You are viewing a plain text version of this content. The canonical link for it is here.
Posted to notifications@shardingsphere.apache.org by to...@apache.org on 2022/07/14 09:06:14 UTC
[shardingsphere] branch master updated: Fix shadow docs style (#19145)
This is an automated email from the ASF dual-hosted git repository.
totalo pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new 979ee27d8e5 Fix shadow docs style (#19145)
979ee27d8e5 is described below
commit 979ee27d8e5a2a8a7a9ce91b51ec1c1a49589719
Author: gin <ja...@163.com>
AuthorDate: Thu Jul 14 17:06:06 2022 +0800
Fix shadow docs style (#19145)
* Fix shadow docs style
* Fix shadow docs table style
---
docs/document/content/features/shadow/_index.cn.md | 27 +-
docs/document/content/features/shadow/_index.en.md | 29 +-
.../document/content/reference/shadow/_index.cn.md | 296 +-----------------
.../document/content/reference/shadow/_index.en.md | 335 ++-------------------
4 files changed, 28 insertions(+), 659 deletions(-)
diff --git a/docs/document/content/features/shadow/_index.cn.md b/docs/document/content/features/shadow/_index.cn.md
index b751ed63606..cddcf4d60a0 100644
--- a/docs/document/content/features/shadow/_index.cn.md
+++ b/docs/document/content/features/shadow/_index.cn.md
@@ -48,31 +48,8 @@ Apache ShardingSphere 全链路在线压测场景下,在数据库层面对于
| *条件类型* | *SQL* | *是否支持* |
| ------------ | -------- | ----------- |
| = | SELECT/UPDATE/DELETE ... WHERE column = value | 支持 |
- | LIKE/NOT LIKE | SELECT/UPDATE/DELETE ... WHERE column LIKE/NOT LIKE value | 支持 | | IN/NOT IN | SELECT/UPDATE/DELETE ... WHERE column IN/NOT IN (value1,value2,...) | 支持 |
+ | LIKE/NOT LIKE | SELECT/UPDATE/DELETE ... WHERE column LIKE/NOT LIKE value | 支持 |
+ | IN/NOT IN | SELECT/UPDATE/DELETE ... WHERE column IN/NOT IN (value1,value2,...) | 支持 |
| BETWEEN | SELECT/UPDATE/DELETE ... WHERE column BETWEEN value1 AND value2 | 不支持 |
| GROUP BY ... HAVING... | SELECT/UPDATE/DELETE ... WHERE ... GROUP BY column HAVING column > value | 不支持 |
| 子查询 | SELECT/UPDATE/DELETE ... WHERE column = (SELECT column FROM table WHERE column = value) | 不支持 |
-
-## 原理介绍
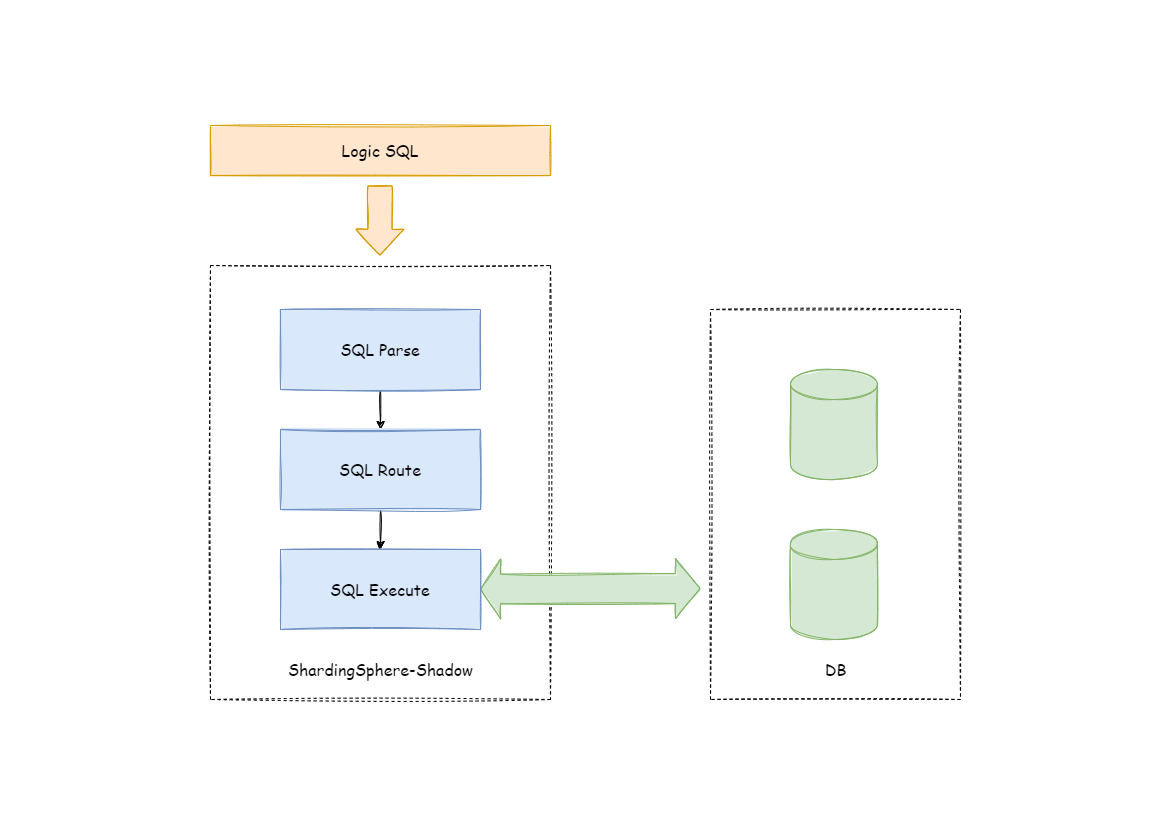
-Apache ShardingSphere 通过解析 SQL,对传入的 SQL 进行影子判定,根据配置文件中用户设置的影子规则,路由到生产库或者影子库。
-
-
-以 INSERT 语句为例,在写入数据时,Apache ShardingSphere 会对 SQL 进行解析,再根据配置文件中的规则,构造一条路由链。 在当前版本的功能中,影子功能处于路由链中的最后一个执行单元,即,如果有其他需要路由的规则存在,如分片,Apache ShardingSphere 会首先根据分片规则,路由到某一个数据库,再执行影子路由判定流程,判定执行SQL满足影子规则的配置,数据路由到与之对应的影子库,生产数据则维持不变。
-
-### DML 语句
-支持两种算法。影子判定会首先判断执行 SQL 相关表与配置的影子表是否有交集。如果有交集,依次判定交集部分影子表关联的影子算法,有任何一个判定成功。SQL 语句路由到影子库。
-影子表没有交集或者影子算法判定不成功,SQL 语句路由到生产库。
-
-### DDL 语句
-仅支持注解影子算法。在压测场景下,DDL 语句一般不需要测试。主要在初始化或者修改影子库中影子表时使用。
-影子判定会首先判断执行 SQL 是否包含注解。如果包含注解,影子规则中配置的 HINT 影子算法依次判定。有任何一个判定成功。SQL 语句路由到影子库。
-执行 SQL 不包含注解或者 HINT 影子算法判定不成功,SQL 语句路由到生产库。
-
-## 相关参考
-[JAVA API:影子库配置](/cn/user-manual/shardingsphere-jdbc/java-api/rules/shadow/)
-
-[YAML 配置:影子库配置](/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/shadow/)
-
-[ Spring Boot Starter:影子库配置 ](/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/shadow/)
-
-[Spring 命名空间:影子库配置](/cn/user-manual/shardingsphere-jdbc/spring-namespace/rules/shadow/)
diff --git a/docs/document/content/features/shadow/_index.en.md b/docs/document/content/features/shadow/_index.en.md
index b69c30365c0..9c32b875545 100644
--- a/docs/document/content/features/shadow/_index.en.md
+++ b/docs/document/content/features/shadow/_index.en.md
@@ -45,33 +45,8 @@ SQL support list
| *condition categories* | *SQL* | *support or not* |
| ------------ | -------- | ----------- |
| = | SELECT/UPDATE/DELETE ... WHERE column = value | support |
- | LIKE/NOT LIKE | SELECT/UPDATE/DELETE ... WHERE column LIKE/NOT LIKE value | support | | IN/NOT IN | SELECT/UPDATE/DELETE ... WHERE column IN/NOT IN (value1,value2,...) | support |
+ | LIKE/NOT LIKE | SELECT/UPDATE/DELETE ... WHERE column LIKE/NOT LIKE value | support |
+ | IN/NOT IN | SELECT/UPDATE/DELETE ... WHERE column IN/NOT IN (value1,value2,...) | support |
| BETWEEN | SELECT/UPDATE/DELETE ... WHERE column BETWEEN value1 AND value2 | do not support |
| GROUP BY ... HAVING... | SELECT/UPDATE/DELETE ... WHERE ... GROUP BY column HAVING column > value | do not support |
| Sub Query | SELECT/UPDATE/DELETE ... WHERE column = (SELECT column FROM table WHERE column = value) | do not support |
-
-## How it works
-
-Apache ShardingSphere determines the incoming SQL via shadow by parsing the SQL and routing it to the production or shadow database based on the shadow rules set by the user in the configuration file.
-
-
-In the example of an INSERT statement, when writing data, Apache ShardingSphere parses the SQL and then constructs a routing chain based on the rules in the configuration file.
-In the current version, the shadow feature is at the last execution unit in the routing chain, i.e. if other rules exist that require routing, such as sharding, Apache ShardingSphere will first route to a particular database according to the sharding rules, and then run the shadow routing determination process to determine that the execution SQL meets the configuration set by shadow rules. Then data is routed to the corresponding shadow database, while the production data remains unchanged.
-
-### DML sentence
-Two algorithms are supported. Shadow determination first determines whether the execution SQL-related table intersects with the configured shadow table. If the result is positive, the shadow algorithm within the part of intersection associated with the shadow table will be determined sequentially. If any of the determination is successful, the SQL statement is routed to the shadow library.
-If there is no intersection or the shadow algorithm determination is unsuccessful, the SQL statement is routed to the production database.
-
-### DDL sentence
-Only supports shadow algorithm with comments attached. In stress testing scenarios, DDL statements are generally not required for testing, and are used mainly when initializing or modifying shadow tables in the shadow database.
-The shadow determination will first determine whether the execution SQL contains comments or not. If the result is a yes, the HINT shadow algorithm configured in the shadow rules determines them in order. The SQL statement is routed to the shadow database if any of the determinations are successful.
-If the execution SQL does not contain comments or the HINT shadow algorithm determination is unsuccessful, the SQL statements are routed to the production database.
-
-## References
-[JAVA API: shadow database configuration](/en/user-manual/shardingsphere-jdbc/java-api/rules/shadow/)
-
-[YAML Configuration: shadow database](/en/user-manual/shardingsphere-jdbc/yaml-config/rules/shadow/)
-
-[ Spring Boot Starter: shadow database configuration](/en/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/shadow/)
-
-[Spring namespace: shadow database configuration](/en/user-manual/shardingsphere-jdbc/spring-namespace/rules/shadow/)
diff --git a/docs/document/content/reference/shadow/_index.cn.md b/docs/document/content/reference/shadow/_index.cn.md
index 9acb04ea384..26af453cc05 100644
--- a/docs/document/content/reference/shadow/_index.cn.md
+++ b/docs/document/content/reference/shadow/_index.cn.md
@@ -4,305 +4,23 @@ title = "影子库"
weight = 6
+++
-## 整体架构
-
+## 原理介绍
Apache ShardingSphere 通过解析 SQL,对传入的 SQL 进行影子判定,根据配置文件中用户设置的影子规则,路由到生产库或者影子库。
-

-## 影子规则
-
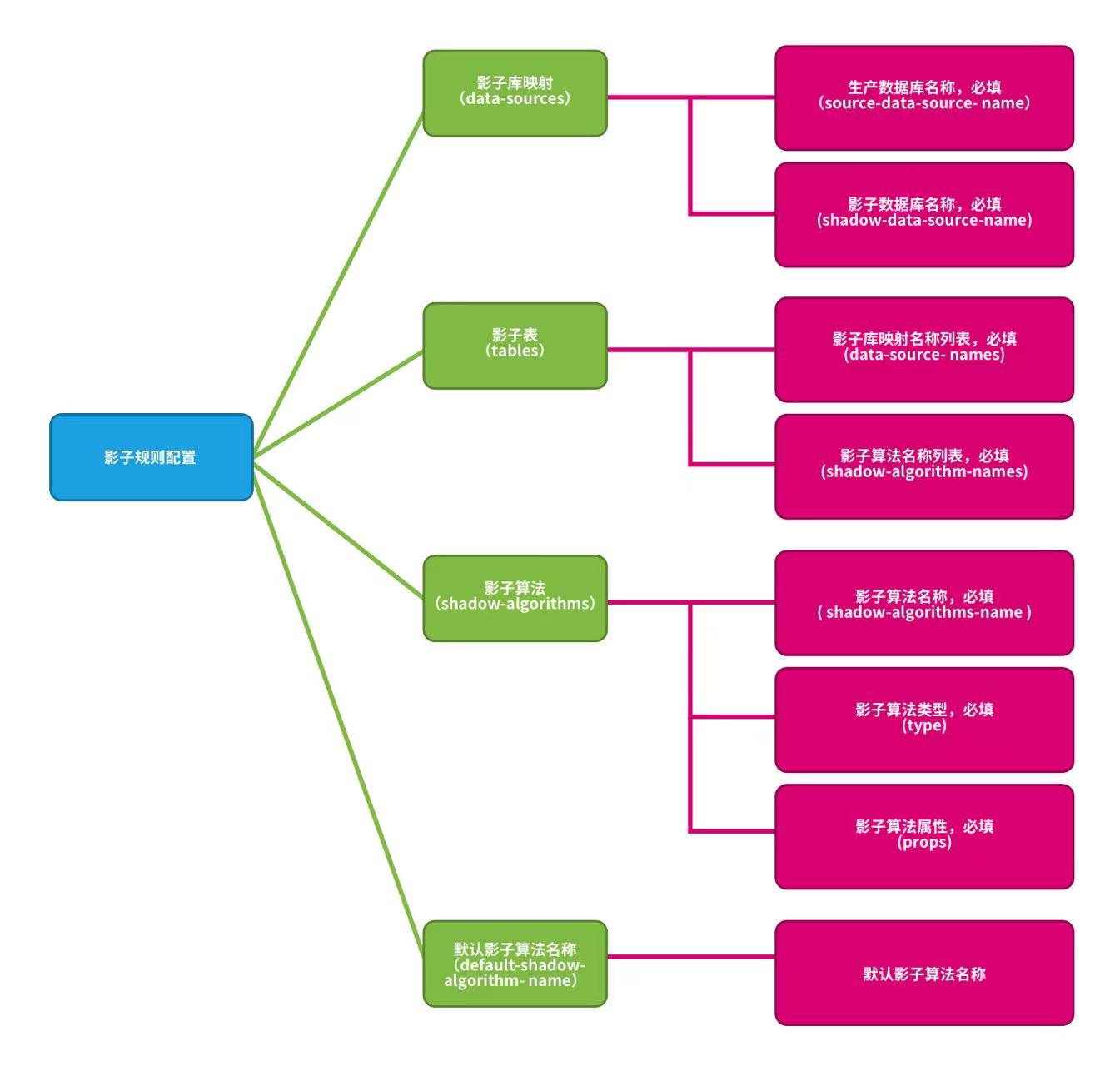
-影子规则包含影子数据源映射关系,影子表以及影子算法。
-
-
-
-**影子库映射**:生产数据源名称和影子数据源名称映射关系。
-
-**影子表**:压测相关的影子表。影子表必须存在于指定的影子库中,并且需要指定影子算法。
-
-**影子算法**:SQL 路由影子算法。
-
-**默认影子算法**:默认影子算法。选配项,对于没有配置影子算法表的默认匹配算法。
-
-## 路由过程
-
-以 INSERT 语句为例,在写入数据时,Apache ShardingSphere 会对 SQL 进行解析,再根据配置文件中的规则,构造一条路由链。
-在当前版本的功能中,影子功能处于路由链中的最后一个执行单元,即,如果有其他需要路由的规则存在,如分片,Apache ShardingSphere 会首先根据分片规则,路由到某一个数据库,再执行影子路由判定流程,判定执行SQL满足影子规则的配置,数据路由到与之对应的影子库,生产数据则维持不变。
-
-## 影子判定流程
-影子库功能对执行的 SQL 语句进行影子判定。影子判定支持两种类型算法,用户可根据实际业务需求选择一种或者组合使用。
+以 INSERT 语句为例,在写入数据时,Apache ShardingSphere 会对 SQL 进行解析,再根据配置文件中的规则,构造一条路由链。 在当前版本的功能中,影子功能处于路由链中的最后一个执行单元,即,如果有其他需要路由的规则存在,如分片,Apache ShardingSphere 会首先根据分片规则,路由到某一个数据库,再执行影子路由判定流程,判定执行SQL满足影子规则的配置,数据路由到与之对应的影子库,生产数据则维持不变。
### DML 语句
-
支持两种算法。影子判定会首先判断执行 SQL 相关表与配置的影子表是否有交集。如果有交集,依次判定交集部分影子表关联的影子算法,有任何一个判定成功。SQL 语句路由到影子库。
影子表没有交集或者影子算法判定不成功,SQL 语句路由到生产库。
### DDL 语句
-
仅支持注解影子算法。在压测场景下,DDL 语句一般不需要测试。主要在初始化或者修改影子库中影子表时使用。
-
影子判定会首先判断执行 SQL 是否包含注解。如果包含注解,影子规则中配置的 HINT 影子算法依次判定。有任何一个判定成功。SQL 语句路由到影子库。
执行 SQL 不包含注解或者 HINT 影子算法判定不成功,SQL 语句路由到生产库。
-## 影子算法
-
-影子算法详情,请参见[内置影子算法列表](/cn/user-manual/shardingsphere-jdbc/builtin-algorithm/shadow)
-
-## 使用案例
-
-### 场景需求
-
-假设一个电商网站要对下单业务进行压测。压测相关表 `t_order` 为影子表,生产数据执行到 `ds` 生产数据库,压测数据执行到数据库 `ds_shadow` 影子库。
-
-### 影子库配置
-
-建议 `config-shadow.yaml` 配置如下:
-
-```yaml
-databaseName: shadow_db
-
-dataSources:
- ds:
- url: jdbc:mysql://127.0.0.1:3306/ds?serverTimezone=UTC&useSSL=false
- username: root
- password:
- connectionTimeoutMilliseconds: 30000
- idleTimeoutMilliseconds: 60000
- maxLifetimeMilliseconds: 1800000
- maxPoolSize: 50
- minPoolSize: 1
- shadow_ds:
- url: jdbc:mysql://127.0.0.1:3306/shadow_ds?serverTimezone=UTC&useSSL=false
- username: root
- password:
- connectionTimeoutMilliseconds: 30000
- idleTimeoutMilliseconds: 60000
- maxLifetimeMilliseconds: 1800000
- maxPoolSize: 50
- minPoolSize: 1
-
-rules:
-- !SHADOW
- dataSources:
- shadowDataSource:
- sourceDataSourceName: ds
- shadowDataSourceName: shadow_ds
- tables:
- t_order:
- dataSourceNames:
- - shadowDataSource
- shadowAlgorithmNames:
- - simple-hint-algorithm
- - user-id-value-match-algorithm
- shadowAlgorithms:
- simple-hint-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
- user-id-insert-match-algorithm:
- type: VALUE_MATCH
- props:
- operation: insert
- column: user_id
- regex: 0
-
-- !SQL_PARSER
- sqlCommentParseEnabled: true
-```
-
-**注意**: 如果使用注解影子算法,需要开启解析 SQL 注释配置项 `sqlCommentParseEnabled: true`。默认关闭。
-请参考 [SQL 解析配置](https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/sql-parser/)
-
-### 影子库环境
-
-* 创建影子库 `ds_shadow`。
-
-* 创建影子表,表结构与生产环境必须一致。假设在影子库创建 `t_order` 表。创建表语句需要添加 SQL 注释 `/*foo:bar,...*/`。即:
-
-```sql
-CREATE TABLE t_order (order_id INT(11) primary key, user_id int(11) not null, ...) /*foo:bar,...*/
-```
-
-执行到影子库。
-
-**注意**:如果使用 MySQL 客户端进行测试,链接需要使用参数:`-c` 例如:
-
-```sql
-mysql> mysql -u root -h127.0.0.1 -P3306 -proot -c
-```
-
-参数说明:保留注释,发送注释到服务端。
-
-执行包含注解 SQL 例如:
-
-```sql
-SELECT * FROM table_name /*shadow:true,foo:bar*/;
-```
-
-不使用参数 `-c` 会被 MySQL 客户端截取注释语句变为:
-
-```sql
-SELECT * FROM table_name;
-```
-
-影响测试结果。
-
-### 影子算法使用
-
-1. 列影子算法使用
-
-假设 `t_order` 表中包含下单用户ID的 `user_id` 列。 实现的效果,当用户ID为 `0` 的用户创建订单产生的数据。 即:
-```sql
-INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...)
-```
-会执行到影子库,其他数据执行到生产库。
-
-无需修改任何 SQL 或者代码,只需要对压力测试的数据进行控制就可以实现在线的压力测试。
-
-算法配置如下:
-
-```yaml
-shadowAlgorithms:
- user-id-insert-match-algorithm:
- type: VALUE_MATCH
- props:
- operation: insert
- column: user_id
- regex: 0
-```
-
-**注意**:影子表使用列影子算法时,相同类型操作(INSERT, UPDATE, DELETE, SELECT)目前仅支持单个字段。
-
-2. 使用 Hint 影子算法
-
-假设 `t_order` 表中不包含可以对值进行匹配的列。添加注解 `/*foo:bar,...*/` 到执行 SQL 中,即:
-
-```sql
-SELECT * FROM t_order WHERE order_id = xxx /*foo:bar,...*/
-```
-
-会执行到影子库,其他数据执行到生产库。
-
-算法配置如下:
-
-```yaml
-shadowAlgorithms:
- simple-hint-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
-```
-
-3. 混合使用影子模式
-
-假设对 `t_order` 表压测需要覆盖以上两种场景,即,
-
-```sql
-INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...);
-
-SELECT * FROM t_order WHERE order_id = xxx /*foo:bar,...*/;
-```
-
-都会执行到影子库,其他数据执行到生产库。
-
-算法配置如下:
-
-```yaml
-shadowAlgorithms:
- user-id-value-match-algorithm:
- type: VALUE_MATCH
- props:
- operation: insert
- column: user_id
- value: 0
- simple-hint-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
-```
-
-4. 使用默认影子算法
-
-假设对 `t_order` 表压测使用列影子算法,其他相关其他表都需要使用 Hint 影子算法。即,
-
-```sql
-INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...);
-
-INSERT INTO t_xxx_1 (order_item_id, order_id, ...) VALUES (xxx..., xxx..., ...) /*foo:bar,...*/;
-
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:bar,...*/;
-
-SELECT * FROM t_xxx_3 WHERE order_id = xxx /*foo:bar,...*/;
-```
-
-都会执行到影子库,其他数据执行到生产库。
-
-配置如下:
-
-```yaml
-rules:
-- !SHADOW
-dataSources:
- shadowDataSource:
- sourceDataSourceName: ds
- shadowDataSourceName: shadow_ds
-tables:
- t_order:
- dataSourceNames:
- - shadowDataSource
- shadowAlgorithmNames:
- - simple-hint-algorithm
- - user-id-value-match-algorithm
-shadowAlgorithms:
- simple-hint-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
- user-id-insert-match-algorithm:
- type: VALUE_MATCH
- props:
- operation: insert
- column: user_id
- regex: 0
-- !SQL_PARSER
- sqlCommentParseEnabled: true
-```
-
-**注意**
-默认影子算法仅支持 Hint 影子算法。
-使用时必须确保配置文件中 `props` 的配置项小于等于 SQL 注释中的配置项,且配置文件的具体配置要和 SQL 注释中写的配置一样,配置文件中配置项越少,匹配条件越宽松
-
-```yaml
-shadowAlgorithms:
- simple-note-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
- foo1: bar1
-```
-
-如当前 `props` 项中配置了 `2` 条配置,在 SQL 中可以匹配的写法有如下:
-
-```sql
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:bar, foo1:bar1, ...*/
-```
-```sql
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:bar, foo1:bar1, foo2:bar2, ...*/
-```
-
-```yaml
-shadowAlgorithms:
- simple-note-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
-```
-
-如当前 props 项中配置了 1 条配置,在 SQL 中可以匹配的写法有如下:
-
-```sql
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:foo*/
-```
-```sql
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:foo, foo1:bar1, ...*/
-```
+## 相关参考
+[JAVA API:影子库配置](/cn/user-manual/shardingsphere-jdbc/java-api/rules/shadow/)
+[YAML 配置:影子库配置](/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/shadow/)
+[ Spring Boot Starter:影子库配置 ](/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/shadow/)
+[Spring 命名空间:影子库配置](/cn/user-manual/shardingsphere-jdbc/spring-namespace/rules/shadow/)
diff --git a/docs/document/content/reference/shadow/_index.en.md b/docs/document/content/reference/shadow/_index.en.md
index 51f6028efee..7413d922139 100644
--- a/docs/document/content/reference/shadow/_index.en.md
+++ b/docs/document/content/reference/shadow/_index.en.md
@@ -4,326 +4,25 @@ title = "Shadow"
weight = 6
+++
-## Overall Architecture
+## How it works
+Apache ShardingSphere determines the incoming SQL via shadow by parsing the SQL and routing it to the production or shadow database based on the shadow rules set by the user in the configuration file.
+
-Apache ShardingSphere makes shadow judgments on incoming SQL by parsing SQL, according to the shadow rules set by the user in the configuration file,
-route to production DB or shadow DB.
-
+In the example of an INSERT statement, when writing data, Apache ShardingSphere parses the SQL and then constructs a routing chain based on the rules in the configuration file.
+In the current version, the shadow feature is at the last execution unit in the routing chain, i.e. if other rules exist that require routing, such as sharding, Apache ShardingSphere will first route to a particular database according to the sharding rules, and then run the shadow routing determination process to determine that the execution SQL meets the configuration set by shadow rules. Then data is routed to the corresponding shadow database, while the production data remains unchanged.
-## Shadow Rule
+### DML sentence
+Two algorithms are supported. Shadow determination first determines whether the execution SQL-related table intersects with the configured shadow table. If the result is positive, the shadow algorithm within the part of intersection associated with the shadow table will be determined sequentially. If any of the determination is successful, the SQL statement is routed to the shadow library.
+If there is no intersection or the shadow algorithm determination is unsuccessful, the SQL statement is routed to the production database.
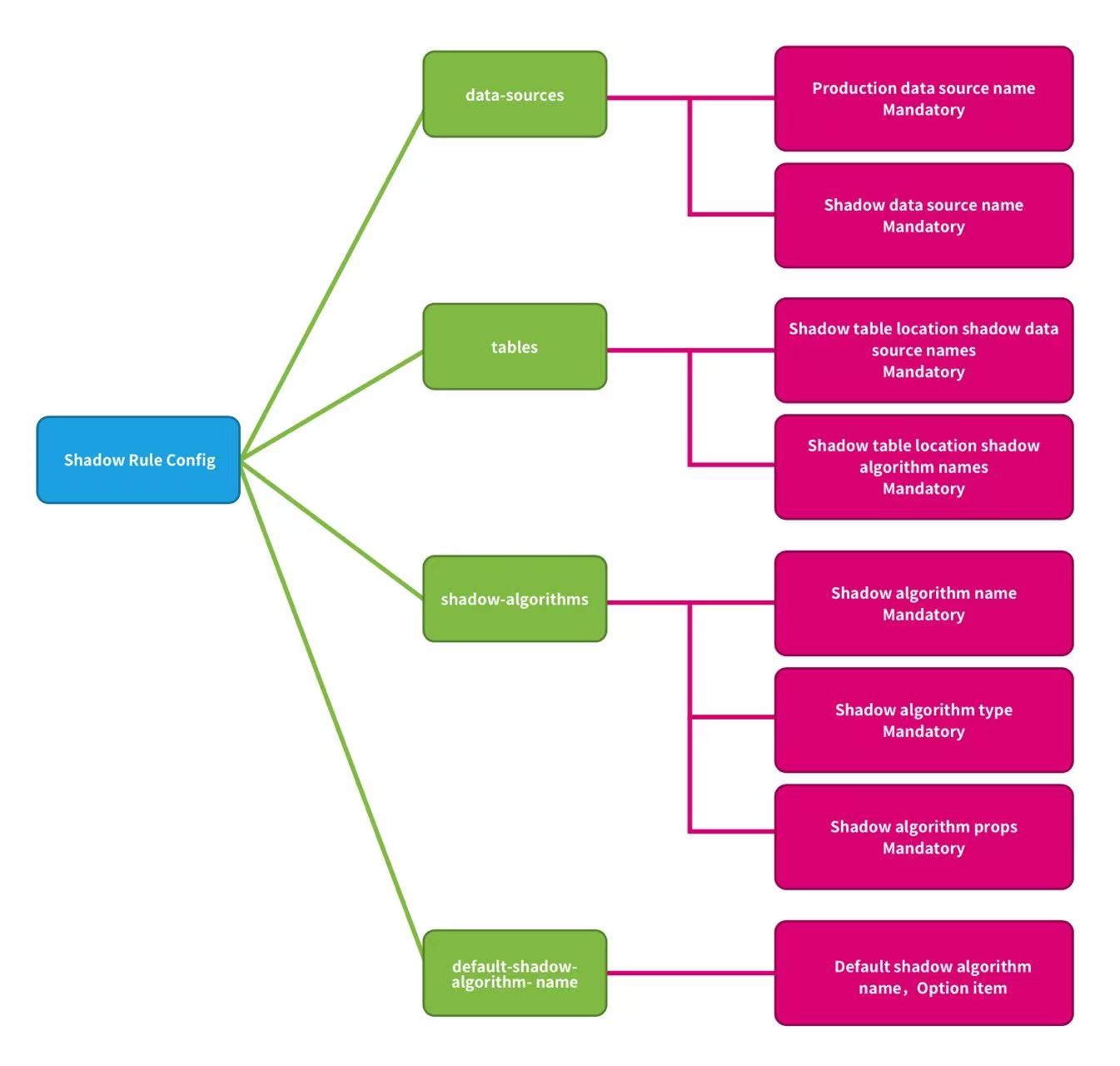
-Shadow rules include shadow data source mapping, shadow tables, and shadow algorithms.
+### DDL sentence
+Only supports shadow algorithm with comments attached. In stress testing scenarios, DDL statements are generally not required for testing, and are used mainly when initializing or modifying shadow tables in the shadow database.
+The shadow determination will first determine whether the execution SQL contains comments or not. If the result is a yes, the HINT shadow algorithm configured in the shadow rules determines them in order. The SQL statement is routed to the shadow database if any of the determinations are successful.
+If the execution SQL does not contain comments or the HINT shadow algorithm determination is unsuccessful, the SQL statements are routed to the production database.
-
-
-**data-sources**:Production data source name and shadow data source name mappings.
-
-**tables**:Shadow tables related to stress testing. Shadow tables must exist in the specified shadow DB, and the shadow algorithm needs to be specified.
-
-**shadow-algorithms**:SQL routing shadow algorithm.
-
-**default-shadow-algorithm-name**:Default shadow algorithm. Optional item, the default matching algorithm for tables that not configured with the shadow algorithm.
-
-## Routing Process
-
-Take the INSERT statement as an example. When writing data Apache ShardingSphere will parse the SQL, and then construct a routing chain according to the rules in the configuration file.
-
-In the current version of the function, the shadow function is the last execution unit in the routing chain, that is, if there are other rules that require routing, such as sharding, Apache ShardingSphere will first route to a certain database according to the sharding rules, and then
-perform the shadow routing decision process.
-
-It determined that the execution of SQL satisfies the configuration of the shadow rule, the data routed to the corresponding shadow database, and the production data remains unchanged.
-
-## Shadow Judgment Process
-
-The Shadow DB performs shadow judgment on the executed SQL statements.
-
-Shadow judgment supports two types of algorithms, users can choose one or combine them according to actual business needs.
-
-### DML Statement
-
-Support two type shadow algorithms.
-
-The shadow judgment first judges whether there is an intersection between SQL related tables and configured shadow tables.
-
-If there is an intersection, determine the shadow algorithm associated with the shadow table of the intersection in turn, and any one of them was successful. SQL statement executed shadow DB.
-
-If shadow tables have no intersection, or shadow algorithms are unsuccessful, SQL statement executed production DB.
-
-### DDL Statement
-
-Only support note shadow algorithm.
-
-In the pressure testing scenarios, DDL statements are not need tested generally. It is mainly used when initializing or modifying the shadow table in the shadow DB.
-
-The shadow judgment first judges whether the executed SQL contains notes.
-
-If contains notes, determine the note shadow algorithms in the shadow rule in turn, and any one of them was successful. SQL statement executed shadow DB.
-
-The executed SQL does not contain notes, or shadow algorithms are unsuccessful, SQL statement executed production DB.
-
-## Shadow Algorithm
-
-Shadow algorithm details, please refer to [List of built-in shadow algorithms](/en/user-manual/shardingsphere-jdbc/builtin-algorithm/shadow)
-
-## Use Example
-
-### Scenario
-
-Assume that the e-commerce website wants to perform pressure testing on the order business,
-
-the pressure testing related table `t_order` is a shadow table, the production data executed to the `ds` production DB, and the pressure testing data executed to the database `ds_shadow` shadow DB.
-
-### Shadow DB configuration
-
-The configuration example of `config-shadow.yaml`(YAML):
-
-```yaml
-databaseName: shadow_db
-
-dataSources:
- ds:
- url: jdbc:mysql://127.0.0.1:3306/ds?serverTimezone=UTC&useSSL=false
- username: root
- password:
- connectionTimeoutMilliseconds: 30000
- idleTimeoutMilliseconds: 60000
- maxLifetimeMilliseconds: 1800000
- maxPoolSize: 50
- minPoolSize: 1
- shadow_ds:
- url: jdbc:mysql://127.0.0.1:3306/shadow_ds?serverTimezone=UTC&useSSL=false
- username: root
- password:
- connectionTimeoutMilliseconds: 30000
- idleTimeoutMilliseconds: 60000
- maxLifetimeMilliseconds: 1800000
- maxPoolSize: 50
- minPoolSize: 1
-
-rules:
-- !SHADOW
- dataSources:
- shadowDataSource:
- sourceDataSourceName: ds
- shadowDataSourceName: shadow_ds
- tables:
- t_order:
- dataSourceNames:
- - shadowDataSource
- shadowAlgorithmNames:
- - simple-hint-algorithm
- - user-id-value-match-algorithm
- shadowAlgorithms:
- simple-hint-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
- user-id-insert-match-algorithm:
- type: VALUE_MATCH
- props:
- operation: insert
- column: user_id
- regex: 0
-
-- !SQL_PARSER
- sqlCommentParseEnabled: true
-```
-
-**Note**: If you use the Hint shadow algorithm, the parse SQL comment configuration item `sql-comment-parse-enabled: true` need to be turned on. turned off by default.
-please refer to [SQL-PARSER Configuration](https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/sql-parser/)
-
-### Shadow DB environment
-
-* Create the shadow DB `ds_shadow`.
-
-* Create shadow tables, tables structure must be consistent with the production environment.
- Assume that the `t_order` table created in the shadow DB. Create table statement need to add SQL comment `/*foo:bar,.. .*/`.
-
-```sql
-CREATE TABLE t_order (order_id INT(11) primary key, user_id int(11) not null, ...) /*foo:bar,...*/
-```
-Execute to the shadow DB.
-
-**Note**: If use the MySQL client for testing, the link needs to use the parameter `-c`, for example:
-
-```sql
-mysql> mysql -u root -h127.0.0.1 -P3306 -proot -c
-```
-
-Parameter description: keep the comment, send the comment to the server
-
-Execute SQL containing annotations, for example:
-
-```sql
-SELECT * FROM table_name /*shadow:true,foo:bar*/;
-```
-
-Comment statement will be intercepted by the MySQL client if parameter `-c` not be used, for example:
-
-```sql
-SELECT * FROM table_name;
-```
-
-Affect test results.
-
-### Shadow algorithm example
-
-1. Column shadow algorithm example
-
-Assume that the `t_order` table contains a list of `user_id` to store the order user ID.
-The data of the order created by the user whose user ID is `0` executed to shadow DB, other data executed to production DB.
-
-```sql
-INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...)
-```
-
-No need to modify any SQL or code, only need to control the data of the testing to realize the pressure testing.
-
-Column Shadow algorithm configuration (YAML):
-
-```yaml
-shadowAlgorithms:
- user-id-insert-match-algorithm:
- type: VALUE_MATCH
- props:
- operation: insert
- column: user_id
- regex: 0
-```
-
-**Note**: When the shadow table uses the column shadow algorithm, the same type of shadow operation (INSERT, UPDATE, DELETE, SELECT) currently only supports a single column.
-
-2. Hint shadow algorithm example
-
-Assume that the `t_order` table does not contain columns that can matching. Executed SQL statement need to add SQL note `/*foo:bar,.. .*/`
-
-```sql
-SELECT * FROM t_order WHERE order_id = xxx /*foo:bar,...*/
-```
-SQL executed to shadow DB, other data executed to production DB.
-
-Note Shadow algorithm configuration (YAML):
-
-```yaml
-shadowAlgorithms:
- simple-hint-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
-```
-
-3. Hybrid two shadow algorithm example
-
-Assume that the pressure testing of the `t_order` gauge needs to cover the above two scenarios.
-
-```sql
-INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...);
-
-SELECT * FROM t_order WHERE order_id = xxx /*foo:bar,...*/;
-```
-
-Both will be executed to shadow DB, other data executed to production DB.
-
-2 type of shadow algorithm example (YAML):
-
-```yaml
-shadowAlgorithms:
- user-id-value-match-algorithm:
- type: VALUE_MATCH
- props:
- operation: insert
- column: user_id
- value: 0
- simple-hint-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
-```
-
-4. Default shadow algorithm example
-
-Assume that the column shadow algorithm used for the `t_order`, all other shadow tables need to use the note shadow algorithm.
-
-```sql
-INSERT INTO t_order (order_id, user_id, ...) VALUES (xxx..., 0, ...);
-
-INSERT INTO t_xxx_1 (order_item_id, order_id, ...) VALUES (xxx..., xxx..., ...) /*foo:bar,...*/;
-
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:bar,...*/;
-
-SELECT * FROM t_xxx_3 WHERE order_id = xxx /*foo:bar,...*/;
-```
-
-Both will be executed to shadow DB, other data executed to production DB.
-
-Default shadow algorithm configuration (YAML):
-
-```yaml
-rules:
-- !SHADOW
-dataSources:
- shadowDataSource:
- sourceDataSourceName: ds
- shadowDataSourceName: shadow_ds
-tables:
- t_order:
- dataSourceNames:
- - shadowDataSource
- shadowAlgorithmNames:
- - simple-hint-algorithm
- - user-id-value-match-algorithm
-shadowAlgorithms:
- simple-hint-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
- user-id-insert-match-algorithm:
- type: VALUE_MATCH
- props:
- operation: insert
- column: user_id
- regex: 0
-- !SQL_PARSER
- sqlCommentParseEnabled: true
-```
-
-**Note**:
-The default shadow algorithm only supports Hint shadow algorithm.
-When using ensure that the configuration items of `props` in the configuration file are less than or equal to those in the SQL comment, And the specific configuration of the configuration file
-should same as the configuration written in the SQL comment. The fewer configuration items in the configuration file, the looser the matching conditions
-
-```yaml
-shadowAlgorithms:
- simple-note-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
- foo1: bar1
-```
-
-For example, the 'props' item have `2` configure, the following syntax can be used in SQL:
-
-```sql
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:bar, foo1:bar1*/
-```
-```sql
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:bar, foo1:bar1, foo2:bar2, ...*/
-```
-
-```yaml
-shadowAlgorithms:
- simple-note-algorithm:
- type: SIMPLE_HINT
- props:
- foo: bar
-```
-
-For example, the 'props' item have `1` configure, the following syntax can be used in SQL:
-
-```sql
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:foo*/
-```
-```sql
-SELECT * FROM t_xxx_2 WHERE order_id = xxx /*foo:foo, foo1:bar1, ...*/
-```
+##References
+[JAVA API: shadow database configuration](/en/user-manual/shardingsphere-jdbc/java-api/rules/shadow/)
+[YAMLconfiguration: shadow database](/en/user-manual/shardingsphere-jdbc/yaml-config/rules/shadow/)
+[ Spring Boot Starter: shadow database configuration](/en/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/shadow/)
+[Spring namespace: shadow database configuration](/en/user-manual/shardingsphere-jdbc/spring-namespace/rules/shadow/)
\ No newline at end of file