You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2021/06/14 12:40:29 UTC
[GitHub] [hudi] karan867 opened a new issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
karan867 opened a new issue #3077:
URL: https://github.com/apache/hudi/issues/3077
**Describe the problem you faced**
I am currently working on a POC to integrate Hudi with our existing Data lake. I am seeing large latencies in hudi writes. It is almost 7x compared to the partitioned parquet writes we perform now.
I am writing around 2.5 million rows (3.9 GB) in two batches with upsert mode. The first write gets completed in 2-3 mins. For the second batch, the latency is around 12-14 mins while writing with our existing system takes around 1.6-2 mins. The data contains negligible updates (99> % inserts and <1% updates). However in the rare case of duplicated trips we want to override the old data points with the new one. In our write use-case, most of the data will impact the recent partitions. Currently, for testing I am creating and writing to 5 partitions according to the probability distribution [10, 10, 10, 10, 60]
Pyspark configs:
conf = conf.set(“spark.driver.memory”, ‘6g’)
conf = conf.set(“spark.executor.instances”, 8)
conf = conf.set(“spark.executor.memory”, ‘4g’)
conf = conf.set(“spark.executor.cores”, 4)
Hudi options:
hudi_options = {
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': 'applicationId,userId,driverId,timestamp',
'hoodie.datasource.write.partitionpath.field': 'packet_date',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.ComplexKeyGenerator',
'hoodie.datasource.write.hive_style_partitioning': 'true',
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'created_at_date',
'hoodie.upsert.shuffle.parallelism': 200,
'hoodie.insert.shuffle.parallelism': 200,
'hoodie.bloom.index.prune.by.ranges': 'false',
'hoodie.bloom.index.filter.type': 'DYNAMIC_V0',
'hoodie.index.bloom.num_entries': 30000,
'hoodie.bloom.index.filter.dynamic.max.entries': 120000,
}
**Environment Description**
* Hudi version : 0.7.0
* Spark version : 2.4.7
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : no
**Additional context**
In addition I have experimented with the following
* Tried decreasing the file sizes
* Increasing 'hoodie.bloom.index.parallelism'
* Setting 'hoodie.metadata.enable' true.
You can see the jobs taking the most time from the screen shot attached
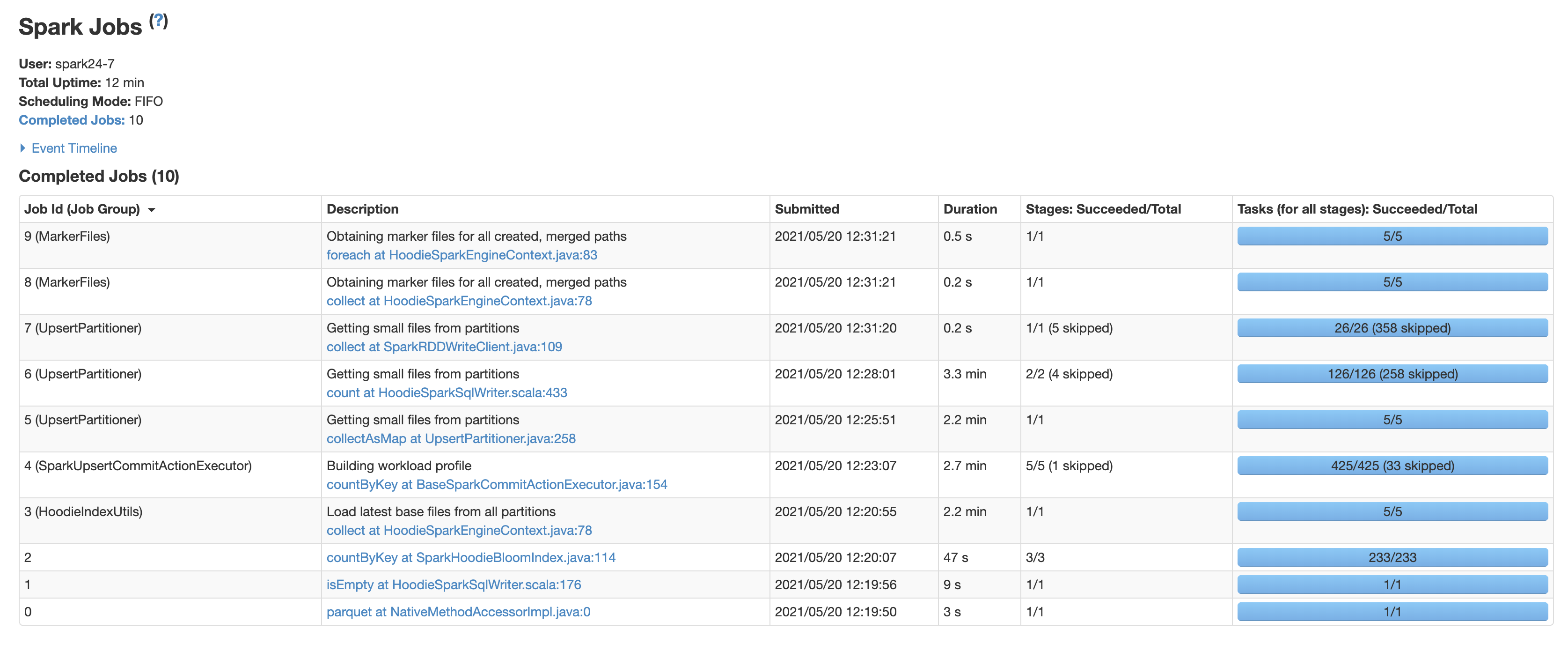
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] karan867 commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
karan867 commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-907269982
@codope Yes, I tried it. MOR also takes significant time in writing.
MOR two commits
<img width="1676" alt="Screenshot 2021-08-27 at 8 32 05 PM" src="https://user-images.githubusercontent.com/85880633/131148500-07bb5cb1-0fc3-4eb1-adbb-f644d0f3be43.png">
COW two commits
<img width="1674" alt="Screenshot 2021-08-27 at 8 31 29 PM" src="https://user-images.githubusercontent.com/85880633/131148520-9787cc60-56cd-4e9f-ae1e-f5febb147d73.png">
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] n3nash commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
n3nash commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-865422129
@karan867 Can you try setting the following parameters ?
1. https://hudi.apache.org/docs/configurations.html#withIndexType -> Set the index type to SIMPLE.
2. https://hudi.apache.org/docs/configurations.html#compactionSmallFileSize -> Set this config to 0.
Both of the above should speed up your ingestion. Hudi attempts to find small files and then pack records into them to ensure that small files are never created. For faster ingestion, this is a trade-off you can take.
For more details, you can check this blog -> https://hudi.apache.org/blog/hudi-file-sizing/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] karan867 commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
karan867 commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-900801622
@nsivabalan Thank you, I will try it. However, I think we initially chose COW instead of MOR because we had negligible updates, and from my initial experiments it appeared that the inserts in MOR were handled in the same way as COW.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-894511500
I went back to your use-case. Since write SLA is very critical for you and most of your writes are inserts, we can try MOR table. Its a write optimized table type in Hudi.
Can you run your POC w/ [table type ](https://hudi.apache.org/docs/configurations#table_type_opt_key)set to "MERGE_ON_READ" and let me know how it goes.
We can take it from there.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] n3nash commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
n3nash commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-865422129
@karan867 Can you try setting the following parameters ?
1. https://hudi.apache.org/docs/configurations.html#withIndexType -> Set the index type to SIMPLE.
2. https://hudi.apache.org/docs/configurations.html#compactionSmallFileSize -> Set this config to 0.
Both of the above should speed up your ingestion. Hudi attempts to find small files and then pack records into them to ensure that small files are never created. For faster ingestion, this is a trade-off you can take.
For more details, you can check this blog -> https://hudi.apache.org/blog/hudi-file-sizing/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] karan867 commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
karan867 commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-900801622
@nsivabalan Thank you, I will try it. However, I think we initially chose COW instead of MOR because we had negligible updates, and from my initial experiments it appeared that the inserts in MOR were handled in the same way as COW.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] karan867 commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
karan867 commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-892413100
@nsivabalan Thank you for the reply.
Please find the answers to the above questions
1. I am using the default file size. I tried decreasing it to 60 MB but that increased the write time by 2-4 mins.
2. Avg record size is 1 KB to 2 KB.
3. I did not specify this for most of my write experiments. The default value is 500000. In some of the experiments, I tried reducing it to 50000. This did not have a significant effect on the write time.
4. I have a timestamp field in my record key and tried to have it as the prefix of the record key. It takes 2.2 mins more in the "prune by ranges" stage so I turned it off. I guess it is because some of the packets may arrive late to our system and the timestamp is of the packet instead of the timestamp when it arrived.
5. The data contains negligible updates (99> % inserts and <1% updates).
6. Yes small size creates new files for inserts. It decreases the write time in the first few commits and then it takes more time as the commits increase.
I have experimented with a lot of things but can't seem to get the time of a single commit writing 100k rows to less than 10 mins. The weird part is if I write 20-30 commits there are 2-3 commits which take really less time (1-4 mins).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] codope commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
codope commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-905427198
@karan867 Did you get a chance to try with MOR table type?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] karan867 commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
karan867 commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-866913205
@n3nash Thank you for the suggestions. I tried the parameters you suggested.
* Setting hoodie.parquet.small.file.limit to zero did not make much difference and the subsequent commits turned slower.
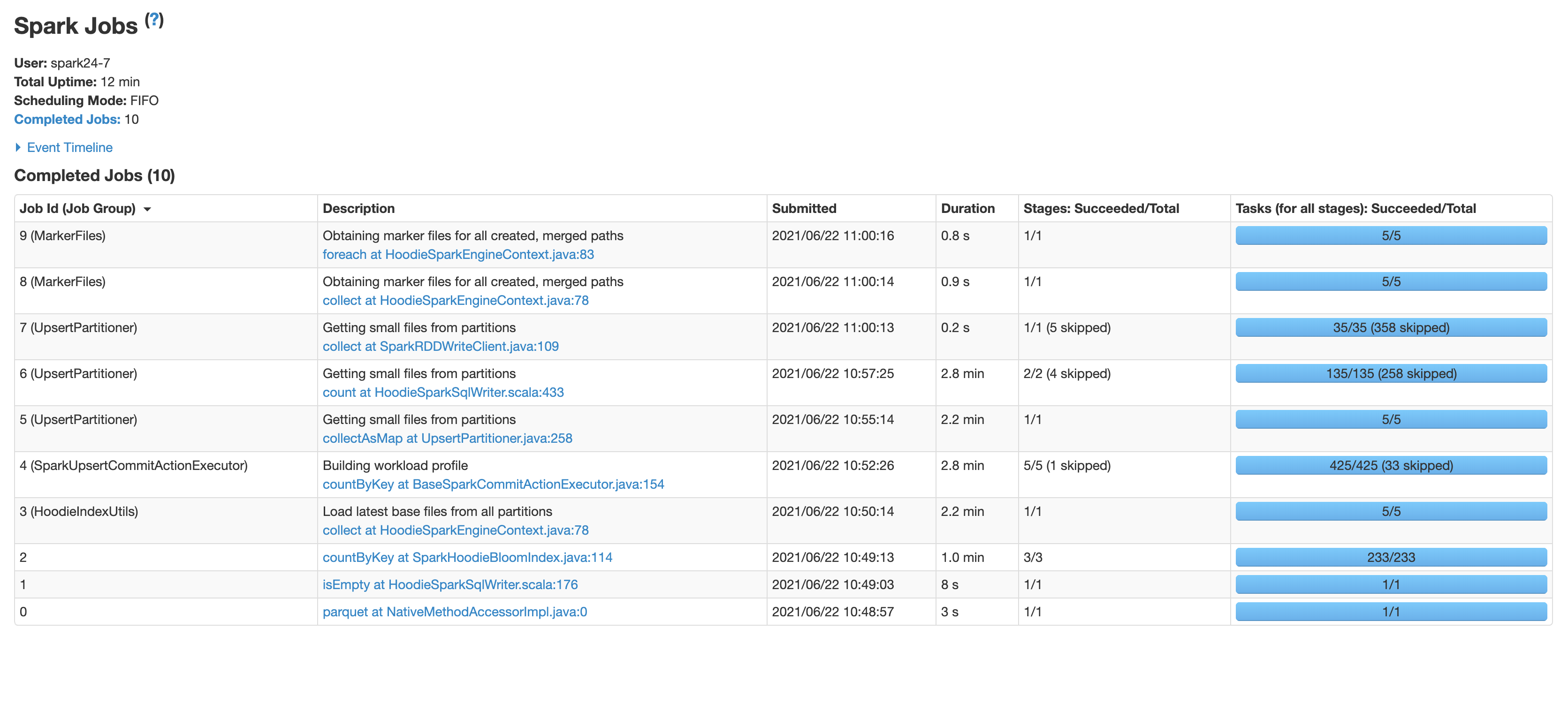
* Setting the index to SIMPLE decreased the time from 12 mins to 9.5 mins. I did not try it out before because in our use case we have hourly batch jobs that will mostly impact the latest partitions and this blog [https://hudi.apache.org/blog/hudi-indexing-mechanisms/](https://hudi.apache.org/blog/hudi-indexing-mechanisms/ ) says that simple index works best if the updates are random. Also is the time complexity of the simple index order of the rows present in the partition. Just want to make sure it does not increase with commits or partitions.
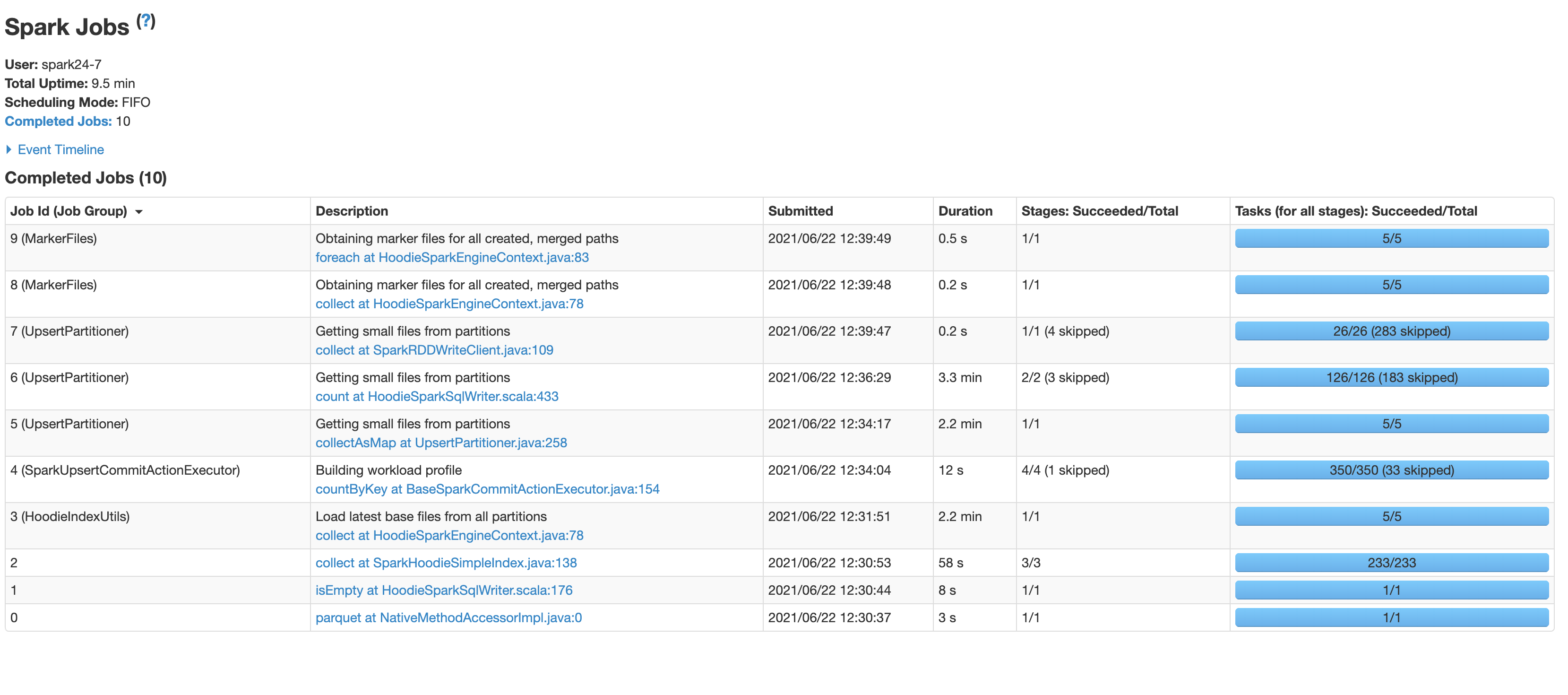
I had a few more questions regarding hudi write
* Can you explain what is happening in the steps taking the most time?
* Load latest base files from partitions
* Building workload profile
* Getting small files from partitions step1
* Getting small files from partitions step2
* Are there some benchmarks of write latencies I can compare to? For example, the time taken to write 100k row of size 1 KB. Some rough estimates from your experience would also do.
* Can we somehow insert the data with duplicates and support updates and deletion? The primary feature for which we are using Hudi is to make our data lake GDPR compliant.
* Is the MOR metadata table created by setting hoodie.metadata.enable' as true used when writing or just when reading the data?
* Randomly in some commits the write takes very less time. Do you have some explanation for that?
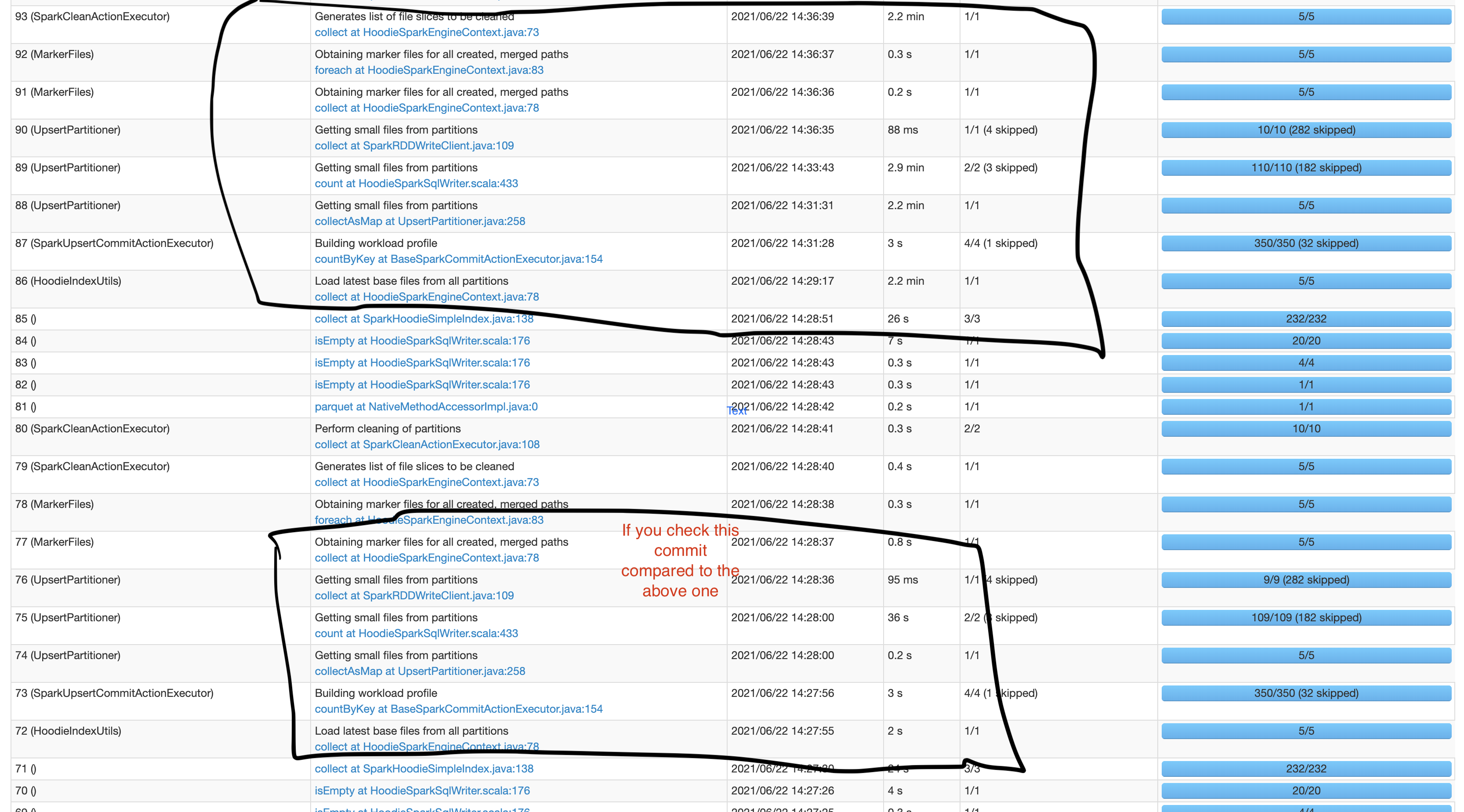
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] karan867 commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
karan867 commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-873844402
@n3nash did you get a chance to look at this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-891916056
@karan867: sorry for the delay. let me try to help you out.
@abdulmuqeeth : Can you please file a new github issue and CC me in that. lets not pollute the same github issue. But feel free to follow for any pointers.
@karan867 : coming back to your use-case.
1. Whats your max parquet size you are setting ? If its default, then its 120Mb files.
2. Whats your avg record size? This will help determine your bloom filter numbers.
3. During your first ingest, what was the config value set for "hoodie.copyonwrite.insert.split.size". This will determine the size of each data file(only during first ingest since hudi does not have any stats to look at to determine the record size).
4. Does your record key have any timestamp ordering characteristics. If yes, then bloom type index would help us a lot. Basically every data file will have a min key and max key stored in footer and hudi will use that to trim out some data files.
If keys are random, then we can disable range pruning and see if that helps. Wrt Simple Index, you are right. it is relative to your data set size. As it grows, time for SIMPLE index time might relatively increase.
5. Whats % of updates vs new inserts in your writes.
6. small file disabling should work. Only updates will get routed to old data files. All new inserts should go into new data files. If not, it could be a regression. can you confirm that once. (i.e. you see inserts going to old data files even after disabling small files).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
danny0405 commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-894041240
Just try Flink SQL writer, with more silky performance for random upserts.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] karan867 edited a comment on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
karan867 edited a comment on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-866913205
@n3nash Thank you for the suggestions. I tried the parameters you suggested.
* Setting hoodie.parquet.small.file.limit to zero did not make much difference and the subsequent commits turned slower.

* Setting the index to SIMPLE decreased the time from 12 mins to 9.5 mins. I did not try it out before because in our use case we have hourly batch jobs that will mostly impact the latest partitions and this blog [https://hudi.apache.org/blog/hudi-indexing-mechanisms/](https://hudi.apache.org/blog/hudi-indexing-mechanisms/ ) says that simple index works best if the updates are random. Also is the time complexity of the simple index order of the rows present in the partition. Just want to make sure it does not increase with commits or partitions.

I had a few more questions regarding hudi write
* Can you explain what is happening in the steps taking the most time?
* Load latest base files from partitions
* Building workload profile
* Getting small files from partitions step1
* Getting small files from partitions step2
* Are there some benchmarks of write latencies I can compare to? For example, the time taken to write 100k row of size 1 KB. Some rough estimates from your experience would also do.
* Can we somehow insert the data with duplicates and support updates and deletion? The primary feature for which we are using Hudi is to make our data lake GDPR compliant.
* Is the MOR metadata table created by setting hoodie.metadata.enable' as true used when writing or just when reading the data?
* Randomly in some commits the write takes very less time. Do you have some explanation for that? (It is not the 1st commit)

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-926241776
There are a few issues around this. We will batch it up and look all structured streaming in one shot.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] abdulmuqeeth commented on issue #3077: [SUPPORT] Large latencies in hudi writes using upsert mode.
Posted by GitBox <gi...@apache.org>.
abdulmuqeeth commented on issue #3077:
URL: https://github.com/apache/hudi/issues/3077#issuecomment-876040512
I have a similar observation. I've done an initial load of 300M rows into a COW hudi table and trying to upsert a batch of 12M which is mostly new data but might occasionally contain a couple thousand rows that are updates. This upsert sometimes takes 8mins and sometimes about 25mins. I've noticed that the stage that's causing the increase in time is **Getting small files from partitions** . Sometimes this stage runs with 12-15 tasks creating 12-15 output files (doesn't obey hoodie.parquet.max.file.size or hoodie.parquet.small.file.limit and this runs quickly ) and sometimes it runs with just 1 task and is very slow. I've tried it with same volume of data and the time it takes varies greatly. Any idea how to control it's parallelism? I would ideally want 2-3tasks to avoid a lot of small files being created if it cannot compact files.

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org