You are viewing a plain text version of this content. The canonical link for it is here.
Posted to github@arrow.apache.org by GitBox <gi...@apache.org> on 2021/07/13 22:05:44 UTC
[GitHub] [arrow] zeroshade opened a new pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
zeroshade opened a new pull request #10716:
URL: https://github.com/apache/arrow/pull/10716
@emkornfield Thanks for merging the previous PR #10379
Here's the remaining files that we pulled out of that PR to shrink it down, including all the unit tests for the Encoding package.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680022978
##########
File path: go/parquet/internal/encoding/encoding_benchmarks_test.go
##########
@@ -0,0 +1,461 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding_test
+
+import (
+ "fmt"
+ "math"
+ "testing"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/array"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/encoding"
+ "github.com/apache/arrow/go/parquet/internal/hashing"
+ "github.com/apache/arrow/go/parquet/internal/testutils"
+ "github.com/apache/arrow/go/parquet/schema"
+)
+
+const (
+ MINSIZE = 1024
+ MAXSIZE = 65536
+)
+
+func BenchmarkPlainEncodingBoolean(b *testing.B) {
+ for sz := MINSIZE; sz < MAXSIZE+1; sz *= 2 {
Review comment:
there isn't a built in construct in GO benchmarks for adjusting batch size?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686975396
##########
File path: go/parquet/internal/encoding/memo_table_test.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding_test
+
+import (
+ "math"
+ "testing"
+
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet/internal/encoding"
+ "github.com/apache/arrow/go/parquet/internal/hashing"
+ "github.com/stretchr/testify/suite"
+)
+
+type MemoTableTestSuite struct {
+ suite.Suite
+}
+
+func TestMemoTable(t *testing.T) {
+ suite.Run(t, new(MemoTableTestSuite))
+}
+
+func (m *MemoTableTestSuite) assertGetNotFound(table encoding.MemoTable, v interface{}) {
+ _, ok := table.Get(v)
+ m.False(ok)
+}
+
+func (m *MemoTableTestSuite) assertGet(table encoding.MemoTable, v interface{}, expected int) {
+ idx, ok := table.Get(v)
+ m.Equal(expected, idx)
+ m.True(ok)
+}
+
+func (m *MemoTableTestSuite) assertGetOrInsert(table encoding.MemoTable, v interface{}, expected int) {
+ idx, _, err := table.GetOrInsert(v)
+ m.NoError(err)
+ m.Equal(expected, idx)
+}
+
+func (m *MemoTableTestSuite) assertGetNullNotFound(table encoding.MemoTable) {
+ _, ok := table.GetNull()
+ m.False(ok)
+}
+
+func (m *MemoTableTestSuite) assertGetNull(table encoding.MemoTable, expected int) {
+ idx, ok := table.GetNull()
+ m.Equal(expected, idx)
+ m.True(ok)
+}
+
+func (m *MemoTableTestSuite) assertGetOrInsertNull(table encoding.MemoTable, expected int) {
+ idx, _ := table.GetOrInsertNull()
+ m.Equal(expected, idx)
+}
+
+func (m *MemoTableTestSuite) TestInt64() {
+ const (
+ A int64 = 1234
+ B int64 = 0
+ C int64 = -98765321
+ D int64 = 12345678901234
+ E int64 = -1
+ F int64 = 1
+ G int64 = 9223372036854775807
+ H int64 = -9223372036854775807 - 1
+ )
+
+ // table := encoding.NewInt64MemoTable(nil)
+ table := hashing.NewInt64MemoTable(0)
+ m.Zero(table.Size())
+ m.assertGetNotFound(table, A)
+ m.assertGetNullNotFound(table)
+ m.assertGetOrInsert(table, A, 0)
+ m.assertGetNotFound(table, B)
+ m.assertGetOrInsert(table, B, 1)
+ m.assertGetOrInsert(table, C, 2)
+ m.assertGetOrInsert(table, D, 3)
+ m.assertGetOrInsert(table, E, 4)
+ m.assertGetOrInsertNull(table, 5)
+
+ m.assertGet(table, A, 0)
+ m.assertGetOrInsert(table, A, 0)
+ m.assertGet(table, E, 4)
+ m.assertGetOrInsert(table, E, 4)
+
+ m.assertGetOrInsert(table, F, 6)
+ m.assertGetOrInsert(table, G, 7)
+ m.assertGetOrInsert(table, H, 8)
+
+ m.assertGetOrInsert(table, G, 7)
+ m.assertGetOrInsert(table, F, 6)
+ m.assertGetOrInsertNull(table, 5)
+ m.assertGetOrInsert(table, E, 4)
+ m.assertGetOrInsert(table, D, 3)
+ m.assertGetOrInsert(table, C, 2)
+ m.assertGetOrInsert(table, B, 1)
+ m.assertGetOrInsert(table, A, 0)
+
+ const sz int = 9
+ m.Equal(sz, table.Size())
+ m.Panics(func() {
+ values := make([]int32, sz)
+ table.CopyValues(values)
+ }, "should panic because wrong type")
+ m.Panics(func() {
+ values := make([]int64, sz-3)
+ table.CopyValues(values)
+ }, "should panic because out of bounds")
+
+ {
+ values := make([]int64, sz)
+ table.CopyValues(values)
+ m.Equal([]int64{A, B, C, D, E, 0, F, G, H}, values)
+ }
+ {
+ const offset = 3
+ values := make([]int64, sz-offset)
+ table.CopyValuesSubset(offset, values)
+ m.Equal([]int64{D, E, 0, F, G, H}, values)
+ }
+}
+
+func (m *MemoTableTestSuite) TestFloat64() {
+ const (
+ A float64 = 0.0
+ B float64 = 1.5
+ C float64 = -0.1
+ )
+ var (
+ D = math.Inf(1)
+ E = -D
+ F = math.NaN()
Review comment:
added tests with 2 other bit representations of NaN for comparisons
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-883459361
@emkornfield @sbinet Bump for visibility to get reviews
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680029295
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
Review comment:
it *should* always return `len(lvls)`, if it returns less that means it encountered an error/issue while encoding. I'll add that to the comment.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686489652
##########
File path: go/parquet/internal/encoding/memo_table.go
##########
@@ -0,0 +1,380 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "math"
+ "unsafe"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/array"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/hashing"
+)
+
+//go:generate go run ../../../arrow/_tools/tmpl/main.go -i -data=physical_types.tmpldata memo_table_types.gen.go.tmpl
+
+// MemoTable interface that can be used to swap out implementations of the hash table
+// used for handling dictionary encoding. Dictionary encoding is built against this interface
+// to make it easy for code generation and changing implementations.
+//
+// Values should remember the order they are inserted to generate a valid dictionary index
+type MemoTable interface {
+ // Reset drops everything in the table allowing it to be reused
+ Reset()
+ // Size returns the current number of unique values stored in the table
+ // including whether or not a null value has been passed in using GetOrInsertNull
+ Size() int
Review comment:
int is 32 bits here? does it pay to have errors returned for the insertion operations if they exceed that range?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680034150
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
Review comment:
so it is up to users to check that? should it propogate an error instead?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] github-actions[bot] commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
github-actions[bot] commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-879433836
https://issues.apache.org/jira/browse/ARROW-13330
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680027388
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
+// of values encoded.
+func (l *LevelEncoder) EncodeNoFlush(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ }
+ return nencoded
+}
+
+// Flush flushes out any encoded data to the underlying writer.
+func (l *LevelEncoder) Flush() {
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rleLen = l.rle.Flush()
+ default:
+ l.bit.Flush(false)
+ }
+}
+
+// Encode encodes the slice of definition or repetition levels based on
+// the currently configured encoding type and returns the number of
+// values that were encoded.
+func (l *LevelEncoder) Encode(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ l.rleLen = l.rle.Flush()
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ l.bit.Flush(false)
+ }
+ return nencoded
+}
+
+// Len returns the number of bytes that were written as Run Length encoded
+// levels, this is only valid for run length encoding and will panic if using
+// deprecated bit packed encoding.
+func (l *LevelEncoder) Len() int {
+ if l.encoding != format.Encoding_RLE {
+ panic("parquet: level encoder, only implemented for RLE")
+ }
+ return l.rleLen
+}
+
+// LevelDecoder handles the decoding of repetition and definition levels from a
+// parquet file supporting bit packed and run length encoded values.
+type LevelDecoder struct {
+ bitWidth int
+ remaining int
Review comment:
a comment on what remaining is might be useful.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686491375
##########
File path: go/parquet/internal/encoding/memo_table_test.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding_test
+
+import (
+ "math"
+ "testing"
+
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet/internal/encoding"
+ "github.com/apache/arrow/go/parquet/internal/hashing"
+ "github.com/stretchr/testify/suite"
+)
+
+type MemoTableTestSuite struct {
+ suite.Suite
+}
+
+func TestMemoTable(t *testing.T) {
+ suite.Run(t, new(MemoTableTestSuite))
+}
+
+func (m *MemoTableTestSuite) assertGetNotFound(table encoding.MemoTable, v interface{}) {
+ _, ok := table.Get(v)
+ m.False(ok)
+}
+
+func (m *MemoTableTestSuite) assertGet(table encoding.MemoTable, v interface{}, expected int) {
+ idx, ok := table.Get(v)
+ m.Equal(expected, idx)
+ m.True(ok)
+}
+
+func (m *MemoTableTestSuite) assertGetOrInsert(table encoding.MemoTable, v interface{}, expected int) {
+ idx, _, err := table.GetOrInsert(v)
+ m.NoError(err)
+ m.Equal(expected, idx)
+}
+
+func (m *MemoTableTestSuite) assertGetNullNotFound(table encoding.MemoTable) {
+ _, ok := table.GetNull()
+ m.False(ok)
+}
+
+func (m *MemoTableTestSuite) assertGetNull(table encoding.MemoTable, expected int) {
+ idx, ok := table.GetNull()
+ m.Equal(expected, idx)
+ m.True(ok)
+}
+
+func (m *MemoTableTestSuite) assertGetOrInsertNull(table encoding.MemoTable, expected int) {
+ idx, _ := table.GetOrInsertNull()
+ m.Equal(expected, idx)
+}
+
+func (m *MemoTableTestSuite) TestInt64() {
+ const (
+ A int64 = 1234
+ B int64 = 0
+ C int64 = -98765321
+ D int64 = 12345678901234
+ E int64 = -1
+ F int64 = 1
+ G int64 = 9223372036854775807
+ H int64 = -9223372036854775807 - 1
+ )
+
+ // table := encoding.NewInt64MemoTable(nil)
+ table := hashing.NewInt64MemoTable(0)
+ m.Zero(table.Size())
+ m.assertGetNotFound(table, A)
+ m.assertGetNullNotFound(table)
+ m.assertGetOrInsert(table, A, 0)
+ m.assertGetNotFound(table, B)
+ m.assertGetOrInsert(table, B, 1)
+ m.assertGetOrInsert(table, C, 2)
+ m.assertGetOrInsert(table, D, 3)
+ m.assertGetOrInsert(table, E, 4)
+ m.assertGetOrInsertNull(table, 5)
+
+ m.assertGet(table, A, 0)
+ m.assertGetOrInsert(table, A, 0)
+ m.assertGet(table, E, 4)
+ m.assertGetOrInsert(table, E, 4)
+
+ m.assertGetOrInsert(table, F, 6)
+ m.assertGetOrInsert(table, G, 7)
+ m.assertGetOrInsert(table, H, 8)
+
+ m.assertGetOrInsert(table, G, 7)
+ m.assertGetOrInsert(table, F, 6)
+ m.assertGetOrInsertNull(table, 5)
+ m.assertGetOrInsert(table, E, 4)
+ m.assertGetOrInsert(table, D, 3)
+ m.assertGetOrInsert(table, C, 2)
+ m.assertGetOrInsert(table, B, 1)
+ m.assertGetOrInsert(table, A, 0)
+
+ const sz int = 9
+ m.Equal(sz, table.Size())
+ m.Panics(func() {
+ values := make([]int32, sz)
+ table.CopyValues(values)
+ }, "should panic because wrong type")
+ m.Panics(func() {
+ values := make([]int64, sz-3)
+ table.CopyValues(values)
+ }, "should panic because out of bounds")
+
+ {
+ values := make([]int64, sz)
+ table.CopyValues(values)
+ m.Equal([]int64{A, B, C, D, E, 0, F, G, H}, values)
+ }
+ {
+ const offset = 3
+ values := make([]int64, sz-offset)
+ table.CopyValuesSubset(offset, values)
+ m.Equal([]int64{D, E, 0, F, G, H}, values)
+ }
+}
+
+func (m *MemoTableTestSuite) TestFloat64() {
+ const (
+ A float64 = 0.0
+ B float64 = 1.5
+ C float64 = -0.1
+ )
+ var (
+ D = math.Inf(1)
+ E = -D
+ F = math.NaN()
Review comment:
ideally, you would test with to different bit representations of Nan
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680074956
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
Review comment:
updated this change to add error propagation to all the necessary spots (and all the subsequent calls and dependencies) so that consumers no longer have to rely on checking the number of values returned but can see easily if an error was returned by the encoders.
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
+// of values encoded.
+func (l *LevelEncoder) EncodeNoFlush(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ }
+ return nencoded
+}
+
+// Flush flushes out any encoded data to the underlying writer.
+func (l *LevelEncoder) Flush() {
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rleLen = l.rle.Flush()
+ default:
+ l.bit.Flush(false)
+ }
+}
+
+// Encode encodes the slice of definition or repetition levels based on
+// the currently configured encoding type and returns the number of
+// values that were encoded.
+func (l *LevelEncoder) Encode(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ l.rleLen = l.rle.Flush()
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ l.bit.Flush(false)
+ }
+ return nencoded
+}
+
+// Len returns the number of bytes that were written as Run Length encoded
+// levels, this is only valid for run length encoding and will panic if using
+// deprecated bit packed encoding.
+func (l *LevelEncoder) Len() int {
+ if l.encoding != format.Encoding_RLE {
+ panic("parquet: level encoder, only implemented for RLE")
+ }
+ return l.rleLen
+}
+
+// LevelDecoder handles the decoding of repetition and definition levels from a
+// parquet file supporting bit packed and run length encoded values.
+type LevelDecoder struct {
+ bitWidth int
+ remaining int
+ maxLvl int16
+ encoding format.Encoding
+ rle *utils.RleDecoder
Review comment:
done
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
+// of values encoded.
+func (l *LevelEncoder) EncodeNoFlush(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ }
+ return nencoded
+}
+
+// Flush flushes out any encoded data to the underlying writer.
+func (l *LevelEncoder) Flush() {
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rleLen = l.rle.Flush()
+ default:
+ l.bit.Flush(false)
+ }
+}
+
+// Encode encodes the slice of definition or repetition levels based on
+// the currently configured encoding type and returns the number of
+// values that were encoded.
+func (l *LevelEncoder) Encode(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ l.rleLen = l.rle.Flush()
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ l.bit.Flush(false)
+ }
+ return nencoded
+}
+
+// Len returns the number of bytes that were written as Run Length encoded
+// levels, this is only valid for run length encoding and will panic if using
+// deprecated bit packed encoding.
+func (l *LevelEncoder) Len() int {
+ if l.encoding != format.Encoding_RLE {
+ panic("parquet: level encoder, only implemented for RLE")
+ }
+ return l.rleLen
+}
+
+// LevelDecoder handles the decoding of repetition and definition levels from a
+// parquet file supporting bit packed and run length encoded values.
+type LevelDecoder struct {
+ bitWidth int
+ remaining int
Review comment:
done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-899963348
+1 merging. Thank you @zeroshade
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686851251
##########
File path: go/parquet/internal/encoding/memo_table.go
##########
@@ -0,0 +1,380 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "math"
+ "unsafe"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/array"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/hashing"
+)
+
+//go:generate go run ../../../arrow/_tools/tmpl/main.go -i -data=physical_types.tmpldata memo_table_types.gen.go.tmpl
+
+// MemoTable interface that can be used to swap out implementations of the hash table
+// used for handling dictionary encoding. Dictionary encoding is built against this interface
+// to make it easy for code generation and changing implementations.
+//
+// Values should remember the order they are inserted to generate a valid dictionary index
+type MemoTable interface {
+ // Reset drops everything in the table allowing it to be reused
+ Reset()
+ // Size returns the current number of unique values stored in the table
+ // including whether or not a null value has been passed in using GetOrInsertNull
+ Size() int
+ // CopyValues populates out with the values currently in the table, out must
+ // be a slice of the appropriate type for the table type.
+ CopyValues(out interface{})
+ // CopyValuesSubset is like CopyValues but only copies a subset of values starting
+ // at the indicated index.
+ CopyValuesSubset(start int, out interface{})
+ // Get returns the index of the table the specified value is, and a boolean indicating
+ // whether or not the value was found in the table. Will panic if val is not the appropriate
+ // type for the underlying table.
+ Get(val interface{}) (int, bool)
+ // GetOrInsert is the same as Get, except if the value is not currently in the table it will
+ // be inserted into the table.
+ GetOrInsert(val interface{}) (idx int, existed bool, err error)
+ // GetNull returns the index of the null value and whether or not it was found in the table
+ GetNull() (int, bool)
+ // GetOrInsertNull returns the index of the null value, if it didn't already exist in the table,
+ // it is inserted.
+ GetOrInsertNull() (idx int, existed bool)
+}
+
+// BinaryMemoTable is an extension of the MemoTable interface adding extra methods
+// for handling byte arrays/strings/fixed length byte arrays.
+type BinaryMemoTable interface {
+ MemoTable
+ // ValuesSize returns the total number of bytes needed to copy all of the values
+ // from this table.
+ ValuesSize() int
Review comment:
No, it's just the raw bytes of the strings as they are stored like in an arrow array (since I back the binary memotable using a `BinaryBuilder` and just call `DataLen` on it). This is specifically used for copying the raw values as a single chunk of memory which is why the offsets are stored separately and copied out separately.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-889976220
sorry I have had less time then I would have liked recently for Arrow reviews, will try to get to this soon.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680026208
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
Review comment:
does it ever return less than the values provided in lvls? If so please document it (if not maybe still note that this is simply for the API consumer's convenience?)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade edited a comment on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade edited a comment on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-896915175
@emkornfield Just to tack on here, another interesting view is looking at a flame graph of the CPU profile for the `BenchmarkMemoTableAllUnique` benchmark case, just benchmarking the binary string case where the largest difference between the two is that in the builtin Go Map based implementation I use a `map[string]int` to map strings to their memo index, whereas in the custom implementation I use an `Int32HashTable` to map the hash of the string to the memo index, with the hash of the string being calculated with the custom hash implementation.
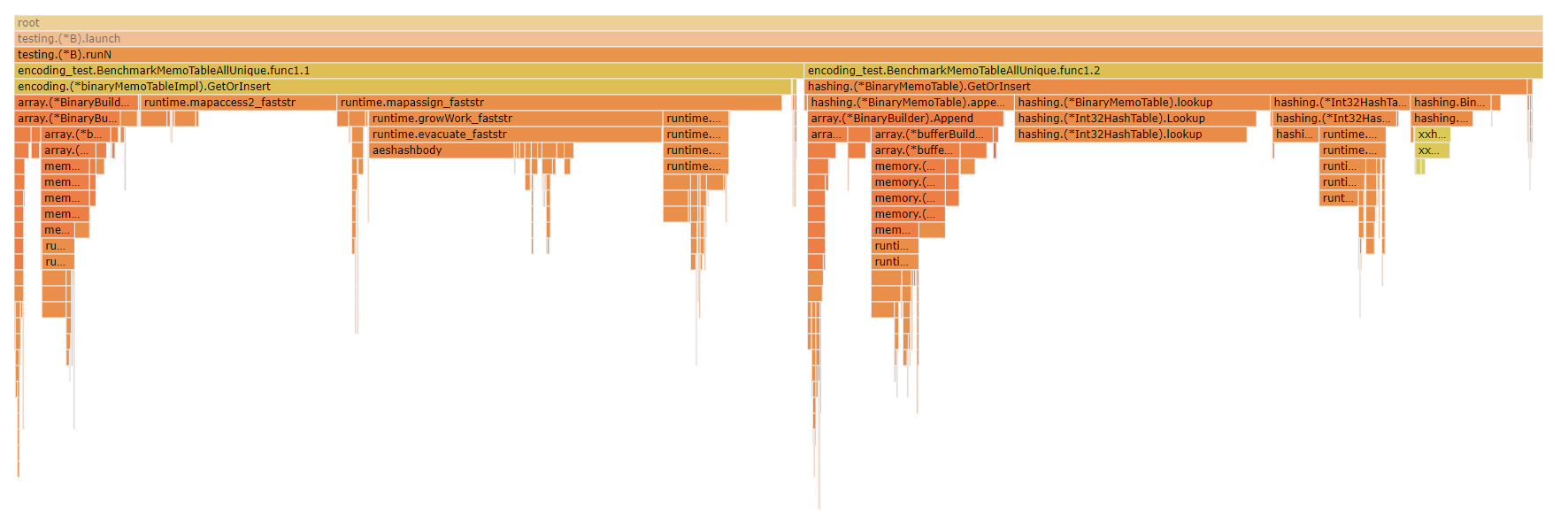
Looking at the flame graph you can see that a larger proportion of the CPU time for the builtin map-based implementation is spent in the map itself whether performing the hashes or accessing/growing/allocating vs adding the strings to the `BinaryBuilder` while in the xxh3 based custom implementation there's a smaller proportion of the time spent actually performing the hashing and the lookups/allocations. In the benchmarks I'm specifically using 0 when creating the new memo table to avoid pre-allocating in order to make the comparison between the go map implementation a closer / better comparison since, to my knowledge, there's no way to pre-allocate a size for the builtin golang map. But if I change that and have it actually use reserve to pre-allocate space the difference can become more pronounced.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686950122
##########
File path: go/parquet/internal/encoding/memo_table.go
##########
@@ -0,0 +1,380 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "math"
+ "unsafe"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/array"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/hashing"
+)
+
+//go:generate go run ../../../arrow/_tools/tmpl/main.go -i -data=physical_types.tmpldata memo_table_types.gen.go.tmpl
+
+// MemoTable interface that can be used to swap out implementations of the hash table
+// used for handling dictionary encoding. Dictionary encoding is built against this interface
+// to make it easy for code generation and changing implementations.
+//
+// Values should remember the order they are inserted to generate a valid dictionary index
+type MemoTable interface {
+ // Reset drops everything in the table allowing it to be reused
+ Reset()
+ // Size returns the current number of unique values stored in the table
+ // including whether or not a null value has been passed in using GetOrInsertNull
+ Size() int
Review comment:
`int` is implementation defined, on 32 bit platforms `int` will be 32 bits, on 64 bit platforms it will be 64 bits.
In this memo table, I guess I assumed that it was unlikely that there'd ever be billions of elements in the table such that it was necessary or likely for a check to exceed the range of an int. Personally i'd prefer to not add the extra check inside of the insertion operation simply because it's a critical path that is likely to be inside of a tight loop so if possible, I'd prefer to avoid adding the check for whether the new size will exceed `math.MaxInt` but rather just document that the memotable has a limitation on the number of unique values it can hold being `MaxInt`. Thoughts?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686852669
##########
File path: go/parquet/internal/encoding/memo_table_test.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding_test
+
+import (
+ "math"
+ "testing"
+
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet/internal/encoding"
+ "github.com/apache/arrow/go/parquet/internal/hashing"
+ "github.com/stretchr/testify/suite"
+)
+
+type MemoTableTestSuite struct {
+ suite.Suite
+}
+
+func TestMemoTable(t *testing.T) {
+ suite.Run(t, new(MemoTableTestSuite))
+}
+
+func (m *MemoTableTestSuite) assertGetNotFound(table encoding.MemoTable, v interface{}) {
+ _, ok := table.Get(v)
+ m.False(ok)
+}
+
+func (m *MemoTableTestSuite) assertGet(table encoding.MemoTable, v interface{}, expected int) {
+ idx, ok := table.Get(v)
+ m.Equal(expected, idx)
+ m.True(ok)
+}
+
+func (m *MemoTableTestSuite) assertGetOrInsert(table encoding.MemoTable, v interface{}, expected int) {
+ idx, _, err := table.GetOrInsert(v)
+ m.NoError(err)
+ m.Equal(expected, idx)
+}
+
+func (m *MemoTableTestSuite) assertGetNullNotFound(table encoding.MemoTable) {
+ _, ok := table.GetNull()
+ m.False(ok)
+}
+
+func (m *MemoTableTestSuite) assertGetNull(table encoding.MemoTable, expected int) {
+ idx, ok := table.GetNull()
+ m.Equal(expected, idx)
+ m.True(ok)
+}
+
+func (m *MemoTableTestSuite) assertGetOrInsertNull(table encoding.MemoTable, expected int) {
+ idx, _ := table.GetOrInsertNull()
+ m.Equal(expected, idx)
+}
+
+func (m *MemoTableTestSuite) TestInt64() {
+ const (
+ A int64 = 1234
+ B int64 = 0
+ C int64 = -98765321
+ D int64 = 12345678901234
+ E int64 = -1
+ F int64 = 1
+ G int64 = 9223372036854775807
+ H int64 = -9223372036854775807 - 1
+ )
+
+ // table := encoding.NewInt64MemoTable(nil)
+ table := hashing.NewInt64MemoTable(0)
+ m.Zero(table.Size())
+ m.assertGetNotFound(table, A)
+ m.assertGetNullNotFound(table)
+ m.assertGetOrInsert(table, A, 0)
+ m.assertGetNotFound(table, B)
+ m.assertGetOrInsert(table, B, 1)
+ m.assertGetOrInsert(table, C, 2)
+ m.assertGetOrInsert(table, D, 3)
+ m.assertGetOrInsert(table, E, 4)
+ m.assertGetOrInsertNull(table, 5)
+
+ m.assertGet(table, A, 0)
+ m.assertGetOrInsert(table, A, 0)
+ m.assertGet(table, E, 4)
+ m.assertGetOrInsert(table, E, 4)
+
+ m.assertGetOrInsert(table, F, 6)
+ m.assertGetOrInsert(table, G, 7)
+ m.assertGetOrInsert(table, H, 8)
+
+ m.assertGetOrInsert(table, G, 7)
+ m.assertGetOrInsert(table, F, 6)
+ m.assertGetOrInsertNull(table, 5)
+ m.assertGetOrInsert(table, E, 4)
+ m.assertGetOrInsert(table, D, 3)
+ m.assertGetOrInsert(table, C, 2)
+ m.assertGetOrInsert(table, B, 1)
+ m.assertGetOrInsert(table, A, 0)
+
+ const sz int = 9
+ m.Equal(sz, table.Size())
+ m.Panics(func() {
+ values := make([]int32, sz)
+ table.CopyValues(values)
+ }, "should panic because wrong type")
+ m.Panics(func() {
+ values := make([]int64, sz-3)
+ table.CopyValues(values)
+ }, "should panic because out of bounds")
+
+ {
+ values := make([]int64, sz)
+ table.CopyValues(values)
+ m.Equal([]int64{A, B, C, D, E, 0, F, G, H}, values)
+ }
+ {
+ const offset = 3
+ values := make([]int64, sz-offset)
+ table.CopyValuesSubset(offset, values)
+ m.Equal([]int64{D, E, 0, F, G, H}, values)
+ }
+}
+
+func (m *MemoTableTestSuite) TestFloat64() {
+ const (
+ A float64 = 0.0
+ B float64 = 1.5
+ C float64 = -0.1
+ )
+ var (
+ D = math.Inf(1)
+ E = -D
+ F = math.NaN()
Review comment:
That's a good point, i'll look up a couple different bit representations of Nan to compare with and add them in.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686489838
##########
File path: go/parquet/internal/encoding/memo_table.go
##########
@@ -0,0 +1,380 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "math"
+ "unsafe"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/array"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/hashing"
+)
+
+//go:generate go run ../../../arrow/_tools/tmpl/main.go -i -data=physical_types.tmpldata memo_table_types.gen.go.tmpl
+
+// MemoTable interface that can be used to swap out implementations of the hash table
+// used for handling dictionary encoding. Dictionary encoding is built against this interface
+// to make it easy for code generation and changing implementations.
+//
+// Values should remember the order they are inserted to generate a valid dictionary index
+type MemoTable interface {
+ // Reset drops everything in the table allowing it to be reused
+ Reset()
+ // Size returns the current number of unique values stored in the table
+ // including whether or not a null value has been passed in using GetOrInsertNull
+ Size() int
+ // CopyValues populates out with the values currently in the table, out must
+ // be a slice of the appropriate type for the table type.
+ CopyValues(out interface{})
+ // CopyValuesSubset is like CopyValues but only copies a subset of values starting
+ // at the indicated index.
+ CopyValuesSubset(start int, out interface{})
+ // Get returns the index of the table the specified value is, and a boolean indicating
+ // whether or not the value was found in the table. Will panic if val is not the appropriate
+ // type for the underlying table.
+ Get(val interface{}) (int, bool)
+ // GetOrInsert is the same as Get, except if the value is not currently in the table it will
+ // be inserted into the table.
+ GetOrInsert(val interface{}) (idx int, existed bool, err error)
+ // GetNull returns the index of the null value and whether or not it was found in the table
+ GetNull() (int, bool)
+ // GetOrInsertNull returns the index of the null value, if it didn't already exist in the table,
+ // it is inserted.
+ GetOrInsertNull() (idx int, existed bool)
+}
+
+// BinaryMemoTable is an extension of the MemoTable interface adding extra methods
+// for handling byte arrays/strings/fixed length byte arrays.
+type BinaryMemoTable interface {
+ MemoTable
+ // ValuesSize returns the total number of bytes needed to copy all of the values
+ // from this table.
+ ValuesSize() int
Review comment:
this includes overhead for string length?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686487920
##########
File path: go/parquet/internal/encoding/encoding_test.go
##########
@@ -0,0 +1,684 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding_test
+
+import (
+ "fmt"
+ "reflect"
+ "testing"
+ "unsafe"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/encoding"
+ "github.com/apache/arrow/go/parquet/internal/testutils"
+ "github.com/apache/arrow/go/parquet/schema"
+ "github.com/stretchr/testify/assert"
+ "github.com/stretchr/testify/suite"
+)
+
+type nodeFactory func(string, parquet.Repetition, int32) *schema.PrimitiveNode
+
+func createNodeFactory(t reflect.Type) nodeFactory {
+ switch t {
+ case reflect.TypeOf(true):
+ return schema.NewBooleanNode
+ case reflect.TypeOf(int32(0)):
+ return schema.NewInt32Node
+ case reflect.TypeOf(int64(0)):
+ return schema.NewInt64Node
+ case reflect.TypeOf(parquet.Int96{}):
+ return schema.NewInt96Node
+ case reflect.TypeOf(float32(0)):
+ return schema.NewFloat32Node
+ case reflect.TypeOf(float64(0)):
+ return schema.NewFloat64Node
+ case reflect.TypeOf(parquet.ByteArray{}):
+ return schema.NewByteArrayNode
+ case reflect.TypeOf(parquet.FixedLenByteArray{}):
+ return func(name string, rep parquet.Repetition, field int32) *schema.PrimitiveNode {
+ return schema.NewFixedLenByteArrayNode(name, rep, 12, field)
+ }
+ }
+ return nil
+}
+
+func initdata(t reflect.Type, drawbuf, decodebuf []byte, nvals, repeats int, heap *memory.Buffer) (interface{}, interface{}) {
+ switch t {
+ case reflect.TypeOf(true):
+ draws := *(*[]bool)(unsafe.Pointer(&drawbuf))
+ decode := *(*[]bool)(unsafe.Pointer(&decodebuf))
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(int32(0)):
+ draws := arrow.Int32Traits.CastFromBytes(drawbuf)
+ decode := arrow.Int32Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(int64(0)):
+ draws := arrow.Int64Traits.CastFromBytes(drawbuf)
+ decode := arrow.Int64Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(parquet.Int96{}):
+ draws := parquet.Int96Traits.CastFromBytes(drawbuf)
+ decode := parquet.Int96Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(float32(0)):
+ draws := arrow.Float32Traits.CastFromBytes(drawbuf)
+ decode := arrow.Float32Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(float64(0)):
+ draws := arrow.Float64Traits.CastFromBytes(drawbuf)
+ decode := arrow.Float64Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(parquet.ByteArray{}):
+ draws := make([]parquet.ByteArray, nvals*repeats)
+ decode := make([]parquet.ByteArray, nvals*repeats)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(parquet.FixedLenByteArray{}):
+ draws := make([]parquet.FixedLenByteArray, nvals*repeats)
+ decode := make([]parquet.FixedLenByteArray, nvals*repeats)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ }
+ return nil, nil
+}
+
+func encode(enc encoding.TypedEncoder, vals interface{}) {
+ switch v := vals.(type) {
+ case []bool:
+ enc.(encoding.BooleanEncoder).Put(v)
+ case []int32:
+ enc.(encoding.Int32Encoder).Put(v)
+ case []int64:
+ enc.(encoding.Int64Encoder).Put(v)
+ case []parquet.Int96:
+ enc.(encoding.Int96Encoder).Put(v)
+ case []float32:
+ enc.(encoding.Float32Encoder).Put(v)
+ case []float64:
+ enc.(encoding.Float64Encoder).Put(v)
+ case []parquet.ByteArray:
+ enc.(encoding.ByteArrayEncoder).Put(v)
+ case []parquet.FixedLenByteArray:
+ enc.(encoding.FixedLenByteArrayEncoder).Put(v)
+ }
+}
+
+func encodeSpaced(enc encoding.TypedEncoder, vals interface{}, validBits []byte, validBitsOffset int64) {
+ switch v := vals.(type) {
+ case []bool:
+ enc.(encoding.BooleanEncoder).PutSpaced(v, validBits, validBitsOffset)
+ case []int32:
+ enc.(encoding.Int32Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []int64:
+ enc.(encoding.Int64Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []parquet.Int96:
+ enc.(encoding.Int96Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []float32:
+ enc.(encoding.Float32Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []float64:
+ enc.(encoding.Float64Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []parquet.ByteArray:
+ enc.(encoding.ByteArrayEncoder).PutSpaced(v, validBits, validBitsOffset)
+ case []parquet.FixedLenByteArray:
+ enc.(encoding.FixedLenByteArrayEncoder).PutSpaced(v, validBits, validBitsOffset)
+ }
+}
+
+func decode(dec encoding.TypedDecoder, out interface{}) (int, error) {
+ switch v := out.(type) {
+ case []bool:
+ return dec.(encoding.BooleanDecoder).Decode(v)
+ case []int32:
+ return dec.(encoding.Int32Decoder).Decode(v)
+ case []int64:
+ return dec.(encoding.Int64Decoder).Decode(v)
+ case []parquet.Int96:
+ return dec.(encoding.Int96Decoder).Decode(v)
+ case []float32:
+ return dec.(encoding.Float32Decoder).Decode(v)
+ case []float64:
+ return dec.(encoding.Float64Decoder).Decode(v)
+ case []parquet.ByteArray:
+ return dec.(encoding.ByteArrayDecoder).Decode(v)
+ case []parquet.FixedLenByteArray:
+ return dec.(encoding.FixedLenByteArrayDecoder).Decode(v)
+ }
+ return 0, nil
+}
+
+func decodeSpaced(dec encoding.TypedDecoder, out interface{}, nullCount int, validBits []byte, validBitsOffset int64) (int, error) {
+ switch v := out.(type) {
+ case []bool:
+ return dec.(encoding.BooleanDecoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []int32:
+ return dec.(encoding.Int32Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []int64:
+ return dec.(encoding.Int64Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []parquet.Int96:
+ return dec.(encoding.Int96Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []float32:
+ return dec.(encoding.Float32Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []float64:
+ return dec.(encoding.Float64Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []parquet.ByteArray:
+ return dec.(encoding.ByteArrayDecoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []parquet.FixedLenByteArray:
+ return dec.(encoding.FixedLenByteArrayDecoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ }
+ return 0, nil
+}
+
+type BaseEncodingTestSuite struct {
+ suite.Suite
+
+ descr *schema.Column
+ typeLen int
+ mem memory.Allocator
+ typ reflect.Type
+
+ nvalues int
+ heap *memory.Buffer
+ inputBytes *memory.Buffer
+ outputBytes *memory.Buffer
+ nodeFactory nodeFactory
+
+ draws interface{}
+ decodeBuf interface{}
+}
+
+func (b *BaseEncodingTestSuite) SetupSuite() {
+ b.mem = memory.DefaultAllocator
+ b.inputBytes = memory.NewResizableBuffer(b.mem)
+ b.outputBytes = memory.NewResizableBuffer(b.mem)
+ b.heap = memory.NewResizableBuffer(b.mem)
+ b.nodeFactory = createNodeFactory(b.typ)
+}
+
+func (b *BaseEncodingTestSuite) TearDownSuite() {
+ b.inputBytes.Release()
+ b.outputBytes.Release()
+ b.heap.Release()
+}
+
+func (b *BaseEncodingTestSuite) SetupTest() {
+ b.descr = schema.NewColumn(b.nodeFactory("name", parquet.Repetitions.Optional, -1), 0, 0)
+ b.typeLen = int(b.descr.TypeLength())
+}
+
+func (b *BaseEncodingTestSuite) initData(nvalues, repeats int) {
+ b.nvalues = nvalues * repeats
+ b.inputBytes.ResizeNoShrink(b.nvalues * int(b.typ.Size()))
+ b.outputBytes.ResizeNoShrink(b.nvalues * int(b.typ.Size()))
+ memory.Set(b.inputBytes.Buf(), 0)
+ memory.Set(b.outputBytes.Buf(), 0)
+
+ b.draws, b.decodeBuf = initdata(b.typ, b.inputBytes.Buf(), b.outputBytes.Buf(), nvalues, repeats, b.heap)
+}
+
+func (b *BaseEncodingTestSuite) encodeTestData(e parquet.Encoding) (encoding.Buffer, error) {
+ enc := encoding.NewEncoder(testutils.TypeToParquetType(b.typ), e, false, b.descr, memory.DefaultAllocator)
+ b.Equal(e, enc.Encoding())
+ b.Equal(b.descr.PhysicalType(), enc.Type())
+ encode(enc, reflect.ValueOf(b.draws).Slice(0, b.nvalues).Interface())
+ return enc.FlushValues()
+}
+
+func (b *BaseEncodingTestSuite) decodeTestData(e parquet.Encoding, buf []byte) {
+ dec := encoding.NewDecoder(testutils.TypeToParquetType(b.typ), e, b.descr, b.mem)
+ b.Equal(e, dec.Encoding())
+ b.Equal(b.descr.PhysicalType(), dec.Type())
+
+ dec.SetData(b.nvalues, buf)
+ decoded, _ := decode(dec, b.decodeBuf)
+ b.Equal(b.nvalues, decoded)
+ b.Equal(reflect.ValueOf(b.draws).Slice(0, b.nvalues).Interface(), reflect.ValueOf(b.decodeBuf).Slice(0, b.nvalues).Interface())
+}
+
+func (b *BaseEncodingTestSuite) encodeTestDataSpaced(e parquet.Encoding, validBits []byte, validBitsOffset int64) (encoding.Buffer, error) {
+ enc := encoding.NewEncoder(testutils.TypeToParquetType(b.typ), e, false, b.descr, memory.DefaultAllocator)
+ encodeSpaced(enc, reflect.ValueOf(b.draws).Slice(0, b.nvalues).Interface(), validBits, validBitsOffset)
+ return enc.FlushValues()
+}
+
+func (b *BaseEncodingTestSuite) decodeTestDataSpaced(e parquet.Encoding, nullCount int, buf []byte, validBits []byte, validBitsOffset int64) {
+ dec := encoding.NewDecoder(testutils.TypeToParquetType(b.typ), e, b.descr, b.mem)
+ dec.SetData(b.nvalues-nullCount, buf)
+ decoded, _ := decodeSpaced(dec, b.decodeBuf, nullCount, validBits, validBitsOffset)
+ b.Equal(b.nvalues, decoded)
+
+ drawval := reflect.ValueOf(b.draws)
+ decodeval := reflect.ValueOf(b.decodeBuf)
+ for j := 0; j < b.nvalues; j++ {
+ if bitutil.BitIsSet(validBits, int(validBitsOffset)+j) {
+ b.Equal(drawval.Index(j).Interface(), decodeval.Index(j).Interface())
+ }
+ }
+}
+
+func (b *BaseEncodingTestSuite) checkRoundTrip(e parquet.Encoding) {
+ buf, _ := b.encodeTestData(e)
+ defer buf.Release()
+ b.decodeTestData(e, buf.Bytes())
+}
+
+func (b *BaseEncodingTestSuite) checkRoundTripSpaced(e parquet.Encoding, validBits []byte, validBitsOffset int64) {
+ buf, _ := b.encodeTestDataSpaced(e, validBits, validBitsOffset)
+ defer buf.Release()
+
+ nullCount := 0
+ for i := 0; i < b.nvalues; i++ {
+ if bitutil.BitIsNotSet(validBits, int(validBitsOffset)+i) {
+ nullCount++
+ }
+ }
+ b.decodeTestDataSpaced(e, nullCount, buf.Bytes(), validBits, validBitsOffset)
+}
+
+func (b *BaseEncodingTestSuite) TestBasicRoundTrip() {
+ b.initData(10000, 1)
+ b.checkRoundTrip(parquet.Encodings.Plain)
+}
+
+func (b *BaseEncodingTestSuite) TestDeltaEncodingRoundTrip() {
+ b.initData(10000, 1)
+
+ switch b.typ {
+ case reflect.TypeOf(int32(0)), reflect.TypeOf(int64(0)):
+ b.checkRoundTrip(parquet.Encodings.DeltaBinaryPacked)
+ default:
+ b.Panics(func() { b.checkRoundTrip(parquet.Encodings.DeltaBinaryPacked) })
+ }
+}
+
+func (b *BaseEncodingTestSuite) TestDeltaLengthByteArrayRoundTrip() {
+ b.initData(10000, 1)
+
+ switch b.typ {
+ case reflect.TypeOf(parquet.ByteArray{}):
+ b.checkRoundTrip(parquet.Encodings.DeltaLengthByteArray)
+ default:
+ b.Panics(func() { b.checkRoundTrip(parquet.Encodings.DeltaLengthByteArray) })
+ }
+}
+
+func (b *BaseEncodingTestSuite) TestDeltaByteArrayRoundTrip() {
+ b.initData(10000, 1)
+
+ switch b.typ {
+ case reflect.TypeOf(parquet.ByteArray{}):
+ b.checkRoundTrip(parquet.Encodings.DeltaByteArray)
+ default:
+ b.Panics(func() { b.checkRoundTrip(parquet.Encodings.DeltaLengthByteArray) })
+ }
+}
+
+func (b *BaseEncodingTestSuite) TestSpacedRoundTrip() {
+ exec := func(vals, repeats int, validBitsOffset int64, nullProb float64) {
+ b.Run(fmt.Sprintf("%d vals %d repeats %d offset %0.3f null", vals, repeats, validBitsOffset, 1-nullProb), func() {
+ b.initData(vals, repeats)
+
+ size := int64(b.nvalues) + validBitsOffset
+ r := testutils.NewRandomArrayGenerator(1923)
+ arr := r.Uint8(size, 0, 100, 1-nullProb)
+ validBits := arr.NullBitmapBytes()
+ if validBits != nil {
+ b.checkRoundTripSpaced(parquet.Encodings.Plain, validBits, validBitsOffset)
+ switch b.typ {
+ case reflect.TypeOf(int32(0)), reflect.TypeOf(int64(0)):
+ b.checkRoundTripSpaced(parquet.Encodings.DeltaBinaryPacked, validBits, validBitsOffset)
+ case reflect.TypeOf(parquet.ByteArray{}):
+ b.checkRoundTripSpaced(parquet.Encodings.DeltaLengthByteArray, validBits, validBitsOffset)
+ b.checkRoundTripSpaced(parquet.Encodings.DeltaByteArray, validBits, validBitsOffset)
+ }
+ }
+ })
+ }
+
+ const (
+ avx512Size = 64
+ simdSize = avx512Size
+ multiSimdSize = simdSize * 33
+ )
+
+ for _, nullProb := range []float64{0.001, 0.1, 0.5, 0.9, 0.999} {
+ // Test with both size and offset up to 3 simd block
+ for i := 1; i < simdSize*3; i++ {
+ exec(i, 1, 0, nullProb)
+ exec(i, 1, int64(i+1), nullProb)
+ }
+ // large block and offset
+ exec(multiSimdSize, 1, 0, nullProb)
+ exec(multiSimdSize+33, 1, 0, nullProb)
+ exec(multiSimdSize, 1, 33, nullProb)
+ exec(multiSimdSize+33, 1, 33, nullProb)
+ }
+}
+
+func TestEncoding(t *testing.T) {
+ tests := []struct {
+ name string
+ typ reflect.Type
+ }{
+ {"Bool", reflect.TypeOf(true)},
+ {"Int32", reflect.TypeOf(int32(0))},
+ {"Int64", reflect.TypeOf(int64(0))},
+ {"Float32", reflect.TypeOf(float32(0))},
+ {"Float64", reflect.TypeOf(float64(0))},
+ {"Int96", reflect.TypeOf(parquet.Int96{})},
+ {"ByteArray", reflect.TypeOf(parquet.ByteArray{})},
+ {"FixedLenByteArray", reflect.TypeOf(parquet.FixedLenByteArray{})},
+ }
+
+ for _, tt := range tests {
+ t.Run(tt.name, func(t *testing.T) {
+ suite.Run(t, &BaseEncodingTestSuite{typ: tt.typ})
+ })
+ }
+}
+
+type DictionaryEncodingTestSuite struct {
+ BaseEncodingTestSuite
+}
+
+func (d *DictionaryEncodingTestSuite) encodeTestDataDict(e parquet.Encoding) (dictBuffer, indices encoding.Buffer, numEntries int) {
+ enc := encoding.NewEncoder(testutils.TypeToParquetType(d.typ), e, true, d.descr, memory.DefaultAllocator).(encoding.DictEncoder)
+
+ d.Equal(parquet.Encodings.PlainDict, enc.Encoding())
+ d.Equal(d.descr.PhysicalType(), enc.Type())
+ encode(enc, reflect.ValueOf(d.draws).Slice(0, d.nvalues).Interface())
+ dictBuffer = memory.NewResizableBuffer(d.mem)
+ dictBuffer.Resize(enc.DictEncodedSize())
+ enc.WriteDict(dictBuffer.Bytes())
+ indices, _ = enc.FlushValues()
+ numEntries = enc.NumEntries()
+ return
+}
+
+func (d *DictionaryEncodingTestSuite) encodeTestDataDictSpaced(e parquet.Encoding, validBits []byte, validBitsOffset int64) (dictBuffer, indices encoding.Buffer, numEntries int) {
+ enc := encoding.NewEncoder(testutils.TypeToParquetType(d.typ), e, true, d.descr, memory.DefaultAllocator).(encoding.DictEncoder)
+ d.Equal(d.descr.PhysicalType(), enc.Type())
+
+ encodeSpaced(enc, reflect.ValueOf(d.draws).Slice(0, d.nvalues).Interface(), validBits, validBitsOffset)
+ dictBuffer = memory.NewResizableBuffer(d.mem)
+ dictBuffer.Resize(enc.DictEncodedSize())
+ enc.WriteDict(dictBuffer.Bytes())
+ indices, _ = enc.FlushValues()
+ numEntries = enc.NumEntries()
+ return
+}
+
+func (d *DictionaryEncodingTestSuite) checkRoundTrip() {
+ dictBuffer, indices, numEntries := d.encodeTestDataDict(parquet.Encodings.Plain)
+ defer dictBuffer.Release()
+ defer indices.Release()
+ validBits := make([]byte, int(bitutil.BytesForBits(int64(d.nvalues)))+1)
+ memory.Set(validBits, 255)
+
+ spacedBuffer, indicesSpaced, _ := d.encodeTestDataDictSpaced(parquet.Encodings.Plain, validBits, 0)
+ defer spacedBuffer.Release()
+ defer indicesSpaced.Release()
+ d.Equal(indices.Bytes(), indicesSpaced.Bytes())
+
+ dictDecoder := encoding.NewDecoder(testutils.TypeToParquetType(d.typ), parquet.Encodings.Plain, d.descr, d.mem)
+ d.Equal(d.descr.PhysicalType(), dictDecoder.Type())
+ dictDecoder.SetData(numEntries, dictBuffer.Bytes())
+ decoder := encoding.NewDictDecoder(testutils.TypeToParquetType(d.typ), d.descr, d.mem)
+ decoder.SetDict(dictDecoder)
+ decoder.SetData(d.nvalues, indices.Bytes())
+
+ decoded, _ := decode(decoder, d.decodeBuf)
+ d.Equal(d.nvalues, decoded)
+ d.Equal(reflect.ValueOf(d.draws).Slice(0, d.nvalues).Interface(), reflect.ValueOf(d.decodeBuf).Slice(0, d.nvalues).Interface())
+
+ decoder.SetData(d.nvalues, indices.Bytes())
+ decoded, _ = decodeSpaced(decoder, d.decodeBuf, 0, validBits, 0)
+ d.Equal(d.nvalues, decoded)
+ d.Equal(reflect.ValueOf(d.draws).Slice(0, d.nvalues).Interface(), reflect.ValueOf(d.decodeBuf).Slice(0, d.nvalues).Interface())
+}
+
+func (d *DictionaryEncodingTestSuite) TestBasicRoundTrip() {
+ d.initData(2500, 2)
+ d.checkRoundTrip()
+}
+
+func TestDictEncoding(t *testing.T) {
+ tests := []struct {
+ name string
+ typ reflect.Type
+ }{
+ {"Int32", reflect.TypeOf(int32(0))},
+ {"Int64", reflect.TypeOf(int64(0))},
+ {"Float32", reflect.TypeOf(float32(0))},
+ {"Float64", reflect.TypeOf(float64(0))},
+ {"ByteArray", reflect.TypeOf(parquet.ByteArray{})},
+ {"FixedLenByteArray", reflect.TypeOf(parquet.FixedLenByteArray{})},
+ }
+
+ for _, tt := range tests {
+ t.Run(tt.name, func(t *testing.T) {
+ suite.Run(t, &DictionaryEncodingTestSuite{BaseEncodingTestSuite{typ: tt.typ}})
+ })
+ }
+}
+
+func TestWriteDeltaBitPackedInt32(t *testing.T) {
+ column := schema.NewColumn(schema.NewInt32Node("int32", parquet.Repetitions.Required, -1), 0, 0)
+
+ tests := []struct {
+ name string
+ toencode []int32
+ expected []byte
+ }{
+ {"simple 12345", []int32{1, 2, 3, 4, 5}, []byte{128, 1, 4, 5, 2, 2, 0, 0, 0, 0}},
+ {"odd vals", []int32{7, 5, 3, 1, 2, 3, 4, 5}, []byte{128, 1, 4, 8, 14, 3, 2, 0, 0, 0, 192, 63, 0, 0, 0, 0, 0, 0}},
+ }
+
+ for _, tt := range tests {
+ t.Run(tt.name, func(t *testing.T) {
+ enc := encoding.NewEncoder(parquet.Types.Int32, parquet.Encodings.DeltaBinaryPacked, false, column, memory.DefaultAllocator)
+
+ enc.(encoding.Int32Encoder).Put(tt.toencode)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ assert.Equal(t, tt.expected, buf.Bytes())
+
+ dec := encoding.NewDecoder(parquet.Types.Int32, parquet.Encodings.DeltaBinaryPacked, column, memory.DefaultAllocator)
+
+ dec.(encoding.Int32Decoder).SetData(len(tt.toencode), tt.expected)
+ out := make([]int32, len(tt.toencode))
+ dec.(encoding.Int32Decoder).Decode(out)
+ assert.Equal(t, tt.toencode, out)
+ })
+ }
+
+ t.Run("test progressive decoding", func(t *testing.T) {
+ values := make([]int32, 1000)
+ testutils.FillRandomInt32(0, values)
+
+ enc := encoding.NewEncoder(parquet.Types.Int32, parquet.Encodings.DeltaBinaryPacked, false, column, memory.DefaultAllocator)
+ enc.(encoding.Int32Encoder).Put(values)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ dec := encoding.NewDecoder(parquet.Types.Int32, parquet.Encodings.DeltaBinaryPacked, column, memory.DefaultAllocator)
+ dec.(encoding.Int32Decoder).SetData(len(values), buf.Bytes())
+
+ valueBuf := make([]int32, 100)
+ for i, j := 0, len(valueBuf); j <= len(values); i, j = i+len(valueBuf), j+len(valueBuf) {
+ dec.(encoding.Int32Decoder).Decode(valueBuf)
+ assert.Equalf(t, values[i:j], valueBuf, "indexes %d:%d", i, j)
+ }
+ })
+}
+
+func TestWriteDeltaBitPackedInt64(t *testing.T) {
+ column := schema.NewColumn(schema.NewInt64Node("int64", parquet.Repetitions.Required, -1), 0, 0)
+
+ tests := []struct {
+ name string
+ toencode []int64
+ expected []byte
+ }{
+ {"simple 12345", []int64{1, 2, 3, 4, 5}, []byte{128, 1, 4, 5, 2, 2, 0, 0, 0, 0}},
+ {"odd vals", []int64{7, 5, 3, 1, 2, 3, 4, 5}, []byte{128, 1, 4, 8, 14, 3, 2, 0, 0, 0, 192, 63, 0, 0, 0, 0, 0, 0}},
+ }
+
+ for _, tt := range tests {
+ t.Run(tt.name, func(t *testing.T) {
+ enc := encoding.NewEncoder(parquet.Types.Int64, parquet.Encodings.DeltaBinaryPacked, false, column, memory.DefaultAllocator)
+
+ enc.(encoding.Int64Encoder).Put(tt.toencode)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ assert.Equal(t, tt.expected, buf.Bytes())
+
+ dec := encoding.NewDecoder(parquet.Types.Int64, parquet.Encodings.DeltaBinaryPacked, column, memory.DefaultAllocator)
+
+ dec.(encoding.Int64Decoder).SetData(len(tt.toencode), tt.expected)
+ out := make([]int64, len(tt.toencode))
+ dec.(encoding.Int64Decoder).Decode(out)
+ assert.Equal(t, tt.toencode, out)
+ })
+ }
+
+ t.Run("test progressive decoding", func(t *testing.T) {
+ values := make([]int64, 1000)
+ testutils.FillRandomInt64(0, values)
+
+ enc := encoding.NewEncoder(parquet.Types.Int64, parquet.Encodings.DeltaBinaryPacked, false, column, memory.DefaultAllocator)
+ enc.(encoding.Int64Encoder).Put(values)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ dec := encoding.NewDecoder(parquet.Types.Int64, parquet.Encodings.DeltaBinaryPacked, column, memory.DefaultAllocator)
+ dec.(encoding.Int64Decoder).SetData(len(values), buf.Bytes())
+
+ valueBuf := make([]int64, 100)
+ for i, j := 0, len(valueBuf); j <= len(values); i, j = i+len(valueBuf), j+len(valueBuf) {
+ decoded, _ := dec.(encoding.Int64Decoder).Decode(valueBuf)
+ assert.Equal(t, len(valueBuf), decoded)
+ assert.Equalf(t, values[i:j], valueBuf, "indexes %d:%d", i, j)
+ }
+ })
+}
+
+func TestDeltaLengthByteArrayEncoding(t *testing.T) {
+ column := schema.NewColumn(schema.NewByteArrayNode("bytearray", parquet.Repetitions.Required, -1), 0, 0)
+
+ test := []parquet.ByteArray{[]byte("Hello"), []byte("World"), []byte("Foobar"), []byte("ABCDEF")}
+ expected := []byte{128, 1, 4, 4, 10, 0, 1, 0, 0, 0, 2, 0, 0, 0, 72, 101, 108, 108, 111, 87, 111, 114, 108, 100, 70, 111, 111, 98, 97, 114, 65, 66, 67, 68, 69, 70}
+
+ enc := encoding.NewEncoder(parquet.Types.ByteArray, parquet.Encodings.DeltaLengthByteArray, false, column, memory.DefaultAllocator)
+ enc.(encoding.ByteArrayEncoder).Put(test)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ assert.Equal(t, expected, buf.Bytes())
+
+ dec := encoding.NewDecoder(parquet.Types.ByteArray, parquet.Encodings.DeltaLengthByteArray, column, nil)
+ dec.SetData(len(test), expected)
+ out := make([]parquet.ByteArray, len(test))
+ decoded, _ := dec.(encoding.ByteArrayDecoder).Decode(out)
+ assert.Equal(t, len(test), decoded)
+ assert.Equal(t, test, out)
+}
+
+func TestDeltaByteArrayEncoding(t *testing.T) {
+ test := []parquet.ByteArray{[]byte("Hello"), []byte("World"), []byte("Foobar"), []byte("ABCDEF")}
+ expected := []byte{128, 1, 4, 4, 0, 0, 0, 0, 0, 0, 128, 1, 4, 4, 10, 0, 1, 0, 0, 0, 2, 0, 0, 0, 72, 101, 108, 108, 111, 87, 111, 114, 108, 100, 70, 111, 111, 98, 97, 114, 65, 66, 67, 68, 69, 70}
Review comment:
where do the expected values come from?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-883490956
Sorry busy week this week, will try to get to it EOW or sometime next week.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-893563947
@emkornfield bump. i've responded to and/or addressed all of the comments so far. :smile:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-897881060
Just to chime in one last piece on this: while it's extremely interesting that a custom hash table is performing better than Go's builtin map in many cases, remember that we're still talking in absolute terms about differences of between 1ms and 0.1ms, so unless you're using it in a tight loop with a TON of entries/lookups, you're probably better off using Go's builtin map just because it's a simpler implementation and built-in rather than having to use a custom hash table implementation with external dependencies as it'll be more than sufficiently performant in most cases, but for this low level handling for dictionary encoding in parquet, the performance can become significant on the scale that this will be used, making it preferable to use the custom implementation.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680037198
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
Review comment:
currently this is an internal only package so it is not exposed for non-internal consumers to call this and the column writers check the return and propagate an error if it doesn't match. Alternately, I could modify the underlying encoders to have Put return an error instead of just a bool and then propagate an error. I believe currently it just returns true/false for success/failure out of convenience and I never got around to having it return a proper error.
I'll take a look at how big such a change would be.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680028297
##########
File path: go/parquet/internal/encoding/encoding_benchmarks_test.go
##########
@@ -0,0 +1,461 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding_test
+
+import (
+ "fmt"
+ "math"
+ "testing"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/array"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/encoding"
+ "github.com/apache/arrow/go/parquet/internal/hashing"
+ "github.com/apache/arrow/go/parquet/internal/testutils"
+ "github.com/apache/arrow/go/parquet/schema"
+)
+
+const (
+ MINSIZE = 1024
+ MAXSIZE = 65536
+)
+
+func BenchmarkPlainEncodingBoolean(b *testing.B) {
+ for sz := MINSIZE; sz < MAXSIZE+1; sz *= 2 {
Review comment:
nope. `b.N` is the number of iterations to run under the benchmarking timer, so by doing this little loop it creates a separate benchmark for each of the batch sizes
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-896879021
@emkornfield The performance difference is actually entirely based on the data and types (which is why I left both implementations in here).
My current theory is that the custom hash table implementation (which I took from the C++ memo table implementation) is that it's simply a case of optimized handling of smaller values resulting is significantly fewer allocations.
With go1.16.1 on my local laptop:
```
goos: windows
goarch: amd64
pkg: github.com/apache/arrow/go/parquet/internal/encoding
cpu: Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz
BenchmarkMemoTableFloat64/100_unique_n_65535/go_map-12 100 12464686 ns/op 7912 B/op 15 allocs/op
BenchmarkMemoTableFloat64/100_unique_n_65535/xxh3-12 230 5325610 ns/op 7680 B/op 2 allocs/op
BenchmarkMemoTableFloat64/1000_unique_n_65535/go_map-12 85 14819479 ns/op 123337 B/op 70 allocs/op
BenchmarkMemoTableFloat64/1000_unique_n_65535/xxh3-12 186 5388082 ns/op 130560 B/op 4 allocs/op
BenchmarkMemoTableFloat64/5000_unique_n_65535/go_map-12 79 16167963 ns/op 493125 B/op 195 allocs/op
BenchmarkMemoTableFloat64/5000_unique_n_65535/xxh3-12 132 7631678 ns/op 523776 B/op 5 allocs/op
BenchmarkMemoTableInt32/100_unique_n_65535/xxh3-12 247 4648034 ns/op 5120 B/op 2 allocs/op
BenchmarkMemoTableInt32/100_unique_n_65535/go_map-12 602 1885666 ns/op 6468 B/op 17 allocs/op
BenchmarkMemoTableInt32/1000_unique_n_65535/xxh3-12 1429 895664 ns/op 87040 B/op 4 allocs/op
BenchmarkMemoTableInt32/1000_unique_n_65535/go_map-12 632 1893139 ns/op 104802 B/op 72 allocs/op
BenchmarkMemoTableInt32/5000_unique_n_65535/xxh3-12 1020 1295938 ns/op 349184 B/op 5 allocs/op
BenchmarkMemoTableInt32/5000_unique_n_65535/go_map-12 489 2457437 ns/op 420230 B/op 187 allocs/op
BenchmarkMemoTable/100_unique_len_32-32_n_65535/xxh3-12 398 2990361 ns/op 16904 B/op 23 allocs/op
BenchmarkMemoTable/100_unique_len_32-32_n_65535/go_map-12 428 2811322 ns/op 19799 B/op 28 allocs/op
BenchmarkMemoTable/100_unique_len_8-32_n_65535/xxh3-12 356 3463212 ns/op 16904 B/op 23 allocs/op
BenchmarkMemoTable/100_unique_len_8-32_n_65535/go_map-12 380 3149174 ns/op 19781 B/op 28 allocs/op
BenchmarkMemoTable/1000_unique_len_32-32_n_65535/xxh3-12 366 3188208 ns/op 176200 B/op 32 allocs/op
BenchmarkMemoTable/1000_unique_len_32-32_n_65535/go_map-12 361 9588561 ns/op 211407 B/op 67 allocs/op
BenchmarkMemoTable/1000_unique_len_8-32_n_65535/xxh3-12 336 3529636 ns/op 176200 B/op 32 allocs/op
BenchmarkMemoTable/1000_unique_len_8-32_n_65535/go_map-12 326 3676726 ns/op 211358 B/op 67 allocs/op
BenchmarkMemoTable/5000_unique_len_32-32_n_65535/xxh3-12 252 4702015 ns/op 992584 B/op 42 allocs/op
BenchmarkMemoTable/5000_unique_len_32-32_n_65535/go_map-12 255 4884533 ns/op 1131141 B/op 181 allocs/op
BenchmarkMemoTable/5000_unique_len_8-32_n_65535/xxh3-12 235 4814247 ns/op 722248 B/op 41 allocs/op
BenchmarkMemoTable/5000_unique_len_8-32_n_65535/go_map-12 244 5340692 ns/op 860673 B/op 179 allocs/op
BenchmarkMemoTableAllUnique/values_1024_len_32-32/go_map-12 4509 271040 ns/op 211432 B/op 67 allocs/op
BenchmarkMemoTableAllUnique/values_1024_len_32-32/xxh3-12 8245 150411 ns/op 176200 B/op 32 allocs/op
BenchmarkMemoTableAllUnique/values_1024_len_8-32/go_map-12 4552 255188 ns/op 211443 B/op 67 allocs/op
BenchmarkMemoTableAllUnique/values_1024_len_8-32/xxh3-12 9828 148377 ns/op 176200 B/op 32 allocs/op
BenchmarkMemoTableAllUnique/values_32767_len_32-32/go_map-12 100 11416073 ns/op 6324082 B/op 1176 allocs/op
BenchmarkMemoTableAllUnique/values_32767_len_32-32/xxh3-12 222 5578530 ns/op 3850569 B/op 49 allocs/op
BenchmarkMemoTableAllUnique/values_32767_len_8-32/go_map-12 100 11123497 ns/op 6323152 B/op 1171 allocs/op
BenchmarkMemoTableAllUnique/values_32767_len_8-32/xxh3-12 212 6094342 ns/op 3850569 B/op 49 allocs/op
BenchmarkMemoTableAllUnique/values_65535_len_32-32/go_map-12 44 25062816 ns/op 12580560 B/op 2384 allocs/op
BenchmarkMemoTableAllUnique/values_65535_len_32-32/xxh3-12 74 15704849 ns/op 10430028 B/op 53 allocs/op
BenchmarkMemoTableAllUnique/values_65535_len_8-32/go_map-12 40 26667808 ns/op 12580008 B/op 2381 allocs/op
BenchmarkMemoTableAllUnique/values_65535_len_8-32/xxh3-12 81 14417075 ns/op 10430024 B/op 53 allocs/op
```
The ones labeled xxh3 are my custom implementation and the go_map is the go builtin map based implementation, if you look closely at the results of the benchmark, in *most* cases, the xxh3 based implementation is fairly significantly faster, sometimes even twice as fast, with significantly fewer allocations per loop (for example, in the binary case with all unique values you can see the 2384 allocations in the go map based implementation vs the 53 in my custom implementation, having a ~37% performance improvement over the go-map based implementation.
But if we look at some other cases, for example the `100_unique_len_32-32_n_65535` and `100_unique_len_8-32_n_65535` cases, which correspond to 65535 binary strings of length 32 or of lengths between 8 and 32 with exactly 100 unique values among them, we see that the go map based implementation is actually slightly more performant despite a few more allocations. The same thing happens with the Int32 memotable with only 100 unique values over 65535 values, but when we increase to 1000 unique values or 5000 unique values my custom one seems to do better. Which seems to indicate that the builtin go map is faster in cases with lower cardinality of unique values, while my custom implementation is more performant for inserting new values. Except in the Float64 case, where my custom implementation is faster in all cases even in the 100 unique value case, which I attribute to the faster hashing of smaller byte values via xxh3.
**TL;DR**: All in all, in *most* cases, the custom implementation is faster but in some cases with lower cardinality of unique values (specifically int32 and binary strings) the implementation using go's map as the basis can be more performant.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686487321
##########
File path: go/parquet/internal/encoding/encoding_test.go
##########
@@ -0,0 +1,684 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding_test
+
+import (
+ "fmt"
+ "reflect"
+ "testing"
+ "unsafe"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/encoding"
+ "github.com/apache/arrow/go/parquet/internal/testutils"
+ "github.com/apache/arrow/go/parquet/schema"
+ "github.com/stretchr/testify/assert"
+ "github.com/stretchr/testify/suite"
+)
+
+type nodeFactory func(string, parquet.Repetition, int32) *schema.PrimitiveNode
+
+func createNodeFactory(t reflect.Type) nodeFactory {
+ switch t {
+ case reflect.TypeOf(true):
+ return schema.NewBooleanNode
+ case reflect.TypeOf(int32(0)):
+ return schema.NewInt32Node
+ case reflect.TypeOf(int64(0)):
+ return schema.NewInt64Node
+ case reflect.TypeOf(parquet.Int96{}):
+ return schema.NewInt96Node
+ case reflect.TypeOf(float32(0)):
+ return schema.NewFloat32Node
+ case reflect.TypeOf(float64(0)):
+ return schema.NewFloat64Node
+ case reflect.TypeOf(parquet.ByteArray{}):
+ return schema.NewByteArrayNode
+ case reflect.TypeOf(parquet.FixedLenByteArray{}):
+ return func(name string, rep parquet.Repetition, field int32) *schema.PrimitiveNode {
+ return schema.NewFixedLenByteArrayNode(name, rep, 12, field)
+ }
+ }
+ return nil
Review comment:
is it a common pattern to return nil for unhandled enum cases in go (and not have an error or compiler detect unhandled cases?)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680075490
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
+// of values encoded.
+func (l *LevelEncoder) EncodeNoFlush(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ }
+ return nencoded
+}
+
+// Flush flushes out any encoded data to the underlying writer.
+func (l *LevelEncoder) Flush() {
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rleLen = l.rle.Flush()
+ default:
+ l.bit.Flush(false)
+ }
+}
+
+// Encode encodes the slice of definition or repetition levels based on
+// the currently configured encoding type and returns the number of
+// values that were encoded.
+func (l *LevelEncoder) Encode(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ l.rleLen = l.rle.Flush()
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ l.bit.Flush(false)
+ }
+ return nencoded
+}
+
+// Len returns the number of bytes that were written as Run Length encoded
+// levels, this is only valid for run length encoding and will panic if using
+// deprecated bit packed encoding.
+func (l *LevelEncoder) Len() int {
+ if l.encoding != format.Encoding_RLE {
+ panic("parquet: level encoder, only implemented for RLE")
+ }
+ return l.rleLen
+}
+
+// LevelDecoder handles the decoding of repetition and definition levels from a
+// parquet file supporting bit packed and run length encoded values.
+type LevelDecoder struct {
+ bitWidth int
+ remaining int
+ maxLvl int16
+ encoding format.Encoding
+ rle *utils.RleDecoder
+ bit *utils.BitReader
+}
+
+// SetData sets in the data to be decoded by subsequent calls by specifying the encoding type
+// the maximum level (which is what determines the bit width), the number of values expected
+// and the raw bytes to decode. Returns the number of bytes expected to be decoded.
+func (l *LevelDecoder) SetData(encoding parquet.Encoding, maxLvl int16, nbuffered int, data []byte) int {
+ l.maxLvl = maxLvl
+ l.encoding = format.Encoding(encoding)
+ l.remaining = nbuffered
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+
+ switch encoding {
+ case parquet.Encodings.RLE:
+ if len(data) < 4 {
+ panic("parquet: received invalid levels (corrupt data page?)")
Review comment:
modified to propagate error instead of panic
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield closed pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield closed pull request #10716:
URL: https://github.com/apache/arrow/pull/10716
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680028272
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
+// of values encoded.
+func (l *LevelEncoder) EncodeNoFlush(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ }
+ return nencoded
+}
+
+// Flush flushes out any encoded data to the underlying writer.
+func (l *LevelEncoder) Flush() {
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rleLen = l.rle.Flush()
+ default:
+ l.bit.Flush(false)
+ }
+}
+
+// Encode encodes the slice of definition or repetition levels based on
+// the currently configured encoding type and returns the number of
+// values that were encoded.
+func (l *LevelEncoder) Encode(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ l.rleLen = l.rle.Flush()
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ l.bit.Flush(false)
+ }
+ return nencoded
+}
+
+// Len returns the number of bytes that were written as Run Length encoded
+// levels, this is only valid for run length encoding and will panic if using
+// deprecated bit packed encoding.
+func (l *LevelEncoder) Len() int {
+ if l.encoding != format.Encoding_RLE {
+ panic("parquet: level encoder, only implemented for RLE")
+ }
+ return l.rleLen
+}
+
+// LevelDecoder handles the decoding of repetition and definition levels from a
+// parquet file supporting bit packed and run length encoded values.
+type LevelDecoder struct {
+ bitWidth int
+ remaining int
+ maxLvl int16
+ encoding format.Encoding
+ rle *utils.RleDecoder
+ bit *utils.BitReader
+}
+
+// SetData sets in the data to be decoded by subsequent calls by specifying the encoding type
+// the maximum level (which is what determines the bit width), the number of values expected
+// and the raw bytes to decode. Returns the number of bytes expected to be decoded.
+func (l *LevelDecoder) SetData(encoding parquet.Encoding, maxLvl int16, nbuffered int, data []byte) int {
+ l.maxLvl = maxLvl
+ l.encoding = format.Encoding(encoding)
+ l.remaining = nbuffered
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+
+ switch encoding {
+ case parquet.Encodings.RLE:
+ if len(data) < 4 {
+ panic("parquet: received invalid levels (corrupt data page?)")
Review comment:
i forget where we landed on this in past reviews, but unless we are checking at a higher level, I think a malformed parquet file could hit this spot (i.e. it might be better return an error). I think the same potentially applies to the panics below in this method.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-888359609
@emkornfield bump
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686846062
##########
File path: go/parquet/internal/encoding/encoding_test.go
##########
@@ -0,0 +1,684 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding_test
+
+import (
+ "fmt"
+ "reflect"
+ "testing"
+ "unsafe"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/encoding"
+ "github.com/apache/arrow/go/parquet/internal/testutils"
+ "github.com/apache/arrow/go/parquet/schema"
+ "github.com/stretchr/testify/assert"
+ "github.com/stretchr/testify/suite"
+)
+
+type nodeFactory func(string, parquet.Repetition, int32) *schema.PrimitiveNode
+
+func createNodeFactory(t reflect.Type) nodeFactory {
+ switch t {
+ case reflect.TypeOf(true):
+ return schema.NewBooleanNode
+ case reflect.TypeOf(int32(0)):
+ return schema.NewInt32Node
+ case reflect.TypeOf(int64(0)):
+ return schema.NewInt64Node
+ case reflect.TypeOf(parquet.Int96{}):
+ return schema.NewInt96Node
+ case reflect.TypeOf(float32(0)):
+ return schema.NewFloat32Node
+ case reflect.TypeOf(float64(0)):
+ return schema.NewFloat64Node
+ case reflect.TypeOf(parquet.ByteArray{}):
+ return schema.NewByteArrayNode
+ case reflect.TypeOf(parquet.FixedLenByteArray{}):
+ return func(name string, rep parquet.Repetition, field int32) *schema.PrimitiveNode {
+ return schema.NewFixedLenByteArrayNode(name, rep, 12, field)
+ }
+ }
+ return nil
+}
+
+func initdata(t reflect.Type, drawbuf, decodebuf []byte, nvals, repeats int, heap *memory.Buffer) (interface{}, interface{}) {
+ switch t {
+ case reflect.TypeOf(true):
+ draws := *(*[]bool)(unsafe.Pointer(&drawbuf))
+ decode := *(*[]bool)(unsafe.Pointer(&decodebuf))
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(int32(0)):
+ draws := arrow.Int32Traits.CastFromBytes(drawbuf)
+ decode := arrow.Int32Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(int64(0)):
+ draws := arrow.Int64Traits.CastFromBytes(drawbuf)
+ decode := arrow.Int64Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(parquet.Int96{}):
+ draws := parquet.Int96Traits.CastFromBytes(drawbuf)
+ decode := parquet.Int96Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(float32(0)):
+ draws := arrow.Float32Traits.CastFromBytes(drawbuf)
+ decode := arrow.Float32Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(float64(0)):
+ draws := arrow.Float64Traits.CastFromBytes(drawbuf)
+ decode := arrow.Float64Traits.CastFromBytes(decodebuf)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(parquet.ByteArray{}):
+ draws := make([]parquet.ByteArray, nvals*repeats)
+ decode := make([]parquet.ByteArray, nvals*repeats)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ case reflect.TypeOf(parquet.FixedLenByteArray{}):
+ draws := make([]parquet.FixedLenByteArray, nvals*repeats)
+ decode := make([]parquet.FixedLenByteArray, nvals*repeats)
+ testutils.InitValues(draws[:nvals], heap)
+
+ for j := 1; j < repeats; j++ {
+ for k := 0; k < nvals; k++ {
+ draws[nvals*j+k] = draws[k]
+ }
+ }
+
+ return draws[:nvals*repeats], decode[:nvals*repeats]
+ }
+ return nil, nil
+}
+
+func encode(enc encoding.TypedEncoder, vals interface{}) {
+ switch v := vals.(type) {
+ case []bool:
+ enc.(encoding.BooleanEncoder).Put(v)
+ case []int32:
+ enc.(encoding.Int32Encoder).Put(v)
+ case []int64:
+ enc.(encoding.Int64Encoder).Put(v)
+ case []parquet.Int96:
+ enc.(encoding.Int96Encoder).Put(v)
+ case []float32:
+ enc.(encoding.Float32Encoder).Put(v)
+ case []float64:
+ enc.(encoding.Float64Encoder).Put(v)
+ case []parquet.ByteArray:
+ enc.(encoding.ByteArrayEncoder).Put(v)
+ case []parquet.FixedLenByteArray:
+ enc.(encoding.FixedLenByteArrayEncoder).Put(v)
+ }
+}
+
+func encodeSpaced(enc encoding.TypedEncoder, vals interface{}, validBits []byte, validBitsOffset int64) {
+ switch v := vals.(type) {
+ case []bool:
+ enc.(encoding.BooleanEncoder).PutSpaced(v, validBits, validBitsOffset)
+ case []int32:
+ enc.(encoding.Int32Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []int64:
+ enc.(encoding.Int64Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []parquet.Int96:
+ enc.(encoding.Int96Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []float32:
+ enc.(encoding.Float32Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []float64:
+ enc.(encoding.Float64Encoder).PutSpaced(v, validBits, validBitsOffset)
+ case []parquet.ByteArray:
+ enc.(encoding.ByteArrayEncoder).PutSpaced(v, validBits, validBitsOffset)
+ case []parquet.FixedLenByteArray:
+ enc.(encoding.FixedLenByteArrayEncoder).PutSpaced(v, validBits, validBitsOffset)
+ }
+}
+
+func decode(dec encoding.TypedDecoder, out interface{}) (int, error) {
+ switch v := out.(type) {
+ case []bool:
+ return dec.(encoding.BooleanDecoder).Decode(v)
+ case []int32:
+ return dec.(encoding.Int32Decoder).Decode(v)
+ case []int64:
+ return dec.(encoding.Int64Decoder).Decode(v)
+ case []parquet.Int96:
+ return dec.(encoding.Int96Decoder).Decode(v)
+ case []float32:
+ return dec.(encoding.Float32Decoder).Decode(v)
+ case []float64:
+ return dec.(encoding.Float64Decoder).Decode(v)
+ case []parquet.ByteArray:
+ return dec.(encoding.ByteArrayDecoder).Decode(v)
+ case []parquet.FixedLenByteArray:
+ return dec.(encoding.FixedLenByteArrayDecoder).Decode(v)
+ }
+ return 0, nil
+}
+
+func decodeSpaced(dec encoding.TypedDecoder, out interface{}, nullCount int, validBits []byte, validBitsOffset int64) (int, error) {
+ switch v := out.(type) {
+ case []bool:
+ return dec.(encoding.BooleanDecoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []int32:
+ return dec.(encoding.Int32Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []int64:
+ return dec.(encoding.Int64Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []parquet.Int96:
+ return dec.(encoding.Int96Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []float32:
+ return dec.(encoding.Float32Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []float64:
+ return dec.(encoding.Float64Decoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []parquet.ByteArray:
+ return dec.(encoding.ByteArrayDecoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ case []parquet.FixedLenByteArray:
+ return dec.(encoding.FixedLenByteArrayDecoder).DecodeSpaced(v, nullCount, validBits, validBitsOffset)
+ }
+ return 0, nil
+}
+
+type BaseEncodingTestSuite struct {
+ suite.Suite
+
+ descr *schema.Column
+ typeLen int
+ mem memory.Allocator
+ typ reflect.Type
+
+ nvalues int
+ heap *memory.Buffer
+ inputBytes *memory.Buffer
+ outputBytes *memory.Buffer
+ nodeFactory nodeFactory
+
+ draws interface{}
+ decodeBuf interface{}
+}
+
+func (b *BaseEncodingTestSuite) SetupSuite() {
+ b.mem = memory.DefaultAllocator
+ b.inputBytes = memory.NewResizableBuffer(b.mem)
+ b.outputBytes = memory.NewResizableBuffer(b.mem)
+ b.heap = memory.NewResizableBuffer(b.mem)
+ b.nodeFactory = createNodeFactory(b.typ)
+}
+
+func (b *BaseEncodingTestSuite) TearDownSuite() {
+ b.inputBytes.Release()
+ b.outputBytes.Release()
+ b.heap.Release()
+}
+
+func (b *BaseEncodingTestSuite) SetupTest() {
+ b.descr = schema.NewColumn(b.nodeFactory("name", parquet.Repetitions.Optional, -1), 0, 0)
+ b.typeLen = int(b.descr.TypeLength())
+}
+
+func (b *BaseEncodingTestSuite) initData(nvalues, repeats int) {
+ b.nvalues = nvalues * repeats
+ b.inputBytes.ResizeNoShrink(b.nvalues * int(b.typ.Size()))
+ b.outputBytes.ResizeNoShrink(b.nvalues * int(b.typ.Size()))
+ memory.Set(b.inputBytes.Buf(), 0)
+ memory.Set(b.outputBytes.Buf(), 0)
+
+ b.draws, b.decodeBuf = initdata(b.typ, b.inputBytes.Buf(), b.outputBytes.Buf(), nvalues, repeats, b.heap)
+}
+
+func (b *BaseEncodingTestSuite) encodeTestData(e parquet.Encoding) (encoding.Buffer, error) {
+ enc := encoding.NewEncoder(testutils.TypeToParquetType(b.typ), e, false, b.descr, memory.DefaultAllocator)
+ b.Equal(e, enc.Encoding())
+ b.Equal(b.descr.PhysicalType(), enc.Type())
+ encode(enc, reflect.ValueOf(b.draws).Slice(0, b.nvalues).Interface())
+ return enc.FlushValues()
+}
+
+func (b *BaseEncodingTestSuite) decodeTestData(e parquet.Encoding, buf []byte) {
+ dec := encoding.NewDecoder(testutils.TypeToParquetType(b.typ), e, b.descr, b.mem)
+ b.Equal(e, dec.Encoding())
+ b.Equal(b.descr.PhysicalType(), dec.Type())
+
+ dec.SetData(b.nvalues, buf)
+ decoded, _ := decode(dec, b.decodeBuf)
+ b.Equal(b.nvalues, decoded)
+ b.Equal(reflect.ValueOf(b.draws).Slice(0, b.nvalues).Interface(), reflect.ValueOf(b.decodeBuf).Slice(0, b.nvalues).Interface())
+}
+
+func (b *BaseEncodingTestSuite) encodeTestDataSpaced(e parquet.Encoding, validBits []byte, validBitsOffset int64) (encoding.Buffer, error) {
+ enc := encoding.NewEncoder(testutils.TypeToParquetType(b.typ), e, false, b.descr, memory.DefaultAllocator)
+ encodeSpaced(enc, reflect.ValueOf(b.draws).Slice(0, b.nvalues).Interface(), validBits, validBitsOffset)
+ return enc.FlushValues()
+}
+
+func (b *BaseEncodingTestSuite) decodeTestDataSpaced(e parquet.Encoding, nullCount int, buf []byte, validBits []byte, validBitsOffset int64) {
+ dec := encoding.NewDecoder(testutils.TypeToParquetType(b.typ), e, b.descr, b.mem)
+ dec.SetData(b.nvalues-nullCount, buf)
+ decoded, _ := decodeSpaced(dec, b.decodeBuf, nullCount, validBits, validBitsOffset)
+ b.Equal(b.nvalues, decoded)
+
+ drawval := reflect.ValueOf(b.draws)
+ decodeval := reflect.ValueOf(b.decodeBuf)
+ for j := 0; j < b.nvalues; j++ {
+ if bitutil.BitIsSet(validBits, int(validBitsOffset)+j) {
+ b.Equal(drawval.Index(j).Interface(), decodeval.Index(j).Interface())
+ }
+ }
+}
+
+func (b *BaseEncodingTestSuite) checkRoundTrip(e parquet.Encoding) {
+ buf, _ := b.encodeTestData(e)
+ defer buf.Release()
+ b.decodeTestData(e, buf.Bytes())
+}
+
+func (b *BaseEncodingTestSuite) checkRoundTripSpaced(e parquet.Encoding, validBits []byte, validBitsOffset int64) {
+ buf, _ := b.encodeTestDataSpaced(e, validBits, validBitsOffset)
+ defer buf.Release()
+
+ nullCount := 0
+ for i := 0; i < b.nvalues; i++ {
+ if bitutil.BitIsNotSet(validBits, int(validBitsOffset)+i) {
+ nullCount++
+ }
+ }
+ b.decodeTestDataSpaced(e, nullCount, buf.Bytes(), validBits, validBitsOffset)
+}
+
+func (b *BaseEncodingTestSuite) TestBasicRoundTrip() {
+ b.initData(10000, 1)
+ b.checkRoundTrip(parquet.Encodings.Plain)
+}
+
+func (b *BaseEncodingTestSuite) TestDeltaEncodingRoundTrip() {
+ b.initData(10000, 1)
+
+ switch b.typ {
+ case reflect.TypeOf(int32(0)), reflect.TypeOf(int64(0)):
+ b.checkRoundTrip(parquet.Encodings.DeltaBinaryPacked)
+ default:
+ b.Panics(func() { b.checkRoundTrip(parquet.Encodings.DeltaBinaryPacked) })
+ }
+}
+
+func (b *BaseEncodingTestSuite) TestDeltaLengthByteArrayRoundTrip() {
+ b.initData(10000, 1)
+
+ switch b.typ {
+ case reflect.TypeOf(parquet.ByteArray{}):
+ b.checkRoundTrip(parquet.Encodings.DeltaLengthByteArray)
+ default:
+ b.Panics(func() { b.checkRoundTrip(parquet.Encodings.DeltaLengthByteArray) })
+ }
+}
+
+func (b *BaseEncodingTestSuite) TestDeltaByteArrayRoundTrip() {
+ b.initData(10000, 1)
+
+ switch b.typ {
+ case reflect.TypeOf(parquet.ByteArray{}):
+ b.checkRoundTrip(parquet.Encodings.DeltaByteArray)
+ default:
+ b.Panics(func() { b.checkRoundTrip(parquet.Encodings.DeltaLengthByteArray) })
+ }
+}
+
+func (b *BaseEncodingTestSuite) TestSpacedRoundTrip() {
+ exec := func(vals, repeats int, validBitsOffset int64, nullProb float64) {
+ b.Run(fmt.Sprintf("%d vals %d repeats %d offset %0.3f null", vals, repeats, validBitsOffset, 1-nullProb), func() {
+ b.initData(vals, repeats)
+
+ size := int64(b.nvalues) + validBitsOffset
+ r := testutils.NewRandomArrayGenerator(1923)
+ arr := r.Uint8(size, 0, 100, 1-nullProb)
+ validBits := arr.NullBitmapBytes()
+ if validBits != nil {
+ b.checkRoundTripSpaced(parquet.Encodings.Plain, validBits, validBitsOffset)
+ switch b.typ {
+ case reflect.TypeOf(int32(0)), reflect.TypeOf(int64(0)):
+ b.checkRoundTripSpaced(parquet.Encodings.DeltaBinaryPacked, validBits, validBitsOffset)
+ case reflect.TypeOf(parquet.ByteArray{}):
+ b.checkRoundTripSpaced(parquet.Encodings.DeltaLengthByteArray, validBits, validBitsOffset)
+ b.checkRoundTripSpaced(parquet.Encodings.DeltaByteArray, validBits, validBitsOffset)
+ }
+ }
+ })
+ }
+
+ const (
+ avx512Size = 64
+ simdSize = avx512Size
+ multiSimdSize = simdSize * 33
+ )
+
+ for _, nullProb := range []float64{0.001, 0.1, 0.5, 0.9, 0.999} {
+ // Test with both size and offset up to 3 simd block
+ for i := 1; i < simdSize*3; i++ {
+ exec(i, 1, 0, nullProb)
+ exec(i, 1, int64(i+1), nullProb)
+ }
+ // large block and offset
+ exec(multiSimdSize, 1, 0, nullProb)
+ exec(multiSimdSize+33, 1, 0, nullProb)
+ exec(multiSimdSize, 1, 33, nullProb)
+ exec(multiSimdSize+33, 1, 33, nullProb)
+ }
+}
+
+func TestEncoding(t *testing.T) {
+ tests := []struct {
+ name string
+ typ reflect.Type
+ }{
+ {"Bool", reflect.TypeOf(true)},
+ {"Int32", reflect.TypeOf(int32(0))},
+ {"Int64", reflect.TypeOf(int64(0))},
+ {"Float32", reflect.TypeOf(float32(0))},
+ {"Float64", reflect.TypeOf(float64(0))},
+ {"Int96", reflect.TypeOf(parquet.Int96{})},
+ {"ByteArray", reflect.TypeOf(parquet.ByteArray{})},
+ {"FixedLenByteArray", reflect.TypeOf(parquet.FixedLenByteArray{})},
+ }
+
+ for _, tt := range tests {
+ t.Run(tt.name, func(t *testing.T) {
+ suite.Run(t, &BaseEncodingTestSuite{typ: tt.typ})
+ })
+ }
+}
+
+type DictionaryEncodingTestSuite struct {
+ BaseEncodingTestSuite
+}
+
+func (d *DictionaryEncodingTestSuite) encodeTestDataDict(e parquet.Encoding) (dictBuffer, indices encoding.Buffer, numEntries int) {
+ enc := encoding.NewEncoder(testutils.TypeToParquetType(d.typ), e, true, d.descr, memory.DefaultAllocator).(encoding.DictEncoder)
+
+ d.Equal(parquet.Encodings.PlainDict, enc.Encoding())
+ d.Equal(d.descr.PhysicalType(), enc.Type())
+ encode(enc, reflect.ValueOf(d.draws).Slice(0, d.nvalues).Interface())
+ dictBuffer = memory.NewResizableBuffer(d.mem)
+ dictBuffer.Resize(enc.DictEncodedSize())
+ enc.WriteDict(dictBuffer.Bytes())
+ indices, _ = enc.FlushValues()
+ numEntries = enc.NumEntries()
+ return
+}
+
+func (d *DictionaryEncodingTestSuite) encodeTestDataDictSpaced(e parquet.Encoding, validBits []byte, validBitsOffset int64) (dictBuffer, indices encoding.Buffer, numEntries int) {
+ enc := encoding.NewEncoder(testutils.TypeToParquetType(d.typ), e, true, d.descr, memory.DefaultAllocator).(encoding.DictEncoder)
+ d.Equal(d.descr.PhysicalType(), enc.Type())
+
+ encodeSpaced(enc, reflect.ValueOf(d.draws).Slice(0, d.nvalues).Interface(), validBits, validBitsOffset)
+ dictBuffer = memory.NewResizableBuffer(d.mem)
+ dictBuffer.Resize(enc.DictEncodedSize())
+ enc.WriteDict(dictBuffer.Bytes())
+ indices, _ = enc.FlushValues()
+ numEntries = enc.NumEntries()
+ return
+}
+
+func (d *DictionaryEncodingTestSuite) checkRoundTrip() {
+ dictBuffer, indices, numEntries := d.encodeTestDataDict(parquet.Encodings.Plain)
+ defer dictBuffer.Release()
+ defer indices.Release()
+ validBits := make([]byte, int(bitutil.BytesForBits(int64(d.nvalues)))+1)
+ memory.Set(validBits, 255)
+
+ spacedBuffer, indicesSpaced, _ := d.encodeTestDataDictSpaced(parquet.Encodings.Plain, validBits, 0)
+ defer spacedBuffer.Release()
+ defer indicesSpaced.Release()
+ d.Equal(indices.Bytes(), indicesSpaced.Bytes())
+
+ dictDecoder := encoding.NewDecoder(testutils.TypeToParquetType(d.typ), parquet.Encodings.Plain, d.descr, d.mem)
+ d.Equal(d.descr.PhysicalType(), dictDecoder.Type())
+ dictDecoder.SetData(numEntries, dictBuffer.Bytes())
+ decoder := encoding.NewDictDecoder(testutils.TypeToParquetType(d.typ), d.descr, d.mem)
+ decoder.SetDict(dictDecoder)
+ decoder.SetData(d.nvalues, indices.Bytes())
+
+ decoded, _ := decode(decoder, d.decodeBuf)
+ d.Equal(d.nvalues, decoded)
+ d.Equal(reflect.ValueOf(d.draws).Slice(0, d.nvalues).Interface(), reflect.ValueOf(d.decodeBuf).Slice(0, d.nvalues).Interface())
+
+ decoder.SetData(d.nvalues, indices.Bytes())
+ decoded, _ = decodeSpaced(decoder, d.decodeBuf, 0, validBits, 0)
+ d.Equal(d.nvalues, decoded)
+ d.Equal(reflect.ValueOf(d.draws).Slice(0, d.nvalues).Interface(), reflect.ValueOf(d.decodeBuf).Slice(0, d.nvalues).Interface())
+}
+
+func (d *DictionaryEncodingTestSuite) TestBasicRoundTrip() {
+ d.initData(2500, 2)
+ d.checkRoundTrip()
+}
+
+func TestDictEncoding(t *testing.T) {
+ tests := []struct {
+ name string
+ typ reflect.Type
+ }{
+ {"Int32", reflect.TypeOf(int32(0))},
+ {"Int64", reflect.TypeOf(int64(0))},
+ {"Float32", reflect.TypeOf(float32(0))},
+ {"Float64", reflect.TypeOf(float64(0))},
+ {"ByteArray", reflect.TypeOf(parquet.ByteArray{})},
+ {"FixedLenByteArray", reflect.TypeOf(parquet.FixedLenByteArray{})},
+ }
+
+ for _, tt := range tests {
+ t.Run(tt.name, func(t *testing.T) {
+ suite.Run(t, &DictionaryEncodingTestSuite{BaseEncodingTestSuite{typ: tt.typ}})
+ })
+ }
+}
+
+func TestWriteDeltaBitPackedInt32(t *testing.T) {
+ column := schema.NewColumn(schema.NewInt32Node("int32", parquet.Repetitions.Required, -1), 0, 0)
+
+ tests := []struct {
+ name string
+ toencode []int32
+ expected []byte
+ }{
+ {"simple 12345", []int32{1, 2, 3, 4, 5}, []byte{128, 1, 4, 5, 2, 2, 0, 0, 0, 0}},
+ {"odd vals", []int32{7, 5, 3, 1, 2, 3, 4, 5}, []byte{128, 1, 4, 8, 14, 3, 2, 0, 0, 0, 192, 63, 0, 0, 0, 0, 0, 0}},
+ }
+
+ for _, tt := range tests {
+ t.Run(tt.name, func(t *testing.T) {
+ enc := encoding.NewEncoder(parquet.Types.Int32, parquet.Encodings.DeltaBinaryPacked, false, column, memory.DefaultAllocator)
+
+ enc.(encoding.Int32Encoder).Put(tt.toencode)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ assert.Equal(t, tt.expected, buf.Bytes())
+
+ dec := encoding.NewDecoder(parquet.Types.Int32, parquet.Encodings.DeltaBinaryPacked, column, memory.DefaultAllocator)
+
+ dec.(encoding.Int32Decoder).SetData(len(tt.toencode), tt.expected)
+ out := make([]int32, len(tt.toencode))
+ dec.(encoding.Int32Decoder).Decode(out)
+ assert.Equal(t, tt.toencode, out)
+ })
+ }
+
+ t.Run("test progressive decoding", func(t *testing.T) {
+ values := make([]int32, 1000)
+ testutils.FillRandomInt32(0, values)
+
+ enc := encoding.NewEncoder(parquet.Types.Int32, parquet.Encodings.DeltaBinaryPacked, false, column, memory.DefaultAllocator)
+ enc.(encoding.Int32Encoder).Put(values)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ dec := encoding.NewDecoder(parquet.Types.Int32, parquet.Encodings.DeltaBinaryPacked, column, memory.DefaultAllocator)
+ dec.(encoding.Int32Decoder).SetData(len(values), buf.Bytes())
+
+ valueBuf := make([]int32, 100)
+ for i, j := 0, len(valueBuf); j <= len(values); i, j = i+len(valueBuf), j+len(valueBuf) {
+ dec.(encoding.Int32Decoder).Decode(valueBuf)
+ assert.Equalf(t, values[i:j], valueBuf, "indexes %d:%d", i, j)
+ }
+ })
+}
+
+func TestWriteDeltaBitPackedInt64(t *testing.T) {
+ column := schema.NewColumn(schema.NewInt64Node("int64", parquet.Repetitions.Required, -1), 0, 0)
+
+ tests := []struct {
+ name string
+ toencode []int64
+ expected []byte
+ }{
+ {"simple 12345", []int64{1, 2, 3, 4, 5}, []byte{128, 1, 4, 5, 2, 2, 0, 0, 0, 0}},
+ {"odd vals", []int64{7, 5, 3, 1, 2, 3, 4, 5}, []byte{128, 1, 4, 8, 14, 3, 2, 0, 0, 0, 192, 63, 0, 0, 0, 0, 0, 0}},
+ }
+
+ for _, tt := range tests {
+ t.Run(tt.name, func(t *testing.T) {
+ enc := encoding.NewEncoder(parquet.Types.Int64, parquet.Encodings.DeltaBinaryPacked, false, column, memory.DefaultAllocator)
+
+ enc.(encoding.Int64Encoder).Put(tt.toencode)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ assert.Equal(t, tt.expected, buf.Bytes())
+
+ dec := encoding.NewDecoder(parquet.Types.Int64, parquet.Encodings.DeltaBinaryPacked, column, memory.DefaultAllocator)
+
+ dec.(encoding.Int64Decoder).SetData(len(tt.toencode), tt.expected)
+ out := make([]int64, len(tt.toencode))
+ dec.(encoding.Int64Decoder).Decode(out)
+ assert.Equal(t, tt.toencode, out)
+ })
+ }
+
+ t.Run("test progressive decoding", func(t *testing.T) {
+ values := make([]int64, 1000)
+ testutils.FillRandomInt64(0, values)
+
+ enc := encoding.NewEncoder(parquet.Types.Int64, parquet.Encodings.DeltaBinaryPacked, false, column, memory.DefaultAllocator)
+ enc.(encoding.Int64Encoder).Put(values)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ dec := encoding.NewDecoder(parquet.Types.Int64, parquet.Encodings.DeltaBinaryPacked, column, memory.DefaultAllocator)
+ dec.(encoding.Int64Decoder).SetData(len(values), buf.Bytes())
+
+ valueBuf := make([]int64, 100)
+ for i, j := 0, len(valueBuf); j <= len(values); i, j = i+len(valueBuf), j+len(valueBuf) {
+ decoded, _ := dec.(encoding.Int64Decoder).Decode(valueBuf)
+ assert.Equal(t, len(valueBuf), decoded)
+ assert.Equalf(t, values[i:j], valueBuf, "indexes %d:%d", i, j)
+ }
+ })
+}
+
+func TestDeltaLengthByteArrayEncoding(t *testing.T) {
+ column := schema.NewColumn(schema.NewByteArrayNode("bytearray", parquet.Repetitions.Required, -1), 0, 0)
+
+ test := []parquet.ByteArray{[]byte("Hello"), []byte("World"), []byte("Foobar"), []byte("ABCDEF")}
+ expected := []byte{128, 1, 4, 4, 10, 0, 1, 0, 0, 0, 2, 0, 0, 0, 72, 101, 108, 108, 111, 87, 111, 114, 108, 100, 70, 111, 111, 98, 97, 114, 65, 66, 67, 68, 69, 70}
+
+ enc := encoding.NewEncoder(parquet.Types.ByteArray, parquet.Encodings.DeltaLengthByteArray, false, column, memory.DefaultAllocator)
+ enc.(encoding.ByteArrayEncoder).Put(test)
+ buf, _ := enc.FlushValues()
+ defer buf.Release()
+
+ assert.Equal(t, expected, buf.Bytes())
+
+ dec := encoding.NewDecoder(parquet.Types.ByteArray, parquet.Encodings.DeltaLengthByteArray, column, nil)
+ dec.SetData(len(test), expected)
+ out := make([]parquet.ByteArray, len(test))
+ decoded, _ := dec.(encoding.ByteArrayDecoder).Decode(out)
+ assert.Equal(t, len(test), decoded)
+ assert.Equal(t, test, out)
+}
+
+func TestDeltaByteArrayEncoding(t *testing.T) {
+ test := []parquet.ByteArray{[]byte("Hello"), []byte("World"), []byte("Foobar"), []byte("ABCDEF")}
+ expected := []byte{128, 1, 4, 4, 0, 0, 0, 0, 0, 0, 128, 1, 4, 4, 10, 0, 1, 0, 0, 0, 2, 0, 0, 0, 72, 101, 108, 108, 111, 87, 111, 114, 108, 100, 70, 111, 111, 98, 97, 114, 65, 66, 67, 68, 69, 70}
Review comment:
The Delta Byte Array Encoding was implemented in another parquet library, so I stole the expected values from their unit tests and also did some manual confirmation to ensure they were the correct values to the best of my knowledge.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] zeroshade commented on pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
zeroshade commented on pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#issuecomment-896915175
@emkornfield Just to tack on here, another interesting view is looking at a flame graph of the CPU profile for the `BenchmarkMemoTableAllUnique` benchmark case, just benchmarking the binary string case where the largest difference between the two is that in the builtin Go Map based implementation I use a `map[string]int` to map strings to their memo index, whereas in the custom implementation I use an `Int32HashTable` to map the hash of the string to the memo index, with the hash of the string being calculated with the custom hash implementation.

Looking at the flame graph you can see that a larger proportion of the CPU time for the builtin map-based implementation is spent in the map itself whether performing the hashes or accessing/growing/allocating vs adding the strings to the `BinaryBuilder` while in the xxh3 based custom implementation there's a smaller proportion of the time spent actually performing the hashing and the lookups/allocations.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r680027195
##########
File path: go/parquet/internal/encoding/levels.go
##########
@@ -0,0 +1,284 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding
+
+import (
+ "bytes"
+ "encoding/binary"
+ "io"
+ "math/bits"
+
+ "github.com/JohnCGriffin/overflow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/parquet"
+ format "github.com/apache/arrow/go/parquet/internal/gen-go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/utils"
+)
+
+// LevelEncoder is for handling the encoding of Definition and Repetition levels
+// to parquet files.
+type LevelEncoder struct {
+ bitWidth int
+ rleLen int
+ encoding format.Encoding
+ rle *utils.RleEncoder
+ bit *utils.BitWriter
+}
+
+// LevelEncodingMaxBufferSize estimates the max number of bytes needed to encode data with the
+// specified encoding given the max level and number of buffered values provided.
+func LevelEncodingMaxBufferSize(encoding parquet.Encoding, maxLvl int16, nbuffered int) int {
+ bitWidth := bits.Len64(uint64(maxLvl))
+ nbytes := 0
+ switch encoding {
+ case parquet.Encodings.RLE:
+ nbytes = utils.MaxBufferSize(bitWidth, nbuffered) + utils.MinBufferSize(bitWidth)
+ case parquet.Encodings.BitPacked:
+ nbytes = int(bitutil.BytesForBits(int64(nbuffered * bitWidth)))
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+ return nbytes
+}
+
+// Reset resets the encoder allowing it to be reused and updating the maxlevel to the new
+// specified value.
+func (l *LevelEncoder) Reset(maxLvl int16) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle.Clear()
+ l.rle.BitWidth = l.bitWidth
+ case format.Encoding_BIT_PACKED:
+ l.bit.Clear()
+ default:
+ panic("parquet: unknown encoding type")
+ }
+}
+
+// Init is called to set up the desired encoding type, max level and underlying writer for a
+// level encoder to control where the resulting encoded buffer will end up.
+func (l *LevelEncoder) Init(encoding parquet.Encoding, maxLvl int16, w io.WriterAt) {
+ l.bitWidth = bits.Len64(uint64(maxLvl))
+ l.encoding = format.Encoding(encoding)
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rle = utils.NewRleEncoder(w, l.bitWidth)
+ case format.Encoding_BIT_PACKED:
+ l.bit = utils.NewBitWriter(w)
+ default:
+ panic("parquet: unknown encoding type for levels")
+ }
+}
+
+// EncodeNoFlush encodes the provided levels in the encoder, but doesn't flush
+// the buffer and return it yet, appending these encoded values. Returns the number
+// of values encoded.
+func (l *LevelEncoder) EncodeNoFlush(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ }
+ return nencoded
+}
+
+// Flush flushes out any encoded data to the underlying writer.
+func (l *LevelEncoder) Flush() {
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ l.rleLen = l.rle.Flush()
+ default:
+ l.bit.Flush(false)
+ }
+}
+
+// Encode encodes the slice of definition or repetition levels based on
+// the currently configured encoding type and returns the number of
+// values that were encoded.
+func (l *LevelEncoder) Encode(lvls []int16) int {
+ nencoded := 0
+ if l.rle == nil && l.bit == nil {
+ panic("parquet: level encoders are not initialized")
+ }
+
+ switch l.encoding {
+ case format.Encoding_RLE:
+ for _, level := range lvls {
+ if !l.rle.Put(uint64(level)) {
+ break
+ }
+ nencoded++
+ }
+ l.rleLen = l.rle.Flush()
+ default:
+ for _, level := range lvls {
+ if l.bit.WriteValue(uint64(level), uint(l.bitWidth)) != nil {
+ break
+ }
+ nencoded++
+ }
+ l.bit.Flush(false)
+ }
+ return nencoded
+}
+
+// Len returns the number of bytes that were written as Run Length encoded
+// levels, this is only valid for run length encoding and will panic if using
+// deprecated bit packed encoding.
+func (l *LevelEncoder) Len() int {
+ if l.encoding != format.Encoding_RLE {
+ panic("parquet: level encoder, only implemented for RLE")
+ }
+ return l.rleLen
+}
+
+// LevelDecoder handles the decoding of repetition and definition levels from a
+// parquet file supporting bit packed and run length encoded values.
+type LevelDecoder struct {
+ bitWidth int
+ remaining int
+ maxLvl int16
+ encoding format.Encoding
+ rle *utils.RleDecoder
Review comment:
maybe comment that exactly one of rle and bit is expected to be set?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] emkornfield commented on a change in pull request #10716: ARROW-13330: [Go][Parquet] Add the rest of the Encoding package
Posted by GitBox <gi...@apache.org>.
emkornfield commented on a change in pull request #10716:
URL: https://github.com/apache/arrow/pull/10716#discussion_r686487476
##########
File path: go/parquet/internal/encoding/encoding_test.go
##########
@@ -0,0 +1,684 @@
+// Licensed to the Apache Software Foundation (ASF) under one
+// or more contributor license agreements. See the NOTICE file
+// distributed with this work for additional information
+// regarding copyright ownership. The ASF licenses this file
+// to you under the Apache License, Version 2.0 (the
+// "License"); you may not use this file except in compliance
+// with the License. You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+package encoding_test
+
+import (
+ "fmt"
+ "reflect"
+ "testing"
+ "unsafe"
+
+ "github.com/apache/arrow/go/arrow"
+ "github.com/apache/arrow/go/arrow/bitutil"
+ "github.com/apache/arrow/go/arrow/memory"
+ "github.com/apache/arrow/go/parquet"
+ "github.com/apache/arrow/go/parquet/internal/encoding"
+ "github.com/apache/arrow/go/parquet/internal/testutils"
+ "github.com/apache/arrow/go/parquet/schema"
+ "github.com/stretchr/testify/assert"
+ "github.com/stretchr/testify/suite"
+)
+
+type nodeFactory func(string, parquet.Repetition, int32) *schema.PrimitiveNode
+
+func createNodeFactory(t reflect.Type) nodeFactory {
+ switch t {
+ case reflect.TypeOf(true):
+ return schema.NewBooleanNode
+ case reflect.TypeOf(int32(0)):
+ return schema.NewInt32Node
+ case reflect.TypeOf(int64(0)):
+ return schema.NewInt64Node
+ case reflect.TypeOf(parquet.Int96{}):
+ return schema.NewInt96Node
+ case reflect.TypeOf(float32(0)):
+ return schema.NewFloat32Node
+ case reflect.TypeOf(float64(0)):
+ return schema.NewFloat64Node
+ case reflect.TypeOf(parquet.ByteArray{}):
+ return schema.NewByteArrayNode
+ case reflect.TypeOf(parquet.FixedLenByteArray{}):
+ return func(name string, rep parquet.Repetition, field int32) *schema.PrimitiveNode {
+ return schema.NewFixedLenByteArrayNode(name, rep, 12, field)
+ }
+ }
+ return nil
Review comment:
NM, this is testing code should be fine.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org