You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/07/17 23:53:59 UTC
[GitHub] [hudi] zuyanton opened a new issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
zuyanton opened a new issue #1847:
URL: https://github.com/apache/hudi/issues/1847
We are noticing that Hudi MoR table on S3 starts perform slow with number of files growing. Although it may sound similar as #1829 , its a different issue, as this time we have tested on table with relatively few partitions (100) and log indicates a different bottleneck. We can manage to keep writing/reading time within acceptable limits if we keep number of files small (compacting every 10 delta commits, setting cleaner to only keep one commit ) however if we try to increase the number of historical commits to 30 - 40 thats when we start noticing increase in upsert and read time. Specifically to reading table: We run simple count query, when checking spark UI we can see that cluster is idled for the first 20 minutes and only master node does some work, after that 20 minutes pause,spark starts running the count job.

When checking logs we observe that first 20 minutes are taken by master node loading all the necessary metadata from s3. More specifically we see a lot of lines like follow:
```
20/07/17 02:16:45 INFO HoodieTableFileSystemView: Adding file-groups for partition :11, #FileGroups=17
20/07/17 02:16:45 INFO AbstractTableFileSystemView: addFilesToView: NumFiles=120, NumFileGroups=17, FileGroupsCreationTime=13226, StoreTimeTaken=0
20/07/17 02:16:45 INFO AbstractTableFileSystemView: Time to load partition (11) =13285
```
we observe FileGroupsCreationTime value is all over the place from less then a second for small partitions to 4 minutes per partition containing 1000+ files. I placed bunch of timer log lines in Hudi code to narrow done the bottle neck and my findings are following: most time consuming lines are this
https://github.com/apache/hudi/blob/bf1d36fa639cae558aa388d8d547e58ad2e67aba/hudi-common/src/main/java/org/apache/hudi/common/table/view/AbstractTableFileSystemView.java#L254
and
https://github.com/apache/hudi/blob/master/hudi-common/src/main/java/org/apache/hudi/common/table/view/AbstractTableFileSystemView.java#L265
more specifically instantiation of HoodieLogFile and HoodieBaseFile more specifically grabbing file length value from FileStatus here https://github.com/apache/hudi/blob/bf1d36fa639cae558aa388d8d547e58ad2e67aba/hudi-common/src/main/java/org/apache/hudi/common/model/HoodieBaseFile.java#L42 and here https://github.com/apache/hudi/blob/bf1d36fa639cae558aa388d8d547e58ad2e67aba/hudi-common/src/main/java/org/apache/hudi/common/model/HoodieLogFile.java#L51 .
so pretty much hoodie iterates all partitions and within each partition sequentially traverses all files and grabs their length, mentioned lines of code in HoodieLogFile and HoodieBaseFile constructors take on average 100 milliseconds ,so every time Hoodie processes partition with 600+ files , it takes 600*100 milliseconds = 1 minute+ per partition.
**Possible ways this process may be sped up**
This are based on my not super deep understanding of Hudi functionality, I can be grossly wrong about them.
From my understanding ```HoodieParquetInputFormat.listStatus``` that gets executed per each partition and that eventually triggers File group creation, gets executed in multiple threads (multiple thread run listStatus) ,so Hudi does not process one partition at a time, there is some multi threading going on, however from my observations this parallelism is pretty small, maybe just handful of threads at a time and I dont know what parameter controls it. Theoretically increasing this number may improve performance.
It looks like Hudi grabs file sizes for all files in partition folder ,which may be unnecessary since if lets say we configured to keep last N commits, then only 1/N th of the folder are parquet files that need to be queried (plus log files of cause), the rest are just historical commits. just grabbing file length of 1/N th of the total files should make file groups creation process faster.
**Environment Description**
* Hudi version : master branch
* Spark version : 2.4.4
* Hive version : 2.3.6
* Hadoop version : 2.8.5
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : no
**Table Info**
We observe read time increasing for all the tests tables, however it gets more obvious pretty quick on tables where every incremental update , updates data in 50+ out of 100 partitions. Initial state of test table was 100 partitions, initial size 100gb, initial file count 6k. compaction is set to be ran every 10 delta commits, cleaner is set to keep last 50 commits. We started observing 20+ minutes table loading time after table grew to 27k files and 400gb.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-661461345
@zuyanton : I am not sure if I can find the source code of this class. @umehrot2 : Can you let me know if the current implementation of FileStatus returned S3NativeFileSystem overrides getLen() ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] zuyanton edited a comment on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
zuyanton edited a comment on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-664064544
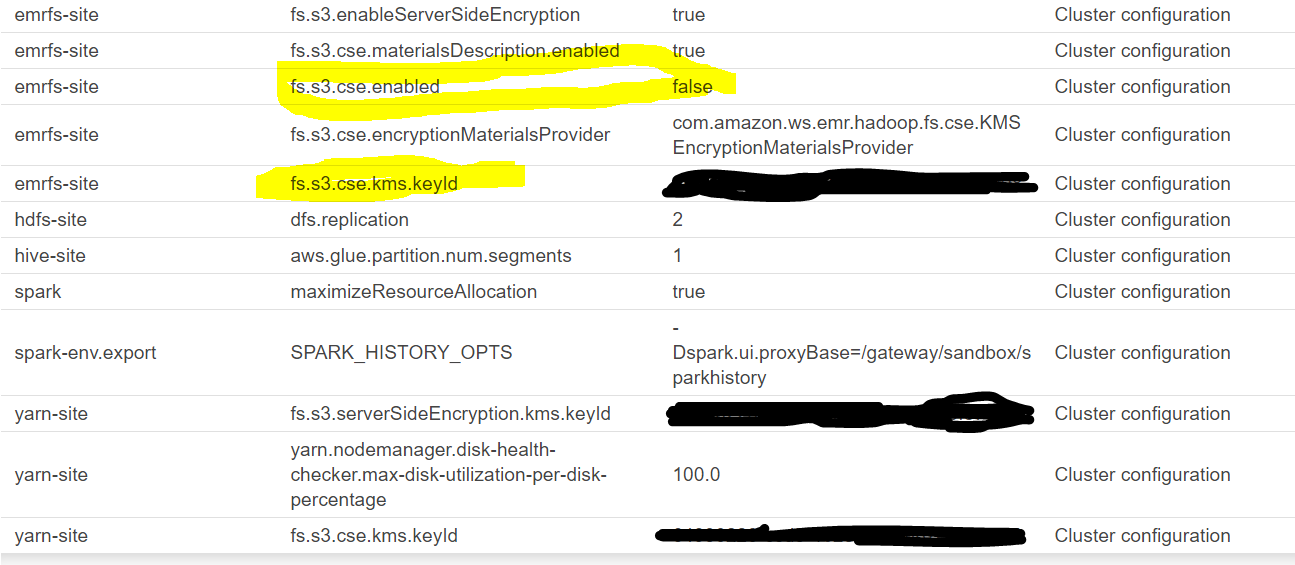
@umehrot2 @bschell Looks like CSE is disabled on the cluster, however I can see that we still specify CSE key id in cluster config. is ```fs.s3.cse.enabled``` is the only flag that triggers EMR to override ```getLen```?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] zuyanton commented on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
zuyanton commented on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-661287128
@bvaradar , logging ```fileStatus.getClass().getName()``` from within ```HoodieBaseFile``` constructor, gives me ```com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-663450319
@bschell : Thanks for the information. As getLen() is used extensively both on read and write side, can you let us elaborate more on what cases does it actually result in RPC calls ? Is there an ability to cache within the implementation ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bschell commented on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
bschell commented on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-663254464
@zuyanton S3NativeFileSystem is part of EMRFS from EMR. EMRFS overrides getLen in certain scenarios. Do you happen to have Client Side Encryption (CSE) enabled?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-685841451
@zuyanton : I am not sure if this is still an issue. Since, this seems specific to EMR, can you open a ticket with EMR folks directly ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-660836081
@zuyanton : Thanks for the detailed write-up. This is very interesting. If you look at the base implementation of FileStatus getLen() method, it returns a cached copy of the length. So, I wouldnt expect it to be the cause of such high variance. Also, 100 milliseconds you had observed would definitely making some blocking operations like RPC calls. Does the EMR/S3 implementation of filesystem overrides these classes ?
```
/**
* Get the length of this file, in bytes.
* @return the length of this file, in bytes.
*/
public long getLen() {
return length;
}
```
@zuyanton : Can you track the class type for the incoming file-status object ?
cc @umehrot2
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] umehrot2 commented on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
umehrot2 commented on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-664709899
@zuyanton yes `fs.s3.cse.enabled` is required for client side encryption to kick in. I wonder why you still have the `fs.s3.cse..kms.keyId` there. Also you don't use EmrFS consistent view right ?
At this point I don't see a reason for `getLen()` taking time, since like @bvaradar mentioned its just cached when the FileStatus is created. However, I would still suggest trying by removing the unnecessary configurations that you have for EmrFS. Another thing that I would like you to do is enable EmrFS debug logs, by going to `/etc/spark/conf/log4j.properties` and add an entry with `DEBUG` log level for `com.amazon.ws.emr.hadoop.fs` namespace. This should give more information if there are any S3 calls being made during that time of 100ms. If it does not reveal anything, I will try to work with you internally to reproduce the issue.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] umehrot2 commented on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
umehrot2 commented on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-663728553
@bvaradar EMR only overrides the `getLen()` if the customer has explicitly enabled `Client Side Encryption` using the EmrFS property `fs.s3.cse.enabled`. In that case I see that EmrFS needs to make a couple of `S3 calls`. But, based on my brief conversation with @zuyanton he mentioned he is most likely not enabling this feature. But I would let him confirm this, and if its true EMR team can further look into the possibility of any optimizations in that code path.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar closed issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
bvaradar closed issue #1847:
URL: https://github.com/apache/hudi/issues/1847
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] zuyanton edited a comment on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
zuyanton edited a comment on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-661287128
@bvaradar , logging ```fileStatus.getClass().getName()``` from within ```HoodieBaseFile``` constructor, gives me ```com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem$3```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] zuyanton commented on issue #1847: [SUPPORT] querying MoR tables on S3 becomes slow with number of files growing
Posted by GitBox <gi...@apache.org>.
zuyanton commented on issue #1847:
URL: https://github.com/apache/hudi/issues/1847#issuecomment-664064544
Looks like CSE is disabled on the cluster, however I can see that we still specify CSE key id in cluster config. is ```fs.s3.cse.enabled``` is the only flag that triggers EMR to override ```getLen```?

----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org