You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2020/02/10 17:45:40 UTC
[GitHub] [spark] huaxingao opened a new pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
huaxingao opened a new pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527
### What changes were proposed in this pull request?
Add FValueRegressionSelector for continuous features and continuous labels.
### Why are the changes needed?
Current Spark only supports the selection of categorical features, while there are many requirements for the selection of continuous distribution features.
I will add two new selectors:
1. FValueRegressionSelector for continuous features and continuous labels.
2. ANOVAFValueClassificationSelector for continuous features and categorical labels.
I will use subtasks to add these two selectors:
1. add FValueRegressionSelector on scala side
2. add FValueRegressionSelector on python side
3. add samples and doc
4. do the same for ANOVAFValueClassificationSelector
### Does this PR introduce any user-facing change?
Yes.
Add a new Selector
### How was this patch tested?
Add new unit tests.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r379299313
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
+ (col, (value - xMeans(col.toInt), (label - yMean)))
Review comment:
--I guess we only need to deal with non-zero values, so maybe use `foreachNonZero` instead.
Then I now think following the logic in `Summizer` maybe more efficient: maintain arrays of sum of `(value - xMeans(col.toInt)` and `(label - yMean)` on each partition, then `treeReduce` to obtain the global sum/mean.--
I just notice that the FValueRegression's logic is different from ChiSqTest, since `ChiSqTest` need to maintain a relative large matrix for each col, so need to flatMap and aggByKey for each col. While in FValueRegression, we only need two arrays (or three arrays if using E(XY)-E(X)E(Y))
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r379299313
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
+ (col, (value - xMeans(col.toInt), (label - yMean)))
Review comment:
I guess we only need to deal with non-zero values, so maybe use `foreachNonZero` instead.
Then I now think following the logic in `Summizer` maybe more efficient: maintain arrays of sum of `(value - xMeans(col.toInt)` and `(label - yMean)` on each partition, then `treeReduce` to obtain the global sum/mean.
I just notice that the FValueRegression's logic is different from ChiSqTest, since `ChiSqTest` need to maintain a relative large matrix for each col, so need to flatMap and aggByKey for each col. While in FValueRegression, we only need two arrays (or three arrays if using E(XY)-E(X)E(Y))
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584247927
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584253608
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584253622
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118173/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584372589
**[Test build #118174 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118174/testReport)** for PR 27527 at commit [`2b519b5`](https://github.com/apache/spark/commit/2b519b5f1b5ffb02a285c80271892d3d0d826e76).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r380457865
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
Review comment:
Use array instead:
```scala
labeledPointRdd.mapPartition { iter =>
if (iter.hasNext) {
val array = Array.ofDim[Double](numFeatures)
while(iter.hasNext) {
val LabeledPoint(label, features) = iter.next
val yDiff = label - yMean
if (yDiff != 0) {
features.iterator.zip(xMeans.iterator)
.foreach { case ((col, x), (_, xMean)) => array(col) += yDiff * (x - xMean) }
}
}
Iterator.single(array)
} else Iterator.empty
}.treeReduce { case (array1, array2) =>
var i = 0
while (i < numFeatures) {
array1(i) += array2(i)
i += 1
}
array1
}
```
Or use `treeAggregate` instead.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r379288066
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
+ (col, (value - xMeans(col.toInt), (label - yMean)))
+ }
+ }.aggregateByKey[(Double, Double)]((0.0, 0.0))(
+ seqOp = {
Review comment:
I suggest to use `E(XY)-E(X)E(Y)` instead, then only one pass is needed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] huaxingao closed pull request #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
huaxingao closed pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584373521
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118174/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584253622
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118173/
Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584373521
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118174/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584247927
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r380455685
##########
File path: mllib/src/test/scala/org/apache/spark/ml/feature/FValueRegressionSelectorSuite.scala
##########
@@ -0,0 +1,215 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.feature
+
+import org.apache.spark.ml.linalg.{Vector, Vectors}
+import org.apache.spark.ml.param.ParamsSuite
+import org.apache.spark.ml.util.{DefaultReadWriteTest, MLTest}
+import org.apache.spark.ml.util.TestingUtils._
+import org.apache.spark.sql.{Dataset, Row}
+
+class FValueRegressionSelectorSuite extends MLTest with DefaultReadWriteTest {
+
+ import testImplicits._
+
+ @transient var dataset: Dataset[_] = _
+
+ override def beforeAll(): Unit = {
+ super.beforeAll()
+
+ // scalastyle:off
+ /*
+ FValue REGRESSION
+ X (features) =
+ [[1.67318514e-01, 1.78398028e-01, 4.36846538e-01, 5.24003164e-01, 1.80915415e-01, 1.98030859e-01],
+ [3.71836586e-01, 6.13453963e-01, 7.15269190e-01, 9.33623792e-03, 5.36095674e-01, 2.74223333e-01],
+ [3.68988949e-01, 5.34104018e-01, 5.24858744e-01, 6.86815853e-01, 3.26534757e-01, 6.92699400e-01],
+ [4.87748505e-02, 3.07080315e-01, 7.82955385e-01, 6.90167375e-01, 6.44077919e-01, 4.23739024e-01],
+ [6.50153455e-01, 8.32746110e-01, 6.88029140e-03, 1.27859556e-01, 6.80223767e-01, 6.25825675e-01],
+
+ [9.47343271e-01, 2.13193978e-01, 3.71342472e-01, 8.21291956e-01, 4.38195693e-01, 5.76569439e-01],
+ [9.96499254e-01, 8.45833297e-01, 6.56086922e-02, 5.90029174e-01, 1.68954572e-01, 7.19792823e-02],
+ [1.85926914e-01, 9.60329804e-01, 3.13487406e-01, 9.59549928e-01, 6.89093311e-01, 6.94999427e-01],
+ [9.40164576e-01, 2.69042714e-02, 5.39491321e-01, 5.74068666e-01, 1.10935343e-01, 2.17519760e-01],
+ [2.97951848e-02, 1.06592106e-01, 5.74931856e-01, 8.80801522e-01, 8.60445070e-01, 9.22757966e-01],
+
+ [9.80970473e-01, 3.05909353e-01, 4.96401766e-01, 2.44342697e-01, 6.90559227e-01, 5.64858704e-01],
+ [1.55939260e-01, 2.18626853e-01, 5.01834270e-01, 1.86694987e-01, 9.15411148e-01, 6.40527848e-01],
+ [3.16107608e-01, 9.25906358e-01, 5.47327167e-01, 4.83712979e-01, 8.42305220e-01, 7.58488462e-01],
+ [4.14393503e-01, 1.30817883e-01, 5.62034942e-01, 1.05150633e-01, 5.35632795e-01, 9.47594074e-04],
+ [5.26233981e-01, 7.63781419e-02, 3.19188240e-01, 5.16528633e-02, 5.28416724e-01, 6.47050470e-03],
+
+ [2.73404764e-01, 7.17070744e-01, 3.12889595e-01, 8.39271965e-01, 9.67650889e-01, 8.50098873e-01],
+ [4.63289495e-01, 3.57055416e-02, 5.43528596e-01, 4.44840919e-01, 9.36845855e-02, 7.81595037e-01],
+ [3.21784993e-01, 3.15622454e-01, 7.58870408e-01, 5.18198558e-01, 2.28151905e-01, 4.42460325e-01],
+ [3.72428352e-01, 1.44447969e-01, 8.40274188e-01, 5.86308041e-01, 6.09893953e-01, 3.97006473e-01],
+ [3.12776786e-01, 9.33630195e-01, 2.29328749e-01, 4.32807208e-01, 1.51703470e-02, 1.51589320e-01]]
+
+ y (labels) =
+ [0.33997803, 0.71456716, 0.58676766, 0.52894227, 0.53158463,
+ 0.55515181, 0.67008744, 0.5966537 , 0.56255674, 0.33904133,
+ 0.66485577, 0.38514965, 0.73885841, 0.45766267, 0.34801557,
+ 0.52529452, 0.42503336, 0.60221968, 0.58964479, 0.58194949]
+
+ Note that y = X @ w, where w = [0.3, 0.4, 0.5, 0. , 0. , 0. ]
+
+ Sklearn results:
+ F values per feature: [2.76445780e+00, 1.05267800e+01, 4.43399092e-02, 2.04580501e-02,
+ 3.13208557e-02, 1.35248025e-03]
+ p values per feature: [0.11369388, 0.0044996 , 0.83558782, 0.88785417, 0.86150261, 0.97106833]
+ */
+ // scalastyle:on
+
+ val data = Seq(
+ (0.33997803, Vectors.dense(1.67318514e-01, 1.78398028e-01, 4.36846538e-01,
+ 5.24003164e-01, 1.80915415e-01, 1.98030859e-01), Vectors.dense(1.78398028e-01)),
+ (0.71456716, Vectors.dense(3.71836586e-01, 6.13453963e-01, 7.15269190e-01,
+ 9.33623792e-03, 5.36095674e-01, 2.74223333e-01), Vectors.dense(6.13453963e-01)),
+ (0.58676766, Vectors.dense(3.68988949e-01, 5.34104018e-01, 5.24858744e-01,
+ 6.86815853e-01, 3.26534757e-01, 6.92699400e-01), Vectors.dense(5.34104018e-01)),
+ (0.52894227, Vectors.dense(4.87748505e-02, 3.07080315e-01, 7.82955385e-01,
+ 6.90167375e-01, 6.44077919e-01, 4.23739024e-01), Vectors.dense(3.07080315e-01)),
+ (0.53158463, Vectors.dense(6.50153455e-01, 8.32746110e-01, 6.88029140e-03,
+ 1.27859556e-01, 6.80223767e-01, 6.25825675e-01), Vectors.dense(8.32746110e-01)),
+ (0.55515181, Vectors.dense(9.47343271e-01, 2.13193978e-01, 3.71342472e-01,
+ 8.21291956e-01, 4.38195693e-01, 5.76569439e-01), Vectors.dense(2.13193978e-01)),
+ (0.67008744, Vectors.dense(9.96499254e-01, 8.45833297e-01, 6.56086922e-02,
+ 5.90029174e-01, 1.68954572e-01, 7.19792823e-02), Vectors.dense(8.45833297e-01)),
+ (0.5966537, Vectors.dense(1.85926914e-01, 9.60329804e-01, 3.13487406e-01,
+ 9.59549928e-01, 6.89093311e-01, 6.94999427e-01), Vectors.dense(9.60329804e-01)),
+ (0.56255674, Vectors.dense(9.40164576e-01, 2.69042714e-02, 5.39491321e-01,
+ 5.74068666e-01, 1.10935343e-01, 2.17519760e-01), Vectors.dense(2.69042714e-02)),
+ (0.33904133, Vectors.dense(2.97951848e-02, 1.06592106e-01, 5.74931856e-01,
+ 8.80801522e-01, 8.60445070e-01, 9.22757966e-01), Vectors.dense(1.06592106e-01)),
+ (0.66485577, Vectors.dense(9.80970473e-01, 3.05909353e-01, 4.96401766e-01,
+ 2.44342697e-01, 6.90559227e-01, 5.64858704e-01), Vectors.dense(3.05909353e-01)),
+ (0.38514965, Vectors.dense(1.55939260e-01, 2.18626853e-01, 5.01834270e-01,
+ 1.86694987e-01, 9.15411148e-01, 6.40527848e-01), Vectors.dense(2.18626853e-01)),
+ (0.73885841, Vectors.dense(3.16107608e-01, 9.25906358e-01, 5.47327167e-01,
+ 4.83712979e-01, 8.42305220e-01, 7.58488462e-01), Vectors.dense(9.25906358e-01)),
+ (0.45766267, Vectors.dense(4.14393503e-01, 1.30817883e-01, 5.62034942e-01,
+ 1.05150633e-01, 5.35632795e-01, 9.47594074e-04), Vectors.dense(1.30817883e-01)),
+ (0.34801557, Vectors.dense(5.26233981e-01, 7.63781419e-02, 3.19188240e-01,
+ 5.16528633e-02, 5.28416724e-01, 6.47050470e-03), Vectors.dense(7.63781419e-02)),
+ (0.52529452, Vectors.dense(2.73404764e-01, 7.17070744e-01, 3.12889595e-01,
+ 8.39271965e-01, 9.67650889e-01, 8.50098873e-01), Vectors.dense(7.17070744e-01)),
+ (0.42503336, Vectors.dense(4.63289495e-01, 3.57055416e-02, 5.43528596e-01,
+ 4.44840919e-01, 9.36845855e-02, 7.81595037e-01), Vectors.dense(3.57055416e-02)),
+ (0.60221968, Vectors.dense(3.21784993e-01, 3.15622454e-01, 7.58870408e-01,
+ 5.18198558e-01, 2.28151905e-01, 4.42460325e-01), Vectors.dense(3.15622454e-01)),
+ (0.58964479, Vectors.dense(3.72428352e-01, 1.44447969e-01, 8.40274188e-01,
+ 5.86308041e-01, 6.09893953e-01, 3.97006473e-01), Vectors.dense(1.44447969e-01)),
+ (0.58194949, Vectors.dense(3.12776786e-01, 9.33630195e-01, 2.29328749e-01,
+ 4.32807208e-01, 1.51703470e-02, 1.51589320e-01), Vectors.dense(9.33630195e-01)))
+
+ dataset = spark.createDataFrame(data).toDF("label", "features", "topFeature")
+ }
+
+ test("params") {
+ ParamsSuite.checkParams(new FValueRegressionSelector)
+ }
+
+ test("Test FValue selector: numTopFeatures") {
+ val selector = new FValueRegressionSelector()
+ .setOutputCol("filtered").setSelectorType("numTopFeatures").setNumTopFeatures(1)
+ val model = selector.fit(dataset)
+ testSelector(selector, dataset)
+ }
+
+ test("Test F Value selector: percentile") {
+ val selector = new FValueRegressionSelector()
+ .setOutputCol("filtered").setSelectorType("percentile").setPercentile(0.17)
+ val model = selector.fit(dataset)
+ testSelector(selector, dataset)
+ }
+
+ test("Test F Value selector: fpr") {
+ val selector = new FValueRegressionSelector()
+ .setOutputCol("filtered").setSelectorType("fpr").setFpr(0.01)
+ val model = selector.fit(dataset)
+ testSelector(selector, dataset)
+ }
+
+ test("Test F Value selector: fdr") {
+ val selector = new FValueRegressionSelector()
+ .setOutputCol("filtered").setSelectorType("fdr").setFdr(0.03)
+ testSelector(selector, dataset)
+ }
+
+ test("Test F Value selector: fwe") {
+ val selector = new FValueRegressionSelector()
+ .setOutputCol("filtered").setSelectorType("fwe").setFwe(0.03)
+ testSelector(selector, dataset)
+ }
+
+ test("Test FValue selector with sparse vector") {
+ val df = spark.createDataFrame(Seq(
+ (4.6, Vectors.sparse(6, Array((0, 6.0), (1, 7.0), (3, 7.0), (4, 6.0))), Vectors.dense(0.0)),
+ (6.6, Vectors.sparse(6, Array((1, 9.0), (2, 6.0), (4, 5.0), (5, 9.0))), Vectors.dense(6.0)),
+ (5.1, Vectors.sparse(6, Array((1, 9.0), (2, 3.0), (4, 5.0), (5, 5.0))), Vectors.dense(3.0)),
+ (7.6, Vectors.dense(Array(0.0, 9.0, 8.0, 5.0, 6.0, 4.0)), Vectors.dense(8.0)),
+ (9.0, Vectors.dense(Array(8.0, 9.0, 6.0, 5.0, 4.0, 4.0)), Vectors.dense(6.0)),
+ (9.0, Vectors.dense(Array(8.0, 9.0, 6.0, 4.0, 0.0, 0.0)), Vectors.dense(6.0))
+ )).toDF("label", "features", "topFeature")
+
+ val selector = new FValueRegressionSelector()
+ .setOutputCol("filtered").setSelectorType("numTopFeatures").setNumTopFeatures(1)
+ val model = selector.fit(df)
+ testSelector(selector, df)
+ }
+
+ test("read/write") {
+ def checkModelData(model: FValueRegressionSelectorModel, model2:
+ FValueRegressionSelectorModel): Unit = {
+ assert(model.selectedFeatures === model2.selectedFeatures)
+ }
+ val fSelector = new FValueRegressionSelector
+ testEstimatorAndModelReadWrite(fSelector, dataset,
+ FValueRegressionSelectorSuite.allParamSettings,
+ FValueRegressionSelectorSuite.allParamSettings, checkModelData)
+ }
+
+ private def testSelector(selector: FValueRegressionSelector, data: Dataset[_]):
+ FValueRegressionSelectorModel = {
+ val selectorModel = selector.fit(data)
+ testTransformer[(Double, Vector, Vector)](data.toDF(), selectorModel,
+ "filtered", "topFeature") {
+ case Row(vec1: Vector, vec2: Vector) =>
+ assert(vec1 ~== vec2 absTol 1e-1)
Review comment:
`1e-1`? maybe too larger?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r380454694
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTestResult.scala
##########
@@ -0,0 +1,103 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.spark.annotation.Since
+
+/**
+ * Trait for selection test results.
+ */
+@Since("3.1.0")
+trait SelectionTestResult {
+
+ /**
+ * The probability of obtaining a test statistic result at least as extreme as the one that was
+ * actually observed, assuming that the null hypothesis is true.
+ */
+ @Since("3.1.0")
+ def pValue: Double
+
+ /**
+ * Test statistic.
+ * In ChiSqSelector, this is chi square statistic
+ * In ANOVAFValueClassificationSelector and FValueRegressionSelector, this is F value
+ */
+ @Since("3.1.0")
+ def statistic: Double
+
+ /**
+ * Returns the degrees of freedom of the hypothesis test.
+ */
+ @Since("3.1.0")
+ def degreesOfFreedom: Int
+
+ /**
+ * String explaining the hypothesis test result.
+ * Specific classes implementing this trait should override this method to output test-specific
+ * information.
+ */
+ override def toString: String = {
+
+ // String explaining what the p-value indicates.
+ val pValueExplain = if (pValue <= 0.01) {
+ s"Very strong presumption against null hypothesis."
+ } else if (0.01 < pValue && pValue <= 0.05) {
+ s"Strong presumption against null hypothesis."
+ } else if (0.05 < pValue && pValue <= 0.1) {
+ s"Low presumption against null hypothesis."
+ } else {
+ s"No presumption against null hypothesis."
+ }
+
+ s"degrees of freedom = ${degreesOfFreedom.toString} \n" + s"pValue = $pValue \n" + pValueExplain
+ }
+}
+
+/**
+ * Object containing the test results for the chi-squared hypothesis test.
+ */
+@Since("3.1.0")
+class ChiSqTestResult private[stat] (override val pValue: Double,
+ override val degreesOfFreedom: Int,
+ override val statistic: Double) extends SelectionTestResult {
Review comment:
lint
```scala
class ChiSqTestResult private[stat] (
override val pValue: Double,
override val degreesOfFreedom: Int,
override val statistic: Double) extends SelectionTestResult
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584279010
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584247941
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22934/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584253608
Merged build finished. Test FAILed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r380457865
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
Review comment:
Use array instead:
```scala
labeledPointRdd.mapPartition { iter =>
if (iter.hasNext) {
val array = Array.ofDim[Double](numFeatures)
while(iter.hasNext) {
val LabeledPoint(label, features) = iter.next
val yDiff = label - yMean
if (yDiff != 0) {
features.iterator.zip(xMeans.iterator)
.foreach { case ((col, x), (_, xMean)) => array(col) += yDiff * (x - xMean) }
}
}
Iterator.single(array)
} else Iterator.empty
}.treeReduce { case (array1, array2) =>
var i = 0
while (i < numFeatures) {
array1(i) += array2(i)
i += 1
}
array1
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584247941
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22934/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] huaxingao commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
huaxingao commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r379951949
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
+ (col, (value - xMeans(col.toInt), (label - yMean)))
+ }
+ }.aggregateByKey[(Double, Double)]((0.0, 0.0))(
+ seqOp = {
Review comment:
I saw this on wikipedia (https://en.wikipedia.org/wiki/Covariance):
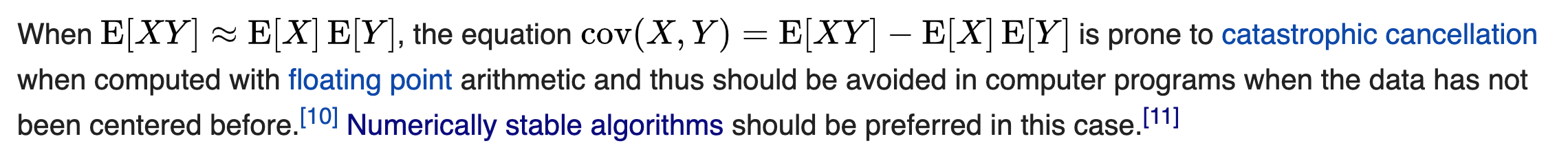
Maybe we should use two pass algorithm instead of one pass?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584247345
**[Test build #118173 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118173/testReport)** for PR 27527 at commit [`d6b1626`](https://github.com/apache/spark/commit/d6b1626df150817484b0142a0c6c8bc8fcfe85ff).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] huaxingao commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
huaxingao commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r377241741
##########
File path: mllib/src/main/scala/org/apache/spark/ml/feature/Selector.scala
##########
@@ -0,0 +1,379 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.feature
+
+import scala.collection.mutable.ArrayBuilder
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml._
+import org.apache.spark.ml.attribute.{AttributeGroup, _}
+import org.apache.spark.ml.linalg._
+import org.apache.spark.ml.param._
+import org.apache.spark.ml.param.shared._
+import org.apache.spark.ml.stat.SelectionTestResult
+import org.apache.spark.ml.util._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql._
+import org.apache.spark.sql.functions._
+import org.apache.spark.sql.types.{DoubleType, StructField, StructType}
+
+
+/**
+ * Params for [[Selector]] and [[SelectorModel]].
+ */
+private[feature] trait SelectorParams extends Params
+ with HasFeaturesCol with HasOutputCol with HasLabelCol {
+
+ /**
+ * Number of features that selector will select, ordered by ascending p-value. If the
+ * number of features is less than numTopFeatures, then this will select all features.
+ * Only applicable when selectorType = "numTopFeatures".
+ * The default value of numTopFeatures is 50.
+ *
+ * @group param
+ */
+ @Since("3.1.0")
+ final val numTopFeatures = new IntParam(this, "numTopFeatures",
+ "Number of features that selector will select, ordered by ascending p-value. If the" +
+ " number of features is < numTopFeatures, then this will select all features.",
+ ParamValidators.gtEq(1))
+ setDefault(numTopFeatures -> 50)
+
+ /** @group getParam */
+ @Since("3.1.0")
+ def getNumTopFeatures: Int = $(numTopFeatures)
+
+ /**
+ * Percentile of features that selector will select, ordered by ascending p-value.
+ * Only applicable when selectorType = "percentile".
+ * Default value is 0.1.
+ * @group param
+ */
Review comment:
In the original ChiSqSelector, the doc for percentile is this:
```
/**
* Percentile of features that selector will select, ordered by statistics value descending.
* Only applicable when selectorType = "percentile".
* Default value is 0.1.
* @group param
*/
```
I changed it to ```ordered by ascending p-value```because in the below definition
```
final val percentile = new DoubleParam(this, "percentile",
"Percentile of features that selector will select, ordered by ascending p-value.",
```
it has "ordered by ascending p-value". Also in the implementation of fit method, it uses pValue instead of statistics value.
```
case "percentile" =>
testResult
.sortBy { case (res, _) => res.pValue }
.take((testResult.length * getPercentile).toInt)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r379299313
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
+ (col, (value - xMeans(col.toInt), (label - yMean)))
Review comment:
---I guess we only need to deal with non-zero values, so maybe use `foreachNonZero` instead.
Then I now think following the logic in `Summizer` maybe more efficient: maintain arrays of sum of `(value - xMeans(col.toInt)` and `(label - yMean)` on each partition, then `treeReduce` to obtain the global sum/mean.---
I just notice that the FValueRegression's logic is different from ChiSqTest, since `ChiSqTest` need to maintain a relative large matrix for each col, so need to flatMap and aggByKey for each col. While in FValueRegression, we only need two arrays (or three arrays if using E(XY)-E(X)E(Y))
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584279056
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22935/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584253568
**[Test build #118173 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118173/testReport)** for PR 27527 at commit [`d6b1626`](https://github.com/apache/spark/commit/d6b1626df150817484b0142a0c6c8bc8fcfe85ff).
* This patch **fails MiMa tests**.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `class FValueRegressionSelector(override val uid: String) extends`
* `trait SelectionTestResult `
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r380462784
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
Review comment:
Make sure the denominator is the same as `computeCovariance`,
if different, adjust it by multiplying `n/(n-1)` or `(n-1)/n` after converting back to variance.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584279056
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/22935/
Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r380451972
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
+ (col, (value - xMeans(col.toInt), (label - yMean)))
+ }
+ }.aggregateByKey[(Double, Double)]((0.0, 0.0))(
+ seqOp = {
Review comment:
Yes, for numerical stablity
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584279010
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] huaxingao commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
huaxingao commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r377244583
##########
File path: mllib/src/main/scala/org/apache/spark/ml/feature/Selector.scala
##########
@@ -0,0 +1,379 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.feature
+
+import scala.collection.mutable.ArrayBuilder
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml._
+import org.apache.spark.ml.attribute.{AttributeGroup, _}
+import org.apache.spark.ml.linalg._
+import org.apache.spark.ml.param._
+import org.apache.spark.ml.param.shared._
+import org.apache.spark.ml.stat.SelectionTestResult
+import org.apache.spark.ml.util._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql._
+import org.apache.spark.sql.functions._
+import org.apache.spark.sql.types.{DoubleType, StructField, StructType}
+
+
+/**
+ * Params for [[Selector]] and [[SelectorModel]].
+ */
+private[feature] trait SelectorParams extends Params
+ with HasFeaturesCol with HasOutputCol with HasLabelCol {
+
+ /**
+ * Number of features that selector will select, ordered by ascending p-value. If the
+ * number of features is less than numTopFeatures, then this will select all features.
+ * Only applicable when selectorType = "numTopFeatures".
+ * The default value of numTopFeatures is 50.
+ *
+ * @group param
+ */
+ @Since("3.1.0")
+ final val numTopFeatures = new IntParam(this, "numTopFeatures",
+ "Number of features that selector will select, ordered by ascending p-value. If the" +
+ " number of features is < numTopFeatures, then this will select all features.",
+ ParamValidators.gtEq(1))
+ setDefault(numTopFeatures -> 50)
+
+ /** @group getParam */
+ @Since("3.1.0")
+ def getNumTopFeatures: Int = $(numTopFeatures)
+
+ /**
+ * Percentile of features that selector will select, ordered by ascending p-value.
+ * Only applicable when selectorType = "percentile".
+ * Default value is 0.1.
+ * @group param
+ */
+ @Since("3.1.0")
+ final val percentile = new DoubleParam(this, "percentile",
+ "Percentile of features that selector will select, ordered by ascending p-value.",
+ ParamValidators.inRange(0, 1))
+ setDefault(percentile -> 0.1)
+
+ /** @group getParam */
+ @Since("3.1.0")
+ def getPercentile: Double = $(percentile)
+
+ /**
+ * The lowest p-value for features to be kept.
+ * Only applicable when selectorType = "fpr".
+ * Default value is 0.05.
+ * @group param
+ */
Review comment:
Here is the original doc for ```fpr``` in ```ChiSqSelector```
```
/**
* The highest p-value for features to be kept.
* Only applicable when selectorType = "fpr".
* Default value is 0.05.
* @group param
*/
```
I changed ```highest p-value``` to ```lowest p-value```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r379299313
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
+ (col, (value - xMeans(col.toInt), (label - yMean)))
Review comment:
~~I guess we only need to deal with non-zero values, so maybe use `foreachNonZero` instead.
Then I now think following the logic in `Summizer` maybe more efficient: maintain arrays of sum of `(value - xMeans(col.toInt)` and `(label - yMean)` on each partition, then `treeReduce` to obtain the global sum/mean.~~
I just notice that the FValueRegression's logic is different from ChiSqTest, since `ChiSqTest` need to maintain a relative large matrix for each col, so need to flatMap and aggByKey for each col. While in FValueRegression, we only need two arrays (or three arrays if using E(XY)-E(X)E(Y))
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] huaxingao commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
huaxingao commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584404980
cc @srowen @zhengruifeng
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584373516
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] huaxingao commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
huaxingao commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-587584326
> However, I think this PR is too large to track, I suggest to split it into three parts...
I will close this PR and open smaller PRs. The comments are addressed in the new PR. Thanks a lot for reviewing!
Please see https://github.com/apache/spark/pull/27623
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r380457200
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
Review comment:
Compute these variables on a pass
```
val Row(xMean: Vector, xStd: Vector, yMean: Double, yStd: Double, count: Long) = dataset
.select(Summarizer.metrics("mean", "std", "count").summary(col($(featuresCol))).as("summary"),
avg(col($(labelCol))).as("yMean"),
stddev(col($(labelCol))).as("yStd"))
.select("summary.mean", "summary.std", "yMean", "yStd", "summary.count")
.first()
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] huaxingao commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
huaxingao commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584820773
### Outline of the changes:
1. Add new abstract classes Selector and SelectorModel. All the common code between ChiSqSelector and this newly added FValueRegressionSelector are put in these abstract classes. There are two abstract methods in Selector:
```
getSelectionTestResult(dataset: Dataset[_]): Array[SelectionTestResult]
createSelectorModel: T
```
2. Make ChiSqSelector extend Selector.
implement ```getSelectionTestResult``` to return an array of ```ChiSqTestResult(pValue, degreeOfFreedom, statistics) ```
pValue is used to rank the features and make selection
implement ```createSelectorModel``` to return a ```ChiSqSelectorModel```
3. FValueRegressionSelector extends Selector.
implement ```getSelectionTestResult``` to return an array of ```
FValueRegressionTestResult(pValue, degreeOfFreedom, statistics)
// statistics is fValue ```
pValue is used to rank the features and make selection
implement ```createSelectorModel``` to return a ```FValueRegressionSelectorModel```
```
fValue calculation: X: feature Y:label N: numOfSample
degreeOfFreedom = N - 2
covariance = sum(((Xi - avg(X)) * ((Yi-avg(Y))) / (N-1)
correlation = covariance / (Xstd * Ystd)
fValue = correlation * correlation / (1 - correlation * correlation) * degreeOfFreedom
```
4. The ChiSqSelectorModel constructor gets changed because two more parameters statistics and pValue were added. I think we should make all the SelectorModel (ChiSqSelectorModel and FRegressionSelectorModel) return statistics (chi square statistics or Fvalue) and P-values. This is to address the comment in https://github.com/apache/spark/pull/27322.
> I found that f_regression in scikit-learn will return both arrays of F-values and P-values, can we also add them to FRegressionSelectorModel?
5. Because of adding two more parameters statistics and pValue in ChiSqSelectorModel constructor, I added a ml-models/chisq-3.0.0 and modified the ChiSqSelectorSuite to make sure pre 3.1.0 model can be loaded OK in 3.1.0.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584276493
**[Test build #118174 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118174/testReport)** for PR 27527 at commit [`2b519b5`](https://github.com/apache/spark/commit/2b519b5f1b5ffb02a285c80271892d3d0d826e76).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584247345
**[Test build #118173 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118173/testReport)** for PR 27527 at commit [`d6b1626`](https://github.com/apache/spark/commit/d6b1626df150817484b0142a0c6c8bc8fcfe85ff).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27527: [SPARK-30776][ML]
Support FValueRegressionSelector for continuous features and continuous
labels
Posted by GitBox <gi...@apache.org>.
SparkQA commented on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584276493
**[Test build #118174 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118174/testReport)** for PR 27527 at commit [`2b519b5`](https://github.com/apache/spark/commit/2b519b5f1b5ffb02a285c80271892d3d0d826e76).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
srowen commented on a change in pull request #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#discussion_r379595713
##########
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##########
@@ -0,0 +1,132 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{DenseVector, Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.mllib.linalg.{Vectors => OldVectors}
+import org.apache.spark.mllib.regression.{LabeledPoint => OldLabeledPoint}
+import org.apache.spark.mllib.stat.{Statistics => OldStatistics}
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.col
+import org.apache.spark.sql.types.DoubleType
+
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of categorical labels and categorical features.
+ * Real-valued features will be treated as categorical for each distinct value.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def chiSquareTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+ val input: RDD[OldLabeledPoint] =
+ dataset.select(col(labelCol).cast(DoubleType), col(featuresCol)).rdd
+ .map {
+ case Row(label: Double, features: Vector) =>
+ OldLabeledPoint(label, OldVectors.fromML(features))
+ }
+ val chiTestResult = OldStatistics.chiSqTest(input)
+ var chiTestResultArray = new Array[SelectionTestResult](chiTestResult.length)
+ for (i <- 0 until chiTestResult.length) {
+ chiTestResultArray(i) = new ChiSqTestResult(chiTestResult(i).pValue,
+ chiTestResult(i).degreesOfFreedom, chiTestResult(i).statistic)
+ }
+ chiTestResultArray
+ }
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector` (`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol: String):
+ Array[SelectionTestResult] = {
+
+ val spark = dataset.sparkSession
+ import spark.implicits._
+
+ SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+ SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+ val yMean = dataset.select(col(labelCol)).as[Double].rdd.stats().mean
+
+ val stats = dataset
+ .select(Summarizer.metrics("mean", "std").summary(col("features")).as("summary"))
+ val xMeans = stats.select("summary.mean").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+ val xStdev = stats.select("summary.std").rdd.collect()(0).get(0).asInstanceOf[DenseVector]
+ .toArray
+
+ val labeledPointRdd = dataset.select(col("label").cast("double"), col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+ val numOfFeatures = labeledPointRdd.first().features.size
+ val numOfSamples = labeledPointRdd.count()
+ val degreeOfFreedom = numOfSamples.toInt - 2
+ var fTestResultArray = new Array[SelectionTestResult](numOfFeatures)
+
+ labeledPointRdd.flatMap { case LabeledPoint(label, features) =>
+ features.iterator.map { case (col, value) =>
+ (col, (value - xMeans(col.toInt), (label - yMean)))
+ }
+ }.aggregateByKey[(Double, Double)]((0.0, 0.0))(
+ seqOp = {
Review comment:
Does this lead to numerical instability? i don't know either way, just know this has been an issue at times. Maybe it's 'worth it' here.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27527:
[SPARK-30776][ML] Support FValueRegressionSelector for continuous features
and continuous labels
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on issue #27527: [SPARK-30776][ML] Support FValueRegressionSelector for continuous features and continuous labels
URL: https://github.com/apache/spark/pull/27527#issuecomment-584373516
Merged build finished. Test PASSed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org