You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/04/08 16:09:49 UTC
[GitHub] [incubator-hudi] vontman opened a new issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
vontman opened a new issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498
**Describe the problem you faced**
I have questions regarding the Hudi table initial loading (migrating from parquet to Hudi table, bulk-insert), because we have encountered significantly high loading time, but first let me add the details for both tables we were trying to load, spark conf, Hudi conf and further modifications.
Sample of attempts:
**Table1**: 6.7GB parquet, 180M records, 16 columns and key is composite of 2 columns. Spark Conf: 1 executor, 12 cores, 16GB, 32 shuffle, 32 bulk-insert-parallelism.
**Table2**: 21GB parquet, 600M records, 16 columns and key is composite of 2 columns. Spark Conf: 4 executor, 8 cores, 32GB, 128 shuffle, 128 bulk-insert-parallelism.
**Table 1 loading time**: 25 min.
**Table 2 loading time**: 47 min.
Both tables read and write from/to local file system.
**To Reproduce**
Code sample used:
```scala
import cluster.SparkConf
import common.DataConfig._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.spark.sql.SaveMode._
import org.apache.spark.sql.SparkSession
object HudiFilewriter {
val COW = "COW"
val MOR = "MOR"
def main(args: Array[String]): Unit = {
val tableName = args(0)
val basePath = args(1)
val tableType = if(COW.equalsIgnoreCase(args(2))) COW_TABLE_TYPE_OPT_VAL else MOR_TABLE_TYPE_OPT_VAL
val rawTablePath = args(3)
val partitionCol = args(4)
val spark = SparkSession.builder()
.getOrCreate()
val logLevel = spark.sparkContext.getConf.get(SparkConf.LOG_LEVEL)
spark.sparkContext.setLogLevel(logLevel)
val shuffle = spark.sparkContext.getConf.get(SparkConf.SHUFFLE_PARTITIONS)
var hudiOptions = Map[String, String](
//HoodieWriteConfig
TABLE_NAME -> tableName,
"hoodie.bulkinsert.shuffle.parallelism" -> shuffle,
//DataSourceWriteOptions
TABLE_TYPE_OPT_KEY -> tableType,
PRECOMBINE_FIELD_OPT_KEY -> UPDATE_COL,
KEYGENERATOR_CLASS_OPT_KEY -> "org.apache.hudi.keygen.ComplexKeyGenerator",
RECORDKEY_FIELD_OPT_KEY -> KEY_COLS.mkString(","),
PARTITIONPATH_FIELD_OPT_KEY -> partitionCol,
OPERATION_OPT_KEY -> BULK_INSERT_OPERATION_OPT_VAL
)
spark.time{
val df = spark.read.parquet(rawTablePath)
df.write.format("org.apache.hudi").
options(hudiOptions).
mode(Overwrite).
save(basePath)
}
}
```
**Expected behavior**
Similar performance to vanilla parquet writing with additional sort overhead.
**Environment Description**
* Hudi version : 0.5.2
* Spark version : 2.4.5
* Hive version : NA
* Hadoop version : NA
* Storage (HDFS/S3/GCS..) : Local file System
* Running on Docker? (yes/no) : no
**Additional context**
**Attempts**:
- We tried multiple different spark configurations, increasing the shuffle and bulk-insert parallelism, increasing the number of executors while maintaining the base resources, increasing memory threshold of the driver/executors.
- Hudi Tables types (MOR partitioned and non-partitioned) (COW partitioned and non-petitioned), for partitioned tables we provided a partitioned version of the base table a long with the partitioned column(s).
- Hudi and spark version: "hudi-spark-bundle" % "0.5.1-incubating", Spark-2.4.3, "spark-avro" % "2.4.3".
- Upgraded Hudi and spark version: "hudi-spark-bundle" % "0.5.2-incubating", Spark-2.4.5, "spark-avro" % "2.4.5".
- Base data preparation, sorted by keys or partitioned.
- Load the data partition by partition, filter base table based on the partition column and bulk-insert each dataframe result, so each partition individually will use the whole app resources during the writing operation, use new app for each partition.
All the above attempts didn't improve the loading time that much or make it worse.
So I would like to know if:
- Is that the normal time for initial loading for Hudi tables, or we are doing something wrong?
- Do we need a better cluster/recoures to be able to load the data for the first time?, because it is mentioned on Hudi confluence page that COW bulkinsert should match vanilla parquet writing + sort only.
- Does partitioning improves the upsert and/or compaction time for Hudi tables, or just to improve the analytical queries (partition pruning)?
- We have noticed that the most time spent in the data indexing (the bulk-insert logic itself) and not the sorting stages/operation before the indexing, so how can we improve that? should we provide our own indexing logic?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [hudi] vinothchandar commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #1498:
URL: https://github.com/apache/hudi/issues/1498#issuecomment-768892942
the row writer in 0.6.0 should have addressed this. we can close
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] ahmed-elfar commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
ahmed-elfar commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-611383523
@bhasudha please consider that we have tested vs master build as well:
Hudi and spark version: "**hudi-spark-bundle" % "0.6.0-incubating**", **Spark-2.4.4**, "**spark-avro" % "2.4.4**", yet still the same performance.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] vinothchandar commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-614378189
@ahmed-elfar do you mind joining our slack channel and we can chat 1-1 to setup a time..
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-614400699
hi @vinothchandar, already in our slack channel.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] vinothchandar edited a comment on issue #1498:
Migrating parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
vinothchandar edited a comment on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-612252471
@vontman @ahmed-elfar First of all. Thanks for all the detailed information!
Answers to the good questions you raised
> Is that the normal time for initial loading for Hudi tables, or we are doing something wrong?
It's hard to know what normal time is since it depends on schema, machine and so many things. But we should n't this very off. Tried to explain few things below.
> Do we need a better cluster/recoures to be able to load the data for the first time?, because it is mentioned on Hudi confluence page that COW bulkinsert should match vanilla parquet writing + sort only.
If you are trying to ultimately migrate a table (using bulk_insert once) and then do updates/deletes. I suggest, testing upserts/deletes rather than bulk_insert.. If you primarily want to do bulk_insert alone to get other benefits of Hudi. Happy to work with you more and resolve this. Perf is a major push for the next release. So we can def collaborate here
> Does partitioning improves the upsert and/or compaction time for Hudi tables, or just to improve the analytical queries (partition pruning)?
Partitioning would benefit the query performance obviously. But for writing itself, the data size matter more, I would say.
> We have noticed that the most time spent in the data indexing (the bulk-insert logic itself) and not the sorting stages/operation before the indexing, so how can we improve that? should we provide our own indexing logic?
Nope. you don't have to supply you own indexing or anthing. Bulk insert does not do any indexing, it does a global sort (so we can pack records belonging to same partition closer into the same file as much) and then writes out files.
**Few observations :**
- 47 min job is gc-ing quite a bit. So that can affect throughput a lot. Have you tried configuring the jvm.
- I do see fair bit of skews here from sorting, which may be affecting over all run times.. #1149 is trying to also provide a non-sorted mode, that tradeoffs file sizing for potentially faster writing.
On what could create difference between bulk_insert and spark/parquet :
- I would also set `"hoodie.parquet.compression.codec" -> "SNAPPY"` since Hudi uses gzip compression by default, where spark.write.parquet will use SNAPPY
- Hudi currently does an extra `df.rdd` conversion that could affect bulk_insert/insert (upsert/delete workloads are bound by merge costs, this matters less there). I don't see that in your UI though..
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [hudi] nsivabalan commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #1498:
URL: https://github.com/apache/hudi/issues/1498#issuecomment-767521426
@vinothchandar : did you get a chance to sync up with the author one on one. Can you update the ticket with any updates. If not, can we follow up on this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] ahmed-elfar edited a comment on issue #1498:
Migrating parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
ahmed-elfar edited a comment on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-613563197
@vinothchandar I apologies for the delayed response, and thanks again for your help and detailed answers.
> Is it possible to share the data generation tool with us or point us to reproducing this ourselves locally? We can go much faster if we are able to repro this ourselves..
Sure, this is the public Repo for generating the data [https://github.com/gregrahn/tpch-kit](url)
And it provides the information you need for data generation, size, etc
> Schema for lineitem
Adding more details and update the schema screenshot mentioned on previous comment:
**RECORDKEY_FIELD_OPT_KEY**: is composite (l_linenumber, l_orderkey)
**PARTITIONPATH_FIELD_OPT_KEY**: optional default (non-portioned), or l_shipmode
**PRECOMBINE_FIELD_OPT_KEY**: l_commitdate, or generating new timestamp column **last_updated**.

This is the **official documentation** for the datasets definition, schema, queries and business logic behind the queries [http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-h_v2.18.0.pdf](url)
> @bvaradar & @umehrot2 will have the ability to seamlessly bootstrap the data into hudi without rewriting in the next release.
Are we talking about the proposal mentioned at [https://cwiki.apache.org/confluence/display/HUDI/RFC+-+12+%3A+Efficient+Migration+of+Large+Parquet+Tables+to+Apache+Hudi](url)
because we need more clarification regarding this approach.
> you ll also have the ability to do a one-time bulk_insert for last N partitions to get the upsert performance benefits as we discussed above
There one of the attempts mentioned on the first comment which might be similar, I will explain in details to check with you if it should work for now or not, **if it provides a valid Hudi table**:
So consider we have table of size 1TB parquet format as an input table either **partitioned** or **non- partitioned**. Spark resource 256GB ram and 32 cores:
**Case non-partitioned**
- We use the suggested/recommended partition column(s), then project this partition column(s) and apply distinct which will provide you with filter values you need to pass to next process of the pipe line.
- The next step submit a sequential spark applications which filter the input data based on the passed filter value(s) resulting in data frame of single partition.
- Write (**bulk-insert**) the filtered dataframe as Hudi table with the provided partition column using save-mode **append**
- Hudi table being written partition by partition.
- Query the Hudi table to check if it is valid table, and it looks valid.
**Case partitioned** same as above, with faster filter operations.
**Pros**:
- Avoided a lot of disk spilling, GC hits.
- Using less resources for initial loading.
**Cons**:
- No time improvements in case you have enough resources to load the table at once.
- We ended up with partitioned table, which might not be needed in some of our use cases.
**Questions**:
- If this approach is valid or going to impact the upsert operations in the future?
> I would be happy to jump on a call with you folks and get this moving along.. I am also very excited to work with a user like yourself and move the perf aspects of the project along more..
We are excited as well to have a call together, please inform me how we can proceed on this meeting.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] ahmed-elfar edited a comment on issue #1498:
Migrating parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
ahmed-elfar edited a comment on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-613563197
@vinothchandar I apologies for the delayed response, and thanks again for your help and detailed answers.
> Is it possible to share the data generation tool with us or point us to reproducing this ourselves locally? We can go much faster if we are able to repro this ourselves..
Sure, this is the public Repo for generating the data [https://github.com/gregrahn/tpch-kit](url)
And it provides the information you need for data generation, size, etc
You can use this command to generate lineitem with scale 10GB
`DSS_PATH=/output/path ./dbgen -T L 10`
---
> Schema for lineitem
Adding more details and update the schema screenshot mentioned on previous comment:
**RECORDKEY_FIELD_OPT_KEY**: is composite (l_linenumber, l_orderkey)
**PARTITIONPATH_FIELD_OPT_KEY**: optional default (non-portioned), or l_shipmode
**PRECOMBINE_FIELD_OPT_KEY**: l_commitdate, or generating new timestamp column **last_updated**.

This is the **official documentation** for the datasets definition, schema, queries and business logic behind the queries [http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-h_v2.18.0.pdf](url)
---
> @bvaradar & @umehrot2 will have the ability to seamlessly bootstrap the data into hudi without rewriting in the next release.
Are we talking about the proposal mentioned at [https://cwiki.apache.org/confluence/display/HUDI/RFC+-+12+%3A+Efficient+Migration+of+Large+Parquet+Tables+to+Apache+Hudi](url)
because we need more clarification regarding this approach.
---
> you ll also have the ability to do a one-time bulk_insert for last N partitions to get the upsert performance benefits as we discussed above
There one of the attempts mentioned on the first comment which might be similar, I will explain in details to check with you if it should work for now or not, **if it provides a valid Hudi table**:
So consider we have table of size 1TB parquet format as an input table either **partitioned** or **non- partitioned**. Spark resource 256GB ram and 32 cores:
**Case non-partitioned**
- We use the suggested/recommended partition column(s) (we pick first column in the partition path), then project this partition column and apply distinct which will provide you with filter values you need to pass to next process of the pipe line.
- The next step submit a sequential spark applications which filter the input data based on the passed filter value resulting in data frame of single partition.
- Write (**bulk-insert**) the filtered dataframe as Hudi table with the provided partition column(s) using save-mode **append**
- Hudi table being written partition by partition.
- Query the Hudi table to check if it is valid table, and it looks valid.
**Case partitioned** same as above, with faster filter operations.
**Pros**:
- Avoided a lot of disk spilling, GC hits.
- Using less resources for initial loading.
**Cons**:
- No time improvements in case you have enough resources to load the table at once.
- We ended up with partitioned table, which might not be needed in some of our use cases.
**Questions**:
- If this approach is valid or going to impact the upsert operations in the future?
---
> I would be happy to jump on a call with you folks and get this moving along.. I am also very excited to work with a user like yourself and move the perf aspects of the project along more..
We are excited as well to have a call together, please inform me how we can proceed on this meeting.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] vinothchandar commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-612709170
Few clarifications:
>For initial bench-marking we generate standard tpch data
Is it possible to share the data generation tool with us or point us to reproducing this ourselves locally? We can go much faster if we are able to repro this ourselves..
>Schema for lineitem
What's your record key and partition key? (was unable to spot this from the snippet above).. If you have monotonically increasing key (say timestamp prefix) and already know the partition to which an increment record (IIUC this means incoming writes) belong to, then upsert performance will be optimal.
>We have 2 versions of generated updates, one which touches only the last quarter of the year and another one generated randomly to touch most of the parquet parts during updates.
If you have a workload that will touch every file, then you could use the #1402 that is being built. Bloom filter checking will anyway lead to opening up all files in that scenario anyway...
>Currently we generate no duplicates for the base table and increments.
By default, upsert will also de-dupe the increments once.. So if this the norm, you can turn off `hoodie.combine.before.upsert=false` to avoid an extra shuffle.
>As you can see the data has been shuffled to disk twice, applying the sorting twice as well.
so this is without overriding the user defined partitioner? btw the two jobs you see is how Spark sort works, first job does reservoir sampling to get ranges, and the second one actually sorts..
> Eagerly persist the input RDD before the bulk-insert, which uses the same sorting provided before the bulk-insert.
bulk_insert was designed to do an initial sort and write data without incurring large memory overheads associated with caching.. Spark cache is a LRU.. so it will thrash a fair bit if you start spilling due to lack of memory. I would not recommend trying this..
> Note: this approach impact the Upsert time significantly specially if you didn't apply any sorting to the data, it might be because the upsert operation touched most of the parquet parts.
yes.. you are right.. sorting gives you a dataset which is initially sorted/ordered by keys and if you have ordered keys, hudi will preserve this and extract upsert performance by filtering out files not in range during indexing.. At Uber, when we moved all the tables to hudi, we found this one time sort, well worth the initial cost.. It repaid itself many times over the course of a quarter.
>it is actually a narrow transformation after the sorting operation.
Its the action that triggers the actual parquet writing. So the 30 second odd you see if the actual cost of writing data..
>If I get your suggestion right, would you suggest to initially load the table using upsert or insert operation for the whole table instead of bulk-insert?
No.. bulk_insert + sorting is what I recommend (with good key design) for large scale deployment like you are talking about.. if you don't want to convert all data, @bvaradar & @umehrot2 will have the ability to seamlessly bootstrap the data into hudi without rewriting in the next release.. (you ll also have the ability to do a one-time bulk_insert for last N partitions to get the upsert performance benefits as we discussed above)..
I would be happy to jump on a call with you folks and get this moving along.. I am also very excited to work with a user like yourself and move the perf aspects of the project along more..
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] vinothchandar edited a comment on issue #1498:
Migrating parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
vinothchandar edited a comment on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-612252471
@vontman @ahmed-elfar First of all. Thanks for all the detailed information!
Answers to the good questions you raised
> Is that the normal time for initial loading for Hudi tables, or we are doing something wrong?
It's hard to know what normal time is since it depends on schema, machine and so many things. But we should n't this very off. Tried to explain few things below.
> Do we need a better cluster/recoures to be able to load the data for the first time?, because it is mentioned on Hudi confluence page that COW bulkinsert should match vanilla parquet writing + sort only.
If you are trying to ultimately migrate a table (using bulk_insert once) and then do updates/deletes. I suggest, testing upserts/deletes rather than bulk_insert.. If you primarily want to do bulk_insert alone to get other benefits of Hudi. Happy to work with you more and resolve this. Perf is a major push for the next release. So we can def collaborate here
> Does partitioning improves the upsert and/or compaction time for Hudi tables, or just to improve the analytical queries (partition pruning)?
Partitioning would benefit the query performance obviously. But for writing itself, the data size matter more, I would say.
> We have noticed that the most time spent in the data indexing (the bulk-insert logic itself) and not the sorting stages/operation before the indexing, so how can we improve that? should we provide our own indexing logic?
Nope. you don't have to supply you own indexing or anthing. Bulk insert does not do any indexing, it does a global sort (so we can pack records belonging to same partition closer into the same file as much) and then writes out files.
**Few observations :**
- 47 min job is gc-ing quite a bit. So that can affect throughput a lot. Have you tried configuring the jvm.
- I do see fair bit of skews here from sorting, which may be affecting over all run times.. #1149 is trying to also provide a non-sorted mode, that tradeoffs file sizing for potentially faster writing.
On what could create difference between bulk_insert and spark/parquet :
- I would also set `"hoodie.parquet.compression.codec" -> "SNAPPY"` since Hudi uses gzip compression by default, where spark.write.parquet will use SNAPPY
- Hudi currently does an extra `df.rdd` conversion that could affect bulk_insert/insert (upsert/delete workloads are bound by merge costs, this matters less there). I don't see that in your UI though..
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] bhasudha commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
bhasudha commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-611334390
@vontman thanks for reporting this. I am trying to see if there is anything missing. @bvaradar do you think of anything here?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] ahmed-elfar commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
ahmed-elfar commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-613563197
@vinothchandar I apologies for the delayed response, and thanks again for your help and detailed answers.
> Is it possible to share the data generation tool with us or point us to reproducing this ourselves locally? We can go much faster if we are able to repro this ourselves..
Sure, this is the public Repo for generating the data [https://github.com/gregrahn/tpch-kit](url)
And it provides the information you need for data generation, size, etc
> Schema for lineitem
Adding more details and update the schema screenshot mentioned on previous comment:
**RECORDKEY_FIELD_OPT_KEY**: is composite (l_linenumber, l_orderkey)
**PARTITIONPATH_FIELD_OPT_KEY**: optional default (non-portioned), or l_shipmode
**PRECOMBINE_FIELD_OPT_KEY**: l_commitdate, or generating new timestamp column **last_updated**.

This is the **official documentation** for the datasets definition, schema, queries and business logic behind the queries [http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-h_v2.18.0.pdf](url)
> @bvaradar & @umehrot2 will have the ability to seamlessly bootstrap the data into hudi without rewriting in the next release.
Are we talking about the proposal mentioned at [https://cwiki.apache.org/confluence/display/HUDI/RFC+-+12+%3A+Efficient+Migration+of+Large+Parquet+Tables+to+Apache+Hudi](url)
because we need more clarification regarding this approach.
> you ll also have the ability to do a one-time bulk_insert for last N partitions to get the upsert performance benefits as we discussed above
There one of the attempts mentioned on the first comment which might be similar, I will explain in details to check with you if it should work for now or not, **if it provides a valid Hudi table**:
So consider we have table of size 1TB parquet format as an input table either **partitioned** or **non- partitioned**. Spark resource 256GB ram and 32 cores:
**Case non-partitioned**
- We use the suggested/recommended partition column(s), then project this partition column(s) and apply distinct which will provide you with filter values you need to pass to next process of the pipe line.
- The next step submit a sequential spark applications which filter the input data based on the passed filter value(s) resulting in data frame of single partition.
- Write the dataframe as Hudi table with the provided partition column using save-mode **append**
- Hudi table being written partition by partition.
- Query the Hudi table to check if it is valid table, and it looks valid.
**Case partitioned** same as above, with faster filter operations.
**Pros**:
- Avoided a lot of disk spilling, GC hits.
- Using less resources for initial loading.
**Cons**:
- No time improvements in case you have enough resources to load the table at once.
- We ended up with partitioned table, which might not be needed in some of our use cases.
**Questions**:
- If this approach is valid or going to impact the upsert operations in the future?
> I would be happy to jump on a call with you folks and get this moving along.. I am also very excited to work with a user like yourself and move the perf aspects of the project along more..
We are excited as well to have a call together, please inform me how we can proceed on this meeting.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [hudi] vinothchandar closed issue #1498: Migrating parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
vinothchandar closed issue #1498:
URL: https://github.com/apache/hudi/issues/1498
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] vontman commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
vontman commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-612156801
@bvaradar
The `.commit` file: https://gist.github.com/vontman/e2242b6b0bd3cfc126ed725bb85ccdea
This is the schema for the table as well: https://gist.github.com/vontman/761e34981994fa36d3c9d22db5a80ea8
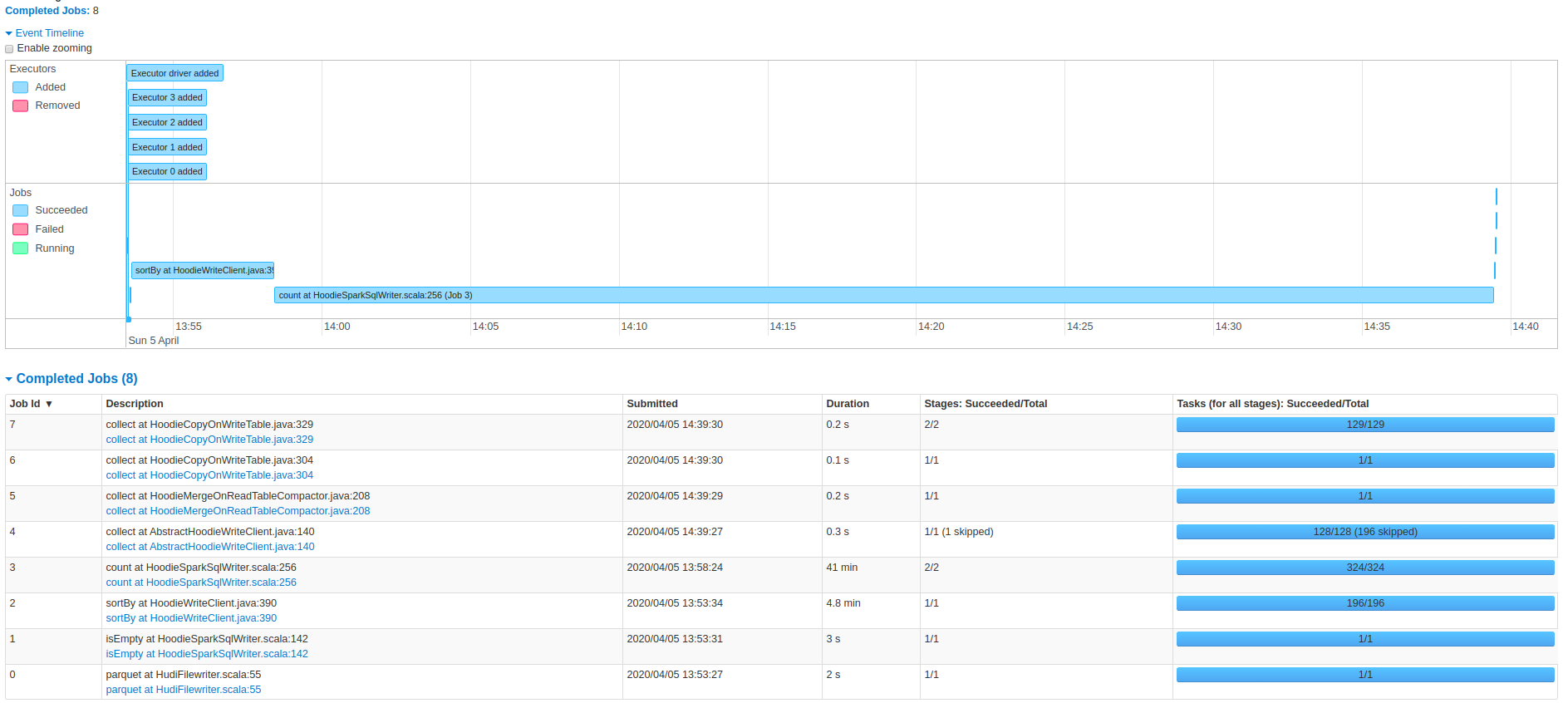
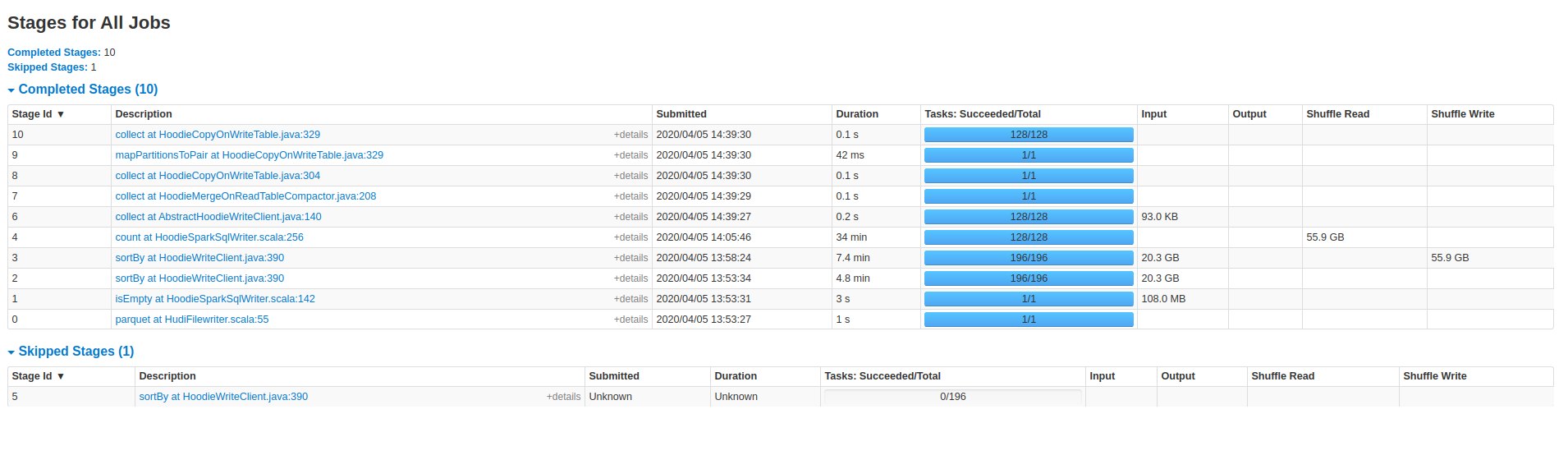
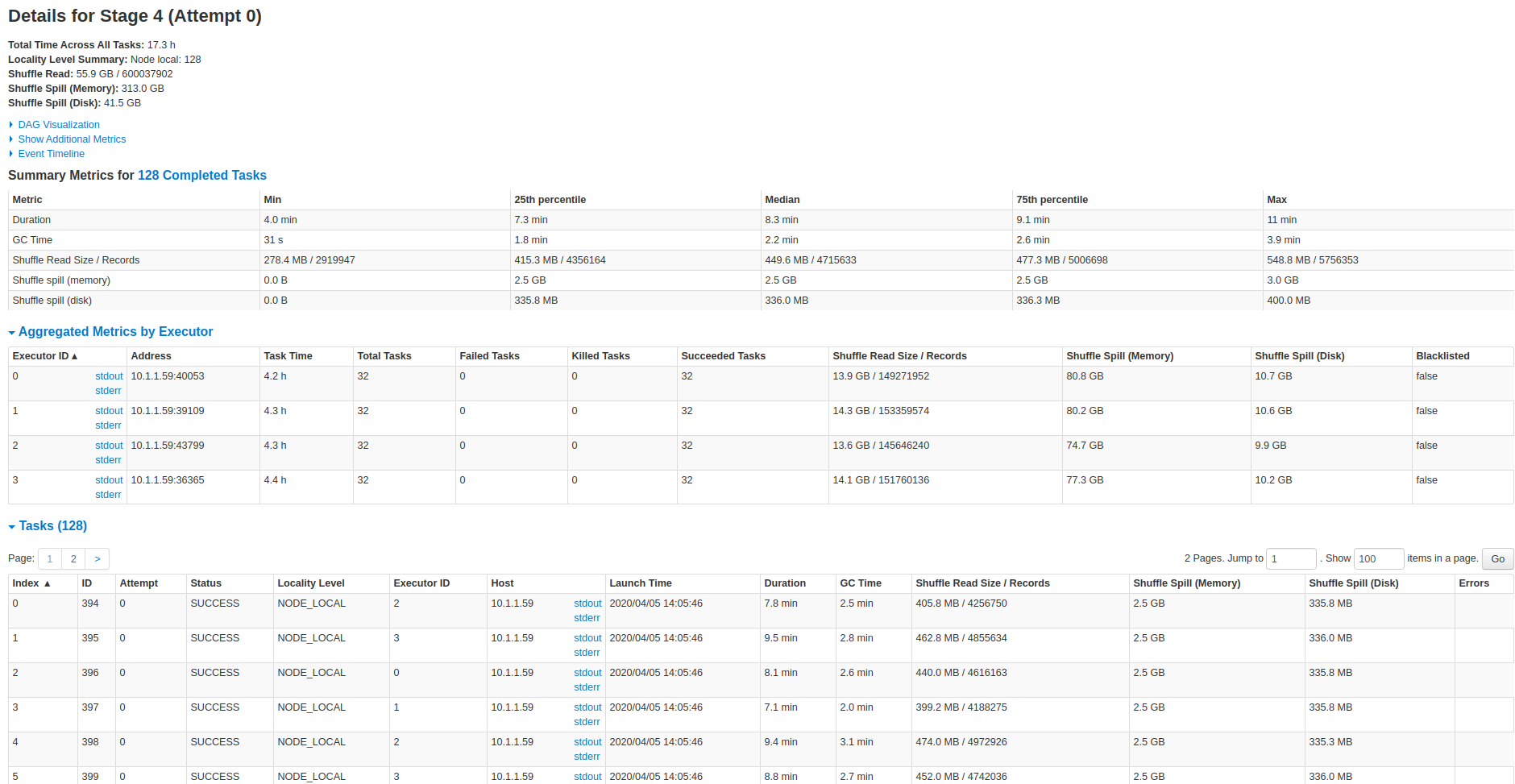
Screenshots from the 47min run:
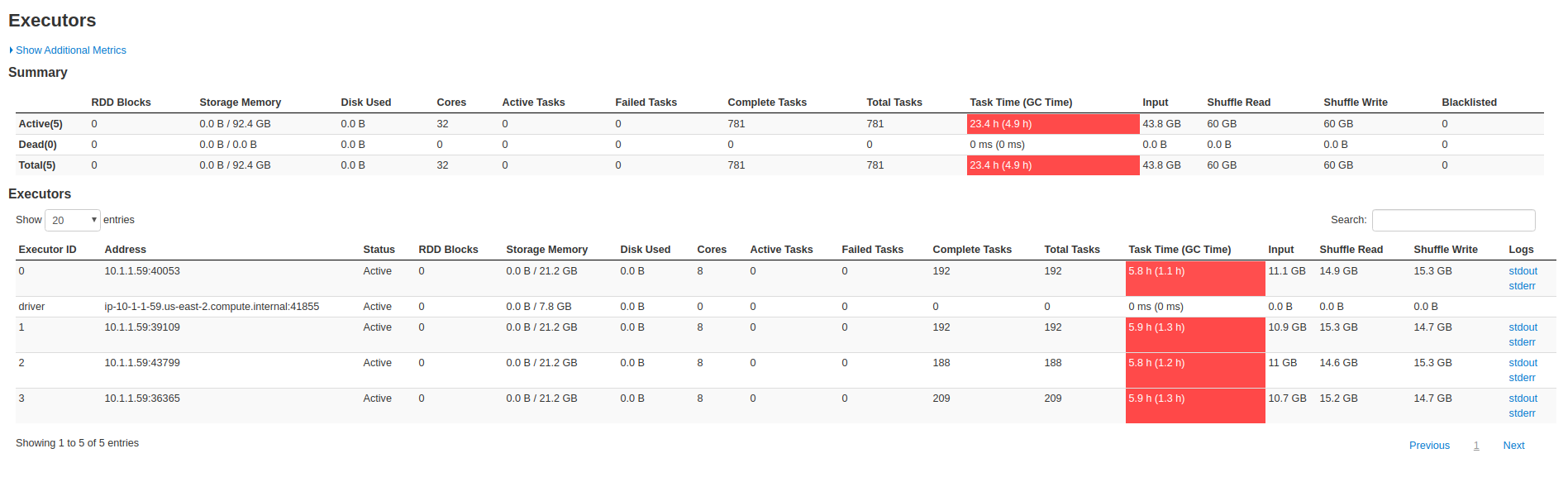
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] bvaradar commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-612113721
@vontman : This looks to me like the columnar file creation is taking close to 17 mins out of 25 mins. Can you also attach the commit metadata (.commit file under .hoodie folder corresponding to each runs) and the UI screenshots for the 47 min run too.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] vontman commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
vontman commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-611440958
These are some screenshots from the spark ui on the 25min job.
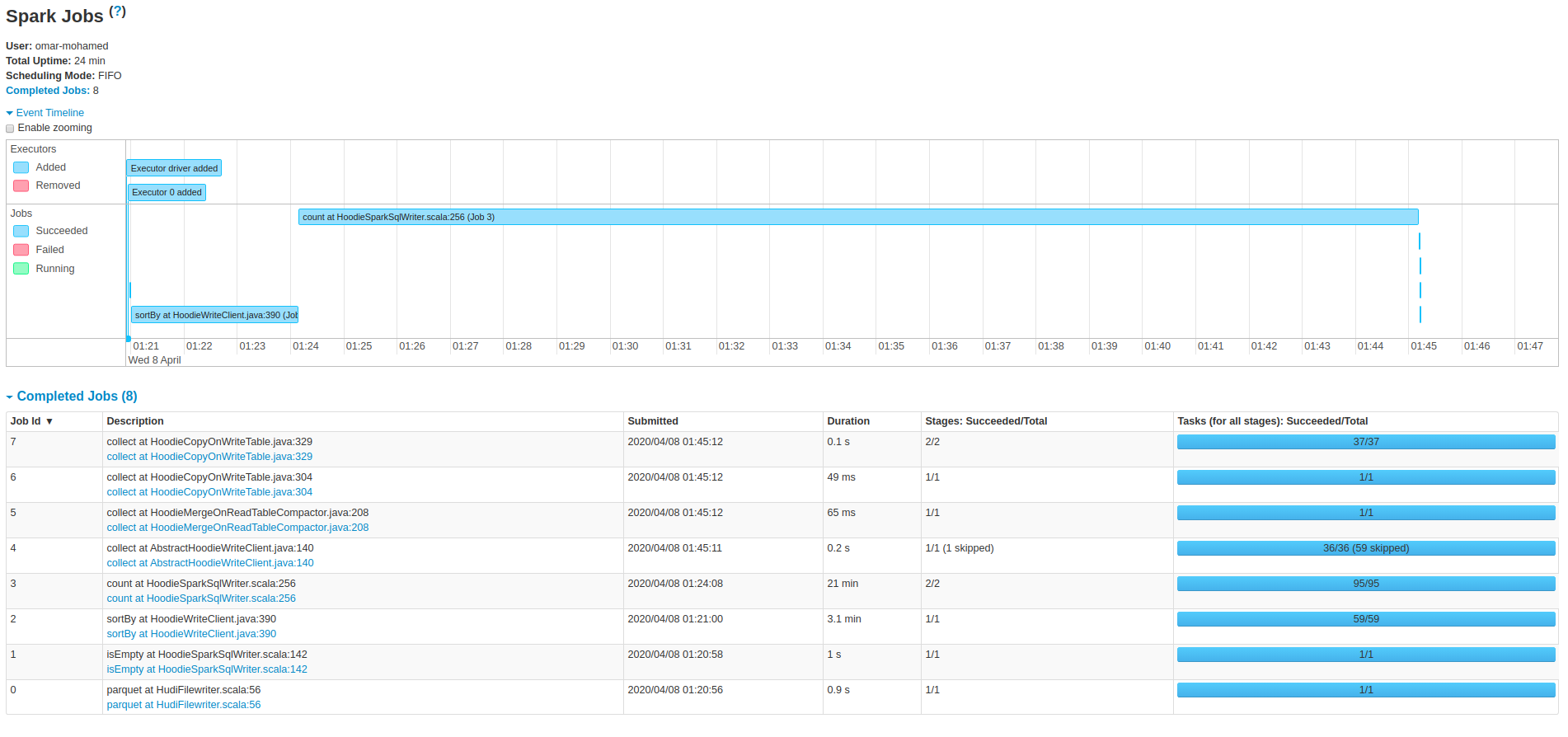
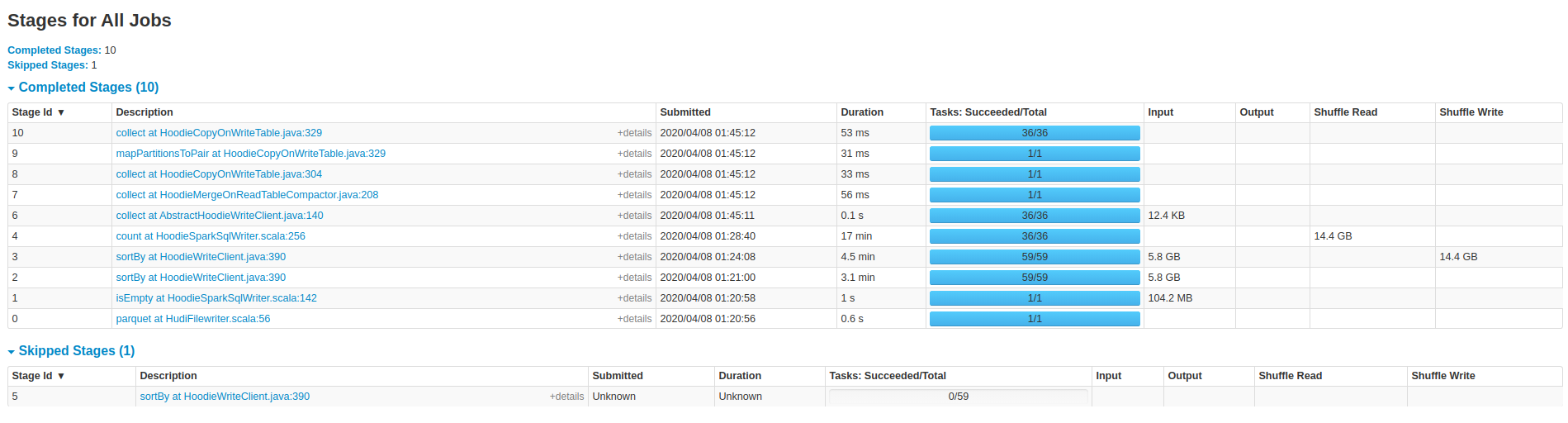
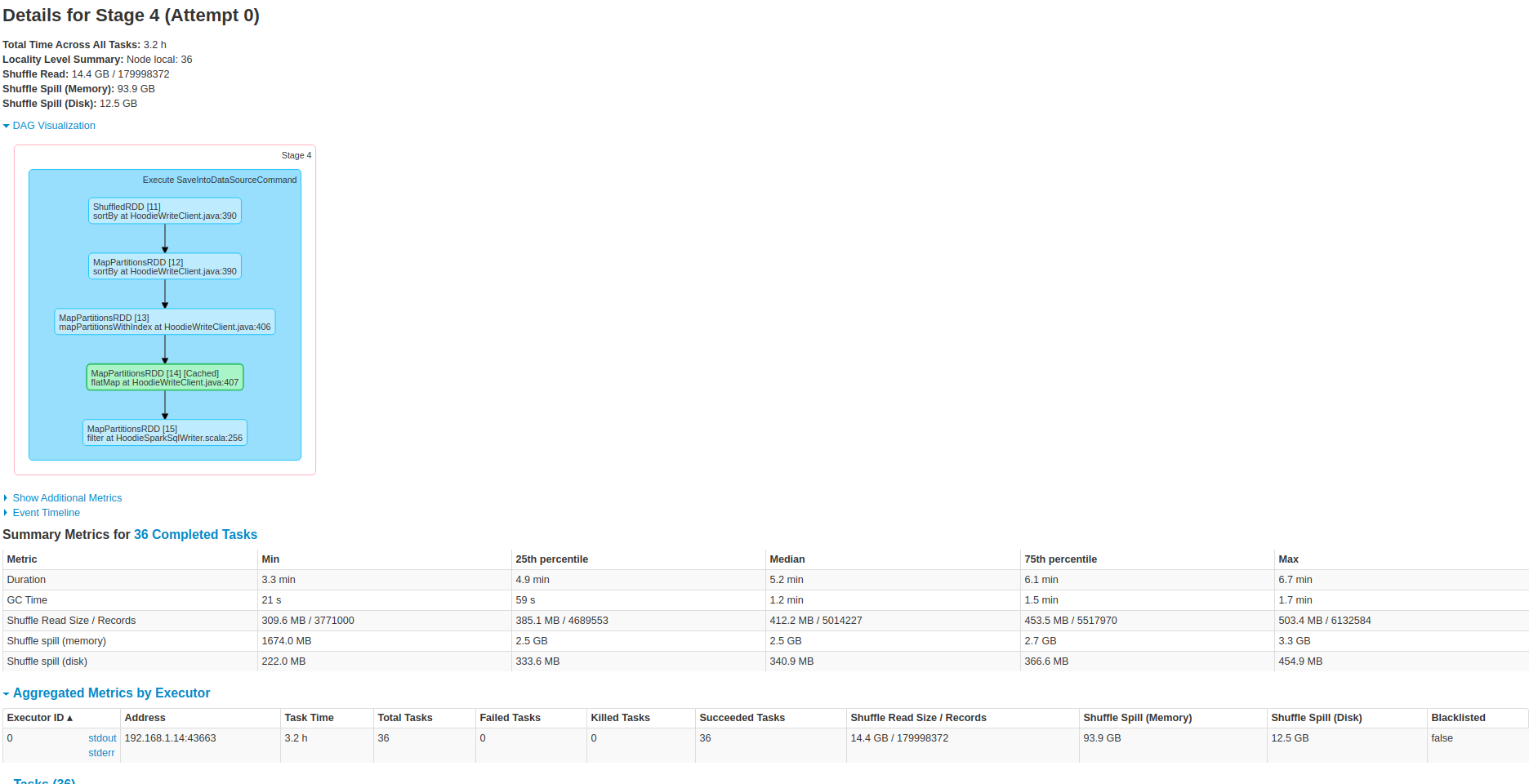
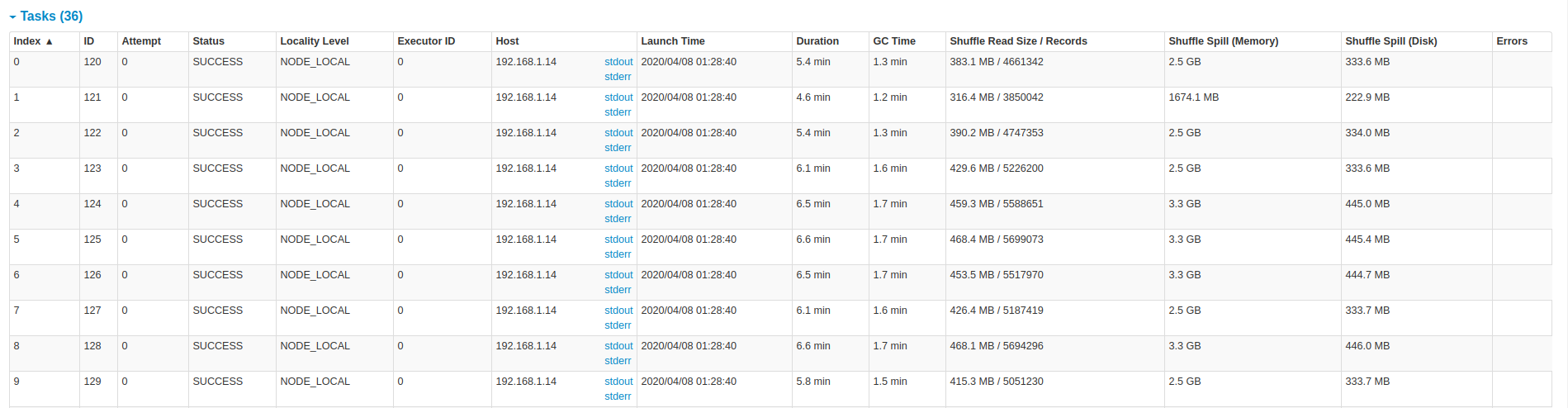
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] ahmed-elfar commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
ahmed-elfar commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-612650421
@vinothchandar Thank you very much for your answer and help, and everyone participated to resolve the issue.
We already have done further attempts with Hudi for bulk-insert, but I didn't want to mention that in the current thread, until we make sure that it is **either we are missing something or there is an initial high cost to migrate the base tables from parquet to Hudi**, because we need to know the pros, cons and limitation before adding Hudi to our product, we are talking about migrating hundreds of GB and/or TB of data from parquet to Hudi table.
So I will share more details which might help, and answer to your suggestions and questions.
First I will share information about the data:
- For initial bench-marking we generate standard **tpch** data 1GB, 10GB, 30GB, 100GB, 265GB and 1TB. The tables mentioned on previous discussion is **lineitem** generated by tpch 30GB and 100GB, which has original parquet size of 6.7GB and 21GB respectively.
- Schema for lineitem
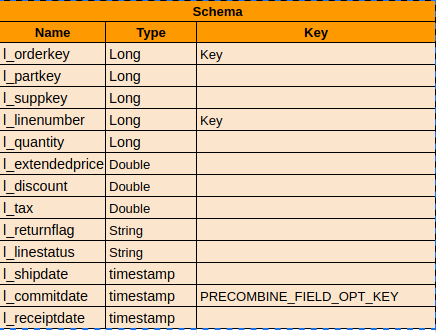
- We have another version of lineitem with additional column last_updated with generated timestamp to define as PRECOMBINE_FIELD_OPT_KEY
- Increments are 3% to 5% of the original base table count, 30% updates and 70% inserts.
- We have 2 versions of generated updates, one which touches only the last quarter of the year and another one generated randomly to touch most of the parquet parts during updates.
- Currently we generate no duplicates for the base table and increments.
Based on the same test data we have done further attempts by modifying HoodieSparkSqlWriter itself, UserDefinedBulkInsertPartitioner, HoodieRecord, change the payload. I will share the test result for defining UserDefinedBulkInsertPartitioner because it looks similar as the approach you mentioned to avoid the sorting for bulk-insert:
Applying bulk-insert for **lineitem** generated from tpch 1GB
**Table** : 213MB parquet, 6M records, 16 columns and key is composite of 2 columns.
**Spark Conf** : 1 executor, 12 cores, 16GB, 32 shuffle, 32 bulk-insert-parallelism.
**Hudi Version**: % "hudi-spark-bundle" % "0.5.2-incubating"
**Spark** : 2.4.5 with hadoop 2.7
**Table Type** : COW
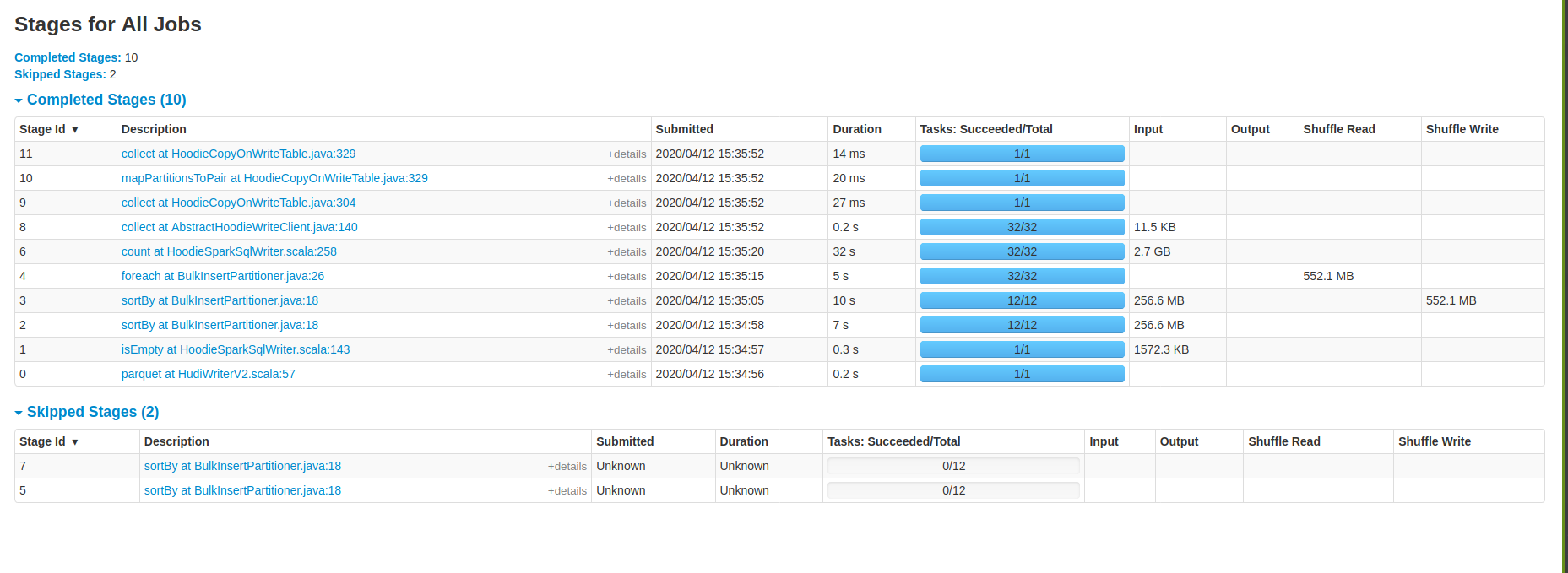
- Using vanilla % "hudi-spark-bundle" % "0.5.2-incubating", spark stages

As you can see the data has been shuffled to disk twice, applying the sorting twice as well.
- Eagerly persist the input RDD before the bulk-insert, which uses the same sorting provided before the bulk-insert.
`@Override
public JavaRDD<HoodieRecord> repartitionRecords(JavaRDD records, int outputSparkPartitions)
{ JavaRDD<HoodieRecord> data = ((JavaRDD<HoodieRecord>)records).sortBy(record -> {
return String.format("%s+%s", record.getPartitionPath(), record.getRecordKey());
}, true, outputSparkPartitions)
.persist(StorageLevel.MEMORY_ONLY());
data.foreach(record -> {});
return data;
}
`
So we avoided additional shuffle to disk, yet the performance still the same as well as we can't persist in memory for very large inputs.
- Just return the RDD as it is, or (sort, partition the data based on the key columns) on the dataframe level before passing the dataframe to HudiSparkSqlWriter, then just return the data.
`@Override
public JavaRDD<HoodieRecord> repartitionRecords(JavaRDD records, int outputSparkPartitions) {
return records;
}`
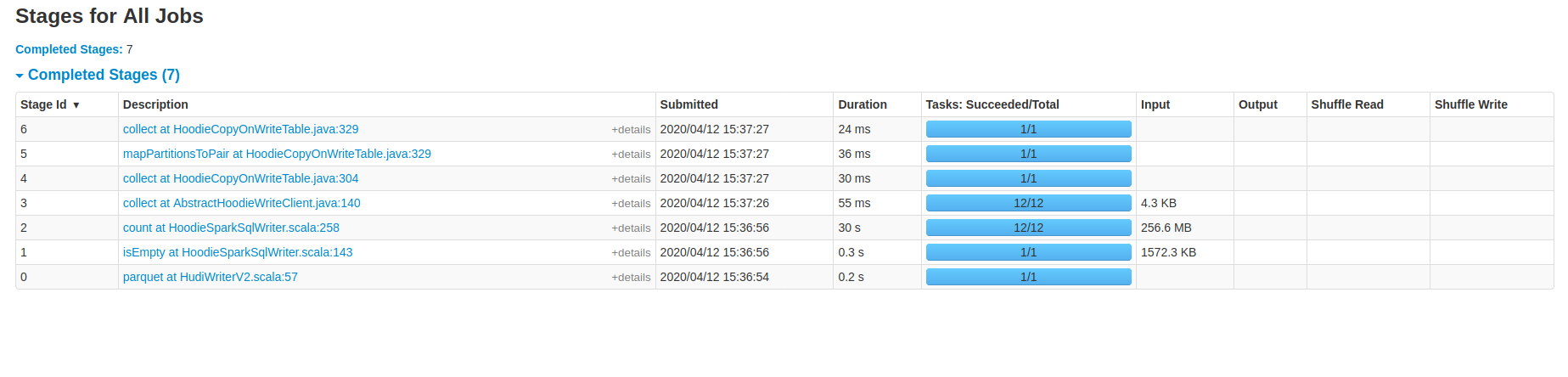
**Note:** this approach impact the Upsert time significantly specially if you didn't apply any sorting to the data, it might be because the upsert operation touched most of the parquet parts.
So please correct me if I am wrong, all the attached spark stages to the thread shows most of time spent (bottle neck) in the count action which filter the records with invalid write status, it is actually a narrow transformation after the sorting operation.
We haven't checked the logic behind this action in details yet, I thought this might be the indexing operation and creating the metadata columns for Hudi table.
Replaying to the questions and suggestion you mentioned:
> If you are trying to ultimately migrate a table (using bulk_insert once) and then do updates/deletes. I suggest, testing upserts/deletes rather than bulk_insert.. If you primarily want to do bulk_insert alone to get other benefits of Hudi. Happy to work with you more and resolve this. Perf is a major push for the next release. So we can def collaborate here
Yes we need to fully migrate the table to Hudi and apply excessive upserts / insert operations over it later.
If I get your suggestion right, would you suggest to initially load the table using upsert or insert operation for the whole table instead of bulk-insert?
We have tried that and it was extremely slower, consuming more memory and disk than bulk-insert.
We followed the documentation as well in the code which suggest to use the bulk-insert for initial table loading.
> Optimizing the spark executor memory to avoid GC hits and using snappy compression
We actually have tried many optimizations related to spark yet the performance improvements is limited or no gain.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] vinothchandar commented on issue #1498: Migrating
parquet table to hudi issue [SUPPORT]
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT]
URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-612252471
@vontman @ahmed-elfar First of all. Thanks for all the detailed information!
Answers to the good questions you raised
> Is that the normal time for initial loading for Hudi tables, or we are doing something wrong?
It's hard to know what normal time is since it depends on schema, machine and so many things. But we should n't this very off. Tried to explain few things below.
> Do we need a better cluster/recoures to be able to load the data for the first time?, because it is mentioned on Hudi confluence page that COW bulkinsert should match vanilla parquet writing + sort only.
If you are trying to ultimately migrate a table (using bulk_insert once) and then do updates/deletes. I suggest, testing upserts/deletes rather than bulk_insert.. If you primarily want to do bulk_insert alone to get other benefits of Hudi. Happy to work with you more and resolve this. Perf is a major push for the next release. So we can def collaborate here
> Does partitioning improves the upsert and/or compaction time for Hudi tables, or just to improve the analytical queries (partition pruning)?
Partitioning would benefit the query performance obviously. But for writing itself, the data size matter more, I would say.
> We have noticed that the most time spent in the data indexing (the bulk-insert logic itself) and not the sorting stages/operation before the indexing, so how can we improve that? should we provide our own indexing logic?
Nope. you don't have to supply you own indexing or anthing. Bulk insert does not do any indexing, it does a global sort (so we can pack records belonging to same partition closer into the same file as much) and then writes out files.
**Few observations :**
- 47 min job is gc-ing quite a bit. So that can affect throughput a lot. Have you tried configuring the jvm.
- I do see fair bit of skews here from sorting, which may be affecting over all run times.. #1149 is trying to also provide a non-sorted mode, that tradeoffs file sizing for potentially faster writing.
On what could create difference between bulk_insert and spark/parquet :
- I would also set `"hoodie.parquet.compression.codec" -> "SNAPPY"` since Hudi uses gzip compression by default, where spark.write.parquet will use SNAPPY
- Hudi currently does an extra `df.rdd` conversion that could affect bulk_insert/insert (upsert/delete workloads are bound by merge costs, this matters less there). I don't see that in your UI though..
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services