行列分隔符或不可见分隔符。
-* 支持通过 Stream Load 导入压缩格式文件。
-* Stream Load支持导入多行格式的 Json 数据。
-
-### 导出
-
-* 支持 Export 导出功能指定 where 过滤条件。支持导出文件使用多字节行列分隔符。支持导出到本地文件。
-* Export 导出功能支持仅导出指定的列。
-* 支持通过 outfile 语句导出结果集到本地磁盘,并支持导出后写入导出成功的标记文件。
-
-### 易用性
-
-* 动态分区功能支持创建、保留指定的历史分区、支持自动冷热数据迁移设置。
-* 支持在命令行使用可视化的树形结构展示查询、导入的计划和 Profile。
-* 支持记录并查看 Stream Load 操作日志。
-* 通过 Routine Load 消费 Kafka 数据时,可以指定时间点进行消费。
-* 支持通过 show create routine load 功能导出 Routine Load 的创建语句。
-* 支持通过 pause/resume all routine load 命令一键启停所有 Routine Load Job。
-* 支持通过 alter routine load 语句修改 Routine Load 的 Broker List 和 Topic。
-* 支持 create table as select 功能。
-* 支持通过 alter table 命令修改列注释和表注释。
-* show tablet status 增加表创建时间、数据更新时间。
-* 支持通过 show data skew 命令查看表的数据量分布,以排查数据倾斜问题。
-* 支持通过 show/clean trash 命令查看 BE 文件回收站的磁盘占用情况并主动清除。
-* 支持通过 show view 语句展示一个表被哪些视图所引用。
-
-### 新增函数
-
-* `bitmap_min`, `bit_length`
-* `yearweek`, `week`, `makedate`
-* `percentile` 精确百分位函数
-* `json_array`,`json_object`,`json_quote`
-* 支持为 `AES_ENCRYPT` 和 `AES_DECRYPT` 函数创建自定义公钥。
-* 支持通过 `create alias function` 创建函数别名来组合多个函数。
-
-### 其他
-
-* 支持访问 SSL 连接协议的ES外表。
-* 支持在动态分区属性中指定热点分区的数量,热点分区将存储在 SSD 磁盘中。
-* 支持通过 Broker Load 导入 Json 格式数据。
-* 支持直接通过 libhdfs3 库访问 HDFS 进行数据的导入导出,而不需要 Broker 进程。
-* select into outfile 功能支持导出 Parquet 文件格式,并支持并行导出。
-* ODBC 外表支持 SQLServer。
-
-## 致谢
-
-Apache Doris(incubating) 0.15.0 Release 版本的发布离不开所有社区用户的支持,在此向所有参与版本设计、开发、测试、讨论的社区贡献者们表示感谢,他们分别是:
-
-* [@924060929](https://github.com/924060929)
-* [@acelyc111](https://github.com/acelyc111)
-* [@Aimiyoo](https://github.com/Aimiyoo)
-* [@amosbird](https://github.com/amosbird)
-* [@arthur-zhang](https://github.com/arthur-zhang)
-* [@azurenake](https://github.com/azurenake)
-* [@BiteTheDDDDt](https://github.com/BiteTheDDDDt)
-* [@caiconghui](https://github.com/caiconghui)
-* [@caneGuy](https://github.com/caneGuy)
-* [@caoliang-web](https://github.com/caoliang-web)
-* [@ccoffline](https://github.com/ccoffline)
-* [@chaplinthink](https://github.com/chaplinthink)
-* [@chovy-3012](https://github.com/chovy-3012)
-* [@ChPi](https://github.com/ChPi)
-* [@copperybean](https://github.com/copperybean)
-* [@crazyleeyang](https://github.com/crazyleeyang)
-* [@dh-cloud](https://github.com/dh-cloud)
-* [@DinoZhang](https://github.com/DinoZhang)
-* [@dixingxing0](https://github.com/dixingxing0)
-* [@dohongdayi](https://github.com/dohongdayi)
-* [@e0c9](https://github.com/e0c9)
-* [@EmmyMiao87](https://github.com/EmmyMiao87)
-* [@eyesmoons](https://github.com/eyesmoons)
-* [@francisoliverlee](https://github.com/francisoliverlee)
-* [@Gabriel39](https://github.com/Gabriel39)
-* [@gaodayue](https://github.com/gaodayue)
-* [@GoGoWen](https://github.com/GoGoWen)
-* [@HappenLee](https://github.com/HappenLee)
-* [@harveyyue](https://github.com/harveyyue)
-* [@Henry2SS](https://github.com/Henry2SS)
-* [@hf200012](https://github.com/hf200012)
-* [@huangmengbin](https://github.com/huangmengbin)
-* [@huozhanfeng](https://github.com/huozhanfeng)
-* [@huzk8](https://github.com/huzk8)
-* [@hxianshun](https://github.com/hxianshun)
-* [@ikaruga4600](https://github.com/ikaruga4600)
-* [@JameyWoo](https://github.com/JameyWoo)
-* [@Jennifer88huang](https://github.com/Jennifer88huang)
-* [@JinLiOnline](https://github.com/JinLiOnline)
-* [@jinyuanlu](https://github.com/jinyuanlu)
-* [@JNSimba](https://github.com/JNSimba)
-* [@killxdcj](https://github.com/killxdcj)
-* [@kuncle](https://github.com/kuncle)
-* [@liutang123](https://github.com/liutang123)
-* [@luozenglin](https://github.com/luozenglin)
-* [@luzhijing](https://github.com/luzhijing)
-* [@MarsXDM](https://github.com/MarsXDM)
-* [@mh-boy](https://github.com/mh-boy)
-* [@mk8310](https://github.com/mk8310)
-* [@morningman](https://github.com/morningman)
-* [@Myasuka](https://github.com/Myasuka)
-* [@nimuyuhan](https://github.com/nimuyuhan)
-* [@pan3793](https://github.com/pan3793)
-* [@PatrickNicholas](https://github.com/PatrickNicholas)
-* [@pengxiangyu](https://github.com/pengxiangyu)
-* [@pierre94](https://github.com/pierre94)
-* [@qidaye](https://github.com/qidaye)
-* [@qzsee](https://github.com/qzsee)
-* [@shiyi23](https://github.com/shiyi23)
-* [@smallhibiscus](https://github.com/smallhibiscus)
-* [@songenjie](https://github.com/songenjie)
-* [@spaces-X](https://github.com/spaces-X)
-* [@stalary](https://github.com/stalary)
-* [@stdpain](https://github.com/stdpain)
-* [@Stephen-Robin](https://github.com/Stephen-Robin)
-* [@Sunt-ing](https://github.com/Sunt-ing)
-* [@Taaang](https://github.com/Taaang)
-* [@tarepanda1024](https://github.com/tarepanda1024)
-* [@tianhui5](https://github.com/tianhui5)
-* [@tinkerrrr](https://github.com/tinkerrrr)
-* [@TobKed](https://github.com/TobKed)
-* [@ucasfl](https://github.com/ucasfl)
-* [@Userwhite](https://github.com/Userwhite)
-* [@vinson0526](https://github.com/vinson0526)
-* [@wangbo](https://github.com/wangbo)
-* [@wangliansong](https://github.com/wangliansong)
-* [@wangshuo128](https://github.com/wangshuo128)
-* [@weajun](https://github.com/weajun)
-* [@weihongkai2008](https://github.com/weihongkai2008)
-* [@weizuo93](https://github.com/weizuo93)
-* [@WindyGao](https://github.com/WindyGao)
-* [@wunan1210](https://github.com/wunan1210)
-* [@wuyunfeng](https://github.com/wuyunfeng)
-* [@xhmz](https://github.com/xhmz)
-* [@xiaokangguo](https://github.com/xiaokangguo)
-* [@xiaoxiaopan118](https://github.com/xiaoxiaopan118)
-* [@xinghuayu007](https://github.com/xinghuayu007)
-* [@xinyiZzz](https://github.com/xinyiZzz)
-* [@xuliuzhe](https://github.com/xuliuzhe)
-* [@xxiao2018](https://github.com/xxiao2018)
-* [@xy720](https://github.com/xy720)
-* [@yangzhg](https://github.com/yangzhg)
-* [@yx91490](https://github.com/yx91490)
-* [@zbtzbtzbt](https://github.com/zbtzbtzbt)
-* [@zenoyang](https://github.com/zenoyang)
-* [@zh0122](https://github.com/zh0122)
-* [@zhangboya1](https://github.com/zhangboya1)
-* [@zhangstar333](https://github.com/zhangstar333)
-* [@zuochunwei](https://github.com/zuochunwei)
-
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/release-note-1.0.0.md b/i18n/zh-CN/docusaurus-plugin-content-blog/release-note-1.0.0.md
deleted file mode 100644
index fa41f9cb5a0..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/release-note-1.0.0.md
+++ /dev/null
@@ -1,254 +0,0 @@
----
-{
- 'title': '[Doris 发版通告] Apache Doris(Incubating) 1.0.0 Release',
- 'summary': '[Doris 发版通告] Apache Doris(Incubating) 1.0.0 Release',
- 'date': '2022-04-18',
- 'author': 'Apache Doris',
- 'tags': ['版本发布'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-# Apache Doris(Incubating) 1.0.0 Release
-
-亲爱的社区小伙伴们,历时数月,我们很高兴地宣布,Apache Doris (incubating) 于 2022 年 4 月 18 日迎来了 1.0 Release 版本的正式发布!**这是 Apache Doris 在进入 Apache 基金会孵化以来的第一个 1 位版本,也是迄今为止对 Apache Doris 核心代码重构幅度最大的一个版本\*\***!**有 **114 位 Contributor** 为 Apache Doris 提交了**超过 660 项优化和修复\*\*,感谢每一个让 Apache Doris 变得更好的你!
-
-在 1.0 版本中,我们引入了向量化执行引擎、Hive 外部表、Lateral View 语法及 Table Function 表函数、Z-Order 数据索引、Apache SeaTunnel 插件等重要功能,增加了对 Flink CDC 同步更新和删除数据的支持,优化了诸多数据导入和查询过程中的问题,对 Apache Doris 的查询性能、易用性、稳定性等多方特效进行了全面加强,欢迎大家下载使用!点击文末“**阅读原文**”即可直接前往下载地址。
-
-每一个不曾发版的日子,背后都有无数贡献者枕戈待旦,不敢停歇半分。在此我们尤其要感谢来自**向量化执行引擎、查询优化器、可视化运维平台 等 SIG (专项兴趣小组)的小伙伴**。自 2021 年 8 月 Apache Doris 社区 SIG 小组成立以来,**来自百度、美团、小米、京东、蜀海、字节跳动、腾讯、网易、阿里巴巴、PingCAP、Nebula Graph 等十余家公司的数十名贡献者**作为首批成员加入到 SIG 中,第一次以专项小组的开源协作形式完成了向量化执行引擎、查询优化器、 Doris Manager 可视化监控运维平台等如此重大功能的开发,**历时半年以上、开展技术调研和分享数十次、召开远程会议近百次、累计提交 Commits 多达数百个、涉及代码行数高达十余万行**,正是因为有他们的贡献,才有 1.0 版本的问世,让我们再次对他们的辛勤付出表示最真诚的感谢!
-
-与此同时,Apache Doris 的贡献者数量已超过 300 人,每月活跃的贡献者数量超过了 60 人,近几周平均每周提交的 Commits 数量也超过 80,社区聚集的开发者规模及活跃度已经有了极大的提升。我们十分期待有更多的小伙伴参与社区贡献中来,与我们一道把 Apache Doris 打造成全球顶级的分析型数据库,也期待所有小伙伴可以与我们一起收获宝贵的成长。如果你想参与社区,欢迎通过开发者邮箱 dev@doris.apache.org 与我们取得联系。
-
-我们欢迎大家在使用过程中,有任何问题通过 GitHub Discussion 或者 Dev 邮件组与我们取得联系,也期待大家参与社区讨论和建设中 。
-
-## 重要更新
-
-### 向量化执行引擎 [Experimental]
-
-过去 Apache Doris 的 SQL 执行引擎是基于行式内存格式以及基于传统的火山模型进行设计的,在进行 SQL 算子与函数运算时存在非必要的开销,导致 Apache Doris 执行引擎的效率受限,并不适应现代 CPU 的体系结构。向量化执行引擎的目标是替换 Apache Doris 当前的行式 SQL 执行引擎,充分释放现代 CPU 的计算能力,突破在 SQL 执行引擎上的性能限制,发挥出极致的性能表现。
-
-基于现代 CPU 的特点与火山模型的执行特点,向量化执行引擎重新设计了在列式存储系统的 SQL 执行引擎:
-
-- 重新组织内存的数据结构,用 Column 替换 Tuple,提高了计算时 Cache 亲和度,分支预测与预取内存的友好度
-- 分批进行类型判断,在本次批次中都使用类型判断时确定的类型,将每一行类型判断的虚函数开销分摊到批量级别。
-- 通过批级别的类型判断,消除了虚函数的调用,让编译器有函数内联以及 SIMD 优化的机会
-
-从而大大提高了 CPU 在 SQL 执行时的效率,提升了 SQL 查询的性能。
-
-在 Apache Doris 1.0 版本中,通过 set batch_size = 4096 和 set enable_vectorized_engine = true 开启向量化执行引擎,多数情况下可显著提升查询性能。在 SSB 和 OnTime 标准测试数据集下,多表关联和宽列查询两大场景的整体性能分别有 3 倍和 2.6 倍的提升。
-
-
-
-
-
-### Lateral View 语法 [Experimental]
-
-通过 Lateral View 语法,我们可以使用 explod_bitmap 、explode_split、explode_jaon_array 等 Table Function 表函数,将 bitmap、String 或 Json Array 由一列展开成多行,以便后续可以对展开的数据进行进一步处理(如 Filter、Join 等)。
-
-### Hive 外表 [Experimental]
-
-Hive External Table 为用户提供了通过 Doris 直接访问 Hive 表的能力,外部表省去了 繁琐的数据导入工作,可以借助 Doris 本身 OLAP 的能力来解决 Hive 表的数据分析问题。当前版本支持将 Hive 数据源接入 Doris,并支持通过 Doris 与 Hive 数据源中的数据进行联邦查询,进行更加复杂的分析操作。
-
-### 支持 Z-Order 数据排序格式
-
-Apache Doris 数据是按照前缀列排序存储的,因此在包含前缀查询条件时,可以在排序数据上进行快速的数据查找,但如果查询条件不是前缀列,则无法利用数据排序的特征进行快速数据查找。通过 Z-Order Indexing 可以解决上述问题,在 1.0 版本中我们增加了 Z-Order 数据排序格式,在看板类多列查询的场景中可以起到很好过滤效果,加速对非前缀列条件的过滤性能。
-
-### 支持 Apache SeaTunnel(Incubating)插件
-
-Apache SeaTunnel 是一个高性能的分布式数据集成框架,架构于 Apache Spark 和 Apache Flink 之上。在 Apache Doris 1.0 版本中,我们增加了 SaeTunnel 插件,用户可以借助 Apache SeaTunnel 进行多数据源之间的同步和 ETL。
-
-### 新增函数
-
-支持更多 bitmap 函数,具体可查看函数手册:
-
-- bitmap_max
-- bitmap_and_not
-- bitmap_and_not_count
-- bitmap_has_all
-- bitmap_and_count
-- bitmap_or_count
-- bitmap_xor_count
-- bitmap_subset_limit
-- sub_bitmap
-
-支持国密算法 SM3/SM4;
-
-> **注意**:以上标记 [Experimental] 的功能为实验性功能,我们将会在后续版本中对以上功能进行持续优化和迭代,并后续版本中进一步完善。在使用过程中有任何问题或意见,欢迎随时与我们联系
-
-### 重要优化
-
-### 功能优化
-
-- 降低大批量导入时,生成的 Segment 文件数量,以降低 Compaction 压力。
-- 通过 BRPC 的 attachment 功能传输数据,以查询过程中的降低序列化和反序列化开销。
-- 支持直接返回 HLL/BITMAP 类型的二进制数据,用于业务在外侧解析。
-- 优化并降低 BRPC 出现 OVERCROWDED 和 NOT_CONNECTED 错误的概率,增强系统稳定性。
-- 增强导入的容错性。
-- 支持通过 Flink CDC 同步更新和删除数据。
-- 支持自适应的 Runtime Filter。
-- 显著降低 insert into 操作的内存占用
-
-### 易用性改进
-
-- Routine Load 支持显示当前 offset 延迟数量等状态。
-- FE audit log 中增加查询峰值内存使用量的统计。
-- Compaction URL 结果中增加缺失版本的信息,方便排查问题。
-- 支持将 BE 标记为不可查询或不可导入,以快速屏蔽问题节点。
-
-### 重要 Bug 修复
-
-- 修复若干查询错误问题。
-- 修复 Broker Load 若干调度逻辑问题。
-- 修复 STREAM 关键词导致元数据无法加载的问题。
-- 修复 Decommission 无法正确执行的问题。
-- 修复部分情况下操作 Schema Change 操作可能出现 -102 错误的问题。
-- 修复部分情况下使用 String 类型可能导致 BE 宕机的问题。
-
-### 其他
-
-- 增加 Minidump 功能;
-
-## 更新日志
-
-详细 Release Note 请查看链接:
-
-https://github.com/apache/incubator-doris/issues/8549
-
-## 致谢
-
-Apache Doris(incubating) 1.0 Release 版本的发布离不开所有社区用户的支持,在此向所有参与版本设计、开发、测试、讨论的社区贡献者们表示感谢,他们分别是:
-
-```
-@924060929
-@adonis0147
-@Aiden-Dong
-@aihai
-@airborne12
-@Alibaba-HZY
-@amosbird
-@arthuryangcs
-@awakeljw
-@bingzxy
-@BiteTheDDDDt
-@blackstar-baba
-@caiconghui
-@CalvinKirs
-@cambyzju
-@caoliang-web
-@ccoffline
-@chaplinthink
-@chovy-3012
-@ChPi
-@DarvenDuan
-@dataalive
-@dataroaring
-@dh-cloud
-@dohongdayi
-@dongweizhao
-@drgnchan
-@e0c9
-@EmmyMiao87
-@englefly
-@eyesmoons
-@freemandealer
-@Gabriel39
-@gaodayue
-@GoGoWen
-@Gongruixiao
-@gwdgithubnom
-@HappenLee
-@Henry2SS
-@hf200012
-@htyoung
-@jacktengg
-@jackwener
-@JNSimba
-@Keysluomo
-@kezhenxu94
-@killxdcj
-@lihuigang
-@littleeleventhwolf
-@liutang123
-@liuzhuang2017
-@lonre
-@lovingfeel
-@luozenglin
-@luzhijing
-@MeiontheTop
-@mh-boy
-@morningman
-@mrhhsg
-@Myasuka
-@nimuyuhan
-@obobj
-@pengxiangyu
-@qidaye
-@qzsee
-@renzhimin7
-@Royce33
-@SleepyBear96
-@smallhibiscus
-@sodamnsure
-@spaces-X
-@sparklezzz
-@stalary
-@steadyBoy
-@tarepanda1024
-@THUMarkLau
-@tianhui5
-@tinkerrrr
-@ucasfl
-@Userwhite
-@vinson0526
-@wangbo
-@wangshuo128
-@wangyf0555
-@weajun
-@weizuo93
-@whutpencil
-@WindyGao
-@wunan1210
-@xiaokang
-@xiaokangguo
-@xiedeyantu
-@xinghuayu007
-@xingtanzjr
-@xinyiZzz
-@xtr1993
-@xu20160924
-@xuliuzhe
-@xuzifu666
-@xy720
-@yangzhg
-@yiguolei
-@yinzhijian
-@yjant
-@zbtzbtzbt
-@zenoyang
-@zh0122
-@zhangstar333
-@zhannngchen
-@zhengshengjun
-@zhengshiJ
-@ZhikaiZuo
-@ztgoto
-@zuochunwei
-```
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/scenario.md b/i18n/zh-CN/docusaurus-plugin-content-blog/scenario.md
deleted file mode 100644
index 0ccdd549b7a..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/scenario.md
+++ /dev/null
@@ -1,213 +0,0 @@
----
-{
- 'title': '打造自助对话式数据分析场景,Apache Doris 在思必驰的应用实践|最佳实践',
- 'summary': '思必驰于 2019 年首次引入 Apache Doris ,基于 Apache Doris 构建了实时与离线一体的数仓架构。相对于过去架构,Apache Doris 凭借其灵活的查询模型、极低的运维成本、短平快的开发链路以及优秀的查询性能等诸多方面优势,如今已经在实时业务运营、自助/对话式分析等多个业务场景得到运用,满足了 设备画像/用户标签、业务场景实时运营、数据分析看板、自助 BI、财务对账等多种数据分析需求',
- 'date': '2022-07-20',
- 'author': '赵伟',
- 'tags': ['最佳实践'],
-}
-
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-> 作者:赵伟,思必驰大数据高级研发,10年大数据开发和设计经验,负责大数据平台基础技术和OLAP分析技术开发。社区贡献:Doris-spark-connector 的实时读写和优化。
-
-# 业务背景
-
-思必驰是国内专业的对话式人工智能平台公司,拥有全链路的智能语音语言技术,致力于成为全链路智能语音及语言交互的平台型企业,自主研发了新一代人机交互平台 DUI 和人工智能芯片 TH1520,为车联网、IoT 及政务、金融等众多行业场景合作伙伴提供自然语言交互解决方案。
-
-思必驰于 2019 年首次引入 Apache Doris ,基于 Apache Doris 构建了实时与离线一体的数仓架构。相对于过去架构,Apache Doris 凭借其灵活的查询模型、极低的运维成本、短平快的开发链路以及优秀的查询性能等诸多方面优势,如今已经在实时业务运营、自助/对话式分析等多个业务场景得到运用,满足了 设备画像/用户标签、业务场景实时运营、数据分析看板、自助 BI、财务对账等多种数据分析需求。在这一过程中我们也积累了诸多使用上的经验,在此分享给大家。
-
-# 架构演进
-
-早期业务中离线数据分析是我们的主要需求,近几年,随着业务的不断发展,业务场景对实时数据分析的要求也越来越高,早期数仓架构逐渐力不从心,暴露出很多问题。为了满足业务场景对查询性能、响应时间及并发能力更高的要求,2019年正式引入 Apache Doris 构建实时离线一体的数仓架构。
-
-以下将为大家介绍思必驰数仓架构的演进之路,早期数仓存在的优缺点,同时分享我们选择 Apache Doris 构建新架构的原因以及面临的新问题与挑战。
-
-## 早期数仓架构及痛点
-
-
-
-如上图所示,早期架构基于 Hive +Kylin 来构建离线数仓,实时数仓架基于 Spark+MySQL 来构建实时分析数仓。
-
-我们业务场景的数据源主要分为三类,业务数据库如 MySQL,应用系统如 K8s 容器服务日志,还有车机设备终端的日志。数据源通过 MQTT/HTTP 协议、业务数据库 Binlog 、Filebeat日志采集等多种方式先写入 Kafka 。在早期架构中,数据经 Kafka 后将分为实时和离线两条链路,首先是实时部分,实时部分链路较短,经过 Kafka 缓冲完的数据通过 Spark 计算后放入 MySQL 中进行分析,对于早期的实时分析需求,MySQL 基本可以满足分析需求。而离线部分则由 Spark 进行数据清洗及计算后在 Hive 中构建离线数仓,并使用 Apache Kylin 构建 Cube,在构建 Cube 之前需要提前做好数据模型的的设计,包括关联表、维度表、指标字段、指标需要的聚合函数等,通过调度系统进行定时触发构建,最终使用 HBase 存储构建好的 Cube。
-
-### **早期架构的优势:**
-
-1. 早期架构与 Hive 结合较好,无缝对接 Hadoop 技术体系。
-
-2. 离线数仓中基于 Kylin 的预计算、表关联、聚合计算、精确去重等场景,查询性能较高,在并发场景下查询稳定性也较高。
-
-早期架构解决了当时业务中较为紧迫的查询性能问题,但随着业务的发展,对数据分析要求不断升高,早期架构缺点也开始逐渐凸显出来。
-
-### **早期架构的痛点:**
-
-1. 依赖组件多。Kylin 在 2.x、3.x 版本中强依赖 Hadoop 和 HBase ,应用组件较多导致开发链路较长,架构稳定性隐患多,维护成本比很高。
-
-2. Kylin 的构建过程复杂,构建任务容易失败。Kylin 构建需要进行打宽表、去重列、生成字典,构建 Cube 等如果每天有 1000-2000 个甚至更多的任务,其中至少会有 10 个甚至更多任务构建失败,导致需要大量时间去写自动运维脚本。
-
-3. 维度/字典膨胀严重。维度膨胀指的是在某些业务场景中需要多个分析条件和字段,如果在数据分析模型中选择了很多字段而没有进行剪枝,则会导致 Cube 维度膨胀严重,构建时间变长。而字典膨胀指的是在某些场景中需要长时间做全局精确去重,会使得字典构建越来越大,构建时间也会越来越长,从而导致数据分析性能持续下降。
-
-4. 数据分析模型固定,灵活性较低。在实际应用过程中,如果对计算字段或者业务场景进行变更,则要回溯部分甚至全部数据。
-
-5. 不支持数据明细查询。早期数仓架构是无法提供明细数据查询的,Kylin 官方给的解决方法是下推给 Presto 做明细查询,这又引入了新的架构,增加了开发和运维成本。
-
-## 架构选型
-
-为解决以上问题,我们开始探索新的数仓架构优化方案,先后对市面上应用最为广泛的 Apache Doris、Clickhouse 等 OLAP 引擎进行选型调研。相较于 ClickHouse 的繁重运维、各种各样的表类型、不支持关联查询等,结合我们的 OLAP 分析场景中的需求,综合考虑,Apache Doris 表现较为优秀,最终决定引入 Apache Doris 。
-
-## 新数仓架构
-
-
-
-如上图所示,我们基于 Apache Doris 构建了实时+离线一体的新数仓架构,与早期架构不同的是,实时和离线的数据分别进行处理后均写入 Apache Doris 中进行分析。
-
-因历史原因数据迁移难度较大,离线部分基本和早期数仓架构保持一致,在Hive上构建离线数仓,当然完全可以在Apache Doris 上直接构建离线数仓。
-
-相对早期架构不同的是,离线数据通过 Spark 进行清洗计算后在 Hive 中构建数仓,然后通过 Broker Load 将存储在 Hive 中的数据写入到 Apache Doris 中。这里要说明的, Broker Load 数据导入速度很快,天级别 100-200G 数据导入到 Apache Doris 中仅需要 10-20 分钟。
-
-实时数据流部分,新架构使用了 Doris-Spark-Connector 来消费 Kafka 中的数据并经过简单计算后写入 Apache Doris 。从架构图所示,实时和离线数据统一在 Apache Doris 进行分析处理,满足了数据应用的业务需求,实现了实时+离线一体的数仓架构。
-
-### **新架构的收益:**
-
-1. 极简运维,维护成本低,不依赖 Hadoop 生态组件。Apache Doris 的部署简单,只有 FE 和 BE 两个进程, FE 和 BE 进程都是可以横向扩展的,单集群支持到数百台机器,数十 PB 的存储容量,并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。在使用 Doris 三年时间中花费的运维时间非常少,相比于基于 Kylin 搭建的早期架构,新架构花费极少的时间去做运维。
-
-2. 链路短,开发排查问题难度大大降低。基于 Doris 构建实时和离线统一数仓,支持实时数据服务、交互数据分析和离线数据处理场景,这使得开发链路变的很短,问题排查难度大大降低。
-
-3. 支持 Runtime 形式的 Join 查询。Runtime 类似 MySQL 的表关联,这对数据分析模型频繁变更的场景非常友好,解决了早期结构数据模型灵活性较低的问题。
-
-4. 同时支持 Join、聚合、明细查询。解决了早期架构中部分场景无法查询数据明细的问题。
-
-5. 支持多种加速查询方式。支持上卷索引,物化视图,通过上卷索引实现二级索引来加速查询,极大的提升了查询响应时间。
-
-6. 支持多种联邦查询方式。支持对 Hive、Iceberg、Hudi 等数据湖和 MySQL、Elasticsearch 等数据库的联邦查询分析。
-
-### **问题和挑战:**
-
-在建设新数仓架构过程中,我们遇到了一些问题:
-
-- 高并发场景对 Apache Doris 查询性能存在一定影响。我们分别在 Doris 0.12 和 Doris 1.1版本上进行测试,同一时间同样的 SQL,10 并发和 50 并发进行访问,性能差别较大。
-
-- 在实时写入场景中,当实时写入的数据量比较大时,会使得 IO 比较密集,导致查询性能下降。
-
-- 大数据量下字符串精确去重较慢。目前使用的是 count distinct 函数、Shuffle 和聚合算子去重,此方式算力比较慢。当前业内常见的解决方法一般是针对去重列构建字典,基于字典构建 Bitmap 索引后使用 Bitmap 函数去重。目前 Apache Doris 只支持数字类型的 Bitmap 索引,具有一定的局限性。
-
-# 业务场景的应用
-
-Apache Doris 在思必驰最先应用在实时运营业务场景以及自助/对话式分析场景,本章节将介绍两个场景的需求及应用情况。
-
-## 实时运营业务场景
-
-
-
-首先是实时运营业务场景,如上图所示,实时运营业务场景的技术架构和前文所述的新版数仓架构基本一致:
-
-- 数据源:数据源新版架构图中一致,包括 MySQL 中的业务数据,应用系统埋点数据以及设备和终端日志。
-
-- 数据导入:离线数据导入使用 Broker Load,实时数据导入使用 Doris-Spark-Connector 。
-
-- 数据存储与开发:几乎所有的实时数仓全部在 Apache Doris 构建,有一部分离线数据放在 Airflow 上执行 DAG 跑批任务。
-
-- 数据应用:最上层是业务侧提出的业务分析需求,包括大屏展示,数据运营的实时看板、用户画像、BI 看板等。
-
-**在实时运营业务场景中,数据分析的需求主要有两方面:**
-
-- 由于实时导入数据量比较大,因此对实时数据的查询效率要求较高
-
-- 在此场景中,有 20+ 人的团队在运营,需要同时开数据运营的看板,因此对实时写入的性能和查询并发会有比较高的要求。
-
-## 自助/对话式分析场景
-
-除以上之外,Apache Doris 在思必驰第二个应用是自助/对话式分析场景。
-
-
-
-如上图所示,在一般的 BI 场景中,用户方比如商务、财务、销售、运营、项目经理等会提出需求给数据分析人员,数据分析人员在 BI 平台上做数据看板,最终把看板提供给用户,用户从 BI 看板上获取所需信息,但是有时候用户想要查看明细数据、定制化的看板需求,或者在某些场景需做任意维度的上卷或者下钻的分析,一般场景下 BI 看板是不支持的的,基于以上所述用户需求,我们打造了自助对话式 BI 场景来解决用户定制化的需求。
-
-与一般 BI 场景不同的是,我们将自助/对话式 BI 场景从数据分析人员方下沉到用户方,用户方只需要通过打字,描述数据分析的需求。基于我们公司自然语言处理的能力,自助/对话式 BI 场景会将自然语言转换成SQL,类似 NL2SQL 技术,需要说明的是这里使用的是定制的自然语言解析,相对开源的 NL2SQL 命中率高、解析结果更精确。当自然语言转换成 SQL 后,将 SQL 给到 Apache Doris 查询得到分析结果。由此,用户通过打字就可以随时查看任意场景下的明细数据,或者任意字段的上卷、下钻。
-
-相比 Apache Kylin、Apache Druid 等预计算的 OLAP 引擎,Apache Doris 符合以下几个特点:
-
-- 查询灵活,模型不固定,支持自由定制场景。
-
-- 支持表关联、聚合计算、明细查询。
-
-- 响应时间要快速。
-
-因此我们很顺利的运用 Apache Doris 实现了自助/对话式分析场景。同时,自助/对话式分析在我们公司多个数据分析场景应用反馈非常好。
-
-# 实践经验
-
-基于上面的两个场景,我们使用过程当中积累了一些经验和心得,分享给大家。
-
-### **数仓** **表设计:**
-
-1. 千万级(量级供参考,跟集群规模有关系)以下的数据表使用 Duplicate 表类型,Duplicate 表类型同时支持聚合、明细查询,不需要额外写明细表。
-
-2. 当数据量比较大时,使用 Aggregate 聚合表类型,在聚合表类型上做上卷索引,使用物化视图优化查询、优化聚合字段。由于 Aggregate 表类型是预计算表,会丢失明细数据,如有明细查询需求,需要额外写一张明细表。
-
-3. 当数据量又大、关联表又多时,可用 ETL 先写成宽表,然后导入到 Doris,结合 Aggregate 在聚合表类型上面做优化,也可以使用官方推荐Doris 的 Join 优化:<https://doris.apache.org/zh-CN/docs/dev/advanced/join-optimization/doris-join-optimization>
-
-### **写入:**
-
-1. 通过 Spark Connector 或 Flink Connector 替代 Routine Load: 最早我们使用的是 Routine Load 实时写入 BE 节点, Routine Load 的工作原理是通过 SQL 在 FE 节点起一个类似于 Task Manager 的管理,把任务分发给 BE 节点,在 BE 节点起 Routine Load 任务。在我们实时场景并发很高的情况下,BE 节点 CPU 峰值一般会达到 70% 左右,在这个前提下,Routine Load 也跑到 BE 节点,将严重影响 BE 节点的查询性能,并且查询 CPU 也将影响 Routine Load 导入, Routine Load 就会因为各种资源竞争死掉。面对此问题,目前解决方法是将 Routine Load 从 BE 节点拿出来放到资源调度上,用 Doris-Spark/Flink-Connector 替换 Routine Load。当时 Doris-spark-Connector 还没有实时写入的功能,我们根据业务需求进行了优化,并将方案贡献给社区。
-
-2. 通过攒批来控制实时写入频率:当实时写入频率较高时,小文件堆积过多、查询 IO 升高,小文件排序归并的过程将导致查询时间加长,进而出现查询抖动的情况。当前的解决办法是控制导入频次,调整 Compaction 的合并线程、间隔时间等参数,避免 Tablet 下小文件的堆积。
-
-### 查询:
-
-1. 增加 SQL 黑名单,控制异常大查询。个别用户在查询时没有加 where 条件,或者查询时选择的时间范围较长,这种情况下 BE 节点的 SQL 会把磁盘的负载和 CPU 拉高,导致其他节点的 SQL 查询变慢,甚至出现 BE 节点宕机的情况。目前的解决方案是使用 SQL 黑名单禁止全表及大量分区实时表的查询。
-
-2. 使用 SQL Cache 和 SQL Proxy 实现高并发访问。同时使用 SQL Cache 和 SQL Proxy 的原因在于,SQL Cache的颗粒度到表的分区,如果数据发生变更, SQL Cache 将失效,因此 SQL Cache 缓存适合数据更新频次较低的场景(离线场景、历史分区等)。对于数据需要持续写到最新分区的场景, SQL Cache 则是不适用的。当 SQL Cache 失效时 Query 将全部发送到 Doris 造成重复的 Runtime 计算,而 SQL Proxy 可以设置一秒左右的缓存,可以避免相同条件的重复计算,有效提高集群的并发。
-
-### 存储:
-
-使用 SSD 和 HDD 做热温数据存储周期的分离,近一年以内的数据存在 SSD,超过一年的数据存在 HDD。Apache Doris 支持对分区设置冷却时间,但只支持创建表分区时设置冷却的时间,目前的解决方案是设置自动同步逻辑,把历史的一些数据从 SSD 迁移到 HDD,确保 1年内的数据都放在 SSD 上。
-
-### 升级:
-
-升级前一定要备份元数据,也可以使用新开集群的方式,通过 Broker 将数据文件备份到 S3 或 HDFS 等远端存储系统中,再通过备份恢复的方式将旧集群数据导入到新集群中。
-
-## **升级前后性能对比**
-
-
-
-思必驰最早是从 0.12 版本开始使用 Apache Doris 的,在今年我们也完成了从 0.15 版本到最新 1.1 版本的升级操作,并进行了基于真实业务场景和数据的性能测试。
-
-从以上测试报告中可以看到,总共 13 个测试 SQL 中,前 3 个 SQL 升级前后性能差异不明显,因为这 3 个场景主要是简单的聚合函数,对 Apache Doris 性能要求不高,0.15 版本即可满足需求。而在 Q4 之后的场景中 ,SQL 较为复杂,Group By 有多个字段、多个字段聚合函数以及复杂函数,因此升级新版本后带来的性能提升非常明显,平均查询性能较 0.15 版本提升 2-3 倍。由此,非常推荐大家去升级到 Apache Doris 最新版本。
-
-# 总结和收益
-
-1. Apache Doris 支持构建离线+实时统一数仓,一个 ETL 脚本即可支持实时和离线数仓,大大缩短开发周期,降低存储成本,避免了离线和实时指标不一致等问题。
-
-2. Apache Doris 1.1.x 版本开始全面支持向量化计算,较之前版本查询性能提升 2-3 倍。经测试,Apache Doris 1.1.x 版本在宽表场景的查询性能已基本与 ClickHouse 持平。
-
-3. 功能强大,不依赖其他组件。相比 Apache Kylin、Apache Druid、ClickHouse 等,Apache Doris 不需要引入第 2 个组件填补技术空档。Apache Doris 支持聚合计算、明细查询、关联查询,当前思必驰超 90% 的分析需求已移步 Apache Doris实现。 得益于此优势,技术人员需要运维的组件减少,极大降低运维成本。
-
-4. 易用性极高,支持 MySQL 协议和标准 SQL,大幅降低用户学习成本。
-
-# 未来计划
-
-1. Tablet 小文件过多的问题。Tablet 是 Apache Doris 中读写数据最小的逻辑单元,当 Tablet 小文件比较多时会产生 2 个问题,一是 Tablet 小文件增多会导致元数据内存压力变大。二是对查询性能的影响,即使是几百兆的查询,但在小文件有几十万、上百万的情况下,一个小小的查询也会导致 IO 非常高。未来,我们将做一个 Tablet 文件数量/大小比值的监控,当比值在不合理范围内时及时进行表设计的修改,使得文件数量和大小的比值在合理的范围内。
-
-2. 支持基于 Bitmap 的字符串精确去重。业务中精确去重的场景较多,特别是基于字符串的 UV 场景,目前 Apache Doris 使用的是 Distinct 函数来实现的。未来我们会尝试的在 Apache Doris 中创建字典,基于字典去构建字符串的 Bitmap 索引。
-
-3. Doris-Spark-Connector 流式写入支持分块传输。Doris-Spark-Connector 底层是复用的 Stream Load,工作机制是攒批,容易出现两个问题,一是攒批可能会会出现内存压力导致 OOM,二是当Doris-Spark-Connector 攒批时,Spark Checkpoint 没有提交,但 Buffer 已满并提交给 Doris,此时 Apacche Doris 中已经有数据,但由于没有提交 Checkpoint,假如此时任务恰巧失败,启动后又会重新消费写入一遍。未来我们将优化此问题,实现 Doris-Spark-Connector 流式写入支持分块传输。
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/ssb.md b/i18n/zh-CN/docusaurus-plugin-content-blog/ssb.md
deleted file mode 100644
index 8b952fe88a6..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/ssb.md
+++ /dev/null
@@ -1,616 +0,0 @@
----
-{
- 'title': 'Apache Doris 1.2 Star-Schema-Benchmark 性能测试报告',
- 'summary': "Doris 1.2 版本在 SSB FlAT 宽表上, Apache Doris 1.2.0-rc01上相对 Apache Doris 1.1.3 整体性能提升了将近4倍,相对于 Apache Doris 0.15.0 RC04 ,性能提升了将近10倍,在标准的 SSB 测试SQL上, Apache Doris 1.2.0-rc01 上相对 Apache Doris 1.1.3 整体性能提升了将近2倍,相对于 Apache Doris 0.15.0 RC04 ,性能提升了将近 31 倍 ",
- 'date': '2022-11-22',
- 'author': 'Apache Doris',
- 'tags': ['技术解析'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-# Star Schema Benchmark
-
-[Star Schema Benchmark(SSB)](https://www.cs.umb.edu/~poneil/StarSchemaB.PDF) 是一个轻量级的数仓场景下的性能测试集。SSB 基于 [TPC-H](http://www.tpc.org/tpch/) 提供了一个简化版的星型模型数据集,主要用于测试在星型模型下,多表关联查询的性能表现。另外,业界内通常也会将 SSB 打平为宽表模型(以下简称:SSB flat),来测试查询引擎的性能,参考[Clickhouse](https://clickhouse.com/docs/zh/getting-started/example-datasets/star-schema)。
-
-本文档主要介绍Apache Doris 在 SSB 100G 测试集上的性能表现。
-
-> 注 1:包括 SSB 在内的标准测试集通常和实际业务场景差距较大,并且部分测试会针对测试集进行参数调优。所以标准测试集的测试结果仅能反映数据库在特定场景下的性能表现。建议用户使用实际业务数据进行进一步的测试。
->
-> 注 2:本文档涉及的操作都在 Ubuntu Server 20.04 环境进行,CentOS 7 也可测试。
-
-在 SSB 标准测试数据集上的 13 个查询上,我们基于 Apache Doris 1.2.0-rc01, Apache Doris 1.1.3 及 Apache Doris 0.15.0 RC04 版本进行了对别测试。
-
-在 SSB FlAT 宽表上, Apache Doris 1.2.0-rc01上相对 Apache Doris 1.1.3 整体性能提升了将近4倍,相对于 Apache Doris 0.15.0 RC04 ,性能提升了将近10倍 。
-
-
-
-在标准的 SSB 测试SQL上, Apache Doris 1.2.0-rc01 上相对 Apache Doris 1.1.3 整体性能提升了将近2倍,相对于 Apache Doris 0.15.0 RC04 ,性能提升了将近 31 倍 。
-
-
-
-## 1. 硬件环境
-
-| 机器数量 | 4 台腾讯云主机(1个FE,3个BE) |
-| -------- | ------------------------------------ |
-| CPU | AMD EPYC™ Milan(2.55GHz/3.5GHz) 16核 |
-| 内存 | 64G |
-| 网络带宽 | 7Gbps |
-| 磁盘 | 高性能云硬盘 |
-
-## 2. 软件环境
-
-- Doris 部署 3BE 1FE;
-- 内核版本:Linux version 5.4.0-96-generic (buildd@lgw01-amd64-051)
-- 操作系统版本:Ubuntu Server 20.04 LTS 64位
-- Doris 软件版本: Apache Doris 1.2.0-rc01、Apache Doris 1.1.3 及 Apache Doris 0.15.0 RC04
-- JDK:openjdk version "11.0.14" 2022-01-18
-
-## 3. 测试数据量
-
-| SSB表名 | 行数 | 备注 |
-| :------------- | :--------- | :--------------- |
-| lineorder | 600,037,902 | 商品订单明细表表 |
-| customer | 3,000,000 | 客户信息表 |
-| part | 1,400,000 | 零件信息表 |
-| supplier | 200,000 | 供应商信息表 |
-| date | 2,556 | 日期表 |
-| lineorder_flat | 600,037,902 | 数据展平后的宽表 |
-
-## 4. SSB 宽表测试结果
-
-这里我们使用 Apache Doris 1.2.0-rc01、 Apache Doris 1.1.3 及 Apache Doris 0.15.0 RC04 版本进行对比测试,测试结果如下:
-
-
-| Query | Apache Doris 1.2.0-rc01(ms) | Apache Doris 1.1.3(ms) | Apache Doris 0.15.0 RC04(ms) |
-| ----- | ------------- | ------------- | ----------------- |
-| Q1.1 | 20 | 90 | 250 |
-| Q1.2 | 10 | 10 | 30 |
-| Q1.3 | 30 | 70 | 120 |
-| Q2.1 | 90 | 360 | 900 |
-| Q2.2 | 90 | 340 | 1020 |
-| Q2.3 | 60 | 260 | 770 |
-| Q3.1 | 160 | 550 | 1710 |
-| Q3.2 | 80 | 290 | 670 |
-| Q3.3 | 90 | 240 | 550 |
-| Q3.4 | 20 | 20 | 30 |
-| Q4.1 | 140 | 480 | 1250 |
-| Q4.2 | 50 | 240 | 400 |
-| Q4.3 | 30 | 200 | 330 |
-| 合计 | 880 | 3150 | 8030 |
-
-**结果说明**
-
-- 测试结果对应的数据集为 scale 100, 约 6 亿条。
-- 测试环境配置为用户常用配置,云服务器 4 台,16 核 64G SSD,1 FE 3 BE 部署。
-- 选用用户常见配置测试以降低用户选型评估成本,但整个测试过程中不会消耗如此多的硬件资源。
-
-## 5. 标准 SSB 测试结果
-
-这里我们使用 Apache Doris 1.2.0-rc01、Apache Doris 1.1.3 及 Apache Doris 0.15.0 RC04 版本进行对比测试,测试结果如下:
-
-| Query | Apache Doris 1.2.0-rc01(ms) | Apache Doris 1.1.3 (ms) | Apache Doris 0.15.0 RC04(ms) |
-| ----- | ------- | ---------------------- | ------------------------------- |
-| Q1.1 | 40 | 18 | 350 |
-| Q1.2 | 30 | 100 | 80 |
-| Q1.3 | 20 | 70 | 80 |
-| Q2.1 | 350 | 940 | 20680 |
-| Q2.2 | 320 | 750 | 18250 |
-| Q2.3 | 300 | 720 | 14760 |
-| Q3.1 | 650 | 2150 | 22190 |
-| Q3.2 | 260 | 510 | 8360 |
-| Q3.3 | 220 | 450 | 6200 |
-| Q3.4 | 60 | 70 | 160 |
-| Q4.1 | 840 | 1480 | 24320 |
-| Q4.2 | 460 | 560 | 6310 |
-| Q4.3 | 610 | 660 | 10170 |
-| 合计 | 4160 | 8478 | 131910 |
-
-**结果说明**
-
-- 测试结果对应的数据集为scale 100, 约6亿条。
-- 测试环境配置为用户常用配置,云服务器4台,16核 64G SSD,1 FE 3 BE 部署。
-- 选用用户常见配置测试以降低用户选型评估成本,但整个测试过程中不会消耗如此多的硬件资源。
-
-
-## 6. 环境准备
-
-请先参照 [官方文档](../install/install-deploy.md) 进行 Apache Doris 的安装部署,以获得一个正常运行中的 Doris 集群(至少包含 1 FE 1 BE,推荐 1 FE 3 BE)。
-
-以下文档中涉及的脚本都存放在 Apache Doris 代码库:[ssb-tools](https://github.com/apache/doris/tree/master/tools/ssb-tools)
-
-## 7. 数据准备
-
-### 7.1 下载安装 SSB 数据生成工具。
-
-执行以下脚本下载并编译 [ssb-dbgen](https://github.com/electrum/ssb-dbgen.git) 工具。
-
-```shell
-sh build-ssb-dbgen.sh
-```
-
-安装成功后,将在 `ssb-dbgen/` 目录下生成 `dbgen` 二进制文件。
-
-### 7.2 生成 SSB 测试集
-
-执行以下脚本生成 SSB 数据集:
-
-```shell
-sh gen-ssb-data.sh -s 100 -c 100
-```
-
-> 注1:通过 `sh gen-ssb-data.sh -h` 查看脚本帮助。
->
-> 注2:数据会以 `.tbl` 为后缀生成在 `ssb-data/` 目录下。文件总大小约60GB。生成时间可能在数分钟到1小时不等。
->
-> 注3:`-s 100` 表示测试集大小系数为 100,`-c 100` 表示并发100个线程生成 lineorder 表的数据。`-c` 参数也决定了最终 lineorder 表的文件数量。参数越大,文件数越多,每个文件越小。
-
-在 `-s 100` 参数下,生成的数据集大小为:
-
-| Table | Rows | Size | File Number |
-| --------- | ---------------- | ---- | ----------- |
-| lineorder | 6亿(600037902) | 60GB | 100 |
-| customer | 300万(3000000) | 277M | 1 |
-| part | 140万(1400000) | 116M | 1 |
-| supplier | 20万(200000) | 17M | 1 |
-| date | 2556 | 228K | 1 |
-
-### 7.3 建表
-
-#### 7.3.1 准备 `doris-cluster.conf` 文件。
-
-在调用导入脚本前,需要将 FE 的 ip 端口等信息写在 `doris-cluster.conf` 文件中。
-
-文件位置和 `load-ssb-dimension-data.sh` 平级。
-
-文件内容包括 FE 的 ip,HTTP 端口,用户名,密码以及待导入数据的 DB 名称:
-
-```shell
-export FE_HOST="xxx"
-export FE_HTTP_PORT="8030"
-export FE_QUERY_PORT="9030"
-export USER="root"
-export PASSWORD='xxx'
-export DB="ssb"
-```
-
-#### 7.3.2 执行以下脚本生成创建 SSB 表:
-
-```shell
-sh create-ssb-tables.sh
-```
-或者复制 [create-ssb-tables.sql](https://github.com/apache/incubator-doris/tree/master/tools/ssb-tools/ddl/create-ssb-tables.sql) 和 [create-ssb-flat-table.sql](https://github.com/apache/incubator-doris/tree/master/tools/ssb-tools/ddl/create-ssb-flat-table.sql) 中的建表语句,在 MySQL 客户端中执行。
-
-下面是 `lineorder_flat` 表建表语句。在上面的 `create-ssb-flat-table.sh` 脚本中创建 `lineorder_flat` 表,并进行了默认分桶数(48个桶)。您可以删除该表,根据您的集群规模节点配置对这个分桶数进行调整,这样可以获取到更好的一个测试效果。
-
-```sql
-CREATE TABLE `lineorder_flat` (
- `LO_ORDERDATE` date NOT NULL COMMENT "",
- `LO_ORDERKEY` int(11) NOT NULL COMMENT "",
- `LO_LINENUMBER` tinyint(4) NOT NULL COMMENT "",
- `LO_CUSTKEY` int(11) NOT NULL COMMENT "",
- `LO_PARTKEY` int(11) NOT NULL COMMENT "",
- `LO_SUPPKEY` int(11) NOT NULL COMMENT "",
- `LO_ORDERPRIORITY` varchar(100) NOT NULL COMMENT "",
- `LO_SHIPPRIORITY` tinyint(4) NOT NULL COMMENT "",
- `LO_QUANTITY` tinyint(4) NOT NULL COMMENT "",
- `LO_EXTENDEDPRICE` int(11) NOT NULL COMMENT "",
- `LO_ORDTOTALPRICE` int(11) NOT NULL COMMENT "",
- `LO_DISCOUNT` tinyint(4) NOT NULL COMMENT "",
- `LO_REVENUE` int(11) NOT NULL COMMENT "",
- `LO_SUPPLYCOST` int(11) NOT NULL COMMENT "",
- `LO_TAX` tinyint(4) NOT NULL COMMENT "",
- `LO_COMMITDATE` date NOT NULL COMMENT "",
- `LO_SHIPMODE` varchar(100) NOT NULL COMMENT "",
- `C_NAME` varchar(100) NOT NULL COMMENT "",
- `C_ADDRESS` varchar(100) NOT NULL COMMENT "",
- `C_CITY` varchar(100) NOT NULL COMMENT "",
- `C_NATION` varchar(100) NOT NULL COMMENT "",
- `C_REGION` varchar(100) NOT NULL COMMENT "",
- `C_PHONE` varchar(100) NOT NULL COMMENT "",
- `C_MKTSEGMENT` varchar(100) NOT NULL COMMENT "",
- `S_NAME` varchar(100) NOT NULL COMMENT "",
- `S_ADDRESS` varchar(100) NOT NULL COMMENT "",
- `S_CITY` varchar(100) NOT NULL COMMENT "",
- `S_NATION` varchar(100) NOT NULL COMMENT "",
- `S_REGION` varchar(100) NOT NULL COMMENT "",
- `S_PHONE` varchar(100) NOT NULL COMMENT "",
- `P_NAME` varchar(100) NOT NULL COMMENT "",
- `P_MFGR` varchar(100) NOT NULL COMMENT "",
- `P_CATEGORY` varchar(100) NOT NULL COMMENT "",
- `P_BRAND` varchar(100) NOT NULL COMMENT "",
- `P_COLOR` varchar(100) NOT NULL COMMENT "",
- `P_TYPE` varchar(100) NOT NULL COMMENT "",
- `P_SIZE` tinyint(4) NOT NULL COMMENT "",
- `P_CONTAINER` varchar(100) NOT NULL COMMENT ""
-) ENGINE=OLAP
-DUPLICATE KEY(`LO_ORDERDATE`, `LO_ORDERKEY`)
-COMMENT "OLAP"
-PARTITION BY RANGE(`LO_ORDERDATE`)
-(PARTITION p1 VALUES [('0000-01-01'), ('1993-01-01')),
-PARTITION p2 VALUES [('1993-01-01'), ('1994-01-01')),
-PARTITION p3 VALUES [('1994-01-01'), ('1995-01-01')),
-PARTITION p4 VALUES [('1995-01-01'), ('1996-01-01')),
-PARTITION p5 VALUES [('1996-01-01'), ('1997-01-01')),
-PARTITION p6 VALUES [('1997-01-01'), ('1998-01-01')),
-PARTITION p7 VALUES [('1998-01-01'), ('1999-01-01')))
-DISTRIBUTED BY HASH(`LO_ORDERKEY`) BUCKETS 48
-PROPERTIES (
-"replication_num" = "1",
-"colocate_with" = "groupxx1",
-"in_memory" = "false",
-"storage_format" = "DEFAULT"
-);
-```
-
-### 7.4 导入数据
-
-我们使用以下命令完成 SSB 测试集所有数据导入及 SSB FLAT 宽表数据合成并导入到表里。
-
-
-```shell
-sh bin/load-ssb-data.sh -c 10
-```
-
-`-c 5` 表示启动 10 个并发线程导入(默认为 5)。在单 BE 节点情况下,由 `sh gen-ssb-data.sh -s 100 -c 100` 生成的 lineorder 数据,同时会在最后生成ssb-flat表的数据,如果开启更多线程,可以加快导入速度,但会增加额外的内存开销。
-
-> 注:
->
-> 1. 为获得更快的导入速度,你可以在 be.conf 中添加 `flush_thread_num_per_store=5` 后重启BE。该配置表示每个数据目录的写盘线程数,默认为2。较大的数据可以提升写数据吞吐,但可能会增加 IO Util。(参考值:1块机械磁盘,在默认为2的情况下,导入过程中的 IO Util 约为12%,设置为5时,IO Util 约为26%。如果是 SSD 盘,则几乎为 0)。
->
-> 2. flat 表数据采用 'INSERT INTO ... SELECT ... ' 的方式导入。
-
-
-### 7.5 检查导入数据
-
-```sql
-select count(*) from part;
-select count(*) from customer;
-select count(*) from supplier;
-select count(*) from date;
-select count(*) from lineorder;
-select count(*) from lineorder_flat;
-```
-
-数据量应和生成数据的行数一致。
-
-| Table | Rows | Origin Size | Compacted Size(1 Replica) |
-| -------------- | ---------------- | ----------- | ------------------------- |
-| lineorder_flat | 6亿(600037902) | | 59.709 GB |
-| lineorder | 6亿(600037902) | 60 GB | 14.514 GB |
-| customer | 300万(3000000) | 277 MB | 138.247 MB |
-| part | 140万(1400000) | 116 MB | 12.759 MB |
-| supplier | 20万(200000) | 17 MB | 9.143 MB |
-| date | 2556 | 228 KB | 34.276 KB |
-
-### 7.6 查询测试
-
-SSB-FlAT 查询语句 :[ssb-flat-queries](https://github.com/apache/doris/tree/master/tools/ssb-tools/ssb-flat-queries)
-
-
-标准 SSB 查询语句 :[ssb-queries](https://github.com/apache/doris/tree/master/tools/ssb-tools/ssb-queries)
-
-#### 7.6.1 SSB FLAT 测试 SQL
-
-
-```sql
---Q1.1
-SELECT SUM(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue
-FROM lineorder_flat
-WHERE LO_ORDERDATE >= 19930101 AND LO_ORDERDATE <= 19931231 AND LO_DISCOUNT BETWEEN 1 AND 3 AND LO_QUANTITY < 25;
---Q1.2
-SELECT SUM(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue
-FROM lineorder_flat
-WHERE LO_ORDERDATE >= 19940101 AND LO_ORDERDATE <= 19940131 AND LO_DISCOUNT BETWEEN 4 AND 6 AND LO_QUANTITY BETWEEN 26 AND 35;
-
---Q1.3
-SELECT SUM(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue
-FROM lineorder_flat
-WHERE weekofyear(LO_ORDERDATE) = 6 AND LO_ORDERDATE >= 19940101 AND LO_ORDERDATE <= 19941231 AND LO_DISCOUNT BETWEEN 5 AND 7 AND LO_QUANTITY BETWEEN 26 AND 35;
-
---Q2.1
-SELECT SUM(LO_REVENUE), (LO_ORDERDATE DIV 10000) AS YEAR, P_BRAND
-FROM lineorder_flat WHERE P_CATEGORY = 'MFGR#12' AND S_REGION = 'AMERICA'
-GROUP BY YEAR, P_BRAND
-ORDER BY YEAR, P_BRAND;
-
---Q2.2
-SELECT SUM(LO_REVENUE), (LO_ORDERDATE DIV 10000) AS YEAR, P_BRAND
-FROM lineorder_flat
-WHERE P_BRAND >= 'MFGR#2221' AND P_BRAND <= 'MFGR#2228' AND S_REGION = 'ASIA'
-GROUP BY YEAR, P_BRAND
-ORDER BY YEAR, P_BRAND;
-
---Q2.3
-SELECT SUM(LO_REVENUE), (LO_ORDERDATE DIV 10000) AS YEAR, P_BRAND
-FROM lineorder_flat
-WHERE P_BRAND = 'MFGR#2239' AND S_REGION = 'EUROPE'
-GROUP BY YEAR, P_BRAND
-ORDER BY YEAR, P_BRAND;
-
---Q3.1
-SELECT C_NATION, S_NATION, (LO_ORDERDATE DIV 10000) AS YEAR, SUM(LO_REVENUE) AS revenue
-FROM lineorder_flat
-WHERE C_REGION = 'ASIA' AND S_REGION = 'ASIA' AND LO_ORDERDATE >= 19920101 AND LO_ORDERDATE <= 19971231
-GROUP BY C_NATION, S_NATION, YEAR
-ORDER BY YEAR ASC, revenue DESC;
-
---Q3.2
-SELECT C_CITY, S_CITY, (LO_ORDERDATE DIV 10000) AS YEAR, SUM(LO_REVENUE) AS revenue
-FROM lineorder_flat
-WHERE C_NATION = 'UNITED STATES' AND S_NATION = 'UNITED STATES' AND LO_ORDERDATE >= 19920101 AND LO_ORDERDATE <= 19971231
-GROUP BY C_CITY, S_CITY, YEAR
-ORDER BY YEAR ASC, revenue DESC;
-
---Q3.3
-SELECT C_CITY, S_CITY, (LO_ORDERDATE DIV 10000) AS YEAR, SUM(LO_REVENUE) AS revenue
-FROM lineorder_flat
-WHERE C_CITY IN ('UNITED KI1', 'UNITED KI5') AND S_CITY IN ('UNITED KI1', 'UNITED KI5') AND LO_ORDERDATE >= 19920101 AND LO_ORDERDATE <= 19971231
-GROUP BY C_CITY, S_CITY, YEAR
-ORDER BY YEAR ASC, revenue DESC;
-
---Q3.4
-SELECT C_CITY, S_CITY, (LO_ORDERDATE DIV 10000) AS YEAR, SUM(LO_REVENUE) AS revenue
-FROM lineorder_flat
-WHERE C_CITY IN ('UNITED KI1', 'UNITED KI5') AND S_CITY IN ('UNITED KI1', 'UNITED KI5') AND LO_ORDERDATE >= 19971201 AND LO_ORDERDATE <= 19971231
-GROUP BY C_CITY, S_CITY, YEAR
-ORDER BY YEAR ASC, revenue DESC;
-
---Q4.1
-SELECT (LO_ORDERDATE DIV 10000) AS YEAR, C_NATION, SUM(LO_REVENUE - LO_SUPPLYCOST) AS profit
-FROM lineorder_flat
-WHERE C_REGION = 'AMERICA' AND S_REGION = 'AMERICA' AND P_MFGR IN ('MFGR#1', 'MFGR#2')
-GROUP BY YEAR, C_NATION
-ORDER BY YEAR ASC, C_NATION ASC;
-
---Q4.2
-SELECT (LO_ORDERDATE DIV 10000) AS YEAR,S_NATION, P_CATEGORY, SUM(LO_REVENUE - LO_SUPPLYCOST) AS profit
-FROM lineorder_flat
-WHERE C_REGION = 'AMERICA' AND S_REGION = 'AMERICA' AND LO_ORDERDATE >= 19970101 AND LO_ORDERDATE <= 19981231 AND P_MFGR IN ('MFGR#1', 'MFGR#2')
-GROUP BY YEAR, S_NATION, P_CATEGORY
-ORDER BY YEAR ASC, S_NATION ASC, P_CATEGORY ASC;
-
---Q4.3
-SELECT (LO_ORDERDATE DIV 10000) AS YEAR, S_CITY, P_BRAND, SUM(LO_REVENUE - LO_SUPPLYCOST) AS profit
-FROM lineorder_flat
-WHERE S_NATION = 'UNITED STATES' AND LO_ORDERDATE >= 19970101 AND LO_ORDERDATE <= 19981231 AND P_CATEGORY = 'MFGR#14'
-GROUP BY YEAR, S_CITY, P_BRAND
-ORDER BY YEAR ASC, S_CITY ASC, P_BRAND ASC;
-```
-
-
-
-#### **7.6.2 SSB 标准测试 SQL**
-
-```sql
---Q1.1
-SELECT SUM(lo_extendedprice * lo_discount) AS REVENUE
-FROM lineorder, dates
-WHERE
- lo_orderdate = d_datekey
- AND d_year = 1993
- AND lo_discount BETWEEN 1 AND 3
- AND lo_quantity < 25;
---Q1.2
-SELECT SUM(lo_extendedprice * lo_discount) AS REVENUE
-FROM lineorder, dates
-WHERE
- lo_orderdate = d_datekey
- AND d_yearmonth = 'Jan1994'
- AND lo_discount BETWEEN 4 AND 6
- AND lo_quantity BETWEEN 26 AND 35;
-
---Q1.3
-SELECT
- SUM(lo_extendedprice * lo_discount) AS REVENUE
-FROM lineorder, dates
-WHERE
- lo_orderdate = d_datekey
- AND d_weeknuminyear = 6
- AND d_year = 1994
- AND lo_discount BETWEEN 5 AND 7
- AND lo_quantity BETWEEN 26 AND 35;
-
---Q2.1
-SELECT SUM(lo_revenue), d_year, p_brand
-FROM lineorder, dates, part, supplier
-WHERE
- lo_orderdate = d_datekey
- AND lo_partkey = p_partkey
- AND lo_suppkey = s_suppkey
- AND p_category = 'MFGR#12'
- AND s_region = 'AMERICA'
-GROUP BY d_year, p_brand
-ORDER BY p_brand;
-
---Q2.2
-SELECT SUM(lo_revenue), d_year, p_brand
-FROM lineorder, dates, part, supplier
-WHERE
- lo_orderdate = d_datekey
- AND lo_partkey = p_partkey
- AND lo_suppkey = s_suppkey
- AND p_brand BETWEEN 'MFGR#2221' AND 'MFGR#2228'
- AND s_region = 'ASIA'
-GROUP BY d_year, p_brand
-ORDER BY d_year, p_brand;
-
---Q2.3
-SELECT SUM(lo_revenue), d_year, p_brand
-FROM lineorder, dates, part, supplier
-WHERE
- lo_orderdate = d_datekey
- AND lo_partkey = p_partkey
- AND lo_suppkey = s_suppkey
- AND p_brand = 'MFGR#2239'
- AND s_region = 'EUROPE'
-GROUP BY d_year, p_brand
-ORDER BY d_year, p_brand;
-
---Q3.1
-SELECT
- c_nation,
- s_nation,
- d_year,
- SUM(lo_revenue) AS REVENUE
-FROM customer, lineorder, supplier, dates
-WHERE
- lo_custkey = c_custkey
- AND lo_suppkey = s_suppkey
- AND lo_orderdate = d_datekey
- AND c_region = 'ASIA'
- AND s_region = 'ASIA'
- AND d_year >= 1992
- AND d_year <= 1997
-GROUP BY c_nation, s_nation, d_year
-ORDER BY d_year ASC, REVENUE DESC;
-
---Q3.2
-SELECT
- c_city,
- s_city,
- d_year,
- SUM(lo_revenue) AS REVENUE
-FROM customer, lineorder, supplier, dates
-WHERE
- lo_custkey = c_custkey
- AND lo_suppkey = s_suppkey
- AND lo_orderdate = d_datekey
- AND c_nation = 'UNITED STATES'
- AND s_nation = 'UNITED STATES'
- AND d_year >= 1992
- AND d_year <= 1997
-GROUP BY c_city, s_city, d_year
-ORDER BY d_year ASC, REVENUE DESC;
-
---Q3.3
-SELECT
- c_city,
- s_city,
- d_year,
- SUM(lo_revenue) AS REVENUE
-FROM customer, lineorder, supplier, dates
-WHERE
- lo_custkey = c_custkey
- AND lo_suppkey = s_suppkey
- AND lo_orderdate = d_datekey
- AND (
- c_city = 'UNITED KI1'
- OR c_city = 'UNITED KI5'
- )
- AND (
- s_city = 'UNITED KI1'
- OR s_city = 'UNITED KI5'
- )
- AND d_year >= 1992
- AND d_year <= 1997
-GROUP BY c_city, s_city, d_year
-ORDER BY d_year ASC, REVENUE DESC;
-
---Q3.4
-SELECT
- c_city,
- s_city,
- d_year,
- SUM(lo_revenue) AS REVENUE
-FROM customer, lineorder, supplier, dates
-WHERE
- lo_custkey = c_custkey
- AND lo_suppkey = s_suppkey
- AND lo_orderdate = d_datekey
- AND (
- c_city = 'UNITED KI1'
- OR c_city = 'UNITED KI5'
- )
- AND (
- s_city = 'UNITED KI1'
- OR s_city = 'UNITED KI5'
- )
- AND d_yearmonth = 'Dec1997'
-GROUP BY c_city, s_city, d_year
-ORDER BY d_year ASC, REVENUE DESC;
-
---Q4.1
-SELECT /*+SET_VAR(parallel_fragment_exec_instance_num=4, enable_vectorized_engine=true, batch_size=4096, enable_cost_based_join_reorder=true, enable_projection=true) */
- d_year,
- c_nation,
- SUM(lo_revenue - lo_supplycost) AS PROFIT
-FROM dates, customer, supplier, part, lineorder
-WHERE
- lo_custkey = c_custkey
- AND lo_suppkey = s_suppkey
- AND lo_partkey = p_partkey
- AND lo_orderdate = d_datekey
- AND c_region = 'AMERICA'
- AND s_region = 'AMERICA'
- AND (
- p_mfgr = 'MFGR#1'
- OR p_mfgr = 'MFGR#2'
- )
-GROUP BY d_year, c_nation
-ORDER BY d_year, c_nation;
-
---Q4.2
-SELECT /*+SET_VAR(parallel_fragment_exec_instance_num=2, enable_vectorized_engine=true, batch_size=4096, enable_cost_based_join_reorder=true, enable_projection=true) */
- d_year,
- s_nation,
- p_category,
- SUM(lo_revenue - lo_supplycost) AS PROFIT
-FROM dates, customer, supplier, part, lineorder
-WHERE
- lo_custkey = c_custkey
- AND lo_suppkey = s_suppkey
- AND lo_partkey = p_partkey
- AND lo_orderdate = d_datekey
- AND c_region = 'AMERICA'
- AND s_region = 'AMERICA'
- AND (
- d_year = 1997
- OR d_year = 1998
- )
- AND (
- p_mfgr = 'MFGR#1'
- OR p_mfgr = 'MFGR#2'
- )
-GROUP BY d_year, s_nation, p_category
-ORDER BY d_year, s_nation, p_category;
-
---Q4.3
-SELECT /*+SET_VAR(parallel_fragment_exec_instance_num=2, enable_vectorized_engine=true, batch_size=4096, enable_cost_based_join_reorder=true, enable_projection=true) */
- d_year,
- s_city,
- p_brand,
- SUM(lo_revenue - lo_supplycost) AS PROFIT
-FROM dates, customer, supplier, part, lineorder
-WHERE
- lo_custkey = c_custkey
- AND lo_suppkey = s_suppkey
- AND lo_partkey = p_partkey
- AND lo_orderdate = d_datekey
- AND s_nation = 'UNITED STATES'
- AND (
- d_year = 1997
- OR d_year = 1998
- )
- AND p_category = 'MFGR#14'
-GROUP BY d_year, s_city, p_brand
-ORDER BY d_year, s_city, p_brand;
-```
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md b/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md
deleted file mode 100644
index 4b960363871..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md
+++ /dev/null
@@ -1,200 +0,0 @@
----
-{
- 'title': '下一个十年,我们需要一款什么样的 OLAP 数据库?',
- 'summary': '十年对于数据库而言,可能是一段从诞生到消逝的完整软件生命周期,也可能是迈过里程碑之后的全新旅程。',
- 'date': '2023-01-06',
- 'author': '陈明雨',
- 'tags': ['重大新闻'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-# **十年对于数据库意味着什么?**
-
-身处在日新月异的时代,我们见惯了技术的兴起与繁荣、变迁与衰落,甚至是朝荣夕灭。信息技术以前所未有的速度更迭,给周遭事物带来了颠覆性地变化。数据库亦是如此,无数数据库悄然湮没在技术更迭的浪潮里,直到在浩渺如海的代码片段中都找不到些许印记。而有的则历久而弥新,经受了时间的考验,彰显出强大的生命力,并以更加繁茂的姿态扎根生长。
-
-十年对于数据库而言,可能是一段从诞生到消逝的完整软件生命周期,也可能是迈过里程碑之后的全新旅程。
-
-所以从 MySQL 1.0 版本诞生,到具备颠覆性意义的 MySQL 5.7 版本正式发布,时间跨度刚好是十年,而十年之后的故事,大家已经都知道了。
-
-所以从 Benoit、Thierry、Marcin 联合创建 Snowflake,到在纽交所成功上市、成为软件行业有史以来最大规模的IPO,再到全面开启云数据仓库时代,时间跨度也差不多十年。
-
-**而对于 Apache Doris,十年意味着什么?**
-
-留个悬念,在回答这个问题之前,我们不妨来回顾下社区发展历程。
-
-尽管最早的历史可以追溯到 2008 年的百度凤巢广告系统,但彼时非 SQL 的单机查询引擎加 KV 存储系统在产品形态上与 OLAP 还有着较大的差异。
-
-**正式确立 OLAP 数据库这一形态是在 2013 年**。通过自研全列式存储引擎 OLAP Engine 并基于 Apache Impala 改造了全新的 MPP 查询引擎,自此,Doris 真正成为了具备大数据量下高效支持数据分析能力的 OLAP 数据库,并在百度内部大规模应用,成为了百度内部统一的 OLAP 分析平台。
-
-往往一个内部项目的发展会有两种演进模式,一种是随着需求的增加系统架构日益臃肿,当面对较为灵活的需求,常因改动成本过大而被彻底重构。另一种则是长期服务某一固定场景、需求逐渐收敛乃至停滞,最终被快速革新的外部技术彻底取代。而开源则是内部项目的一场新生,在更广阔的应用场景、更多样的开发者群体以及更高效的研发模式加持下开启新的篇章。
-
-于是在数个版本的迭代与优化后,2017年 Doris 的前身在 GitHub 上开源,2018 年进入 Apache 基金会孵化,并正式更名为 Apache Doris。(GitHub 地址:<https://github.com/apache/doris>)
-
-**时至 2022 年,正是 Apache Doris 在 OLAP 领域深耕的十年之际。**
-
-**# 我们该如何回顾过去的 2022 年?**
-
-2022 年,外部世界正处在前所未有的变化之中,无数魔幻时刻在现实中发生。需要庆幸的是,技术和开源的力量帮助我们穿越了许多不确定性。而这一年势必成为 Apache Doris 发展历程中有着浓墨重彩的一年,我们从几个角度来回顾一下 Apache Doris 过去一年的发展:
-
-### **社区重要指标**
-
-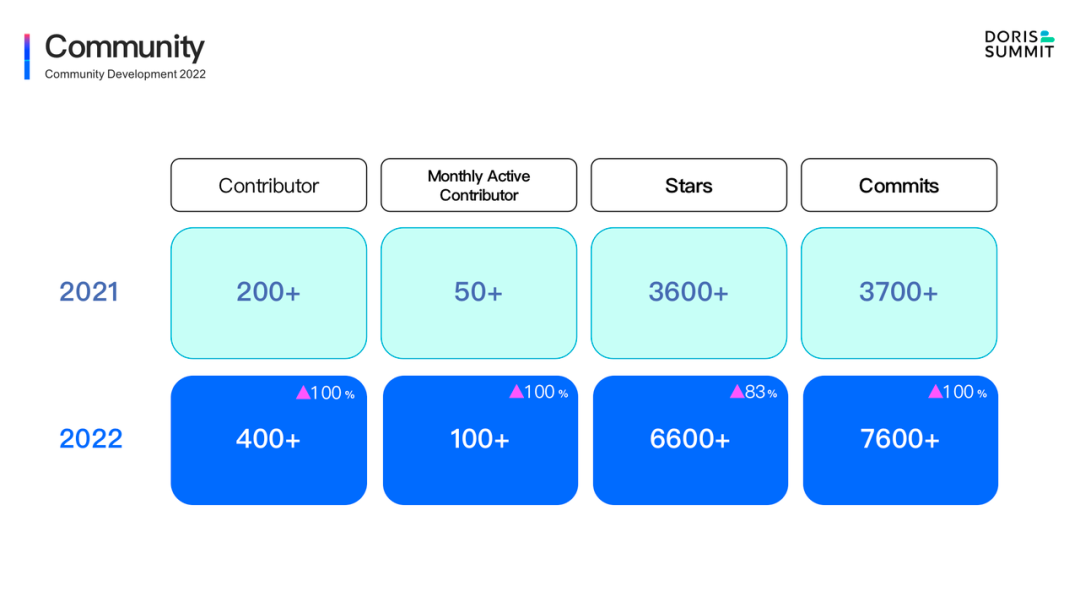
-
-**过去一年中:**
-
-- 社区累计贡献者的数量从 200 余位增长至近 420 位,同比增长**超过 100%** ,目前仍在持续上升中。
-- 每月活跃贡献者的数量从 50 位增长至 100 位,同样呈现**翻倍**增长的趋势。
-- GitHub Star 数量从 3.6k 增长至 6.8k,多次登上 GitHub Trengding 日/周/月度**榜单前列**。
-- 全部 Commits 数量从 3.7k 增长至 7.6k,过去一年新提交代码量超越了以往多年累加总和。
-
-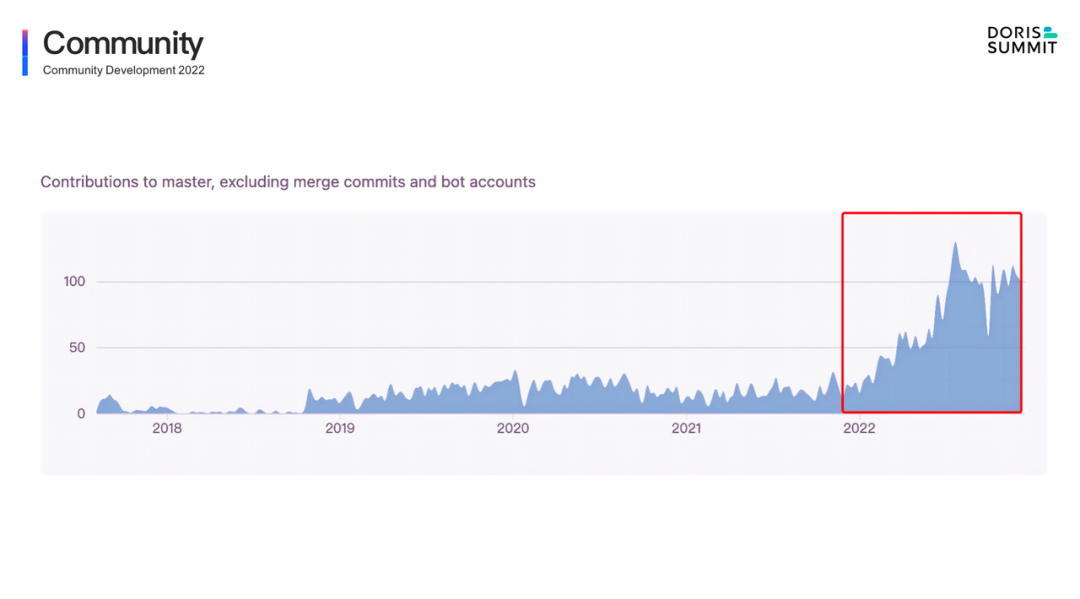
-
-从这些数据中,我们可以感受到 2022 年是 Apache Doris 全面爆发的一年,各个维度数据指标几乎都有了 100% 的增长。这一年的努力也使 **Apache Doris 成为了全球大数据和数据库领域最为活跃的开源社区之一**,上方 GitHub Contribution 增长趋势图更是证明了这一点。而这一切,正是由社区所有的用户和开发者共同创造的。
-
-另外值得纪念的是,在 2022 年 6 月, Apache Doris 迎来了开源以来最重要的里程碑之一,正式从 Apache 孵化器毕业、成为了 **Apache 顶级项目**。
-
-
-
-### **开源用户规模**
-
-得益于社区成立的专职工程师团队,为 Apache Doris 社区用户提供义务的技术支持,2022 年我们在用户连接与沟通方面变得更加顺畅,可以更直面用户、去倾听用户真实的声音。
-
-在过去的一年里,Apache Doris 已经在互联网、金融、电信、教育、汽车、制造、物流、能源、政务等数十个行业应用落地,尤其是在以海量数据著称的互联网行业。在中国市值或估值排行前 50 的互联网公司中,有 80% 企业在长期使用 Apache Doris 来解决自身业务中的数据分析问题,其中包含了百度、美团、小米、腾讯、京东、字节跳动、网易、新浪、360、 米哈游、知乎等头部知名企业。
-
-
-
-在全球范围内,**Apache Doris 已经得到了超过 1000 家企业用户的认可**,并且这一数字仍在快速增长中。这 1000 多家企业用户中,绝大多数与社区有着直接联系,并通过各种方式参与到社区建设中来。他们中的许多企业用户也参与到本次 Doris Summit 的议题分享中,将自身基于真实业务场景的实践经验分享给大家。
-
-### **版本更新迭代**
-
-如果说过去版本将使用和运维的简易性作为第一追求的话,那么 2022 年发布版本则是在**性能、稳定性、易用性**等多方面特性的全面进化。
-
-- 4 月份社区发布了自开源以来的首个 1 位版本—— Apache Doris 1.0,在 1.0 版本中,意义非凡的向量化执行初次与大家见面,标志着 Apache Doris 开始迈入极速数据分析时代。
-- 6 月份发布的 1.1 版本,我们对向量化引擎进行了进一步完善和优化,并将其作为正式功能默认开启。与此同时,社区建立了 LTS 版本发布机制,以每月发布一个 3 位版本的速度,对 1.1 版本进行快速地 Bug 修复和功能优化,力求满足更多社区用户在稳定性方面的高要求。
-- 在综合考虑版本迭代节奏和用户需求后,我们决定将众多新特性在 1.2 版本中发布。同时期社区的稳定性和质量保障工作也取得了显著的成效,测试 Case 得到了极大程度地丰富,并在 Master 分支上构建了流水线。通过一系列质量手段,Apache Doris 的代码质量和稳定性得到进一步提升,这也使得版本发布有着更加严格的准出标准。
-- 12 月初 1.2 版本正式面世。这一版本的发布不仅使查询性能有了近十倍的提升,同时我们还推出了过去半年时间里研发的诸多重磅功能,包括 Unique Key 模型 Merge-on-Write 的数据更新模式、支持无缝对接多种数据湖的 Multi-Catalog 多源数据目录、Java UDF 、Array 数组类型和 JSONB 类型等,让 Apache Doris 在更多数据分析场景具备了更强的适应性和可能性。
-- 我们也针对系统稳定性进行了大量的工作,一方面,利用 SQL Smith 等自动化测试工具以及各个知名开源项目的测试用例,构建了数以百万计的测试用例集;另一方面,通过社区准入流水线和完善的回归测试框架,保证了代码合入的质量。因此1.2 版本不论从功能、性能还是稳定性方面,都是一次厚积薄发后的全面进化,也是对所有开发者在 2022 年辛苦付出的最好回报。
-
-### **核心特性演进**
-
-核心特性方面,社区的研发力量主要围绕四个方面开展工作,分别是**性能、实时性、半结构化数据支持与 Lakehouse**。
-
-- **查询性能提升**。从 1.0 版本面世到 1.2 版本发布,Apache Doris 在性能方面取得了极为显著的成绩。在单表场景上,Apache Doris 荣登 Clickhouse 公司推出的 Clickbench 数据库性能榜单,并取得了**前三名**的优秀成绩。在多表关联场景上,得益于向量化执行引擎及各种查询优化技术,相对 2021 年底发布的 0.15 版本 ,Apache Doris 在 SSB 和 TPC-H 等标准测试数据集下均**取得了数倍乃至数十倍的性能提升**。这一系列性能方面的优化,已经成功让 Apache Doris 跻身全球数据库性能最优阵列中!
-
-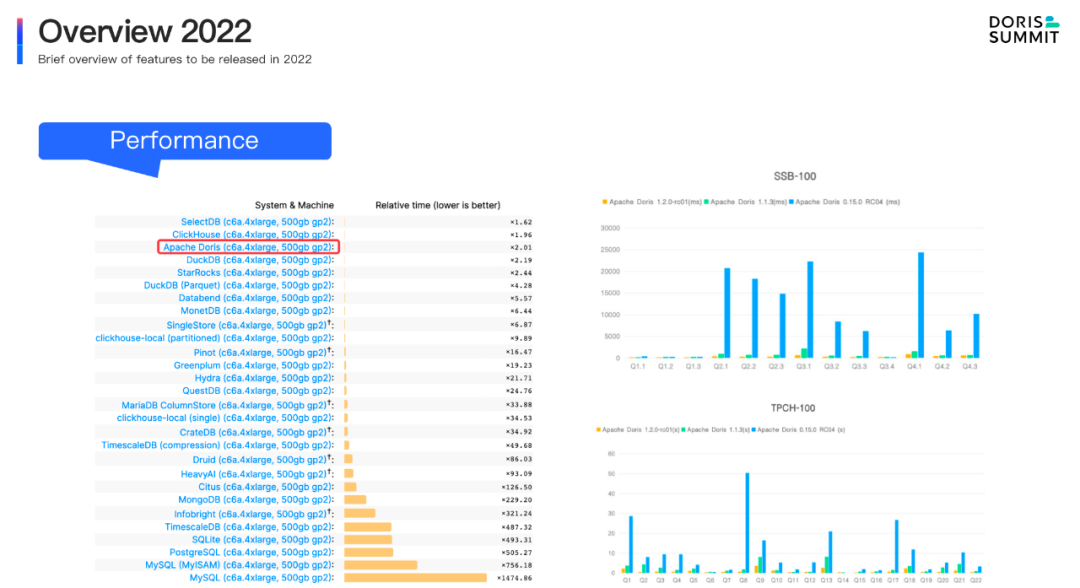
-
-- **实时场景优化。** 在 1.2 版本中,我们在原有 Unique Key 数据模型上实现了Merge-On-Write 的数据更新方式,查询性能在高频更新时有 **5-10 倍的提升**,实现了在可更新数据上的低延迟实时分析体验。另外还实现了轻量 Schema Change 功能,对于数据的加减列不再需要转换历史数据,可通过 Flink CDC 等工具快速便捷地同步上游事务数据库中的 DML 或 DDL 操作,使数据同步工作能够更加流畅统一。
-- **半结构化数据支持。** 目前 Apache Doris 支持了 Array 和 JSONB 类型,其中 Array 类型不仅能更方便地存储复杂的数据结构,还可以通过 Array 函数满足用户行为分析等场景的业务需求。而 JSONB 是一种二进制 JSON 存储方式,它不但比纯文本 Text JSON 的访问性能快 4 倍,同时也有更低的内存消耗。通过 JSONB 可以方便地导入各种 JSON 格式的日志数据结构,并能取得优异的查询效率。这也是 Apache Doris 在日志分析领域所做的探索之一。
-
-
-
-- **Lakehouse**。在最新发布的 1. 2 版本中,我们引入了全新的 Catalog 概念,正式将 Apache Doris 迈入湖仓一体时代。通过简单的命令便可以方便地连接到各自外部数据源并自动同步元数据,实现统一的分析体验。通过 Native Format Reader、延迟物化、异步 IO、数据预取等多项针对外部数据源的性能优化,并充分利用自身的高性能执行引擎和查询优化器,在对外表访问性能上,Apache Doris 可以达到 Trino/Presto 的 **3- 5 倍**、Hive 的 **10-100 倍**。
-
-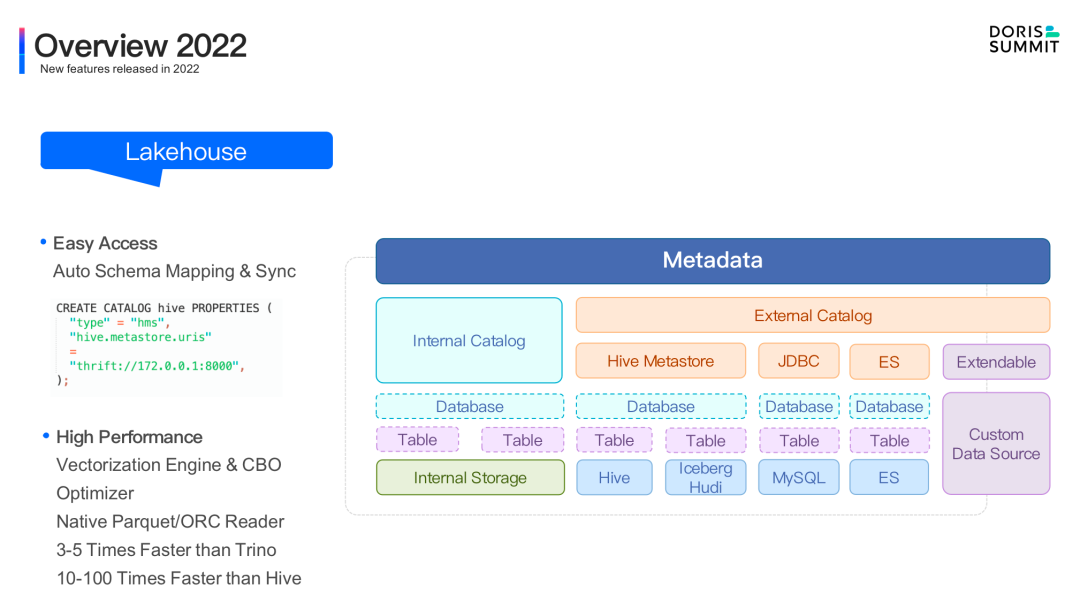
-
-## **2023 RoadMap**
-
-承前而启后,2023 年,Apache Doris 社区在以上几方面特性持续完善的同时,也将开启更多有意义的工作。**全年的 RoadMap 以及明年 Q1 的具体计划,可以参考以下的全景图:**
-
-
-
-稳定的版本发布和迭代速度对于开源软件至关重要。在 2023 年,我们将以每季度一个 2 位版本的节奏,开始 Apache Doris 2.x 版本的迭代。同时,针对每个 2 位版本,我们也将以每月一个 3 位版本的速度进行功能维护和优化。
-
-**从功能角度来看,后续研发工作将会围绕以下几个主要方向展开:**
-
-### **高性能**
-
-高性能是 Apache Doris 不断追求的目标,过去一年在 Clickbench、TPC-H 等公开测试数据集上的优异表现,已经证明了其在执行层以及算子优化方面做到了业界领先。未来我们也会不断优化各个场景下的性能表现,回馈用户极速的数据分析体验,具体包括:
-
-- **更复杂SQL性能提升:** 2022 年我们已经启动全新查询优化器的设计与开发,而这一成果在 2023 年一季度就将与大家见面。全新查询优化器提供了丰富的规则模型,实现了更智能的代价选择,可以更高效地支撑复杂查询,能够完整执行 TPC-DS 全部 99 个SQL。同时全新查询优化器还具备全查询场景的自适应优化,便于用户在面对不同分析负载和业务场景时都获得一致性的使用体验。
-- **更高的点查询并发:** 高并发一直是 Apache Doris 所擅长的场景,而 2023 年我们将会进一步加强这一能力,通过 Short-Circuit Plan、Prepare Statement、Query Cache 等一系列技术,实现单机数万 QPS 的超高并发支持,并具备随集群规模的拓展进而线性提升并发的能力。
-- **更灵活的多表物化视图:** 在过去版本中,通过强一致的单表物化视图,Apache Doris 加速了固定维度数据的分析效率。而全新的多表物化视图将会解耦 Base 表与 MV 表的生命周期,通过异步刷新和灵活的增量计算方式,满足多表关联以及更复杂 SQL 的预计算加速需求,这一特性将在接下来的 2023 年第一季度与大家见面!
-
-### **高性价比**
-
-成本和效率对企业而言是赢得市场竞争的关键,对数据库而言亦是如此。过去 Apache Doris 凭借在易用性方面的诸多设计帮助用户大幅节约了计算与存储资源成本,后续我们也会引入一系列云原生能力,在不影响业务效率的同时进一步降低成本,具体包括:
-
-- **更低的存储成本:** 我们将探索与云上对象存储系统和文件系统的结合,帮助用户进一步降低存储成本,包括更完善的冷热数据分离能力,将冷数据智能转移至更廉价的对象存储或文件系统中。结合单一远程副本、冷数据 Cache 以及冷热智能转换等技术,保证业务查询效率不受影响的同时实现存储成本大幅降低,这一功能将于 2023 年第一季度发布。
-- **更弹性的计算资源:** 剥离存储与计算状态,引入仅用于计算的 Elastic Compute Node 。由于不存储数据,弹性计算节点具备更加快速的弹性伸缩能力,便于用户在业务高峰期进行快速扩容,进一步提升在海量数据计算场景(如数据湖分析)的分析效率,这一功能已经处于最终调试阶段,即将与大家见面。后续我们还将通过对集群内存和 CPU 运行指标的监控和自动策略配置,实现自动的节点扩缩容(Auto-scaling)。
-
-### **混合负载**
-
-随着用户规模的极速扩张,越来越多的用户将 Apache Doris 用于构建企业内部的统一分析平台。这一方面需要 Apache Doris 去承担更大规模的数据处理和分析,另一方面也需要 Apache Doris 同时去应对更多分析负载的挑战,从过去的实时报表和 Ad-hoc 等典型 OLAP 场景,扩展到 ELT/ETL 、日志检索与分析等更多场景的统一。为了能更好适配这些场景,许多工作已经进入紧锣密鼓的研发中,并将于 2023 年陆续与大家见面,具体包括:
-
-- **更灵活的 Pipeline 执行引擎*** *:**与传统的火山模型相比,Pipeline 模型无需手动设置并发度,可以实现不同管道之间的并行计算,充分利用多核的计算能力,实现更灵活的执行调度,提升在混合负载场景下的综合性能表现。
-- **Workload Manager:** 在性能提升的同时,也亟需完善的资源隔离和划分的能力。我们将会基于 Pipeline 执行引擎实现更细粒度和更灵活的负载管理、资源队列以及共享隔离等功能,兼顾多种混合负载场景下的查询性能与稳定性。
-- **轻量级容错:** 轻量级容错能力也是我们后续持续完善的地方,既能利用 MPP 的高效率又能对错误进行容忍,以更好适应用户在 ETL/ELT 场景的挑战。
-- **函数兼容与多语言UDF:** 与此同时,后续也将支持 Hive/Trino/Spark 函数的兼容性以及多语言的 UDF,来帮助用户更灵活地进行数据加工,也可以更方便地从其他数据库系统迁移到 Apache Doris。
-
-### **多模数据分析**
-
-在过去 Apache Doris 更多是是擅长于结构化数据分析,随着对半结构化、非结构化数据分析需求的增加,从 1.2 版本起我们增加了 Array 和 JSONB 类型以实现数据的 Native 支持,后续版本仍将持续加强这一能力,为日志分析场景提供性价比更高、性能更强的解决方案,**具体包括:**
-
-- **更丰富的复杂数据类型*** *:**除 Array/JSONB 类型以外,2023 年第一季度我们将增加对 Map/Struct 类型的支持,包括高效写入、存储、分析函数以及类型之间的相互嵌套,以更好满足多模态数据分析的支持。后续将支持更加丰富的数据类型,包括 IP、GEO 地理信息等数据类型,并会探索在时序数据场景的高效数据分析。
-- **更高效的文本分析算法:** 对于文本数据,我们将引入更多的文本分析算法,包括自适应 Like、高性能子串匹配、高性能正则匹配,Like 语句的谓词下推、Ngram Bloomfilter 等,同时基于倒排索引实现全文检索能力,在日志分析场景提供比 ES 更高性能和性价比的分析能力。这些功能都已经处于就绪阶段,将在 2023 年初与大家见面。
-- **动态 Schema 表:** 传统数据库在设计之初 Schema 是静态的,Schema 变更时需要执行 DDL ,而这一操作往往具有阻塞性。在越来越多的现代数据分析场景中,表结构会随时间推移而变化,因此我们引入了 Dynamic Table,可以根据数据写入自动适应 Schema ,不再需要执行 DDL,由过去的人工干预数据结构进化为数据自驱动,极大提升了灵活数据分析的便捷性。这一功能将在 2022 年第一季度正式发布。
-
-### **Lakehouse**
-
-随着数据湖技术的发展,分析性能成为发挥数据湖效用、挖掘数据价值最大的掣肘。基于一款简单易用和高性能的查询分析引擎在数据湖之上构建分析服务,成为新的技术趋势。在过去一年,通过在数据湖上的诸多性能优化、结合自身的高性能执行引擎和查询优化器以及,Apache Doris 实现了数据湖上极速易用的分析体验,性能较 Presto/Trino 有 3-5 倍的提升。在 2023 年,我们将会继续完善这一能力,具体包括:
-
-- **更简易的数据对接:** 在 1.2 版本中我们发布了 Multi-Catalog,支持了多种异构数据源的元数据自动映射与同步,实现了数据湖的无缝对接,后续将对 Delta Lake 的支持以及 Iceberg、Hudi 等更多数据格式的支持。
-- **更完整的数据湖能力支持:** 提供数据湖上数据的增量更新与查询,还会支持将分析结果写回数据湖、外表写入内表,实现数据分析流程的全闭环。同时还将支持多版本 Snapshot 读取和删除,并进一步在 Apache Doris 为数据湖数据提供物化视图。
-
-### **实时性与存储引擎优化**
-
-数据价值会随着时间推移而降低,因此实时性对于高时效性要求的用户而言至关重要。在 1.1 版本中我们在 Compaction 和 Flink 实时写入方面进行了诸多优化,同时 1.2 版本的 Merge-on-Write 数据更新模式进一步使 Apache Doris 在实时更新与极速查询得以统一。2023 年我们将会持续强化对存储引擎的优化,具体包括:
-
-- **更稳定的数据写入:** 通过一系列 Compaction 操作和批量数据写入方面的优化,节省资源开销,降低写放大问题,并结合全新的内存管理框架提升写入过程的内存稳定性,进而提升系统稳定性。
-- **更完善的数据更新支持:** 过去部分列更新是通过 Agg 模型上的 Replace_if_not_null 来实现的,后续我们将会增加 Unique Key 模型上的部分列更新支持,并完整实现 Delete、Update、 Merge 等数据更新的操作。
-- **更统一的数据模型:** 当前 Apache Doris 的三种数据模型在各个场景均有丰富的应用,后续我们将尝试统一现有几种数据模型,使用户在使用体验上更加统一。
-
-### **易用性和稳定性**
-
-除了功能方面的丰富与完善,更简单、更易用、更稳定同样也是 Apache Doris 一直追求的目标,2023 年我们将在以下几方面出发,让用户具有更简易和放心的使用体验:
-
-- **简化建表:** 目前 Apache Doris 在建表时分区已经支持了时间函数,后续我们将进一步消除 Bucket 设置,帮助用户最大程度简化建表建模。
-- **安全性:** 目前已经实现基于 RBAC 模型的权限管理机制,使用户权限更安全可靠;并对 ID-federation、行列级别权限,数据脱敏等进行了优化,后续将进一步完善。
-- **可观测性:** Profile 是定位查询性能问题的重要手段,后续我们将加强对 Profile 的监控并提供可视化 Profile 工具,帮助用户更快定位问题。
-- **更好的 BI 兼容性和更完善的数据集成迁移方案:** 当前各 BI 工具可以通过 MySQL 协议连接到 Apache Doris,后续我们将对主流 BI 软件进一步适配,保证更佳的查询体验。随着 DBT、Airbyte 等新兴数据集成和迁移工具的兴起,越来越多用户使用此类系统将数据同步至 Apache Doris ,后续我们也会提供对此些系统的官方支持。
-
-## **开启下一个十年!**
-
-###### 或许有读者或听众还记得我在开头提的问题,对于 Apache Doris,十年意味着什么?
-
-有两层含义,上一个十年和下一个十年。
-
-**上一个十年,是 Apache Doris 起源的十年**。从诞生到开源、从默默无闻到被越来越多人熟知和使用,开源赋予了 Apache Doris 更加旺盛的生命力和创造力。
-
-**而下一个十年,则是一场新的旅程**。
-
-正如我在本次 Doris Summit 分享的主题,New Journey of Apache Doris。如果说过去 Apache Doris 更多是服务于在线报表场景和 Ad-hoc 分析的 OLAP 引擎的话,那么在所有社区和开发者的努力下,当前 Apache Doris 已经具备了更为广阔的定位,即极速、易用、实时、统一的多模分析型数据库。
-
-这其中的统一,既包含了架构的统一、也包含了业务和数据的统一。用户可以通过 Apache Doris 构建多种不同场景的数据分析服务、同时支撑在线与离线的业务负载、高吞吐的交互式分析与高并发的点查询;通过一套架构实现湖和仓的统一、在数据湖和多种异构存储之上提供无缝且极速的分析服务;也可通过对日志/文本等半结构化乃至非结构化的多模数据进行统一管理和分析、来满足更多样化数据分析的需求。
-
-这是我们希望 Apache Doris 能够带给用户的价值,**不再让用户在多套系统之间权衡,仅通过一个系统解决绝大部分问题,降低复杂技术栈带来的开发、运维和使用成本,最大化提升生产力。**
-
-“我们已经出发了太久,以至于忘记了为什么出发。”
-
-希望通过这一定位的转变迎接下一个十年的挑战,或许技术趋势会有变化,架构将会革新,但我们解决用户数据分析问题的初衷不会改变。
-
-希望继续带着上一个十年出发的初心,开启下一个十年的旅程。
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/tpch.md b/i18n/zh-CN/docusaurus-plugin-content-blog/tpch.md
deleted file mode 100644
index 52162918e47..00000000000
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/tpch.md
+++ /dev/null
@@ -1,884 +0,0 @@
----
-{
- 'title': 'Apache Doris 1.2 TPC-H 性能测试报告',
- 'summary': "在 TPC-H 标准测试数据集上的 22 个查询上,我们基于 Apache Doris 1.2.0-rc01, Apache Doris 1.1.3 及 Apache Doris 0.15.0 RC04 版本进行了对别测试, Apache Doris 1.2.0-rc01上相对 Apache Doris 1.1.3 整体性能提升了将近 3 倍,相对于 Apache Doris 0.15.0 RC04 ,性能提升了将近 11 倍",
- 'date': '2022-11-22',
- 'author': 'Apache Doris',
- 'tags': ['技术解析'],
-}
----
-
-<!--
-Licensed to the Apache Software Foundation (ASF) under one
-or more contributor license agreements. See the NOTICE file
-distributed with this work for additional information
-regarding copyright ownership. The ASF licenses this file
-to you under the Apache License, Version 2.0 (the
-"License"); you may not use this file except in compliance
-with the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing,
-software distributed under the License is distributed on an
-"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-KIND, either express or implied. See the License for the
-specific language governing permissions and limitations
-under the License.
--->
-
-# TPC-H Benchmark
-
-TPC-H是一个决策支持基准(Decision Support Benchmark),它由一套面向业务的特别查询和并发数据修改组成。查询和填充数据库的数据具有广泛的行业相关性。这个基准测试演示了检查大量数据、执行高度复杂的查询并回答关键业务问题的决策支持系统。TPC-H报告的性能指标称为TPC-H每小时复合查询性能指标(QphH@Size),反映了系统处理查询能力的多个方面。这些方面包括执行查询时所选择的数据库大小,由单个流提交查询时的查询处理能力,以及由多个并发用户提交查询时的查询吞吐量。
-
-本文档主要介绍 Doris 在 TPC-H 100G 测试集上的性能表现。
-
-> 注1:包括 TPC-H 在内的标准测试集通常和实际业务场景差距较大,并且部分测试会针对测试集进行参数调优。所以标准测试集的测试结果仅能反映数据库在特定场景下的性能表现。建议用户使用实际业务数据进行进一步的测试。
->
-> 注2:本文档涉及的操作都在 CentOS 7.x 上进行测试。
-
-在 TPC-H 标准测试数据集上的 22 个查询上,我们基于 Apache Doris 1.2.0-rc01, Apache Doris 1.1.3 及 Apache Doris 0.15.0 RC04 版本进行了对别测试, Apache Doris 1.2.0-rc01上相对 Apache Doris 1.1.3 整体性能提升了将近 3 倍,相对于 Apache Doris 0.15.0 RC04 ,性能提升了将近 11 倍 。
-
-
-
-## 1. 硬件环境
-
-| 硬件 | 配置说明 |
-| -------- | ------------------------------------ |
-| 机器数量 | 4 台腾讯云主机(1个FE,3个BE) |
-| CPU | Intel Xeon(Cascade Lake) Platinum 8269CY 16核 (2.5 GHz/3.2 GHz) |
-| 内存 | 64G |
-| 网络带宽 | 5Gbps |
-| 磁盘 | ESSD云硬盘 |
-
-## 2. 软件环境
-
-- Doris部署 3BE 1FE;
-- 内核版本:Linux version 5.4.0-96-generic (buildd@lgw01-amd64-051)
-- 操作系统版本:CentOS 7.8
-- Doris 软件版本: Apache Doris 1.2.0-rc01、 Apache Doris 1.1.3 、 Apache Doris 0.15.0 RC04
-- JDK:openjdk version "11.0.14" 2022-01-18
-
-## 3. 测试数据量
-
-整个测试模拟生成 TPCH 100G 的数据分别导入到 Apache Doris 1.2.0-rc01, Apache Doris 1.1.3 及 Apache Doris 0.15.0 RC04 版本进行测试,下面是表的相关说明及数据量。
-
-| TPC-H表名 | 行数 | 导入后大小 | 备注 |
-| :-------- | :----- | ---------- | :----------- |
-| REGION | 5 | 400KB | 区域表 |
-| NATION | 25 | 7.714 KB | 国家表 |
-| SUPPLIER | 100万 | 85.528 MB | 供应商表 |
-| PART | 2000万 | 752.330 MB | 零部件表 |
-| PARTSUPP | 8000万 | 4.375 GB | 零部件供应表 |
-| CUSTOMER | 1500万 | 1.317 GB | 客户表 |
-| ORDERS | 1.5亿 | 6.301 GB | 订单表 |
-| LINEITEM | 6亿 | 20.882 GB | 订单明细表 |
-
-## 4. 测试SQL
-
-TPCH 22 个测试查询语句 : [TPCH-Query-SQL](https://github.com/apache/incubator-doris/tree/master/tools/tpch-tools/queries)
-
-**注意:**
-
... 1545 lines suppressed ...
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@doris.apache.org
For additional commands, e-mail: commits-help@doris.apache.org