You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@pulsar.apache.org by GitBox <gi...@apache.org> on 2021/11/15 13:30:26 UTC
[GitHub] [pulsar] Jason918 opened a new issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Jason918 opened a new issue #12812:
URL: https://github.com/apache/pulsar/issues/12812
**Is your enhancement request related to a problem? Please describe.**
Optimize zookeeper client performance for loading amounts of topics.
Our use case is described here #12651 .
**Describe the solution you'd like**
Introduce [zk multi ops](http://zookeeper.apache.org/doc/r3.7.0/apidocs/zookeeper-server/org/apache/zookeeper/ZooKeeper.html#multi-java.lang.Iterable-org.apache.zookeeper.AsyncCallback.MultiCallback-java.lang.Object-) to optimize the zk client performance.
Our team did a perf test on the zk multi ops, here is the result.
|Op type | Single Op (ops/s) | Batch 8 with Multi (ops/s)|
|--|--|--|
|Create|25k|60k|
|Write(with pre-created 5M nodes)|25|90k|
|Read|25k|200k|
Here is the settings:
- Single node size : 256 Bytes
- zk server version: 3.4.6
- Cpu usage: 6/40 on core bare metal server.
- OS : centos 7
- ZK server disk: 8TB Nvme SSD
It's clear that with multi, we can achieve much more performance with the same cpu usage, especially with read operations.
The basic idea of implementation will be add two queue (one for read ops and one for write ops) in PulsarZooKeeperClient, all zk ops will be added to the queue first, and a background thread will batch theses requests and sends to zk server in one "multi op".
This implementation will introduce the follow parameter in broker configs:
- **enableAutoBatchZookeeperOps**, this feature is optional, as it may increase metadata latency with small amount of topics.
- **autoBatchZookeeperOpsMaxNum** and **autoBatchZookeeperOpsMaxDelayMills** Just like auto batching parameters in pulsar producer. Limits the max number of ops in one batch and max delay time to wait for a batch.
**Describe alternatives you've considered**
Add a ratelimiter for topic loading, see #12651
**Additional context**
Here is the explanation why multi ops works much better with read ops.
- All write ops needs to go through a single thread processor in master. And we have reach the max qps in the previous perf test.
- Read ops can be handled by slave nodes. We can get more qps with larger batch size in the previous perf test.
Here is the flame graph of the bottleneck thread in master.
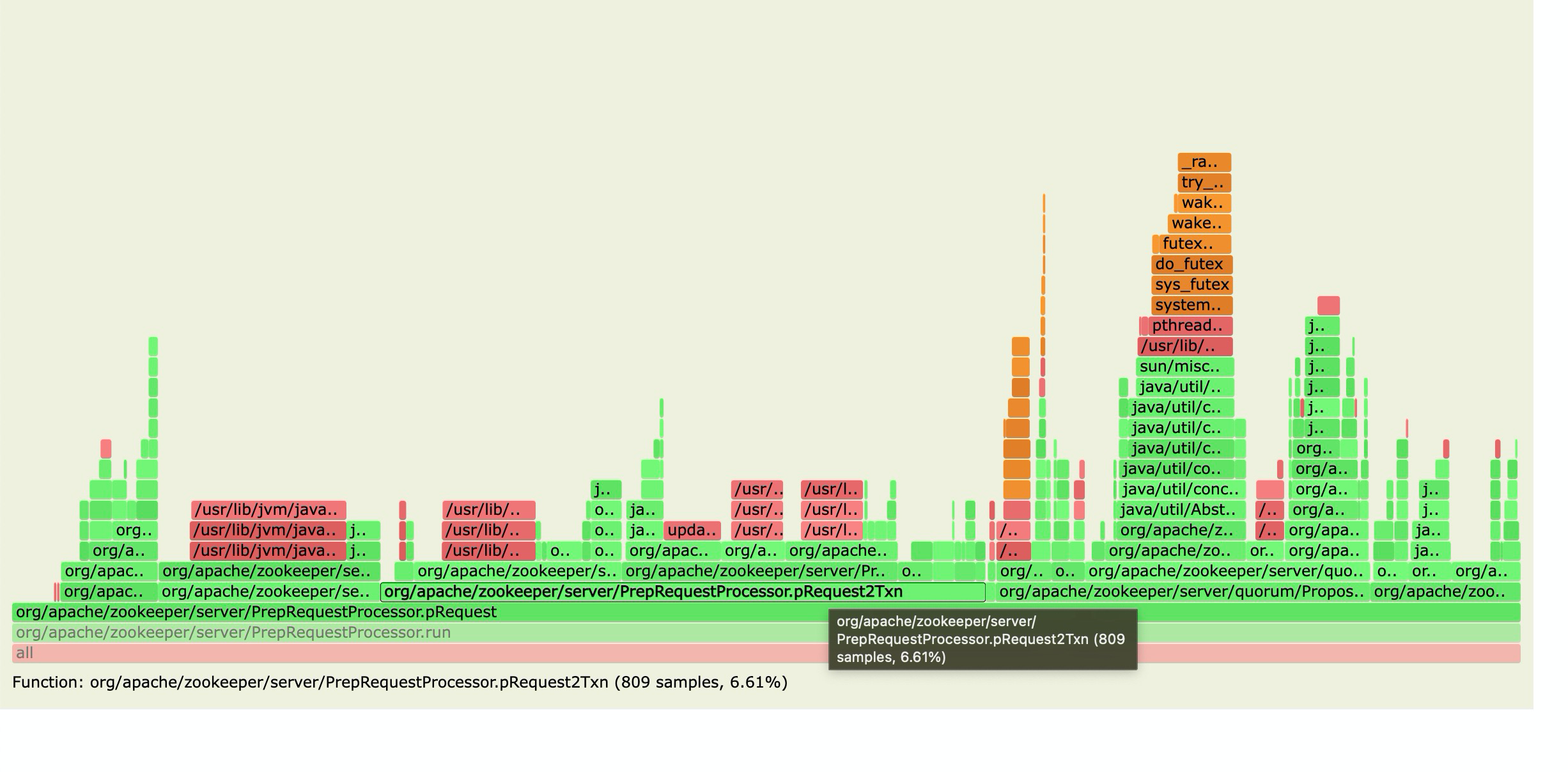
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] merlimat commented on issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
merlimat commented on issue #12812:
URL: https://github.com/apache/pulsar/issues/12812#issuecomment-971805730
👍 This is precisely what I wanted to do next on the `ZKMetadataStore` implementation.
Also, I believe this could be generalized across multiple backend implementations, so we could add a `AbstractBatchedMetadataStore extends AbstractMetadataStore`.
Regarding configuration, I think we should keep it generic for different implementations:
* `metadataStoreBatchingEnable=true`
* `metadataStoreBatchingMaxDelayMillis=5`
* `metadataStoreBatchingMaxOperations=100`
* `metadataStoreBatchingMaxSizeKb=128`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] Jason918 closed issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
Jason918 closed issue #12812:
URL: https://github.com/apache/pulsar/issues/12812
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] frankjkelly commented on issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
frankjkelly commented on issue #12812:
URL: https://github.com/apache/pulsar/issues/12812#issuecomment-1018455374
Congrats on this change - do we know what release we will see this in? 2.10?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] Jason918 commented on issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
Jason918 commented on issue #12812:
URL: https://github.com/apache/pulsar/issues/12812#issuecomment-971457605
> We'd better do not expose any zookeeper-specific configurations, it's better to use metadata instead. And, can we avoid exposing such configurations to users? We have more and move configurations, I think for this one we can just keep it as default 5ms batch delay? @merlimat WDYT
- Totally +1 for stop adding more unnecessary configurations for users. There is too much already. And normal user don't care about most of these configuration at all. But there are always some corner cases user would have to config these. Maybe we can introduce some kind of implicit configurations? One form would be like setting these config through system properties :` final long autoBatchZookeeperOpsMaxDelayMills = Long.parseLong(System.getProperty("pulsar.xxx", "5"));`
- IMHO, metadata store configuration is a common issue. Like #12776 , There are tons of configs in RocksDB, so I added a `metadataStoreConfigPath` to store the meta data config in a separated file.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] codelipenghui commented on issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
codelipenghui commented on issue #12812:
URL: https://github.com/apache/pulsar/issues/12812#issuecomment-971385306
We'd better do not expose any zookeeper-specific configurations, it's better to use metadata instead.
And, can we avoid exposing such configurations to users? We have more and move configurations, I think for this one we can just keep it as default 5ms batch delay? @merlimat WDYT
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] frankjkelly edited a comment on issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
frankjkelly edited a comment on issue #12812:
URL: https://github.com/apache/pulsar/issues/12812#issuecomment-1018455374
Congrats on this change - do we know what release we will see this in? 2.10?
UPDATE: NVM I see the `2.10.0` label on #13043. Thanks again!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] Jason918 commented on issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
Jason918 commented on issue #12812:
URL: https://github.com/apache/pulsar/issues/12812#issuecomment-1018217871
Implemented with #13043
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] merlimat commented on issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
merlimat commented on issue #12812:
URL: https://github.com/apache/pulsar/issues/12812#issuecomment-972046724
Few additional notes:
* > zk server version: 3.4.6
Newer ZK versions have better performance (eg: better txn pipelining in leader) and ways to configure group commit on the transaction log to improve throughput.
* We should do a test with a 3/5 nodes ZK cluster, not just a single server
* It would be good to simulate a mix write/read scenario, perhaps adding a YCSB driver (https://github.com/brianfrankcooper/YCSB) based on metadata store API.
Finally, we should consider what happens when batching reads, of which we don't know upfront the collective size. If we are exceeding the ZK max frame size, we should be able to automatically switch back to non-batched read.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] merlimat commented on issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
merlimat commented on issue #12812:
URL: https://github.com/apache/pulsar/issues/12812#issuecomment-972532919
There is one tricky part around creating parent z-nodes automatically: during create or setData, if we're getting a NONODE exception, we need to recursively create the parent z-nodes. When this is part of a batch, it may impose additional complexity as we need to retry the whole batch.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [pulsar] Jason918 commented on issue #12812: Optimize zookeeper client performance for loading amounts of topics.
Posted by GitBox <gi...@apache.org>.
Jason918 commented on issue #12812:
URL: https://github.com/apache/pulsar/issues/12812#issuecomment-972459284
> * Newer ZK versions have better performance (eg: better txn pipelining in leader) and ways to configure group commit on the transaction log to improve throughput.
> * We should do a test with a 3/5 nodes ZK cluster, not just a single server
My bad, we did this perf test on zk version 3.6.3, with 3 nodes cluster.
Zk 3.4.6 is the version we use in production.
> * It would be good to simulate a mix write/read scenario, perhaps adding a YCSB driver (https://github.com/brianfrankcooper/YCSB) based on metadata store API.
Totally agreed. But it's a bit tricky to simulate perfect mix write/read scenario. And we have a perf cluster ready for million topic scenario. So We plan to just test it with a quick implementation of `BatchedMetadataStore`.
> Finally, we should consider what happens when batching reads, of which we don't know upfront the collective size. If we are exceeding the ZK max frame size, we should be able to automatically switch back to non-batched read.
Thanks for the reminding, automatic fallback mechanism will be added.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@pulsar.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org