You are viewing a plain text version of this content. The canonical link for it is here.
Posted to github@arrow.apache.org by GitBox <gi...@apache.org> on 2022/01/24 01:09:24 UTC
[GitHub] [arrow-datafusion] houqp opened a new issue #1652: ARROW2: Performance benchmark
houqp opened a new issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652
Perform thorough testing to make sure the arrow2 branch will indeed result in better performance across the board.
Please give https://github.com/apache/arrow-datafusion/tree/arrow2 a try for your workloads and report any regression you find here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
alamb commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1023667162
arrow-rs 8 has some improvements for nullable columns as well now courtesy of @tustvold https://github.com/apache/arrow-rs/pull/1054
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] sunchao commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
sunchao commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1023620113
> It will (in version after 8.0.0) preserve dictionary encoding (meaning the output of a dictionary encoded column will also be dictionary encoded) which should be a large win for low cardinality columns
This is nice 👍 . By dictionary-based row group filtering I mean we can first decode only the dictionary pages for the column chunks where pushed down predicates (e.g., in predicate) are associated to, and skip the whole row group if no keys in the dictionary match.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):
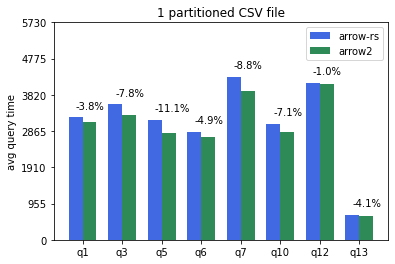
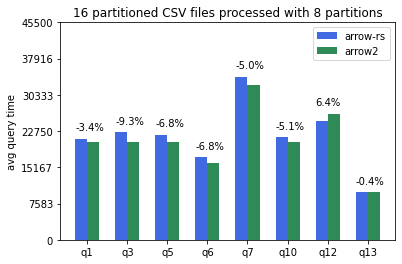
CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):
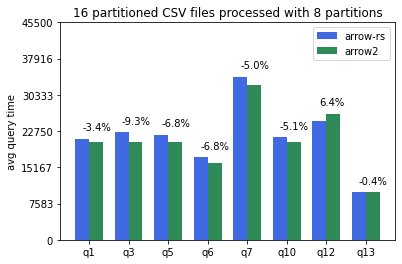
Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):
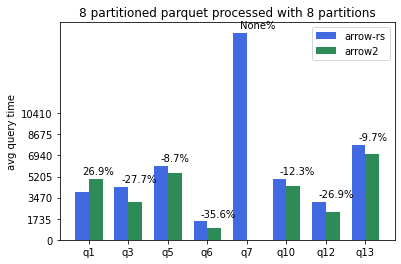
Note query 7 not able to complete with arrow2 due to OOM. Arrow2 parquet reader currently consumes almost double the memory is a known issue.
Q1 is significantly slower in arrow2 compared to the other queies.
Both of these two regressions require deep dive.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):

CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Data generated with:
```
PARTITIONS=16
for i in `seq 1 ${PARTITIONS}`; do
echo "generating partition $i"
./dbgen -vf -s 16 -C ${PARTITIONS} -S $i
ls -lh
done
```
Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Note query 7 could not complete with arrow2 due to OOM. Arrow2 parquet reader currently consuming almost double the memory compared to arrow-rs is a known issue. Related upstream issue: https://github.com/jorgecarleitao/arrow2/issues/768.
Q1 is significantly slower in arrow2 compared to the other queies (perhaps related to predicate pushdown?).
I think both of these two regressions require deepdive before we merge arrow2 into master.
Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] tustvold commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
tustvold commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1023655722
> skip the whole row group if no keys in the dictionary match.
You'd need to check that column chunk hadn't spilled, but yes that is broadly speaking the access pattern I wish to support with the work in https://github.com/apache/arrow-rs/issues/1191. Specially exploit https://github.com/apache/arrow-rs/pull/1180 to cheaply get dictionary data, evaluate predicates on it, and use this to construct a refined row selection to fetch.
As @alamb alludes to the timelines for this effort are not clear, and there may be other more pressing things for me to spend time on, but it is definitely something that I _hope_ to deliver in the next month or so.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] tustvold commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
tustvold commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019913842
Big :+1: to this, getting some concrete numbers would be really nice.
FWIW some ideas for whoever picks this up that I at least would be very interested in:
* Performance against current arrow-rs master, a number of non-trivial performance improvements have landed in the last month, with more currently in progress
* Performance of floating point aggregates, I seem to remember all the TPCH queries testing such fail to run correctly, but I could be mistaken
* Performance of dictionary arrays, there is a substantial amount of work completed and in-flight to improve this situation as it has historically been poor (and still is WIP)- https://github.com/apache/arrow-datafusion/issues/1610, https://github.com/apache/arrow-datafusion/issues/1474, https://github.com/apache/arrow-rs/pull/1180, etc...
* Performance on parquet files with reasonable row group sizes, the OOM would suggest they aren't teeny but wanted to clarify - there is currently a limitation of arrow-rs's parquet writer that makes it produce impractically small row groups - https://github.com/apache/arrow-rs/issues/1211
* Performance of specific operators, e.g. FilterExec or SortPreservingMerge or ParquetExec, I'd basically be interested in where the performance gains are, and where we might gain or lose performance a potential switch. Perhaps some execution plan metrics, or a perf dump or something :thinking:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):

CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Note query 7 not able to complete with arrow2 due to OOM. Arrow2 parquet reader currently consumes almost double the memory is a known issue.
Q1 is significantly slower in arrow2 compared to the other queies.
I think both of these two regressions require deepdive before we merge arrow2 into master.
Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] matthewmturner commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
matthewmturner commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1059660855
checking in on this - has anyone rerun tpch on master and arrow2 branches since the arrow-rs 9 release?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1020422537
bummer that the dictionary encoding optimization will need to wait for the 9.0 release, but we can test it with a 9.0 datafusion branch if needed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):

CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Data generated with:
```
PARTITIONS=16
for i in `seq 1 ${PARTITIONS}`; do
echo "generating partition $i"
./dbgen -vf -s 16 -C ${PARTITIONS} -S $i
ls -lh
done
```
Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Note query 7 could not complete with arrow2 due to OOM. Arrow2 parquet reader currently consuming almost double the memory compared to arrow-rs is a known issue. Related upstream issue: https://github.com/jorgecarleitao/arrow2/issues/768.
Q1 is significantly slower in arrow2 compared to the other queies (perhaps related to predicate pushdown?).
I think both of these two regressions require deepdive before we merge arrow2 into master.
Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
alamb commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1023624424
> This is nice 👍 . By dictionary-based row group filtering I mean we can first decode only the dictionary pages for the column chunks where pushed down predicates (e.g., in predicate) are associated to, and skip the whole row group if no keys in the dictionary match.
this would definitely be a neat optimization
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):

CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Data generated with:
```
PARTITIONS=16
for i in `seq 1 ${PARTITIONS}`; do
echo "generating partition $i"
./dbgen -vf -s 16 -C ${PARTITIONS} -S $i
ls -lh
done
```
Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Note query 7 could not complete with arrow2 due to OOM. Arrow2 parquet reader currently consuming almost double the memory compared to arrow-rs is a known issue. Related upstream issue: https://github.com/jorgecarleitao/arrow2/issues/768.
Q1 is significantly slower in arrow2 compared to the other queies (perhaps related to predicate pushdown?).
I think both of these two regressions require deepdive before we merge arrow2 into master.
Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] tustvold edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
tustvold edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019913842
Big :+1: to this, getting some concrete numbers would be really nice.
FWIW some ideas for whoever picks this up that I at least would be very interested in:
* Performance against current arrow-rs master, a number of non-trivial performance improvements have landed in the last month, with more currently in progress
* Performance of floating point aggregates, I seem to remember all the TPCH queries testing such fail to run correctly, but I could be mistaken
* Performance of dictionary arrays, there is a substantial amount of work completed and in-flight to improve this situation as it has historically been poor (and still is WIP)- https://github.com/apache/arrow-rs/issues/1113, https://github.com/apache/arrow-datafusion/issues/1610, https://github.com/apache/arrow-datafusion/issues/1474, https://github.com/apache/arrow-rs/pull/1180, etc...
* Performance on parquet files with reasonable row group sizes, the OOM would suggest they aren't teeny but wanted to clarify - there is currently a limitation of arrow-rs's parquet writer that makes it produce impractically small row groups - https://github.com/apache/arrow-rs/issues/1211
* Performance of specific operators, e.g. FilterExec or SortPreservingMerge or ParquetExec, I'd basically be interested in where the performance gains are, and where we might gain or lose performance in a potential switch. Perhaps some execution plan metrics, or a perf dump or something :thinking:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] tustvold edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
tustvold edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019913842
Big :+1: to this, getting some concrete numbers would be really nice.
FWIW some ideas for whoever picks this up that I at least would be very interested in:
* Performance against current arrow-rs master, a number of non-trivial performance improvements have landed in the last month, with more currently in progress
* Performance of floating point aggregates, I seem to remember all the TPCH queries testing such fail to run correctly, but I could be mistaken
* Performance of dictionary arrays, there is a substantial amount of work completed and in-flight to improve this situation as it has historically been poor (and still is WIP)- https://github.com/apache/arrow-rs/issues/1113, https://github.com/apache/arrow-datafusion/issues/1610, https://github.com/apache/arrow-datafusion/issues/1474, https://github.com/apache/arrow-rs/pull/1180, etc...
* Performance on parquet files with reasonable row group sizes, the OOM would suggest they aren't teeny but wanted to clarify - there is currently a limitation of arrow-rs's parquet writer that makes it produce impractically small row groups - https://github.com/apache/arrow-rs/issues/1211
* Performance of specific operators, e.g. FilterExec or SortPreservingMerge or ParquetExec, I'd basically be interested in where the performance gains are, and where we might gain or lose performance a potential switch. Perhaps some execution plan metrics, or a perf dump or something :thinking:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
alamb edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1023608032
DataFusion does implement row group pruning based on statistics (that arrow-rs creates)
arrow-rs creates statistics. It will (in version after 8.0.0) preserve dictionary encoding (meaning the output of a dictionary encoded column will also be dictionary encoded) which should be a large win for low cardinality columns
It does not currently create or use column indexes or bloom filters
I believe that @tustvold has a plan for implementing more sophisticated predicate pushdown (aka that a filter on one column could be used to avoid decoding swaths of others) but I am not sure what the timeline on that is -- https://github.com/apache/arrow-rs/issues/1191
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
alamb commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1020025480
A number of the performance improvements will be in arrow-rs 8.0.0, though some such as https://github.com/apache/arrow-rs/pull/1180 will not be released until arrow-rs 9.0.0
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):

CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Note query 7 could not complete with arrow2 due to OOM. Arrow2 parquet reader currently consumes almost double the memory is a known issue. Related upstream issue: https://github.com/jorgecarleitao/arrow2/issues/768.
Q1 is significantly slower in arrow2 compared to the other queies (perhaps related to predicate pushdown?).
I think both of these two regressions require deepdive before we merge arrow2 into master.
Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1020422537
bummer that the dictionary encoding optimization will need to wait for the 9.0 release, but we can test it with a 9.0 datafusion branch if needed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] tustvold commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
tustvold commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1059726826
I added some further benchmarks in #1738 which I would also be interested in the numbers for
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):

CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):
Data generated with:
```
PARTITIONS=16
for i in `seq 1 ${PARTITIONS}`; do
echo "generating partition $i"
./dbgen -vf -s 16 -C ${PARTITIONS} -S $i
ls -lh
done
```
Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Note query 7 could not complete with arrow2 due to OOM. Arrow2 parquet reader currently consuming almost double the memory compared to arrow-rs is a known issue. Related upstream issue: https://github.com/jorgecarleitao/arrow2/issues/768.
Q1 is significantly slower in arrow2 compared to the other queies (perhaps related to predicate pushdown?).
I think both of these two regressions require deepdive before we merge arrow2 into master.
Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):

CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Note query 7 not able to complete with arrow2 due to OOM. Arrow2 parquet reader currently consumes almost double the memory is a known issue. Related upstream issue: https://github.com/jorgecarleitao/arrow2/issues/768.
Q1 is significantly slower in arrow2 compared to the other queies (perhaps related to predicate pushdown?).
I think both of these two regressions require deepdive before we merge arrow2 into master.
Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] alamb commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
alamb commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1023608032
DataFusion does implement row group pruning based on statistics (that arrow-rs creates)
arrow-rs creates statistics. It will (in version after 8.0.0) preserve dictionary encoding (meaning the output of a dictionary encoded column will also be dictionary encoded) which should be a large win for low cardinality columns
It does not currently create or use column indexes or bloom filters
I believe that @tustvold has a plan for implementing more sophisticated predicate pushdown (aka that a filter on one column could be used to avoid decoding swaths of others) but I am not sure what the timeline on that is
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] sunchao commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
sunchao commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1023586608
I think a big part of perf improvement comes from Parquet predicate pushdown (e.g., stats, dictionary, bloom filter and column index). Does either arrow-rs or arrow2 implement (some of) these currently?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] jorgecarleitao commented on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
jorgecarleitao commented on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1023661427
* arrow-rs: group filter push down
* arrow2: group filter push down, page filter push down
afaik both support reading and writing dictionary encoded arrays to dictionary-encoded column chunks (but neither supports pushdown based on dict values atm).
TBH, imo the biggest limiting factor in implementing anything in parquet is its lack of documentation - it is just a lot of work to decipher what is being requested, and the situation is not improving. For example, I spent a lot of time in understanding the encodings, have [a PR](https://github.com/apache/parquet-format/pull/170) to try to help future folks implementing it, and it has been lingering for ~9 months now. I wish parquet was a bit more inspired by e.g. Arrow or ORC in this respect.
Note that datafusion's benchmarks only use "required" / non-nullable data, so most optimizations on the null values are not seen from datafusion's perspective. Last time I benched [arrow2/parquet2 was much faster](https://docs.google.com/spreadsheets/d/12Sj1kjhadT-l0KXirexQDOocsLg-M4Ao1jnqXstCpx0/edit#gid=1919295045) in nullable data; I am a bit surprised to see so many differences in non-nullable data.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):

CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Note query 7 not able to complete with arrow2 due to OOM. Arrow2 parquet reader currently consumes almost double the memory is a known issue.
Q1 is significantly slower in arrow2 compared to the other queies (perhaps related to predicate pushdown?).
I think both of these two regressions require deepdive before we merge arrow2 into master.
Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow-datafusion] houqp edited a comment on issue #1652: ARROW2: Performance benchmark
Posted by GitBox <gi...@apache.org>.
houqp edited a comment on issue #1652:
URL: https://github.com/apache/arrow-datafusion/issues/1652#issuecomment-1019622028
Here are some of the TPCH results I got from running our tpch benchmark suite on an 8 cores x86-64 Linux machine.
The base commit from I used as baseline for arrow-rs is 2008b1dc06d5030f572634c7f8f2ba48562fa636. The commit for arrow2 is c0c9c7231f9c5685fda5fc9294fdc1711384b6fb.
Default single partition CSV files generated from our [tpch gen script](https://github.com/apache/arrow-datafusion/blob/6ec18bb4a53f684efd8d97443c55035eb37bda14/benchmarks/entrypoint.sh#L21) (--batch-size 4096):

CSV tables partitioned into 16 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Parquet tables partitioned in 8 files and processed with 8 datafusion partitions (--batch-size 4096 --partitions 8):

Note query 7 could not complete with arrow2 due to OOM. Arrow2 parquet reader currently consuming almost double the memory compared to arrow-rs is a known issue. Related upstream issue: https://github.com/jorgecarleitao/arrow2/issues/768.
Q1 is significantly slower in arrow2 compared to the other queies (perhaps related to predicate pushdown?).
I think both of these two regressions require deepdive before we merge arrow2 into master.
Overall, arrow2 is around 5% faster for CSV tables and 10-20% faster for parquet tables across the board.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org