You are viewing a plain text version of this content. The canonical link for it is here.
Posted to jira@kafka.apache.org by GitBox <gi...@apache.org> on 2020/10/28 13:07:42 UTC
[GitHub] [kafka] viktorsomogyi opened a new pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5
viktorsomogyi opened a new pull request #9519:
URL: https://github.com/apache/kafka/pull/9519
Introduces a new offset map in the log cleaner which uses Murmur hashing
algorithm instead of the current MD5.
This commit:
- Moves Murmur3 from Streams into Clients
- Changes SkimpyOffsetMap to use Murmur3 hashing
- Removes the option to change hashing algorithm in SkimpyOffsetMap
- Adds benchmark tests
### Committer Checklist (excluded from commit message)
- [ ] Verify design and implementation
- [ ] Verify test coverage and CI build status
- [ ] Verify documentation (including upgrade notes)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] lbradstreet commented on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
lbradstreet commented on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-729745702
@viktorsomogyi I think a hash collision for the full sized hash will mean that a message is incorrectly cleaned. Are you measuring the collision rate in the probes? I am less worried about those as they are expected, though it's good to know their rate as they will affect performance.
Have you measured the rate of collision for the full sized hashes? Those are the main concern when it comes to the safety of this change.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#discussion_r514141334
##########
File path: jmh-benchmarks/src/main/java/org/apache/kafka/jmh/server/OffsetMapBenchmark.java
##########
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.jmh.server;
+
+import kafka.log.SkimpyOffsetMap;
+import org.openjdk.jmh.annotations.Benchmark;
+import org.openjdk.jmh.annotations.BenchmarkMode;
+import org.openjdk.jmh.annotations.Fork;
+import org.openjdk.jmh.annotations.Level;
+import org.openjdk.jmh.annotations.Measurement;
+import org.openjdk.jmh.annotations.Mode;
+import org.openjdk.jmh.annotations.OutputTimeUnit;
+import org.openjdk.jmh.annotations.Param;
+import org.openjdk.jmh.annotations.Scope;
+import org.openjdk.jmh.annotations.Setup;
+import org.openjdk.jmh.annotations.State;
+import org.openjdk.jmh.annotations.Threads;
+import org.openjdk.jmh.annotations.Warmup;
+
+import java.nio.ByteBuffer;
+import java.nio.charset.Charset;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Map;
+import java.util.Random;
+import java.util.Set;
+import java.util.concurrent.TimeUnit;
+import java.util.stream.Collectors;
+
+@Warmup(iterations = 3)
+@Measurement(iterations = 5)
+@Fork(1)
+@OutputTimeUnit(TimeUnit.NANOSECONDS)
+@State(value = Scope.Benchmark)
+@BenchmarkMode(Mode.AverageTime)
+public class OffsetMapBenchmark {
+
+ @Param({"10000000"})
+ public int logLength;
+
+ @Param({"100"})
+ public int numKeys;
+
+ @Param({"10"})
+ public int keyLength;
+
+ @Param({"1048576"})
+ public int memory;
+
+ private Random random = new Random();
+
+ private SkimpyOffsetMap skimpyOffsetMap;
+ private ByteBuffer[] keys;
+ private Map<Long, ByteBuffer> offsetToKeyMap;
+
+ @Setup(Level.Trial)
+ public void setupTrial() {
+ skimpyOffsetMap = new SkimpyOffsetMap(memory);
+ Set<String> keysSet = new HashSet<>(numKeys);
+ for (int i = 0; i < numKeys; ++i) {
+ String nextRandom;
+ do {
+ nextRandom = nextRandomString(keyLength);
+ } while (keysSet.contains(nextRandom));
+ keysSet.add(nextRandom);
+ }
+ keys = keysSet
+ .stream()
+ .map(k -> ByteBuffer.wrap(k.getBytes(Charset.defaultCharset())))
+ .collect(Collectors.toList()).toArray(new ByteBuffer[]{});
+ offsetToKeyMap = new HashMap<>(logLength);
+ for (long i = 0; i < logLength; ++i) {
+ offsetToKeyMap.put(i, ByteBuffer.wrap(keys[random.nextInt(numKeys)].array()));
+ }
+ }
+
+ private String nextRandomString(int length) {
Review comment:
the ```length``` is neglected
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi commented on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi commented on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-736027069
@lbradstreet it is really hard to give an exact answer to this as collision rate is hard to calculate mathematically as it is very dependant on the size and values of the testset. For non-cryptographic hashes it is possible to generate DDoS attacks where everything gets placed into the same bucket and thus slows down lookups. On the theoretical side though Murmur3 passes the most often cited Chi Square test, it has a very good avalanche effect and thus generates a hashes that are very close to the uniform distribution.
Because of the lack of available mathematical articles on this topic (murmur vs MD5) I started brute-force tests where I generated a few billion unique keys and inserted them into a Bloom Filter (which had a 1% false positive probability). That showed that Murmur3 is actually on the same level as MD5, it generates roughly the same amount of collisions. I have to types of datasets: the first can use any UTF8 characters and the second works only from the printable ASCII characters. In fact both MD5, murmur3 128bit, murmur3 64bit and xxhash64 bit generated around the same amount of collisions which was 0.016% out of 200 million unique keys. I added Murmur3 32bit for a baseline but it was significantly worse, around 2% of collisions. Maybe to show the difference we need a much larger keyset, I'll try to do what I can.
I'll publish my code in the following days I just have to work on something else too so it's a bit slow, sorry :).
On the other hand if we want to make sure that there will be no collisions, I don't think it's possible with either of these solutions, there is always a chance. To completely cut this off we either have to store the user key-hash maps similarly to the offset indexes or use perfect hashes (but that couldn't work well as it requires the knowledge of the full keyset or have to rebuild the cache in each insert or at least often).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi commented on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi commented on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-1050869998
@lbradstreet @ijuma @junrao I'd like to revive this. This is a bit old I know, but I'd like to close out dangling open issues. Is this needed in the Apache Kafka distribution? (We've been using Murmur3 for the Cloudera distro for 2 years now, didn't have any problems with it since then so it's somewhat time tested.)
If you think this is needed, then please reply within a week, otherwise I close this PR to keep my own list clear. Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi commented on a change in pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi commented on a change in pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#discussion_r514135717
##########
File path: jmh-benchmarks/jmh.sh
##########
@@ -37,6 +37,6 @@ echo "gradle build done"
echo "running JMH with args [$@]"
-java -jar ${libDir}/kafka-jmh-benchmarks-all.jar "$@"
+java -Xms256M -Xmx8G -jar ${libDir}/kafka-jmh-benchmarks-all.jar "$@"
Review comment:
Thanks for calling this out, this option actually isn't needed so I'll remove that. It works without it (just needed for some development iterations).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi edited a comment on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi edited a comment on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-736027069
@lbradstreet it is really hard to give an exact answer to this as collision rate is hard to calculate mathematically as it is very dependant on the size and values of the testset. For non-cryptographic hashes it is possible to generate DDoS attacks where everything gets placed into the same bucket and thus slows down lookups. On the theoretical side though Murmur3 passes the most often cited Chi Square test, it has a very good avalanche effect and thus generates a hashes that are very close to the uniform distribution.
Because of the lack of available mathematical articles on this topic (murmur vs MD5) I started brute-force tests where I generated a few billion unique keys and inserted them into a Bloom Filter (which had a 1% false positive probability). That showed that Murmur3 is actually on the same level as MD5, it generates roughly the same amount of collisions. I have to types of datasets: the first can use any UTF8 characters and the second works only from the printable ASCII characters. In fact both MD5, murmur3 128bit, murmur3 64bit and xxhash64 bit generated around the same amount of collisions which was 0.016% out of 200 million unique keys. I added Murmur3 32bit for a baseline but it was significantly worse, around 2% of collisions. Maybe to show the difference we need a much larger keyset, I'll try to do what I can.
I'll publish my code in the following days I just have to work on something else too so it's a bit slow, sorry :).
On the other hand if we want to make sure that there will be no collisions, I don't think it's possible with either of these solutions, there is always a chance. To completely cut this off we either have to store the user key-hash maps similarly to the offset indexes and reject new, colliding keys or resolve the collision or use perfect hashes (but that couldn't work well as it requires the knowledge of the full keyset or have to rebuild the cache in each insert or at least often).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi edited a comment on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi edited a comment on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-725539926
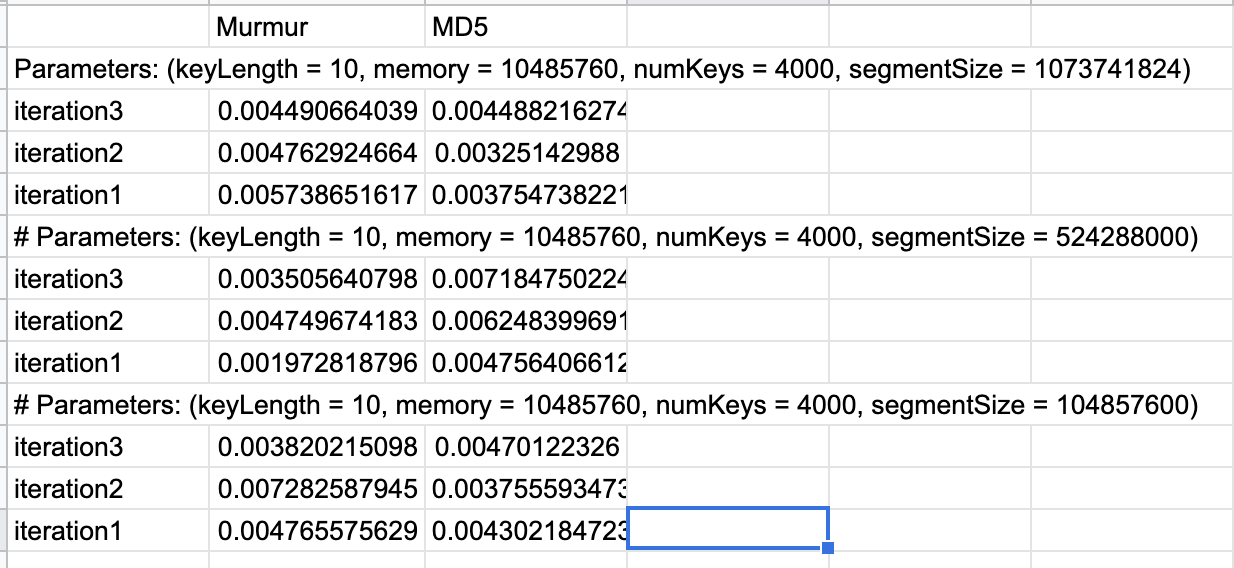
@ijuma I don't think I looked at it but will try it out soon, its speed seems promising. I haven't found a 128bit java implementation but I can try out the 64bit in lz4 as well. I need to see if the collision rate changes significantly if we reduce the hash size to 64. Theoretically for 100 million distinct keys the probability of collision is 1.469367×10^-23 with 18 bit while for 64 bits it's 2.710138×10^-4 which is significantly larger but it might be enough for the log cleaning use-case.
@junrao I can compile a statistic for this but in my tests the collision rate was on the same level, sometimes slightly better, sometimes slightly worse. The attached image is what I collected manually for the largest test cases but I'll do something more elaborate if you think so :) - but based on this I think yes, the uniqueness of the generated hashes is on the same level.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi edited a comment on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi edited a comment on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-736027069
@lbradstreet it is really hard to give an exact answer to this as collision rate is hard to calculate mathematically as it is very dependant on the size and values of the testset. For non-cryptographic hashes it is possible to generate DDoS attacks where everything gets placed into the same bucket and thus slows down lookups. On the theoretical side though Murmur3 passes the most often cited Chi Square test, it has a very good avalanche effect and thus generates a hashes that are very close to the uniform distribution.
Because of the lack of available mathematical articles on this topic (murmur vs MD5) I started brute-force tests where I generated a few billion unique keys and inserted them into a Bloom Filter (which had a 1% false positive probability). That showed that Murmur3 is actually on the same level as MD5, it generates roughly the same amount of collisions. I have two types of datasets: the first can use any UTF8 characters and the second works only from the printable ASCII characters. In fact both MD5, murmur3 128bit, murmur3 64bit and xxhash64 bit generated around the same amount of collisions which was 0.016% out of 200 million unique keys. I added Murmur3 32bit for a baseline but it was significantly worse, around 2% of collisions. Maybe to show the difference we need a much larger keyset, I'll try to do what I can.
I'll publish my code in the following days I just have to work on something else too so it's a bit slow, sorry :).
On the other hand if we want to make sure that there will be no collisions, I don't think it's possible with either of these solutions, there is always a chance. To completely cut this off we either have to store the user key-hash maps similarly to the offset indexes and reject new, colliding keys or use perfect hashes (but that couldn't work well as it requires the knowledge of the full keyset or have to rebuild the cache in each insert or at least often).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi edited a comment on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi edited a comment on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-1050869998
@lbradstreet @ijuma @junrao I'd like to revive this. This is a bit old I know, but I'd like to close out dangling open issues. Is this needed in the Apache Kafka distribution? (We've been using Murmur3 for the Cloudera distro for 2 years now, didn't have any problems with it since then so it's somewhat time tested.)
If you think this is needed, then please reply within a week and I resolve the conflicts, otherwise I close this PR to keep my own list clear. Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi commented on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi commented on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-736624841
I ran another test with 2,000,000,000 keys being inserted into a Bloom Filter with 1% false positive rate (and it ran for 7 hours and 21 minutes). The test set was created by generating random printable ASCII characters and adding an incremental counter in a random position within a string. The counter was formatted to display 10 digits, so 16 would look like 0000000016 in the string, therefore preserving the length of the strings (which was 110 characters with the counter included).
MD5 hash collisions: 3,325,038 (0.1662%)
Murmur3 128bit hash collisions: 3,330,883 (0.1665%)
Murmur3 64bit hash collisions: 3,327,266 (0.1663%)
Murmur3 32bit hash collisions: 401,833,502 (20.0916%)
XXHash 64bit hash collisions: 3,327,266 (0.1663%)
It shows that interestingly there were slightly more collisions in Murmur3 than in MD5 (MD5 was 0.0002% better, which is 5845 collisions) and interestingly the 64bit hashes performed the best (and I won't mention the 32bit hash :D). Given that there were 2 billion unique keys, that 5845 statistically well within any range of error (it's 0,1% of 3,330,883). I don't expect that with more test runs we'll have significantly bigger differences. As I observed the values were growing linearly with values close together (sometimes MD5 falling behind, sometimes getting ahead) so I think this 0.0002% doesn't mean too much. I didn't save this progress data out as I thought about this 4 hours into the test but I'll do it for the next one.
I'd also like to try out xxHash 128bit but I haven't found any Java JNIs for it yet but I'll keep searching. I expect though that it would perform similarly to the other 128bit hashes but overall I think this could be a good foundation for using traditional hashing algorithms instead of the slow MD5.
Another experiment could be to try out SHA1. As I saw it should be somewhat faster and more collision resistant than MD5, however I never did any kind of experiments, so we'll see if its performance gets meaningfully better (meaning it exceeds at least the 1% error rate).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi edited a comment on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi edited a comment on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-725539926
@ijuma I don't think I looked at it but will try it out soon, its speed seems promising. I haven't found a 128bit java implementation but I can try out the 64bit in lz4 as well. I need to see if the collision rate changes significantly if we reduce the hash size to 64. Theoretically for 100 million distinct keys the probability of collision is 1.469367×10^-23 with 128 bit while for 64 bits it's 2.710138×10^-4 which is significantly larger but it might be enough for the log cleaning use-case.
@junrao I can compile a statistic for this but in my tests the collision rate was on the same level, sometimes slightly better, sometimes slightly worse. The attached image is what I collected manually for the largest test cases but I'll do something more elaborate if you think so :) - but based on this I think yes, the uniqueness of the generated hashes is on the same level.

----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
ijuma commented on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-724723348
This looks interesting. Did we consider https://github.com/Cyan4973/xxHash instead of murmur3?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi commented on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi commented on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-725539926
@ijuma I don't think I looked at it but will try it out soon, its speed seems promising. I haven't found a 128bit java implementation but the 64bit in lz4 can be tried out as well. I need to see if the collision rate changes significantly if we reduce the hash size to 64. Theoretically for 100 million distinct keys the probability of collision is 1.469367×10^-23 with 18 bit while for 64 bits it's 2.710138×10^-4 which is significantly larger but it might be enough for the log cleaning use-case.
@junrao I can compile a statistic for this but in my tests the collision rate was on the same level, sometimes slightly better, sometimes slightly worse. The attached image is what I collected manually for the largest test cases but I'll do something more elaborate if you think so :)

----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] junrao commented on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
junrao commented on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-725090806
@viktorsomogyi : Thanks for the PR. We use crypto algorithms like MD5 as the unique representation for a corresponding key. murmur3 has the same length as MD5. Does it guarantee similar uniqueness as MD5?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
chia7712 commented on a change in pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#discussion_r513527322
##########
File path: jmh-benchmarks/jmh.sh
##########
@@ -37,6 +37,6 @@ echo "gradle build done"
echo "running JMH with args [$@]"
-java -jar ${libDir}/kafka-jmh-benchmarks-all.jar "$@"
+java -Xms256M -Xmx8G -jar ${libDir}/kafka-jmh-benchmarks-all.jar "$@"
Review comment:
Does the new benchmark test need large memory? Could this change be replaced by jmh parameter (for example ```@Fork(jvmArgsAppend = "-Xmx8g")```)?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi edited a comment on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi edited a comment on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-725539926
@ijuma I don't think I looked at it but will try it out soon, its speed seems promising. I haven't found a 128bit java implementation but the 64bit in lz4 can be tried out as well. I need to see if the collision rate changes significantly if we reduce the hash size to 64. Theoretically for 100 million distinct keys the probability of collision is 1.469367×10^-23 with 18 bit while for 64 bits it's 2.710138×10^-4 which is significantly larger but it might be enough for the log cleaning use-case.
@junrao I can compile a statistic for this but in my tests the collision rate was on the same level, sometimes slightly better, sometimes slightly worse. The attached image is what I collected manually for the largest test cases but I'll do something more elaborate if you think so :) - but based on this I think yes, the uniqueness of the generated hashes is on the same level.

----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi edited a comment on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi edited a comment on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-736027069
@lbradstreet it is really hard to give an exact answer to this as collision rate is hard to calculate mathematically as it is very dependant on the size and values of the testset. For non-cryptographic hashes it is possible to generate DDoS attacks where everything gets placed into the same bucket and thus slows down lookups. On the theoretical side though Murmur3 passes the most often cited Chi Square test, it has a very good avalanche effect and thus generates a hashes that are very close to the uniform distribution.
Because of the lack of available mathematical articles on this topic (murmur vs MD5) I started brute-force tests where I generated a few billion unique keys and inserted them into a Bloom Filter (which had a 1% false positive probability). That showed that Murmur3 is actually on the same level as MD5, it generates roughly the same amount of collisions. I have to types of datasets: the first can use any UTF8 characters and the second works only from the printable ASCII characters. In fact both MD5, murmur3 128bit, murmur3 64bit and xxhash64 bit generated around the same amount of collisions which was 0.016% out of 200 million unique keys. I added Murmur3 32bit for a baseline but it was significantly worse, around 2% of collisions. Maybe to show the difference we need a much larger keyset, I'll try to do what I can.
I'll publish my code in the following days I just have to work on something else too so it's a bit slow, sorry :).
On the other hand if we want to make sure that there will be no collisions, I don't think it's possible with either of these solutions, there is always a chance. To completely cut this off we either have to store the user key-hash maps similarly to the offset indexes and reject new, colliding keys or use perfect hashes (but that couldn't work well as it requires the knowledge of the full keyset or have to rebuild the cache in each insert or at least often).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] viktorsomogyi commented on pull request #9519: KAFKA-10650: Use Murmur3 instead of MD5 in SkimpyOffsetMap
Posted by GitBox <gi...@apache.org>.
viktorsomogyi commented on pull request #9519:
URL: https://github.com/apache/kafka/pull/9519#issuecomment-717964936
@ijuma what do you think about this? I replaced MD5 with Murmur3 in SkimpyOffsetMap and log segment cleaning sped up by 30% (stable) according to benchmarks (attached to the jira).
Do you know what was the motivation to use MD5 in the first place? I don't think it's necessary to use crypto algorithm here.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org