You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2022/11/25 07:25:49 UTC
[GitHub] [spark] beliefer opened a new pull request, #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
beliefer opened a new pull request, #38799:
URL: https://github.com/apache/spark/pull/38799
### What changes were proposed in this pull request?
introduce a new node `WindowGroupLimit` to filter out unnecessary rows based on rank computed on partial dataset.
it supports following pattern:
```
SELECT (... (row_number|rank|dense_rank)()
OVER (
PARTITION BY ...
ORDER BY ... ) AS rn)
WHERE rn (==|<|<=) k
AND other conditions
```
For these three rank-like functions (row_number|rank|dense_rank), the rank of a key computed on partial dataset always <= its final rank computed on the whole dataset,so we can safely discard rows with partial rank > k, anywhere.
This PR also take over some functions from https://github.com/apache/spark/pull/34367.
### Why are the changes needed?
1. reduce the shuffle write
2. solve skewed-window problem, a practical case was optimized from 2.5h to 26min.
3. improve the performance and TPC-DS.
**Micro Benchmark**
TPC-DS data size: 2TB.
This improvement is valid for TPC-DS q67 and no regression for other test cases.
### Does this PR introduce _any_ user-facing change?
'No'.
Just update the inner implementation and add a new config.
### How was this patch tested?
1. new test suites
2. new micro benchmark
```
[info] Benchmark Top-K: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] -----------------------------------------------------------------------------------------------------------------------------------------------
[info] ROW_NUMBER (PARTITION: , WindowGroupLimit: false) 13036 15052 969 1.6 621.6 1.0X
[info] ROW_NUMBER (PARTITION: , WindowGroupLimit: true) 4269 4650 303 4.9 203.6 3.1X
[info] ROW_NUMBER (PARTITION: PARTITION BY b, WindowGroupLimit: false) 24159 25238 919 0.9 1152.0 0.5X
[info] ROW_NUMBER (PARTITION: PARTITION BY b, WindowGroupLimit: true) 6466 6594 104 3.2 308.3 2.0X
[info] RANK (PARTITION: , WindowGroupLimit: false) 11291 11691 252 1.9 538.4 1.2X
[info] RANK (PARTITION: , WindowGroupLimit: true) 3376 3709 218 6.2 161.0 3.9X
[info] RANK (PARTITION: PARTITION BY b, WindowGroupLimit: false) 24778 24927 69 0.8 1181.5 0.5X
[info] RANK (PARTITION: PARTITION BY b, WindowGroupLimit: true) 6531 6613 68 3.2 311.4 2.0X
[info] DENSE_RANK (PARTITION: , WindowGroupLimit: false) 11468 11730 142 1.8 546.8 1.1X
[info] DENSE_RANK (PARTITION: , WindowGroupLimit: true) 3459 3658 201 6.1 164.9 3.8X
[info] DENSE_RANK (PARTITION: PARTITION BY b, WindowGroupLimit: false) 24809 24961 173 0.8 1183.0 0.5X
[info] DENSE_RANK (PARTITION: PARTITION BY b, WindowGroupLimit: true) 6512 6579 44 3.2 310.5 2.0X
```
3. manual test on TPC-DS
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1111759712
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,249 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(SimpleLimitIterator(_, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => SimpleLimitIterator(input, limit)))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => RankLimitIterator(output, input, orderSpec, limit)))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => DenseRankLimitIterator(output, input, orderSpec, limit)))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ var rank = 0
+
+ var nextRow: UnsafeRow = null
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ override def hasNext: Boolean = rank < limit && input.hasNext
+
+ override def next(): InternalRow = {
+ if (!hasNext) throw new NoSuchElementException
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ increaseRank()
+ nextRow
+ }
+
+ def reset(): Unit
+}
+
+case class SimpleLimitIterator(
+ input: Iterator[InternalRow],
+ limit: Int) extends BaseLimitIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+trait OrderSpecProvider {
+ def output: Seq[Attribute]
+ def orderSpec: Seq[SortOrder]
+
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var currentRankRow: UnsafeRow = null
+}
+
+case class RankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ var count = 0
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank = count
+ currentRankRow = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ count = 0
+ }
+}
+
+case class DenseRankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ override def increaseRank(): Unit = {
+ if (currentRankRow == null) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank += 1
+ currentRankRow = nextRow.copy()
+ }
+ }
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+class GroupedLimitIterator(
+ input: Iterator[InternalRow],
+ output: Seq[Attribute],
+ partitionSpec: Seq[Expression],
+ createLimitIterator: Iterator[InternalRow] => BaseLimitIterator)
+ extends Iterator[InternalRow] {
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ }
+ }
+ fetchNextRow()
+
+ var groupIterator: GroupIterator = _
+ var limitIterator: BaseLimitIterator = _
+ if (nextRowAvailable) {
+ groupIterator = new GroupIterator()
+ limitIterator = createLimitIterator(groupIterator)
+ }
+
+ override final def hasNext: Boolean = limitIterator.hasNext || {
+ groupIterator.skipRemainingRows()
+ limitIterator.reset()
+ groupIterator.hasNext
Review Comment:
How about
```
def hasNext: Boolean = {
if (!limitIterator.hasNext) {
// comments
groupIterator.skipRemainingRows()
limitIterator.reset()
}
limitIterator.hasNext
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1340278339
@zhengruifeng @cloud-fan Could you have any other suggestion ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046751527
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, ExpressionSet, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty || ExpressionSet(limits.map(_._2)).size > 1) {
+ filter
+ } else {
+ val minLimit = limits.minBy(_._1)
+ minLimit match {
Review Comment:
```suggestion
limits.minBy(_._1) match {
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036828144
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala:
##########
@@ -627,6 +627,87 @@ abstract class SparkStrategies extends QueryPlanner[SparkPlan] {
}
}
+ /**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+ object WindowGroupLimit extends Strategy with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = {
+ if (conf.windowGroupLimitThreshold == -1) return Nil
+
+ plan match {
+ case filter @ Filter(condition,
+ window @ logical.Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[logical.Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
Review Comment:
do we really require the window to only contain rank like functions?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1034474429
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{ExternalAppendOnlyUnsafeRowArray, SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ // Only show warning when the number of bytes is larger than 100 MiB?
+ logWarning("No Partition Defined for Window operation! Moving all data to a single "
+ + "partition, this can cause serious performance degradation.")
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
Review Comment:
Yes. I have another PR to improve this issue.
Please see https://github.com/apache/spark/pull/38689
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1033303620
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.forall {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (!conf.windowGroupLimitEnabled) return plan
+
+ plan.transformWithPruning(
+ _.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && !child.isInstanceOf[Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
Review Comment:
We should only check related window expressios. e.g. `select other_window_func, row_number() ... as rn where rc = 1` should be supported.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1330127603
+1 on add a separate config as the threshold to trigger this optimization.
since new logical and physical plans are added, should also consider how it affect existing rules.
thanks for taking this over @beliefer
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100230288
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##########
@@ -2580,6 +2580,18 @@ object SQLConf {
.intConf
.createWithDefault(SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD.defaultValue.get)
+ val WINDOW_GROUP_LIMIT_THRESHOLD =
+ buildConf("spark.sql.optimizer.windowGroupLimitThreshold")
+ .internal()
+ .doc("Threshold for filter the dataset by the window group limit before" +
Review Comment:
```
Threshold for triggering `InsertWindowGroupLimit`. 0 means disabling the optimization.
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046764675
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, ExpressionSet, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty || ExpressionSet(limits.map(_._2)).size > 1) {
Review Comment:
> ExpressionSet(limits.map(_._2)).size > 1
Do we really need this condition? We are inserting a limit-like operator, and we can just randomly pick one supported window function to do limit.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046756910
##########
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimitSuite.scala:
##########
@@ -0,0 +1,308 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.catalyst.dsl.expressions._
+import org.apache.spark.sql.catalyst.dsl.plans._
+import org.apache.spark.sql.catalyst.expressions.{CurrentRow, DenseRank, Literal, NthValue, NTile, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding}
+import org.apache.spark.sql.catalyst.plans.PlanTest
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation, LogicalPlan}
+import org.apache.spark.sql.catalyst.rules.RuleExecutor
+import org.apache.spark.sql.internal.SQLConf
+
+class InsertWindowGroupLimitSuite extends PlanTest {
+ private object Optimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates,
+ InsertWindowGroupLimit) :: Nil
+ }
+
+ private object WithoutOptimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates) :: Nil
+ }
+
+ private val testRelation = LocalRelation.fromExternalRows(
+ Seq("a".attr.int, "b".attr.int, "c".attr.int),
+ 1.to(10).map(i => Row(i % 3, 2, i)))
Review Comment:
This is optimizer test, we don't need data.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1067823587
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,241 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
Review Comment:
When current group doesn't have more rows, `clearRank` will be called.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "beliefer (via GitHub)" <gi...@apache.org>.
beliefer commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1423565384
> there are 3 tpc queries having plan change, what's their perf result?
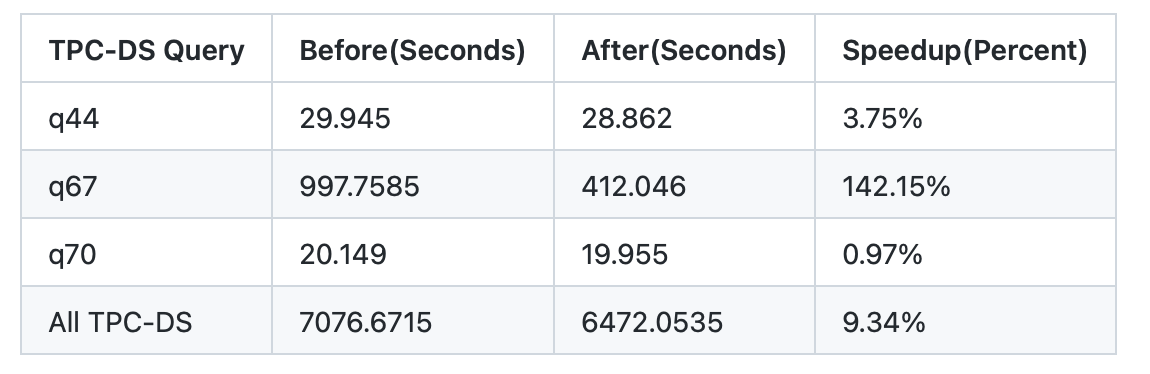
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1108420829
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,281 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(SimpleLimitIterator(_, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ var rank = 0
+
+ var nextRow: UnsafeRow = null
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ override def hasNext: Boolean = rank < limit && input.hasNext
+
+ override def next(): InternalRow = {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ increaseRank()
+ nextRow
+ }
+}
+
+case class SimpleLimitIterator(
+ input: Iterator[InternalRow],
+ limit: Int) extends BaseLimitIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+}
+
+trait OrderSpecProvider {
+ def output: Seq[Attribute]
+ def orderSpec: Seq[SortOrder]
+
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var currentRankRow: UnsafeRow = null
+}
+
+case class RankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ var count = 0
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank = count
+ currentRankRow = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+}
+
+case class DenseRankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ override def increaseRank(): Unit = {
+ if (currentRankRow == null) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank += 1
+ currentRankRow = nextRow.copy()
+ }
+ }
+ }
+}
+
+trait WindowIterator extends Iterator[InternalRow] {
Review Comment:
let's make it simpler:
```
class GroupedLimitIterator(input, partitionSpec, createLimitIterator: Iterator => BaseLimitIterator) ... {
var groupIterator = null
var limitIterator = null
if (input.hasNext) {
groupIterator = new GroupIterator(input, partitionSpec)
limitIterator = createLimitIterator(groupIterator)
}
def hasNext = limitIterator != null && limitIterator.hasNext
def next = {
if (!hasNext) throw NoSuchElementException
val res = limitIterator.next
if (!limitIterator.hasNext) {
groupIterator.skipRemainingRows()
limitIterator.reset()
}
res
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "beliefer (via GitHub)" <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100920458
##########
sql/core/src/test/scala/org/apache/spark/sql/DataFrameWindowFunctionsSuite.scala:
##########
@@ -1265,4 +1265,168 @@ class DataFrameWindowFunctionsSuite extends QueryTest
)
)
}
+
+ test("SPARK-37099: Insert window group limit node for top-k computation") {
+
+ val nullStr: String = null
+ val df = Seq(
+ ("a", 0, "c", 1.0),
+ ("a", 1, "x", 2.0),
+ ("a", 2, "y", 3.0),
+ ("a", 3, "z", -1.0),
+ ("a", 4, "", 2.0),
+ ("a", 4, "", 2.0),
+ ("b", 1, "h", Double.NaN),
+ ("b", 1, "n", Double.PositiveInfinity),
+ ("c", 1, "z", -2.0),
+ ("c", 1, "a", -4.0),
+ ("c", 2, nullStr, 5.0)).toDF("key", "value", "order", "value2")
+
+ val window = Window.partitionBy($"key").orderBy($"order".asc_nulls_first)
+ val window2 = Window.partitionBy($"key").orderBy($"order".desc_nulls_first)
+
+ Seq(-1, 100).foreach { threshold =>
+ withSQLConf(SQLConf.WINDOW_GROUP_LIMIT_THRESHOLD.key -> threshold.toString) {
+ Seq($"rn" === 0, $"rn" < 1, $"rn" <= 0).foreach { condition =>
+ checkAnswer(df.withColumn("rn", row_number().over(window)).where(condition),
+ Seq.empty[Row]
+ )
+ }
+
+ Seq($"rn" === 1, $"rn" < 2, $"rn" <= 1).foreach { condition =>
+ checkAnswer(df.withColumn("rn", row_number().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", rank().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", dense_rank().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+ }
+
+ Seq($"rn" < 3, $"rn" <= 2).foreach { condition =>
+ checkAnswer(df.withColumn("rn", row_number().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 2),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("b", 1, "n", Double.PositiveInfinity, 2),
+ Row("c", 1, "a", -4.0, 2),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", rank().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("b", 1, "n", Double.PositiveInfinity, 2),
+ Row("c", 1, "a", -4.0, 2),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", dense_rank().over(window)).where(condition),
+ Seq(
+ Row("a", 0, "c", 1.0, 2),
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("b", 1, "n", Double.PositiveInfinity, 2),
+ Row("c", 1, "a", -4.0, 2),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+ }
+
+ val condition = $"rn" === 2 && $"value2" > 0.5
+ checkAnswer(df.withColumn("rn", row_number().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 2),
+ Row("b", 1, "n", Double.PositiveInfinity, 2)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", rank().over(window)).where(condition),
+ Seq(
+ Row("b", 1, "n", Double.PositiveInfinity, 2)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", dense_rank().over(window)).where(condition),
+ Seq(
+ Row("a", 0, "c", 1.0, 2),
+ Row("b", 1, "n", Double.PositiveInfinity, 2)
+ )
+ )
+
+ val multipleRowNumbers = df
+ .withColumn("rn", row_number().over(window))
+ .withColumn("rn2", row_number().over(window))
+ .where('rn < 2 && 'rn2 < 3)
+ checkAnswer(multipleRowNumbers,
+ Seq(
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("b", 1, "h", Double.NaN, 1, 1),
+ Row("c", 2, null, 5.0, 1, 1)
+ )
+ )
+
+ val multipleRanks = df
+ .withColumn("rn", rank().over(window))
+ .withColumn("rn2", rank().over(window))
+ .where('rn < 2 && 'rn2 < 3)
+ checkAnswer(multipleRanks,
+ Seq(
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("b", 1, "h", Double.NaN, 1, 1),
+ Row("c", 2, null, 5.0, 1, 1)
+ )
+ )
+
+ val multipleDenseRanks = df
+ .withColumn("rn", dense_rank().over(window))
+ .withColumn("rn2", dense_rank().over(window))
+ .where('rn < 2 && 'rn2 < 3)
+ checkAnswer(multipleDenseRanks,
+ Seq(
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("b", 1, "h", Double.NaN, 1, 1),
+ Row("c", 2, null, 5.0, 1, 1)
+ )
+ )
+
+ val multipleWindowsOne = df
+ .withColumn("rn2", row_number().over(window2))
+ .withColumn("rn", row_number().over(window))
Review Comment:
Yes. The inner Window will not be optimized.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1352608435
The failure GA is unrelated with this PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046828353
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextPartition()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (exceedingLimit() && nextGroup == currentGroup) {
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+ nextRowAvailable && nextGroup == currentGroup
+ } else {
+ nextRowAvailable
+ }
+ }
+
+ def next(): InternalRow = {
+ val currentRow = nextRow.copy()
+ increaseRank()
+ fetchNextRow()
+ currentRow
+ }
+ }
+ }
+}
+
+case class SimpleGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ stream: Iterator[InternalRow],
+ limit: Int) extends WindowIterator {
+ var count = 0
+
+ override def exceedingLimit(): Boolean = {
+ count >= limit
+ }
+
+ override def increaseRank(): Unit = {
+ count += 1
+ }
+
+ override def clearRank(): Unit = {
+ count = 0
+ }
+}
+
+case class RankGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ stream: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends WindowIterator {
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var count = 0
+ var rank = 0
+ var currentRank: UnsafeRow = null
+
+ override def exceedingLimit(): Boolean = {
+ rank >= limit
+ }
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRank = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRank, nextRow) != 0) {
+ rank = count
+ currentRank = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+
+ override def clearRank(): Unit = {
+ count = 0
+ rank = 0
+ currentRank = null
+ }
+}
+
+case class DenseRankGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ stream: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends WindowIterator {
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var rank = 0
Review Comment:
For `SimpleGroupLimitIterator`, rank is simply the count.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1365007428
ping @cloud-fan
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1330155848
> since new logical and physical plans are added, should also consider how it affect existing rules.
How about we do this optimization as a planner rule? then logical plan won't change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036918161
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##########
@@ -2568,6 +2568,17 @@ object SQLConf {
.intConf
.createWithDefault(SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD.defaultValue.get)
+ val WINDOW_GROUP_LIMIT_THRESHOLD =
+ buildConf("spark.sql.window.group.limit.threshold")
+ .internal()
+ .doc("Threshold for filter the dataset by the window group limit before" +
+ " window-based top-k computation. By setting this value to -1 window group limit can be" +
+ " disabled.")
+ .version("3.4.0")
+ .intConf
+ .checkValue(_ >= -1, "The threshold of window group limit must be 0 or positive integer.")
Review Comment:
are we going to enable it by default? @cloud-fan
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1108125372
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,310 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(new SimpleLimitIterator(output, _, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(new RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(new DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ var rank = 0
+
+ var nextRow: UnsafeRow = null
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ override def hasNext: Boolean = rank < limit && input.hasNext
+
+ override def next(): InternalRow = {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ increaseRank()
+ nextRow
+ }
+}
+
+class SimpleLimitIterator(
+ val output: Seq[Attribute],
+ val input: Iterator[InternalRow],
+ val limit: Int) extends BaseLimitIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+}
+
+trait OrderSpecProvider {
+ def output: Seq[Attribute]
+ def orderSpec: Seq[SortOrder]
+
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var currentRankRow: UnsafeRow = null
+}
+
+class RankLimitIterator(
+ val output: Seq[Attribute],
+ val input: Iterator[InternalRow],
+ val orderSpec: Seq[SortOrder],
+ val limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ var count = 0
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank = count
+ currentRankRow = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+}
+
+class DenseRankLimitIterator(
+ val output: Seq[Attribute],
+ val input: Iterator[InternalRow],
+ val orderSpec: Seq[SortOrder],
+ val limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ override def increaseRank(): Unit = {
+ if (currentRankRow == null) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank += 1
+ currentRankRow = nextRow.copy()
+ }
+ }
+ }
+}
+
+trait WindowIterator extends BaseLimitIterator {
Review Comment:
I think the main job of this iterator is to do grouping, and then we can build a `SimpleLimitIterator` or its friends with each group. Something like
```
class GroupIterator(input, currentRow) extends Iterator[InternalRow] {
val currentGroup = grouping(currentRow)
// Manage the stream and the grouping.
var nextGroup: UnsafeRow = null
var nextRow: UnsafeRow = null
protected[this] def fetchNextRow(): Unit = {
if (input.hasNext) {
nextRow = input.next().asInstanceOf[UnsafeRow]
nextGroup = grouping(nextRow)
} else {
nextRow = null
nextGroup = null
}
}
fetchNextRow()
def hasNext = nextGroup != null && nextGroup == currentGroup
def next = {
val res = nextRow
fetchNextRow()
res
}
}
trait WindowIterator extends Iterator[InternalRow] {
var limitIterator = null
def createLimitIterator = {
if (input.hasNext) {
val groupIterator = new GroupIterator(input, itput.next)
limitIterator = createSimpleLimitIterator(groupIterator)
} else {
limitIterator = null
}
}
createLimitIterator()
def hasNext = limitIterator != null && limitIterator.hasNext
def next = {
val res = limitIterator.next()
if (!limitIterator.hasNext) createLimitIterator
res
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1111594711
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,257 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(SimpleLimitIterator(_, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => SimpleLimitIterator(input, limit)))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => RankLimitIterator(output, input, orderSpec, limit)))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => DenseRankLimitIterator(output, input, orderSpec, limit)))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ var rank = 0
+
+ var nextRow: UnsafeRow = null
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ override def hasNext: Boolean = rank < limit && input.hasNext
+
+ override def next(): InternalRow = {
+ if (!hasNext) throw new NoSuchElementException
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ increaseRank()
+ nextRow
+ }
+
+ def reset(): Unit
+}
+
+case class SimpleLimitIterator(
+ input: Iterator[InternalRow],
+ limit: Int) extends BaseLimitIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+trait OrderSpecProvider {
+ def output: Seq[Attribute]
+ def orderSpec: Seq[SortOrder]
+
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var currentRankRow: UnsafeRow = null
+}
+
+case class RankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ var count = 0
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank = count
+ currentRankRow = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ count = 0
+ }
+}
+
+case class DenseRankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ override def increaseRank(): Unit = {
+ if (currentRankRow == null) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank += 1
+ currentRankRow = nextRow.copy()
+ }
+ }
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+class GroupedLimitIterator(
+ input: Iterator[InternalRow],
+ output: Seq[Attribute],
+ partitionSpec: Seq[Expression],
+ createLimitIterator: Iterator[InternalRow] => BaseLimitIterator) extends Iterator[InternalRow] {
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ }
+ }
+ fetchNextRow()
+
+ var groupIterator: GroupIterator = _
+ var limitIterator: BaseLimitIterator = _
+ if (nextRowAvailable) {
+ groupIterator = new GroupIterator()
+ limitIterator = createLimitIterator(groupIterator)
+ }
+
+ override final def hasNext: Boolean = nextRowAvailable
+
+ override final def next(): InternalRow = {
+ if (!hasNext) throw new NoSuchElementException
+ if (!limitIterator.hasNext && nextRowAvailable) {
+ groupIterator.skipRemainingRows()
+ limitIterator.reset()
+
+ if (!nextRowAvailable) {
+ // After skip remaining row in previous partition, all the input rows have been processed,
+ // so returns the last row directly.
+ return nextRow
+ }
+ }
+
+ limitIterator.next()
+ }
+
+ class GroupIterator() extends Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ var currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = nextRowAvailable && nextGroup == currentGroup
+
+ def next(): InternalRow = {
+ if (!hasNext) throw new NoSuchElementException
+ val currentRow = nextRow.copy()
+ fetchNextRow()
+ currentRow
+ }
+
+ def skipRemainingRows(): Unit = {
+ if (nextRowAvailable && nextGroup == currentGroup) {
+ // Skip all the remaining rows in this group
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
Review Comment:
nit:
```
while (nextRowAvailable && nextGroup == currentGroup) {
fetchNextRow()
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1108108508
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,310 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(new SimpleLimitIterator(output, _, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(new RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(new DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ var rank = 0
+
+ var nextRow: UnsafeRow = null
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ override def hasNext: Boolean = rank < limit && input.hasNext
+
+ override def next(): InternalRow = {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ increaseRank()
+ nextRow
+ }
+}
+
+class SimpleLimitIterator(
+ val output: Seq[Attribute],
Review Comment:
We can remove this parameter
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036903257
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala:
##########
@@ -627,6 +627,87 @@ abstract class SparkStrategies extends QueryPlanner[SparkPlan] {
}
}
+ /**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+ object WindowGroupLimit extends Strategy with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = {
+ if (conf.windowGroupLimitThreshold == -1) return Nil
+
+ plan match {
+ case filter @ Filter(condition,
+ window @ logical.Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[logical.Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
Review Comment:
No, if the window exists at least one rank like function, we can apply the optimization.
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,235 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = {
+
+ abstract class WindowIterator extends Iterator[InternalRow] {
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1035760439
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = {
+
+ abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, child.output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean = {
+ val found = (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+ found
+ }
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
Review Comment:
It's not the same.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046864508
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala:
##########
@@ -146,7 +146,9 @@ abstract class Optimizer(catalogManager: CatalogManager)
operatorOptimizationRuleSet: _*) ::
Batch("Push extra predicate through join", fixedPoint,
PushExtraPredicateThroughJoin,
- PushDownPredicates) :: Nil
+ PushDownPredicates) ::
+ Batch("Insert window group limit", Once,
+ InsertWindowGroupLimit) :: Nil
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046763580
##########
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimitSuite.scala:
##########
@@ -0,0 +1,308 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.catalyst.dsl.expressions._
+import org.apache.spark.sql.catalyst.dsl.plans._
+import org.apache.spark.sql.catalyst.expressions.{CurrentRow, DenseRank, Literal, NthValue, NTile, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding}
+import org.apache.spark.sql.catalyst.plans.PlanTest
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation, LogicalPlan}
+import org.apache.spark.sql.catalyst.rules.RuleExecutor
+import org.apache.spark.sql.internal.SQLConf
+
+class InsertWindowGroupLimitSuite extends PlanTest {
+ private object Optimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates,
+ InsertWindowGroupLimit) :: Nil
+ }
+
+ private object WithoutOptimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates) :: Nil
+ }
+
+ private val testRelation = LocalRelation.fromExternalRows(
+ Seq("a".attr.int, "b".attr.int, "c".attr.int),
+ 1.to(10).map(i => Row(i % 3, 2, i)))
+ private val a = testRelation.output(0)
+ private val b = testRelation.output(1)
+ private val c = testRelation.output(2)
+ private val rankLikeFunctions = Seq(RowNumber(), Rank(c :: Nil), DenseRank(c :: Nil))
+ private val unsupportedFunctions = Seq(new NthValue(c, Literal(1)), new NTile())
+ private val windowFrame = SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
+ private val supportedConditions = Seq($"rn" === 2, $"rn" < 3, $"rn" <= 2)
+ private val unsupportedConditions = Seq($"rn" > 2, $"rn" === 1 || b > 2)
+
+ test("window without filter") {
+ for (function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("spark.sql.window.group.limit.threshold = -1") {
+ withSQLConf(SQLConf.WINDOW_GROUP_LIMIT_THRESHOLD.key -> "-1") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+ }
+
+ test("Insert window group limit node for top-k computation") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
+ val originalQuery0 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ val correctAnswer0 =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery0.analyze),
+ WithoutOptimize.execute(correctAnswer0.analyze))
+
+ val originalQuery1 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ val correctAnswer1 =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ comparePlans(
+ Optimize.execute(originalQuery1.analyze),
+ WithoutOptimize.execute(correctAnswer1.analyze))
+
+ val originalQuery2 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ val correctAnswer2 =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery2.analyze),
+ WithoutOptimize.execute(correctAnswer2.analyze))
+
+ val originalQuery3 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ val correctAnswer3 =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ comparePlans(
+ Optimize.execute(originalQuery3.analyze),
+ WithoutOptimize.execute(correctAnswer3.analyze))
+ }
+ }
+
+ test("Unsupported conditions") {
+ for (condition <- unsupportedConditions; function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("Unsupported window functions") {
+ for (condition <- supportedConditions; function <- unsupportedFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("Insert window group limit node for top-k computation: Empty partitionSpec") {
+ rankLikeFunctions.foreach { function =>
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where('rn <= 4)
+
+ val correctAnswer =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 4)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where('rn <= 4)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(correctAnswer.analyze))
+ }
+ }
+
+ test("Insert window group limit node for top-k computation: multiple rank-like functions") {
+ rankLikeFunctions.foreach { function =>
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"),
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn2"))
+ .where('rn < 2 && 'rn2 === 3)
+
+ val correctAnswer =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 1)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"),
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn2"))
+ .where('rn < 2 && 'rn2 === 3)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(correctAnswer.analyze))
+ }
+ }
+
+ test("multiple different rank-like window function and only one used in filter") {
Review Comment:
let's add one more test: supported window function + unsupported windown function, we can still optimize.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046943216
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/RemoveRedundantWindowGroupLimits.scala:
##########
@@ -0,0 +1,46 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.window.{Final, Partial, WindowGroupLimitExec}
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * Remove redundant partial WindowGroupLimitExec node from the spark plan. A partial
+ * WindowGroupLimitExec node is redundant when its child satisfies its required child distribution.
+ */
+object RemoveRedundantWindowGroupLimits extends Rule[SparkPlan] {
+
+ def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.getConf(SQLConf.REMOVE_REDUNDANT_WINDOW_GROUP_LIMITS_ENABLED)) {
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046765714
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/RemoveRedundantWindowGroupLimits.scala:
##########
@@ -0,0 +1,46 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.window.{Final, Partial, WindowGroupLimitExec}
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * Remove redundant partial WindowGroupLimitExec node from the spark plan. A partial
+ * WindowGroupLimitExec node is redundant when its child satisfies its required child distribution.
+ */
+object RemoveRedundantWindowGroupLimits extends Rule[SparkPlan] {
+
+ def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.getConf(SQLConf.REMOVE_REDUNDANT_WINDOW_GROUP_LIMITS_ENABLED)) {
Review Comment:
This doesn't need a feature flag. We won't see `WindowGroupLimitExec` if the entire feature is not enabled.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1422790848
there are 3 tpc queries having plan change, what's their perf result?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "beliefer (via GitHub)" <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100921709
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
Review Comment:
Yes. I have another PR do the work.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1108108103
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,310 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(new SimpleLimitIterator(output, _, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(new RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(new DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def output: Seq[Attribute]
Review Comment:
the `output` is not used in this parent class, do we really need to define it here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1108410153
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,281 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(SimpleLimitIterator(_, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ var rank = 0
+
+ var nextRow: UnsafeRow = null
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ override def hasNext: Boolean = rank < limit && input.hasNext
+
+ override def next(): InternalRow = {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ increaseRank()
+ nextRow
+ }
+}
+
+case class SimpleLimitIterator(
+ input: Iterator[InternalRow],
+ limit: Int) extends BaseLimitIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+}
+
+trait OrderSpecProvider {
+ def output: Seq[Attribute]
+ def orderSpec: Seq[SortOrder]
+
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var currentRankRow: UnsafeRow = null
+}
+
+case class RankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ var count = 0
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank = count
+ currentRankRow = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+}
+
+case class DenseRankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ override def increaseRank(): Unit = {
+ if (currentRankRow == null) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank += 1
+ currentRankRow = nextRow.copy()
+ }
+ }
+ }
+}
+
+trait WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ }
+ }
+ fetchNextRow()
+
+ var limitIterator: BaseLimitIterator = _
+
+ override final def hasNext: Boolean =
+ (limitIterator != null && limitIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((limitIterator == null || !limitIterator.hasNext) && nextRowAvailable) {
+ if (limitIterator != null) {
+ limitIterator.input.asInstanceOf[GroupIterator].skipRemainingRows()
+ }
+
+ if (nextRowAvailable) {
+ limitIterator = createLimitIterator(new GroupIterator())
+ } else {
+ // After skip remaining row in previous partition, all the input rows have been processed,
+ // so returns the last row directly.
+ return nextRow
+ }
+ }
+
+ if (limitIterator != null && limitIterator.hasNext) {
+ limitIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ class GroupIterator() extends Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = nextRowAvailable && nextGroup == currentGroup
+
+ def next(): InternalRow = if (nextRowAvailable && nextGroup == currentGroup) {
+ val currentRow = nextRow.copy()
+ fetchNextRow()
+ currentRow
+ } else {
+ throw new NoSuchElementException
+ }
+
+ def skipRemainingRows(): Unit = {
+ if (nextRowAvailable && nextGroup == currentGroup) {
+ // Skip all the remaining rows in this group
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+ }
+ }
+
+ protected def createLimitIterator(groupIterator: GroupIterator): BaseLimitIterator
+}
+
+case class SimpleGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ limit: Int) extends WindowIterator {
+
+ override def createLimitIterator(groupIterator: GroupIterator): BaseLimitIterator = {
+ SimpleLimitIterator(groupIterator, limit)
Review Comment:
for the worst case (one row per window group), this will instantiate one iterator each row, which can be bad for GC.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046761416
##########
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimitSuite.scala:
##########
@@ -0,0 +1,308 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.catalyst.dsl.expressions._
+import org.apache.spark.sql.catalyst.dsl.plans._
+import org.apache.spark.sql.catalyst.expressions.{CurrentRow, DenseRank, Literal, NthValue, NTile, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding}
+import org.apache.spark.sql.catalyst.plans.PlanTest
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation, LogicalPlan}
+import org.apache.spark.sql.catalyst.rules.RuleExecutor
+import org.apache.spark.sql.internal.SQLConf
+
+class InsertWindowGroupLimitSuite extends PlanTest {
+ private object Optimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates,
+ InsertWindowGroupLimit) :: Nil
+ }
+
+ private object WithoutOptimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates) :: Nil
+ }
+
+ private val testRelation = LocalRelation.fromExternalRows(
+ Seq("a".attr.int, "b".attr.int, "c".attr.int),
+ 1.to(10).map(i => Row(i % 3, 2, i)))
+ private val a = testRelation.output(0)
+ private val b = testRelation.output(1)
+ private val c = testRelation.output(2)
+ private val rankLikeFunctions = Seq(RowNumber(), Rank(c :: Nil), DenseRank(c :: Nil))
+ private val unsupportedFunctions = Seq(new NthValue(c, Literal(1)), new NTile())
+ private val windowFrame = SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
+ private val supportedConditions = Seq($"rn" === 2, $"rn" < 3, $"rn" <= 2)
+ private val unsupportedConditions = Seq($"rn" > 2, $"rn" === 1 || b > 2)
+
+ test("window without filter") {
+ for (function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("spark.sql.window.group.limit.threshold = -1") {
+ withSQLConf(SQLConf.WINDOW_GROUP_LIMIT_THRESHOLD.key -> "-1") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+ }
+
+ test("Insert window group limit node for top-k computation") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
Review Comment:
```suggestion
for (condition <- supportedConditions; function <- rankLikeFunctions; moreCond <- Seq(true, false)) {
```
This can further deduplicate tests with and without `& b > 0`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046770685
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
Review Comment:
per window group ordering can be done later via `Utils.takeOrdered`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046824348
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextPartition()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (exceedingLimit() && nextGroup == currentGroup) {
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+ nextRowAvailable && nextGroup == currentGroup
+ } else {
+ nextRowAvailable
+ }
+ }
+
+ def next(): InternalRow = {
+ val currentRow = nextRow.copy()
Review Comment:
why do we need to copy?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036958043
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala:
##########
@@ -627,6 +627,87 @@ abstract class SparkStrategies extends QueryPlanner[SparkPlan] {
}
}
+ /**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+ object WindowGroupLimit extends Strategy with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = {
+ if (conf.windowGroupLimitThreshold == -1) return Nil
+
+ plan match {
+ case filter @ Filter(condition,
+ window @ logical.Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[logical.Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.filter(_.isDefined)
+
+ // non rank-like functions or multiple different rank-like functions unsupported.
+ if (limits.isEmpty || limits.groupBy(_.get._2).size > 1) {
+ return Nil
+ }
+ val minLimit = limits.minBy(_.get._1)
+ minLimit match {
+ case Some((limit, rankLikeFunction)) if limit <= conf.windowGroupLimitThreshold =>
+ if (limit > 0) {
+ // TODO: [SPARK-41337] Add a physical rule to remove the partialLimitExec node,
+ // if there is no shuffle between the two nodes (partialLimitExec's
+ // outputPartitioning satisfies the finalLimitExec's requiredChildDistribution)
+ val partialLimitExec = execution.window.WindowGroupLimitExec(partitionSpec,
+ orderSpec, rankLikeFunction, limit, execution.window.Partial, planLater(child))
+ val finalLimitExec = execution.window.WindowGroupLimitExec(partitionSpec,
+ orderSpec, rankLikeFunction, limit, execution.window.Final, partialLimitExec)
+ val windowExec = execution.window.WindowExec(
+ windowExpressions, partitionSpec, orderSpec, finalLimitExec)
+ windowExec.setLogicalLink(window)
+ val filterExec = execution.FilterExec(condition, windowExec)
+ filterExec :: Nil
+ } else {
+ val localTableScanExec = LocalTableScanExec(filter.output, Seq.empty)
Review Comment:
This rule extracts limit value -1 from `row_number < 0` and it cannot satisfy the `windowGroupLimitThreshold`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036856699
##########
sql/core/src/test/resources/tpcds-plan-stability/approved-plans-v1_4/q44/simplified.txt:
##########
@@ -13,51 +13,63 @@ TakeOrderedAndProject [rnk,best_performing,worst_performing]
Filter [rnk,item_sk]
InputAdapter
Window [rank_col]
- WholeStageCodegen (3)
- Sort [rank_col]
- InputAdapter
- Exchange #1
- WholeStageCodegen (2)
- Filter [rank_col]
- Subquery #1
- WholeStageCodegen (2)
- HashAggregate [ss_store_sk,sum,count] [avg(UnscaledValue(ss_net_profit)),rank_col,sum,count]
- InputAdapter
- Exchange [ss_store_sk] #3
- WholeStageCodegen (1)
- HashAggregate [ss_store_sk,ss_net_profit] [sum,count,sum,count]
- Project [ss_store_sk,ss_net_profit]
- Filter [ss_store_sk,ss_addr_sk]
- ColumnarToRow
- InputAdapter
- Scan parquet spark_catalog.default.store_sales [ss_addr_sk,ss_store_sk,ss_net_profit,ss_sold_date_sk]
- HashAggregate [ss_item_sk,sum,count] [avg(UnscaledValue(ss_net_profit)),item_sk,rank_col,sum,count]
- InputAdapter
- Exchange [ss_item_sk] #2
- WholeStageCodegen (1)
- HashAggregate [ss_item_sk,ss_net_profit] [sum,count,sum,count]
- Project [ss_item_sk,ss_net_profit]
- Filter [ss_store_sk]
- ColumnarToRow
- InputAdapter
- Scan parquet spark_catalog.default.store_sales [ss_item_sk,ss_store_sk,ss_net_profit,ss_sold_date_sk]
+ WindowGroupLimit [rank_col]
+ WholeStageCodegen (3)
+ Sort [rank_col]
+ InputAdapter
+ Exchange #1
+ WindowGroupLimit [rank_col]
Review Comment:
we should support whole-stage-codegen for it. This can be done later.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1067823961
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,241 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (rank >= limit && nextGroup == currentGroup) {
Review Comment:
Yes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "beliefer (via GitHub)" <gi...@apache.org>.
beliefer commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1437962007
@cloud-fan @zhengruifeng @LuciferYang @ulysses-you Thank you for review.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100225550
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def support(
+ windowExpression: NamedExpression): Boolean = windowExpression match {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && windowExpressions.exists(support) &&
+ orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) if support(alias) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty) {
+ filter
+ } else {
+ limits.minBy(_._1) match {
Review Comment:
one more optimization: if limit is the same, pick `Rank` as it's cheaper to evaluate.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100230831
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##########
@@ -2580,6 +2580,18 @@ object SQLConf {
.intConf
.createWithDefault(SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD.defaultValue.get)
+ val WINDOW_GROUP_LIMIT_THRESHOLD =
+ buildConf("spark.sql.optimizer.windowGroupLimitThreshold")
+ .internal()
+ .doc("Threshold for filter the dataset by the window group limit before" +
+ " window-based top-k computation. By setting this value to -1 window group limit can be" +
+ " disabled.")
+ .version("3.4.0")
+ .intConf
+ .checkValue(_ >= -1,
+ "The threshold of window group limit must be -1, 0 or positive integer.")
Review Comment:
why can't 0 indicate disable?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100265866
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
Review Comment:
I'm wondering if we should optimize for the special case where the function is row_number and the partition spec is empty. For this case, we just need to do a top n, no need to sort the entire input.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100268804
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
Review Comment:
I find this nested iterator makes the code harder to understand. Shall we flatten all the states in the `WindowIterator` and only implement one `hasNext` and `next`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1327269123
ping @zhengruifeng cc @cloud-fan
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036903257
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala:
##########
@@ -627,6 +627,87 @@ abstract class SparkStrategies extends QueryPlanner[SparkPlan] {
}
}
+ /**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+ object WindowGroupLimit extends Strategy with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = {
+ if (conf.windowGroupLimitThreshold == -1) return Nil
+
+ plan match {
+ case filter @ Filter(condition,
+ window @ logical.Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[logical.Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
Review Comment:
If the window exists at least one rank like function, we can apply the optimization.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1333530415
I just image a special case: if the child's (e.g a SMJ) output ordering happens to satisfy the requirement of this filter, then there will be no extra SortExec, is it always beneficial to apply this optimization?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046750710
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, ExpressionSet, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
Review Comment:
The enter condition is `windowExpressions.exists`, so here we should make sure we are really matching rank like functions. How about
```
def support(windowExpr: NamedExpression) ...
...
case Filter(...Window(... if windowExpressions.exists(support) ...
...
case alias @ Alias(WindowExpression(rankLikeFunction ... if support(alias) =>
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046759151
##########
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimitSuite.scala:
##########
@@ -0,0 +1,308 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.catalyst.dsl.expressions._
+import org.apache.spark.sql.catalyst.dsl.plans._
+import org.apache.spark.sql.catalyst.expressions.{CurrentRow, DenseRank, Literal, NthValue, NTile, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding}
+import org.apache.spark.sql.catalyst.plans.PlanTest
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation, LogicalPlan}
+import org.apache.spark.sql.catalyst.rules.RuleExecutor
+import org.apache.spark.sql.internal.SQLConf
+
+class InsertWindowGroupLimitSuite extends PlanTest {
+ private object Optimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates,
+ InsertWindowGroupLimit) :: Nil
+ }
+
+ private object WithoutOptimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates) :: Nil
+ }
+
+ private val testRelation = LocalRelation.fromExternalRows(
+ Seq("a".attr.int, "b".attr.int, "c".attr.int),
+ 1.to(10).map(i => Row(i % 3, 2, i)))
+ private val a = testRelation.output(0)
+ private val b = testRelation.output(1)
+ private val c = testRelation.output(2)
+ private val rankLikeFunctions = Seq(RowNumber(), Rank(c :: Nil), DenseRank(c :: Nil))
+ private val unsupportedFunctions = Seq(new NthValue(c, Literal(1)), new NTile())
+ private val windowFrame = SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
+ private val supportedConditions = Seq($"rn" === 2, $"rn" < 3, $"rn" <= 2)
+ private val unsupportedConditions = Seq($"rn" > 2, $"rn" === 1 || b > 2)
Review Comment:
```suggestion
private val unsupportedConditions = Seq($"rn" > 2, $"rn" === 1 || b < 2)
```
To prove the problem is not `>`, but `b`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046770129
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
Review Comment:
```suggestion
Seq(partitionSpec.map(SortOrder(_, Ascending)))
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046774390
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
Review Comment:
```suggestion
def exceedLimit(): Boolean
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046885232
##########
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimitSuite.scala:
##########
@@ -0,0 +1,308 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.catalyst.dsl.expressions._
+import org.apache.spark.sql.catalyst.dsl.plans._
+import org.apache.spark.sql.catalyst.expressions.{CurrentRow, DenseRank, Literal, NthValue, NTile, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding}
+import org.apache.spark.sql.catalyst.plans.PlanTest
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation, LogicalPlan}
+import org.apache.spark.sql.catalyst.rules.RuleExecutor
+import org.apache.spark.sql.internal.SQLConf
+
+class InsertWindowGroupLimitSuite extends PlanTest {
+ private object Optimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates,
+ InsertWindowGroupLimit) :: Nil
+ }
+
+ private object WithoutOptimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates) :: Nil
+ }
+
+ private val testRelation = LocalRelation.fromExternalRows(
+ Seq("a".attr.int, "b".attr.int, "c".attr.int),
+ 1.to(10).map(i => Row(i % 3, 2, i)))
+ private val a = testRelation.output(0)
+ private val b = testRelation.output(1)
+ private val c = testRelation.output(2)
+ private val rankLikeFunctions = Seq(RowNumber(), Rank(c :: Nil), DenseRank(c :: Nil))
+ private val unsupportedFunctions = Seq(new NthValue(c, Literal(1)), new NTile())
+ private val windowFrame = SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
+ private val supportedConditions = Seq($"rn" === 2, $"rn" < 3, $"rn" <= 2)
+ private val unsupportedConditions = Seq($"rn" > 2, $"rn" === 1 || b > 2)
Review Comment:
Yes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100225550
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def support(
+ windowExpression: NamedExpression): Boolean = windowExpression match {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && windowExpressions.exists(support) &&
+ orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) if support(alias) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty) {
+ filter
+ } else {
+ limits.minBy(_._1) match {
Review Comment:
one more optimization: if limit is the same, pick `RowNumber ` as it's cheaper to evaluate.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1111754220
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,249 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(SimpleLimitIterator(_, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => SimpleLimitIterator(input, limit)))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => RankLimitIterator(output, input, orderSpec, limit)))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => DenseRankLimitIterator(output, input, orderSpec, limit)))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ var rank = 0
+
+ var nextRow: UnsafeRow = null
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ override def hasNext: Boolean = rank < limit && input.hasNext
+
+ override def next(): InternalRow = {
+ if (!hasNext) throw new NoSuchElementException
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ increaseRank()
+ nextRow
+ }
+
+ def reset(): Unit
+}
+
+case class SimpleLimitIterator(
+ input: Iterator[InternalRow],
+ limit: Int) extends BaseLimitIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+trait OrderSpecProvider {
+ def output: Seq[Attribute]
+ def orderSpec: Seq[SortOrder]
+
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var currentRankRow: UnsafeRow = null
+}
+
+case class RankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ var count = 0
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank = count
+ currentRankRow = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ count = 0
+ }
+}
+
+case class DenseRankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ override def increaseRank(): Unit = {
+ if (currentRankRow == null) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank += 1
+ currentRankRow = nextRow.copy()
+ }
+ }
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+class GroupedLimitIterator(
+ input: Iterator[InternalRow],
+ output: Seq[Attribute],
+ partitionSpec: Seq[Expression],
+ createLimitIterator: Iterator[InternalRow] => BaseLimitIterator)
+ extends Iterator[InternalRow] {
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ }
+ }
+ fetchNextRow()
+
+ var groupIterator: GroupIterator = _
+ var limitIterator: BaseLimitIterator = _
+ if (nextRowAvailable) {
+ groupIterator = new GroupIterator()
+ limitIterator = createLimitIterator(groupIterator)
+ }
+
+ override final def hasNext: Boolean = limitIterator.hasNext || {
+ groupIterator.skipRemainingRows()
Review Comment:
let's add comments:
```
if `limitIterator.hasNext` is false, we should jump to the next group if present
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036831598
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = {
+
+ abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, child.output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean = {
+ val found = (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+ found
+ }
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
Review Comment:
ok
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1037916329
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{ExternalAppendOnlyUnsafeRowArray, SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ // Only show warning when the number of bytes is larger than 100 MiB?
+ logWarning("No Partition Defined for Window operation! Moving all data to a single "
+ + "partition, this can cause serious performance degradation.")
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100212345
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
Review Comment:
```
Inserts a `WindowGroupLimit` below `Window` if the `Window` has rank-like functions
and the function results are further filtered by limit-like predicates. Example query:
{{{
SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
}}}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100212345
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
Review Comment:
```
Inserts a `WindowGroupLimit` below `Window` if the `Window` has rank-like functions
and the function results are futher filtered by limit-like predicates.
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "beliefer (via GitHub)" <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100909992
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def support(
+ windowExpression: NamedExpression): Boolean = windowExpression match {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && windowExpressions.exists(support) &&
+ orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) if support(alias) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty) {
+ filter
+ } else {
+ limits.minBy(_._1) match {
Review Comment:
Good idea.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100267210
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
Review Comment:
We can do this later if there is no TPC query hitting it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100238179
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkOptimizer.scala:
##########
@@ -81,6 +81,7 @@ class SparkOptimizer(
ColumnPruning,
PushPredicateThroughNonJoin,
RemoveNoopOperators) :+
+ Batch("Insert window group limit", Once, InsertWindowGroupLimit) :+
Review Comment:
is there a particular reason to run this rule so late?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "beliefer (via GitHub)" <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100919419
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##########
@@ -2580,6 +2580,18 @@ object SQLConf {
.intConf
.createWithDefault(SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD.defaultValue.get)
+ val WINDOW_GROUP_LIMIT_THRESHOLD =
+ buildConf("spark.sql.optimizer.windowGroupLimitThreshold")
+ .internal()
+ .doc("Threshold for filter the dataset by the window group limit before" +
Review Comment:
0 means the output results is empty.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100268804
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
Review Comment:
I find this nested iterator makes the code harder to understand. Shall we flatten all the states in the `WindowIterator` and only implement one `hasNext` and `next`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1111752872
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,249 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(SimpleLimitIterator(_, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => SimpleLimitIterator(input, limit)))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => RankLimitIterator(output, input, orderSpec, limit)))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => DenseRankLimitIterator(output, input, orderSpec, limit)))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ var rank = 0
+
+ var nextRow: UnsafeRow = null
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ override def hasNext: Boolean = rank < limit && input.hasNext
+
+ override def next(): InternalRow = {
+ if (!hasNext) throw new NoSuchElementException
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ increaseRank()
+ nextRow
+ }
+
+ def reset(): Unit
+}
+
+case class SimpleLimitIterator(
+ input: Iterator[InternalRow],
+ limit: Int) extends BaseLimitIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+trait OrderSpecProvider {
+ def output: Seq[Attribute]
+ def orderSpec: Seq[SortOrder]
+
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var currentRankRow: UnsafeRow = null
+}
+
+case class RankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ var count = 0
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank = count
+ currentRankRow = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ count = 0
+ }
+}
+
+case class DenseRankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ override def increaseRank(): Unit = {
+ if (currentRankRow == null) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank += 1
+ currentRankRow = nextRow.copy()
+ }
+ }
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+class GroupedLimitIterator(
+ input: Iterator[InternalRow],
+ output: Seq[Attribute],
+ partitionSpec: Seq[Expression],
+ createLimitIterator: Iterator[InternalRow] => BaseLimitIterator)
+ extends Iterator[InternalRow] {
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ }
+ }
+ fetchNextRow()
+
+ var groupIterator: GroupIterator = _
+ var limitIterator: BaseLimitIterator = _
+ if (nextRowAvailable) {
+ groupIterator = new GroupIterator()
+ limitIterator = createLimitIterator(groupIterator)
+ }
+
+ override final def hasNext: Boolean = limitIterator.hasNext || {
+ groupIterator.skipRemainingRows()
+ limitIterator.reset()
+ groupIterator.hasNext
Review Comment:
```suggestion
limitIterator.hasNext
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1042908731
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,98 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(
+ _.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && !child.isInstanceOf[Window] &&
Review Comment:
Removed and added test cases.
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,98 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(
+ _.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && !child.isInstanceOf[Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.filter(_.isDefined)
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty || limits.groupBy(_.get._2).size > 1) {
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046913550
##########
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimitSuite.scala:
##########
@@ -0,0 +1,308 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.catalyst.dsl.expressions._
+import org.apache.spark.sql.catalyst.dsl.plans._
+import org.apache.spark.sql.catalyst.expressions.{CurrentRow, DenseRank, Literal, NthValue, NTile, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding}
+import org.apache.spark.sql.catalyst.plans.PlanTest
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation, LogicalPlan}
+import org.apache.spark.sql.catalyst.rules.RuleExecutor
+import org.apache.spark.sql.internal.SQLConf
+
+class InsertWindowGroupLimitSuite extends PlanTest {
+ private object Optimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates,
+ InsertWindowGroupLimit) :: Nil
+ }
+
+ private object WithoutOptimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates) :: Nil
+ }
+
+ private val testRelation = LocalRelation.fromExternalRows(
+ Seq("a".attr.int, "b".attr.int, "c".attr.int),
+ 1.to(10).map(i => Row(i % 3, 2, i)))
+ private val a = testRelation.output(0)
+ private val b = testRelation.output(1)
+ private val c = testRelation.output(2)
+ private val rankLikeFunctions = Seq(RowNumber(), Rank(c :: Nil), DenseRank(c :: Nil))
+ private val unsupportedFunctions = Seq(new NthValue(c, Literal(1)), new NTile())
+ private val windowFrame = SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
+ private val supportedConditions = Seq($"rn" === 2, $"rn" < 3, $"rn" <= 2)
+ private val unsupportedConditions = Seq($"rn" > 2, $"rn" === 1 || b > 2)
+
+ test("window without filter") {
+ for (function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("spark.sql.window.group.limit.threshold = -1") {
+ withSQLConf(SQLConf.WINDOW_GROUP_LIMIT_THRESHOLD.key -> "-1") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+ }
+
+ test("Insert window group limit node for top-k computation") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
+ val originalQuery0 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ val correctAnswer0 =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery0.analyze),
+ WithoutOptimize.execute(correctAnswer0.analyze))
+
+ val originalQuery1 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ val correctAnswer1 =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ comparePlans(
+ Optimize.execute(originalQuery1.analyze),
+ WithoutOptimize.execute(correctAnswer1.analyze))
+
+ val originalQuery2 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ val correctAnswer2 =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery2.analyze),
+ WithoutOptimize.execute(correctAnswer2.analyze))
+
+ val originalQuery3 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ val correctAnswer3 =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ comparePlans(
+ Optimize.execute(originalQuery3.analyze),
+ WithoutOptimize.execute(correctAnswer3.analyze))
+ }
+ }
+
+ test("Unsupported conditions") {
+ for (condition <- unsupportedConditions; function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("Unsupported window functions") {
+ for (condition <- supportedConditions; function <- unsupportedFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("Insert window group limit node for top-k computation: Empty partitionSpec") {
+ rankLikeFunctions.foreach { function =>
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where('rn <= 4)
+
+ val correctAnswer =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 4)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where('rn <= 4)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(correctAnswer.analyze))
+ }
+ }
+
+ test("Insert window group limit node for top-k computation: multiple rank-like functions") {
+ rankLikeFunctions.foreach { function =>
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"),
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn2"))
+ .where('rn < 2 && 'rn2 === 3)
+
+ val correctAnswer =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 1)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"),
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn2"))
+ .where('rn < 2 && 'rn2 === 3)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(correctAnswer.analyze))
+ }
+ }
+
+ test("multiple different rank-like window function and only one used in filter") {
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "LuciferYang (via GitHub)" <gi...@apache.org>.
LuciferYang commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1413247314
Does this one have a chance to Spark 3.4?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046901129
##########
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimitSuite.scala:
##########
@@ -0,0 +1,308 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.catalyst.dsl.expressions._
+import org.apache.spark.sql.catalyst.dsl.plans._
+import org.apache.spark.sql.catalyst.expressions.{CurrentRow, DenseRank, Literal, NthValue, NTile, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding}
+import org.apache.spark.sql.catalyst.plans.PlanTest
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation, LogicalPlan}
+import org.apache.spark.sql.catalyst.rules.RuleExecutor
+import org.apache.spark.sql.internal.SQLConf
+
+class InsertWindowGroupLimitSuite extends PlanTest {
+ private object Optimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates,
+ InsertWindowGroupLimit) :: Nil
+ }
+
+ private object WithoutOptimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates) :: Nil
+ }
+
+ private val testRelation = LocalRelation.fromExternalRows(
+ Seq("a".attr.int, "b".attr.int, "c".attr.int),
+ 1.to(10).map(i => Row(i % 3, 2, i)))
+ private val a = testRelation.output(0)
+ private val b = testRelation.output(1)
+ private val c = testRelation.output(2)
+ private val rankLikeFunctions = Seq(RowNumber(), Rank(c :: Nil), DenseRank(c :: Nil))
+ private val unsupportedFunctions = Seq(new NthValue(c, Literal(1)), new NTile())
+ private val windowFrame = SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
+ private val supportedConditions = Seq($"rn" === 2, $"rn" < 3, $"rn" <= 2)
+ private val unsupportedConditions = Seq($"rn" > 2, $"rn" === 1 || b > 2)
+
+ test("window without filter") {
+ for (function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("spark.sql.window.group.limit.threshold = -1") {
+ withSQLConf(SQLConf.WINDOW_GROUP_LIMIT_THRESHOLD.key -> "-1") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+ }
+
+ test("Insert window group limit node for top-k computation") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
+ val originalQuery0 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ val correctAnswer0 =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery0.analyze),
+ WithoutOptimize.execute(correctAnswer0.analyze))
+
+ val originalQuery1 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ val correctAnswer1 =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ comparePlans(
+ Optimize.execute(originalQuery1.analyze),
+ WithoutOptimize.execute(correctAnswer1.analyze))
+
+ val originalQuery2 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ val correctAnswer2 =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery2.analyze),
+ WithoutOptimize.execute(correctAnswer2.analyze))
+
+ val originalQuery3 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ val correctAnswer3 =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ comparePlans(
+ Optimize.execute(originalQuery3.analyze),
+ WithoutOptimize.execute(correctAnswer3.analyze))
+ }
+ }
+
+ test("Unsupported conditions") {
+ for (condition <- unsupportedConditions; function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("Unsupported window functions") {
+ for (condition <- supportedConditions; function <- unsupportedFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("Insert window group limit node for top-k computation: Empty partitionSpec") {
+ rankLikeFunctions.foreach { function =>
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
Review Comment:
Thank you for you reminder.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046762409
##########
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimitSuite.scala:
##########
@@ -0,0 +1,308 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.catalyst.dsl.expressions._
+import org.apache.spark.sql.catalyst.dsl.plans._
+import org.apache.spark.sql.catalyst.expressions.{CurrentRow, DenseRank, Literal, NthValue, NTile, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding}
+import org.apache.spark.sql.catalyst.plans.PlanTest
+import org.apache.spark.sql.catalyst.plans.logical.{LocalRelation, LogicalPlan}
+import org.apache.spark.sql.catalyst.rules.RuleExecutor
+import org.apache.spark.sql.internal.SQLConf
+
+class InsertWindowGroupLimitSuite extends PlanTest {
+ private object Optimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates,
+ InsertWindowGroupLimit) :: Nil
+ }
+
+ private object WithoutOptimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Insert WindowGroupLimit", FixedPoint(10),
+ CollapseProject,
+ RemoveNoopOperators,
+ PushDownPredicates) :: Nil
+ }
+
+ private val testRelation = LocalRelation.fromExternalRows(
+ Seq("a".attr.int, "b".attr.int, "c".attr.int),
+ 1.to(10).map(i => Row(i % 3, 2, i)))
+ private val a = testRelation.output(0)
+ private val b = testRelation.output(1)
+ private val c = testRelation.output(2)
+ private val rankLikeFunctions = Seq(RowNumber(), Rank(c :: Nil), DenseRank(c :: Nil))
+ private val unsupportedFunctions = Seq(new NthValue(c, Literal(1)), new NTile())
+ private val windowFrame = SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
+ private val supportedConditions = Seq($"rn" === 2, $"rn" < 3, $"rn" <= 2)
+ private val unsupportedConditions = Seq($"rn" > 2, $"rn" === 1 || b > 2)
+
+ test("window without filter") {
+ for (function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("spark.sql.window.group.limit.threshold = -1") {
+ withSQLConf(SQLConf.WINDOW_GROUP_LIMIT_THRESHOLD.key -> "-1") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+ }
+
+ test("Insert window group limit node for top-k computation") {
+ for (condition <- supportedConditions; function <- rankLikeFunctions) {
+ val originalQuery0 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ val correctAnswer0 =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery0.analyze),
+ WithoutOptimize.execute(correctAnswer0.analyze))
+
+ val originalQuery1 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ val correctAnswer1 =
+ testRelation
+ .windowGroupLimit(a :: Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ comparePlans(
+ Optimize.execute(originalQuery1.analyze),
+ WithoutOptimize.execute(correctAnswer1.analyze))
+
+ val originalQuery2 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ val correctAnswer2 =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery2.analyze),
+ WithoutOptimize.execute(correctAnswer2.analyze))
+
+ val originalQuery3 =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ val correctAnswer3 =
+ testRelation
+ .windowGroupLimit(Nil, c.desc :: Nil, function, 2)
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition && b > 0)
+
+ comparePlans(
+ Optimize.execute(originalQuery3.analyze),
+ WithoutOptimize.execute(correctAnswer3.analyze))
+ }
+ }
+
+ test("Unsupported conditions") {
+ for (condition <- unsupportedConditions; function <- rankLikeFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("Unsupported window functions") {
+ for (condition <- supportedConditions; function <- unsupportedFunctions) {
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(a :: Nil, c.desc :: Nil, windowFrame)).as("rn"))
+ .where(condition)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+ }
+
+ test("Insert window group limit node for top-k computation: Empty partitionSpec") {
+ rankLikeFunctions.foreach { function =>
+ val originalQuery =
+ testRelation
+ .select(a, b, c,
+ windowExpr(function,
+ windowSpec(Nil, c.desc :: Nil, windowFrame)).as("rn"))
Review Comment:
seems it's already tested: https://github.com/apache/spark/pull/38799/files#diff-3152a64564129e341027e179be3483e40972174b650b1228a0ac9755ab92adb3R134
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046991886
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
Review Comment:
The output of rank-like function is related to `orderSpec`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046753470
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala:
##########
@@ -146,7 +146,9 @@ abstract class Optimizer(catalogManager: CatalogManager)
operatorOptimizationRuleSet: _*) ::
Batch("Push extra predicate through join", fixedPoint,
PushExtraPredicateThroughJoin,
- PushDownPredicates) :: Nil
+ PushDownPredicates) ::
+ Batch("Insert window group limit", Once,
+ InsertWindowGroupLimit) :: Nil
Review Comment:
is there a specific reason to put the rule here, instead of the very end of the optimizer? e.g., right before `Batch("User Provided Optimizers", fixedPoint, experimentalMethods.extraOptimizations: _*)` in ·SparkOptimizer·.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046754926
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##########
@@ -1723,6 +1723,14 @@ object SQLConf {
.booleanConf
.createWithDefault(true)
+ val REMOVE_REDUNDANT_WINDOW_GROUP_LIMITS_ENABLED =
+ buildConf("spark.sql.execution.removeRedundantWindowGroupLimits")
Review Comment:
```suggestion
buildConf("spark.sql.optimizer.windowGroupLimitThreshold")
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046820898
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
Review Comment:
```suggestion
private[this] def fetchNextGroup(): Unit = {
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] ulysses-you commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
ulysses-you commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1066778326
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,241 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
Review Comment:
`mapPartitions` -> `mapPartitionsInternal`
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,241 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (rank >= limit && nextGroup == currentGroup) {
Review Comment:
We should fetch next row until rank > limit for `Rank` and `DenseRank`, since the next row can be the same rank with previous in one group
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala:
##########
@@ -1229,6 +1229,22 @@ case class Window(
copy(child = newChild)
}
+case class WindowGroupLimit(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ child: LogicalPlan) extends OrderPreservingUnaryNode {
Review Comment:
why it can be an `OrderPreservingUnaryNode`, should the ordering be affected by `orderSpec` ?
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,241 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
Review Comment:
it's not a big issue but shall we call `clearRank` if does not have next to be consistent with previous ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan closed pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
URL: https://github.com/apache/spark/pull/38799
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100224037
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def support(
+ windowExpression: NamedExpression): Boolean = windowExpression match {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && windowExpressions.exists(support) &&
+ orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) if support(alias) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
Review Comment:
is this comment accurate? I think `limit.isEmpty` means there is no limit-like predicate.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100273726
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (rank >= limit && nextGroup == currentGroup) {
+ // Skip all the remaining rows in this group
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ false
+ } else {
+ // Returns true if there are more rows in this group.
+ nextGroup == currentGroup
+ }
+ } else {
+ false
+ }
+ }
+
+ def next(): InternalRow = {
+ val currentRow = nextRow.copy()
+ increaseRank()
+ fetchNextRow()
+ currentRow
+ }
+ }
+ }
+}
+
+case class SimpleGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ limit: Int) extends WindowIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+
+ override def clearRank(): Unit = {
+ rank = 0
+ }
+}
+
+case class RankGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends WindowIterator {
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var count = 0
+ var currentRank: UnsafeRow = null
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRank = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRank, nextRow) != 0) {
+ rank = count
+ currentRank = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+
+ override def clearRank(): Unit = {
+ count = 0
+ rank = 0
+ currentRank = null
+ }
+}
+
+case class DenseRankGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends WindowIterator {
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var currentRank: UnsafeRow = null
Review Comment:
```suggestion
var currentRankRow: UnsafeRow = null
```
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (rank >= limit && nextGroup == currentGroup) {
+ // Skip all the remaining rows in this group
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ false
+ } else {
+ // Returns true if there are more rows in this group.
+ nextGroup == currentGroup
+ }
+ } else {
+ false
+ }
+ }
+
+ def next(): InternalRow = {
+ val currentRow = nextRow.copy()
+ increaseRank()
+ fetchNextRow()
+ currentRow
+ }
+ }
+ }
+}
+
+case class SimpleGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ limit: Int) extends WindowIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+
+ override def clearRank(): Unit = {
+ rank = 0
+ }
+}
+
+case class RankGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends WindowIterator {
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var count = 0
+ var currentRank: UnsafeRow = null
Review Comment:
```suggestion
var currentRankRow: UnsafeRow = null
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1042275820
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,98 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(
+ _.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && !child.isInstanceOf[Window] &&
Review Comment:
why can't the child be another window?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1042278667
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala:
##########
@@ -146,7 +146,9 @@ abstract class Optimizer(catalogManager: CatalogManager)
operatorOptimizationRuleSet: _*) ::
Batch("Push extra predicate through join", fixedPoint,
PushExtraPredicateThroughJoin,
- PushDownPredicates) :: Nil
+ PushDownPredicates) ::
+ Batch("Insert window group limit", fixedPoint,
Review Comment:
should it be a once batch?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1034477295
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{ExternalAppendOnlyUnsafeRowArray, SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ // Only show warning when the number of bytes is larger than 100 MiB?
+ logWarning("No Partition Defined for Window operation! Moving all data to a single "
+ + "partition, this can cause serious performance degradation.")
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = {
+ val inMemoryThreshold = conf.windowExecBufferInMemoryThreshold
+ val spillThreshold = conf.windowExecBufferSpillThreshold
Review Comment:
Because the buffer has been removed, so the two config not needed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1329040563
This PR basically adds a per-window-group limit before and after the shuffle to reduce the input data of window processing.
More specifically, the before-shuffle per-window-group limit:
1. adds an extra local sort to determine window group boundaries
2. applies per-group limit to reduce the data size of shuffle, and all the downstream operators.
This is beneficial, assuming the per-group data size is large. Otherwise, the extra local sort is pure overhead.
The after-shuffle per-window-group limit just applies a per-group limit to reduce the data size of window processing. This is very cheap as it only needs to iterate the sorted data (window operator needs to sort the input) once and do some row comparison to determine group boundaries and rank values. It's more efficient to merge it into the window operator, but probably doesn't worth it as the overhead is small.
I think the key here is to make sure the before-shuffle per-group limit is very unlikely to introduce regressions. It's very hard to know the per-group data size ahead of time (can CBO help?), and we need some heuristics to trigger it. Some thoughts:
1. shall we add a config as the threshold of the limit? e.g. we can set the config as 10 and then `where rn = 11` won't trigger it.
2. shall we have a special sort that stops earlier when the input is very distinct? This means the per-group data size is small and we shouldn't do this optimization.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1327389947
Very happy to see this optimization work restart
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1042277374
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,98 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(
+ _.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && !child.isInstanceOf[Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.filter(_.isDefined)
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty || limits.groupBy(_.get._2).size > 1) {
Review Comment:
We should use `ExpressionSet` to check semantically equals expressions, not just `groupBy`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036961597
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala:
##########
@@ -627,6 +627,87 @@ abstract class SparkStrategies extends QueryPlanner[SparkPlan] {
}
}
+ /**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+ object WindowGroupLimit extends Strategy with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = {
+ if (conf.windowGroupLimitThreshold == -1) return Nil
+
+ plan match {
+ case filter @ Filter(condition,
+ window @ logical.Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[logical.Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.filter(_.isDefined)
+
+ // non rank-like functions or multiple different rank-like functions unsupported.
+ if (limits.isEmpty || limits.groupBy(_.get._2).size > 1) {
+ return Nil
+ }
+ val minLimit = limits.minBy(_.get._1)
+ minLimit match {
+ case Some((limit, rankLikeFunction)) if limit <= conf.windowGroupLimitThreshold =>
+ if (limit > 0) {
+ // TODO: [SPARK-41337] Add a physical rule to remove the partialLimitExec node,
+ // if there is no shuffle between the two nodes (partialLimitExec's
+ // outputPartitioning satisfies the finalLimitExec's requiredChildDistribution)
+ val partialLimitExec = execution.window.WindowGroupLimitExec(partitionSpec,
+ orderSpec, rankLikeFunction, limit, execution.window.Partial, planLater(child))
+ val finalLimitExec = execution.window.WindowGroupLimitExec(partitionSpec,
+ orderSpec, rankLikeFunction, limit, execution.window.Final, partialLimitExec)
+ val windowExec = execution.window.WindowExec(
+ windowExpressions, partitionSpec, orderSpec, finalLimitExec)
+ windowExec.setLogicalLink(window)
+ val filterExec = execution.FilterExec(condition, windowExec)
+ filterExec :: Nil
+ } else {
+ val localTableScanExec = LocalTableScanExec(filter.output, Seq.empty)
Review Comment:
> maybe we can put it in other empty-relation related rules.
Maybe we can move it into `PruneFilters`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1035453396
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala:
##########
@@ -627,6 +627,22 @@ abstract class SparkStrategies extends QueryPlanner[SparkPlan] {
}
}
+ object WindowGroupLimit extends Strategy {
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
+ case logical.WindowGroupLimit(partitionSpec, orderSpec, rankLikeFunction, limit, child) =>
+ // TODO: add a physical rule to remove the partialWindowGroupLimit node, if there is no
Review Comment:
should we file a new jira to tracking this TODO
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(
+ _.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && !child.isInstanceOf[Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }
+
+ // multiple different rank-like functions unsupported.
+ if (limits.filter(_.isDefined).groupBy(_.get._2).size > 1) {
+ return filter
+ }
+ val minLimit = limits.sortBy(_.get._1).head
Review Comment:
could we change to use `minBy`?
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = {
+
+ abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, child.output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean = {
+ val found = (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
Review Comment:
need the local `val found`?
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = {
+
+ abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, child.output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean = {
+ val found = (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+ found
+ }
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
Review Comment:
Is this condition equal to `!hasNext`? not sure
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036906761
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##########
@@ -2568,6 +2568,17 @@ object SQLConf {
.intConf
.createWithDefault(SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD.defaultValue.get)
+ val WINDOW_GROUP_LIMIT_THRESHOLD =
+ buildConf("spark.sql.window.group.limit.threshold")
+ .internal()
+ .doc("Threshold for filter the dataset by the window group limit before" +
+ " window-based top-k computation. By setting this value to -1 window group limit can be" +
+ " disabled.")
+ .version("3.4.0")
+ .intConf
+ .checkValue(_ >= -1, "The threshold of window group limit must be 0 or positive integer.")
Review Comment:
```suggestion
.checkValue(limit => limit == -1 || limit > 0, "The threshold of window group limit must be -1 or positive integer.")
```
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##########
@@ -2568,6 +2568,17 @@ object SQLConf {
.intConf
.createWithDefault(SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD.defaultValue.get)
+ val WINDOW_GROUP_LIMIT_THRESHOLD =
+ buildConf("spark.sql.window.group.limit.threshold")
+ .internal()
+ .doc("Threshold for filter the dataset by the window group limit before" +
+ " window-based top-k computation. By setting this value to -1 window group limit can be" +
+ " disabled.")
+ .version("3.4.0")
+ .intConf
+ .checkValue(_ >= -1, "The threshold of window group limit must be 0 or positive integer.")
Review Comment:
are we going to enable it by default?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1057443215
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (rank >= limit && nextGroup == currentGroup) {
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+ nextRowAvailable && nextGroup == currentGroup
Review Comment:
The code here looks a bit confusing. How about
```
if (nextRowAvailable) {
if (rank >= limit && nextGroup == currentGroup) {
// Skip all the remaining rows in this group
do {
fetchNextRow()
} while (nextRowAvailable && nextGroup == currentGroup)
false
} else {
// Returns true if there are more rows in this group.
nextGroup == currentGroup
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1437957471
thanks, merging to master!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "beliefer (via GitHub)" <gi...@apache.org>.
beliefer commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1414640391
> Does this one have a chance to Spark 3.4?
Maybe. I testing the performance now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100226290
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def support(
+ windowExpression: NamedExpression): Boolean = windowExpression match {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && windowExpressions.exists(support) &&
+ orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) if support(alias) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty) {
+ filter
+ } else {
+ limits.minBy(_._1) match {
+ case (limit, rankLikeFunction) if limit <= conf.windowGroupLimitThreshold =>
+ if (limit > 0) {
+ val windowGroupLimit =
+ WindowGroupLimit(partitionSpec, orderSpec, rankLikeFunction, limit, child)
+ val newWindow = window.withNewChildren(Seq(windowGroupLimit))
+ val newFilter = filter.withNewChildren(Seq(newWindow))
+ newFilter
Review Comment:
```suggestion
filter.withNewChildren(Seq(newWindow))
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100224863
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def support(
+ windowExpression: NamedExpression): Boolean = windowExpression match {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && windowExpressions.exists(support) &&
+ orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) if support(alias) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty) {
+ filter
+ } else {
+ limits.minBy(_._1) match {
Review Comment:
let's add a comment: `pick a rank function with the smallest limit`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100236177
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def support(
+ windowExpression: NamedExpression): Boolean = windowExpression match {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] && windowExpressions.exists(support) &&
+ orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) if support(alias) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty) {
+ filter
+ } else {
+ limits.minBy(_._1) match {
Review Comment:
or more aggressively: always pick `RowNumber` first if it has a limit.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1111597640
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,257 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(SimpleLimitIterator(_, limit))
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => SimpleLimitIterator(input, limit)))
+ case _: Rank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(RankLimitIterator(output, _, orderSpec, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => RankLimitIterator(output, input, orderSpec, limit)))
+ case _: DenseRank if partitionSpec.isEmpty =>
+ child.execute().mapPartitionsInternal(DenseRankLimitIterator(output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(new GroupedLimitIterator(_, output, partitionSpec,
+ (input: Iterator[InternalRow]) => DenseRankLimitIterator(output, input, orderSpec, limit)))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class BaseLimitIterator extends Iterator[InternalRow] {
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ var rank = 0
+
+ var nextRow: UnsafeRow = null
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ override def hasNext: Boolean = rank < limit && input.hasNext
+
+ override def next(): InternalRow = {
+ if (!hasNext) throw new NoSuchElementException
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ increaseRank()
+ nextRow
+ }
+
+ def reset(): Unit
+}
+
+case class SimpleLimitIterator(
+ input: Iterator[InternalRow],
+ limit: Int) extends BaseLimitIterator {
+
+ override def increaseRank(): Unit = {
+ rank += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+trait OrderSpecProvider {
+ def output: Seq[Attribute]
+ def orderSpec: Seq[SortOrder]
+
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var currentRankRow: UnsafeRow = null
+}
+
+case class RankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ var count = 0
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank = count
+ currentRankRow = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ count = 0
+ }
+}
+
+case class DenseRankLimitIterator(
+ output: Seq[Attribute],
+ input: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends BaseLimitIterator with OrderSpecProvider {
+
+ override def increaseRank(): Unit = {
+ if (currentRankRow == null) {
+ currentRankRow = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRankRow, nextRow) != 0) {
+ rank += 1
+ currentRankRow = nextRow.copy()
+ }
+ }
+ }
+
+ override def reset(): Unit = {
+ rank = 0
+ }
+}
+
+class GroupedLimitIterator(
+ input: Iterator[InternalRow],
+ output: Seq[Attribute],
+ partitionSpec: Seq[Expression],
+ createLimitIterator: Iterator[InternalRow] => BaseLimitIterator) extends Iterator[InternalRow] {
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ }
+ }
+ fetchNextRow()
+
+ var groupIterator: GroupIterator = _
+ var limitIterator: BaseLimitIterator = _
+ if (nextRowAvailable) {
+ groupIterator = new GroupIterator()
+ limitIterator = createLimitIterator(groupIterator)
+ }
+
+ override final def hasNext: Boolean = nextRowAvailable
+
+ override final def next(): InternalRow = {
+ if (!hasNext) throw new NoSuchElementException
+ if (!limitIterator.hasNext && nextRowAvailable) {
+ groupIterator.skipRemainingRows()
+ limitIterator.reset()
+
+ if (!nextRowAvailable) {
+ // After skip remaining row in previous partition, all the input rows have been processed,
+ // so returns the last row directly.
+ return nextRow
+ }
+ }
+
+ limitIterator.next()
+ }
+
+ class GroupIterator() extends Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ var currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = nextRowAvailable && nextGroup == currentGroup
+
+ def next(): InternalRow = {
+ if (!hasNext) throw new NoSuchElementException
+ val currentRow = nextRow.copy()
+ fetchNextRow()
+ currentRow
+ }
+
+ def skipRemainingRows(): Unit = {
+ if (nextRowAvailable && nextGroup == currentGroup) {
+ // Skip all the remaining rows in this group
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+
+ // Switch to next group
+ currentGroup = nextGroup.copy()
Review Comment:
We should only do it if this is not the last group. How about
```
if (nextRowAvailable) currentGroup = nextGroup.copy()
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046766381
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/RemoveRedundantWindowGroupLimits.scala:
##########
@@ -0,0 +1,46 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.window.{Final, Partial, WindowGroupLimitExec}
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * Remove redundant partial WindowGroupLimitExec node from the spark plan. A partial
+ * WindowGroupLimitExec node is redundant when its child satisfies its required child distribution.
+ */
+object RemoveRedundantWindowGroupLimits extends Rule[SparkPlan] {
+
+ def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.getConf(SQLConf.REMOVE_REDUNDANT_WINDOW_GROUP_LIMITS_ENABLED)) {
+ plan
+ } else {
+ removeWindowGroupLimits(plan)
+ }
+ }
+
+ private def removeWindowGroupLimits(plan: SparkPlan): SparkPlan = plan transform {
+ case outer @ WindowGroupLimitExec(
+ _, _, _, _, Final, WindowGroupLimitExec(_, _, _, _, Partial, child))
+ if child.outputPartitioning.satisfies(outer.requiredChildDistribution.head) =>
+ val newOuter = outer.withNewChildren(Seq(child))
+ newOuter
Review Comment:
```suggestion
outer.withNewChildren(Seq(child))
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046773737
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def stream: Iterator[InternalRow]
Review Comment:
```suggestion
def input: Iterator[InternalRow]
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046827770
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextPartition()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (exceedingLimit() && nextGroup == currentGroup) {
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+ nextRowAvailable && nextGroup == currentGroup
+ } else {
+ nextRowAvailable
+ }
+ }
+
+ def next(): InternalRow = {
+ val currentRow = nextRow.copy()
+ increaseRank()
+ fetchNextRow()
+ currentRow
+ }
+ }
+ }
+}
+
+case class SimpleGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ stream: Iterator[InternalRow],
+ limit: Int) extends WindowIterator {
+ var count = 0
+
+ override def exceedingLimit(): Boolean = {
+ count >= limit
+ }
+
+ override def increaseRank(): Unit = {
+ count += 1
+ }
+
+ override def clearRank(): Unit = {
+ count = 0
+ }
+}
+
+case class RankGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ stream: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends WindowIterator {
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var count = 0
+ var rank = 0
+ var currentRank: UnsafeRow = null
+
+ override def exceedingLimit(): Boolean = {
+ rank >= limit
+ }
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRank = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRank, nextRow) != 0) {
+ rank = count
+ currentRank = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+
+ override def clearRank(): Unit = {
+ count = 0
+ rank = 0
+ currentRank = null
+ }
+}
+
+case class DenseRankGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ stream: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends WindowIterator {
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var rank = 0
Review Comment:
We can move `var rand = 0` to the parent class, then we don't need to add `def exceedingLimit`
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextPartition()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (exceedingLimit() && nextGroup == currentGroup) {
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+ nextRowAvailable && nextGroup == currentGroup
+ } else {
+ nextRowAvailable
+ }
+ }
+
+ def next(): InternalRow = {
+ val currentRow = nextRow.copy()
+ increaseRank()
+ fetchNextRow()
+ currentRow
+ }
+ }
+ }
+}
+
+case class SimpleGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ stream: Iterator[InternalRow],
+ limit: Int) extends WindowIterator {
+ var count = 0
+
+ override def exceedingLimit(): Boolean = {
+ count >= limit
+ }
+
+ override def increaseRank(): Unit = {
+ count += 1
+ }
+
+ override def clearRank(): Unit = {
+ count = 0
+ }
+}
+
+case class RankGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ stream: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends WindowIterator {
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var count = 0
+ var rank = 0
+ var currentRank: UnsafeRow = null
+
+ override def exceedingLimit(): Boolean = {
+ rank >= limit
+ }
+
+ override def increaseRank(): Unit = {
+ if (count == 0) {
+ currentRank = nextRow.copy()
+ } else {
+ if (ordering.compare(currentRank, nextRow) != 0) {
+ rank = count
+ currentRank = nextRow.copy()
+ }
+ }
+ count += 1
+ }
+
+ override def clearRank(): Unit = {
+ count = 0
+ rank = 0
+ currentRank = null
+ }
+}
+
+case class DenseRankGroupLimitIterator(
+ partitionSpec: Seq[Expression],
+ output: Seq[Attribute],
+ stream: Iterator[InternalRow],
+ orderSpec: Seq[SortOrder],
+ limit: Int) extends WindowIterator {
+ val ordering = GenerateOrdering.generate(orderSpec, output)
+ var rank = 0
Review Comment:
We can move `var rank = 0` to the parent class, then we don't need to add `def exceedingLimit`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1336035124
> I just image a special case: if the child's (e.g a SMJ) output ordering happens to satisfy the requirement of this filter, then there will be no extra SortExec, is it always beneficial to apply this optimization?
Fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046925478
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##########
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute, CurrentRow, DenseRank, EqualTo, Expression, ExpressionSet, GreaterThan, GreaterThanOrEqual, IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper, Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding, WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation, LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+ if (conf.windowGroupLimitThreshold == -1) return plan
+
+ plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+ window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[WindowGroupLimit] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.flatten
+
+ // multiple different rank-like functions unsupported.
+ if (limits.isEmpty || ExpressionSet(limits.map(_._2)).size > 1) {
Review Comment:
Good idea.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1046988790
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,251 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def stream: Iterator[InternalRow]
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = stream.hasNext
+ if (nextRowAvailable) {
+ nextRow = stream.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ // Whether or not the rank exceeding the window group limit value.
+ def exceedingLimit(): Boolean
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextPartition(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextPartition()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (exceedingLimit() && nextGroup == currentGroup) {
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+ nextRowAvailable && nextGroup == currentGroup
+ } else {
+ nextRowAvailable
+ }
+ }
+
+ def next(): InternalRow = {
+ val currentRow = nextRow.copy()
Review Comment:
Because `fetchNextRow` changes `nextRow`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100255241
##########
sql/core/src/test/scala/org/apache/spark/sql/DataFrameWindowFunctionsSuite.scala:
##########
@@ -1265,4 +1265,168 @@ class DataFrameWindowFunctionsSuite extends QueryTest
)
)
}
+
+ test("SPARK-37099: Insert window group limit node for top-k computation") {
+
+ val nullStr: String = null
+ val df = Seq(
+ ("a", 0, "c", 1.0),
+ ("a", 1, "x", 2.0),
+ ("a", 2, "y", 3.0),
+ ("a", 3, "z", -1.0),
+ ("a", 4, "", 2.0),
+ ("a", 4, "", 2.0),
+ ("b", 1, "h", Double.NaN),
+ ("b", 1, "n", Double.PositiveInfinity),
+ ("c", 1, "z", -2.0),
+ ("c", 1, "a", -4.0),
+ ("c", 2, nullStr, 5.0)).toDF("key", "value", "order", "value2")
+
+ val window = Window.partitionBy($"key").orderBy($"order".asc_nulls_first)
+ val window2 = Window.partitionBy($"key").orderBy($"order".desc_nulls_first)
+
+ Seq(-1, 100).foreach { threshold =>
+ withSQLConf(SQLConf.WINDOW_GROUP_LIMIT_THRESHOLD.key -> threshold.toString) {
+ Seq($"rn" === 0, $"rn" < 1, $"rn" <= 0).foreach { condition =>
+ checkAnswer(df.withColumn("rn", row_number().over(window)).where(condition),
+ Seq.empty[Row]
+ )
+ }
+
+ Seq($"rn" === 1, $"rn" < 2, $"rn" <= 1).foreach { condition =>
+ checkAnswer(df.withColumn("rn", row_number().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", rank().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", dense_rank().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+ }
+
+ Seq($"rn" < 3, $"rn" <= 2).foreach { condition =>
+ checkAnswer(df.withColumn("rn", row_number().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 2),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("b", 1, "n", Double.PositiveInfinity, 2),
+ Row("c", 1, "a", -4.0, 2),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", rank().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("b", 1, "n", Double.PositiveInfinity, 2),
+ Row("c", 1, "a", -4.0, 2),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", dense_rank().over(window)).where(condition),
+ Seq(
+ Row("a", 0, "c", 1.0, 2),
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("b", 1, "n", Double.PositiveInfinity, 2),
+ Row("c", 1, "a", -4.0, 2),
+ Row("c", 2, null, 5.0, 1)
+ )
+ )
+ }
+
+ val condition = $"rn" === 2 && $"value2" > 0.5
+ checkAnswer(df.withColumn("rn", row_number().over(window)).where(condition),
+ Seq(
+ Row("a", 4, "", 2.0, 2),
+ Row("b", 1, "n", Double.PositiveInfinity, 2)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", rank().over(window)).where(condition),
+ Seq(
+ Row("b", 1, "n", Double.PositiveInfinity, 2)
+ )
+ )
+
+ checkAnswer(df.withColumn("rn", dense_rank().over(window)).where(condition),
+ Seq(
+ Row("a", 0, "c", 1.0, 2),
+ Row("b", 1, "n", Double.PositiveInfinity, 2)
+ )
+ )
+
+ val multipleRowNumbers = df
+ .withColumn("rn", row_number().over(window))
+ .withColumn("rn2", row_number().over(window))
+ .where('rn < 2 && 'rn2 < 3)
+ checkAnswer(multipleRowNumbers,
+ Seq(
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("b", 1, "h", Double.NaN, 1, 1),
+ Row("c", 2, null, 5.0, 1, 1)
+ )
+ )
+
+ val multipleRanks = df
+ .withColumn("rn", rank().over(window))
+ .withColumn("rn2", rank().over(window))
+ .where('rn < 2 && 'rn2 < 3)
+ checkAnswer(multipleRanks,
+ Seq(
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("b", 1, "h", Double.NaN, 1, 1),
+ Row("c", 2, null, 5.0, 1, 1)
+ )
+ )
+
+ val multipleDenseRanks = df
+ .withColumn("rn", dense_rank().over(window))
+ .withColumn("rn2", dense_rank().over(window))
+ .where('rn < 2 && 'rn2 < 3)
+ checkAnswer(multipleDenseRanks,
+ Seq(
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("a", 4, "", 2.0, 1, 1),
+ Row("b", 1, "h", Double.NaN, 1, 1),
+ Row("c", 2, null, 5.0, 1, 1)
+ )
+ )
+
+ val multipleWindowsOne = df
+ .withColumn("rn2", row_number().over(window2))
+ .withColumn("rn", row_number().over(window))
Review Comment:
How does this work? If there are two window specs, then the query has two Window node?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100227760
##########
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala:
##########
@@ -1229,6 +1229,22 @@ case class Window(
copy(child = newChild)
}
+case class WindowGroupLimit(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ child: LogicalPlan) extends OrderPreservingUnaryNode {
Review Comment:
Good point. `WindowGroupLimit` will sort the input data. @beliefer please fix this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100300812
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
Review Comment:
note: it's allowed to call `next()` without calling `hasNext()` for java iterator. It's safe to make `hasNext` simple
```
def hasNext = nextRowAvailable && nextGroup == currentGroup
def next = ... heavy logic
```
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
Review Comment:
note: it's allowed to call `next()` without calling `hasNext()` for java iterator. It's safer to make `hasNext` simple
```
def hasNext = nextRowAvailable && nextGroup == currentGroup
def next = ... heavy logic
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by "cloud-fan (via GitHub)" <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100294739
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+ SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitionsInternal(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
Review Comment:
shall we check if `bufferIterator` is null? It may happen if the child plan produces no data at all.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1057443215
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (rank >= limit && nextGroup == currentGroup) {
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+ nextRowAvailable && nextGroup == currentGroup
Review Comment:
The code here looks a bit confusing. How about
```
if (nextRowAvailable) {
if (rank >= limit && nextGroup == currentGroup) {
// Skip all the remaining rows in this group
do {
fetchNextRow()
} while (nextRowAvailable && nextGroup == currentGroup)
false
} else {
// Returns true if there are more rows in this group.
nextRowAvailable && nextGroup == currentGroup
}
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1057569960
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,237 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction match {
+ case _: RowNumber =>
+ child.execute().mapPartitions(SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+ case _: Rank =>
+ child.execute().mapPartitions(
+ RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ case _: DenseRank =>
+ child.execute().mapPartitions(
+ DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan): WindowGroupLimitExec =
+ copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
+
+ // Manage the stream and the grouping.
+ var nextRow: UnsafeRow = null
+ var nextGroup: UnsafeRow = null
+ var nextRowAvailable: Boolean = false
+ protected[this] def fetchNextRow(): Unit = {
+ nextRowAvailable = input.hasNext
+ if (nextRowAvailable) {
+ nextRow = input.next().asInstanceOf[UnsafeRow]
+ nextGroup = grouping(nextRow)
+ } else {
+ nextRow = null
+ nextGroup = null
+ }
+ }
+ fetchNextRow()
+
+ var rank = 0
+
+ // Increase the rank value.
+ def increaseRank(): Unit
+
+ // Clear the rank value.
+ def clearRank(): Unit
+
+ var bufferIterator: Iterator[InternalRow] = _
+
+ private[this] def fetchNextGroup(): Unit = {
+ clearRank()
+ bufferIterator = createGroupIterator()
+ }
+
+ override final def hasNext: Boolean =
+ (bufferIterator != null && bufferIterator.hasNext) || nextRowAvailable
+
+ override final def next(): InternalRow = {
+ // Load the next partition if we need to.
+ if ((bufferIterator == null || !bufferIterator.hasNext) && nextRowAvailable) {
+ fetchNextGroup()
+ }
+
+ if (bufferIterator.hasNext) {
+ bufferIterator.next()
+ } else {
+ throw new NoSuchElementException
+ }
+ }
+
+ private def createGroupIterator(): Iterator[InternalRow] = {
+ new Iterator[InternalRow] {
+ // Before we start to fetch new input rows, make a copy of nextGroup.
+ val currentGroup = nextGroup.copy()
+
+ def hasNext: Boolean = {
+ if (nextRowAvailable) {
+ if (rank >= limit && nextGroup == currentGroup) {
+ do {
+ fetchNextRow()
+ } while (nextRowAvailable && nextGroup == currentGroup)
+ }
+ nextRowAvailable && nextGroup == currentGroup
Review Comment:
OK
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1034340755
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{ExternalAppendOnlyUnsafeRowArray, SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ // Only show warning when the number of bytes is larger than 100 MiB?
+ logWarning("No Partition Defined for Window operation! Moving all data to a single "
Review Comment:
I think we don't need this warning, since `WindowExec` log this warning anyway
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{ExternalAppendOnlyUnsafeRowArray, SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ // Only show warning when the number of bytes is larger than 100 MiB?
+ logWarning("No Partition Defined for Window operation! Moving all data to a single "
+ + "partition, this can cause serious performance degradation.")
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = {
+ val inMemoryThreshold = conf.windowExecBufferInMemoryThreshold
+ val spillThreshold = conf.windowExecBufferSpillThreshold
Review Comment:
are the two config dedicated to WindowExec?
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{ExternalAppendOnlyUnsafeRowArray, SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ // Only show warning when the number of bytes is larger than 100 MiB?
+ logWarning("No Partition Defined for Window operation! Moving all data to a single "
+ + "partition, this can cause serious performance degradation.")
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
Review Comment:
for `row_number` and small `k`, can use `Utils.takeOrdered` to relax the requirement of ordering.
For a special case, row_number < k without partitionSpec, it can avoid the extra SortExec.
just a suggestion, do not need to be in this PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036836089
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,236 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{ExternalAppendOnlyUnsafeRowArray, SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ // Only show warning when the number of bytes is larger than 100 MiB?
+ logWarning("No Partition Defined for Window operation! Moving all data to a single "
+ + "partition, this can cause serious performance degradation.")
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
Review Comment:
shall we make it part of this PR? This is different from https://github.com/apache/spark/pull/38799/files#diff-21f071d73070b8257ad76e6e16ec5ed38a13d1278fe94bd42546c258a69f4410R688 and we are likely to change many code in this file to add it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036836402
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##########
@@ -0,0 +1,235 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples, ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]]
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]]
+ * @param rankLikeFunction The function to compute row rank, should be RowNumber/Rank/DenseRank.
+ */
+case class WindowGroupLimitExec(
+ partitionSpec: Seq[Expression],
+ orderSpec: Seq[SortOrder],
+ rankLikeFunction: Expression,
+ limit: Int,
+ mode: WindowGroupLimitMode,
+ child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+ case Partial => super.requiredChildDistribution
+ case Final =>
+ if (partitionSpec.isEmpty) {
+ AllTuples :: Nil
+ } else {
+ ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+ Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = {
+
+ abstract class WindowIterator extends Iterator[InternalRow] {
Review Comment:
can we move it out as a top-level class?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1036940423
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkStrategies.scala:
##########
@@ -627,6 +627,87 @@ abstract class SparkStrategies extends QueryPlanner[SparkPlan] {
}
}
+ /**
+ * Optimize the filter based on rank-like window function by reduce not required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1 WHERE 5 >= rn
+ * }}}
+ */
+ object WindowGroupLimit extends Strategy with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+ val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ }
+
+ if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def supports(
+ windowExpressions: Seq[NamedExpression]): Boolean = windowExpressions.exists {
+ case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber, WindowSpecDefinition(_, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) => true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): Seq[SparkPlan] = {
+ if (conf.windowGroupLimitThreshold == -1) return Nil
+
+ plan match {
+ case filter @ Filter(condition,
+ window @ logical.Window(windowExpressions, partitionSpec, orderSpec, child))
+ if !child.isInstanceOf[logical.Window] &&
+ supports(windowExpressions) && orderSpec.nonEmpty =>
+ val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) =>
+ extractLimits(condition, alias.toAttribute).map((_, rankLikeFunction))
+ }.filter(_.isDefined)
+
+ // non rank-like functions or multiple different rank-like functions unsupported.
+ if (limits.isEmpty || limits.groupBy(_.get._2).size > 1) {
+ return Nil
+ }
+ val minLimit = limits.minBy(_.get._1)
+ minLimit match {
+ case Some((limit, rankLikeFunction)) if limit <= conf.windowGroupLimitThreshold =>
+ if (limit > 0) {
+ // TODO: [SPARK-41337] Add a physical rule to remove the partialLimitExec node,
+ // if there is no shuffle between the two nodes (partialLimitExec's
+ // outputPartitioning satisfies the finalLimitExec's requiredChildDistribution)
+ val partialLimitExec = execution.window.WindowGroupLimitExec(partitionSpec,
+ orderSpec, rankLikeFunction, limit, execution.window.Partial, planLater(child))
+ val finalLimitExec = execution.window.WindowGroupLimitExec(partitionSpec,
+ orderSpec, rankLikeFunction, limit, execution.window.Final, partialLimitExec)
+ val windowExec = execution.window.WindowExec(
+ windowExpressions, partitionSpec, orderSpec, finalLimitExec)
+ windowExec.setLogicalLink(window)
+ val filterExec = execution.FilterExec(condition, windowExec)
+ filterExec :: Nil
+ } else {
+ val localTableScanExec = LocalTableScanExec(filter.output, Seq.empty)
Review Comment:
detect a filter like `row_number < 0` or `rank < -1` and then return an empty local table, this is always benifitial.
maybe we can put it in other empty-relation related rules.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on PR #38799:
URL: https://github.com/apache/spark/pull/38799#issuecomment-1333564211
> I just image a special case: if the child's (e.g a SMJ) output ordering happens to satisfy the requirement of this filter, then there will be no extra SortExec, is it always beneficial to apply this optimization?
`WindowGroupLimitExec` need the child 's output ordering like `WindowExec`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org