You are viewing a plain text version of this content. The canonical link for it is here.
Posted to dev@metron.apache.org by cestella <gi...@git.apache.org> on 2017/11/06 19:24:40 UTC
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
GitHub user cestella opened a pull request:
https://github.com/apache/metron/pull/831
METRON-1302: Split up Indexing Topology into batch and random access sections
## Contributor Comments
Currently we have the indexing topology handle writing to both random access indices (e.g. elasticsearch) as well as batch write indices (e.g. hdfs). We should split these up and configure them separately.
In terms of manual testing, full-dev should continue to function in that:
* Elasticsearch should have data written to it
* HDFS should have data written to it
* The indexing configuration should have separate subsections for random access and batch index writers
## Pull Request Checklist
Thank you for submitting a contribution to Apache Metron.
Please refer to our [Development Guidelines](https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=61332235) for the complete guide to follow for contributions.
Please refer also to our [Build Verification Guidelines](https://cwiki.apache.org/confluence/display/METRON/Verifying+Builds?show-miniview) for complete smoke testing guides.
In order to streamline the review of the contribution we ask you follow these guidelines and ask you to double check the following:
### For all changes:
- [x] Is there a JIRA ticket associated with this PR? If not one needs to be created at [Metron Jira](https://issues.apache.org/jira/browse/METRON/?selectedTab=com.atlassian.jira.jira-projects-plugin:summary-panel).
- [x] Does your PR title start with METRON-XXXX where XXXX is the JIRA number you are trying to resolve? Pay particular attention to the hyphen "-" character.
- [x] Has your PR been rebased against the latest commit within the target branch (typically master)?
### For code changes:
- [x] Have you included steps to reproduce the behavior or problem that is being changed or addressed?
- [x] Have you included steps or a guide to how the change may be verified and tested manually?
- [x] Have you ensured that the full suite of tests and checks have been executed in the root metron folder via:
```
mvn -q clean integration-test install && build_utils/verify_licenses.sh
```
- [x] Have you written or updated unit tests and or integration tests to verify your changes?
- [x] If adding new dependencies to the code, are these dependencies licensed in a way that is compatible for inclusion under [ASF 2.0](http://www.apache.org/legal/resolved.html#category-a)?
- [x] Have you verified the basic functionality of the build by building and running locally with Vagrant full-dev environment or the equivalent?
### For documentation related changes:
- [x] Have you ensured that format looks appropriate for the output in which it is rendered by building and verifying the site-book? If not then run the following commands and the verify changes via `site-book/target/site/index.html`:
```
cd site-book
mvn site
```
#### Note:
Please ensure that once the PR is submitted, you check travis-ci for build issues and submit an update to your PR as soon as possible.
It is also recommended that [travis-ci](https://travis-ci.org) is set up for your personal repository such that your branches are built there before submitting a pull request.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/cestella/incubator-metron indexing_topo_split
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/metron/pull/831.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #831
----
----
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by mraliagha <gi...@git.apache.org>.
Github user mraliagha commented on the issue:
https://github.com/apache/metron/pull/831
That sounds great. We had a huge headache to find good tuning parameters for "indexing" topology.
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by nickwallen <gi...@git.apache.org>.
Github user nickwallen commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r150336506
--- Diff: metron-platform/metron-indexing/src/main/scripts/start_hdfs_topology.sh ---
@@ -0,0 +1,22 @@
+#!/bin/bash
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+METRON_VERSION=${project.version}
+METRON_HOME=/usr/metron/$METRON_VERSION
+TOPOLOGY_JAR=metron-elasticsearch-$METRON_VERSION-uber.jar
+storm jar $METRON_HOME/lib/$TOPOLOGY_JAR org.apache.storm.flux.Flux --remote $METRON_HOME/flux/indexing/batch/remote.yaml --filter $METRON_HOME/config/hdfs.properties
--- End diff --
Very true. I think you're right, @ottobackwards
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by ottobackwards <gi...@git.apache.org>.
Github user ottobackwards commented on the issue:
https://github.com/apache/metron/pull/831
The batch v. hdfs stuff still confuses me, I thought we decided on a different name?
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r151190210
--- Diff: metron-deployment/packaging/ambari/metron-mpack/src/main/resources/common-services/METRON/CURRENT/package/scripts/indexing_commands.py ---
@@ -162,34 +164,77 @@ def start_indexing_topology(self, env):
self.__params.metron_principal_name,
execute_user=self.__params.metron_user)
- start_cmd_template = """{0}/bin/start_elasticsearch_topology.sh \
- -s {1} \
- -z {2}"""
- start_cmd = start_cmd_template.format(self.__params.metron_home,
- self.__indexing_topology,
- self.__params.zookeeper_quorum)
+ start_cmd_template = """{0}/bin/start_hdfs_topology.sh"""
+ start_cmd = start_cmd_template.format(self.__params.metron_home)
Execute(start_cmd, user=self.__params.metron_user, tries=3, try_sleep=5, logoutput=True)
else:
- Logger.info('Indexing topology already running')
+ Logger.info('Batch Indexing topology already running')
- Logger.info('Finished starting indexing topology')
+ Logger.info('Finished starting batch indexing topology')
- def stop_indexing_topology(self, env):
- Logger.info('Stopping ' + self.__indexing_topology)
+ def start_random_access_indexing_topology(self, env):
+ Logger.info('Starting ' + self.__random_access_indexing_topology)
--- End diff --
Definitely, @nickwallen I think we're thinking the same thing. This is literally just the first baby step toward a broader vision of pluggable writers. I think we probably want to start here with a discuss thread. Where I was thinking of going next in here was merging the flux files into one and pulling the configs from zookeeper, which would be a step towards your vision.
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by ottobackwards <gi...@git.apache.org>.
Github user ottobackwards commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r150316808
--- Diff: metron-deployment/packaging/ambari/metron-mpack/src/main/resources/common-services/METRON/CURRENT/package/scripts/indexing_commands.py ---
@@ -162,34 +164,77 @@ def start_indexing_topology(self, env):
self.__params.metron_principal_name,
execute_user=self.__params.metron_user)
- start_cmd_template = """{0}/bin/start_elasticsearch_topology.sh \
- -s {1} \
- -z {2}"""
- start_cmd = start_cmd_template.format(self.__params.metron_home,
- self.__indexing_topology,
- self.__params.zookeeper_quorum)
+ start_cmd_template = """{0}/bin/start_hdfs_topology.sh"""
+ start_cmd = start_cmd_template.format(self.__params.metron_home)
Execute(start_cmd, user=self.__params.metron_user, tries=3, try_sleep=5, logoutput=True)
else:
- Logger.info('Indexing topology already running')
+ Logger.info('Batch Indexing topology already running')
- Logger.info('Finished starting indexing topology')
+ Logger.info('Finished starting batch indexing topology')
- def stop_indexing_topology(self, env):
- Logger.info('Stopping ' + self.__indexing_topology)
+ def start_random_access_indexing_topology(self, env):
+ Logger.info('Starting ' + self.__random_access_indexing_topology)
--- End diff --
I like this a lot. I would like to see the indexing be like the parses, where you start with a name parameter. I think the flux files make it difficult though. I would be +1 exploring this approach though, maybe a feature branch?
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r160161476
--- Diff: metron-platform/metron-indexing/src/test/java/org/apache/metron/indexing/integration/IndexingIntegrationTest.java ---
@@ -197,9 +140,7 @@ public void test() throws Exception {
//assert that our input docs are equivalent to the output docs, converting the input docs keys based
// on the field name converter
assertInputDocsMatchOutputs(inputDocs, docs, getFieldNameConverter());
- assertInputDocsMatchOutputs(inputDocs, readDocsFromDisk(hdfsDir), x -> x);
- } catch(Throwable e) {
- e.printStackTrace();
+ //assertInputDocsMatchOutputs(inputDocs, readDocsFromDisk(hdfsDir), x -> x);
--- End diff --
Nope
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by merrimanr <gi...@git.apache.org>.
Github user merrimanr commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r159322924
--- Diff: metron-deployment/packaging/ambari/metron-mpack/src/main/resources/common-services/METRON/CURRENT/package/templates/hdfs.properties.j2 ---
@@ -0,0 +1,44 @@
+# Licensed to the Apache Software Foundation (ASF) under one
--- End diff --
Should this file be git ignored since it is copied in at build time?
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r151189543
--- Diff: metron-deployment/packaging/ambari/metron-mpack/src/main/resources/common-services/METRON/CURRENT/configuration/metron-indexing-env.xml ---
@@ -73,18 +98,31 @@
<display-name>Indexing Update Column Family</display-name>
</property>
<property>
- <name>indexing_workers</name>
+ <name>ra_indexing_workers</name>
+ <description>Number of Indexing Topology Workers</description>
--- End diff --
That sounds good. Which one would you guys prefer:
* display names in the mpack of "Elasticsearch" and "HDFS"
* variable prefixes of `es` and `hdfs`
I think I'd prefer the first as I really have been trying to set us up to a world where we can make things pluggable (this is the first baby step).
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r151189633
--- Diff: metron-deployment/packaging/ambari/metron-mpack/src/main/resources/common-services/METRON/CURRENT/configuration/metron-indexing-env.xml ---
@@ -73,18 +98,31 @@
<display-name>Indexing Update Column Family</display-name>
</property>
<property>
- <name>indexing_workers</name>
+ <name>ra_indexing_workers</name>
+ <description>Number of Indexing Topology Workers</description>
--- End diff --
I should add, or some other 3rd option that I haven't anticipated. ;)
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/metron/pull/831
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by ottobackwards <gi...@git.apache.org>.
Github user ottobackwards commented on the issue:
https://github.com/apache/metron/pull/831
So we are basically saying, that each indexing strategy/endpoint should be it's own topology?
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r160161491
--- Diff: metron-deployment/packaging/ambari/metron-mpack/src/main/resources/common-services/METRON/CURRENT/package/templates/hdfs.properties.j2 ---
@@ -0,0 +1,44 @@
+# Licensed to the Apache Software Foundation (ASF) under one
--- End diff --
Yep
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on the issue:
https://github.com/apache/metron/pull/831
Ok, I thought the general consensus was different. As per my comment:
```
That sounds good. Which one would you guys prefer:
* display names in the mpack of "Elasticsearch" and "HDFS"
* variable prefixes of es and hdfs
I think I'd prefer the first as I really have been trying to set us up to a world where we can make things pluggable (this is the first baby step).
```
Nobody commented on that, so I went with adjusting the display names rather than variable prefixes. The reason why I preferred to do that was that when we do a better job of including Solr or other indices, prefixing the variables `elasticsearch` will be confusing. The flux files are generic to the writer type for the random access indices. I can understand the confusion for the user given we only really support HDFS and elasticsearch right now, which is why I changed the display names.
Can we recap the reasons against this approach?
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on the issue:
https://github.com/apache/metron/pull/831
So, this is sitting with one +1 and I think I've addressed the comments, but I'd like to make sure that my explanations are sufficient and persuasive. Any comments here?
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by mmiklavc <gi...@git.apache.org>.
Github user mmiklavc commented on the issue:
https://github.com/apache/metron/pull/831
> I went with adjusting the display names rather than variable prefixes.
@cestella I agree with this approach. On the front-end, make it specific to the technology for the administrator. In back, where things are pluggable, I think the more general/abstract prefixes you proposed make sense. This way the back end doesn't have to change all the time when we introduce a new batch and/or ra system.
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by merrimanr <gi...@git.apache.org>.
Github user merrimanr commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r159321881
--- Diff: metron-platform/metron-indexing/src/test/java/org/apache/metron/indexing/integration/IndexingIntegrationTest.java ---
@@ -197,9 +140,7 @@ public void test() throws Exception {
//assert that our input docs are equivalent to the output docs, converting the input docs keys based
// on the field name converter
assertInputDocsMatchOutputs(inputDocs, docs, getFieldNameConverter());
- assertInputDocsMatchOutputs(inputDocs, readDocsFromDisk(hdfsDir), x -> x);
- } catch(Throwable e) {
- e.printStackTrace();
+ //assertInputDocsMatchOutputs(inputDocs, readDocsFromDisk(hdfsDir), x -> x);
--- End diff --
Is this comment intentional?
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by ottobackwards <gi...@git.apache.org>.
Github user ottobackwards commented on the issue:
https://github.com/apache/metron/pull/831
So, all of these parameters with the more generic names will be uniformly applicable to all possible backends?
We will never have more than one of a given type at any time? ( s3/hdfs or something?)
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by nickwallen <gi...@git.apache.org>.
Github user nickwallen commented on the issue:
https://github.com/apache/metron/pull/831
> @cestella Nobody commented on that, so I went with adjusting the display names rather than variable prefixes...
I think there is some confusion as to what exactly you mean here. You never responded to @ottobackwards 's last [comment](https://github.com/apache/metron/pull/831#issuecomment-351589022). I think that comment indicates some clarification is needed.
I'm just looking for you to say "hey, this PR is how I want it and its ready for review." Because hey, there is no better clarifier than code.
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by mmiklavc <gi...@git.apache.org>.
Github user mmiklavc commented on the issue:
https://github.com/apache/metron/pull/831
Unless there are other things I should test, I think it looks pretty good. Data is coming through to ES + Kibana (with the new ES 5.6.2 code, no less!), the topologies appear as expected and without error in Storm, data is being written to HDFS, and the menu options appear correct in Ambari. +1 home skillet.
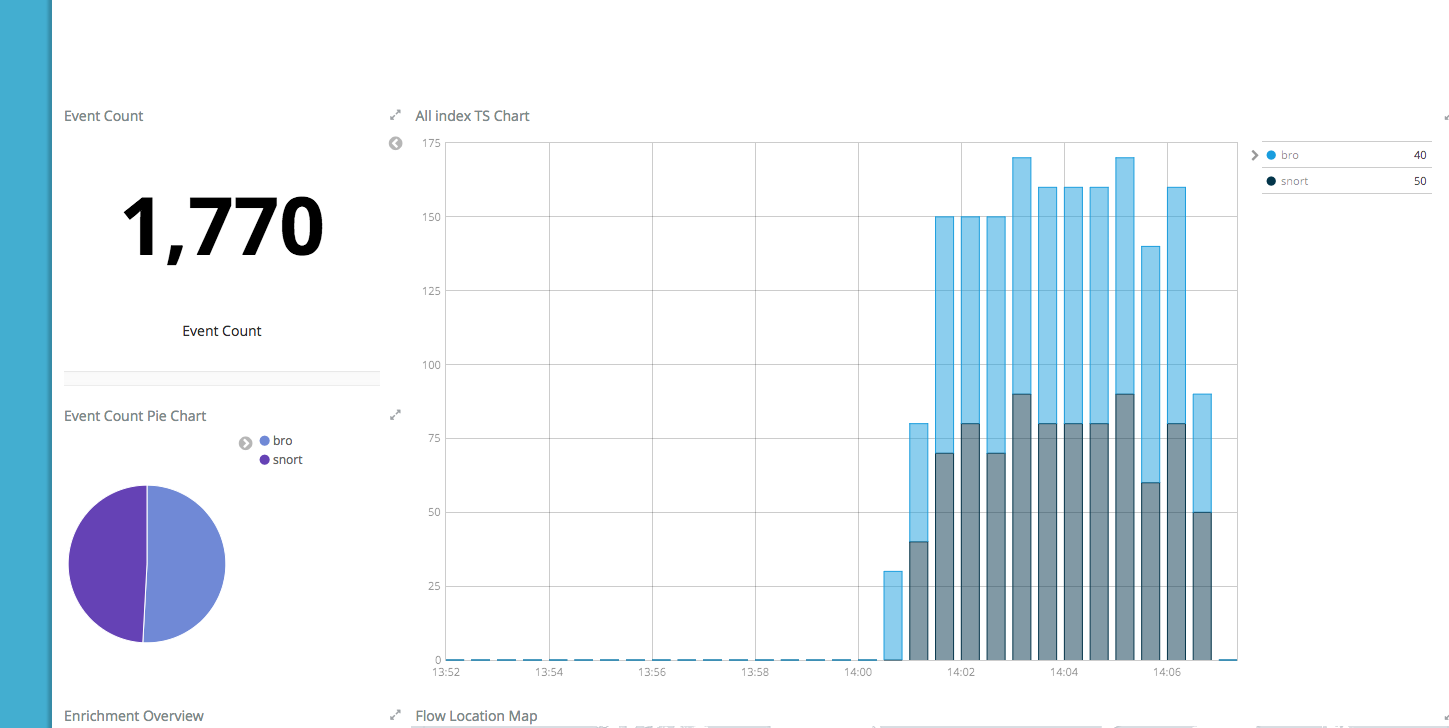
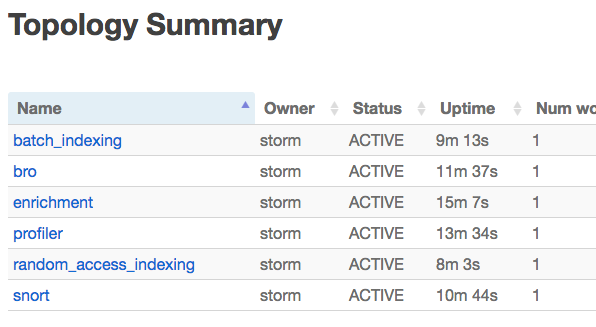
And data in HDFS
```
[root@node1 indexing]# hdfs dfs -ls -R /apps/metron/indexing/indexed
drwxrwxr-x - storm hadoop 0 2018-01-08 21:00 /apps/metron/indexing/indexed/bro
-rw-r--r-- 1 storm hadoop 2984217 2018-01-08 21:00 /apps/metron/indexing/indexed/bro/enrichment-hdfsIndexingBolt-2-0-1515445254997.json
drwxrwxr-x - storm hadoop 0 2018-01-08 21:10 /apps/metron/indexing/indexed/error
-rw-r--r-- 1 storm hadoop 6670648 2018-01-08 21:10 /apps/metron/indexing/indexed/error/enrichment-hdfsIndexingBolt-2-0-1515445818471.json
drwxrwxr-x - storm hadoop 0 2018-01-08 21:01 /apps/metron/indexing/indexed/snort
-rw-r--r-- 1 storm hadoop 2374289 2018-01-08 21:01 /apps/metron/indexing/indexed/snort/enrichment-hdfsIndexingBolt-2-0-1515445279421.json
```
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by mmiklavc <gi...@git.apache.org>.
Github user mmiklavc commented on the issue:
https://github.com/apache/metron/pull/831
I'm looking at this deeper and thinking through how status_params.py works with the config files. I'm looking for a dynamic way to manage the endpoints, in the future (not for this PR). For instance, we currently have this to load the config (in master)
```
# common-services/METRON/CURRENT/package/scripts/params/params_linux.py
# Indexing
indexing_kafka_start = config['configurations']['metron-indexing-env']['indexing_kafka_start']
```
This PR currently sets `ra_indexing_kafka_start` as the property name and `Elasticsearch Indexing Offset` as the display name. I think this is fine, but I'm unclear how best to manage 1..n indexing endpoints in later PR's because I don't know that Ambari (yet) offers a way to have dynamic config based on the type of service you choose to install. Maybe we can leverage a dropdown option as part of metron-env that we then leverage to dynamically choose the indexing config type you selected. So metron-env has the following:
```
<property>
<name>ra_indexing_framework</name>
<description>How you like to index for RA, friend?</description>
<value>Elasticsearch</value>
<display-name>Indexing Framework for Random Access</display-name>
<value-attributes>
<type>value-list</type>
<entries>
<entry>
<value>Elasticsearch</value>
</entry>
<entry>
<value>Solr</value>
</entry>
</entries>
<selection-cardinality>1</selection-cardinality>
</value-attributes>
</property>
```
and the earlier snippet above looks something like:
```
# common-services/METRON/CURRENT/package/scripts/params/params_linux.py
# Indexing
indexing_kafka_start = config['configurations'][ra_indexing_framework + '-env']['indexing_kafka_start']
```
Not sure if you can do that, just thinking out loud. Also, this handles the ability to plug in multiple providers from which you can select only one, but it does not handle the 1..n providers scenario simultaneously, if there were such a need.
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on the issue:
https://github.com/apache/metron/pull/831
I think I managed to address the issues here. Is there anything else outstanding that I missed? If not, then bump.
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on the issue:
https://github.com/apache/metron/pull/831
@nickwallen Whoops, sorry, I totally misunderstood. This PR *is* how *I* would like it. I'm just going to copy this here to justify my position:
```
The reason why I preferred to do that was that when we do a better job of including Solr or other indices, prefixing the variables elasticsearch will be confusing. The flux files are generic to the writer type for the random access indices. I can understand the confusion for the user given we only really support HDFS and elasticsearch right now, which is why I changed the display names and kept the command line clients named as they were before. Eventually, when we provide actual proper extension points to the indices, we should genericize the display names and scripts IMO.
```
I hope that clarifies my position on the matter (or at least why I made it the way it is). If there are other thoughts, I'd like to be able to discuss them. @mmiklavc chimed in in support, but I'd like to hear differing opinions if my argument is not persuasive.
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on the issue:
https://github.com/apache/metron/pull/831
@ottobackwards Not all of them, some of them are specific to the specific implementations (many aren't though), but I wasn't ready to remove them. Ultimately, when we provide support for pluggable indices, we'll want to move those configs to the zookeeper config.
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by mmiklavc <gi...@git.apache.org>.
Github user mmiklavc commented on the issue:
https://github.com/apache/metron/pull/831
The code itself looks good to me. I'm running this up in full dev now and will report back. Fingers crossed that the extra slot is not a problem with the extra mem required for ES 5.
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by nickwallen <gi...@git.apache.org>.
Github user nickwallen commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r150315275
--- Diff: metron-deployment/packaging/ambari/metron-mpack/src/main/resources/common-services/METRON/CURRENT/configuration/metron-indexing-env.xml ---
@@ -73,18 +98,31 @@
<display-name>Indexing Update Column Family</display-name>
</property>
<property>
- <name>indexing_workers</name>
+ <name>ra_indexing_workers</name>
+ <description>Number of Indexing Topology Workers</description>
--- End diff --
Actually, I see the display name is different. Doh. But here we are using the terms "Elasticsearch" and "HDFS", rather than "Random Access" and "Batch". We should probably stick with one nomenclature.
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r151190365
--- Diff: metron-platform/metron-indexing/src/main/scripts/start_hdfs_topology.sh ---
@@ -0,0 +1,22 @@
+#!/bin/bash
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+METRON_VERSION=${project.version}
+METRON_HOME=/usr/metron/$METRON_VERSION
+TOPOLOGY_JAR=metron-elasticsearch-$METRON_VERSION-uber.jar
+storm jar $METRON_HOME/lib/$TOPOLOGY_JAR org.apache.storm.flux.Flux --remote $METRON_HOME/flux/indexing/batch/remote.yaml --filter $METRON_HOME/config/hdfs.properties
--- End diff --
Yeah, I prefer to keep the scripts `hdfs` and `elasticsearch`
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by merrimanr <gi...@git.apache.org>.
Github user merrimanr commented on the issue:
https://github.com/apache/metron/pull/831
I ran this up in full dev and everything worked as advertised. I only noticed a couple minor issues and left comments for those.
I also am a little confused by the ra/batch vs es/hdfs issue. I still see places (Ambari config parameter names, Ambari MPack scripts, Flux file paths, Flux properties, Storm topology names, etc) where the prefixes are ra/batch and not es/hdfs. Reading through the PR comments I'm still not clear on what approach we decided on but I think consistency would be good.
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by nickwallen <gi...@git.apache.org>.
Github user nickwallen commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r150314117
--- Diff: metron-deployment/packaging/ambari/metron-mpack/src/main/resources/common-services/METRON/CURRENT/package/scripts/indexing_commands.py ---
@@ -162,34 +164,77 @@ def start_indexing_topology(self, env):
self.__params.metron_principal_name,
execute_user=self.__params.metron_user)
- start_cmd_template = """{0}/bin/start_elasticsearch_topology.sh \
- -s {1} \
- -z {2}"""
- start_cmd = start_cmd_template.format(self.__params.metron_home,
- self.__indexing_topology,
- self.__params.zookeeper_quorum)
+ start_cmd_template = """{0}/bin/start_hdfs_topology.sh"""
+ start_cmd = start_cmd_template.format(self.__params.metron_home)
Execute(start_cmd, user=self.__params.metron_user, tries=3, try_sleep=5, logoutput=True)
else:
- Logger.info('Indexing topology already running')
+ Logger.info('Batch Indexing topology already running')
- Logger.info('Finished starting indexing topology')
+ Logger.info('Finished starting batch indexing topology')
- def stop_indexing_topology(self, env):
- Logger.info('Stopping ' + self.__indexing_topology)
+ def start_random_access_indexing_topology(self, env):
+ Logger.info('Starting ' + self.__random_access_indexing_topology)
--- End diff --
First off, I think we definitely need to make this happen. Each index destination is going to have very different performance characteristics that need to be tuned in isolation. I think this is a step in the right direction.
As I read this we have effectively hard-coded two indexing topologies; random access and batch. This is definitely the most logical way to get to separate topologies based on our existing code base. But I am wondering if we might think about this in a slightly different way.
What I really like about indexing is that we have the idea of multiple, independent destinations. For example, my indexing configuration could look like this.
```
{
"elasticsearch": {
"index": "foo",
"enabled" : true
},
"hdfs": {
"index": "foo",
"batchSize": 1,
"enabled" : true
}
}
```
What if we introduced logic that consumes the indexing configuration, determines that it needs to launch 2 topologies in this case, and then launches those 2 separate topologies? If I had 3 destinations configured, then it would launch 3 topologies; one for each destination?
I can definitely see the extra complexity in doing this. You have to make sure the user can independently configure each of the topologies. You have to respond to configuration changes made by the user. And probably a few other complications.
But these are already complications that we need to deal with in Parsing. A user can define 1 to N Parsing topologies. It seems like if we can solve these challenges for Parsing, we can do the same for Indexing.
Anywho, I can totally see this PR as a near-term solution to the immediate problem, which might lead towards a longer-term solution like I propose. I just wanted to see if anyone had related thoughts.
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by nickwallen <gi...@git.apache.org>.
Github user nickwallen commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r150314839
--- Diff: metron-platform/metron-indexing/src/main/scripts/start_hdfs_topology.sh ---
@@ -0,0 +1,22 @@
+#!/bin/bash
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+METRON_VERSION=${project.version}
+METRON_HOME=/usr/metron/$METRON_VERSION
+TOPOLOGY_JAR=metron-elasticsearch-$METRON_VERSION-uber.jar
+storm jar $METRON_HOME/lib/$TOPOLOGY_JAR org.apache.storm.flux.Flux --remote $METRON_HOME/flux/indexing/batch/remote.yaml --filter $METRON_HOME/config/hdfs.properties
--- End diff --
In the MPack we refer to this as the "batch" topology. But in this script we refer to it as the "HDFS" topology. We should probably stick with one nomenclature.
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by nickwallen <gi...@git.apache.org>.
Github user nickwallen commented on the issue:
https://github.com/apache/metron/pull/831
> I also am a little confused by the ra/batch vs es/hdfs issue.
I think the general consensus was to be explicit and use "hdfs" and "elasticsearch". @cestella Let us know when you've made this change and are happy with it.
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by nickwallen <gi...@git.apache.org>.
Github user nickwallen commented on the issue:
https://github.com/apache/metron/pull/831
+1 Looks good @cestella
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by mmiklavc <gi...@git.apache.org>.
Github user mmiklavc commented on the issue:
https://github.com/apache/metron/pull/831
One additional note, I think we may be reaching the limits of what can reasonably fit on 1 box memory-wise. After about 40 minutes, the REST api and Elasticsearch went down. I recall this sort of thing happening independent of this PR, but just thought I'd mention it as something we could look at down the pike.
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by ottobackwards <gi...@git.apache.org>.
Github user ottobackwards commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r150317133
--- Diff: metron-platform/metron-indexing/src/main/scripts/start_hdfs_topology.sh ---
@@ -0,0 +1,22 @@
+#!/bin/bash
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+METRON_VERSION=${project.version}
+METRON_HOME=/usr/metron/$METRON_VERSION
+TOPOLOGY_JAR=metron-elasticsearch-$METRON_VERSION-uber.jar
+storm jar $METRON_HOME/lib/$TOPOLOGY_JAR org.apache.storm.flux.Flux --remote $METRON_HOME/flux/indexing/batch/remote.yaml --filter $METRON_HOME/config/hdfs.properties
--- End diff --
I almost think that if it is going to be hdfs, we should call it hdfs. If we have multiple topologies based on the batch indexer, each will end up with a unique name anyways ( S3 indexer etc ).
---
[GitHub] metron issue #831: METRON-1302: Split up Indexing Topology into batch and ra...
Posted by cestella <gi...@git.apache.org>.
Github user cestella commented on the issue:
https://github.com/apache/metron/pull/831
Yep, so they can be tuned entirely independently.
---
[GitHub] metron pull request #831: METRON-1302: Split up Indexing Topology into batch...
Posted by nickwallen <gi...@git.apache.org>.
Github user nickwallen commented on a diff in the pull request:
https://github.com/apache/metron/pull/831#discussion_r150314308
--- Diff: metron-deployment/packaging/ambari/metron-mpack/src/main/resources/common-services/METRON/CURRENT/configuration/metron-indexing-env.xml ---
@@ -73,18 +98,31 @@
<display-name>Indexing Update Column Family</display-name>
</property>
<property>
- <name>indexing_workers</name>
+ <name>ra_indexing_workers</name>
+ <description>Number of Indexing Topology Workers</description>
--- End diff --
With the name and description the same for the random access and batch topologies; can the user distinguish which is which?
---