You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2022/06/05 03:35:18 UTC
[GitHub] [spark] zhengruifeng commented on a diff in pull request #36438: [SPARK-39092][SQL] Propagate Empty Partitions
zhengruifeng commented on code in PR #36438:
URL: https://github.com/apache/spark/pull/36438#discussion_r889643683
##########
sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/PropagateEmptyPartitions.scala:
##########
@@ -0,0 +1,185 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+
+package org.apache.spark.sql.execution.adaptive
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.exchange._
+import org.apache.spark.sql.execution.joins._
+
+/**
+ * A rule to propagate empty partitions, so that some unnecessary shuffle read can be skipped.
+ *
+ * The general idea is to utilize the shuffled join to skip some partitions.
+ *
+ * For example, assume the shuffled join has 4 partitions, and L2 and R3 are empty:
+ * left: [L1, L2, L3, L4]
+ * right: [R1, R2, R3, R4]
+ *
+ * Suppose the join type is Inner. Then this rule will skip reading partitions: L2, R2, L3, R3.
+ *
+ * Suppose the join type is LeftOuter. Then this rule will skip reading partitions: L2, R2, R3.
+ *
+ * Suppose the join type is RightOuter. Then this rule will skip reading partitions: L2, L3, R3.
+ *
+ * Suppose the join type is FullOuter. Then this rule will skip reading partitions: L2, R3.
+ */
+object PropagateEmptyPartitions extends AQEShuffleReadRule {
+
+ override val supportedShuffleOrigins: Seq[ShuffleOrigin] =
+ Seq(ENSURE_REQUIREMENTS, REPARTITION_BY_NUM, REPARTITION_BY_COL,
+ REBALANCE_PARTITIONS_BY_NONE, REBALANCE_PARTITIONS_BY_COL)
+
+ override def apply(plan: SparkPlan): SparkPlan = {
+ if (!conf.propagateEmptyPartitionsEnabled) {
+ return plan
+ }
+
+ // If there is no ShuffledJoin, no need to continue.
+ if (plan.collectFirst { case j: ShuffledJoin => j }.isEmpty) {
+ return plan
+ }
+
+ val stages = plan.collect { case s: ShuffleQueryStageExec => s }
+ // currently, empty information is only extracted from and propagated to shuffle data.
+ // TODO: support DataScan in the future.
+ if (stages.size < 2 || !stages.forall(_.isMaterialized)) {
+ return plan
+ }
+
+ val (_, emptyGroupInfos) = collectEmptyGroups(plan)
Review Comment:
When one side is empty, the SMJ ends quickly.
But it seems that the operations ahead of SMJ (shuffle fetch and the sorting in `SortExec`) still need to to be executed.
SMJ need to firstly advance the `streamedIter`, so if the `streamedIter` is not emty and the `bufferedIter` is empty, it still need to fetch and sort all the data in the streamed side.
take this case for example:
```
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
spark.conf.set("spark.sql.shuffle.partitions", 4)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", false)
spark.range(0, 100000000, 1, 11).selectExpr("id as key1", "id as value1").write.mode("overwrite").parquet("/tmp/df1.parquet")
spark.range(0, 10000000, 1, 6).selectExpr("id as key2", "id as value2").where(pmod(hash(col("key2")), lit(4)) =!= 0).write.mode("overwrite").parquet("/tmp/df2.parquet")
val df1 = spark.read.parquet("/tmp/df1.parquet")
val df2 = spark.read.parquet("/tmp/df2.parquet")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", false)
joined.write.mode("overwrite").parquet("/tmp/tmp1.parquet")
```
there are 4 partitions, and the partition-0 on the buffered side is empty.
SMJ still need to fetch and sort the partion-0 on the streamed side:

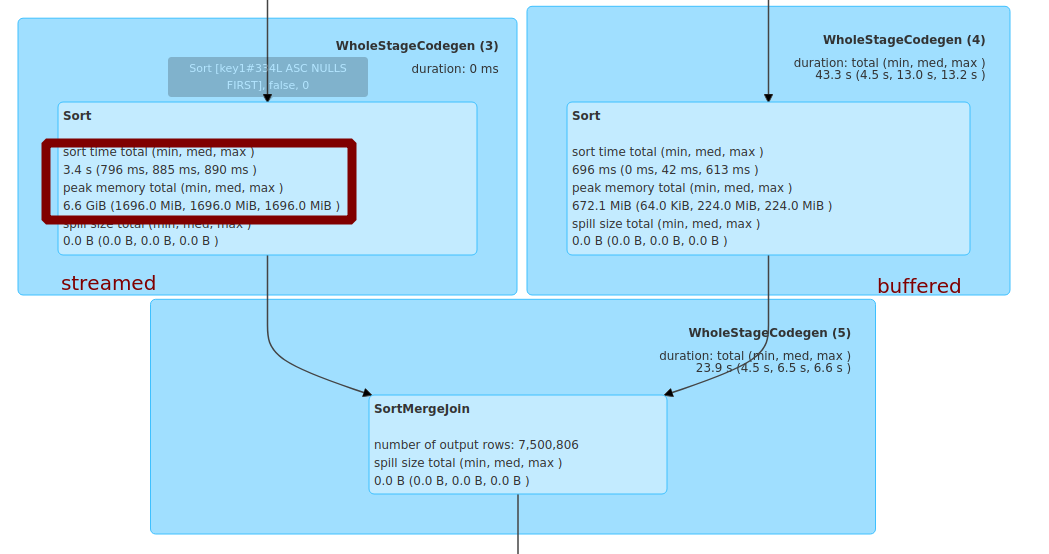
I think the main benefit is to avoid unnecessary shuffle fetch when the cluster is busy,
but it still should be somewhat benefitial to end-to-end performance. let's take another example, the task-parallelism is 12:
```
spark.conf.set("spark.sql.adaptive.enabled", true)
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
spark.conf.set("spark.sql.shuffle.partitions", 32)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", false)
spark.range(0, 100000000, 1, 11).selectExpr("id as key1", "id as value1").write.mode("overwrite").parquet("/tmp/df1.parquet")
spark.range(0, 100000000, 1, 6).selectExpr("id as key2", "id as value2").where(pmod(hash(col("key2")), lit(32)) % 2 === 0).write.mode("overwrite").parquet("/tmp/df2.parquet")
val df1 = spark.read.parquet("/tmp/df1.parquet")
val df2 = spark.read.parquet("/tmp/df2.parquet")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", false)
joined.write.mode("overwrite").parquet("/tmp/tmp1.parquet")
val df1 = spark.read.parquet("/tmp/df1.parquet")
val df2 = spark.read.parquet("/tmp/df2.parquet")
val joined = df1.join(df2, col("key1") === col("key2"), "inner")
spark.conf.set("spark.sql.adaptive.propagateEmptyPartitions.enabled", true)
joined.write.mode("overwrite").parquet("/tmp/tmp2.parquet")
```
the total duration was reduced from 16s to 14s, and the `Total Time Across All Tasks`
was reduced from 1.9min to 1.6min.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org