You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2021/04/16 08:07:03 UTC
[GitHub] [spark] itholic opened a new pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
itholic opened a new pull request #32204:
URL: https://github.com/apache/spark/pull/32204
### What changes were proposed in this pull request?
This PR proposes move JSON data source options from Python, Scala and Java into a single page.
### Why are the changes needed?
So far, the documentation for JSON data source options is separated into different pages for each language API documents. However, this makes managing many options inconvenient, so it is efficient to manage all options in a single page and provide a link to that page in the API of each language.
### Does this PR introduce _any_ user-facing change?
Yes, the documents will be shown below after this change:
- Python
<img width="714" alt="Screen Shot 2021-04-16 at 5 04 11 PM" src="https://user-images.githubusercontent.com/44108233/114992491-ca0cef00-9ed5-11eb-9d0f-4de60d8b2516.png">
- Scala
<img width="726" alt="Screen Shot 2021-04-16 at 5 04 54 PM" src="https://user-images.githubusercontent.com/44108233/114992594-e315a000-9ed5-11eb-8bd3-af7e568fcfe1.png">
- Java
<img width="911" alt="Screen Shot 2021-04-16 at 5 06 11 PM" src="https://user-images.githubusercontent.com/44108233/114992751-10624e00-9ed6-11eb-888c-8668d3c74289.png">
### How was this patch tested?
Manually build docs and confirm the page.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r630662846
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -233,114 +233,13 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
path : str, list or :class:`RDD`
string represents path to the JSON dataset, or a list of paths,
or RDD of Strings storing JSON objects.
- schema : :class:`pyspark.sql.types.StructType` or str, optional
- an optional :class:`pyspark.sql.types.StructType` for the input schema or
- a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
- mode : str, optional
- allows a mode for dealing with corrupt records during parsing. If None is
- set, it uses the default value, ``PERMISSIVE``.
-
- * ``PERMISSIVE``: when it meets a corrupted record, puts the malformed string \
- into a field configured by ``columnNameOfCorruptRecord``, and sets malformed \
- fields to ``null``. To keep corrupt records, an user can set a string type \
- field named ``columnNameOfCorruptRecord`` in an user-defined schema. If a \
- schema does not have the field, it drops corrupt records during parsing. \
- When inferring a schema, it implicitly adds a ``columnNameOfCorruptRecord`` \
- field in an output schema.
- * ``DROPMALFORMED``: ignores the whole corrupted records.
- * ``FAILFAST``: throws an exception when it meets corrupted records.
- columnNameOfCorruptRecord: str, optional
- allows renaming the new field having malformed string
- created by ``PERMISSIVE`` mode. This overrides
- ``spark.sql.columnNameOfCorruptRecord``. If None is set,
- it uses the value specified in
- ``spark.sql.columnNameOfCorruptRecord``.
- dateFormat : str, optional
- sets the string that indicates a date format. Custom date formats
- follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to date type. If None is set, it uses the
- default value, ``yyyy-MM-dd``.
- timestampFormat : str, optional
- sets the string that indicates a timestamp format.
- Custom date formats follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to timestamp type. If None is set, it uses the
- default value, ``yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]``.
- multiLine : str or bool, optional
- parse one record, which may span multiple lines, per file. If None is
- set, it uses the default value, ``false``.
- allowUnquotedControlChars : str or bool, optional
- allows JSON Strings to contain unquoted control
- characters (ASCII characters with value less than 32,
- including tab and line feed characters) or not.
- encoding : str or bool, optional
- allows to forcibly set one of standard basic or extended encoding for
- the JSON files. For example UTF-16BE, UTF-32LE. If None is set,
- the encoding of input JSON will be detected automatically
- when the multiLine option is set to ``true``.
- lineSep : str, optional
- defines the line separator that should be used for parsing. If None is
- set, it covers all ``\\r``, ``\\r\\n`` and ``\\n``.
- samplingRatio : str or float, optional
- defines fraction of input JSON objects used for schema inferring.
- If None is set, it uses the default value, ``1.0``.
- dropFieldIfAllNull : str or bool, optional
- whether to ignore column of all null values or empty
- array/struct during schema inference. If None is set, it
- uses the default value, ``false``.
- locale : str, optional
- sets a locale as language tag in IETF BCP 47 format. If None is set,
- it uses the default value, ``en-US``. For instance, ``locale`` is used while
- parsing dates and timestamps.
- pathGlobFilter : str or bool, optional
Review comment:
Thanks for the comment, @HyukjinKwon
It's documented in [Generic File Source Options](https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html#path-global-filter), so removed it from the docstring.
Then, should we add the link to Generic File Source Options, too? or just keep it here??
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843064865
**[Test build #138678 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138678/testReport)** for PR 32204 at commit [`b7171f2`](https://github.com/apache/spark/commit/b7171f2348db967bcefbb5efa7400deab15f5f23).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840315107
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43012/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842401491
**[Test build #138633 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138633/testReport)** for PR 32204 at commit [`cd9f103`](https://github.com/apache/spark/commit/cd9f103683deb5c5d722dbddf9f6c9505336f8bd).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `case class UpdatingSessionsExec(`
* `class UpdatingSessionsIterator(`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840312271
@itholic:
1. Please check the option **one by one** and see if each exists.
2. Document general options in https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html if there are missing ones
3. If you're going to do this separately in a separate JIRA, don't remove general options in API documentations for now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840934265
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43050/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic edited a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic edited a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840913159
Thanks, @HyukjinKwon .
I checked one by one, and seems like the general options are already documentd to the https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html. I think the parameters I documented & removed are all of JSON specific options ??
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841040366
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43070/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840291088
**[Test build #138492 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138492/testReport)** for PR 32204 at commit [`a386788`](https://github.com/apache/spark/commit/a386788b44fb5255d2784ce423e3f879ba97f53c).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r631575888
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -1196,39 +1097,13 @@ def json(self, path, mode=None, compression=None, dateFormat=None, timestampForm
----------
path : str
the path in any Hadoop supported file system
- mode : str, optional
Review comment:
mode is a general option
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845617127
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43302/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r632177276
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -1196,39 +1097,13 @@ def json(self, path, mode=None, compression=None, dateFormat=None, timestampForm
----------
path : str
the path in any Hadoop supported file system
- mode : str, optional
Review comment:
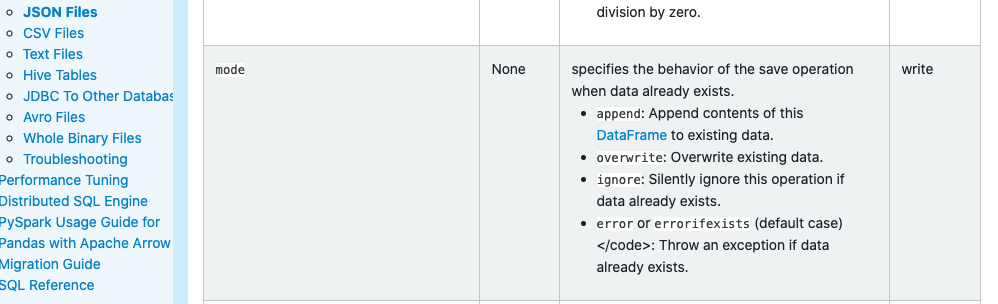
yeah, so I documented this to the "Data Source Options" table in JSON Files page, and removed here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon closed pull request #32204:
URL: https://github.com/apache/spark/pull/32204
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822298400
**[Test build #137597 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137597/testReport)** for PR 32204 at commit [`c31c6f0`](https://github.com/apache/spark/commit/c31c6f07db757ed3cb44e0b142f544c499f82a7d).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r636568884
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/DataFrameReader.scala
##########
@@ -441,81 +390,13 @@ class DataFrameReader private[sql](sparkSession: SparkSession) extends Logging {
* This function goes through the input once to determine the input schema. If you know the
* schema in advance, use the version that specifies the schema to avoid the extra scan.
*
- * You can set the following JSON-specific options to deal with non-standard JSON files:
- * <ul>
- * <li>`primitivesAsString` (default `false`): infers all primitive values as a string type</li>
- * <li>`prefersDecimal` (default `false`): infers all floating-point values as a decimal
- * type. If the values do not fit in decimal, then it infers them as doubles.</li>
- * <li>`allowComments` (default `false`): ignores Java/C++ style comment in JSON records</li>
- * <li>`allowUnquotedFieldNames` (default `false`): allows unquoted JSON field names</li>
- * <li>`allowSingleQuotes` (default `true`): allows single quotes in addition to double quotes
- * </li>
- * <li>`allowNumericLeadingZeros` (default `false`): allows leading zeros in numbers
- * (e.g. 00012)</li>
- * <li>`allowBackslashEscapingAnyCharacter` (default `false`): allows accepting quoting of all
- * character using backslash quoting mechanism</li>
- * <li>`allowUnquotedControlChars` (default `false`): allows JSON Strings to contain unquoted
- * control characters (ASCII characters with value less than 32, including tab and line feed
- * characters) or not.</li>
- * <li>`mode` (default `PERMISSIVE`): allows a mode for dealing with corrupt records
- * during parsing.
- * <ul>
- * <li>`PERMISSIVE` : when it meets a corrupted record, puts the malformed string into a
- * field configured by `columnNameOfCorruptRecord`, and sets malformed fields to `null`. To
- * keep corrupt records, an user can set a string type field named
- * `columnNameOfCorruptRecord` in an user-defined schema. If a schema does not have the
- * field, it drops corrupt records during parsing. When inferring a schema, it implicitly
- * adds a `columnNameOfCorruptRecord` field in an output schema.</li>
- * <li>`DROPMALFORMED` : ignores the whole corrupted records.</li>
- * <li>`FAILFAST` : throws an exception when it meets corrupted records.</li>
- * </ul>
- * </li>
- * <li>`columnNameOfCorruptRecord` (default is the value specified in
- * `spark.sql.columnNameOfCorruptRecord`): allows renaming the new field having malformed string
- * created by `PERMISSIVE` mode. This overrides `spark.sql.columnNameOfCorruptRecord`.</li>
- * <li>`dateFormat` (default `yyyy-MM-dd`): sets the string that indicates a date format.
- * Custom date formats follow the formats at
- * <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html">
- * Datetime Patterns</a>.
- * This applies to date type.</li>
- * <li>`timestampFormat` (default `yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]`): sets the string that
- * indicates a timestamp format. Custom date formats follow the formats at
- * <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html">
- * Datetime Patterns</a>.
- * This applies to timestamp type.</li>
- * <li>`multiLine` (default `false`): parse one record, which may span multiple lines,
- * per file</li>
- * <li>`encoding` (by default it is not set): allows to forcibly set one of standard basic
- * or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If the encoding
- * is not specified and `multiLine` is set to `true`, it will be detected automatically.</li>
- * <li>`lineSep` (default covers all `\r`, `\r\n` and `\n`): defines the line separator
- * that should be used for parsing.</li>
- * <li>`samplingRatio` (default is 1.0): defines fraction of input JSON objects used
- * for schema inferring.</li>
- * <li>`dropFieldIfAllNull` (default `false`): whether to ignore column of all null values or
- * empty array/struct during schema inference.</li>
- * <li>`locale` (default is `en-US`): sets a locale as language tag in IETF BCP 47 format.
- * For instance, this is used while parsing dates and timestamps.</li>
- * <li>`pathGlobFilter`: an optional glob pattern to only include files with paths matching
- * the pattern. The syntax follows <code>org.apache.hadoop.fs.GlobFilter</code>.
- * It does not change the behavior of partition discovery.</li>
- * <li>`modifiedBefore` (batch only): an optional timestamp to only include files with
- * modification times occurring before the specified Time. The provided timestamp
- * must be in the following form: YYYY-MM-DDTHH:mm:ss (e.g. 2020-06-01T13:00:00)</li>
- * <li>`modifiedAfter` (batch only): an optional timestamp to only include files with
- * modification times occurring after the specified Time. The provided timestamp
- * must be in the following form: YYYY-MM-DDTHH:mm:ss (e.g. 2020-06-01T13:00:00)</li>
- * <li>`recursiveFileLookup`: recursively scan a directory for files. Using this option
- * disables partition discovery</li>
- * <li>`allowNonNumericNumbers` (default `true`): allows JSON parser to recognize set of
- * "Not-a-Number" (NaN) tokens as legal floating number values:
- * <ul>
- * <li>`+INF` for positive infinity, as well as alias of `+Infinity` and `Infinity`.
- * <li>`-INF` for negative infinity), alias `-Infinity`.
- * <li>`NaN` for other not-a-numbers, like result of division by zero.
- * </ul>
- * </li>
- * </ul>
+ * You can find the JSON-specific options for reading JSON files in
+ * <a href="https://spark.apache.org/docs/latest/sql-data-sources-json.html#data-source-option">
+ * Data Source Option</a> in the version you use.
+ * More general options can be found in
+ * <a href=
+ * "https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html">
+ * Generic Files Source Options</a> in the version you use.
Review comment:
Shall we remove this too?
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -507,102 +479,15 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
schema : :class:`pyspark.sql.types.StructType` or str, optional
an optional :class:`pyspark.sql.types.StructType` for the input schema
or a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
- mode : str, optional
- allows a mode for dealing with corrupt records during parsing. If None is
- set, it uses the default value, ``PERMISSIVE``.
-
- * ``PERMISSIVE``: when it meets a corrupted record, puts the malformed string \
- into a field configured by ``columnNameOfCorruptRecord``, and sets malformed \
- fields to ``null``. To keep corrupt records, an user can set a string type \
- field named ``columnNameOfCorruptRecord`` in an user-defined schema. If a \
- schema does not have the field, it drops corrupt records during parsing. \
- When inferring a schema, it implicitly adds a ``columnNameOfCorruptRecord`` \
- field in an output schema.
- * ``DROPMALFORMED``: ignores the whole corrupted records.
- * ``FAILFAST``: throws an exception when it meets corrupted records.
-
- columnNameOfCorruptRecord : str, optional
- allows renaming the new field having malformed string
- created by ``PERMISSIVE`` mode. This overrides
- ``spark.sql.columnNameOfCorruptRecord``. If None is set,
- it uses the value specified in
- ``spark.sql.columnNameOfCorruptRecord``.
- dateFormat : str, optional
- sets the string that indicates a date format. Custom date formats
- follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to date type. If None is set, it uses the
- default value, ``yyyy-MM-dd``.
- timestampFormat : str, optional
- sets the string that indicates a timestamp format.
- Custom date formats follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to timestamp type. If None is set, it uses the
- default value, ``yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]``.
- multiLine : str or bool, optional
- parse one record, which may span multiple lines, per file. If None is
- set, it uses the default value, ``false``.
- allowUnquotedControlChars : str or bool, optional
- allows JSON Strings to contain unquoted control
- characters (ASCII characters with value less than 32,
- including tab and line feed characters) or not.
- lineSep : str, optional
- defines the line separator that should be used for parsing. If None is
- set, it covers all ``\\r``, ``\\r\\n`` and ``\\n``.
- locale : str, optional
- sets a locale as language tag in IETF BCP 47 format. If None is set,
- it uses the default value, ``en-US``. For instance, ``locale`` is used while
- parsing dates and timestamps.
- dropFieldIfAllNull : str or bool, optional
- whether to ignore column of all null values or empty
- array/struct during schema inference. If None is set, it
- uses the default value, ``false``.
- encoding : str or bool, optional
- allows to forcibly set one of standard basic or extended encoding for
- the JSON files. For example UTF-16BE, UTF-32LE. If None is set,
- the encoding of input JSON will be detected automatically
- when the multiLine option is set to ``true``.
- pathGlobFilter : str or bool, optional
- an optional glob pattern to only include files with paths matching
- the pattern. The syntax follows `org.apache.hadoop.fs.GlobFilter`.
- It does not change the behavior of
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- recursiveFileLookup : str or bool, optional
- recursively scan a directory for files. Using this option
- disables
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- allowNonNumericNumbers : str or bool, optional
- allows JSON parser to recognize set of "Not-a-Number" (NaN)
- tokens as legal floating number values. If None is set,
- it uses the default value, ``true``.
- * ``+INF``: for positive infinity, as well as alias of
- ``+Infinity`` and ``Infinity``.
- * ``-INF``: for negative infinity, alias ``-Infinity``.
- * ``NaN``: for other not-a-numbers, like result of division by zero.
+ Other Parameters
+ ----------------
+ Extra options (keyword argument)
+ For the extra options, refer to
+ `Data Source Option <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#data-source-option>`_ # noqa
+ and
+ `Generic File Source Options <https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html`>_ # noqa
+ in the version you use.
Review comment:
Shall we remove this too?
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -236,112 +190,15 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
schema : :class:`pyspark.sql.types.StructType` or str, optional
an optional :class:`pyspark.sql.types.StructType` for the input schema or
a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
- mode : str, optional
- allows a mode for dealing with corrupt records during parsing. If None is
- set, it uses the default value, ``PERMISSIVE``.
-
- * ``PERMISSIVE``: when it meets a corrupted record, puts the malformed string \
- into a field configured by ``columnNameOfCorruptRecord``, and sets malformed \
- fields to ``null``. To keep corrupt records, an user can set a string type \
- field named ``columnNameOfCorruptRecord`` in an user-defined schema. If a \
- schema does not have the field, it drops corrupt records during parsing. \
- When inferring a schema, it implicitly adds a ``columnNameOfCorruptRecord`` \
- field in an output schema.
- * ``DROPMALFORMED``: ignores the whole corrupted records.
- * ``FAILFAST``: throws an exception when it meets corrupted records.
-
- columnNameOfCorruptRecord: str, optional
- allows renaming the new field having malformed string
- created by ``PERMISSIVE`` mode. This overrides
- ``spark.sql.columnNameOfCorruptRecord``. If None is set,
- it uses the value specified in
- ``spark.sql.columnNameOfCorruptRecord``.
- dateFormat : str, optional
- sets the string that indicates a date format. Custom date formats
- follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to date type. If None is set, it uses the
- default value, ``yyyy-MM-dd``.
- timestampFormat : str, optional
- sets the string that indicates a timestamp format.
- Custom date formats follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to timestamp type. If None is set, it uses the
- default value, ``yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]``.
- multiLine : str or bool, optional
- parse one record, which may span multiple lines, per file. If None is
- set, it uses the default value, ``false``.
- allowUnquotedControlChars : str or bool, optional
- allows JSON Strings to contain unquoted control
- characters (ASCII characters with value less than 32,
- including tab and line feed characters) or not.
- encoding : str or bool, optional
- allows to forcibly set one of standard basic or extended encoding for
- the JSON files. For example UTF-16BE, UTF-32LE. If None is set,
- the encoding of input JSON will be detected automatically
- when the multiLine option is set to ``true``.
- lineSep : str, optional
- defines the line separator that should be used for parsing. If None is
- set, it covers all ``\\r``, ``\\r\\n`` and ``\\n``.
- samplingRatio : str or float, optional
- defines fraction of input JSON objects used for schema inferring.
- If None is set, it uses the default value, ``1.0``.
- dropFieldIfAllNull : str or bool, optional
- whether to ignore column of all null values or empty
- array/struct during schema inference. If None is set, it
- uses the default value, ``false``.
- locale : str, optional
- sets a locale as language tag in IETF BCP 47 format. If None is set,
- it uses the default value, ``en-US``. For instance, ``locale`` is used while
- parsing dates and timestamps.
- pathGlobFilter : str or bool, optional
- an optional glob pattern to only include files with paths matching
- the pattern. The syntax follows `org.apache.hadoop.fs.GlobFilter`.
- It does not change the behavior of
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- recursiveFileLookup : str or bool, optional
- recursively scan a directory for files. Using this option
- disables
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- allowNonNumericNumbers : str or bool
- allows JSON parser to recognize set of "Not-a-Number" (NaN)
- tokens as legal floating number values. If None is set,
- it uses the default value, ``true``.
-
- * ``+INF``: for positive infinity, as well as alias of
- ``+Infinity`` and ``Infinity``.
- * ``-INF``: for negative infinity, alias ``-Infinity``.
- * ``NaN``: for other not-a-numbers, like result of division by zero.
- modifiedBefore : an optional timestamp to only include files with
- modification times occurring before the specified time. The provided timestamp
- must be in the following format: YYYY-MM-DDTHH:mm:ss (e.g. 2020-06-01T13:00:00)
- modifiedAfter : an optional timestamp to only include files with
- modification times occurring after the specified time. The provided timestamp
- must be in the following format: YYYY-MM-DDTHH:mm:ss (e.g. 2020-06-01T13:00:00)
+ Other Parameters
+ ----------------
+ Extra options
+ For the extra options, refer to
+ `Data Source Option <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#data-source-option>`_ # noqa
+ and
+ `Generic File Source Options <https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html`>_ # noqa
+ in the version you use.
Review comment:
Shall we remove this too?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r633025442
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>prefersDecimal</code></td>
+ <td>None</td>
+ <td>infers all floating-point values as a decimal type. If the values do not fit in decimal, then it infers them as doubles. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowComments</code></td>
+ <td>None</td>
+ <td>ignores Java/C++ style comment in JSON records. If None is set, it uses the default value, <code>false</code></td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedFieldNames</code></td>
+ <td>None</td>
+ <td>allows unquoted JSON field names. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowSingleQuotes</code></td>
+ <td>None</td>
+ <td>allows single quotes in addition to double quotes. If None is set, it uses the default value, <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNumericLeadingZero</code></td>
+ <td>None</td>
+ <td>allows leading zeros in numbers (e.g. 00012). If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowBackslashEscapingAnyCharacter</code></td>
+ <td>None</td>
+ <td>allows accepting quoting of all character using backslash quoting mechanism. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>columnNameOfCorruptRecord</code></td>
+ <td>None</td>
+ <td>allows renaming the new field having malformed string created by <code>PERMISSIVE</code> mode. This overrides spark.sql.columnNameOfCorruptRecord. If None is set, it uses the value specified in <code>spark.sql.columnNameOfCorruptRecord</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dateFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a date format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to date type. If None is set, it uses the default value, <code>yyyy-MM-dd</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>timestampFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a timestamp format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to timestamp type. If None is set, it uses the default value, <code>yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>multiLine</code></td>
+ <td>None</td>
+ <td>parse one record, which may span multiple lines, per file. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedControlChars</code></td>
+ <td>None</td>
+ <td>allows JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) or not.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
+ <td>None</td>
+ <td>allows to forcibly set one of standard basic or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If None is set, the encoding of input JSON will be detected automatically when the multiLine option is set to <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>lineSep</code></td>
+ <td>None</td>
+ <td>defines the line separator that should be used for parsing. If None is set, it covers all <code>\r</code>, <code>\r\n</code> and <code>\n</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>samplingRatio</code></td>
+ <td>None</td>
+ <td>defines fraction of input JSON objects used for schema inferring. If None is set, it uses the default value, <code>1.0</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dropFieldIfAllNull</code></td>
+ <td>None</td>
+ <td>whether to ignore column of all null values or empty array/struct during schema inference. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>locale</code></td>
+ <td>None</td>
+ <td>sets a locale as language tag in IETF BCP 47 format. If None is set, it uses the default value, <code>en-US</code>. For instance, <code>locale</code> is used while parsing dates and timestamps.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNonNumericNumbers</code></td>
+ <td>None</td>
+ <td>allows JSON parser to recognize set of “Not-a-Number” (NaN) tokens as legal floating number values. If None is set, it uses the default value, <code>true</code>.<br>
+ <ul>
+ <li><code>+INF</code>: for positive infinity, as well as alias of <code>+Infinity</code> and <code>Infinity</code>.</li>
+ <li><code>-INF</code>: for negative infinity, alias <code>-Infinity</code>.</li>
+ <li><code>NaN</code>: for other not-a-numbers, like result of division by zero.</li>
+ </ul>
+ </td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>compression</code></td>
+ <td>None</td>
+ <td>compression codec to use when saving to file. This can be one of the known case-insensitive shorten names (none, bzip2, gzip, lz4, snappy and deflate).</td>
+ <td>write</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
Review comment:
Can you combine with `encoding` option above?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r634194606
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/DataFrameReader.scala
##########
@@ -443,20 +443,6 @@ class DataFrameReader private[sql](sparkSession: SparkSession) extends Logging {
*
* You can set the following JSON-specific options to deal with non-standard JSON files:
* <ul>
- * <li>`primitivesAsString` (default `false`): infers all primitive values as a string type</li>
- * <li>`prefersDecimal` (default `false`): infers all floating-point values as a decimal
- * type. If the values do not fit in decimal, then it infers them as doubles.</li>
- * <li>`allowComments` (default `false`): ignores Java/C++ style comment in JSON records</li>
- * <li>`allowUnquotedFieldNames` (default `false`): allows unquoted JSON field names</li>
- * <li>`allowSingleQuotes` (default `true`): allows single quotes in addition to double quotes
- * </li>
- * <li>`allowNumericLeadingZeros` (default `false`): allows leading zeros in numbers
- * (e.g. 00012)</li>
- * <li>`allowBackslashEscapingAnyCharacter` (default `false`): allows accepting quoting of all
- * character using backslash quoting mechanism</li>
- * <li>`allowUnquotedControlChars` (default `false`): allows JSON Strings to contain unquoted
- * control characters (ASCII characters with value less than 32, including tab and line feed
- * characters) or not.</li>
* <li>`mode` (default `PERMISSIVE`): allows a mode for dealing with corrupt records
Review comment:
mode in read path is an option for JSON and CSV. write mode (overwrite, etc.) isn't an option.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842429046
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-821022487
**[Test build #137474 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137474/testReport)** for PR 32204 at commit [`89d9be1`](https://github.com/apache/spark/commit/89d9be177539d307ef008c42c7245e90effec7e1).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841039764
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43070/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843268988
**[Test build #138681 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138681/testReport)** for PR 32204 at commit [`3316616`](https://github.com/apache/spark/commit/3316616593f72196fc98b6dc13bb6e19110207ca).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635793918
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -1204,31 +1055,13 @@ def json(self, path, mode=None, compression=None, dateFormat=None, timestampForm
* ``ignore``: Silently ignore this operation if data already exists.
* ``error`` or ``errorifexists`` (default case): Throw an exception if data already \
exists.
- compression : str, optional
- compression codec to use when saving to file. This can be one of the
- known case-insensitive shorten names (none, bzip2, gzip, lz4,
- snappy and deflate).
- dateFormat : str, optional
- sets the string that indicates a date format. Custom date formats
- follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to date type. If None is set, it uses the
- default value, ``yyyy-MM-dd``.
- timestampFormat : str, optional
- sets the string that indicates a timestamp format.
- Custom date formats follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to timestamp type. If None is set, it uses the
- default value, ``yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]``.
- encoding : str, optional
- specifies encoding (charset) of saved json files. If None is set,
- the default UTF-8 charset will be used.
- lineSep : str, optional
- defines the line separator that should be used for writing. If None is
- set, it uses the default value, ``\\n``.
- ignoreNullFields : str or bool, optional
- Whether to ignore null fields when generating JSON objects.
- If None is set, it uses the default value, ``true``.
+
+ Other Parameters
+ ----------------
+ Extra options
+ For the extra options, refer to
+ `Data Source Option <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#data-source-option>`_ # noqa
+ in the version you use.
Review comment:
Here you didn't link generic options but you did for Parquet. What's diff?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-821056642
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42050/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r638679043
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,168 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of
+ * `DataFrameReader`
+ * `DataFrameWriter`
+ * `DataStreamReader`
+ * `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <!-- TODO(SPARK-35433): Add timeZone to Data Source Option for CSV, too. -->
+ <td><code>timeZone</code></td>
+ <td>None</td>
+ <td>Sets the string that indicates a time zone ID to be used to format timestamps in the JSON datasources or partition values. The following formats of <code>timeZone</code> are supported:<br>
+ <ul>
+ <li>Region-based zone ID: It should have the form 'area/city', such as 'America/Los_Angeles'.</li>
+ <li>Zone offset: It should be in the format '(+|-)HH:mm', for example '-08:00' or '+01:00'. Also 'UTC' and 'Z' are supported as aliases of '+00:00'.</li>
+ </ul>
+ Other short names like 'CST' are not recommended to use because they can be ambiguous. If it isn't set, the current value of the SQL config <code>spark.sql.session.timeZone</code> is used by default.
+ </td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>Infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>prefersDecimal</code></td>
+ <td>None</td>
+ <td>Infers all floating-point values as a decimal type. If the values do not fit in decimal, then it infers them as doubles. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowComments</code></td>
+ <td>None</td>
+ <td>Ignores Java/C++ style comment in JSON records. If None is set, it uses the default value, <code>false</code></td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedFieldNames</code></td>
+ <td>None</td>
+ <td>Allows unquoted JSON field names. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowSingleQuotes</code></td>
+ <td>None</td>
+ <td>Allows single quotes in addition to double quotes. If None is set, it uses the default value, <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNumericLeadingZero</code></td>
+ <td>None</td>
+ <td>Allows leading zeros in numbers (e.g. 00012). If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowBackslashEscapingAnyCharacter</code></td>
+ <td>None</td>
+ <td>Allows accepting quoting of all character using backslash quoting mechanism. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>mode</code></td>
+ <td>None</td>
+ <td>Allows a mode for dealing with corrupt records during parsing. If None is set, it uses the default value, <code>PERMISSIVE</code><br>
+ <ul>
+ <li><code>PERMISSIVE</code>: when it meets a corrupted record, puts the malformed string into a field configured by <code>columnNameOfCorruptRecord</code>, and sets malformed fields to <code>null</code>. To keep corrupt records, an user can set a string type field named <code>columnNameOfCorruptRecord</code> in an user-defined schema. If a schema does not have the field, it drops corrupt records during parsing. When inferring a schema, it implicitly adds a <code>columnNameOfCorruptRecord</code> field in an output schema.</li>
+ <li><code>DROPMALFORMED</code>: ignores the whole corrupted records.</li>
+ <li><code>FAILFAST</code>: throws an exception when it meets corrupted records.</li>
+ </ul>
+ </td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>columnNameOfCorruptRecord</code></td>
+ <td>None</td>
+ <td>Allows renaming the new field having malformed string created by <code>PERMISSIVE</code> mode. This overrides spark.sql.columnNameOfCorruptRecord. If None is set, it uses the value specified in <code>spark.sql.columnNameOfCorruptRecord</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dateFormat</code></td>
+ <td>None</td>
+ <td>Sets the string that indicates a date format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to date type. If None is set, it uses the default value, <code>yyyy-MM-dd</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>timestampFormat</code></td>
+ <td>None</td>
+ <td>Sets the string that indicates a timestamp format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to timestamp type. If None is set, it uses the default value, <code>yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>multiLine</code></td>
+ <td>None</td>
+ <td>Parse one record, which may span multiple lines, per file. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedControlChars</code></td>
+ <td>None</td>
+ <td>Allows JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) or not.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
+ <td>None</td>
+ <td>For reading, allows to forcibly set one of standard basic or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If None is set, the encoding of input JSON will be detected automatically when the multiLine option is set to <code>true</code>. For writing, Specifies encoding (charset) of saved json files. If None is set, the default UTF-8 charset will be used.</td>
Review comment:
Also fix the docs properly from `None` to something else. That only applies to Python side.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843120435
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43199/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840913159
Thanks, @HyukjinKwon .
I checked one by one, and seems like the general options are already documentd to the https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html. I think the parameters I removed are all of JSON specific options ??
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822161426
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840318050
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43012/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-821024116
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137474/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841159281
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138551/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843131573
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43202/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842385801
**[Test build #138636 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138636/testReport)** for PR 32204 at commit [`6ea843a`](https://github.com/apache/spark/commit/6ea843ae13b7489b580dbffdc2ff66927c305c8b).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842554341
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138636/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843072997
**[Test build #138681 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138681/testReport)** for PR 32204 at commit [`3316616`](https://github.com/apache/spark/commit/3316616593f72196fc98b6dc13bb6e19110207ca).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840934265
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43050/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r632177276
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -1196,39 +1097,13 @@ def json(self, path, mode=None, compression=None, dateFormat=None, timestampForm
----------
path : str
the path in any Hadoop supported file system
- mode : str, optional
Review comment:
yeah, so I documented this to the JSON data source options table, and removed here.
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -504,105 +504,15 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
path : str
string represents path to the JSON dataset,
or RDD of Strings storing JSON objects.
- schema : :class:`pyspark.sql.types.StructType` or str, optional
Review comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843105567
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43202/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841037057
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43070/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843139794
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822151683
**[Test build #137551 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137551/testReport)** for PR 32204 at commit [`c31c6f0`](https://github.com/apache/spark/commit/c31c6f07db757ed3cb44e0b142f544c499f82a7d).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845798560
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43306/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841040366
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43070/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840930479
Kubernetes integration test unable to build dist.
exiting with code: 1
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43050/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843245078
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138678/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842878723
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43186/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842553101
**[Test build #138636 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138636/testReport)** for PR 32204 at commit [`6ea843a`](https://github.com/apache/spark/commit/6ea843ae13b7489b580dbffdc2ff66927c305c8b).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840916300
**[Test build #138529 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138529/testReport)** for PR 32204 at commit [`2b6b066`](https://github.com/apache/spark/commit/2b6b066de16a3820cb89de21f31ffbe1b08e66e8).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845028984
**[Test build #138753 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138753/testReport)** for PR 32204 at commit [`e3bf606`](https://github.com/apache/spark/commit/e3bf606fb51a26e48445974913e129027c1d6548).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r631576139
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -504,105 +504,15 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
path : str
string represents path to the JSON dataset,
or RDD of Strings storing JSON objects.
- schema : :class:`pyspark.sql.types.StructType` or str, optional
Review comment:
I don't think this is a general option
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822302956
**[Test build #137551 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137551/testReport)** for PR 32204 at commit [`c31c6f0`](https://github.com/apache/spark/commit/c31c6f07db757ed3cb44e0b142f544c499f82a7d).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-821024097
**[Test build #137474 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137474/testReport)** for PR 32204 at commit [`89d9be1`](https://github.com/apache/spark/commit/89d9be177539d307ef008c42c7245e90effec7e1).
* This patch **fails Python style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842821977
**[Test build #138665 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138665/testReport)** for PR 32204 at commit [`52b6ba8`](https://github.com/apache/spark/commit/52b6ba8994747ec6132bb2cb40307cdf09aaa88f).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r632177319
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -504,105 +504,15 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
path : str
string represents path to the JSON dataset,
or RDD of Strings storing JSON objects.
- schema : :class:`pyspark.sql.types.StructType` or str, optional
Review comment:
ditto. I documented this to the "Data Source Options" table in JSON Files page, and removed here.

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-844935046
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43263/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635791028
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -110,18 +110,6 @@ def option(self, key, value):
"""Adds an input option for the underlying data source.
You can set the following option(s) for reading files:
- * ``timeZone``: sets the string that indicates a time zone ID to be used to parse
- timestamps in the JSON/CSV datasources or partition values. The following
- formats of `timeZone` are supported:
-
- * Region-based zone ID: It should have the form 'area/city', such as \
- 'America/Los_Angeles'.
- * Zone offset: It should be in the format '(+|-)HH:mm', for example '-08:00' or \
- '+01:00'. Also 'UTC' and 'Z' are supported as aliases of '+00:00'.
-
- Other short names like 'CST' are not recommended to use because they can be
- ambiguous. If it isn't set, the current value of the SQL config
- ``spark.sql.session.timeZone`` is used by default.
* ``pathGlobFilter``: an optional glob pattern to only include files with paths matching
Review comment:
I can you can remove these too and link Generic options page
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842327538
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635906645
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,171 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
Review comment:
Thanks for the review, @gengliangwang .
Do you mean combine the 101 and 102 ??
such as
```
the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter` or `DataStreamReader` or `DataStreamWriter`
```
???
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-828919424
**[Test build #138063 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138063/testReport)** for PR 32204 at commit [`538b4cc`](https://github.com/apache/spark/commit/538b4cc75fb838665e0470b425c00066527199a1).
* This patch **fails Python style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-828918789
**[Test build #138063 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138063/testReport)** for PR 32204 at commit [`538b4cc`](https://github.com/apache/spark/commit/538b4cc75fb838665e0470b425c00066527199a1).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-828919440
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138063/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-837540657
**[Test build #138344 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138344/testReport)** for PR 32204 at commit [`cbecf61`](https://github.com/apache/spark/commit/cbecf615af28f371b3cd847438a861b8ce2e58ae).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843259281
**[Test build #138680 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138680/testReport)** for PR 32204 at commit [`3ac7c45`](https://github.com/apache/spark/commit/3ac7c454d7eb1ccc17bf8d4364f585d8ffb93198).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845144924
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843023049
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138665/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon edited a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840312271
@itholic:
1. Please check the option **one by one** and see if each exists.
2. Document general options in https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html if there are missing ones
3. If you're going to do 2. separately in another PR and JIRA, don't remove general options in API documentations for now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843283637
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822534430
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137597/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635792634
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -110,18 +110,6 @@ def option(self, key, value):
"""Adds an input option for the underlying data source.
You can set the following option(s) for reading files:
- * ``timeZone``: sets the string that indicates a time zone ID to be used to parse
- timestamps in the JSON/CSV datasources or partition values. The following
- formats of `timeZone` are supported:
-
- * Region-based zone ID: It should have the form 'area/city', such as \
- 'America/Los_Angeles'.
- * Zone offset: It should be in the format '(+|-)HH:mm', for example '-08:00' or \
- '+01:00'. Also 'UTC' and 'Z' are supported as aliases of '+00:00'.
-
- Other short names like 'CST' are not recommended to use because they can be
- ambiguous. If it isn't set, the current value of the SQL config
- ``spark.sql.session.timeZone`` is used by default.
* ``pathGlobFilter``: an optional glob pattern to only include files with paths matching
Review comment:
Let's just remove all for now since these are already documented in generic source options.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845028984
**[Test build #138753 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138753/testReport)** for PR 32204 at commit [`e3bf606`](https://github.com/apache/spark/commit/e3bf606fb51a26e48445974913e129027c1d6548).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842334470
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43152/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842554341
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138636/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r638686804
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,168 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of
+ * `DataFrameReader`
+ * `DataFrameWriter`
+ * `DataStreamReader`
+ * `DataStreamWriter`
Review comment:
Can you add JSON functions here too
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845899153
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138784/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842385801
**[Test build #138636 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138636/testReport)** for PR 32204 at commit [`6ea843a`](https://github.com/apache/spark/commit/6ea843ae13b7489b580dbffdc2ff66927c305c8b).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822165014
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42123/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-828933241
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42582/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r629803248
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -504,105 +504,13 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
path : str
string represents path to the JSON dataset,
or RDD of Strings storing JSON objects.
- schema : :class:`pyspark.sql.types.StructType` or str, optional
Review comment:
this doc doesn't exist anymore too. we should keep it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
gengliangwang commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635870655
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,171 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
Review comment:
Could you provide screenshot for this page as well?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842821977
**[Test build #138665 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138665/testReport)** for PR 32204 at commit [`52b6ba8`](https://github.com/apache/spark/commit/52b6ba8994747ec6132bb2cb40307cdf09aaa88f).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841016640
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138529/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822170412
**[Test build #137573 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137573/testReport)** for PR 32204 at commit [`89d9be1`](https://github.com/apache/spark/commit/89d9be177539d307ef008c42c7245e90effec7e1).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822148716
**[Test build #137548 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137548/testReport)** for PR 32204 at commit [`0a5412c`](https://github.com/apache/spark/commit/0a5412ce556fa69cbfbf669d53eb48add9d341e3).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845286972
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138753/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843103727
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43201/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841016640
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138529/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r633025358
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
Review comment:
Capitalize it
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635793237
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/DataFrameReader.scala
##########
@@ -441,81 +390,13 @@ class DataFrameReader private[sql](sparkSession: SparkSession) extends Logging {
* This function goes through the input once to determine the input schema. If you know the
* schema in advance, use the version that specifies the schema to avoid the extra scan.
*
- * You can set the following JSON-specific options to deal with non-standard JSON files:
- * <ul>
- * <li>`primitivesAsString` (default `false`): infers all primitive values as a string type</li>
- * <li>`prefersDecimal` (default `false`): infers all floating-point values as a decimal
- * type. If the values do not fit in decimal, then it infers them as doubles.</li>
- * <li>`allowComments` (default `false`): ignores Java/C++ style comment in JSON records</li>
- * <li>`allowUnquotedFieldNames` (default `false`): allows unquoted JSON field names</li>
- * <li>`allowSingleQuotes` (default `true`): allows single quotes in addition to double quotes
- * </li>
- * <li>`allowNumericLeadingZeros` (default `false`): allows leading zeros in numbers
- * (e.g. 00012)</li>
- * <li>`allowBackslashEscapingAnyCharacter` (default `false`): allows accepting quoting of all
- * character using backslash quoting mechanism</li>
- * <li>`allowUnquotedControlChars` (default `false`): allows JSON Strings to contain unquoted
- * control characters (ASCII characters with value less than 32, including tab and line feed
- * characters) or not.</li>
- * <li>`mode` (default `PERMISSIVE`): allows a mode for dealing with corrupt records
- * during parsing.
- * <ul>
- * <li>`PERMISSIVE` : when it meets a corrupted record, puts the malformed string into a
- * field configured by `columnNameOfCorruptRecord`, and sets malformed fields to `null`. To
- * keep corrupt records, an user can set a string type field named
- * `columnNameOfCorruptRecord` in an user-defined schema. If a schema does not have the
- * field, it drops corrupt records during parsing. When inferring a schema, it implicitly
- * adds a `columnNameOfCorruptRecord` field in an output schema.</li>
- * <li>`DROPMALFORMED` : ignores the whole corrupted records.</li>
- * <li>`FAILFAST` : throws an exception when it meets corrupted records.</li>
- * </ul>
- * </li>
- * <li>`columnNameOfCorruptRecord` (default is the value specified in
- * `spark.sql.columnNameOfCorruptRecord`): allows renaming the new field having malformed string
- * created by `PERMISSIVE` mode. This overrides `spark.sql.columnNameOfCorruptRecord`.</li>
- * <li>`dateFormat` (default `yyyy-MM-dd`): sets the string that indicates a date format.
- * Custom date formats follow the formats at
- * <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html">
- * Datetime Patterns</a>.
- * This applies to date type.</li>
- * <li>`timestampFormat` (default `yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]`): sets the string that
- * indicates a timestamp format. Custom date formats follow the formats at
- * <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html">
- * Datetime Patterns</a>.
- * This applies to timestamp type.</li>
- * <li>`multiLine` (default `false`): parse one record, which may span multiple lines,
- * per file</li>
- * <li>`encoding` (by default it is not set): allows to forcibly set one of standard basic
- * or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If the encoding
- * is not specified and `multiLine` is set to `true`, it will be detected automatically.</li>
- * <li>`lineSep` (default covers all `\r`, `\r\n` and `\n`): defines the line separator
- * that should be used for parsing.</li>
- * <li>`samplingRatio` (default is 1.0): defines fraction of input JSON objects used
- * for schema inferring.</li>
- * <li>`dropFieldIfAllNull` (default `false`): whether to ignore column of all null values or
- * empty array/struct during schema inference.</li>
- * <li>`locale` (default is `en-US`): sets a locale as language tag in IETF BCP 47 format.
- * For instance, this is used while parsing dates and timestamps.</li>
- * <li>`pathGlobFilter`: an optional glob pattern to only include files with paths matching
- * the pattern. The syntax follows <code>org.apache.hadoop.fs.GlobFilter</code>.
- * It does not change the behavior of partition discovery.</li>
- * <li>`modifiedBefore` (batch only): an optional timestamp to only include files with
- * modification times occurring before the specified Time. The provided timestamp
- * must be in the following form: YYYY-MM-DDTHH:mm:ss (e.g. 2020-06-01T13:00:00)</li>
- * <li>`modifiedAfter` (batch only): an optional timestamp to only include files with
- * modification times occurring after the specified Time. The provided timestamp
- * must be in the following form: YYYY-MM-DDTHH:mm:ss (e.g. 2020-06-01T13:00:00)</li>
- * <li>`recursiveFileLookup`: recursively scan a directory for files. Using this option
- * disables partition discovery</li>
- * <li>`allowNonNumericNumbers` (default `true`): allows JSON parser to recognize set of
- * "Not-a-Number" (NaN) tokens as legal floating number values:
- * <ul>
- * <li>`+INF` for positive infinity, as well as alias of `+Infinity` and `Infinity`.
- * <li>`-INF` for negative infinity), alias `-Infinity`.
- * <li>`NaN` for other not-a-numbers, like result of division by zero.
- * </ul>
- * </li>
- * </ul>
+ * You can find the JSON-specific options for reading JSON files in
Review comment:
ditto. It says JSON specific options but it mentions "Generic Files Source Options"
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-821024116
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137474/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822305152
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137551/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845088029
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43275/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r636575493
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -507,102 +479,15 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
schema : :class:`pyspark.sql.types.StructType` or str, optional
an optional :class:`pyspark.sql.types.StructType` for the input schema
or a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
- mode : str, optional
- allows a mode for dealing with corrupt records during parsing. If None is
- set, it uses the default value, ``PERMISSIVE``.
-
- * ``PERMISSIVE``: when it meets a corrupted record, puts the malformed string \
- into a field configured by ``columnNameOfCorruptRecord``, and sets malformed \
- fields to ``null``. To keep corrupt records, an user can set a string type \
- field named ``columnNameOfCorruptRecord`` in an user-defined schema. If a \
- schema does not have the field, it drops corrupt records during parsing. \
- When inferring a schema, it implicitly adds a ``columnNameOfCorruptRecord`` \
- field in an output schema.
- * ``DROPMALFORMED``: ignores the whole corrupted records.
- * ``FAILFAST``: throws an exception when it meets corrupted records.
-
- columnNameOfCorruptRecord : str, optional
- allows renaming the new field having malformed string
- created by ``PERMISSIVE`` mode. This overrides
- ``spark.sql.columnNameOfCorruptRecord``. If None is set,
- it uses the value specified in
- ``spark.sql.columnNameOfCorruptRecord``.
- dateFormat : str, optional
- sets the string that indicates a date format. Custom date formats
- follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to date type. If None is set, it uses the
- default value, ``yyyy-MM-dd``.
- timestampFormat : str, optional
- sets the string that indicates a timestamp format.
- Custom date formats follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to timestamp type. If None is set, it uses the
- default value, ``yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]``.
- multiLine : str or bool, optional
- parse one record, which may span multiple lines, per file. If None is
- set, it uses the default value, ``false``.
- allowUnquotedControlChars : str or bool, optional
- allows JSON Strings to contain unquoted control
- characters (ASCII characters with value less than 32,
- including tab and line feed characters) or not.
- lineSep : str, optional
- defines the line separator that should be used for parsing. If None is
- set, it covers all ``\\r``, ``\\r\\n`` and ``\\n``.
- locale : str, optional
- sets a locale as language tag in IETF BCP 47 format. If None is set,
- it uses the default value, ``en-US``. For instance, ``locale`` is used while
- parsing dates and timestamps.
- dropFieldIfAllNull : str or bool, optional
- whether to ignore column of all null values or empty
- array/struct during schema inference. If None is set, it
- uses the default value, ``false``.
- encoding : str or bool, optional
- allows to forcibly set one of standard basic or extended encoding for
- the JSON files. For example UTF-16BE, UTF-32LE. If None is set,
- the encoding of input JSON will be detected automatically
- when the multiLine option is set to ``true``.
- pathGlobFilter : str or bool, optional
- an optional glob pattern to only include files with paths matching
- the pattern. The syntax follows `org.apache.hadoop.fs.GlobFilter`.
- It does not change the behavior of
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- recursiveFileLookup : str or bool, optional
- recursively scan a directory for files. Using this option
- disables
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- allowNonNumericNumbers : str or bool, optional
- allows JSON parser to recognize set of "Not-a-Number" (NaN)
- tokens as legal floating number values. If None is set,
- it uses the default value, ``true``.
- * ``+INF``: for positive infinity, as well as alias of
- ``+Infinity`` and ``Infinity``.
- * ``-INF``: for negative infinity, alias ``-Infinity``.
- * ``NaN``: for other not-a-numbers, like result of division by zero.
+ Other Parameters
+ ----------------
+ Extra options (keyword argument)
Review comment:
I'll remove this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r633025492
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -236,33 +236,9 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
schema : :class:`pyspark.sql.types.StructType` or str, optional
an optional :class:`pyspark.sql.types.StructType` for the input schema or
a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
mode : str, optional
Review comment:
This mode is an option. `mode` in write is not an option.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-837543153
**[Test build #138344 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138344/testReport)** for PR 32204 at commit [`cbecf61`](https://github.com/apache/spark/commit/cbecf615af28f371b3cd847438a861b8ce2e58ae).
* This patch **fails Python style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r632177319
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -504,105 +504,15 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
path : str
string represents path to the JSON dataset,
or RDD of Strings storing JSON objects.
- schema : :class:`pyspark.sql.types.StructType` or str, optional
Review comment:
ditto. so I documented this to the JSON data source options table, and removed here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822151683
**[Test build #137551 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137551/testReport)** for PR 32204 at commit [`c31c6f0`](https://github.com/apache/spark/commit/c31c6f07db757ed3cb44e0b142f544c499f82a7d).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822149406
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137548/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-828919440
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138063/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845596372
**[Test build #138778 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138778/testReport)** for PR 32204 at commit [`2379a6d`](https://github.com/apache/spark/commit/2379a6d21370d6165c7f2d1f1cd9aa1168d603f3).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822170412
**[Test build #137573 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137573/testReport)** for PR 32204 at commit [`89d9be1`](https://github.com/apache/spark/commit/89d9be177539d307ef008c42c7245e90effec7e1).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822167378
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42126/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-837591889
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42866/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-844886889
**[Test build #138741 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138741/testReport)** for PR 32204 at commit [`f4d9843`](https://github.com/apache/spark/commit/f4d9843145fdb6709caf466efba314c8db0db2d1).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843072997
**[Test build #138681 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138681/testReport)** for PR 32204 at commit [`3316616`](https://github.com/apache/spark/commit/3316616593f72196fc98b6dc13bb6e19110207ca).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840291088
**[Test build #138492 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138492/testReport)** for PR 32204 at commit [`a386788`](https://github.com/apache/spark/commit/a386788b44fb5255d2784ce423e3f879ba97f53c).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842896222
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43186/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-844935046
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43263/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
github-actions[bot] commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-821000334
**[Test build #754872701](https://github.com/itholic/spark/actions/runs/754872701)** for PR 32204 at commit [`89d9be1`](https://github.com/itholic/spark/commit/89d9be177539d307ef008c42c7245e90effec7e1).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840436292
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138492/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845867967
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138778/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-828918789
**[Test build #138063 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138063/testReport)** for PR 32204 at commit [`538b4cc`](https://github.com/apache/spark/commit/538b4cc75fb838665e0470b425c00066527199a1).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842295623
**[Test build #138633 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138633/testReport)** for PR 32204 at commit [`cd9f103`](https://github.com/apache/spark/commit/cd9f103683deb5c5d722dbddf9f6c9505336f8bd).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-844935022
Kubernetes integration test unable to build dist.
exiting with code: 1
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43263/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r629803050
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -233,114 +233,13 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
path : str, list or :class:`RDD`
string represents path to the JSON dataset, or a list of paths,
or RDD of Strings storing JSON objects.
- schema : :class:`pyspark.sql.types.StructType` or str, optional
- an optional :class:`pyspark.sql.types.StructType` for the input schema or
- a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
- mode : str, optional
- allows a mode for dealing with corrupt records during parsing. If None is
- set, it uses the default value, ``PERMISSIVE``.
-
- * ``PERMISSIVE``: when it meets a corrupted record, puts the malformed string \
- into a field configured by ``columnNameOfCorruptRecord``, and sets malformed \
- fields to ``null``. To keep corrupt records, an user can set a string type \
- field named ``columnNameOfCorruptRecord`` in an user-defined schema. If a \
- schema does not have the field, it drops corrupt records during parsing. \
- When inferring a schema, it implicitly adds a ``columnNameOfCorruptRecord`` \
- field in an output schema.
- * ``DROPMALFORMED``: ignores the whole corrupted records.
- * ``FAILFAST``: throws an exception when it meets corrupted records.
- columnNameOfCorruptRecord: str, optional
- allows renaming the new field having malformed string
- created by ``PERMISSIVE`` mode. This overrides
- ``spark.sql.columnNameOfCorruptRecord``. If None is set,
- it uses the value specified in
- ``spark.sql.columnNameOfCorruptRecord``.
- dateFormat : str, optional
- sets the string that indicates a date format. Custom date formats
- follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to date type. If None is set, it uses the
- default value, ``yyyy-MM-dd``.
- timestampFormat : str, optional
- sets the string that indicates a timestamp format.
- Custom date formats follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to timestamp type. If None is set, it uses the
- default value, ``yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]``.
- multiLine : str or bool, optional
- parse one record, which may span multiple lines, per file. If None is
- set, it uses the default value, ``false``.
- allowUnquotedControlChars : str or bool, optional
- allows JSON Strings to contain unquoted control
- characters (ASCII characters with value less than 32,
- including tab and line feed characters) or not.
- encoding : str or bool, optional
- allows to forcibly set one of standard basic or extended encoding for
- the JSON files. For example UTF-16BE, UTF-32LE. If None is set,
- the encoding of input JSON will be detected automatically
- when the multiLine option is set to ``true``.
- lineSep : str, optional
- defines the line separator that should be used for parsing. If None is
- set, it covers all ``\\r``, ``\\r\\n`` and ``\\n``.
- samplingRatio : str or float, optional
- defines fraction of input JSON objects used for schema inferring.
- If None is set, it uses the default value, ``1.0``.
- dropFieldIfAllNull : str or bool, optional
- whether to ignore column of all null values or empty
- array/struct during schema inference. If None is set, it
- uses the default value, ``false``.
- locale : str, optional
- sets a locale as language tag in IETF BCP 47 format. If None is set,
- it uses the default value, ``en-US``. For instance, ``locale`` is used while
- parsing dates and timestamps.
- pathGlobFilter : str or bool, optional
Review comment:
the doc for this doesn't exist anymore. also `pathGlobFilter` isn't json specific option so you will have to keep it for now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843070572
**[Test build #138680 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138680/testReport)** for PR 32204 at commit [`3ac7c45`](https://github.com/apache/spark/commit/3ac7c454d7eb1ccc17bf8d4364f585d8ffb93198).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-828933241
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42582/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841017158
**[Test build #138551 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138551/testReport)** for PR 32204 at commit [`8b48e6f`](https://github.com/apache/spark/commit/8b48e6fee602ce1df5345c677b81bf731b8a05ee).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r636570482
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -507,102 +479,15 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
schema : :class:`pyspark.sql.types.StructType` or str, optional
an optional :class:`pyspark.sql.types.StructType` for the input schema
or a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
- mode : str, optional
- allows a mode for dealing with corrupt records during parsing. If None is
- set, it uses the default value, ``PERMISSIVE``.
-
- * ``PERMISSIVE``: when it meets a corrupted record, puts the malformed string \
- into a field configured by ``columnNameOfCorruptRecord``, and sets malformed \
- fields to ``null``. To keep corrupt records, an user can set a string type \
- field named ``columnNameOfCorruptRecord`` in an user-defined schema. If a \
- schema does not have the field, it drops corrupt records during parsing. \
- When inferring a schema, it implicitly adds a ``columnNameOfCorruptRecord`` \
- field in an output schema.
- * ``DROPMALFORMED``: ignores the whole corrupted records.
- * ``FAILFAST``: throws an exception when it meets corrupted records.
-
- columnNameOfCorruptRecord : str, optional
- allows renaming the new field having malformed string
- created by ``PERMISSIVE`` mode. This overrides
- ``spark.sql.columnNameOfCorruptRecord``. If None is set,
- it uses the value specified in
- ``spark.sql.columnNameOfCorruptRecord``.
- dateFormat : str, optional
- sets the string that indicates a date format. Custom date formats
- follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to date type. If None is set, it uses the
- default value, ``yyyy-MM-dd``.
- timestampFormat : str, optional
- sets the string that indicates a timestamp format.
- Custom date formats follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to timestamp type. If None is set, it uses the
- default value, ``yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]``.
- multiLine : str or bool, optional
- parse one record, which may span multiple lines, per file. If None is
- set, it uses the default value, ``false``.
- allowUnquotedControlChars : str or bool, optional
- allows JSON Strings to contain unquoted control
- characters (ASCII characters with value less than 32,
- including tab and line feed characters) or not.
- lineSep : str, optional
- defines the line separator that should be used for parsing. If None is
- set, it covers all ``\\r``, ``\\r\\n`` and ``\\n``.
- locale : str, optional
- sets a locale as language tag in IETF BCP 47 format. If None is set,
- it uses the default value, ``en-US``. For instance, ``locale`` is used while
- parsing dates and timestamps.
- dropFieldIfAllNull : str or bool, optional
- whether to ignore column of all null values or empty
- array/struct during schema inference. If None is set, it
- uses the default value, ``false``.
- encoding : str or bool, optional
- allows to forcibly set one of standard basic or extended encoding for
- the JSON files. For example UTF-16BE, UTF-32LE. If None is set,
- the encoding of input JSON will be detected automatically
- when the multiLine option is set to ``true``.
- pathGlobFilter : str or bool, optional
- an optional glob pattern to only include files with paths matching
- the pattern. The syntax follows `org.apache.hadoop.fs.GlobFilter`.
- It does not change the behavior of
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- recursiveFileLookup : str or bool, optional
- recursively scan a directory for files. Using this option
- disables
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- allowNonNumericNumbers : str or bool, optional
- allows JSON parser to recognize set of "Not-a-Number" (NaN)
- tokens as legal floating number values. If None is set,
- it uses the default value, ``true``.
- * ``+INF``: for positive infinity, as well as alias of
- ``+Infinity`` and ``Infinity``.
- * ``-INF``: for negative infinity, alias ``-Infinity``.
- * ``NaN``: for other not-a-numbers, like result of division by zero.
+ Other Parameters
+ ----------------
+ Extra options (keyword argument)
Review comment:
Why does it have "(keyword argument)" alone?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843243485
**[Test build #138678 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138678/testReport)** for PR 32204 at commit [`b7171f2`](https://github.com/apache/spark/commit/b7171f2348db967bcefbb5efa7400deab15f5f23).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842859104
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43186/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845629104
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43302/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845634702
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43302/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845127534
**[Test build #138741 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138741/testReport)** for PR 32204 at commit [`f4d9843`](https://github.com/apache/spark/commit/f4d9843145fdb6709caf466efba314c8db0db2d1).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840436292
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138492/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843023049
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138665/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r636008760
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,171 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
Review comment:
> yes, or we can itemize them:
> the `.option`/`.options` methods of
>
> * DataFrameReader
> * DataFrameWriter
> * ...
Sounds good!!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822340184
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137573/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840339404
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43012/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822340184
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137573/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842896222
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43186/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845262061
**[Test build #138753 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138753/testReport)** for PR 32204 at commit [`e3bf606`](https://github.com/apache/spark/commit/e3bf606fb51a26e48445974913e129027c1d6548).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-821055819
Kubernetes integration test unable to build dist.
exiting with code: 1
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/42050/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r638678641
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,168 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of
+ * `DataFrameReader`
+ * `DataFrameWriter`
+ * `DataStreamReader`
+ * `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <!-- TODO(SPARK-35433): Add timeZone to Data Source Option for CSV, too. -->
+ <td><code>timeZone</code></td>
+ <td>None</td>
+ <td>Sets the string that indicates a time zone ID to be used to format timestamps in the JSON datasources or partition values. The following formats of <code>timeZone</code> are supported:<br>
+ <ul>
+ <li>Region-based zone ID: It should have the form 'area/city', such as 'America/Los_Angeles'.</li>
+ <li>Zone offset: It should be in the format '(+|-)HH:mm', for example '-08:00' or '+01:00'. Also 'UTC' and 'Z' are supported as aliases of '+00:00'.</li>
+ </ul>
+ Other short names like 'CST' are not recommended to use because they can be ambiguous. If it isn't set, the current value of the SQL config <code>spark.sql.session.timeZone</code> is used by default.
+ </td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>Infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>prefersDecimal</code></td>
+ <td>None</td>
+ <td>Infers all floating-point values as a decimal type. If the values do not fit in decimal, then it infers them as doubles. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowComments</code></td>
+ <td>None</td>
+ <td>Ignores Java/C++ style comment in JSON records. If None is set, it uses the default value, <code>false</code></td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedFieldNames</code></td>
+ <td>None</td>
+ <td>Allows unquoted JSON field names. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowSingleQuotes</code></td>
+ <td>None</td>
+ <td>Allows single quotes in addition to double quotes. If None is set, it uses the default value, <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNumericLeadingZero</code></td>
+ <td>None</td>
+ <td>Allows leading zeros in numbers (e.g. 00012). If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowBackslashEscapingAnyCharacter</code></td>
+ <td>None</td>
+ <td>Allows accepting quoting of all character using backslash quoting mechanism. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>mode</code></td>
+ <td>None</td>
+ <td>Allows a mode for dealing with corrupt records during parsing. If None is set, it uses the default value, <code>PERMISSIVE</code><br>
+ <ul>
+ <li><code>PERMISSIVE</code>: when it meets a corrupted record, puts the malformed string into a field configured by <code>columnNameOfCorruptRecord</code>, and sets malformed fields to <code>null</code>. To keep corrupt records, an user can set a string type field named <code>columnNameOfCorruptRecord</code> in an user-defined schema. If a schema does not have the field, it drops corrupt records during parsing. When inferring a schema, it implicitly adds a <code>columnNameOfCorruptRecord</code> field in an output schema.</li>
+ <li><code>DROPMALFORMED</code>: ignores the whole corrupted records.</li>
+ <li><code>FAILFAST</code>: throws an exception when it meets corrupted records.</li>
+ </ul>
+ </td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>columnNameOfCorruptRecord</code></td>
+ <td>None</td>
+ <td>Allows renaming the new field having malformed string created by <code>PERMISSIVE</code> mode. This overrides spark.sql.columnNameOfCorruptRecord. If None is set, it uses the value specified in <code>spark.sql.columnNameOfCorruptRecord</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dateFormat</code></td>
+ <td>None</td>
+ <td>Sets the string that indicates a date format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to date type. If None is set, it uses the default value, <code>yyyy-MM-dd</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>timestampFormat</code></td>
+ <td>None</td>
+ <td>Sets the string that indicates a timestamp format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to timestamp type. If None is set, it uses the default value, <code>yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>multiLine</code></td>
+ <td>None</td>
+ <td>Parse one record, which may span multiple lines, per file. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedControlChars</code></td>
+ <td>None</td>
+ <td>Allows JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) or not.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
+ <td>None</td>
+ <td>For reading, allows to forcibly set one of standard basic or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If None is set, the encoding of input JSON will be detected automatically when the multiLine option is set to <code>true</code>. For writing, Specifies encoding (charset) of saved json files. If None is set, the default UTF-8 charset will be used.</td>
Review comment:
It's for both read and write
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-821022487
**[Test build #137474 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137474/testReport)** for PR 32204 at commit [`89d9be1`](https://github.com/apache/spark/commit/89d9be177539d307ef008c42c7245e90effec7e1).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843064865
**[Test build #138678 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138678/testReport)** for PR 32204 at commit [`b7171f2`](https://github.com/apache/spark/commit/b7171f2348db967bcefbb5efa7400deab15f5f23).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842295623
**[Test build #138633 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138633/testReport)** for PR 32204 at commit [`cd9f103`](https://github.com/apache/spark/commit/cd9f103683deb5c5d722dbddf9f6c9505336f8bd).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822298400
**[Test build #137597 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137597/testReport)** for PR 32204 at commit [`c31c6f0`](https://github.com/apache/spark/commit/c31c6f07db757ed3cb44e0b142f544c499f82a7d).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845634702
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43302/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r633025337
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>prefersDecimal</code></td>
+ <td>None</td>
+ <td>infers all floating-point values as a decimal type. If the values do not fit in decimal, then it infers them as doubles. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowComments</code></td>
+ <td>None</td>
+ <td>ignores Java/C++ style comment in JSON records. If None is set, it uses the default value, <code>false</code></td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedFieldNames</code></td>
+ <td>None</td>
+ <td>allows unquoted JSON field names. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowSingleQuotes</code></td>
+ <td>None</td>
+ <td>allows single quotes in addition to double quotes. If None is set, it uses the default value, <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNumericLeadingZero</code></td>
+ <td>None</td>
+ <td>allows leading zeros in numbers (e.g. 00012). If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowBackslashEscapingAnyCharacter</code></td>
+ <td>None</td>
+ <td>allows accepting quoting of all character using backslash quoting mechanism. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>columnNameOfCorruptRecord</code></td>
+ <td>None</td>
+ <td>allows renaming the new field having malformed string created by <code>PERMISSIVE</code> mode. This overrides spark.sql.columnNameOfCorruptRecord. If None is set, it uses the value specified in <code>spark.sql.columnNameOfCorruptRecord</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dateFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a date format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to date type. If None is set, it uses the default value, <code>yyyy-MM-dd</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>timestampFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a timestamp format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to timestamp type. If None is set, it uses the default value, <code>yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>multiLine</code></td>
+ <td>None</td>
+ <td>parse one record, which may span multiple lines, per file. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedControlChars</code></td>
+ <td>None</td>
+ <td>allows JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) or not.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
+ <td>None</td>
+ <td>allows to forcibly set one of standard basic or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If None is set, the encoding of input JSON will be detected automatically when the multiLine option is set to <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>lineSep</code></td>
+ <td>None</td>
+ <td>defines the line separator that should be used for parsing. If None is set, it covers all <code>\r</code>, <code>\r\n</code> and <code>\n</code>.</td>
+ <td>read</td>
Review comment:
read/write
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-844886889
**[Test build #138741 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138741/testReport)** for PR 32204 at commit [`f4d9843`](https://github.com/apache/spark/commit/f4d9843145fdb6709caf466efba314c8db0db2d1).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r629756911
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -209,14 +209,7 @@ def load(self, path=None, format=None, schema=None, **options):
else:
return self._df(self._jreader.load())
- def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
- allowComments=None, allowUnquotedFieldNames=None, allowSingleQuotes=None,
- allowNumericLeadingZero=None, allowBackslashEscapingAnyCharacter=None,
- mode=None, columnNameOfCorruptRecord=None, dateFormat=None, timestampFormat=None,
- multiLine=None, allowUnquotedControlChars=None, lineSep=None, samplingRatio=None,
- dropFieldIfAllNull=None, encoding=None, locale=None, pathGlobFilter=None,
- recursiveFileLookup=None, allowNonNumericNumbers=None,
- modifiedBefore=None, modifiedAfter=None):
+ def json(self, path):
Review comment:
Just reverted the changes. Thanks, @HyukjinKwon !
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842295623
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r638688806
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,168 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of
+ * `DataFrameReader`
+ * `DataFrameWriter`
+ * `DataStreamReader`
+ * `DataStreamWriter`
Review comment:
also mention:
```
* `OPTIONS` clause at [CREATE TABLE USING DATA_SOURCE](sql-ref-syntax-ddl-create-table-datasource.html)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r631553255
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -504,105 +504,13 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
path : str
string represents path to the JSON dataset,
or RDD of Strings storing JSON objects.
- schema : :class:`pyspark.sql.types.StructType` or str, optional
Review comment:
I added it to Data Source Options table!
<img width="806" alt="Screen Shot 2021-05-13 at 1 30 11 PM" src="https://user-images.githubusercontent.com/44108233/118077601-62bc5f00-b3ef-11eb-9350-c62b370e167c.png">
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon edited a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-844738326
@gengliangwang, @HeartSaVioR, @WeichenXu123 would you mind taking a look too please when you find some times? It touches some docs of the options you added.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845120837
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43275/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845803959
Merged to master.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843283637
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843096567
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43199/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822329343
**[Test build #137573 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137573/testReport)** for PR 32204 at commit [`89d9be1`](https://github.com/apache/spark/commit/89d9be177539d307ef008c42c7245e90effec7e1).
* This patch **fails PySpark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822534430
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137597/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845798560
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43306/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r638678641
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,168 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of
+ * `DataFrameReader`
+ * `DataFrameWriter`
+ * `DataStreamReader`
+ * `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <!-- TODO(SPARK-35433): Add timeZone to Data Source Option for CSV, too. -->
+ <td><code>timeZone</code></td>
+ <td>None</td>
+ <td>Sets the string that indicates a time zone ID to be used to format timestamps in the JSON datasources or partition values. The following formats of <code>timeZone</code> are supported:<br>
+ <ul>
+ <li>Region-based zone ID: It should have the form 'area/city', such as 'America/Los_Angeles'.</li>
+ <li>Zone offset: It should be in the format '(+|-)HH:mm', for example '-08:00' or '+01:00'. Also 'UTC' and 'Z' are supported as aliases of '+00:00'.</li>
+ </ul>
+ Other short names like 'CST' are not recommended to use because they can be ambiguous. If it isn't set, the current value of the SQL config <code>spark.sql.session.timeZone</code> is used by default.
+ </td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>Infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>prefersDecimal</code></td>
+ <td>None</td>
+ <td>Infers all floating-point values as a decimal type. If the values do not fit in decimal, then it infers them as doubles. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowComments</code></td>
+ <td>None</td>
+ <td>Ignores Java/C++ style comment in JSON records. If None is set, it uses the default value, <code>false</code></td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedFieldNames</code></td>
+ <td>None</td>
+ <td>Allows unquoted JSON field names. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowSingleQuotes</code></td>
+ <td>None</td>
+ <td>Allows single quotes in addition to double quotes. If None is set, it uses the default value, <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNumericLeadingZero</code></td>
+ <td>None</td>
+ <td>Allows leading zeros in numbers (e.g. 00012). If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowBackslashEscapingAnyCharacter</code></td>
+ <td>None</td>
+ <td>Allows accepting quoting of all character using backslash quoting mechanism. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>mode</code></td>
+ <td>None</td>
+ <td>Allows a mode for dealing with corrupt records during parsing. If None is set, it uses the default value, <code>PERMISSIVE</code><br>
+ <ul>
+ <li><code>PERMISSIVE</code>: when it meets a corrupted record, puts the malformed string into a field configured by <code>columnNameOfCorruptRecord</code>, and sets malformed fields to <code>null</code>. To keep corrupt records, an user can set a string type field named <code>columnNameOfCorruptRecord</code> in an user-defined schema. If a schema does not have the field, it drops corrupt records during parsing. When inferring a schema, it implicitly adds a <code>columnNameOfCorruptRecord</code> field in an output schema.</li>
+ <li><code>DROPMALFORMED</code>: ignores the whole corrupted records.</li>
+ <li><code>FAILFAST</code>: throws an exception when it meets corrupted records.</li>
+ </ul>
+ </td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>columnNameOfCorruptRecord</code></td>
+ <td>None</td>
+ <td>Allows renaming the new field having malformed string created by <code>PERMISSIVE</code> mode. This overrides spark.sql.columnNameOfCorruptRecord. If None is set, it uses the value specified in <code>spark.sql.columnNameOfCorruptRecord</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dateFormat</code></td>
+ <td>None</td>
+ <td>Sets the string that indicates a date format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to date type. If None is set, it uses the default value, <code>yyyy-MM-dd</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>timestampFormat</code></td>
+ <td>None</td>
+ <td>Sets the string that indicates a timestamp format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to timestamp type. If None is set, it uses the default value, <code>yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>multiLine</code></td>
+ <td>None</td>
+ <td>Parse one record, which may span multiple lines, per file. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedControlChars</code></td>
+ <td>None</td>
+ <td>Allows JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) or not.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
+ <td>None</td>
+ <td>For reading, allows to forcibly set one of standard basic or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If None is set, the encoding of input JSON will be detected automatically when the multiLine option is set to <code>true</code>. For writing, Specifies encoding (charset) of saved json files. If None is set, the default UTF-8 charset will be used.</td>
Review comment:
For reading? It's for both read and write
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842334470
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845867967
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138778/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-821056642
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42050/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635976346
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/streaming/DataStreamReader.scala
##########
@@ -269,73 +218,20 @@ final class DataStreamReader private[sql](sparkSession: SparkSession) extends Lo
* This function goes through the input once to determine the input schema. If you know the
* schema in advance, use the version that specifies the schema to avoid the extra scan.
*
- * You can set the following JSON-specific options to deal with non-standard JSON files:
+ * You can set the following structured streaming option(s):
* <ul>
* <li>`maxFilesPerTrigger` (default: no max limit): sets the maximum number of new files to be
* considered in every trigger.</li>
- * <li>`primitivesAsString` (default `false`): infers all primitive values as a string type</li>
- * <li>`prefersDecimal` (default `false`): infers all floating-point values as a decimal
- * type. If the values do not fit in decimal, then it infers them as doubles.</li>
- * <li>`allowComments` (default `false`): ignores Java/C++ style comment in JSON records</li>
- * <li>`allowUnquotedFieldNames` (default `false`): allows unquoted JSON field names</li>
- * <li>`allowSingleQuotes` (default `true`): allows single quotes in addition to double quotes
- * </li>
- * <li>`allowNumericLeadingZeros` (default `false`): allows leading zeros in numbers
- * (e.g. 00012)</li>
- * <li>`allowBackslashEscapingAnyCharacter` (default `false`): allows accepting quoting of all
- * character using backslash quoting mechanism</li>
- * <li>`allowUnquotedControlChars` (default `false`): allows JSON Strings to contain unquoted
- * control characters (ASCII characters with value less than 32, including tab and line feed
- * characters) or not.</li>
- * <li>`mode` (default `PERMISSIVE`): allows a mode for dealing with corrupt records
- * during parsing.
- * <ul>
- * <li>`PERMISSIVE` : when it meets a corrupted record, puts the malformed string into a
- * field configured by `columnNameOfCorruptRecord`, and sets malformed fields to `null`. To
- * keep corrupt records, an user can set a string type field named
- * `columnNameOfCorruptRecord` in an user-defined schema. If a schema does not have the
- * field, it drops corrupt records during parsing. When inferring a schema, it implicitly
- * adds a `columnNameOfCorruptRecord` field in an output schema.</li>
- * <li>`DROPMALFORMED` : ignores the whole corrupted records.</li>
- * <li>`FAILFAST` : throws an exception when it meets corrupted records.</li>
- * </ul>
- * </li>
- * <li>`columnNameOfCorruptRecord` (default is the value specified in
- * `spark.sql.columnNameOfCorruptRecord`): allows renaming the new field having malformed string
- * created by `PERMISSIVE` mode. This overrides `spark.sql.columnNameOfCorruptRecord`.</li>
- * <li>`dateFormat` (default `yyyy-MM-dd`): sets the string that indicates a date format.
- * Custom date formats follow the formats at
- * <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html">
- * Datetime Patterns</a>.
- * This applies to date type.</li>
- * <li>`timestampFormat` (default `yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]`): sets the string that
- * indicates a timestamp format. Custom date formats follow the formats at
- * <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html">
- * Datetime Patterns</a>.
- * This applies to timestamp type.</li>
- * <li>`multiLine` (default `false`): parse one record, which may span multiple lines,
- * per file</li>
- * <li>`lineSep` (default covers all `\r`, `\r\n` and `\n`): defines the line separator
- * that should be used for parsing.</li>
- * <li>`dropFieldIfAllNull` (default `false`): whether to ignore column of all null values or
- * empty array/struct during schema inference.</li>
- * <li>`locale` (default is `en-US`): sets a locale as language tag in IETF BCP 47 format.
- * For instance, this is used while parsing dates and timestamps.</li>
- * <li>`pathGlobFilter`: an optional glob pattern to only include files with paths matching
- * the pattern. The syntax follows <code>org.apache.hadoop.fs.GlobFilter</code>.
- * It does not change the behavior of partition discovery.</li>
- * <li>`recursiveFileLookup`: recursively scan a directory for files. Using this option
- * disables partition discovery</li>
- * <li>`allowNonNumericNumbers` (default `true`): allows JSON parser to recognize set of
- * "Not-a-Number" (NaN) tokens as legal floating number values:
- * <ul>
- * <li>`+INF` for positive infinity, as well as alias of `+Infinity` and `Infinity`.
- * <li>`-INF` for negative infinity, alias `-Infinity`.
- * <li>`NaN` for other not-a-numbers, like result of division by zero.
- * </ul>
- * </li>
* </ul>
*
+ * You can find the JSON-specific options for reading JSON file stream in
+ * <a href="https://spark.apache.org/docs/latest/sql-data-sources-json.html#data-source-option">
+ * Data Source Option</a> in the version you use.
+ * More general options can be found in
Review comment:
Since you mentioned general option in the link above (https://github.com/apache/spark/pull/32204/files#diff-6e4a756777531c9ed7ce32f71a50efde9ca7b73f54da2fb552486bb7ded15514R258), we could remove this sentence
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-837591889
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42866/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842420866
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43156/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-837540657
**[Test build #138344 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138344/testReport)** for PR 32204 at commit [`cbecf61`](https://github.com/apache/spark/commit/cbecf615af28f371b3cd847438a861b8ce2e58ae).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842416332
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43156/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842429045
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822165014
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42123/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r633025267
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>prefersDecimal</code></td>
+ <td>None</td>
+ <td>infers all floating-point values as a decimal type. If the values do not fit in decimal, then it infers them as doubles. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowComments</code></td>
+ <td>None</td>
+ <td>ignores Java/C++ style comment in JSON records. If None is set, it uses the default value, <code>false</code></td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedFieldNames</code></td>
+ <td>None</td>
+ <td>allows unquoted JSON field names. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowSingleQuotes</code></td>
+ <td>None</td>
+ <td>allows single quotes in addition to double quotes. If None is set, it uses the default value, <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNumericLeadingZero</code></td>
+ <td>None</td>
+ <td>allows leading zeros in numbers (e.g. 00012). If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowBackslashEscapingAnyCharacter</code></td>
+ <td>None</td>
+ <td>allows accepting quoting of all character using backslash quoting mechanism. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>columnNameOfCorruptRecord</code></td>
+ <td>None</td>
+ <td>allows renaming the new field having malformed string created by <code>PERMISSIVE</code> mode. This overrides spark.sql.columnNameOfCorruptRecord. If None is set, it uses the value specified in <code>spark.sql.columnNameOfCorruptRecord</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dateFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a date format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to date type. If None is set, it uses the default value, <code>yyyy-MM-dd</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>timestampFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a timestamp format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to timestamp type. If None is set, it uses the default value, <code>yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>multiLine</code></td>
+ <td>None</td>
+ <td>parse one record, which may span multiple lines, per file. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedControlChars</code></td>
+ <td>None</td>
+ <td>allows JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) or not.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
+ <td>None</td>
+ <td>allows to forcibly set one of standard basic or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If None is set, the encoding of input JSON will be detected automatically when the multiLine option is set to <code>true</code>.</td>
+ <td>read</td>
Review comment:
read/write
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>prefersDecimal</code></td>
+ <td>None</td>
+ <td>infers all floating-point values as a decimal type. If the values do not fit in decimal, then it infers them as doubles. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowComments</code></td>
+ <td>None</td>
+ <td>ignores Java/C++ style comment in JSON records. If None is set, it uses the default value, <code>false</code></td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedFieldNames</code></td>
+ <td>None</td>
+ <td>allows unquoted JSON field names. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowSingleQuotes</code></td>
+ <td>None</td>
+ <td>allows single quotes in addition to double quotes. If None is set, it uses the default value, <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNumericLeadingZero</code></td>
+ <td>None</td>
+ <td>allows leading zeros in numbers (e.g. 00012). If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowBackslashEscapingAnyCharacter</code></td>
+ <td>None</td>
+ <td>allows accepting quoting of all character using backslash quoting mechanism. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>columnNameOfCorruptRecord</code></td>
+ <td>None</td>
+ <td>allows renaming the new field having malformed string created by <code>PERMISSIVE</code> mode. This overrides spark.sql.columnNameOfCorruptRecord. If None is set, it uses the value specified in <code>spark.sql.columnNameOfCorruptRecord</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dateFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a date format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to date type. If None is set, it uses the default value, <code>yyyy-MM-dd</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>timestampFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a timestamp format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to timestamp type. If None is set, it uses the default value, <code>yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>multiLine</code></td>
+ <td>None</td>
+ <td>parse one record, which may span multiple lines, per file. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedControlChars</code></td>
+ <td>None</td>
+ <td>allows JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) or not.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
+ <td>None</td>
+ <td>allows to forcibly set one of standard basic or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If None is set, the encoding of input JSON will be detected automatically when the multiLine option is set to <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>lineSep</code></td>
+ <td>None</td>
+ <td>defines the line separator that should be used for parsing. If None is set, it covers all <code>\r</code>, <code>\r\n</code> and <code>\n</code>.</td>
+ <td>read</td>
Review comment:
read/write
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
Review comment:
Captalize
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
Review comment:
Capitalize it
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>prefersDecimal</code></td>
+ <td>None</td>
+ <td>infers all floating-point values as a decimal type. If the values do not fit in decimal, then it infers them as doubles. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowComments</code></td>
+ <td>None</td>
+ <td>ignores Java/C++ style comment in JSON records. If None is set, it uses the default value, <code>false</code></td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedFieldNames</code></td>
+ <td>None</td>
+ <td>allows unquoted JSON field names. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowSingleQuotes</code></td>
+ <td>None</td>
+ <td>allows single quotes in addition to double quotes. If None is set, it uses the default value, <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNumericLeadingZero</code></td>
+ <td>None</td>
+ <td>allows leading zeros in numbers (e.g. 00012). If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowBackslashEscapingAnyCharacter</code></td>
+ <td>None</td>
+ <td>allows accepting quoting of all character using backslash quoting mechanism. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>columnNameOfCorruptRecord</code></td>
+ <td>None</td>
+ <td>allows renaming the new field having malformed string created by <code>PERMISSIVE</code> mode. This overrides spark.sql.columnNameOfCorruptRecord. If None is set, it uses the value specified in <code>spark.sql.columnNameOfCorruptRecord</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dateFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a date format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to date type. If None is set, it uses the default value, <code>yyyy-MM-dd</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>timestampFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a timestamp format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to timestamp type. If None is set, it uses the default value, <code>yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>multiLine</code></td>
+ <td>None</td>
+ <td>parse one record, which may span multiple lines, per file. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedControlChars</code></td>
+ <td>None</td>
+ <td>allows JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) or not.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
+ <td>None</td>
+ <td>allows to forcibly set one of standard basic or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If None is set, the encoding of input JSON will be detected automatically when the multiLine option is set to <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>lineSep</code></td>
+ <td>None</td>
+ <td>defines the line separator that should be used for parsing. If None is set, it covers all <code>\r</code>, <code>\r\n</code> and <code>\n</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>samplingRatio</code></td>
+ <td>None</td>
+ <td>defines fraction of input JSON objects used for schema inferring. If None is set, it uses the default value, <code>1.0</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dropFieldIfAllNull</code></td>
+ <td>None</td>
+ <td>whether to ignore column of all null values or empty array/struct during schema inference. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>locale</code></td>
+ <td>None</td>
+ <td>sets a locale as language tag in IETF BCP 47 format. If None is set, it uses the default value, <code>en-US</code>. For instance, <code>locale</code> is used while parsing dates and timestamps.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNonNumericNumbers</code></td>
+ <td>None</td>
+ <td>allows JSON parser to recognize set of “Not-a-Number” (NaN) tokens as legal floating number values. If None is set, it uses the default value, <code>true</code>.<br>
+ <ul>
+ <li><code>+INF</code>: for positive infinity, as well as alias of <code>+Infinity</code> and <code>Infinity</code>.</li>
+ <li><code>-INF</code>: for negative infinity, alias <code>-Infinity</code>.</li>
+ <li><code>NaN</code>: for other not-a-numbers, like result of division by zero.</li>
+ </ul>
+ </td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>compression</code></td>
+ <td>None</td>
+ <td>compression codec to use when saving to file. This can be one of the known case-insensitive shorten names (none, bzip2, gzip, lz4, snappy and deflate).</td>
+ <td>write</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
Review comment:
Can you combine with `encoding` option above?
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -236,33 +236,9 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
schema : :class:`pyspark.sql.types.StructType` or str, optional
an optional :class:`pyspark.sql.types.StructType` for the input schema or
a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
mode : str, optional
Review comment:
This mode is an option. `mode` in write is not an option.
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/functions.scala
##########
@@ -4131,6 +4131,9 @@ object functions {
* @param schema the schema to use when parsing the json string
* @param options options to control how the json is parsed. Accepts the same options as the
* json data source.
+ * See
+ * <a href="http://127.0.0.1:4000/sql-data-sources-json.html#data-source-option">
Review comment:
`http://127.0.0.1:4000` seems weird
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822149397
**[Test build #137548 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137548/testReport)** for PR 32204 at commit [`0a5412c`](https://github.com/apache/spark/commit/0a5412ce556fa69cbfbf669d53eb48add9d341e3).
* This patch **fails Python style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845286972
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138753/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843139798
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r631575888
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -1196,39 +1097,13 @@ def json(self, path, mode=None, compression=None, dateFormat=None, timestampForm
----------
path : str
the path in any Hadoop supported file system
- mode : str, optional
Review comment:
mode is not a general option
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845144924
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-844738326
@gengliangwang would you mind taking a look too please when you find some times? It touches some docs of the options you added.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842334470
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43152/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842334470
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843070572
**[Test build #138680 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138680/testReport)** for PR 32204 at commit [`3ac7c45`](https://github.com/apache/spark/commit/3ac7c454d7eb1ccc17bf8d4364f585d8ffb93198).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-837543189
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138344/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r624858107
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -209,14 +209,7 @@ def load(self, path=None, format=None, schema=None, **options):
else:
return self._df(self._jreader.load())
- def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
- allowComments=None, allowUnquotedFieldNames=None, allowSingleQuotes=None,
- allowNumericLeadingZero=None, allowBackslashEscapingAnyCharacter=None,
- mode=None, columnNameOfCorruptRecord=None, dateFormat=None, timestampFormat=None,
- multiLine=None, allowUnquotedControlChars=None, lineSep=None, samplingRatio=None,
- dropFieldIfAllNull=None, encoding=None, locale=None, pathGlobFilter=None,
- recursiveFileLookup=None, allowNonNumericNumbers=None,
- modifiedBefore=None, modifiedAfter=None):
+ def json(self, path):
Review comment:
Can you keep the parameters though? I meant to fix the documentation only.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r636007949
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,171 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
Review comment:
Sure, I'll add it. Thanks!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-837543189
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138344/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r633025267
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>prefersDecimal</code></td>
+ <td>None</td>
+ <td>infers all floating-point values as a decimal type. If the values do not fit in decimal, then it infers them as doubles. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowComments</code></td>
+ <td>None</td>
+ <td>ignores Java/C++ style comment in JSON records. If None is set, it uses the default value, <code>false</code></td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedFieldNames</code></td>
+ <td>None</td>
+ <td>allows unquoted JSON field names. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowSingleQuotes</code></td>
+ <td>None</td>
+ <td>allows single quotes in addition to double quotes. If None is set, it uses the default value, <code>true</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowNumericLeadingZero</code></td>
+ <td>None</td>
+ <td>allows leading zeros in numbers (e.g. 00012). If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowBackslashEscapingAnyCharacter</code></td>
+ <td>None</td>
+ <td>allows accepting quoting of all character using backslash quoting mechanism. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>columnNameOfCorruptRecord</code></td>
+ <td>None</td>
+ <td>allows renaming the new field having malformed string created by <code>PERMISSIVE</code> mode. This overrides spark.sql.columnNameOfCorruptRecord. If None is set, it uses the value specified in <code>spark.sql.columnNameOfCorruptRecord</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>dateFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a date format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to date type. If None is set, it uses the default value, <code>yyyy-MM-dd</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>timestampFormat</code></td>
+ <td>None</td>
+ <td>sets the string that indicates a timestamp format. Custom date formats follow the formats at <a href="https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html"> datetime pattern</a>. This applies to timestamp type. If None is set, it uses the default value, <code>yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]</code>.</td>
+ <td>read/write</td>
+ </tr>
+ <tr>
+ <td><code>multiLine</code></td>
+ <td>None</td>
+ <td>parse one record, which may span multiple lines, per file. If None is set, it uses the default value, <code>false</code>.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>allowUnquotedControlChars</code></td>
+ <td>None</td>
+ <td>allows JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) or not.</td>
+ <td>read</td>
+ </tr>
+ <tr>
+ <td><code>encoding</code></td>
+ <td>None</td>
+ <td>allows to forcibly set one of standard basic or extended encoding for the JSON files. For example UTF-16BE, UTF-32LE. If None is set, the encoding of input JSON will be detected automatically when the multiLine option is set to <code>true</code>.</td>
+ <td>read</td>
Review comment:
read/write
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635975929
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/streaming/DataStreamReader.scala
##########
@@ -269,73 +218,20 @@ final class DataStreamReader private[sql](sparkSession: SparkSession) extends Lo
* This function goes through the input once to determine the input schema. If you know the
* schema in advance, use the version that specifies the schema to avoid the extra scan.
*
- * You can set the following JSON-specific options to deal with non-standard JSON files:
+ * You can set the following structured streaming option(s):
Review comment:
```suggestion
* You can set the following option(s):
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841017158
**[Test build #138551 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138551/testReport)** for PR 32204 at commit [`8b48e6f`](https://github.com/apache/spark/commit/8b48e6fee602ce1df5345c677b81bf731b8a05ee).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841015636
**[Test build #138529 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138529/testReport)** for PR 32204 at commit [`2b6b066`](https://github.com/apache/spark/commit/2b6b066de16a3820cb89de21f31ffbe1b08e66e8).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `case class AgeExample(birthday: Expression, child: Expression) extends RuntimeReplaceable `
* `class SessionExtensionsWithLoader extends SparkSessionExtensionsProvider `
* `class SessionExtensionsWithoutLoader extends SparkSessionExtensionsProvider `
* `case class AvroWrite(`
* `case class KafkaWrite(`
* `case class TryEval(child: Expression) extends UnaryExpression with NullIntolerant `
* `case class TryAdd(left: Expression, right: Expression, child: Expression)`
* `case class TryDivide(left: Expression, right: Expression, child: Expression)`
* ` new RuntimeException(s\"Failed to convert value $value (class of $cls) \" +`
* `trait FileWrite extends Write `
* `case class CSVWrite(`
* `case class JsonWrite(`
* `case class OrcWrite(`
* `case class ParquetWrite(`
* `case class TextWrite(`
* `trait ShuffledJoin extends JoinCodegenSupport `
* `class ConsoleWrite(schema: StructType, options: CaseInsensitiveStringMap)`
* `class ForeachWrite[T](`
* `class MemoryWrite(sink: MemorySink, schema: StructType, needTruncate: Boolean) extends Write `
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822148716
**[Test build #137548 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137548/testReport)** for PR 32204 at commit [`0a5412c`](https://github.com/apache/spark/commit/0a5412ce556fa69cbfbf669d53eb48add9d341e3).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843245078
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138678/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843007631
**[Test build #138665 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138665/testReport)** for PR 32204 at commit [`52b6ba8`](https://github.com/apache/spark/commit/52b6ba8994747ec6132bb2cb40307cdf09aaa88f).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon edited a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840312271
@itholic:
1. Please check the option **one by one** and see if each exists, and is matched.
2. Document general options in https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html if there are missing ones
3. If you're going to do 2. separately in another PR and JIRA, don't remove general options in API documentations for now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-837577081
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic edited a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic edited a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840913159
Thanks, @HyukjinKwon .
I checked one by one, and seems like the general options are already documentd to the https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html. I think the parameters I documented & removed are all of JSON specific options or generic options that already documented at https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html ??
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822149406
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137548/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-842295623
**[Test build #138633 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138633/testReport)** for PR 32204 at commit [`cd9f103`](https://github.com/apache/spark/commit/cd9f103683deb5c5d722dbddf9f6c9505336f8bd).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r633025559
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/functions.scala
##########
@@ -4131,6 +4131,9 @@ object functions {
* @param schema the schema to use when parsing the json string
* @param options options to control how the json is parsed. Accepts the same options as the
* json data source.
+ * See
+ * <a href="http://127.0.0.1:4000/sql-data-sources-json.html#data-source-option">
Review comment:
`http://127.0.0.1:4000` seems weird
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
gengliangwang commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635909326
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,171 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
Review comment:
yes, or we can itemize them:
the `.option`/`.options` methods of
* DataFrameReader
* DataFrameWriter
* ...
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822305152
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/137551/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822531197
**[Test build #137597 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137597/testReport)** for PR 32204 at commit [`c31c6f0`](https://github.com/apache/spark/commit/c31c6f07db757ed3cb44e0b142f544c499f82a7d).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840430061
**[Test build #138492 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138492/testReport)** for PR 32204 at commit [`a386788`](https://github.com/apache/spark/commit/a386788b44fb5255d2784ce423e3f879ba97f53c).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] gengliangwang commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
gengliangwang commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-844846176
+1 for the approach
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r636575493
##########
File path: python/pyspark/sql/streaming.py
##########
@@ -507,102 +479,15 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
schema : :class:`pyspark.sql.types.StructType` or str, optional
an optional :class:`pyspark.sql.types.StructType` for the input schema
or a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
- mode : str, optional
- allows a mode for dealing with corrupt records during parsing. If None is
- set, it uses the default value, ``PERMISSIVE``.
-
- * ``PERMISSIVE``: when it meets a corrupted record, puts the malformed string \
- into a field configured by ``columnNameOfCorruptRecord``, and sets malformed \
- fields to ``null``. To keep corrupt records, an user can set a string type \
- field named ``columnNameOfCorruptRecord`` in an user-defined schema. If a \
- schema does not have the field, it drops corrupt records during parsing. \
- When inferring a schema, it implicitly adds a ``columnNameOfCorruptRecord`` \
- field in an output schema.
- * ``DROPMALFORMED``: ignores the whole corrupted records.
- * ``FAILFAST``: throws an exception when it meets corrupted records.
-
- columnNameOfCorruptRecord : str, optional
- allows renaming the new field having malformed string
- created by ``PERMISSIVE`` mode. This overrides
- ``spark.sql.columnNameOfCorruptRecord``. If None is set,
- it uses the value specified in
- ``spark.sql.columnNameOfCorruptRecord``.
- dateFormat : str, optional
- sets the string that indicates a date format. Custom date formats
- follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to date type. If None is set, it uses the
- default value, ``yyyy-MM-dd``.
- timestampFormat : str, optional
- sets the string that indicates a timestamp format.
- Custom date formats follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to timestamp type. If None is set, it uses the
- default value, ``yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]``.
- multiLine : str or bool, optional
- parse one record, which may span multiple lines, per file. If None is
- set, it uses the default value, ``false``.
- allowUnquotedControlChars : str or bool, optional
- allows JSON Strings to contain unquoted control
- characters (ASCII characters with value less than 32,
- including tab and line feed characters) or not.
- lineSep : str, optional
- defines the line separator that should be used for parsing. If None is
- set, it covers all ``\\r``, ``\\r\\n`` and ``\\n``.
- locale : str, optional
- sets a locale as language tag in IETF BCP 47 format. If None is set,
- it uses the default value, ``en-US``. For instance, ``locale`` is used while
- parsing dates and timestamps.
- dropFieldIfAllNull : str or bool, optional
- whether to ignore column of all null values or empty
- array/struct during schema inference. If None is set, it
- uses the default value, ``false``.
- encoding : str or bool, optional
- allows to forcibly set one of standard basic or extended encoding for
- the JSON files. For example UTF-16BE, UTF-32LE. If None is set,
- the encoding of input JSON will be detected automatically
- when the multiLine option is set to ``true``.
- pathGlobFilter : str or bool, optional
- an optional glob pattern to only include files with paths matching
- the pattern. The syntax follows `org.apache.hadoop.fs.GlobFilter`.
- It does not change the behavior of
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- recursiveFileLookup : str or bool, optional
- recursively scan a directory for files. Using this option
- disables
- `partition discovery <https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery>`_. # noqa
- allowNonNumericNumbers : str or bool, optional
- allows JSON parser to recognize set of "Not-a-Number" (NaN)
- tokens as legal floating number values. If None is set,
- it uses the default value, ``true``.
- * ``+INF``: for positive infinity, as well as alias of
- ``+Infinity`` and ``Infinity``.
- * ``-INF``: for negative infinity, alias ``-Infinity``.
- * ``NaN``: for other not-a-numbers, like result of division by zero.
+ Other Parameters
+ ----------------
+ Extra options (keyword argument)
Review comment:
I'll add it to all docstring.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845899153
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138784/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
gengliangwang commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r635870120
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,171 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
Review comment:
Shall we combine this two lines?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r630662846
##########
File path: python/pyspark/sql/readwriter.py
##########
@@ -233,114 +233,13 @@ def json(self, path, schema=None, primitivesAsString=None, prefersDecimal=None,
path : str, list or :class:`RDD`
string represents path to the JSON dataset, or a list of paths,
or RDD of Strings storing JSON objects.
- schema : :class:`pyspark.sql.types.StructType` or str, optional
- an optional :class:`pyspark.sql.types.StructType` for the input schema or
- a DDL-formatted string (For example ``col0 INT, col1 DOUBLE``).
- primitivesAsString : str or bool, optional
- infers all primitive values as a string type. If None is set,
- it uses the default value, ``false``.
- prefersDecimal : str or bool, optional
- infers all floating-point values as a decimal type. If the values
- do not fit in decimal, then it infers them as doubles. If None is
- set, it uses the default value, ``false``.
- allowComments : str or bool, optional
- ignores Java/C++ style comment in JSON records. If None is set,
- it uses the default value, ``false``.
- allowUnquotedFieldNames : str or bool, optional
- allows unquoted JSON field names. If None is set,
- it uses the default value, ``false``.
- allowSingleQuotes : str or bool, optional
- allows single quotes in addition to double quotes. If None is
- set, it uses the default value, ``true``.
- allowNumericLeadingZero : str or bool, optional
- allows leading zeros in numbers (e.g. 00012). If None is
- set, it uses the default value, ``false``.
- allowBackslashEscapingAnyCharacter : str or bool, optional
- allows accepting quoting of all character
- using backslash quoting mechanism. If None is
- set, it uses the default value, ``false``.
- mode : str, optional
- allows a mode for dealing with corrupt records during parsing. If None is
- set, it uses the default value, ``PERMISSIVE``.
-
- * ``PERMISSIVE``: when it meets a corrupted record, puts the malformed string \
- into a field configured by ``columnNameOfCorruptRecord``, and sets malformed \
- fields to ``null``. To keep corrupt records, an user can set a string type \
- field named ``columnNameOfCorruptRecord`` in an user-defined schema. If a \
- schema does not have the field, it drops corrupt records during parsing. \
- When inferring a schema, it implicitly adds a ``columnNameOfCorruptRecord`` \
- field in an output schema.
- * ``DROPMALFORMED``: ignores the whole corrupted records.
- * ``FAILFAST``: throws an exception when it meets corrupted records.
- columnNameOfCorruptRecord: str, optional
- allows renaming the new field having malformed string
- created by ``PERMISSIVE`` mode. This overrides
- ``spark.sql.columnNameOfCorruptRecord``. If None is set,
- it uses the value specified in
- ``spark.sql.columnNameOfCorruptRecord``.
- dateFormat : str, optional
- sets the string that indicates a date format. Custom date formats
- follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to date type. If None is set, it uses the
- default value, ``yyyy-MM-dd``.
- timestampFormat : str, optional
- sets the string that indicates a timestamp format.
- Custom date formats follow the formats at
- `datetime pattern <https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html>`_. # noqa
- This applies to timestamp type. If None is set, it uses the
- default value, ``yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]``.
- multiLine : str or bool, optional
- parse one record, which may span multiple lines, per file. If None is
- set, it uses the default value, ``false``.
- allowUnquotedControlChars : str or bool, optional
- allows JSON Strings to contain unquoted control
- characters (ASCII characters with value less than 32,
- including tab and line feed characters) or not.
- encoding : str or bool, optional
- allows to forcibly set one of standard basic or extended encoding for
- the JSON files. For example UTF-16BE, UTF-32LE. If None is set,
- the encoding of input JSON will be detected automatically
- when the multiLine option is set to ``true``.
- lineSep : str, optional
- defines the line separator that should be used for parsing. If None is
- set, it covers all ``\\r``, ``\\r\\n`` and ``\\n``.
- samplingRatio : str or float, optional
- defines fraction of input JSON objects used for schema inferring.
- If None is set, it uses the default value, ``1.0``.
- dropFieldIfAllNull : str or bool, optional
- whether to ignore column of all null values or empty
- array/struct during schema inference. If None is set, it
- uses the default value, ``false``.
- locale : str, optional
- sets a locale as language tag in IETF BCP 47 format. If None is set,
- it uses the default value, ``en-US``. For instance, ``locale`` is used while
- parsing dates and timestamps.
- pathGlobFilter : str or bool, optional
Review comment:
Thanks for the comment, @HyukjinKwon
It's documented in [Generic File Source Options](https://spark.apache.org/docs/latest/sql-data-sources-generic-options.html#path-global-filter), so I removed it from the docstring.
Then, should we add the link to Generic File Source Options, too? or just keep it here??
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822167347
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32204: [SPARK-34494] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-822167378
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/42126/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840916300
**[Test build #138529 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138529/testReport)** for PR 32204 at commit [`2b6b066`](https://github.com/apache/spark/commit/2b6b066de16a3820cb89de21f31ffbe1b08e66e8).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #32204:
URL: https://github.com/apache/spark/pull/32204#discussion_r633025358
##########
File path: docs/sql-data-sources-json.md
##########
@@ -94,3 +94,146 @@ SELECT * FROM jsonTable
</div>
</div>
+
+## Data Source Option
+
+Data source options of JSON can be set via:
+* the `.option`/`.options` methods of `DataFrameReader` or `DataFrameWriter`
+* the `.option`/`.options` methods of `DataStreamReader` or `DataStreamWriter`
+
+<table class="table">
+ <tr><th><b>Property Name</b></th><th><b>Default</b></th><th><b>Meaning</b></th><th><b>Scope</b></th></tr>
+ <tr>
+ <td><code>primitivesAsString</code></td>
+ <td>None</td>
+ <td>infers all primitive values as a string type. If None is set, it uses the default value, <code>false</code>.</td>
Review comment:
Captalize
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-845616015
**[Test build #138784 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138784/testReport)** for PR 32204 at commit [`a10586c`](https://github.com/apache/spark/commit/a10586c3d2887463de16984adb72d205f85f3796).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-840339404
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/43012/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841141011
**[Test build #138551 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/138551/testReport)** for PR 32204 at commit [`8b48e6f`](https://github.com/apache/spark/commit/8b48e6fee602ce1df5345c677b81bf731b8a05ee).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-843126981
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/43201/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-828928841
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32204: [SPARK-34494][SQL][DOCS] Move JSON data source options from Python and Scala into a single page
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #32204:
URL: https://github.com/apache/spark/pull/32204#issuecomment-841159281
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/138551/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org